Phonology
http://journals.cambridge.org/PHO Additional services for
Phonology:
Email alerts: Click here Subscriptions: Click here Commercial reprints: Click here Terms of use : Click here
Testing the role of phonetic knowledge in
Mandarin tone sandhi
Jie Zhang and Yuwen Lai
Phonology / Volume 27 / Issue 01 / May 2010, pp 153 - 201 DOI: 10.1017/S0952675710000060, Published online: 16 April 2010
Link to this article: http://journals.cambridge.org/abstract_S0952675710000060 How to cite this article:
Jie Zhang and Yuwen Lai (2010). Testing the role of phonetic knowledge in Mandarin tone sandhi. Phonology, 27, pp 153-201 doi:10.1017/
S0952675710000060
Request Permissions : Click here
Testing the role of
phonetic knowledge in
Mandarin tone sandhi*
Jie Zhang
University of Kansas
Yuwen Lai
National Chiao Tung University
Phonological patterns often have phonetic bases. But whether phonetic substance should be encoded in synchronic phonological grammar is controversial. We aim to test the synchronic relevance of phonetics by investigating native Mandarin speakers’ applications of two exceptionless tone sandhi processes to novel words : the contour reduction 213E21/_T (Tl213), which has a clear phonetic mo-tivation, and the perceptually neutralising 213E35/_213, whose phonetic motivation is less clear. In two experiments, Mandarin subjects were asked to produce two individual monosyllables together as two different types of novel disyllabic words. Results show that speakers apply the 213E21 sandhi with greater accuracy than the 213E35 sandhi in novel words, indicating a synchronic bias against the phonetically less motivated pattern. We also show that lexical frequency is relevant to the application of the sandhis to novel words, but cannot account alone for the low sandhi accuracy of 213E35.
* This work could not have been done without the help of many people. We are grateful to Paul Boersma and Mietta Lennes for helping us with Praat scripts, Juyin Chen, Mickey Waxman and Xiangdong Yang for helping us with statistics and Hongjun Wang, Jiangping Kong and Jianjing Kuang for hosting us at Beijing University during our data collection in 2007. For helpful comments on various versions of this work, we thank Allard Jongman, James Myers, three anonymous reviewers and an associate editor for Phonology, and audiences at the 2004 NYU Workshop on ‘ Redefining elicitation ’, the Department of Linguistics at the University of Hawaii, the Department of Psychology and the Child Language Program at the University of Kansas, and the 2005 Annual Meeting of the Linguistic Society of America. We owe a special debt to Hsin-I Hsieh, whose work on wug-testing Taiwanese tone sandhi inspired this research. All remaining errors are our own. This research was partly supported by research grants from the National Science Foundation (0750773) and the University of Kansas General Research Fund (2301760).
doi:10.1017/S0952675710000060
1 Introduction
1.1 The relevance of phonetics to phonological patterning
Phonological patterns are often influenced by phonetic factors. The in-fluence is manifested in a number of ways, the most common of which is the prevalence in cross-linguistic typology of patterns that have articulatory or perceptual bases and the scarcity of those that do not. For example, velar palatalisation before high front vowels, postnasal voicing and regressive assimilation for major consonant places have clear phonetic motivations and are extremely well attested, while velar palatalisation before low back vowels, postnasal devoicing and progressive consonant place assimilation are nearly non-existent. The typological asymmetry can also be mani-fested in terms of implicational statements. For example, in consonant place assimilation, if oral stops are targets of assimilation in a language, then ceteris paribus, nasal stops are also targets of assimilation (Mohanan 1993, Jun 1995, 2004). This is to be expected perceptually, as nasal stops have weaker transitional place cues and are thus more likely to lose their contrastive place than oral stops when articulatory economy is of concern (the Production Hypothesis ; Jun 1995, 2004).
Evidence for the relevance of phonetics can also be found in the periph-eral phonology of a language even when the phonetic effects are not directly evident in its core phonology. Such peripheral phonology may include the phonology of its established loanwords (Fleischhacker 2001, Kang 2003, Kenstowicz 2007) and the speakers’ judgements on poetic rhyming (Steriade & Zhang 2001). For example, Steriade & Zhang (2001) show that although postnasal voicing is not neutralising in Romanian, its phonetic effect is crucial in accounting for poets’ preference for /Vnt/~/Vnd/ as a semi-rhyme over /Vt/~/Vd/.
The parallels between the traditionally conceived categorical/ phonological and gradient/phonetic patterns also indicate their close re-lation. Flemming (2001), for instance, outlines the similarity of patterning between phonological assimilation and phonetic coarticulation as well as a number of other processes present in both the traditional phonological and phonetic domains.
1.2 Where should phonetic explanations reside ?
Although the existence of some form of relationship between phonological typology and phonetics is relatively uncontroversial, the precise way in which this relationship should be captured is a continuous point of con-tention among phonologists. One possibility is to consider the phonetic basis to be part of the intrinsic mechanism of the synchronic phonological grammar. Many theories have been proposed within rule-based pho-nology to encode this relation, from the abbreviation conventions of SPE (Chomsky & Halle 1968) and the innateness of articulatorily based phonological processes in Natural Phonology (Stampe 1979) to the
grounding conditions for universal constraints in Grounded Phonology (Archangeli & Pulleyblank 1994). Optimality Theory (Prince & Smolensky 1993) further invites phonetic explanations into synchronic phonology, due to its ability to state phonetic motivations explicitly in the system as markedness constraints (Hayes & Steriade 2004). Work by Boersma (1998), Steriade (1999, 2001, 2008), Kirchner (2000, 2001, 2004), Flemming (2001) and Zhang (2002, 2004), among others, has proposed constraints that directly encode phonetic properties and intrinsic rankings based on such properties in synchronic phonology to capture typological asymmetries. There are various approaches as to how the phonetic substance gets to be encoded in the grammar. The strongest position is that the phonetically based constraints, intrinsic rankings, grounding conditions or other formal mechanisms are simply part of the design nature of the grammar on the level of the species (Universal Grammar (UG) ; Chomsky 1986), and they predict true, exceptionless universals of phonological typology. It is also possible that the design scheme of the grammar only includes an analytical bias that draws from a type of grammar-external phonetic knowledge (Kingston & Diehl 1994) and restricts the space of constraints and constraint rankings (weightings) to be learned by the speaker (Hayes 1999, Wilson 2006). This type of approach predicts strong universal tendencies in favour of phonetically motivated patterns, but allows ‘ unnatural ’ patterns to surface in gram-mars and be learned by speakers.
An alternative to the synchronic approach above is that the effect of phonetics on phonological typology takes place in the realm of diachronic sound change. The typological asymmetries in phonology are then due to the different frequencies with which phonological patterns can arise through diachronic sound change, which is caused by phonetic factors such as misperception (e.g. Anderson 1981, Ohala 1981, 1990, 1993, 1997, Blevins & Garrett 1998, Buckley 1999, 2003, Hale & Reiss 2000, Hansson 2001, Hyman 2001, Blevins 2004, Yu 2004, Silverman 2006a, b).1Among researchers working in this framework, there are different positions on the role of UG in synchronic phonology in general, from categorical rejection (Ohala 1981, 1990, 1993, 1996, Silverman 2006a) to selective permission (Blevins 2004) to utmost importance (Hale & Reiss 2000). But all pro-ponents of this approach agree that Occam’s Razor dictates that if a diachronic explanation based on observable facts exists for typological asymmetries in phonological patterning, a UG-based synchronic expla-nation, which is itself hypothetical and unobservable, is not warranted (e.g. Hale & Reiss 2000 : 158, Blevins 2004 : 23, Hansson 2008 : 882). For a
1 There are disagreements as to whether the speaker plays any active role in sound
change : for example, Ohala considers sound change to be listener-based and non-teleological, while Bybee’s (2001, 2006) usage-based model places great importance on the speaker’s production in the initiation of sound change ; Blevins’ Evolutionary Phonology (Blevins 2004) also ascribes the speaker a more active role in sound change than Ohala’s model.
comprehensive review on the diachronic explanations of sound patterns, see Hansson (2008).
The synchrony vs. diachrony debate is very often centred around the strongest form of the phonetics-in-UG hypothesis. Earlier proponents of the synchronic approach in the OT framework were primarily concerned with establishing stringent implicational statements on phonological be-haviour from typological data, discovering the phonetic rationales behind the implications, and proposing optimality-theoretic models from which the implicational statements fall out as predictions (e.g. Jun 1995, Steriade 1999, Kirchner 2001, Zhang 2002). Conversely, critics of the synchronic approach, beyond proposing explicit frameworks for the evolution of phonological systems, and for how perception, and possibly production, may have shaped the evolution, have made efforts to identify counter-examples to the phonetically based typological asymmetries and provide explanations for the emergence of such ‘ unnatural ’ patterns based on a chain of commonly attested diachronic sound changes (Hyman 2001, Yu 2004, Blevins 2006 ; see also Bach & Harms 1972, Anderson 1981). The debate between Blevins (2006) and Kiparsky (2006) on whether there exist true cases of coda voicing is a case in point. Regardless of the outcome of particular debates, this seems to be a losing battle for the synchronic approach in the long run, as the implicational statements gathered from cross-linguistic typology are necessarily inductive – provided that we have not looked at all languages, we cannot be certain that no counterexamples will ever emerge. Moreover, experimental studies showing that phoneti-cally arbitrary patterns can in fact be readily learned by speakers (Dell et al. 2000, Onishi et al. 2002, Buckley 2003, Chambers et al. 2003, Seidl & Buckley 2005) also seem to provide additional arguments in the diachronic approach’s favour.
However, as we have mentioned earlier, a synchronic approach does not necessarily assume the strongest form of phonetics as a design feature. The analytical bias approach (e.g. Wilson 2006, Moreton 2008), for example, only favours the learning of particular patterns in the process of phonological acquisition, but does not in principle preclude the emerg-ence or learning of other patterns. Pitched against the diachronic approach, the form of argument from either approach should come from experimental studies that show whether speakers indeed exhibit any learning biases in favour of phonetically motivated patterns, not whether phonetically unmotivated patterns can be learned at all.2
Relatedly, there is a crucial difference between phonological patterns observed in a language and the speaker’s internal knowledge of such 2 Hansson (2008 : 882) argues that the substantive bias approach is not necessarily
incompatible with the diachronic approach, as such biases can be considered as one of the potential sources of ‘ external errors ’ in language evolution. But we think that there is a fundamental difference between the two approaches in terms of the im-portance ascribed to phonetics in the grammar and the extent to which answers to asymmetries in both typological patterns and speakers’ internal phonological knowledge lie in the formal grammatical module.
patterns. Many recent works have shown that speakers may know both more and less than the lexical patterns of their language. For example, Zuraw (2007) demonstrated that Tagalog speakers possess knowledge of the splittability of word-initial consonant clusters that is absent in the lexicon but projectable from perceptual knowledge, and that they can apply the knowledge to infixation in stems with novel initial clusters ; Zhang & Lai (2008) and Zhang et al. (2009a, b), pace earlier works on Taiwanese tone sandhi such as Hsieh (1970, 1975, 1976) and Wang (1993), show that the phonologically opaque ‘ tone circle ’ is largely unproductive in wug tests, despite its exceptionlessness in the language itself. This opens up a new area of inquiry for the synchrony vs. diachrony debate : provided that we are interested in the tacit knowledge of the speaker, then we need to look beyond the typological patterns to see which approach provides a better explanation for experimental results that shed light on the speakers’ internal knowledge. One likely fruitful comparison is to see whether there are productivity differences between two patterns that differ in the level of phonetic motivation, but are otherwise comparable.3 1.3 Experimental studies addressing the role of phonetics
in learning
In this section we provide a brief review of the relevant experimental literature on the role of phonetics in different types of learning situations. One possible line of investigation is to examine in a language with phonological patterns that differ in the degree of phonetic motivation whether the patterns with stronger phonetic motivations are acquired more quickly and with greater accuracy in language acquisition.
The claim that phonetically motivated morphophonological processes are acquired earlier and with fewer errors has been made in the literature (e.g. MacWhinney 1978, Slobin 1985, Menn & Stoel-Gammon 1995). For example, Slobin compared the effortless acquisition of final devoicing by Turkish children and the error-ridden acquisition of stop–spirant alternations in Modern Hebrew by Israeli children and suggested that there is a hierarchy of acceptable alternation based on universal predis-positions that favour assimilation and simplification in the articulatory output (1985 : 1209).
Buckley (2002) points out that the role of such universal predispositions can only be established if the accessibility of the pattern, such as its dis-tribution and regularity, is teased apart from the phonetic naturalness of the pattern. In demonstrating that many unnatural patterns are acquired 3 Hansson (2008 : 881) worries that it would be ‘ all too easy to explain away apparent
counterexamplesº as being lexicalized, morphologized, or in some other way not belonging to the ‘ real ’ phonology of the language’. But one should insist that any claims about whether a pattern falls outside the ‘ real ’ phonology of a language be supported by experimental evidence. Moreover, the argument is more likely in a subtler form of whether there are any detectable differences between patterns, not whether a pattern is categorically in or out of ‘ real ’ phonology.
readily, due to their high regularity and high frequency of occurrence, while many natural patterns are acquired with much difficulty due to their low accessibility, Buckley argues that accessibility, but not phonetic naturalness, determines the ease of learning. However, Buckley (2002) does not show that when accessibility is matched, a process lacking phonetic motivations can be acquired just as easily as a phonetically motivated process. The only such comparisons that can be found in Buckley (2002) are in Hungarian – the more natural backness harmony vs. the less natural /a/-lengthening, both of which are highly accessible, and the more natural rounding harmony vs. the less natural /e/-lengthening, both of which have low accessibility. MacWhinney (1978)’s original work, cited by Buckley, showed that backness harmony is acquired earlier than /a/-lengthening, but rounding harmony is acquired later than /e/-lengthening. Therefore, phonetic naturalness does seem to affect the order of acquisition, but it is unclear what the precise effect is. Moreover, given that these comparisons are only made under a crude control of ‘ accessi-bility ’, the results cannot be deemed conclusive.
Another approach is to test the learning of patterns with different de-grees of phonetic motivations in an artificial language. The artificial grammar paradigm (see Reber 1967, 1989, Redington & Chater 1996) has been widely used to investigate the learnability of phonological patterns in both children and adults. The paradigm typically involves two stages – the exposure stage, in which the subject is presented with stimuli generated by an artificial grammar, and the testing stage, in which the subject is tested on their learning of the patterns in the artificial grammar, measured by their ability to distinguish legal vs. illegal test stimuli, reaction time or looking time in the head-turn paradigm for infant studies. It is particularly suited for the comparison of the learning of different patterns, as the relevant patterns can be designed to have matched regularity, lexical frequency and transitional probability. This line of research has been actively pursued, with conflicting results. Seidl & Buckley (2005) reports two experiments that tested whether nine-month-old infants learn pat-terns with different degrees of phonetic motivation differently. The first experiment tested whether the infants preferred a phonetically grounded pattern in which only fricatives and affricates, but not stops, occur inter-vocalically, or an arbitrary pattern in which only fricatives and affricates, but not stops, occur word-initially. The second experiment tested the difference between two patterns : a grounded pattern in which a labial consonant is followed by a rounded vowel and a coronal consonant is followed by a front vowel, and an arbitrary pattern in which a labial consonant is followed by a high vowel and a coronal consonant is followed by a mid vowel. In both experiments, the infants learned both patterns fairly well and showed no learning bias towards the phonetically grounded pattern, suggesting that phonetic grounding does not play a role in the learning of synchronic phonological patterns. But in Experiment 1, all fricatives and affricates used were stridents, and as Kirchner (2001, 2004) shows, the precise articulatory control necessary for stridents in fact
makes them less desirable in intervocalic position. Moreover, Thatte (2007 : 7) points out that there exist phonological generalisations other than the ones that Seidl & Buckley intended in their stimuli, and the infants might have responded to these generalisations. Therefore, Seidl & Buckley’s claim that there is no learning bias towards phonetically grounded patterns is open to debate. In Jusczyk et al. (2003), 4.5-month-old infants were presented with sets of three words, or ‘ triads ’, which consisted of two monosyllabic pseudo-words with the forms VC1and C2V, followed by a disyllabic word in which either C1or C2assimilates in place to the adjacent consonant (an, bi, ambi ; an, bi, andi). The C1assimilation pattern is perceptually motivated and cross-linguistically extremely com-mon, while the C2assimilation pattern has no clear perceptual grounding and cross-linguistically extremely rare. In a head-turn procedure, infants showed no difference in looking time between the triads with regressive and progressive assimilations, indicating the lack of a priori preference for phonetically motivated phonological patterns. However, Thatte (2007)’s study, which compared intervocalic voicing (pa, fi, pavi) and devoicing (pa, vi, pafi) using a similar methodology, showed that 4.5-month-old infants exhibited a preference for the phonetically motivated intervocalic voicing, while 10.5-month-old infants preferred the phonetically un-motivated intervocalic devoicing. Thatte argues that the 4.5-month-olds’ results support the view that infants have an innate preference for pho-netically based patterns and tentatively interpreted the 10.5-month-olds’ results as the combined effect of their overall lower boredom threshold and their becoming bored with the phonetically motivated pattern earlier. In addition to the conflicting results, as Seidl & Buckley (2005) point out, the A, B, AB triad procedure is quite novel in infant research, and the assumption that the infants take the AB string to be a concatenation of A and B may not be valid. Therefore, the extent to which the phonetic bases of phonological patterns are directly relevant to first language acquisition remains an open question.
Pycha et al. (2003) tested adult English speakers’ learning of three non-English patterns – ‘ palatal vowel harmony ’ (stem and suffix vowels agree in [back]), ‘ palatal vowel disharmony ’ (stem and suffix vowels disagree in [back]) and ‘ palatal arbitrary ’ (an arbitrary relation between stem and suffix vowels) – and found that although subjects exhibited better learning of the harmony and disharmony patterns than the arbitrary pattern, there was no difference between harmony and disharmony. Taking harmony to have a stronger phonetic motivation than disharmony, they concluded that phonetic naturalness is not relevant to the construction of the syn-chronic grammar. Wilson (2003), in two similar experiments with similar results, interpreted the results differently, however. Wilson argued that both assimilation and dissimilation can find motivations in phonetics and thus both have a privileged cognitive status in phonological grammar. Wilson (2006) showed that when speakers were presented with highly impoverished evidence of a new phonological pattern, they were able to extend the pattern to novel contexts predicted by a phonetically based
phonology and linguistic typology, but not to other contexts ; for instance, speakers presented with velar palatalisation before mid vowels could extend the process before high vowels, but not vice versa. A phonology that encodes no substantive bias cannot predict these experimental observations.
Two experiments on the learning of natural vs. unnatural allophonic rules in an artificial language conducted by Peperkamp and collaborators (Peperkamp et al. 2006, Peperkamp & Dupoux 2007) returned conflicting results. In both experiments, French subjects were exposed to alternations that illustrate intervocalic voicing (e.g. [p t k]E[b d g] / V_V) or a random generalisation (e.g. [p g z]E[Z f t] / V_V). In the test phase, the subjects did not show a learning difference between the two types of alternations in a phrase–picture-matching task (Peperkamp & Dupoux 2007), but did show a strong bias in favour of intervocalic voicing in a picture-naming task (Peperkamp et al. 2006). Peperkamp and colleagues surmise that the different results might be due to a ceiling effect in the cognitively less demanding phrase–picture-matching task, and the difference between natural and unnatural alternations could lie in either the speed with which they are learned – natural alternations are learned faster – or the ease with which they can be used in processing once they have been learned – natural alternations can be used more easily, especially in cognitively demanding tasks. In either case, the account allows random alternations to be learned, but also admits that the phonetic nature of the alternation plays a role in its acquisition.
An additional issue with using the artificial language paradigm in adult research is that artificial learning at best approximates second language acquisition, whose mechanism is arguably very different from first language acquisition (Cook 1969, 1994, Dulay et al. 1982, Bley-Vroman 1988, Ellis 1994, among others), but the learning issue of interest here is the relevance of phonetics during the construction of native phonological grammars. Moreover, the artificial language paradigm often involves a heavy dose of explicit learning, while second language acquisition, like first language acquisition, often involves a significant amount of implicit learning. This increases the distance between artificial language learning and real language acquisition.
1.4 The current study
The current study complements the experimental works above by using a nonce-probe paradigm (‘ wug ’ test) (Berko 1958) with adult speakers. In a typical wug test, subjects are taught novel forms in their language and then asked to provide morphologically complex forms, using the novel forms as the base. This paradigm has been widely used to test the pro-ductivity of regular and irregular morphological rules (e.g. Bybee & Pardo 1981, Albright 2002, Albright & Hayes 2003, Pierrehumbert 2006) and morphophonological alternations (e.g. Hsieh 1970, 1975, 1976, Wang 1993, Zuraw 2000, 2007, Albright et al. 2001, Hayes & Londe 2006). Our
study wug-tests two patterns of tonal alternation (tone sandhi) that differ in the degree of phonetic motivation in Mandarin Chinese and compares the accuracies with which the sandhi patterns apply to nonce words.
This approach is in line with the assumption that the phonological patterns observed in the language may not be identical to the speakers’ knowledge of the patterns, and provides us with a novel opportunity to test the role of phonetics in synchronic phonology. It uses real phonological patterns that exist in the subjects’ native language, which circumvents the learning-strategy problem with the artificial language paradigm. It also allows easier manipulations of confounding factors such as lexical frequency and thus minimises the control problem in studying phono-logical learning in a naturalistic setting.
1.5 Organisation of the paper
We discuss the details of two tone sandhi patterns under investigation in Mandarin in w2. The methodology and results for the two experiments that compare the productivity of the two sandhi patterns are discussed inww3 and 4. Theoretical implications of the results are further discussed inw5. w6 is the conclusion.
2 Tone sandhi in Mandarin Chinese and the general
hypotheses
Mandarin Chinese is a prototypical tone language. The standard variety of Mandarin spoken in Mainland China, particularly Beijing, has four lexical tones – 55, 35, 213 and 51 – as shown in (1).4
(1) Mandarin tones Tone 1 Tone 2 Tone 3 Tone 4 ma55 ma35 ma213 ma51 ‘mother’ ‘hemp’ ‘horse’ ‘to scold’
The pitch tracks of the four tones with the syllable [ma] pronounced in isolation by a male speaker, each averaged over five tokens, are given in Fig. 1. Although Tone 2 is usually transcribed as a high-rising tone 35, there is a small pitch dip at the beginning of the tone, creating a turning point, and research has shown that the perceptual difference between Tones 2 and 3 lies primarily in the timing and pitch height of the turning 4 Tones are marked with Chao tone numbers (Chao 1948, 1968) here. ‘ 5 ’ indicates
the highest pitch used in lexical tones, while ‘ 1 ’ indicates the lowest pitch. Contour tones are marked with two juxtaposed numbers. For example, 51 indicates a falling tone from the highest pitch to the lowest pitch.The variety of Mandarin spoken in Taiwan has a slightly different tonal inventory : Tone 3 is pronounced as 21, without the final rise, even in prosodic final position. This is not the variety of Mandarin studied here.
point (Shen & Lin 1991, Shen et al. 1993, Moore & Jongman 1997). Notice also that the different tones in Fig. 1 have different durational properties ; in particular, Tone 3 has the longest duration. These ob-servations will become important in the discussion of Mandarin tone sandhi and the experimental results.
In tone languages, a tone may undergo alternations conditioned by adjacent tones or the prosodic and/or morphosyntactic position in which the tone occurs. This type of alternation is often referred to as tone sandhi (e.g. Chen 2000). Mandarin Chinese has two tone sandhi patterns, both of which involve Tone 3 (213). Specifically, 213 becomes 35 when followed by another 213 (the ‘ third-tone sandhi ’) ; but 213 becomes 21 when followed by any other tone (the ‘ half-third sandhi ’). These sandhis are exemplified in (2).
Mandarin tone sandhi 213£35 /_213 xAu213 tçjou213 xAu213-»u55 xAu213-3@n35 xAu213-kHan51 xAu21-»u55 xAu21-3@n35 xAu21-kHan51 ‘good book’ ‘good person’ ‘good looking’ a. 213£21 /_{55, 35, 51} b. £ £ £
xAu35-tçjou213 ‘good wine’ £
(2)
The pitch tracks for the four examples in (2) pronounced in isolation by a male speaker, each averaged over five tokens, are given in Fig. 2.
Both of these sandhi patterns are fully productive in Mandarin disyllabic words and phrases, and they are both ‘ phonological ’ in the traditional sense, in that they involve language-specific tone changes that cannot be predicted simply by tonal coarticulation. However, we consider the half-third sandhi to have a stronger phonetic basis than the third-tone sandhi. Our judgement is based on the following three factors.
F0 (Hz) 200 150 100 50 0 time (ms) 50 100 150 200 250 300 350 turning point turning point Tone 1 (55) Tone 2 (35) Tone 3 (213) Tone 4 (51) Figure 1
First, in terms of the phonetic mechanism of the tone change, although both sandhis involve simplification of a complex contour in prosodic non-final position, which has articulatory and perceptual motivations (Zhang 2002, 2004), the third-tone sandhi also involves raising of the pitch, which cannot be accounted for by the phonetic motivation of reducing pitch contours on syllables with insufficient duration. The half-third sandhi, however, only involves truncation of the second half of the contour. The third-tone sandhi is also structure-preserving, at least in perception.5 Based on the closer phonetic relation between the base and sandhi pair in the half-third sandhi and the contrastive status of the sandhi tone 35 in the third-tone sandhi, we assume that the perceptual distance between the base and sandhi tones in the half-third sandhi is smaller than that in the third-tone sandhi. We take this as an argument for the stronger phonetic motivation for the half-third sandhi (cf. the P-map ; Steriade 2001, 2008). Second, in the traditional Lexical Phonology sense, the third-tone sandhi has lexical characteristics – it is structure-preserving (in percep-tion), and its application to a polysyllabic compound is dependent on syntactic bracketing ; but the half-third sandhi is characteristic of a post-lexical rule – it is allophonic and applies across the board. The syntactic dependency of the third-tone sandhi is illustrated in the examples in (3) and (4). The examples in (3a) and (b) show that for underlying third-tone sequences, the output tones differ depending on the syntactic branching structure : a right-branching sequence [213 [213 213]] has two possible output forms, 35 35 213 and 21 35 213, as in (3a), while a left-branching sequence [[213 213] 213] has only one output, 35 35 213, as in (3b) (from
F0 (Hz) 200 150 100 50 0 time (ms) 50 100 150 0 50 100 150 200 250 300 3+1 3+2 3+3 3+4 Figure 2
Representative pitch tracks for the tone sandhis in Mandarin.
5 A detailed acoustic study by Peng (2000) shows that this sandhi is
non-neutralising as far as production is concerned – the sandhi tone is lower in overall pitch than the lexical Tone 2. But this difference cannot be reliably perceived by native adult listeners. Therefore, /mai213 ma213/ ‘ buy horse ’ and /mai35 ma213/ ‘ bury horse ’ are in effect perceived as homophonous by native speakers.
Duanmu 2000 : 238). Examples (3c) and (d), on the other hand, illustrate that the application of the half-third sandhi is not influenced by the branching structure : an underlying 213 35 213 sequence, regardless of branching structure, is realised as 21 35 213.
Left-vs. right-branching phrases [mai buy 213 35 21 [xAu good 213 35 35 tçjou]] wine 213 213 213
‘buy good wine’
[[213 213] 213]£35 35 213 only [[mai buy 213 35 *21 xAu] done 213 35 35 tçjou] wine 213 213 213
‘finished buying wine’
[213 [35 213]]£21 35 213 [çjAu little 213 21 [xuN red 35 35 ma]] horse 213 213
‘little red horse’
[[213 35] 213]£21 35 213 [[çjAu Xiao 213 21 xuN] hong 35 35 pHAu] run 213 213 ‘Xiaohong runs’ [213 [213 213]]£35 35 213 or 21 35 213 (3) a. input output 1 output 2 b. input output c. input output d. input output
The examples in (4a) and (4b) show that prepositions have a special status, in that they permit the non-application of the third-tone sandhi. (4a) illustrates that in a [213 [[213 213] 213]] sequence, if the second syllable is a preposition such as [wAN] ‘ to ’, there are three possible outputs : 35 35 35 213, 21 35 35 213 or 35 21 35 213. But if the second syllable is not a preposition, as in (4b), there are only two possible outputs : 35 35 35 213 or 21 35 35 213 ; *35 21 35 213, where the third-tone sandhi is blocked on the second syllable, is not a possible output (from Zhang 1997 : 294–295). By contrast, (4c) and (4d) illustrate that a [55 [[213 51] 213]] sequence, regardless of whether the second syllable is a preposition, is realised as 55 21 51 213, demonstrating again the irrelevance of gram-matical structure to the application of the half-third sandhi.6
6 For more discussion on the application of the Mandarin third-tone sandhi, see Shih
The special status of prepositions [ma horse 213 35 21 35 [[wAN to 213 35 35 21 pei] north 213 35 35 35
‘The horse walks to the north.’ [213 [[213non-prep 213] 213]]£35 35 35 213 or 21 35 35 213 [ma horse 213 35 21 *35 [[x@n very 213 35 35 21 »Au] rarely 213 35 35 35
‘Horses rarely roar.’
[55 [[213prep 51] 213]]£55 21 51 213 [tHa he 55 55 [[wAN to 213 21 xou] back 51 51
‘He walks backwards.’
[55 [[213non-prep 51] 213]]£55 21 51 213 [tHa he 55 55 [[x@n very 213 21 ai] love 51 51
‘He loves dogs very much.’ [213 [[213prep 213] 213]]£35 35 35 213, 21 35 35 213 or 35 21 35 213 (4) a. input output 1 output 2 output 3 b. input output 1 output 2 c. input output d. input output tsou]] walk 213 213 213 213 xou]] roar 213 213 213 213 tsou]] walk 213 213 kou]] dog 213 213
We should recognise that the third-tone sandhi is not truly lexical : it clearly applies across word boundaries ((3), (4)), its application in long strings is affected by speech rate ((3), (4)), and it is not structure-preserving in production under careful acoustic scrutiny (note 5). What is uncontroversial, however, is the clear difference between the two sandhis, in that the third-tone sandhi exhibits certain lexical characteristics, while the half-third sandhi does not. The close relation between the postlexical status of a phonological rule and its phonetic motivation is well established in the Lexical Phonology literature (e.g. Kiparsky 1982, 1985, Mohanan 1982), and we take it as another piece of evidence that the half-third sandhi has a stronger phonetic motivation than the third-tone sandhi.
The third reason is that the third-tone sandhi corresponds to a historical sandhi pattern in Chinese, namely shangEyang ping /_shang, where shangand yang ping refer to the historical tonal categories from which 213 and 35 respectively descended. This historical sandhi pattern dates back to at least the 16th century (Mei 1977). According to Mei’s reconstruction,
the pitch values for shang and yang ping in 16th century Mandarin were low level (22) and low-rising (13) respectively. The present-day rendition of the sandhi in Mandarin is the result of historical tone changes that morphed shang into low-falling-rising and yang ping into high-rising. The Mandarin third-tone sandhi was therefore not originally motivated by the phonetic rationale of avoiding a complex pitch contour on a short duration. The same point is made by the variable synchronic realisations of the same historical sandhi in related Mandarin dialects (Court 1985). For instance, in Tianjin it is 13E45 /_13 (Yang et al. 1999), in Jinan 55E42 /_55 (Qian & Zhu 1998) and in Taiyuan 53E11 /_53 (Wen & Shen 1999). The half-third sandhi, on the other hand, does not have a similar historical origin ; and due to the different tonal shapes of the historical shang tone in different present-day dialects, it does not have comparable synchronic realisations.
The differences between the third-tone sandhi and the half-third sandhi in their phonetic characteristics, morphosyntactic properties and historical origins all point to the possibility that the half-third sandhi has a stronger synchronic phonetic basis than the third-tone sandhi. It is important to note that we have not committed ourselves to an absolute cut-off point for what is phonetically based and what is not – to identify patterns that are useful for testing the synchronic relevance of phonetics, such a threshold is not necessary, nor do we believe that it exists. However, it is crucial to be able to make comparisons between patterns along the lines that we have considered for Mandarin in order to identify the relevant ones for the test.
Given the difference in phonetic grounding between the two sandhi patterns, the general question we pursue is whether Mandarin speakers exhibit different behaviours on the two sandhis in a wug test. Specifically, we test whether there is a difference in productivity between the two sandhis. In line with the synchronic approach, we hypothesise that the sandhi with the stronger phonetic motivation – the half-third sandhi – will apply more productively in wug words than the third-tone sandhi. This greater productivity may be reflected in two ways. First, the half-third sandhi may apply to a greater percentage of the wug tokens than the third-tone sandhi. Second, there is no difference in the rate of application, but there is incomplete application for the third-tone sandhi in wug words as compared to real words, while the half-third sandhi applies to the wug words the same way as it applies to the real words. In light of the earlier discussion on the difference between Tones 2 and 3, we specifically expect a lower and later turning point and a longer duration for the sandhi tone in wug words than in real words for the third-tone sandhi.7
7 We also hypothesised that the reaction times for the two sandhis would be
signifi-cantly different, due to the potentially different types of processing for the two sandhis. But it was difficult to decouple the allophonic differences in rhyme duration among different tones from differences in reaction time, and this hypothesis was not borne out in the two experiments that we conducted. We do not report the reaction time results here. Interested readers can consult a previous version of this article, in
Finally, we must acknowledge that the third-tone sandhi and the half-third sandhi do not have the same lexical frequency in Mandarin. Calculations based on a syllable-frequency corpus (Da 2004) containing 192,647,157 syllables indicate that the numbers of legal syllable types with Tones 1–4 are 258, 224, 254 and 318 respectively, while syllables with Tones 1–4 account for 16.7 %, 18.4 %, 14.8 % and 42.5 % of all syllables in the corpus.8 In other words, Tone 3 has the third-lowest type frequency and the lowest token frequency, which means that disyllabic words with the 3+3 tonal combination may have relatively low frequency. Moreover, the third-tone sandhi also has a limited environment as compared to the half-third sandhi. The environments in which the half-third sandhi ap-plies, which include _55, _35 and _51, account for 75.9% of all sandhi environments by type-frequency counts. Therefore, we pay special attention in our study to whether the half-third sandhi behaves as a unified process before 55, 35 and 51. If so, it will present a challenge to the goal of the study, as any effect that conforms to our hypothesis may be due to the considerably higher lexical frequency of the half-third sandhi. If not, the frequency profile of the four tones in Mandarin will provide us with an opportunity to study the potential effect of lexical frequency on sandhi productivity and its interaction with the effect of phonetics. If lexical frequency influences sandhi productivity, we primarily expect a type-frequency effect (Bybee 1985, 2001, Baayen 1992, 1993, Ernestus & Baayen 2003, Pierrehumbert 2003, 2006, etc.), and thus a low productivity of the half-third sandhi for 3+2 sequences. But we also cannot exclude the possible effect of token frequency, which has been shown to be relevant to the productivity of Taiwanese tone sandhi in Zhang & Lai (2008) and Zhang et al. (2009a, b). If the frequency effect is mainly based on token frequency, we would expect 3+3 to have the lowest productivity.
3 Experiment 1
3.1 Methods
3.1.1 Stimuli. Following Hsieh (1970, 1975, 1976)’s experimental de-sign for a Taiwanese wug test, we constructed five sets of disyllabic test words in Mandarin. The first set includes real words, denoted by AO-AO (where AO=actual occurring morpheme). This set serves as the control for the experiment and is the set with which results of wug words are compared. The other four sets are wug words : *AO-AO, where both syllables are actual occurring morphemes, but the disyllable is non-occurring ; AO-AG (AG=accidental gap), where the first syllable occurs, but the second syllable is an accidental gap in Mandarin syllabary ; AG-AO, where the first syllable is an accidental gap and the second syllable actually occurs ; and AG-AG, where both syllables are accidental
which reaction time results are reported (available (December 2009) at http:// www2.ku.edu/~ling/faculty/zhang.shtml).
gaps. The AGs were selected by the authors, who are both native speakers of Mandarin Chinese. In each AG, both the segmental composition and the tone of the syllable are legal in Mandarin, but the combination happens to be missing. For example, [pHan] is a legal syllable, and occurs with tones 55 ‘ to climb ’, 35 ‘ plate ’ and 51 ‘ to await eagerly ’, but it ac-cidentally does not occur with Tone 3 (213). Therefore, [pHan213] is a possible AG.
For each set of words, we used four different tonal combinations : the first syllable always has Tone 3 (213), and the second syllable has one of the four Mandarin tones. Each tonal combination is therefore in the ap-propriate environment to undergo either the third-tone or the half-third sandhi. Eight words for each tonal combination were used, making a total of 160 test words (8[4[5).
The AO-AO words were all high-frequency words, selected from Da (1998)’s Feng Hua Yuan character and digram frequency corpus. For the four wug sets, the digram frequencies are all zero, and we used the same first syllable to combine with the four different tones in the second syllable. For example, for AG-AG we used [pHi@N213 ew@n55], [pHi@N213 tHG35], [pHi@N213 tsGN213] and [pHi@N213 tea51], along with seven other such sets. In the recorded stimuli, the same token was combined with different second syllables. The identity of the first syllable allows for the comparison of the two types of sandhi that the first syllable may undergo. To avoid neighbourhood effects in wug words at least to some extent, we ensured that any disyllabic wug word was not a real word with any tonal combination, not just the one used for the disyllable. We specifically controlled for the tonal neighbours, because research on homophony judgement (Taft & Chen 1992, Cutler & Chen 1997), phoneme (toneme) monitoring (Ye & Connine 1999) and legal-phonotactic judgement (Myers 2002) has shown that phonemic tonal differences are perceptually less salient than segmental differences, which entails that tonal neighbours in a sense make closer neighbours.
Finally, to disguise the purpose of the experiment, we also used 160 disyllabic filler words. All filler syllables were real syllables in Mandarin ; half of the disyllabic fillers were real words, and the other half were wug words.
All test stimuli and fillers were read by the first author, a native speaker of Mandarin who grew up in Beijing. The Tone 3 syllables were all read with full third tones. The entire set of test stimuli, as well as additional information about the stimuli and fillers are given in the Appendix. 3.1.2 Experimental set-up. The experiment was conducted with the software package SuperLab (Cedrus) in the Phonetics and Psycho-linguistics Laboratory at the University of Kansas. There were 320 stim-uli in total (160 test items+160 fillers). Each stimulus consisted of two monosyllabic utterances separated by an 800 ms interval. The stimuli were played through a headphone worn by the subjects. For each stimulus, the subjects were asked to put the two syllables together and
pronounce them as a disyllabic word in Mandarin. Their response was collected by a Sony PCM-M1 DAT recorder through a 33-3018 Optimus dynamic microphone placed on the desk in front of them. The sampling rate for the DAT recorder was 44.1 kHz. The digital recording was then downsampled to 22 kHz onto a PC hard drive using Praat (Boersma & Weenink 2003). There was a 2000 ms interval between stimuli. If the subject did not respond within 2000 ms after the second syllable played, the next stimulus would begin. The stimuli were divided into two blocks of the same size (A and B) with matched stimulus types ; there was a five-minute break between the blocks. Half of the subjects took block A first, and the other half took block B first. Within each block, the stimuli were automatically randomised by SuperLab. Before the experiment began, the subjects heard a short introduction in Chinese through the headphones which explained the task both in prose and with examples ; they simul-taneously read it on a computer screen. There was then a practice session involving 14 words (two each of AO-AO, *AO-AO, AO-AG, AG-AO and AG-AG, two real-word fillers and two wug fillers). The experiment began after a verbal confirmation from the subjects that they were ready. The entire experiment took around 45 minutes.
3.1.3 Subjects. Twenty native speakers of Mandarin (12 male, 8 female), recruited at the University of Kansas, participated in the study. All speakers were from northern areas of Mainland China, and, in the opinion of the authors, spoke Standard Mandarin natively, without any noticeable accent. Except for one speaker who was 45 years old and had been in the United States for 20 years, all speakers ranged from 23 to 35, and had been in the United States for less than four years at the time of the experiment. Each subject was paid a nominal fee for participating in the study. 3.1.4 Data analyses. All test tokens from the subjects were listened to by the two authors. A token was not used in the analysis if there was a large enough gap between the two syllables that they clearly did not form a disyllabic word. For the rest of the tokens, it was judged that both the third-tone sandhi and the half-third sandhi applied 100 % of the time. Non-application of the sandhi processes should be easy to detect for native speakers, as they involve clear phonotactic violations (*213 non-finally). Therefore, the test for the productivity of the sandhis lies in the accuracy of their applications to the wug words. To investigate the accuracy of sandhi application, we extracted the F0 of the rhyme in the first syllable of the subjects’ disyllabic response, using Praat. We then took a F0 measurement every 10 % of the duration of the rhyme, giving eleven F0 measurements for each rhyme. For each tonal combination (3+1, 3+2, 3+3, 3+4), we did two comparisons. The first was between AO-AO and the rest of the word groups (*AO-AO, AO-AG, AG-AO, AG-AG) ; i.e. real disyllables vs. wug disyllables. The other was between AO-AO, *AO-AO, AO-AG and AG-AO, AG-AG ; i.e. real w1 vs. wug w1. The rationale for the two comparisons is that lexical listing could be at the
disyllabic word or monosyllabic morpheme level ; doing both comparisons allows us to tease apart the two possibilities. Our hypothesis for these comparisons is that the difference in sandhi tones between real words and wugs should be greater for cases of third-tone sandhi than half-third sandhi, due to the stronger phonetic motivation for the latter. In particu-lar, we expect incomplete application of the third-tone sandhi in wugs, i.e. Tone 3 in w1 will resist the change to Tone 2. Again, given the acoustic characteristics of Tones 2 and 3 in Mandarin, the hypothesis translates into a lower and later turning point and a longer duration for the sandhi tone in wug words than in real words.
Among the twenty speakers, there were two speakers (one male and one female) whose F0 values could not be reliably measured by Praat, due to high degrees of creakiness in their voice. We discarded these speakers’ data in the F0 analysis.
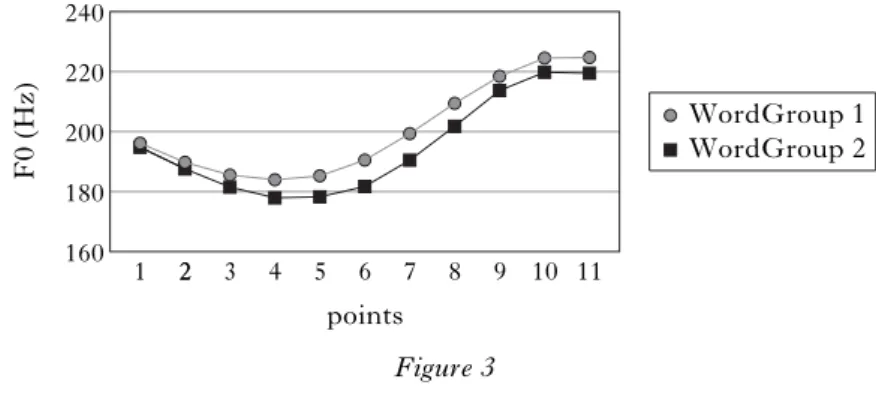
Figure 3 illustrates how we compared two F0 curves. We conducted a two-way Huynh-Feldt repeated-measures ANOVA, which corrected for sphericity violations, with WordGroup and Point as independent variables. The WordGroup variable has two levels, WordGroup 1 and WordGroup 2, and a significant main effect would indicate that the two F0 curves representing the two word groups have different average pitches. The Point variable has eleven levels, representing the eleven points where F0 data are taken. A significant interaction between WordGroup and Point would indicate that the two curves have different shapes. This method of comparing two F0 curves is used by Peng (2000).
For w1 in 3+3 combinations, we also measured the F0 drop and the duration from the beginning of the rhyme to the pitch turning point, as shown in Fig. 4. Comparisons between real and wug disyllables and between real and wug w1on these measurements were made using one-way repeated-measures ANOVAs. We expected the F0 drop to be greater and the TP duration to be longer for wug words than real words.
Finally, we measured the w1rhyme duration for all the disyllabic com-binations, and compared real and wug disyllables and real and wug w1’s for each tonal combination, using one-way repeated-measures ANOVAs.
points 1 2 WordGroup 1 WordGroup 2 240 220 200 180 160 F0 (Hz) 2 3 4 5 6 7 8 9 10 11 Figure 3
Based on the synchronic approach, we expected to find a longer rhyme duration for the wug words in 3+3 combinations, but no difference between wug and real words in other combinations.
3.2 Results
3.2.1 F0 contour. In this section, we report the results of comparison on the F0 of the first syllable of the subjects’ response between real disyllables and wug disyllables, and between real-w1words and wug-w1words.
The results from the half-third sandhi comparisons are given in Fig. 5. In this and all following figures, ‘ n.s. ’ indicates no significant difference and ‘ * ’, ‘ ** ’ and ‘ *** ’ indicate significant differences at the p<0.05, p<0.01 and p<0.001 levels respectively. As we can see in Fig. 5, for Tones 1 and 4 the subjects ’ performance on the half-third sandhi on wug words is generally identical to that on real words in terms of both the average F0 and the F0 contour shape. This is true for both the disyllabic and w1comparisons for Tone 1 and the w1comparisons for Tone 4. When w2has Tone 2, the shape of the F0 contour on w1is significantly different for real and wug words, for both comparisons. The statistical results for these comparisons are given in Table I.
Figure 5 also shows that the F0 shape difference between real and wug words for 3+2 lies in the fact that the F0 shape for the wug words has a turning point at around 70 % into the tone, while the F0 shape for the real words falls monotonically throughout the rhyme. This indicates that there may be incomplete application of the half-third sandhi in 3+2 ; hence its lower accuracy/productivity in this particular environment.9We currently
duration
TP duration turning
point BF0
Figure 4
A schematic of the measurements taken from the pitch curve of the rhyme in w1in 3+3 combinations. ‘ EF0 ’ and ‘ TP duration ’ are the pitch drop and duration from the beginning of the rhyme to the turning point respectively.
‘ Duration ’ is the duration of the entire rhyme.
9 The pitch rise at the end of the first syllable in 3+1 and 3+4 for real disyllable and
real w1words is likely due to coarticulation with the high pitch onset of the following tone (Tone 1=55, Tone 4=51).
have no account for why there is a significant F0 shape difference between AO-AO and other word groups for 3+4.
The results from the third-tone sandhi comparisons are given in Fig. 6. Two-way repeated-measures ANOVAs indicate that although the average F0 is the same for both comparisons, the F0 contour shape is significantly different between the real words and wug words for both comparisons. The ANOVA results are summarised in Table II.
We can also see in Fig. 6 that for the curves representing wug words the turning points are both lower and later than their counterparts for the
1 2 230 210 190 170 150 F0 (Hz) 2 3 4 5 6 7 8 9 10 11 ao ag 1 2 230 210 190 170 150 2 3 4 5 6 7 8 9 10 11 ao-ao others
(a) real vs. wug disyllables (b) real s1 vs. wug s1 words
3+1 3+1 points points F0 average: n.s. F0 shape: n.s. F0 average: n.s. F0 shape: n.s. 1 2 230 210 190 170 150 F0 (Hz) 2 3 4 5 6 7 8 9 10 11 ao ag 1 2 230 210 190 170 150 2 3 4 5 6 7 8 9 10 11 ao-ao others 3+2 3+2 F0 average: n.s. F0 shape: *** F0 average: n.s. F0 shape: *** 1 2 230 210 190 170 150 F0 (Hz) 2 3 4 5 6 7 8 9 10 11 ao ag 1 2 230 210 190 170 150 2 3 4 5 6 7 8 9 10 11 ao-ao others 3+4 3+4 F0 average: n.s. F0 shape: * F0 average: n.s. F0 shape: n.s. Figure 5
F0 curves of the first syllable for the half-third sandhi. (a) represents the real disyllable vs. wug disyllable comparisons for the first syllable in 3+1, 3+2 and 3+4 ; (b) represents the real w1vs. wug w1comparisons
curves representing real words, indicating that there may be incomplete application of the sandhi. To quantify these turning point differences in w1 of the 3+3 combination, we defined EF0 as the difference between the F0 of the beginning of the rhyme and the F0 turning point in the rhyme and TP duration as the duration from the beginning of the rhyme to the
1 2 230 210 190 170 150 F0 (Hz) 2 3 4 5 6 7 8 9 10 11 1 2 230 210 190 170 150 2 3 4 5 6 7 8 9 10 11 ao ag ao-ao others (a) (b) 3+3 3+3 F0 average: n.s. F0 shape: *** F0 average: n.s. F0 shape: *** points points
real s1 vs. wug s1 words real vs. wug disyllables
Figure 6
F0 curves of the first syllable for the third-tone sandhi. (a) and (b) represent the real disyllable vs. wug disyllable and real w1vs. wug w1comparisons respectively.
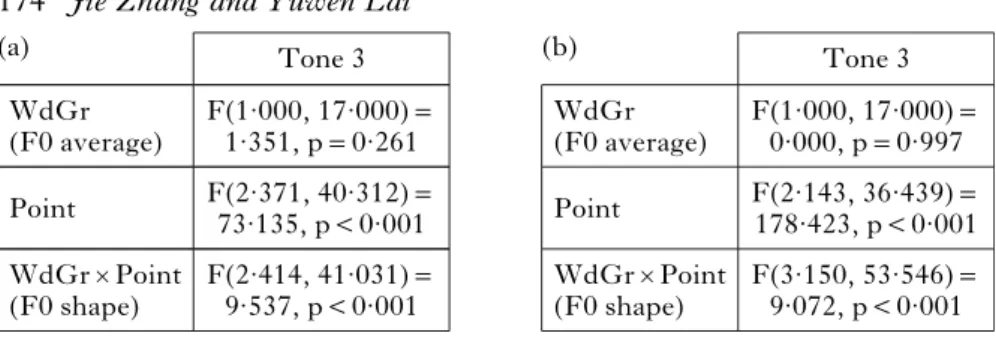
Table I
Two-way repeated-measures ANOVA results for the first syllable F0 curves in the half-third sandhi: (a) real vs. wug disyllables; (b) real s1 vs. wug s1 words.
Tone 1 F(1·000, 17·000)= 0·005, p=0·945 WdGr (F0 average) Tone 2 F(1·000, 17·000)= 0·805, p=0·382 Tone 4 F(1·000, 17·000)= 0·000, p=1·000 F(3·187, 54·180)= 125·614, p<0·001 Point F(2·119, 36·023)= 168·840, p<0·001 F(2·663, 45·263)= 133·073, p<0·001 WdGrXPoint (F0 shape) F(3·574, 60·750)= 0·880, p=0·472 F(2·824, 48·012)= 13·036, p<0·001 F(3·436, 58·409)= 3·535, p=0·016 (a) Tone 1 F(1·000, 17·000)= 0·061, p=0·808 WdGr (F0 average) Tone 2 F(1·000, 17·000)= 0·000, p=0·997 Tone 4 F(1·000, 17·000)= 0·189, p=0·670 F(3·275, 55·680)= 167·524, p<0·001 Point F(2·143, 36·439)= 178·423, p<0·001 F(2·651, 45·059)= 117·356, p<0·001 WdGrXPoint (F0 shape) F(2·545, 43·265)= 2·178, p=0·113 F(3·150, 53·546)= 9·072, p<0·001 F(2·942, 50·011)= 2·265, p=0·093 (b)
turning point. Results of comparisons between real and wug disyllables and between real and wug w1’s on EF0 and TP duration for 3+3 are given in Figs 7 and 8 respectively. In these and following figures, error bars indicate one standard deviation. One-way repeated-measures ANOVAs with WordGroup as the independent factor indicate that for EF0, AO-AO is significantly different from other word groups (F(1.000, 17.000)= 8.543, p<0.01), as is w1=AO from w1=AG (F(1.000, 17.000)=48.254, p<0.001) ; for TP duration, AO-AO is significantly different from other word groups (F(1.000, 17.000)=19.561, p<0.001), as is w1=AO from w1=AG (F(1.000, 17.000)=21.343, p<0.001). These results support our hypothesis : with a lower and later turning point, the sandhi tone on wug words is more similar to the original Tone 3 than that on real words, indicating incomplete application of the sandhi in wug words.
3.2.2 Rhyme duration. The results for w1rhyme duration for all the tonal combinations are given in Fig. 9, and the statistical results are summarised
Table II
Two-way repeated-measures ANOVA results for the first syllable F0 curves in the third-tone sandhi: (a) real vs. wug disyllables; (b) real s1 vs. wug s1 words.
Tone 3 F(1·000, 17·000)= 1·351, p=0·261 WdGr (F0 average) Tone 3 F(1·000, 17·000)= 0·000, p=0·997 F(2·371, 40·312)= 73·135, p<0·001 Point F(2·143, 36·439)= 178·423, p<0·001 WdGrXPoint (F0 shape) F(2·414, 41·031)= 9·537, p<0·001 F(3·150, 53·546)= 9·072, p<0·001 (a) (b) WdGr (F0 average) Point WdGrXPoint (F0 shape) (a) 40 (b) 30 20 10 0 B F0 (Hz) wug disyllables B F0 (Hz) 40 30 20 10 0 ** *** real disyllables wug s1 words real s1 words Figure 7
EF0 results for 3+3. (a) and (b) represent the real disyllable vs. wug disyllable and real w1vs. wug w1comparisons respectively.
in Table III. One-way repeated-measures ANOVAs with WordGroup as the independent factor show that there are no significant differences be-tween AO-AO and other word groups for any of the tonal combinations. But for 3+3, the difference approaches significance, at p<0.05 (F(1.000,
3+1 3+2 3+3 3+4 (a) 300 250 200 150 100 50 0 s1 duration (ms) ao-ao others 3+1 3+2 3+3 3+4 (b) 300 250 200 150 100 50 0 s1 duration (ms) ao ag * Figure 9
Rhyme duration of w1for all tonal combinations. (a) and (b) represent the real disyllable vs. wug disyllable and real w1vs.wug w1comparisons respectively.
(a) 100 (b) 80 60 40 20 0 TP duration (ms) TP duration (ms) *** *** 100 80 60 40 20 0 wug disyllables real disyllables wug s1 words real s1 words Figure 8
TP duration results for 3+3. (a) and (b) represent the real disyllable vs. wug disyllable and real w1vs.wug w1comparisons respectively.
17.000)=4.218, p=0.056), and the difference is in the expected direction, i.e. wug>real. For AO vs. AG, 3+3 is the only combination in which the wug words have a significantly longer w1 rhyme duration than the real words (F(1.000, 17.000)=5.653, p<0.05). These results support our hypothesis : the durational property for the sandhi syllables is identical for real and wug words for the half-third sandhi, but for the third-tone sandhi, the sandhi-syllable rhyme duration in wug words is longer than in real words, again indicating incomplete application of the sandhi in wug words. These results are consistent with an approach that encodes phonetic biases in the grammar, but not with a frequency-only approach, as the latter predicts a greater durational difference between real and wug words for 3+2 than for 3+3, due to the former’s lower lexical frequency.
3.3 Discussion
Our third-tone sandhi results indicate a significant difference between real words and wug words in the contour shape of the sandhi tone ; in particular, the contour shape of the sandhi tone in wug words shares a greater similarity with the original Tone 3 in having a lower and later turning point and a longer tone duration. Given that we did not judge any 3+3 tokens in the data to have non-application of the third-tone sandhi, the difference between real and wug words for the third-tone sandhi was due not to the non-application of the sandhi to a limited number of tokens/speakers, but to the incomplete application of the sandhi to a large number of tokens. The real vs. wug comparison for the half-third sandhi, however, showed identical contour shapes for the sandhi tone for Tone 1, an inconsistent contour-shape difference for Tone 4 (a difference at p<0.05 level (p=0.016) for the disyllabic comparison, but no difference for the AO vs. AG comparison), and a significant contour shape difference
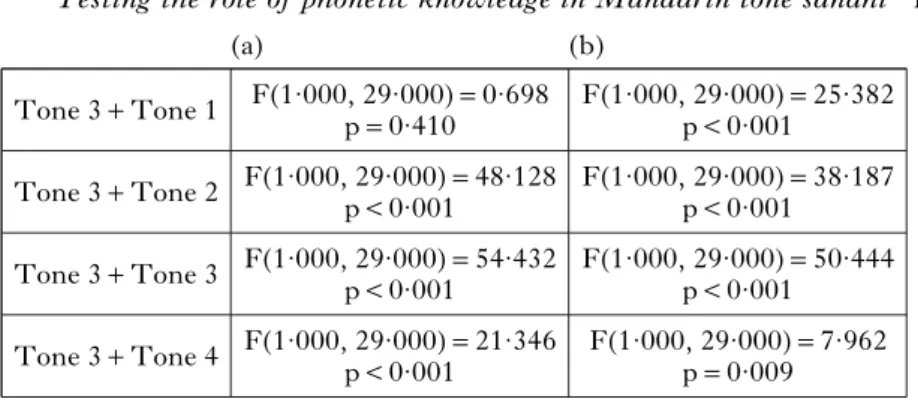
Tone 3+Tone 3
Table III
One-way repeated-measures ANOVA results for the s1 rhyme duration in all tonal combinations: (a) real vs. wug disyllables; (b) real s1 vs. wug s1 words.
F(1·000, 17·000)=0·660 p=0·428 Tone 3+Tone 1 F(1·000, 17·000)=0·206 p=0·656 Tone 3+Tone 2 F(1·000, 17·000)=4·218 p=0·056 (a) (b) F(1·000, 17·000)=0·620 p=0·442 Tone 3+Tone 4 F(1·000, 17·000)=0·097 p=0·759 F(1·000, 17·000)=0·559 p=0·465 F(1·000, 17·000)=5·653 p=0·029 F(1·000, 17·000)=1·118 p=0·305
for Tone 2, which indicates incomplete application of the sandhi. This shows (a) that the half-third sandhi behaves differently in different en-vironments, and (b) that the sandhi with the lowest type frequency (3+2) also applies less consistently to wug words than to real words.
The real disyllable vs. wug disyllable and real-w1vs. wug-w1 compari-sons returned similar results. But the difference between the two sandhis is more apparent in the real-w1vs. wug-w1comparison, as indicated by the equal or more significant difference for the third-tone sandhi and the equal or less significant difference for the half-third sandhi between the two groups for all F0 measures.
Therefore, our hypothesis that the difference in sandhi tones between real words and wugs should be greater for cases of third-tone sandhi than half-third sandhi finds support in the facts that (a) the difference between real and wug words for the third-tone sandhi can be translated into in-complete application for the sandhi in wug words, and (b) there is no consistent difference between real and wug words for the half-third sandhi. We have also found an effect that is potentially due to type fre-quency : the half-third sandhi in 3+2 also applies incompletely to wug words. The effects overall, however, are not consistent with a frequency-only account, as the differences between real and wug words are more consistent for 3+3 than 3+2, as evidenced by the lack of rhyme duration difference in 3+2.
These results must be interpreted cautiously, however, for two reasons. First, the differences between real and wug words in the third-tone sandhi, although statistically highly significantly, are quite small. It is thus important for us to be able to replicate these results in a separate exper-iment. Second, although all of our participants came from northern areas of Mainland China and spoke Standard Mandarin natively without any noticeable accent, they did have backgrounds in different Northern Chinese dialects. This could potentially have an effect on the results. Experiment 2 was designed to address these issues.
4 Experiment 2
The goals of Experiment 2 are twofold : first, it serves as a replication of Experiment 1 ; second, it includes only participants who grew up in Beijing, and thus minimises the potential dialectal effects on the results.
4.1 Methods
The methods of Experiment 2 were identical to those of Experiment 1, except that the experiment was conducted in the Phonetics Laboratory of the Department of Chinese Language and Literature at Beijing University in China, and that the recordings were made by a Marantz solid state recorder PMD 671 using a EV N/D 767a microphone. The sampling rate
of the solid state recorder was 44.1 kHz, and the digital recording was not further downsampled.10
Thirty-one native speakers of Beijing Chinese (9 male, 22 female), recruited at Beijing University, participated in the experiment. All sub-jects had grown up and gone through their primary and secondary schooling in Beijing, and none reported being conversant with any other dialects of Chinese. The subjects ranged from 19 to 37 years in age. Each subject was paid a nominal fee for participating in the study. Due to technical problems with Superlab, we were not able to use one male speaker’s data. We therefore report data from 30 speakers.
4.2 Results
4.2.1 F0 contour. The F0 contour results for the half-third sandhi comparisons are given in Fig. 10. For both Tones 1 and 4, the subjects’ performance on the half-third sandhi on wug words is generally identical to that on real words in terms of both the average F0 and the F0 contour shape. This is true for both the disyllabic and w1comparisons for Tone 1 and the w1 comparisons for Tone 4. For the disyllabic comparison for Tone 1, however, the p value is right at 0.05, and this needs to be acknowledged. When w2has Tone 2, the average F0 pitch on w1is signifi-cantly lower for wug words than real words for the disyllabic comparison, and the F0 shape between real and wug words is significantly different for the AO vs. AG comparisons. The statistical results for these comparisons are given in Table IV.
The difference in the F0 shapes of real-w1and wug-w1words for 3+2 lies in the fact that the F0 shape for the wug words has a turning point at around 80 % into the tone, while the F0 shape for the real words falls monotonically throughout the rhyme. This is similar to the F0 shape difference in both real vs. wug comparisons in Experiment 1. It again indicates that there may be incomplete application, and hence lower ac-curacy/productivity, of the half-third sandhi in 3+2.
The results from the third-tone sandhi comparisons are given in Fig. 11. Two-way repeated-measures ANOVAs indicate that both the average F0 and the F0 contour shape are significantly different for real words and wug words, for both comparisons. The ANOVA results are summarised in Table V.
We have replicated our major finding regarding the F0 contours in Experiment 1 : the w1 in 3+3 sequences show consistent contour-shape 10 We manipulated the duration of the second syllable of the stimuli in Praat in the
following way. We took the median rhyme duration of the 160 second syllables in the test stimuli (454 ms), and either expanded or shrank the duration of the rhymes of all second syllables to the same duration. We then calculated the expansion or shrinkage ratio of each rhyme and applied the same ratio to the VOT, frication duration or sonorant duration of its onset consonant. The duration of the fillers remained unchanged. This duration manipulation was conducted in order to minimise the allophonic durational differences among different tones so that the reaction time hypothesis could be better tested (cf. note 7).
differences for the real and wug words in the two comparisons. This experiment also shows that there is an average pitch difference for 3+3 between real and wug words. Moreover, other tonal sequences do not show differences between real words and wug words, except for 3+2 – the tonal combination that has the lowest type frequency. However, 3+2 differences between real and wug words are less consistent than 3+3 differences. This would not be consistent with a frequency-only account, but would be consistent with an account in which both phonetics and frequency are relevant.
From Fig. 11, we can see that the contour shape difference between real and wug words for 3+3 is similar to that in Experiment 1 : the turning
1 2 230 210 190 170 150 F0 (Hz) 2 3 4 5 6 7 8 9 10 11 ao ag 1 2 230 210 190 170 150 2 3 4 5 6 7 8 9 10 11 ao-ao others (a) (b) 3+ +1 points points F0 average: n.s. F0 shape: n.s. F0 average: n.s. F0 shape: n.s. 1 2 230 210 190 170 150 F0 (Hz) 2 3 4 5 6 7 8 9 10 11 ao ag 1 2 230 210 190 170 150 2 3 4 5 6 7 8 9 10 11 ao-ao others 3+ +2 F0 average: *** F0 shape: n.s. F0 average: n.s. F0 shape: * 1 2 230 210 190 170 150 F0 (Hz) 2 3 4 5 6 7 8 9 10 11 ao ag 1 2 230 210 190 170 150 2 3 4 5 6 7 8 9 10 11 ao-ao others 3+ 1 3 2 3 4 3+4 F0 average: n.s. F0 shape: n.s. F0 average: n.s. F0 shape: n.s.
real vs. wug disyllables real s1 vs. wug s1 words
Figure 10
points for wug words are both lower and later than their counterparts in real words, indicating that there may be incomplete application of the sandhi in the wug words.
The comparisons between real and wug disyllables and between real and wug w1’s on EF0 for 3+3 are given in Fig. 12. A one-way repeated-measures ANOVA indicates that AO-AO has a significantly smaller EF0
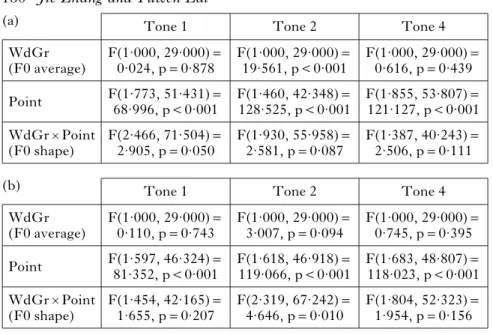
Table IV
Two-way repeated-measures ANOVA results for the first syllable F0 curves in the half-third sandhi: (a) real vs. wug disyllables; (b) real s1 vs. wug s1 words.
Tone 1 F(1·000, 29·000)= 0·024, p=0·878 WdGr (F0 average) Tone 2 F(1·000, 29·000)= 19·561, p<0·001 Tone 4 F(1·000, 29·000)= 0·616, p=0·439 F(1·773, 51·431)= 68·996, p<0·001 Point F(1·460, 42·348)= 128·525, p<0·001 F(1·855, 53·807)= 121·127, p<0·001 WdGrXPoint (F0 shape) F(2·466, 71·504)= 2·905, p=0·050 F(1·930, 55·958)= 2·581, p=0·087 F(1·387, 40·243)= 2·506, p=0·111 (a) Tone 1 F(1·000, 29·000)= 0·110, p=0·743 WdGr (F0 average) Tone 2 F(1·000, 29·000)= 3·007, p=0·094 Tone 4 F(1·000, 29·000)= 0·745, p=0·395 F(1·597, 46·324)= 81·352, p<0·001 Point F(1·618, 46·918)= 119·066, p<0·001 F(1·683, 48·807)= 118·023, p<0·001 WdGrXPoint (F0 shape) F(1·454, 42·165)= 1·655, p=0·207 F(2·319, 67·242)= 4·646, p=0·010 F(1·804, 52·323)= 1·954, p=0·156 (b) points points 1 2 230 210 190 170 150 F0 (Hz) 2 3 4 5 6 7 8 9 10 11 1 2 230 210 190 170 150 2 3 4 5 6 7 8 9 10 11 ao ag ao-ao others 3+3 3+3 F0 average: * F0 shape: *** F0 average: ** F0 shape: ***
(a) real vs. wug disyllables (b) real s1 vs. wug s1 words
Figure 11
than other word groups (F(1.000, 29.000)=4.457, p<0.05), as does w1= AO in comparison with w1=AG (F(1.000, 29.000)=28.523, p<0.001).
Comparisons between real and wug words for TP duration of 3+3 are given in Fig. 13. A one-way repeated-measures ANOVA indicates that AO-AO has a significantly shorter TP duration than other word groups (F(1.000, 29.000)=28.793, p<0.001), as does w1=AO in comparison with w1=AG (F(1.000, 29.000)=56.235, p<0.001).
Given that we will see inw4.2.3 that wug words generally have a longer w1rhyme duration than real words, we also calculated the TP duration as a percentage of the entire w1 rhyme duration and compared the real words with wug words, to ensure that the longer TP duration in wug words is not simply due to the longer w1 duration. These comparisons are shown in Fig. 14. ANOVA results show that the AO-AO turning point is still sig-nificantly earlier than that of other word groups (F(1.000, 29.000)=5.082, p<0.05), as is w1=AO in comparison with w1=AG (F(1.000, 29.000)= 34.617, p<0.001).
Table V
Two-way repeated-measures ANOVA results for the first syllable F0 curves in the third-tone sandhi: (a) real vs. wug disyllables; (b) real s1 vs. wug s1 words.
Tone 3 F(1·000, 29·000)= 4·946, p=0·034 WdGr (F0 average) Tone 3 F(1·000, 29·000)= 11·153, p=0·002 F(1·643, 47·654)= 154·695, p<0·001 Point F(1·720, 49·893)= 192·180, p<0·001 WdGrXPoint (F0 shape) F(2·161, 62·678)= 12·291, p<0·001 F(2·319, 67·250)= 18·352, p<0·001 (a) (b) WdGr (F0 average) Point WdGrXPoint (F0 shape) real disyllables wug disyllables real s1 words wug s1 words * *** (a) 20 (b) 15 10 5 0 B F0 (Hz) B F0 (Hz) 20 15 10 5 0 Figure 12 EF0 results for 3+3.
We have replicated our turning point results in Experiment 1 : the w1 turning point in 3+3 sequences is significantly lower and later in wug words than real words, which makes the tone more similar to the original Tone 3 in wug words, indicating incomplete application of the sandhi in wug words.
4.2.2 Rhyme duration. The results for w1rhyme duration for all the tonal combinations are given in Fig. 15. For the AO-AO vs. other comparison, a repeated-measures ANOVA shows that there is a significant WordGroup effect : F(1.000, 29.000)=58.058, p<0.001 ; the ANOVA results within each tone, summarised in Table VI, show that except for 3+1, the wug words have a significantly longer w1 rhyme duration than AO-AO. For the AO vs. AG comparison, the ANOVA again shows a significant WordGroup effect : F(1.000, 29.000)=58.576, p<0.001 ; the ANOVA results within each tone, also summarised in Table VI, show that the AG words have a significantly longer w1rhyme duration than AO words for all of the tonal combinations.
(a) 50 (b) 40 30 20 10 0 TP duration (%) TP duration (%) * *** 50 40 30 20 10 0 real disyllables wug disyllables real s1 words wug s1 words Figure 14
TP duration as a percentage of the entire w1rhyme duration in 3+3.
(a) 100 (b) 80 60 40 20 0 TP duration (ms) TP duration (ms) *** *** 100 80 60 40 20 0 real disyllables wug disyllables real s1 words wug s1 words Figure 13
To compare the real vs. wug durational difference in different tonal combinations, we calculated the durational difference between AO-AO and other word groups, as well as between w1=AO and w1=AG for each tonal combination, as shown in Fig. 16, and we conducted a one-way
Tone 3+Tone 3
Table VI
One-way repeated-measures ANOVA results for the s1 rhyme duration in all tonal combinations: (a) real vs. wug disyllables; (b) real s1 vs. wug s1 words.
F(1·000, 29·000)=0·698 p=0·410 Tone 3+Tone 1 F(1·000, 29·000)=48·128 p<0·001 Tone 3+Tone 2 F(1·000, 29·000)=54·432 p<0·001 (a) (b) F(1·000, 29·000)=21·346 p<0·001 Tone 3+Tone 4 F(1·000, 29·000)=25·382 p<0·001 F(1·000, 29·000)=38·187 p<0·001 F(1·000, 29·000)=50·444 p<0·001 F(1·000, 29·000)=7·962 p=0·009 3+1 3+2 3+3 3+4 (a) 300 250 200 150 100 50 0 s1 duration (ms) ao-ao others 3+1 3+2 3+3 3+4 (b) 300 250 200 150 100 50 0 s1 duration (ms) ao ag *** *** *** *** *** ** *** Figure 15