國
立
交
通
大
學
資訊工程學系
博 士 論 文
中文寫作自動評閱之概念化方法
Conceptualization Methodology for Chinese Automatic Essay Scoring
研 究 生:張道行
指導教授:李嘉晃 教授
中文寫作自動評閱之概念化方法
Conceptualization Methodology for Chinese Automatic Essay Scoring
研 究 生:張道行 Student:Tao-Hsing Chang
指導教授:李嘉晃 Advisor:Chia-Hoang Lee
國 立 交 通 大 學
資 訊 工 程 學 系
博 士 論 文
A DissertationSubmitted to Department of Computer Science College of Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Ph. D.
in
Computer Science June 2007
Hsinchu, Taiwan, Republic of China
中文寫作自動評閱之概念化方法
學生 : 張道行 指導教授:李嘉晃 博士 國立交通大學資訊學院 資訊工程學系中文摘要
寫作自動評閱技術在教育研究領域是相當重要的研究工具。雖然已經有許多 英文的寫作自動評閱工具問世,然而由於其主要的架構設計仍依靠文法分析,因 此後續的發展及應用均受到很大的限制。另外,由於寫作架構本質上的差異,使 得中文寫作也無法使用現有工具進行自動評閱。本論文以寫作者的概念發展歷程 為基礎,提出以概念-連結架構進行評閱的新方法,目的在測量概念發展過程中 的表現。因為這樣的架構設計著重於作品的語意分析,使得中文寫作自動評閱技 術發展的困難得以突破,其評閱結果也較具有教育上的應用價值。實驗結果顯示 這個以寫作本質特徵為基礎的方法具有相當良好的效能。Conceptualization Methodology for Chinese Automatic
Essay Scoring
Student : Tao-Hsing Chang Advisor:Prof. Chia-Hoang Lee
Department of Computer Science College of Computer Science National Chiao Tung University
Abstract
Automatic essay scoring system is a very important research tool for such areas as educational testing and psychometrics. Although some English AES systems have been proposed and developed successfully, it is still a difficult and interesting issue for Chinese AES. The thesis proposed a novel methodology for scoring Chinese essays based on the extraction and analysis of conceptual frameworks in essays. There are three characteristics in the methodology. First, it performs well based on the analysis of semantics in essays even if it does not employ surface features and syntax features. Second, the result of evaluation can be used for instructional feedback to the authors because it refers the conceptualization progress of authors to evaluate the quality of essays. Third, it overcomes the difficulties of applying current English AES systems to Chinese. Experimental results show that the performance of the methodology is quite close to that of current English AES systems.
誌 謝
本文提出了一個假設: 一個次概念只有在其他次概念存在時存在。從 開始這個論文題目起的幾千個日子,經歷的人生波折實在刻骨銘心。但是 有許多關心我、照顧我、陪伴我、幫助我的人,讓我可以走到現在。沒有 這些人,我和這篇論文的存在也就沒有意義。我不想像頒獎典禮致謝詞般 的點名致謝,因為這些人就是我的存在、我的過去、我的未來。謹以此文獻給影響我ㄧ生的人們
CONTENTS
Abstract (in Chinese)………i
Abstract………..ii Acknowledgements………iii Contents………iv List of Tables………..………vi List of Figures………vii Chapter 1 Introduction...1
Chapter 2 Previous Studies...4
2.1 Current AES ...4 2.2 Contrastive Rhetoric ...7 2.2.1 Sentence structure ...8 2.2.2 Topics...8 2.2.3 Organization...9 2.2.4 Figure-of-Speech...10
2.3 Extraction and Classification of Chinese Words...10
Chapter 3 Conceptualization of Essays ...12
3.1 Extraction of Words in Subconcepts...14
3.2 Unknown Word Extraction ...16
3.2.1 Retrieving Meaningful Strings...17
3.2.2 Filtering Familiar Strings...18
3.2.3 Recovering Prefixed/Suffixed Words ...19
3.2.4 Comparison with Previous Method ...20
3.3 Unknown Word Classification ...21
3.3.1 Inferring Category Based on Morphological Rules ...22
3.3.2 Inferring Category Based on Contextual Rules ...23
3.4 Thematic Subconcept Hierarchy...24
3.4.1 Asymmetrical Semantic Relation Matrix...25
3.4.2 Constructing Thematic Subconcept Hierarchy ...26
Chapter 4 Selection of Concepts ...29
4.1 Set of Literary Sememes...30
4.2 Extraction of Literary Sememes ...31
4.2.1 The Correlation between Candidate and Essay ...31
4.2.2 Using Candidate Sets to Score Essays ...31
4.2.3 Estimating the Performance of Candidates Quantitatively...32
4.3 Usefulness of Literary Sememes for Scoring Essays ...33
4.3.2 Performance of Literary Sememes for Scoring Essays...35
Chapter 5 Connection of Concepts...36
5.1 Extraction and Transformation of the Concepts in C-L Structure ...36
5.2 Inter-paragraph Connections...37
5.2.1 Similarity Measure between Inter-paragraph Connections...37
5.3 Intra-paragraph Connections...39
5.3.1 Similarity Measure between Intra-paragraph Connections...41
5.3.2 Scoring Essays by Intra-paragraph Connections ...42
5.4 Usefulness of C-L Structures for Scoring Essays ...42
Chapter 6 Decoration of Concepts ...44
6.1 Building Sets of Connectives and Literary Connectives ...45
6.2 Extracting FOS “Pi-yu” ...46
6.3 Extracting FOS “Pai-bi” ...47
6.4 Usefulness for Scoring Essays ...48
Chapter 7 Performance of Conceptualization for Scoring Essays...49
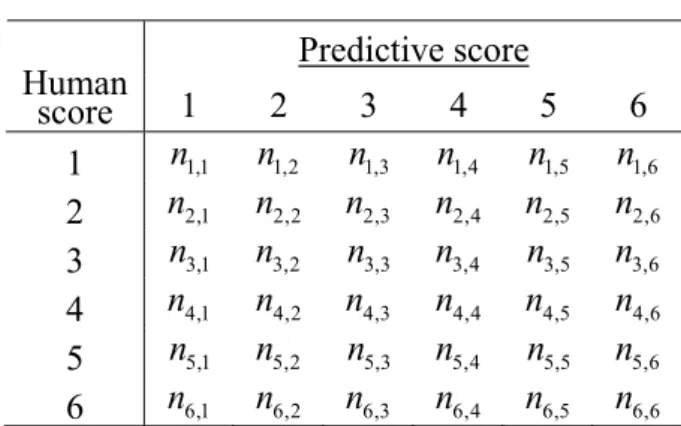
7.1 Predicting Model...49
7.2 Performance of Predicting Model...51
Chapter 8 Conclusions...53
LIST OF TABLES
Table 3.1 Part of the Morphological Rule Base...20
Table 3.2 An Example for Morphological Rules Containing Two Categories ...22
Table 4.1 A Performance Table...32
Table 4.2 A Weighted Table ...33
Table 4.3 Performance of Using Literary Sememes to Scoring Essays...35
Table 5.1 Performance of Inter-paragraph Connection...43
Table 5.2 Performance of Intra-paragraph Connection...43
Table 6.1 The Distributions of the Ratios of Essays to All Essays ...48
Table 7.1 Performance of the Improved MBM for Scoring Essays...52
LIST OF FIGURES
Fig. 3.1 Two Viewpoints for Semantic Structure of Chinese Essays...12
Fig. 3.3 Design for Extracting Concepts in C-L Structure...14
Fig. 3.4 Methods for Achieving Set of Words in Subconcepts ...15
Fig. 3.5 Architecture of Unknown Word Extraction and Classification...16
Fig. 3.6 Comparison the Proposed Method with [28]...21
Fig. 3.7 An Example for Estimating Association among Words ...26
Fig. 3.8 Part of a Thematic Subtopic Hierarchy ...27
Fig. 3.9 Algorithm for Determining the Levels of Subconcepts...28
Fig. 5.1 Methods for Predicting Scores Using the Connection of Concepts ...36
Fig. 5.2 Illustration for C-chains...37
Fig. 5.3 Illustration for P-chains and S-chains...38
Fig. 5.4 An Example of Principles for Scoring S-chains...39
Fig. 5.5 Forms of R-chains ...40
Chapter 1 Introduction
Automatic essay scoring (AES) system is a very important research tool for such areas as educational testing and psychometrics because studies in these domains often rely on a large number of writings to conduct various analyses. It is, however, often very difficult to obtain a large number of graded writings due to expensive cost and time consuming process of human grading. In English, successful development of automatic essay scoring system in the past has overcome these limitations and largely facilitated the progress of the stated research area. By contrast, the lack of Chinese automatic essay scoring system (CAES) has limited the scale, validity and progress of these research areas.
AES is still a difficult, intricate and interesting issue for researchers in artificial intelligences and natural language processing though some English AES systems have been proposed and developed successfully. In general, current syntactical and lexical analysis tools and techniques serve the basis for AES systems. However, AES systems should analyze the semantic characteristics of an essay, since the essence of an essay is the semantic representation of an author on given theme. Presently, the issue of AES systems lack the methodology for analyzing contextual semantics is still quite difficult in the domains of artificial intelligences and natural language processing. The development of such methodology will play an important role in overcoming the bottleneck of the researches in AES.
In addition, many studies also indicate semantic analysis is crucial and critical factor for Chinese AES. Some studies demonstrate that Chinese essays tend to be organized with parataxis structure connecting concepts with their semantics. By contrast, English essays tend to be organized with hypotaxis connecting concepts with grammatical framework and connectives. The studies for extracting hypotaxis structure in English essays have been used to develop English AES successfully. Based on the observation, developing methods for extracting parataxis structure become a very important task for constructing Chinese AES.
Furthermore, the linguistic difference of the languages between other languages and English also suggest the need to reconsider such factors as syntactic structure in designing AES for other languages. For example, current English AES systems successfully analyze the syntax and sentence structure of an essay by developing effective parser and grade the essays accordingly. By contrast, to develop of a
effective parser in Chinese is an extremely difficult task because the grammar specification is quite loose and fuzzy. Accordingly, identifying and extracting valid sentences is quite difficult task for machine. Beside, the importance of grammar and sentence structure may not play the same role as that in English.
We propose to employ the conceptualization progress of writing to the semantic analysis of essays for next generation AES systems, especially Chinese AES. Essays can be regarded as a set consisting of concepts on a given theme and the semantic association among the concepts, while a concept represents a subset consisting of the subconcepts of the concept and the semantic association. Based on the observation, writing progress is composed of three conceptualization phases. First, an author selects major concepts from his background knowledge based on a given theme. Then, the author organizes and arranges the occurrence order and space of these concepts. Finally, the author develops and constructs the major concepts with many subconcepts, and uses many writing skills to enrich and enhance the subconcepts. In this thesis, the three phases are respectively denoted as the selection of concepts, the connections among concepts and the decorations for concepts.
The conceptual framework of an essay represents the outcome of conceptualization progress of an author on a given theme. In this thesis, we will explore the various issues and effectiveness of using conceptual framework to score an essay. There are three tasks we have to solve before scoring. First is to develop the extraction, classification and organization of concepts on given theme. These concepts will be transformed into set of subconcepts and these subconcepts will be into a subconcept hierarchy. Using the concepts and subconcept hierarchy, essays can then be decomposed into conceptual frameworks. Second task is to construct the extractions of concepts, connections and decorations in the frameworks. Third is to design an integrated model for predicting scores from various components in the frameworks
This thesis will be organized as follows. In Section Chapter 2, some current English AES systems will be discussed and some studies about contrastive rhetoric which indicate the difference between essays in English and Chinese are reviewed. In addition, some approaches for Chinese text processing are also studied. Section Chapter 3 defines and analyzes conceptual structure of essays and discusses some methods for constructing subconcept hierarchy. The subconcept hierarchy is used to various conceptual methods for Chinese AES in Section Chapter 4, Chapter 5 and
Chapter 6. Section Chapter 4 develops methods for collecting particular subconcepts and then using them to score essay. Section Chapter 5 proposes methods for constructing the structures of inter-paragraph and intra-paragraph in essays and then measuring similarities between the structures to score essay. In Section Chapter 6, some identification methods for figures-of-speech are discussed. These figures-of-speech will be input features of scoring system. Section Chapter 7 discusses an improved multi-variate Bernoulli model for CAES which integrates various conceptual features. Section 8 gives a conclusion.
Chapter 2 Previous Studies
This section reviews previous studies related to the various design issues of Chinese AES. Subsection 2.1 surveys the methodologies and performances of current AES systems. Subsection 2.2 explores intrinsic differences between Chinese essays and English essays based on many studies of contrastive rhetoric. Since there are no blank separating Chinese words, Chinese essays need to be first segmented into a set of words. This task includes such related procedures as word segmentation, unknown word extraction and classification. Subsection 2.3 will review previous methods and techniques for above procedures.
2.1 Current AES
All current AES systems are designed and implemented for English essays. A few of these systems claim that they are also suited for other languages. In the earlier 1990s, various AES methods were proposed and further commercialized. Although the technical details of the AES systems are rarely published in academic literatures due to business secret, some studies [16][48][54] for evaluating current AES systems are available. Below, five AES systems will be reviewed based on these studies. PEG
PEG [44] is an AES system developed early in 1960s and being still improved even in recent years. The design of PEG bases on an assumption denoted as trins-proxes: the intrinsic variables of an essay could be measured using the approximations of the variables. For instance, the length of an essay can approximate intrinsic variable fluency; the number of preposition and relative pronouns represents the degree of complexity of sentence structure; the variation of word length displays author’s writing skill on diction. In PEG, the intrinsic variables and corresponding approximations are denoted as trins and proxes respectively.
PEG predicts the score of a test essay using the following three steps. Firstly, PEG calculates the values of all proxes of each essay in training corpus. Secondly, the values of proxes and the scores of training essays are used as input to a statistical model called multiple linear regression. The model yields the coefficients of regression function which represent the relationship between the values and the scores
given by human. Finally, PEG calculates the values of proxes in a test essay, and then regression function generates a predictive score for the test essay.
The advantages of PEG are easy implementation and fast operation. Experimental results show the multiple regression correlation between predictive score and graded score as 0.87. However, PEG is criticized for lack of evaluating the semantics of an essay. The drawback results in that PEG is easily tricked by prankish essays. Furthermore, since PEG only relied on proxes, it cannot provide instructional feedback to students.
IEA
IEA [30] is an AES system based on latent semantics analysis (LSA) technique. LSA uses a two dimensional matrix to express the semantic space of documents and words. For example, a set of 200 essays containing 3000 words could construct a 200 ×3000 matrix to represent the semantic space of the set. Since the space is often sparse, LSA uses singular value decomposition (SVD) to transform the semantic space to three smaller-dimension matrices. The algebraic operation could also discover latent semantic relations between documents and words. For instance, although an essay containing term “president of United State” does not mention term “white house”, the semantic relation between the essay and other essays mentioning term “white house” could be constructed against SVD.
The vectors in new semantic space can represent the semantics of essays more exactly and precisely. IEA uses the vectors to estimate the semantic similarity between a test essay and training essays scored by human. Then, IEA gives the predictive score of the test essay with the score of the training essay which is most similar to the test essay. The accuracy of similarity measurement of essays on semantics also increases. Experimental results show that the accuracy of IEA is between 0.85 and 0.91. In addition, IEA can effectively detect plagiarism while most AES systems cannot. The characteristic is very necessary to high-stake assessments because plagiarism affects the validation of assessments.
Although IEA has the advantages mentioned above, its application is still limited due to lack of other aspects of human graders, e.g. sentence structure and organization. The drawback results in that IEA cannot satisfy instructional requirements and provide meaningful feedback to students.
e-rater
e-rater [1][4] employs corpus-based methods to extract the features of scoring rubrics by analyzing essays scored by human graders. The basic tasks are to identify such features as discourse, syntax and topic-domain.
Discourse organization is identified by using the concept framework of conjunctive relations. The concept framework can be extracted by cue words, terms or sentence structures. For instance, cue word “perhaps” may express a belief; term “in summary” may represent a conclusion; complement clauses may identify the beginning of a new argument.
The versatility of syntactic structures can be evaluated by identifying the subjects, verbs and various clausal structures in sentences. These components in sentences can be derived by Microsoft natural language processing tool (MsNLP).
Features of topic-domain are used to evaluate the vocabulary usage of essays. It uses cosine as the metric to evaluate the similarity on the variety and type of vocabulary between a test essay and training essays. The basic assumption is that good essays usually resemble that of other good essays and differ from that of poor essays.
e-rater employs two modules to score test essays based on the above features. One module assigns different weights to features while the other module measures the similarity of features between a test essay and training essays. It then predicts the score of the test essay according to the result of the comparison.
By contrast to IEA, e-rater considers more aspects of scoring rubrics. e-rater has been applied to score over 75000 essays of famous assessment GMAT and the accuracy of scoring essays is between 0.87 and 0.94. Since e-rater heavily relied on grammar structure features, it cannot be applied to many languages in which grammar parsers are difficult to design.
BETSY
BETSY [46] uses feature-based Bayesian models to predict the score of an essay. Different Bayesian models have been widely applied to text classification. BETSY uses multi-variate Bernoulli model (MBM) as one of its predictive modules. MBM can effectively incorporate with various features to predict score. BETSY claims that it uses the best features from PEG, IEA and e-rater as the features of MBM. It also
employs three procedures, namely stemming, stop words and feature selection, to normalize text in order to extract features more precisely and grades essays more accurately. Experimental results show that the accuracy of scoring essays by BETSY is over 0.8.
BETSY has two major advantages: (i) it employs the features from different aspects of scoring rubrics. (ii) it uses a high-performance classifier to increase the accuracy of predicting scores. However, there are still two constraints in BETSY. First, BETSY requires a large number of training essays. Secondly, BETSY also needs an effective grammar parser to maintain the accuracy.
IntelliMetric
IntelliMetric [17] is a business AES system developed by Vantage Learning Company. The basic architecture of IntelliMetric is also feature-based methods. IntelliMetric claims that it contains over 300 semantic-, syntactic- and discourse-related features. These features can be classified into five categories of scoring rubrics: focus and unity, organization, development and elaboration, sentence structure, and mechanics and conventions. IntelliMetric contains two powerful tools CogniSearch and QuantumReasoning. CogniSearch includes a grammar parser to analyze sentence structure. It also uses training essays to construct a non-linear scoring model. However, the detail of features, tools and scoring model in IntelliMetric is not available. The company claims that the accuracy of IntelliMetric is high as 0.96 and can be applied to other languages.
2.2 Contrastive Rhetoric
A large number of researches [5][6][32], called contrast rhetoric and contrast linguistics, standard the difference of writing features between Chinese and English. These studies focus on four directions covering sentence structure, organization, topics as well as figures-of-speech. Sentence structure compares the difference of syntax and its structure. Topics and organization studies the difference in thinking and plot skill. Although organization can be analyzed at the levels of both paragraph and essay, it will be treated as the same in this study. Figures-of-speech compare the difference for the usage and categories of figures-of-speech between Chinese and English writings. Below, we will discuss the issues separately.
2.2.1 Sentence structure
Many studies pointed out that the syntax in Chinese is more flexible and loose than that in English. Jaio [24] noted three fundamental differences. First, the sentence structure in English can be perceived as a tree structure while the sentence structure in Chinese can be perceived as a linear structure. Second, sentences in English emphasize hypotaxis which refers to grammatical subordination while sentences in Chinese focus on parataxis which refers to grammatical coordination. Parataxis often places sentences side by side without any connectives while hypotaxis uses word to express the temporal, logical and syntactic relations between sentences. Third, the sentence boundary in English is very crisp. As long as the subject and predicate appears, the sentence is basically complete. By contrast, the amount of information in Chinese sentence is not strictly constrained. A sentence is complete only when a sequence of actions is over. Each of the long sequence of actions can appear as a complete sentence or short sentence or a single action or modifier. Hence it is much harder to identify the boundary of a sentence.
Lee and Zeng [33] pointed out that the ordering of three basic elements (subject, verb and object) and the type of tags show no fundamental difference in both Chinese and English discourse. However, the constituents may be very different. For instance, the verb and the adjective can be used as subject in Chinese while the verb and adjective have to be changed into infinitive or participle before it can be used as a subject in English. The same restriction also appears in the predicates. In the case of structure changes, Chinese can move the predicate to the beginning of a sentence to form a derived sentence. By contrast, in English, there is no such pattern.
The above discussion illustrates that the Chinese syntax is quite flexible and more diversity in patterns than that in English. Hence, developing a powerful parser for Chinese is a quite difficult task.
2.2.2 Topics
One writing requirement is to select materials and the illustration has to be consistent with the topic. However the material selection is quite different due to the difference of East West cultures. Chinese students often quote authoritative argument and classical article, and seldom express personal opinion and feelings. The usage of rhetoric is quite indirect and moderate. By contrast, western students like to present many evidences to support their arguments or viewpoints. Critical and logical
discussions are quite important for English writings. The observation indicates that the material selections of a Chinese essay should not be judged by the English automatic scoring system because of the different perspectives.
2.2.3 Organization
Many studies noted a fundamental difference of discourse organization in Chinese and English writing. In particular, Kaplan [25] pointed out that the organization of discourse in English writing often appears as a linear sequence. By contrast, the discourse organization in Chinese writing often appears like a spiral pattern. A good organization in English writing starts with a topical sentence and develops various arguments in succeeding sentences to illustrate the topic. On the other hand, a good organization in Chinese will discuss the topic from various perspectives and repeatedly illustrate the topic with various semantic expressions without word connection. Hu [21] further observes either the last paragraph or the end of the middle paragraph often contains highlight in Chinese.
Some studies made a further analysis on the difference of the discourse organizations. Zeng [58] pointed out that grammatical framework connecting subject and verb does not exist in Chinese writing. Instead of using connectives for combining sentences, it uses the sequence and logical order to connect sentences. Many times, topic idea is not evident in a paragraph. Instead it likely contains an invisible or a subconscious topic idea. On the other hand, the principles of organization for paragraph and discourse are consistent. They all submit to coherence, completeness. Hence, topic sentence, concluding sentence and supporting sentence can be seen quite often. The tree structure of discourse [36] also shows that the coherence of discourse in English tends towards the relationship between main clause and subjective clause. By contrast, the structure of Chinese discourse tends towards parallel sequence.
Although, effective paragraph all stresses unity, coherence, and completeness in both English and Chinese writing, the different thinking process behavior from the east and west culture would naturally lead to distinction in their own discourse. For instance, Scollon et al. [47] remarks that people in western cultures use a deductive method of reasoning or argument, while people in eastern cultures use an inductive method of reasoning. This indicates that human grader from different cultures may give different judgments for the topic organization.
2.2.4 Figure-of-Speech
The usage of figure-of-speech is an important factor for high quality of writing. Although there are many common usages of figures-of-speech in Chinese and English writing, each language has its own unique figures-of-speech. Bai and Shi [3] studied the differences of figures-of-speech in Chinese and English. Of 16 figures-of-speech used in Chinese and 26 figures-of-speech in English, they each have 6 figures-of-speech not observed in another language. Even, for the similar figures-of-speech, the occasions and skill to use it are different. Hence, the grading factors may be different in using the figures-of-speech to judge essays.
2.3 Extraction and Classification of Chinese Words
Most studies have focused either on word extraction [14][19][28][35][37][49][57] or word classification [2][11][41][43][50][53]. This subsection briefly reviews extraction and classification approaches for the purpose of comparison and discussion.
Extraction approaches can be categorized into rule-based [14][19][35][49] and statistics-based [28][37][57] methods. Rule-based extraction approaches generally analyze the characteristics of unknown words in terms of linguistic factors such as morphemes, roots and semantic networks, to identify whether unknown words occur and to locate their boundaries. Although the precision rates of these approaches are usually higher than those of statistics-based approaches, they suffer three major drawbacks. First, a rule base cannot easily include all rules for identifying unknown words. Second, both semantic and syntactic ambiguities reduce the reliability of the rules. Third, the approaches need to rely on a large training corpus, in which the sentences are segmented and the terms are tagged, to generate rules. Large, prepared and domain-specific corpora are impractical in the domain of this work.
Statistics-based extraction approaches considered characters that occur frequently together as possible evidence of a word. Although these statistical approaches overcome some of the drawbacks discussed above in the rule-based approaches, they have two shortcomings. First, the statistical approaches often extract meaningless strings as unknown words. Second, they perform badly for unknown words that appear rarely even though the training corpus is very large.
possible categories of unknown words, critical parameters in statistical models, cannot be obtained from current lexica. The rule-based approaches often first generate morphological, syntactical and contextual rules from universal lexica or corpora, and then apply these rules to generate a set of possible categories of unknown words. They also suffer such drawbacks as reliability of the rules and incompleteness of the rule base discussed before. Additionally, properties such as affixes in alphabetic languages cannot be used in approaches for non-alphabet languages.
Although these extraction and classification approaches are inadequate for domain-specific small corpora, several studies contain interesting observations. Chen and Ma [14] proposed a refined rule-based extraction method, which first applies a rule-based approach to detect the occurrence of Chinese unknown words, and then applies morphological rules and statistical methods to confirm the boundaries of the unknown word. Finally, a verification procedure, which depends on the validity of the structure and syntax, and on local consistency, is utilized to refine and improve the result of previous steps. Lai and Wu [28] proposed an effective statistics-based method to extract unknown words, in which the PLU-based likelihood ratios (PLR) of all Chinese character sequences are computed from the co-occurrence in the sequences. The sequences with a high PLR value or frequency are then classified into several groups, in which quality sequences are regarded as unknown words.
Tzeng et al. [53] proposed a hybrid method to classify Chinese unknown verbs into subcategories by utilizing a set of morphological rules to determine the categories of the unknown verbs. An instance-based categorization algorithm is then employed to classify words that cannot be classified using morphological rules. Manning and Schutze [40] observed that all successful classification approaches are based on lexical information from words. The lexical information, gathered from a huge corpus in which the words are segmented and tagged, is essential because of the extremely uneven distribution of a word’s usage across different parts of speech. Since the lexicon information of unknown words cannot be obtained directly from the corpus, Bai et al. [2] scored possible categories of the unknown word using contextual rules to simulate its lexicon information, and then classifies it with the highest-scoring category.
Chapter 3 Conceptualization of Essays
Many studies mentioned in Subsection 2.2.3 point out the organization of essays in Chinese is parataxis structure. Concepts are crucial elements in parataxis structure because concepts are semantic units for expressing paragraphic topic. Furthermore, the connection among concepts, including the order and position of the appearances of concepts, also perform latent semantics. Both selection and arrangement of concepts, hence, affect the quality of essays.
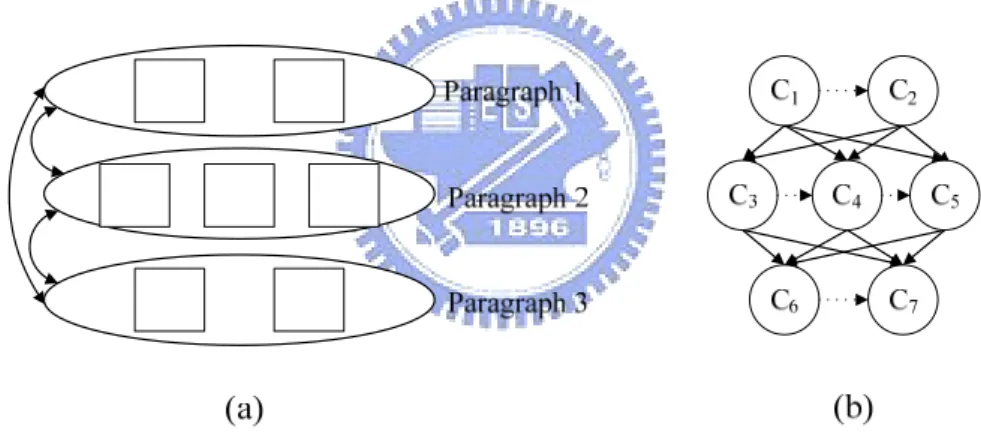
A general viewpoint for semantic structure of Chinese essays is shown in Fig. 3.1(a). The essay in Fig. 3.1 (a) consists of three paragraphs and seven concepts for a theme. Conventional viewpoint considers that a paragraph interprets a subtopic of the theme and all subtopics should be semantically related to each other. It is abstract and incomplete because the model does not express the importance of selection and arrangement of concepts in paragraphs.
Fig. 3.1 Two Viewpoints for Semantic Structure of Chinese Essays
Fig. 3.1(b) shows an extension and modification of the essay structure in Fig. 3.1(a). In Fig. 3.1(b), the paragraphs are transformed to three sets of concepts and the relations among adjacent paragraphs are translated into unidirectional relations between concepts. In addition, the concepts in a paragraph are related to each other. The essay structure in Fig. 3.1 (b), denoted concept-link structure, C-L structure for short, has two characteristics. Firstly, the total sum of the semantics for all concepts in a set of concept can fully represent the semantics of subtopic in the corresponding paragraph. Secondly, different appearance orders of concepts represent different semantics. C-L structure will serve as the basis for developing methods for automatic scoring essays in Section Chapter 4, Chapter 5 and Chapter 6.
first: (i) how to define concepts of C-L structure in essays? (ii) how to extract the concepts of essays? This thesis employs subconcepts and thematic subtopic hierarchy to define and extract the concepts respectively. In general, the semantics of an essay entitled a theme can be distinguished hierarchically as three layers of subtopic, concept and vocabulary. Subtopic contains several concepts while vocabularies are the components of concepts. Instead of defining and extracting concepts and subtopics, most of the studies use the associations of vocabularies to analyze the semantics of documents, for it is a very difficult task to precisely define the semantics of the concept and subtopics. However, the usage of vocabulary often performs poorly because the associations are uncertain and imprecise.
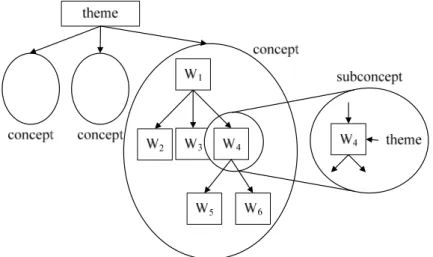
Using a set of subconcepts to represent concept can overcome above dilemma. The relation between concept and its subconcepts is shown as Fig. 3.2. Concepts are defined herein as a set of subconcepts. A subconcept consists of a word and the relations between subconcepts on given theme. The semantics of subconcepts is defined by the theme and other related subconcepts, not the semantics of the word of the subconcept in lexicon. Using subconcepts and the relations between them, the semantics of a concept can be presented clearly and concretely. Furthermore, a concept often contains one or more major subconcepts while other subconcepts are the assistants of major subconcepts. For example, concept “events in classroom” includes subconcepts “classroom”, “textbook”, “classmates”, “conversation” and so on. In the concept, subconcept “classroom” is a major subconcept and other subconcepts are its assistant. Hence, major subconcepts of a concept can be regarded as the representatives of the concept.
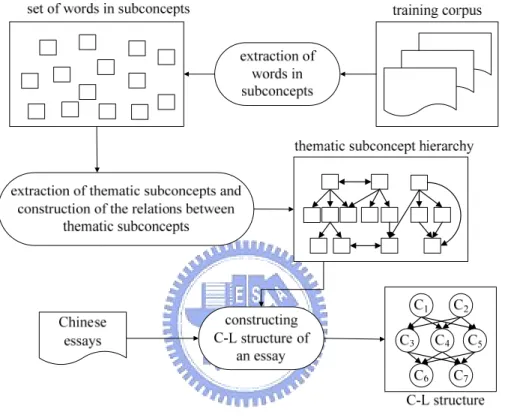
Subconcepts can be also used to extract concepts in C-L structure. Fig. 3.3 shows our design containing of three procedures for extracting the concepts. First procedure extracts words in subconcepts in training corpus. Second procedure employs an algorithm and the co-occurrence of the words to construct a thematic subconcept hierarchy. Since the hierarchy contains the classes of all subconcepts on a theme, third procedure can transform an essay into C-L structure using the hierarchy.
Fig. 3.3 Design for Extracting Concepts in C-L Structure
Below subsections will further discuss three important and fundamental issues. Subsection 3.1 introduces our methods for extracting the words in subconcepts. Since the words of some subconcepts are not appear in lexicon, Subsection 3.2 and 3.3 proposed our methods for extracting and classifying unknown words of subconcepts. Subsection 3.4 discusses the extraction of thematic subconcepts and the construction of thematic subtopic hierarchy.
3.1 Extraction of Words in Subconcepts
The words in subconcepts are often used to describe such important elements as person, place, action and events, these words can be collected from nouns, verbs, adverb and adjective in essays. This task is trivial for English essays, but not for Chinese because there is no blank between Chinese words. Chinese sentences must
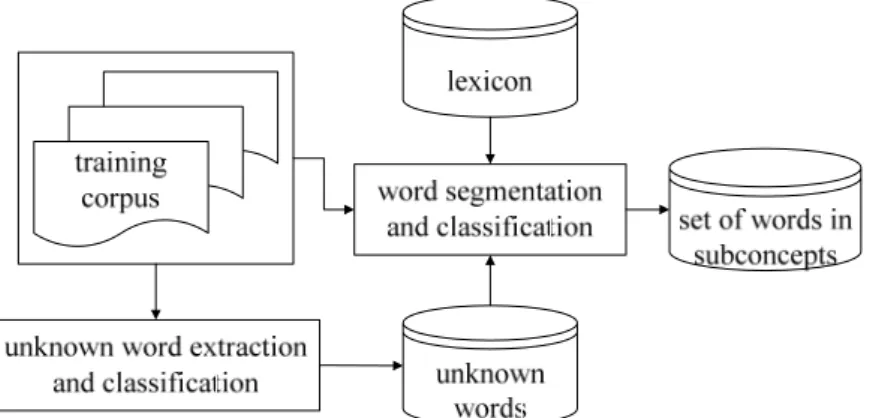
first be segmented into words and phrases. Our strategy for this issue, which is shown in Fig. 3.4, consists of two steps: (i) extracting and classifying unknown words to be known words first. (ii) segmenting text into words of subconcepts. Sinica Autotag [38] is one of the tools developed to segment text into known words and tag these words precisely.
Fig. 3.4 Methods for Achieving Set of Words in Subconcepts
However, none of current approaches work well for unknown words in a small corpus. The limitation greatly decreases the performance of Chinese AES because most of training corpora is small in real AES applications. Hence, based on two inferences, this thesis proposes new methods for unknown word extraction and classification. First, extraction should remove meaningless strings based on strict conditions, and recall meaningful terms from the strings based on high-accuracy rules. The hybrid design can maintain both precision and recall rates of extraction. Second, conversely, classification procedure employs high-accuracy rules as far as possible to tag unknown words, and classify the remaining unknown words with the contextual rules in both universal and domain-specific corpora.
Fig. 3.5 shows the architecture of the proposed method, which consists of training, extracting, and classifying phases. The training phase generates morphological and contextual rule bases using a current lexicon and corpus. Both rule bases are referenced by the procedures in the extracting and classifying phases. The detail of extracting and classifying phases will be discussed in Subsection 3.2 and 3.3.
Fig. 3.5 Architecture of Unknown Word Extraction and Classification
3.2 Unknown Word Extraction
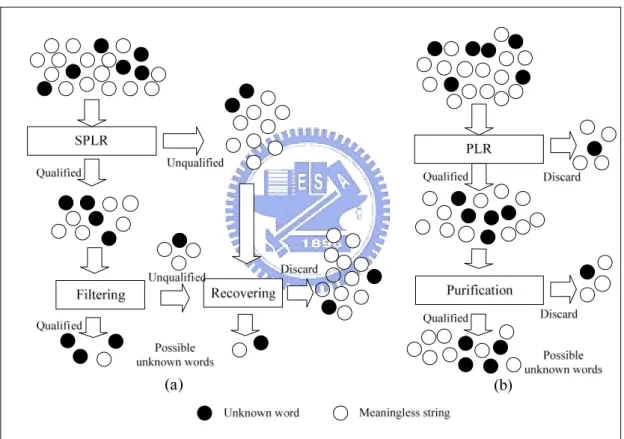
The extracting phase of the proposed method shown in Fig. 3.5 contains three procedures, namely retrieving possible unknown words, filtering familiar strings and recovering prefix/suffix words. The retrieval procedure estimates the probability that a series of characters is an unknown word. The filtering procedure uses a syntactic approach to eliminate familiar patterns that appear frequently in the corpus but do not form specific words. The recovery procedure reexamines all removed strings and recall qualified ones to the set of unknown words based on the morphological rule base. The three procedures will be discussed in below subsections.
3.2.1 Retrieving Meaningful Strings
The retrieval procedure in the proposed method estimates the probability that a series of characters is an unknown word based on a strict concept of PLR called SPLR. In contrast to conventional PLR approaches, the proposed SPLR method uses a strict condition to exclude a large number of meaningless terms, at the risk of sacrificing a few meaningful terms. The proposed method first retrieves all strings, and computes their frequencies of occurrence in a corpus where the maximum length of strings is previously defined and set. Additionally, stop words are removed from the set of these strings.
The following assumption is used throughout this work. For a frequently occurring string t of n charactersc1,c2,c3,...,cn, the substring tL of t is defined as the first n−1 characters c1,c2,c3,...,cn−1, the substring tR of t is defined to be the last n−1 characters c2,c3,...,cn−1,cn. Apart from the monosyllabic strings, each string t always has tLand tR, of which the length of each is one less than that of the string t. Next the parent strings tp of t are defined to be c0,c1,c2,c3,...,cn or c c c1, , ,..., ,2 3 c c for n n+1
some c0 or cn+1. The parent string is clearly not unique. The example t= “學習步道” ,
tL = “學習步”, tR = “習步道” and tp=“在學習步道” illustrates these notations. The strict phrase likelihood ratio (SPLR) of t is defined as
)) ( ), ( max( ) ( ) ( R L tf t t tf t tf t SPLR = , (3.1) where tf represents the frequency of occurrence of a string in documents. Since the number of occurrences of a string t must be less than that of both tL and tR, the SPLR of any string is less than 1.
A string t with high-SPLR value signifies that neither substrings tLand tR appear in other contexts themselves but appear only when string t appears. Conversely, a string with low-SPLR value indicates that at least one of its substrings frequently appears in another context. Hence, a string t with high-SPLR can reasonably be considered as a likely unknown word, because it cannot be reduced to a smaller substring. This observation is reflected in the first part of Condition (3) in (3.2).
However, this approach still admits many meaningless terms into the set of unknown words. The next observation, reflected in the first part of Condition (4) in (3.2), is that if there is a parent string tpof t such that both of tp and t are frequently
co-occur and cannot be separated, then the string t cannot be considered as an unknown word, even if it satisfies Condition (3). To summarize the observations discussed above, a string t that meets the following four conditions is considered as a possible unknown word:
2 (1) 1 (2) ( ) ( ) ( ) (3) ( ) 1 or ( ( )) (4) ( ) ( ) or p ( ) ( ) p n tf t c SPLR t tf t SPLR t d length t tf t tf t SPLR t SPLR t ε ν μ ⎧ > ⎪ ⎪ ⎪ ≥ ⎪ ⎨ ⋅ ⎪ ≥ − ≥ ⎪ ⎪ ≥ ⋅ ≥ ⋅ ⎪⎩ (3.2)
where length(t) represents the number of Chinese characters comprising t; tp represents the parent strings of t; c and d represent thresholds from experiments; ε, μ ν represent the coefficients from experiments which are used to deal with real data, and n represents the length of t.
The first condition states that monosyllabic strings are removed from the set of unknown words. The second condition states that the number of occurrences of a string must exceed a threshold. The second part of the third condition handles disyllabic strings, which often have SPLR values below the threshold. The second part of the fourth condition handles very frequent strings.
3.2.2 Filtering Familiar Strings
The set of possible unknown words identified by SPLR approaches includes familiar strings. For instance, the string “從教室裡衝出來” (rushing out of the classroom) can be seen quite often in the essays entitled “Recess at School”. Obviously, it is a familiar string but not an unknown word. Because unknown compounds are difficult to distinguish from familiar strings, any statistics-based procedures would admit both into the set of unknown words irrespective of how the threshold is adjusted.
Notably, familiar strings often comprise common words from domain-specific corpora, while unknown compounds often comprise particular words. For instance, from the essays entitled “Recess at School”, the familiar string “從教室裡衝出來” (rushing out of the classroom) contains the common words “從“, “教室” and “衝出
來”. By contrast, the unknown compound “文具用品”(stationery) comprises words “ 文 具 ”(stationery) and “ 用 品 ”(appliance), both of which rarely occur in domain-specific corpus. Thus, a familiar string t can be easily distinguished from the unknown compounds by the following condition:
τ ≤ ) tf(t t tf c min ) ( , (3.3)
where tc represents a set of known words included in t, and τ represents a threshold from experiments.
3.2.3 Recovering Prefixed/Suffixed Words
SPLR can successfully eliminate meaningless strings, but it also sacrifices some meaningful terns comprising a familiar stem and a monosyllabic prefix or suffix. For instance, the string “總領隊” (總(general)領隊(leader), general leader) would not be identified as an unknown word because “leader” often appears as a familiar stem, resulting in a low SPLR value for “general leader”. Instead of lowering the threshold used in Formula (3.2), which would reduce the accuracy of extraction, morphological procedure is employed to identify these unknown words.
Many approaches based on morphological rules [13][14][41][50][53] to extract and classify unknown words have been explored recently. In our case, a morphological rule represents a pattern comprising a monosyllabic prefix or suffix and the category of a meaningful stem. The pattern can be formed from various known words. For instance, “總經理”(總(general)經理(manager), general manager), “總教練”(總(general)教練(coach), head coach), and “總司令部” (總(general)司令 部(headquarters), headquarters) are known words listed in the CKIP lexicon [15]. These known words generate a pattern, called a morphological rule, which comprises the monosyllabic prefix “general” and category “Na” of a meaningful stem. Since the string “總領隊” can match the morphological rule, it can then be called an unknown word.
Table 3.1 Part of the Morphological Rule Base Type Affix The category of stem Frequency
Prefix 總(General) Na 15
Prefix 副(Assistant) Na 22
Suffix 局(Department) Na 47
Suffix 室(Room) VC 18
Table 3.1 shows some of the morphological rules generated by the proposed algorithm. To accelerate the matching procedure, all morphological rules can be initially generated from lexica.
3.2.4 Comparison with Previous Method
The difference between the performances of previous PLR-based method and our proposed method derives from their assumptions. Previous method [28] bases on an assumption: if two substrings of a string always occur together, the string is identified probably as an unknown word or phrase. The assumption could function well in universal and large corpora, but the familiar strings in a domain-specific corpus will be treated as unknown word based on the assumption. For example, the string “多同 學” is meaningless but quite familiar in the corpus on theme “class recess”. Both frequency and PLR of string “多同學” satisfy the conditions of the previous method and is therefore classified as an unknown word. Although the method uses a purification procedure to further sieve out some of the meaningless strings, it is still not sufficient. For example, the string “多同學” could not be filtered out because it is the substring of various strings such as “很多同學”(many classmates) and “許多同 學”(numerous classmates) and does not meet the criterion of the purification procedure. Therefore, numerous familiar and meaningless strings would be extracted by the PLR-based methods.
Our proposed method bases on different assumption: if a string appears much less often than any of its substring, the string would not be classified as an unknown word. Our proposed method does not classified the string “多同學” as a unknown word because its substring “ 同 學 ” (classmates) appears much often. The experiments [8] show that the SPLR method could deal with the difficult issue of familiar and meaningless strings.
Fig. 3.6 shows how the PLR and SPLR procedures affect the performance of the extraction methods. Although the PLR approach can efficiently extract unknown words from a small corpus, it also misclassifies many meaningless strings as unknown words. Furthermore the purification process can only discard a small number of meaningless strings; many other meaningless strings will survive the process and remain as unknown word classification. By contrast, the SPLR approach not only effectively extracts unknown words but also discards many meaningless strings. Filtering procedure will further exclude more meaningless strings. The fact that SPLR can efficiently eliminate many meaningless strings greatly helps to increase the performance of extracting unknown words in a domain-specific small corpus.
Fig. 3.6 Comparison the Proposed Method with [28]
3.3 Unknown Word Classification
The classifying phase of the proposed method shown in Fig. 3.5 comprises two procedures, namely morphological and contextual rule classification. The unknown words that can be identified by the recovery procedure in the extracting phase are classified through the procedure of morphological rules, while the remaining unknown words are classified through the procedure of contextual rules.
respectively. For unknown concepts extracted from recovering procedure, morphological rules are used to infer their categories. For unknown concepts extracted from filtering procedure, contextual rules from corpora are created to compute the degrees of the likelihood of an unknown concept conditioned on categories, denoted as LD. Based on the degrees, the category of the unknown concept can be determined by the current tagging method [40].
3.3.1 Inferring Category Based on Morphological Rules
The morphological rules comprise a monosyllabic prefix or suffix and a category of meaningful stem. Since morphological rules are generated from known words in lexica, the categories of the known words can be used to infer the category of an unknown word according to the rules. For instance, a morphological rule comprises a prefix “general” and a category of general noun, as revealed by such known phrases as “ 總 經 理 ” (general manager), “ 總 教 練 ”(head coach) and “ 總 司 令 部 ” (headquarters). These known words all have a general noun as their category, hence the unknown word “總領隊”(general leader) can be inferred as a general noun. However, the known words that generate the same rule do not necessarily have the same category, as shown in Table 3.2 which includes two categories of known words associated with a morphological rule. Additionally, the stem of an unknown word can have multiple categories, complicating the inference process. In these cases, the Hidden Markov Model (HMM) can be used to infer the category of the unknown words.
Table 3.2 An Example for Morphological Rules Containing Two Categories type affix POS of stem POS of word frequency
Na 6 suffix 界 (the world of) Na
Nc 40
An HMM-based method [40] uses the lexical information of a word, which includes the probabilities of the word conditioned on categories, to infer the category of the word. Because unknown words have no lexicon information, the probability of the unknown word on category ci can be estimated from both the frequency of the stem on category ci, and the frequency of the rule that infers category ci. The degree of the likelihood of unknown word w conditioned on category ci, denoted as LD, can
be computed as follows. ( | ) ( | ) ( | ) , ( ) ( ) i i i tf b c tf m c LD w c m S tf b tf m = ⋅
∑
∈∑
(3.4)where b represents the stem of unknown word w; S represents the set of the rules matched by w, and function tf represents the parameter frequency. Once the LDs of unknown word w on different categories are available, the tagging method [40] can treat the LDs as the lexicon information of w, and thus infer its category.
3.3.2 Inferring Category Based on Contextual Rules
Unknown words that do not match any morphological rule can be classified based on their contextual information in both universal and tagged corpora and the corpora in our domain. Consider a sequence of words p, t, s in documents where t represents an unknown word, p represents a preceding known word, and s represents a succeeding known word. A form is defined as p*s, where * represents a wild card representing context cue associated with t. In the tagged corpora, the form may appear in many different locations, or may not appear at all, while the wild card may match various words or none at all. If these words are tagged with a common category, then the unknown word can be assigned to the same category. For instance, unknown word “空蕩蕩” appears on the following sentence in documents:
原本 空蕩蕩 的 球場 被 大家 的 歡笑聲 填滿 (The originally empty field is filled with people’s laughter.)
The form of “empty” includes preceding word “原本”(originally), wild card and succeeding word “的” (of). In corpus CKIP, the form matches the following fragments: ”原本 優異(excellent) 的”, “原本 光禿禿(bare) 的”, and “原本 追漲 (Overheated) 的”. Since the words, matched with the wild card, “excellent”, “bare”, and “overheated” are all tagged with category “VH”, the word “empty” is classified as category “VH”.
The inference is reliable and reasonable, but two exceptions should be considered. First, the middle words of a form may belong to different categories. Second, the form of an unknown word may not appear in tagged corpora. To integrate these observations, Formula (3.5) is developed to estimate the degree of the likelihood
of an unknown word conditioned on categories and associated with a form, denoted as FLD. Assuming the form m of unknown word w, the FLD of w conditioned on category ci is as follows: ( | ) ( | ) ( | ) (1 ) ( ) ( ) i i m i ff m c ef m c FLD w c ff m ef m α α = + − (3.5)
where ff(m) represents the number of form m in a universal corpus; ef(m) represents the number of the extension of m in the corpus; ff(m| ci) represents the number of m conditioned on category ci in the corpus. The extension of form p*s comprises three types, c(p)*s, p*c(s) and c(p)*c(s), where c(p) and c(s) represents the category of p and
s, respectively. For instance, the format comprising preceding category “ADV” and
succeeding word “的” (of) is one of the extensions of the form comprising preceding word “原本” (originally) and succeeding word “的”(of). The second term of Formula (3.5) is designed to be a major factor only when the form seldom appears in tagged corpora, so the value of coefficient α in Formula (3.5) should be very close to 1.
The FLDs of an unknown word conditioned on categories can be obtained from a form by Formula (3.5). Furthermore, the unknown word may appear many times and in various ways in domain-specific corpora, so could have many forms. The LD of unknown word w conditioned on category ci can be estimated from the FLDs of w
associated with various forms as follows:
( | )i ( ) ( m| ), i w
LD w c =
∑
f m FLD w c⋅ m F∈ (3.6) where Fw represents a set of the forms of w, and f(m) represents the number of occurrences of form m in the corpora.Like the LDs yielded by Formula (3.4), the LDs computed by Formula (3.6) can be used as the lexical information of an unknown word, which then enables an HMM-based method [40] to classify the unknown word into a unique category.
3.4 Thematic Subconcept Hierarchy
The thematic subconcepts in general represent familiar subconcepts in essays on a theme while the hierarchy formed by thematic subconcepts is used to extract concepts in C-L structures. A subconcept may play different roles in different themes. For instance, subconcept “concert” is difficult to associate with the theme “recess at
school” while the “concert” is easy to associate with the theme “activity on holiday”. For purpose of describing the hierarchy, we define the subordinate subconcept as a subconcept which is not easy to associate with a theme. The subordinate subconcept is often used to specialize other subconcepts which are called superordinate subconcepts.
A superordinate subconcept may be a subordinate subconcept of another subconcept. For example, on theme “recess at school”, subconcept “conversation” is the superordinate subconcept of “concert” and the subordinate subconcept of “classroom”. Hence, the category of a subconcept is determined by theme as well as other subconcepts.
Based on the superordinate-subordinate relations between subconcepts, all subconcepts can form a hierarchy relation. Our proposed methods will generate an asymmetrical semantic relation matrix to represent the superordinate-subordinate relations, and then use the matrix to construct a thematic subconcept hierarchy.
3.4.1 Asymmetrical Semantic Relation Matrix
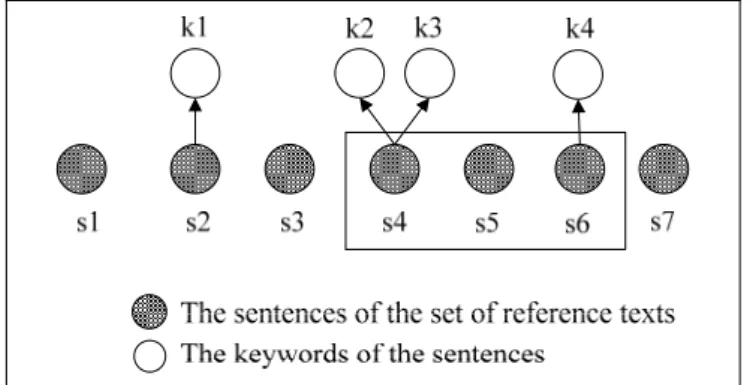
The association, describing the relationship between words in two subconcepts, is computed in a passage consisting of a fixed number of sequential sentences. The co-occurrence of two words in a passage is a good indicator for association since both words can be considered to address the same semantic or topic. Furthermore, the degree of association between the two words [42][54][55] is often measured and determined by both frequency and distance of the co-occurrence of two words.
In this thesis, the distance is defined as the number of the sentences between the two words. Fig. 3.7 illustrates the concepts of the co-occurrence and the distance of two keywords where the distance between word k2 and k3 is 1, and the distance between word k3 and k4 is 3. Since the length of the passage in Fig. 3.7 is set to be 3, word k2, k3, and k4 are co-occurrence words in the passage, but word k1 and k4 are not.
Fig. 3.7 An Example for Estimating Association among Words
Based on the concepts of both co-occurrence and distance, our method will generate a matrix, denoted as asymmetrical semantic relation matrix, to record the degrees of the association among cue words. First, all of cue words are retrieved from training corpus. Assume there are n reference words in a corpus and relative semantics matrix R is a n×n matrix. The element ri,j of matrix R represents the association degree of ith word w
i to jth word wj, and is computed as following:
, ( , ) ( ) i j t T p t i j i occ w w r freq w ∈ ∈ =
∑ ∑
(3.7)where freq(wi) is the number of occurrences of word wi in the training corpus; t is the text in the corpus T; p is a text segment in the text t, and occ(wi, wj) is
1
, where the words and both exist in . ( , ) ( , ) 0 , otherwise i j i j wi wj p dist w w occ w w ⎧ ⎪ = ⎨ ⎪ ⎩ (3.8)
where dist(wi, wj) is the distance between words wi and wj in p.
3.4.2 Constructing Thematic Subconcept Hierarchy
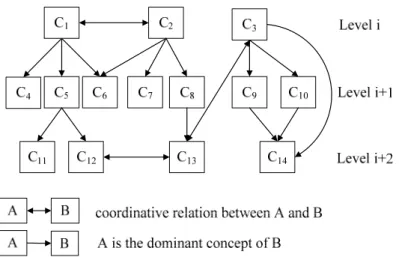
Because of the asymmetric of matrix R, ri,j and rj,i in R may be different. If ri,j is high for the two words wi and wj, it means that j always occurs whenever i occurs, which allows us to use wj to represent wi. On the other hand, if ri,j is low, then there is no reason for wj to represent wi. Based on above discussion, there are three relations between words wi and wj. First, the relation between wi and wj is coordinate each other if both ri,j and rj,i are high. Second, wi is the subordinate word of wj if ri,j is
much higher than rj,i. Third, there is no relation between wi and wj if both ri,j and rj,i are low. The three relations among words can be used to construct a thematic subconcept hierarchy.
Fig. 3.8 Part of a Thematic Subtopic Hierarchy
A thematic subconcept hierarchy shown in Fig. 3.8 can be constructed by the algorithm shown in Fig. 3.9. There are two characteristics in thematic subconcept hierarchy. First, each subconcept serves as the subordinate subconcept of at least one superordinate subconcept. Secondly, the levels of two subconcepts on a path represent the relative relation between them, i.e. c1 is the superordinate subconcept of c11. The thematic subconcept hierarchy constructed from all training essays can be regarded as the collective opinion of writers about the knowledge structure of a theme.
Fig. 3.9 Algorithm for Determining the Levels of Subconcepts
DeterminingLevelandRelatedSubconcepts(relative semantics matrix R)
variable:
ri,j: the entry of matrix R which represents the relation between word i and j Mi: a set of word, degree and attribute of relation words for word i
ai,j: the attribute of word j relative to word i which is one of superordinate, subordinate correlation and processed.
THr: threshold of relations which is effective
THk: maximum of the number of relation words in set Mi THd: maximum of the deepness of concept hierarchy
main {
/* step1: get k relative words of each word in which relationship is the highest top k
for i:=1 to n for j:=1 to n
if (ri,j + rj,i) >THr then {
if (ri,j > THk) or (k > the number of elements in Mi ) then { if (ri,j < rj,i +e) then ai,j := subordinate
else if (ri,j > rj,i +e) then ai,j := superordinate else ai,j := correlation
remove word d from Mi if ri,d is smallest relation degree in Mi add word j, ai,j and ri,j to Mi
THr := ri,j }
}
/* step2: given the level of Mi processing_level := 0
repeat
for i:=1 to n {
if the attributes of all words in Mi are subordinate, correlation or processed
then the level of Mi := processing_level }
for j:=1 to n {
if (the level of Mj is unknown) then
if (word p∈Mj) and (the level of Mp has been given) then aj,p := processed
}
processing_level := processing_level+1
until (processing_level>THd) or (there is no subconcept whose level is assigned in this cycle.)
the level of sets M will be assigned with processing level if its level is unknown
return
Chapter 4 Selection of Concepts
Given a theme, a writer must use concepts and subconcepts to present his/her observations, opinions and illustrations for the theme. In general, writers must first select a set of concepts and organize them around the theme. Furthermore, writers often tend to adopt some concepts with which he/she is familiar because there are differences between the writing abilities of writers. For example, on theme “recess at school”, most of writers can describe subconcept “classroom” sufficiently and effortlessly. Conversely, the description of subconcept “campus scenery” is laborious for some writers for lack of observation, literary device or the abilities for organizing concepts and subconcepts on a theme. These writers may either neglect or choose not to use such concepts and subconcepts.
Based on the discussions mentioned above, this thesis makes a simple assumption: some concepts denoted as literary concepts only performed by skillful writers. Given the assumption, it becomes important to extract the literary concepts in essays. Since the definition and extraction of concepts are very difficult, concepts including literary concepts are first transformed into set of subconcepts in this thesis.
However, it is not an easy task to extract literal subconcepts either. Although it is obvious that literary subconcepts usually appear more often in high-scored essays than the low-scored essays, extracting literary subconcepts directly from high-scored essay based on frequency does not work well. This is due partly to small size of training corpora. In small training corpus, some literary subconcepts do not necessarily appear and can not be collected into a set of literary subconcepts. Besides, above method may extract some subconcepts appeared in both low-scored and high-scored essays and treat them as literary subconcepts.
The usage of HowNet, a universal semantic network in Chinese, can overcome above difficulties derived from small training corpora. HowNet constructs its semantic network with two major elements: term and sememe. A term corresponding to subconcept uses one or more sememes to represent its semantics while various terms may share some sememes. For instance, term “school” consists of sememes “place”, “education”, “learning” and “teaching” while term “teacher” consists of “education” and “person”. The task of extracting sememes will be easier than that of extracting literary subconcepts. For example, subconcept “school” appears in small training corpus while subconcept “teacher” does not. But, sememe “education” of
subconcept “teacher” will be identified because of subconcept “school”. It indicates that a set of sememes can be obtained from small training corpus.
Based on the discussion mentioned above, our proposed method will employ literary sememes to score essays. Below, Subsections 4.1 and 4.2 will introduce our methods for extracting literary sememes. Subsection 4.3 shows the performance of using literary sememes to score essay.
4.1 Set of Literary Sememes
Literary sememes are defined as the sememes which frequently occur in higher-score essays but do not occur in lower-score essays. The degree of the literature of sememe s and the reliability of its degree, denoted as d(s) and r(s) respectively, are shown as follows.
( ) H , ( ) A
d s r s
L T
= = (4.1)
where T represents the number of the essays in training corpus; A represents the number of the essays in which sememe s occurs; H represents the number of the high-scored essays in which sememe s occurs; L represents the number of the low-scored essays in which sememe s occurs. Obviously, higher d(s) represents sememe s seldom occurs in low-scored essays and higher r(s) represents the value of
d(s) is reliable.
Based on Formula (4.1), various sets of sememes can be created. A sememe set
i
CS can be defined as follows
{ | ( ) and ( ) , }
i i i
CS = s d s ≥D r s ≥R s S∈ (4.2)
where D and i R respectively represent the thresholds of being literary sememes. i
Different values of D and i R will generate different sets i CS . The set of i
literary sememes on a theme is defined as the CS which yields highest accuracy for i
scoring essays when the scoring is based on the number of the occurrences of literary sememes in the essay. Next subsection will discuss an automatic procedure to determine the set of literary sememes from the sets of sememes denoted as candidates.
4.2 Extraction of Literary Sememes
An evaluation procedure consisting of three steps is designed for determining set of literary sememes. First step is to use sememes in a candidate to calculate the numbers of the sememes in a scored essay. Second step is to employ the numbers of sememes in an essay to predict the score of the essay. Third is to use the predictive scores and an evaluation function to calculate the accuracy of the candidate for scoring essays. The three steps in above procedure will be discussed in following subsections.
4.2.1 The Correlation between Candidate and Essay
Given a candidate for the set of literary sememes, a numerical set is first generated from the candidate and the training essays. Assume candidate set C consists of sememes c1,c2,...,cn and the training corpus T contains essays e1,e2,...,ek. The degree of correlation between C and essay ej can be computed using the following evaluation function. 1 ( )j n ( |i j) i h e freq c e = =
∑
(4.3)where ci∈ and C freq(ci |ej) represents the number of the occurrence of sememe
i
c in essay ej. Furthermore, let R be the set consisting of the degree of correlation
between C and each essay in T:
{ j | j ( ), j j , 1 }
R= a a =h e e ∈T ≤ ≤j k (4.4)
Next, the following set M is obtained by sorting the elements in set R.
1 1
{ p| p , p p p ,1 }
M = m m ∈R m − ≤m ≤m + ≤ ≤p k (4.5)
4.2.2 Using Candidate Sets to Score Essays
The candidate set M, which is an ordered set, will be divided into several ordered subsets M which satisfy the following three conditions: i