行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※
※ ※
※ 利用樹狀決策架構製作關鍵詞辨認系統 ※
※ ※
※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:v個別型計畫 □整合型計畫
計畫編號:NSC89-2213-E-009-119-
執行期間:88 年 8 月 1 日至 89 年 7 月 31 日
計畫主持人:王逸如
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
執行單位:國立交通大學電信工程學系
中 華 民 國 89 年 9 月 10 日
行政院國家科學委員會專題研究計畫成果報告
利用樹狀決策架構製作關鍵詞辨認系統
The Keywor d spotting system using decision tr ee cluster ing
計畫編號:NSC89-2213-E-009-119-
執行期限:88 年 8 月 1 日至 89 年 7 月 31 日
主持人:王逸如 國立交通大學電信工程學系
計畫參與人員
:游山瑞、謝寶華、周樂生
一、中文摘要
本計畫使用決策樹方式建立國語 411 音節之右 文相關之聲韻母 HMM 模式作為一個關鍵詞 辨認系統中之關鍵詞模式,並利用決策樹方式 產生一套較粗糙之右文相關模式來做為填充 模式,以期獲得較佳之關鍵詞辨認系統。 在計畫中,首先使用 MAT-2000(電話語音)作 為訓練語料,利用決策樹建立右文相關之韻母 辨認模式,對 500 句測試語料可獲得 67.3%的 辨認率。在關鍵詞辨認系統之製作,關鍵詞辨 認使用上述辨認模式,填充模式則使用一組較 粗糙之右文相關模式,對一個以 1013 個人名 為 關 鍵 詞 的 電 話 號 碼 查 詢 系 統 上 , 可 得 到 86.43%的關鍵詞辨認率(FOM 為 0.38FA/KW/hr)。 關鍵詞:決策樹分類、關鍵詞辨認、相似度量 測、關鍵詞確認Abstr act
In this project, we improved our previous HMM models, containing 100 RFD initial and 40 CI final models, by using a decision-tree clustering method to refine these 40 final models into a set of RCD models. Performance of the method was examined by experiments using the MAT-2000 telephone-speech database as the training data and a 500-utterance set as the testing data. A recognition rate of 67.3% was achieved. A keyword-spotting system was then constructed by using these RCD HMM models in keyword recognition with filler models formed from coarser CD models found by the decision-tree clustering method. A keyword recognition rate of 86.43% with FOM of 0.38FA/KW/hr was achieved in a telephone number inquiry system with 1013 keywords.
Keywords: Decision tree clustering、Keyword
spotting、Similarity measure、Keyword Verification
二、緣由與目的
在經電話網路語音辨認應用系統,常是目的明 確的簡單對話系統。因為在許多電話語音辨認 的應用中,只要關鍵詞辨認正確即可。一個成 功的關鍵詞辨認系統可以讓許多語音辨認之 應用成真。三、研究報告內容
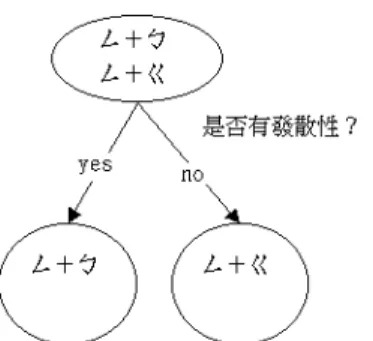
本計畫首先利用決策樹方法來建立 HMM 國語 語音辨認模型。HMM 辨認系統中採用『梅爾 倒頻譜參數』(Mel-ceptrum feature),並且是 混 合 高 斯 的 由 左 至 右 隱 藏 式 馬 可 夫 模 型 (Mixture Gaussian HMM),加入通道和語者 效應的消除(signal bias removal),而以加瑪 (Gamma)分布模擬模型中之狀態長度分布。 1. 決策樹之原理與製作步驟 利 用 決 策 樹 的 分 裂 產 生 右 文 相 關 的 韻 母 模 型。這種結合語音學和語言學的方法使得相關 模型的產生較為客觀,以下是整個決策樹分裂 的流程: (A)根節點的選取 針對我們所要處理的聲母或韻母,把其特徵參 數集合起來成為一個根節點(root node)。所以 如果我們有 40 種不相關韻母模型,則有 40 個 根節點,每個節點皆可自行長出一棵樹,所以 共可長出 40 棵決策樹。 (B)問題集的選取 根據韻母右邊所接的聲母,利用問題集裏的問 題,把根節點分成符合此問題跟不符合此問題 兩群資料,求出分成兩群資料與原來一群資料 間所相對應之相似度改變量(ΔL)。以ㄥ+ ㄅ及ㄥ+ㄍ為例,見圖 1。 對於問題集的選取,是採用中文的發音特性 【1】,來訂出合適的問題【2,3】,並配合中 文之聲母、韻母特性把問題集做一個整理。 (C)分裂的標準 一個母節點利用一個問題可分裂成兩個的子 節點時,其相似度(maximum likelihood)的變 化以ΔL 代表。對不同問題如果ΔL 大,表示圖 1 決策樹利用問題做資料分裂示意圖。 此問題可以把母節點內語料分成兩個差異性 較大的子節點。每次分裂都是以擁有最大的相 似度變化的母節點來分裂,則可以想見,這棵 決策樹最後剩下的末節點(left node)彼此間 的相似度變化應是最大的。不同模型間彼此差 異性大,也表示所得的每一個模型其所含特徵 參數的分布是最相似的【4】。 在此計畫中採用的相似度改變量有兩種: (1)假設特徵向量呈高斯函數分布,則相似度的 比值(likelihood ratio)
λ
,表示當一個高斯分 布分成兩個高斯分布時相似度的變化。而且λ
是對平均的相似度比值和變異量的相似 度比值的乘積【5】: ) log (log cov meanL=− λ + λ ∆ (1) 2 2 1 1 2 1 2 2 1 ( ) ( )) 1 ( n t mean u u W u u n n n − − − − × + = λ ; 2 / ) 1 ( 2 1 cov | | | | | | n W Σ ⋅ Σ = α −α λ ; 2 2 1 1Σ + Σ = n n n n W , n n1 = α ; 其中
u
i、Σi及ni是兩個子節點資料特徵參數 的平均向量、變異量矩陣及資料數目;其中變 異量矩陣假設為 diagonal。 (2)如果根據一些假設條件經過適當的簡化,可 以得到下面公式: ) ( | | log | | log | | log ) ( 2 1 2 2 1 1 2 1 n n n n n n L + Σ × − Σ × − Σ × + = ∆ (2) (D)停止分裂的條件 停止分裂的條件有二【6】:一為節點內的音 框數太少;一為最大相似度變化(ΔL)過小。 (E)合併 如果最後所得的模型數太多,則對所有葉節點 (leaf nodes)找出其分裂時之ΔL 小的兩個節點 合併回去,直到模型數符合所需。 2. 利用決策樹製作右文相關模式之辨認效果 訓練語料是使用「台灣之國語語音資料庫」 (MAT)中的第四(短句詞彙)與第五(平衡 長句)部份,總共約 48 萬個音節。測試語料 是 TEST-500,是 1998 年語音辨認評比時採用 之自行測試語料,其中包含 50 句單音節、150 句短句詞彙及 300 句平衡長句,總共有 4731 個音節。 基本系統是以100個韻母相關的聲母模型,40 個不相關韻母模型(independent final models) 做辨認,基本系統的辨認率為63.94%(插入及 刪除型錯誤率個為1.84%及1.14%)。其餘兩組 實驗則是把韻母利用決策樹方法做聲母相關 的韻母模型。在表1中使用相似度改變量量測(1) 及不同模型數目,可以發現模型數量越多,辨 認率越高。在表2中則比較使用相似度改變量 量測之辨認結果。 表 1. 使用相似度改變量量測(1)及不同模型數 目之辨認率。 Number of RCD final modelsIns(%) Del(%) Sub(%)
Syllable correct rate (%) Female:386 Male :293 4.0 0.7 28.7 66.7 Female : 293 Male : 293 3.7 0.7 29.4 66.3 Female : 240 Male : 240 3.6 0.7 29.6 66.1 表 2.使用不同相似度改變量量測之辨認結果之 比較。 Measures and Number of RCD final models
Ins(%) Del(%) Sub(%)
Syllable correct rate (%) Measure (1) Female:293 Male :293 3.7 0.7 29.4 66.3 Measure (2) Female : 290 Male : 290 3.8 0.6 28.3 67.3 3. 關鍵詞辨認系統 本系統是多關鍵詞系統。測試語料則從工研院 電話分機查詢系統挑出 500 句查詢人名的語 料。共 1144 秒,包含 239 個音節。系統是以 1013 個人名為關鍵詞,加入光速搜尋法。在搜 尋多條最佳路徑時採用 A* algorithm,並以詞 為單位【7】,做最佳路徑的選擇,辨認結果 為詞組序列(word sequence),而我們僅留下關 鍵詞之資料,每一個詞組序列可能包含多個關 鍵詞。 在本計畫中之關鍵詞辨認器中,對關鍵詞部份 使 用 gender-dependent 的 context-dependent model(100 韻母相關的聲母模型及 250 個聲母
相關的韻母模型,40 個不相關韻母模型)。並 且對辨認結果認為是關鍵詞的音框其辨認分 數加一個正的嘉獎量。所使用之填充模式則為 下列幾種精細程度不同的聲韻母模式: (A)填充模型 A:100 個韻母相關的聲母模型, 100 個聲母相關的韻母模型及 40 個韻母不 相關模型組成 411 個音節填充模型。 (B)填充模型 B:100 個韻母相關的聲母模型, 39 個不相關的韻母模型,組成 411 個音節填 充模型。 (C)填充模型 C:29 個不相關的聲母模型,39 個不相關的韻母模型,組成 411 個音節填充 模型。 對使用不同填充模式之關鍵詞辨認系統進行 測 試 。 在 此 光 束 搜 尋 法 中 的 光 束 寬 度 設 為 3000。 表 3. 利用不同填充模型所得之關鍵詞辨認結 果。 辨認率 % 假警報 (FOM) 填充模型 A top1 85.2 0.63 填充模型 A top10 92.4 0.34 填充模型 B top1 85.2 0.53 填充模型 B top10 93.4 0.44 填充模型 C top1 84.6 0.88 填充模型 C top10 89.2 0.63 由表 3 發現,模型數量的增加,可以得到一定 的好處,使用較粗略的填充模型辨認效果不佳 (填充模型 B、C)。因為用粗略的填充模型, 在不能明確的描述下,非關鍵詞會吃掉一些關 鍵詞的部份聲母,這都會造成關鍵詞辨認的困 擾。不過模型數持續的增加,並不能帶來更多 的好處,原因在於利用精細填充模型的辨認分 數跟關鍵詞非常相近且關鍵詞的位置較為準 確,此時嘉獎量只用來凸顯關鍵詞,嘉獎量太 大則會使長詞優先,並且產生過多的假警報; 太小則關鍵詞的分數會輸給由填充模型組合 而成的辨認分數。粗略的填充模型辨認的分數 低,而且不夠精確,所以嘉獎量大,可以使關 鍵詞容易凸顯,並彌補關鍵詞前後因填充模型 粗略所喪失的分數。 4. 關鍵詞的確認 在前節關鍵詞 Top n 之辨認,找出多條最佳路 徑後,必須在做確認的工作(verification)。在此 必須定義新的關鍵詞辨認分數,再重新挑出最 佳的關鍵詞。 假警報的產生,往往都是因為短詞效應,原因 在於系統對辨認成關鍵詞的部份加上一個嘉 獎量,且輸入的語音要和一個短詞相似較為容 易。結果造成原本沒有關鍵詞的地方,多辨認 出一個關鍵詞,即假警報。所以假設真正關鍵 詞每個音節的平均音框長度會比假警報來的 長。另外,由於每個單音辨認的難易度不同, 有些單音本身就很容易和別的音混淆,辨認分 數低,因此絕對的分數沒有太大意義,應該要 和此時其他填充模型的分數做比較,求出相對 的分數,才能去除語者效應和音節辨認分數上 的差異。 在關鍵詞辨認時,我們留下與關鍵詞切割位置 最接近的填充模型字串之辨認分數,並考慮音 框數不同的情況,關鍵詞與填充模式辨認分數 均除以音框長度作為關鍵詞確認時之輸入參 數。此外,因為假警報發生不但此短詞發生機 率較高,而且常常音節長度也十分的短(會得到 較高的 per frame 分數)。所以在此,定義了兩 個參數作為確認步驟的輸入參數: Score_Ratio = (關鍵詞分數/關鍵詞音框數) (非 -20 -15 -10 -5 0 5 10 0 10 20 30 40 50 60 70 80 Ratio fra m e /( s y l n u m b e r) -20 -15 -10 -5 0 5 10 0 10 20 30 40 50 60 70 80 Ratio fra m e /( s y l n u m b e r) 臨界線 臨界線 (a) 關鍵詞特性圖 (b) 假警報特性圖 圖 2. 關鍵詞與假警報的確認參數之分佈情形。
關鍵詞數/非關鍵詞音框數) Lengthen = 關鍵詞音框數/關鍵詞音節數 在圖 2 中,標示了關鍵詞與假警報這兩個確認 參數之分佈圖。我們可以訂定一個確認函式(臨 界線)來參除部分假警報。從表 4 中也看到在設 定臨界線後,Top-10 之辨認率雖然有些許下 降,不過卻能刪除大量假警報。 辨認率 假警報 (FOM) 拒絕率 原本 Top10 93.41% 0.44 0.002 經確認後 90.62% 0.25 0.004 表 4. 經確認後假警報與辨認率關係圖。 接著我們要從 Top 10 關鍵詞組序列中找出最 佳詞組序列,由於在每個詞組序列中關鍵詞之 總長度不同,且每個音節的辨認分數都不一 樣,其長度也有所不同,所以我們從訓練語料 裏對每個音節求出每個音框之平均辨認分數 及平均音框數,進而得知其平均長度的辨認分 數。有了此項依據,就可以把各關鍵詞組的辨 認分數正規化(normalization)再做比較。挑 選一句裡面含有比平均長度辨認分數高最多 的關鍵詞為最後結果。除了針對關鍵詞辨認分 數,還可以加入關鍵詞長度跟一般平均長度的 考量。首先,我們定義:Score 為關鍵詞的辨 認分數;Frame為關鍵詞的音框長度;關鍵詞
之平均音框分數S =Score/Frame,Scoreest為從
訓 練 語 料 估 計 出 的 關 鍵 詞 平 均 辨 認 分 數 ;
Frameest為從訓練語料估計出的關鍵詞平均音
框 長 度 ; 關 鍵 詞 之 估 計 平 均 音 框 分 數
est est
est Score Frame
S = / 。由於辨認的分數是取 對數後的結果,所以比較時是採用相減運算。 實驗結果於表 5 中: 關鍵詞重排名之量 測值 辨認率 假警報 FOM 拒絕 率 est S S− 82.24% 0.44 0.02 (S−Sest)+Weight* (Frame/Frameest) 86.43% 0.38 0.004 表 5. 關鍵詞組重排名後之結果。 從上面的結果可以看出考慮平均長度分數的 因素,效果較好,如此便去除了不同音節辨認 分數不同造成比較的不公平。而對於關鍵詞的 長度部份,對辨認分數加入一個跟平均長度有 關的分數後效果確有改善。 5. 結論 在關鍵詞辨認問題中,較粗糙的填充模式,雖 可以將非關鍵詞的辨認分數降低並降低假警 報,但是隨之而來的是切割位置較不正確,使 得關鍵詞的辨認分數下降。若將填充模型變的 較精細,雖然關鍵詞的切割位置可以較正確, 不過非關鍵詞的辨認分數將會提高,連帶的假 警報也會隨之提高。由於利用決策樹,我們可 以隨意的製造出想要的模型數,可訓練精細的 模型做關鍵詞辨認,較粗略的當填充模型,使 得填充模型可以有彈性的變化。在關鍵詞的確 認方面,我們首先僅用關鍵詞部分的辨認分數 刪除了一半的假警報。在利用正規化後之關鍵 詞辨認分數做關鍵詞確認工作。
四、計畫成果自評
利用決策樹方式建立國語 411 音節辨認器。(2) 建立一套較佳的關鍵詞辨認填充模式。(3)利用 (2)之填充模式建立一關鍵詞辨認系統。本計畫 中利用決策樹方式建立國語 411 音節辨認器結 果將發表於 2000 年國際中文語言處理研討會 (ISCSLP-2000)中【8】。五、參考文獻
【1】 國立台灣師範大學國音教材編輯委員編 纂, “國音學”,中正書局。 【2】 梁伯宇, “國語連續語音辨識之聲學模型 研究”,國立台灣大學碩士論文,民國八十 七年六月。【3】 Po-yu Liang, Jia-lin Shen, Lin-shan Lee, “Class-Triphone Acoustic Modeling Based On Decision Tree For Mandarin Continuous Speech Recognition “, ISCALP-98.
【4】 Julian James Odell, “The Use of Context in Large Vocabulary Speech Recognition”, Ph.D tesis, University of Cambridge, U.K., March 1995.
【5】 A. Kannan, M. Ostendorf, and J. R. Rohlicek, “Maximum Likelihood Clustering of Gaussians for Speech Recognition,” IEEE Trans. on Speech and Audio Processing. Vol. 2, NO. 3, pp.453-455, July 1994.
【6】 L. R. Bahl, P. V. de Souza, P.S. Gopalakrishnan, D. Nahamoo, M.A. Picheny, “Decision Trees for Phonological Rules in Continuous Speech,” IBM Research, T.J. Watson Research Center, IEEE 1991. 【7】 Mei-Yuh Huang, Xue-Dong Huang,
“Dynamically Configurable Acoustic Models for Speech Recognition,” ICASSP 1998, Vol. 2.
【8】 Yih-Ru Wang, and Ke-Shiu Chen, ' RCD Sub-Syllable Hmm Modeling By Decision Tree Clustering Using Mat-2000 Database, ', to be appeared in International Conf. on Chinese Spoken Language Processing 2000, Beijing, China, Oct. 2000.