The role of learning experience on the perceptual
organization of Chinese characters
Su-Ling Yeh and Jing-Ling Li
Department of Psychology, National Taiwan University, Taipei, Taiwan
Tatsuto Takeuchi
NTT Communication Science Laboratories, NTT Corporation, Japan
Vincent C. Sun
Department of Psychology, Fu-Jen Catholic University, Taipei, Taiwan
Wen-Ren Liu
Educational Psychology Program, Pennsylvania State University, USA
The effect of learning experience on the perceived graphemic similarityof Chinese characters was examined bycomparing results of the constrained (Experiment 1) and unconstrained (Experiment 2) shape-sorting tasks obtained from various groups of participants with different learning experiences and ages. The results from hierarchical cluster analysis showed that both Taiwanese and Japanese undergraduates classified characters in relation to their configurational structures, whereas American undergraduates, Taiwanese illiterate adults, and kindergartners categorized characters based on strokes or components. Although a trend of developmental changes from local details to more globallydefined patterns was found, the identification of structure as consistentlyperceived byskilled readers has to be nourished bylearning experience and cannot be obtained solelythrough maturation.
Chinese characters, the basic writing units in Chinese script, are square-shaped and roughlythe same size in a text. Each character is constructed with three levels of hierarchical organization: Stroke, component, and structure. Strokes are simple features such as dots, lines, and curves, as shown in the character .
Please address all correspondence to: Su-Ling Yeh, Department of Psychology, National Taiwan University, No. 1, Sec. 4, Roosevelt Rd., Taipei, Taiwan, 10764. E-mail: [email protected]
We thank the children at Taipei Montessori Kindergarten and Proud-of-Heaven Kindergarten in Chia-Yi for their participation in this study. This research was supported by a grant from the National Science Council of Taiwan (NSC87-2413-H-002-027-G5) to Su-Ling Yeh.
# 2003 Psychology Press Ltd
The number of strokes in Chinese characters ranges from 1 to 30, but the majorityof characters possess 8±18 strokes (Cheng & Chen, 1991), with a mean of 9.1 strokes for the most frequentlyused 2965 characters (Tsai, 1996). Components are independent, meaningful parts that are constructed with strokes. Although what is defined as a stroke is relativelyclear, what is defined as a component is usuallyequivocal. For example, the character can be perceived as formed from the following three combinations: (1) , (2) , and (3) .1All constituents in these three combinations are legal characters, and, as is obvious from this example, the number of components in a character varies from 4 to 2, depending on the definition of the components. Whether each character is analysed into its constituent components, and what the identifiable or separable components are during the character recognition process, are still under hot debate (Chen, 1984; Fang & Wu, 1989; Feldman & Siok, 1997; Flores d'Arcais, Saito, & Kawakami, 1995; Lai & Huang, 1988; Taft & Zhu, 1997; Yu, Feng, Cao, & Li, 1990; Zhou & Marslen-Wilson, 1999).
The components can be arranged left±right, as in the character ( + ), top-down, as in ( + ), or one component enclosed byanother, as in ( + ). The arrangement of different components at various positions thus forms the structure of the character. Although it is generallyassumed that there are different structures inherent in Chinese characters, most studies have stated the nature and the number of structure types more or less subjectively, causing the number of structure types to vary from 16 to 2 (e.g., Chan, 1992; Fu, 1985; Leck, Weekes, & Chen, 1995; Liu, 1984; Liu & Yeh, 1977; Yeh & Liu, 1982; but see Yeh, 2000; Yeh, Li, & Chen, 1997, 1999).
Therefore, how the three hierarchical levels of information in Chinese characters are perceived byreaders with different learning experiences, especiallywhen compared with the waytheyare perceived byskilled readers, maytell us what the difference between experts and novices is and how experience plays a role in obtaining the key elements for skilled reading. To examine this, we adopted shape-sorting tasks in this study. In Experiment 1, three groups of college students from different countries conducted a con-strained sorting task in which sampled characters were to be sorted into various numbers of piles according to the similarities in the character shapes. In Experiment 2, two groups of illiterate Taiwanese of different ages (kindergart-ners and adults) were recruited to conduct an unconstrained sorting task in which the participants sorted characters into as manypiles as theydesired. Another
1Two types of component are usually identified: The radical component and the nonradical
component. The radical component is the approximately214 basic meaning-conveying units (called /but4 shou3/) that are used to locate the characters in a Chinese dictionary. The nonradical component is usuallythe phonetic element, carrying the sound of the whole character. In this example, the character (/hu2/, meaning ``paste'') is said to be composed of the semantic radical
group of Taiwanese undergraduates conducted the same unconstrained sorting task to provide the basis for comparison of the two kinds of sorting tasks and for evaluation of the learning effect. The rationale for using the shape-sorting task to examine the perceptual organization of Chinese characters bydifferent groups of participants is as follows.
First, recent studies on categorization have shown that the implicit acquisition of categoryknowledge is a common process in everydayexperience, and it can occur whenever individuals encounter a large group of related items (Reed, Squire, Patalano, Smith, & Jonides, 1999). In this aspect, Chinese characters are excellent stimulus items for use in examining the representation through sorting tasks, since, over years of exposure, Chinese characters can be said to be the most common items encountered byskilled Chinese readers.
Second, theories of similarityand categorization have emphasized both the bottom-up, feature-based perceptual functions and the top-down, knowledge-based cognitive functions (Markman & Gentner, 1993; Medin, 1989; Palmeri & Blalock, 2000; Wisniewski & Medin, 1994). In this sense, how people with different word knowledge categorize Chinese characters maythen manifest such interplaybetween perception and knowledge. Word knowledge is mainly obtained from learning experience and mayinteract with the perceptual developmental stage of the learner. Therefore, we have selected groups of participants with different learning experience while keeping their development stage constant (i.e., college students from different countries), as well as parti-cipants with different perceptual development while keeping the learning experience constant (i.e., illiterate children and adults) for comparison.
Third, categorization provides a mechanism for rapid information processing (e.g., Ingling, 1972) in that the processing load can be reduced in an organized wayto extract useful information relevant to the task. Therefore, byexamining how skilled readers categorize Chinese characters, what information is useful and therefore is extracted after repetitive exposure to characters (and what is irrelevant) can then be identified. In this aspect, since Chinese is a logographic system, it may depend more on the visual/graphemic aspects than alphabetic systems (Biederman & Tsao, 1979; Chen, Flores d'Arcais, & Cheung, 1995; Chen & Juola, 1982; Leck et al., 1995; Park & Arbuckle, 1977; Sasanuma, 1975; Wang, 1973). It is thus worthwhile to compare the categorization of individuals with different learning experience and see how other aspects of Chinese char-acters, particularly, their pronunciation, affect the categorization. In this sense, Japanese undergraduates who learn Chinese characters that have the same forms but maynot be associated with the same pronunciations provide an excellent comparison group for examining the possible role of sound on the perceptual organization of Chinese characters.
Fourth, in the case of English, theories of reading development have emphasized the visual and graphemic cues during earlydevelopment, and the unit of processing seems to be enlarged with experience (e.g., Rayner &
Pollatsek, 1989). We are also interested in how a visual strategyis developed for a logographic script such as Chinese. Finding how people with different lan-guage backgrounds and experiences perceive Chinese character shapes differ-entlycan reveal important elements in recognizing Chinese characters, as well as provide important educational implications for teaching written Chinese.
EXPERIMENT 1:
CONSTRAINED SORTING BY TAIWANESE,
JAPANESE, AND AMERICAN COLLEGE STUDENTS
Three groups of college students in Taiwan, Japan, and the United States par-ticipated in the sorting task. During their education years, Japanese under-graduates learn Chinese characters in the form of Kanji characters designated for dailyuse bythe Japanese government, so the Kanji theyhave learned are quite restricted not onlyin content but also in quantity. Kanji are learned gradually and in a fixed sequence planned over the range of the first nine years of formal schooling, with a total of 1945 Kanji learned. In learning Chinese characters, theyalso learn the radical and the nonradical components that comprise the characters. In most cases, the meaning of the Kanji is the same as in Chinese, but the pronunciation differs. Therefore, except for the limited number of characters learned and their different pronunciations, the learning process seems to be quite similar to that in Taiwan. In comparing the sorting results of Taiwanese and Japanese undergraduates, who share similar learning experiences regarding the shapes but not the pronunciations of the characters, the effects of shape and sound in categorization as well as the separabilityof these two factors can be examined.
Native English speaking participants were also chosen according to the control of learning experience: Those chosen had no experience of learning Chinese. As English is an alphabetic system that is quite different from the nonalphabetic system of Chinese, Americans who have not learnt Chinese may differ in their perception of Chinese characters from Taiwanese considerably, despite the fact that after training, Americans can also learn the concept of ``same component'' embedded in different Chinese characters (Hull, 1920). For the comparison of the Taiwanese, Japanese, and American undergraduates, we aimed at seeing how different language backgrounds influence the form cate-gorization of Chinese characters.
Method
Participants. Three groups of participants, each comprised of 24 college students, were solicited from universities in Taiwan, Japan, and the United States. Theyhad no known historyof previous participation in related Chinese character experiments designed bythe authors. All reported having normal or corrected-to-normal vision and were naõÈve about the purpose of the experiment.
The Taiwanese undergraduates (TWc, standing for Taiwanese in constrained sorting) were students enrolled in introductorypsychologycourses at National Taiwan Universityand received course credit for their participation. The Japanese undergraduates (JP) were recruited from several universities near Tokyo and went to the NTT Communication Science Laboratories to conduct the experiment. The American undergraduates (AM) were students at the Universityof Chicago and were paid for their participation. It was confirmed before the experiment that none of the AM had ever studied Chinese.
Stimuli and design. The stimuli are shown in Table 1. Characters belonging to three ranges of stroke counts were specified: Low-stroke (LS, 3±8), middle-stroke (MS, 9±13), and high-middle-stroke (HS, 14±21). The reason for separating
TABLE 1
Sample characters used in this study Stroke count Category LS MS HS 1. Horizontal: 2 parts (H2) 2. Horizontal: 3 parts (H3) 3. Vertical: 2 parts (V2) 4. Vertical: 3 Parts (V3) 5. P-shaped (P) 6. L-shaped (L) 7. Enclosed (E)
The occurrence frequencyis within the range of 46±193 per million characters (Chinese Knowledge Information Processing Group, 1993).
characters into different ranges of stroke counts is that differences in stroke count have been found to affect character recognition, recall, and sorting (e.g., Cheng, 1981; Hue & Erickson, 1988; Li, 1998; Yeh & Liu, 1982). Since the contrast in stroke counts between character samples would affect the sorting results, and this factor was not to be further explored in this study, we preferred to constrain the range of stroke counts within each sorting session so that other important factors, such as structure or constituent component, could be more clearlymanifested.
Each stroke count condition contained seven categories prespecified bythe authors, with three sample characters for each category. This step was to ensure that unbiased samples as broad as possible to cover the range of structural variation could be selected (see Yeh et al., 1997). These 63 characters were each printed in black and pasted in the centre of 9 6 5.4 cm white cards. Theywere set up in the Xi-Ming ( ) font of 36 points in Microsoft Word font. When printed, each character occupied 1.2 6 1.2 cm in space. A mixed design with one between-participants factor (three groups of participants: TWc, JP, and AM), and one within-participants factor (three stroke-count conditions: HS, MS, and LS) was employed.
Procedure. The participants were escorted individuallyinto the experi-mental room. Theywere seated at a table beside the experimenter and instructed to judge the similarityof the shapes of the characters and to put similar characters into the same pile, and dissimilar characters into different piles. The three stroke-count conditions (LS, MS, and HS) were conducted separatelyin different blocks of trials. During each session of the sorting task, the 21 cards were shuffled and then presented with the characters facing up at random locations on the desktop. These cards had to be put into a predesignated number of piles (two, three, four, or five piles) as requested in each trial, and the sequence of the numbers of piles to create was counterbalanced among participants. For a particular number of to-be-classified piles, each participant finished all three stroke-count conditions before proceeding to the next number of piles. After theyfinished all four levels of predesignated piles, the entire sequence was repeated once in reverse order. Therefore, there were, in total, eight sessions for each stroke-count condition.
Upon completing the sorting task, the participants were asked to perform a memorytask: Theyhad to write down the characters theycould remember from the sorting task. This was intended to see how different groups of parti-cipants recalled the stimuli in the sorting task when theyhad not been told beforehand that theywould have to do so. After the memorytask, theywere asked to write down the rules theyhad used for sortingÐrules theyhad deter-mined themselves with no instructionÐin order to complete the entire experiment.
Results and discussion
Similarity matrices. For each participant's initial sorting of the 21 characters in each stroke-count condition, a 21 6 21 matrix (Pairij, i = 1~21, j = 1~21) was built with values in each cell indicating how manytimes characters i and j were placed in the same piles. Each cell in the matrix was assigned a value of ``1'' if the pair of characters were shown in the same pile and a value of ``0'' if in different piles. For each participant, the highest score was 8 and the lowest was 0 for each pair. A pooled matrix was then calculated bysumming up all the individual matrices for each group of participants (N = 24); thus the highest and lowest scores in the pooled similaritymatrix were 192 and 0, respectively. The nine similarity matrices (the LS, MS, and HS conditions for each of the three groups of participants, TWc, JP, and AM) were submitted to hierarchical cluster analysis as described below.
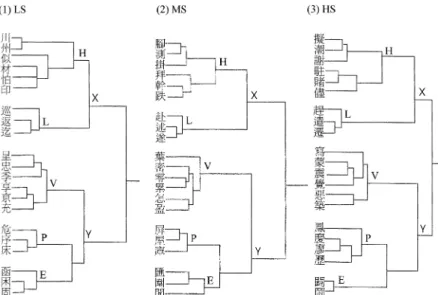
Hierarchical cluster analysis. Hierarchical cluster analysis is a multi-variate procedure to group items into clusters based on the properties these items possess. The resulting hierarchical clusters of items should then exhibit high within-cluster homogeneityand high between-cluster heterogeneity. We adopted one of the most common joining algorithms for nonmetric (rank-order) psychological data, the complete linkage method, to compute the distance of one item (or cluster) from another, and to determine whether the two items (or clusters) should be merged at each step, with the most distant pair of items in two clusters used to compute the between-cluster distance (Johnson, 1967). The tree diagrams obtained from the three stroke-count conditions are shown in Figure 1 for TWc, Figure 2 for JP, and Figure 3 for AM.
Inspection of the cluster diagrams from the results of TWc (Figure 1) and JP (Figure 2) shows that the patterns of results obtained from these two groups are highlysimilar. Generally, the resulting trees had five main clusters. Cluster H contains horizontal-structured characters; L contains L-shaped characters; V contains vertical-structured characters; P contains P-shaped characters; and E contains enclosed (three-sided or completelyenclosed) characters. For all three stroke-count conditions, clusters H and L are then merged as one big cluster, X; and V, P, and E as another big cluster, Y. The tree structures can then be represented as: [H, L] [V, (P, E)].
The results obtained from AM (Figure 3), however, were quite different from those obtained from the previous two college groups. First, characters with vertical and horizontal structures, being two distinct clusters in the previous two college groups, were not consistentlyperceived as such byAM. For example, in the LS condition, the characters with vertical structures, and (E), were not clustered with the other four vertical characters, , , , and (C). The same is true for the other two conditions. For example, and in the MS
in Experiment 1 for (1) the LS (low stroke-count) condition; (2) the MS (middle stroke-count) condition; and (3) the HS (high stroke-count) condition.
Figure 2. The results of heirarchical cluster analyses obtained from the Japanese undergraduates in Experiment 1 for (1) the LS (low stroke-count) condition; (2) the MS (middle stroke-count) condition; and (3) the HS (high stroke-count) condition.
condition (A) and and in the HS condition (D) were not clustered with other vertical characters, either.
Second, from the perspective of character structure, how characters were perceived and classified as similar seemed to varyin different stroke count conditions, unlike TWc and JP, which showed quite consistent results across different stroke count conditions. For example, and (E) in the LS con-dition were clustered with all the P-shaped characters, , , and . How-ever, and in the MS condition (A) were clustered with horizontal characters, and ; and and in the HS condition (D) were clustered with a horizontal character, .
Third, the enclosed characters were not all clustered together, as in the previous two college groups. For example, in the MS condition was clustered with two horizontal characters, and (E). However, though the enclosed character in the HS condition was not clustered with the other enclosed characters ( and in cluster B) either, and was instead clustered with the three P-shaped characters, , , and (C), this pattern is nevertheless the same as that found in TWc and JP.
Fourth, the three P-shaped characters, though clustered together, were also judged to be similar to the other types of characters, but not to the same types across different stroke count conditions. For example, , , and in the LS condition were clustered with vertical characters and (E); , , and
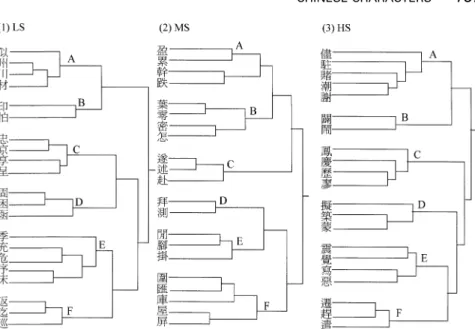
Figure 3. The results of hierarchical cluster analyses obtained from the American undergraduates in Experiment 1 for (1) the LS (low stroke-count) condition; (2) the MS (middle stroke-count) condition; and (3) the HS (high stroke-count) condition.
in the MS condition with enclosed characters and (F); and , , and in the HS condition with an enclosed character, (C). This indicates that these P-shaped characters were not sorted based on their common structure.
Despite these discrepancies, there also existed sorting clusters in AM similar to those in TWc and JP. For AM, besides the aforementioned cluster C in the HS condition ( , , , and , which is in cluster P in TWc and JP), the three L-shaped characters (F, C, and F in the LS, MS, and HS conditions, respectively) were also consistentlyseparated from the other types of characters, as in TWc and JP (cluster L in Figures 1 and 2).
From these results, it is clear that character structure consistentlyplays an important role in the classification schemes of TWc and JP, but it is not so for AM. Although it seemed that the general pattern of the sorting results of AM did not deviate too much from those of TWc and JP, the underlying bases of per-ceived similaritymaydiffer substantially. Take the following case as an example. Some of the stroke patterns (formed bystrokes but not distinctively separable parts as the ``components'' defined above) that were embedded within the entire structure mayhave gone unnoticed byTWc and JP, yet became salient for AM instead, and thus affected AM's classifications accordingly. For instance, the four characters , , , and in the LS condition were clustered together for all these three groups of college students (V, V, and C for TWc, JP, and AM, respectively). However, for TWc and JP, the reason for classifying the four characters as similar may be due to their vertical structures, whereas for AM it maybe due to another totallydifferent reason: All of these characters contain a common stroke pattern: `` ''.
This conjecture can be further examined through several other examples.2 First, in the LS condition the two vertical characters and (E) were not clustered with , , , and (C) for AM, as theywere for TWc and JP (V). Theywere clustered with the three P-shaped characters, , , and , instead, obviouslydue to their common curved strokes. Similarly, in the MS condition, and (A) were separated from their vertical-structured partners , , , and (B), and were clustered with horizontal-structured characters and . This maybe due to the same reason, that , , , and shared certain squares that were missed or were not as salient in the vertical-structured characters , , , and .
Second, the enclosed character (E) in the MS condition was separated from other enclosed characters and put together with and , probablydue to the common component `` '' in and , and several horizontal strokes in
2Originally, these conjectures were to be confirmed by the recalled principles of the participants.
However, due to the procedure used in this experiment, it is difficult to obtain anyuseful information from AM. Such a confirmation was made possible in the next experiment in which the procedure was changed so that the illiterate adults and kindergartners were asked about the categorization rules right after theyfinished each sorting session.
, , and . In the HS condition, the horizontal character (D) was separated from other horizontal characters and clustered with vertical-structured characters and , probablydue to their common curved strokes such as and .
Consider the onlyconsistent cluster of the three L-shaped characters. These L-shaped characters were all clustered together and formed one distinct class for all three groups of college students, probablydue to the salient L-shaped radical components. These L-shaped components not onlycontain the left and hor-izontal curved strokes that occupied the left and bottom area of each character (i.e., ), but also determine each character's overall structure; theyare also the semantic radicals of these characters. Therefore, the three L-shaped characters maybe clustered together due to their overall structure for TWc and JP, but due to their common salient strokes for AM. We call these stroke patterns ``struc-tural components'' for their important roles in determining the overall structure. Although the P-shaped and enclosed characters have similar properties (and so the components and can also be called ``structural components''), they maynot be perceived as consistentlysalient and unambiguous as the L-shaped component. This effect can be observed from the cluster of the four characters , , , and , in which the enclosed character was clustered with the P-shaped characters for all three college groups (P, P, and C for TWc, JP, and AM, respectively). This may be due to the dominant effect that certain strokes have on the perceived similaritybetween these characters, such as the top and left strokes (i.e., ) that all four characters ( , , , and ) share, though
actuallyis an enclosed character.
Comparison of the similarity matrices. The three similaritymatrices obtained from TWc, JP, and AM were compared bycalculating the correlation values between each pair of matrices under the same stroke-count conditions. For the LS condition, the correlations of TWc±JP, TWc±AM, and JP±AM were .97, .68, and .69, respectively; for the MS condition, they were .97, .60, and .60; for the HS condition, .95, .55, and .58. All correlation values were significant at the .005 level.
To examine the group pair comparison, the correlation values were trans-formed into Z scores. The differences between TWc±JP and TWc±AM were significant at the .05 level for all three stroke count conditions; Z = 12.6, 13.9, and 12.1 for the LS, MS, and HS conditions, respectively. The differ-ences between JP±AM and JP±TWc were also significant at .05 level for all three stroke count conditions; Z = 12.4, 13.9, and 11.6, for the LS, MS, and HS conditions, respectively. The differences between AM±JP and AM±TWc did not reach the significant value for anyof the three stroke-count condi-tions, however.
It is thus clear that the resulting similaritymatrices were highlysimilar for those obtained from TWc and JP, but the similaritymatrices obtained from AM
were less similar to both TWc and JP. The quantitative analyses were consistent with the tree structures revealed bythe cluster analyses.
Recall. Precise counts of the number of correct characters recalled can be obtained from TWc and JP, but not from AM, as the Americans were not able to perform the memorytask. Note that 15 characters in our 63 sample characters are absent from ``the Kanji characters designated for dailyuse'' assigned bythe Japanese government. These characters are: and (LS); , , , , , and (MS); and , , , , , , and (HS). In addition, the two characters and are not even included in a standard dictionaryof Kanji characters published in Japan (which contains an average of 9000 Kanji characters). Also, the three characters , , and are printed in simplified forms in Japan, rather than the complicated forms theysaw during the experiment.
For TWc, the percentage of characters recalled in the LS, MS, and HS conditions were 33%, 23%, and 26%, respectively. For JP they were 19%, 11%, and 9%. JP reported fewer characters than TWc did, probablydue to their lower familiaritywith these characters. More characters in the LS conditions were recalled than in the other two conditions for both TWc and JP. Despite the discrepancyin the percentage of characters recalled, the results of cluster analysis for TWc and JP were highly similar, even though 15 characters were not recognizable to them, indicating little effect of lexical knowledge on the categorization of the shapes of Chinese characters once the perceptual organi-zation of the character structure has been achieved.
For AM, although theyalso wrote down what theycould remember after the sorting task, not surprisingly, no meaningful count of the correct characters can be obtained for this group of participants. Nevertheless, some interesting pat-terns can be seen from their reports, as shown in Figure 4. First, theyused some familiar codes to encode the characters. For example, several people reported the character as ``EP''. Second, theynoticed and wrote down some of the local details or single features, such as the small triangle in the right corner of the horizontal line segment (e.g. `` ''), which is prevalent in Chinese chiro-graphy. We refer to these as ``chirographic features''. Sorting based on these chirographic features was never reported byTWc and JP, but, as will be noted later, these features are also prevalent in the reports from kindergartners. Third, theyseemed to perceive the characters as some kind of picture drawings and depicted them as such. This maybe due to certain preconceptions theypossessed about Chinese characters, i.e., that Chinese is a pictographic, ideographic, or logographic system. Finally, many recalled seeing salient strokes or stroke patterns, such as the L-shaped, P-shaped, and enclosed strokes. As mentioned before, these can also be the structural components determining the overall structure of the character. Interestingly, although AM did not seem to use the P-shaped and enclosed structures for sorting as consistentlyas those shown in
TWc and JP, theyseemed to notice these salient structural components, as indicated bytheir recall data. Again, even in this categorytheyalso depicted characters as graphics, reflecting their concept of Chinese characters.
Notice that the different patterns of results obtained for the three groups demonstrated the differences in how theyperceived these characters and treated
Figure 4. Typical examples of recall patterns from the American undergraduates. N indicates the number of participants that had the depicted response.
them in their mental representations. For TWc and JP, years of experience with learning characters led to their development of different representations from those of AM. One of the differences maybe characterized as picture vs. lan-guage, which are processed in different hemispheres byskilled readers (e.g., Hasuike, Tzeng, & Hung, 1986) such as TWc and JP, but maybe viewed and processed in the same hemisphere byAM.
Summary. Based on the participants' sorting data, the similaritymatrices were submitted to hierarchical cluster analysis and the results showed that for TWc and JP in all three stroke-count conditions five major clusters were found in the general form of [H, L] [V, (P, E)], indicating the categorization basis for TWc and JP was the overall layout of the character, i.e., the character structure. AM's sorting, however, seems to be based on certain salient strokes or stroke patterns, rather than structures. The deviation of the AM's result from those of the TWc and JP was confirmed bytheir relative correlations of the similarity matrices. Therefore, learning experience affects the character sorting in that repetitive exposure to characters makes the character structure become useful in organizing and perceiving the characters in relation to their shapes, regardless of their constituent components and individual pronunciations.
EXPERIMENT 2:
UNCONSTRAINED SORTING BY TAIWANESE
COLLEGE STUDENTS, ILLITERATE ADULTS,
AND KINDERGARTNERS
The previous experiment examined the effect of experience byrecruiting par-ticipants from the same age group (all college students). This experiment changed the comparison to the vertical dimension byrecruiting participants from different age groupsÐthe illiterate adults (IL) and kindergartners (KG). Ori-ginallywe planned to use the same constrained sorting task as in Experiment 1, but it turned out to be too difficult for most of the illiterate adults to perform, and almost impossible for the children. Therefore, unconstrained sorting was adopted instead. In the unconstrained sorting, all 21 cards were placed on the desktop, and the participants could sort these cards into as manypiles as they liked. Also, theywere required to sort these cards onlyonce. To provide a basis of comparison, another group of Taiwanese undergraduates (denoted as TWu, standing for Taiwanese in unconstrained sorting) was recruited to perform the same unconstrained sorting in this experiment.
The KG and IL have little, if any, explicit learning experience with Chinese characters, and so theywere chosen to examine the effect of learning experience and age on the categorization of characters, while keeping the language environment constant. Two different outcomes maybe expected. On the one hand, since the abilityto ignore irrelevant information increases with
develop-ment (Crane & Ross, 1967; Gibson, 1969; Kemler, Shepp, & Foote, 1976; Smith, Kemler, & Aronfreed, 1975; Strutt, Anderson, & Well, 1975), the categorization of IL mayreveal more useful information than KG. On the other hand, the effect of development maybe relevant to perceiving natural objects or scenes, but not to reading. That is, reading (or reading of Chinese characters) is a specific learning process that cannot be transferred from other more general perceptual development.
The ages of the IL were higher than those of the TWu, due to the fact that the rate of illiteracyis verylow when the experiment was conducted (5.08% in 1998, according to the Ministryof Education in Taiwan, 2001). Since it is difficult to find illiterate adults whose ages matched the ages of the samples of undergraduates, we had to search for a wider age range, usuallytoward the higher end. It is assumed that the sorting basis used byTWu is stable and will not change as theyage. Thus the difference between TWu and IL mayreflect the effect of learning experience on categorization of Chinese characters, and the difference between IL and KG mayreflect the effect of perceptual development. Note that although IL and KG have no explicit learning experiences with Chinese characters, theyshould have implicit exposure to the characters when theywatch TV and movies and see all sorts of advertisements in their environments. Given that IL have lived longer than KG, it is reasonable to infer that IL should have a larger implicit exposure to Chinese characters than KG. Whether the difference in the amount of implicit exposure would lead to extraction of the configuration of Chinese characters can also be answered by comparing the results of the IL, KG, and TWu.
Method
Participants. Three groups of participants were recruited in Taiwan. The first group consisted of 24 kindergarten children (KG) from 4 to 6.5 years old who had learned few, if any, Chinese characters. These children were recruited from two kindergartens located in the northern and middle parts of Taiwan. The experiment was conducted in their school buildings. There were eight children in each of the three age subgroups: 4, 5, and 6 years old. After the completion of the experiment, a confirmation was done to check whether theyknew the characters byasking them to pick out the characters theycould recognize. For the lowest age group, none of the characters used in this studywere recognizable to them. For the highest age group, no more than three characters were recognizable, and these were all related to their own names. Therefore, no systematic pattern of recognizable characters could be found among these children.
The second group consisted of 24 illiterate adults (IL), aged between 40 and 77 (mean = 64.04, SD = 9.54). Except for one, all were aged above 50. None had received anyformal education or learned to read or write Chinese characters on
other occasions before. Some participants, especiallythose older ones, often stated that theyknew nothing about character recognition, so theywere unable to sort these cards as requested. The experimenter had to convince them that it had nothing to do with word knowledge in order to have them complete the experiment. As with the KG group, a confirmation was done after the experi-ment to check whether these IL recognized the characters. Five participants knew one or two characters, all related to their names. Another three participants could recognize 4, 6, and 12 characters out of the 63 characters. The experiment was conducted in private rooms that were either in or near their homes.
The last group, the comparison group, consisted of 24 undergraduate students (TWu) and participated in this experiment for course credit.
Procedure. The participant was seated at a table beside the experimenter. The 21 cards in each of the stroke-count conditions were shuffled and then presented with the characters facing up at random locations on the desktop. The participant was instructed to judge the similarityof the shapes of characters and to put similar characters into the same pile, and dissimilar characters into different piles. The LS, MS, and HS conditions were presented separately, and each stroke-count condition was presented onlyonce. Within each group of participants, the sequence of the three stroke-count conditions was counter-balanced between participants.
After the participant finished each sorting condition, he/she was asked to report the rules theyused for sorting while still facing the sorted piles. The experimenter then picked up all the cards, shuffled them, and presented these characters facing up at random locations on the desktop again. The participants were asked to pick up and read the characters that theycould recognize. This was done to determine how manycharacters theyrecognized. A pilot studyhad shown that all the TWu recognized each of the sample characters; thus, no such confirmation was performed in this group. No memorytask was performed in this experiment. All the differences between this experiment and Experiment 1 resulted from failures in a pilot studyto conduct exactlythe same procedure.
A somewhat different procedure was employed for KG. Before the formal experiment, there was a training phase in which various simple forms and colours were presented for the children to sort. This was done to ensure their comprehension of the instructions and their abilities to perform the sorting task.
Results and discussion
Similarity matrices. Again, for each of the participants' initial sorting of the 21 characters in each stroke-count condition, a 21 6 21 matrix (Xij, i = 1~21, j = 1~21) was constructed with entries indicating how manytimes characters i and j were placed in the same piles. The highest and lowest scores in each of the cells in the individual matrices for the three groups were 1 and 0, respectively. Within
each group, a pooled similaritymatrix was obtained bysumming up all the participants' (N = 24) individual matrices. The highest and lowest scores in the three pooled similaritymatrices were then 24 and 0, respectively. The mean, standard deviation, and mode of the number of piles placed bythese participants are listed in Table 2. It can be seen that for IL in the MS and HS conditions, and for KG in all three stroke conditions, the modes of the number of piles sorted were around 10. This means that theymainlysorted the cards two cards per pile, which is not the case for TWu. Also note that since each stroke-count condition was sorted onlyonce, the total scores obtained for each cell in the similarity matrices were lower than those in the previous experiment.
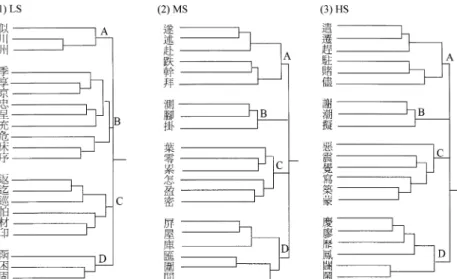
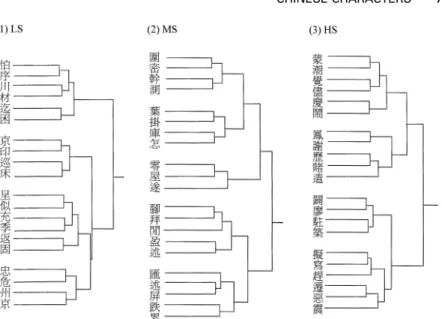
Hierarchical cluster analysis. For each group, the three pooled similarity matrices (the LS, MS, and HS conditions) were each submitted to hierarchical cluster analysis. The tree diagrams obtained from the three conditions for each group are shown in Figure 5 (TWu), Figure 6 (IL), and Figure 7 (KG).
To see whether there are differences between the results obtained from unconstrained and constrained sorting, we show the results of TWu first. For TWu (Figure 5), the overall pattern of results is similar to those obtained from TWc in Experiment 1 (Figure 1), yet several differences still could be identified. First, instead of five major clusters as in the constrained sorting, the unconstrained sorting results showed four major clusters in all three conditions. Second, two-part horizontal characters were separated from the three-part horizontal ones, such as , , and (C) and , , and (A) in the LS condition; , , and (A) and , , and (B) in the MS condition; and , , and (A) and , , and (B) in the HS condition. Third, the L-shaped characters were clustered with the two-part horizontal characters in all three conditions (C, A, and A in the LS, MS, and HS conditions, respectively). Fourth, there were interactions between stroke count and the clusters obtained. In the LS condition, the P-shaped characters , , and were clustered with the vertical characters (B), while in both the MS and HS conditions, the P-shaped characters were clustered with the enclosed characters (D). Therefore, the global pattern that emerged here seems to be that three major clusters can be
TABLE 2
The mean, mode, and standard deviation of the number of piles in Experiment 2
TWu IL KG
LS MS HS LS MS HS LS MS HS Mean 7.88 7.67 7.83 11.2 11.44 10.96 10.05 10.48 9.62 Standard deviation 2.21 2.85 2.66 3.11 3.84 3.56 2.85 3.06 2.85
in Experiment 2 for (1) the LS (low stroke-count) condition; (2) the MS (middle stroke-count) condition; and (3) the HS (high stroke-count) condition.
Figure 6. The results of hierarchical cluster analyses obtained from the illiterate Taiwanese adults in Experiment 2 for (1) the LS (low stroke-count) condition; (2) the MS (middle stroke-count) condition; and (3) the HS (high stroke-count) condition.
identified: H, V, and E. The P-shaped characters were perceived as more similar either to the V characters (B in the LS condition) or the E characters (D and D in the MS and HS conditions), depending on their stroke counts. The L-shaped characters were perceived as similar to the two-part horizontal characters, and these two can be merged as one big cluster. In general, what is consistently revealed in TWc and TWu is the pattern that P, V, and E are similar to each other, and H and L are similar to each other. This pattern of results is largely consistent with that in TWc of Experiment 1.
For IL (Figure 6), it seems that there is a greater tendencyto classifychar-acters in relation to their strokes or stroke patterns. For example, two horizontal characters, and , were clustered with vertical characters , , , and (C), indicating that certain strokes or stroke patterns, rather than structures, were used for classification. For example, the stroke pattern maybe commonly shared bythese characters. Most noticeably, the vertical characters were not all clustered together, instead being distributed in different clusters, such as and (B) and , , and (C) in the LS condition; , , and (B), (C), and and (D) in the MS condition; and (C) and (E) in the HS condition. Similarly, the horizontal characters seemed to be distributed over different clusters as well, such as (C) and (D) in the MS condition, and and (B) and (C) in the HS condition. It is evident that although the overall pattern still indicates certain major clusters, the distinction between
Figure 7. The results of hierarchical cluster analyses obtained from the Taiwanese kindergartners in Experiment 2 for (1) the LS (low stroke-count) condition; (2) the MS (middle stroke-count) condition; and (3) the HS (high stroke-count) condition.
horizontal and vertical structures is not as stable as that made byTWu. Note that the clusters that were more consistentlyclustered for IL were P-shaped, L-shaped, and enclosed characters, which can be attributed to certain common strokes the cluster members share. These three structure types all have salient structural strokes, such as , , and . This is also true for AM, as shown by their results from cluster analyses (Figure 3) and their recall patterns (Figure 4). It thus seems that the five structure types can be separated into two subgroups, (L, P, E) vs. (H, V), according to the ease of extracting the structural infor-mation. The structural information obtained in the former group can be mediated bysalient stroke patterns, whereas that in the latter group is ``pure'' structural in the sense that the global structure has to be perceived in the absence of any salient stroke patterns. Therefore, whether character structure is stablyand consistentlyperceived and utilized in form categorization mayhave to relyon the two ``pure'' structure types: Horizontal and vertical structures, as shown in the results of TW and JP. The clusters of L, P, and E characters, however, may be formed either bytheir overall structures or bycertain salient strokes.
Such a tendencyto ignore the character structure and emphasize the strokes or stroke patterns becomes even more evident for the group KG (Figure 7). Structure did not seem to playanyrole in their classification, since almost all of the major clusters include characters that have different structures. It thus seemed that the classifications of the group KG might be based on common strokes. This conjecture, however, would have to be proved bythe categoriza-tion principles provided bythese participants. Details about how these children perceived the characters and classified them will be provided later.
Comparison of the similarity matrices. The three similaritymatrices obtained from TWu, IL, and KG were compared bycalculating the correlation values between each pair of matrices under the same stroke-count conditions. For the LS condition, the correlation values of TWu±IL, TWu±KG, and IL±KG were .79, 7.61, and 7.63, respectively; for the MS condition, they were .68, 7.59, and 7.51; for the HS condition, .62, 7.49, and 7.55. All correlation values were significant at the .005 level.
To examine the group pair comparison, the correlation values were again transformed into Z scores. The differences between KG±IL and TWu±IL for the LS and MS conditions were significant at the .05 level, with Z = 18 and 13.9, respectively. The differences between TWu±KG and TWu±IL for the LS and MS conditions were also significant, with Z = 17.7 and 15, respectively. The differences between IL±KG and TWu±KG did not reach the significance level for anyof the three stroke-count conditions.
Therefore, the resulting similaritymatrices were moderatelysimilar for those obtained from TWu and IL. The similaritymatrices obtained from KG were negativelycorrelated with those from TWu and IL. These quantitative analyses were also consistent with the tree structures revealed bythe cluster analyses.
Categorization basis. Figure 8 shows the reported categorization basis by the four groups of participants: TW, JP, IL and KG. Not everyparticipant could articulate the rules he/she used for sorting, thus the percentage of report is obtained bydividing the number of depicted responses bythe total number of responses within each group of participants. No reliable data were collected from AM because in the constrained sorting task used in Experiment 1 the participants were required to report the grouping principles upon which their classification was based after all the sorting sessions were completed, which made it difficult for the Americans to recall anyconsistent principles. This did not present a problem for TWc and JP. In the unconstrained sorting task used in Experiment 2, however, the participants were asked to report the sorting principles right after theyhad finished each stroke count condition while the alreadysorted piles of characters were still displayed on the table. This proved to help KG and IL vocalize the ways they used to sort these characters. Since there should not be anya priori reason whysuch procedural differences would produce different reporting principles in the skilled readers, the data obtained from the TWc and TWu in Experiments 1 and 2 were collapsed. Note that, nevertheless, due to the difference in the experimental procedure, not too much should be read into the comparison presented here.
What Figure 8 reveals is that TW and JP share similar categorization bases. The similarities in the structural configuration of the characters were reported by these two groups in high proportions (see the categoryof ``structure'' in Figure 8). This is consistent with the cluster results. We differentiated structural component from nonstructural component in that the structural components (the L-, P-, and E-shaped components) are important for determining the overall
Figure 8. The categorization bases reported bythe four groups of participants. TW: Taiwanese undergraduates; JP: Japanese undergraduates; IL: illiterate adults; KG: kindergartners.
structures, and yet they are also salient strokes. When the participants reported the rules bytheir overall structures, e.g., all characters were enclosed, P-shaped, or L-shaped, these responses were encoded as ``structure''. When theyreported the rules bypointing to the specific salient strokes or stroke patterns such as or , these responses were encoded as ``structural component''. Nonstructural components were those not belonging to these L-, P-, or E-shaped stroke pat-terns. Note that TW and JP also reported the rules based on structural compo-nents in high proportions (mostlythe L- or P-shaped stroke patterns), but on nonstructural components (such as small squares embedded in the whole char-acter) in verylow proportions.
Sorting byseparability(i.e., simple characters or compound characters) was also considered to be a sorting rule byTW and JP, but not in the other groups. Note that there were actuallyno characters in our samples that were inseparable simple characters, so that the inseparable characters these participants referred to were in fact vertical or P-shaped characters. The categorization ``others'' refers to rules that do not relate to anyof the clearlyrelevant physical properties. Interestingly, in this ``others'' category, JP tended to report properties of roughness (hard vs. soft), temperature (cold vs. warm), and sharpness (sharp vs. dull) that were not reported byother groups of participants.
The group of KG reported rules for determining the similarityof characters as follows: (1) Nonstructural component, such as embedded in ; (2) one or two strokes, such as the or in ; or (3) chirographic features such as the small triangle on the top-right end of the horizontal line segment (e.g. ), which is, as mentioned before, prevalent in Chinese chirography. TW and JP reported rules based on none of these chirographic features. Some KG also reported rules based on structures bymentioning that the characters were all in enclosed shapes or L shapes. Some reported rules based on structural components, too.
The rules reported byIL appeared to fall between those of the undergraduates (TW and JP) and KG. Interestingly, the rules used by IL, such as enclosed structure, structural components, nonstructural components, salient strokes, and chirographic features, are also shown in the recall patterns of AM (see Figure 4). The correlation values of the similaritymatrices between IL and AM were .64, .53, and .56 for LS, MS, and HS conditions, respectively, also indicating moderate similaritybetween the sorting results obtained from these two groups. Note that the correlation values for JP and TWc in the LS, MS, and HS conditions were .97, .97, and .95, respectively. For AM and TWc they were .68, .60, and .55, and for IL and TWu theywere .79, .68, and .62. Although the correlation seemed to be slightlyhigher for IL and TWu than for AM and TWc, neither had reached as high a correlation as that between JP and TWc. Thus, learning experience is necessaryfor acquiring the perception of global structure in Chinese characters. Although IL mayhave a larger implicit exposure to Chinese characters than KG so as to yield more similar sorting results with TWu than KG, such implicit exposure is not sufficient to reach skilled readers' level
of perceptual organization. To what extent the implicit exposure to the char-acters contributes to the perceptual organization of Chinese charchar-acters can be further investigated byusing American kindergartners as controls to estimate the effect of perceptual development of AM, which can then be used to contrast the difference found between IL and KG in the present study.
The trend that lower the stroke counts led to higher the correlations of IL and TWu (as well as that of AM and TWc) mayindicate the effect of pattern complexityon the formation of a perceptual unit, which is in line with what Hull (1920) obtained. He examined the process of concept formation byasking American undergraduates who were ignorant of Chinese characters to associate sets of Chinese characters containing the same components to fixed responses, and found that simpler characters are more efficient than complex ones to extract the concept.
Although the data are incomplete in the sense that we lacked reliable data from AM, it is informative that KG grouped the characters and reported their bases of categorization quite differentlyfrom those of adults. Theyseemed to have a greater tendencyto notice local features, which maynot be so dominantly perceived byadults. This is hinted at bythe supplementarynature or bimodal distribution in Figure 8. We suspect that as age increases, global patterns are more likelyto be perceived and thus reported as the basis of categorization. If this is the case, the data should reflect that single features, such as ``triangles'' or ``points'', were reported bythe youngest age group, and the stroke patterns by older children, although a systematic pattern of this sort has yet to emerge. Whether this local to global perception of Chinese characters is a stable developmental trend certainlyshould be examined.
Summary. The results of TWu obtained from cluster analysis yielded similar patterns to those of TWc in that character structure is the determining factor in sorting. For inexperienced readers such as KG, however, structure does not seem to playa major role. Rather, local patterns such as chirographical features and strokes are more dominantlyperceived and used for sorting. The size of the perceptual unit tends to increase from KG to IL. Although as age increases, the perceptual units tend to be increased, the extraction of the useful information in perceiving Chinese characters (i.e., structure) needs to be nourished bylearning experience.
GENERAL DISCUSSION
The current studywas designed to investigate the effects of learning experience on perceptual organization of Chinese characters revealed byshape sorting. The results can be summarized as follows: (1) TWc, TWu, and JP perceived and organized Chinese characters based on the overall configurational structure. (2) The results of TWc and JP were verysimilar, regardless of the individual
pronunciations of the characters. (3) The two kinds of sorting tasks, constrained sorting and unconstrained sorting, also obtained consistent results from Tai-wanese undergraduates, despite the smaller amount of data and thus the larger variations obtained in the unconstrained sorting task. Therefore, the results of IL and KG, also from the unconstrained sorting, should be representative. (4) AM, IL, and KG, all lacking the learning experiences of Chinese script, tended to perceive the constituent strokes or components, rather than the overall structure, indicating the necessityof learning experience on obtaining the higher order organization (i.e., the structure) of Chinese characters. (5) Although mere maturation is not enough for reaching the higher organizational level of skilled readers so as to perceive the character structure, a trend of perceptual development from local details to more globallydefined patterns was found in that AM and IL seemed to perceive larger units than KG. In addition to the perceptual development, greater exposure to Chinese characters in the environments of IL than those of KG mayhave also contributed to the larger units observed in the sorting results of IL than in those of KG.
The effect of learning experience can be seen, in Experiment 1, bythe comparison between the three groups of undergraduates, TWc, JP, and AM. Americans who had never learned Chinese characters showed different bases of categorization from those in the other two college groups. Structural informa-tion, though explicitlyused byTWc and JP, was not always present in the classification scheme of AM. It thus seems that learning experience affects how people perceive Chinese characters and classifythem. Through learning, the word knowledge becomes influential. More importantly, this knowledge, when applied to consideration of the shapes of characters, concerns the overall structures of characters, such as horizontal, vertical, and enclosed structures.
In addition, the resemblance in the results between TWc and JP adds further supporting evidence for the skilled reader's perception of Chinese characters. In Japanese, Kanji are used as content words, and their pronunciations can differ depending on the context. If a Kanji's dominant usage is to represent a verb or an adjective, it is usuallyaccompanied bya Kana suffix to form a meaningful word, which means that a single Kanji presented alone would inevitablyinvoke multiple pronunciations. This is not the case with monosyllabic Chinese char-acters. Even though the pronunciations of the Japanese Kanji are typically dif-ferent from those of Chinese characters, this difference did not affect the form-categorization of Chinese characters. This provides evidence for the separability of the shapes and sounds of Chinese characters in the shape-sorting task used here.
In Experiment 2, the comparison of TWu and IL also revealed the same pattern: Skilled readers perceived the overall structure of the characters, while illiterate adults perceived constituent strokes and components. The emphasis on the individual strokes or even smaller units such as chirographic features is even more prominent in the results of kindergartners. Earlier studies on perceptual development of object perception portrayed young children as holistic
pro-cessors, perceiving objects as undifferentiated wholes, and through develop-mental shifts, spatial analytic processing becomes more accessible (e.g., Gibson, 1969; Shepp & Swartz, 1976; Smith & Kemler, 1978; Ward, 1983). However, such a developmental view of holistic to analytic processing has been challenged bymore recent studies, which have also demonstrated an active analytic mode in young children (e.g., Cook & Odom, 1992; Enns & Girgus, 1985; Feeney & Stiles, 1996; Tada & Stiles, 1996; Ward & Vela, 1986). For example, children as young as 3 years' old perceive the pattern ``+'' as four independent short seg-ments radiating from the centre, while older children (4±5 years' old) perceive the same pattern as either being one long segment plus two short ones (such as -|-), or as being two long segments crossing each other. Such developmental changes from attending to constituent parts to the relation between the parts and the whole have been consistentlydemonstrated in a reconstruction task (Tada & Stiles, 1996), in perceptual judgement and copying tasks (Feeney & Stiles, 1996), and more relevantly, in Chinese character perception (Liu, 1993; Luo & Fang, 1987; Wu, 1990). Our results are in favour of this view.
What is not so clear is whether this is a difference in preference or a dif-ference in ability. That is, can children perceive and classify characters the way adults do, but simplyprefer to categorize characters differently, or, instead, do theyreallylack the abilityto perceive characters from a more global perspec-tive? Evidently, perceiving the character structure as horizontal, vertical, enclosed, L-shaped, or P-shaped, as skilled readers do, requires more advanced analytic as well as integral abilities. It takes learned experience to gain the useful character knowledge, as adults who lack such experience, such as AM and IL, also failed to perceive character structure in the waythat TW and JP did. The tendencyto perceive the relations between different strokes in a more global manner from KG to AM and IL is, nevertheless, in line with the developmental changes of the pattern from local to global. Inspection of the age-related dif-ferences in KG has indicated the existence of such a tendency, although con-firmation of this awaits more systematic investigation. At what age do children perceive like adults without the influence of word knowledge? From our results, the older kindergartners still categorized the characters differentlythan AM and IL. However, even the adult groups of AM and IL did not perceive the characters in the same wayas skilled readers did. Therefore, to perceive the global structure, the experience of learning Chinese characters maybe a necessary condition, as this perception cannot be obtained solelythrough maturation.
Relation to object superiority effect and word
superiority effect
Two phenomena relevant to the results we observed here are the object-superiorityeffect and the word object-superiorityeffect; the former refers to better identification of a brieflypresented target line in structuralized configuration (i.e., an object) than in random configuration (Weisstein & Harris, 1974), and
the latter refers to better identification of a brieflypresented target letter in words than in nonwords (Cattell, 1886/1947; Reicher, 1969). Past experience obviouslyplays an important role in both phenomena, since familiaritywith certain configurations, be theymeaningful objects or words, defines, in the observers' view, the status of objects versus nonobjects and words versus nonwords. Thus, both phenomena indicate that familiar configurations facilitate the processing of the constituent parts. Similarly, the overall structures of individual Chinese characters, through familiarization with these overall con-figurations of characters, mayalso serve the same function of facilitating the processing of the constituents. A major difference in these two phenomena, nevertheless, lies in the process that each of the effects is involved: Pattern recognition for the object superiorityeffect and word recognition for the word superiorityeffect.
Although how objects and words are represented and whether pattern recognition and word recognition involve completelyor partiallydifferent pathways in the human brain have yet to be determined (Farah, 2000), our results mayreveal one important and unique aspect of Chinese character recognition. On the one hand, for those who have not learned Chinese, such as our participant groups AM, IL, and KG, Chinese characters maybe viewed as more like visual patterns or objects. Thus, when theysee these characters, the pattern recognition process is activated, and the degree of familiarity affects how the ``patterns'' of these characters are perceived. Higher degree of familiaritywith these patterns lead to extraction of larger units, such as simple or structural components relative to smaller units, as in features or strokes, and the difference in the degree of familiaritymayhave resulted from implicit exposure to these characters (e.g., for IL) or to patterns similar to characters (e.g., for AM). The different resultant patterns found between IL and KG, between AM and IL, and between AM and KG maythus all be attributed to difference in the extent of the familiarityeffect on the pattern recognition process.
For those who have explicit learning experience with Chinese characters, such as our participant groups TW and JP, on the other hand, additional/different process or pathway, i.e., character recognition process, may be activated when theysee these characters. For skilled readers, one of the major differences in the process of Chinese characters from that of visual patterns is the extraction of configurational structure. Without explicit learning experience, such ortho-graphic knowledge would never be achieved, as the orthoortho-graphic knowledge is specific to the language process. Neither perceptual maturation (e.g., the results of AM) nor implicit exposure to these characters (e.g., the results of IL) is sufficient for the extraction of this kind of orthographic knowledge. Because the configurational structure of the character is one of the keyelements in the orthographic rules of Chinese characters, it should be treated as a ``linguistic'' property, rather than a ``figural'' property.
Future studies mayuse brain-imaging techniques to seek the brain areas of the skilled Chinese readers that are responsible for the extraction of the character structure. This can be done bycomparing the brain areas activated when skilled readers view Chinese characters versus when theyview visual patterns or by comparing the areas activated byskilled readers with those of who are ignorant of these characters when both groups of participants view Chinese characters. If our conjecture is correct, areas activated bythe tasks demanding the extraction of the character structure should be more closelyrelated to the language process than the general pattern recognition process.
Effect of past experience on perceptual organization
Among the various principles of perceptual organization (e.g., similarity, proximity, continuity, common fate, and closure) that were identified by Gestalt psychologists, past experience was once specified as one of the factors of grouping (Wertheimer, 1923/1955). However, due to the trend that later studies have mainlyfocused on the stimulus factors (e.g., Kanizsa, 1979; Koffka, 1935) and emphasized the serial processing stages in the order of perceptual grouping, figure±ground segregation, and object recognition (e.g, Marr, 1982; Neisser, 1967; Triesman, 1986), a conventional view has been that past experience exerts its effect at or after the recognition stage. In this view, past experience affects the output of the perceptual organization.
Our results, however, support the view that experience has contributed to the formation of perceptual organization, rather than the more prevalent view that experience affects the object recognition process, at which perceptual organi-zation has alreadybeen completed. Several other studies, while using different paradigms from ours, have reached a similar conclusion in this aspect. As these studies are highlyrelevant to the present study, we discuss them in slightlymore detail.
Using dot patterns somewhat like Chinese characters and controlling for eye movements, Nazir and O'Regan (1990) trained their participants to discriminate targets from nontargets at a fixed retinal location. More errors were found when the pattern had to be recognized at a new retinal location than at the same location. The imperfect translation invariance thus indicates that their partici-pants, while reaching 95% discrimination accuracyin the learning phase, did not applya global transposition transformation to the retinal image. Despite the fact that recognition performance dropped as position changed, nevertheless, it was still much better than the chance level, indicating that some position-insensitive units that are larger than single dots must have been formed in the internal representation during the learning process.
Based on this, as well as the substantial individual differences observed and variances of translation effect found for various stimulus sets, Nazir and O'Regan (1990) hypothesized that learning new patterns involves the process to
code the pattern as several feature units, and onlywhen enough experience with different patterns has accumulated can the association of different retinal acti-vations produced bypatterns with the same set of units be established. The variabilityin the translation effect found with different stimulus sets and dif-ferent participants can thus be accounted for byassuming that the degree of familiaritythat affected whether particular sets of features can be extracted varies among individuals and with different stimulus patterns. Though aiming at explaining the imperfect translation invariance of the retinal image, such an account, i.e., that learning and experience lead to the extraction of feature units, can also explain what we have found here.
Beck and Palmer (2002) used a repetition discrimination task in which the participant was to report whether the successivelyrepeated pattern was a circle or a square. The repeated target patterns were either within a perceptual group defined by color similarity, proximity, common region, or connectedness, or between different perceptual groups. The grouping effect, indexed byfaster RT when repetition occurs within a group than between groups, was affected bythe probabilitymanipulation of the repetition within groups, especiallyfor grouping based on common region and connectedness. Though theyhave shown that perceptual organization is affected bytop-down influences such as the know-ledge of the probabilityof repetition occurring within a group, it is not entirely clear whether this top-down factor contributes to the earlyformation of per-ceptual organization or if it occurs onlyafterwards.
In this aspect, Hock and Marcus (1976) and Kimchi and Hadad (2002) demonstrated more clearlythat past experience contributes to the earlyforma-tion of percepearlyforma-tion organizaearlyforma-tion, rather than affecting the output of grouping. As these two studies are similar in manyaspects and Kimchi and Hadad used an improved design to provide more detailed information, we will focus on their study. A primed matching paradigm was used in which a prime was presented for various durations and followed bya test pair. The participants had to respond as quicklyas possible whether the two patterns in the test pair were the same or different. Familiarityis manipulated bypresenting upright letters or inverted letters as prime, and the process of perceptual organization is examined by comparing the priming effect from the intact letter (no grouping is needed) with that from the fragmented letter (grouping is required).
Byvarying the prime duration, the earlyand late representations of the grouping process can be tapped, and the time course of the effect of familiarity with the letters can be examined in scrutiny. The results showed that upright letters primed the same upright letters as earlyas 40 ms, regardless of whether these prime letters were intact or fragmented. With fragmented inverted letters as primes, however, the priming effect on the same inverted letters occurred later in time. That is, past experience contributes to the grouping of the frag-mented lines into recognized letters during the time course when the rapid formation of perceptual organization is still at work.
Similarly, our results also suggest that learning experience contributes to the formation of perceptual organization of Chinese characters, though in a much extended time scale: Manyyears of experience. Kimchi and Hadad (2002) used Hebrew letters as stimuli and undergraduates of Israel as participants. It would be interesting to know, as indicated by our study, whether the ``familiarity'' with the Hebrew letters viewed bytheir participants also contain the two aspects as in Chinese characters: The visual aspect that is more related to the pattern recognition process and the structural aspect that is more related to the linguistic process.
Chunking mechanism in perceiving Chinese
characters
The results found in this studymanifest the fact that a certain chunking mechanism (Miller, 1956) underlies the perception of Chinese characters so that learners tend to organize information into chunks to reduce the processing load under the constraint of limited capacity. Skilled Chinese readers versus illiter-ates, verymuch like chess masters versus duffers (Chase & Simon, 1973), use their perceptions of relevant chunks to focus on the most useful information for the task at hand, and such chunking is a function of learning experiences that mayverywell be domain-specific (e.g., Allard & Starkes, 1991).
The chunking mechanism of EPAM (ElementaryPerceiver and Memorizer) developed byFeigenbaum and Simon (1962, 1984) provides a theoretical framework to explain the results we obtained. EPAM models the chunking process bya hierarchical discrimination network in which extracted features are sorted bythe tests of the network to access a pointer (i.e., an index) to a node within long-term memory. The discrimination network is a structure of branching tree in which the leaf node stores the memorized image and the other nodes are test nodes. A perfect match found between the stimulus and a leaf node signifies recognition of that stimulus, and this can occur, for example, for a stimulus±image pair such as dog±dog, but not for dog±dot.
Learning occurs when no perfect match can be found. In the case that the image is a subset of the stimulus, e.g., the pair dog±do, additional features are added to the image. In the case that the image does not match the stimulus, e.g., the pair dog±dot, the network is augmented. Thus, a new test for the third letter will replace the do- leaf with branches for g and t, and with images of dog and dot at the leaves of these branches. Since EPAM assumes that the human central processing operates serially, and chunks are the largest familiar units, learning involves a hierarchical chunking process. For the two learning processes specified in EPAM, for example, FAMILIARIZE acquires information about a memorized chunk and DISCRIMINATE permits a new chunk to be added to the network through finding the discrepancybetween that new chunk and the memorized chunks.