英文介系詞片語定位與英文介系詞推薦 - 政大學術集成
113
0
0
全文
(2) 英文介系詞片語定位與英文介系詞推薦 Attachment of English Prepositional Phrases and Suggestions of English Prepositions. 研 究 生: 蔡家琦. Student : Chia-Chi Tsai. 指導教授: 劉昭麟. Advisor : Chao-Lin Liu. 資訊科學系 碩士論文. 學 ‧. ‧ 國. 立. 政 治 大 國立政治大學. y. Nat. n. er. io. sit. A Thesis submitted to Department of Computer Science al iv National n C h Chengchi University i Urequirements e n g cofhthe in partial fulfillment for the degree of Master in Computer Science. 中華民國一百一年七月. July 2012.
(3) 英文介系詞片語定位與英文介系詞推薦 摘要 英文介系詞在句子裡所扮演的角色通常是用來使介系詞片語更精確地補述 上下文,英文的母語使用者可以很直覺地使用。然而電腦不瞭解語義,因 此不容易判斷介系詞修飾對象;非英文母語使用者則不容易直覺地使用正 確的介系詞。所以本研究將專注於介系詞片語定位與介系詞推薦的議題。. 政 治 大. 在本研究將這二個介系詞議題抽象化為一個決策問題,並提出一個一. 立. 般化的解決方法。這二個問題共通的部分在於動詞片語,一個簡單的動詞. ‧ 國. 學. 片語含有最重要的四個中心詞(headword):動詞、名詞一、介系詞和名詞. ‧. 二。由這四個中心詞做為出發點,透過 WordNet 做階層式的選擇,在大量 的案例中尋找語義上共通的部分,再利用機器學習的方法建構一般化的模. y. Nat. io. sit. 型。此外,針對介系詞片語定的問題,我們挑選較具挑戰性介系詞做實驗。. n. al. er. 藉由使用真實生活語料,我們的方法處理介系詞片語定位的問題,比. iv. Ch 同樣考慮四個中心詞的最大熵值法( Max Entropy U n )好;但與考慮上下文的 engchi. Stanford 剖析器差不多。而在介系詞推薦的問題裡,較難有全面比較的對 象,但我們的方法精準度可達到 53.14%。 本研究發現,高層次的語義可以使分類器有不錯的分類效果,而透過 階層式的選擇語義能使分類效果更佳。這顯示我們確實可以透過語義歸納 一套準則,用於這二個介系詞的議題。相信成果在未來會對機器翻譯與文 本校對的相關研究有所價值。. i.
(4) Attachment of English Prepositional Phrases and Suggestions of English Prepositions Abstract This thesis focuses on problems of attachment of prepositional phrases (PPs) and problems of prepositional suggestions. Determining the correct PP attachment is not easy for computers. Using correct prepositions is not easy for learners of English as a second language. I transform the problems of PPs attachment and prepositional suggestion into an abstract model, and apply the same computational procedures to solve these two problems.. 政 治 大. The common model features four headwords, i.e., the verb, the first noun, the preposition,. 立. and the second noun in the prepositional phrases. My methods consider the semantic fea-. ‧ 國. 學. tures of the headwords in WordNet to train classification models, and apply the learned models for tackling the attachment and suggestion problems. This exploration of PP at-. ‧. sit. Nat. attach to the verb and the first noun were used in the study.. y. tachment problems is special in that only those PPs that are almost equally possible to. The proposed models consider only four headwords to achieve satisfactory perfor-. io. er. mances. In experiments for PP attachment, my methods outperformed a Maximum En-. n. a. v. l C four headwords.The tropy classifier which also considered n i performances of my methods. i U. h. e n gwhile c h the Stanford parsers had access to the and of the Stanford parsers were similar,. complete sentences to judge the attachments. In experiments for prepositional suggestions, my methods found the correct prepositions 53.14% of the time, which is not as good as the best performing system today. This study reconfirms that semantic information is instrument for both PP attachment and prepositional suggestions. High level semantic information helped to offer good performances, and hierarchical semantic synsets helped to improve the observed results. I believe that the reported results are valuable for future studies of PP attachment and prepositional suggestions, which are key components for machine translation and text proofreading.. ii.
(5) 致謝 寫到此頁代表結束這本論文的時候到了,內心充滿了無限感謝的話想 說,深深地感謝這一路陪我走過來的人。 很幸運劉昭麟老師能成我的指導老師,這一路很感謝老師給了我一次 又一次的機會,讓我知道原來我也可以做到,讓我知道原來還有其它的選 擇,讓我知道原來世界沒有這麼難,增加了我人生路途更多的選擇,使我 不再只是空想羨慕他人。在這短短的二年,老師不僅在學業上幫助我,也 在各式各樣大小事情上幫助我,使我成長。會有這一切的一切都要感謝我. 政 治 大 一直以都在背後支持我的家人,感謝你們長久以來不斷支持我所做的 立. 敬愛的 劉昭麟老師。. ‧ 國. 學. 決定,讓我能夠無所固慮地探索這個世界。謝謝父母總是在我做事投入時, 適時地提醒我,謝謝媽媽的「吃飯囉」,謝謝爸爸的「早點休息」。也謝謝. ‧. 妹妹總是幫我這個忘東忘西的姊姊跑腿。因為有你們,所以才有今天。. y. Nat. 感謝昀彥這些年一直陪著我,不僅老是聽著我碎碎念,還帶我看到了. er. io. sit. 許多無限的可能,讓我接觸了我從來沒有想過的事,使我思想更加的開闊。 也因為有你,如今我的興趣變成了培養新的興趣,謝謝你帶我看到這個世. n. al. 界有趣的一面。. Ch. engchi. i Un. v. 這二年我也要謝謝 MIG 的夥伴們的陪伴,謝謝學長姊怡軒、建良和裕 淇不吝嗇的給我許多建議,謝謝同屆的柏廷和瑞平一起互相扶持,謝謝學 弟瑋杰和孫暐的協助幫忙。也謝謝更多的 MIG 夥伴,因為你們,使我這二 年的生活更加的豐富。 也謝謝口試委員 張嘉惠老師與 高照明老師的指導。 最後,特別感謝在這幾個月裡,被我不斷地纏著幫我校對論文的媽媽 和昀彥。 家琦 2012 年 9 月. iii.
(6) 目錄. 1.1. 研究背景 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 1. 1.2. 研究方法. 3. 1.3. 研究成果. 文獻回顧. 治 ............... . . . . . .政 . . . . . . . .大 . .立 . . . . . . . . . . . . . . . . . . . . . . . . . . .. 5 8. 介系片語定位 . . . . . . . . . . . . . . . . . . . . . . . . . .. 2.2. 介系詞推薦 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10. 12. er. sit. y. 8. 語料庫 . . . a. . . . . . . . . . . . . . . . . . . . . . . . . . . 12. iv l C n . . . .h. . . . . . . . U. . . . engchi. n. 3.1. io. 語料處理. ‧. 2.1. Nat. 3. 1. 學. 2. 緒論. ‧ 國. 1. 3.1.1. RRR. . . . . . . . . . . . 13. 3.1.2. PTB3 . . . . . . . . . . . . . . . . . . . . . . . . . . . 13. 3.1.3. 華爾街日報與紐約時報 . . . . . . . . . . . . . . . . . 14. 3.2. 詞彙資料庫:WordNet . . . . . . . . . . . . . . . . . . . . . . 15. 3.3. 前處理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18. 3.4. 3.3.1. 句子剖析與斷句 . . . . . . . . . . . . . . . . . . . . . 19. 3.3.2. 中心詞抽取. 3.3.3. 雜訊過濾 . . . . . . . . . . . . . . . . . . . . . . . . . 22. 3.3.4. 挑選具挑戰性的介系詞 . . . . . . . . . . . . . . . . . 23. . . . . . . . . . . . . . . . . . . . . . . . 19. 目的語料 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24. 3.4.1. 介系詞片語定位語料 . . . . . . . . . . . . . . . . . . 25 iv.
(7) 3.4.2 研究方法. 特徵量化 . . . . . . . . . . . . . . . . . . . . . . . . . 32. 4.1.2. 特徵加權 . . . . . . . . . . . . . . . . . . . . . . . . . 38. 特徵選擇 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39. 4.2.1. 階層式選擇. 4.2.2. 篩選條件 . . . . . . . . . . . . . . . . . . . . . . . . . 44. 模型建構 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46 基準模型建構 . . . . . . . . . . . . . . . . . . . . . . 46. 4.3.2. 傳統模型建構 . . . . . . . . . . . . . . . . . . . . . . 48. 立. 學. 高階模型建構 . . . . . . . . . . . . . . . . . . . . . . 49. ‧. 實驗. 51. 實驗設計 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51. Nat. 5.1. 政 治 大. 4.3.1 4.3.3 5. . . . . . . . . . . . . . . . . . . . . . . . 40. y. 4.3. 4.1.1. 基準模型實驗 . . . . . . . . . . . . . . . . . . . . . . 51. 5.1.2. 傳統模型實驗 . . . . . . . . . . . . . . . . . . . . . . 53. a. 高階模型實驗 . . . . . . . . . i.v . . . . . . . . . . . . 54 l. n. 5.1.3. io. 5.1.1. sit. 4.2. 特徵處理 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31. er. 4.1. 31. ‧ 國. 4. 介系詞推薦語料 . . . . . . . . . . . . . . . . . . . . . 28. n U .e. n. g . c . h . .i . . . .. Ch. 5.2. 實驗評量 . . . . . .. 5.3. 實驗分析:介系詞片語定位 . . . . . . . . . . . . . . . . . . 56. 5.4. . . . . . . . . . . . . 54. 5.3.1. 不同條件組合之分析 . . . . . . . . . . . . . . . . . . 56. 5.3.2. 階層式特徵選擇之分析 . . . . . . . . . . . . . . . . . 73. 5.3.3. 高階模型建構之分析 . . . . . . . . . . . . . . . . . . 74. 5.3.4. 綜合評比與最大熵值法之分析 . . . . . . . . . . . . . 78. 5.3.5. 綜合評比與 Stanford 剖析器之分析 . . . . . . . . . . 79. 實驗分析:介系詞推薦 . . . . . . . . . . . . . . . . . . . . . 81. 5.4.1. 不同條件組合之分析 . . . . . . . . . . . . . . . . . . 81. 5.4.2. 高階模型建構之分析 . . . . . . . . . . . . . . . . . . 85. 5.4.3. 綜合比較 . . . . . . . . . . . . . . . . . . . . . . . . . 85 v.
(8) 5.4.4 6. 大語料庫 . . . . . . . . . . . . . . . . . . . . . . . . . 88. 結論. 90. 6.1. 討論 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91. 6.2. 未來工作 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92. 參考文獻. 94. 附錄 I. 98. 同義詞集種類. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. vi. i Un. v.
(9) 圖目錄. 1.1. 研究架構流程圖 . . . . . . . . . . . . . . . . . . . . . . . . .. 4. 3.1. PTB3 的結構樹 . . . . . . . . . . . . . . . . . . . . . . . . . . 14. 3.2. 14. 3.3. 治 政 紐約時報的段落文章 . . . . . . . 大 . . . . . . . . . . . . . . . 立 WordNet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 3.4. 前處理流程圖 . . . . . . . . . . . . . . . . . . . . . . . . . . 19. 3.5. 動詞片語: 修飾名詞 . . . . . . . . . . . . . . . . . . . . . . . 20. 3.6. 動詞片語: 修飾動詞 . . . . . . . . . . . . . . . . . . . . . . . 20. 3.7. 修飾名詞樣式 . . . . . . . . . . . . . . . . . . . . . . . . . . 21. 3.8. 修飾動詞樣式 . . . . . . . . . . . . . . . . . . . . . . . . . . 21. 4.1. 二元量化 . . a. l. . . . . . . . . . . . . i.v . . . . . . . . . . . . 33. 4.2. 平均法 . . . . . . .. 4.3. 累計量化 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37. 4.4. 階層式選擇流程圖 . . . . . . . . . . . . . . . . . . . . . . . . 43. 4.5. 階層式選擇範例: 簡化的 WordNet 結構 . . . . . . . . . . . . 43. 4.6. Naïve Bayes 結構 . . . . . . . . . . . . . . . . . . . . . . . . . 47. 4.7. 基準模型結構 . . . . . . . . . . . . . . . . . . . . . . . . . . 47. 4.8. 高階模型建構 . . . . . . . . . . . . . . . . . . . . . . . . . . 50. 5.1. 比較不同門檻值之詞義詞頻 . . . . . . . . . . . . . . . . . . 61. 5.2. 比較不同門檻值之共現同義詞集 . . . . . . . . . . . . . . . . 62. 5.3. 比較不同加權方法 . . . . . . . . . . . . . . . . . . . . . . . . 63. 17. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. n U .e. n. g . c . h . .i . . . .. Ch. vii. . . . . . . . . . . . . 35.
(10) 5.4. 比較不同量化方法 . . . . . . . . . . . . . . . . . . . . . . . . 64. 5.5. 比較不同共現同義詞集組合 . . . . . . . . . . . . . . . . . . 65. 5.6. 基於詞義頻率之詞頻與共現同義詞集組合之比較 . . . . . . 66. 5.7. 實驗組合一之特徵量 . . . . . . . . . . . . . . . . . . . . . . 67. 5.8. 實驗組合二之特徵量 . . . . . . . . . . . . . . . . . . . . . . 68. 5.9. 實驗組合三之特徵量 . . . . . . . . . . . . . . . . . . . . . . 69. 5.10 實驗組合四之特徵量 . . . . . . . . . . . . . . . . . . . . . . 70 5.11 實驗組合五之特徵量 . . . . . . . . . . . . . . . . . . . . . . 71 5.12 實驗組合六之特徵量 . . . . . . . . . . . . . . . . . . . . . . 72. 政 治 大 不同實驗組合之特徵量 . . . . . . . . . . . . . . . . . . . . . 立. 5.13 不同實驗組合之結果 . . . . . . . . . . . . . . . . . . . . . . 83. 學 ‧. ‧ 國 io. sit. y. Nat. n. al. er. 5.14. Ch. engchi. viii. i Un. v. 84.
(11) 表目錄. 1.1. RRR 語料庫,NPP 與 VPP 的數量 . . . . . . . . . . . . . . .. 6. 3.1. RRR 語料庫實際範例 . . . . . . . . . . . . . . . . . . . . . . 13. 3.2. 22. 3.3. 治 政 中心詞抽取 . . . . . . . . . . . . . 大 . . . . . . . . . . . . . . . 立 RRR 前處理結果: 訓練語料 . . . . . . . . . . . . . . . . . . .. 3.4. RRR 前處理結果: 驗證語料 . . . . . . . . . . . . . . . . . . . 26. 3.5. RRR 前處理結果: 測試語料 . . . . . . . . . . . . . . . . . . . 26. 3.6. PTB3 前處理結果: 訓練語料 . . . . . . . . . . . . . . . . . . 26. 3.7. PTB3 前處理結果: 驗證語料 . . . . . . . . . . . . . . . . . . 27. 3.8. PTB3 前處理結果: 測試語料 . . . . . . . . . . . . . . . . . . 27. 3.9. PTB3 前處理結果:測試語料原句句數 a v . . . . . . . . . . . . 27. 26. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. l. i. C h Stanford 剖析器比較用途之測試語料 3.10 PTB3 前處理結果:與 Un engchi. 27. 3.11 RRR 前處理結果: 訓練語料 . . . . . . . . . . . . . . . . . . . 28 3.12 RRR 前處理結果: 驗證語料 . . . . . . . . . . . . . . . . . . . 28 3.13 RRR 前處理結果: 測試語料 . . . . . . . . . . . . . . . . . . . 29 3.14 華爾街日報與紐約時報前處理結果: 訓練語料 . . . . . . . . 29 3.15 華爾街日報與紐約時報前處理結果: 驗證語料 . . . . . . . . 29 3.16 華爾街日報與紐約時報前處理結果: 測試語料 . . . . . . . . 30 4.1. 平均法範例 -路線量化 . . . . . . . . . . . . . . . . . . . . . . 34. 4.2. 平均法範例 -合併同義詞集 . . . . . . . . . . . . . . . . . . . 34. 4.3. 平均法範例 -合併路徑量化 . . . . . . . . . . . . . . . . . . . 35. 4.4. 累計法範例 -路線量化 . . . . . . . . . . . . . . . . . . . . . . 36 ix.
(12) 4.5. 累計法範例 -合併同義詞集 . . . . . . . . . . . . . . . . . . . 36. 4.6. 累計法範例 -計算詞頻量化 . . . . . . . . . . . . . . . . . . . 36. 4.7. 語義頻率量化 . . . . . . . . . . . . . . . . . . . . . . . . . . 39. 4.8. 語義深度量化 . . . . . . . . . . . . . . . . . . . . . . . . . . 39. 4.9. 階層式選擇範例: 簡化語料庫案例 . . . . . . . . . . . . . . . 42. 4.10 階層式選擇範例: 第 0 世代 . . . . . . . . . . . . . . . . . . . 44 4.11 階層式選擇範例: 第 1 世代 . . . . . . . . . . . . . . . . . . . 44 4.12 階層式選擇範例: 第 2 世代 . . . . . . . . . . . . . . . . . . . 44 4.13 階層式選擇範例: 第 3 世代 . . . . . . . . . . . . . . . . . . . 44. 政 治 大. 4.14 以“eat”為例計算 P r(svi |V ) . . . . . . . . . . . . . . . . . . 48. 立. 基準模型所使用得名詞同義詞集 . . . . . . . . . . . . . . . . 52. 5.2. 條件組合 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53. 5.3. 介系詞片語定位實驗比較 . . . . . . . . . . . . . . . . . . . . 54. 5.4. 挑選傳統模型條件 . . . . . . . . . . . . . . . . . . . . . . . . 54. 5.5. 實驗組合一 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58. 5.6. 實驗組合二 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58. 5.7. 實驗組合三 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59. ‧. ‧ 國. 學. 5.1. er. io. sit. y. Nat. n. a. v. 5.8. 實驗組合四 . . l. C . . . . . . . . . . . n. i. . . . . . . . . . . . . 59. 5.9. 實驗組合五 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60. hengchi U. 5.10 實驗組合六 . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60 5.11 RRR 傳統模型實驗結果 . . . . . . . . . . . . . . . . . . . . . 74 5.12 PTB3 傳統模型實驗結果 . . . . . . . . . . . . . . . . . . . . 75 5.13 RRR 高階模型實驗結果 . . . . . . . . . . . . . . . . . . . . . 76 5.14 RRR 最佳高階模型 . . . . . . . . . . . . . . . . . . . . . . . 76 5.15 PTB3 高階模型實驗結果 . . . . . . . . . . . . . . . . . . . . 77 5.16 PTB3 最佳高階模型 . . . . . . . . . . . . . . . . . . . . . . . 77 5.17 RRR 實驗結果 . . . . . . . . . . . . . . . . . . . . . . . . . . 78 5.18 PTB3 實驗結果(1) . . . . . . . . . . . . . . . . . . . . . . 80. x.
(13) 5.19 SP 答題狀況 . . . . . . . . . . . . . . . . . . . . . . . . . . . 80 5.20 PTB3 實驗結果(2) . . . . . . . . . . . . . . . . . . . . . . 80 5.21 RRR 傳統模型之結果 . . . . . . . . . . . . . . . . . . . . . . 82 5.22 RRR 高階模型實驗結果 . . . . . . . . . . . . . . . . . . . . . 86 5.23 混淆矩陣: 高階模型 (2):Naïve Bayes . . . . . . . . . . . . . . 87 5.24 混淆矩陣: 高階模型 (3):SVM . . . . . . . . . . . . . . . . . . 87 5.25 混淆矩陣: 表現最佳的單一模型 . . . . . . . . . . . . . . . . 87 5.26 混淆矩陣: 表現次佳的單一模型 . . . . . . . . . . . . . . . . 87 5.27 華爾街日報與紐約時報實驗結果 . . . . . . . . . . . . . . . . 88. 政 治 大 混淆矩陣: 華爾街日報與紐約時報 . . . . . . . . . . . . . . . 立. 5.28 對照組,P、R 和 F 在原文中表示到小數後第二位 . . . . . . 89. 學 ‧. ‧ 國 io. sit. y. Nat. n. al. er. 5.29. Ch. engchi. xi. i Un. v. 89.
(14) 第1章. 緒論. 英文介系詞的使用對於英文母語的使用者而言是很直覺,即使英文母語的使用者不知. 政 治 大. 道文法結構,仍然可以精確地表達語義。但對於電腦而言卻很難知道語義,因此不容易. 立. 判斷正確的修飾對象。對於非英文母語的使用者,自然且正確地表達是有困難的。在現. ‧ 國. 學. 今資訊科技盛行爆炸的時代,我們期望透過大量資料以及資訊技術來輔助人類解決問. n. al. er. io. sit. y. Nat. 1.1 研究背景. ‧. 題,並將我們研究應用於電腦自動化的流程。. Ch. i Un. v. 英文介系詞一般出現在動詞語片裡,一個動詞片語的結構表示成「動詞 -名詞片語一. engchi. -介系詞 -名詞片語二 (V-NP1-P-NP2)」。其中「介系詞 -名詞片語二」的結構稱為介系詞 片語。由動詞片語結構所衍生出來的兩個有趣問題,也就是介系詞片語定位與介系詞推 薦。本研究,我們將深入探討並且試圖解決這二個介系詞相關的議題。 介系詞片語定位問題是我們要如何定位介系詞片語修飾對象?如果站在人類的角 度來看,很自然地我們可以設想一些情境,進而能夠馬上判斷出合理的介系詞定位。另 一方面,如果我們想利用資訊技術來解決這個問題的話,我們會直覺地認為如果電腦 也可以演算出一個適當的情境那麼電腦也許可以像人類一樣正確地判斷出介系詞定位。 也就是說,在這樣的直覺裡,我們假設電腦有能力去全面且完整地解析、瞭解甚至推導. 1.
(15) 出語義,但這個假設在這裡顯然和現實情況不符合。因為,若要能夠瞭解語義,那麼電 腦必然需要能夠先瞭解該介系詞片語修飾的對象,此時電腦才有可能真正認識到完整 的語義。然而,電腦其實需要利用句子語義幫忙做定位介系詞問題,因此我們不可能使 電腦先瞭解到完整的語義後,才解決定位介系詞片語問題。這類似雞生蛋、蛋生雞的問 題;解決語義問題需要能夠定位介系詞片語,而定位介系詞片語也需要靠語義。 以一個具體的例子做說明,以句 1為例子。首先我們先想像這句話的情境,在我 們主觀的認知中比較容易連想的語境是:這群小孩用湯匙吃蛋糕。根據剛才想像的語 境那麼“with a spoon”這個介系詞片語修飾的應該是“ate”這個動詞,如句 2底線所. 政 治 大. 標示。但是其實句 1也可以有另外一種語境的可能,如句 3的情況,對於句 3的解讀應. 立. 該是這群小孩吃的是旁邊有放湯匙的蛋糕,這時“with a spoon”修飾的對象就是“the. ‧ 國. 學. cake”這個名詞片語。. ‧. 句 1. The children ate the cake with a spoon.1. Nat. io. sit. y. 句 2. The children ate the cake with a spoon.. n. al. er. 句 3. The children ate the cake with a spoon.. Ch. i Un. v. 英文介系詞推薦的問題是如何推薦正確的介系詞使得動詞片語能正確地表達語義。. engchi. 這對於英文母語的使用者是很自然可以判斷的問題,但對於非母語的使用者來說缺少 了可以自然使用介系詞的直覺,只能透過介系詞的功能面決定它的用途。有些介系詞 在功能面是類似的,例如 in、on、at 在時間的用途上是經常被混洧的。一般而言,“at” 是比較強調某個時間點,“on”則是強調特定的日期,“in”是某個時段。非英文母語的 使用者只能透過這些大略的準則判斷介系詞的使用,然而有些介系詞在相似的功能面 上容易是受到使用者的母語影響,再以句 1為例,有些使用者可能會誤用為句 4,因為 在以中文為母語的情況下,by 或許會被理解成為「倚靠」的意思。 句 4. The children ate the cake by a spoon. 1 出自. Chris Manning 和 Hinrich Schütze,Foundations of statistical natural language prochessing 書中 8.3 節. 2.
(16) 因為介系詞的使用是如此的廣泛,但是讓電腦瞭解語義和非英文母語的使用者來 說都是有相當的門檻,所以我們對於介系詞的議題感到有興趣。為了可以更精確地使用 介系詞,我們將深入探討這二種介系詞的議題。如果能夠解決這些議題,就可以將此應 用做為機器翻譯基石和文本校對用途。. 1.2 研究方法 我們的研究嘗試找出上下文無關(context-free)的解決方案。這二個問題共通的部分. 政 治 大. 是動詞片語,其結構是「動詞 -名詞片語一 -介系詞 -名詞片語二」的結構,簡化為四. 立. 個中心詞「動詞 -名詞一 -介系詞 -名詞二(V-N1-P-N2)」。中心詞的定義為詞組中最核. ‧ 國. 學. 心被修飾的詞,以句 1為例,將句 1拆成句 5到句 8好幾個詞組,底線的部分是中心詞;. ‧. 句 5是一個動詞片語,動詞片語的中心詞是動詞;句 6與句 8是名詞片語,名詞片語的 中心詞是名詞;句 7是介系詞片語,中心詞是介系詞。我們直接探討動詞片語所抽出的. y. Nat. er. io. sit. 四個主要中心詞並以此做為研究的出發點。再利用 WordNet2 階層式的概念將中心詞提 升到較抽象的語義層級,也就是找出上位詞,並利用資訊技術從大量的語料中找尋是否. n. al. ni Ch 有一套準則能定位介系詞片語和推薦正確的介系詞。 U engchi 句 5. ate the cake with spoon 句 6. the cake. —. —. 動詞片語. 名詞片語一 介系詞片語. 句 7. with a spoon. —. 句 8. a spoon. 名詞片語二. —. v. 我們以一套一般化的方法同時應用於介系詞片語定位與介系詞推薦問題上,研究 方法可參考圖 1.1。第一部分語料處理,這部分包了各種語料的前處理:斷句、剖析、 2 http://wordnet.princeton.edu/. 3.
(17) 中心詞抽取、雜訊過濾和挑選具挑戰性介系詞。第二部分是特徵處理,這部分是特徵數 值化。第三部分是應用 WordNet 階層式的概念挑選特徵。第四部分是模型的建構,我們 共設計了三種不同程度的模型解決問題。最後一部分,則是實際測試和評量模型成效。 語 料 .處 理. 特徵處理. 立. 選擇 政特 徵治 大. ‧. ‧ 國. 學. 模型建構. 案例測試. n. al. er. io. sit. y. Nat. 圖 1.1: 研究架構流程圖. i Un. v. 在本研究,我們將介系詞片語定位問題與介系詞推薦問題分別做了一些假設與簡. Ch. engchi. 化。介系詞片語定位問題,在現實生活中,可能有的答案包含:修飾動詞、修飾名詞、 二者皆可或其它。為了將這個複雜的問題轉換成較單純的二分類問題,我們簡化為只有 修飾動詞與修飾名詞二種可能。介系詞推薦的問題,在只提供動詞、名詞一和名詞二的 資訊下,答案可能不只一個介系詞。因此我們將問題簡化成只有一個答案,只處理只有 一個答案的案例。另外,只挑選數量較多的介系詞做實驗。 介系詞片語定位的問題依上述的假設是一個二分類的問題,介系詞推薦的問題則 是一個多分類問題,所以,顯然地,我們可以看出推薦問題可能比定位問題的難度要 高。. 4.
(18) 額外值得一提的是,針對介系詞片語定位的問題,許多學者大多希望能夠對所有 介系詞找出一套一般化的通則。然而我們從 Ratnaparkhi 等人 [20] 所彙整的中心詞語料 庫,也就是 RRR 語料庫3 ,統計各個介系詞數量分布的情況,結果如表 1.1所示,其中. NPP 為修飾名詞的介系詞片語,而 VPP 為修飾動詞的介系詞片語。可以發現每一個介 系詞的定位情況都不相同,因此在我們的研究會針對各個介系詞歸納適用的準則。. 1.3 研究成果. 政 治 大. 研究成果的部分,依研究的問題可以分成介系詞片語定位與介系詞推薦二部分。. 立. 介系詞片語定位的問題,成果可以分成四大類:(一)與同樣以中心詞做為出發. ‧ 國. 學. 點的研究做比較,比較的研究方法是 Ratnaparkhi 等人 [20] 提出的最大熵值法,若使用. ‧. 我們的方法效果是比較好;(二)與以上下文之語義為出發的研究比較,比較的對象是. Klein 和 Manning[12] 的 Stanford 剖析器,雙方實驗的成果則是差不多。我們的優點在. y. Nat. er. io. sit. 於所使用的語義資訊是較少的,缺點則是我們假設中心詞是已知的資訊。在考慮上下文 的情況,雖需要的資訊是比較多,但是沒有中心詞的問題;(三)我們直接使用高層抽. al. n. iv n C 象語義也可以有不錯的分類效果,但使用階層式選擇尋找抽象語義的方法比直接使用高 hengchi U. 層抽象語義更好。(四)為每個介系詞特製化的分類器效果雖然與混合介系詞差不多, 但特製化的分類器可以觀察各個介系詞相關連的抽象詞彙,且混合介系詞訓練語料量 遠較各別的介系詞大,因此若能提升語料量,相信特製化的分類器可以表現的再更好。 介系詞推薦的問題,目前是較難與現有的方法做比較,因為目前現有的方法所使 用得語料庫都不相同。因此,我們只能依靠大量語料所做得成果和語料庫中介系詞的 分布情況,參考我們實驗成果的好壞。成果可以分成二大類:(一)以 RRR 語料庫為主 的實驗,我們從語料庫中挑選了 6 個數量差不多的介系詞做實驗,實驗成果顯示我們 的方法是比隨意猜測好;(二)以華爾街日報與紐約時報所組成的大型語料庫為主的實 3 https://sites.google.com/site/adwaitratnaparkhi/publications/ppa.tar.gz?attredirects=0&d=1. 5.
(19) 表 1.1: RRR 語料庫,NPP 與 VPP 的數量. y. sit. er. ‧ 國. ‧. n. al. 政 治 大. 學. io. NPP like 30 near 4 next 2 notwithstanding 0 of 6553 off 8 on 736 onto 1 out 0 outside 4 over 62 past 0 per 12 plus 1 10 since than 82 through 13 throughout 2 to 566 toward 26 towards 1 under 25 unlike 0 until 1 unto 1 up 1 upon 1 versus 2 via 1 whether 1 while 0 with 397 10 within without 6 Total 13265. VPP Total 86 273 15 21 20 27 89 112 110 205 6 9 2 2 14 15 57 99 0 1 25 36 497 620 594 760 23 31 64 74 9 18 5 5 2 2 1 1 1 3 28 137 11 17 0 2 326 477 0 2 14 14 2 3 102 110 2 4 1310 2652 716 1076 2 3 2061 4060 2 3 341 369. 立. Nat. about above across after against along alongside amid among amongst around as at because before behind below beneath beside besides between beyond but by de despite down during except for from if in inside into. NPP 187 6 7 23 95 3 0 1 42 1 11 123 166 8 10 9 0 0 0 2 109 6 2 151 2 0 1 8 2 1342 360 1 1999 1 28. Ch. engchi. i Un. v. VPP 21 8 23 1 61 28 826 1 3 3 132 4 3 0 24 11 127 10 1486 13 1 92 3 29 0 3 9 0 10 0 1 739 48 68 10325. Total 51 12 25 1 6614 36 1562 2 3 7 194 4 15 1 34 93 140 12 2052 39 2 117 3 30 1 4 10 2 11 1 1 1136 58 74 23590. 驗,因為語料量遠較 RRR 語料庫大,所以我們選擇詞頻最高的 11 個介系詞做實驗。並 參考以 RRR 語料庫為主的實驗中,找到最佳模型的方法,並再重複一次方法流程。實 驗的成果顯示我們的模型易受到各個類別語料量的影響,模型容易偏好決策數量較多 的類別。我們參考比較的對象是 De Felice 和 Pulman[6] 考慮上下文語義的方法,視窗大. 6.
(20) 小(window size)設為 6。我們的方法與 De Felice 和 Pulman 的方法相比較是有一小段 差距,但我們使用得語義資訊較少,這也表示我們實驗成果仍有進步的空間。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 7. i Un. v.
(21) 第2章. 文獻回顧. 介系詞的相關研究議題,一直是許多學者努力研究的目標,Baldwin 等人 [3] 於 2009 年. 政 治 大. 時,回顧近十年各式各樣介系詞相關的議題,其中包含了本研究有興趣的二個介系詞議. 立. 題。本章將回顧過往介系詞議題等相關研究,包含了以四個中心詞或以上下文等方法. ‧ 國. 學. 解決介系詞片語定位問題、介系詞歧義問題和介系詞推薦問題。依據 Baldwin 等人的觀. ‧. 點,使用中心詞處理問題是較屬於比較偏向語法(syntex)層面的方法。雖然本研究也 是以中心詞分析為主,但亦使用了 WordNet 查詢中心詞的語義,所以本研究不單純只. er. io. sit. y. Nat. 在語法的層次,我們也進入了語義的層次。. 近 幾 年,也 出 現 了 許 多 不 少 與 介 系 詞 相 關 的 工 作 坊(workshop),如 SemEval. al. n. iv n 2 C 2007 Task 6 和 Helping Our Own 2012 U 是 相 關 的 介 系 詞 專 案,如 The h eShared h i 。或 n g cTask 1. Preposition Project(Litkowski 和 Hargraves[14])。這些都一再顯示了介系詞的重要性。. 2.1 介系片語定位 介系詞片語定位一直是自然語言處理的一個大問題。對於人類而言,在有語境的情況 下,可以較輕易地判斷介系詞片語的定位對象,但是人類對於介系詞片語定位的判定正 確率也不是百分之百。在 Ratnaparkhi 等人 [20] 曾經做過請人判讀介系詞片語定位的實. 1 http://nlp.cs.swarthmore.edu/semeval/index.php 2 http://clt.mq.edu.au/research/projects/hoo/hoo2012/index.html. 8.
(22) 驗。若只給定動詞片語中的四種中心詞,那麼人類判讀的準確率可以到達 88.2%。但是 如果再加入上下文等語境,那麼人類的判讀可以高達 93.2%。而 Ratnaparkhi 等人的研 究方法,電腦判讀僅有 78.0% 的準確率。 從早期開始,有不少學者採用機率統計的方式試圖解決介系詞片語定位問題(如. Hindle 和 Rooth[10]、Liu 等人 [15] 和 Ratnaparkhi 等人)。經常使用得基本特徵資訊包含 動詞片語的四個中心詞:動詞、名詞一、介系詞和名詞二。透過四個中心詞,再經由機 率統計模型計算介系詞片語可能的定位。 然而對假設已知四個中心詞,Atterer 和 Schütze[2] 指出這個假設不是憑空而來。. 政 治 大. 但本研究依舊假設中心詞是已知條件,將中心詞的取得視為前處理的一部分,我們抽取. 立. 中心詞的研究則是依靠 Stanford 剖析器3 ,而 Stanford 剖析則是建立在 Collins[4] 的研究. ‧ 國. 學. 之上。. ‧. 對於介系詞片語定位而言,語料的來源也是讓人頭疼的問題。到現在最常被使用. sit. y. Nat. 得語料庫都還是 Penn Treebank 3(以下簡稱 PTB3)。但在現今介系詞定位問題幾乎都倚. io. er. 靠機器學習方法解決,語料多寡便成了最直接影響實驗成果的因素之一。依照語料是. al. 否有答案可以將學習的方式分成二類:監督式學習(supervised learning)與非監式學習. n. iv n C (unsupervised learning);前者需要有答案,後者不需要。 h e n g c h i U Ratnaparkhi 等人以監督式學習 的演算法最大熵值法(Maximum Entropy)訓練模型。監督式學習往往語料較為稀少, 非監督式學習語料來源較不受限,因此數量較多。Pantel 和 Lin[18] 使用非監督式學習 方法,透過大量的語料做實驗。也有學者指出比起單獨使用監督式或非監督式學習方 法,混合二種方法而成的半監督式學習方法更可以有效的預測介系詞片語定位問題,如. Volk[24] 與 Coppola 等人 [5] 等。一般來說,相對於非監督式學習的方法,監督式學習 的效果比較好。本研究是以監督式學習解決問題。 從語義歧義的問題角度看,也有不少關於介系詞片語定位的研究是先處理語 義歧問題再決解定位問題。這時,有些學者會考慮上下文資訊的特徵,如 Olteanu 和 3 http://nlp.stanford.edu/nlp/javadoc/javanlp/edu/stanford/nlp/trees/SemanticHeadFinder.html. 9.
(23) Moldovan[17]。這樣做得好處是可以看較全面的資訊,但使用得特徵也會比較多。此 外,介系詞本身也有語義歧義的問題,例如 O’Hara 和 Wiebe[16]、Tratz 和 Hovy[23] 和. Hovy 等人 [11] 都曾試圖決解此問題。本研究則是不處理上述這些問題。 在不少文獻中,可以看到每個介系詞均有自己的特色,如 Stetina 和 Nagao[21] 試 圖為每一個介系詞製作合適的分類器。且大部分的介系詞更是有慣用方式,可參考 表 1.1,例如介系詞“of”大多數的時候都是定位名詞。因此 Coppola 等人將語料中有 “of”的案例去除。另外,Coppola 等人也去除了名詞一是代名詞的情況,因為代名詞通 常不會被定位為修飾名詞。將這些接近幾乎慣用的案例去除後,可以使得實驗結果更可. 政 治 大. 以被信賴。所以,在我們的研究中,我們將挑選具有挑戰性的介系詞,並為每個介系詞. 立. 特製化分類器。. ‧ 國. 學. 實驗比較部分,我們的研究除了與同樣都是使用四個中心詞研究比較外,同時也. ‧. 與剖析器做比較。然而 Agirre 等人 [1] 指出這是不公平的比較,因此他們透過改良剖析. sit. y. Nat. 器的效果證明他們的研究方法確實可以公平的與剖析器比較。但在這裡因為時間、人力. io. al. n. 析器比較研究成果。. er. 有限的情況下,我們無法一一為每個剖析器改善其效果,因此我們仍是直接與現有的剖. Ch. engchi. i Un. v. 2.2 介系詞推薦 推薦問題與定位問題的歷史相比較,是屬於比較年輕的問題。目前許多研究大多視為 是文本校對的應用,且視為是「介系詞校正」的問題,較早的相關研究有 De Felice 和. Pulman[6]、Gamon 等人 [8] 和 Tetreault 和 Chodorow[22]。 Han 等人 [9] 使用真實的誤用的語料庫建構校正系統。Leacock 等人 [13] 以網際網 路為基礎透過搜尋引擎建議合適的介系詞。在 Helping Our Own 2012 Shared Task 更是有 一半的工作著重於介系詞校正的議題上,相關研究如 Wu 等人 [25] 和 Quan 等人 [19]。. 10.
(24) 綜合大部分的研究結果顯示,使用真實犯錯語料是比較困難的問題。 校正嚴格來說可以分成二階段:第一個階段是偵錯,第二個階段是更正。De Felice 和 Pulman[7]、Gamon 等人和 Helping Our Own 2012 Shared Task 都是二個階段皆著重。. De Felice 和 Pulman[6] 是著重於後者。本研究也是著重於後者,廣義來說,我們將推薦 視為是一種校正,但因為本研究不包含偵錯,所以我們強調是介系詞推薦。. De Felice 和 Pulman[6] 的研究與本研究的介系詞推薦是較相近,同樣是使用文法 正確的語料庫訓練模型,且將實驗限縮在常用的介系詞。然而使用得語料庫不太相同, 因此無法直接比較,但我們參考 Gamon 等人藉由語料庫中介系詞的分布,參考比較自 己目前的實驗效果。. 立. 政 治 大. ‧. ‧ 國. 學. n. er. io. sit. y. Nat. al. Ch. engchi. 11. i Un. v.
(25) 第3章. 語料處理. 本章將介紹本研究所使用得語料庫以及詞彙資料庫 WordNet。我們所使用的語料庫,不. 政 治 大. 論直接或間接均來自於 Penn Treebank。我們不僅直接從 PTB3 彙整出需要的資訊,也間. 立. 接的使用了 Ratnaoarkhi 等人 [20] 從 PTB 0.5 彙整而成的 RRR 語料庫。此外,我們也從. ‧ 國. 學. 華爾街日報1 與紐約時報2 的網站上蒐集報導。WordNet 這部辭典是用於查詢詞彙意義,. ‧. 用以將詞彙抽象化。本章第一部分為語料介紹,包含 RRR、PTB 3 的華爾街日報和網路. y. Nat. 上蒐集的華爾街日報與紐約時報;第二部分為介紹 WordNet 和詞彙概念;第三部分為. er. io. sit. 語料前處理,包含斷句與剖析、中心抽取、雜訊過濾和挑選出具挑戰性的介系詞;第四 部分是前處理完畢的目的語料。. n. al. Ch. engchi. i Un. v. 3.1 語料庫 我們使用的語料庫共有三種種類。RRR 與 PTB3 是目前現有的語料庫,其中 PTB3 會經 由前處理處理成 RRR 的格式。華爾街日報與紐約時報則是從網路上蒐集而來,經由斷 句、剖析後,再辨識出「動詞 -名詞片語一 -介系詞 -名詞片語二」的結構,並抽取結構 的中心詞,最後處理成 RRR 格式。本研究使用 RRR 與 PTB3 來作為介系詞片語定位問 題的語料庫,用 RRR 以及自行蒐集的報導資料當作介系詞推薦的語料庫。. 1 http://asia.wsj.com/home-page 2 http://www.nytimes.com/. 12.
(26) 3.1.1 RRR RRR 是由 Ratnaparkhi、Reynar 和 Roukos 三人製作,因此合稱為 RRR 語料庫。RRR 語 料庫是從 PTB0.5 版中分離出來的,其中每一筆資料都紀錄 PTB0.5 動詞片語中的四個 中心詞與定位標記,如表 3.1所示,我們將這種紀錄方式稱之為 RRR 格式。 表 3.1裡每一筆資料都是實際語料庫所表示。每筆資料在資料庫裡都有一個編號表 示 PTB0.5 的原句,並且有標記該介系詞片語的定位對象:以 V 表示修飾動詞,而以 N 表示修飾名詞一。RRR 語料裡共有 23500 多句,分布情況可參考表 1.1。. 政 治 大. 表 3.1: RRR 語料庫實際範例. 立 名詞一. 名詞二 director N.V. conglomerate. 定位 V N N. n. al. er. io. sit. y. Nat. 3.1.2 PTB3. board chairman director. 介系詞 as of of. ‧. ‧ 國. 動詞 join is named. 學. 編號 0 1 2. Ch. i Un. v. Penn Treebank 是一個將自然語言結構化的資料庫,在許多自然語言處理的研究都被視. engchi. 為是黃金標準。本研究使用的版本是現行版本第三版,其中內容包含了三年份華爾街 日報共 2499 篇報導,共有 98732 句結構化的句子,並且將這些句子分成 25 節。採用. Penn Treebank 風格做語法標記。 本研究中所關心句子是含有介系詞的動詞片語,例如說,圖 3.1是 PTB3 裡一個真 實的結構樹,而底線部分是動詞片語也就是我們關心的結構。第 3 行到第 9 行是一個. VP 表示動詞片語,第 4 行到第 7 行是 NP 表示名詞片語,第 8 行到第 9 行是 PP 表示介 系詞片語,在 PP 內部的第 9 有一個 NP 表示名詞片語,前者稱為名詞片語一,後者稱 為名詞片語二。在這四個片語中都各包含了一個中心詞,圖中以粗體表示中心詞,動詞 片語中心詞是“set”,名詞片語一的中心詞是“floor”,介系詞片語中心詞“on”,最後 13.
(27) 名詞片語二的中心詞為“bidding”。. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.. ( (S (NP-SBJ (DT The) (JJ Venezuelan) (JJ central) (NN bank) ) (VP (VBD set) (NP (NP (DT a) (ADJP (CD 30) (NN %) ) (NN floor) ) (PP (IN on) (NP (DT the) (NN bidding) )))) (. .) )). 圖 3.1: PTB3 的結構樹. 立. 政 治 大. 學. ‧ 國. 3.1.3 華爾街日報與紐約時報. ‧. 我們從華爾街日報與紐約時報的網站上蒐集了 2011 年部分報導內容,其中包含了華爾. y. Nat. 街日報的 68983 句和紐約時報的 55358 句。內容屬性上,華爾街日報是屬於財經類報. er. io. al. iv n C 圖 3.2是一篇實際的段落文章,目標是抓取動詞片語的四個中心詞。以圖 3.2的第 hengchi U n. 法。. sit. 導,而紐約時報是屬於綜合類的報導。這二類報導文章的句型句法都是屬於較現代的用. 一句為例,底線部分是動詞片語,粗體是中心詞。. Officials have long shunned proposals that would make banks and other creditors share some losses on Greek debt. But European leaders are taking the calculated risk that they can avoid spooking investors by expanding the aid package to include other troubled countries on Europe’s periphery. 圖 3.2: 紐約時報的段落文章. 14.
(28) 3.2 詞彙資料庫:WordNet WordNet 是一個詞彙的資料庫,收入動詞、名詞、形容詞和副詞四種詞性的詞彙,並 以階層式的架構描述詞彙語義的關係,我們使用的版本是 WordNet3.0。對於 WordNet 我們所關心的詞性是動詞和名詞,以及 WordNet 描述詞彙之間的二種關係。這二種 關係的概念分別是:(一)上下位詞關係或 IS A ,越在上位的詞彙表示越是越抽象的 概念,越下位則是越具體的概念;(二)種類(lexicographic),其中動詞有 25 種種類,. 政 治 大 節點可以分為上下二部分:上半部分表示同義詞集(synset),在 WordNet 收入的名詞 立. 名詞則有 15 種種類,可參考附錄 I。圖 3.3是一個 WordNet 的名詞結構範例,每一個. ‧ 國. 學. 與動詞的同義詞集共有 171359 個3 。若一個節點有二個以上的詞彙,表示這些詞彙 互為同義詞,可以互相替換,例如“cutlery”和“eating utensil”互為同義詞而我們以. ‧. {cutlery, eating utensil} 來表示一個同義詞集。樹狀結構的父母與小孩的關係是上下位. sit. y. Nat. 詞或 IS A 的概念,例如,“spoon”的下位詞是“wooden spoon”,上位詞是“cutlery”或. n. al. er. io. “eating utensil”,我們以 {wooden spoon} − {spoon} − {cutlery, eating utensil} 來表示這. i Un. v. 種關係。從這個例子我們可以看到上位詞的概念比下位詞抽象,因此我們定義同義詞集. Ch. engchi. 的抽象化是以該同義詞集的上位詞表示;圖 3.3中一個節點下半部表示的是這個同義詞 集的種類,各種種類之間也是有階層式的關係。 許多研究都把 WordNet 解釋為是一個樹狀結構的辭典,我們這邊也是如此。一旦 將 WordNet 簡化當成樹狀結構,我們定義越在上位的詞彙稱為越高層,反之越下位的 詞彙稱為越低層。由上下位詞的觀點來看,{entity} 是所有名詞的最抽象化的詞,也就 是根節點(root);從種類的觀點來看,{entity} 是屬於 noun.Tops 種類。noun.Tops 位於 種類的最上層,也被稱為唯一始點(unique beginners)4 。同樣都是種類的始點還有 11 個抽象概念的同義詞集;動詞不同於名詞的結構,動詞並不具有一個共通的根節點,它 3 http://wordnet.princeton.edu/wordnet/man/wnstats.7WN.html 4 http://wordnet.princeton.edu/wordnet/man/uniqbeg.7WN.html. 15.
(29) 是一個森林結構。不過有時在某些研究上為了某些原因,會再在森林的結構上再多加一 個虛擬的根節點 {∗ ∗ root ∗ ∗},使森林變為樹狀結構。 雖然簡化成樹狀結構會有利於我們使用以及解釋 WordNet,但 WordNet 實質上並 不是樹狀結構,例如說在圖 3.3右下角的同義詞集 {wooden spoon} 有 {woodenware} 和. {spoon} 二個上位詞。所以在本研究中,我們不將它簡化為樹狀結構,而是將它視為是 一個單向網路結構。 在現實的生活中,一個詞彙可能會有多個意思,而透過 WordNet 我們也可以將 這些意思都找出,這些不同的意思在 WordNet 裡,稱之為詞義(sense)。例如“spoon”. 政 治 大. 這個詞彙作“湯匙”解釋時,對應到 WordNet 是同義詞集 {spoon};而當“spoon”作. 立. “一匙的量”解釋時,對應到 WordNet 則是同樣詞集 {spoon, spoonful},而這二個由. ‧ 國. 學. “spoon”所查詢的同義詞集的上位詞也不一樣。像這樣一個詞彙可以有多個意義的問題. ‧. 被稱為語義歧義,在本研究中,我們不解決語義歧義問題。. y. Nat. 除了詞彙的語義查詢之外,WordNet 還提供我們一個詞彙當作某一個詞義的頻率。. er. io. sit. 以“spoon”為例,若表示 {spoon} 同義詞集,則頻率是 1。若表示 {spoon, spoonful} 這 個同義詞集,則頻率也是 1。若以“spoonful”查詢 WordNet,則 {spoon, spoonf ul} 頻. n. al. 率是 0。. Ch. engchi. i Un. v. 本研究使用 WordNet 的目的是用以將詞彙抽象化,也就是我們使用 WordNet 將詞 彙的概念作更概括性的解釋。在這裡,我們透過查詢同義詞集的上位詞來達到抽象化的 目的。比較句 9的“a spoon”和句 10的“a fork”,“a spoon”和“a fork”都是屬於動詞 片語中的名詞片語二。這二句看起來是相似的句子,在介系詞片語定位的問題裡,一般 直覺上,比較容易想像這二個句子的介系詞片語定位於動詞“ate”。因為對於“ate”這 個動詞而言,“spoon”和“fork”都是一種進食的工具,所以如果我們同樣把名詞二代 換為任何種類進食的工具,如圖 3.3下方的虛框中的詞彙“table knife”、“wooden spoon” 和“tablespoon”等,那麼我們應該也可以很大膽的推測在一般情況下這樣的例句皆是. 16.
(30) entity . noun.Tops physical entity. Hypernym 或 IS A. noun.Tops. Lexicographic. physical entity noun.Top object, physical object noun.Tops. 政 治 location 大 noun.Tops. whole, unit noun.Tops artifact, artefact noun.Tops. 學. here noun.location. there noun.location. ‧. ‧ 國. 立. sit. y. Nat. article noun.Tops. n. al. er. io. ware noun.artifact. Ch. woodenware noun.artifact. metalware noun.artifact. wooden spoon. tole noun.artifact. noun.artifact. spoon. engchi. i Un. cutlery, eating utensil noun.artifact. noun.artifact. fork noun.artifact. wooden spoon. teaspoon. tablespoon. noun.artifact. noun.artifact. noun.artifact. 圖 3.3: WordNet. 17. v. tableware noun.artifact dinnerware noun.artifact table knife noun.artifact. chopstick noun.artifact.
(31) 定位於動詞。在介系詞推薦的問題裡,同樣的不管把名詞二代換成何種進食工具,都不 影響介系詞是使用“with”。在這個例子中,這些可互相代換的名詞二,它們的共同點 是在逐步抽象化的過程中擁有共同的上位詞 {cutlery, eatingutensil},透過這樣的抽象 化,我們便有機會解決這二個介系詞的問題。圖 3.3右上的虛框中的“here”與“there” 這二個詞彙在語義上也有相似的部分,因此,透過抽象化的過程,我們就會找出這兩個 詞彙共有的上位詞 {location}。 句 9. The children ate the cake with a spoon.. 政 治 大. 句 10. The children ate the cake with a fork.. 立. ‧. ‧ 國. 學. 3.3 前處理. 前處理的部分包含了句子的斷句與剖析、中心詞抽取、雜訊過濾以及挑選有挑戰性的介. y. Nat. sit. 系詞等工作。流程圖可參考圖 3.4,圖中上半部是前處理的流程,下半部表示的是語料. n. al. er. io. 庫進入前處理的階段。使用華爾街日報與紐約時報需要從斷句與剖析句子的流程開始. Ch. i Un. v. 處理;使用 PTB3 語料庫,則是從結構樹中抽取中心詞的流程開始處理;使用 RRR 語. engchi. 料庫直接從雜訊過濾開始處理。最後所有語料彙整成 RRR 的資料格式,再統一處理雜 訊。雜訊過濾是一件重要的工作,雜訊包含了中心詞是定冠詞、代名詞等情況或是碰撞 問題等情況。對於介系詞片語定位問題,挑選挑戰性介系詞是找出修飾動詞與修飾名詞 機率相近的介系詞。每個語料庫介系詞分布情況大致上差不多,但仍有些許差異,因此 我們以 RRR 語料庫為主。對於介系詞推薦的問題,則是找到數量較多或是差不多的介 系詞。. 18.
(32) . 斷句和剖析. . 中心詞抽取. .. .. 華爾街日報 . 紐約時報. . PTB3. 挑選具挑戰 . 性介系詞. . 雜訊過濾 .. .. . RRR. 圖 3.4: 前處理流程圖. 3.3.1 句子剖析與斷句. 政 治 大. 我們從華爾街日報與紐約時報的網站上蒐集大量的文章報導,並將文章斷句與剖析. 立. 成結構樹。我們先利用 Stanford 剖析器5 與 Lingpipe6 將所搜集的語料斷句,僅留下二. ‧ 國. 學. 者斷句結果有共識的句子。接著再利用 Stanford 剖析器剖析留下的句子,使用的文法. 結構樹。. ‧. (grammar)是 wsjFactored.ser.gz,並將 MAX_ITEMS 參數設為 500000,剖析後可得到. n. al. er. io. sit. y. Nat 3.3.2 中心詞抽取. Ch. engchi. i Un. v. 我們的目標是從結構樹抽出動詞片語的四個中心詞,圖 3.5和圖 3.6表示二種的動詞片 語的結構,以 Penn Treebank 風格表示,二圖分別表示介系詞片語修飾對象是名詞和動 詞。圖 3.5和圖 3.6裡 VP 下方最左邊的節點表示是不同形態的動詞,如過去式、過去分 詞等;IN 表示的是介系詞;而在 Penn Treebank 風格的語法標記下,“to”這個介系詞會 另外被表示成 TO。圖 3.5與圖 3.6這二個結構最大的不同點在於 PP 這個節點是掛在 NP 或是 VP 之下。我們以圖 3.1中的結構樹作為中心詞抽取的例子,句 11是將圖 3.1平面化 之後的結果,底線是我們要抽取的目標,它符合圖 3.6結構。. 5 Stanford. Parser 2.0 版(2012 年 2 月 3 日),http://nlp.stanford.edu/software/lex-parser.shtml. 6 http://alias-i.com/lingpipe/. 19.
(33) VB| VBD| VBG| VBN| VBP| VBZ. . VP NP PP. NP1 IN| TO. NP2. 圖 3.5: 動詞片語: 修飾名詞. VB| VBD| VBG| VBN| VBP| VBZ. 立. . VP. PP. NP1. 政 治 大 IN| NP2 TO. ‧ 國. 學. 圖 3.6: 動詞片語: 修飾動詞. ‧. 我們使用 Stanford Tregrex7 並利用圖 3.7和圖 3.8的樣式比對含有上述二種動詞片語 結構的句子。如果一個句子符合圖 3.7和圖 3.8的樣式,就可以從動詞片語中比對四個主. y. Nat. er. io. sit. 要詞組結構,句 11被比對的詞組結構如表 3.2裡片語一欄所示。再利用 Stanford 剖析器 的 SemanticHeadFinder8 類別將動詞片語的四個主要詞組結構的中心詞找出,最後得到. n. al. Ch 的結果如表 3.2裡中心詞一欄所示。. engchi. i Un. v. 句 11. ( ( S (NP-SBJ (DT The) (JJ Venezuelan) (JJ central) (NN bank) ). (VP (VBD set) (NP (PP (NP (DT a)(ADJP (CD 30) (NN %) )(NN floor) ) (IN on)(NP (DT the) (NN bidding) ))))(. .) )). 7 Stanford. Tregrex 2.0.1 版(2012 年 1 月 6 日),http://nlp.stanford.edu/software/tregex.shtml. 8 http://nlp.stanford.edu/nlp/javadoc/javanlp/edu/stanford/nlp/trees/SemanticHeadFinder.html. 20.
(34) io. ‧ 國. engchi. 21. i Un. v. sit. y. 圖 3.8: 修飾動詞樣式. er. "@/VP.?/ [" + "< (VB=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBD=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBG=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBN=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBP=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBZ=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VB=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBD=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBG=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBN=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBP=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2)))) |" + "< (VBZ=verb $++ (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2))))" + "]". ‧. Ch. 學. n. al. 圖 3.7: 修飾名詞樣式. Nat. "@/VP.?/ [" + "< (VB=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBD=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBG=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBN=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBP=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBZ=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (IN=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VB=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBD=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBG=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBN=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBP=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2))))) |" + "< (VBZ=verb $++ (NP < (@/NP.?/=np1 $++ (@/PP.?/=pp < (TO=prep < PREP $++ @/NP.?/=np2)))))" + "]". 立. 政 治 大.
(35) 表 3.2: 中心詞抽取 動詞 名詞片語一 介系詞 名詞片語二. 片語 (VBD set) (NP (NP (DT a) (ADJP (CD 30) (NN %) ) (NN floor))) (IN for) (NP (DT the) (NN bidding) ). 中心詞 set floor for bidding. 3.3.3 雜訊過濾 雜訊過濾的目的是為了提升語料的品質,增進實驗的可靠度。底下我們將一一介紹在本. 政 治 大 通常我們會認為詞彙有一些固定的用法,因此通常我們假設詞彙有固定的語義與 立. 研究中被視為雜訊的情況。. ‧ 國. 學. 詞性。舉個例子,“google”在一般的認知中,很直覺地會被認定是名詞,因為這是一 個公司的名稱。然而“google”在目前可以說是國際上知名度最高的搜尋引擎9 ,因此不. ‧. 僅成了搜尋引擎的代名詞,更成了搜尋的別稱,“google”一詞也因此出現了新的用法,. Nat. sit. y. 例如我們有時可能會聽到“Have you ever googled that?”,在這個例句中“google”已經. n. al. er. io. 被當成是動詞在使用了,然而“google”作為動詞的用法在以前的辭典中是不會被記 載。. Ch. engchi. i Un. v. 在我們的語料庫裡,也有不少句子因為語法上的關係,可能會有一些特殊的符號 和數字被當成是中心詞,例如:“%”可能會出在名詞的位置。然而這些符號和數字在 我們的方法中是很難抽象化的,因此我們會事先將這些符號和數字過濾。 除了上述情況之外,我們也發現雖然 RRR 的語料庫經由 Ratnaparkhi 等人整理過, 但 Pantel 和 Lin[18] 在 RRR 語料庫裡找到 133 筆名詞一或名詞二為“the”,PTB3 裡也 有出現“the”的被當成是名詞的案例。另外在 RRR 與 PTB3 語料庫也均有一些名詞是 “a”或“an”的情況。類似的情況,我們亦將之視為雜訊。 此外,我們會先利用 WordNet 做詞幹還原。接著,再給定還原後的詞彙和詞性, 9 2012. 年9月5日. 22.
(36) 如果 WordNet 沒有查詢任何同義詞集,那麼也會被過濾。. Coppola 等人 [5] 曾提到,如果名詞一是代名詞,則介系詞片語有較高的機率是定 位於動詞。另一方面,代名詞不被收入於 WordNet 內,因此當名詞是代名詞的情況在 我們的二個研究問題中也會過濾。 對於介系詞定位問題,碰撞是指當有二個以上的動詞片語具有四個相同的中心詞 但介系詞定位卻不相同的情況。對於介系詞推薦問題,碰撞是指當動詞、名詞一和名詞 二相同,但介系詞有二個以上的情況。上述這二類的案例,目前在本研究中暫不處理, 因此也將之視為雜訊。. 政 治 大. 當我們處理 PTB3 的語料時,會發現某些句子因為語境等因素而使得名詞一被省. 立. 略而標記成“-NONE- *”,此時若使用圖 3.7和圖 3.8的樣式比對,這類的語料也會被我. ‧ 國. 學. 們比對到。然而這類的語料實際上我們無從得知本來的名詞一,因此這類的情況也被我. ‧. 們過濾。. sit. y. Nat. n. al. er. io. 3.3.4 挑選具挑戰性的介系詞. i Un. v. 挑選具挑戰性的介系詞的目的是希望可以挑選出較值得做實驗的介系詞。而挑戰性的. Ch. engchi. 介系詞對於介系詞片語定位與介系詞推薦問題各有不同的定義。 以往有許多學者的目標是希望能做一套適用一般化介系詞片語定位的分類器,但 根據我們初步的觀察表 1.1,每種介系詞對於修飾名詞與修飾動詞都有不同偏好程度, 因此我們認為如果能夠針對各別的介系詞片語做分類,效果可能會比較好。 但有些介系詞片語定位偏好很明顯,隨意猜測也可以達到不錯的效果,例如 表 1.1中的“of”,我們可以看到“of”相當的偏好修飾名詞,根據其修飾名詞與修飾動 詞的數量來看,只要直接猜測“of”是修飾名詞,那麼約有高於 9 成的機率可以答對, 因此,我們希望可以排除這種情況的介系詞。 我們採用 Entropy 如式 (3.1) 和頻率這二個指標來衡量某一個介系詞對於修飾名詞 23.
(37) 與修飾動詞的偏好程度,數值越大表示偏好二類的程度越相當,是越具有挑戰性的介系 詞。我們的目的是找數量多且平衡的介系詞,可惜往往數量多的介系詞也是最不平衡的 而數量少的介系詞則反而會比較平衡。. Entropy =. ∑. −P r(d) log2 P r(d). (3.1). d∈D. 式 (3.1) 中,以“of”為例,介系詞片語定位問題 D 只有二個分類:修飾名詞與修 飾動詞。因此 D = {V P P, N P P },P r(d) 為修飾名詞或修飾動詞所佔的比例。所以我. 政 治 大 雖然比起介系詞數量的多寡,我們更重視介系詞平衡的情況,但是我們也不希望 立. 們可以知道 P r(N P P ) = 6553/6614、P r(V P P ) = 16/6614,最後可以計算出 Entropy。. ‧ 國. 學. 介系詞數過少。因此我們設立雙重門檻值的篩選機制將介系詞分成二個等級:第一個等 級是最平衡且滿足一定的數量的介系詞,第二個等級是修飾名詞與修飾動詞比例約為 2. ‧. 比 3、1 比 2 或反之的情況,但仍是滿足一定數量的門檻值限制。透過這樣的門檻值限. Nat. sit. y. 制,我們可以找到較具挑戰性的介系詞,並針對個別的介系詞做特製化的分類器。. al. n. 詞做實驗。. er. io. 在介系詞推薦的問題裡,我們會從語料庫挑選數量較多或是數量上較接近的介系. Ch. engchi. i Un. v. 3.4 目的語料 目的語料是我們經由 3.3節前處理的方法得到的結果。介系詞片語定位問題的語料,我 們將以 RRR 所選到的介系詞為主,實際上,在我們的統計中,每個語料庫的介系詞分 布幾乎都是差不多的。介系詞推薦問題則是依個別介系詞數量多寡不同而選擇的介系 詞。對這二個問題我們設定了一個分布線(Distribution),分布線的意義是亂猜可以達 到最佳的精準度。 介系詞片語定位問題,根據的介系詞數量分布的情況,分布線定義,如式 (3.2)。. 24.
(38) 式 (3.2) 的 P r(V P P ) 與 P r(N P P ) 表示修飾動詞與修飾名詞在語料庫裡佔得總量的比 例。. Distribution = M ax(P r(V P P ), P r(N P P )). (3.2). 介系詞推薦問題,我們比較著重於分析各個介系詞分類的情況,因此設定以介系 詞在語料庫佔得總量計算分布線,如式 (3.3),其中 |x| 表示 x 出現的頻率。而總體的分 布線,則是以單獨分布線較高者為準。. 治 政 |P reposition| Distribution = 大 |T otal| 立. (3.3). ‧ 國. 學. 3.4.1 介系詞片語定位語料. ‧. y. Nat. 表 3.3、表 3.4和表 3.5是 RRR 語料經由篩選過慮後的結果,我們選出“for”、“on”、“in”. er. io. sit. 、“with”、“from”和“to”,其中前三個介系詞都是數量多且較平衡的情況,而後三者 則是數量多但較不平衡的情況,混合表示是將這六個介系詞一起做實驗。訓練語料、驗. n. al. ni Ch 證語料和測試語料的分布大致上都是差不多。 U engchi. v. 表 3.6、表 3.7和表 3.8是 PTB3 過濾後的結果,分布的情況與 RRR 大致是相同的。 為與 Stanford 剖析器做比較,我們選用 PTB3 的 02 到 21 節做測試語料,22 節做驗證語 料,00、01、23 和 24 節做測試語料。 表 3.9是表 3.8測試語料的原句句數統計。若將原句給 Stanford 剖析器剖析,可能 會出現原本是動詞片語的結構,但 Stanford 剖析器卻無法辨識;或者不是動詞片語,但 卻被 Stanford 剖析器誤認的情況。若將這二種情況去除可得表 3.10,細節參考 5.3.5。. 25.
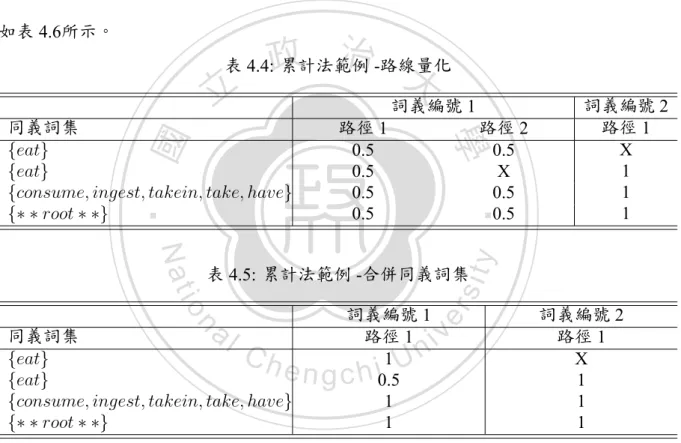
(39) 表 3.3: RRR 前處理結果: 訓練語料 介系詞 for on in with from to 混合. v 829 512 1392 454 451 1145 4783. n 869 485 1314 268 237 394 3567. 總數 1698 997 2706 722 688 1539 8350. Entropy 0.9996 0.9995 0.9994 0.9516 0.9290 0.8207 0.9846. v(%) 48.82 51.35 51.44 62.88 65.55 74.40 57.28. n(%) 51.18 48.65 48.56 37.12 34.45 25.60 42.72. 分布線 (%) 51.18 51.35 51.44 62.88 65.55 74.40 57.28. n(%) 53.48 45.45 51.52 39.17 41.27 30.15 45.76. 分布線 (%) 53.48 54.55 51.52 60.83 58.73 69.85 54.24. n(%) 57.14 58.49 56.18 38.89 34.78 36.02 50.04. 分布線 (%) 57.14 58.49 56.18 61.11 65.22 63.98 50.04. n(%) 54.93 50.53 44.77 37.41 39.67 23.95 42.87. 分布線 (%) 54.93 50.53 55.23 62.59 60.33 76.05 57.13. 表 3.4: RRR 前處理結果: 驗證語料. 48.48 60.83 58.73 69.85 54.24. n 148 93 200 35 32 76 584. n. al. 總數 259 159 356 90 92 211 1167. Ch. Entropy 0.9852 0.9791 0.9890 0.9641 0.9321 0.9428 1.0000. engchi. sit. y. 表 3.5: RRR 前處理結果: 測試語料. io. v 111 66 156 55 60 135 583. 0.9993 0.9659 0.9779 0.8831 0.9948. v(%) 42.86 41.51 43.82 61.11 65.22 63.98 49.96. er. ‧ 國. 立. Entropy v(%) 治 政 0.9965 大 46.52 0.9940 54.55. 總數 316 220 561 120 126 272 1615. ‧. n 169 100 289 47 52 82 739. Nat. 介系詞 for on in with from to 混合. v 147 120 272 73 74 190 876. 學. 介系詞 for on in with from to 混合. i Un. v. 表 3.6: PTB3 前處理結果: 訓練語料 介系詞 for on in with from to 混合. v 732 512 1531 450 441 1064 4730. n 892 523 1241 269 290 335 3550. 總數 1624 1035 2772 719 731 1399 8280. Entropy 0.9930 0.9999 0.9921 0.9538 0.9690 0.7941 0.9853. 26. v(%) 45.07 49.47 55.23 62.59 60.33 76.05 57.13.
(40) 表 3.7: PTB3 前處理結果: 驗證語料 介系詞 for on in with from to 混合. v 23 30 72 10 14 34 183. n 39 22 61 5 10 16 153. 總數 62 52 133 15 24 50 336. Entropy 0.9514 0.9829 0.9951 0.9183 0.9799 0.9044 0.9942. v(%) 37.10 57.69 54.14 66.67 58.33 68.00 54.46. n(%) 62.90 42.31 45.86 33.33 41.67 32.00 45.54. 分布線 (%) 62.90 57.69 54.14 66.67 58.33 68.00 54.46. n(%) 62.17 49.27 50.09 40.80 37.40 29.73 47.27. 分布線 (%) 62.17 50.73 50.09 59.20 62.60 70.27 52.73. 表 3.8: PTB3 前處理結果: 測試語料. n 189 101 289 51 46 77 753. ‧ 國. 立. Entropy v(%) 治 政 0.9568 37.83 大. 總數 304 205 577 125 123 259 1593. 0.9998 1.0000 0.9754 0.9537 0.8780 0.9978. 50.73 49.91 59.20 62.60 70.27 52.73. ‧. v 115 104 288 74 77 182 840. 學. 介系詞 for on in with from to combine. y. Nat. n. al. er. io. 介系詞 for on in with from to. sit. 表 3.9: PTB3 前處理結果:測試語料原句句數. Ch. engchi. i Un. v. 句數 296 203 546 122 120 232. 表 3.10: PTB3 前處理結果:與 Stanford 剖析器比較用途之測試語料 介系詞 for on in with from to 混合. v 89 87 233 63 66 153 691. n 158 86 236 48 39 64 631. 總數 247 173 469 111 105 217 1322. Entropy 0.9430 1.0000 1.0000 0.9868 0.9518 0.8750 0.9985. 27. v(%) 36.03 50.29 49.68 56.76 62.86 70.51 52.27. n(%) 63.97 49.71 50.32 43.24 37.14 29.49 47.73. 分布線 (%) 63.97 50.29 50.32 56.76 62.86 70.51 52.27.
(41) 3.4.2 介系詞推薦語料 表 3.11、表 3.12和表 3.13是使用 RRR 語料所挑選出的介系詞,在 RRR 語料數量較少的 情況下,我們盡量挑選了數量較多且差不多的介系詞,測試語料的數量是希望最少也接 近 100 筆左右。“of”是屬於數量較多的介系詞,但由於它的數量級與其它 6 個介系詞 相差過多,因此“of”不在我們的實驗之中。 表 3.14、表 3.15和表 3.16是華爾街日報與紐約時報前處理後的結果,這是數量較 大的語料庫,我們將處理後的語料以 6 比 2 比 2 切成訓練、驗證、測試語料,並從中選. y. sit er. io. al. ‧. 數量 1604 945 2471 650 688 1413 7771. Nat. 介系詞 for on in with from to 總數. 學. ‧ 國. 治 政 大RRR 的結果是差不多的。 出數量較多的 11 個介系詞做實驗。整體而言,分布與 立 表 3.11: RRR 前處理結果: 訓練語料 分布線 (%) 20.64 12.16 31.80 8.85 8.36 18.18 31.80. n. iv n C 表 3.12: h RRR 前處理結果:U e n g c h i 驗證語料. 介系詞 for on in with from to 總數. 數量 310 214 549 118 125 265 1581. 28. 分布線 (%) 19.61 13.54 34.72 7.46 7.91 16.76 34.72.
(42) 表 3.13: RRR 前處理結果: 測試語料 介系詞 for on in with from to 總數. 數量 263 158 345 90 91 201 1148. 分布線 (%) 22.91 13.76 30.05 7.84 7.93 17.51 30.05. 表 3.14: 華爾街日報與紐約時報前處理結果: 訓練語料. n. engchi. y. sit. io. Ch. er. Nat. al. ‧. 5353 2892 2471 2248 1625 1300 1109 694 522 329 25884. ‧ 國. 立. 治 政 數量 大 7341. 學. 介系詞 of in for to on with from at as by about 總數. i Un. v. 分布線 (%) 28.36 20.68 11.17 9.55 8.68 6.28 5.02 4.28 2.68 2.02 1.27 28.36. 表 3.15: 華爾街日報與紐約時報前處理結果: 驗證語料 介系詞 of in for to on with from at as by about 總數. 數量 2424 1828 894 829 725 596 451 369 211 171 130 8628. 29. 分布線 (%) 28.09 21.19 10.36 9.61 8.40 6.91 5.23 4.28 2.45 1.98 1.51 28.09.
(43) 政 治 大 表 3.16: 華爾街日報與紐約時報前處理結果: 測試語料 立. n. engchi. 30. y. sit er. ‧ 國 io. Ch. ‧. Nat. al. 數量 2390 1801 916 892 768 572 413 359 239 162 112 8624. 學. 介系詞 of in for to on with from at as by about 總數. i Un. v. 分布線 (%) 27.71 20.88 10.62 10.34 8.91 6.63 4.79 4.16 2.77 1.88 1.30 27.71.
(44) 第4章. 研究方法. 經過第3章語料處理後,可以得到動詞片語的四個中心詞:動詞、名詞一、介系詞和名. 政 治 大. 詞二。在我們的研究裡,我們將這四個中心詞視為是已知條件,在這樣的條件下,對介. 立. 系詞片語定位與介系詞推薦問題建構一般化的模型。研究方法可以分成三部分,第一部. ‧ 國. 學. 分特徵處理將介紹特徵數值化;第二部分介紹利用 WordNet 做階層式的特徵選擇;第. n. al. er. io. sit. y. Nat. 4.1 特徵處理. ‧. 三部分介紹三種不同階段的模型建構方法。. Ch. i Un. v. 經過 WordNet 查詢而來的同義詞集被我們視為是特徵,然而這樣的特徵只是一個符號,. engchi. 但在現行許多機器學習的演算法,大多都是需要量化後的數值,因此如何將特徵量化是 一個重要的議題。 本節特徵的處理包含了特徵量化與特徵加權,特徵加權可視為是廣義特徵量化的 過程,因為加權本身也是將特徵數值化的一個過程。而本這節特徵量化特別強調如何表 現特徵的存在,我們稱之為狹義特徵量化的定義。特徵加權主要是基於狹義特徵量化再 給予不同的詮釋面向。 廣義特徵量化的過程在目前並沒有一個公認的做法,將一個文字符號量化的過程 很容易因為研究者本身的偏見(bias)而造成資訊的遺失,而往往這些遺失的資訊會造. 31.
(45) 成最後研究的成果有所偏差。但若研究者本沒有偏見,也無法向前邁進。所以如何量化 特徵才是合理,只能靠研究者對於特徵量化的詮釋與實驗的驗證。 就本節所指的狹義特徵量化的方法可分為三種:二元(binary)法、平均法和累計 法,特徵加權則是考慮詞義頻率與語義深度二種方法,其中針對平均法與累計法量化的 結果再乘上特徵加權的結果。量化的過程中,我們將會考慮一個詞彙的所有詞義包含所 有同義詞集與該同義詞集至根節點間所有的上位詞,這些上位詞同時也是同義詞集。. 4.1.1 特徵量化. 立. 政 治 大. 我們對於這三種量化的方式都有不同的詮釋:在一個透過 WordNet 查詢的詞彙中,從. ‧ 國. 學. 查詢到的第一個同義詞集到根節點所有的同義詞集,二元法考慮的面向是將所有節點 都視為是均等的存在;平均法考慮的是每個節點平均負擔的語義;累計法考慮的是每一. ‧. 條至根節路徑中每一個節點被使用的頻率。下面我們將一一介紹每一種量化的方式:. er. io. sit. y. Nat. 二元法. al. n. iv n C 二元法表示我們的特徵值只有 1 與h0,這代表所有同義詞集都視為是均等的存在。一個 engchi U 詞彙透過 WordNet 可以查詢的同義詞集以及至根節點間所有的同義詞集,凡是用到的 同義詞集均以 1 表示,反之沒有用到以 0 表示。 以動詞“eat”為例,如圖 4.1所示,圖中是所有“eat”的同義詞集以及至根節點間 所有的同義詞集,所有的節點都被標示為 1。. 平均法 二元法單純只考慮了同義詞集出現與否,然而一個同義詞集可能會有二個以上的上位 詞,這使得一個同義詞集到根節點的路徑不只一條,因此我們認為這些分叉的路徑應該 32.
(46) **root** . 1 consume, ingest, take in, take, have 1. Ch 4.. ‧. al. corrode, eat, rust 1. 1. consume, eat up, use up, eat, deplete, exhaust, run through, wipe out. sit. y. 5.. worry, vex 1. n. 特徵值. io. 同義詞集. 6.. spend, expend, drop. perturb, unhinge, disquiet, trouble, cark, distract, disorder 1. Nat. 詞義 編號. 1. 1. 政 治 大. 立 eat 1. damage pay. 學. .. eat 1. 1. disturb, upset, trouble 1. feed, eat 1. 1. give. er. 1.. 3.. ‧ 國. 2.. change, alter, modify. transfer 1. affect, impress, move, strike 1. engchi. i Un. eat, eat on 1. v. 1. 圖 4.1: 二元量化 平均分擔這個詞彙的語義,這代表每個同義詞集在該詞彙裡平均負擔的語義。將原本是 二元法的特徵值除以路徑數,若分叉的路徑有相同的同義詞集,那麼我們會再將該節點 的特徵值合併,最後再將所有的路徑計算平均。藉此衡量同義詞集在一個詞彙中的重要 性。 以圖 4.2左半部的詞義編號 1 與詞義編號 2 作例子。路線量化的結果如表 4.1,詞義. 33.
(47) 編號 2 的路徑是 {eat} − {consume, ingest, takein, take, have} − {∗ ∗ root ∗ ∗},因為詞義 編號 2 ,只有走過這條路徑此,因此每個被走過的節點量化結果皆為 1。詞義編號 1 的 路徑二條分別是 {eat} − {eat} − {consume, ingest, takein, take, have} − {∗ ∗ root ∗ ∗} 和. {eat} − {consume, ingest, takein, take, have} − {∗ ∗ root ∗ ∗},這時候我們會把 1 平均 分擔於這二條路徑,因此這二條路徑上的每個量化的節點各是 0.5。接著我們合併同一 個詞彙中相同的同義詞集,在詞義編號 1 的例子裡,二條路徑有 3 個同義詞集 {eat}、. {consume, ingest, takein, take, have} 和 {∗ ∗ root ∗ ∗} 是重複的,因此我們把原本分擔 於二條路徑上的 0.5 相加,使之成為 1,X 的部分視為 0,結果如表 4.2所示。最後,再. 政 治 大. 計算每個同義詞集平均被經過的次數。以表 4.2詞義編號 1 與詞義編號 2 中的二個 {eat}. 立. 為例,較抽象的 {eat} 被經過次數只有一次,因此合併每個詞義量化後的結果再除以. ‧ 國. 學. 1;較具體的 {eat} 被經過的次數有二次,因此量化的結果相加後再除以 2。量化的結果. 表 4.1: 平均法範例 -路線量化. Nat. y. ‧. io. 同義詞集 {eat} {eat} {consume, ingest, takein, take, have} {∗ ∗ root ∗ ∗}. n. al. Ch. 路徑 1 0.5 0.5 0.5 0.5. engchi. sit. 詞義編號 1. er. 如表 4.3所示。. i Un. v. 路徑 2 0.5 X 0.5 0.5. 詞義編號 2 路徑 1 X 1 1 1. 表 4.2: 平均法範例 -合併同義詞集 詞義編號 1 路徑 1 1 0.5 1 1. 同義詞集 {eat} {eat} {consume, ingest, takein, take, have} {∗ ∗ root ∗ ∗}. 34. 詞義編號 2 路徑 1 X 1 1 1.
(48) 表 4.3: 平均法範例 -合併路徑量化 同義詞集 {eat} {eat}. 合併 1 1.5. 量化結果 1 0.75. **root** . 1. ‧ 國. io. al. pay. Ch. 詞義 編號. engchi 5.. worry, vex 1. 同義詞集 特徵值 4.. 1. y. 1. perturb, unhinge, disquiet, trouble, cark, distract, disorder 1. n. .. eat 1. damage. sit. Nat. 1.. 1. disturb, upset, trouble 1. feed, eat 1. 1. give. er. 3.. eat 0.75. 立. ‧. 2.. change, alter, modify. transfer 治 政 大1. affect, impress, move, strike 1. 學. consume, ingest, take in, take, have 1. eat, eat on 1. spend, expend, drop. i Un. v. 1. consume, eat up, use up, eat, deplete, exhaust, run through, wipe out 1. 圖 4.2: 平均法. 35. 6.. corrode, eat, rust 1.
數據


Outline
相關文件
Al atoms are larger than N atoms because as you trace the path between N and Al on the periodic table, you move down a column (atomic size increases) and then to the left across
You are given the wavelength and total energy of a light pulse and asked to find the number of photons it
好了既然 Z[x] 中的 ideal 不一定是 principle ideal 那麼我們就不能學 Proposition 7.2.11 的方法得到 Z[x] 中的 irreducible element 就是 prime element 了..
Allan (Eds.), Proceedings of the 38th Conference of the International Group for the Psychology of Mathematics Education and the 36th Conference of the North American Chapter
volume suppressed mass: (TeV) 2 /M P ∼ 10 −4 eV → mm range can be experimentally tested for any number of extra dimensions - Light U(1) gauge bosons: no derivative couplings. =>
For pedagogical purposes, let us start consideration from a simple one-dimensional (1D) system, where electrons are confined to a chain parallel to the x axis. As it is well known
The observed small neutrino masses strongly suggest the presence of super heavy Majorana neutrinos N. Out-of-thermal equilibrium processes may be easily realized around the
incapable to extract any quantities from QCD, nor to tackle the most interesting physics, namely, the spontaneously chiral symmetry breaking and the color confinement..
