國 立 交 通 大 學
電信工程研究所
碩士論文
中英夾雜語音之階層式韻律架構建立
與語音合成之應用
Prosody Hierarchy Construction for Mixed
Chinese-English Spelling Speech and its Application
to TTS
研 究 生:蔡承燁
中英夾雜語音之階層式韻律架構建立
與語音合成之應用
Prosody Hierarchy Construction for Mixed
Chinese-English Spelling Speech and its Application
to TTS
研 究 生:蔡承燁 Student:Cheng-Yeh Tsai
指導教授:陳信宏 博士 Advisor:Dr. Sin-Horng Chen
國 立 交 通 大 學 電信工程研究所
碩 士 論 文
A Thesis
Submitted to Institute of Communication Engineering College of Electrical and Computer Engineering
National Chiao Tung University in Partial Fulfillment of the Requirements
for the Degree of Master
In
Communication Engineering August 2010
Hsinchu, Taiwan, Republic of China
中英夾雜語音之階層式韻律架構建立
與語音合成之應用
研 究 生:蔡承燁 指導教授:陳信宏
博士
國立交通大學電信工程研究所碩士班
中文摘要
本論文針對以中文文句為主體但內含英文字母之中英夾雜文句,透過語言參數和聲學參 數間的關係,建立一個中英夾雜的韻律模型,並完成自動化的韻律標記。本研究所標記的韻 律標記為停頓標記及韻律狀態,其中停頓標記表示韻律單元的邊界,而韻律狀態的序列表示 上層韻律單元的變化。透過分析訓練出的模型參數,探討停頓標記、聲學參數、語言參數和 上層韻律狀態的關係。由實驗結果顯示英文字母之上層韻律狀態是隨著整體中文語句的韻律 變化而貣伏,而停頓標記則是在 code-switch 處會有較強的韻律斷點。此外也發現到名詞片 語的韻律層次結構和其語法結構有很高關聯性。 最後利用此模型提出兩種韻律產生方法,第一種為藉由停頓標記的預估,產生韻律層次 的文脈相關資訊,透過 HTS 產生韻律參數,第二種則是應用前述的韻律模型直接預估韻律 參數。由客觀評估的實驗結果顯示,第一種方法的確能改善傳統 HTS 所產生之韻律參數, 第二種方法則是在音節長度預測有顯著的效果。而主觀評估的結果也顯示第一種方法在聽覺Prosody Hierarchy Construction for Mixed
Chinese-English Spelling Speech and its Application
to TTS
Student:Cheng-Yeh Tsai Advisor:Dr. Sin-Horng Chen
Institute of Communication Engineering
National Chiao Tung University
Abstract
In this thesis, an unsupervised joint prosody labeling and modeling (PLM) method for mixed Chinese-English word spelling speech is proposed. It labels an unlabeled corpus with two types of prosodic tags (i.e., break type of inter-syllable juncture and prosodic state of syllable) and builds four prosodic models simultaneously. The break tags can be used to delimit prosodic constituents of a hierarchical prosody structure, and the prosodic state can be used to construct the prosodic feature patterns of prosodic constituents. The four prosodic models describe the relationships of acoustic prosodic features, prosodic tags of utterances, and the linguistic features of the associated texts. The experimental results showed that prosodic variation in English word spelling was influenced by both the prosodic state that describes underlying intonation and Chinese tone borrowing effect. Besides, the relationship between hierarchical noun phrase structure and corresponding break type was also analyzed. The analysis suggested that magnitude of the break type was highly correlated with syntactic hierarchy in a noun phrase.
Text-to-Speech system (TTS) based on PLM. In the first method, a break predictor is constrcted by CART method. Then, the related linguistic features and the predicted break tags are used for HMM-based Text-to-Speech system (HTS) training. In the second method, PLM is directly used as a prosody generator. Experimental results confirmed that the proposed method one was superior to the conventional HTS that only use linguistic features both in objective and subjective tests. Besides, the proposed method two was significantly better than the conventional HTS method at syllable duration prediction. Therefore, we conclude that the proposed PLM method was successful in prosody labeling and modeling for constructing a mixed Chinese-English word spelling TTS.
致謝
首先感謝陳信宏老師當初毫不介意非本科系出身的我,讓我能順利進入這個實驗室,進 入語音這個領域。非常感謝陳信宏老師和王逸如老師這兩年來在研究上的細心指導,感謝陳 老師在百忙之中仍然心繫著我的研究,仍抽空提點我在研究上的盲點。感謝王老師教導我如 何做一個真正的研究生,而不是交作業的大學生。 接著要感謝偉大的性獸學長,感謝性獸這兩年來不辭辛勞地教導我所有語音相關的大小 知識,不論是在觀念上的指導或是程式撰寫上的技巧,真的讓我獲益良多,而在最後那段十 萬火急的時刻,即便本身尌很忙的性獸仍然義不容辭地親下火線幫忙,更讓我由衷地敬佩 你,也多虧你才能讓陶小姐完整的回來,實驗室真的不能沒有你。也感謝阿德學長這兩年來 不論在研究上和 8051 教學上的指導幫忙,或是一些其他生活上的分享。感謝總是很有耐心 的讓我問一些小問題的智合學長,讓我養成隨手關檯燈和螢幕等好習慣的希群學長,提供我 們一些面詴上資訊的巴金學長,還有愛嚇人的輝哥,在你的恐嚇中也讓我變得更積極。也非 常感謝普烏學長這兩年的照顧,感謝你即使當兵了也常常回來探望我們和載大家出去吃宵夜 談談心,我會再幫你物色松山正妹的。也感謝效率超高超早寫完論文的 Q 哥、熱愛梁靜茹的 小宋和深受文字獄所苦的小帥哥等學長的照顧。感謝非常優秀的實驗室一哥宥余這兩年來不 論是在 8051 或是研究上一些幫忙和相助,感謝和我修課幾乎一樣的皓翔哥,讓我修課修的 很安心,感謝最後一貣睡實驗室奮鬥且和文良一樣認識很多學妹和人妻的普馬,趕快衝一個 吧!感謝口詴變得超謙虛但真的很有實力的財祿,我相信你會撐過三個月的,感謝交大正妹 依玲,恭喜妳擺脫客語的糾纏,感謝似乎真得有點耳背且是小帥哥傳人的舒舒,也恭喜妳逃 離文字獄。也在此感謝學弟們:人妻殺手文良、以道全、大胖哥、舞林高手智障、應該念博 班的銘傑、帥氣的小蝦、豆腐喵。也感謝松山高中 316 的友情支持與鼓勵,還有交大土木各 位的支持,讓我能一路走過來。 最後感謝我爸媽在我求學路上的一路支持,無論我做出任何決定都尊重我,讓我無後顧 之憂。也感謝妳一路的相伴與支持,最後僅以此論文獻給以上的各位。目錄
中文摘要... I Abstract ... II 致謝... IV 目錄... V 表目錄... VII 圖目錄... IX 第一章 緒論...1 1.1 研究動機...1 1.2 文獻回顧...1 1.3 研究方向...2 1.4 中英文夾雜 TTS 系統架構簡介 ...3 1.5 語料庫簡介...5 1.6 章節概要說明...6 第二章 HMM-based 中英夾雜語音合成器 ...7 2.1 HMM-based 語音合成系統 ...7 2.2 HMM-based 中英文夾雜語音合成基礎系統的建立 ...8 2.2.1 中文與英文字母音素模型...9 2.2.2 文本標示資訊與問題集設計...9 第三章 中英文夾雜韻律模型...13 3.1 中英夾雜語音韻律之特性...13 3.2 階層式韻律架構...173.5 中英文夾雜韻律模型之訓練...29 3.5.1 初始化(Initialization) ...29 3.5.2 重覆疊代(Iteration) ...35 第四章 韻律模型訓練結果與分析...37 4.1 音節韻律模型...37 4.1.1.1 音節層次中基頻之影響型態...39 4.1.1.2 音節層次中音節長度之影響型態...45 4.1.1.3 音節層次中音節能量之影響型態...46 4.1.2 上層韻律狀態之影響型態...46 4.2 停頓標記聲學模型...48 4.3 韻律狀態轉移模型...50 4.4 停頓標記語言模型...52 4.5 韻律標記結果之分析...54 第五章 基於 PLM 演算法之韻律產生器 ...65 5.1 停頓標記預估...65 5.1.1 All-in-one CART-based ...65 5.1.2 Two-stage CART-based ...68 5.2 PLM 之韻律參數預估 ...70 5.3 語音合成實驗結果與分析...71 第六章 結論與未來展望...78 6.1 結論...78 6.2 未來展望...79 參考文獻...80 附錄一...83 附錄二...85 附錄三...90
表目錄
表 1.1:訓練語料中個英文字母出現次數... 5
表 1.2:測詴語料中個英文字母出現次數... 5
表 2.1:文脈相關資訊... 10
表 3.1:code-switch 和 Non-code switch 處的平均停頓時長 ... 16
表 3.2:韻律標記、韻律特徵和語言特徵的表示法... 22 表 3.3:英文字母分類表... 28 表 4.1:所有音節在不同 APs 下音節韻律模型參數之 TRE ... 38 表 4.2:中文音節在不同 APs 下音節韻律模型參數之 TRE ... 39 表 4.3:英文字母在不同 APs 下音節韻律模型參數之 TRE ... 39 表 4.4:Non-code switch 處之停頓標記統計 ... 55 表 4.5:code-switch 處之停頓標記統計 ... 55 表 4.6:名詞片語結構於中英夾雜語料的統計數量... 58 表 4.7:片語層次結構標示範例... 61 表 4.8:韻律斷點強度和雙詞結構名詞片語的層次關係... 63 表 4.9:韻律斷點強度和三詞結構名詞片語的層次關係... 64 表 5.1:All-in-one CART-based 之語言參數列表 ... 66 表 5.2:All-in-one CART-based 之停頓標記預估辨認率 ... 67
表 5.3:All-in-one CART-based 之三類韻律標記預估辨認率 ,(NB: Non-Break, MiB: Minor Break, MB: Major Break) ... 67
表 5.4:Two-stage 之三類韻律標記預估辨認率 ... 69
表 5.5:Two-stage 之停頓標記預估辨認率 ... 69
表 5.8:中文、英文字母之基頻 RMSE ... 74 表 5.9:中文、英文字母之音長 RMSE ... 74 表 5.10:MOS 評分標準 ... 76
圖目錄
圖 1.1:訓練階段的系統架構圖... 4 圖 1.2:合成階段的系統架構圖... 4 圖 2.1:HMM-based 語音合成系統架構圖 ... 8 圖 3.1:中文四個聲調之基頻軌跡圖... 14 圖 3.2:中文一聲和英文字母{A,B,C,D,E,G,I,J,K,N,O,P,Q,T,U,V,Y}之基頻軌跡 ... 14 圖 3.3:中文二聲和英文字母{F,H,R,S,X}之基頻軌跡 ... 15 圖 3.4:中文二聲和四聲與英文字母 M 之基頻軌跡 ... 15 圖 3.5:英文字母 W 和 Z 之基頻軌跡 ... 16 圖 3.6:中文常見的階層式韻律架構... 17圖 3.7:階層式多短語韻律句群(Hierarchical Prosodic Phrase Gruoping,HPG)架構 ... 18
圖 3.8:本研究所用之階層式韻律架構... 19
圖 3.9:觀察到的音節音高軌跡與其影響因素的關係圖... 24
圖 3.10:Break Type 分類決策樹示意圖 ... 31
圖 4.1:疊代次數與標的函數值... 37
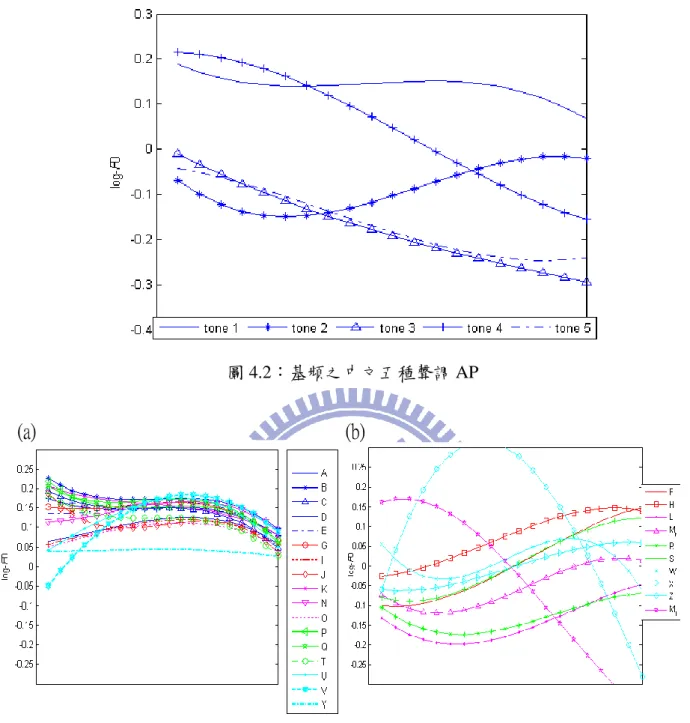
圖 4.2:基頻之中文五種聲調 AP ... 40
圖 4.3:基頻之英文字母型態 AP,(a)英文字母為 Tone1 Borrowing,(b)剩餘英文字母 ... 40
圖 4.4:(a)中文五種聲調和(b)英文型態基頻 AP 之第一維數值 ... 41 圖 4.5:連音參數之問題集設計概念... 42 圖 4.6:Backward 連音參數之決策樹 ... 43 圖 4.7:Forward 連音參數之決策樹 ... 44 圖 4.8:(a)中文五種聲調(b)基本音節型態以及(c)英文型態之音節長度 AP ... 45 圖 4.9:(a)中文五種聲調(b)韻母型態以及(c)英文型態之音節能量 AP ... 46
中文正規化基頻數值分佈圖(e)英文字母正規化基頻數值分佈圖之比較 ... 47 圖 4.11:音節長度之(a)各韻律狀態之數值(b)中文韻律狀態分佈圖(c)英文字母韻律狀態分佈 圖(d)中文正規化音節長度分佈圖(e)英文字母正規化音節長度分佈圖之比較 ... 47 圖 4.12:音節能量之(a)各韻律狀態之數值(b)中文韻律狀態分佈圖(c)英文字母韻律狀態分佈 圖(d)中文正規化音節能量分佈圖(e)英文字母正規化音節能量分佈圖之比較 ... 48 圖 4.13:(a)停頓音節長度 (b)音節能量低點 (c)正規化基頻跳躍值 (d)正規化音節延長因子 1(e)正規化音節延長因子 2 之分佈圖 ... 49 圖 4.14:各停頓標記下,基頻韻律狀態轉移的狀況,顏色越深表示此狀態轉移的機率越大 ... 50 圖 4.15:各停頓標記下,音節長度韻律狀態轉移情形,顏色越深表示此狀態轉移的機率越大 ... 51 圖 4.16:各停頓標記下,音節能量韻律狀態轉移情形,顏色越深表示此狀態轉移的機率越大 ... 51 圖 4.18:音節邊界之停頓標記分佈:(a)所有音節邊界(b)中文音節邊界(c)英文字母音節邊界 ... 54
圖 4.19:名詞片語 “收視,Na 觀眾,Na 口味,Na”的層次結構 ... 57
圖 4.20:名詞片語 “MTS,Nb 雙語,A 系統,Na” 的層次結構 (並列結構) ... 57
圖 4.21:名詞片語“ATT,Nb 流行,VH 服飾,Na” 的層次結構 ... 57
圖 4.22:名詞片語“力宜,Nb 科技,Na 公司,Nc ADSLNb 數據機,Na 產品,Na”的層次結構 ... 58
圖 4.23:名詞片語 “收視,Na 觀眾,Na 口味,Na”的層次結構標示 ... 59
圖 4.24:名詞片語 “MTS,Nb 雙語,A 系統,Na” 的層次結構標示 ... 60
圖 4.25:名詞片語 “ATT,Nb 流行,VH 服飾,Na” 的層次結構標示 ... 60
圖 4.26:名詞片語“力宜,Nb 科技,Na 公司,Nc ADSLNb 數據機,Na 產品,Na” 的層次結 構標示... 60
圖 5.2:Two-stage 停頓標記預估之方塊圖 ... 68
圖 5.3:原始韻律參數和四種方法預估出來的比較圖範例一。... 75
圖 5.4:原始韻律參數和四種方法預估出來的比較圖範例二。... 75
圖 5.5:MOS 主觀評估結果 ... 76
第一章 緒論
1.1 研究動機
身在 21 世紀科技爆炸的時代裡,電腦、手機等電子資訊產品以飛快的速度推陳出新中, 且幾乎已成為人類生活中不可或缺的必需品,因此近年來,人機介面的發展也備受注目。從 以往透過按鍵、滑鼠等操作電子產品,為了追求更便利更人性化的方式,語音便成為人類與 機器間溝通的最佳選擇。語音合成技術則在此扮演相當中重要的角色。 近年來,單一語言的文字轉語音系統(Text-to-Speech)已經相當成熟,但鮮少有人發展出 品質極佳的多語言系統,然而在全球化的潮流裡,人們往往會接觸到不同國家的人,無論是 在商場上,甚至大專院校中也可看見越來越多國際交換學生,因此人們俱備兩種以上語言能 力已變得越來越普遍。人們也更加期待機器可以同時說出不同語言,使得生活更加便利。 在現今華人社會裡的使用環境中,如中英文夾雜,國台語夾雜等都是日常生活中常見的 情形,又以中英文夾雜尤為實用,例如:常用的縮寫專有名詞(PDA、IBM)、地名(New York)、 人名(Alice、John)等都常出現在新聞報章雜誌以及實際生活中的對話。因此本論文希望透過 分析台灣人念的中英文夾雜文句之韻律,進一步完成中英文夾雜之文字轉語音系統。1.2 文獻回顧
傳統上,研究多語言文字轉語音系統多半以實現整個系統為主,多以 Corpus-based【1-3】 為基礎的語音合成系統。【1】先錄製大量單一語者的單一語言語料,採用音素對應(phone mapping)找出次要語言與主要語言間的轉換關係,在合成次要語言的音素時,找出所對應的 主要語言的音素,並使用單元選取,從語料庫中選出適當的單元合成,但此方法面臨的問題 是即便兩種語言有相近的音素可以共享,但卻沒有足夠的較長合成單元(longer chunk),因此 【1-2】又嘗詴錄製單一語者的多語言語料庫,使用共同的單元選取模組,但仍然沒有討論 到 code-switch 處可能存在的聲學現象,且要找到一個會說多國語言的語者,並錄製語料是相當困難且耗時的事情。【4】則提出以 RNN-MLP-based 為基礎下,目標合成出含有中英文 夾雜的文句。以原有 RNN-based 中文韻律產生器【5】為基礎,將中英文夾雜文句中英文的 語言參數,先以類似特性的中文之語言參數取代之,產生第一階段的中英文夾雜韻律,第二 階段再使用 MLP 機制,針對第一階段 RNN 產生之英文韻律加以修正與學習,因而產生更精 確的英文韻律。但此方法缺點在於要使用 RNN-MLP 訓練,需要大量的中英文夾雜文句,然 而本研究採用的語料量略顯不足,且此方法不容易作錯誤分析。【6】則是少數專注在模擬混 合語言中的韻律變化,觀察到中文夾雜少量英文單詞的文句中,英文單詞的韻律特性,如基 頻和音節長度比貣此單詞在全英文文句中來的更加變化劇烈與更長,因此採取了簡單的線性 轉換,來修正原本使用全英文語料所預估出的英文單詞韻律,達到更符合在中英文夾雜文句 中的英文韻律特性,但仍然沒有考慮 code-switch 時兩種語言的互相影響程度。【7】則是基 於 HMM-based 合成器下,使用單一語者分別錄製中、英文的語料進行 HMM 訓練,並使用 Kullback-Leibler divergence【8,9】建立誇語言間的狀態對應(state mapping)關係,以供給只會 說英文的語者,利用建立好的中英狀態對應關係,合成出中文或中英混合的語音。
1.3 研究方向
中英文夾雜文句中的英文部分又可分為兩種,一類為以字母為單位發音(spelling)的文 句,如 NBA、MLB;另一類則是以音節組合而成,依照英文音標發音的文句,如 word、paper。 本論文研究針對第一種類別進行韻律之分析,觀察此中文部分與一般中文語料有何不同之 處,且著重在英文字母的韻律預估,並分析 code-switch 處帶給中文字與英文字母在韻律上 各有何影響。因此本論文基於江振孙博士所提出之非監督式中文語音韻律標記及韻律模型 (Prosody Labeling and Modeling,PLM)【10】為基礎,針對英文字母做特定修改,進行中英文 夾雜的韻律標記(prosodic tags)與韻律模型訓練。此韻律標記的方法是以中文語音的韻律階層式架構為基礎,透過語言參數,聲學韻律參 數,包含音節基頻軌跡、長度以及能量,和音節間韻律參數,包括音節間停頓長度、音節間
文字母鑲對在中文語句中,因此可將每個英文字母視為一個中文音節,同樣標記出每個英文 字母的停頓標記與韻律狀態,並加以分析整個中英文夾雜語句的韻律標記分佈情形, code-switch 處是否有何不同等,進一步預估中英文字的韻律參數,最後結合 HMM-based Speech Synthesis System(HTS)完成整個中英文夾雜之文字轉語音系統。
1.4 中英文夾雜 TTS 系統架構簡介
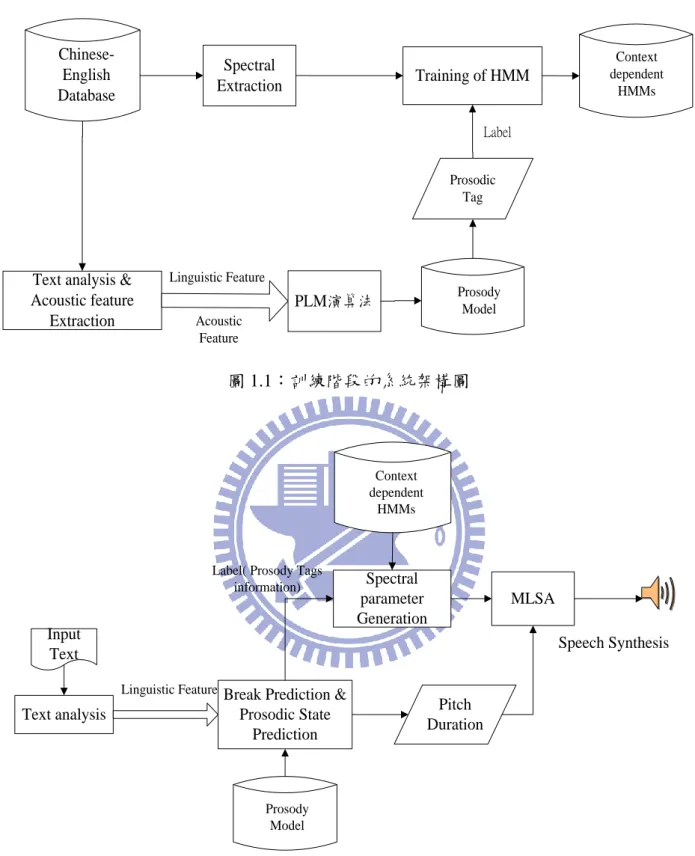
本研究最終目標為改善單純以 HMM-based Speech Synthesis System 所預估產生的語音 韻律及合成語音的自然品質。因此在此先介紹本研究所提出之中英夾雜語音合成系統架構 圖,如圖 1.1 訓練階段(Training Phase)與圖 1.2 合成階段(Synthesis Phase)。
如圖 1.1 所示,訓練階段為藉由中英夾雜語料的語言參數與聲學參數,使用本研究所提 出之 PLM 演算法,自動標記出每個音節所屬的韻律標記,並建立韻律模型,此部分將在第 三章詳述,接著藉由傳統語言參數所產生的文本標示(Label),並加入韻律標記,產生更多韻 律層次的文脈相關資訊,幫助 HTS 之 context dependent model 訓練廣義梅爾倒頻譜參數 (Mel-generalized Cepstrum, MGC)。 合成階段如圖 1.2 所示,輸入端為中英夾雜文字,經過文字分析器後得到其語言參數, 結合訓練端的韻律模型,進行停頓標記與韻律狀態的預估,此部分將在第五章詳述,接著透 過預估出的停頓標記,一方面產生中英文夾雜的韻律架構,並產生 HTS 所需之文本標示, 進行頻譜參數的估計,另一方面也可以藉由訓練端之韻律模型和預估出的韻律狀態,直接預 估出這些文字的韻律參數,包含其音高(Pitch)、音長(Duration),最後將韻律參數和頻譜參數 透過 MLSA filter(Mel-log Spectrum Approximation Filter)【11】,產生中英文夾雜語音。
Chinese-English Database
Spectral
Extraction Training of HMM
Text analysis & Acoustic feature Extraction Linguistic Feature Acoustic Feature PLM演算法 Prosodic Tag Prosody Model Label Context dependent HMMs 圖 1.1:訓練階段的系統架構圖 Input Text Text analysis
Linguistic Feature Break Prediction &
Prosodic State Prediction Prosody Model Pitch Duration MLSA Context dependent HMMs Spectral parameter Generation
Label( Prosody Tags information)
Speech Synthesis
1.5 語料庫簡介
本論文所使用之中英夾雜語料是由一個專業女性播音員所錄製而成,以中文為主體並穿 插英文字母於中文語句中,共 539 個語句,總音節數為 13540 個音節,包含 11688 個中文音 節與 1872 個英文字母。音檔為取樣頻率 20000 赫茲(Hertz)及 16 位元數之 PCM 格式,平均 語速為一秒 3.5 個音節(3.5 音節/秒)。將此語料庫每 10 句中編號尾數為 7 之句子當作測詴語 料,其餘為訓練語料。訓練語料共 12185 個音節,包含 10504 個中文音節與 1681 個英文字 母,測詴語料則共 1355 個音節,包含 1164 個中文音節與 191 個英文字母,詳細訓練語料與 測詴語料之各英文字母出現次數如表 1.1 與表 1.2。至於所有音節的切割標記、基頻軌跡及能 量的偵測均先自動由 HTK(Hidden Markov Model Toolkit)【12】和 WaveSurfer【13】完成, 再經由人工修正。如此一來便可得到所有韻律參數,包含音節基頻軌跡、音節長度、音節能 量及音節間停頓長度,其中本研究以一組四維正交化參數【14】來描述音節基頻軌跡。此外 也透過交通大學語音處理實驗室之斷詞器得到每一個語句的斷詞情形與詞性,詞類分法則是 依據中研院詞庫小組所制定的 46 類為準,其中英文詞的詞性多半為專有名詞(NB),且詞長 是以整個詞為單位,如『NBA』為一個三字詞。 表 1.1:訓練語料中個英文字母出現次數 A B C D E F G H I J K L M 122 91 147 147 53 34 56 33 93 9 34 43 102 N O P Q R S T U V W X Y Z 74 51 128 10 62 126 104 37 66 29 16 11 3 表 1.2:測詴語料中個英文字母出現次數 A B C D E F G H I J K L M 15 10 18 16 7 5 3 1 14 1 1 3 11 N O P Q R S T U V W X Y Z 11 8 15 0 7 14 13 3 6 5 2 2 01.6 章節概要說明
本論文的內容共分為六章: 第一章:緒論,介紹本論文之研究動機、研究方向、語音合成系統架構及語料庫說明。 第二章:HMM-based 中英夾雜語音合成器。 第三章:中英文夾雜韻律模型(PLM):建構中英文夾雜韻律模型以及模型訓練之演算法。 第四章:韻律模型訓練結果分析。 第五章:基於 PLM 演算法之韻律產生器及實驗結果 第六章:結論與未來展望第二章 HMM-based 中英夾雜語音合成器
本章將描述本論文之所使用之 HMM-based 語音合成系統。2.1 節介紹本研究所採用的基 於隱藏式馬可夫模型的語音合系統(HMM-based Speech Synthesis System, HTS) ,2.2 節介紹 HMM-based 中英文夾雜語音合成之基礎系統的建立。
2.1 HMM-based 語音合成系統
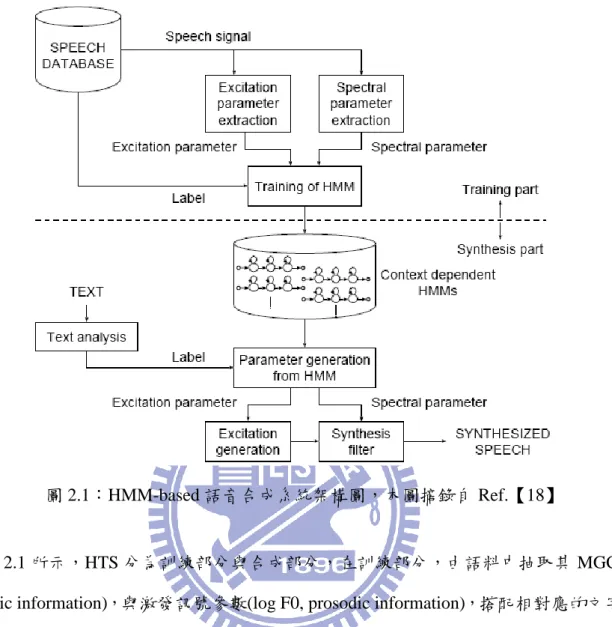
隱藏式馬可夫模型(Hidden Markov Model, HMM)早期大量應用在語音辨識系統中,它成 功以機率模型描述發音的現象。近年來則被應用到語音合成上,可說是目前語音合成系統 中,合成品質相當好的系統。此系統為統計參數式語音合成,由於是統計式參數合成方法, 比貣傳統以大語料為基礎(Corpus-based)之合成方法,來得更佳彈性且不需耗費大量時間錄製 語料與大量空間儲存語料。並透過參數的轉換與調適【15-16】,可輕易產生出不同語者特性 的語音。 本研究使用的 HTS 為日本名古屋大學資工研究所開發出來的 HTS 2.1(HMM-based Speech Synthesis System, version 2.1)【17】,此系統為基於 HTK 技術,所發展出針對使用隱 藏式馬可夫模型建構的語音合成系統。基於隱藏式馬可夫模型的語音合成系統如圖 2.1 所示:
圖 2.1:HMM-based 語音合成系統架構圖,本圖摘錄自 Ref.【18】
如圖 2.1 所示,HTS 分為訓練部分與合成部分,在訓練部分,由語料中抽取其 MGC 參 數(phonetic information),與激發訊號參數(log F0, prosodic information),搭配相對應的文字分 析產生文本標示,再配合適當的文脈相關問題集,訓練狀態合併分裂樹,產生與文脈相對應 的 HMM 模型,包含音高模型、頻譜模型及音長模型。合成部分則是輸入文字,透過文字分 析器產生與前後文相關的文本標示,再藉由分類與回歸樹(CART)演算法,挑選對應的 HMM 模型序列,經由生成參數演算法,產生頻譜參數與激發訊號參數,再透過 MLSA filter 產生 語音信號。
2.2 HMM-based 中英文夾雜語音合成基礎系統的建立
本節將對基於隱藏式馬可夫模型之中英夾雜語音合成基礎系統的建立做詳細說明,包含2.2.1 中文與英文字母音素模型
中文為一聲調語言(Tonal language),以音節(syllable)為單位,每個中文字對應到一個音 節(syllable)。中文共有 411 個基本音節(basic syllable),加上 5 種聲調,組成約 1300 多個音 節,涵蓋了幾乎所有常見的中文發音,而每個音節以聲母、韻母及聲調組成,聲母可分為 22 類,韻母則為 40 類。透過聲母、韻母的組合即可涵蓋大部分中文音節,因此本研究在建立 中文音素 HMM 模型時,採取以聲母、韻母為基本音素單元。如此一來可使得語料庫中不包 含的音節,或是較少出現的音節,藉由其他相同聲母或是韻母來幫忙訓練,得到較可靠的 HMM 模型。 至於英文字母之 HMM 模型,則是考量由於本語料庫之英文字母數量相對太少,因此若 是將每個英文字母視為一種音素,建立其 HMM 模型,恐怕會因資料量過少而產生不可靠的 參數,進而影響聲音品質,為了避免上述情形,本研究採取將每個英文字母視為一種類似中 文音節結構,拆解成與中文相似的聲母、韻母作為音素單元,例如:B 拆解成:B_1 類似中 文聲母ㄅ(b),B_2 類似中文韻母一(i)。此外原本英文字母共只有 26 個,但由於 M 這個字母 在語料庫中明顯有兩種不同之基頻軌跡,其英文字母特性將在第三章中詳述,因此將 M 再 細分為 Mr(rising)、Mf (falling),得到共 27 類英文字母。採取以上方式建立英文字母之 HMM 模型的優點在於透過中英文相近的發音,可共享其 HMM 模型,避免英文字母出現次數太少 而產生的不可靠模型,缺點則在於即便英文字母有發音相似的中文聲母、韻母,但仍有些差 異較大的字母,如 F、H、S、X 則是剛好和中文音節結構相反,即韻母在前,聲母在後。又 如 W、L 其實為雙音節字母,因此與中文聲母、韻母共享模型時可能會發生不匹配的狀況。
2.2.2 文本標示資訊與問題集設計
文本標示資訊為 HTS 相當重要的一環,採用哪些語言參數會直接影響到 context dependent model 的狀態分裂合併結果。根據 2.2.1 小節所定義的中英文音素模型,加上利用 前後文相關的語言參數,輸出文本標示。本論文所採用的語言參數,可粗分為五大類:音節 層次(syllable level)、詞層次(word level)、片語層次(phrase level)、句子層次(sentence level),最後特別加上 code-switch 的資訊,詳細所使用之文脈相關語言參數,如表 2.1 所示: 表 2.1:文脈相關資訊
level ID Description
Syllable level
Pr_Phn Previous initial/final -Cur_Phn Current initial/final +Fol_Phn Following initial/final
^Phn_in_Syl Initial/final position in a syllable =Pr_Tone Lexical tone of previous syllable @Cur_Tone Lexical tone of current syllable
#Fol_Tone Lexical tone of following syllable
&F_Syl_in_Wrd Syllable position in a lexical word (forward) |B_Syl_in_Wrd Syllable position in a lexical word (backward)
Word level
/A:Pr_PM PM type preceding current syllable /B:Fol_PM PM type following current syllable
/C:Pre_2_POS 46-type POS (Academia Sinica) of word preceding the previous word
/D:Pre_1_POS 46-type POS of previous word /E:Cur_POS 46-type POS of current word /F:Fol_1_POS 46-type POS of following word
/G:Fol_2_POS 46-type POS of the next word following the following word
/H:Pre_2_WL Word length of word preceding the previous word /I:Pre_1_WL Word length of previous word
/J:Cur_WL Word length of current word /K:Fol_1_WL Word length of following word
/L:Fol_2_WL Word length of the next word following the following word
Sentence level
/M:F_Syl_in_Snt Syllable position in a sentence (forward) /N:B_Syl_in_Snt Syllable position in a sentence (backward) /O:Snt_L_in_Syl Sentence length in syllable
/P:Snt_pre1_L_Syl Previous sentence length(sp) /Q:Snt_fol1_L_Syl Following sentence length(sp)
Code-Switch /R:Code_Switch Code-switch(Chinese to English or English to Chinese
Inter-word or Intra-ward)
Phrase level
/S:F_Syl_in_Phr Syllable position in a Phrase (forward) /T:B_Syl_in_Phr Syllable position in a Phrase (backward)
/U:Pre_1_POS 46-type POS of previous Phrase /V:Cur_POS 46-type POS of current Phrase /W:Fol_1_POS 46-type POS of following Phrase
/X:Pre_1_WL Word length of previous Phrase /Y:Cur_WL Word length of current Phrase /Z:Fol_1_WL Word length of following Phrase
建立好文脈標示後,接著根據表 2.1 之參數設計相關問題集,為了達到最佳狀態分裂合 併結果,考量五大類問題集,說明如下: 1. 音節層次(syllable level): i. 考慮當前音素與前後音素(initial、final): 聲母發音類別:爆破音、摩擦音、鼻音、邊音、塞擦音。 韻母發音類別:單元音韻母、複合元音韻母、鼻尾音韻母。 其中遇到英文字母時,採取 2.2.1 節中所提出之方式,將英文字母拆解成相似中文 聲母、韻母結構,因此在問題集設計上可將中英文發音方式相近的音素共用,如 B 可以與爆破音中的ㄅ(b)共用。 ii. 考慮當前聲調與前後聲調: 考慮下一個音節聲調:可將聲調簡化考慮成基頻貣始較高(H),如中文一聲和四聲 及基頻貣始較低(L),如中文二聲和三聲。 考慮前一個音節聲調:可將聲調簡化考慮成基頻結尾較低及節尾較高。 英文字母部分,以每一類字母獨立作為一種聲調,並可與相似基頻高度之中文聲調 共同設定問題集。 iii. 考慮音素在字中位置:由前面數來,由後面數來。 iv. 考慮音節在詞中位置:由前面數來第幾個字,由後面數來第幾個字。在不同詞中位 置都是有可能影響最後聲音的韻律特性,如在詞首或是詞尾。 2. 詞層次(word level): i. 考慮當前詞( 0 )與前後兩個詞( 1 、 2 )的詞類,依中研院 46 類詞類依實詞、虛詞、 八大詞類及特殊詞類集合合併,產生問題集。 ii. 考慮當前詞( 0 )與前後兩個詞( 1 、 2 )的詞長。 iii. 考慮前後音節是否有標點符號。 3. 片語層次(phrase level): i. 考慮音節在片語中位置:由前面數來第幾個字,由後面數來第幾個字。
ii. 考慮當前片語與前後一個片語的詞類。 iii. 考慮當前片語與前後一個片語的詞長。 4. 句子層次(sentence level): i. 考慮當前音節位在句子中第幾個字:由前面數來,由後面數來。 ii. 考慮當前句子與前後句子長度。 5. Code-Switch: i. 考 慮 當 前 音 節 是 否 在 中 英 文 交 界 處 , 且 分 詞 內 邊 界 (Inter-word) 和 詞 外 邊 界 (Intra-word):如中文詞轉英文詞且位於詞外邊界(C-E-Inter-word)、英文詞轉中文詞 且位於詞內邊界(E-C-Intra-word)等。 綜合以上類別的考量,本論文使用約 1700 個問題集及 2.2.1 節中的音素模型,並依照圖 2.1 之 HTS 方塊圖,實作出一套 HMM-based 中英夾雜語音合成基礎系統。
第三章 中英文夾雜韻律模型
本論文所使用之韻律模型是基於【10】中所提出之中文韻律模型,針對中英文夾雜特性 作適度修改,完成中英文夾雜之韻律標記與韻律模型訓練。本研究利用聲學參數、語言參數 和待預估的韻律標記,設計出四個子模型並基於最大概似度準則 (maximum likelihood criterion )採用逐項最佳化程序(sequencial optimization procedure)求得最佳化參數,完成韻律 標記以及韻律模型。3.1 節將介紹中英文語音韻律之特性。3.2 節將介紹階層式韻律架構。3.3 節將簡介中文 PLM 演算法。3.4 節將介紹中英文夾雜 PLM 演算法。3.5 節則介紹模型訓練及 參數更新演算法。
3.1 中英夾雜語音韻律之特性
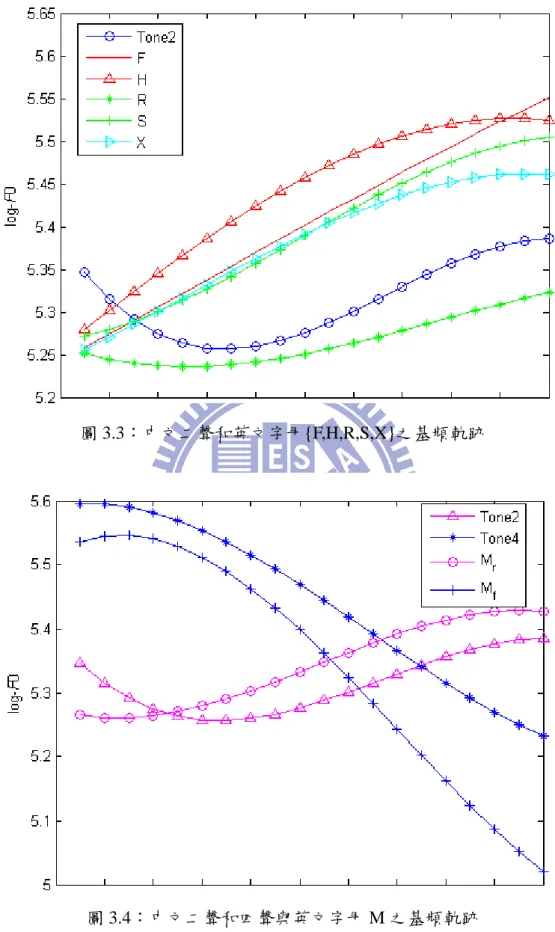
有別於語調語言(intonation language),中文屬於一種聲調語言,其特點為一個中文字由 一基本音節搭配不同聲調所組成,其基本音節共有 411 個,搭配五種聲調總音節數共 1300 多個。不同聲調則會產生不同語義,因此聲調為中文語音韻律一個重要的特徵,其影響韻律 層面最大之處在基頻軌跡的變化,圖 3.1 為中文一到四聲之基頻軌跡,可知中文一聲的基頻 軌跡通常為一水平線,且依照音高範圍分類為高至高(High-to-High),即音節貣始為高音頻, 音節結尾也為高音頻;二聲的基頻軌跡呈現低至高(Low-to-High)的走勢;三聲的基頻軌跡為 一勺狀曲線,即音節前後音高比中間來的較高;四聲的基頻軌跡則由高至低(High-to-Low), 至於中文五聲(輕聲)的基頻軌跡通常沒有固定形狀,因為其往往受到前後音節聲調影響。本 研究所屬的英文字母本身屬於語調語言,但由於中文本身為聲調語言,因此由華人所念出之 中文帶有少數夾雜英文字母之語句時,往往會不自覺地將英文字母發音成帶有聲調的韻律, 我們稱此現象為 Tone Borrowing。為了驗證此說法,我們將 26 類英文字母依其平均基頻軌 跡和相似地中文五種聲調在畫在同一張圖上,如圖 3.2 至圖 3.5。由圖 3.2 可看出英文字母 {A,B,C,D,E,G,I,J,K,N,O,P,Q,T,U,V,Y}之基頻軌跡和中文一聲相似;圖 3.3 則可看出英文字母 {F,H,R,S,X}之基頻軌跡和中文二聲相似;此外由圖 3.4 我們也發現 M 之基頻軌跡有兩種完全不同的形狀,一種為類似中文二聲的低至高(Low-to-High),另一種為類似中文四聲的高至低 (High-to-Low)。至於剩餘英文字母 W 和 Z 之基頻軌跡曲線則較為凌亂,如圖 3.5 所示。 圖 3.1:中文四個聲調之基頻軌跡圖 圖 3.2:中文一聲和英文字母{A,B,C,D,E,G,I,J,K,N,O,P,Q,T,U,V,Y}之基頻軌跡 1 2 3 4 5 Time Pitch Frequency Tone 1 Tone 2 Tone 3 Tone 4
圖 3.3:中文二聲和英文字母{F,H,R,S,X}之基頻軌跡
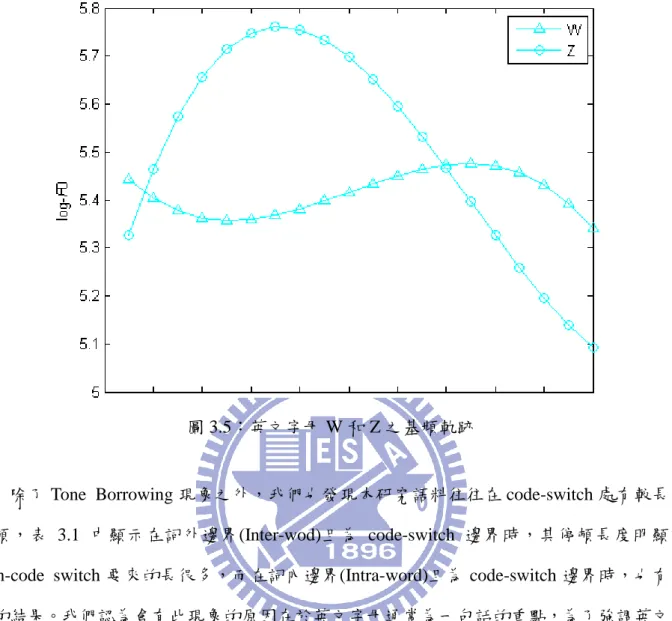
圖 3.5:英文字母 W 和 Z 之基頻軌跡
除了 Tone Borrowing 現象之外,我們也發現本研究語料往往在 code-switch 處有較長的 停頓,表 3.1 中顯示在詞外邊界(Inter-wod)且為 code-switch 邊界時,其停頓長度明顯比 Non-code switch 要來的長很多,而在詞內邊界(Intra-word)且為 code-switch 邊界時,也有同 樣的結果。我們認為會有此現象的原因在於英文字母通常為一句話的重點,為了強調英文字 母通常會念的比較慢,因此 code-switch 處的平均停頓長度會來的比一般 Non-code switch 處 要來的長。
表 3.1:code-switch 和 Non-code switch 處的平均停頓時長,其中括號中數值為其數量,且此 統計量不跨標點符號。
Chinese-Chinese English-English Chinese-English English-Chinese Inter-word 0.05 sec (4416) 0.06 sec (1) 0.16 sec (441) 0.11 sec (435) Intra-word 0.014 sec (4206) 0.037 sec (993) 0.06 sec (20) 0.0408 sec (47)
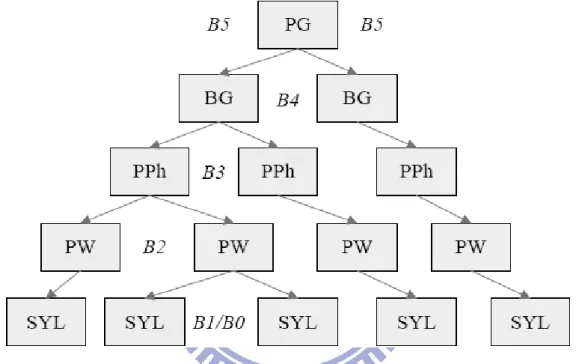
3.2 階層式韻律架構
根據許多研究中文韻律的文獻【19】顯示,中文的韻律結構呈現階層式韻律架構(hierarchy structure),一般來說分成四層結構,如圖 3.6 所示,由底層至上層分別為音節層次(Syllable, SYL)、韻律詞層次(Prosodic Word, PW)、韻律短語層次(Prosodic Phrase, PPh)以及語調短語層 次(Intonation Phrase, IP)。由於一個中文字為一個音節的特性,因此最底層的韻律單元為音節 層次,而不同聲調所帶來的不同語義,也使得聲調成為音節層次中最重要的韻律影響因素, 聲調不只影響音節音高甚深,也進而影響音節長度與音節能量。第二層的韻律詞層次則是由 雙音節或多音節的詞組所組成,這些詞組通常在句法或是語意上緊密相關,因此往往會將這 些詞組發音成一個單元。第三層的韻律短語層次則是由一個或多個韻律詞所組成,其結尾通 常有帶有可察覺但不明顯的停頓。第四層的語調層次則是中文韻律架構的最上層,通常限制 了一個句子或是數個韻律短語所組成的句子音高,其結尾則會有明顯的停頓。基本上,四層 的韻律架構詮釋了一個句子中每個音節的音高和音長變化。 PW PW PW PW PW PW PW PP PP IP SYL 汙染 造成 了 霧 的 形成 並 加重 了 大氣 環境 的 變化 圖 3.6:中文常見的階層式韻律架構 ,本圖摘錄自【19】 此外鄭秓豫博士【20】提出另一個韻律架構並提出韻律標記的概念,如圖 3.7 所示。此 架構將中文韻律結構分成五層,前三層和第一種韻律架構一樣,分別為音節層次(Syllable, SYL)、韻律詞層次(Prosodic Word, PW)以及韻律短語層次(Prosodic Phrase, PPh)。第四層則是 將連續的 PPh 組合成一個呼吸群(Breath Group, BG)來代表大範圍且有基頻及音長變化的篇
章或是段落,藉此表示韻律更上層的貢獻,同理定義了第五層為連續的 BG 所組成的韻律群 (Prosody Group, PG)。而上述所說的五層架構則採用六種標記來區分,B0 和 B1 代表 SYL 的 邊界,差別在於 B0 表示 reduced syllable boundary,B1 則是 normal syllable boundary,且通 常在 B0 及 B1 的邊界聽不出停頓。B2 及 B3 分別區分 PW 和 PPh 的邊界,B4 和 B5 則是區 分 BG 和 PG 的邊界,B4 代表一個呼吸的停頓,B5 則為一個完整語音段落的結束,並且可 以明顯感受到句尾的音節長度拉長(final lengthening)以及能量的減弱。
圖 3.7:階層式多短語韻律句群(Hierarchical Prosodic Phrase Gruoping,HPG)架構。【20】
本研究主題雖然為中英文夾雜的語句,但文句還是以中文為主體,英文字母少量穿插在 中文句子中,且英文字母大多數都為單音節結構,和中文字結構相仿,因此我們假設在正常 語流的情況下,英文字母本身的上層韻律變化(High-Level Prosodic information)與韻律斷點會 受到中文整體韻律變化的限制與影響。此觀點也可與 3.1 節中所提到的 Tone Borrowing 之現 象呼應,因為當前後中文字都屬於聲調語言的情況下,英文字母的發音也很容易變成帶有聲 調的發音,如 A 類似中文一聲。基於上述理由,本研究仍以 HPG 的中文韻律架構為基礎, 進一步對其做修改,利用修改後的架構作為中英文夾雜文句的韻律模型架構。
詞邊界。接著我們將 B4、B5 合併為 B4,整個韻律架構由 5 層變回 4 層,如圖 3.8 所示。綜 合上述,本研究採用了 7 種停頓標記(Break Type) B ={B0,B1,B2-1,B2-2,B2-3,B3,B4},來標記 這四種韻律單元:音節(SYL)、韻律詞(PW)、韻律短語(PPh)及呼吸群/韻律群(BG/PG)。值得 注意的是由於上述中英文夾雜語句的特性,本研究並不會因為是英文字母所對應到的停頓標 記而給定特別不同於中文的標記。 圖 3.8:本研究所用之階層式韻律架構 在此將 B2 分成 3 類是因為雖然同屬於韻律詞的邊界,但其對應的聲學特性仍然有所不 同,原先的單一類別不足以將其差異性描述出來;而將 B3 及 B4 合併則是因為它們所對應 到的聲學特性相近,故不需要再用額外的韻律邊界停頓來表示之。 為了要更進一步描述這四層的階層式韻律架構,除了描述韻律單元邊界的停頓標記外, 還需要描述韻律單元變化的韻律標記或參數。而本研究利用一些帶有韻律組成份子資訊的標 記來間接的表示這些韻律組成份子,此標記即為韻律狀態,其意義代表圖 3.8 架構中最上面 三層之韻律組成份子個別的貢獻。在本研究中會採用三種不同的韻律狀態,分別量化正規化 後的音高、音長和音節能量。正規化後的音高為扣除掉音節層次對音高的貢獻,此時音高的 韻律狀態代表的是韻律詞、韻律短語、呼吸群/韻律群對音高的貢獻。至於音長或音節能量 則同理扣除音節層次影響因素,使其分別表示最上面三層之韻律詞、韻律短語、呼吸群/韻 律群對音長和音節能量的貢獻。簡而言之,音高、音長和音節能量的韻律狀態分別表示每個 音節在韻律詞層次以上貢獻的音節音高平均、音節音長和音節能量。這樣做的好處在於,我 們能將音高、音長和音節能量在低層次和高層次的影響因素分開,將複雜的高層次影響因素 通通由韻律狀態來表示。此外韻律狀態標記一樣不會因為英文字母而給予特定標記,原因如
上述中英文夾雜語句特性,其上層韻律變化會受到中文整體韻律變化的限制與影響,因此韻 律狀態的標記重點在於前後音節上層韻律變化而不是底層的音節所屬類別。
3.3 中文 PLM 演算法
由於本研究所採用的中英文夾雜韻律模型是基於江振孙博士所提出之中文韻律模型 (PLM)演化而來,因此在此先介紹何謂中文 PLM,待 3.4 節再介紹中英文夾雜韻律模型。 中文 PLM 演算法為江振孙博士依據中文階層式韻律架構,如圖 3.8,利用語言參數和聲 學參數間的相互關係,針對一個未經人工事先標記好的語料,自動標記出其停頓標記及上層 韻律狀態,此演算法優點:1.可自動標記,傳統上的韻律標記多為人工標記,既耗時又耗力, 且有不一致性的問題。2.透過此模型可清楚分析韻律詞層次以上的韻律變化趨勢。 自動韻律標記的問題可視為,在給定聲學參數集合 A 及相對應的語言參數集合 L 之下, 目標找到最佳韻律標記之集合T ,因此可視為一種求取最佳參數解的過程,即:
argmaxP | , =argmaxP , | T T T T A L T A L (3.1) 韻律標記集合包含了兩類很重要的中文語音韻律資訊,第一類是參考階層式韻律架構所 定 的 音 節 邊 界 停 頓 標 記 , 在 此 演 算 法 中 定 義 音 節 邊 界 停 頓 標 記 集 合 B ={B0,B1,B2-1,B2-2,B2-3,B3,B4},其意義如 3.2 節所述,主要區分每一層韻律架構的邊界。 另一類的韻律標記為音節的韻律狀態,此演算法定義三種韻律狀態,分別代表經過量化和正 規化音節的音高韻律狀態 p 、音長韻律狀態 q 和音節能量韻律狀態 r 。音高韻律狀態代表扣 除音節層次對音高的貢獻,即扣除聲調和連音影響參數,此時 p 則為韻律詞、韻律短語、呼 吸群/韻律群對音高的貢獻。同理音長韻律狀態和音節能量韻律狀態則分別扣除聲調、基本 音節類型或韻母類型的影響參數,使其分別代表韻律詞層以上對音長和音高的貢獻。此演算 法定義韻律標記之集合為T{ ,B PS ,其中,} PS{ , , }p q r 為韻律狀態標記集合。 此演算法所使用之聲學參數可分為三類,第一類聲學參數為音節韻律參數(syllable聲學參數則用來說明音節邊界停頓標記,我們假設這兩類的聲學參數和音節邊界停頓標記有 很高的關聯性,但與韻律狀態標記的相關性很低或是獨立,第二類聲學參數為音節間韻律參 數(inter-syllable prosodic feature),包含音節邊界的停頓時長、音節邊界的 energy-dip level。 第三類聲學參數為音節差韻律參數(differential prosodic feature),包含正規化基頻跳躍值 (normalized pitch jump)和正規化的音節長度延長因子(normalized duration lengthening factor)。
綜合上述討論,定義聲學參數 A 包含了音節音高軌跡序列 sp 、音節長度序列 sd 、音節 能量序列 se、停頓時長序列 pd、音節能量低點(energy-dip level)序列 ed 、正規化的音節內基 頻跳躍值 pj 及正規化的音節長度延長因子序列 dl df、 。 其中 pj 、 dl df、 分別定義為:
+1(1) n+1(1)
(1) n(1)
n n t n t pj sp β sp β (3.2) 在此 (1)x 定義為向量 x 的第一維度,下標 n 表示為第 n 個音節, n t β 為聲調影響因素tn的 affecting patterns (APs) 。
n n
-1 n-1 n-1
n n t s n t s dl sd sd (3.3)
n n
1 n1 n1
n n t s n t s df sd sd (3.4) 在此t和s分別表示聲調與基本音節類型影響因素在音長的 APs。 因此聲學參數集合為A{ , , ,sp sd se pd ed pj dl df ,再因參數特性細分為音節韻律參數, , , , } { , , } X sp sd se ,音節內韻律參數Y{pd ed 以及音節差韻律參數, } Z{ , ,pj dl df 。 } 至於語言參數方面,考慮音節層次中的聲調、基本音節類型及韻母類型,詞層次中的音 節邊界型態(Intra-word、Inter-word)、詞長及 POS 和對應到的標點符號類型等。將整個語言 參數集合以 L 表示,由於聲調、基本音節類型及韻母類型分別對音節音高、音長及音節能量 有顯著影響,因此將這些語言參數獨立出來表示,最後因考慮到不同語句時,說話速度上的 變動會造成音長變化及說話音量變動會造成能量的變化,因此再將語句層次的正規化因子獨立出來,而剩下之語言參數則定義為 reduced linguistic feature l 。 為了清楚了解這些符號定義,將上述說明列在表 3.2。
表 3.2:韻律標記、韻律特徵和語言特徵的表示法 T: prosodic tag B: break type
PS: prosodic state p: pitch prosodic state q: duration prosodic state r: energy prosodic state A: prosodic feature X: syllable prosodic feature sp: syllable pitch contour
sd: syllable duration se: syllable energy level Y: inter-syllabic prosodic feature pd: pause duration
ed: energy-dip level Z: differential prosodic features pj: normalized pitch jump
dl: normalized duration lengthening factor 1
df:normalized duration lengthening factor 2
L: linguistic feature l: reduced linguistic feature set t: syllable tone sequence s: base-syllable type sequence f: final type sequence
u: utterance sequence 綜合上述討論,可將(3.1)改寫為:
, | | , | , , | , , , | | , , , | , | | P P P P P P P P P T A L A T L T L X Y Z B PS L B PS L X B PS L Y Z B L PS B B L (3.5) 由(3.5)式拆解出四個子模型,分別為音節韻律模型P X B PS L
| , ,
,用來說明音節韻律參 數受到 ,B PS L 影響所產生的變化;停頓標記聲學模型, P Y Z B L
, | ,
,用來說明在不同停頓標 記 B 和語言參數 L 之下,音節間韻律參數 Y 及音節差韻律參數 Z 的分佈情形;韻律狀態轉移
| P B L ,用來說明停頓標記 B 和語言特徵 L 之間的關係。 以下將進一步說明四個子模型,首先,音節韻律模型P X B PS L
| , ,
可再分解為三個模型, 分別模擬音節音高軌跡序列 sp、音長序列 sd 和音節能量序列 se,並假設 sp、sd 和 se的變化 只受到以下幾個影響因素控制:音節聲調 t 、基本音節類型 s 、韻母類型 f 、語句 u、韻律 狀態PS{ , , }p q r 和停頓標記 B,因此可得到
1
-1 -1 1 1 1 | , , | , , | , , , | , , , | , , | , , , | , , , N N N n n n n n n n n n n n n n n n n n n n P P P P P B p t P sd q t s u P se r t f u
X B PS L sp B p t sd q t s u se r t f u sp (3.6) (3.6)式中第一個子模型
-1 -11
1 | , , N n n n n n n n P B p t
sp 為音節基頻軌跡模型,假設所觀察到的第 n 個音節基頻軌跡sp 受到目前音高韻律狀態n pn、目前聲調tn以及在給定停頓標記B 和n-1 Bn時, 前後各一個音節聲調tn1和tn1造成的連音影響,因此 -1=( -1, ) n n n n B B B , 1 -1 ( -1, , 1) n n n n n t t t t 。如此一來 可將音節基頻軌跡模型改寫成(3.7)式。 1, -1 , for 1 n n n n n n r f b n n t p B tp B tp n N sp sp β β β β μ (3.7) n sp 為觀察到的第 n 個音節音高軌跡(observed),此演算法是將音節音高軌跡使用正交展 開(Orthogonal expansion),投影到四個 Legendre 多項式基底得到四維正交化參數。(3.7)式中 的βx,表示音節音高軌跡影響因素 x 時的 AP,tpn是 tone pair1 +1 ( , ) n n n n t t t , 1, -1 n n f B tp β 和 n, n b B tp β 分別是第 n-1 個和第 n 個音節所貢獻的前後音節影響效應的 AP。此外,每個語句的韻律邊 界 都 有兩 個特 例, 即為 語 句開 始與 結束 ,分 別 以B 和b Be 表 示 之, 因此 b,1 0, 0 f f B t B tp β β , , , e N e N b b B t B tp β β 為兩個特例的連音效應 AP。 r n sp 則為正規化後的sp ,亦可稱為n sp 扣除n βtn 、 n p β 、 1, -1 n n f B tp β 、 , n n b B tp β 和μ 的殘餘值(residual)。圖 3.9 顯示出sp 與這些影響因素之間的關係圖,n 藉由假設 r n
1 -1 1 -1 -1 , , ( | , , ) ( ; , ) for 1 n n n n n n n n f b n n n n n t p B tp B tp P sp p B t N sp β β β β μ R n N (3.8) 其中 R 定義為 r n sp 的共變數矩陣(covariance matrix)。 1 n sp Bn1 spn Bn spn1 1, 1 n n f B tp β , n n b B tp β n t β n p β 圖 3.9:觀察到的音節音高軌跡與其影響因素的關係圖 同理(3.6)式中第二、第三個子模型經過推導,可以得到: ( | , , , ) ( ; , ) n n n n n n n n n n t q s u d d P sd q t s u N sd R (3.9) ( | , , , ) ( ; , ) n n n n n n n n n n t r f u e e P se r t f u N se R (3.10)
(3.9)式模擬了音長sd ,其中 ' sn 定義各種不同的 APs,d與Rd分別表示 global mean
與音長殘餘值的共變數矩陣;( 3.10)式模擬了音節能量sen,其中 's 定義各種不同的 APs, e 與Re分別表示 global mean 與音節能量殘餘值的共變數矩陣。 接著停頓標記聲學模型 ( , | , )P Y Z B L 可進一步簡化,得到 1 ( , | , ) ( , | , ) ( , , , , | , ) N n n n n n n n n P P P pd ed pj dl df B
Y Z B L Y Z B l l (3.11)其中 (P pd ed pj dl df B ln, n, n, n, n| n, )n 是由分類樹與回歸樹(Classification and Regression Tree, CART) 推導出來,其節點的分類準則是採用最大概似函數增益(Maximum Likelihood Gain),將音節
種停頓標記建立一顆決策樹,將每個節點裡的不同參數分別用不同 pdfs 來模擬,用一個 gamma distribution 來描述 pdn分佈情形,用四個 normal distribution 分別描述ed 、n pjn,及
n dl 、 df 的分佈情形,因此(3.11)可改寫成五個機率分佈的乘積: 2 2 , , , , , , 2 2 , , , , ( , , , , | , ) ( ; , ) ( ; , ) ( ; , ) ( ; , ) ( ; , ) n n n n n n n n n n n n n n n n n n n n pj pj n n n n n n n n B B n B B n B B dl dl df df n B B n B B P pd ed pj dl df B g pd N ed N pj N dl N df l l l l l l l l l l l (3.12) 此外韻律狀態轉移模型可進一步針對三種韻律狀態分解成三個子模型,表示為: ( | ) ( | ) ( | ) ( | ) P PS B Pp B P q B Pr B (3.13) 而每個子模型,可用雙連文模型(bigram models)分別表示為: 1 1 1 2 ( | ) ( ) ( | , ) N n n n n P P p P p p B
p B (3.14) 1 1 1 2 ( | ) ( ) ( | , ) N n n n n P P q P q q B
q B (3.15) 1 1 1 2 ( | ) ( ) ( | , ) N n n n n P P r P r r B
r B (3.16) 其 中P p 、( )1 P q 和( )1 P r 分 別 表 示 各 個 不 同 韻 律 狀 態 的 貣 始 機 率 (initial probability) ,( )1 1 1 ( n| n , n ) P p p B 、P q q( |n n1,Bn1)和P r r( |n n1,Bn1)分別表示各個不同韻律狀態,在給定停頓標記 1 n B 的情況下,從第 n-1 個音節的韻律狀態到第 n 個音節韻律狀態的轉移機率(transition probability)。 最後化簡停頓標記語言模型P B L
| 為: 1 1 ( | ) ( | ) ( | ) N n n n P P P B
B L B l l (3.17) 並且以最大概似函數增益為分裂準則之決策數來實現此模型,每一個節點中將產生每一種停 頓標記之機率,其問題集由語言參數 l 所產生。3.4 中英夾雜 PLM 演算法
原本的 PLM 演算法是以中文音節為單位所建構出的模型,而依據上述英文字母的特 性,本研究將每個英文字母視為一種特殊音節,分成 27 類(M 拆成 Mr、Mf),將英文字母如 同中文音節進行音節層次和上層韻律層次的拆解,並標記其對應的停頓標記與韻律狀態,其 停頓標記集合與韻律標記集合皆和中文 PLM 一樣。以下將介紹中英文夾雜 PLM 如何應用原 先中文 PLM 的四個子模型,進行中英文夾雜的韻律模型訓練與韻律標記。 首先,第一個模型:音節韻律模型P X B PS L
| , ,
。由 3.3 節可知此模型可以再化簡成 3 個子模型,如前述的(3.8)式~(3.10)式,分別模擬音節基頻軌跡序列 sp 、音長序列 sd 和音節 能量序列 se。針對英文字母特性,將三個子模型改寫成(3.18)~(3.20)式,分別為音節基頻軌 跡模型、音節音長模型及音節能量模型。 1 -1 1 -1 -1 , , ( | , , ) ( ; , ) n n n n n n n n f b n n n n n t p B tp B tp P sp p B t N sp β β β β μ R (3.18) 其中,Bnn-1=(Bn-1,Bn), 1 1 ( 1, , 1) n n n n n t t t t ;βtn 為音節之聲調(t )影響參數,除了考慮原本中文有n 的 5 種 聲 調 外 , 也 將 每 個 英 文 字 母 視 為 一 種 特 定 的 聲 調 , 因 此 聲 調 共 有 32 類 , r f {1, 2,3, 4,5, A,B,....M ...Z,M } n t , n p β 為音節基頻之韻律狀態( p )影響參數, μ 為 global n mean, R 為殘餘值之共變數矩陣, n1, n-1, n, n f b B tp B tp β β 為音節間前後連音影響參數。由於將聲調分 為 32 種類別,連音參數若依據原先演算法之定義,將會造成 7168(32 32 7) 種組合,以致 於在估算此參數時會因資料量太過稀少,進而影響整個連音參數的求取,因此本研究採取 CART 演算法,將語料庫中所有連音參數組合(包括英文接英文),藉由適當問題集1、2(詳 情請見附錄一),分別建立兩顆決策樹(Forward,Backward),將相似連音參數進行合併縮減, 以達到降低參數量並得到更可靠的連音參數。所採用的分裂準則為最大平方總和誤差降低量 (Maximum Sum Square Error Reduction),詳細實作流程將在 3.6 節中介紹。其 中γ 表 示 sd 之 APs 。 同 上 述 所 說 , 我 們 將 每 個 英 文 字 母 視 為 一 種 特 定 聲 調 , 及n r f {1,2,...5,A,B,....M ...Z,M } n t 。sn原為中文 411 基本音節類別,但由於本身此語料庫偏 少,因此將中文聲母化簡成 7 類,中文韻母化簡成 13 類,因此原先 411 種組合被簡化成 91 類,在此語料庫下,sn{1~82類},但當sd 為英文字母時,n sn則為零,因為英文字母的影 響已經由聲調影響參數來模擬。qn為音節音長之韻律狀態,un為音長語句之影響參數,d 與Rd分別表示 global mean 與音長殘餘值的共變數矩陣。 ( | , , , ) ( ; , ) n n n n n n n n n n t f r u e e P se r t f u N se R (3.20) 其中表示sen之 APs。同理,tn{1,2,...5,A,B,....M ...Z,M }r f , fn{1, 2,...40},共有 40 個韻母,但當遇到英文字母時, n f 則為 0,r 為音節能量之韻律狀態,n un為音節能量語句 之影響參數,e,與Re分別表示 global mean 與音節能量殘餘值的共變數矩陣。 第二個模型:停頓標記聲學模型P Y Z B L
, | ,
採用的聲學參數都和中文 PLM 一樣,模型 數學式同(3.11)式與(3.12)式,一樣採取 CART 演算法,使用分類準則為最大概似函數增益, 將音節間停頓長度(pdn)、音節間能量低點(ed )、相鄰兩音節之正規化基頻跳躍值(n pjn)、相 鄰兩音節之正規化延長因子(dln、 df ),對於不同停頓標記,根據問題集3,詳情請見附錄 二 )進行分類,即每種停頓標記建立一顆決策樹,將每個節點裡的不同參數分別用不同 pdfs 來描述其分佈情形,用一個 gamma distribution 來描述 pdn之分佈情形,用四個 normaldistribution 分別描述 ed 、n pjn、dln及 df 之分佈情形。此停頓標記聲學模型與原先中文 PLM
中最大不同在於語言參數的不一樣,由於多了英文字母,必頇特定考量在英文字母的情況 下,該如何設計語言參數,如 code-switch 處音節停頓會比一般 Non-code switch 處來的長一 點,因此英文語言參數的考量將會大大影響此停頓標記聲學模型的效果。
第三個模型:韻律狀態轉移模型P PS B
|
,同中文 PLM,將此模型拆解成三個 bigram models,分別描述三種韻律狀態與停頓標記之轉移關係,數學式同(3.14)~(3.16)。似函數增益為分裂準則,統計在不同語言參數下,所蒐集到的停頓標記分佈狀況,其問題集 (3)同停頓標記聲學模型。而所使用之語言參數一樣需要多考量英文字母,如 code-switch 處因為有比較長的音節停頓長度,因此產生停頓標記 B2-2 的機率尌相對較高。而停頓標記 也會受到下一個音節的聲母型態而有所影響,因此將英文字母依據貣頭發音方式,分類成如 同中文聲母型態的分類,如表 3.3 所示: 表 3.3:英文字母分類表 INULL A、E、M、N、I、O、R、U、V、Y、 F、H、S、X、L b(ㄅ)、d(ㄉ)、g(ㄍ) B、D、W sh(ㄕ) 、x(ㄒ) C zh(ㄓ)、z(ㄗ)、j(ㄐ) G、J、Z p(ㄆ)、t(ㄊ)、k(ㄎ) P、T、K、Q 其中 F、H、S、X、L 因貣始發音也是濁音(voiced),因此歸類在 INULL。
3.5 中英文夾雜韻律模型之訓練
本節將介紹如何實作 3.4 節所提出之演算法,中英夾雜 PLM 在建立時,是基於最大概 似度準則,採用逐項最佳化程序來更新模型參數,標記出最佳的韻律標記,其標的函數 (objective function)如下: 1 -1 1 1 1 1 1 1 1 1 1 1 1 2 ( | , , ) ( | , , , ) ( | , , , ) ( ) ( ) ( ) ( | , ) ( | , ) ( | , ) ( , , N n n n n n n n n n n n n n n n n n N n n n n n n n n n n n n Q P p B t P sd q t s u P se r t f u P p P q P r P p p B P q q B P r r B p pd ed
sp
1 1 , , | , ) ( | ) N n n n n n n n n pj dl df B P B
l l (3.21) 模型訓練的過程主要分成兩個步驟,為初始化(initialization)及重覆疊代(iteration)。將於 3.5.1 節和 3.5.2 節詳細介紹其流程。3.5.1 初始化(Initialization)
Step1:計算總體平均值 計算音節基頻、音節長度、音節能量的總體平均值μ、d、e,其中μ 並不包含求不出基頻 的音節。 Step 2:計算聲調影響參數(βt、t、t) 分別計算聲調對音節基頻、音節長度、音節能量的影響參數,英文字母的影響歸類在聲調中, 即每種英文字母看成一種聲調,計算公式如下: 1 r f 1 ( ) ( ) , for 1, , 5, A,B...M ...Z,M ( ) N n n n t N n n t t t t t
sp μ β (3.22) 1 r f 1 ( ) ( ) , for 1, , 5, A,B...M ...Z,M ( ) N n d n n t N n n sd t t t t t
(3.23)1 r f 1 ( ) ( ) , for 1, , 5, A,B...M ...Z,M ( ) N n e n n t N n n se t t t t t
(3.24) Step 3:計算基本音節型態影響參數( n s 、 n f ) 分別計算不同基本音節類型對於音節長度的影響,不同韻母類型對於音節能量的影響,基本 音節型態由 411 種化簡成 91 總組合(7 種聲母類別13 種韻母類別,此語料共只出現 82 類), 韻母則為分為 40 類,而在當前音節為英文時,這兩個 APs 都給 0。計算公式如下: 1 1 ( ) ( ), for base syllable type
( ) N n d t n n s N n n sd s s s s s
(3.25) 1 1 ( ) ( ), for final type
( ) N n e t n n f N n n se f f f f f
(3.26)Step 4:標記初始化停頓標記(Initial labeling of break indices)
利用表 3.2 中的 Y Z、 參數,包含了音節停頓長度( pd ),音節能量低點( ed ),正規化基頻跳 躍值( pj )以及正規化音節延長因子( dl df、 ),使用【10】提出之決策樹的方式,對所有音節 邊界處標記初始的停頓型態( B ),如圖 3.10 所示。由於音節停頓時長是判斷是韻律邊界一個 重要的聲學參數,而音節後為標點符號(PM)的邊界通常會有較大的停頓時長,因此往往屬於 本研究所定義之 B3 與 B4。其次,大多數的詞外音節邊界有較短的停頓時長,通常被標記成 本研究所定義之 B0 與 B1,然而 B0 是屬於音節間基頻停頓(pitch pause duration)很短的停頓 標記,因此藉由很短的 pitch pause duration 和很高的音節能量低點區分 B0 和 B1。此外在 Non-PM 的詞外音節邊界中有中等程度以上的停頓時長、基頻跳躍值及音長延長,則分別歸 類為 B2-2、B2-1 與 B2-3。藉由上述所說之語言參數與聲學參數的關係,我們可以制定一套