A
Reasoning Framework for
Heterogeneous XML
Yuh-Pyng Shieh, Chung-Chen Chen, and Jieh Hsiang
Department of Computer Science and Information Engineering,
National Taiwan University, Taipei, Taiwan.
arping,
johnson)@turing.csie.ntu.edu.tw,
hsiang@csie.ntu.edu.tw
Abstract-XML is designed to structure data for exchange. It is also a new trend to use XML to encode knowledge on the Web. An important project for this purpose is the Semantic Web of W3C. They proposed several speciiications, including RDFlRDFS and OWL, for knowledge representation. In the architecture of SW, they proposed XML for the syntax layer, RDF/RDFS for the semanti? layer, and OWL for the ontology layer. However, Languages for the logic layer and proof layer are not yet defined.
We propose a different approach for knowledge representation and reasoning in this paper. We define a logic-based framework to transform XML documents into logical facts, and to reason about these facts. The transforming and reasoning processes are based on a logic programming language, Path Inference Longuogc (PIL),
which i s specifically designed for tree-structure documents like XML. People may write a PIL program to extract logical facts from X M L documents, and the extracted logical facts are imported into a logic-based ontology in
PIL
for reasoning. Based on PIL, we intend to develop a simple and powerful framework for people to interpret the semantics of XMLeasily.
I n d a Terms-Antomated Reasoning, Logic Programming,
Ontology.
1. INTRODUCTION
Rer the first release of
XML
annouuced byW3C
in 1998, thousands of XML specifications have been developed to encode data into XML format. It is easy for people to define their own metadata as their needs using XML. However, the interpretation XML has become more and more difficult as the number of metadata grows. This is because XML focuses on the syntax of data instead of the semantics. Several problems may occur if one wants to deal with several different types at once, as the following simple example illustrates.A
Researchsupported inpanby GrantNSC91-2213-E-002-039andNSC 91-2811-E-002-022 of the National Science Council of the Republic of China.
<private security="L112481632'~ <name> Yuh-Pyng Shieh 4 n m e > <father> Ye Fu Shieh </father> </private>
CSP %xt>
<+i%>atf
$4*%>
%x12-28825252c/$ %>
U/gP
aFx-)> <person sex= "ale'2<security>LI 124816324security> < M m 0
<iirst-name>Yuh-Pyng </first-name> <last-nam+ Shieh aast-name> 4na n10
<father> LI 86619019 </father> <brother> An Shieh <mrother>
I
4person>I
Figure 1. Heterogeneous XML
T h e three XML documents above are of three different types, and describe information about the sameperson. When we want to handle them all at once, we may encounter the following problems.
1. Different tae names: T h e lags <private>, <person>, and
< 8 $
'w#>
are all about personal data, but have different names.Different locations: In <private> the ID number is recorded as an attribute of <private>, but in <person> the ID number is recorded in a sub-tag.
Yuh-Pyng Shieh and
%tfF
are the names of the same person (the first author), hut is in English and the other in Chinese.The tags <name> in <private> and <name> in <person> have different skuclue. The latter splits a name to first and last.
Different semantics: The meaning of <father> in <private> and <father> in <penon> are very different. The former is the name of the person's father, while the latter is the father's ID number.
minded solution is to require that all tags have the same meaning. A more reasonable one is to design a mechanism to Uansform documents of one type into other types.
Several projects were initiated to unify XML tags using ontology. The most well known is the Semantic Web project [I ,2]
of W3C. The SW working group of W3C proposed a series of languages including XML, XPATH, XSLT, RDF, RDFS and OWL. XML is used to encode data on the Web m a standard markup format. XPATH is to locate nodes in XML documents. XSL is for showing the same XML document in different .presentational styles. RDF is used IO encode XML documents
in
standard objecturiented format for machine to read and write. RDFS is used 10 encode the meaning of XML tags. And OWL is for representing ontology in XML format. More specifically, RDF contains a set of standard tags used to describe data as objects, and RDFS contains a set of tags to describe the meanings of user-defined tags. OWL is a language evolved f"OIL
andDAML,
and contains a set of tags such as "subclassof' and 'onPmpeny" to define the simple set-theoretic semantics of the ontology. Those who want to understand the relationship among these languages can read the tutorial paper of Decker et al[31.Figure 2. The specifreation stack of
S W
171 Figure 2 shows the specification stack of the Semantic Web project. In SW, XML is a language for the syntax layer; RDF/RDFS are languages for the semantic layer; andDAML,
OIL and OWL are for the ontology layer. Languages for the logic and p m f layers are not yet defined. The languages proposed by S W so far have adopted the objecturiented approach that encodes objects m X M L .Another possible way to represent ontology is the logic-based approach. The solid foundation of mathematical logic had attracted people to design programming languages based on logic. One ofthe most notable is Prolog [6]. Logic-based languages such as Prolog offer a number of advantages. First. it can treat a program and the data that it wants to, operate on in a uniform way. Second, Pmlog adopts resolution as its execution mechanism. Thus, executing a program and reasoning about a program can be done in the same environment. Third. logic is a vely convenient way to specify relations, which is exactly the purpose of ontologies.
For these reasons, we propose a logic-based programming language, the Path /nference language (PIL), for reasoning about Web documents. The same language is used for specifyhp the
semantics of XML, describing ontologies, and for reasoning. In other words, in our framework we simplified the SW specification stack into just two layers, as shown in Figure 3.
Logic
Layer
(PIL)
I
Syntax
Layer
(XML)
Figure 3. The spccification stack ofour framework The scenario goes
as
follows: 1nstc3d of using hcavy languages such as RDFiS to define relations bctween tags. we use PIL tountc extraclon (PIL programs) to exmct elements f" XML documents The extract eicments arc logrcal facts (also PIL p r o p " ) The lopcil facts can then be cxponcd IO the world of ontologies for reasoning. But since ontolugtcs arc also dcscnbed as PIL prognms. the execution mechanism of PIL c3n be used for reasoning
as
well.Thrs pap- 1s organrzcd
as
follows Section 2 shows an overview Cor our logic-bawd framework to transform XAlL mto the logic world, including the cxtracnon prmess and the reasoning process. Thc framework is based on PIL to extract logical facts from XML documents and to reason using thcsr (acts. Swoon 3 shows the syntax, denotational and operational semantics of PIL. Section 4 shows how to extract logical f3ns from XML documents by PIL. Section 5 shows how to represent ontology and r e m n wth PIL. We summarize our approach and present a cornpanson with SW m section 6.11. O V E R v l t W
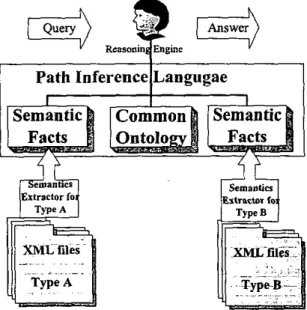
Our logic-based fnmework i s intended to integrate hcterogencous XML documents into a unified semantics s m c t m . Our approach IS to tranrfonn heterogeneous XML documents mto loeical facu with unilorm Semantics for reasoning.
Path Inference Langugae
I
Figure 4. The architecture of our logic-based framework Figure 4 shows the architecture of 0u1 proposed framework.
The framework contains the following pa-, a set of XML documents of several different types, a set of semantic extractors in PIL, a common ontology in PIL, and a reasoning engine. In the architecture of Figure 4, logical facts are extracted from XML documents via a semantic extractor, and then a reasoning process based on the extracted logical facts and the common ontology is used to answer questions by reasoning.
In order to illustrate our aoproach, the following
..
-
X M L
document about the customer '"Peter" IS used as 30 exampleI
<customer ~~~ me="Petcr"> ~~~ ~~ ~I
<teD886-2-23445267</tel,
A semantic e x b c to r contains a set of extraction rules. An </customer>
extraction rule IS a rule in the following form.
I
Matching Part => Transformatron P3nThe matching pan and tranrlonnauon pan here 31c both logical expressions with the extension of operator '*.".The operator ''_n is
an object-oriented extension to the logical expression to access the members of the object. The following example shows an extraction rule to extract the value of tag <telephone in the block exlosed by the "customer" tag, and then to transform it into logical facts "person(F').telephone(#V)".
I
customer(P).tel(T#V) => person(P).telephone(#V)I
The condition-pan working like the XPATH, but it is in the form of object-oriented logical expression. It is designed to be embedded into PIL naturally.A variable in an extraction rule is an address of a node. For example, the variable "P" binds to nodes with tag '"customer" in XML documents, and the variable "T" binds to nodes with tag <teP
in
XML documents. The operator "#" is a symbol to separate the node from its value. For example, the "V" in the matching part '"customer(T).tel(T#V)" binds to the value of the node"T'.
The matching-pan is used to locate nodes in the XML documents, and the wnsformation-part i s used to transform the located nodes into logical facts. For example, the "custamer(P).tel(T#V)" is used to match nodes in XML documents with tag < te P associated with the tag (cusfomer>, and the "permn(p).telephone(#V)" is used to transform the matching nodes into object-oriented logical facts where the predicate "peno~p)" has a member predicate "telephone(#V)". The transformation-pm of an exection rule is a hom-clause with the extension of
"."
operator. The syntax of transformation-pan is similar to Prolog with the following syntax.1
Conclusion pm :- Premise panWe emphasize that semantic extractors are not used to do syntax transformation, but to do semantic extractions. See the "Different semantics" Droblem in Section I . The followines are
I
I
p e ~ n ~ X ) . f ~ t h c r ( Y # Z ) = ~ f ~ t h e r ~ o ~ W , X ~ - p c r s o n ( W ) secunly(nZ)I
A mlc in common ontolow-_
IS a hom-clause lust the same as the transformation part of an extraction rule. Matchlng pan IS no longer needed because allXML
documents are transformed into logtcal facts. The common ontology should encompass theuniverse of the logical facts.
We emphasize that the left hand side of"=>" is the XML world which has its own syntax and semantics, and the right hand size of is the logic world which has its own syntax. So
'=>"
"person(X)=>person(X)" is not useless which means if person(X) is evaluated as m e in XML world then put person()() into logic world.
Seeing Figure 4, when we want to do reasoning on heterogeneous XML documents, the first thing is to choose a suitable ontology about the concemed domain, and the second is to write suitable semantic extractors for each type of XML documents.
paro~S387).slcp~~#(#'8862-2~SZ6r~
pna@).mIbn(#Tawln') :- pcm@).rClcpba~#v) & kIck(#V, ?386[0-9)]'")
...._.__.
. ..p~Q387)mtbn(b'Tawln")
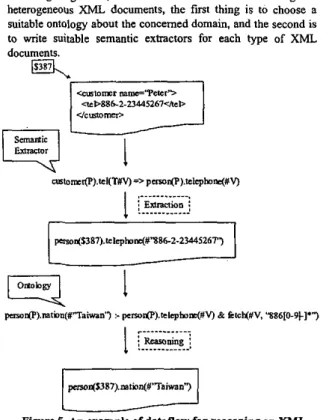
Figure S. An example of dataflow for reasoning on XML In Figure 5 , we w e one ontology and one type of XML documents to show the dataflow of our framework. The same condition holds on different types of XML documents. An
XML
document about a customer of Citibank named "Peter" is used as the input some . The node with "customer" tag in XML documents is assigned with a unique address "$387". A rule "customer(P).tel(T#V) => person(P).telephone(#V)" is used to locate the related nodes in the document and to transform a found
one into the logical fact
p~n($387).tel~phon~(#"886-2-23445267"). This fact can be used in the reasoning process.
The
rule fetcb(#V, "886[0-91-]*") in the common ontology is used to reason with the logical fact. The function "fetch" is an embedded function to match string, where "886[0-91-1''' is a regular expression. In the reasoning process, the variable "P" is bound to "$387" and the variable "V" is bound to "886-2-23445267". Finally, the conclusion person(5387).nation(#"Taiwan") is reached from the reasoning.111. THE PAM INFERENCE
LANGUAGE
In this chapter, we talk about the Path Inference Language (PIL). The syntax, denotational semantics and operational semantics will be discussed in detail. PlL is not only used to be a language to write extraction rules, but also a language to write ontologies.
A . S y n r a
.
We adopted Prolog-like syntax in the Path Inference Language (PIL). A program is a set of statements. Each statement is a rule or.an
atom followed by a“.”
symbol. Each tule is of a form “A.-AS”where A is an atom and
AS
is a set of atoms. The syntax of an atomis
much different from the definition of predicates in Prolog. A predicate in Prolog is a name string followed by parentheses with parameters. For example, penon(a) or first-name(a,”lack‘3 are predicates in Prolog. But an atom in PIL may be a normal predicate with some arguments or a sequence of basic atom connected with I‘.*’ or”_.”
operators. Each basic atom is of formsI(&), r(n), r, I(*), n#t, n, or #t where r is a label, n i s a node symbol or variable, and t is a term. Generally speaking, a basic atom is a name string followed by parentheses with a node address and a basic datum separated by a ‘Yf’ symbol. For example,
person(a) and first-name(&Jack“) are basic atoms. For a formal defmition of syntax of PIL. see the followings.
Syntax of PILA syntax of
PIL
is consmcted by a tuple (VN,VD,L,P,F,C). VN andVD
are
two disjoint sets of variables. VN is a set of node variables, andVD
is a set of data variables. L is a set of labels, P is a set ofnormal predicates, F is a set of functions, and C is a set of node symbols (node constants). Then, we are going to mnsmct four sets: a term setT,
a basic atom set B,an
atom s t A, and a sentence set S by induction.1. XCT, ifxeVD.
2. f(t,,t2,$
,._..
QcT, if fEF, feT, and the arity o f f is k. 3 . r(n#t), r(n), r(#t), r, n#t, n, NEB, if r s L , ncCuVN, tcT. 4. bplb-&y3....t.lbr E AifbisB,andeach*;isa”.”symbolor 5.p(tl,t2,t3..__,
td E
A,ifpeP,fcT~CwVN,andchearityafpis 6. a.ES,
if acA.7. g:-a,,a*,a,
,._.,
at. ES, if& EA.8 . sI s2sl
.. .
sk is a program, if ~ E S . a “__” symbol.k.
Figure 6. The syntax of PIL language B. Denororionnl SemonIicr
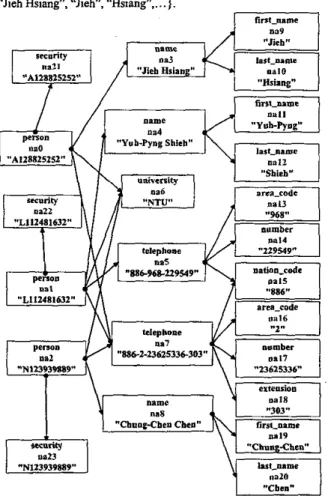
The universe of a model M in PIL is a directed graph G=(N,E,L,D), when N is a set ofnodes, E is a ret ofdirected links between nodes, each node is labeled by a label in L and associated at most one datum in D. The universe is just a part of a model. A model M also has to interpret the variable, function, predicate symbols in syntax deftnitions. For example, the fallowing directed graph is an universe o f a model M where N=(naO,nal,
...,
na23), E={(naO,na3), (naO,na6), (naO,na7), (naOpa21),._.
}, L=(pcrson, name, first-name, last-name, telephone, nation-code, area-code, number, extension, security, university}, and D=1“A128825252”,Figure 7. A graph model of some PIL program In Figue 7, each node has a unique identifier called node address. For example, na0, na I ,
. .
.
and na23 are node addresses. Each node is associated with a label and a datum of some basic data rype. For example, the nodena6
is labeled by “university” and associated with a dahxn “NTU”. Each label “s” representsWO sets. One is the set of nodes labeled by s. The other is the set of
data
associated with the nodes labeled by s. For example, the label “last-name” represents a set of nodes (nalO, na12, ~ 1 9 ) and a set of data (“Hsiang”, “Shieh, T hen” ) . Since a label can represent two sets, each label can also be taken as WO predicates. One is a node predicate with a node argument, and the other is a datum predicate with a datum argument. For example, last-name(nal0) and last-name(“Hsiang”) will be evaluated to be m e and last-name(na0) or last-name(“Liu”) will be evaluated to be false. In order to distinguish between these two predicates, we put a ‘w’ symbol before the datum argument. For example, last-name(X) is a node predicate and last-name(#Y) is a datum predicate. Also the ”#“ symbol is also a binary predicate. X#Y meansY
is the datum associated on the node X. Sometimes, we will compose these predicates lo coosmct a more strong predicate la r t - m e ( WY ) , which means last-name(X), last-name(#Y) andX#Y. For example, last-name(naZO#”Chen”) is true and iast-name(nal3#”Shieh”) is false.
After describing property of nodes, we will describe the relations between nodes. For each node x and y. x.y means there is a directed link from x to y. So the
“.”
operator represents a directed links, also a binary relation. For example, naO.na3 is trueand naO.nd0 is false. Also, we will compose the
”:’
operator with node predicates and datum predicates. person(naO).name(na3) means penon(na0). name(na3) and n a 0 . d . There should be some natural association between the two predicates of the operator”:’.
For instance, in penon(X).name(#Y) the natural meaning is that X is person whose name is Y. We further remark that the logical meaning of person(X).name(#Y) is actually that there exists a node z such that person(x).name(Z#Y). Sometimes we Will use a sequence ofpredicates connected with“.” operators. For example, person(X).name(Y).last=ame(Z) means person(X).name(Y) and name(Yl.last-name(Z). Also person(X).nams.last-name(Y) means that there exists a node 2 such that p m o ~ . n a m e ( Z ) . l a e ( Y l . Since we use “.” operator to represent a link relation, we use“_.”
operator to represent the path relation. For example, pman(X)..last-name(Z) means that person(X), last-name(Z) and there exists a path from X to 2.So the facts described in the graph can be encoded in the following program, and converiely the model M with universe G in Figure 7 is a model of following program.
$xamle.oil person(naO).seeurity(#”A128825252”). naO.name(na3).fust-n~=(#”Jieh’7. naO.university(naS%“TU”). na~.te~ephone(na7).~tion~~ode(nal SW’S86”). na3.last-name(#”Hsiang”). na7.area-code(#’2). na7.number(#‘23625336”). M7.extension(#”303 ”). person(nal).security(#”Ll l2481632”). nal . n a m e ( n a 4 ) . f i a t _ n a m e ( ~ Y ~ - ~ g ” ) . nal .tekphone(na5).nal5. na4.last-name(#”Shieh”). naS.areacode(#”968”). na5.number(#’229549”). nal.1~7. na2.na6. naha7.
na2.name(naX).first_name(#“Chung-Chen’3.
na8.last-name(#“Chen”). XfyConcatenation(Y ,Z)) :- name(X).firs-name(#Y), X.last-name(#Z). X#(Concatenation(Y,”-“,Z,”-”S.l,”-” :- telephone(X), X.natiarccode(#Y), X.area-code(#Z), X.number(#N), X.extension(#E).X#(Concatenation(Y,’””)) :- telephone(X), Xmation-code(#Y), X.area-code(#Z), X.number(#N). X#Y :- persono(), X.security(#Y).
person(na2).secunty(#”N123939889”).
Figure 8. A PIL. program
For the formal defmition of semantics, see the following definitions.
Denotational Semantics of
P E .
Remark that the syntax of a program is constructed by a tuple (VN,VD,L,P,F,C). The universe of a modelM
is atuple G of (N,E,
L,D)
whereN
is a set of nodes, E is a binary relation to represent the directed link between nodes, and D is a universe of data. Each node in N is labeled by a label in L, and associated by at most one datum in D. A model M also has to interpret each symbol, label, predicate or function in VN, VD, L P, F, and C.1. x ~ T . i f x e V D .
M maps VO to I D , and x to x M .
2.
&&& ,.,..
tk)ET. if fEF. !ET. and the aritv of f is k. M mans Ftobe a function h m Dk to D and f(t,,t2,t3,...,
t d to 3. For each node symbol n in C or VN, M maps n to nM in N. 4. dn#t).dn). d # t l r . n#t. n. #teB. i f r e l . nsCuVN, ET.M C r(n#t), if node nM is labeled by label r and associated with a datum
p.
MTr(n), if node nM i s labeled by label r. M kr(#t), if M Fr(n#t) for some n in VN. M Cr, if
M
kr(n) for some n in VN.M
k
n#t, if the node nM is associated with a datum t’.MCnalways,sinceMhastomapeachninCorVNtonMinN. M C#t, if M for same n in VN.
M k n 1.n 2, if there exists a directed link (nlM,mM) in E. M k n I..n2, if there exists a directed path in G=(N,EL,D) from nrMtonZM.
6. For each b in B with the form r(n#t), r(n), n#t, r, r(#t), #t, or n, we defme N@) to the set (n) if b=r(n#t),
(n),
n#t,n
or the set VN ifk,
r(#t), #t. We also define b(x) to be r(x#t),r(x), x#t, r(x), r(x#t), x#t when b is r(n#t), r(n), n#t, I, r(#t), #trespectively. For each bl,
9
in B,M Cbl.b,,ifM bbl(n,),haCh(n3andM h I - n 2 , f o r s o m e n l in N(bJ and some n2 in N@2) where .=”.” or
“..”.
svmbol or a ”_.” svmbol.
M kbl.lbl.lb-3 ,___, *k.l&, ifM Cbl.,b2, M kbp2b3, MTbi*,br
,..., MTh.pk.lh.
5. For each symbol n,, n2 in C o r
VN,
7. ~ ~ ~ ~ b + b 5 y . . . * ~ . , 4 E A ifbicB. and each may be a
“.”
8. j&&.tl..__. E A. if DEP. ET, and the ariw ofD is k. M maps p to be a set p M a k : And M ~ ( t l . t 2 , t l .
....
td
if (tlM,tr.tAM,....
t”)
is an element ofpM.M k a . i f a a .
M Cao:-al,a2,a],..
..ax.
if M kq,or
M does not satisfy a, for some i.S&SI
._.
sr is a Drowm if S~ES. MCsls,s,...
&,ifMChforeachi.Figure 9. The denotational semantics ofPIL language 9. a. ES. ifasA.
IO. --1
...._
a,. cS.ifa. EA.C. Operalional Semantics
We use Prolog as the OpeIatiOMl semantics by transforming a L program into a h l o g program.
If xeVD, then x itself is in hotog.
If f(t,,t2,t3,
...,
tt)eT, then it is already in Prolog as long as the function?
is an embedded function in h l o g .For each node symbol n in C or VN, it is already a Prolog statement.
If r(n#t), r(n), r(#t), I, n#t, n, #teB, we do the following. For each r in L, we comrmct predicates r-nt(n.1). r-n(n), r-t(t), r to
encode r(n#t), r(n), r(#t), and r. Also, we construct predicates -nt(n,t), t ( t ) to encode n#t and #t. we have to encode the relationsbetween these predicates in the followings. mt(n,t):-r-n(n),nt(n,t). r-n(n):-r-nt(n,t). - nt(n.1):-r-nt(n.t). r-t(t):-mnt(n,t). r:-r(n). -t(t):.-nt(n,t). -t(t):-r-W.
.
FornI.n,,andnI..n~, weoutputE(ni,n2)andPath(nl,n& Also, we have to put the relations between E and Path. Path(X,Y):-E(X,Y).Path(X,Y):-E(XZ), Path(Z,y).
.
For each b in B with the form r(n#t), r(n), n#t, I, r(#t), #t, or n, we define b’ to be r(n#t), r(n), n#I, r(v), r(v#t), v#t, n, respectively, and b” to be r(n#t), <n), n#f <c), r(c#t). c#t, n. respectively where v is a unused node variable in VN and c is iunused node symbol in C. We defme n w ) to be n or v according the form of b‘ and define n@”) to be n or c accordinl the form of b”. Then, for a atom blab, in the right hand side 0:
some rule, we output bl’,
b‘,
n@t’)* n W ) otherwise we output b,”:-rhs.b,”:-rhs.
when the mle is h,.b2:-rhs. n(bl”) n@z”):-rhs.
’.
For bi-lbp2bp~....t.lb, E A, we output bl-,b, b*zbj. ;. For p(tl,t2,tJ,..., 43
E A,we
transform each 4 into Prolog.1. Fora.,and+:-a,,a,,a,
,.._,
at. ~ S, w et r an sf o m eac h q in t o 0. F o r a p r o g r a m ~ ~ s r s ]... sk, wehansformeachs;intoPrologb * h . . , b,-x*t-1b,.
Rolog.
Figure 10. The operational semantics of PIL language We note that the main difference between PIL and Prolog is the addition of three operators, “_”, “__”, and ‘YI”. The first two capture the parent-child node and ancestor-descendant node relationships in an XML document. The “P operator specifies data in a node. Although these operators can be encoded as Prolog pm-s, these Rdog programs can he complicated and hard to
write. It is therefore convenient to designate special operators for these purposes.
IV. LOGIC BASED O N T O ~ Y
Ontology in our sense is just background howledge. Seeing Figure 4, a logic-based ontology is just a program of PIL encoding background howledge. An ontology together with logical facts exnacted from heterogeneous documents can be used to do some reasoning. For example, example.pil in last section can be divided into two parts. One pail is directly extracted &om XML documents. The other pm can be seen as background knowledge. We put them there as an ontology person.pi1. We emphasize, however, that an ontology can also include facts.
g&QL.pg
X#(Concatenation(Y.Z)) :- name(X).fint-name(#Y), X.last_name(#Z).
X.nation-code(#Y), X.area-code(#Z), X.number(#N), X.extenrion(#E).
X.natiokcode(#Y), X.area-code(#Z), X.number(#N). X#Y :-person@), X.security(#Y).
person(Y).telephone(z).
X#(Concatenation(Y,”-”Z,”-”,N,”-“,E)) :- telephone(X),
X#(Concatenauon(Y,”-”,Z,”-“,N)) :- telephone(X),
WorkingTogether(X.Y) :- pnson(X).telephone(Z), Figure 11. A loglc based ontology
V.
SEMANnCEx7RA~ORFORXMLWhen we want to do reasoning on heterogeneous XML documents, we should first choose a suitable ontology about the concerned domain. We then design suitable semantic extractors far each type of XML documents.
Here we take one ontology and one type of XML documents to
demonstrate how the semantic extractor works. The same condition holds on heterogeneous XML documents. We use the ontology person.pil in the Section 4, and the following XML fdes with a private.dtd to illustrate our point.
private.dtd
<?xml version=”l .I”?> <!DOCTYPE private[
<!ELEMENT private (name,father?,bmtheR.advisor?,tel+) -r!ATTLIST private
security CDATA #REQUIRED sex (malelfmale)
>
7
<!ELEMENT name (CDATAp <!ELEMENT father (CDATAP <!ELEMENT brother (CDATAp <!ELEMENT advisor (CDATAp <!ELEMENT tel (CDATAP
I>
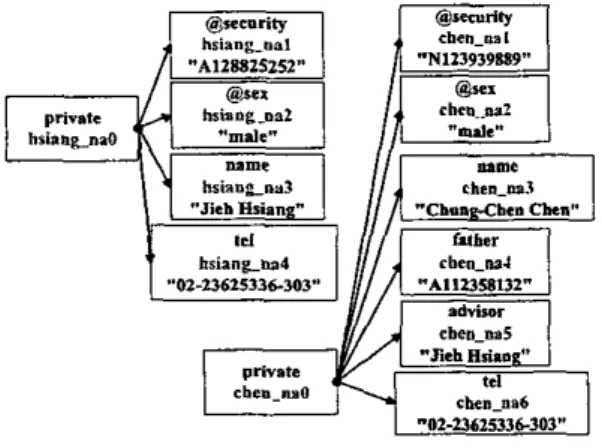
hsiane.xm1
<private securiy’A 128825252” sex=”male’> <name>Jieh Hsiang4name
<tel>02-23625336-303qtel> </private>
chen.xml
<private security=”’N 123939889’’ sex=”male’2 <name>Chung-Chen Chen4name>
<father>Al12358132</father, <advisor>Jieh HsiangqadvisoD
<I& 02-23625336-303<1teI> </private,
The logical facts in the above XML documents can of course be composed manually in PIL. A semantic extractor, on the other hand, can extract them from these
XML
files automatically.Given a set of XML documents, each document can be represented as a rooted tree. Each node is labeled by the tag name, or attribute name. We pnt a "@" symbol in front of the anribute 'name to distinguish these two types of labels. Each node can also be associated by a datum of type smng. For example, we can draw two trees for the above two XML documents.
Figure 12. The tree structure of X h U documents These moted trees can also be thought together as a directed graph. So we can use our PIL language to ask which atom is true under our directed graph model. For example, private(chen-naO).@security(#"Nl 23939889") is uue.
A semantic extractor (".sem" file) indicates
that
when the extractor matches some property of an XML file, the extractor will output some instruction into the ontology.The
syntax of a .sem file is a set of rules. Each rule is of the form "AS => SS.",where AS is a set of atoms and SS is a set of sentences. On the lee hand side of =>, the atoms describe the world of XML files, and on the right hand side, the sentence describes the world of ontology. On the left hand side, the atoms have its own syntax different from the right hand side. See the following sem file as an example. private.sem private(X).@security(#Y) => person(X).security(#y). private(X).@ex(ff'"le") e- &em). private(X).name(Z#Y), fetch(Y,"[[a-zA-Z]*l] [[a-u\-Z]/A][[
1'1")
=~efjon(X).nam~Z).last_oame(#A), Z.iirst-name(#F). private(X).tel(Z#Y), fetch(Y~O[[O-9~A]-[[0-91*~]-[[0-91*/E~) =>person(X).teIephone(Z#Y).nation-=od=(~'SS~),Z.area-code(#A), Z.number(#N), Z.extension(#E).
private(X).advisor(#~>advisor-of(X.Z):-person(Z).n~me(#Y), private(X).father(#y)=>father-o~X,Z):-pe~n(Z).se~urity(#Y),
Figure 13. A semantic extractor
The syntax of left hand side is constructed by (VN,
VD,
L, P, F, C) where VN=(XZ), VD=(Y,A,F,N,E), L=(privaIe, @security, @sex, name, father, advisor, tel}, F=("N123939889", "male", "Chung-Chen Chen",...
), P={fetch) and C-{chen-MO, =hen-nal,...
1.
Andthe syntaxofrighthandsideis constructedby (VN, VD, L, F, C) where vN={X,Z), VD=(Y,A,F,N,E}, L={person, security, name, firs-name, telephone, ...), F=("N123939889", "male", "Chung-Chen Chen", ...), +(male) and C=(chen-naO, chexnal....
).The behavior of the extractor engine is to evaluate the truth-value of atoms on lhe left hand side, and (if it is me) then output the right hand side (by substitution) into the ontology. Here we can see there is a special predicate fetch which is used to divide a smng into small piece using the regular expression decomposition. For example, the meaning of fetch(Y~0[[0-9~A]-[[0-9]*~].[[0-9]*/E~) is to check whether Y is a sting of the form "0[[0-91l-[[0-9]*]-[[0-9]*~, and (if yes) put the part [0-9] to variable A, [O-91' to variable N and [0-9]* to variable E, respectively. How many data processing function we should provide? We still take them into considerations.
Seeing the last W O rules in this s e m t i e extractor, an interesting observation is that the meanings of the contents in advisor and father tags are different. One is the "NAME" of
X's
advisor, but the other is the "SECURITY" number of X's father. This is why theDTD
file cannot provide the semantics hutSEM
file can.So when we use private.sem to extract the meanings of hsiang.xml, and chen.xml, will output some statements for the semantic facts in
XML
files as follows.orivate.dl
person~siangnaO).security(#"A128825252). male(hsiangna0). person(hsiangnaO).name(hsiang~#"Jieh Hsiang").last_name(#"Hsiang"). hsiangna3 .fint-name(#"Jieh"). p e r s o n ~ s i a n g n a O ) . t e l ~ p h ~ ~ e ~ s i a n g ~ 4 # " 0 2 - 2 3 6 2 5 3 3 ~ 3 0 ~ ) nation-code(P'886'). hsiangna4 .area-code(#"T). hsiangna4,number(#"32533~). hsiangna4.extension(#"303"),... ...
Figure 14. Semantic facts extracted From XML documents And then together with the ontology person.pil, we can do some reasoning in the ontology. For example, we can find out whether Chung-Chen works together with Jieh Hsiang by asking whether WorkingTogether(X,Y). X.name("Chung-Chen Chen"), Y.name("Jieh Hsiang ") is hue or false.
VI. SUMMARY AND DISCUSSION
In this paper we proposed a logic-based framework for reasoning about XML documents. This includes a logic
programming language, PIL, for describing ontologies and elements in XML documents as logic programs. We also presented a method to write semantic extractors in PIL extracting logical facts (also PIL programs) from XML documents, and a method for reasoning about these facts using ontologies. We tbink this framework can be used for integrating heterogeneous
XML
documents into uniform semantic rules, and for reasoning about them.
Our
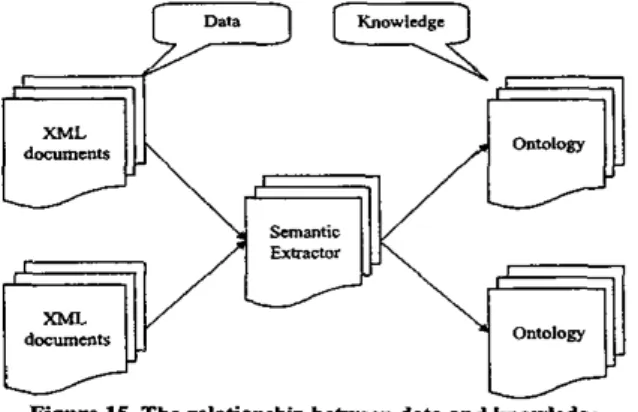
approach simplifies the specification stack of Semantic Web into just WO layers, data and knowledge. XML describes the.data. The knowledge part, including the specification of relations, ontologies, logic, and proof, can all be handled by PIL. A semantic extractor is the bridge to connect data and knowledge. Figure IS shows the relationship between XML documents, semantic extractor and ontology.
Figure 15. The relationship hehveen d a h and knowledge The separation of data and knowledge results in a flexible model. Data creators write XML documents as they like without having to follow smdard. Knowledge workers may focus on the problem of knowledge consmtction for specific domains. Programmers may build applications by write program in P L to extract logical facts from XML documents into ontology. Different programmers may have different ways to extract logical facts from data and put them into different ontologies for reasoning. This flexibility provides a good solution for knowledge engineering to scale up.
We now give a brief comparison between OUT approach and Semantic Web. The SW project was built in a bottom-up fashion. The languages for different layers were proposed incrementally (with those for the logic and reasoning layers still in the waiting.) Because the languages were built incrementally, there are heavy in notion and quite restricted. For instance, only binary relations can be expressed in RDF, and even OWL can only deal with simple set-theoretic relations.
In the model of SW, data builders must write documents based on the RDF specifications. Those XML documents that do not follow the
RDF
specification will be ignored. In our model, data builders may construct data as they like, and define tags as they need. They do not have to follow any specifications other than XML to conshllct documents. People who want to interpret these documents may write exkaction rules to extract logical facts from XML documents, and then write NICS of common ontology forreasoning. Logical rules in OWL are written m XML format. For example, the "intersection" operator is encoded as '*owl:intersectionOf
...
4owl:intersectionOD". In PIL, on the other hand, logical rules are described naturally as Ham clauses such as "+) :- p(x) & q(y)". So PIL expressions are clearlv more readable thanR D F
or OWL,Ontologies encoded in RDF and OWL can also be extracted by PIL into logical facts for reasoning. These can be done using the transformation mechanism given earlier.
We plan to extend PIL with object-oriented syntax and semantics, such as inheritance and polymorphism. We will design more embedded functions for string matching and processing. Funbermore, we will try to solve problems in a variety of domains to justify the practicality of our logic-based framework.
A C K N O W L E D O m
We would like to thank Szu-Pei Chen and Hou-leong Ho for
fruitful discussions.
REFEREWCES
[I] T. Bemers-Lee. Semantic Web Roadmap. World Wide
WebConsonium (W3C). 1998
http://~w.w3.org/Designlssues/Semantic.b~ [2] T. Bemers-Lee, I. Hendler and 0. Lasila. The Semantic
Web, Scientific American, May (2001) 34-43.
[3] S. Decker, S. Melnik, F. van Harmelen, D. Fensel, M. Klein, J. Broeksna, M. Erdmann, and 1. Hormcks. The'semantic web the roles of XML and RDF. IEEE Internet Computing, 43:2--13.2000.
[4] M. Minsky (1975). A framework for representing howledge. Available in Readings in Knowledge Representation, Brachman, R.J. & Levesque, H.J., Eds. (1985). Morgan KaUf".
[ 5 ] R. Ifikes, and I. Kehler, (198s). The role of frame-based representation in reasaning. Communications of the ACM, Volume 28 Number 9. Semember
_ .
1985....
nv.
904-920. 161 R.A. Kowalski, The Early Years of Logic Programming,CACM, January 1988, pages 38-43.
[7] T. Bemers-Lee. RDF and the Semantic Web. h t r o : / i u w w . p c a . o ~ ' a t ~ ~ ~ ' 2 0 ~ conferences/XML 2000;k nowlcdee.htm#ler