ORIGINAL PAPER
A Newborn Screening System Based on Service-Oriented
Architecture Embedded Support Vector Machine
Kai-Ping Hsu&Sung-Huai Hsieh&Sheau-Ling Hsieh& Po-Hsun Cheng&Yung-Ching Weng&Jang-Hung Wu& Feipei Lai
Received: 16 February 2009 / Accepted: 21 April 2009 / Published online: 5 May 2009 # Springer Science + Business Media, LLC 2009
Abstract The clinical symptoms of metabolic disorders are rarely apparent during the neonatal period, and if they are not treated earlier, irreversible damages, such as mental retardation or even death, may occur. Therefore, the practice of newborn screening is essential to prevent permanent disabilities in newborns. In the paper, we design, implement a newborn
screening system using Support Vector Machine (SVM) classifications. By evaluating metabolic substances data collected from tandem mass spectrometry (MS/MS), we can interpret and determine whether a newborn has a metabolic disorder. In addition, National Taiwan University Hospital Information System (NTUHIS) has been developed and implemented to integrate heterogeneous platforms, protocols, databases as well as applications. To expedite adapting the diversities, we deploy Service-Oriented Architecture (SOA) concepts to the newborn screening system based on web ser-vices. The system can be embedded seamlessly into NTUHIS.
Keywords Web services . Newborn screening .
Service-Oriented Architecture . Tandem mass spectrometry . Support Vector Machine
Introduction
Background
National Taiwan University Hospital (NTUH) initiated its investigation on newborn screening in 1981, and has received and carried on for screening newborn metabolic diseases nationwide since July, 1985. As medical science progressing, more and more advanced newborn screening tests are issued, required. To meet the demands, the hospital has developed and launched the Second Generation
Newborn Screening Information System (SGNSIS) [1, 2]
to improve, enhance the effectiveness of the system while dealing with large and complex data as well as leading to faster and more accurate diagnoses.
As applying the SGNSIS nationwide in Taiwan, innova-tions and refinements of the screening methodology using modern tandem mass spectrometry (MS/MS) becomes DOI 10.1007/s10916-009-9305-6
S.-H. Hsieh (*)
:
S.-L. Hsieh:
Y.-C. Weng:
F. LaiInformation Systems Office, National Taiwan University Hospital, No.7, Chung-San South Road,
Taipei, Taiwan
e-mail: hsiehsh2008@gmail.com
K.-P. Hsu
:
S.-H. Hsieh:
Y.-C. Weng:
F. LaiDepartment of Computer Science and Information Engineering, National Taiwan University,
Taipei, Taiwan F. Lai
Department of Electrical Engineering, National Taiwan University,
Taipei, Taiwan S.-L. Hsieh
:
J.-H. WuNetwork and Computer Centre, National Chiao Tung University, Hsin Chu, Taiwan
F. Lai
Graduate Institute of Biomedical Electronics and Bioinformatics, National Taiwan University,
Taipei, Taiwan P.-H. Cheng
Software Engineering Department, National Kaohsiung Normal University, Kaohsiung, Taiwan
increasingly important. MS/MS can quantify concentrations of up to 35 metabolites simultaneously from a single blood spot [3–5]. Consequently, it leads to high dimensional data for each newborn. Thus, there are two issues raised.
First, the classic cut-off value screening technique can not perform adequately or accurately while handling high dimensional data. Moreover, the manipulating strategies of multi-tiered cut-off schemes [6–8] without conjunction with clinical observations, additional sampling simultaneously, lower sensitivities, specificities or predictive values for metabolic disorder diseases can occur. For instance, the accuracy of MMA (Methylmalonic Acidemia) is between
56∼73% [9]. The inadequate accuracy can cause newborns
losing the opportunities to be treated earlier if they have the metabolic disorder diseases [10].
Secondly, the initiation of screening tests is based upon the past clinical experience of the targeted diseases. Undoubtedly, most screening programs, including MS/MS, can detect subtle variances of the diseases [11]. The natural history of those variances is still unclearly revealed. Now MS/MS can provide large amount of data. Therefore, we can perform data mining processes in order to retrieve, classify more knowledge about those variances.
Related work
The introduction of tandem mass spectrometry (MS/MS) in Portuguese national neonatal screening lab (with over 110,000 samples/year) has led to the development of a new application—NeoScreen—which can help technicians to handle the large amount of data involved (more than 80 parameters/sample) and assist in the implementation of a reliable quality control procedure [12,13]. The application architecture includes Data Acquisition, Processing, Visual-ization and Configuration. The Acquisition reads MS/MS files; the Processing analyzes individual samples, testing for possible diseases and storing results into the NeoScreen database; the Visualization converts data or results into graphical representations; the Configuration provides algo-rithms to identify metabolic diseases. Furthermore, the application provides a mathematical tool or editor. It can automatically generate metabolites expressions as well as dynamic adaptation of diagnostic criterion.
NeoMate [14] and PerkinElmer [15], both provide a
complete Laboratory Information Management System (LIMS) for public health and biomedical research especial-ly for expanded newborn screening. The key features encompass user friendly, customizable demographics entry, automation of specimen receiving, validation, tracking, instrument integration as well as quality control for quantitative measurements of screening results. In addition, PerkinElmer equips a flexible, wide range of facilities for
selected samples’ spectrum or chromatogram presentation
and interrogation. The applications support useful mecha-nisms to simply the newborn screening daily operations.
Furthermore, owing to the amount and complexity of the generated MS/MS screening experimental data, machine learning techniques to investigate patterns for high-dimensional metabolic data are a must. The Support Vector Machine (SVM) is a new technique for data classification
[16–18]. The classification task usually involves with
training and testing data instances; by feeding the algorithms, SVM can construct classification rules, models with high discriminatory power. In addition, a comparison of the SVM to other classifiers has been conducted by Meyer, Leisch and Hornik [19]. The SVM indicates mostly significant perform-ances both on classifications and regression tasks.
Methodologies
Machine learning techniques offer an obvious and
promis-ing approach to examine high dimensional data [20]. Thus,
the goal of the paper is to design, implement a newborn screening analysis system. The system utilizes machine learning techniques, i.e., SVM, and mining knowledge to establish the classification models for metabolic disorders screenings and diagnoses. The models can generate high discrimination and improve prediction accuracies.
In addition, the SGNSIS [2] has been developed, deployed based on middleware, SOA technologies [21,22], i.e., Web Services.NET [23,24]. SOA represents the current pinnacle of interoperability, in which resources distributed over networks are available as individual, loosely-coupled and
independent services [25–28]. SOA is a desirable and
inevitable solution to integrate diverse platforms, database as well as further merging, extending into NTUHIS.
In the following sections of the paper, we first elaborate the design of the overall Web Services Newborn Screening System Architecture including SVM classification features. In“SVM web services components”, detailed descriptions of system components, SVM modules, functionalities, as well as communication mechanisms among the components are illustrated. In“Integrated scenarios and implementation”, an integrated SVM services with data flow scenario and sequence are provided. The measurements, experimental results are presented in“Experimental data flow and results”. Finally, the paper discusses and concludes particularly in “Discussion” and “Conclusion”.
SOA SVM screening system architecture
Overall architecture
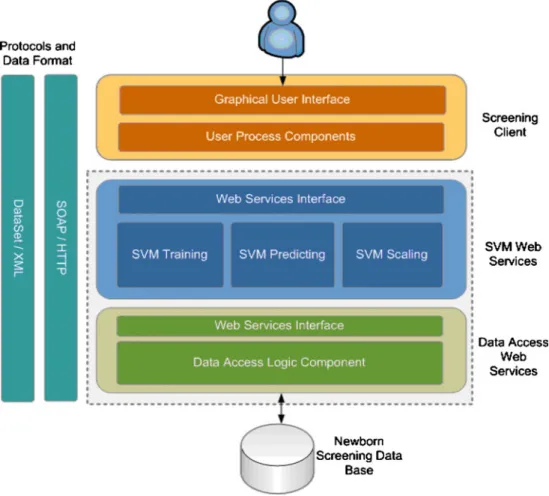
The SOA-based SVM screening system architecture contains three major portions: the Client, the Server and the Database as
depicted in Fig.1. The Client, which is accessed by physicians or healthcare practitioners, provides a friendly graphical user interface to interact with the Server and the Database. At the Server, we implement the SVM functionalities, such as SVM Training, SVM predicting, SVM scaling, and Data Access Logic, embedded under the Web Services.NET environment. The Database stores the Newborn Screening data collected from the MS/MS, the SVM classifiers, or the Trained Models generated by the training results. All system components utilize the eXtensible Markup Language (XML) format for exchanging messages, and the communication mechanism is based on a Simple Object Access Protocol (SOAP) over HTTP handled internally by the .NET [2,9,29,30].
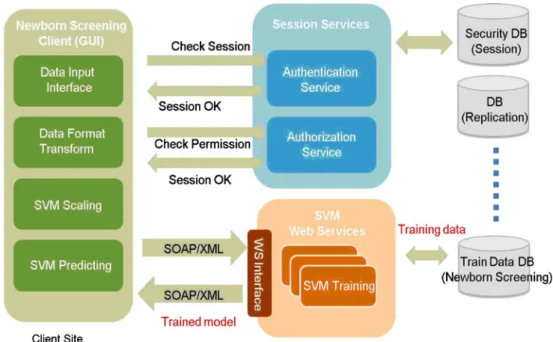
Authentication/authorization
Medical records including screening data and results must be protected from unauthorized access to comply with Health Insurance Portability and Accountability Act (HIPAA) regulations.
Figure2indicates that prior to the SVM screening users
from Client Site must be authenticated and authorized. After validation, the SVM methods i.e., MS/MS data repository and transformation, SVM scaling as well as
SVM predicting can be performed. Afterwards, the trained models will be calculated, stored in Database.
SVM web services components
The descriptions of the components are illustrated in this section.
SVM screening system approach
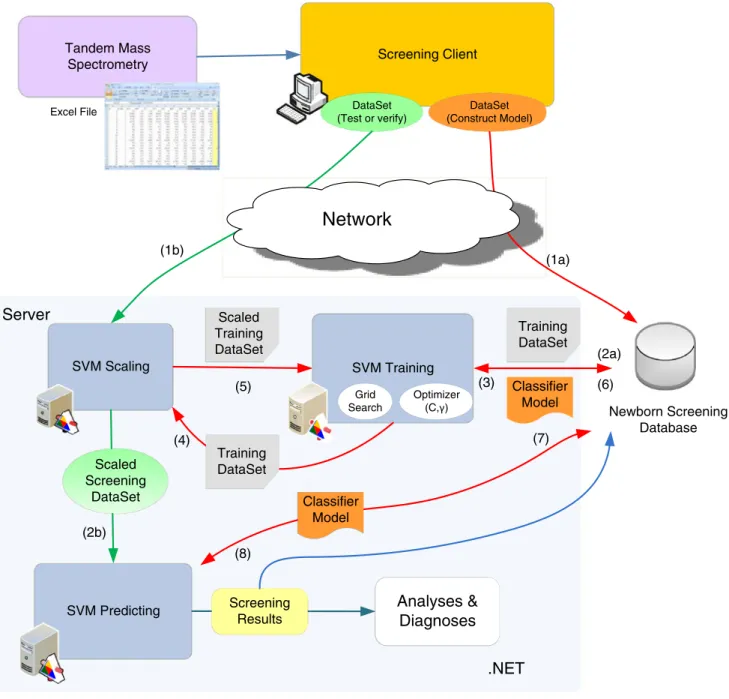
SVM Screening system activities are depicted in Fig.3. In
the diagram, after the experimental dataset (i.e., the Excel file) from MS/MS is transformed into a.Net DataSet. At the Screening Client site, the DataSet is randomly separated into two portions. One portion is the training data, which is used for constructing the Trained Model (1a). The other portion is used as the testing data for predicting (1b). Both data are temporarily placed at the Client Site for the training and predicting processes. The results can be analyzed and diagnosed to clarify the accuracy of the research.
In the diagram, while a Screening Client asking for testing (1b), the Server retrieves Training DataSet from the Database (2a:request & 3:response respectively). Both the
Fig. 1 Support vector machine screening system based on service-oriented architecture
Testing DataSet and the Training DataSet need to be scaled (SVM Scaling Module) prior to passing to either SVM Training or SVM Predicting Modules in (2b & 5). According to the Scaled Training DataSet (5), the Trained Model will be generated, deposited into the Database (6). While constructing the classifier, the optimization processes are performed repeatedly to increase the accuracy of the Model. The accuracy of the SVM Model is largely dependent on the selection of the model parameters, i.e., C and Gamma. A Grid Search and an RBF (Radial Basis Function) kernel function with two parameters C and Gamma are used to optimize the model selection. During the computational iteration, the ranges of parameters, C and Gamma, are resizing accordingly [31]. Therefore, the classifier, or Trained Model, can accurately predict an unknown dataset, or the Testing DataSet. The SVM predicting module performs discriminat-ing to a scaled Testdiscriminat-ing DataSet accorddiscriminat-ing to a Trained Model. The Trained Model is retrieved from the System Database, previously stored by the SVM Training Module (2b, 7:request & 8:response respectively).
Screening client site
The Screening Client is an application. It provides a friendly user graphical interface. The application supports functionalities as listed below:
1. Read or input the metabolic substances concentration data, an Excel file as shown in the left upper corner of
Fig. 1, generated by the Tandem Mass Spectrometry.
The application converts or transforms the file into a DataSet (the format required by .NET). The concentra-tion data can be either a set of data retrieved from well
known metabolic diseases to establish SVM Trained Model or a set of unknown data to be verified for diagnosis, analyzing later.
2. Invoke the SVM-Training Method and obtain the Trained Model, i.e., SVM classifier, as the return value. The Model is later stored into the Newborn Screening System Database.
3. Pass a newborn’s DataSet and a Trained Model as parameters to the SVM Predicting Method; according to the Predicting result, determine whether the neonatal has metabolic disorder disease specified by the Trained Model. 4. Store the results into the Newborn Screening System
Database.
SVM methods based on web services
The Server supports the following functionalities, methods. 1. SVM Training Method: the primary function: svm_train,
indicated in Fig. 3, is to perform separating the
metabolic substances DataSet retrieved from the Data-base, proceed optimizing, and generate the Trained Model. In the diagram, there are accessory functions to assist the training processes as well (Fig.4).
2. SVM Predicting Method: the module performs predicting of a scaled Testing DataSet according to a Trained Model. The Trained Model is retrieved from the System Database, previously stored by the SVM Training Module (as shown in Fig. 1, (2), (7) & (8)). The Predicting Method returns the screening results, display them, and store them into the System Database for further analyses and diagnoses. The outcomes classify, or interpret the possibilities of metabolic disorder diseases.
Fig. 2 Authentications and authorizations by session services
3. SVM Scaling: the function is to avoid data attributes, either Testing DataSet or Training DataSet, in larger numeric ranges and induce calculating difficulties. 4. Data Access Services: the Services provide interfaces to
either Clients or accessing the Newborn Screening System Database.
Integrated scenarios and implementation
The sequence diagrams for the SOA Newborn Screening
System operational scenarios are depicted in Fig. 5. The
System has integrated the SVM mechanisms, such as
Training, Scaling, Predicting Modules, etc., under a Web Services.NET environment.
At first, the experimental dataset was collected according to an anonymous subset of all data obtained from the Newborn Screening Centre of NTUH between 2001 and 2006. Blood samples which had been taken within a few days of the newborns’ birth were analyzed by MS/MS using a high throughput process, and the measured metabolic datasets (35 measured metabolites including amino acids, long fatty acid chains and acyl carnitines) were saved in Excel files and were stored in a database. This study primarily focuses on improving the accuracy of identifying the MMA (Methylmalonic Acidemia) metabolic
Screening Client Tandem Mass
Spectrometry
Excel File DataSet
(Test or verify) SVM Training SVM Predicting
.NET
Server
Analyses &
Diagnoses
Screening Results Grid Search Optimizer (C, ) SVM ScalingNetwork
(1a) (2a) (4) (5) (6) (8) (3) Classifier Model Training DataSet Scaled Training DataSet Training DataSet Classifier Model (7) (1b) (2b) Newborn Screening Database DataSet (Construct Model) Scaled Screening DataSetdisease. This approach can definitely be extended to analyze other diseases as well.
First, by invoking the SVM Training Service, additional optimization processes occur repeatedly in order to obtain a
highly accurate classifier. The classifier is then utilized by the SVM Predicting Service as an input parameter. Before activating both Services, the input datasets (either the Training DataSet or the Testing DataSet for prediction) Fig. 4 SVM server functionalities
Tandem Mass
Spectrometry SVM Training SVM Predicting
Screening Clinet SVM Scaling Data Access Logic Newborn Screening Data Base Get MS/MS result Excel file
Input Excel file Invoke SVMTraining
ACK
Display Predicting Result
Return Predicting Result Request Training Dataset
Return Training Dataset
Store Trained Model Scaling the Training Dataset
Return Scaled Training Dataset
Pass Dataset, invoke SVM
Predicting Request Trained Model
Store Max, Min Value of Marker
Return Trained Model Scaling DataSet
Return Scaled DataSet
Request Max, Min Value of Marker Return Max, Min Value of Marker
Confirmed case
Store Confirmed Case to DataBase Fig. 5 System operational
are scaled via the SVM Scaling Service in order to avoid data attributes in large numerical ranges, which can induce calculation difficulties. Requests and responses among the associated components in the operational scenarios are clearly indicated in Fig.5.
Experimental data flow and results
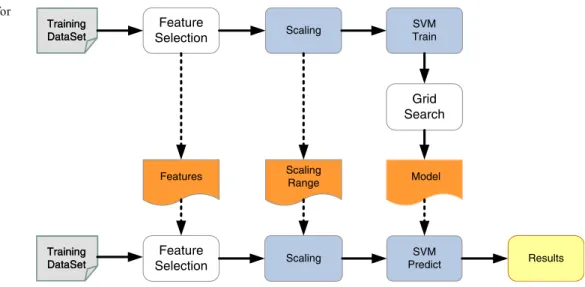
In the study, we propose a proper supervised classification data flow [18] to enhance the accuracy and sensitivity of Newborn Screening process, as depicted in Fig.6. In the diagram, the Train Dataset undergoes learning to produce the SVM prediction model; the New Dataset processes the same methods to obtain the prediction result according to the trained model. Before training or predicting, the dataset is preprocessed by the MS/MS machine. The Feature Selection part will generate the most relevant features by a Pearson-like
formula [32]. The Scaling method is used to avoid biasing
and to improve computing efficiency. The SVM machine learning with Grid Search as well as Cross validation then generates the prediction model for the New Dataset [33].
During the experiment, we focused on the Methylma-lonic Acidemia (MMA) metabolic disorder preliminarily. We collected 360 newborn samples gained from Newborn Screening Centre of National Taiwan University Hospital between 2001 and 2006. All the samples are divided into three parts, 1/2 for Train DataSet, 1/4 for the Validation DataSet, the rest for predicted New DataSet. The effective-ness of the classifiers is summarized in Table1.
In the Table1, the first four rows present the cases that used traditional cut-off value screening method; the last row means the results from SVM web services proposed in this paper. The Sensitivity column shows the developed SVM method get the best 95.9% sensitivity. In Specificity column displays that the SVM approach achieves the highest 95.6% specificity compared with the classic cut-off
technique listed in low 1–4. Similarly, it also indicates that SVM performs the highest accuracy as listed in the last column. Obviously, the SVM approach, using higher dimensional selected features method, demonstrates better discrimination power and increase the accuracy accordingly.
Discussion
The NTUH newborn screening Program has educational and monitoring mechanisms in place to prevent and investigate any possible problems [1]. However, it is still critical for health care providers to remain watchful for any signs or symptoms of these disorders in their patients. Any signs or symptoms of a disorder should be followed up immediately. The possibility of a disorder should not be ruled out solely on the basis of the newborn screening test result. A newborn screening result should not be considered diagnostic, and cannot replace the individualized evaluation and diagnosis of an infant by a well-trained, knowledgeable healthcare provider. Undoubtedly, the timely delivery of complete and accurate information can enhance the oppor-tunities to immunize the newborns. Performance: SVM pilot stage education cannot be obtained. After integration T
Trraaiinniinngg D DaattaaSSeett Feature Selection Scaling SVM Train T Trraaiinniinngg D DaattaaSSeett Features Scaling Range Grid Search Model SVM Predict Results Scaling Feature Selection
Fig. 6 Data flow model for newborn screening
Table 1 The sensitivity, specificity and accuracy results detected on the experiment results
Metabolites (MMA) Sensitivity (%) Specificity (%) Accuracy (%) C3 81.4 76.2 73.1 C2 67.7 88.5 63.2 C3/C2 76.0 90.6 56.7 C4DC 70.4 84.8 68.6 SVM 95.9 95.6 96.8
with HIS, We can provide detailed performance of evalua-tion data.
The purpose of newborn screening test is to sort out apparently healthy individuals who have a disease from those who probably do not. However, screening programs are, by nature, imperfect. In setting cutoffs, a balance must be struck between time, money, anxiety caused by false positives, and an acceptable number of missed cases. On one hand, laboratory advances in tandem mass spectrometry make it possible to screen newborns for many rate inborn errors of metabolism. This raises many policy issues including screen-ing’s cost-effectiveness, ethics, quality, and oversight. On the other hand, new techniques in genetics surveillance have facilitated an improved public health approach to the detection of, and interventions offered for, a range of important genetic conditions. Over the past 10 years, scientific advances associated with genetic have been increasing at an explosive rate. This has meant that an increasing number of diagnostic, predictive and carrier tests are available, for instance, leaning towards data mining technologies.
Conclusion
Based on SOA concepts, we developed three main functions of the SVM (i.e., training, predicting, scaling) using Web Services techniques. The design inherited SOA flexibilities and will provide additional cooperation for further integration and deployment.
In the study, we also proposed a Newborn Screening System that predicts whether the newborn has metabolic disorder diseases based on modified Support Vector Machines (SVM) classifier. Applying the architecture, the predicting accuracy of MMA can be improved from 56∼73% (cut-off value approach) to over 96%, the sensitivity can be improved from 70∼81% to over 95%.
Up to now, the MS/MS newborn screening at the NTUH has accumulated around 400,000 pieces of data in 5 years. The NTUH has dedicated the manpower to digitize the paper data, and after the data is converted, they provide opportu-nities to apply the SVM-based Screening System for classifying other metabolic disorder diseases and to obtain higher discrimination accuracies. Ultimately, the System can replace the classic cut-off value screening technique.
The newborn screening programs in Taiwan are continu-ing to refine and expand their Newborn Screencontinu-ing Services. There are many research projects ongoing, for instances, the particular interests are: (1) congenital adrenal hyperplasia; (2) glucose-6-phosphate dehydrogenase deficiency; (3) galactosemia; (4) congenital hypothyroidism; (5) Fabry disease; 6) Pompe disease. In the future, we hope that this successful mining experience with MS/MS newborn screen-ing may be extended to other newborn diseases.
Acknowledgments The authors would like to acknowledge mem-bers of the Pediatrics and Medical Genetics Office, the Information Systems Office at NTUH for their assistance.
References
1. Tu, C.-M., Chang, H.-Y., Tang, M.-Y., Lai, F., et al., The design and implementation of a next generation information system for newborn screening, HEALTHCOM 2007, June, 2007.
2. Hsieh, S.-h., Hsieh, S.-L., Chien, Y.-H., Wang, Z., and Lai, F.,A newborn screening system based on the service-oriented architec-ture. J. Med. Syst. Mar. 24, 2009; SCI, doi: 10.1007/s10916-009-9265-x.
3. Chace, D. H., Kalas, T. A., and Naylor, E. W., Use of tandem mass spectrometry for multianalyte screening of dried blood specimens from newborns. Clin. Chem. 49:1797–1817, 2003. doi:10.1373/clinchem.2003.022178.
4. Pinheiro, M., Oliveira, J. L., Santos, M. A. S., Rocha, H., Cardoso, M. L., and Vilarinho, L., NeoScreen: A software application for MS/MS newborn screening analysis. In Biological and Medical Data Analysis (ISBMDA'2004), Lecture Notes in Computer Science—Volume 3337, Barcelona, Spain, 2004. 5. Expanded Newborn Screening using Tandem Mass Spectrometry
Financial, Ethical, Legal and Social Issues (FELSI),http://www. newbornscreening.info.
6. Olgemoller, B., et al: Screening for congenital adrenal hyperpla-sia: adjustment of 17-hydroxyprogesterone cut-off values to both age and birth weight markedly improves the predictive value. J. Clin. Endocrinol. Metab. 88(12):5790–5794, 2003. doi:10.1210/ jc.2002-021732.
7. McGhee, S. A., Stiehm, E. R., Cowan, M., Krogstad, P. and McCabe, E. R. B., Two-tiered universal newborn screening strategy for severe combined immunodeficiency, Nov. 2, 2005;
http://www.sciencedirect.com.
8. Webster, D., Quality performance of newborn screening systems: Strategies for improvement. J. Inherit. Meta. Dis. 30:576–584, 2007. 9. Tu, C.-M., The New Generation of Information System for Newborn Screening—A Case Study of National Taiwan University Hospital, Dept. of Computer Science and Information Engineering, National Taiwan University, Taiwan, Master Thesis, June, 2007.
10. Georgia Newborn Screening Manual for Metabolic Diseases and Hemoglobinopathies, Georgia Department of Human Resources, Division of Public Health, 2007.
11.http://www.slh.wisc.edu/wps/scm/connect/extranet/, “Wisconsin Newborn Screening Laboratory.
12. Pinheiro, M., Oliveira, J. L., Santos, M. A. S., Rocha, H., Cardoso, M. L., and Vilarinho, L., NeoScreen: A software application for MS/MS newborn screening analysis. In Biological and Medical Data Analysis (ISBMDA'2004), Lecture Notes in Computer Science—Volume 3337, Barcelona, Spain, 2004. 13. Pinheiro, M., Oliveira, J. L., Santos, M. A. S., Rocha, H.,
Cardoso, M. L., and Vilarinho, L., A computer-based solution for screening of inherited metabolic diseases. J. Inherit. Metab. Dis. 27(Suppl. 1):4, 2004. (abstract).
14. Accelerated Technology Laboratories, Inc.http://www.atlab.com/ Neomate.php. As of 09/01/2008
15. Perkinelmer.http://www.perkinelmer.com/. As of 09/01/2008. 16. Cortes, C., and Vapnik, V. (1995). Support-vector network. 17. Chen, P. H., Fan, R. E., and Lin, C. J., A study on SMO-type
decomposition methods for support vector machines, January 2005. 18. Baumgartner, C., Böhm, C., and Baumgartner, D., Modelling of classification rules on metabolic patterns including machine learning and expert knowledge. J. Biomed. Inform. 38(2):89–98, 2005. doi:10.1016/j.jbi.2004.08.009.
19. Meyer, D., Leisch, F., and Hornik, K., Support vector machines. Neurocomputing. 55(1–2):169–186, 2003.
20. Michie, D., Spiegelhalter, D. J., Taylor, C. C., and Campbell, J., Machine learning, neural and statistical classification, 1995. 21. Papazoglou, M. P., and van den Heuvel, W.-J., Service-oriented
architectures: approaches, technologies and research issues. VLDB J. 16(3):389–415, 2007. doi:10.1007/s00778-007-0044-3. 22. Papazoglou, M. P., Service-Oriented Computing: Concepts,
characteristics and directions. Proceedings of the Fourth Interna-tional Conference on Web Information Systems Engineering, p.3, December 10–12, 2003.
23. Krafzig, D., Banke, K., and Slama, D., Enterprise SOA: Service oriented architecture best practices. Prentice-Hall, Englewood Cliffs, 2005.
24. Shepherd, M., Zitner, D., and Watters, C.,“Medical portals: Web-based access to medical information. Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, pp. 1–10, 2000.
25. Freudenstein, P., Nussbaumer, M., Majer, F., et al., A Workflow-Driven Approach for the Efficient Integration of Web Services in Portals, Services Computing, SCC 2007, IEEE International Conference, pp. 410–417, 2007.
26. Murray, M., Strategies for the successful implementation of workflow systems within healthcare: a cross case comparison, System Sciences, 2003. Proceedings of the 36th Annual Hawaii International Conference, pp. 10, 2003.
27. Bunge, R., Chung, S., and Endicott-Popovsky et al., An Operational Framework for Service Oriented Architecture Net-work Security”, Hawaii International Conference on System Sciences, Proceedings of the 41st Annual, pp. 312–312, 2008. 28. Lewis, G. A., Morris, E., Simanta, S., et al., Common
Mis-conceptions about Service-Oriented Architecture, Commercial-off-the-Shelf (COTS)-Based Software Systems, ICCBSS ‘07, Sixth International IEEE Conference, pp. 123–130, 2007. 29. World Wide Web Consortium (W3C), “(SOAP) specifications”
http://www.w3.org/TR/soap/, Feb, 2006.
30. World Wide Web Consortium (W3C),“WSDL Note Version 1.1,” 15 March, 2001,http://www.w3c.org/TR/wsdl/.
31. Ward, J. J., McGuffin, L. J., Buxton, B. F., and Jones, D. T., Secondary structure prediction with support vector machine. Bioinformatics. 19:1650–1655, 2003. doi:10.1093/bioinformatics/ btg223.
32. Forthofer, N., Lee, E. S., and Hernandez, M., Biostatistics, Second Edition: A Guide to Design, Analysis and Discovery, 2006. 33. A Library for Support Vector Machines:http://www.csie.ntu.edu.
tw/∼cjlin/libsvm/index.html.
34. Ohkubo, S., Shimozawa, K., Matsumoto, M., and Kitagawa, T., Analysis of blood spot 17α-hydroxyprogesterone concentration in premature infants—proposal for cut-off limits in screening for congenital adrenal hyperplasia. Acta Paediatr. Jpn. 34:126–133, 1992. 35. Health Information Privacy.http://www.hhs.gov/ocr/privacy/index.