computers &
mathematics
mm-
PERGAMON Computers and Mathematics with Applications 46 (2003) 831-848
www.eleevier.com/locate/camwa
Acquisition
of Compound
Skills and Learning
Costs for Expanding
Competence
Sets
YI-CHUNG Hu
Department of Business Administration Chung Yuan Christian University
Chungli 320, Taiwan, R.O.C.
RUEY-SHUN CHEN
Institute of Information Management National Chiao Tung University
Hsinchu 300, Taiwan, R.O.C.
GWO-HSHIUNG TZENG* AND Yu-JING CHIU
Institute of Management of Technology National Chiao Tung University
Hsinchu 300, Taiwan, R.O.C. ghtzengQcc.nctu.edu.tw
(Received March 2002; revised and accepted June 2002)
Abstract-fir each decision problem, there is a competence set consisting of ideas, knowledge,
information, and skills for solving that problem. When decision makers have not acquired the com- petence set, it is more difficult for them to make decisions. In order to effectively acquire a needed competence set to cope with the problem they face, finding an appropriate learning sequence for acquiring needed single shills for decision makers, the so-called competence set expaneion, is very necessary. A compound skill represents a collection of single skills that might be acquired, and some useful compound skills can be added to the needed competence set to help acquire some single skills. To effectively expand the competence set, effective acquisitions of compound skills and learning costs are both neceaeary. This paper thus propoees a data mining technique to extract potentially useful compound skills from single skills. Subsequently, an effective method is proposed to obtain the learn- ing cost between any two skills. A computer simulation is employed to further show that it is feasible to use those potentially useful compound skills to facilitate the acquisition of single skills through a known integer programming method for expanding the competence set. @ 2003 Elsevier Ltd. All rights reserved.
Keyword-competence set, Data mining, Neural networks, Fuzzy sets, Integer programming.
1. INTRODUCTION
With competence sets ss proposed by Yu and Zhang (11, f or each decision problem (e.g., pro- moting products or improving services for a business) there exists a competence set consisting of ideas, knowledge, information, and skills for solving that problem. When decision makers
*Author to whom all correspondence should be sddreesed.
089&1221/03/S - see front matter @ 2003 Elsevier Ltd. All rights reserved. doi: lO.l016/SO896-1221(03)00289-X
832 Y.-C. Hu et al
have acquired the needed competence set and are proficient in it, they will be comfortable and confident in making decisions [2,3]. Otherwise, they must acquire the needed competence set to solve the.problem. In order to acquire a needed competence set to cope with a decision they face, finding appropriate learning sequences of acquiring needed single skills, the so-called competence set expansion, is very necessary. For example, the courses “Introduction to Computer Science”,
“Data Structures”, and “Algorithms” are single skills in the needed competence set for obtain- ing the Bachelor’s degree of Computer Sciences. A more appropriate learning sequence can be arranged as: learning “Introduction to Computers” is learned first, “Data Structures” is learned subsequently, and then “Algorithms” is learned last.
It is known that learning directly from one skill to another skill requires learning cost, which can be measured by time or money. For example, a student may spend one year to acquire “Data Structures” after he had acquired “Introduction to Computer Science”. Usually, an appropriate learning sequence is a learning sequence with minimum learning costs. Moreover, a compound skill represents a collection of single skills that might be acquired by decision makers. Some useful compound skills can be added to the needed competence set for helping to acquire some single skills. For example, it seems to be easier for us to acquire “Algorithms” after both “Introduction to Computer Science” and “Data Structures” have already been acquired in comparison with the situation when only “Introduction to Computer Science” has been acquired. However, it seems that for some problems those useful compound skills are not completely known in advance. Actually, effective acquisitions of compound skills and learning costs between any two skills in the needed competence set are actually two significant tasks before expanding the competence set.
In fact, several well-known models regarding competence set expansion have focused on the development of effective methods for generating learning sequences with minimum learning cost. For example, the deduction graph with an integer programming method [4,5], the minimum span- ning table method [6], the tree expansion process with an integer programming method [7], and the stage expansion method [3] h ave been proposed for expanding the competence set. However, compound skills and learning costs were hypothesized to be known in all these models.
Therefore, there are two purposes for this paper. The first is to propose a data mining technique to discover potentially useful compound skills from single skills by viewing each skill as a linguistic value, and the second is to obtain the learning cost between any two skills. From the viewpoint of data mining, which extracts implicit, previously unknown, and potentially useful knowledge from data [8], potentially useful compound skills extracted from single skills should be added to the needed competence set including all single skills. Furthermore, we consider that it seems to be impossible to exactly measure learning costs by either money or time since how much money or time will be spent should be determined by decision makers. Since there actually exist relationships between any two skills [5], the learning cost must reflect those relationships. Generally speaking, the larger the relationship that exists between two skills, the smaller is learning cost between these two skills. We thus propose a relationship-based method to determine learning costs.
For this, we employ a computer simulation to further demonstrate that it is possible to use those potentially useful compound skills to facilitate the acquisition of single skills through an integer programming method for expanding the competence set proposed by Li [5]. That is, when a user-specified threshold, which can reflect the preference of decision makers, of the proposed data mining technique is given for determining which compound skills are potentially useful, it is feasible to obtain learning sequences with smaller minimum learning cost ,by using single skills and potentially useful compound skills instead of using only single skills.
In the following sections, the notations used in this paper are first stated in Section 2. In Section 3, we introduce the concepts of the competence set and its expansion. The proposed data mining technique used for finding potentially useful compound skills is described in Section 4. The concepts of linguistic values used for describing the competence set are also presented in
detail. Subsequently, the relationship-based method used for determining the learning costs is described in Section 5. Li’s method is also briefly described in Section 6. A computer simulation for demonstrating the feasibility of facilitating the acquisition of six single skills is demonstrated in Section 7. Discussions and conclusions are presented in Sections 8 and 9, respectively.
2. NOTATIONS
Notations used in following sections are as follows:
K Number of single skills fP pth single skill, where 1 5 p 5 K
n Number of criteria 14 Length of the uth potentially useful G ith criterion for evaluating each compound skill denoted by s,,,
skill, where 1 < i 5 n 2
I lsul I K
Wi Weight of Q, where 1 5 i < n 4fi9 fj) Learning cost for directly learn- ing fj from fi, where 1 5 i, j 5 K
3. COMPETENCE
SET
For each decision problem E, there is a competence set, denoted by CS(E), consisting of ideas, knowledge, information, and skills for successfully solving the problem. In addition, there exists a skill set denoted by Sk(E) that has been acquired by decision makers, and a truly needed competence set denoted by Tr(E). Roughly speaking, CS(E) is the union of Sk(E) and Tr( E). However, it may be impossible to resolve E using only Sk(E) since Sk(E) may cover partial ‘h(E). That is, decision makers must acquire 73(E) \ Sk(E) fr om the existing competence set (i.e., Sk(E)) through the competence set expansion. A competence set expansion represents the way to find an effective way to generate learning sequences of acquiring the truly needed skills so that Tr(E) \ Sk(E) can be obtained [S]. We depict the concept of the competence set expansion in Figure 1, where the shaded area is exactly Tr(E) \ Sk(E). In this paper, for simplicity we assume that Tr(E) \ Sk(E) only contains all single skills and potentially useful compound skills, and Sk(E) is an empty set.
Figure 1. Competence set expansion.
As we have mentioned above, the skills in the competence set are interrelated [5]. We consider that if the relationship that exists between two single skills, say fi and fa, is much larger than another two skills, say fs and fs, then it is more practical to acquire f3 from fi instead of from fs. That is, the learning costs c(fi, fs) and c(f2, f3) must reflect individual grades of relationships such that c(fi, fs) < c(fs, f3). We further interpret c(fi, fj) to be unhelpful grades for acquiring fj from fj.
Sometimes, a compound skill can facilitate the acquisition of other single skills. If c(fi A fs, f3) < c( fi , fs) < c(fs, fs) holds, then fi A A can facilitate the acquisition of fs, where fi A fs is a compound skill and represents both fi and f2 have been already acquired. In comparison with
fi
andf2,
the grade of the relationship betweenfi
Af2
andf3
is largest. However, ifc(fl, f3) < c(fl A f2, fd < c(fz, f3) or c(fl, fd < c(f2, f3) < c(fl A f2, fd holds, then we can say
that
fi
Af2
is not helpful for acquiringf3.
4. FIND
POTENTIALLY
USEFUL
COMPOUND
SKILLS
The proposed data mining technique for finding potentially useful compound skills is based on the well-known a priori property [9] introduced in the a priori algorithm proposed by Agrawal
834 Y.-C. Hu et al
et al. [lo]. In Section 4.1, we introduce concepts of data mining and the a priori property.
The discovery of potentially useful compound skills from single skills is presented in Section 4.2.
Subsequently, the proposed algorithm is completely demonstrated in Section 4.3.
4.1. Data Mining
Data mining is the exploration and analysis of large quantities of data in order to discover
meaningful patterns [ll]. It extracts implicit, previously unknown, and potentially useful patterns
from data [8]. Recently, association rule mining has become an important research topic, and
association rules have been applied to analyze market baskets to help managers determine which
items are frequently purchased at the same time by customers [9,11].
The a priori algorithm is an influential algorithm that can be used to find association rules.
In this algorithm, a candidate Ic-itemset (k 2 l), containing Ic items, is considered frequent (i.e.,
frequent k-itemset) if its support is larger than or equal to a user-specified minimum support,
which can reflect the preference of decision makers. For example, any set of fruits, say {Apple,
Orange}, sold in one supermarket is a candidate two-itemset. If the purchase frequency (i.e.,
divide the number of transactions in which both apples and oranges were purchased by the total
number of transactions) of {Apple, Orange} is larger than or equal to a user-specified minimum
support, then {Apple, Orange} is a frequent two-itemset. Subsequently, we can use frequent
itemsets to generate association rules. In principle, the larger the support of one frequent itemset
is, the more practical is further processing (i.e., rule generation).
In addition, the a priori property employed in association rule mining shows that any subset
of a frequent itemset must also be frequent [9]. In other words, any superset of an infrequent
k-itemset cannot be frequent. For example, if {Apple, Orange, Banana} is frequent, then all
its subsets (i.e., {Apple}, {Orange}, {B anana}, {Apple, Orange}, {Apple, Banana}, {Orange,
Banana}) are also frequent. It is clear that the frequent itemsets are potentially useful for mining
association rules. However, not all frequent itemsets can appear in the association rules consisting
of antecedences and consequences. If the relationships that hold between one frequent itemset
and the other frequent itemsets are not sufficiently significant, then this itemset cannot appear
in any association rule.
In a similar manner, the proposed algorithm tries to find all potentially useful compound skills
for expanding the competence set. Except for single skills in the needed competence set, those
potentially useful compound skills discovered from the single skills by the proposed data mining
technique can be added to the needed competence set. Indeed, the potentially useful compound
skills are potentially useful for generating learning sequences. Actually, not all potentially useful
compound skills can appear in the generated learning sequence.
4.2. Evaluation of Each Skill
Without losing generality, each element in the competence set can be viewed as a single skill.
Let f, = (fp17 fp,, . , fP,) where fPi (0 5 j”,, I 1) is the part-worth of the ith criterion with
respect to
f,.
That is, we assume that each single skill can be evaluated by various criteria.Furthermore, if “the skill which we desire to acquire” is a name that is specified to a linguistic
variable, as originally proposed by Zadeh [12], in the universe of discourse U = {cl, cz, . . . , G},
then one possible set of names of linguistic values is {ji, fs, . . , f~}. Formally, a linguistic
variable is characterized by a quintuple [13,14] denoted by (CC, T(z), U, G, M), in which z is the
name of the variable; T(z) denotes the set of names of linguistic values or terms, which are
linguistic words or sentences in a natural language [15], of s; U denotes a universe of discourse;
G is a syntactic rule for generating values of z; and M is a semantic rule for associating a linguistic
where p~fJ%) is the degree to which q belongs to fP. We use the well-known simple additive weighting (SAW) method, which can yield extremely close approximations to “true” value func- tions (161, in order to summarize the part-worths of criteria with individual weights to obtain the evaluation of f,. That is,
e(f,) = 2 wfpi, (2)
i=l
where
2 wi = 1. (3).
i=l
If a compound skill s, consists of j single skills, then we define that the length of s, denoted by Is,] is j. For example, ]fi Afz] = 2 holds. Of course, a single skill whose length is just one can be viewed as a compound skill. From equation (l), the linguistic value fi A fi+r A. . . A fj-i A fj with length, denoted by ] fi A fi+l A . . . A fj-1 A fj 1, j - i + 1 can be represented as
fi A fi+l A . . . A fj-1 A fj = C n PjiXfi+lX"'Xfj-lX.fj (4 ,
i=l (-2
where ~fixf~+lx...xfj+,xfj(~) is the degree to which ci belongs to fi A fi+l A. ” A fj-1 A fj and is equal to CLAN . ~f;+~ (ci) .. . /.~f~-*(ci) . pfj(ci) [17]. Based on equation (4), the evaluation of fi A fi+l A . . A fj-1 A fj is computed a~
e(fi A fi+l A.. . Afj-1 Afj) = ~WilLf.Xf.+lX--X~j-~x~j(~)’
i=l
We say that fi A fi+l A . . + A fj-1 A fj is a “candidate” compound skill and contains j - i + 1 single skills (i.e., fi, fi+l, . . ., fj-1, fj)u Significantly, we say that fi A fi+l A . .. A fj-1 A fj is “potentially useful” if e(fi A fi+l A . . . A fj-1 A fj) is larger than or equal to the user-specified minimum threshold. That is, fi A fi+l A ’ * . A fj-1 A fj can be added to the needed competence set. The threshold can indicate the tolerant or acceptable lower bound value of evaluations. Also, it can indicate the subjectivity or past experiences of decision makers. Since all single skills must be acquired, the user-specified minimum threshold must be smaller than or equal to min{e(f,) 1 1 5 p 5 K}. In fact, the terms “candidate” and “potentially useful” are derived from the concepts of “candidate” and “frequent”, respectively, used in the a priori algorithm. We also emphasize that since each single skill is evaluated by various criteria, the important degree for evaluating each skill is defined. Moreover, the potentially useful compound skills can be further discovered.
For any two potentially useful compound skills, say fi A fi+l A.. . A fj-1 A fj and fi A fi+l A ..‘Afj-lAfjAfj+l, since PfiX ji+lX...XfjXfj+l('i) 5 Pfi fi x +Ix...xfj-lxfj(G) from (41, fiAfi+lA
. . A fj-1 A fj A fj+l c fi A fi+l A. . . A fj-1 A fj thus holds. We may view it as a special property for mining potentially useful compound skills. It is clear that any subset of a potentially useful compound skill must also be potentially useful. It should be noted that if there exist K single skills, then the maximum length of a compound skill is at most K.
4.3. The Proposed Algorithm
In the a priori algorithm, two frequent (k - l)-itemsets are actually considered to be joined to be a candidate k-itemset; and these two frequent itemsets share (Ic - 2) items for satisfying the a priori property. For example, if {Apple, Orange} and {Apple, Banana} are two frequent itemsets and they share one item (i.e., Apple), then a candidate three-itemset {Apple, Orange, Banana} is generated. Of course, {Apple, Orange, Banana} can also be derived by joining {Apple, Orange} with {Orange, Banana}.
836 Y.-C. Hu et al
In a similar manner, a candidate compound skill with length Ic (2 5 k 5 K) can be derived by joining two useful compound skills with length (k - l), and these two useful compound skills share (k - 2) single skills. For example, if fi A fs and fi A fs are two potentially useful compound skills and they share one single skill (i.e., fr), then a candidate compound skill fi A fs A fs with length 3 is generated. We describe the proposed data mining technique as follows.
ALGORITHM: ALGORITHM FORFINDING POTENTIALLY USEFUL COMPOUND SKILLS. Input:
(a) A set of single skills
(b) User-specified minimum threshold Output: Potentially useful compound skills Method:
Step 1. Initialization
Set k = 1.
Step 2. Generate potentially useful compound skills with length k
Step 2-l: Set k + 1 to k.
Step 2-2:
For any two potentially use&l compound skills s, and s, (u # u) with length (k - 1) do
If the following conditions are satisfied, then s, and s, can be joined to be a potentially useful compound skill s, A s,:
(1) szL and s, share (k - 2) single skills; (2) s, A s, has not been generated;
(3) e(s, A s,,) is larger than or equal to the minimum threshold.
End
Step 3. Termination test
If a potentially useful compound skill with length k is generated, then return to Step 2. Otherwise, stop the algorithm.
Subsequently, we must determine the learning cost between any two skills in the needed com- petence set. A relationship-based method is proposed in the following section.
5. FIND
LEARNING
COSTS
As we have mentioned above, decision makers must determine how much money or time will be spent during the learning process. For example, one student may spend one year to acquire “Data Structures” after he or she had acquired “Introduction to Computer Science”, whereas another student may spend only six months. Since skills in the competence set are strongly interrelated [5], there exist relationships between any two skills. That is, it is necessary to find the learning costs that can reflect those relationships. Intuitively, if the relationship that exists between two skills is much larger, then it is much easier to acquire one skill after the other skill has been acquired.
There exist distinct relationships between any two subsystems in the real world (181, although we do not know exactly what these relationships are. Grey theory, as proposed by Deng [18], can perform grey relational analysis for these subsystems by dealing with finite and incomplete output data series obtained from these subsystems [19]. We can view each needed skill fp as a subsystem, and its finite output data series is just (fpl, fPa , . . . , fp,). Then, the grey relations can be employed to find the learning cost between any two skills. Generally speaking, the larger the grey relation that exists between two skis, say f, and fi, the smaller is learning cost between fp and fi.
In this section, we introduce concepts of grey relations in Section 5.1. In Section 5.2, a relationship-based method is proposed for finding learning costs.
5.1. Grey Relations
Grey relational analysis is a method that can find the relationships between one major sequence and the other sequences in a given system [20]. Given one reference sequence’, 4ay fP (1 I p 5 K), and some comparative sequences, say fi (1 5 i < K), we can easily obtain the grey relation between fP and fi by viewing fP as a desired goal [21]. Formally, given the reference sequence
fp
and the comparative sequences fi with the normalized form, the grey relational coefficient (GRC)c(fpj, fij)
betweenfpj
andfij
(1 5 j I n) can be computed as [19,20]Amin + ~&mu
r(fij 7 f%) = A, + PAmax
7
(6)where p is the discriminative coefficient (0 5 p < l), and usually p = 0.5 [20]. It should be noted that the appropriate- value of p is dependent on requirements of individual applications.
Moreover, ’
Amin = m)” mp 1
fpj - fij 1 ,
lii<K, lljln, (7) A ,m=mtVmJFIfpj -fijI > l<ilK, l<j<n, (8)A, = lfpj - fij I >
(9)
where ] . ] denotes the absolute value. Clearly, [(
fij, fpj)
is between zero and one. Then, the grey relational grade (GRG) denoted byT(fi, f,)
can be computed as0 5 T(fi, fp) 5 1 thus holds. The larger the value of T(fi, fp), the closer the relationship is
between f,, and fi. The main difference between correlation analysis and grey relational analysis
is that correlation analysis measures the relationship between any two random variables, and grey relational analysis tries to find the relationships between one reference sequence and other comparative sequences by viewing the reference sequence as a desired goal that each comparative sequence expects to attain [21].
5.2. The Relationship-Based Method First, c(fi, fp) is heuristically computed as
C(fi, fp) = 1 - Vfi, fp), 1 I i,p 5 K. (11)
It is clear that 0 < c(fi, f,) 5 1 also holds. Basically, (11) indicates the relationship between
the learning cost (i.e., c(fi, fp)) and the grade of relationship (i.e., T(fi, fp)). An initial learning
cost table can be thus built. An example of an initial learning cost table is shown as Table 1, in which we can see that there are six single skiils. By using the initial learning costs table, we can subsequently compute c(s,, fp) (1 5 p < K), where i, is discovered by the proposed data
mining technique.
Table 1. Initial learning cost table with six single skills.
Compound Skill Sing1
fl f2 f3 fl dfl, fl) 4flI f2) dfl, f3) le I Skill f4 4f1, f4) c(f2, f4) C(f3! f4) C(f4rf4) 4f5r f4) 4fc%f4) f5 C(fl, f5) C(fi,f5) C(f3rf5) c(f4, f5) c(fs* fs) c(f6, f5)
838 Y.-C. Hu et al.
From Table 1, we can observe that if there are K single skills, then there are K2 various learning costs in the initial learning costs table. In addition, there implicitly exists a function that can map from Vi,, . . , f~, , e(h), fp,, . , f,., ,e(&)) to c(fi, fp). A th ree-layer neural network trained by the backpropagation algorithm can serve as a tool of the approximation of functions like regression [22]. We illustrate the architecture of the three-layer network employed in this paper in Figure 2. Here, we can see that there are 2n + 3 input nodes (i.e., n + 1 nodes for fi, n + 1 nodes for
f,,
and one bias node with input 1) and one output node. It should be noted that it has been proved that a single hidden layer is sufficient to approximate any continuous function [23]. However, how many hidden nodes are necessary is generally not known [24].e(&J .l
Output Layer
H.&n Layer
Input Layer
Figure 2. A three-layer neural network.
The three-layer network can be trained by using given K2 training data from the initial learning costs table, and the optimal weights can be further determined when a termination condition is reached. Usually, we can stop the training when the mean squared error E,,,, shown as (12), reaches below the pregiven tolerant error
Em = & $(dj - oj)‘,
j=l(12)
where dj and oj are the actual output and the desired output of the jth input training data, respectively, and N (e.g., N = K2) is the number of training data. For example, if the input training data is (fi,, . . , fi,, e(fi), fpl, . . . , fP, , e(f,)), then its desired output is c(fi, fP). Subse- quently, c(su, f,) (1 5 p 5 K) of acquiring fP from s, can ,be estimated by feeding (s,, , . . . , s,,, , e(s,), fP1,. . . , fP,, e(fP)) to the trained network. But, due to the restrictions on the representa- tion of compound skills that are described in the following section, it is not necessary to compute C(%, t-p).
A relationship-based method proposed for obtaining learning costs by grey relations and a three-layer neural network is described as follows.
ALGORITHM: RELATIONSHIP-BASED METHOD FOR GENERATING THE LEARNING COSTS.
Input:
(1) Single skills fi (1 5 i 5 K) and potentially useful compound skills discovered by the proposed data mining technique.
(2) The number of hidden nodes used in the three-layer neural network. Output: Learning costs table.
Method
Step 1. Generate initial learning costs table
1.1. Calculate T(fi,fp) by equation (lo), 1 5 i,p < K. 1.2. Calculate c(fi, fP) by equation (ll), 1 5 i,p 5 K.
Step 2. Train the three-layer neural network
Use K2 training data obtained from the initial learning costs table to train the three-layer neural network by the backpropagation algorithm.
Step 3. Generate complete learning costs table
Generate c(s,, f,) by feeding (sul, . . . , stl,, e(s,), f,,, . . . , f,,, e(fP)) to the trained neural network, 1 5 p 5 K
After the learning costs are obtained by the above-mentioned method, we must select one effective method to expand the competence set. An integer programming method proposed by Li [5] is determined to be appropriate and is introduced in the following section.
6. GENERATE
LEARNING
SEQUENCES
If a learning cost exists between any two skills in a competence set, then the expansion of this competence set can be categorized as a cyclic expansion problem (51. To resolve this problem, below, we briefly describe an integer programming method proposed by Li [5], which is used to generate learning sequences with minimum learning cost in the subsequent section. For prob- lem E, we also make several revisions to Li’s method for coping with Sk(E) = 8, since in Li’s method Sk(E) was assumed to be not empty.
Actually, single skills and compound skills construct a digraph G consisting of subgraphs S and T, and each skill corresponds to a node. S consists of skills in Sk(E), and T consists of skills in Tr(E)\Sk(E). The learning sequences are generated for Tr(E) \Sk(E) by starting from Sk(E). A node representing a compound skill, say fi l\fi+i A. * * A f+ i A fj , is called a compound node and is depicted as Figure 3, for example. In Figure 3, several nodes, referred to as decomposed nodes
(i.e.,
fi,fi+l,
. . ,fj-1 andfj),
are directly linked through dotted arcs to the node representingfi
Afi+l
A . Afj-1
Afj.
However, there are two restrictions for representing a compound node in G: the first restriction is that there is no arc between the decomposed nodes of a compound node; and the second restriction is that no nodes can be directly linked to a compound node except its decomposed nodes. For example, the node cr representingfl
cannot be directly linked to the node ,0 representingf2
Af3.
In G, the other arcs are directed except dotted arcs. For example, the directed arc denoted by r(p,a) connecting the node CY from the node ,8 with cost c(f2 Af3, fi)
represents that to learn skillfl
fromf2
Af3
requires c(f2 Af3, fi)
cost units.Figure 3. Compound node.
Significantly, a learning sequence can be represented by a directed path [5]. On the other hand, it is impossible to learn a single skill, say
fi,
fromfi
Af2
Af3
since iffi
Af2
Af3
is acquired, then it indicates that decision makers had already acquiredfl, f2,
andf3.
And, there also does not exist .a learning cost for each dotted arc between a compound node and its decomposed nodes. For example, we can set a null value (not zero) to c(fi A f2, fi). Furthermore, c(fp, fp)(~<P<K) a o oes not exist. In principle, all nodes representing single skills must take part b d
in the generation of the final learning sequence. But only partial nodes representing potentially useful compound skills can appear in the final learning sequence since not all of them can facilitate the acquisition of single skills.
For G, several definitions must be given. First, define IA(i)! and ]B(i)( as the numbers of nodes immediately before node i and immediately after node i, respectively. In addition, define ui for
840 Y.-C. Hu et al.
node i as u, = 1 if node i takes part in the generation of the learning sequence; otherwise uz = 0. Also define v(i,j) for the arc connecting node i to node j as w(i,j) = 1 if w(i,j) is one path of the learning sequence; otherwise w(i,j) = 0. Let V(S) and V(T) be sets of nodes of S and T,
respectively. Then both ui and ~(i, j) are O-l variables and satisfy the following properties: (a) ui = 1, for each i E V(S) or i corresponding to a single skill in T; (13)
(b) IA(i)lui 2 c w(i,j), if i E V(S); (14)
jEA(i)
(c) ui 5 c ~(j, i), if i E V(T) and i is not a compound node; (15)
jGB(i)
(d) (IA(i)l + IB(i)l)ui > C ~(j,i) + C ~(i,j), if i E V(T). (16)
jEB(i) jEA(i)
In addition, let Xi be the sequence number of node i in the learning sequence; then the following relations hold:
(a) Xi = 0, if i E V(S), (17)
(b) Xi -Xj + KW(i,j) 5 K- 1, (18)
(C) Ui 5 Xi < KUi, (19)
where Xi is an integer variable. For each compound node i, if its decomposed nodes are nodes il,iz,.. . , il, then the following relations also hold:
cw (21) Generally speaking, if Xi and Xj are the same and Xi - X, = 1, then fi and fj can be learned simultaneously when f, has been already acquired. Basically, (13)-(16) find those arcs which can be contained in the learning sequence. Equations (17)-( 19) find the sequence number of each node in the learning sequence. Equations (20),(21) control the sequence of a compound node and its decomposed nodes; that is, the sequence number of a compound node is not larger than that of each of its decomposed nodes. We omit the detailed discussions of the above-mentioned properties, which can be found in [5].
Since in this paper Sk(E) is assumed to be an empty set, several revisions of Li’s method must be made. Let S consist of a virtual node labeled by 0 (i.e., V(S) = (0)). Furthermore, the virtual node (i.e., node 0) is directly linked to each node i by a directed arc with learning cost being equal to zero, where node i E T and node i is not a compound node. Our purpose is to find the starting node labeled by niT’ (i.e., nhT’ E V(T)) immediately after node 0 in the learning sequence. That is, np) corresponds to a single skill which we suggest decision makers to learn first. If nodes ii, i2, . , iK represent single skills fr, fz, . . . , f~, respectively, then the following relation holds:
K
CW(O,ij) = 1. (22)
j=l
An integer program can be further formulated by combining (12)-(21) and giving an object function as follows:
minimize cost(G) = c c(i,j) . w(i,j),
r(i,j)EE
(23)
where E is the set of arcs of G. In the subsequent section, we use a computer simulation to demonstrate the effectiveness of the potentially useful compound skills through Li’s method.
,7. SIMULATIONS
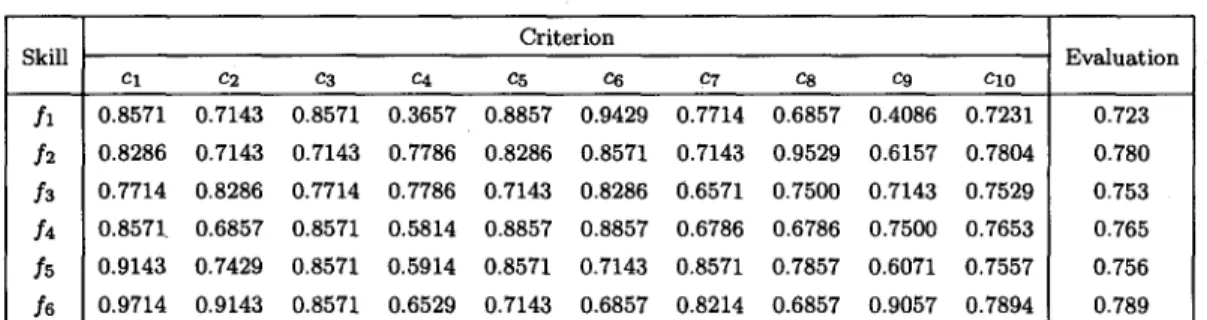
We assume that, for one decision problem E, six single skills (i.e., fi , fi, fs, f4, fs, and fs) must be acquired, as shown in Table 2, where we can see that each skill is evaluated by ten criteria. For simplicity, all criteria have equal weights (i.e., wi = 0.1, 1 5 i 5 10). The evaluation of each single skill can be obtained by (2). In real application, the part-worths of criteria with respect to each single skill and the weights of criteria may be obtained by questionnaire. In addition, decision makers can determine their own preferable minimum threshold.
Table 2. Six single skills. Criterion Skill Evaluation Cl CZ c3 c4 C5 cs C? cs c9 Cl0 fl 0.8571 0.7143 0.8571 0.3657 0.8857 0.9429 0.7714 0.6857 0.4086 0.7231 0.723 f2 0.8286 0.7143 0.7143 0.7786 0.8286 0.8571 0.7143 0.9529 0.6157 0.7804 0.780 f3 0.7714 0.8286 0.7714 0.7786 0.7143 0.8286 0.6571 0.7500 0.7143 0.7529 0.753 f4 0.8571 0.6857 0.8571 0.5814 0.8857 0.8857 0.6786 0.6786 0.7500 0.7653 0.765 f5 0.9143 0.7429 0.8571 0.5914 0.8571 0.7143 0.8571 0.7857 0.6071 0.7557 0.756 f6 0.9714 0.9143 0.8571 0.6529 0.7143 0.6857 0.8214 0.6857 0.9057 0.7894 0.789 Train a three-layer neural network for estimating the learning costs
The relationship-based method described in Section 5 is used to obtain learning costs. A three- layer network can be trained by using training data from the initial learning costs table. To obtain a sufficiently large size of training data, we heuristically add another two virtually single skills to play an auxiliary role. That is, the part-worth of each criterion is zero for one skill, and it is one for the other skill. To obtain the initial learning cost table, these two skills serve as comparative sequences for other six single skills (i.e., fi, fs, fs, f4, f s, and fs). The initial learning cost table can be thus obtained by (9) and (10) and is shown as Table 3, although those two virtual skills are omitted in this table. It is clear that there are 48 training data (i.e., 62 + 2 x 6) used for training the neural network with 23 input nodes (i.e., 2 x 10 + 3) and ten hidden nodes. In addition, when Eave is smaller than 0.0005, we terminate the progress of training. The trained network is subsequently used for estimating the learning costs c(sU, f,) (1 5 p 5 6) if all s, have been obtained by the proposed learning algorithm described in Section 4.3.
Computer Skill fl f2 f3 f4 f5 f6
Table 3. Initial learning cost table. Single Skill fl f2 f3 f4 f5 f6 0.000 0.189 0.241 0.120 0.179 0.217 0.190 0.000 0.155 0.173 0.188 0.224 0.220 0.139 0.000 0.172 0.200 0.173 0.112 0.160 0.177 0.000 0.155 0.186 0.174 0.182 0.216 0.163 0.000 0.148 0.221 0.228 0.196 0.204 0.155 0.000 Generate a learning sequence with minimum cost for only single skills
We now obtain the potentially useful compound skills. At first, the user-specified minimum threshold is set to 0.65. This is a valid value since min{e(f,) 1 1 5 p 5 6) = e(fi) = 0.723. We find that no potentially useful compound skills can be found from the six single skills. Let fi be the ith node (1 5 i 2 6) in G; a mathematical integer program of finding a learning sequence
842 Y.-C. Hu et al. with minimum learning cost is thus formulated below.
Minimize cost(G) = O.l89v(l, 2) + 0.241~(1,3) + 0.120~(1,4) + O.l79v(l, 5) + 0.217~(1,6) + O.l9Ov(2,1) + 0.155~(2,3) + 0.173~(2,4) + 0.188~(2,5) + 0.224~(2,6)
+0.220w(3,1) + O.l39v(3,2) + O.l72w(3,4) + 0.200~(3,5) + O.l73w(3,6) +0.112~(4,1) + O.l6Ow(4,2) + O.l77w(4,3) + O.l55w(4,5) + 0.186~(4,6) +0.174~(5,1) + O.l82w(5,2) + 0.216~(5,3) + 0.163~(5,4) + O.i48v(5,6) +0.221~(6,1) + 0.228~(6,2) + O.l96w(6,3) + 0.204~(6,4) + 0.155~(6,5), S.t. Uj, = 1, Oli<S, 6 6~0 2 c ~(0, i), i=l )yw(O,i) = 1, i=l 6 6 lb) c4j,i) + ~4G.d I 11, i # j. j=o j=l x0 = 0,
Xi - Xj + S~(i,j) 5 5, O<i<6, l<j<S and ifj, 1<Xi<6, l<i<6.
Solve the above program by the LINGO package to obtain the optimal solution as
w(O,3) = w(3,2) = v(3,4) = w(4,l) = w(4,5) = w(5,6) = 1,
Since X3 = 1, therefore nr) = 3 holds. That is, f3 is suggested for decision makers to learn first among the six single skills. The learning sequence with minimum learning cost of 0.726 is depicted in Figure 4. We can see that fs and f4 can be learned simultaneously when
f3
has already been acquired. We can also observe that although max{e(fp) 1 1 5 p 5 6) = e(js) = 0.789, fs is not suggested to be learned first. It is noted that the minimum learning cost can be regarded as the minimum degree of the difficulty for acquiring all single skills.Find potentially useful compound skills
We now try to set a smaller value, 0.60, to the user-specified minimum threshold. Three potentially useful compound skills, fz A fs with e(fs A fs) = 0.614, f4 A fs with e(f4 A fs) = 0.606, and fs A fs with e(fs A fs) = 0.601 can be further discovered from the six single skills. For example, since fz Af6 = 0.8049/c~+0.6531/c~+0.6122/c~ +0.5083/~+ 0.5918/cs+O.5878/ce+ 0.5867/c, + 0.65341~ + 0.4222/o, + 0.7246/c rc, therefore e(fs A f6) = 0.10. (0.8049 +0.6531 +
0.6122 + 0.5083 + 0.5918 + 0.5878 + 0.5867 + 0.6534 + 0.4222 + 0.7246) = 0.614 1 0.60 holds. We then employ the trained neural network to estimate the learning cost, with the results as shown in Table 4. For example, the estimation of c(fz A fs, fr) = 0.171 can be obtained by feeding (0.8049, 0.6531, 0.6122, 0.5083, 0.5918, 0.5878, 0.5867, 0.6534, 0.4222, 0.7246, 0.614; 0.8571, 0.7143, 0.8571, 0.3657, 0.8857, 0.9429, 0.7714, 0.6857, 0.4086, 0.7231, 0.723) to the trained network. By displaying nothing in the corresponding location, some null values are given.
Table 4. Learning cost table for potentially useful compound skills
Generate learning sequerices by potentially useful compound skills
Let fs A fs, f4 A
f6,
andfs
Af6
be the seventh, eighth, and ninth nodes in G, respectively; a mathematical integer program of finding a learning sequence with minimum learning cost is thus formulated below.Minimize cost(G) = O.l89w(l, 2) + 0.241~(1,3) + 0.120~(1,4) + O.l79u(l, 5) + 0.217?~(1,6), + 0.19@@, 1) + 0.155~(2,3) + 0.173~(2,4) + 0.188~(2,5) + 0.224~(2,6)
+0.220~(3,1) + O.l39w(3,2) + 0.172~(3,4) + 0.200~(3,5) + O.l73w(3,6) + O.l12w(4,1) + O.l6Ow(4,2) + O.l77w(4,3) + O.l55w(4,5) + 0.186~(4,6) + 0.174~(5,1) + 0.182~(5,2) + 0.216~(5,3) + 0.163~(5,4) + O.l48w(5,6) + 0.221~(6,1) + 0.228~(6,2) + O.l96w(6,3) + 0.204~(6,4) + O.l55w(6,5) + 0.171~(7,1) + 0.210~(7,3) + 0.173~(7,4) + O.l63w(7,5) + 0.327~(8,1) + 0.327~(8,2) + 0.358~(8,3) + 0.281~(8,5) + 0.324w(9,1) + 0.396w(9,2) + 0.357w(9,3) + 0.357w(9,4), s.t. ui = 1, O<i<S, 6210 1 kw(O,i), i=l &w(O,i) = 1, i=l for i = 1,
$w(j, 4 2 1,
j # 1,
j=O $w(j,i)+f:w(i,j)S14, j#l; j=O j=l844 for i = 2, Y.-C. Hu et al. ~w(j,i)+w(8,2)+~(9,2)~1, j=O ~w(j,i)+w(8,2)+~(9,2)+~w(i,j)~13, j=o j=l for i = 3, -&ii) 2 1, j # 3, j=O &w(j,i) +f:w(i,j) 514, j # 3; j=O j=l for i = 4, &(j,i) +w(7,4) +v(9,4) > 1 - 7 j=O ~u(j,i)+w(7,4)+w(9,4)+f:w(i,j) 2 13, j=O j=l for i = 5, &(j, i) + w(7,5) + w(8,5) 2 i, j=O ~w(j,i)+w(7,5)+~(8,5)+~w(i,j) < 13, j=O j=l j # 27 j # 2; j # 4, j # 4; j f5, j # 5; for i = 6, j=O 6 6
cw(j,i) +cv(Gj) Ill,
j #
6. j=O j=l x0 = 0,Xi - Xj + 6w(i, j) 5 5, OIi16, l<jlS, and i#j,
1 <_ Ai 5 6, lsi<6,
X7 - X1 + 6w(7,1) 5 5; X7 - X1 + 6w(7,3) < 5; A, - Xq f 6w(7,4) 5 5; A, - As + 6w(7,5) < 5;
x8 - ii1 + 6w(8,1) 5 5; x8 - ii2 + 6w(8,2) 5 5; x8 - & + 6w(8,3) 5 5; x8 - &i + 6w(8,5) 5 5;
2217 5 ‘112 +?&; x7 1 x1; x7 2 x6, 2~8 <u~+u& x8 2 x4; x8 2 x6; 2u9 <u5+%; x9 1 x5; x9 2 x6.
However, the optimal solution of this program is the same as the case that sets the minimum threshold to 0.65. This result indicates that the current potentially useful compound skills (i.e., f2 A fe, f4 A fs, and
f5
Af6)
‘are not sufficient to reduce the minimum learning cost obtained by the case that sets the minimum threshold to 0.65. That is, it seems that the minimum threshold may be too large to find more potentially useful compound skills. In the following, we thus pay attention to how the minimum threshold can affect the obtainable minimum learning costs.Obtain minimum learning costs for various minimum thresholds
Among all potentially useful compound skills, we can intuitively observe that
fl A f2 A f3
Af4
Afs A
f6
is not useful for facilitating the acquisition of single skills, as we have mentioned above,since if
fi
Af2
Af3
Af4
Afb
Af#j
is acquired, then it indicates that decision makers had alreadyacquired all six single skills. To show various minimum thresholds could affect the minimum learning costs, the minimum threshold is arranged at intervals of 0.05 from 0.55 to 0.25, and the simulation results are shown in Table 5. From this table, we can see that nearly all (i.e., 62) potentially useful compound skills can be discovered when the user-specified minimum threshold is 0.25. It seems that the minimum learning cost, obtained by the case sets the minimum threshold to 0.65, can be decreased as the minimum threshold gradually decreases. However, the obtainable minimum learning cost can stay at a stable point when the minimum threshold is smaller than or equal to one real value.
Table 5. Learning cost table for potentially useful compound skills.
0.65 6 0.726 0.60 9 0.726 0.55 20 0.480 0.50 21 0.480 0.45 32 0.474 0.40 41 0.414 0.35 49 0.414 0.30 56 0.414 0.25 62 0.414
Minimum Threshold 1 Number 1 Minimum Learnine Cost
However, decision makers must have their own preferable threshold in real applications. When the minimum threshold is set to a preferable value, say 0.50, a learning sequence depicted in Figure 5 with minimum learning cost 0.480 can be obtained. The learning sequence with minimum learning cost 0.414, when the threshold is set to 0.35, is also depicted in Figure 6. Further issues are discussed below.
8. DISCUSSION
The main contribution of this paper is to develop a practical model to generate learning se- quences of acquiring needed single skills by potentially useful compound skills discovered by the proposed data mining technique to support the decision making. In addition, we provide a more reasonable method to measure the learning cost between any two skills by grey relational analysis.
846 Y.-C. Hu et al. 3
P
0.100(y*2 Q --- 2Y’o.098
\
“‘-~~.,~, 0.100 & @ “c 0.0000
1Figure 5. Learning sequence for minimum threshold 0.50
Figure 6. Learning sequence for minimum threshold 0.35.
Significantly, this is a starting point for integrating data mining techniques with the expansion of the competence set.
The generated learning sequence corresponding to a user-specified threshold is a sequence that should be more appropriate for decision makers to progressively acquire required skills. From the simulation results, we can see that it is possible to obtain smaller minimum learn- ing cost (e.g., 0.414) by using those potentially useful compound skills in comparison with the case that uses only single skills (i.e., 0.726), when a user-specified minimum threshold is given (e.g., 0.35). If decision makers only pay attention to the issue of obtaining a learning sequence with a cost as small as possible, then the minimum threshold should be set to a smaller value (e.g, 0.10).
Indeed, there exists a trade-off between the required efficiency and the expected optimality. When the number of single skills is too large and the minimum threshold is too small, the processing time may suffer from performing the proposed data mining technique and Li’s method. In addition, the generated learning sequence may be inappropriate for decision makers. If almost all compound skills are potentially useful, then only a multilayer neural network must be trained to obtain learning costs by giving an initial learning cost table. In real applications, decision makers should give a reasonable minimum threshold, which can indicate the tolerant or acceptable lower bound value of skills’ evaluations. That is, they should determine their own preferable threshold depending on their past experiences or subjectivity.
For evaluating each skill, SAW, which assumes that any two criteria are independent, is one of the possible methods. However, it seems that any two criteria are interrelated. Therefore, the methods other than SAW which admit existing the dependent criteria, such as the fuzzy integral approach [25], can be considered to evaluate each skill in the proposed data mining technique.
On the other hand, it seems that our methods for acquiring compound skills and learning costs could also be widely applied in various problems. For example, if there are 20 projects that must be executed to attain one goal, then we can view these projects as single skills. Then, a generated learning sequence with minimum learning cost can be further viewed as the working sequence. It seems to be inappropriate to arrange a sequence only according to the evaluations, since the evaluations represent the individual significance of skills rather than the relative working order in the sequence.
9. CONCLUSIONS
When decision makers have already acquired the competence set to solve a decision problem they face, they will be confident in making decisions. Otherwise, they must expand the needed competence set from the acquired competence set to resolve the problem.
As we have mentioned above, effective acquisitions of potentially useful compound skills and learning costs are two significant tasks before expanding the competence set. However, in previous models, compound skills and learning costs were hypothesized to be known. We thus propose a data mining technique based on the well-known a priori property and a relationship-baaed method baaed on grey relations to discover compound skills and determine learning costs, respectively. In addition, the relationship-based method provides a reasonable way to give the learning costs by measuring the grade of the relationship between any two skills rather than by money or time.
Then, we employ a known integer programming method proposed by Li [5] to generate learning sequences. From the simulation results, we can see that it is more feasible to obtain a learning sequence with smaller minimum learning cost by using those potentially useful compound skills instead of using only single skills, when a threshold of the proposed data mining technique is given by decision makers for determining which compound skills are potentially useful.
In the discussions, we also suggest several approaches to improve the proposed approach, such as the evaluation of one skill. In addition, it seems that our methods could also be applied in various problems.
REFERENCES
1. P.L. Yu and D. Zhang, A foundation for competence set analysis, Mathematical Social Sciences 20 (3), 251-299, (1990).
2. M.J. Hwang, C.I. Chiang, I.C. Chiu and G.H. Teeng, Multi-stages optimal expansion of competence sets in fuzzy environment, International Journal of i%zzy Systems 3 (3), 486-492, (2001).
3. J.M. Li, C.I. Chiang and P.L. Yu, Optimal multiple stage expansion of competence set, Ezlropeun Journal of Operational Research 120 (3), 511-524, (2000).
4. H.L. Li and P.L. Yu, Optimal competence set expansion using deduction graph, Journal of Optimization Theory and Application 80 (l), 75-91, (1994).
5. H.L. Li, Incorporating competence sets of decision makers by deduction graphs, Operdtions Research 47 (2), 209-220, (1999).
6. J.W. Feng and P.L. Yu, Minimum spanning table and optimal expansion of competence set, Journal of Optimization Theory and Application 99 (3), 655-679, (1998).
7. D.S. Shi and P.L. Yu, Optimal expansion and design of competence sets with asymmetric acquiring costs, Journal of Optimizaation Theory and Application 88 (3), 643458, (1996).
8. P. Adriaans and D. Zantinge, Data Mining, Addison-Wesley, Harlow, (1996).
9. J.W. Han and M. Kamber, Data Mining: Concepts and Techniques, Morgan Kaufmann, San Francisco, CA, (2001).
10. R. Agrawal, H. Mannila, R. Srikant, H. Toivonen and A.I. Verkamo, Fast discovery of association rules, In Advances in Knowledge Discovery and Data Mining, (Edited by U.M. Fayyad, G. Piatetsky-Shapiro, P. Smyth and R. Uthurueamy), AAAI Press, Menlo Park, CA, (1996).
11. M. Berry and G. Linoff, Data Mining Techniques: For Marketing, Sales, and Customer Support, John Wiley & Sons, New York, (1997).
12. L.A. Zadeh, The concept of a linguistic variable and its application to approximate reasoning, Information Science (Part 1) 8 (3), 199-249, (1975); (Part 2) 8 (4), 301-357, (1975).
13. H.J. Zimmermann, Fuzzy Set Theory and Its Applications, Kluwer, Boston, MA, (1991).
14. W. Pedrycz and F. Gomide, An Introduction to Puz.zy Sets: Analysis and Design, MIT Press, Cambridge, MA, (1998).
15. SM. Chen and W.T. Jong, Fuzzy query translation for relational database systems, IEEE Thmsactions on Systems, Man, and Cybernetics 27 (4), 714-721, (1997).
16. K.P. Yoon and C.L. Hwang, MuZtipZe Attribute Decision Making: An Introduction, Sage Publications, Lon- don, (1995).
17. Y.C. Hu, R.S. Chen and G.H. Tzeng, Generating learning sequences for decision makers through data mining and competence set expansion, IEEE tinsactions on Systems, Man, and Cybernetics (Part B) 32 (5), 679-686, (2002).
18. J.L. Deng, Control problems of grey systems, Systems and Control Letters 1 (5), 288-294, (1982).
19. Y.P. Huang and C.H. Huang, Real-valued genetic algorithms for fuzzy grey prediction system, fi%zy Sets and Systems 87 (3), 265-276, (1997).
848 Y.-C. Hu et al.
20. Y.T. Hsu and C.M. Chen, A novel fuzzy logic system based on N-version programming, IEEE lPransactions on Fwy Systems 8 (2), 155-170, (2000).
21. Y.C. Hu, R.S. Chen, Y.T. Hsu and G.H. Tzeng, Grey self-organizing feature maps, Newocomputing 48 (l), 863-877, (2002).
22. K.A. Smith and J.N.D. Gupta, Neural networks in business: Techniques and applications for the operations researcher, Cokputers and Operations Research 27 (11/12), 1023-1044, (2000).
23. G. Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of Control, Signals, and Systems 2, 303-314, (1989).
24. J. Hertz, A. Krogh and R.G. Palmer, Introduction to the Theory of Neural Computation, Addison-Wesley, Redwood City, CA, (1991).
25. T. Murofushi and M. Sugeno, Some quantities represented by the Choquet integral, Fwq Sets and Systems 56, 229-235, (1993).