行政院國家科學委員會專題研究計畫 成果報告
短距高速無線收發機基頻數位訊號處理器之研製(I)
計畫類別: 整合型計畫 計畫編號: NSC93-2215-E-002-033- 執行期間: 93 年 08 月 01 日至 94 年 07 月 31 日 執行單位: 國立臺灣大學資訊工程學系暨研究所 計畫主持人: 顧孟愷 計畫參與人員: 簡義興 黎煥昇 王亞群 報告類型: 精簡報告 報告附件: 出席國際會議研究心得報告及發表論文 處理方式: 本計畫可公開查詢中 華 民 國 94 年 12 月 13 日
Project Final Report
1. Project Overview
Due to its capability to resolve multipath and narrow-band interference efficiently, orthogonal frequency division multiplexing (OFDM) is a very attractive modulation scheme for wireless communication. In this project, we introduced novel digital baseband architectural improvements for OFDM transceivers. We work on advanced forward error correction schemes to improve the coding gain of OFDM receiver. Due to the high coding gain of the LDPC codes, the antenna power can be reduced without sacrificing the wireless communication range. Joint LDPC code search and hardware design methodology are studied to achieve high coding gain performance with a reasonable hardware implementation cost. Another area of research interest the peak-to-average power ratio (PAR) reduction techniques for OFDM transceiver. The high PAR of OFDM requires the RF/Analog circuit to support a large dynamic range with linearity. Coding techniques for the OFDM modulated signal is proposed to reduce the PAR ratio.
2. Research Result Highlights
2.1 Hardware-Aware GA-based LDPC Code Search
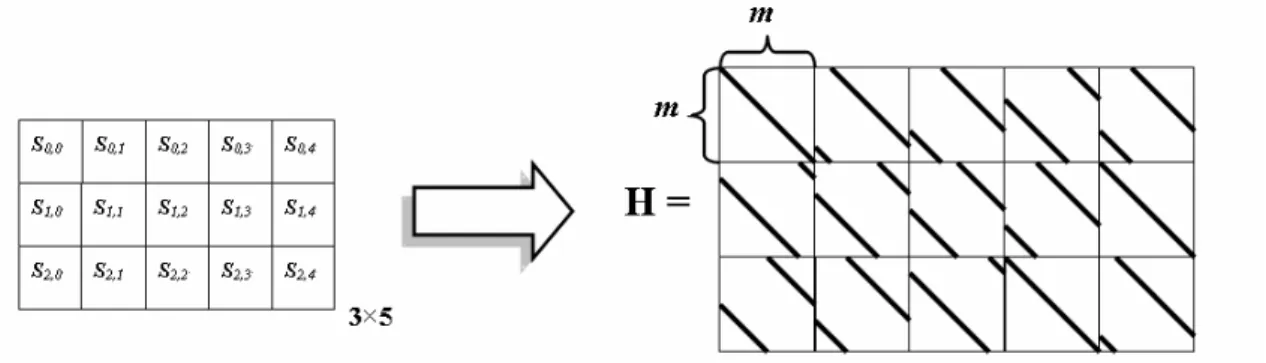
LDPC codes with short to medium block sizes shows favorable coding gain performance than the conventional convolutional code. The goal of our LDPC code search tool is to generate short-to-medium sized parity check matrix that is optimized for hardware implementation. High performance LDPC codes can be constructed by observing the properties of corresponding Tanner graphs. In the meantime, implementation friendly code designs need to minimize hardware cost and reduce decoding complexity. Based on these two goals we choose the regular quasi-cyclic LDPC code [1]. As shown in Fig 1, the regular quasi-cyclic LDPC code has parity check matrix that is composed of cyclically shifted identity matrices. Each cyclically shifted identity matrix is made from identity matrix with cyclically shift right certain steps according to its offset.
Fig. 1. Quasi-cyclic parity check matrix for LDPC code parity check matrix
The structure of quasi-cyclic LDPC code is very regular and block based such that the memory address generation in decoding can be simplified. Researches [2] and our own simulations have verified that quasi-cyclic LDPC codes can achieve excellent performance for short to moderate code length. We proposed a code search method based on Genetic Algorithm (GA) as code search engine. GA is a fast search and optimization algorithm that can have multiple screening criterions. Algebraic-based code construction method, code performance simulation and hardware architecture specific constraints are used as screening criterions in our GA search algorithm. By defining evaluation functions (constraints) for performance evaluation and crossover, mutation, selection strategies for GA operations, we can effectively search the LDPC code that meet our requirements. The codes found by our algorithm will possess the good properties of the algebraic-based code with coding gain performance verified in the same time.
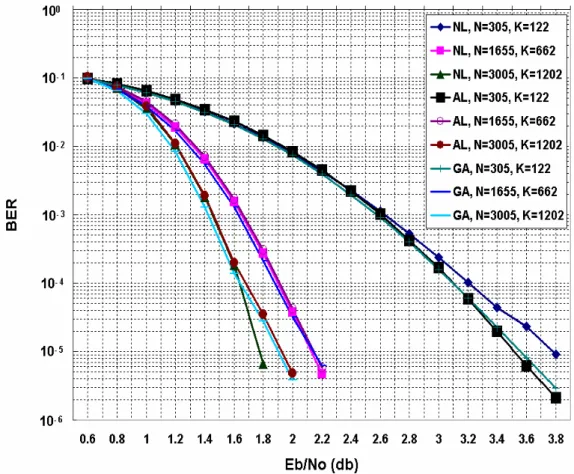
Fig. 2 shows the simulation results of GA search codes, algebraically constructed codes and Neal’s random generated codes. We compared (3,5)-regular LDPC code with code length 305, 1655 and 3005 respectively. The size of sub-matrix of quasi-cyclic codes is 61, 331, and 601 respectively. The parameters of GA operation are 50 generations, population size is 30, crossover rate is 0.8, and mutation rate is 0.2. Number of decoding iteration is 100. The performance of our GA search codes equals the algebraically constructed codes and randomly generated codes while satisfying constraints specific to our hardware architectures.
Fig. 2. Simulated results of Neal’s random generated codes (NL) , algebraic constructed code (AL) and GA search codes (GA)
2.2 Overlapped Pipeline LDPC Decoder Architecture Design
Iterative LDPC decoding algorithms such as sum-product or min-sum algorithms passes information back and forth between the check node and variable nodes in LDPC Tanner graph until correct codeword is found. Some of the decoder designs use modified decoding algorithm to reduce algorithm complexity and minimizing coding gain degradation [3]. Optimized decoding operation sequence can eliminate or reduce waiting time of data dependency [4]. We proposed a two-phase overlapped pipelined architecture shown in figure 3. The check node function unit (CNFU) and variable node function unit (VNFU) updates the check nodes and variable nodes respectively. The core of our architecture is the Jump-Reset scheduling algorithm that allows CNFU and VNFU to access the dual port memory without conflict. The memory schedule places constraint on the parity check matrix generation. The time offset value w for our overlapped pipelined LDPC decoder architecture is determined by the parity check matrix. The constraint w<½m is used as evaluation function. The offset value need to be less than half of the size of the circulant sub-matrix for our decoder architecture to function correctly. Lower offset value w also reduces the latency of decoders.
Fig. 3. Overlapped Pipelining of check node’s and variable node’s function units
The block diagram of the LDPC decoder is shown in Fig. 4. Our semi-parallel architecture has multiple CNFU and VNFU working at the same time to improve throughput. There is no bubble in the scheduling results in very high hardware utilization efficiency.
Fig. 4. Block Diagram of LDPC Decoder
We have implemented our LDPC decoder design on Altera Excalibur EPXA10 development board. It shows that Jump-reset scheduling algorithm can offer high hardware utilization with minimal BER performance loss. The results show that our architecture can support very large parity check matrices. The hardware cost and performance is summarized in the following table.
Code Rate 1/2 B0,1 Address Generator VNFU Control Unit Wcx B B0,0 B1,0 B2,0 B1,1 B2,1 B0,5 B1,5 B2,5 CNFU CNFU CNFU Wcx B VNFU VNFU Syndrome Channel Value HD Mem
Code Length 12288 bits
BRAM 307200 bits
Logic Cell 3064 LCs
Clock Frequency 32.64 MHz
Throughput 19.11 Mbps
Table 1: LDPC Decoder Implementation Summary
2.3 OFDM Peak-to-Average Power Ratio Reduction
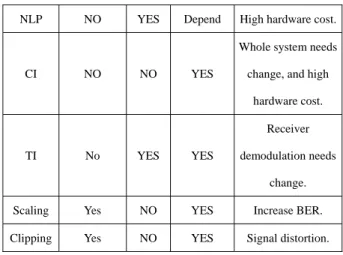
Various methods have been devised to reduce the PAPR in OFDM system[5-12]. Many criterions need to be considered when choosing the PAPR reduction schemes, such as PAPR reduction performance, power increase in transmit signal, BER increase at the receiver, data rate loss and most important of all is the hardware implementation cost. For example, one of the best PAPR reduction schemes is the nonlinear programming (NLP), which can be used to find the optimal solution. However, the NLP has too high a hardware cost to be implemented directly. We made a thorough investigation on promising PAPR reduction schemes with good PAPR reduction performance before picking a scheme that combines the strength of TR and ACE.
Table. 2: summarizes these schemes.
Schemes Distortion Increase Power 100% Data Rate Main drawback
TR NO YES NO Lose data rate. Equalizer NO NO YES RX need change
ACE NO NO YES
Higher modulation schemes lower the
reduction performance Guard
band
Yes Yes YES
Interference the adjacent channel.
PTS NO NO YES
Whole system needs change. Scramblin
g
NO NO YES
Whole system needs change.
Coding NO NO YES
Low code rate or ROM size too big. Trellis
Shaping
NO NO YES
Whole system needs change.
NLP NO YES Depend High hardware cost.
CI NO NO YES
Whole system needs change, and high
hardware cost.
TI No YES YES
Receiver demodulation needs
change. Scaling Yes NO YES Increase BER. Clipping Yes NO YES Signal distortion.
Table. 3. PAPR schemes comparison.
The important issue of combine two reduction schemes is that the PAPR reduction performance in every modulation schemes should be as closely as possible, hence can increase the power efficient of PA. We choose ACE for the QPSK modulation, the performance is shown in Fig. 4.. The TR is used for high QAM such as 16 QAM, 64 QAM and 256QAM. Therefore the TR must design to close to 8dB. The parameter of ACE is almost fixed. The only thing need to be noted is that the step size must be correct. 7 8 9 10 11 12 10-4 10-3 10-2 10-1 100
Peak-to-Average Power Ratio (dB)
CCD F(PA PR> v al u e) Original PAPR ACE
Fig. 4. ACE performance of QPSK
Here we consider the parameter choices issues for the design the TR scheme so it matches the ACE performance.
A. The architecture for square root
B. Number of reservation tones
C. Iterations: The PAPR reduction performance is proportional to the number of
D. Reduction level
E. Constant step size issue F. Number of reduction targets
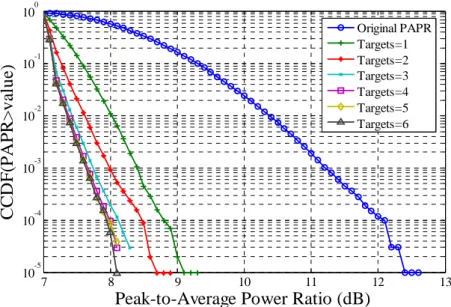
The following figure shows the performance of final tone reservation algorithm that is matched to that of the ACE algorithm. We proposed the combined PAPR reduction scheme that considers hardware cost and PA power efficiency. The combined scheme provides good PAPR reduction performance for all constellations from QPSK to 256QAM. A complete OFDM transmitter is implemented in FPGA to verify our design. In the future, we would like to modify our design so it can be reconfigured to suit various OFDM system requirements. 7 8 9 10 11 12 13 10-5 10-4 10-3 10-2 10-1 100
Peak-to-Average Power Ratio (dB)
C C DF (P AP R > v al u e) Original PAPR Targets=1 Targets=2 Targets=3 Targets=4 Targets=5 Targets=6
Fig. 5. Final TR performance to match ACE.
3. Self Evaluation
In this project, we investigated essential building blocks for wireless OFDM receivers. For the LDPC codec work, we proposed an efficient overlapped pipeline LDPC decoder architecture that achieves 100% hardware utilization in decoding. We proposed a novel scheduling algorithm that arranges the memory access of check functional unit (CFU) and bit functional unit (BFU) so there will not be any memory access conflict. We proposed a GA(genetic algorithm) based LDPC code search algorithm that can efficiently look for high coding gain quasi-cyclic (QC) LDPC codes. The code generated by this program is guaranteed to work for our hardware architecture. For the OFDM peak-to-average power ratio (PAPR) reduction algorithm, we made a comprehensive survey of existing PAPR architectures, and proposed a PAPR scheme that employs different PAPR algorithm for different constellation size to achieve the optimal performance.
The preliminary results of our research are published in VLSICAD 2005[13][14] and EITC 2005[15]. Manuscripts are being prepared to submit to journals and overseas conferences. My teams of graduate students learn a great deal about communication system and architecture design from this project. Three students graduated and found work in the industry, including HTC and Via. One student decided to stay for doctoral work on high performance LDPC decoder ASIC design based on our work. There are many exciting research opportunities in LDPC related systems, and my group is actively pursuing these opportunities.
Overall, I think we have made good progress on both the research and IP implementation front. In the future, my group will push forward on new frontiers, for example, 802.11n and 802.16e LDPC codec design, rate compatible LDPC design, LDPC coded modulation, and hardware-aware LDPC encoder design. More students will be trained on this cutting edge error correction technology, and we wish to transfer our technology to the communication industry in Taiwan.
Reference:
[1] Fossorier, M.P.C., ”Quasi-cyclic low-density parity-check codes from circulant permutation matrices,” IEEE Transactions on Information Theory, vol. 50, no. 8, pp.1788 – 1793, Aug. 2004
[2] D. Sridhara, T. E. Fuja, and R. M. Tanner, “Low density parity check codes from permutation matrices,” in Proc. Conf. Information Sciences and Systems, Baltimore, MD, pp. 142, Mar. 2001
[3] Marjan Karkooti and Joseph R. Cavallaro, “Semi-Parallel Reconfigurable Architectures for Real-Time LDPC Decoding,” ITCC Proceeding of International Conference, Information Technology: Coding and Computing, vol.1, pp.579-585, April 2004
[4] Yanni Chen and Keshab K. Parhi, “Overlapped Message Passing for Quasi-Cyclic Low-Density Parity Check Codes”, IEEE Trans., Circuits and Systems, vol. 51, pp.1106-1113, June 2004
[5] Jose Tellado, “Multicarrier Modulation with Low PAPR: Applications to DSL and Wireless” 2000.
[6] Krongold, B.S.; Jones, D.L.; “An active-set approach for OFDM PAR reduction via tone reservation” Signal Processing, IEEE Transactions on [see also Acoustics, Speech, and Signal Processing, IEEE Transactions on Volume 52, Issue 2, Feb. 2004.
[7] Akhtman, J.; Bobrovsky, B.Z.; Hanzo, L.; “Peak-to-average power ratio reduction for OFDM modems”, Vehicular Technology Conference, 2003. VTC 2003-Spring.
The 57th IEEE Semiannual, Volume 2, 22-25 April 2003 Page(s):1188 - 1192 vol.2.
[8] S.H.; Huber, J.B.; “OFDM with reduced peak-to-average power ratio by optimum combination of partial transmit sequences Muller”, Electronics Letters, Volume: 33 Issue: 5, 27 Feb. 1997 Page(s): 368 -369.
[9] Jayalath, A.D.S.; Tellambura, C.; “A blind SLM receiver for PAR-reduced OFDM”, Vehicular Technology Conference, 2002. Proceedings. VTC 2002-Fall. 2002 IEEE 56th Volume 1, 24-28 Sept. 2002 Page(s):219 – 222.
[10] Paterson, K.G.; Tarokh, V.; “On the existence and construction of good codes with low peak-to-average power ratios”, Information Theory, IEEE Transactions on, Volume: 46 Issue: 6, Sept. 2000 Page(s): 1974 -1987.
[11] Ochiai, H.; “A novel trellis-shaping design with both peak and average power reduction for OFDM systems”, Communications, IEEE Transactions on Volume 52, Issue 11, Nov. 2004 Page(s):1916 – 1926.
[12] Wiegandt, D.A.; Nassar, C.R.; Wu, Z.; “The elimination of peak-to-average power ratio concerns in OFDM via carrier interferometry spreading codes: a multiple constellation analysis”, System Theory, 2004. Proceedings of the Thirty-Sixth Southeastern Symposium on 2004 Page(s):323 – 327
[13] Yi-hsing Chien and Mong-Kai Ku, ”SCALABLE HIGH HARDWARE UTILITZATION EFFICIENCY LDPC DECODER,” in Proceedings of the 16th VLSI Design/CAD symposium, Hua-Lien, Taiwan, August 2005.
[14] Ya-Cheng Wang, Mong-Kai Ku, “DESIGN AND IMPLEMENTATION OF OFDM TRANSMITTER WITH LOW PEAK-TO-AVERAGE POWER RATIO,” in Proceedings of the 16th VLSI Design/CAD symposium, Hua-Lien, Taiwan, August 2005.
[15] Mong-Kai Ku, Yi-hsing Chien, Huan-Sheng Li, “Code Design and Decoder Implementation of Low Density Parity Check Code,” in Proceedings of The 2005 Emerging Information Technology Conference (EITC 2005), Taipei, Taiwan, August 2005.