MAI-Free MC-CDMA Systems Based on
Hadamard–Walsh Codes
Shang-Ho Tsai, Yuan-Pei Lin, Senior Member, IEEE, and C.-C. Jay Kuo, Fellow, IEEE
Abstract—It is known that multicarrier code-division mul-tiple-access (MC-CDMA) systems suffer from multiaccess interference (MAI) when the channel is frequency-selective fading. In this paper, we propose a Hadamard–Walsh code-based MC-CDMA system that achieves zero MAI over a frequency-selec-tive fading channel. In particular, we will use appropriately chosen subsets of Hadamard–Walsh code as codewords. For a multipath channel of length , we partition a Hadamard–Walsh code of size into subsets, where is a power of two with . We will show that the codewords in any of the subsets yields an MAI-free system. That is, the number of MAI-free users for each codeword subset is . Furthermore, the system has the additional advantage that it is robust to carrier frequency offset (CFO) in a multipath environment. It is also shown that the MAI-free property allows us to estimate the channel of each user separately and the system can perform channel estimation much more easily. Owing to the MAI-free property, every user can enjoy a channel diversity gain of order to improve the bit error performance. Finally, we discuss a code priority scheme for a heavily loaded system. Simulation results are given to demonstrate the advantages of the proposed code and code priority schemes.
Index Terms—Carrier frequency offset (CFO), Hadamard– Walsh code, interference free, large-area synchronized (LAS) code, multiaccess interference (MAI)-free, multicarrier code-divi-sion multiple-access (MC-CDMA), multiuser detection (MUD).
I. INTRODUCTION
M
ULTIACCESS interference (MAI) or multiuser inter-ference (MUI) is a major impairment that limits the performance of code-division multiple-access (CDMA)-based systems. In a synchronous CDMA (S-CDMA) system where a user’s timing is aligned within a fraction of a chip-time interval, MAI can be reduced via the use of orthogonal codewords [21]. S-CDMA can be used in downlink transmission in large cells such as those for the digital cellular IS-95 standard and in both downlink and uplink transmissions in micro cells such as those for the personal communication services (PCS) system [21]. However, orthogonality of these codewords could be destroyed in a multipath environment. For downlink transmission in large cells, the multipath length is often longer than the duration Manuscript received February 4, 2005; revised August 22, 2005. This work was presented in part at International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Philadelphia, PA,2005. The associate editor co-ordinating the review of this manuscript and approving it for publication was Dr. Behrouz Farhang-Boroujeny.S.-H. Tsai and C.-C. J. Kuo are with the Department of Electrical Engi-neering and Integrated Media Systems Center, University of Southern Cali-fornia, Los Angeles, CA 90089-2564 USA (e-mail: [email protected]; [email protected]).
Y.-P. Lin is with the Department of Electrical and Control Engineering, Na-tional Chiao Tung University, Hsinchu, Taiwan, R.O.C. (e-mail: [email protected]. edu.tw).
Digital Object Identifier 10.1109/TSP.2006.875387
of several chips and the induced MAI will limit the system performance. Even in micro cells, the multipath effect could be serious in an urban area [18]. Multiuser detection (MUD) [25] or related signal-processing techniques have been developed to mitigate MAI. However, their complexity is usually high, and this imposes a computational burden on the receiver. Moreover, the channel information is needed for the application of the MUD scheme so that effective channel estimation plays an essential role in the system [23].
Recently, multicarrier CDMA (MC-CDMA) has been pro-posed as a promising multiaccess technique. MC-CDMA sys-tems can be divided into two types [10]. For the first type, one symbol is transmitted per time slot. The input symbol is spread into several chips, which are then allocated to different subchan-nels. The number of subchannels is equal to the number of chips [8], [27]. For the second type, a vector of symbols is formed via the serial-to-parallel conversion, and each symbol is spread into several chips. The chips corresponding to the same symbol are allocated to the same subchannel [13], which is often called MC-DS CDMA. When compared with conventional CDMA systems, MC-CDMA can combat intersymbol interference (ISI) more effectively. Moreover, the frequency diversity gain can be fully exploited if the maximum ratio combing (MRC) technique [10], [18] is used at the receiver in MC-CDMA systems. Despite the above advantages, the performance of MC-CDMA systems is still limited by MAI in a multipath environment. Even though MAI can be reduced by MUD [25] and other signal-processing [10] techniques, the diversity gain provided by multipath chan-nels could be sacrificed since the received chips are no longer optimally combined under MRC. Furthermore, channel status information is needed for MRC and MUD. In a multiuser en-vironment, multiuser channel estimation is more complicated and its accuracy degrades as the number of users increases [24], which will in turn degrade the system performance.
In this paper, we approach the MAI reduction problem for MC-CDMA systems from another angle. That is, we investi-gate a novel way to select a set of “good” spreading codes so as to completely eliminate the MAI effect while keeping the transceiver structure simple and the computational burden low. Some earlier work has been done along this direction. For con-ventional CDMA systems, Scaglione et al. [19] used a code to reduce MAI in a multipath environment. However, since the performance curves in [19] have a slope similar to the orthog-onal frequency-division multiple-access (OFDMA) system, this code design does not offer a full diversity gain. Oppermann et al. [16] examined several code sequences and selected some code-words to reduce MAI by experiments with little theoretical ex-planation of the MAI reduction performance. Chen et al. [5] proposed a code scheme based on the complementary code to 1053-587X/$20.00 © 2006 IEEE
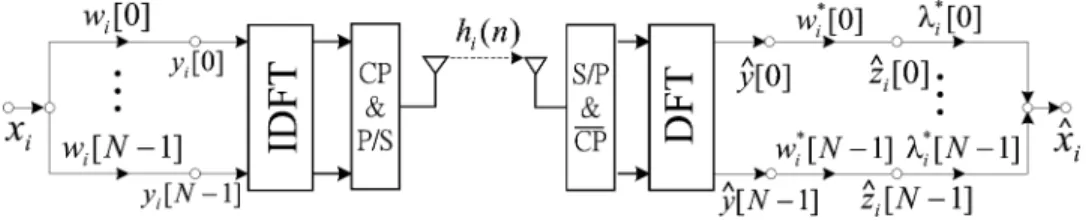
Fig. 1. The block diagram of an MC-CDMA system.
achieve an MAI-free CDMA system in a flat fading channel. Even though the number of supportable users is much less than the codeword length, this scheme can achieve higher spectrum efficiency than conventional CDMA system with a successive transmitting structure. In a multipath environment, this scheme is no longer MAI-free, and a recursive receiver structure is de-manded for symbol detection. A large-area synchronized (LAS) code was proposed by LinkAir and was examined in [22] to design a code that has an area with zero off-peak autocorre-lation and zero crosscorreautocorre-lation for CDMA. This code scheme has zero ISI and MAI in a multipath environment. The number of supportable users to achieve ISI- and MAI-free conditions depends on the multipath length. The LAS code is generalized to MC-DS-CDMA systems in [26]. As for MC-CDMA sys-tems, Shi and Latva-aho [20] proposed a code scheme for down-link MC-CDMA with little theoretical analysis. Moreover, this scheme is not optimal in minimizing the bit error probability in both uplink and downlink directions. Cai et al. [4] proposed a group-orthogonal (GO-) MC-CDMA scheme. By assigning only one user to each group, this scheme can be MAI-free and with a maximum channel diversity gain. Moreover, in a heavily loaded situation, the required computation for MUD to achieve the MAI-free property is small. However, in a CFO environment which causes MAI, relatively complicated multiuser CFO esti-mation methodology is demanded to estimate every user’s CFO. In this paper, a code design based on Hadamard–Walsh codes is proposed to achieve the MAI-free property in a synchronous MC-CDMA system [8], [27]. To be more specific, let and denote, respectively, the spreading factor and the multipath length. The Hadamard–Walsh codewords are parti-tioned judiciously into subsets, where with
and . Then we can obtain an MAI-free system and each user can fully exploit the diversity gain provided by the multipath channel using any subset of codewords in frequency-selective channels. The number of supportable MAI-free users in each codeword subset is . It is worthwhile to point out that, under the same multipath length and discrete Fourier transform (DFT)/(inverse DFT) size , the number of support-able MAI-free users in GO-MC-CDMA [4] is exactly the same as the proposed code scheme. Using the proposed code scheme, we also show a procedure to estimate the channel information for individual users under an MAI-free environment. Moreover, we consider the performance of the proposed code scheme in a carrier frequency offset (CFO) environment. It is shown that the proposed code scheme can reduce the CFO-induced MAI effect to a negligible amount under an interested CFO level. Some codewords can even achieve MAI-free in a CFO environ-ment. Furthermore, we study the relationship between the
mul-tipath length and the number of allowed users to maintain the MAI-free property and the full diversity gain with the proposed code. Finally, a code priority scheme is presented for a heavily loaded system.
The rest of this paper is organized as follows. The system model is presented in Section II. The MAI effect and the code scheme to achieve an MAI-free system are discussed in Sec-tion III. Using the proposed code design, we discuss an effective way to estimate the channel status under an MAI-free environ-ment in Section IV. Then, we examine the performance of the proposed code scheme in the presence of CFO in Section V. Simulation results are provided in Section VI to corroborate an-alytical results. Practical considerations about the relationship between the multipath length and the number of users to main-tain the MAI-free property and the full diversity gain with re-spect to the proposed code is discussed in Section VII. Finally, concluding remarks are given in Section VIII.
II. SYSTEMMODEL
The block diagram of the MC-CDMA system in uplink di-rection (from the mobile station to the base station) is shown in Fig. 1, where the signal path demonstrates a signal trans-mitted by user and detected by user . Note that the analysis is conducted in the uplink direction because it is a more general case, where the channel fading of individual users are different. (However, the analytical results can be adapted to the downlink direction as well. To obtain the analysis for the downlink direc-tion, we can simply set the channel fading of every user to be the same.) At each time slot, the input is a data symbol. Sup-pose that there are users. Let the symbol from user be . In the first stage, is spread by chips to form an 1 vector, denoted by . Let the th element of be . The relation
between and is given by
(1) where is the th element of the th orthogonal code. Note that we consider the short code scenario here, where the spreading code for a target user is the same for any time slot. After spreading, is passed through the IDFT matrix. Then, the output is parallel-to-serial (P/S) converted and the cyclic prefix (CP) of length 1 is added to combat the ISI, where is the considered maximum delay spread.
At the receiver side, the receiver removes the CP and passes each block of size through the DFT matrix. Since
there are users, the th element of the DFT output can be written as [3], [7]
(2)
where is the th component of the -point DFT of user ’s channel impulse response and is the received noise after DFT. Based on , we will detect symbols for users. As shown in Fig. 1, to detect symbols transmitted by the th user, is multiplied by and frequency gain , where denotes the complex-conjugate operation. Here, the channel information of every user is assumed to be known to the receiver. (The estimation of channel information under an MAI-free environ-ment will be described in Section IV.) After being multiplied with the frequency gains, chips are summed up to form re-constructed symbol . Using (1) and (2) is given by
(3) where MAI denotes the MAI from user to user . Note that, when the channel noise is additive white Gaussian noise, the process from to is called the maximum ratio combining (MRC) technique [10], which ensures the minimum bit error probability for detected symbols [18], or the maximum achievable diversity gain provided by multipath channels [17].
For any target user , if MAI , the reconstructed symbol will be affected only by his/her own transmitted sym-bols and the corresponding channel response . Thus, this allows the system to use some simple detection schemes without involving multiuser detection. When the channel has flat fading,
and are independent of and MAI if
orthog-onal codes such as the Hadamard–Walsh codes are used. How-ever, in practical situations, the channel environment is usually frequency-selective and the orthogonality of orthogonal codes will be lost under MRC.
In downlink transmission, the signal for every user expe-riences the same fading. In this situation, MAI-free can be achieved using orthogonality restoring combining (ORC) [10], i.e., the combining gain is instead of in (3). However, for subchannels with serious fading, ORC tends to amplify the noise in these subchannels. Thus, the performance will degrade dramatically. That is, the use of ORC may lead to the loss of the diversity gain from multipath channels. In the following sections, we will design such that MAI
under the multipath environment. Moreover, the proposed code design allows MRC to be used in both uplink and downlink transmissions. Thus, a full diversity gain from the multipath channel can be achieved.
III. MAI ANALYSISOVERFREQUENCY-SELECTIVEFADING
Let be the DFT matrix with the element
at the th row and the th column given by
and the maximum length of channel
impulse response be , i.e., , for . The
MAI term in (3) can be expressed using matrix representation as MAI (4) where .. . diag
superscript denotes the Hermitian operation [11], and diag is the function that puts the elements along the diagonal.
To have zero MAI for a frequency-selective fading channel, we need to have MAI for all nonzero and . This means that in (4) should be the zero matrix for all
. It is clear that
(5)
where , and that matrix is diagonal, i.e.,
diag with
Let . Then, it is well known that is
a circulant matrix [9]. That is, the first column of , , is the -point IDFT of , where
. Matrix is an upper
left submatrix of , i.e.,
.. . ..
. . ..
(6)
To have means that
samples and the last samples of the IDFT of are zeros. Hence, we have
(7)
Lemma 1: Suppose the channel length is and the spreading gain is . To achieve MAI-free property, should be greater than or equal to .
Proof: From (7), there should be at least elements for the codewords. However, if , all elements of the codewords are zeros. Therefore, .
Note that Lemma 1 holds for both real and complex code de-sign. In what follows, we show how to achieve the MAI-free conditions in (7) using the Hadamard–Walsh codes. Before pro-ceeding, let us recall a well-known property of the Hadamard
matrix [2]. An Hadamard matrix with ,
, can be recursively defined using the Hadamard matrix of order two, i.e.,
(8) where is the Kronecker product [2], [11] and
Our proposed code scheme is stated below. Suppose
and , where . The columns of an
Hadamard matrix form the Hadamard–Walsh codes. We divide the codewords into subsets. Each subset has codewords. That is, the th subset, denoted by ,
has codewords , where is
the th column of and . For instance, let
and . Then, contains codewords
and contains codewords .
Lemma 2: Let be an 1 vector with the th element
being . For and that belong to the
same subset, is equal to one of the codewords in ex-cluding codeword .
Proof: Let us first prove that for and , is again a codeword within . According to (8), the
upper left submatrix of is a Hadamard
matrix. Thus, the product of any two columns of this submatrix is again a column of this submatrix (see [12]). The codewords in subset 0 are the first columns of , which is obtained by repeating the submatrix by times. Hence, for
and in subset 0, is a codeword in subset 0.
Now, let us consider for and that are in the same subset other than subset 0. Recall that is the th element of the th codeword. It can also be used to denote the th element of
the th column of . According to (8), for ,
we have the following property:
. (9)
We see from (9) that the product of any two columns in the last half 2 columns is equal to that of the two corresponding columns in the first half 2 columns, i.e.,
(10) Suppose that we divide the codewords into two sets, de-noted by and , respectively. The first 2 half codewords form , while the last 2 half codewords form . Hence, as proved in the beginning of the lemma that for and in
, is again a codeword in . For and in , is
equal to a codeword in based on (10). Using a similar proce-dure, we can divide into two sets and . Thus, for and in , is a codeword in . Now, we prove that
for and in , is a codeword in . From (8), for
, we have the following property: or
or .
(11)
We see from (11) that the product of any two columns in the second quarter is equal to the product of the two corresponding columns in the first quarter, i.e.,
(12) From (14), for and in , is again a codeword in . Similarly, we can divide into two sets, i.e., and ,
and show that for and in either or , is again
a codeword in . Using the same procedure, we can continue to divide the codewords until we have subsets, and show that for and in the same subset, is a codeword of subset 0.
Lemma 3: Let , , , be
the -point IDFT of the codewords in excluding . Then, has the following property:
(13)
Proof: For , it is easy to see
since there are an equal number of 1 and 1 for any
code-word except . For , since is the IDFT of the
codewords in , we have
(14)
Let , , ; we
can rewrite (14) as
(15)
Since codewords in are the first columns of ,
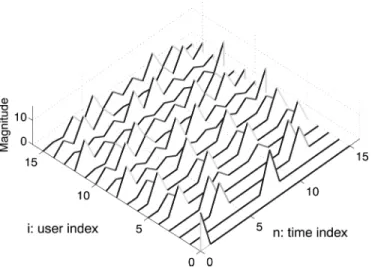
sub-Fig. 2. j ~w (n)j as a function of user index i and time index n with N = 16.
matrix of by times. Hence, ,
, . We can rewrite (15) as (16) where with otherwise. Therefore, we obtain with otherwise (17) From (17) and , we are led to (13).
From (13) and Lemma 2, we have the following property:
(18) where denotes the th element of the IDFT of within the same subset.
Let us give an example to illustrate Lemma 3. Let ; the -point DFT of the Hadamard–Walsh codewords are shown in Fig. 2. From this figure, we see that, except the all-one codeword, the IDFT of any codeword has zero at . If , we have eight subsets and each subset has two code-words. From Lemma 3, for and in the same subset, is equal to . From the figure, the first eight elements of are zeros. If , then we have four subsets, and each subset has four codewords. Again from Lemma 3, for and in the same subset, is equal to , , or . From the figure, the
first four elements of , , and are zeros.
Based on the above discussion, we have established one of the main results of this paper as stated below.
Theorem 1: Let the channel length be . We divide the Hadamard–Walsh codewords into subsets with , where
Fig. 3. An example of frequency reuse using the proposed code scheme with G = L = 4.
and are power of two and each subset consists of codewords. Then, using any one of the subsets of codewords, the corresponding MC-CDMA system is completely MAI-free. Note that Theorem 1 holds for arbitrary multipath coeffi-cients. Moreover, the maximum number of MAI-free users in each subset depends on the spreading gain and multipath length . Hence, the system can be designed accordingly. Dif-ferent applications may have difDif-ferent concerns. We describe two application scenarios below.
Application Scenario 1: In cellular systems, frequency
reuse for different cells is an important issue since im-proper frequency reuse will lead to significant cochannel interference [18]. The proposed scheme divides the code-words into several subsets to achieve MAI-free property. It is intuitive to use distinct subsets of codewords in neigh-boring cells to reduce cochannel interference. Let us give an example to illustrate this point. Let . Thus, the orthogonal codes are divided into four subsets, i.e., subsets 0, 1, 2, and 3. Fig. 3 gives an example of frequency planning using the proposed code scheme. For a larger , should be increased accordingly to be MAI-free. In this situation, we have more subsets, and the distance among the same subset in reuse can be increased to reduce cochannel interference further.
Application Scenario 2: In wireless local-area network
(WLAN) applications, the distance among cells is not as close as that in cellular systems. Hence, cochannel interfer-ence may not be a major concern. According to Theorem 1, the maximum number of users that a cell can support while maintaining the MAI-free property depends on and hence the multipath number . Thus, a smaller value of or enables the system to support more users in one cell. In this situation, should be much larger than to support more users. For a fixed sample frequency, this can be done by increasing the OFDM-block duration. Hence, if the complexity is ignored, can be as large as possible if the duration of one block does not exceed the channel coherent time. Generally speaking, this concept stands in contrast with that in an MC-CDMA system, where
should be chosen to be close to so that subchannels have less correlation and a more random signature waveform. However, as stated in Theorem 1, when the proposed code design is used, the system is completely MAI-free so that we can choose that is much larger than to support more users in WLAN applications.
IV. CHANNELESTIMATIONUNDERMAI-FREECONDITION In the last section, we assume that the channel information
for every user is known to the receiver. Without accurate channel information, neither ORC nor MRC can be performed at the receiver end. For non-MAI-free schemes, channel infor-mation is needed for the MUD-based technique in the receiver. If channel information is not available, it has to be estimated by some techniques [23], [24]. For uplink transmission, every user experiences a different fading. Thus, multiuser channel es-timation is required if the system is not MAI-free. For down-link transmission, although the mixed signal of all users from the base station experiences the same channel fading, orthog-onality of users’ codes may be destroyed as a result of fre-quency-selective fading. Unless the base station uses the same training sequence and spreading code for every user at the same time slot, it would be difficult for an individual user to acquire his/her own downlink channel information without extra signal-processing techniques. However, this reduces the system flexibility since all users have to be coordinated for training with the same signature waveform at the same time slot. Thus, it is desirable to design a system where channel estimation is conducted under an MAI-free environment. In this section, we will show that the channel information can be obtained in an MAI-free environment if the proposed code scheme is used. Thus, there is no need to do multiuser estimation in the uplink di-rection, and the training procedure is more flexible in the down-link transmission.
To get is equivalent to obtaining its time-domain
im-pulse response , . We will show how to
obtain every user’s without worrying about MAI. Again, the result derived here is for the more general uplink case. It can be adapted for the downlink case as well. Referring to Fig. 1 and from (2), if the real Hadamard–Walsh code is used, the 1 chip vector of user before gain combining is
(19) where is the noise vector after DFT. Taking the -point IDFT of in (19), we have
(20) where the second term is the interference term from other users. Since the channel path is of length , if the first elements of are zeros for all , we can obtain channel without worrying about the interference from other users.
Theorem 2: Suppose that the channel length is equal to and the code scheme as stated in Theorem 1 is used, where . Then, if we use any one subset of codewords in the MC-CDMA system, the first elements of are zeros. As a result, we can
estimate the channel in a completely MAI-free environment. That is
(21)
where is the th element of and is the th
ele-ment of .
Proof: Let us express the DFT matrix as , in (20) can be manipulated as
(22) From the discussion in Section III, if any one subset of codewords are used. Hence, the first elements of are zeros, and we get (21).
According to (21), if is a known training symbol, we can
obtain , , without worrying about the
inter-ference from symbols of other users. That is, channel estimation can be done in a completely MAI-free environment.
1) Discussion on System Parameters and Performance Tradeoff: From the discussion above, when the number of
users increases, we may increase the spreading gain or decrease the number of partitioned subsets to accommo-date more users. The adjustment of parameters and dynamically is an interesting problem, which is under our current investigation. When the system is heavily loaded in the sense that the number of active users is approaching , the proposed code design provides a set of optimal codes for the system in terms of MAI reduction and multipath diversity.
Another tradeoff results from the change of the multipath length . Under the condition , if becomes larger (or smaller), the number of allowed users decreases (or increases). For a fixed , since the diversity gain of a user is equal to , there exists a tradeoff between the number of users and the di-versity gain [17].
Finally, it is interesting to examine the case where the number of active users exceeds . Under this scenario, to get an MAI-free system, MUD can be used in the uplink direction while the ORC scheme [10] can be performed in the downlink direction. However, the full diversity gain may be lost due to noise amplification by MUD and ORC. Moreover, if no MUD is used, there exist an MAI effect. We observe from computer simulation in Section VI that the proposed code scheme still out-performs other codes in terms of MAI reduction (even though the system is not completely MAI-free in this case). Thus, the proposed code scheme is still a preferred choice.
V. PERFORMANCE OF THEPROPOSEDCODEDESIGN IN THE PRESENCE OFCFO
In this section, we consider the CFO effect and show that it can be handled by the use of the proposed code design. In particular, we show that the MAI due to the CFO effect can be reduced to zero or a negligible amount. Consider the th chip of the received vector after DFT in a CFO environment, i.e.,
where is the received noise after DFT and is the re-ceived signal due to channel fading and the CFO effect. Suppose the th user has a normalized CFO , which is the actual CFO normalized by 1 of the overall bandwidth and
. in (23) can be expressed by [14]
(24)
where and are given by
(25) The first term of (24) is the distorted chip and the second term is the ICI caused by the CFO. Note that, when there is no CFO, equals as in (2). From (3) and (23), if the real Hadamard–Walsh code is used, we see that under CFO is given by
(26) where is the desired signal and is the MAI of user due to the th user’s CFO. Using (24) and (26), it can be shown that the MAI term is given by
MAI MAI (27)
where MAI
(28)
and we have (29) as shown at the bottom of the page. Note that if there is no CFO for user , i.e., and , MAI
and MAI is equal to the MAI term defined in (3). This gives us an intuition that MAI is the dominating MAI term when the CFO is small. Hence, if we can find a way that makes MAI , the MAI due to the CFO can be reduced to a negligible amount. According to (3), (28), and Theorem 1, we have the following lemma.
Lemma 4: Let the channel length be and the code scheme as stated in Theorem 1 be used. Then, if we use any one of the subsets of codewords for the MC-CDMA system with , the dominating MAI term MAI in (28) is zero.
Now, let us look at another interference term MAI , which is called the “residual MAI” for convenience. Define . Then, we have the following lemma.
Lemma 5: Let the channel length be and the code scheme as stated in Theorem 1 be used. Then, if we use any one of the subsets of codewords for the MC-CDMA system with , the residual MAI term MAI in (29) becomes
MAI (30) where diag (31) and .. . (32)
Proof: The proof is given in the Appendix.
Since the MAI due to the CFO is divided into two terms, i.e., the dominating MAI in (28) and the residual MAI in (29), if we can make both terms equal zero, the system can be MAI-free under a CFO environment. From Lemma 4, MAI with the proposed code. Thus, our goal now is to find a way to make MAI . Let us further manipulate in (30) as
(33)
MAI
According to (30) and (33), if for all ,
we have MAI .
Lemma 6: Suppose the codeword set is used: the two codewords and will have zero MAI term. That is,
MAI and MAI .
Proof: For the all-one code , we have
Hence, we have , for
. Since is a diagonal matrix with diagonal elements drawn from , from the discussion in Section III,
for all . Hence, MAI .
For , which is a codeword with a sign change for every
consecutive code symbol, i.e., , its
circulant shift is either or .
Hence, we have
even, odd,
From Lemma 2, Lemma 3, and Theorem 1, we can conclude
that MAI .
Lemma 6 suggests to use the zeroth codeword set so that there are two codewords to preserve the MAI-free property under the CFO environment. Since codewords and are completely MAI-free under the CFO environment when is used, we can use them as training sequences to estimate the channel and/or CFO for each user. That is, in uplink direction, every user uses these two codewords in turn to acquire his/her own channel and/or CFO information. In the downlink direction, one of these two codewords can be reserved as the pilot signal for CFO esti-mation. In this case, any single-user CFO estimation algorithm (e.g., the one given in [14]) can be applied, while sophisticated MUD or signal-processing techniques can be avoided. This re-sult stands in contrast with the CFO estimation for GO-MC-CDMA systems [4], where multiuser estimation is demanded to acquire accurate CFO information.
VI. SIMULATIONRESULTS
Computer simulation results are provided in this section to corroborate theoretical results derived earlier. In the simula-tion, we considered the performance in the uplink direction so that every user has a different channel fading and CFO value. Note that the Hadamard–Walsh codewords are generated using the Kronecker product in (8) so that the codeword indexes are adopted based on this fact.
Example 1: Illustration of the MAI-Free Property: In this
example, we show that MC-CDMA is MAI-free with the pro-posed code scheme. The simulation was conducted under the
following setting: , or . The transmit power
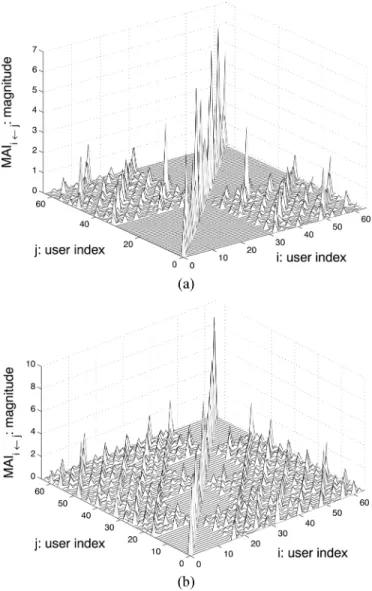
had a unit variance. The taps of the channel were independent identically distributed (i.i.d.) random variables with an unit vari-ance. We evaluate the MAI as given in (3). For , one realization of MAI as a function of user indexes and is shown in Fig. 4(a). As shown in the figure, there are two zones where the MAI is zero; i.e., the zone with codewords from 1 to 32 and the zone with codewords from 33 to 64. The peak values
Fig. 4. jMAI j as a function of user indexes i and j with N = 64: (a) L = 2 and (b)L = 4.
appear along the diagonal since they correspond to the recon-structed desired signal power for each user. Thus, the system is MAI-free if either one of the two subsets of codewords is in use. For , the performance is shown in Fig. 4(b). We see four zones where the MAI is equal to zero. Hence, if we use either one of these four subsets, we can achieve an MAI-free system. These results corroborate the claim in Theorem 1.
Example 2: Illustration of the Diversity Gain: In this
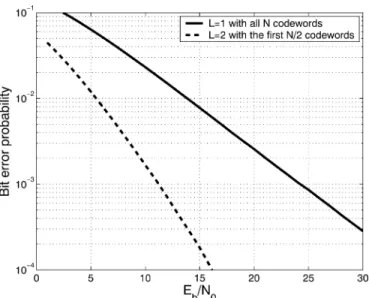
ex-ample, we would like to show that, when the proposed code scheme is used, every user can achieve a low bit error prob-ability to reflect the diversity gain . The binary phase-shift keying modulation and Hadamard–Walsh codes of
were adopted. The channel coefficients were i.i.d. complex Gaussian random variables of unit variance. For each individual user, the Monte Carlo method was run for more than 250 000 symbols. The bit error probabilities of two systems were shown in Fig. 5. The solid curve is obtained from a system with flat fading, i.e., , with full codewords used. The dashed curve results from a system of multipath length and with the proposed Hadamard–Walsh codes . Since there is no MAI, simulation results are consistent with the theoretical results in [1] and [17].
Fig. 5. The bit error rate as a function ofE =N to illustrate the diversity order of the proposed code scheme.
We see that, when grows form one to two with the pro-posed code scheme, the bit error probability improves dramat-ically due to the increase of the diversity order. Actually, the dashed curve is the same as that for a system with and two receive antennas with MRC [1]. That is, a diversity order of two is achieved via code design in the frequency domain rather than the space domain (see [17, p. 777]). This example also ex-plains the interplay between the diversity order and the number of users allowed. That is, when grows, we need to divide codewords into more subsets to achieve MAI-free. Hence, fewer users can be supported within each cell. However, these users can enjoy a higher diversity order as increases.
Note that frequency diversity is inherent in MC-CDMA sys-tems. However, without a proper code design, the system has MAI that will degrade the bit error rate (BER) performance as the number of users increases. Under this situation, MAI will dominate system performance and increasing diversity gain alone may not necessarily improve overall performance [10]. If the proposed code design is used together with receive an-tennas, a diversity order of can be achieved for each indi-vidual user.
Example 3: MAI in the Presence of CFO: In this example,
we demonstrate that the dominating MAI due to the CFO effect can be completely eliminated by the use of the pro-posed code design. The system configuration was the same as that in Example 2 with multipath length . Since the simulation was conducted in the uplink direction, every user has his/her own CFO value. Let us consider the worst case, where every user is randomly assigned a CFO either or . According to (3), when there is no CFO, the
desired signal will be scaled by . Thus, we
normalize the MAI by for fair comparison. The
dominating total MAI of user , denoted by MAI , is
ob-tained by averaging MAI
for more than 250 000 symbols. Similarly, the residual total MAI, denoted by MAI , is obtained by averaging
MAI for more than
Fig. 6. The dominating and the residual MAI as a function of CFO in a fully loaded situation.
Fig. 7. The dominating and the residual MAI as a function of CFO in a half-loaded situation with Shi and Latva-aho’s scheme.
250 000 symbols. To illustrate the MAI effect clearer, we did not add noise in this example.
First, let us consider the fully loaded case, i.e., . The slim-triangular curves in Fig. 6 show the dominating and the residual total MAI of each individual user. The bold-diamond curve, denoted by MAI , is the averaged dominating total MAI for the 16 slim-triangular curves of MAI . Note that the 16 slim-triangular curves of MAI are tightly clustered and thus overlap with the bold-diamond curve. Similarly, the bold-square curve, denoted by MAI , is the averaged residual total MAI for the 16 slim-circle curves of MAI . We see that MAI is larger than MAI by 5–32 dB. Hence, it confirms that the dominating MAI term defined in (28) is indeed the key MAI impairment, which is due to CFO.
Now, we consider several half-loaded scheme. First, we examine Shi and Latva-aho’s scheme [20] for a half-loaded
system, i.e., , , , , , , , and . The
Fig. 8. MAI reduction via the proposed code schemes using codewords in (a)G and (b) G .
Fig. 6, we see that both the dominating MAI and the residual MAI decrease by only about 3 dB, which shows a reasonable but not satisfactory MAI reduction as the number of users decreases to half in the system.
Next, let us consider the proposed code selection schemes with half-loaded. Since , we divide the codewords into two subsets. contains the first 2 codewords and con-tains the last 2 codewords. The performance is shown in Fig. 8(a) and (b), respectively. Note that the dominating MAI term MAI is equal to zero so that it is not shown here. More-over, there are only six curves in Fig. 8(a) for MAI , since the two codewords and are completely MAI-free under the CFO environment.
By examining Fig. 6 and Fig. 8(a) and (b), we see that the dominating MAI can be completely eliminated by the proposed code scheme. In this case, the residual MAI will determine the system performance. Furthermore, the residual MAI decreases around 5 dB. These results show that the MAI due to the CFO
Fig. 9. The bit error rate as a function of CFO (with fixedE =N = 15 dB).
effect can be greatly reduced using the proposed code schemes. Moreover, if the codewords of are used, users of and can still have zero MAI under the CFO environment.
Example 4: BER in the Presence of CFO: In this example,
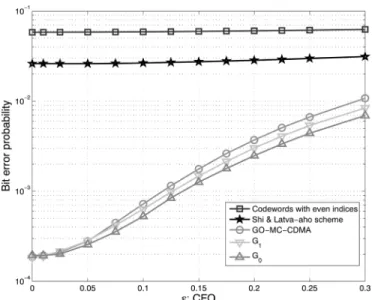
we consider the BER performance in the presence of the CFO effect for several code schemes of MC-CDMA and the GO-MC-CDMA scheme [4]. The parameter setting remains the same as that in Example 3. For MC-CDMA, we consider the pro-posed schemes and , Shi and Latva-aho’s scheme [20],
and the even indexed codewords, i.e., . For
GO-MC-CDMA, since , we divide 16 subcarriers into eight groups, where each group can support two users. Since the system is half-loaded, each group has exactly one user so that the system is MAI-free when there is no CFO. We assume that every scheme can accurately estimate individual user’s CFO. With , this can be achieved using estimation algorithms for single-user OFDM systems since there are two MAI-free code-words even in a multiuser CFO environment. In contrast, other schemes need to use multiuser CFO estimation. The CFO ef-fect is compensated at the receiver without any feedback. Fig. 9 shows the BER as a function of the CFO with signal-to-noise ratio (SNR) fixed at 15 dB for different schemes. It is clear that the proposed code schemes and outper-form Shi and Latva-aho’s scheme and the set of even-indexed codewords significantly. They also outperform GO-MC-CDMA slightly. We see from this figure that codeword set slightly outperforms codeword set . This is because and are free from MAI in the presence of CFO.
Example 5: CFO Estimation With a Single-User Algorithm:
It was shown in Example 4 that the GO-MC-CDMA system can achieve comparable performance with the proposed code scheme in a CFO environment. However, this result is obtained under the assumption that every user’s CFO can be estimated accurately. For the MC-CDMA system with codeword set , users with codewords and do not have MAI from others in a CFO environment and, consequently, accurate CFO can be estimated if each user adopts these codewords to estimate his/her own CFO in turn. In this case, estimation algorithms developed for single-user OFDM can be used for the proposed
Fig. 10. The mean squared error of CFO estimation as a function of CFO for the proposed and the GO-MC-CDMA schemes.
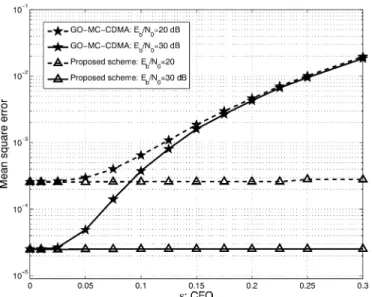
scheme. In contrast, we need more sophisticated estimation algorithms for multiuser OFDM systems for GO-MC-CDMA since none of the users in GO-MC-CDMA is free from MAI in a CFO environment. In this example, we will evaluate the CFO estimation error for the proposed system and the GO-MC-CDMA system when the single-user CFO estimation algorithm given in [14] is used.
The parameter setting remains the same as that in Example 4. Since both MC-CDMA and GO-MC-CDMA spread one symbol into several chips, the detection output is actually one symbol. Hence, we only need two symbols for CFO estimation. Refer-ring to Fig. 1, we denote the two successive output symbols, i.e., the current and the next ones, by and . The CFO estimation can be obtained via [14]
where and are the real and the imaginary parts of . For the proposed scheme, all eight codewords in are ac-tive. For the GO-MC-CDMA, each user occupies one of the eight groups and there are eight users [4]. Without loss of gen-erality, is used for CFO estimation in the proposed scheme. For GO-MC-CDMA, the user who occupies the zeroth and the eighth subcarriers with the all-one codeword is used for CFO estimation. The Monte Carlo method is used to run for more than 20 000 realizations. The estimation mean square errors, i.e., , as a function of CFO for both systems are shown in Fig. 10. We see that the estimation error in GO-MC-CDMA increases as the CFO value becomes larger. This is because the CFO-induced MAI increases as the CFO value increases, which deteriorates estimation accuracy. On the other hand, the estima-tion error in the proposed MC-CDMA system with remains constant in a multiuser CFO environment. This shows that the use of codeword set has a better CFO estimation result in a multiuser environment.
Example 6: Code Priority of MC-CDMA: In this example, we
consider a code priority scheme for a fully loaded MC-CDMA system using the proposed code scheme. The system setting is
Fig. 11. The bit error rate as a function of the number of users with SNR= 18 dB.
the same as that in Example 4 except that SNR is set to 18 dB while CFO is set to zero. The Monte Carlo method is used with more than 10 000 000 symbols for all users in the simulation.
We first consider two code priority schemes that assign code-words according to the following order:
Priority Scheme
(34) Priority Scheme
(35) Scheme I assigns the next user an even-indexed (or odd-in-dexed) codeword in whenever the current user is assigned an even-indexed (or odd-indexed) codeword in . Since even-in-dexed (or odd-ineven-in-dexed) codewords in cause more serious MAI to even-indexed (or odd-index) codewords, the first code priority has poor performance. It is adopted as a performance benchmark. Scheme II assigns even- and odd-indexed code-words from and alternatively for the first eight users. It serves as another performance benchmark. Furthermore, we also implement the code priority scheme proposed by Shi and Latva-aho in [20]. Since this scheme only considers a system up to the half-loaded situation, its performance curve is plotted up to eight users.
Finally, we consider the proposed code priority scheme, where we first assign eight codewords in to the first eight active users. When the number of active users exceeds eight, we will use codewords in . One such code priority scheme can be written as
Proposed Priority Scheme
(36) If there is no CFO, the system is MAI-free using only eight codewords in either or according to Theorem 1. The order of the first eight codewords can be changed arbitrarily. Also, we can assign codewords all from first and then from
.
The bit error rate is plotted as a function of the number of ac-tive users for the above four code priority schemes in Fig. 11.
Scheme I has the worst performance as expected. The perfor-mance of the proposed code priority stays the same when the number of active users is smaller than nine due to the MAI-free property. When exceeds eight, the performance of the pro-posed scheme degrades dramatically. However, its performance remains at least as good as schemes I and II. We also see that for Shi and Latva-aho’s scheme, it has the same performance as the proposed code priority when the numbers of users are 1, 2, 3, and 5. This is reasonable since codewords of these user num-bers fall in the set of and, hence, they are free from MAI. However, for other numbers of users, its performance is worse than the proposed code priority scheme. Moreover, in Shi and Latva-aho’s priority, if the number of active users changes, some users will need to change their codewords, which complicates the actual deployment of this scheme.
VII. PRACTICALCONSIDERATIONS ONAPPLICABILITY OF THE PROPOSEDSCHEME
The proposed scheme is applicable to both upper and down links in a multiuser system. The basic assumption of having a synchronous channel holds in the downlink. As to the up-link, we may consider a quasi-synchronous channel, where the time offset is within one chip. Such a channel holds in the up-link direction for a micro cell, e.g., see [21, pp. 1179–1195]. In practice, quasi-synchronism can be achieved by the use of the Global Positioning System. Therefore, there are several systems or code designs based on this assumption; e.g., GO-MC-CDMA system [4], Lagrange/Vandermonde code [19], the code scheme for MC-CDMA in [20], and the LAS code in [22]. Even if the system is not perfectly synchronized, time delay can still be in-cluded in the channel impulse response. In this case, we may have larger and, hence, the number of supportable users to meet the MAI-free property decreases.
As presented above, there is a close connection between the multipath length, the spreading gain (i.e., the number of subcar-riers) and the number of users that can be supported by the pro-posed technique. In particular, in order to achieve a zero MAI, the system load has to be significantly reduced for a larger mul-tipath length. This is a potential disadvantage for the proposed scheme. In practice, under a reasonable sampling frequency, the multipath length is in general moderate. For example, in an outdoor environment, the most commonly used multipath du-ration is around 1–3 s [18]. For the IS-95 standard, the chip rate is 1.2288 M chips/s in the uplink direction. Hence, the resolvable multipath length is around one to three taps. In an indoor environment, the maximum multipath duration for an office building is around 0.27 s. If we take the sampling fre-quency of WLAN of 20 MHz as an example, the resolvable mul-tipath length is around five taps. However, the indoor mulmul-tipath duration is in general under 0.1 s. In this case, the resolvable multipath length is around two to three taps. It is worthwhile to point out that under a fixed multipath and DFT/IDFT size , the GO-MC-CDMA system [4] without MUD supports exactly the same number of MAI-free users as the proposed system. Al-though the number of MAI-free users in both systems decreases as channel length increases, every MAI-free user in these sys-tems can enjoy an increased channel diversity order .
As commented by Chen in [6] “all existing CDMA systems fail to offer satisfactory performance and capacity, which is usu-ally far less than half of the processing gain of CDMA systems.” Hence, the choice of the spreading code to reduce MAI can be a direction for the design of next-generation CDMA systems. We approach the MAI reduction problem from a similar view-point. That is, for fixed channel conditions, we attempt to select a subset of codewords that can lead to an MAI-free system and hence provide a high date rate with simple transceiver design. This design concept stands in contrast with that of conventional CDMA systems. For instance, as the number of users increases in IS-95, the achievable data rate decreases in order to support the full-loaded user capacity. If a higher data rate is desired in IS-95, we need to use the more sophisticated MUD, which will increase the transceiver burden.
VIII. CONCLUSION
A code design to achieve MAI-free MC-CDMA systems in both uplink and downlink directions was proposed by prop-erly choosing a subset of codewords from Hadamard–Walsh codes. This method does not destroy the diversity gain of the MC-CDMA system. We also demonstrated how to perform channel estimation for each individual user under an MAI-free environment. As a result, there is no need to use MUD or so-phisticated signal processing for symbol detection and channel estimation. Furthermore, we considered the CFO effect for the proposed code and showed that the proposed code scheme can mitigate the MAI effect due to CFO to zero or a negligible amount. Thus, there is no need to perform multiuser estimation to estimate every user’s CFO. Note that the number of sup-portable users to achieve the MAI-free property is less than or equal to the ratio , where is the spreading gain and is the multipath length. However, if a fully loaded MC-CDMA system is demanded, the proposed code scheme can also be used in the design of a code priority scheme.
APPENDIX PROOF OFLEMMA5
Proof: It can be shown that in (29) is given by
(37) For convenience, let us define
(38) Since
and , , we have
. Hence
Let ; we can rewrite (39) as
(40)
Let ; we can rewrite (40) as
(41) Let denote modulo [15]. Then, (41) can be rewritten as
(42) From (38) and (42), we can rewrite (37) as
(43)
Since for , we have
for . Therefore,
(43) can be rewritten as
(44) From (44) and using matrix representation in (4), we can rewrite (29) as that given in (30).
ACKNOWLEDGMENT
The authors would like to thank the anonymous reviewers for their constructive suggestions, which have significantly im-proved the quality of this paper.
REFERENCES
[1] S. M. Alamouti, “A simple transmit diversity technique for wire-less communications,” IEEE J. Sel. Areas Commun., vol. 16, pp. 1451–1458, Oct. 1998.
[2] K. G. Beauchamp, Walsh Functions and Their Applications. New York: Academic, 1975.
[3] J. A. C. Bingham, “Multicarrier modulation for data transmission: An idea whose time has come,” IEEE Commun. Mag., vol. 28, pp. 5–14, May 1990.
[4] X. Cai, S. Zhou, and G. B. Giannakis, “Group-orthogonal multicarrier CDMA,” IEEE Trans. Commun., vol. 52, pp. 90–99, Jan. 2004. [5] H. H. Chen, J. F. Yeh, and N. Suehiro, “A multicarrier CDMA
ar-chitecture based on orthogonal complementary codes for new gener-ations of wideband wireless communicgener-ations,” IEEE Commun. Mag., pp. 126–135, Oct. 2001.
[6] H. H. Chen and M. Guizani, “Guest editorial: Multiple access tech-nologies for B3G wireless communications,” IEEE Commun. Mag., pp. 65–67, Feb. 2005.
[7] J. S. Chow, J. C. Tu, and J. M. Cioffi, “A discrete multitone transceiver system for HDSL applications,” IEEE J. Sel. Areas Commun., vol. 9, pp. 895–908, Aug. 1991.
[8] A. Chouly, A. Brajal, and S. Jourdan, “Orthogonal multicarrier tech-niques applied to direct sequence spread spectrum CDMA systems,” in
Proc. IEEE GLOBECOM, Dec. 1993, vol. 3, pp. 1723–1728.
[9] R. M. Gray, “On the asymptotic eigenvalue distribution of Toeplitz ma-trices,” IEEE Trans. Inf. Theory, vol. IT-18, pp. 725–730, Nov. 1972. [10] S. Hara and R. Prasad, “Overview of multicarrier CDMA,” IEEE
Commun. Mag., vol. 35, Dec. 1997.
[11] R. A. Horn and C. R. Johnson, Matrix Analysis. Cambridge, U.K.: Cambridge Univ. Press, 1985.
[12] B. L. N. Kennett, “A note on the finite Walsh transform,” IEEE Trans.
Inf. Theory, vol. IT-16, pp. 489–491, Jul. 1970.
[13] S. Kondo and L. B. Milstein, “Performance of multicarrier DS CDMA systems,” IEEE Trans. Commun., vol. 44, pp. 238–246, Feb. 1996. [14] P. H. Moose, “A technique for orthogonal frequency division
multi-plexing frequency offset correction,” IEEE Trans. Commun., vol. 42, pp. 2908–2914, Oct. 1994.
[15] A. V. Oppenheim and R. W. Schafer, Discrete-Time Signal
Pro-cessing. Englewood Cliffs, NJ: Prentice-Hall, 1989.
[16] I. Oppermann, P. Van Rooyen, and B. Vucetic, “Effect of sequence selection on MAI suppression in limited spreading CDMA systems,”
Wireless Networks, no. 4, pp. 471–478, 1998.
[17] J. G. Proakis, Digital Communications, 3rd ed. New York: McGraw-Hill, 1995.
[18] T. S. Rappaport, Wireless Communications. Englewood Cliffs, NJ: Prentice-Hall, 2002.
[19] A. Scaglione, G. B. Giannakis, and S. Barbarossa, “Lagrange/Vander-monde MUI eliminating user codes for quasi-synchronous CDMA in unknown multipath,” IEEE Trans. Signal Process., vol. 48, no. 7, pp. 2057–2073, Jul. 2000.
[20] Q. Shi and M. Latva-aho, “Simple spreading code allocation scheme for downlink MC-CDMA,” Electron. Lett., vol. 38, pp. 807–809, Jul. 2002.
[21] M. K. Simon, J. K. Omura, R. A. Scholtz, and B. K. Levitt, Spread
Spectrum Communications Handbook Electronic Edition, electronic
ed. New York: McGraw-Hill, 2002.
[22] S. Stanczak, H. Boche, and M. Haardt, “Are LAS-codes a miracle?,” in Proc. IEEE GLOBECOM, Nov. 2001, vol. 3, pp. 589–593. [23] M. Torlak, G. Xu, and H. Liu, “An improved signature waveform
ap-proach exploiting pulse shaping information in synchronous CDMA systems,” in Proc. IEEE Int. Conf. Communications (ICC), Jun. 1996, vol. 2, pp. 23–27.
[24] U. Tureli, D. Kivanc, and H. Liu, “Channel estimation for multicarrier CDMA,” in Proc. IEEE Int. Conf. Acoustics, Speech, Signal Processing
(ICASSP), Jun. 2000, vol. 5.
[25] S. Verdu, Multiuser Detection. Cambridge, U.K.: Cambridge Univ. Press, 1998.
[26] H. Wei, L.-L. Yang, and L. Hanzo, “Iterference-free broadband single-and multicarrier DS-CDMA,” IEEE Commun. Mag., pp. 68–73, Feb. 2005.
[27] N. Yee, J. P. Linnartz, and G. Fettweis, “Multi-carrier CDMA in in-door wireless radio networks,” IEICE Trans. Commun., vol. E77-B, pp. 900–904, Jul. 1994.
Shang-Ho Tsai was born in Kaohsiung, Taiwan, R.O.C., in 1973. He received
the B.S. degree in electrical engineering from Tamkang University, Taiwan, in 1995, the M.S. degree in electrical and control engineering from National Chiao-Tung University, Taiwan, in 1999, and the Ph.D. degree in electrical engineering from the University of Southern California, Los Angeles, in 2005.
From 1999 to 2002, he was with Silicon Integrated Systems Corp., Taiwan, where he participated in the VLSI design for DMT-ADSL systems. His research interests include signal processing for communications, particularly the areas of multicarrier systems and space-time processing.
Dr. Tsai received a government scholarship for overseas study from the Min-istry of Education, Taiwan, in 2002–2005.
Yuan-Pei Lin (S’93–M’97–SM’04) was born in Taipei, Taiwan, R.O.C., in
Chiao-Tung University, Taiwan, in 1992 and the M.S. and Ph.D. degrees in electrical engineering from the California Institute of Technology, Pasadena, in 1993 and 1997, respectively.
She joined the Department of Electrical and Control Engineering, National Chiao-Tung University, Taiwan, R.O.C., in 1997. Her research interests include digital signal processing, multirate filter banks, and signal processing for digital communication, particularly the area of multicarrier transmission.
Dr. Lin received the 2004 Ta-You Wu Memorial Award. She is currently an Associate Editor of the IEEE TRANSACTIONS ONSIGNALPROCESSING, the IEEE TRANSACTIONS ONCIRCUITS ANDSYSTEMSII, the EURASIP Journal on
Applied Signal Processing, and the Multidimensional Systems and Signal Pro-cessing. She is also a Distinguished Lecturer of the IEEE Circuits and Systems
Society (2006–2007).
C.-C. Jay Kuo (S’83–M’86–SM’92–F’99) received the B.S. degree from the
National Taiwan University, Taipei, Taiwan, R.O.C., in 1980 and the M.S. and
Ph.D. degrees from the Massachusetts Institute of Technology, Cambridge, in 1985 and 1987, respectively, all in electrical engineering.
He is with the Department of Electrical Engineering, the Signal and Image Processing Institute (SIPI), and the Integrated Media Systems Center (IMSC) at the University of Southern California (USC), Los Angeles, as a Professor of electrical engineering, computer science, and mathematics. His research inter-ests are in the areas of digital media processing, multimedia compression, com-munication and networking technologies, and embedded multimedia system design. He is a coauthor of about 800 technical publications in international conferences and journals, as well as seven books.
Dr. Kuo He is Editor-in-Chief of the Journal of Visual Communication and
Image Representation and Editor of the Journal of Information Science and Engineering and the EURASIP Journal of Applied Signal Processing.
He was on the Editorial Board of the IEEE Signal Processing Magazine. He was an Associate Editor of the IEEE TRANSACTIONS ONIMAGEPROCESSING from 1995 to 1998, the IEEE TRANSACTIONS ONCIRCUITS ANDSYSTEMS FOR VIDEOTECHNOLOGY from 1995 to 1997, and the IEEE TRANSACTIONS ON SPEECH ANDAUDIOPROCESSINGfrom 2001 to 2003.