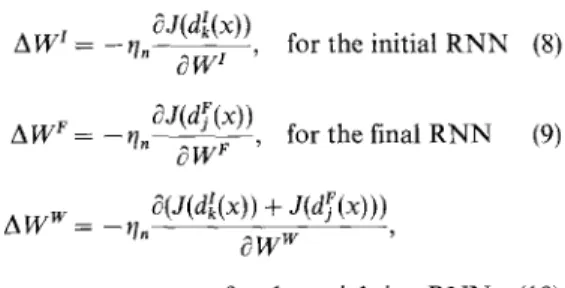Pergamon
Copyright @ 1995 Pattern Recognition Society Printed in Great Britain. All rights reserved 0031 3203/95 $9.50+.000031-3203(94) 00145-6
SPEECH R E C O G N I T I O N WITH H I E R A R C H I C A L
R E C U R R E N T N E U R A L N E T W O R K S
WEN-YUAN CHEN*, Y U A N - F U LIAO and S I N - H O R N G CHEN
Department of Communication Engineering, National Chiao Tung University, Hsinchu, Taiwan, Republic of China
(Received 26 October 1993; in revised form 29 October 1994; received for publication 30 November 1994)
Abstraet--A hierarchical recurrent neural network (HRNN) for speech recognition is presented. The HRNN is trained by a generalized probabilistic descent (GPD) algorithm. Consequently, the difficulty of empirically selecting an appropriate target function for training RNNs can be avoided. Results obtained in this study indicate the proposed HRNN has the advantages of being capable of absorbing the temporal variation of speech patterns as well as possessing effective discrimination capabilities. The scaling problem of RNNs is also greatly reduced. Additionally, a realization of the system using initial/final sub-syllable models for isolated Mandarin syllable recognition is also undertaken for verifying its effectiveness. The effectiveness of the proposed HRNN is confirmed by the experimental results.
Speech recognition Hierarchical Recurrent neural networks Generalized probabilistic d e s c e n t Discriminative training
l. INTRODUCTION
Speech is unmistakably produced by a slowly moving vocal tract. Features extracted from speech signals are therefore distributed over time in a complex manner. The temporally distributed features of speech signal make it difficult to recognize. The hidden Markov model (HMM) is a conventional method applied in coping with this difficulty. In HMMs, a speech pattern is treated as if it is the output of a stochastic system with its associated internal state being a process governed by probabilistic laws. In this sense, HMMs do not directly deal with time warping; however, they learn statistical distribution of a training set which contains time warped patterns, m Consequently, HMMs recognizing a test pattern which is far away from the statistical distribution of the training set would be rather unlikely. Conducting within-class training with- out competition with hostile classes is yet another vulnerability of HMMs; that is, they are trained with a maximum likelihood criterion. Hence, elements of confusing words are not emphasized as essential cues when distinguishing between them. Some criteria, e.g. the maximum mutual information, actually provide an approach of discriminative training for HMMs; how- ever, these criteria require much hypotheses to be solved.
Multi-layer perceptrons (MLPs), on the other hand, possess effective discrimination capabilities through competitive training for static patterns to produce outputs which discriminate between the classes to re- cognize. Since speech signal is inherently dynamic, a
* Author to whom all correspondence should be addressed.
network which accepts a stream of speech requires recurrent connections for maintaining a representation of previous cues. Unfortunately, the structure of MLPs being a feedforward network does not directly conform to the speech recognition because of no memory to represent the process of state transitions over time. Some approaches toward MLP-based speech recog- nition have been studied in recent years to solve the problem caused by temporal distortion in speech signal/2-6/The time delayed neural network (3) (TDNN) and the dynamic programming neural network (4) (DNN) are two typical examples of these approaches. T D N N deals with the time-alignment problem through the mapping of a temporal variation of the speech signal into interconnections which are present between neurons of different delay periods. The cells of the T D N N integrate activities from adjacent time-delayed vectors, which allows each vector to be separately weighted in time. Even so, T D N N does not work well for recognizing dynamic speech signals since the local features from adjacent time-delayed vectors do not directly contribute to the final classification. The D N N applies the conventional dynamic programming 17) (DP) algorithm toward optimistically aligning the MLP input cells with the input utterance. The DP, although an efficient strategy of searching for the optimum path among all L L possible paths, still requires ~ O ( L 2) operations, (1~ where L is the frame length of the input. Additionally, one operation here represents all of the calculations involved in evaluating the score of one path. The DP is later demonstrated here as not being required whenever using the proposed HRNN. This exclusion is a dramatic saving in the computation power.
796 W.-Y. CHEN et al.
The conventional neural network architectural con- figurations have obtained a high recognition rate for small vocabulary speech recognition. If these confi- gurations are extended for large vocabulary speech recognition, however, the training time becomes exces- sively large according to the scale of the network. Moreover, searching for an optimal solution in the solution space of a large network configuration be- comes increasingly difficult and causes the network to fall into local minima instead of the global minimum. A large network also requires a substantial amount of training data; otherwise, the network simply memorizes the training samples, thereby resulting in a poor gene- ralization. Some approaches based on hierarchical neural nefworks have already been studied in light of the fact that scaling up a conventional network for large vocabulary speech recognition is not realis- tic. (8-13) In hierarchical neural networks, each indivi- dual network is only faced with a partial task of solving a large problem in its entirety and, consequently, can be trained with less training samples. Additionally, the experimenter has the option of assigning subproblems to individual networks as well as structuring communi- cation between networks in a manner that reflects knowledge of the domain. (14) Matsuoka et al. ~ 2) pro- posed an integrated neural network, which consists of a control network and several sub-networks, to re- cognize 62 syllables. Hampshire II and Wiabel (l°'lx) proposed the Meta-Pi network consisting of a multi-network T D N N which performs multi-speaker phoneme discrimination (/b, d, 9/). The Meta-Pi archi- tecture is a multi-source connectionist pattern classifier that is comprised of a number of source dependent sub-networks that are integrated by a combinational superstructure. Hild and Waibel (9~ improved multi- state T D N N (MS-TDNN) for speaker independent connected letter recognition by exploring network architectures with "internal speaker models". How- ever, all of these systems are implemented in MLP- based neural networks which have inherited the draw- backs from MLPs. Some of these systems are only appropriate in dealing with static patterns. Others deal with the temporal problem using either the T D N N structure or the DP algorithm.
The architectural configuration of RNN is one in which the state of the network at any time depends on a complex aggregate of previous inputs. Consequently, RNN-based systems more easily catch dynamic in- formation than those MLP-based systems. Nossair and Zahorian ~ 5~ demonstrated that features extracted from dynamic spectrum are superior to features ex- tracted from the static spectrum. RNNs are therefore potentially suitable for recognizing speech patterns. However, two main limitations involving application of RNNs to speech recognition still remain unsolved and require further studies, i.e. the selection of appro- priate target functions for training the network as well as its applicability toward large vocabulary speech recognition. The desired outputs of RNNs must be expressed as functions of time, as indicated in previous
studies. (16'iv) The setting of proper target functions over time is rather critical for RNNs because it deter- mines how the network's weights can be updated. The setting target functions for RNNs is totally different from the approach of training a static network, e.g. an M L P , by setting fixed desired targets for a specific input pattern. The selection of appropriate time- dependent target functions is unfortunately still an empirical process. The limitation of applying an RNN to large vocabulary speech recognition is a scaling problem. The RNN should be sufficiently large to discriminate all of the word patterns in the vocabulary. However, the learning time and the number of weights required for accurately distinguishing all word patterns would grow exponentially and become unacceptable as the network becomes large.
A hierarchical RNN (HRNN) system for speech recognition is proposed in this study. Speech signal of an utterance is first phonetically divided into sub-word units. Each subword unit is then separately discrimina- ted using an RNN. Next, a sequence of RNNs formed by serially cascading these basic RNN recognizers is utilized as the syllable recognizer. Besides, an addi- tional RNN is employed in generating weighting func- tions for softly segmenting the input utterance as well as for unequally combining outputs of the sequential network. The segmentation of the input utterance is notably a soft one. This system is suitable for large- vocabulary speech recognition applications in light of the fact that sub-word units are adopted herein. Additionally, a novel training scheme based on a gene- ralized probabilistic descent (GPD) algorithm (is) is also introduced for training the HRNN. The difficulties of empirically selecting appropriate target functions for training RNNs can be avoided by using the G P D competitive training algorithm. The proposed HRNN has the advantages of absorbing the temporal variation of speech patterns as well as possessing efficient dis- crimination capabilities.
This paper is organized as follows. The proposed H R N N system for speech recognition is presented in Section 2. A realization of the system based on initial/ final sub-word models for Mandarin syllables recogni- tion is also discussed. Performance of the system is examined by simulations discussed in Section 3. Conclusions are finally made in Section 4.
2. HIERARCHICAL R E C U R R E N T N E U R A L NETWORKS
2.1. Recurrent neural networks
The architectural configuration of the basic RNN used in this study is shown in Fig. 1. In the RNN, outputs of hidden units are delayed and fed back as supplementary inputs of the network. The activation function of output neuron k at time n is defined as
Ok(n) = • wk jO j(n) (1)
J
where Wkj is the feedforward connection strength from hidden neuron j to output neuron k. Additionally, Oj
I
0 / ~ i ~ k j . . . ,Q output layer hit ,
'eden
layer - - L ' J - " ' - ; ' - i " > " " ~ " ' " L ) input layerxl(n) xi(n)
Xrn(n)
input featuresFig. 1. The architectural configuration of a recurrent neural network. Previous outputs of hidden nodes are fed back to inputs. All nodes in the input layer are fully connected to the
nodes in the hidden layer.
is the activation function of hidden n e u r o n j, defined as
Oj(n)
= Sigmoid(netj(n)) (2)netj(n) =
Z w jixi(n) Jr- ~ r jlOl(n --
1)i l
where Sigmoid() is a sigmoidal function defined by Sigmoid(x) = 1/(1 + e-~);
O~(n -
1) is the activation value of hidden n e u r o n l at time n - 1;rjz
is the recurrent connection strength from hidden n e u r o n 1 to hidden n e u r o n j; andx~(n)
is the input value of input n e u r o n i at time n.2.2.
The proposed H R N N for Mandarin speech
recognition
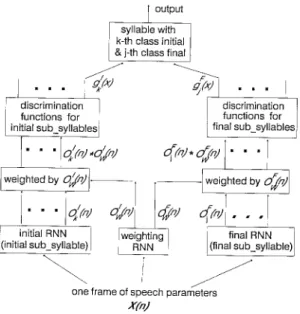
Each character in M a n d a r i n speech is p r o n o u n c e d as a syllable. An isolated M a n d a r i n syllable can be phonetically decomposed into initial a n d final sub- syllable units. Only 22 initials, including a d u m m y one, and 39 finals are available in M a n d a r i n speech. The initial of a syllable is simply composed of a single c o n s o n a n t if it exists at all. As a result of the simple phonetic structure, all of the 408 M a n d a r i n syllables form m a n y confusing sets because m a n y syllables have rather similar p h o n e m e constituents. A H R N N speech recognition system is proposed here for discriminating between isolated M a n d a r i n syllables. The H R N N is composed of a sequential network and a weighting RNN. The sequential network utilizes sub-syllables, i.e. initials a n d finals, as basic recognition units in this study. By decomposing each M a n d a r i n syllable into an initial a n d a final, two separate R N N s are contained in the sequential network a n d employed so as to dis- criminate them, respectively. Also, the weighting R N N is applied towards producing two weighting functions for segmenting the input utterance as well as for un- equally emphasizing the outputs of these two RNNs. By serially cascading these two weighted RNNs, a H R N N is formed a n d taken as the syllable recognizer. The block diagram of the proposed H R N N , as com- posed of two R N N s a n d a weighting RNN, is displayed
I output I syllable with
k-th class initial I & -th class final J
I " "
r discrimination ] functions for initial sub syllable~
[wei?hted bY .02z"J 1 - - mite RNN
i(initial
sub_syllable) discrimination functions for i final sub_syllable4 nj.4nj •. "!
- - _ _ ~ w e i g h t e d by oF~Tfl weighting ] final RNN i RNN I(final sub_syllable) Ione frame of speech parameters
XfnJ
Fig. 2. The proposed hierarchical recurrent neural networks (HRNN) composed of three RNNs. The initial RNN and the final RNN are employed to distinguish initial sub-syllables and final sub-syllables, respectively. The weighting RNN is applied towards producing two weighting functions for seg- menting the input utterance as well as unequally emphasizing
the outputs of initial and final RNNs.
m Fig. 2. Discriminant functions for initial a n d final sub-syllables can be calculated by
L 1
gl(x) = ~ Ol(n)O{v(n),
for initials (3) n = 0L 1
gf(x) = ~ Of(n)Ofv(n),
for finals (4) n = owhere L is the length of the input utterance;
Of(n)
andOf(n)
are the kth output of the initial R N N and t h e j t h output of the final RNN, respectively; a n dO~(n)
a n dv
Ow(n)
are t h e weighting functions produced by the weighting R N N for the initial a n d the final RNNs, respectively. The final decision rule involves selecting candidates for the initial a n d the final with maximal discriminant functions. The input utterance is recogni- zed as a syllable which has the kth class of initials ifg[(x) > g[(x)
for all l ¢ k and the j t h class of finals ifgf(x) > gf(x)
for all 1 ¢ j .2.3.
Applying a GPD algorithm for training the H R N N
Recently, Juanget el.
have proposed a G P D algo- rithm for speech recognition./is 2°) The G P D algorithm, which is a systematic training algorithm employed for minimizing the recognition error rate, is adopted in this study for training the H R N N . The procedure of applying the G P D algorithm towards training the weights of the H R N N is stated as follows. Two mis- classification measures for an input utterance x with the kth class of initial and the j t h class of final are defined on the basis of the discriminant functions of798 W.-Y. CHEN et al. equations (3) and (4): I I 1 d~(x) = [ --gk(x) + gp(X)3~ (5) r 1 dr(x) = [ - g f ( x ) + gq(X)] L (6)
where p and q are the most probable incorrect classes of initial and final, respectively. Next, a loss function
J(d) is defined for evaluating the costs of the current
decisions for the initial and the final sub-syllables. The loss function should be a monotonically increasing, differentiable function. If a well approximating 0 - 1 cost function is used for J ( d ) , J 1 = Z x J ( d ~ ( x ) ) and
j r = 3 ~ , j ( d f ( x ) ) would approximately represent the total recognition errors of initials and finals, respec- tively. The sigmoidal function shown below
1
d(d) (7)
1 + e - v d
is selected in this study as the loss function J(cl), where v is a scalar to control the rate of adjustment. The loss function J(d) would clearly induce the training algo- rithm for emphasizing those utterances which are loca- ted at a short distance from the decision boundary; in addition, the scalar v serves to scale that distance. The objective of the G P D algorithm involves recursively adjusting the weights of the H R N N so as to achieve a m i n i m u m of j1 and j r . The a m o u n t of weight change in the H R N N can be expressed through the G P D algorithm as
AW t = --t/, , for the initial R N N (8)
g W ~ Oj(dr(x))
A W e = - - t / n - - , for the final R N N (9) g W F
g(J(d~(x)) + J(df(x))) A W w = - r l ,
O W w
for the weighting R N N (10) where q~ is the learning rate at the nth iteration. The scheme of selecting a proper learning rate can be found in K o m o r i and Katagiri's study) 21) These three deri- vative terms can actually be c o m p u t e d via application of the chain ruleJ 22) The training of the H R N N c a n b e accomplished by applying a bootstrap strategy. The training procedure is described as follows:
Step 1 - - r a n d o m l y initialize all of the weights of
these R N N s to small values;
Step 2 - - s e g m e n t each training utterance into two
parts, i.e. an initial and a final, by using the gene- ralized m i n i m u m distortion segmentation ( G M D S ) m e t h o d J TM Modify these two segments such that they are overlapped by several frames. D a t a in b o t h seg- ments are used in training the weighting R N N by the standard error back p r o p a g a t i o n (EBP) training alg0r- i t h m ) 21) The target for the o u t p u t node associated with initial (final) weighting function is set to 1.0 when
the input signal lies in the initial (final) segment, and 0.0 otherwise. This procedure is repeated for several passes of the training set until it converges;
Step 3 - - m a i n t a i n all of the weights of the weighting
R N N fixed. Next, apply the G P D algorithm towards training the initial and the final R N N s by using equa- tions (8) and (9);
Step 4 - - k e e p all of the weights of the initial and the
final R N N s fixed. Next, retrain the weighting R N N by the G P D algorithm using equation (10); and
Step 5 - - s t e p s 3 and 4 are iterated until a convergence
is reached.
3. S I M U L A T I O N S
3.1. Database
The performance of the proposed speech recognition m e t h o d was examined by simulations on a multi- speaker speech recognition task. A database (241 con- taining utterances of 54 confusable M a n d a r i n m o n o - syllables with the first tone was employed in the test. These 54 syllables are the set of all possible combina- tions of 22 initials and four finals i n c l u d i n g / e n / , / e n g / , /in/, and ring/. Table 1 lists these 54 syllables with a numerical label set to indicate a legal c o m b i n a t i o n of initial and final. Each of these 54 syllables was pro- nounced three times by seven males and four females. T w o repetitions of each speaker were used for training and the remaining one repetition for testing. O n e other speaker, a female, uttered each syllable 13 times, i.e. 10 times for training and three times for testing. There were a total of 1728 training utterances and 756 testing utterances. All speech signals in the database were digitized into 16-bit data format at a rate of 8 k H z and pre-emphasized with a high-pass filter, 1-0.98 z - 1. Next, a short-time spectral analysis by 256:point F F T was performed over every 32 ms H a m m i n g - w i n d o w e d frame with 8 ms frame shift. A bank of filters (in mel- scale) was then implemented to extract 12 log-com- pressed energies from the spectrum of each frame. 12 delta log-compressed energies were also calculated for each frame. The recognition features include these 24 parameters.
Table 1. 54 Mandarin monosyllables with the first tone. These 54 syllables are the set of all possible combinations of 22
initials and four finals
b d p t m n I j(i) oh(i) s(i)
en 1 2 3 4 5 eng 6 7 8 9 10 11 12 in 13 14 15 16 17 18 19 20 21 ing 22 23 24 25 26 27 28 29 30 31 32 j ch sh dz ts s h f g k r en 33 34 35 36 37 38 39 40 41 42 43 eng 44 45 46 47 48 49 50 51 52 53 54
3.2.
Experimental results and analysis
The effectiveness of the proposed H R N N speech recognizer was next examined by using the database. As mentioned previously, the H R N N is comprised of a sequential network and a weighting RNN. The se- quential network is composed of two RNNs, one for initial sub-syllables and the other for final sub-syllables. The number of output nodes was set to 22 for the initial RNN, and four for the final RNN. Two output nodes were used for the weighting R N N so as to produce two weighting functions for initial and final sub-syllables, respectively. The number of hidden units was empiri- cally selected to be 48 for the initial RNN, and 24 for the other two RNNs. Input features for all three RNNs consisted of 12 log-compressed energies and 12 delta log-compressed energies generated from frame-based spectra. Two other parameters were also set for training the HRNN. The learning rate q, in equations (8)-(10) was initially set to 0.1 and then linearly decayed with time. The scalar v of the loss function used in the G P D training algorithm was set to 1.
Table 2 summarizes the recognition results attained by the proposed H R N N recognizer. A recognition rate of 73.5% was achieved. Notably, the values shown in parentheses indicate the numbers of correct classifica- tions out of 756 testing utterances. For performance comparison, the continuous density hidden Markov model (CDHMM) method was also tested. Each syl- lable used in the C D H M M method was modelled by a six-state left-to-right network with a single transition. The observation features in each state were modelled by a five-mixture Gaussian distribution. As shown in Table 2, the recognition rate achieved by the C D H M M method was 67.2%. Obviously the proposed method performed much better in the study than the C D H M M method.
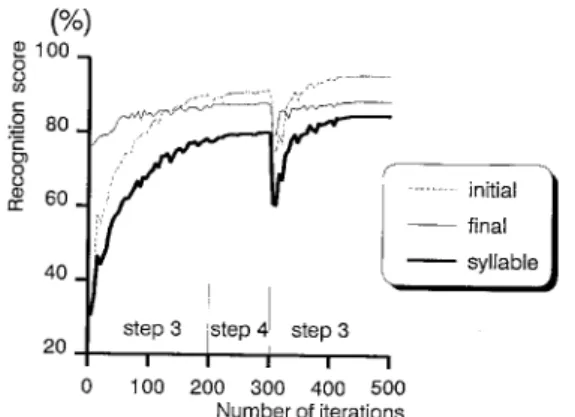
Detailed analyses of the H R N N are worthwhile since a better understanding regarding its behaviors can be obtained and may be conducive for further improvement in future studies. The learning curves of the H R N N for training data were first scrutinized. Figure 3 shows the learning curves of recognition rates for initial sub-syllables, final sub-syllables, and syllables. The weighting RNN had been initially trained with the EBP algorithm discussed in Steps 1 and 2 of the H R N N training procedure described in Section 2.3. This figure displays the training results of the G P D algorithm which alternately executes Steps 3 and 4 of the HRNN training procedure. This same figure reveals
Table 2. The recognition results of 54 confusable Mandarin monosyllables. The figures in parentheses indicate the number of correct classification. The total utterance for testing is 756
Initial Final Syllable
CDHMM 67.2% (508) RNNs based 88.8% 81.1~ 73.5% (671) (613) (556)
(%
100
8 if)g 80,
o60.
r c40.
!
step 3 iO tep
step 3
20
i
'
i
i
0
100 200 300 400 500
Number of iterations
... syllablefinalinitial
i
Fig. 3. Learning rates of the initial sub-syllable, the final sub-syllables, and the syllable corresponding to the number of learning iterations. The three RNNs had initially been trained by using the EBP training algorithm. Next, the training on the HRNN was directed by interlacing the training pro-
cedure of Step 3 or Step 4.
that all three learning curves increase gradually as the training procedure progresses until the 300th iteration. They all fall abruptly at the 301th iteration and then rise again thereafter. This phenomenon is accounted for as follows. At the end of the 300th iteration, one complete training process from Step 1 to Step 4 had just been performed for the HRNN. Both initial and final RNNs had been properly trained in Step 3 with the guidance of the initially-trained weighting RNN. Furthermore, the weighting RNN had been updated in Step 4. The training procedure then jumped to Step 3 at the 301th iteration to retrain both initial and final RNNs with the guidance of the updated weighting RNN. Due to the fact that the effective initial/final boundaries of many syllables determined by the old weighting RNN were inaccurate and had been corrected by the updated weighting RNN, a portion of training data which was previously guided by the old weighting RNN to train the initial (final) RNN was switched to train the final (initial) RNN with the guidance of the updated weighting RNN, This effect causes the abrupt fall off these three learning curves at the 30 lth iteration. Fortunately, the updated weighting RNN performed better than the original one so as to guide the retraining process in a correct direction. All three learning curves went up as the training procedure was continued and converged to better recognition rates.
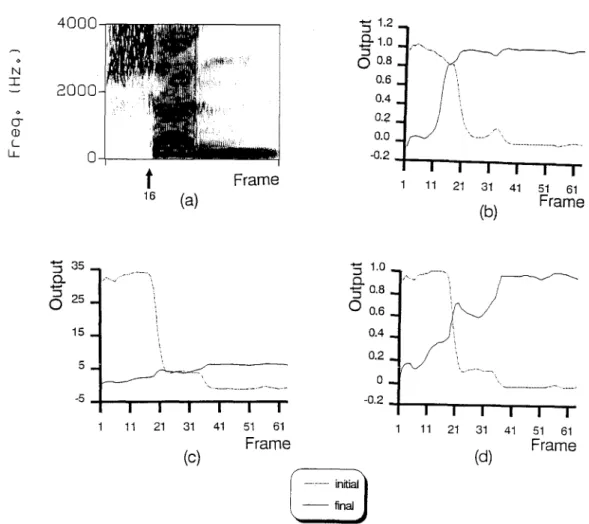
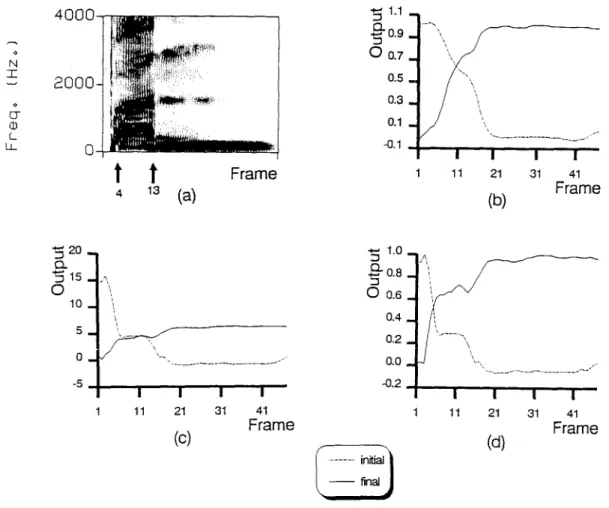
Next, the effectiveness of the weighting RNN in assisting the discrimination of confusing syllables and on softly segmenting the test utterance was examined by observing the weighting functions it produced. An example is shown in Fig. 4. The spectrogram of the utterance/sh-~n/is first displayed in Fig. 4(a). A spec- trogram is a three-dimensional pattern showing the magnitude spectrum on grey-level display with time and frequency taken as the horizontal and the vertical axes, respectively. This figure indicates that the genuine initial-final boundary located at the 16th frame was accurately detected by the GMDS method. Figure 4(b)
800 W.-Y. CHEN et al. ¢. U q- <, o - (_ I J_
4 0 0 0
2000-
0
f
Frame
16 ( a ) *-' 1.2 'm 121-1. 0 'm 0 0.8 0.6 0 . 4 _ 0 , 2 _ 0 . 0 _ -0,2, I I I I I I 11 21 31 41 51 61Frame
(b)
-1 3 5 _ 0..0 25_
15_ 5 _ -5i
J I I I 11 21 31(c)
I I I 41 51 61Frame
" " 1.0 m D.. '0,-' 0.8 0 o.6_ 0 . 4 _ 0 . 2 _ O _ -0.2 I .---., ... initial~ f i n ~ J~
f----.---vF--~
I I I I I I 11 21 31 41 51 61Frame
(d)
Fig. 4. Analysis of the weighting RNN. (a) the spectrogram of an input utterance/sh-~n/and the initial-final boundary segmented by a GMDS method is at the 16th frame. Outputs of the weighting RNN: (b) result of an initial training procedure by using the EBP training algorithm, (c) result of the complete training procedure by using the proposed GPD training algorithm, (d) normalized result of (c) such that peak values
of two functions are equal to 1.
displays the weighting functions generated by the weighting RNN trained in Step 2 of the HRNN training procedure with targets set on the basis of the segmenta- tion result from the GMDS method. This figure reveals that these two functions can be approximately regarded as 1 0 and 0-1 step functions to indicate the ini- tial and the final parts of the utterance, respectively. Figure 4(c) displays the weighting functions generated by the updated weighting RNN trained in Step 4 of the HRNN training algorithm. This same figure reveals that both of these two functions give different weights to the three acoustic events of the utterance. Additionally, the initial weighting function gives a very heavy weight to the initial, light weight to the vowel, and a very light weight to the nasal. On the contrary, the final weighting function gives a heavy weight to the nasal, light weight to the vowel, and a very light weight to the initial. The overall effects of these two weighting functions specially emphasize the initial part of the input signal as well as emphasize the nasal part of the input signal. According to the phonetic structure of Mandarin syllable, initial and nasal are the two most important parts to distin-
guish these 54 syllables. Therefore, using these two weighting functions can assist the H R N N syllable re- cognizer in increasing its discrimination capability. To verify the effectiveness of the updated weighting RNN in segmenting the input utterance, the weighting func- tions displayed in Fig. 4(c) are normalized with peak values set to 1. Figure 4(d) shows these two normalized weighting functions. This figure indicates that the initial- final boundary can still be correctly detected. Another example using an utterance of/b-~n/is shown in Fig. 5. Similar results have been found from the figure except for that the initial/final boundary determined by the old weighting RNN is an incorrect one. This would result not only in providing unsuitable weighting func- tions to the initial and the final sub-syllables for final decision, but also in misguiding the training of the initial and the final RNNs. Fortunately, as shown in Fig. 5(d), the mis-segmentation had been corrected in the updated weighting function. Actually, in the training process, many mis-segmentations occurred for utter- ances with voiced plosive initials having very short durations had been corrected by the updated weighting
o N 52 o ET d) (._
t
1'
Frame
4
13
(a)
"~ 1.1 1 - 0 . 9 O 0.7 0.5 0.3 0.1 -0.1 II
I
I
11 21 31 41Frame
(b)
" " 20 O_ " ~ 1 5_
O
1 0 _ 5 _ 0 _ - 5I
I
I
I
11 21 31 41Frame
(c)
• ,~ 1 . 0 _ '--iQ.
.-, 0.8_
-1
0 0.6_
0 . 4 m0,2 _
0.0 -0.2Q ... initial~
final J
I
I
I
'I
11 21 31 41Frame
(d)
Fig. 5. Analysis of the weighting RNN. (a) the spectrogram of an input utterance/b-~n/and the boundaries segmented by the GMDS method and a manual vision are located at the 13th and fourth frames, respectively. Outputs of the weighting RNN: (b) result of an initial training procedure by using an EBP training algorithm, (c) result of the complete training procedure by using the proposed training procedure, (d) normalized result
of (c) such that peak values of two functions are equal to l.
RNN. The benefit of correcting mis-segmentations is two-fold. One advantage is to provide correct and appropriate weighting functions to unequally empha- size different parts of input signal for discriminating confusing syllables. The other is to correctly guide the training for both the initial and the final RNNs. Some utterances which were previously mis-classified can therefore be correctly recognized.
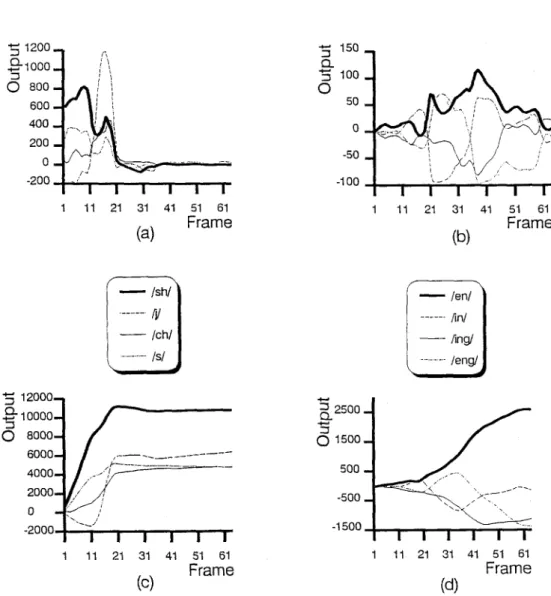
An examination is then made of the effect of combin- ing the outputs of the initial and the final RNNs with the weighting functions generated by the weighting RNN for syllable recognition. An example to recognize an utterance o f / s h - ~ n / i s shown in Fig. 6. Weighted scores for initial and final sub-syllables are obtained by multiplying the initial and the final weighting func- tions to the corresponding outputs of the initial and final RNNs. Figure 6(a) and (b) display the weighted scores for the best four initial sub-syllables and for the four final sub-syllables, respectively. Their cumulative weighted scores are displayed in Fig. 6(c) and (d). Figure 6(a) and (c) indicate that the final part of the input utterance starting from the 20th frame to the
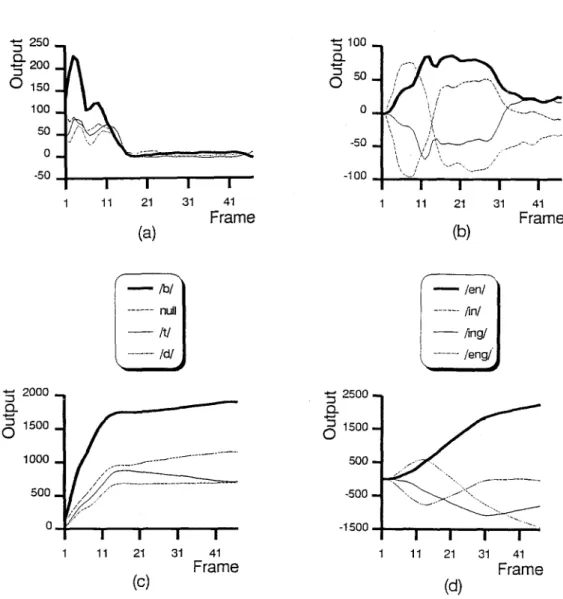
ending frame makes almost no contribution to the cumulative weighted scores of initials. Similarly, as shown in Fig. 6(b) and (d), the contributions from the initial part to the cumulative weighted scores of finals are negligible. The discriminant functions of syllables for final recognition decision are calculated by simply combining the corresponding cumulative weighted scores of initial and final sub-syllables. In this example, the utterance was correctly recognized. Figure 7 pro- vides yet another example which recognizes an utter- ance of/b~n/. Similar results can also be found in this figure.
From above analyses, we can conclude that a well- trained weighting RNN is capable of generating proper weighting functions to unequally emphasize acoustic events relevant to speech discrimination as well as softly segment the input utterance. Finally, no dynamic programming is notably required to be performed in the HRNN to optimally map the input testing utterance to the sequential network. Hence, the recognition pro- cess can be made more efficiently.
802 W.-Y. C H E N et al. • ~ 1 2 0 0 . ~0"-1000_
0 800
- 600 - 400 - 200 . 0 . -200 P~/i
i . i i I I I I i I 11 21 31 41 5~ 61 F r a m e(a)
"-' 150 Q.~
loo 0 50 0 -50 -100 - " ... , I I I i I I 11 21 31 41 51 61 F r a m e(b)
i
r . / s ~ i fj/ /ch",, ... Is~ j
/enl )
/eng/J 12000- ~Q'IO000-0
8000- 6000- 4000~ I 2000-- 0 - -2000&2soo_
0 1 6 0 o _ 500 - -500 _ / / t " ' - ~ / -1500 I I I I I I 11 21 31 41 51 61 F r a m e(c)
I i I I I I 11 21 31 41 51 61 F r a m e(d)
Fig. 6. For an input utterance/sh-~n/, the best four weighted outputs of the initial RNN, (b) weighted outputs of the final RNN, (c) the best four discrimination functions for initials, (d) discrimination functions
"-' 250 0.. ~-- 2 0 0 _ 0 1 5 o . 100 _ 50 -50 I I I I 11 21 31 41
Frame
(a)
"*-'100 Q_ 500
0 -50 -100 / I I I 11 21 31 41Frame
(b)
Iq
. . . nl - -
L
. . ./d/j
i en," I
/in/ /
/ing/.J
/ e n g / J -'-' 2000 0.. ..¢-., D 15000
1000 _ 500 _ ~-~ ~ 0 0~,.,..,.
....
~Q-
15000
500 -500, -1500 I I I I 11 21 31 41Frame
(c)
I I I I 11 21 31 41Frame
(d)
Fig. 7. For an input utterance/b-en/, (a) the best four weighted outputs of the initial RNN, (b) weighted outputs of the final RNN, (c) the best four discrimination functions for the initial RNN, (d) discrimination
804 W.-Y. CHEN et al.
4. CONCLUSIONS
A novel hierarchical R N N - b a s e d a p p r o a c h for speech r e c o g n i t i o n was p r o p o s e d in this study. T h e p r o p o s e d m e t h o d has successfully solved the t i m e - a l i g n m e n t p r o b l e m a n d retains the merit of c o m p e t i t i v e l e a r n i n g of artificial n e u r a l n e t w o r k s via using a n H R N N net- work with a discriminative training algorithm. Besides, the a p p l i c a t i o n of sub-syllable r e c o g n i t i o n units h a s m a d e it p o t e n t i a l l y suitable for scaling u p to a large v o c a b u l a r y application. Validity of the p r o p o s e d ap- p r o a c h was c o n f i r m e d via s i m u l a t i o n s o n a multi- speaker speech recognition of recognizing 54 confusable M a n d a r i n syllables. E x p e r i m e n t a l results c o n f i r m e d t h a t the a p p r o a c h o u t p e r f o r m s the C D H M M m e t h o d . E x t e n d i n g this a p p r o a c h t o w a r d s a p p l i c a t i o n of iso- lated speech r e c o g n i t i o n for all 408 M a n d a r i n syllables w o u l d be a w o r t h w h i l e task in future r e s e a r c h efforts.
Acknowledgement--This authors wish to thank Telecom-
munication Labs, Ministry of Transportation and Communi- cations, Republic of China, for their support of the database. They also wish to thank the anonymous reviewers for their insightful comments of the paper.
REFERENCES
1. G.Z. Sun, H. H. Chen, Y. C. Lee and Y. D. Liu, Time warping recurrent neural networks, Proc. Int. Jt Conf.
Neural Networks ( I J C N N ) , Vol. I, 431 436 (1992).
2, W. Y. Chen and S. H. Chen, Word recognition based on the combination of a sequential neural network and the G P D M discriminative training algorithm, Proc. IEEE
Neural Networks for Signal Processing (NNSP). pp. 376-
384 (1991).
3. K. J. Lang and A. H. Waibel, A time-delay neural network architecture for isolated word recognition, Neural Net-
work 3, 23-43 (1990).
4. H. Sakoe, R. Isotani, K. Yoshida, K. Iso, and T. Watanabe, Speaker-independent word recognition using dynamic programming neural networks, Proc. IEEE Int. Conf.
Acoustics, Speech and Signal Processing (ICASSP), pp.
29-32 (1989).
5. K.I. Iso, Speech recognition using dynamical model of speech production, Proc. IEEE Int, Conf. Acoustics,
Speech and Signal Processing (ICASSP), Vol. II, pp.
283-286 (1993).
6. J. Tebelskis, Performance through consistency: connec- tionist large vocabulary continuous speech recognition,
Proc. IEEE Int. Conf. Acoustics, Speech and Signal Proces- sing (ICASSP), Vol. II, pp. 259-262 (1993).
7. H. Sakoe and S. Chiba, Dynamic programming algorithm optimization for spoken word recognition, IEEE Trans.
Acoust. Speech and Signal Process. 26, 43-49 (1978).
8. Y. Chen, B. Yuan and B. Lin, Real time Chinese syllable
recognition with hierarchically structured neural network and transputer system, Proc. Int. dt Conf. Neural Net-
works ( I J C N N ) , Vol. IV, pp. 743 748 (1992).
9. H. Hild and A. Waibel, Multi-speaker/speaker indepen- dent architectures for the multi-state time delay neural network, Proc. 1EEE int. Conf. Acoustics, Speech and
Signal Processing (ICASSP), Vol. II, pp. 255-258 (1993).
10. J. B. Hampshire II and A. H. Waibel, The meta-pi net- work: connectionist rapid adaption for high performance multi-speaker recognition, Proc. IEEE Intern. Conf.
Acoustics, Speech and Signal Processing (1CASSP), pp.
165-168 (1990).
11. J. B. Hampshire II and A. Waibel, The meta-pi network: building distributed knowledge representations for robust multisource pattern recognition, IEEE Trans. Pattern
Analy. Mach. IntelL 14, 751-769 (1992).
12. T. Matsuoka, H. Hamada and R. Nakatsu, Syllable recognition using integrated neural networks, Proc. Int.
Jt Conf. Neural Networks ( I J C N N ), Vol. I, pp. 251-258
(1990).
13. A. Waibel, H. Sawai and K. Shikano, Modularity and scaling in large phonemic neural networks, IEEE Trans.
Acoust. Speech Signal Process. 37. 1888-1898 (1989).
14. R.A. Jacobs, Initial experiments on constructing do- mains of expertise and hierarchies in connectionist systems,
Proc. Connectionist Models Summer School, San Mateo,
CA, pp. 144-153 (1988).
15. Z. B. Nossair and S. A. Zahorian, Dynamic spectral shape features as acoustic correlates for initial stop consonants,
J. Acoust. Soc. Am. 89(6), 2978-2991 (1991).
16. S. J. Lee, K. C. Kim, H. Yoon and J. W. Cho, Application of fully recurrent neural networks for speech recognition.
Proc. IEEE Int. Conf. Acoustics, Speech and Signal Proces- sing (ICASSP), pp. 77-80 (1991).
17. G. Kuhn, Connected recognition with a recurrent net- work, Speech Commun., 9, 41-48 (1990).
18. S. Katagiri, C. H. Lee and B. H. Juang, New discrimi- native training algorithms based on the generalized prob- abilistic descent method, Proc. IEEE Neural Networks
for Signal Processing ( N N S P ) , pp. 299-308 (1991).
19. P. C. Chang and B. H. Juang, Discriminative training of dynamic programming based speech recognizes, IEEE
Trans. Speech Audio Process. 1(2), 135 143 (1993).
20. B. H. Juang and S. Katagiri, Discriminative training, J.
Acoust. Soc. Jpn (E) 13(6), 333-339 (1992).
21. T. Komori and S. Katagiri, G P D training of dynamic programming-based speech recognizers, d. Acoust. Soc.
Jpn (E) 13(6), 341-349 (1992).
22. D. E. Rumelhart, G. E. Hinton and R. J. Williams, Learn- ing internal representation by error propagation, in
Parallel Distributed Processing: Exploration in the Micro- structure of Cognition. The MIT Press, London (1986).
23. S. H. Chen and Y. R. Wang, Vector quantization of pitch information in Mandarin speech, IEEE Trans. Comm. 38(9), 1317 1320, (1990).
24. J. S. Liou, R. G. Chert, S. M. Yu, J. R. Hwang and I. C. Jou, The speech database of Telecommunication Labora- tories, Ministry of Transportation and Communications, R.O.C., Proc. of Telecommunications Syrup., Taiwan, pp. 128 132 (1990).
About the Author--WEN-YUAN CHEN received the B.S. and M.S. degrees from the National Taiwan Institute of Technology, Taipei, Taiwan, and the National Tsing Hua University, Hsinchu, Taiwan, in 1985 and 1987, respectively, both in electrical engineering. Currently he is working toward a Ph.D. in electronic engineering at National Chiao Tung University, Hsinchu, Taiwan. Since 1987, he has been with Industrial Technology Research Institute, Hsinchu, Taiwan where he is involved in research work on speech recognition and audio signal processing. His current interests include speech recognition, pattern recognition and audio signal processing.
About the Author--YUAN-FU LIAO received the B.S. and M.S. degrees in 1991 and 1993, respectively, and has been a Ph.D. student since 1993, all in the communication engineering of National Chiao Tung University, Taiwan. His current research interests include speech recognition, neural networks for signal processing.
About the Author--SIN-HORNG CHEN received the B.S. degree in communication engineering and the M.S. degree in electronics engineering from National Chiao Tung University, Hsinchu, Taiwan, Republic of China, in 1976 and 1978, respectively, and the Ph.D. degree in electrical engineering from Texas Tech University, Lubbock, in 1983. Form 1978 to 1980, he was an Assistant Engineering for Telecommunication Laboratories, Taiwan. He became an Associate Professor at the Department of Communication Engineering, National Chiao Tung University in August 1983, and a professor in August 1990. He also became the Chairman from August 1985 to June 1988, and from October 1991 to August 1993. He is currently doing research in the areas of digital communication and speech processing, specially concentrating on the problems of Mandarin speech recognition and text-to-speech.