行政院國家科學委員會專題研究計畫 成果報告
自組織映射圖網路於水文屬性均一區劃分之研究:以設計雨
型為例
計畫類別: 個別型計畫 計畫編號: NSC92-2211-E-002-066- 執行期間: 92 年 08 月 01 日至 93 年 07 月 31 日 執行單位: 國立臺灣大學土木工程學系暨研究所 計畫主持人: 林國峰 報告類型: 精簡報告 處理方式: 本計畫可公開查詢中 華 民 國 93 年 8 月 26 日
摘 要 劃分水文均一區有二個重要步驟,第一步是水文性質的群集分析。在傳統群 集分析中,無論是使用階層式的群集分析法或是非階層群集分析法,不同的群集 組數常會導致差異極大的分析結果,且並無客觀之方法決定適當的群集數目。因 此對於水文屬性均一區的劃分,如何決定適當的群集組數乃是重要的課題。而劃 分水文均一區的的另一重要步驟是建立將水文性質外插到未設站區域的數學模 型,為本研究下一年度之研究目標。本研究於今年度利用自組織映射圖網路來解 決水文性質的群集分析問題。自組織映射圖網路是屬於非監督式及競爭式學習的 網路模型。其功能是將高維度的資料映射至低維度的圖形中,並保存資料原本的 拓樸結構及顯現資料內在的統計特徵。本年度,本研究提出利用自組織映射圖網 路進行群集分析的方法,稱為自組織映射圖網路群集分析,簡稱為SOMCA,並 將 其 運 用 於 台 灣 北 部 地 區 簡 單 尺 度 不 變 性 高 斯 馬 可 夫(Simple Scaling Gauss-Markov,簡稱 SSGM)雨型上。結果顯示,SOMCA 與傳統群集分析法相較, 其優點適當的群集數目可觀察由 SOMCA 導出之分類圖(classification map)而簡 單及客觀的決定。綜合而言,本研究所得之成果,對於水文性質的群集分析具有 相當大的貢獻。
Abstract
There are two crucial processes for the delineation of homogeneous areas of hydrological properties. The first process is the cluster analysis on certain hydrological properties. Obviously, different numbers of clusters lead to significantly different results. However, determination the proper number of clusters is a subjective task for conventional cluster analysis methods no matter what clustering technique, the hierarchical method or the nonhierarchical method, is used. The second crucial process for the delineation of homogeneous areas is to establish a method to extrapolate hydrological data from sites, at which records have been collected, to other sites at which values are required but unavailable, which is the goal of the next year’s research. In this year’s study, the self-organizing maps (SOM) are introduced for the cluster analysis of hydrological properties. The SOM, which can project high dimensional patterns into a lower dimensional space, keep their original topological structures and capture the intrinsic statistical features of the patterns, is one of the unsupervised and competitive neural networks models. A clustering technique, self-organizing maps cluster analysis (SOMCA), is proposed and applied to the cluster analysis of the simple scaling Gauss-Markov (SSGM) design hyetographs of northern Taiwan. From the results, the advantage of the SOMCA over the conventional cluster analysis methods is that the proper number of clusters
can be easily and objectively selected by visually inspecting the classification map derived from the SOMCA. In summary, the achievements of this study significantly contribute to the clustering techniques of hydrological properties.
一、前言
進行水利工程規劃及設計時,常會遭遇到所欲建立工程之處並無設計該工程 所必需要的資料的問題。例如,欲進行在某地設置水庫的可行性分析時,需要該 地諸如洪水頻率曲線、不同頻率的設計雨型、進行降雨—逕流模擬所需的參數等 資訊。然由於該地在之前並未設立水文觀測站或雖已設站但取樣樣本數不足之 故,因此並無所需資訊其能提供的資訊無法滿足設計之所需。而水文屬性均一區 之劃分乃為解決此種問題的一種方式。水文屬性均一區之劃分亦可稱之為區域化 (regionalization)或者是區域分析(regional analysis)。水文屬性均一區之劃分常被使 用來利用已知各種水文性質的地點去外插未設測站之地點的某種被需要的水文 資料。在進行水文屬性均一區之劃分時,常將研究區域劃分為若干個較小的區 域,令這些小區域具有更為相似的水文特性,而使得外插的行為具有更好的可信 度(Nathan and McMahon, 1990)。而根據不同的需求有不同定義的水文屬性均一 區,例如洪水頻率均一區、低流量均一區、設計雨型均一區等不同定義的水文屬 性均一區。二、研究目的
群集分析及建立將水文性質外插到未設站區域的數學模型則是劃分水文均 一區的二個重要步驟。其中,群集分析是一種能根據資料之相似性與相異性,進 行分群的邏輯程序。其針對某種指定之特性,將欲進行分類之資料依此特性劃分 為多個群集,使同一群集中具有高度之均一性(homogeneity),不同群集彼此具有 明顯的異質性(heterogeneity)。傳統的群集分析大致可分為階層式(hierarchical)的 群集分析法如單一鏈結法(single linkage method)、華德法(Ward’s method)及非階 層式(non-hierarchical)的群集分析法如 K-means 法。群集分析的基本假設乃是資 料間確實存在著群集的關係。階層式的群集分析法進行分群的依據乃是根據分析 後所得的樹狀圖,其幫助了瞭解資料間的相對距離,然並無客觀決定群集組數的 方法,端視研究者的需要及經驗決定。非階層群集分析法通常需在進行分析之前 決定群集的組數,然而不同的群集組數常會導致差異極大的分析結果。對於水文 屬性均一區的劃分來說,判定資料是否確實存在群集的關係及如何決定適當的群 集組數乃是一重要的課題。 有鑑於此,本研究利用類神經網路中一種知名的網路模型—自組織映射圖網 路(self-organizing maps)來進行水文屬性均一區劃分,利用自組織映射圖網路的特性來解決如何判別資料的群集關係、決定適當的群集組數及建立水文性質外插到 未設站區域的方法,並以設計雨型為例進行設計雨型均一區的劃分,以提供其他 研究者進行相似研究時可以遵循的方法。
三、文獻回顧
在水文屬性均一區劃分的研究中,NERC (1975)之研究中選擇面積、年平均 雨量、機率雨量、主流坡度、河川頻率、土壤含水量等變量來定義均一區。Mosely(1981)與 Bhaskar and O’Connor (1989)以年平均比洪水量(Qsp)及變異係數(Cv)為變
量利用群集分析將其相似洪水反應之集水區歸納為同類。Burn (1989)加入測站之 相對位置為分類變量以其分類結果能結合地理位置。Guttman (1993)利用位置經 度、緯度、高程、年平均降雨量、連續最小二個月降雨總量對連續最大二個月降 雨總量之比值及分別之起始月份等七個變量來描述降雨並定義乾旱區。在國內易 任(1990)以平均降雨量數列為變量,利用主成分分析及群集分析探討台灣年降雨 量空間分佈之群集特性。楊道昌、游保杉(1994)取九個百分比延時流量值,利用 主成分分析及群集分析劃分流量延時曲線均一區。游保杉、陳嘉榮(1996)選擇測 站降雨延時曲線、年平均雨量、變異係數及測站位置等變量,利用主成分分析、 群集分析及模糊群集分析理論探討降雨-延時曲線之群集特性,期能合理劃分測 站之空間屬性均一區。左承修(1997)在研究區域洪水頻率分析中,亦導入群集分 析的方法,有助於精確地推估在特定重現期距下之洪水。 類神經網路(neural network)是目前廣受歡迎且知名的研究工具,其在解決大 量且複雜的資料探勘(data mining)、複雜的函數逼近(function approximation)及樣 式的辨別(pattern recognition)等工作具有強大的潛力。本研究所使用的自組織映
射圖網路是由Kohonen(1995)所提出,是屬於非監督式及競爭式學習的網路模
型。其功能是將高維度的資料映射至低維度的圖形中,並保存資料原本的拓樸結 構及顯現資料內在的統計特徵。Vesanto and Alhoniemi (2000) 利用自組織映射圖 網路進行了二步驟的群集分析。首先使用自組織映射圖網路分析原始資料,待原 始資料被映射至低維度之圖形,再以其他群集分析方法分析前一步驟所得的特徵 圖(feature map),利用此二步驟的分析所得之效果較傳統方法更佳且可大幅減低 群集分析所需的計算時間。Kiang (2001) 則將 contiguity-constrained clustering method 引入了自組織映射圖網路來進行群集分析並與其他群集方法比較,說明 引入了contiguity-constrained clustering method 的自組織映射圖網路的強健性。 Zhang and Li (1993) 則提出了利用自組織映射圖網路找出資料的群集關係及群 集邊界的方法,稱之為自組織映射圖網路分析 (SOMA)。Mangiameli et al. (1996) 曾經比較了自組織映射圖網路與七種階層式群集分析法,結果顯示出自組織映射 圖網路能顯示出較佳了群集分析的結果。Michaelides et al. (2001)運用自組織映射 圖網路分析降雨的變異性以提供給更精確的氣候模型的使用,其結果顯示自組織
映射圖網路較階層式群集分析法更能顯示出降雨變異性的細節。
四、研究方法
4.1 自組織映射圖網路概述(self-organizing maps)
SOM 是一種知名的類神經網路模型,常用在資料探勘、樣式分類等用途。 SOM 模型是由 Kohonen (1981)所提出。一個典型的 SOM 由一個輸入層與一個計 算層所組成。輸入層由一組的輸入節點所組成,而計算層由一組的神經元(neuron) 所構成。在計算層中,神經元的排列方式可為一維的線狀(linear)排列、二維的網 格式(lattice)排列或者是更高維度的排列方式,然以二維的排列方式較為常用。以 學習過程來分類SOM,SOM 是以競爭式學習為基礎的網路模型。所謂的競爭式 學習,是指在每次的學習中,網路神經元彼此相互競爭以得到被激發的權利。每 一次的學習只有一個神經元會被激發,該被激發的神經元稱為優勝的神經元 (winning neuron),後文中將該神經元稱為優勝神經元。SOM 的每一個神經元與 輸入層中的每一個節點均是完全連接的(fully connected)。不僅神經元與輸入層的 節點相連接,各神經元中亦存在著橫向的相互作用,此種作用的目的在於抑制某 神經元附近的神經元被激發而使得該神經元自己被激發。SOM 的主要功能是要 將高維度的輸入樣式(input pattern)轉為低維的輸出,保持其原來的拓樸結構次序 並 將 其 展 現 出 來 。SOM 的 學 習 過 程 包 含 三 個 重 要 的 程 序 , 分 別 是 競 爭 (competition),合作(cooperation),鍵結值的調整(adaptation)。當網路訓練完成後, 所得到的SOM 可反映出輸入樣式內在的統計特徵。一個輸入層含有三個節點及 一個二維的計算層包含有9 個神經元的 SOM 如圖 1 所示。 圖 1 典型的二維 SOM 4.2 自組織映射圖網路演算法 SOM 的學習包含了三個重要的程序,其細節如下所述: 競爭程序(competitive process) 將具有m 個維度的輸入樣式表示成
[
]
T m x x x1, 2,Λ , = x (1)網路中各個神經元的鍵結(synaptic weight)與輸入樣式擁有相同數目的維度。神經 元的鍵結可表示如下式
[
wj wj wjm]
T j l j = 1, 2,Λ , =1,2,Λ , w (2) 其中l 是網路中所有神經元的個數。在每一次的競爭中,網路中的每個神經元均 互相比較以求得被激發的權利。比較的基準乃是以與輸入樣式的相似程度為準。 常用的相似程度量度是歐氏距離(Euclidean distance),本研究亦採用之。決定優 勝神經元的程序可以下式表示( )
x w j l i j j , 1,2, , min arg x = − = Λ (3) 其中i( )
x 表示與輸入樣式x最為相似的神經元。每一次競爭的程序中均有一個輸 入樣式被輸入網路中,接著計算此輸入樣式與網路中每個神經元的相似程度,選 擇與該輸入樣式相似程度最高的神經元,將其激發並進行後續的程序。相似度最 高乃表示該輸入樣式與對應的神經元的歐氏距離最短。而與其等價的計算方式乃 是計算輸入樣式與各神經元鍵結的內積(inner product)ωTx j ,並選擇與輸入樣式內 積之值最大的神經元,即優勝神經元,此法減少許多計算歐氏距離時間。在經過 競爭程序後,高維度的輸入樣式可被映射(mapping)到較低維度的空間中。 4.2.1 合作(cooperative process) 當一個競爭程序完成後,即產生一個優勝神經元,而該神經元標定了拓樸鄰 域的中心。事實上,神經元之間亦存在著橫向的交互作用。此交互作用的影響與 神經元間的距離成反比,當距離愈長,影響愈小;反之則愈大。拓樸鄰域可以高 斯函數表示如下式 ( ) − = 2 2 , x , 2 exp σ i j i j d h (4) 其中hj,i( )x 表示在優勝神經元i鄰近的拓樸鄰域,包含被包圍在拓樸鄰域中的一組 神經元j。dj,i則是神經元j與優勝神經元i的距離,當dj,i趨近無限大時,拓樸 鄰域則趨近於零,這是SOM收斂的必要條件。σ 表示拓樸鄰域的有效寬度 (effective width),其大小與在優勝神經元附近的神經元參與學習過程的數目成正 比。拓樸鄰域的另一個重要特徵是其會隨著時間的推演(即疊代次數)而逐漸減 少。達成此目的的方法乃是令有效寬度隨著時間逐漸減少,如下所示( )
exp 0,1,2,..., 1 0 = − = n τ n n σ σ (5) 其中σ0為σ 在演算時的初始值,疊代次數,τ1為常數。因此拓樸鄰域可寫成 ( )( )
( )
− = n σ d n hji 2ji 2 , x , 2 exp (6)上式又稱為鄰域函數(neighborhood function),其會隨著時間(疊代次數)改變而 改變。 4.2.2 鍵結值的調整(adaptive process) 在神經元的鍵結調整過程中,神經元的鍵結被調整往靠近輸入樣式的方向。 其調整的方式以原始的Hebbian (1949)假設為主,然此假設並未能完全滿足自組 織映射圖網路的需求。因此需引進一個失憶項(forgetting term)修正原始的 Hebbian假設,所得到鍵結值的調整的方式如下所示 ( )
(
j)
i j j h w = x x−w ∆ η , (7) 神經元鍵結的差值由上式可得。所以新的神經元的鍵結值可由下式得到。(
n 1)
wj( ) ( )
n η n hji( )( )
n(
x wj( )
n)
w + = + , x − (8) 其中η為學習率。而只有被包含在拓樸鄰域內的神經元的鍵結才會被調整。在不 斷將輸入樣式輸入到網路時,拓樸鄰域在每一次輸入樣式輸入到網路中時就更新 一次,因此自組織映射圖網路逐漸能捕捉到輸入樣式的統計特性。在收斂的自組 織映射圖網路中,相鄰的神經元具有相似的鍵結,距離較遠的神經元的鍵結則相 差較多。 在鍵結值的調整的過程中有二個重要階段,分別是自組織(self-organizing)或 稱排序階段及收斂階段(Kohonen, 1982, 1997)。 1. 自組織階段 這是鍵結值調整的過程中第一個階段。在這個階段中,神經元的鍵結向量開 始進行其拓樸排序。其學習率需保持在靠近0.1的數量級,但不得低於0.01。而 其拓樸鄰域在一開始需包含整個網路中的神經元,再隨著疊代次數的增加而減 少。這個階段可能需要1000以上的疊代次數。 2. 收斂階段 在這個階段,網路開始進行微調的工作以提供更精確的有關輸入樣式的統計 量化的描述。為得到更好的結果,在這個階段中學習率應該保持在0.01左右的 數量級,而拓樸鄰域應該只包含最靠近優勝神經元的神經元。而這個階段需要幾 千次的疊代次數。 4.3 自組織映射圖網路演算的流程 總結上文可得自組織映射圖網路演算的流程。在初始化的階段,首先決定自 組織映射圖網路的架構。得到輸入樣式的維度後,即可決定神經元的鍵結維度。 決定神經元的鍵結維度後,以介於0和1的亂數產生器產生神經元的鍵結。接下 來,則是取樣階段。隨機選擇一輸入樣式,以進行網路的訓練。再來是相似性量 度,也就是選擇一個與輸入樣式最相似的神經元並將其激發。其後市更新神經元 的鍵結,亦即根據式(7)與式(8)調整神經元的鍵結。最後檢查收斂與否,若未收 斂則回到取樣,重複疊代,直到自組織映射圖網路收斂為止。 4.4 自組織映射圖網路群集分析(SOMCA)當SOM訓練結束且已收斂時,以網格表示網路中所有的神經元,再將原先 的輸入樣式輸入到SOM並將其對應激發的神經元及輸入樣式的編號或其名稱分 別標示在網格中,即得到特徵圖(feature map)。被標示的網格元素表示網路中的 神經元被某特定的輸入樣式所激發,該元素則稱為該特定輸入樣式的映像 (image)。在特徵圖中,一個輸入樣式只會擁有唯一的映像,但是一個映像卻可以 同時是其他很多不同輸入樣式的映像。計算每個映像所對應的輸入樣式數目並將 其填入該網格中即可得到分類圖(classification map),從中可以得知輸入樣式在 SOM密度圖散佈的情形。輸入樣式之間若具有相似的特性,其會有坐落在SOM 密度圖同一區域的傾向;而輸入樣式之間的差異較大時,其在SOM密度圖上的 位置則會較為分散。換句話說,當輸入樣式之間確實存在某些群集的情況時,其 群集的情形會顯示在SOM密度圖。在輸入樣式較密集的區域,SOM密度圖會顯 示出高原(plateau)的存在,表示群集存在於此區域;在輸入樣式較稀疏的區域 SOM密度圖會顯示出山谷(valley),顯示出群集間的界線。此性質可被應用在高 維度資料的群集分析中。
五、結果與討論
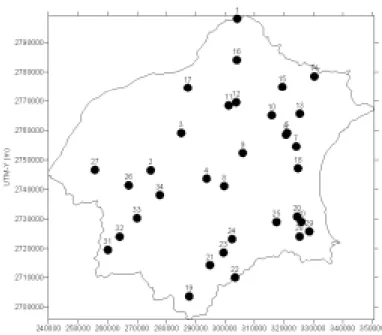
本研究以分佈於台灣北部地區34個雨量站(圖 2)分析所得的簡單尺度不變性高斯馬可夫(Simple Scaling Gauss-Markov,簡稱SSGM)雨型資料(鄭克聲 等,2001)為研究主體。
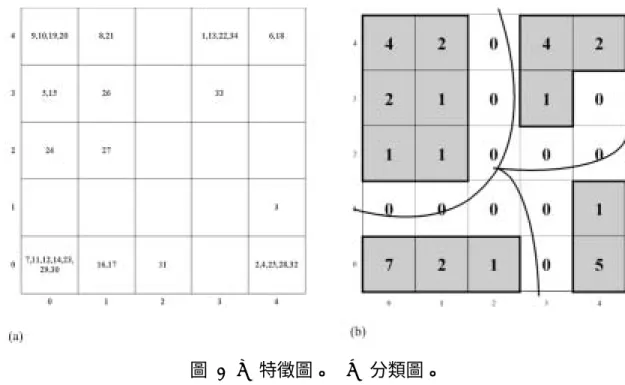
圖 3 (a) 特徵圖。 (b) 分類圖。 依前述方法,對於SSGM進行SOMCA分析後可得圖 3(a)特徵圖及(b)分類 圖。由圖 3分析可知台北地區的SSGM雨型可分為四類。各分類的SSGM雨型 隸屬的雨量站列於表 1。將各分類的SSGM雨型平均後繪於圖 4。由圖 4可得 到各分類雨型相異的主要特徵為降雨尖峰時段。各分類的降雨尖峰時段亦列於表 1。因此可以說本研究所提出的方法可以有效的辨識資料的自然分群數,而各分 群間的相異性極為顯著,而在群內各成員的相似性亦極高。 圖 4 各類別的平均雨型 利用SOMCA進行群集分析有一極大優點。一是不需要事先決定資料中群集 的數目。適當的群集數目可觀察SOM密度圖中山谷及高原的分布型態而簡單及 客觀的決定,且可同時決定那些資料屬於同一個群集中。傳統的群集方法通常在 分析之前需先決定群集的數目,而不同的群集數目常導致差異極大的分析結果;
或者從分析後的樹狀圖主觀地決定群集的數目。而利用SOMCA可避免這二種困 擾。 表 1 隸屬各雨量站的SSGM雨型的分類結果。及各類別中的SSGM雨型的平均 降雨尖峰時段 類別 成員 平均尖峰時段 (無因次) 1 9, 10, 19, 20, 8, 21, 5, 15, 26, 24, 27 14 2 1, 13, 22, 34, 6, 18, 33 15 3 3, 2, 4, 25, 28, 32 12 4 7, 11, 12, 14, 23, 29, 30, 16, 17, 31 13
六、計畫成果自評
本年度的研究進度與預期研究進度相符,而研究內容亦與計畫內容吻合。研 究成果除可大幅增進估計未設測站地區的水文資料的技術,同時亦減低分析的困 難與複雜度。由於本研究提出之方法實用性極高,且具有創見,相當適合發表於 學術性刊物上。因此,本研究所得到的方法亦應用台灣南部地區的水文地質資 料,提出一對於台灣南部低流量資料的區域化的簡單且實用的方法,並投稿於國 際期刊(審查中)。綜合而言,本研究所得之成果,對於未設測站地區水文分析 具有相當大的貢獻。 參考文獻 易任,1990。「主成分分析與群集分析應用於雨量空間分佈之研究」,國科會專題 報告研究計畫成果,計畫編號:NSC79-0410-E002-06。 楊道昌、游保杉,1994。「台灣南部流域均一性之劃分」,台灣水利,第42卷第 2期,第63-79頁。 游保杉、陳嘉榮,1996。「台灣北部區域雨量強度公式之研究」,財團法人中興工 程顧問社專案研究報告,編號SEC/R-HY-96-03。 左承修,1997。「區域洪水頻率分析之研究」,台灣大學土木工程學研究所碩士論 文。 鄭克聲、王如意、林國峰、許銘熙、虞國興、游保杉、李光敦,2001。「水文設 計應用手冊」,經濟部水資源局。Bhaskar, N.R., O’Connor, C.A., 1989. Comparison of method of residuals and cluster analysis for flood regionalization. Journal of Water Resources Planning and
Management, 155(6), 793-808.
Burn, D.H., 1989. Cluster analysis as applied to regional flood frequency. Journal of Water Resources Planning and Management, 115(5), 567-582.
model for design storm hyetographs. Journal of the American Water Resources Association, 37(3), 723-735.
Guttman, N.B., 1993. The use of L-moments in determination a regional precipitation climate. Journal of Climate, 6, pp. 2309-2325.
Haykin, S., 1999. Neural Networks, 2nd edition, Prentice Hall.
Kohonen,T., 1982. Self-organized formation of topologically correct feature maps. Biological Cybernetics, 43, 59-69.
Hebb, D.O., 1949. The Organization of Behavior: A Neuropsychological Theory, Wiley, New York.
Kiang. M.Y., 2001. Extending the Kohonen self-organizing map networks for clustering analysis. Computational Statistics & Data Analysis, 38, 161–180. Vesanto, J., Alhoniemi, E., 2000. Clustering of the self-organizing map. IEEE Transactions on neural networks, 11(3), 586-600.
Kohonen, T., 1995. Self-Organizing Maps, 3rd edition, Springer.
Kohonen, T., 1997. Exploration of very large databases by self-organizing maps. Proceedings of the International Conference on Neural Networks, Vol. Ⅰ, pp. PL1-PL6, Houston.
Mangiameli, P., Chen, S.K., West, D., 1996. A comparison of SOM neural network and hierarchical clustering methods. European Journal of Operational Research, 93, 402-417.
Mosley, M.P., 1981. Delimitation of New Zealand hydrological regions, Journal of Hydrology, 49, 173-192.
Nathan R.J., McMahon, T.A., 1990. Identification of homogeneous regions for the purpose of regionalization. Journal of Hydrology, 121, 217-238.
Nature Environment Research Council (NERC), 1975. Flood Studies Report, Vol. Ⅰ, Ⅱ
Michaelides, S.C., Pattichis, C.S., Kleovoulou, G., 2001, Classification of rainfall variability by using artificial neural networks. Int. J. Climatol., 21, 1401-1414.
Zhang, X., Li, Y., 1993. Self-organizing map as a new menthod for clustering and data analysis. Proceeding of 1993 International Joint Conference on Neural Networks, pp. 2448-2451.