All rights reserved. Printed in Great Britain 0031-3203/98 $19.00#0.00
PII: S0031-3203(97)00077-0
FAST FULL SEARCH IN MOTION ESTIMATION BY
HIERARCHICAL USE OF MINKOWSKI’S INEQUALITY
(HUMI)
-JING-YI LU, KUANG-SHYR WU and JA-CHEN LIN*
Department of Computer and Information Science, National Chiao Tung University, Hsinchu, Taiwan 30010, R.O.C.
(Received 21 March 1996; in revised form 19 November 1996)
Abstract—In this paper, we extend the idea of successive elimination algorithm (SEA) to obtain a fast full search (FS) algorithm accelerating the block matching procedure of motion estimation. Based on the monotonic relation between the accumulated absolution distortions (AAD) obtained for distinct layers of a pyramid structure, the proposed method successfully rejects many impossible candidates considered in the FS. The derivation of the monotonicity relation repeatedly uses in a four-dimensional vector space the
l1-version of Minkowski’s inequality, an inequality which is quite well-known in the field of mathematics.
Simulation results show that the processing speed is faster than that of several well-known fast full search methods, including the SEA that uses just once the Minkowski’s inequality (in a vector space of 256 dimension when the block size is 16]16). The processing speed of the proposed method is also competitive with that of the three-step search (TSS), which is often used for block matching in interframe video coding, although the visual quality performance of TSS is usually a little poorer than that of the FS. ( 1998 Pattern Recognition Society. Published by Elsevier Science Ltd. All rights reserved
Motion estimation Block matching Position vector Motion vector Accumulated absolute distortion Minkowski’s inequality l1-norm
1. INTRODUCTION
The block-matching algorithm (BMA) is popularly used for the motion estimation of interframe video coding. The ideal approach to BMA is the FS, which exhaustively searches for a block whose, say, accumu-lated absolute distortion (AAD) to an input block, is minimal among all possible blocks within a search window. Although the FS can find the optimal sol-tuion, i.e. the best-matched block mentioned above, the serious computation burden needed will make the hardware implementation difficult(1) if the window size becomes large (in the application to HDTV or super high-resolution TV). Many existing methods save computation but degrade the visual quality; examples include the TSS,(2) the orthogonal search,(3) or the two algorithms introduced in reference (4) which use alternating patterns. On the other hand, an elegant algorithm called the successive elimination algorithm (SEA) was developed recently in reference (5) by Li and Salari to alleviate the computation burder of FS while the visual quality was kept to be identical to that of the FS. Note that SEA used dir-ectly in a 256-dimensional vector space (if each block has size 16]16 and is treated as a 256-dimensional vector) the l1-version of Minkowski’s inequality—an inequality quite well-known in the field of
* Author to whom correspondence should be addressed. -This study was supported by the National Science
Coun-cil, Republic of China, under contract number: NSC86-2213-E009-108.
mathematics(6)—to eliminate impossible candidate vectors. Another technique widely used in industry is to use the partial distortion elimination(7) (PDE) to eliminate impossible candidates at certain stages be-fore completing the evaluation of the distortions from those impossible candidates to the discussed block. The PDE technique could also yield the visual quality identical to that of the FS.
In this paper, we extend the idea of SEA to obtain a pyramid based fast searching algorithm for the block matching. The monotonic relation between the AAD of distinct layers of the pyramid will be derived in Appendix A using in a four-dimensional vector space the l1-version of Minkowski’s inequality. With the derived monotonic relation, many impossible can-didates can be kicked out without doing time-con-suming computation. The proposed method keeps the good visual quality, i.e. the minimized AAD error, of the FS (and hence of the PDE and SEA), while the processing speed is greatly improved.
2. DEFINITIONS AND THE PROPOSED ALGORITHM
In this section, we define the AAD that will be used to measure the matching error for the block matching. For a specified block G of size 2N]2N [G will be referred to hereafter as the incoming (or input) block] in the current frame t, the corresponding AAD(x, y) is defined as
AAD(x, y)"2 N + i/1 2N +
j/1D f t(i, j)!f t~1(i#x, j#y)D.(1)
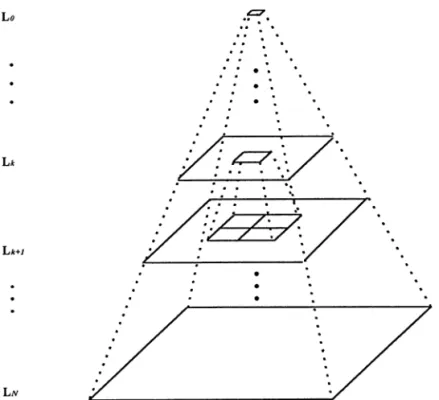
Fig. 1. The structure of the pyramid.
Here, ft(i, j) represents the gray value at pixel (i, j) of G in frame t, and ft~1(i#x, j#y) denotes the gray value at pixel (i#x, j#y) in frame t!1. As for the vector (x, y), which is called the position vector, de-notes the relative displacement of a candidate block (in the previous frame t!1) to the specified block G (in the current frame t).
In the BMA, the current frame t is often divided into non-overlapping blocks of size 2N]2N (16]16 in this paper, i.e. N"4). The goal of the BMA is to find for each block G its best position vector (m, n) within a search window W (in this paper the window size is (2N`1#1)](2N`1#1)"33]33) such that
AAD(m, n)" min ~2N4x, y4
2N
AAD(x, y). (2) Hereafter, the position vector which is the best among all 33]33 position vectors M(x, y)N will be called the ‘‘motion vector’’ (for the block G). The basic concept to obtain the motion vector (m, n) quickly is to elimin-ate from the candidelimin-ate space W those position vectors (x, y) which are impossible to be the best. We first review below a pyramid structure so that those im-possible candidates can be eliminated layer by layer. For every block B, the corresponding pyramid of (N#1) layers (from layer 0 to layer N) is a sequence ML0, L1,...,LNN, with each layer defined as follows: the layer LN of size 2N]2N is exactly the original block B, the LN~1 of size 2N~1]2N~1 is a size-reduced layer derived from LN, the LN~2 of size 2N~2]2N~2 is a size-reduced layer derived from LN~1,. . . , and finally, the layer L0, which consists of a single pixel only, is a size-reduced layer derived from L1 (see Fig. 1). For each layer Lk~1 (where 14k4N), each
pixel value fk~1(i, j) (where 14i42k~1 and 14j42k~1) is obtained by a summation of the 2]2 corresponding pixel values of Lk. In other words, the pixel values are computed by
fk~1(i, j)"fk(2i!1, 2j!1)#fk(2i!1, 2j)
#
fk(2i, 2j!1)#fk(2i, 2j)
for 14i, j42k~1 and 14k4N. (3) [To save computation, we do not want to divide the right-hand side of equation (3) by 4, although the division will make the value of fk~1(i, j) staying in the range 0—255.] Since each layer Lk can be considered as a (low-resolution) image (except that the pixel values are in fact the so-called ‘‘generalized’’ gray values because they are not in the range 0—255), the AADk(x, y) between layer Lk of an input G, and layer Lk of the block corresponding to a motion vector candidate (x, y), can be defined by generalizing equa-tion (1), namely, AADk(x, y)"2 k + i/1 2k + j/1D f tk(i, j)!f *t~1 ;(x, y)+ k (i, j)D for 04k4N. (4)
Here, the ftk(i, j) represents the (generalized) gray value at the (low-resolution) pixel (i, j) in layer Lk construc-ted from the 2N]2N block G in frame t; and
f*t~1;(x, y)+
k (i, j) denotes the (generalized) gray value at
the (low resolution) pixel (i, j) in layer Lk constructed from a 2N]2N block in frame t!1, with the center of that 2N]2N block being (x, y) units away from the center of the 2N]2N block G.
The relation among the AAD of distinct layers is introduced below. For two arbitrarily given sets P"Mp1, p2,...,pzN and Q"Mq1, q2,..,qzN of non-negative real numbers, where P and Q have the same number of elements, the l1-version of the very famous Minkowski’s inequality
DDP!QDD5DEPE!EQED
[see Theorem 8.13 of reference (6) for the definition and proof of the infinitely many versions l1—l= of the Minkowski’s inequality] implies that
z + i/1Dpi!qiD"EP!QE5DEPE!EQED "
K
+z i/1DpiD! z + i/1DqiDK
"K
+z i/1pi! z + i/1qiK
. (5)This well-known fact can also be interpreted geomet-rically as: in the l1-norm space (also know as the city-block-norm space), the triangular inequality still holds (the length of the third edge (p-q-) is not shorter than the difference of the lengthsEp-El
1and
Eq-El
1 of the two edges p-"( p1, p2,...,pz) and q-"(q1,q2,...,qz). The assumption pi50 and qi50 for all i makes Ep-El
1"+DpiD"+pi and
EquMEl
1"+DqiD"+qi when we evaluate the l1-norm).
According to inequality (5), the inequality AADk(x, y)5AADk~1(x, y) for 14k4N (6) can be proved (the proof is given in Appendix A). From the pyramid structure and equation (6), we can efficiently search for the motion vector, i.e. the best position vector. Without loss of generality, we assume that a part of the 33]33"1089 position vectors in W have been inspected; the ‘‘so far’’ best position vector is stored in (m, n); and the corresponding dis-tortion AAD(m, n) is stored in AAD.*/. Then the following corollary is always true:
Corollary. If AADk(x, y)5AAD.*/ for some
k 3M0, 1, . . . , NN, then
AAD(x, y)5AAD.*/,
i.e., in the previous frame t!1, the block obtained by translating the input block (x, y) units will not be better than the block obtained by translating the input block (m, n) units.
This corollary comes directly from equation (6): because AADN(x, y) is in fact AAD(x, y) and AADN(x, y)5AADN~1(x, y)5. . .5AAD0(x, y) al-ways holds by equation (6), we therefore obtain
AAD(x, y)"AADN(x, y)5AADk(x, y)5AAD.*/. Hence, (x, y) could not be better than (m, n), and thus, (x, y) should be rejected. Note that the computation of AADk(x, y) grows when k increases. More precisely, the computation load of AADk(x, y) is about four
times heavier than that of AADk~1(x, y). Therefore, the proposed algorithm uses the ‘‘top-down’’ ap-proach (from L0 to LN) to reject impossible candidates (x, y) layer by layer. Some are rejected in L0, some are rejected in L1, etc. Of course, the overhead to con-struct the pyramid (the concon-struction is bottom-up, however) should also be considered. But, we found that, even with this overhead, the total CPU time is still saved somewhat using the above corollary.
Note that if we let z"2N]2N"22N in equation (5), then
AAD(x, y)" + 14
i, j4
2ND f t(i, j)!f t~1(i#x, j#y)D
5
K
+ 14 i, j4 2ND f t(i, j)D ! + 14 i, j4 2ND f t~1(i#x, j#y)DK
by the definition (1) of AAD(x, y). SEA therefore elim-inates a position vector (x, y) if
K
+ 14 i, j4 2ND f t(i, j)D!14+ i, j4 2ND f t~1(i#x, j#y)DK
5 AAD.*/[whereas we eliminate (x, y) if AADk(x, y)5AAD.*/ for some k 3M0, 1, . . . , NN].
For the reader’s benefit, we give below the algo-rithm that utilizes the proposed method to eliminate those ‘‘impossible position vectors’’ for a given G. Note that the motion vector obtained for the corre-sponding block (i.e. the block having identical loca-tion as G) in frame t!1 is used as the initial guess for the motion vector (m, n) of G of the current frame t.
Algorithm
Goal: Find the motion vector, i.e. the best position
vector within a search window W in the pre-vious frame t!1 for an incoming block G in the current frame t.
Input: 1. An incoming block G of size 2N]2N
"16]16 in frame t.
2. 33]33"1089 candidates, i.e. 1089 posi-tion vectors, in W of frame t!1.
Output: The motion vector (m, n), i.e. the position of
the best-matched block.
Initial conditions: (1) Assume that the pyramids for
all blocks in frame t!1 have been established. (The over-head is only about 12 MH op-erations for the frame of size
M]H, as is shown in
Appen-dix B).
(2) Let the initial guess of the motion vector (m, n) be the motion vector obtained for the corresponding block of G in frame t!1.
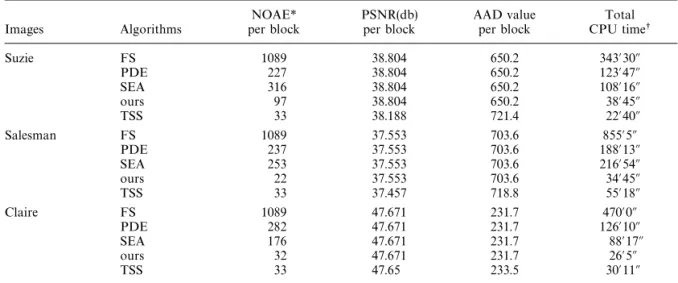
Table 1. Performance comparison among the five algorithms using different image sequences. NOAE meant the ‘‘number of AAD evaluations’’ needed for each block, although CPU time was for the whole sequence (150, 300, and 168 frames,
respectively)
NOAE* PSNR(db) AAD value Total Images Algorithms per block per block per block CPU times Suzie FS 1089 38.804 650.2 343@30A PDE 227 38.804 650.2 123@47A SEA 316 38.804 650.2 108@16A ours 97 38.804 650.2 38@45A TSS 33 38.188 721.4 22@40A Salesman FS 1089 37.553 703.6 855@5A PDE 237 37.553 703.6 188@13A SEA 253 37.553 703.6 216@54A ours 22 37.553 703.6 34@45A TSS 33 37.457 718.8 55@18A Claire FS 1089 47.671 231.7 470@0A PDE 282 47.671 231.7 126@10A SEA 176 47.671 231.7 88@17A ours 32 47.671 231.7 26@5A TSS 33 47.65 233.5 30@11A
* Preprocessing overhead (e.g. building the pyramids) was not included in NOAE, although the overhead for elimination test
(e.g. Step 5 of our algorithm) was included.
s CPU time included all overheads (preprocessing, elimination test, etc.).
Steps:
Step 1: Use Formula (3) to construct the pyramid
for G. [This construction uses additions only, and the number of additions used is not more than the additions used in equa-tion (1). Hence, doing Step 1 takes shorter CPU time than doing Step 2.]
Step 2: Evaluate the AAD for the initial guess (m, n)
and let AAD.*/"AAD(m, n).
Step 3: If all position vectors have been checked,
then go to Step 8.
Step 4: Pick up from the search window W a
posi-tion vector (x, y) which is not processed yet by Step 5.
Step 5: For k"0 to N do
if (AADk(x, y)5AAD.*/ for the current value of k) then delete (x, y) from W and go to Step 3.
Step 6: Replace the contents of AAD.*/ and (m, n)
by AADN(x, y) and (x, y), respectively. In symbol, AAD.*/QAADN(x, y), mQx, and
nQy. (This step updates the ‘‘so far’’
min-imal AAD and the ‘‘so far’’ best position vector.)
Step 7: Go to Step 3.
Step 8: Print out the final value of (m, n) because its
content now is indeed the motion vector.
3. EXPERIMENTAL RESULTS
In this section, the FS, PDE, SEA, TSS, and the proposed method are compared. Note that the partial distortion elimination (PDE) technique widely used in industry is to check the rth partial AAD
r
+
i/1
2N
+
j/1D f t(i, j)!f t~1(i#x, j#y)D
(7)
for r"1, 2, 3, . . . [see equation (1)] against the current AAD.*/ during the matching; should there exists an
r(2N making the partial AAD exceed the current
AAD.*/, then quit the summation process in equation (1) and kick out the impossible candidate vector (x, y) because it is trivial that the full sum in equation (1) would certainly be larger than equation (7), and hence larger than the current AAD.*/. Tables 1 and 2 illus-trate the performance of the FS, PDE, SEA, TSS and the proposed method by comparing the NOAE (num-ber-of-AAD-evaluations), total CPU time, AAD and PSNR values. Table 1 used three 288]352 luminance video sequences (Suzie, Salesman, and Claire), where-as Table 2 used three 176]144 luminance video se-quences (Car phone, Foreman, and Mother-and-daughter) grabbed from the International Telecom-munication Union. The total CPU time shown in Tables 1 and 2 includes the overhead. (Note that the FS, PDE and TSS have no preprocessing while the SEA and the proposed method have.) It is easy to see that the proposed method outperforms the other four methods. As for the values of AAD or PSNR, it can be seen that PDE, SEA and the proposed method pro-duce the same values as those of the FS. This should be of no surprise because they are just some kinds of fast implementation of the FS. The TSS, however, has worse values in both AAD and PSNR, because TSS is not a kind of FS. (The TSS uses a hard rule to by-pass many candidates without even giving these candidates a chance of being checked. Unfortunately, it happens quite often that some of these candidates by-passed by TSS are the ones that yield optimized match.)
In the column NOAE in Tables 1 and 2, the works to evaluate the AADk [defined in equation (4), 04k4N] for our method were all collected to-gether and expressed in terms of the work needed to
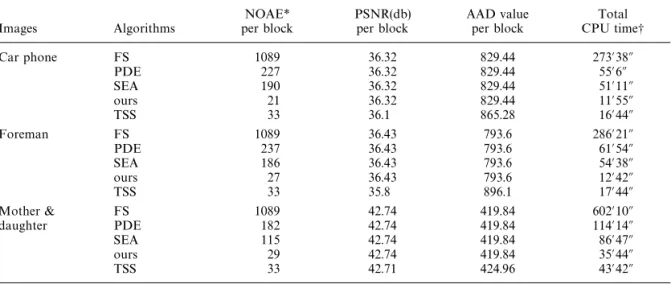
Table 2. Same as Table 1 except that other data were used. CPU time was for the whole sequence (382, 400, and 961 frames, respectively)
NOAE* PSNR(db) AAD value Total Images Algorithms per block per block per block CPU time-Car phone FS 1089 36.32 829.44 273@38A
PDE 227 36.32 829.44 55@6A SEA 190 36.32 829.44 51@11A ours 21 36.32 829.44 11@55A TSS 33 36.1 865.28 16@44A Foreman FS 1089 36.43 793.6 286@21A PDE 237 36.43 793.6 61@54A SEA 186 36.43 793.6 54@38A ours 27 36.43 793.6 12@42A TSS 33 35.8 896.1 17@44A
Mother & FS 1089 42.74 419.84 602@10A daughter PDE 182 42.74 419.84 114@14A SEA 115 42.74 419.84 86@47A ours 29 42.74 419.84 35@44A
TSS 33 42.71 424.96 43@42A
evaluate AADN. (If we consider the number of pixels in each layer, we can find that the work of each evaluation of AADN is approximately the work 41"4 evaluations of AADN~1, or, the work of 42"16 evaluations of AADN~2, etc.) Since AADN is in fact the traditional AAD defined in equation (1), the col-lection we just obtained can also be said to be ex-pressed in terms of the work needed to evaluate the traditional AAD. Therefore, this number was entered for out method in the column with the title NOAE. As for the NOAE of the PDE method, analogous proced-ure had been used to express the work for the rth partial AAD [see equation (7)] in terms of that for the full AAD [see equation (1)]. The detail is trivial and hence not explained here.
Note especially that, for the image sequence Sales-man listed in Table 1, averagely speaking [the average was taken not only between the (288/16)](352/16) blocks G contained in a frame, but also between the 300 frames of the image sequence], only 22 evalu-ations of the traditional AAD, i.e. AAD4, were needed. This number is even smaller than that of the TSS. The advantage still exists even if the overhead is also included. (In fact, for 300 frames, the total CPU time used in our workstation was 34 min for the proposed method, and, 55 min for the TSS.) We explain below how the number ‘‘22’’ was obtained for the image sequence Salesman. For a given block G, there were (33)2"1089 candidate blocks. One of them was used as the initial guess, and the remaining 1088 candidates were examined layer by layer. Averagely speaking, the number of candidates kicked out in layers 0, 1, 2, and 3, were 837, 195 40, and 11, respectively. In other words, only 1088!837!195!40!11"5 candi-dates reached Layer 4. Note that, by Step 5 of the algorithm, if a candidate needs to evaluate AADk, then, this candidate also needs to evaluateMAAD0, AAD1, .. . , AADk~1N. Therefore,
837#195#40#11#5"1088 candidates needed to evaluate AAD0; 195#40#11#5"251 candidates needed to evaluate AAD1; 40#11#5"56 candidates needed to evaluate AAD2; 11#5"16 candidates needed to evaluate AAD3; and 5 candidates needed to
evaluate AAD4. Since an evaluation of AAD4 equals, as stated in the previous Section, 41"4 evaluations of AAD3, or equivalently, 42"16 evaluations of AAD2, etc., we have
1088/44#251/43#56/42#16/4#5"21 evaluations of AAD4. Together with the AAD evalu-ation used for the initial guess (see Step 2 of the algorithm), we have 21#1"22 evaluations of AAD4.
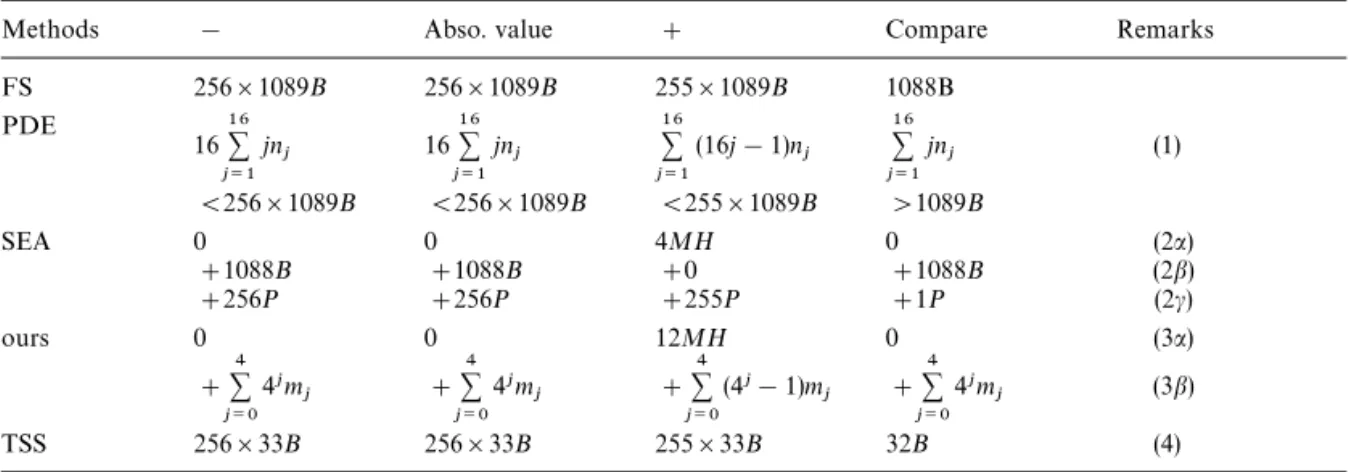
For the reader’s benefit, we also listed in Table 3 the computational cost needed for each frame. Here, we assume that there are B"(M/16)](H/16) blocks in the frame; and hence, there are about 1089B position vectors to be processed. Since MH"256B, 4MH and 12MH appearing in Table 3 for SEA and our methods equal 1024B and 3072B, respectively. Also note that if the image sequence is the Salesman, then theMmjN4j/0 mentioned in Table 3 for our method are m0"1088B,
m1"251B, m2"56B, m3"16B, and m4"5B#
1B"6B, respectively, by the paragraph right above. (The 1B appearing in m4 is due to the AAD["AAD4] evaluation of the initial guess, as stated at the end of last section.) Therefore,
4 + j/0 4j mj"2"256
C
1088B 256 # 251B 64 # 56B 16# 16B 4 # 5B#1B 1D
Table 3. Computation cost per frame (Assume there are B"1
16M#161H blocks; hence, about 1089B position vectors and each vector is 256-dim.)
Methods ! Abso. value # Compare Remarks FS 256]1089B 256]1089B 255]1089B 1088B PDE 1616+ j/1jnj 1616+ j/1jnj 16 + j/1(16j!1)nj 16 + j/1jnj (1) (256]1089B (256]1089B (255]1089B '1089B SEA 0 0 4MH 0 (2a) #1088B #1088B #0 #1088B (2b) #256P #256P #255P #1P (2c) ours 0 0 12MH 0 (3a) #+4 j/0 4jmj #+4 j/0 4jmj #+4 j/0 (4j!1)mj #+4 j/0 4jmj (3b) TSS 256]33B 256]33B 255]33B 32B (4) Note. (1) Note +16
j/1nj"1089B. Here, nj (14j415) is the number of position vectors that was
eliminated by the PDE test after summing up only j of the 16 rows, and n16 corresponds to the number of vectors that need the total evaluations of AAD.
(2a) For l1-norm set-up (4MH"1024B). (2b) For l1-norm elimination test.
(2c) For the AAD evaluations of the P position vectors not eliminated by the l1-norm test. (Note P41089B. In fact, P seldom exceeds 350B.)
(3a) For pyramids set-up (12MH"256]12B)
(3b) For the kick-out test (AADj, j"0,1,2,3) and traditional AAD ("AAD4) evaluation. Note mj is the number of position vectors that need to evaluate AADj. Also note m0"(1089!1)B"1088B'm1'm2'm3'm4. (See the Salesman example given in the last two section of the text. Note m1"251B, m2"56B, m3"16B, m4"5B#1B"6B, and
+4
j/04j mj+256]22B there by the text around equation (8).)
(4) The authors of reference (5) used 33 of the 1089 position vectors as TSS candidates for each block. We also used 33 here.
"256[4.25B#3.92B#3.5B#4B#6B] +256]22B
;256]1089B (8)
indicates that the subtractions, absolute value evalu-ations, and additions needed for ours are much less than those for FS. As for the comparison operations, although FS used fewer comparisons, this advantage of FS is nothing to the whole work if we notice that just the number of subtractions used by FS (256]1089B) is much greater than the total opera-tions (including the comparisons) needed by ours [256](22B]4#12B)"256]100B].
4. CONCLUSIONS
In this paper, the idea of SEA is extended to obtain a fast searching algorithm for the block matching of motion estimation. With the image reconstruction quality identical to that of the full search, the pro-posed method uses the monotonicity property (6) of the AAD relation between adjacent layers of the pyr-amid structure to alleviate the search burden of the FS. Note that the derivation of the monotonicity property (6) used in a four-dimensional vector space the l1-version of Minkowski’s inequality which is quite well-known in the field of mathematics. The experiment results showed that the proposed method really reduced the computations needed. The method outperformed both the SEA method (which applied the l1-version of Minkowski’s inequality to a 256-dimensional vector space if block size is 16]16) and
the PDE method commonly used in industry. More-over, the computation speed was competitive with (often even better than) that of the TSS, although the TSS usually obtained non-optimal position vector only. As a final remark, note that the AAD we tried to minimize [see equation (1)] is in fact a kind of l1-norm which is easito-compute than the mean square er-ror (MSE) that many researchers used.
Acknowledgement—The authors wish to thank the reviewer
for giving helpful suggestions.
APPENDIX A
The statement AADk`1(x, y)5AADk(x, y) holds for all k 3M0, 1, . . . , N!1N. Proof. By (3)—(5), we get AADk`1(x, y)"2 k`1 + i/1 2k`1 + j/1D f tk`1 (i, j)!f*t~1;(x, y)+ k`1 (i, j)D (A1) "2 k + i/1 2k + j/1
A
1 + a/0 1 + b/0D f tk`1 (2i!a, 2j!b) !f*t~1;(x, y)+ k`1 (2i!a, 2j!b)DB
(A2) 52 k + i/1 2k + j/1K
1 + a/0 1 + b/0 ft k`1(2i!a, 2j!b) !+1 a/0 1 + b/0 f*t~1;(x, y)+ k`1 (2i!a, 2j!b)K
(A3)Fig. 2. Some of the (M!15)](H!15) pyramids in the previous frame t!1. Assume that the image size is M]H, and the block size (the size of the pyramid base) is 16]16.
"2 k + i/1 2k + j/1D f tk (i, j)!f*t~1;(x, y)+ k (i, j)D " AADk(x, y).
The derivation of equation (A2) from equation (A1) is just a change of the indices so that the 2k`1]2k`1 pixels in equation (A1) are decomposed into 2k]2k groups with each group having four adjacent pixels. The derivation of equation (A3) from equation (A2) is again by the Minkowski’s inequality (in the
four-di-mensional vector space). K
APPENDIX B
If each image frame is of size M]N, and if each block G is of size 16]16, then the overhead of constructing all the needed pyramids in frame t!1 is about 12MH operations (more definitely, about 12MH additions).
Proof. We discuss here the overhead to construct ‘‘all’’
pyramids in the previous frame t!1 (each pyramid will be used by some blocks G of the current frame t). As shown in Fig. 2, if the base of each pyramid contains 16]16 pixels, then, to construct the (M!15)](H!15) pyramids (some pyramids might have partially overlapping bases, see Fig. 2) for an
M]H image frame (frame t!1), the computations of
the (generalized) pixel values of the four layers (¸0—¸3) are required. (The pixel values of each ‘‘base’’ layer ¸4 has no need to compute, because each base layer coincides with a portion of the given image frame t!1, and each pixel value is thus known.) Note that in each layer Lk~1 (where 14k44), each pixel value fk~1(i, j) (where 14i42k~1 and 14j42k~1) is obtained by a summation of the 2]2 correspond-ing pixel values of Lk, and the summation of the 2]2 pixel values needs only three additions [see equation (3)]. Therefore, the total computation to obtain these (generalized) pixel values for the M]H image frame is 3](total number of generalized pixels).
If we consider all generalized pixels in layer 3, then, due to the overlap of pyramid bases, there are (M!1)](H!1) generalized pixels (all pyramids to-gether) in layer ¸3 for frame t!1. Similarly, there are (M!3)](H!3), (M!7)](H!7), (M!15)] (H!15) generalized pixels (all pyramids together) in ¸2, ¸1, ¸0, respectively. The total number of gen-eralized pixels is therefore (M!1) (H!1)# ( M ! 3 ) ( H ! 3 ) # ( M ! 7 ) ( H ! 7 ) # ( M ! 1 5 ) (H!15), and the total number of operations to get their (generalized) pixel values are thus
º"3[(M!1) (H!1)#(M!3)(H!3) #(M!7) (H!7)#(M!15)(H!15)] "12MH!78M!78H#852
+12MH. K
REFERENCES
1. L. W. Lee, J. F. Wang, J. Y. Lee and J. D. Shie, Dynamic search-window adjustment and interlaced search for block-matching algorithm, IEEE ¹rans. Circuits System »ideo ¹echnol. 3(1), 85—87 (1993).
2. T. Koga, K. Iinuma, A. Hirano, Y. Iijima and T. Ishiguro, Motion compensated interframe coding for video conf.
Proc. Nat. ¹elecommun. Conf., New Orleans, LA, pp.
G5.3.1—G.5.3.5 (1981).
3. A. Puri, H. M. Hang and D. L. Schilling, An efficient block-matching algorithm for motion compensated cod-ing, Proc. IEEE ICASSP, pp. 25.4.1—25.4.4 (1987). 4. B. Liu and A. Zaccarin, New fast algorithms for the
estimation of block motion vectors, IEEE ¹rans. Circuits
System »ideo ¹echnol. 3(2), 148—157 (1993).
5. W. Li and E. Salari, Successive elimination algorithm for motion estimation, IEEE ¹rans. Image Process. 4(1), 105—107 (1995).
6. R. L. Wheeden and A. Zygmund, Measure and Integral:
An Introduction to Real Analysis, Vol. 131. Marcel
Dekker, New York (1977).
7. ITU-T Recommendation H.263 software implementa-tion, Digital Video Coding Group at Telenor R&D (1995).
About the Author—JING-YI LU was born in 1971 in Taiwan, Republic of China. She received her B.S. degree in 1994 and M.S. degree in 1996, both from the Computer and Information Science Department of National Chiao Tung University, Taiwan. Her recent research interests include image processing and signal processing.
About the Author—KUANG-SHYR WU was born in 1963 in Taiwan, Republic of China. He received his B. S. degree in 1988 from National Chung Cheng Institute of Technology, Taiwan. Since 1994 he has been studying toward the Ph.D. degree and he is currently a Ph.D. candidate in the Computer and Information Science Department of Chiao Tung University. His recent research interests include image processing and document analysis.
About the Author—JA-CHEN LIN was born in 1955 in Taiwan, Republic of China. He received his B.S. degree in computer science in 1977 and M.S. degree in applied mathematics in 1979, both from National Chiao Tung University, Taiwan. In 1988 he received his Ph.D. degree in mathematics from Purdue University, U.S.A. In 1981—1982, he was an instructor at National Chiao Tung University. From 1984 to 1988, he was a graduate instructor at Purdue University. He joined the Department of Computer and Information Science at National Chiao Tung University in August 1988, and is currently an Associate Professor there. His recent research interests include pattern recognition, image processing, and parallel computing. Dr Lin is a member of the Phi-Tau-Phi Scholastic Honor Society, the Image Processing and Pattern Recognition Society, and the IEEE Computer Society.
 pyramids in the previous frame t!1. Assume that the image size is M ]H, and the block size (the size of the pyramid base) is 16]16.](https://thumb-ap.123doks.com/thumbv2/9libinfo/7628066.134110/7.753.123.619.96.385/fig-pyramids-previous-frame-assume-image-block-pyramid.webp)
