行政院國家科學委員會專題研究計畫 成果報告
利用重傳來控制多媒體經由區域無線網路的傳訊錯誤的方
法研究
計畫類別: 個別型計畫 計畫編號: NSC92-2213-E-009-111- 執行期間: 92 年 08 月 01 日至 93 年 07 月 31 日 執行單位: 國立交通大學電信工程學系 計畫主持人: 廖維國 報告類型: 精簡報告 處理方式: 本計畫可公開查詢中 華 民 國 93 年 11 月 1 日
行政院國家科學委員會補助專題研究計畫
■成果報告
□ 期 中
進度
報告
利用重傳來控制多媒體經由區域無線網路的傳訊錯誤的方
法研究
計畫類別:■ 個別型計畫 □ 整合型計畫
計畫編號:NSC
92-2213-E-009-111-
執行期間: 92 年 8 月 1 日至 93 年 7 月 1 日
計畫主持人:
廖維國
共同主持人:
計畫參與人員:
陳怡中、劉政澤、廖怡翔、林國瑋、林于彰、黃健智、
陳憲良
成果報告類型(依經費核定清單規定繳交):■精簡報告 □完整報告
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
處理方式:除產學合作研究計畫、提升產業技術及人才培育研究計畫、
列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查
詢
執行單位:
國立交通大學/電信工程學系
中 華 民 國 93 年 10 月 31 日
附件一行政院國家科學委員會專題研究計畫成果報告
計畫編號:NSC 91-2219-E-009-015-
執行期限:92 年 8 月 1 日至 93 年 10 月 31 日
主持人:廖維國 國立交通大學電信工程系
計畫參與人員:陳怡中、劉政澤、廖怡翔、林國瑋、林于彰、黃健智、
陳憲良
國立交通大學電信工程系
I. 中文摘要 隨著無線區域網路快速發展,新的應用不 斷出現。在能源消耗方面,服務品質方面, 硬體成本方面都已經有相當的突破。然而 為了要商業化,整合性的探討是必要的。 也就是說,如何同時討論這些特性以及它 們之間彼此的影響是必要的。 我們所提出的解決方案是:報酬!任何 有價值的東西我們都可以用這樣東西的報 酬來描述。語音的品質我們可以用報酬來 描述;無線資源的使用效率我們可以用報 酬來描述;即使是服務提供者也可以用報 酬來描述。我們基於無線通道符合馬爾克 夫模型的假設,運用動態程式技巧試圖找 尋最佳化的報酬。 關鍵詞:多媒體應用,重傳,終點對終點 服務品質,馬可夫決策隨機程序。 Abstract
Coming prevalence of wireless LAN invokes the aspiration for adequate and lucrative applications over it. Prevalent researches have been done about energy consumption of mobile stations, implementation of quality of service, architecture modification and cost-down of devices, etc. However, in order to commercialize usage of wireless LAN, integration of all these fields is important. In other words, how to balance so many tradeoffs, simultaneously, is of concern. Could there be any easy way to take into account all these tradeoffs at one time?
attributes into a notion called reward. All things with value, either to operators or to users, can be attributed to reward. Quality of the voice can be described as reward. Efficiency of wireless resource can be described as reward. Income of the service provider, too, can be described as reward! On the assumption of certain wireless channel model, which at this moment we have is a two-state Markovian one, we can appeal to dynamic programming to find the best way to maximize our reward.
Keywords: Multimedia applications,
retransmission, end-to-end QoS, Markov Decision Process
II. Motivations and Objectives
Wireless communication channels are error-prone due to various interferences imposed on the channels. Very often, the error tends to be bursty, results in the serious packet corruption, and thus the packet will be entirely lost when exceeding the capability of error correcting scheme.
To overcome such an error, employing the retransmitting schemes to protect the packets is mandatory. However, it is obvious that retransmissions will inevitably result in undesired late transmission of the following packets. Thus guaranteeing the satisfaction of stringent timely constraint for all the packets transmitted over the wireless channel is unlikely.
real-time communication into a flexible one is a solution worthwhile for close investigation. To be more specific, when the demand cannot be satisfied for the communication, the sending end system early (or intentionally) drops the packets with less investment in order to allow more times to retransmit the important packets in case of errors without violating their timing constraints. A potential implementation is that the source of the communication marks each packet with different color to indicate the impact of the packet to the transmission quality; the wireless sending end system then tradeoffs the resource demands according to the colors of the packets, and traffic-related profile, and current channel condition.
In this project, we investigate the policy to adaptively select the retransmission-based error control action to resolve such a tradeoff, i.e., to maximize the resulting transmission quality for real-time communication when the channel is error-prone. Due to that the channel condition is time-varying, performing such a control for real-time communication is a challenging issue
We first model the decision problem within the context of Markov decision theory. In deciding whether to perform an action, it is often to evaluate its impact by expected cost first and then taking the action with the minimum expected cost. Assigning the expected cost to the action of retransmission-based error control is of particular challenge due to that the system behavior is dictated by many factors.
The basic idea behind our proposal is to consider the selection of error control actions within the context of Markov decision process. It has been reported that modeling many wireless channels with finite-state Markovian process is adequate. With a reasonable assumption on arrival process of a real-time flow, thereby the whole sending system, including the buffer system, can be well fitted into the finite-state Markov process. In this way, we derive the Howard relative cost function to assess the future impact of each error-control action and find
the policy to achieve the least average cost.
Given this, our proposal is notably different from the previous approaches on the deadline-driven wireless scheduling schemes where the cost function is defined upon the packet, unlike our proposal where the cost is defined upon the action. As will be discussed later, our analysis is more comprehensive and the resultant service discipline derived from our analysis is quite different.
III. Results and Discussions
Different wireless channel conditions require different optimal policies. Since we now have a grasp of what a policy and what an optimal policy is, we turn to ask ourselves: What is the wireless channel condition? More precisely, how to characterize wireless channel condition?
Fig 1: Status of Packet Transmission Identical and independent channel model we use in our last intuitive reasoning will not work properly simply because it extremely abstracts what happens in wireless channel, making any conclusion from this model rhetorical but not applicable. Obviously other channel models must be proposed instead. In Mr. Wang and Mr. Chang’s work “On verifying the First-Order Markovian Assupmtion for a Rayleigh Fading Channel Model”[1], information theory is used to lay down the theoretical foundation of first-order Markovian model for Rayleigh fading channel. On top of that, Mr. Zorzi and Mr. Rao applied this Markovian model as well as renewal theory to analyze performance of data link layer protocol, such as ARQ Go-Back-N protocol and ARQ selective repeat protocol [2]-[6]. Though some prominence disagreed [7], and came up with the shortcomings and limitations for first-order Markov modeling for the Rayleigh fading channel, first-order Markovian model is good enough for analytical purpose.
In our first-order two-state Markov channel model, the channel condition at current period of time, i.e., in the current slot, will affect the channel condition of next slot. The definitions of these four conditional probabilities are described as follows, and the very four conditional probabilities can fully characterize our two-state Markov channel:
p = Pr {next packet success | last packet success}
q = Pr {next packet fail | last packet success}
r = Pr {next packet success | last packet fail}
s = Pr {next packet fail | last packet fail}
Because we have assumed that transmitter has infinite data to transmit, transmitter ignores failing transmission, and each packet to be transmitted is of the same length, we have a certain kind of traffic. We can, by the above reasoning in the last paragraph, assign every packet a unique value, a unique reward. Because the exact and meaningful value of reward is closely related to coding algorithm, which is out of our discussion, we assign arbitrary reward here for convenience. Consider the following examples:
Successful transmission of current packet gives receiver satisfaction of 9 units if transmission of last packet is successful.
Failing transmission of current packet gives receiver satisfaction of 3 units if transmission of last packet is successful. Successful transmission of current
packet gives receiver satisfaction of 3 units if transmission of last packet fails Failing transmission of current packet
gives receiver satisfaction of -7 units if transmission of last packet fails.
It can be depicted in the following diagram.
Fig 2: Transition Diagram with Rewards
The transition matrix defining channel condition and specific rewards
our spotlight.
Finally, we apply policy iterative routine to obtain the optimal policy. We here use simulation to prove that our proposal in last section. We try to use simulation to find the speed of convergence of our proposed method. We call it online decision method, which demands online collection of the statistics that we need. Initially we have assigned p, q, r, s, α and β to be 0.5. When transmission proceeds, the value of these parameters will be updated continuously. We pick up two extreme cases to verify our proposed online decision method. The results are shown in the following figures.
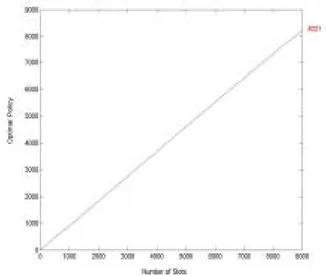
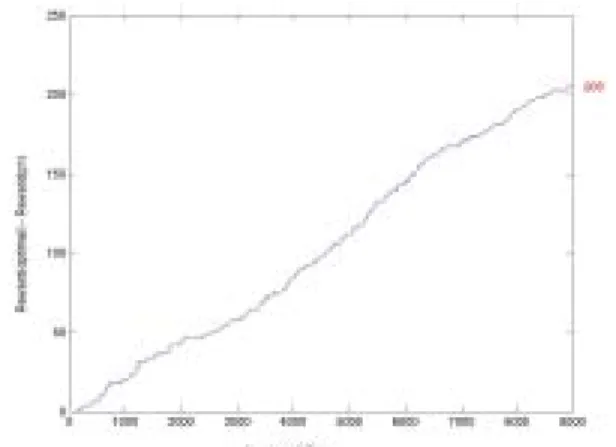
Case one we have p=0.9, q=0.1, r=0.5, s=0.5, and α=β=0.5. Fig. 3 through Fig. 5 are the results.
Fig. 3 Rewards Of Optimal Policy (p=0.9, q=0.1, r=0.5, s=0.5, α=β=0.5)
q=0.1, r=0.5, s=0.5, α=β=0.5)
Fig. 5 Difference Rewards Poptimal-P2 (p=0.9,
q=0.1, r=0.5, s=0.5, α=β=0.5)
Fig. 3 shows total rewards obtained by optimal policy which we found by our online decision method. Fig. 4 shows rewards difference between optimal policy and policy one. We find that optimal policy is exactly the policy since there is no difference between their rewards. Under this environment, i.e., p=0.9, q=0.1, r=0.5, s=0.5, α=β=0.5, the optimal policy indeed is the policy one. This shows that our online decision method works. Meanwhile we can tell the convergence speed of our online decision method from Fig. 4. Recall that we initiate all the parameters with the value of 0.5. But in fact, in this case, we have p=0.9, and q=0.1. However, we see little fluctuation at the beginning of transmission time in Fig. 4. That shows our online decision method finds the optimal policy very quickly. The same result can reasoning can also be found and applied in another extreme case: p=0.1, q=0.9, r=0.5, s=0.5, α=β=0.5, where Fig 6 through Fig. 8 show its results.
Fig. 6 Rewards of Optimal Policy (p=0.1,
q=0.9, r=0.5, s=0.5, α=β=0.5)
Fig. 7 Difference Rewards Poptimal-P1 (p=0.1,
q=0.5, r=0.5, s=0.5, α=β=0.5)
Fig. 8 Difference Rewards Poptimal-P2 (p=0.1,
q=0.9, r=0.5, s=0.5, α=β=0.5)
IV. Self-Assessment
We have identified a new way to tradeoff the resource demand during the transmission over wireless link to sustain the resultant quality as high as possible. As shown in our simulation, our proposal obtains remarkable results. In the coming years, we will keep exploring the wireless controls from current achievements.
References
[1] Hong Shen Wang, Pao-Chi Chang, “On Verifying the First-Order Markovian Assumption for a Rayleigh Fading Cahnnel” In IEEE Transactions On
Vehicular Technology, VOL. 45, NO. 2, May 1996
[2] Michele Zorzi, Ramesh R. Rao, Laurence. B. Milstein, “On the Accuracy of a First-Order Markov Model for Data Transmission on Fading Channels” In ICUP’95, TOKYO,
JAPAN, Nov. 1995.
[3] Michele Zorzi, Ramesh R. Rao, “On the Use of Renewal Theory in the Analysis of ARQ Protocols”, In IEEE
Transactions on Communication.
[4] Michele Zorzi, Ramesh R. Rao, “Bounds on the Throughput Performance of ARQ Go-Back-N Protocol in Markov Channels”, In
MILCOM’95, San Diego, CA, NOV. 1995..
[5] Michele Zorzi, Ramesh R. Rao, “Throughput Analysis of ARQ Selective-Repeat Protocol with Time Diversity in Markov Channels”, In
GLOABECOM’95, Singapore, NOV., 1995.
[6] Michele Zorzi, Ramesh R. Rao, “Energy Efficiency of TCP in a Local Wireless Environment”, In Mobile
Networks and Applications 6, 265-278, 2001.
[7] Christopher C. Tan, Norman C. Beaulieu, “On First-Order Markov Modeling for the Rayleigh Fading Channel” In IEEE Transactions on
Communications, VOL. 48, NO. 12, DEC. 2000.
[8] Ronald A. Howard “Dynamic Programming and Markov Processes”,
The MIT Press, Cambridge, Massachusetts, MAR. 1962.