行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※※※
※ ※
※ 寬頻網際網路服務品質保證(II)─總計劃 ※
※ ※
※※※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:□個別型計畫 þ整合型計畫
計畫編號:NSC-89-2219-E-009-003
執行期間: 88 年 08 月 01 日至 89 年 07 月 31 日
計畫主持人:李 程 輝 國立交通大學電信工程學系 教授
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
執行單位:國立交通大學電信工程研究所
中 華 民 國 89 年 月 日
目錄
Abstr act
... 2
中文摘要
... 10
第 一 章 前言
... 13
第 二 章 計劃緣起與目的
... 16
一、大容量路由器與訊務管制技術... 16 二、寬頻網際網路之允入控制及排程技術... 16 三、寬頻網際網路「負載控制服務」以量測為基礎的允諾控制與擁塞避免機制... 18 四、寬頻網際網路中服務品質路由之研究... 19第 三 章 研究方法及結果
... 25
(一)、使用於寬頻網際網路之 GIGABIT路由器與訊務管制技術... 25 A. 適用可變長度封包之 Crossbar 交換機... 25 B. 訊務區分器... 28 B.1 三級訊務區分演算法... 28 B.2 搜尋程序... 30 B.3 演算法分析... 30 (二)、寬頻網際網路「負載控制服務」以量測為基礎的允諾控制與擁塞避免機制31 A. 流量量測... 31 B. 無壅塞傳輸服務模型... 31 (三)、寬頻網際網路中服務品質路由之研究... 33 A. Hierarchical Routing... 33B. Cost Functions for Hierarchical QoS Routing... 34
C. Update Poicies... 35
D. Crankback Approaches... 36
E. Simulation Results... 37
(四)、整合服務與差別服務網路之相容運作技術... 49
A. QOSPF with Overflowed Cache (PER-PAIR/OC)... 49
B. QOSPF With Overflowed Cache With Two-Phase Routing (PER-PAIR/OCTP)... 49
C. QOSPF Using Per-Class Routing Mark (PER-PAIR/PC)... 50
D. Performance Evaluation... 50
D.2 Granularity and Performance Metrics... 51
(五)、寬頻網際網路之允入控制與訊務排程... 53
A. The VQS System... 53
B. Implementation Architecture... 54
C. Results and Merit Review of the Project... 54
第 四 章 結 論
... 56
LIST OF TABLE
Table page
1. Link capacity assignments… … … ...… … … 44
2. The Traffic Model Of The Simulation… … … ..… … … … ..… … … 51
3. Cache Granularities Of The Simulation… ..… … … ..… … … 51
LIST OF FIGURE
Figur e page 1 . 系 統 概 觀 … … … . . … 2 5 2 . 系 統 架 構 … … … . 2 6 3 . 埠 控 制 器 功 能 方 塊 圖 … … … . … … … . . … … … . … … . . . 2 7 4. SLIP 交換機與我們的交換機在不同負載量之封包平均延遲與輸入佇列長度的比 較: (a)平均延遲(b)平均輸入佇列長度。… … … .… … … . 2 9 5. 1999/8/25 凌晨 2:00、取樣時間為 100ms 的流量負載分配圖.… ..… ...… … … . 32 6 . 1 9 9 9 / 8 / 2 5 淩 晨 2 : 0 0 、 不 同 取 樣 區 間 ( 1 s e c , 1 0 0 m s , 2 0 m s ) 的 流 量 負 載 分 配 圖… … … ..… … .… … … ..… . 33 7. 動態頻寬分配與緩衝區管理模型示意圖… … … .. 33 8. Network topology… … … .… … … … . … … … … .… … … .… … … … . 389. Fractional reward loss… … … .… … … . … … … … ..… … … .… … … … . 39
10. Crankback per requested calls. … … .… … … ..… … … ... 40
11. Fractional reward loss of five update policies… … ..… … … ...41
12. Average number of crankback per connection request … … … 42
13. Average number of re-aggregation per unit of time..… … … .. 42
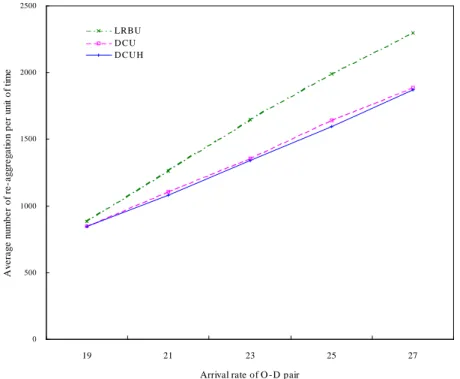
14. Average number of re-aggregation per unit of time yielded by DCU, DCUH, and LRBU policies… … … .… … … .… … … .… … … … . 43
15. Network topology.… … … .… … … ..45
16. Fractional reward loss of different crankback schemes under PNNIU update policy… 46 17. Average hops count of crankback of different crankback schemes under PNNIU update policy… … … ..… … … 47
18. Fractional reward loss of different crankback schemes under LRBU update policy… … 48
19. Average hops count of crankback of different crankback schemes under LRBU update pol ic y… … … . .. . 4 8 20. Overflowed Cache mechanism (Per-pair/OC)… … … .49
21. VQS implementation architecture… … … ..… ..55
Abstr act
Continuous rapid growth of the Internet in recent years makes it the most probable future integrated services network. However, current Internet architecture is inadequate in providing real-time applications. It cannot guarantee delay bound requirements of real-time applications. Moreover, non-real-time applications may be terminated if real-time traffic causes congestion. Internet 2 is thus proposed to meet future needs. In order to support the realization of future broadband Internet with guarantee of wide quality of service (QoS) requirements, this integrated project consisting of five sub-projects constantly improves the results in the first year and further investigates the following key technologies:
A.
High-capacity (Gigabit) routers: Sub-project I investigated two key technologies of developing high-capacity routers: switch architecture and longest prefix matching with hardware (or hardware routing). We employed space-division architecture, such as the crossbar, to build a real large-capacity router. In addition, we designed queue management and fast scheduling algorithms to (partially) remove head-of-line blocking in an attempt to improve the router’s throughput. This study mainly focuses on designing a switch for variable-length packets to reduce idle time on output port in achieving better performance in terms of throughput and packet delay. Through simulation, the result showed that switches designed for fixed-length packets are inadequate for network environment of variable-length packets on the fly. Besides, to efficiently classify arriving packets, this study proposed a three-phase packet classification algorithm based on destination/source IP addresses, destination/source port numbers and protocol ID fields and designed efficient hardware routing schemes to speed up routing decision.B.
Admission control/QoS scheduling: QoS scheduling for broadband Internet is aimed to provide bounded delay and fairness while retaining a minimum of computational complexity. Prevailing weight-based scheduling disciplines advocate the use of multiplequeues and engage in timestamp computation. These disciplines achieve either superior QoS performance at the expense of higher complexity or degraded performance in return for computational simplicity. In the sub-project IV of this year, we have designed a weight-based Versatile QoS Scheduler (VQS) and its feasible VLSI hardware implementation architecture. VQS is capable of being implemented in various network elements in broadband Internet facilitating proper trade-off balance between performance and complexity. Taking advantage of simpler single-queue management and lack of timestamp computation, VQS governs packet insertion in a shared data structure comprising a sequence of fixed-size windows based
on weights. Within a given widow, the maximum number of packets from a session is proportional to the session weight and the Window Size (WS). Simulation results demonstrate
that, applying a smaller WS for high-power network elements, VQS performs as superior as
WF2Q with respect to throughput fairness, mean delay, and worst-case delay fairness. Moreover, compatible to WF2
Q, VQS outperforms WFQ with respect to 99-percentile delay bound and jitter in the presence of traffic burstiness.
C.
Traffic measurement and statistics collection/admission control: Sub-project III considers resource allocation in the support of “Congestion- Free Service” in Broadband Internet. First, we studied traffic characterization under different measurement models via analyzing traffic traces collected from National Taiwan University campus network. The results show that traffic load can be approximated by the Normal distribution. In the second part of the work, we proposed a dynamic bandwidth and queue management scheme to support “Congestion-Free Service.” Simulation results show that in order to maintain a maximum packet loss rate, it is important that the system avoids operating at heavy loads, i.e. high link utilization. In a link sharing system, dynamic bandwidth allocation based on input loads can effectively avoid congestion. Furthermore, when combined with active queuenetworks, ATM Private Network-to-Network Interface (PNNI) adopts hierarchical routing. Consequently, although routing complexity is significantly reduced, numerous issues in PNNI routing require further study to achieve more efficient, accurate, scalable, and QoS-aware routing. In this year, we proposed several methods to achieve efficient, scalable, and QoS-aware ATM PNNI routing. First, an efficient aggregation scheme, referred to as Asymmetric Simple, is proposed. The aggregated routing information includes available bandwidth, delay and cost. Second, two approaches for defining link costs are investigated, namely, the Markov Decision Process (MDP) approach and the Competitive On-Line (COL) routing approach, and these are compared with the Widest Path (WP) approach. Third, a dynamic update policy, referred to as the dynamic cost-based update (DCU) policy, is proposed to improve the accuracy of the aggregated information and the performance of hierarchical routing, while decreasing the frequency of re-aggregation and information distribution. Finally, we proposed CIS (Crankback Information Stack) and CT (Cost Threshold) approaches to reduce crankback overhead. Simulation results demonstrate that the proposed Asymmetric Simple aggregation scheme yields very good network utilization while significantly reducing the amount of advertised information. Between these two links cost functions, the MDP approach provides a systematic method of defining call admission function and yields better network utilization than the COL approach. The proposed DCU policy also yields an enhanced network utilization while significantly reducing the frequency of re-aggregation. Meanwhile, the proposed CIS and CT approaches reduce crankback overhead significantly. Especially, the combination of CIS and CT approach achieves further improvement.
E.
RSVP (ReSource reserVation Protocol) to PHB (Per-Hop Behavior) mapping: Sub-project V investigates how granularity of routing decision significantly affects the scalability and blocking performance of QoS routing based on QoS routing extensions to OSPF. Three mechanisms, overflowed-cache, two-phase routing, and per-class routing mark, are also proposed to achieve computational and storage scalability as well as low blocking probabilityin wire-speed packet-switching networks. Simulation results of various routing and forwarding granularities, including per-destination, per-pair, per-flow, per-pair/ overflowed-cache, per-pair/two-phase, per-pair/class, indicate that the proposed mechanisms can significantly lower blocking probability, increase fairness, as well as lower storage and computational overhead. Also, two or three classes are sufficient for per-class routing which is suitable for DiffServ core networks. Comparing flow driven mechanisms like per-flow and per-pair/overflowed-cache with topology driven mechanisms like per-destination, per-pair, per-pair/two-phase, and per-pair/class reveals that the former usually perform better in blocking probability, fairness, and state accuracy, while the latter result in less overhead.
Keywords: Broadband Internet, Quality of service, QoS routing, Gigabit router, Signaling,
中文摘要
隨著網際網路的盛行,許多網路應用程式相繼出現,這些應用需要得到一定程度的 傳輸頻寬與服務品質保證,才能讓使用者感受到其實用性,但目前的網際網路只提供盡 力服務,並不能給予這些應用程式有效的支援與滿足使用者的需求。為了支援未來寬頻 網際網路的實現及有效保證服務品質,本計畫由五個子計劃整合,除了延續第一年的研 究成果,並深入發展下列關鍵技術:A.
使用於寬頻網際網路之 Gigabit 路由器與訊務管制:子計劃(一)擴充交換機的 功能,使之具有第三層硬體路由技術、第四層防火牆功能、支援群播功能、port trunking 以及八種優先權處理。交換機的架構主要採用 crossbar,並發展佇列管理和快速排程演 算法來移除佇列前端擁塞問題,進而提昇路由器的傳輸率;特別是本交換機適用於可變 長度封包的網路環境,以減小輸出埠閒置時間來提高效率降低封包延遲。此外,此子計 畫設計了一個三級式多欄位訊務區分器演算法,透過 hashing、search tree、linear search 三個步驟,可以將 filter 集合有效分散開來,減少搜尋所需要的運算量,以達成高速訊 務區分的目的。B.
寬頻網際網路之允入控制及排程技術:寬頻網際網路上的 QoS(Quality-of-Service)排程必須提供有限延遲與公平性的考量且保持最小之計算複雜度。Prevailing weight-based 的排程原則提倡應用 multiple queues 和 engage 於 timestamp 的計算。這些 原則在高複雜度的花費下,可以達到最佳之 QoS 效能,也可以為了計算簡化,達到次級 之效能。子計畫(二)設計了一個 weight-based Versatile QoS Scheduler (VQS) 和其可行 之 VLSI 硬體實作架構。為了促進較適當之效能與複雜度間的平衡,VQS 可以在寬頻網 際網路內用不同之網路元件來實作。VQS 利用較簡單之 single-queue 與不需 timestamp 計算之優點,以 weight 來控制封包插入於一分享式之資料結構。此資料結構包含了一系 列固定大小之 windows。在一給定的 window 內,由一個 session 來的最大封包個數,是 和此 session 的 weight 和 window 大小成正比。實驗結果證明,應用較小之 window 於 high-power 的網路元件,VQS 可以在 throughput fairness、mean delay、與 worst-case delay
fairness 等項目上表現和 WF2
Q 一樣好。甚至在和 WF2
Q 相容與具備 traffic burstiness 的 情況下,VQS 較 WFQ 優越約 99%之 delay bound 和 jitter。
C.
支援寬頻網際網路「負載控制服務」以量測為基礎的允諾控制與壅塞避免控制: 目前已經發展出一些即時媒體應用能夠視封包遭遇到的延遲動態調整資料的傳送,他們 並不需要絕對可靠的封包延遲上限,但必須盡可能避免封包在傳輸過程中被丟棄,子計 劃(三)之研究即針對這類應用程式提供『無壅塞服務』,我們將其定義為『保證聚合 資料流的最大封包遺失率為ε』,希望將來可以應用於 IETF 整合服務架構下的負載控制 服務。本研究首先對台大校園骨幹網路做實際流量的量測及趨勢分析,以瞭解網路資料 流的特性。結果顯示網路負載具有近似常態分配的特性,可進一步用於網路流量的預測 以及網路資源的規劃與控制。此外,我們針對『無壅塞服務』的提供,提出一個動態頻 寬與緩衝區分配的方法。實驗結果顯示避免頻寬使用率太高及動態分配頻寬可以有效抑 制壅塞的發生。當網路流量的自我相似性不是很顯著時,配置適量的緩衝區更有助於封 包遺失率的降低。D.
寬頻網際網路中服務品質路由之研究:ATM Private Network-to-Network Interface(PNNI) 提出階層式選徑通信協定來減少網路資訊以實現一大型 ATM 網路的可擴展 性,必然地,降低了選徑的複雜度,但是如何使 PNNI 網路提供一更高效率、正確資訊、 擴展性與服務品質保證的選徑問題是需要許多的研究。子計劃(四)提出四項方法以實 現一更高效率、正確資訊、擴展性與服務品質保證的 PNNI 選徑機制。第一、提出一高 效率且低複雜度的聚集方法,稱之為 Asymmetric Simple 聚集法;第二、提出以馬可夫 理論(MDP)為基礎的鏈路成本定義機制,並將此法與線上競爭法(COL)和最寬頻寬法 (WP)作比較;第三、提出以成本為機礎的動態資訊更新政策(DCU),以提高資訊的正確 性同時減少資訊更新頻率;最後,以 CIS 與 CT 方法減少 crankback overhead。結果顯 示 Asymmetric Simple 聚集法可有效提供良好的網路使用率同時減低網域劇集的複雜 度。MDP 方法提供系統化的 call admission 機制且考慮 calld 到達率,因此與 COL 和 WP
降低 crankback overhead,尤其以結合兩者時更為顯著。
E.
整合服務與差別服務網路之相容運作技術:子計劃(五)探討路由決策的粗細 度對服務品質路由的延展性及阻絕率的影響。並且提出三個機制--溢流快取、兩階段式 路由、和路由記號分類轉送等技術,目的在線速封包網路上達到計算上及儲存上的延展 性,並降低阻絕率。在各種粗細度的系統模擬中,結果顯示所提機制確有不錯的效果, 尤其路由記號分類轉送技術使用二或三種分類很適合差別服務的核心網路中。總結比 較,flow driven 的路由技術如 per-flow 和 per-pair/overflowed-cache 會有較佳阻絕率、公 平性、和狀態準確性,data driven 的路由技術如 per-destination、per-pair、per-pair/two-phase 和 per-pair/class 會有較少的 overhead。關鍵詞:
寬頻網際網路、服務品質、服務品質路由、Gigabit 路由器、信號、管制、排第 一 章
前言
由於傳統電信網路與數據的網路服務對象不同,而分別採用了電路交換(Circuit switching)與分封交換(Packet switching)為多工與交換的技術。雖然是針對服務對象 設計,使其效率很高。但是卻有重複投資線路與設備、以及不同網管的缺點,增加基礎 建設的成本。而目前多媒體應用的普及化,使用者需求的頻寬急速增加,且要求的服務 品質(Quality of Service)亦不同,促使網路朝寬頻整合服務的方向演進。此外,隨著 網際網路的使用人口與訊務呈指數倍數成長,加上高速乙太網路(Fast Ethernet, 100Mbps)與乙太交換器(Ethernet Switch)的問世,網際網路極可能成為未來整合服務 網路。 然而現有網際網路並無法提供即時應用。它不能保證即時應用的延遲與延遲變 異等服務品質。同時,若即時應用的訊務造成擁塞,非即時應用的運作可能會被中止。 換言之,目前的網際網路也無法有效保護非即時性應用的連線。為滿足未來整合服務的 需求,於是最近產生了寬頻網際網路。 寬頻網際網路無疑的將會面臨各類不同服務品質需求的應用,在面對訊務急速增加 的情況下,為了有效保證服務品質,它需要: (1) 大容量路由器:提升網路容量。 (2) QoS 路由:改善網路使用效率。 (3) 信號:提供訊務源特性與資源保留。 (4) 排程(Scheduling):提供各種不同的服務品質。 (5) 允入控制(Admission Control):限制網路資源之使用。 (6) 訊務管制(Traffic Policing):確保連線之服務品質。(7) 網路規劃與管理(Network Planning and Management):監控網路效能與規
劃。
有第三層硬體路由技術、第四層防火牆功能、支援群播功能、port trunking 以及八種優 先權處理。交換機的架構主要採用 crossbar,並發展佇列管理和快速排程演算法來移除 佇列前端擁塞問題,進而提昇路由器的傳輸率;特別是本交換機適用於可變長度封包的 網路環境,以減小輸出埠閒置時間來提高效率降低封包延遲。此外,此子計畫設計了一 個三級式多欄位訊務區分器演算法,透過 hashing、search tree、linear search 三個步驟, 可以將 filter 集合有效分散開來,減少搜尋所需要的運算量,以達成高速訊務區分的目 的。
子計畫二(交通大學資訊工程研究所楊啟瑞教授主持)主要在研究服務排程技術與 允入控制,以提供各種服務品質。寬頻網際網路上的 QoS (Quality-of-Service)排程必須 提供有限延遲與公平性的考量且保持最小之計算複雜度。本年度的計畫設計了一個 weight-based Versatile QoS Scheduler (VQS) 和其可行之 VLSI 硬體實作架構。為了促進 較適當之效能與複雜度間的平衡,VQS 可以在寬頻網際網路內用不同之網路元件來實 作。 子計畫三(台灣大學資訊管理研究所孫雅麗教授主持)主要研究如何透過量測訊務來 提升網路使用效率及避免擁塞發生;近來許多網路上的即時媒體應用對於傳輸服務品質 的要求較為寬鬆,針對不需嚴格封包延遲、但需避免封包遺失的應用,有必要提供可保 障封包遺失率的無壅塞傳輸服務。於此子計劃,首先實地量測台大校園網路的流量,確 認流量負載具有常態分配的特性,利用此特性及量測窗方式,設計了一套動態頻寬分配 與緩衝區管理模型,可有效降低封包遺失率,但若要更精確地控制封包遺失率,則需要 進一步的研究。 子計畫四(中正大學資訊工程研究所黃仁竑副教授主持)主要在研究如何選定 QoS 的 metrics 與 routing algorithm,以及搭配 RSVP 時,若資源保留要求失敗時,如何 re-routing;此子計劃提出四項方法以實現一更高效率、正確資訊、擴展性與服務品質保證 的 PNNI 選徑機制。第一、提出一高效率且低複雜度的聚集方法,稱之為 Asymmetric Simple 聚集法;第二、提出以馬可夫理論(MDP)為基礎的鏈路成本定義機制,並將此法 與線上競爭法(COL)和最寬頻寬法(WP)作效能比較;第三、提出以成本為機礎的動態資
訊更新政策(DCU),以提高資訊正確性的同時減少資訊更新頻率,降低了選徑的複雜度; 最後,以 CIS 與 CT 方法減少 crankback overhead。
子計畫五(交通大學資訊科學研究所林盈達副教授主持)主要探討路由決策的粗細度 對服務品質路由的延展性及阻絕率的影響;並且提出三個機制─溢流快取、兩階段路 由、與路由記號分類轉送技術,目的在限速封包網路上達到計算上級儲存上的延展性, 並降低阻絕率。
第 二 章
計劃緣起與目的
寬頻網際網路的產生是為了解決目前 Internet 頻寬不足且無法保證服務品質(Quality of Service)的缺點;但由於 QoS control 牽涉的技術很廣,並非一人得以獨力完成,透 過群體計畫可收集思廣益之效,提出整體性的解決方案。相關子計劃的研究項目著重在 提昇網路頻寬與保證服務品質的關鍵技術,敘述如下。
一、大容量路由器與訊務管制技術:
高效能網路交換機採用 crossbar 交換結構作為交換核心漸漸成為一種趨勢。而 crossbar 交換機需要一套交換排程演算法(Switch scheduling algorithm)來決定輸出入埠 配對,目前存在的排程演算法,例如 PIM(Parallel Iteration Matching)、RRM(Round-robin matching)與 SLIP,均是為固定長度封包所設計,雖然經由切割再重組的方式可以處理 可變長度的封包,卻可能造成輸出、入埠所需的緩衝空間與封包交換延遲的增加。本研 究針對可變長度封包設計一交換機架構,以減小輸出埠閒置時間來提高效率,並降低封 包延遲。此外,高速的多欄位訊務區分器是現今發展服務保證網路最重要的核心技術之 一。傳統的訊務區分器僅根據第三階層的標頭欄位來分類,並不適用於較高階層之表頭 欄位分類器;另外,網路頻寬與使用者需求的指數倍數成長使得路由器的傳輸率要求相 對提高。所以,為了支援多欄位分類與高傳輸率的需求,我們提出一個三級式多欄位訊 務區分器演算法,透過 hashing、search tree、linear search 三個步驟,可以將 filter 集合 有效分散開來,減少搜尋所需要的運算量,以達成高速訊務區分的目的。
二、寬頻網際網路之允入控制及排程技術:
Scheduling disciplines proposed in the literature have been either single-queue or multiple-queue-based. Single-queue- based disciplines advocate the maintenance of a single shared queue for each output link. Different-session packets destined to the same output link are inserted in the shared queue in accordance with, for instance, the deadlines or priorities of
packets. Packets are then transmitted in a FIFO manner. Consequently, scheduling complexity completely resides in the enqueueing process. Examples of this class include Earliest Deadline First (EDF), Threshold Based Priority (TBP), and Precedence with Partial Push-Out (PPP). The EDF discipline was shown to successfully support tight delay bound. However, it undergoes two major limitations- a priori deadline assumption and high implementation complexity due to packet sorting. Although TBP and PPP were justified effective for switches supporting two priorities, they fail to provide bounded delay and throughput fairness in the presence of malicious sessions.
Multiple-queue-based disciplines, on the other hand, adopt multiple queues maintained at each output link, one for each session. Packets arriving from different sessions are simply placed at the end of their corresponding queues. Scheduling complexity in this class resides in the dequeueing process instead. Prevailing disciplines in this class, which are weight-based, include Weighted Fair Queueing (WFQ), Worst-case Fair Weighted Fair Queueing (WF2Q), Self-Clocked Fair Queueing (SCFQ), and Frame-based Fair Queueing (FFQ).
In this project, we aim to design a weight-based, highly versatile QoS scheduler, referred to as VQS, capable of being implemented in diverse network elements facilitating proper trade-off balance between performance and complexity. Taking advantage of simpler single-queue management and lack of timestamp computation, VQS governs the insertion of packets belonging to the same output link in a shared data structure comprising a sequence of fixed-size windows. Within a given widow, the maximum number of packets from a session is
proportional to the session weight and the Window Size (WS). Packets being placed at the
same window are transmitted on a FIFO basis, limiting short-term unfairness to within a window interval. Packets being arranged outside of the window trigger new windows to be activated, enforcing weight-proportional service to be exerted.
三、支援寬頻網際網路「負載控制服務」以量測為基礎的允諾控制與擁
塞避免機制:
為了因應即時媒體應用對傳輸服務品質的需求,IETF 制訂了兩個可提供傳輸服務 品 質 的 架 構 , 分 別 是 整 合 服 務 (Integrated Service) 以 及 差 異 化 服 務 (Differentiated Service)。傳統的即時媒體服務研究主張對每個封包提供絕對(absolute)的延遲上限(delay bound),而且不允許有任何封包在排隊(queueing)時被丟棄,這樣的服務被稱為保證服務 (Guaranteed Service),但並不是所有即時媒體應用都需要這麼高水準的服務品質,目前 已經發展出一些應用程式如 vat、nv、vic 等,能夠視封包遭遇到的延遲動態調整資料的 傳送,對這些應用程式而言,並不需要絕對可靠的封包延遲上限,盡可能避免封包在傳 輸過程中被丟棄而順利抵達目的地,反而是較為必要的傳輸服務品質。 寬鬆的傳輸服務品質保證對於網路資源的管理提供了更大的彈性,也為路由器在允 諾控制(admission control)、封包排程(packet scheduling)及緩衝區管理(buffer management) 等各項功能設計上提供了一個新的思考面向。我們認為提供低封包遺失率且有最小傳輸 率保證的無壅塞服務,對現存以及將來可能出現的應用,應會具有相當的實用性。而透 過以量測為基礎的方法即時了網路流量特性,以從事允諾控制及動態配置資源,相信將 非常有助於促成無壅塞服務的實現。
目前文獻上以量 測為基礎(measurement-based)的流量控制主要應用在允諾控制 (admission control)上。傳統的允諾控制以參數為基礎(parameter- based) ,如的 equivalent capacity 及的 effective bandwidth,亦即必須事先(a priori)明確描述出既有流量及新進資 料流的行為才能發揮作用,但目前在網路上的應用程式日益多元,很難精確而完整地得 到允諾控制所需的相關參數。以量測為基礎的允諾控制以實際量測的方式了解網路流量 目前的狀況,如此一來就可以破除需要事先知道流量參數的限制,使允諾控制在應用上 有更大的彈性。 在 諸 多 以 量 測 為 基 礎 的 允 諾 控 制 演 算 法 中 , 所 提 出 的 方 法 是 使 用 量 測 窗 (measurement window)估計並預測網路流量,並將此資訊應用於允諾控制的判斷,以提
供一個具有寬鬆延遲上限保證的預測服務(predictive service)。另外,可以利用 equivalent capacity 的原理來描述流量,它以量測值來估計目前流量的平均到達率(average arrival rate),利用 Hoeffding bound 計算出 equivalent capacity 用於判斷目前流量所需使用的頻 寬,希望提供的是一種讓封包遺失率維持某一水準以下的服務。此法雖然亦著眼於提供 無壅塞服務,但卻未考慮到緩衝區對減輕封包遺失的效益。
四、寬頻網際網路中服務品質路由之研究:
The ATM PNNI standard adopts a source-based hierarchical routing for supporting scalability and security in a large network. The main advantage of the hierarchical routing is reducing large communication overhead while achieving efficient routing. The scalability and performance of hierarchical networks depend on various design schemes, such as the aggregation scheme for aggregating routing information, the cost functions for defining link and path costs, and update policies for advertising the aggregated information. Nevertheless, how to design these schemes remains an open issue. In this project, we propose several solutions, including the efficient Asymmetric Simple aggregation scheme, the QoS-capable COL and MDP link cost approaches, the dynamic cost-based update policy, and CIS and CT for reducing crankback overhead to achieve an efficient hierarchical QoS routing in large ATM networks. These methods are briefly described below.
A. Hierarical Routing
In this project, we study the PNNI standard, source-based hierarchical routing in ATM networks. The source-based hierarchical routing problem can be decomposed into two issues: how to aggregate routing information and how to perform hierarchical routing. For routing information aggregation, Iwata et al. proposed two aggregation schemes, star and simple node,
scheme, and Awerbuch et al. compared the performances of several aggregation schemes,
including a star with radius equal to half the cost of the network diameter (DIA), a star with radius equal to half the average cost between border nodes (AVE), Minimum Spanning Tree (MST), Random Spanning Tree (RST), and t-spanner. Our earlier work proposed a novel aggregation scheme, called Asymmetric Simple and compared it with two existing aggregation schemes (Simple Node and Full-Mesh) using various performance metrics, such as representation size and representation accuracy for routing information, and network revenues.
For hierarchical routing, Guo et al. applied probabilistically routing to hierarchical
networks. Meanwhile, Mieghem presented the unicast hierarchical routing based on PNNI standard. Furthermore, , Montgomery et al. and Xie et al. applied the theory of reduced load
approximation to analyze the blocking probability of PNNI hierarchical networks. Finally, Hao et al. investigated the call rejection probability for routing with crankback.
Our numerical results first demonstrate that an effective aggregation scheme reduces overhead for call set up while yielding high traffic throughput. The proposed Asymmetric Simple aggregation scheme can yield competitive performance compared to the Full Mesh aggregation scheme.
B. Cost Functions for Hierarchical QoS Routing
In this project, we define the objective of hierarchical QoS routing as to maximize network revenue under the constraint that each established connection is guaranteed with certain QoS requirements. This optimization problem is generally re-formulated as, for each new arriving connection, to find the path with minimum cost while satisfying certain QoS requirements. Two issues can be identified that differ from QoS routing in flat networks. First, owing to the inaccuracy of aggregated information, a chosen hierarchical path may not satisfy the end-to-end QoS requirement. In this case, the crankbank scheme can be employed to
reroute the connection to an alternate path. The crankback scheme is further discussed in chapter 2. The second issue is how to define the link cost function and aggregate link cost functions in a peer group. A good link cost function should comprise two properties; maximizing network revenue by minimizing path cost, and providing a systematic call admission function.
In this project, we study two approaches for defining link cost functions in a hierarchical network, namely the Markov Decision Process (MDP) approach and the Competitive On-Line (COL) approach. The theory of Markov decision process is a pledge method in a lot of network-related issues. Various network control schemes have been developed based on the Markov decision process. For example, many MDP-based routing algorithms, which compute the link cost based on the MDP theory, have been proposed and demonstrated to perform very well. However, Gawlick, et al., proposed an on-line optimal routing algorithm, referred to as
the Competitive On-Line (COL) algorithm. This approach defines the link cost function as an exponential function of the residual bandwidth. They have shown good routing performance based on this cost function. We proposed MDP-based cost function for hierarchical QoS routing.
In this project, we compare the performance of the MDP-based and the COL-based cost functions with the Widest Path (WP) approach, which routes an incoming connection to the path with maximum residual bandwidth. The residual bandwidth of a path is defined as the minimum of the residual bandwidth of all links on the path. The simulation results show that the MDP and the COL approaches outperform the WP approach. The MDP approach yields the best network utilization. A further advantage of the MDP approach is that it provides a systematic call admission function.
with dynamic network traffic. Furthermore, the accuracy of aggregated information is depended on the update interval, with a reduced update interval meaning more accurate aggregated information. However, in this situation the overhead of re-aggregation and information distribution increases. Awerbuch et al. proposed the logarithmic update approach, which is based on the residual bandwidth of a link, to reduce the computational overhead of re-aggregation.
An event-based update policy typically suffers from oscillation, which can be avoided by hystersis. The technique of hysteresis has been applied to various areas of high-speed networks. For example, Jong applied hysteresis to ATM rate control to enhance system stability, and Orda et al. proposed an adaptive virtual path allocation policy using hysteresis to prevent excessive processing of requests due to oscillations around thresholds. Meanwhile, Shun-Ping Chung and Jin-Chang Lee propose a dynamic reservation with hysteresis as CAC for cellular multiservice networks.
We proposed an event-driven update policy based on the link cost. Furthermore, to avoid oscillation, the hystersis technique was applied. The proposed policies are called the Dynamic Cost-based Update (DCU) policy and the DCU with hysteresis (DCUH) policy. The performance of the proposed policies is compared to other time-driven and event-driven update policies, including the PNNI time-based update approach (PNNIU), full update approach (FU), logarithm of residual bandwidth update approach (LRBU), and dynamic cost-based update policy without hysteresis. Simulation results show that the DCUH policy performs best among these update policies.
D. Crankback Approaches
Alternate path routing approaches can be used to achieve lower connection blocking probabilities and higher network throughput in ATM networks. Conventional alternate path routing techniques tend to fall into two classes: progressive control. Hwang, R.H. etc. noted
that progressive control, as compared to the originating control, provides a higher blocking probability but smaller connection setup time The primary advantage of progressive control is the ability to provide fast connection setup, while the disadvantages of progressive control are the use of sub-optimal alternate path. Chung proposed an ICD (information about the crankback destination nodes) approach in a connection setup messages, hence they could predict the crankback destination node. Meanwhile, Spieqel et al. presented an approach to
combine the features of progressive and originating control approaches, allowing for fast connection setup as well as near minimum cost paths. Felstaine et al. proposed to allocate a
“quota” to the PGs along the message path and then to “sub-allocate” quota to the son PGs of these PGs.
The purpose of this section is to study mechanisms for reducing the crankback overhead in PNNI hierarchical networks. Two heuristics are proposed herein to reduce crankback overhead. First, if we can predict where to crank back, referred to as the destination node, the call setup message need not to crank back to the source node, thus the call set up overhead at the common nodes along the path can be reduced. Second, the aggregated path cost represents the expected cost for setting up the call on the path of O-D pair. Therefore, a call setup message on a path with high path cost is likely to be blocked. Consequently, avoiding setting up a call on a path with high path cost will reduce the crankback overhead. Based on these two heuristics, we proposed two approaches to reduce crankback overhead. The first approach adds additional information, referred to as CIS, to predict the crankback destination node. In this approach, we keep CIS in the call setup message while crossing the PG. When call setup message encounters a block link, the intermediate node using CIS to find the crankback destination node. Hence, the call setup message needs not to crank back to the ingress node. The second approach uses aggregated path cost, referred to as CT, to determine whether call
call setup message failed on the path with minimum cost, then call set up on alternate paths with higher path cost will likely to be failed. Simulation results show that both of these two approaches reduce the crankback overhead significantly. Furthermore, when we combine CIS with CT, referred to as CIS_CT, the crankback overhead can be reduced more conspicuously.
五、整合服務與差別服務網路之相容運作技術:
To achieve both low blocking probability and high scalability, this study proposes three QoS routing extensions to OSPF, overflowed-cache, two-phase routing, and per-class routing mark. The overflowed-cache mechanism divides the packet-forwarding cache into a per-pair
cache (P-cache) and an overflowed per-flow cache (O-cache). The flows that the P-cache
indicated paths cannot satisfy with the required QoS are routed individually and their forwarding decisions are overflowed into the O-cache. The two-phase routing reserves a block
of bandwidth that exceeds the bandwidth requirement of a flow when the first flow between an S-D pair is established. The per-class routing aggregates QoS flows into a number of
classes via a marking technique. Therefore, flows with the same mark for the specific S-D
pair are routed on the same path. This routing mechanism is suitable for DiffServ networks, where packets are marked at edge routers and fast-forwarded in the core network.
第 三 章
研究方法及結果
(一)
、使用於寬頻網際網路之 Gigabit 路由器與訊務管制技術
A. 適用可變長度封包之 Crossbar 交換機
整個系統劃分成輸出入埠控制器與交換核心兩個子系統。所有網路介面都做成相同 的模組,輸出入埠控制器位於這些獨立的介面卡上。模組的一端是網路介面,另一端則 是與背版相連的匯流排插槽。交換核心則位於交換機背版,所有進入交換機的封包都經 由交換機背版完成交換的動作。系統架構類似傳統電話交換機。交換機的組成如圖 3.1 所示,這樣的架構使得系統具有彈性,能夠依照不同流量需求增減介面卡數目,達到較 好的成本效益比。此外,若使用具有熱抽換功能的匯流排介面(如 Compact PCI),則可 在不關閉系統的情況下進行介面卡更換。這個特性對骨幹網路交換機是非常重要的。 圖 3.1 系統概觀A.1 系統架構
整個系統架構方塊圖顯示於圖 3.2。由網路進入交換機的封包首先由輸出入埠控制 器(I/O Port Controller,如圖 3.3 所示)對標頭做處理,並將封包佇存在輸入埠的緩衝 區(memory)內。每個輸出入埠控制器都有一組 P 通道(P_n in & P_n out)與交換核Backplane Crossbar Switch Fabric Interface cards Bus Network Interface Bus Interface Memory Port Controller
心(如圖 3 所示)連接,此通道是對交換核心下達指令以及傳送封包的途徑。交換 核心藉由串連所有埠控制器的回應通道(RSP)送出連接請求指令。核心內的仲裁器用來 決定連結的建立與否,仲裁結果同樣透過此通道傳出。群播封包則經由專屬的群播通道 (MC)傳送到各個輸出入埠控制器。此外,還有一個控制通道(CTRL)作為中央處理 器與輸出入埠之間溝通的管道。 圖 3.2 系統架構
A.2 輸出入埠控制器
輸出入控制器負責封包標頭的解讀與轉換,以及對封包進行存取控制。它可以是單 埠或多埠控制器。以多埠的共享緩衝式交換晶片作為埠控制器能組成大埠數交換機。目 前商品化的單一晶片共享緩衝式交換機已可容納十六個 Fast Ethernet 網路介面。控制器 內部的功能方塊如圖 3.3。其中 Data Path 單元以分時多功的方式處理由網路介面 (PHY+MAC)送入的封包,並將封包標頭送至查表單元(Table Lookup Engine),封 包內容則交由佇列管理單元(Queue Manager)處理。佇列管理單元根據查表結果,將 送往不同輸出埠的封包分別放入 VOQ,並依照封包等級排序。佇列管理單元還負責將 Crossbar Switch Element Port Controller Port Controller CPU P_0 in P_0 out P_N in P_N out RSP MC RSP MC RAM RAM CTRL CTRL DRAM....
P_n in : input port of n th port controllerP_n out : output port of n th port controller
RSP : response channel MC : multicast channel CTRL : control channel
各 VOQ 狀態及排頭封包的等級告知交換核心介面單元(Crossbar Interface)。封包的傳 輸透過埠控制器與交換核心間的三個管道進行;交換核心介面單元負責送出封包,P_n out 通道接收交換核心送出的封包,群播封包則經由 MC 通道收送。查表單元根據封包 標頭找出對應的輸出埠與該封包的等級,然後將結果告知佇列管理單元。此外,它還必 須根據由中央控制器介面(CPU Interface)送入的指令進行路由表(routing table)與分 級表(classification table)的更新。中央控制器也經由此介面向佇列管理單元蒐集網管所需 的資訊。分開的控制通道可避免不同作用的資料發生壅塞,提高運作速率。與交換核心 的介面由兩個單元組成。回應監視單元(RSP Monitor)負責 RSP 通道訊號的解碼,核 心介面單元則根據解碼的結果,將對應的 VOQ 狀態或佇列內的封包,經由 P_n in 通道 送出。 圖 3.3 埠控制器功能方塊圖
A.3 交換核心
交換核心包含了命令解碼器(Command Decoder)、仲裁器(Arbitration Logic)、回應編 碼器(Response encoder)、狀態監視器(Status Monitor)、請求佇列(Request Queue) 縱橫式交換陣列(Crossbar matrix)與點陣控制電路(Matrix controller)等數個部分。圖 3.4 顯示了這些功能區塊的配置。 Table Lookup Engine MAC Queue Manager Data Path
...
Packet Memory Table Memory RSP Monitor Crossbar Interface MAC CPU Interface P_n in RSP CTRL Crossbar Interface P_n out MC PHY PHY命令解碼器跟據協定單元的標頭辨別其為發號或資料協定單元,並將協定單元所乘 載的資料送至仲裁器或交換陣列。若協定單元的內容是 VOQ 的連接等級,則解碼器根 據提出請求的輸出埠號,由 BUS1 將內容傳送至對應的仲裁器。若內容為封包資料,則 直接送往交換陣列。仲裁器根據我們設計的方法決定連線建立與否,並將結果由 BUS2 送往陣列控制器與回應編碼器。陣列控制器依據仲裁結果控制縱橫式陣列內部交換元件 的啟閉。回應編碼器則把仲裁結果做格式轉換後由 RSP 通道送出。交換陣列的輸出除了 直接接出交換核心外,還透過 BUS3 送至狀態編碼器。狀態監視器則根據是否偵測到代 表封包結束的字符(T+I)或暫停指令,將輸出埠忙碌或閒置狀態轉換成輸出埠請求指令, 並記錄在請求佇列中。請求指令與回應指令以多工方式共用 RSP 通道。 為了使交換機有較高的運作效能,我們以輸出埠的角度來設計交換機;當輸出埠由 忙碌變成閒置狀態時,立即向所有輸入埠要求送封包過來,除非都沒有以此輸出埠為目 的的之封包進入交換機,或擁有送往此輸出埠封包的輸入埠正處於忙碌狀態,則輸出埠 將經過一或數個仲裁週期後,開始送出封包。交換機以減少輸出埠閒置時間來提高較 率。而仲裁器以找出具最高優先權輸入埠的方式使交換機具有差別服務功能,並使用輪 轉法避免飢饉現象。
A.4 交換機效能模擬
以軟體模擬來分析比較 SLIP 交換機與本計劃所設計的交換機之封包延遲與輸入佇 列長度,如圖 3.4(a)與(b)所示,相關參數設定為 s_size=16、MaxPktSize=1500、 MinPktSize=64、PSN=5000、及 CellSize= 64。結果顯示根據固定長度封包所設計的交換 機並不適用於可變封包長度的網路環境。B. 訊務區分器
B.1 三級訊務區分演算法
第一級:Hashing選擇特定 bits 的排列將所有的 filter 區分開來。考慮於五個欄位共 104 個 bit 裡選 m
m
N
2 個 filter(其中 N 是 filter 總數),依此方法,將可大幅減少需要找尋的 filter 數目。
我們採用的策略是於 Source IP address 與 Destination IP address 各取三個 bits,取一個 bit 以
(a) (b)
圖 3.4 SLIP 交換機與我們的交換機在不同負載量之封包平均延遲與輸入佇列長度的比
較:(a)平均延遲 (b)平均輸入佇列長度。
以區分 UDP 與 TCP 的 protocol 欄位,總共 7 個 bits 來進行 Hashing 的運作,以期將 filter space 作最平均的分割。
根據各個 filter 的 IP prefix 建立 search tree。建立順序為 Source IP address> Destination Ip address>Protocol 欄位;此外,為了提升速度,所建立的樹並非單純的二元樹,而是能
夠一次檢查 m bits 所建立的 2m-ary Search Tree。建構樹的過程中,為了避免建立整個
search tree 所浪費的記憶體空間,我們限定當節點的 filter 數超過一定值的時候,才建立 下一層的節點,如此便可簡化建立 search tree 的複雜度。
第三級:Conflict Check and Sorting
將位於每個部分的 filters 根據其 cost 來排序,以加快整體封包 search 的速度。然而, 由於 IP address 是採用 longest prefix matching,即 mask 較少的 filter 擁有較高的 priority, 因此可能造成 mask 較長的 filter 永遠不會被 match;此為 conflict problem。為了防止 conflict 發生,於排序之前,尚需執行 conflict check 運作,定義如下:1)若 mask 較長之 Filter i,其實際的優先權≤ mask 較短之 Filter j 的優先權,則移除 Filter i。2)若 mask 較
長之 Filter i 的優先權> mask 較短之 Filter j 的優先權,則將此兩者的 costs 對調。完成 conflict check 之後,依 filters’ cost 之高低排序,由於 filter 數目已非常少,一般的線性 排序就可相當快速地完成,故此,我們採用氣泡排序法(bubble sort)。
B.2 搜尋程序
1)根據 Hashing 特定位置的 bits,找到對應 search tree 的根(root)。
2)依照 Source IP、Destination IP 的順序,利用 prefix 尋找節點,當節點上的 filter 數目不為零時,表示路徑搜尋完成。
3)以 Linear Search 的方式尋找符合條件的 filter,第一個符合條件的 filter 即為 best matching filter。
B.3 演算法分析
假設 filter 總數為 n、hashing key 為 b bits、2m
-array search tree 的 depth 為h(n),則
平均每個節點所含的 filter 數目為 b n mh n 2 2 ,因此 search 一個 filter 所需的複雜度約為: + ) 2 ( 2 ) 2 ( b n mh b n O n h O 。
檢查的 prefix 恰小於 address mask,即 m×K< Address Mask<m×(K+1),則 depth=K+1 時,
必須複製[(K+1)×m-Address Mask]×2 個 filters。所以當最後 depth=P(P>K+1)時,總共
需要複製
( )
2m P-(K+1)[(K+1)×m-Address Mask]×2=2m(P−K−1)+1[(K+1)×m-Address Mask]。現假 設 n 個 filters 中,有 i 個 filters 需要複製,其複製起始的 depth 以 Ki表示,address mask為 aMaski,則最後 search 所需的運算複雜度約為
(
)
( )[
(
)
]
− + + × − +∑
= + − − ) 2 ( 1 1 1 ) ( 2 1 2 ) 2 ( b i n mh i a i i K n h m b aMask m K i n O n h O。
(二)
、支援寬頻網際網路「負載控制服務」以量測為基礎的允諾
控制與擁塞避免機制
A.
流量量測
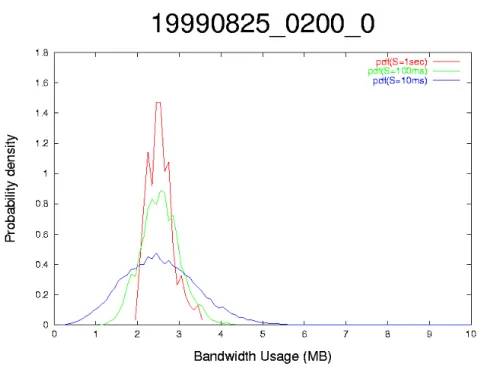
為了以較精確的方式描述流量變化,我們希望找出流量負載(traffic load)是否遵循某 種統計分配。經實際量測台大校園網路一段 oc3 link 的流量,發現在不同時段、不同取 樣區間(sampling interval)下,當取樣數量夠多時,聚合(aggregate)流量負載均相當近似於 常態分配(以量測到的流量負載之平均數及標準差為參數),如圖 3.5 的機率密度函數(pdf, probability density function)所示。需要注意的是,取樣區間的不同會影響量測結果。如圖 3.6 所示,同一時段,採用 較小的取樣區間,由於可以捕捉到更多流量暴衝(burst)現象,也就是更能反應出流量的 瞬間變化,因此流量負載的變異程度也較大,從 pdf 圖來看就形成略為扁平而兩端分佈 較廣的鐘形(bell shape);反之,當取樣區間較大時,就不容易看出流量的變異。 從這樣的結果可以發現,在量測流量負載時,必須謹慎選擇取樣區間,以免低 估或高估流量的瞬間變化,對流量產生誤判,進而影響網路資源的配置。
B.
無壅塞傳輸服務模型
窗(大小為 T),以 S 為取樣區間在一個量測窗內取樣 T/S 個流量負載,給定一個比例δ(0< δ<1),依據常態分配的特性,以該量測窗內流量負載的平均值 AvgLoad 及標準差 StdLoad 等式(1)計算出一個對應的頻寬使用量 EC,使得流量負載有δ的機會大於 EC,並以 EC 作為該量測窗的頻寬保留量,其中等式(1)的 z 值是使累積機率等於 1-δ所對應的標準常 態變數值。由於流量負載具常態分配的特性,因此應該有(T/S)×δ筆流量負載值會超過 EC,由於已保留了 EC 的頻寬,因此配置緩衝區時,只要考慮這(T/S)×δ筆流量負載值 超過 EC 的部份就可以控制封包遺失率,令量測窗內的最大流量負載值為 MaxLoad,若 對每個高過 EC 的流量負載都保留(MaxLoad-EC)×S 的緩衝區容量,理論上就不應有任何 封包被丟棄(drop),綜合上述說明,該量測窗所需配置的緩衝區即如等式(2)所示。 (2) ) ( ] ) [( (1) EC MaxLoad T S EC MaxLoad S T BufferSize StdevLoad z AvgLoad EC − × × = × − × × = × + = δ δ 模擬結果顯示,當δ、取樣區間及量測窗大小搭配得宜時,不管流量是否具有自我 相似(self-similar)的特性,封包遺失率都可以控制在相當低的水準,甚至能夠讓封包遺失 率維持在 0。但此法尚未找到δ、取樣區間、量測窗大小及目標封包遺失率ε之間的關 係,亦即還無法預知在某種上述參數組合下所能達成的封包遺失比例,如何更精準地控 制封包遺失率,有待更進一步的研究。 圖 3.5. 1999/8/25 凌晨 2:00、取樣時間為 100ms 的流量負載分配圖
圖 3.6. 1999/8/25 淩晨 2:00、不同取樣區間(1sec, 100ms, 20ms)的流量負載分配圖
Time
Traffic
load
Tn Tn+1 MaxLoad EC 圖 3.7 動態頻寬分配與緩衝區管理模型示意圖(三)
、寬頻網際網路中服務品質路由之研究
A.
Hier ar chical Routing
information aggregation, Iwata et al. proposed two aggregation schemes, star and simple node, with three aggregation versions, aggressive, conservative and simple no-aggregation. These schemes transform a non-linear programming problem into a linear problem for the corresponding QoS parameters. Meanwhile, Lee proposed a spanning tree aggregation scheme, and Awerbuch et al. compared the performances of several aggregation schemes, including a star with radius equal to half the cost of the network diameter (DIA), a star with radius equal to half the average cost between border nodes (AVE), Minimum Spanning Tree (MST), Random Spanning Tree (RST), and t-spanner. Our earlier work proposed a novel aggregation scheme, called Asymmetric Simple and compared it with two existing aggregation schemes (Simple Node and Full-Mesh) using various performance metrics, such as representation size and representation accuracy for routing information, and network revenues.
For hierarchical routing, Guo et al. applied probabilistically routing to hierarchical networks. Meanwhile, Mieghem presented the unicast hierarchical routing based on PNNI standard. Furthermore, Montgomery et al. and Xie et al. applied the theory of reduced load approximation to analyze the blocking probability of PNNI hierarchical networks. Finally, Hao et al. investigated the call rejection probability for routing with crankback.
Our numerical results first demonstrate that an effective aggregation scheme reduces overhead for call set up while yielding high traffic throughput. The proposed Asymmetric Simple aggregation scheme can yield competitive performance compared to the Full Mesh aggregation scheme.
B.
Cost Functions for Hier ar chical QoS Routing
In this project, we define the objective of hierarchical QoS routing as to maximize network revenue under the constraint that each established connection is guaranteed with certain QoS requirements. This optimization problem is generally re-formulated as, for each new arriving connection, to find the path with minimum cost while satisfying certain QoS requirements. Two issues can be identified that differ from QoS routing in flat networks. First,
owing to the inaccuracy of aggregated information, a chosen hierarchical path may not satisfy the end-to-end QoS requirement. In this case, the crankbank scheme can be employed to reroute the connection to an alternate path. The crankback scheme is further discussed in section 2. The second issue is how to define the link cost function and aggregate link cost functions in a peer group. A good link cost function should comprise two properties; maximizing network revenue by minimizing path cost, and providing a systematic call admission function.
In this project, we study two approaches for defining link cost functions in a hierarchical network, namely the Markov Decision Process (MDP) approach and the Competitive On-Line (COL) approach. The theory of Markov decision process is a pledge method in a lot of network-related issues. Various network control schemes have been developed based on the Markov decision process. For example, many MDP-based routing algorithms, which compute the link cost based on the MDP theory, have been proposed and demonstrated to perform very well. In this project, we adopt the idea for its simplicity and efficiency. However, Gawlick, et al., proposed an on-line optimal routing algorithm, referred to as the Competitive On-Line (COL) algorithm. This approach defines the link cost function as an exponential function of the residual bandwidth. They have shown good routing performance based on this cost function. We proposed MDP-based cost function for hierarchical QoS routing.
In this project, we compare the performance of the MDP-based and the COL-based cost functions with the Widest Path (WP) approach, which routes an incoming connection to the path with maximum residual bandwidth. The residual bandwidth of a path is defined as the minimum of the residual bandwidth of all links on the path. The simulation results show that the MDP and the COL approaches outperform the WP approach. The MDP approach yields the best network utilization. A further advantage of the MDP approach is that it provides a
On the other hand, PNNI adopts time-based update policy which is inadequate to cope with dynamic network traffic. Furthermore, the accuracy of aggregated information is depended on the update interval, with a reduced update interval meaning more accurate aggregated information. However, in this situation the overhead of re-aggregation and information distribution increases. Awerbuch et al. proposed the logarithmic update approach, which is based on the residual bandwidth of a link, to reduce the computational overhead of re-aggregation.
An event-based update policy typically suffers from oscillation, which can be avoided by hystersis. The technique of hysteresis has been applied to various areas of high-speed networks. For example, Jong applied hysteresis to ATM rate control to enhance system stability, and Orda et al. proposed an adaptive virtual path allocation policy using hysteresis to prevent excessive processing of requests due to oscillations around thresholds.
We proposed an event-driven update policy based on the link cost. Furthermore, to avoid oscillation, the hystersis technique was applied. The proposed policies are called the Dynamic Cost-based Update (DCU) policy and the DCU with hysteresis (DCUH) policy. The performance of the proposed policies is compared to other time-driven and event-driven update policies, including the PNNI time-based update approach (PNNIU), full update approach (FU), logarithm of residual bandwidth update approach (LRBU), and dynamic cost-based update policy without hysteresis. Simulation results show that the DCUH policy performs best among these update policies.
D.
Cr ankback Appr oaches
We further study mechanisms for reducing the crankback overhead in PNNI hierarchical networks. Two heuristics are proposed to reduce crankback overhead. First, if we can predict where to crank back, referred to as the destination node, the call setup message need not to crank back to the source node, thus the call set up overhead at the common nodes along the path can be reduced. Second, the aggregated path cost represents the expected cost for setting
up the call on the path of O-D pair. Therefore, a call setup message on a path with high path cost is likely to be blocked. Consequently, avoiding setting up a call on a path with high path cost will reduce the crankback overhead. Based on these two heuristics, we proposed two approaches to reduce crankback overhead. The first approach adds an addition information, referred to as CIS, to predict the crankback destination node. In this approach, we keep CIS in the call setup message while crossing the PG. When call setup message encounters a block link, the intermediate node using CIS to find the crankback destination node. Hence, the call setup message needs not to crank back to the ingress node. The second approach uses aggregated path cost to determine whether call setup on alternate paths should be tried. In PNNI hierarchical network, paths with smaller hierarchical path cost are tried first. If the aggregated path cost information is accurate and a call setup message failed on the path with minimum cost, then call set up on alternate paths with higher path cost will likely to be failed.
E.
Simulation Results
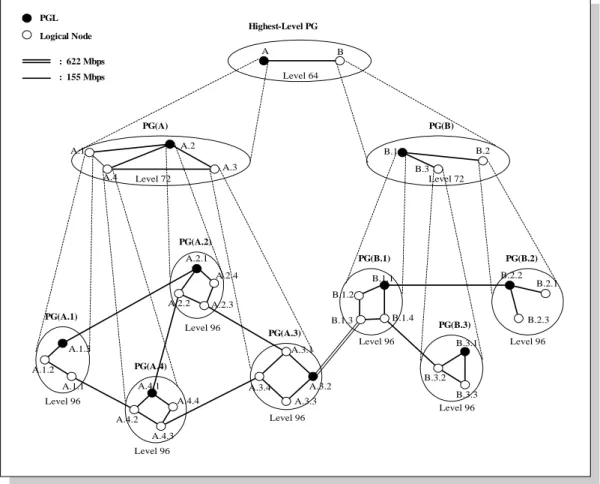
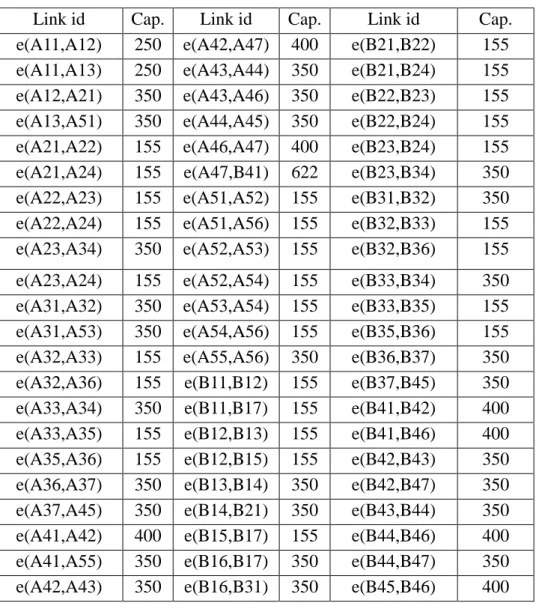
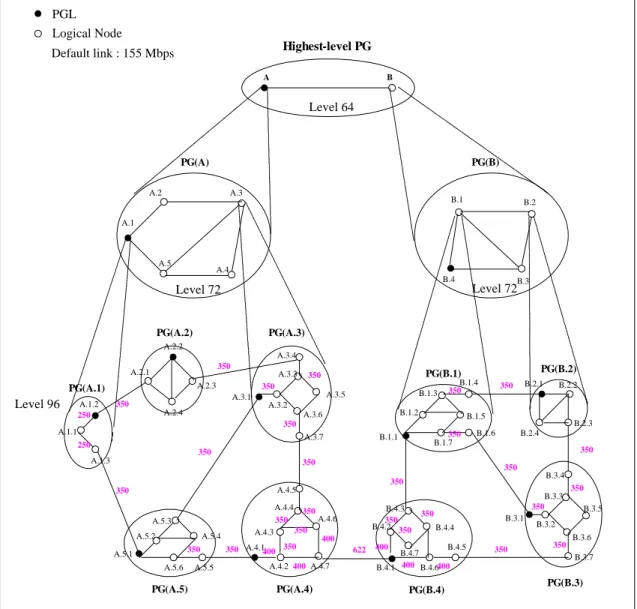
This section evaluates the performance of hierarchical routing with different aggregation schemes and cost functions via simulations. Figure 3.8 shows the network topology of the simulations. The capacity of each link is 155 Mbps, except for link(A.3.2-B.1.3) and link(B.1.3-A.3.2), which are 622 Mbps. Each link has a delay of 1ms.
In the simulations, the network supports two classes of traffic. The class 1 traffic has a bandwidth requirement of b1= 1 Mbps, and an end-to-end delay bound of d1= 15 ms. Class 1 traffic is assumed to arrive at any O-D pair with the same arrival rate λω1 =λ , while the class 2 traffic is assumed to have a bandwidth requirement of b2= 5 Mbps, an end-to-end delay
bound of d2= 15 ms, and an arrival rate of λω2 =λ / b2 between each O-D pair. The average holding times of these two classes of traffic are normalized to unity.
A.1.1 A.1.2 A.1.3 A.2.3 A.2.2 A.2.1 A.3.1 A.3.4 A.3.3 A.3.2 B.1.2 B.1.3 B.1.1 B.2.2 B.2.1 B.2.3 PG(A.1) PG(A.2) PG(A.3) PG(B.1) PG(B.2) PG(A) PG(B) A.1 A.3 A.2 B.1 B.2 A B Highest-Level PG Level 96 Level 96 Level 96 Level 96 Level 96 Level 72 Level 72 Level 64 PGL Logical Node A.4 A.4.3 A.4.2 A.4.1 PG(A.4) Level 96 B.3.2 B.3.3 B.3.1 PG(B.3) Level 96 B.3 A.4.4 B.1.4 A.2.4 : 622 Mbps : 155 Mbps
Figure 3.8 Network topology
call holding time. The initial 100 time units are estimated as the transient period and, thus, performance samples are discarded.
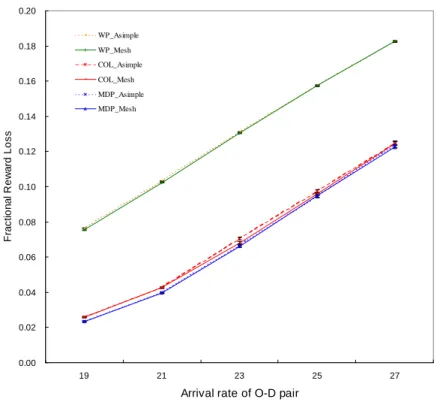
Figure 3.9 shows the fractional reward loss of calls under different arrival rates, when two aggregation schemes are used for the WP and the MDP and the COL link cost functions. The figure shows that the fractional reward loss increases as the arrival rate increases. Meanwhile, the fractional reward loss of the Asymmetric Simple scheme of the COL link cost is slightly higher than for the Full Mesh scheme. The fractional reward loss of Asymmetric Simple scheme of MDP link cost is almost the same as Full Mesh scheme. Meanwhile, the MDP approach yields a better performance than the COL in both the Asymmetric Simple and Full Mesh schemes. This superiority is because the MDP approach considers the arrival rate, and so can provide more accurate cost information and call admission function. However, the MDP and COL cost-based approaches significantly outperform the WP approach. The main reason is that the bandwidth-based approach only considers the maximum residual bandwidth
0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 0.16 0.18 0.20 19 21 23 25 27
Arrival rate of O-D pair
F ra c ti o n a l R e w a rd L o s s WP_Asimple WP_Mesh COL_Asimple COL_Mesh MDP_Asimple MDP_Mesh
Figure 3.9 Fractional reward loss.
of bottleneck link among all candidate paths. However, the cost-based approaches first transfer the residual bandwidth of link into a reasonable cost and then route the minimum path cost.
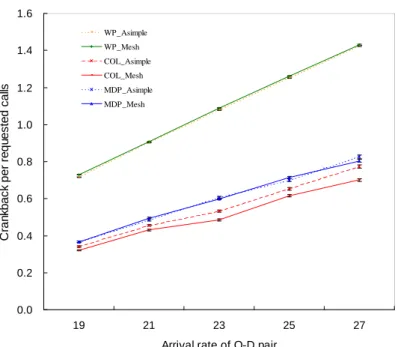
Figure 3.10 shows the average number of crankbacks per connection request under different arrival rates, when two aggregation schemes are used. The figure shows that the average number of crankbacks increases as the arrival rate increases. The average number of crankbacks of the Asymmetric Simple of the COL link cost function is higher than for the Full Mesh scheme. Meanwhile, the average number of crankbacks of the Asymmetric Simple of MDP link cost function is almost the same as that of the Full Mesh scheme. The COL approach of all schemes requires less crankbacks than the MDP. The reasons for this phenomenon are that the cost function is less accurate and the call admission of COL approach is less conscientious than that of the MDP approach. Consequently, a call may be routed to non-optimal path that requires more network resources and thus increases call
0.0 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 19 21 23 25 27
Arrival rate of O-D pair
C ra n k b a c k p e r re q u e s te d c a lls WP_Asimple WP_Mesh COL_Asimple COL_Mesh MDP_Asimple MDP_Mesh
Figure 3.10 Crankback per requested calls.
higher call blocking probability. However, the MDP approach provides more accurate aggregated cost and precise call admission policy because the link cost is computed based on Markov decision theory. This approach results in less calls being blocked due to call admission at the hierarchical routing procedure, but more blocking due to the call admission at the physical network level. Hence, the MDP approach results in more crankbacks. Additionally, the number of crankbacks of the WP approach is more than that of the COL and MDP approaches. Clearly, the reason is that the WP approach is not a good approach for hierarchical routing.
Figure 3.11 shows the fractional reward loss yielded by the five update policies under different arrival rates. As figure 3.11 illustrates, the FU policy yields the lowest fractional reward loss, because it provides the most accurate routing updates. However, the LRBU, DCU, and DCUH policies all yield very competitive fractional reward loss as compared to the FU policy. Figure 3.11 shows that the DCUH policy yields slightly lower fractional reward loss than the LRBU and DCU policies. Meanwhile, figure 3.11 also illustrates that PNNIU policies yield worse performance than the other four policies. The performance of PNNIU
0.00 0.02 0.04 0.06 0.08 0.10 0.12 0.14 19 21 23 25 27
A rrival rate of O -D pair
F ra c ti o n a l R e w a rd Lo ss FU PNNIU_1 PNNIU_4 LRBU DCU DCUH
Figure 3.11 Fractional reward loss of five update policies.
policy can be improved if the update interval reduces. For example, the PNNIU_1 policy outperforms the PNNIU_4 policy.
Figure 3.12 shows the average number of crankbacks per connection request under different arrival rates. Intuitively, the more accurate the aggregated routing information, the less the average number of crankbacks. Hence, the average number of crankbacks per connection request is an important performance metric for update policies. Figure 3.12 illustrates that FU, LRBU, DCU, and DCUH have almost the same number of crankbacks per connection while the PNNIU policies have a much higher number of crankbacks.
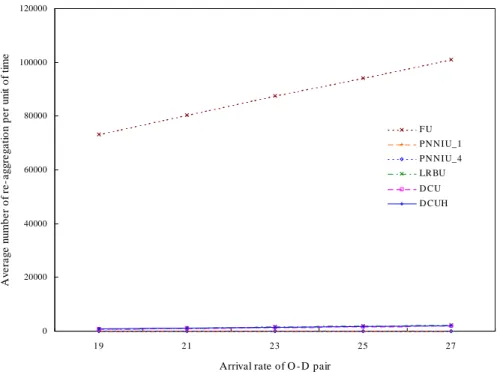
Figures 3.13 and 3.14 show the number of information re-aggregations and distributions per unit of time under different arrival rates. Intuitively, the FU policy should have the highest re-aggregation frequency, and the two figures confirm this. On the other hand, adjusting the update interval gives the PNNU policy the least update frequency. Comparing the LRBU, DCU, and DCUH policies reveals that the DCU and DCUH policies yield less overhead
re-0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 19 21 23 25 27
Arrival rate of O - D pair
A v e ra g e n u m b e r o f c ra n k b a c k p e r c o n n e c ti o n r e q u e st FU P N N IU _ 1 P N N IU _ 4 LR B U D C U D C U H
Figure 3.12 Average number of crankback per connection request.
0 20000 40000 60000 80000 100000 120000 19 21 23 25 27
Arrival rate of O - D pair
A v e ra g e n u m b e r o f re -a g g re g a ti o n p e r u n it o f ti m e F U P N N I U_1 P N N I U_4 LRBU D CU D CUH
Figure 3.13 Average number of re-aggregation per unit of time.
DCU policy does not suffer much from oscillation. The effect of hysteresis requires further investigation.