IEEE TRANSACTIONS ON PATTERN ANALYSIS A N D MACHINE INTELLIGENCE. VOL. 12. NO. I . JULY 1990 695
Fig. 1. Some relations among the classes of weighted languages associated to SFSA’s, HMM’s, LRHMM’s, MSM’s, and SRG’s.
nition, the here-adopted probabilistic formalism is widely used for leaming or estimation purposes (Baum-Welch algorithm), and for recognition. However, a general problem is to find an optimal se- quence of states which are compatible with an observed sequence of acoustic symbols (Viterbi algorithm). In this case, the results of this work are not directly applicable, and further work is necessary in this direction. Nevertheless, the difference between both points of view is merely the weighted space over which the weighted lan- guages are defined. The relationships between weighted languages generated by stochastic finite automata by using one space or an- other has been already studied by Santos [ 2 5 ] .
We would like to point out that LRHMM’s and LRHMMT’s are among the most widely used in automatic speech recognition, and there are particular cases that are not equivalent from a probabilis- tic point of view. From a theoretical perspective, this can affect the application of reestimation and recognition procedures and the mathematical properties of the estimated models (e.g., Baum- Welch theorem). From a practical point of view, on the other hand, it is not clear what is the actual impact of the differences in the applications of the LRHMM and the LRHMMT to automatic speech recognition. Consequently, it is not obvious which formalism can be better used to represent the knowledge in automatic speech rec- ognition.
All the results presented in this correspondence are of an essen- tially theoretical nature. Further research is clearly necessary, to establish what the actual consequences of these results are on the practical aspects of the application of stochastic finite state net- works to automatic speech recognition.
ACKNOWLEDGMENT
The author wishes to thank Dr. E. Vidal and the anonymous reviewers for their criticisms and suggestions.
REFERENCES
[I] L. Bahl, F. Jelinek, and R. Mercer, “A maximum likelihood ap- proach to continuous speech recognition,” IEEE Trans. Pattern Anal. Machine Intell., vol. PAMI-5, no. 2, pp. 179-190, 1983. 121 F. Jelinek, “Continuous speech recognition by statistical methods,”
Proc. IEEE, vol. 64, no. 4, pp. 532-556, 1976.
[3] L. Rabiner and B. Juang, “Introduction to hidden Markov models,” IEEE ASSP Mag., pp. 4-16, Jan. 1986.
[4] J. Baker, “The Dragon system-An overview,” IEEE Trans. Acoust., Speech, Signal Processing, vol. ASSP-23, no. 1, pp. 24-29, 1975. [5] L. Rabiner, S. Levinson, and M. Sondhi, “On the application of vec-
tor quantification and HMM’s to speaker independent, isolated word recognition,” Bell Sysr. Tech. J . , vol. 62, no. 4, pp. 1075-1105, 1983.
161 S . Levinson, L. Rabiner, and M. Sondhi, “An introduction to the application of the theory of probabilistic functions of a Markov pro- cess to automatic speech recognition,” Bell Sysr. Tech. J . , vol. 62, no. 4, pp. 1035-1074, 1983.
[7] S . Levinson, “Structural methods in automatic speech recognition,” Proc. IEEE, vol. 73, no. 11, pp. 1625-1650, 1985.
181 L. Rabiner, “Mathematical foundations of hidden Markov models,” in Recent Advances in Automatic Speech Understanding and Dialog, H. Niemann, Ed. (NATO AS1 Series). New York: Springer, 1988.
[9] A. Salomaa, Formal Languages. New York: Academic, 1973. [lo] R. Kashyap, “Syntactic decision rules for recognition of spoken words
and phrases using stochastic automaton,” IEEE Trans. Pattern Anal. Machine Intell., vol. PAMI-1, no. 2, pp. 154-163, 1979. [ l I] R. Schwarth et a l . , “Acoustic-phonetic decoding of speech,” in Re-
cent Advances in Speech Understanding and Dialog Systems, H. Nie- mann, Ed.
[I21 H. Cerf-Danon et a l . , “Speech recognition experiments with 10000 word dictionary,” in Pattern Recognition and Applications, P. Dev- ijver and J. Kittler, Eds. New York: Springer, 1987.
[ 131 K. Fu, Syntactic Pattern Recognition and Applications. Englewood Cliffs, NJ: Prentice-Hall, 1982.
[I41 R. Gonzalez and M. Thomason, Syntactic Partern Recognition: An Introduction. Reading, MA: Addison-Wesley, 1978.
[15] L. Miclet, Structural Methods in Pattern Recognition. North Ox- ford Academic, 1986.
[16] N. Abramson, Information Theory and Coding. New York: Mc- Graw-Hill, 1966.
171 C. Wetherell, “Probabilistic languages: A review and some open questions,” Comput. Surveys, vol. 12, no. 4, pp. 361-379, 1980. 181 H. Rulot and E. Vidal, “An efficient algorithm for the inference of
circuit-free automata,” in Proc. NATO Advanced Research Workshop Syntactic Pattern Recognition, Ferrate et a l . , Eds. New York: Springer, 1988.
191 S. Levinson, “A unified theory of composite pattern analysis for au- tomatic speech recognition,” in Computer Speech Processing, F. Fallside and W. Woods, Eds. Englewood Cliffs, NJ: Prentice-Hall, 1985.
[20] -, “Some experiments with a linguistic processor for continuous speech recognition,” IEEE Trans. Acoust., Speech, Signal Process- ing, vol. ASSP-31, no. 6, pp. 1549-1556, 1983.
[21] A. Derouault and B. Merialdo, “Natural language modeling for pho- neme to text transcription,” IEEE Trans. Pattern Anal. Machine In- tell., vol. PAMI-8, no. 6, pp. 742-749, 1986.
[22] S . Nakagawa and M. Jilan, “Syllable-based connected spoken word recognition by two pass O ( n ) DP matching and hidden Markov model,” in Proc. ICASSP86, 1986, pp. 21.14.1-21.14.4.
[23] B. Merialdo, “Phonetic recognition using HMM’s and maximum mu- tual information training,” in Proc. ICASSP88, 1988, pp. l l 1-1 14. [24] P. F. Brown, “The acoustic-modeling problem in automatic speech recognition,” IBM Res. Center, Yorktown Heights, NY, Res. Rep. RC-12750, May 1987.
[25] E. S. Santos, “Realizations of fuzzy languages by probabilistic max- product and max-min automata,” Inform. Sci., vol. 8, pp. 39-53,
1975.
[26] K. F. Lee, “Large-vocabulary speaker-independent continuous speech recognition: The SPHNIX systems,” Camegie-Mellon Univ., Tech. Rep. CMU-(3-88-148, 1988.
New York: Springer, 1988.
A Mandarin Dictation Machine Based Upon a
Hierarchical Recognition Approach and
Chinese Natural Language Analysis
LIN-SHAN LEE, CHIU-YU TSENG, K. J. CHEN, JAMES HUANG, CHIA-HWA HWANG, PEI-YIH TING.
LONG-JI LIN, A N D C. C. CHEN
Abstract-This correspondence describes the first experimental Mandarin dictation machine developed in the world for the input of Manuscript received May 17, 1988; revised November 23, 1989. Rec- ommended for acceptance by C. Y. Suen.
t . - s . Lee, C.-h. Hwang, P:Y. Ting, L.-j. Lin, and C. C. Chen are with the Department of Electrical Engineering, National Taiwan Univer- sity, Taipei, Taiwan, Republic of China.
C.-y. Tseng and K. J . Chen are with the Institute of Information Sci- ence, Academia Sinica, Taipei, Taiwan, Republic of China.
J. Huang is with the Department of Modem Languages and Linguistics, Come11 University, Ithaca, NY 14853.
IEEE Log Number 9034828.
696 IEEE TRANSACTIONS ON PATTERN ANALYSIS A N D MACHINE INTELLIGENCE, VOL. 12, NO. 7, JULY 1990
Mandarin speech (spoken Chinese language) into computers. Consid- ering the special characteristics of the Chinese language, syllables are chosen as the basic units for dictation. The machine is designed based on a hierarchical language recognition approach, in which acoustic sig- nals are first recognized as a sequence of syllables, possible word hy- potheses are then formed from the syllables, and the complete sen- tences are finally obtained. This approach is implemented by two subsystems. The first recognizes the syllables using speech signal pro- cessing techniques, including the recognition of the finals, initials, and tones of the syllables, respectively. Because every syllable can repre- sent many different characters with completely different meaning, and can possibly form different multisyllabic words with syllables on its right or left, the second subsystem then identifies the exact characters from the syllables and corrects the errors in syllable recognition by first forming all possible word hypotheses from the syllables then find- ing out one combination of the word hypotheses which is grammati- cally valid in a sentence. The detailed syllable recognition algorithms, word formation rules, parser, grammar, and the syntactic checking algorithms are described in the correspondence. Using everyday news- paper text in the form of isolated syllables as input, the preliminary test results indicate that such a dictation machine is not only practically attractive, but technically achievable.
Index Tenns-Chart parser, hierarchical approach, Mandarin
Chinese, natural language, speech recognition, syllables, syntactic checking, word hypotheses.
I. INTRODUCTION
Although the computer was introduced to the Chinese commu- nity more than 20 years ago, the input of Chinese characters (ideo- graphs) into computers is still a very difficult and unsolved problem [I]. The primary reason is that Chinese language is not alphabetic. Every Chinese character is a complicated square graph, many of which are composed of different radicals organized in a very irreg- ular manner. There are at least 20 thousand commonly used differ- ent characters. Today, for the input of Chinese characters to com- puters, although there are at least more than 100 different methods developed, it is well known that none of them can provide the users a convenient input system with efficiency comparable to alphabetic languages [ 11. These methods are either too slow, or too compli- cated, or need special training. For example, the radical input sys- tems have rules too difficult to remember and the phonetic symbol input systems are too slow. This is the basic motivation for the development of a Mandarin dictation machine. From the computer input point of view, the desire for a dictation machine is much stronger for Chinese than for English.
The development of such a dictation machine is very difficult; we therefore define the scope of the research by the following lim- itations. The input speech is in the form of isolated syllables in- stead of continuous speech (the choice of syllables as the dictation unit will be discussed in detail later). This avoids the problem of processing continuous speech waveforms. Also, due to the mono- syllabic nature of Mandarin, distinct syllables appear to be rather acceptable and even more enunciated in Chinese. In other words, even if the voice input is made by isolated syllables, such an input method is not only much more efficient than any of the currently existing Chinese input systems, but considered very convenient and natural in practical applications. The dictation machine is speaker dependent only. The fact that it is trained for only one user at a time is completely acceptable considering practical applications. The first phase goal of this system is 90% accuracy for the sen- tences in the Chinese textbooks of the primary schools in Taiwan, Republic of China. This means for a sentence of 10 characters, one of the characters will be wrong on the average and will be found by the user on the screen and corrected from the keyboard. Such a performance is still much more efficient than any of the currently existing input systems, and the primary school Chinese textbooks already cover most of the everyday Chinese language. The final
goal of such research is of course to have a real-time system, al- though currently the real-time requirement is not considered cru- cial. In other words, the first phase goal is to develop a machine which, although not real-time, has the potential to be improved and implemented in real-time in the future. This is because the primary purpose of this research is to demonstrate the technical feasibility of a Mandarin dictation machine instead of actually implementing a prototype system. Due to the same reason, only a small dictionary for demonstration purposes is to be established in the first phase. As will be discussed in detail later, for the Chinese textbooks of the primary schools, it is estimated that a dictionary consisting of about 35 thousand Chinese words is necessary. However, our first phase dictionary consists of only 5 thousand words. Therefore the machine will work well for sentences formed by these words, but new words will have to be added to the dictionary as needed. Such a system is in fact sufficient to demonstrate the technical feasibility in dictating Mandarin speech by machines, as will be clear later. Based upon the above definitions and limitations on the task goals, such a Mandarin dictation machine is not only practically attractive if implemented as a product, but technically obtainable using cur- rently available technologies. As will be clear later in this paper, the above goals are almost achieved in our system. Although sim- ilar systems have been designed or implemented for other lan- guages with different approaches [2]-[5], this is believed to be the first experimental dictation machine developed for Mandarin Chinese in the world [6].
Based on the detailed discussion in the next section considering the special structure of the Chinese language, Mandarin syllables instead of Chinese word hypotheses (most of them are multisylla- bic) are chosen as the basic units for the dictation. The dictation machine is designed based on a hierarchical language recognition approach, in which acoustic signals are first recognized as a se- quence of syllables, possible word hypotheses are then formed from the syllables, and the complete sentences are finally obtained. This approach is implemented by two subsystems. The first one is to recognize the syllables using speech signal processing techniques. However, this is not very helpful at all because in general every syllable can represent many different characters with completely different meaning, and can possibly form different multisyllabic words with syllables on its right or left. Therefore the second sub- system is to identify the correct characters from the syllables by forming correct word hypotheses (most of them have more than one characters) which are grammatically valid in a sentence. This sub- system is designed by carefully considering the characteristics of the Chinese natural language, primarily the syntactic structure. In the following, the basic approach of the machine considering the special structure of the Chinese language will be discussed in Sec- tion 11, the complete language recognition hierarchy will be de- scribed in Section 111, and the detailed techniques will be presented in the next few sections. Test results and conclusions will finally be given.
11. CONSIDERATIONS FOR THE SPECIAL STRUCTURE OF CHINESE LANGUAGE
There are at least some 80 thousand commonly used words in Chinese [ 7 ] . Even if word formation rules are used to reduce the number of different words which are necessary in the vocabulary as will be discussed in detail later, it is estimated that at least 35 thousand words are needed for everyday Chinese language. Such a size is still prohibitively large for today’s speech recognition tech- nology. Therefore the words cannot be used as the dictation units if a practical dictation machine is to be designed. On the other hand, there at least 20 thousand commonly used Chinese charac- ters, each character being monosyllabic. Each of the 80 thousand commonly used Chinese words is composed of from one to several characters (a very small fraction of them have only one character), therefore most of the words are multisyllabic and a small fraction of them are monosyllabic. Although the total number of monosyl- labic words is small, they appear in everyday Chinese language
IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE. VOL. 12. NO. 7. JULY 1990 697 very frequently. Nevertheless, we note that the total number of
phonologically allowed syllables in Mandarin speech is only about 1300. In other words, if we use the 1300 syllables as the dictation units, all the words or characters will be covered. Therefore, use of these syllables as the dictation units will allow the replacement of the 20 thousand commonly used characters by the 1300 syllables for computer input. However, the small number of syllables im- plies another difficult problem, that is, a relatively high number of homonyms for which many different characters will share the same syllable. In other words, after a syllable is recognized from speech signal, it may form different multisyllabic words with adjacent syl- lables on its right or left, and it can also be a monosyllabic word. However, as far as the complete grammatical sentence is con- cerned, there will be only one correct solution. This is where the Chinese natural language analysis becomes very important, and is exactly the way the Chinese people listen to their language. There are also some additional reasons to use syllables as the dictation units. First, all of these syllables are of open syllabic structure, i.e., they always end with a vowel with the exceptions of vowels plus nasals -n and -ng. This makes the detection of the end points relatively easier. Furthermore, although most of the Chinese words are multisyllabic with several characters, most of the morphemes, i.e., the minimum meaningful units, in Chinese are monosyllabic and composed of only a single character. Based on the above ob- servations on the special structure of Chinese language [7], the use
of
syllables as the basic units to recognize Mandarin Chinese sen- tences in the dictation machine is a very natural choice.Another very special important feature of Mandarin Chinese lan- guage is the existence of the lexical tones for the syllables. Chinese is a tonal language in general; every character is assigned a tone and the tones have lexical meaning in Mandarin. There are basi- cally four different tones, i.e., the high-level tone (usually referred to as the first tone), the mid-rising tone (the second tone), the mid- falling-rising tone (the third tone), and the high-falling tone (the fourth tone). It has been shown [SI, [9] that the primary difference for the tones is the pitch contours, there exist standard patterns for the pitch contours for the different tones, and the tones are essen- tially independent of other acoustic properties of the syllables. One example is shown in Fig. 1, where the pitch contours for the four tones of three vowels and two diphthongs [a‘. U, i, ai, au-1, 2, 3 , 41 for the same speaker are plotted as functions of time. In each drawing the horizontal scale is the time in units of frame number; the vertical scale is the pitch period in units of sampling period. The number on each curve indicates the tone. It can be seen that although the vowels or diphthongs are completely different, the basic patterns for the pitch contours for the four tones are essen- tially the same, and they are in fact the same for all different syl- lables. If the differences among the syllables due to lexical tones are disregarded, only 418 syllables are required to represent all the pronunciations for Mandarin Chinese. This means every syllable can be considered as the combination of two completely indepen- dent parts, a first-tone syllable among the 418 possible syllables (disregarding the tones) and the tone among the four possible choices [8], [9]. This means the recognition of the syllables can also be divided into two parallel procedures, and by removing the effect of the tones the number of different candidates for the syl- lable recognition is reduced to 418, which is a very reasonable size.
111. THE COMPLETE LANGUAGE RECOGNITION HIERARCHY Based on the considerations described above, the basic system structure for the Mandarin dictation machine is shown in Fig. 2. The system is divided into two subsystems. The first subsystem is used to recognize the syllables using speech signal processing tech- niques, for example, to transform the input sequence in Mandarin
‘The transliteration symbols used in this paper are the Mandarin Pho- netic Symbols I1 (MPS 11). The numerical numbers following each syllable denotes the lexical tone of the syllable.
1 5 10 15 20 I 5 10 15 20,00 I . ’ - . , - 9 , ‘ I . . ‘ . a-1 , 2 , 3 , 4 a i - 1 , 2 , 3 , 4 5 10
,
. .
. . I ? .. .
?OlOO , Q Q 1 5 10 15 20 1 aoFig. I . The pitch contours of [a, U, i , ai, au, - 1, 2 , 3 , 41 for the same speaker, sampling period versus frame number. The horizontal axis is the time in units of frame number, the vertical axis the pitch period in units of sampling period. The number on each curve indicates the tone.
subsystem 1 Subsystem 2
Character Recognition Identification
t
Output Characters lnput Speech Syllables SyUables
In,-31 Ish41 11-2) cia41
[huei4l ltieng-I1 [guo-21 [tu-31
[de-51 [dim41 [nau-3]
Fig. 2. The basic structure of the Mandarin dictation machine.
speech form, such as
‘ ‘ 4 $ J j 3 - $ ~ @ ~ ~ 2 $ 9 ~ J $ j ’ ’
(you are a com- puter who can listen to Mandarin) into its corresponding syllables, i.e., [ni-31 [shr-41 [i-2] uia-41 [huei-4] [tieng-1] [guo-21 tiu-31 [de-51
[dian-41 [nau-31. Here the input speech signal is assumed to be a sequence of isolated syllables, therefore the endpoint detection is easy and the primary task is to recognize the syllables. The second subsystem is then to identify the correct character for each syllable using Chinese natural language analysis approaches. Every sylla- ble like tni-31 or [shr-41 in the above example can represent many completely different characters with the same pronunciation, but there exists only one set of characters, such as in the above ex-ample,
‘
‘
4
~
~
:
-
~
which can form meaningful~
~
~
i
~
~
~
~
~
~
,
’
’
multisyllabic words such as ‘‘ (Mandarin)” and “ (Com-puter)” and a grammatically valid sentence. Therefore the task of the second subsystem is to transform the input sequence of sylla- bles into the output text formed by characters. As long as 90% of the characters are correct, the performance will be satisfactory.
698
Subsystem
i
IEEE TRANSACTIONS ON PATTERN ANALYSIS A N D MACHINE INTELLIGENCE. VOL. 12. N O . 7. JULY 1990
Correction
+----+l
OutputText 1-Syntactic Analysis and Checkin to Determine
the Wmctm
Word Hypothesis Formation
[ni-31
?%R;f%E
[nil R ” the Tones Subsystem Endpoint DetectionI
II
I
Input Speech Syllables
Fig. 3 . The complete hierarchy and overall system structure for the Man- darin dictation machine.
The complete recognition hierarchy is shown in Fig. 3. For the first subsystem of syllable recognition, the endpoints for each syl- lable are first detected, the corresponding first-tone syllable (dis- regarding the tones, such as [nil for the first syllable in the above example) and the tone (such as the third tone for the same example) are then recognized independently in parallel, because as discussed previously every syllable can be considered as the combination of these two independent parts. The results are then combined to de- termine the syllable [ni-31. It will be shown later that the recogni- tion of the first-tone syllable and the tones are both difficult, and errors always occur. We therefore have to provide information for confusing first-tone syllables. For example, [nil being not a very confident result and the second choice being [mi], and confusing tones, for example, the second choice being the fourth tone, to the second subsystem such that the errors in the first subsystem or acoustic level recognition can hopefully be corrected by the second subsystem or syntactic level identification.
For the second subsystem of identifying the correct characters for each syllable, we need to first form multisyllabic word hy- potheses from each syllables. To use the above example, although there are many characters all correspond to the syllable [guo-21 and many to [iu-3], there is only one multisyllabic word ‘‘ Hi;Z(Man- darin)” has the pronunciation “[guo-21 [iu-3].” Similarly, there are many characters all pronounced as the syllable [dian-41 and many as the syllable [nau-31, but there is only one multisyllabic word “ Sr&(Computer)” pronounced as “[dian-4] [nau-31.” This
can be achieved by matching with the words in a dictionary. But this does not solve the problem well. First, although there is a rel- atively small number of monosyllabic words, they appear very fre- quently in everyday Chinese language. In the above example, syl- lables such as [ni-3], [shr-4], [i-2], bia-41, [huei-41, [tieng-I] all correspond to monosyllabic words. The corresponding characters or words for them cannot be identified in the above way. They can even form ambiguous multisyllabic word hypotheses; for example,
the syllable [i-2] can combine with the syllable to its left [shr-41 to form a wrong word hypothesis
‘ ‘ S B
(Suitable, [shr-41 [i-2]),” or with the syllable to its right bia-41 to form a wrong word hypoth- esis “ (Move, [i-21 bia-4]).” The problem becomes evenworse when errors occur in the recognized syllable, for example, if the tone of the first syllable [ni-31 is incorrectly recognized as the fourth tone, than the wrong syllable [ni-4] can be combined with the syllable [shr-41 to its right to form a wrong word hypoth- esis “ @%(Bad Situation, [ni-41 [shr-4]).” The next operation of
syntactic analysis then serves as a filter to rule out all ungrammat- ical combinations of multisyllabic and monosyllabic word hy- potheses and only a single syntactically valid sentence will be ob- tained and appear on the screen as the output text. Any errors in this output sentence can then be further corrected by the user man- nually from the keyboard. From the above description, it can be seen that in this approach although the first phase dictionary has only five thousand words which is significantly smaller than the necessary size, the vocabulary can be easily extended by simply enlarging the dictionary size without affecting the syllable recog- nition procedure or the entire system operation. This is why only a small experimental dictionary is used in the first phase research. The recognition of the 418 first tone syllables in the first sub- system is in fact very difficult [lo]. This is because the 418 first tone syllables consist of about 38 confusing sets, each of which has from about 4 to 19 confusing syllables [IO]. Good examples are the A-set: {[a], P a l , [pal, [mal, [fa], [dal, [tal, [nal, [la], [gal, [ka], [ha], bal, [cha], [sha], [tza], [tsa], [sa]} and AN-set: {[an], [ban], [pan], [man], [fan], [danl, [tan], [nanl , [lanl , [ganl, [kanl, [han], ban], [chan], [shan], [ran], [tzan], [tsan], [san]}. It has been shown [IO] that with standard approaches of the Dynamic Time Warping or Hidden Markov Models, LPC, and Itakura distance measures to recognize these syllables, the achievable recognition rates are as low as 60-70%. This tells how difficult it is to correctly recognize these syllables and why curently available techniques for English words cannot be applied directly. An initialhnal two-phase recognition approach is thus specially designed [ 111 to recognize these very confusing syllables, whose block diagram is in Fig. 4 . Here “final” means the vowel or diphthong parts of the syllable but including the medials and nasal ending (if any), and “initial” is the inital consonant of the syllable. Because of the open-syllabic structure, the ending point is easy to detect and the final of every syllable is relatively long and steady with a clear single peak in energy, we can therefore first detect the final part and recognize the final form a total of 38 different finals. Once the final is deter- mined, we then try to recognize the initial preceding the final among at most 19 candidate initials. In this way the complicated problem of recognizing 418 very confusing syllables is reduced into two smaller problems, but the accurate recognition of the final is very important [I I]. Although in this way segmentation of the syllable into two parts would very likely cause new problems, and different approaches in which the syllables are recognized as a whole are also under development currently, our results show that this initial/ final two-phase recognition approach is the most attractive and fea- sible in terms of achievable recognition rates and computation complexity requirements.
IV. THE RECOGNITION OF THE FINALS
The initialhnal discrimination can first be performed by check- ing the periodicity of several successive frames [12]. For the final frames, there must be strong evidence of periodicity. For the initial frames except the initials [m], [n], [l], and [r], no periodicity can be observed. Spectrum characteristics are then needed to provide reliable initiallfinal discrimination for syllables beginning with the above four special initials.
Table I lists all the 38 possible finals for the 418 Mandarin syl- lables. The recognition of these finals is still very difficult because there are again many confusing final sets, such as {[a], ria], [ua]} , {[ai], (iai], [uail}, etc., in which the medials [i], [U] are very dif- ficult to recognize. In our research it was found that using multi-
IEEE TRANSACTIONS ON PATTERN ANALYSIS A N D MACHINE INTELLIGENCE. VOL. 12. N O . 7. JULY 1990 699
End Paint
;GI,
-
Detection --e
1
InitiaVFinaJ Final Initial
Detection
-
Recognition-
RecognitionInida;
Fmal Pan
Fig. 4. The initialifinal two-phase recognition scheme TABLE I
THE LIST OF ALL FINALS IN MANDARIN SYLLABLES
nasal en uen
1
iuenending
1
iangI
uang engI
iengI
uengl iueng special er$
section vector quantization (MSVQ) techniques with branch-and- bound algorithm operated on the filter bank coefficients can give very good results while maintaining relatively simple hardware/ software implementation [ 121. The multisection vector quantiza- tion (MSVQ) technique is first proposed by Burton et al. [13]. In this approach, isolated words are recognized by means of se- quences of VQ codebooks, called multisection codebooks. A sep- arate multisection codebook is designed for each word in the vo- cabulary by dividing the word into equal-length sections and designing a standard VQ codebook for each section. Unknown words are classified by dividing them into corresponding sections, encoding them with the multisection code-books, and finding the multisection codebook that yields the minimum average distortion. Our final recognition system basically adopts the above concept.
The MSVQ recognition approach is demonstrated in Fig. 5. Let ck, k = 1 , 2,
. . .
, M ,
represent the multisection codebook for the kth final, where k is the index for the candidate finals andM
is the total number (38) of possible finals. Each multisection codebookck
is composed of N section codebooks, each for one section of the final, i.e., c k = {ckJ,
j = 1, 2 ,. . .
, N }, w h e r e j is the index for sections, and N is the total number of sections for every final, and c k J is the codebook for the j t h section of the kth final. Each section codebookckJ
further consists of a total of nkJ codewords, i.e., Ck, = {ckJl, i = 1, 2,. * .
, nk,}, where i is the index for codewords, and nk, is the total number of codewords in the section codebook ckJ. Let x,, I = 1 , 2 , *. .
, Nm be the sequence of featurevectors for the frames of an unknown test final, Nm is the total number of frames. Apparently when the test final is divided into N
equal-length sections, each section has exactly m frames. The dis- tortion for t h e j t h section with respect to the kth final is then
i
Test fmal
( x , . t = l , 2 ,..._.. 5 m )
Fig. 5 . The MSVQ recognition procedure for N = 5
where d ( x , y ) is the distance measure between two feature vectors x , y , and the average distortion with respect to the kth final is
I N
Dk = - dkj.
Nm j = l
The final with minimum average distortion with respect to the test final is then the recognition result. In this way, the section deter- mination has the consequences of linear-time-warping which achieves gross time alignment. Fine time alignment is then achieved by codeword search. Since the section determination is only gross, this method is less robust than DTW if the words have many syl- lables. However, the MSVQ approach is in fact superior to the traditional DTW system for monosyllabic vocabulary such as Man- darin finals for the following two aspects [12]. First, time align- ment is approximately done by section determination and codeword search, which is less time-consuming than dynamic programming based time alignment (DTW). Second, the MSVQ codebooks are composed of codewords which are more flexible than the word tem- plates in most DTW systems, and thus storage saving can also be achieved. In fact, we have found that due to the monosyllabic structure and spectrum continuity properties of the Mandarin finals, the multisection recognition procedure will cause much less prob- lem in Mandarin finals than English words.
A branch-and-bound classification algorithm is further devel- oped for the search process as follows to improve the computation efficiency. During the classification process, each multisection codebook maintains an accumulated distortion value. The most promising path and the impossible paths are then defined according to the accumulated distortion. When the current most promising path is forwarded one step, i.e., one more frame is calculated, the decision about the next most promising path is made. When a cer- tain path is ending (reaching the ending frame), the impossible paths are deleted and the surviving paths go on as the above strategy. The key points are how to find the most promising path and the impossible paths efficiently. This can be solved by maintaining a queue sorted by the current accumulated distortion value (from minimum to maximum) of each path. So the first element of the queue is for the most promising path. The paths behind the ending path are the impossible paths. The first path must be inserted into the queue after proceeding one step if it is no longer the most prom- ising. This can also be done efficiently because the queue is sorted. Further improvements can be made when the common codebook concept is used in which common codebooks are trained for the first few sections of the finals having the same first phoneme such as [a], [ai], [au]. [an], etc.
700 IEEE TRANSACTIONS ON PATTERN ANALYSIS A N D MACHINE INTELLIGENCE, VOL. 12, N O . 7, JULY 1990
kHz bandwidth, sampled at 10 kHz rate, and digitized in 16 bits. All the 418 possible Mandarin syllables in first tone are recorded. Two male speakers each uttered five randomized repetitions of these 418 isolated syllables in five sessions respectively. There is an in- terval of at least two days between every two sessions. These syl- lables are then segmented by locating the end points, and the final parts and initial parts are obtained separately for experiments. Be- cause the total number of finals is 38, on the average more than 10 different syllables having the same final but different initials will contribute to the training of a given final. In every test, the finals obtained from one session (test session) are used as the test finals, and those from the other four sessions (training sessions) are used in training. After all the five sessions of data are used as test ses- sions, the averaged result is taken as the recognition result. In our experiments, it was found that feature vectors obtained from uni- form filter bank with 16 filters, Euclidean distance measures, five equal-length sections for each final ( N = 5 ) , fixed-size codebook and clustering training algorithm together provide a recognition rate of 93.4 %, for which most parameters have been optimized, and this rate is almost identical to that of dynamic time warping, but with much less computation. Although the results for two speakers only here are not sufficient to determine the robustness as well as the achievable recognition rates, they at least serve as a rough in- dicator to tell the possible achievable performance of the approach. In order to provide confusing finals for the second subsystem to correct the recognition errors in the syntactic level, an algorithm is designed such that when the distortion measures for the two most possible candidate finals are close enough, the output will be a first choice final and a second choice final. They will be combined with the possible choices of initials and possible choices of tones to ob- tain possible choices of syllables in addition to the first choice syl- lable. Some of the combinations will be automatically deleted, for example, the syllable [bia-41 does not exist in Mandarin.
v . THE RECOGNITION OF T H E INITIALS
All the 21 possible initials of Mandarin syllables are listed in Table 11. The recognition of these initials is even more difficult then the finals because the initials are relatively short, unstable, and confusing. In our research, it was found that many well-known approaches cannot yield very good recognition results even with complicated algorithms, for example, the continuous hidden Mar- kov models [ 141. We found that finite-state vector quantization (FSVQ) seems to be one of the best approaches to recognize the Mandarin initials [15] when both the achievable recognition rates and computation complexity requirements are considered. A finite- state vector quantizer (VQr) is a trellis structured vector encoder, as was illustrated in Fig. 6. It consists of a set of VQr’s which are switched by some well trained transition functions. The encoding process includes a full-search comparison stage and a next-VQr- prediction stage alternatively. It can be specified by a finite state space S , an initial state so, and three functions: 1) an encoder a: A
X S + B where A denotes the observation space and B is a fi?ite
set of all encoded symbols; 2 ) a decoder
0:
S X B + A where A isthe reproduction space; 3) a next state function or transition func- tionf: S x B + S . They operate as follows, where x, is the feature
vector for the initial frames at the time t , U , is the encoded symbol,
and s, is the state at time t :
\
2, = P(s,, U,) 2, Ea.
decoderApparently the point is that the next VQr (s, + ) to be used is a function of the current VQr(s,) being used and the corresponding encoded symbol (U,). The encoder a keeps a copy of the decoder /3 and selects the encoded symbol U , by minimum distortion rule:
U, = a(.,, s,) = arg min d(x,, P(s,, U)).
U E B
TABLE I1
CLASSIFICATION O F MANDARIN CONSONANTS ACCORDING TO THEIR PLACES
AND MANNERS OF ARTICULATION
t+l Input Vectors
c
h A Statesc
c
Decoded Vectors xt-1 xt u t = a ( x , , s t 1 n Decoder x t = p ‘ s t , U , ) EncoderFig. 6. The concept of finite state vector quantization (FSVQ).
This is demonstrated in Fig. 6 . Just as done for finals previously, FSVQ can be applied easily in initial recognition. FSVQr’s can be trained for all candidate initials. The test initial is then encoded by these FSVQr’s and the average distortion are evaluated. The can- didate giving minimum distortion will be the recognized initial. Experiments discussed later show that in this way the switching among many possible VQr’s by well-trained transition functions will minimize the distortion between the test initial and the correct candidates, thus improves the recognition performance [15]. The computation required for this algorithm, however, is on the same order as MSVQ previously discussed for the recognition of finals and much less than Dynamic Time Warping.
Our initial recognition approach using FSVQ has a block dia- gram shown in Fig. 7. The experiments show that such a structure gives the highest recognition rate. The test initial is first classified into two categories, GI and G,, where GI = {[bl, [dl, [gl, [ml, [nl, [U, [rl, [?I
1
andGZ
= {[PI, [fl , [tl , [kl , [hl , tjrl, [chrl, [shrl, [tz], [SI, [ji], [chi], [shi]}. [?I in GI represents the initial part for syllables without a consonant in the beginning. The classification is performed by evaluation of a classification function based on some simple time domain features such as average energy, average vibration count, zero-crossing rate, and the length of the initial. It was found that the two categories of initials can be recognized using slightly different algorithms such that the overall recognition re- sults can be optimized. For the category G , , the standard FSVQ described above can be used for recognition. For the category G,, on the other hand, a modified FSVQ algorithm should be used, inIEEE TRANSACTIONS ON PATTERN ANALYSIS A N D MACHINE INTELLIGENCE, VOL. 12, NO. 7 . JULY 1990 GI S V Q ( R = l )
1
ClassificationI
+-
FSVQ With S C R=13which the present state is a function of the state and encoded sym- bol R frames earlier instead of simply one frame earlier, i.e.,
S , + R = f ( S , , f
and simulations indicate that R = 13 gives the highest recognition rate.
In the experiments, the initials are taken from exactly the same database for the 418 syllables as described previously. Because the total number of initials is 22 (21 initials plus [?I), on the average about 20 syllables with the same initial but different finals will con- tribute to the training of an initial. The overall recognition rate is on the order of 93.6% for two speakers only, which is the highest result we have ever obtained for the Mandarin initials.
VI. THE RECOGNITION OF THE TONES AND THE COMBINED
Although there are only four different tones, the correct recog- nition of the tone is in fact difficult. One example problem is the confusion caused by the third and the fourth tones. In most of the cases, only the first half of the third tone will be pronounced, which will be very close to a fourth tone. A good example is shown in Fig. 8 , where the two curves are the pitch frequencies (the inverse of the pitch period as used in Fig. 1) plotted as functions of time for two syllables [iu-3] and [iu-4]. It can be seen that the basic shapes are very close, the only difference is in the dynamic range and the slope. We use here the tone recognition method developed by J.-C. Lee [16], in which the sum and difference of the log pitch frequencies for adjacent frames are taken as feature parameters,
fJI = P,+l +
P,
U2 = PI + I - PIwhere p I is the log pitch frequency for the i-th frame. In fact these two parameters represent the average pitch level and the pitch slope, respectively. These two feature parameters are then used to form a two-dimensional vector, U = [ v I , v2], and vector quantization (VQ) codebooks with codebook size 16 for the four tones are trained using the weighted mean square error as the distortion measure, in which the inverse of covariance matrix is taken as the weighting function. Three-state, left-to-right hidden Markm models (HMM) are then developed based on these vectors and used to recognize the tones [16]. The above system parameters have been optimized with respect to a database in which eight males and eight females each uttered about a hundred different syllables, each with four different tones, and it was found that the average recognition rate for the tones is 98.3% for speaker dependent case, and the algo- rithm can be easily implemented on a personal computer.
Combining the results for the final, initial and tone recognition, the total recognition rate for the syllables is only on the order of
RESULT FOR T H E S Y L L A B L E S
701
-
Energy 300.
P i t c h
-
contour for [iu-33100 ’ 0 100 200 3 0 0 400 KM 600 700 800 900 IO00 1100 as (a) -Energy P i t c h c o n t o u r 300 250 200 1 50 100 50 0 100 200 300 400 500 600 700 800 900 IO00 1100 as (b)
Fig. 8. The pitch contours for (a) a third tone with only the first half and (b) a fourth tone.
85.9%. This number is relatively low. However, considering the fact that the Mandarin syllables are highly confusing and the rec- ognition rate of 60-70% for the standard approaches of dynamic time warping or hidden Markov models, LPC and Itakura distance measures [ 101, very significant improvements have been made and the results are rather satisfactory.
VII. FORMATION OF W O R D HYPOTHESES FROM S Y L L A B L E S This is the next level operation in our recognition hierarchy, or the first part of the second subsystem. It transforms the series of input syllables into corresponding characters in forms of possible monosyllabic and multisyllabic word hypotheses. Its operation will be described here using the previously mentioned example. The output characters and word hypotheses for the example, [ni-3] [shr-4] [i-21 [$a41 [huei-41 [tieng-I] [guo-2] [iu-3] [de-5] [dian-41 [nan-31, is shown in Fig. 9 . First, all multisyllabic word hy- potheses which can be found by matching with the words in the dictionary will be obtained, such as the word hypotheses
‘ ‘ @ B
(Suitable, [shr-4] [i-2]),” “
@ %
(Move, [i-2] [jia-41),” “EEl$j
(Mandarin, [guo-2] [iu-3]),”
‘‘ZM
(Computer, [dian-41 [nau-3]).” Note that the first two are incorrect word hypotheses, but the last two are desired words. Secondly, all syllables which cannot form multisyllabic word hypotheses with adjacent syllables on its left or right must correspond to monosyllabic word hy- potheses. But usually more than one monosyllabic words can share the same syllable, therefore only the most frequently used and sec- ond frequently used (if any) monosyllable word hypotheses will be found from the dictionary and given, such as‘‘4%
(You)” and ‘‘@ (Plan)” for [ni-31 “ $?(Can)” for [huei-41, and “ E ( L i s t e n to)”and ‘‘ hall)" for [tieng-11. Thirdly, if some of the syllables in the multisyllabic word hypotheses obtained in the first step corre-
702 IEEE TRANSACTIONS ON PATTERN ANALYSIS A N D MACHINE INTELLIGENCE. VOL. 12. N O . 7. JULY 1990
[ni-3]
-
fi (You). gi (Plan)1shr41 4 & p (Suitable) --+
-
(Are). P (Affair) L (A)Ii-’l
I-+
8 % (Move)Ljia-41 + ‘I(Set), I (Drive)
lhuci-41
-
pI (Can)[tieng-I] + & (Listen To), I (Hall) I g U 0 - 2 I
llu-3,
}+
&E- (Mandarin)Lk-51 --t 8t/ (mat)
ldian-41 --+ E (Shop)
:E (Rain)
)-*
s
(Computer)1st step 2nd Step 3rd Step Fig. 9. The steps in word hypothesis formation from syllables. Only the
underlined words are correct.
Matching With the
Words in Dictionary
spond to very frequently used monosyllabic words, such as
‘ ‘ z
(Are)” and “0
(Affair)” for [Shr-41, “ ~~- (A)” for [i-2], ‘‘%(Set)” and “ E ( D r i v e ) ” for [jia-41 in the multisyllabic word hy- potheses ‘‘
%I?
(Suitable, [Shr-4] [i-2])” and “88%
(Move, ti-21[jia-41)” in the above example, these very frequently used mono- syllabic word hypotheses are also given. In other words, the op- eration tries to provide all possible multisyllabic and monosyllabic word hypotheses which can be found in the dictionary.
In the dictionary, the words are organized in a special structure called word trees such that all words (monosyllabic and multisyl- labic) having the same first syllable will be organized in the same tree, and all words in the same tree having the same second syllable will be organized under the same node, etc. Such a structure will improve the searching speed in matching processes. In order to reduce the total number of words which have to be stored in the dictionary, some additional word formation rules are designed to generate new words from given words in the dictionary [ 171. For example, a verb followed by the character “@’ ([guo-4]) simply represent the past tense, such as “ G ( E a t , [chr-11)” and
“B”
form“ UZB(Ate, [chr-1] [guo-4]),”
“%
(See, [kan-4)),” and“B’
form
‘‘%B
(Saw, [kan-41 [guo-4]),” etc. Also, a very large num- ber of nouns can be formed by combining two other nouns. For example, the nouns‘ ‘ w
(Pig, [ju-11)” and“F8
(Meat, [rou-4])” form a new noun “ (Pork, [ju-1] [rou-4])” based on very sim-ple general rules, etc. According to these word formation rules, it is estimated that the total number of commonly used Chinese words which have to be stored in the dictionary can be reduced from about 80 thousand to about 35 thousand.
Some additional word deletion rules are also designed such that redundant or impossible word hypotheses can be automatically de- leted without going to the syntactic level [17]. One example rule is as follows. Any shorter word hypotheses within a longer word hypothesis should be deleted if they do not extend across the boundary of the longer word hypothesis. For example, the shorter word hypotheses “
S;.J
(Taiwan, [tai-21 [wan-11)’’ and‘‘A!$!
University, [da-41 [shiue-21)” will both be deleted if the longer word hypothesis “
b@
(Taiwan University, [tai-21 [wan-1][da-41 [shiue-2])” exists and only this longer word hypothesis will be left. Another example rule tells that all word hypotheses which cannot be connected by other word hypotheses on both ends (ex- cept in the sentence beginning and ending positions) should be de- leted. For example, for the four syllables [jueng-l] [wen-21 [shu-l] [ru-4], the word hypotheses “ @* (Chinese Character, [jueng-11
[wen-2]),” “
$$A
(Input, [shu-1] [ru-4]),” ‘‘+
(Center,[jueng-l]),” ‘‘
2%
(Documents, [wen-21 [shu-11)” will all be formed, but only the first two will be left and the last two will be deleted because the syllable [ru-41 cannot represent a monosyllabic word in today’s Chinese sentence and therefore the word hy- potheses ‘‘ +(Center)” and ‘‘2 3
(Documents)” cannot find any word hypothesis to be connected to the right, thus should be de- leted. Structure of the Dictionary Input SyllablesI
I IA
I
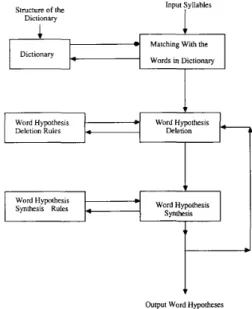
I IOutput Word Hypotheses Fig. 10. The complete word hypothesis formation processes.
The above word hypothesis formation process is summarized in Fig. 10, which has been successfully implemented on a VAX mini- computer using Franz Lisp. The primary problem is that to build a large enough dictionary is a very time consuming task. Therefore our first phase dictionary consists of 5 thousand words only, which practically limits the possibility of a complete and rigorous test, but the feasibility to transform syllables into word hypotheses is completely demonstrated as discussed earlier.
VIII. S Y N T A C T I C A N A L Y S I S T O I D E N T I F Y C O R R E C T W O R D S This is the highest level operation in our recognition hierarchy, or the second part of the second subsystem. The input is the set of all possible monosyllabic and multisyllabic word hypotheses cor- responding to the recognized syllables. The goal is to find the only correct combination of these word hypotheses which form a gram- matically valid sentence. The approach is simply to take all pos- sible combinations of the word hypotheses and parse them one by one based on a Chinese grammar [18], [19]. The ungrammatical combinations will be ruled out and only the correct solution will be left and shown on the screen. There are a few cases in which two combinations are both grammatically valid, or none of the combinations are valid. In both cases the output will be either a random choice or a most probable choice (for example, with the most frequently used monosyllabic word hypothesis).
A syntactic analysis system for Chinese sentences (SASC) is employed here to parse the possible sentences and rule out ungram- matical combinations [20], [21]. In the SASC system, Chinese sen- tences are syntactically analyzed from the viewpoints of generative grammar. It uses a bottom-up parser instead of a top-down parser, because the former tends to be more efficient for Chinese sentence analysis. The parser uses charts as global working structures, be- cause many natural language processing systems have proved the chart to be an efficient data structure to record what has been done
so far in the course of parsing. A parser based on charts can avoid
the inefficiency in duplicating many computations that a top-down parser often suffers when backtracking occurs. The parser parses sentences in such a way that phrases are built up on the chart by starting with their heads and adjoining constituents on the left or right of the heads. For example, according to the phrase structure rule
(PSR),
“ N P --t Q PE,’’
N (noun) is the head of NP (NounIEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE. VOL. 12, NO. 1. JULY 1990 703 NP by starting with the noun and adjoining the preceding quantity
phrase (QP). According to the PSR, “VP +
5
NP,” V-n (tran-sitive verb) is the head of VP (Verb Phrase). When encountering a transitive verb, the parser’s action is similar except that it tries to adjoin the following NP as its object. But if its following NP is not yet parsed by the parser, the expectation to build a VP is suspended until an NP is built up in the object position. The parser using the above algorithm constructs syntax trees of input sentences exactly from bottom to top. The algorithm used seems to be a good com- bination of data-driven parsing and hypothesis-driven parsing. The grammar used is a modification of ATN grammar, which is made up of states classified into HEADS (Head State) and STATE. A state indicates a stage of parsing and describes the information and actions needed to deal with the current situation. A list of some fundamental PSR’s for Chinese sentences implemented in our sys- tem is shown in Fig. 11.
In order to solve the complicated syntactic phenomena such as passivization, relativization, topicalization, and Ba-transformation in Chinese sentences, a raise-bind mechanism based upon the lin- guistic theory of empty categories is developed [21). In this way, the SASC parser will treat the above different transformations very easily in the same way, i.e., if an empty element is inserted into the right position, the syntactic structure will become easy. Fig. 12 lists some typical examples of Chinese sentences with empty categories to be used in analysis. In sentences (1)-(6) the solid lines indicate the antecedant of each empty category. The notation [ s
. . .
] denotes the presence of a clause. The missing element in sentence (7), however, does not refer to any element within the sentence. For these sentences, the parser first generates an empty NP inserted into the vacant position where an NP is expected to appear. Then the empty NP will be raised up in some way along the parsing tree, when the tree is growing up (recall that the parser works bottom-up), until its antecedant is parsed. At this point, the parser binds the empty NP by setting it to refer to its antecedant. Once being bound, the empty NP will not be raised any further. This is because an empty NP has exactly one antecedant and cannot be bound more than one time. Using this approach, many syntact- ically valid sentences can be easily parsed.The SASC has been successfully implemented on a VAX mini- computer using Franz Lisp. The parsing operation can be per- formed with very high speed. In average it takes only 15
-
20 ms per word to parse the sentences. Due to the limited vocabulary of the dictionary implemented in the system as discussed previously, only preliminary tests can be performed. However, the results show that at least 92-95 % of sentences in Chinese textbooks of primary schools in this country can be successfully analyzed by the system, if the words used are already in or keyed into the dictionary.IX. PRELIMINARY TEST RESULTS A N D CONCLUDING REMARKS All the different operations described above have been success- fully implemented individually. The recognition of finals, initials, and tones of syllables are separately implemented on three IBM personal computers with additional TMS 320 signal processing boards. They all work in real-time (the recognition is completed in 0.2 s), but the recognition rates are slightly worse than the software simulation results described previously. The word hypothesis for- mation and syntactic analysis operations, on the other hand, are implemented in a VAX 11/785 minicomputer. They work well ex- cept for problems with a relatively small dictionary which limits the scope of practical tests. Although the integration of different parts into a single system is currently in progress, these individual operations are connected to perform some preliminary dictation tests. The text for the test sentences is taken from everyday news- papers and read in isolated syllables by the same speaker as in the training of the syllable recognition systems. New words have to be keyed into the dictionary if they are not in the dictionary already. The syllables together with at most two other confusing syllables
( l ) S = b a r + S-bar PRTAG I S PKUG (2) S-bar + Topic S
(3)s + (NP) VP
(4) NP + (XPDE) (QP) (AD]) H I
(QP) (XPDE) (ADJ) I NP !&€&SI
(5)XPDE + S INP 9 IPP
(6)VP + (AUX I ADV I PP I NP)* l5bl (7) V-bar -+ Y QP I Y SI y W ADVl
y (NP) (NP I PP I VP I S I S-bar)
(8)PP + PREP NP
Fig. 11. The list of some fundamental PSR’s for Chinese language used in our system.
( I ) ba-transformation:
%
a
(you) ma) &)
&?)
(a&ctma&er) (empty)I I
( You hun him.) (2) passivization:
fk $d c tsa 7
(he) (by) (you) (hurt) (aspect marker) (em ty) -
I
( He was hurt by you.) (3) topicalization:
81% w
m
a 4a (that) (dog) (I) (never) olaveseen) (empty)7 I
( I have never seen that dog.) 5iS R 4% ?€ 7
(4) relativilization:
(empty) (playing) (de) (kids) (gone) (aspect marker)
I -r
(The kids who were playing are gone.) (5) null pronominals:
L Biz ilrs .
ole) (ur) I S (empty) (escape) 1
V i sto escape.)
( 6 ) pivot construction:
C 04 E
ex
.h e , (ask) (kids) [ S (empty) (takedumer)l
( He asked the kids
-
to take dinner.) (7) zero pronoun:C
sf&
ole) ( l i e ) (empty)
( He likes it.)
Fig. 12. Some typical examples of Chinese sentences with empty cate- gories to be used in analysis.
(if any) can be recognized in real-time and sent to the VAX com- puter for higher level recognition. The problem with higher level recognition is that very often large numbers of word hypotheses give hundreds of possible combinations for syntactic checking even in a relatively simple sentence. It is therefore hard to tell now the average speed in dictating a sentence. Apparently, a more efficient algorithm is needed to direct the system toward most probable word hypothesis combinations instead of simply analyzing all of them exhaustively. A total of 600 sentences are dictated in the first phase test. The rate for syllable recognition (first choice) is on the aver- age 81.6% which is 4 . 3 % lower than the simulation result, but the final rate for dictation (i.e., the correction rate for the characters) is on the order of 88-90% depending on the text of the sentences. In other words, some errors made in the acoustic level can be fi- nally corrected in the syntactic level; this is the result of our hier- archical language recognition approach, and the number is close to the first phase goal of the research as described in the beginning. Further improvements should be made on each part of the system and there is still a very long way to go before a real-time, integrated