ARTICLE NO. VC960346
Video Content Representation, Indexing, and Matching in
Video Information Systems
Chueh-Wei Chang and Suh-Yin Lee
Institute of Computer Science and Information Engineering, National Chiao Tung University, Hsinchu, Taiwan, Republic of China Received April 18, 1996; accepted December 12, 1996
graph of words, a related image. It allows a user to generate
Changing between frames is one of the most obvious informa- queries containing both temporal and spatial concepts, and
tion in video data. This frame-by-frame time series data is also provides content-based searching. However, how to
essential to many application areas. However, how to extract extract and compare video contents in a video information and compare video contents in a video information system is system is still an important problem to be solved. still an important problem to be solved. In this paper, we focus Therefore, the problem we deal with is the design of a on the problem of design a fast searching method in a video
video information system with an efficient video content
information system to locate video segments that match a
con-representation, an effective multilevel query processing
tent-based query, approximately by time series feature values.
capability, and a fast searching method. According our
The idea is to extract video contents via low-level feature
extrac-researches, frame-to-frame object changing is one of the
tion and/or high level semantic retrieval mechanisms according
most obvious information in video data. With temporal
to a specific point of view, then segment video contents into
bounding boxes via a box segmentation mechanism by their extension, frame-to-frame object changing cause a series
time series feature values. Video content indexing is constructed of frame-by-frame data. This frame-by-frame time series
by the characteristics of prominent points that accompany data is essential to many areas, such as gesture recognition bounding boxes. We also propose an efficient and effective in human-centered information systems, dynamic indus-video content matching algorithm to find similar sequences. trial processed monitoring, scene segmentation [1, 2], auto-With the help of the video indexing and matching mechanisms,
matic object tracking, and dynamic scene understanding.
several high level box-to-box and low level point-to-point query
That is, the searching method should include an indexing
types can be requested. The implementation and performance
and a matching mechanism that can search a video
informa-evaluation of our video information prototype system is
tion system by time-series feature values or even by
multi-described. 1997 Academic Press
level semantic meanings, in order to locate video subse-quences that match a query sequence approximately.
1. INTRODUCTION Furthermore, time-series data indexing and matching
mechanism can also be applied to many other applications, such as banking, policy decisions, inventory control, and Due to advances in data acquisition and computer
tech-scientific databases, where the history and prediction are nologies, many new applications involving the video
infor-important. mation retrieval system are emerging. Video is a medium
In current video database systems, only fundamental with high complexity. It has temporal and spatial
character-techniques, such as keyword-based searching [3], hierarchi-istics. Information related to position, timing, distance,
cal video icon browsing and indexing [4], are provided. temporal and spatial relationships are included in video
Most of the previous researches in video data are focused data implicitly. Also, a variety of statistical features is
con-on moticon-on and scene analysis. Very little work has been tained in a video frame, such as object color, shape, and
done on the design of index structures that combine spatial location.
and temporal attributes for video databases. In order to manage information in video data, a video
information system must be provided. A number of special In this paper, we provide several algorithms to solve these indexing and content-based matching problems. In requirements distinguish the video information system
de-sign approach from traditional databases. A video informa- Section 2, we describe a generic architecture of a content-based video information system, and survey some of the tion system needs complex structural representation of its
multilevel contents. Video content in a video information research projects relevant to our work. In Section 3, we define the video representation and evaluation model for system can be represented as a text-type keyword, a
para-107
1047-3203/97 $25.00 Copyright1997 by Academic Press All rights of reproduction in any form reserved.
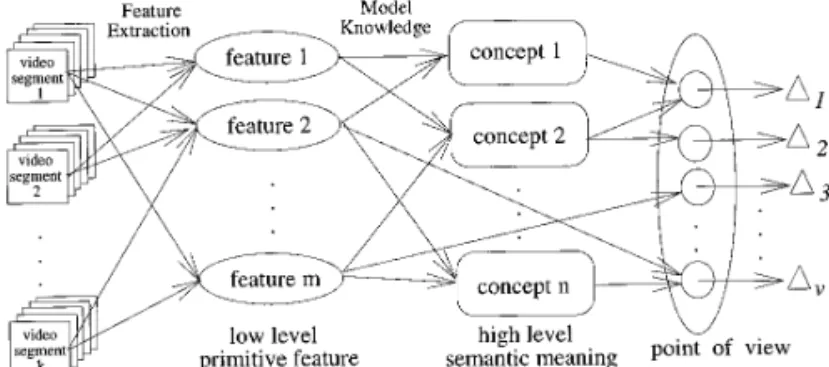
Next, users can make content-based retrievals via the Query Processing Module and watch the video segments of query results using the Interactive Browser Module. There are several approaches for content-based retrieval of video data. One is to attach textual and/or numerical information describing the contents and/or features to the video data. Another type of approach is to evaluate video data directly by an evaluation formula. These content-based retrieval techniques need multiple useful query types, similarity measure criteria, and user interfaces that let users pose and refine queries visually and navigate their way through the database visually. The types of queries
FIG. 1. Generic video information system architecture.
may include free-text query, object class hierarchy selec-tion and image/video feature-based retrieval queries.
In a video information system, a special type of video a video sequence. In Section 4, we show the bounding box content always needs special access and indexing method. concepts, box segmentation and indexing mechanism. In Video Indexing Module [5, 6] provides the annotation and Section 5, we solve the video content approximation other information with indices to speed up retrieval of the matching problem starting from the definition of a similar- desired video segments.
ity measure. After that, a time-series video content query Every video segment in this system can be edited with processing mechanism is proposed. Section 6 is the descrip- some other video segments and composed with computer tion of the implementation details of our video information graphics special effects by using the digital video editing prototype system, including the performance evaluation functions in the Interactive Browser Module. Then, the of our point-to-point approximate matching method. Sec- editing results can be stored in the video storage and tion 7 includes concluding remarks. treated as another video segments.
Currently, raw video data is always very large. It must
2. OVERVIEW be compressed to reduce the storage space and speed up
network transfer time. A Video Management Module has We first present an overview of a video information the capability to compress video data from video sources system on which our proposed methods are based. Next, to save storage space and to decompress it for playing. It we introduce several related topics in order to make the also provides internal level physical storage structure and scope of our research on time-series video content match- an access path for the database, including an assisted
ing more clear. knowledge store [10], video indices, and raw video data.
2.1. Video Information System
2.2. Related Work A generic video information system architecture, as
il-lustrated in Fig. 1, contains six modules: (i) Content Basically, we can classify content-based video queries into four categories as follows: Type-1 query by alphanu-Acquisition/Retrieval Module, (ii) Object Annotation
Module, (iii) Video Indexing Module, (iv) Interactive meric data and answer by alphanumeric data; Type-2 query by alphanumeric data and answer by video data; Type-3 Browser Module, (v) Query Processing Module, and (vi)
Video Information Management Module. query by video data and answer by alphanumeric data; Type-4 query by video data and answer by video data. In An Object Annotation Module provides users an
inter-face to build annotations of each video sequence. A video Type-3 query, there should contain many kinds of video computing and representations, with high or low level tem-may include a variety of information that is interrelated
Type-1 and Type-3 queries, even though these queries e.g., measuring the speed of a car, encountered in interpre-ting a single video frame.
involve accessing video data, the answer is just a list of
text strings. Type-2 and Type-4 queries ask for relevant In our definition, a video segment1is a meaningful scene,
V5 hvi, vi11, . . . , vi1r21j, where viis the starting frame of
video footage. With formal definition, content-based
re-trieval of video data is a rere-trieval process based on the a video sequence with frame number (or time code) i, and r is the duration of this segment. A video segment consists understanding of the semantics of the objects in a collection
[9]. Content-based video query allows incompletely speci- of several meaningful objects, such as a dog, a color, or even a thought, appearing in this video segment. That is, fied queries, which are processed through a knowledge
module [10]. Most early video content retrieval systems each video segment has content attributes and associated attribute values to describe the contents. Prior to storing are text-based, where relevant text keywords and/or
anno-tations are attached to each video sequence as the basis video content into the video information system, the video content annotation module must first identify the relevant for retrieval [3, 4, 11]. Unfortunately, the users of such
systems sometimes need to provide a long list of textual objects automatically or manually, then give descriptive representations of objects. Therefore, we designed a Video query constraints to locate the desired video sequences in
the video database. Several researches have been done in Segment Description Model (VSDM) with the annotation structures and related operations [17]. Annotations of a content-based retrieval for image and video data [12, 13],
but they do not provide the capability for content matching video segment can be described by attributes with several different data types. They can be a text type keyword, a in the temporal extension.
Further researches by Arman [14] and Hampapur [1] paragraph of words, a related spatial position in one video frame, a series of specific video features in this video se-work in the detection of boundaries and transitions
be-tween camera shots and the classification of different types quence (time-series data), or even another content related video segment. As depicted in Fig. 2, a video segment can of camera operations. As stated in their paper, a camera
shot, consisting of one or more frames recorded contigu- also be represented by a video icon with image data type, a salient clip with video segment data type recursively, and ously and representing a continuous action in time and
space, is treated as the smallest unit for video indexing. secondary information, such as video ID, video segment ID. In this paper, we only address the indexing and match-Breaking a video into its components allows a video to be
indexed and retrieved. It is the first step toward structured ing problem on time-series data of video segments. video [8, 15]. One of a similar model about time-series
subsequence indexing and matching is discussed by Fa- 3.2. Time-Series Data and Point of View loutsos et al. [16]. They use R*-tree as their basic storage
In this subsection, we explore the relationships between structure and access method. Their subsequence matching
the time-series data and the point of view. From a video method does not provide the multilevel searching
capabili-segment, the frame changing can occur in combination of ties for a variety of query types we propose in this paper.
primitive feature(s), such as color, size, shape, and/or high Therefore, we need to design a new mechanism for this
level feature(s), such as action and timing, used to describe content-based video indexing and multilevel query
match-objects or behavior of match-objects in the video frames. After ing problem.
the image processing, annotation, or media conversion pro-cesses [10], a sequence of raw video data can be
trans-3. VIDEO CONTENT REPRESENTATION
formed into a variety of attribute values of text, or numeri-cal data types with temporal extension. A specific point of The video information system allows a complex
struc-view, addreviated as a struc-view, in a video sequence can be tural representation of its contents. The design of an
appro-represented by a special projection of these features, as priate video content representation model will ensure
pre-illustrated in Fig. 3. The evaluation value of a specific cise association between the descriptive annotations and
view generated by domain knowledge can be a single real the objects in the video.
number obtained from the combinations of relevant fea-3.1. Video Segment Description Model tures in a single video frame and this evaluation value is application dependent. For example, the evaluation value A video segment is a sequence of video shots
concate-can be a weighted sum of relevant features, or some other nated by scene transitions (e.g., fade in/out, cross dissolve,
formula specified by users and/or domain knowledge. In . . . etc.). A meaningful scene is a video segment with the
different video applications, different viewpoints and dif-result of continuity in perceived, temporal, or spatial
di-ferent similarity criteria may be required. Those relevant mensions from the view points of the users. These temporal
and/or spatial meanings in a video segment change frame-by-frame. By using this frame changing information con- 1
We use video segment and video subsequence interchangeably in this paper.
FIG. 2. An example of video segmentation description model.
feature values for the evaluation value can be calculated tion function of this view, as defined in Definition 1. Each by image processing or feature extraction routines. Using evaluation function can be treated as a function of time, the notions proposed in [12] and [18], similarity measure and also be called a curve in this paper. Notice that an of evaluation value can be specified according to different evaluation function can be a mapping from multidimension application domains. relevant feature space to one dimension evaluation value, the design of an evaluation function should take care of 3.3. Evaluation Function
the problem of similarity ranking.
If we use the surveillance of road traffic as our example For a specific view in a video sequence, we call this
frame-by-frame time-series evaluation values the evalua- of application [5], the average car velocity can be an
erty of being stepwise constant during each interval. In Fig. 4b, several large peaks appear in this curve distribution (e.g., the frame difference in a cut detection process). This case is very important since it represents the suddenly happened events. Figure 4c shows a situation of smooth changing (e.g., slow motion object or slow color intensity change). Figure 4d represents the randomly distributed irregular curve (e.g., fast action). According to our census, the evaluation functions of video sequences are irregularly
FIG. 4. Typical curve distribution in sequence evaluation
func-distributed in most of the video applications. To overcome
tion. (a) Stepwise; (b) peak; (c) smooth change; (d) irregular.
this irregular distributed time-series data indexing and matching case, we need to design a feature point finding and segmentation mechanism.
tion function of this application. The overall approach of this application is based on a moving object recognition
4.2. Bounding Box Principle procedure. A moving object in one video frame is searched
for in a succeeding video frame. If the corresponding mov- In this paper, we propose a bounding box principle as ing object is found, the velocity is calculated from the the basis of curve segmentation mechanism. Because con-positional shift and perspective transformation. That is, tents in video segments can be represented as streams of the average car velocity is the specific view of this applica- symbols, the bounding box concept is motivated by the tion, and the car velocity is obtained by calculating a combi- problems which arise in fields of pattern matching and nation of several position features extracted from the video similarity measure. As stated in Section 3.3, we can define sequences as well as the help of specific model knowledge. an evaluation function that analyzes a video segment by using its low level features, such as representative color, DEFINITION 1. An evaluation function of a video
seg-and/or high level semantic meaning, such as the running ment V according to a specific view with q features is
and jumping of a person. Therefore, each video segment defined as
can be segmented into several structured units by a set of special evaluation values or semantic meanings. This E(V, A, Ts, Te)5 D(Ti), (1)
mechanism of video segmentation using bounding box principle is so called video structuring, and the result is a whereD is the formula of relevant feature vector
combina-structured video. tion; Ti is the time interval from starting frame Tsto ending
In consequence of segmentation, the video subsequence frame Te; A 5 [ f1, f2, . . . , fq] is a set of features for the
between two special successive feature points can be sepa-specific video view. We use E(t) that stands for the single
rated and bounded by a bounding box. That is, the evalua-evaluation value at time t for a specific video segment and
tion function of a video segment can be divided into a point of view.
series of bounding boxes by special feature points, as shown in Fig. 5. We call these special feature points the prominent
4. VIDEO CONTENT SEGMENTATION
index points (or prominent point, for short). Each
seg-AND INDEXING
mented subsequence is represented as a rectangle box with prominent point value and related information. Except the In this section, we attempt to divide those evaluation
prominent point value, the following box features can also functions into manageable units by finding the prominent
be included in the related information if necessary: se-feature points. We classify curve distribution and bounding
quence and box ID, minimum and maximum values in this box pattern matching constraints into several categories
box, offset of duration (box length), interbox connection for making our discussion clear. After that, the bounding
type, starting frame/time number, density information of box concept, box segmentation strategy, and indexing
box, previous and next subsequence linkages, and high method are described.
level semantic meaning. An example of related informa-tion in bounding boxes is shown in Table 1.
4.1. Curve Distributions of Evaluation Functions Before we provide a segmentation strategy, we first
ex-4.3. Box Segmentation and Prominent Points amine several typical curve distributions which occur in
time-series video contents. Figure 4a shows the changing According to the curve distributions, several kinds of curve features can be found. We classify the curve features of semantic meaning in the video segment, or the variation
over time in the number of a certain object (e.g., cars on into four categories. They are suddenly up edge, suddenly down edge, increase out of range, and decrease out of a street). We say that this curve distribution has the
prop-FIG. 5. Transformation between evaluation function and bounding boxes. (a) Original sequence; (b) divided bounding boxes.
range in a curve. We can derive seven connection types where E(t) is the evaluation function value at time t and P(c) is the value of current prominent point.
from these four categories. Notice that connection type 0
is used for the unstable area, such as a starting and an • Connection Type 6. Long duration l of steady situa-tion, as shown in Fig. 9.
ending box.
Therefore, a prominent point can be defined, as shown • Connection Type 1. Large pulse when edge up and
in Definition 2, by these seven connection types. The pa-down happens in a short time period, e.g., 1/30 sec, as
rameters r, s, andl are used to justify whether two se-shown in Fig. 6.
quences are similar. They could be either user-defined or • Connection Type 2, 3. Edge up/down, as shown in
determined automatically by the distribution of time-series Fig. 7.
data. The method that we use is to find the prominent points with a large peak of value change (Connection Type (a) E(t)2 E(t 2 1) .rfor edge up
1, 2, 3) or with local increase/decrease in evaluation value (b) E(t)2 E(t 2 1) , 2rfor edge down, in the data stream (Connection Type 4, 5). No matter how the data stream is shifted, the edge-type prominent point of this evaluation function is unique. Same or similar curves where E(t2 1) and E(t) are the evaluation function values
will get same or similar prominent points if they follow at time t2 1 and t, respectively.
the same prominent point definitions. That is, if we find • Connection Type 4, 5. Increase/decrease, as shown in
two curves with same or similar sequence of prominent Fig. 8.
points and similar related information, we can say that they are approximate. We can take advantage of this obser-(a) E(t)2 P(c) .sfor increase
vation of prominent points for efficient indexing in a large database.
(b) E(t)2 P(c) , 2sfor decrease,
TABLE 1
An Example of Prominent Points and Related Information
Box Prominent Minimum Maximum Box Connection Starting Average Accumulated
ID point value value offset type position value difference
1 158 158 283 13 0 0 215 51 2 324 323 451 10 4 13 393 58 3 484 387 491 3 4 23 454 55 4 331 331 467 3 5 26 406 68 5 481 481 481 1 4 29 481 0 6 220 220 304 3 3 30 272 47 7 390 270 475 22 4 33 347 51 8 214 137 228 5 5 55 197 43 9 436 325 436 2 4 60 380 111 10 241 241 241 1 5 62 241 0 11 409 409 409 1 4 63 409 0 . . .
FIG. 8. Increase/decrease cases. (a) E(t)2 P(c) .sfor increase; (b) E(t)2 P(c) , 2sfor decrease.
FIG. 6. Large pulse case.
For each new bounding box, inserting a new prominent point in the index tree is done by a searching index tree DEFINITION2. A prominent index point of evaluation
and adding the prominent point in a node. The related function at time t is the point P that satisfies at least one
information about this bounding box is stored in the stor-of the following conditions:
age space of a corresponding link list structure and can be (i) An evaluation value at time/frame t has a change accessed through a link list pointer accompanied with the from previous point t2 1 prominent point in the leaf node. Overflowing nodes are split and splits are propagated to parent nodes. If the prom-uEt2 Et21u .r, (2) inent point in the index tree has already existed, the related information of this new bounding box will be attached at where Etis the current evaluation value at time/frame t, the front of this corresponding link list. That is, the linked
andris the threshold value. list refers to index structure in which an index point may be associated with a list of reference fields pointing to (ii) The evaluation value difference between the
previ-video sequences that contain the same or similar prominent ous prominent point and the current evaluation point is
points. By using the linked list, we can easily find the greater than a threshold
bounding boxes with similar prominent points and similar box shapes. Figure 10 is an example of index structure with
uEt2 Pcu .s, (3)
an index tree of order 4 (nine branch pointers for each node) with integer search value and a box link list. where Etis the current evaluation value at time/frame t,
To avoid too many index points in the index tree, we can and Pcis the current prominent point at time/frame c. s
concatenate several prominent points with similar values in is the threshold value.
the same child node by using prominent point quantization (iii) The time/frame difference between the previous
mechanism, or by proper selection of the threshold values prominent point and the current evaluation point is greater
r,s, andl. The best choices of threshold values are depen-than a thresholdl.
dent on the distribution characteristics of evaluation values and the query behaviors. We can see these variations in 4.4. Video Indexing
the performance evaluation of Section 6. We use B-tree [19] as our index structure with prominent
4.5. Prominent Point Quantization points as the keys because B-tree has the efficient storage
structure and is a robust access method for data points. The purpose of quantization is to reduce the number of keys and storage space for an index structure. But it will
FIG. 7. Edge up/down cases. (a) E(t)2 E(t 2 1) .rfor edge
FIG. 10. An example of video indexing structure.
increase the index structure searching time for the existing The demand of finding an exact match between two video segments of specific view might be too strict since of potential search values. Quantization is defined as
divi-sion of each prominent point by its corresponding quan- the real numbers may vary widely. In most of the video applications, users often require finding close or similar tizer step size, followed by rounding to the nearest integer:
but not necessarily exact occurrences. Alternatively, an approximate matching is to find all subsequences in sample Pq5 IntegerRound
S
pStep
D
. (4) video sequences that are close to a query video segment according to some similarity criteria. Therefore, multilevel approximate queries of video segments can be diversified5. VIDEO SEQUENCE QUERY PROCESSING into several categories:
Generally speaking, the time-series video content query (i) Box-to-Box Matching is the problem of pattern matching with the help of
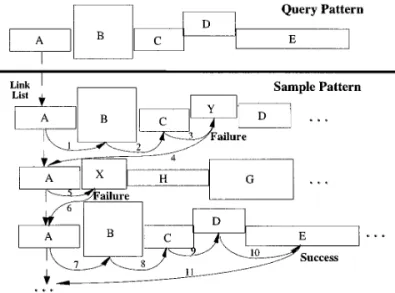
in-dexing. Two steps must have been done before proceeding • Existence matching. Find those shortest sample box to the matching process. One is the choice of video content sequences that for each box in the query box sequence, query type. Another is the choice of query constraints. there exists at least one box, which has the same box type, in the matched sample sequence. The order of box types 5.1. Multilevel Video Content Query Types in the matched sample sequences can be neglected. An example is shown in Fig. 11a. Notice that sample and query In a video information system, it is necessary to be able
sequences do not need to have the same box length. The to locate some or all occurrences of similar box patterns
letters in each box stand for the semantic meaning or the quickly. We know that the contents of a video segment
prominent points in each bounding box. should be expressed in terms of a set of low level primitive
• Sequence matching. Find those shortest sample box features, and/or combine low level features to form more
sequences that for each box in the query box sequence, complex high level semantics. For example, we can specify
the corresponding box in the sample box sequence has the the query ‘‘A person walks on the sidewalk, then suddenly
same box type and also has the same order. runs across the street and sits on a street chair’’ by a high
case 1. Exact Sequence Matching—exact one-to-level query pattern ‘‘(walk)(run)(sit).’’ Another example
one mapping, as shown in Fig. 11b. is the sequence of video shot types for parsing of news
case 2. Partial Ordering Matching—can have a re-episode in [2]. From the bounding box principle, no matter
dundant pattern within sample sequence, as shown in what kind of video content expressions, the query patterns
Fig. 11c. are considered to be a sequence of values provided by
search pattern in the video information system within a similarity threshold.
DEFINITION 3. Given two sequences of patterns, X5 x1x2? ? ? xn(sample pattern) and Y5 y1y2? ? ? ym (query
pattern), over an infinite alphabet of real numbers, where n and m are respective length of sequence X and Y, if there exists a position (alignment) k in X such that for each pair of corresponding alphabet in these two sequences the similarity measure is smaller than the similarity thresh-oldt, then subsequence X9 5 xkxk11? ? ? xk1m21is a good-match with Y.
5.2. Query Constraints and Similarity Measure of Query Types
The query result for each query type by some specific query constraint is a set of qualified candidates and the candidates’ similarity factor. The result returning from the filtering process of query constraint is a list of qualified candidates that have passed all the checking of the selection conditions. The similarity factor (or accumulated penalty) is the summation of similarity measures between the query pattern and the qualified sample patterns for the selected query types.
Except the prominent point, a query constraint can be composed by the selection of the box connection type, min/max range, box density, box aspect ratio, semantic meaning, etc. For example, the box density is defined as the average value of the accumulated difference between two consecutive evaluation values within the same bounding box, D(Bs, Be)5
O
Be t5Bs11 E(t)2 E(t 2 1) (Be2 Bs2 1) , (5)FIG. 11. Query types. (a) Existence matching; (b) exact sequence matching; (c) partial ordering matching.
where E(t) is the evaluation value at time t, and Bs and
Be are the starting and ending frames of a bounding
• Exact Curve Matching. Find those sample sequences box, respectively. that the corresponding values are exactly the same as
The point-to-point similarity measure between two sin-query values.
gle video frames is defined in Definition 4. The box-to-• Approximate Curve Matching with Error Toler- box similarity measure between two bounding boxes is ance. Find those sample sequences that the distance
be-defined in Definition 5. The penalty function determines tween query and sample sequences are within the tolerance
the difference between two bounding boxes. This function of similarity threshold. In other words, those candidates
value is dependent on how dissimilar these two boxes are should have a similarity relation for each corresponding
and also what kind of query constraints they select. The value.
value of similarity threshold, as defined in Definition 6, is application dependent and can be specified by users. This Both types of point-to-point curve matching are based
on a definition of the good-match [20] criterion, as defined similarity threshold value is the error tolerance for an ap-proximate matching and can heavily affect the perfor-in Defperfor-inition 3. The good-match retrieval is to fperfor-ind the
sequence of patterns or evaluation values that are suffi- mance of searching. If the similarity threshold increases, the number of qualified subsequences would increase. If ciently similar within some distance (t p 0). With the
definition of the good-match, the matching approach the similarity threshold is equal to zero, this process be-comes an exact match.
DEFINITION5. The box-to-box similarity measure (box-to-box distance) of a specific view between two bounding boxes biand bjis defined as
Sb(V1, V2, A, C, bi, bj)5
O
n k51Penalty(Ck, bi, bj), (7)
FIG. 12. An example of box-to-box exact sequence matching.
where biand bjare bounding boxes of sample video
se-quence V1and query video sequence V2, respectively. C is the set of n query constraints for this query. Penalty(?)
is the penalty function for each specified type of con- Output. A list of similar subsequences with good-match
straint Ck. criterion.
Method. DEFINITION6. The evaluation function E(V1, A, ti, tj)
find first bounding box with connection type 1, 2, or 3; and E(V2, A, ti, tj) or bounding box bi and bj have the
search index structure by prominent point value of first similarity relationp, if and only if
bounding box to find the link list of the starting position of candidate boxes;
Sp(V1, V2, A, ti, tj),tp, for point-to-point matching or (8) for each of the candidate boxes
if a consecutive sequence of boxes related to the
Sb(V1, V2, A, C, bi, bj),tb, for box-to-box matching, (9)
candidate starting box satisfy the query con-straints then
wheretp andtb are the similarity threshold of
point-to-print out the sequence ID, starting position and point matching and box-to-box matching, respectively.
similarity factor; end-of-if
5.3. Matching Strategies and Box-to-Box end-of-for
Approximate Matching End-of-Algorithm Approximate Box Searching. Because existence matching is easy to handle, and also
In our approximate box searching approach, we use the partial ordering matching can be considered as the longest
first box with pulse or edge connection types (type 1, 2, common subsequence problem [21], their matching
algo-or 3) in the query sequence as the alignment box. After a rithms will not be discussed in this paper. Therefore, we
searching in index structure by the prominent point of focus our matching problems only on exact sequence
alignment box, several candidates with the same or approx-matching and point-to-point approx-matching.
imate prominent point value will be found. According to In the matching processes, we first divide the query
se-the specified query constraints, we can discard or prune quence into its bounding box representation form. Then,
some of the cases which do not satisfy the box-to-box these bounding boxes compare with the sample sequences
similarity threshold when searching for the candidates in in the video information system with the help of an index
the index structure. An example of query constraint check-structure. No matter what kind of query type it is, either
ing procedure for box-to-box exact sequence matching is box-to-box or point-to-point basis, we always start our
depicted in Fig. 12. matching process from an approximate box searching
ap-This approximate box checking algorithm acts as a filter proach, as shown in Algorithm 1.
to quickly reduce the number of possible candidates and generates a candidate set as the result of query constraint ALGORITHM1. Approximate Box Searching
Input. A sequence of bounding boxes with related box checking. Notice that false alarms are possible in these steps, but no false dismissal will occur. Further processing information corresponding to query sequence, an
FIG. 13. Similarity relation checking between bounding boxes. (a)umins2 minqu .tp; (b)umaxs2 maxqu .tp; (c) both of them.
5.4. Point-to-Point Matching Algorithm 6.2. User Interface
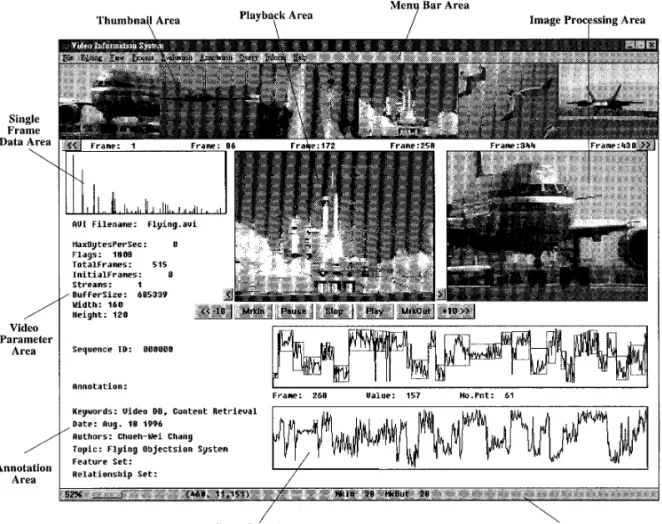
In this prototype system, we separate the user interface For a point-to-point matching, two necessary query
con-straints should be checked. They are the point-to-point into nine different function areas, as shown in Fig. 14. In the Thumbnail Area, it can act as a display of six-divided similarity measure and the box-offset checking. After the
box alignment step and the index structure searching, the frames, or a set of still salient images of active video se-quences, or an A-to-F roll editing monitor each with a next step is the query constraint checking. If we check the
similarity relation for the corresponding evaluation values different video file, or the video icons of query results. In the Playback Area, it has the functions of mark in/out in the candidate box point-to-point, it will be very
time-consuming. Therefore, we provide a min/max bound simi- logging, nonlinear editing preview window, active video file playback, current processing frame display. In the Image larity relation checking mechanism.
As stated in Theorem 1, we stop the searching when Processing Area, it shows the results of video/image pro-cessing functions (for example, color key, caption, special the difference of minimum and/or maximum values of
bounding boxes of two corresponding sequences exceeds effects, etc.), temporary duplicated still frame, region-based color feature extraction. In Single Frame Data Area, point-to-point similarity thresholdtp, as shown in Fig. 13.
We can declare these two corresponding sequences to be it shows the feature values in a current processing frame (for example, histogram, region size, etc.). In the Curve dissimilar and prune this sequence from the candidate set.
If all of the segmented subsequences satisfy the similar Data Area, it shows the evaluation curve, bounding boxes, query and matched curve. In the Video Parameter Area, relation, we are sure that the whole sequence satisfies the
similar relation. it shows the related parameters of a current active video
file. In the Annotation Area, it shows the default annota-THEOREM1. There exists at least one evaluation value
tion about video contents. In the Status Bar Area, it shows in the query box that can not satisfy the similarity relation, if
the process percentage, current cursor coordinate and cor-responding R, G, B color intensity, evaluation function umins2 minqu .tp, or (10)
value of curves, the video editing mark in/out cue points. In the Menu Bar Area, it provides the annotation, feature umaxs2 maxqu .tp, (11)
extraction, indexing, query processing and database man-agement functions, as stated in Section 2.1, for this video where minsand maxsare the minimum value and maximum
value of a sample box, respectively; minq and maxq are information system.
the minimum value and maximum value of a query box,
6.3. Performance Evaluation respectively.tp is the point-to-point similarity threshold.
We have built up a video database of more than 500
6. IMPLEMENTATION DETAILS video segments and time-series sample curves. We
exam-ined this indexing and matching mechanism by several 6.1. A Video Information System Prototype
feature extraction methods: the most significant color, the histogram difference, and the motion tracks of a specific We have implemented a prototype system on an
IBM-PC compatible computer with MS-Windows 95 by using object in video.
In order to see the performance and behaviors of our C11 language to test our indexing and approximate
matching mechanism. In the experimental stages of our point-to-point approximate matching method, we started from several experiments. We ran these experiments on design, we do not concern ourselves with finding an
appro-priate video file format, and are using default size 1603 our video database of approximately 75,000 sample points. Each point was an integral number. We divided these sam-120 AVI file. Another video file format such as MPEG II,
is under consideration for fast playback speed and good ple points into three different sequence sets, Set 1, 2, and 3, according to their behavior of distributions. Sequence compression rate.
FIG. 14. The video information system prototype.
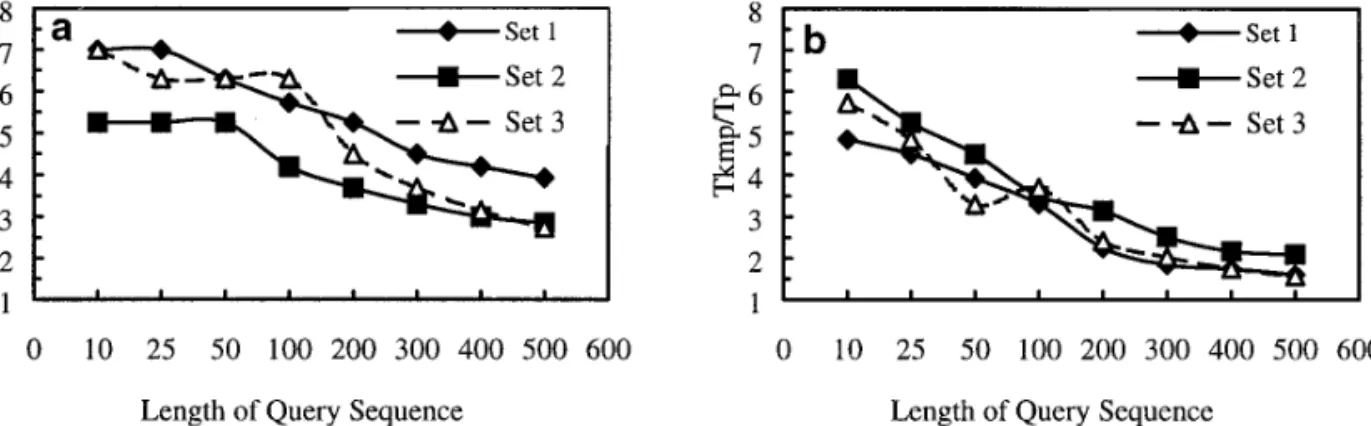
Set 1 has the largest data variation and Set 3 has the Group B, in those three sequence sets. The graph shows that Group A always has a faster response time than smallest one. We also set out two different segmentation
groups, Group A and Group B, of experiments to compare Group B (time ratio Group B/Group A. 1). That is, ap-propriate selection of threshold parameters according the query response time between our matching method
and the single subsequence approximate matching [5] (ap- to the curve distributions can provide a better matching performance.
proximate KMP algorithm). Each segmentation group has different threshold parameterss,r, andl. The query
se-quences were generated randomly. A small similarity 7. CONCLUSIONS thresholdtp (,1%) was specified.
Figures 15a and 15b give the relative query response By providing multilevel content-based retrieval, applica-tions of digital video are broad in many aspects. Video time of the approximate KMP method versus our
index-assisted matching method. In these experiments, the re- records the changes of scenes according to time. Related change of objects between different frames provides much sponse time of our matching method is five to seven times
faster than approximate KMP method when the length of information about the behavior of these objects in the video. These time-series changes of video objects are useful query sequence is short (,50 integer values), and at least
has two times faster when query sequence is long (.100). for dynamic scene and motion analysis.
In this paper, we have presented the design of an approx-However, it is true that the number of bounding boxes is
proportional to the length of query sequences. The increase imate video content matching algorithm. The idea is to extract video contents via low level feature extraction and/ in the number of bounding boxes leads to an increased
box-to-box sequence matching process time. We can see or high level semantic retrieval mechanisms according to a specific point of view, and then segment video contents these phenomena when query sequence is long (.300).
Furthermore, Fig. 16 illustrates the ratio of response time into bounding boxes via a box segmentation mechanism by their time series feature values. With the help of indexing under different threshold parameters, Group A versus
FIG. 15. Relative response time vs. query length. (a) Group A (r5 240,s5 180, andl5 80); (b) Group B (r5 160,s5 120 and
l5 80).
mechanism using prominent index points, the searching S Similarity measure p Similarity relation speed is faster than the sequential scanning method. A
video information prototype system example and several Bs, Be Start frame and end frame of a bounding box
experimental results show how these mechanisms work. Notice that time-series data indexing and matching
mecha-REFERENCES
nism can also be applied to many other applications, such as banking, policy decisions, inventory control, and scientific
1. A. Hampapur, R. Jain, and T. Weymouth, Digital video segmentation,
databases, where the history and prediction are important.
in Proceedings, ACM Multimedia, San Francisco, CA, 1994, pp. 357–364.
APPENDIX: LIST OF SYMBOLS 2. H. J. Zhang, S. Y. Tan, S. W. Smoliar, and G. Yihong, Automatic parsing and indexing of news video, Multimedia Systems, 2, 1995,
E Evaluation function 256–266.
D Formula of feature vector combination 3. E. Oomoto and K. Tanaka, OVID: Design and implementation of A A set of features for the specific video view a video–object database system, IEEE Trans. Knowledge Data Eng.,
5(4), 1993, 629–643.
t Similarity threshold
4. S. W. Smoliar and H. Zhang, Content-based video indexing and
E(t) Evaluation function at time t
retrieval, IEEE Multimedia, Summer 1994, 62–72.
P Prominent index point at time t
5. C. W. Chang and S. Y. Lee, Indexing and approximate matching for
Pc Current prominent index point
Content-based time-series data in video database, in Proceedings,
r Edge threshold
First International Conference on Visual Information Systems,
Mel-s Increase/decrease threshold bourne, Australia, 1996, pp. 567–576.
l Offset threshold 6. S. Y. Lee and H. M. Kao, Video indexing—An approach based on Pq Quantized prominent index point at time t
moving object and track, in Proceedings, SPIE Storage and Retrieval for Image and Video Databases, Vol. 1908, 1993, pp. 25–36.
D Bounding box density
7. Y. F. Day, S. Dagtas, M. I. A. Khokhar, and A. Ghafoor, Object-oriented conceptual modeling of video data, in Proceedings, IEEE 11th International Conference on Data Engineering, Taipei, Taiwan, 1995, pp. 401–408.
8. A. Nagasaka and Y. Tanaka, Automatic video indexing and full-video search for object appearances, in Visual Database Systems II (E. Knuth and L. M. Wegner Eds.), pp. 113–127, Elsevier, Amsterdam/New York, 1992.
9. A. D. Narasimhalu, Special section on content-based retrieval, Multi-media Systems, 3, Feb. 1995.
10. A. Yoshitaka, S. Kishida, M. Hirakawa, and T. Ichikawa, Knowledge-assisted content-based retrieval for multimedia databases, in Proceed-ings, IEEE International Conference on Multimedia Computing and Systems, Boston, MA, 1994, pp. 131–139.
11. T. D. C. Little et al., A digital on-demand video service supporting content-based queries, in Proceedings, ACM First International Con-ference on Multimedia, Anaheim, CA, 1993, pp. 427–436.
CHUEH-WEI CHANG received his B.S. and M.S. degree in computer 15. Y. Tonomura, A. Akutsu, Y. Taniguchi, and G. Suzuki, Structured engineering in 1984 and 1986 from Chiao Tung University. His research video computing, IEEE Multimedia, Fall 1994, 34–43. interests include multimedia information systems, data models, image processing, and computer graphics applications. He is a doctoral student 16. C. Faloutsos, M. Ranganathan, and Y. Manolopoulos, Fast
subse-in Institute of Computer Science and Information Engsubse-ineersubse-ing at Chiao quence matching in time-series databases, in Proceedings, ACM
SIG-Tung University. MOD, Minneapolis, MN, 1994, pp. 419–429.
17. C. W. Chang, K. F. Lin, and S. Y. Lee, The characteristics of digital video and considerations of designing video databases, in Proceed-ings, ACM Fourth International Conference on Information and Knowledge Management CIKM’95, Baltimore, MD, 1995, pp. 370–377.
18. K. Wakimoto, M. Shima, S. Tanaka, and A. Maeda, Content-based retrieval applied to drawing image database, in Proceedings, SPIE, Vol. 1908, 1993, pp. 74–84.
19. D. Comer, The ubiquitous B-tree, ACM Comput. Surv. 11 (2), 1979, 121–137.
SUH-YIN LEE received the B.S.E.E. degree from Chiao Tung Univer-20. T. Ito and M. Kizawa, Hierarchical file organization and its application
sity in 1972 and the M.S. degree in computer science from the University of to similar string matching, ACM Trans. Database Systems 8(3),
Washington, Seattle, in 1975. She received the Ph.D. degree in electronic 1983, 410–433.
engineering in 1982. She is now a professor in the Department of Com-puter Science and Information Engineering at Chiao Tung University. 21. Y. P. Wang and T. Pavlidis, Optimal correspondence of string
subse-Her current research interests include image database, multimedia infor-quences, IEEE Trans. Patt. Anal. Mach. Intell. 12(11), 1990, 1080–
mation system, and computer networks. 1087.