Mining Frequent Patterns with Item, Aggregation, and Cardinality
Constraints
Wen-Yang Lin
1, Ko-Wei Huang
2, He-Yi Li
1, Chang-Long Jiang
2,
1Department of Computer Science and Information Engineering
National University of Kaohsiung
Kaohsiung 811, Taiwan
[email protected], [email protected]
2
Department of Electrical Engineering
National University of Kaohsiung
Kaohsiung 811, Taiwan
{m0955108, m0955107}@mail.nuk.edu,tw
Abstract
Recently, the topic of constraint-based association mining has received increasing attention within the data mining research community. By allowing more user-specified constraints other than traditional rule measurements, e.g., minimum support and confidence, research work on this topic endeavor to reflect real
interest of analysts and relief them from the
overabundance of rules, and ultimately, fulfill an interactive environment for association analysis. So far most work on constraint-based frequent patterns (itemsets) mining has been single-constraint oriented, i.e., only one specific type of constraint is considered. Surprisingly little research has been conducted to deal with multiple types of constraints. This paper is an investigation on this problem. Specifically, three types
of constraints are considered, including item
constraint, aggregation constraint, and cardinality constraint. We propose an efficient algorithm, MCFP
(Multi-Constrained Frequent Pattern mining) to
accomplish the task of discovering frequent itemsets satisfying all three types of constraints. Experimental results show that our algorithm is significantly faster than the intuitive approach, post processing the generated frequent patterns against user-specified constraints.
1. Introduction
Recently, the topic of constraint-based association mining has received increasing attention within the data mining research community [2-11]. By allowing more
user-specified constraints other than traditional rule measurements, e.g., minimum support and minimum confidence, research work on this topic endeavor to reflect real interest of analysts and relief them from the overabundance of rules, and ultimately, to fulfill an interactive environment for association analysis. The key for realizing such a mining environment is designing an efficient frequent itemsets mining algorithm that takes account of all user-specified constraints. So far most work on constraint-based frequent patterns (itemsets) mining has been single-constraint oriented, i.e., only one specific type of constraint, such as item constraint (certain forms of user-specified itemsets) or aggregation constraint (constraint on aggregation functions of itemsets) is considered. Surprisingly little research has been conducted to deal with multiple types of constraints. This paper is an investigation on this problem. Specifically, three types of constraints are considered, including item constraint, aggregation constraint, and cardinality constraint. We propose an efficient algorithm, called MCFP (Multi-Constrained Frequent Pattern mining), to accomplish the task of discovering frequent itemsets satisfying all three types of constraints. Rather than proceeding in a level-wise style of candidate itemsets generation such as those proposed in [11], our proposed algorithm exploits the item constraint directly to construct an initial set of candidate itemsets, thus can lessen the overhead in generating lots of intermediate candidates. Experimental results show that our algorithm is significantly faster than the intuitive approach, post processing the generated frequent patterns against user-specified constraints..
The rest of this paper is organized as follows. The problem statement is described in Section 2. In Section 3, we describe the proposed constrained frequent itemset mining algorithm. Experiments of our algorithm are described in Section 4. Finally, conclusion and future work are stated in Section 5.
2. Problem statement
2.1. Constraint-based Mining
Let I = {i1, i2, …, im} be a set of items, where each
item is associated with a value attribute, such as cost, or price, etc. Let D be a transaction database consisting of a set of transactions, where a transaction T =tid, It
is a set of items It with identifier tid and It I. An
itemset S, SI, is contained in a transaction T if S It.
The support sup(S) of an itemset S in a transaction database D is the fraction of transactions in D containing S. Given a support threshold ξ(0 ≤ξ≤1), an itemset S is frequent provided sup(S)ξ.
A constraint C is a predicate on the powerset of I, C:
2I → {True, False}. An itemset S satisfies C if and
only if C(S) = True. The set of itemsets satisfying a constraint C and minimum support threshold is
SATc (S) ∩sup(S) ≥ξ= {True}. In this paper, we
consider three different kinds of constraints, including aggregation constraint, item constraint, and cardinality constraint, each of which is defined in what follows.
2.2. Aggregation constraint
An aggregation constraint is a constraint defined on an aggregation function of itemsets, such as avg, sum, and median. An aggregation constraint is of the form
avg(S)θv, sum(S)θv, or median(S)θv, where S is a n
itemset, v a real value, and θa comparison operator, i.e., θ{, >, , <}. For example, avg(S) ≥30 or
sum(S)≤20.
According to the study conducted by Pei et al. [10], the aggregation constraints can be classified as
anti-monotone or anti-monotone. A constraint Cam is
anti-monotone if and only if whenever an itemset S violates
Cam, so does any superset of S. A constraint Cm is
monotone if and only if whenever an itemset S satisfiesCm, so does any superset of S. For example,
sum(S) ≤ 20 is anti-monotone if all items have
nonnegative values.
Besides, an aggregation constraint can be
convertible or inconvertible. An aggregation
constraint Cagis convertible provided there is an order
R (ascending or descending) on items such that
constraint is convertible anti-monotone or convertible monotone; otherwise, we say that aggregation constraint is inconvertible. A comprehensive discussion on the monoticity, anti-monoticity, and convertibility of typical SQL-based aggregation constraints can be found in [10].
2.3. Item constraint
Item constraint [11] is used to express the presence of items that are interesting to the users. Specifically, an item constraint β is expressed as a boolean expression over I, in d isj unctive no rmal form D1
∨D1∨....∨Dm, where each disjunct Diis of the form
α1∧ α2∧ ... ∧ αn, and each element αi I. For
example, β= (a∧b)∨(c∧d)).
2.4. Cardinality constraint
A cardinality constraint specifies the requirement on the length of an itemset, expressed in the form of
card(S)θv. For example, card(S) ≥3.
3. Mining algorithm
In this section, we describe the proposed MCFP algorithm for mining frequent itemsets over a minimum support and satisfying a set of user-specified constraints that consists of up to three types of constraints, i.e., item, aggregation, and cardinality constraints.
Our mining algorithm consists of five main phases: (1) item sorting phase; (2) initial candidate construction phase, (3) aggregation constraint checking phase; (4) support counting phase; and (5) new candidate generation phase. Each of them is detailed in what follows.
(1) Item Sorting Phase
First, we generate two sorted lists L and L’of all items that appear in the item constraint β, respectively in descending order and ascending order of their values. These lists are prepared for later use in aggregation constraint checking and new candidate generation, having the implicit effect of converting some aggregation constraint into monotone or anti-monotone.
(2) Initial Candidate Construction Phase.
In this phase, we exploit the disjunctive of item constraint βto generate an initial set of candidate itemsets,K = K1∪K2∪...∪Km, where Kidenote the
set of candidate i-itemsets. For example, let β= (a∧b) ∨(c∧d). Then K = {ab, cd}.
(3) Aggregation Constraint Checking Phase.
Our main task in this phase is to test where each candidate itemset satisfies the user-specified expression of aggregation constraints.
We proceed by first checking the expression of aggregation constraints to see whether it contains some convertible monotone aggregation constraints. For example, consider avg(S) ≥ 20 ∧ sum(S) ≥ 50. Clearly, sum(S) ≥50 is convertible monotone with respect to a value ascending order. Then we perform the constraint checking task and adopt an efficient candidate pruning strategy that is based on the following two lemmas.
Lemma 3.1 Consider a convertible anti-monotone
aggregation constraint Cagwith respect to an order R
over a set of items I. Let χbe a frequent itemset satisfying Cagand a1, a2, ..., ambe a set of frequent
items listed in the order of R.
(1) If itemset χ∪{ai}(1 ≤i < m) violates Cag, then
for some k, i < k ≤m, itemset χ∪akalso violates
Cag.
(2) If itemset χ∪{al} (1 ≤l < m) satisfiesCag, but
χ∪{al, al+1) violates Cag, then no frequent itemset
having χ∪alas a proper prefix satisfiesCag.
Lemma 3.2 Consider a convertible monotone
aggregation constraint Cagwith respect to an order R
over a set of items I. Let χbe a frequent itemset satisfying Cagand a1, a2, ..., ambe a set of frequent
items listed in the order of R.
(1) If itemset χviolates Cagand for some k, i < k ≤
m, itemset χ∪{ak} satisfiesCag, then any itemset
having χ∪{ak} as a proper prefixsatisfiesCag.
(2) If itemset χ∪{al} (1 ≤l < m) violates Cag, but χ
∪{al, al+p} (1 ≤p < m) satisfies Cag, then any
itemset having χ∪{al} as a proper prefixsatisfiesCag.
For example, if a candidate itemset χsatisfies
avg(χ) ≥20 but violates sum(χ) ≥50, then according
to Lemma 3.2 we have to keep χ; on the contrary, if χ violates avg(χ) ≥20 but satisfies sum(χ) ≥50, then χ has to be pruned according to Lemma 3.1.
The remaining candidate itemsets then undergo the next step to count their supports.
(4) Support Counting Phase.
We have adopted the vertical counting technique proposed by Zaki [12] to accomplish this task. The
tidlists (bitmap vector) for each item that exists in at
least one candidate pattern are created. Then the
support of a candidate itemset can be readily obtained by performing bitmap intersection of the tidlists forming that itemsets. All candidate itemsets with their supports larger than the threshold and their lengths satisfying the cardinality constraint are then reported as qualified frequent itemsets. Let this set of qualified frequent itemsets be denoted as F.
(5) New Candidate Generating Phase.
The new set of candidates is generated by performing a Cartesian union between all pairs of elements in F and L, and eliminating the duplicated old patterns. For example, let F = {ab, ac} and L = {c, d}. Then FL = {abc, abd, acd}. Note {ac}∪{c} = {ac} is discarded. But indeed, we can avoid generating many spurious candidates by utilizing the property exhibited in Lemma 3.1. More precisely, consider a frequent itemset χin F and item aiin L. If χ∪{ai} violates a
convertible anti-monotone constraint, then we can assure so does any combination χ∪{aj} for j > i.
Phases 3 to 5 are repeated until no new candidates are generated.
3.1 An Example
Consider a transaction database D in Table 1, with item of values in Table 2. Assume that the support threshold ξ= 2 and a set of constraints is defined below:
avg(S) ≥20∧Sum(S) ≥50∧β= (p∧d) ∧card(S) ≥3.
Table 1. Transaction Database.
TID Items in transaction 10 b, c, d, o, p 20 b, c, g 30 b, c, d, o, p, r 40 a, b, d, p 50 b, d, e, o, p
Table 2. Values of items in Table 1.
Item Value a -20 b 30 c 0 d 10 e -10 o 40 p 50 r -30
(3)-(5) Because pd satisfies all aggregation constraints, we perform the pairwise union between F = {pd} and L = {p, o, b, d, c, e, a, r}, obtaining new candidates = {pod, pbd, pdc}. Note that pd∪e = pde violates avg(S)
≥20 and avg(S) ≥20 is anti-monotone. So there is no
need to generate pda and pdr , according to Lemma 3.1. Repeating these phases, we finally obtain the complete frequent itemsets {pod, pbd, pdc, pobd, podc}.
4. Experimental Results
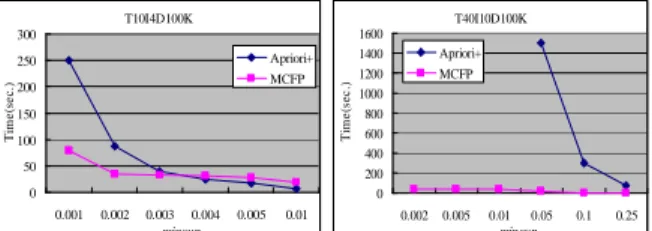
To evaluate the effectiveness and efficiency of the proposed algorithm, we performed a preliminary experiment over two synthetic data sets generated by the IBM generator [1], T10I4D100K and T40I4D100K. The number of distinct items is 1000. We compared our proposed algorithm MCFP with the Apriori+ algorithm under different support thresholds, ranging from 0.1% to 25%. Here, Apriori+ refers to the approach by applying the Apriori algorithm, followed by a post processing of the frequent itemsets. The constraints consist of two aggregation constraints, one item constraint composed of three disjuncts, and a cardinality constraint. All programs were implemented in C++. The experiments were performed on an ASUS workstation with two 1.8GHz Intel Xeon CPUs and 4GB main memory, running Windows Server 2003. The results in Figure 1 demonstrates that our MCFP are significantly faster than Apriori+ by a factor up to 5 for T10I4D100K, but over two orders of magnitude for T40I10D100K. T10I4D100K 0 50 100 150 200 250 300 0.001 0.002 0.003 0.004 0.005 0.01 minsup T im e (s e c .) Apriori+ MCFP T40I10D100K 0 200 400 600 800 1000 1200 1400 1600 0.002 0.005 0.01 0.05 0.1 0.25 minsup T im e (s e c .) Apriori+ MCFP
Figure 1 Performance evaluation of MCFP against Apriori+.
5. Conclusions
Recent work has highlighted the essence of allowing user-specified constraints into the model of association rules to facilitate an on-line, interactive mining environment of association rules. The key for realizing such a mining system is the design of an efficient frequent itemsets mining algorithm that takes account of all user-specified constraints. In this paper, we have considered this problem, specifically focusing on three
types of user-specified constraints, item constraint, aggregation constraint, and cardinality constraint, and have proposed an efficient algorithm to discover qualified frequent patterns. In the future, we will consider taxonomy and extend the model by allowing multiple minimum support specifications.
References
[1] R. Agrawal and R. Srikant, “Fast algorithms for mining association rules in large databases,”in Proc. 20th Intl
Conf. on Very Large Data Bases, pages 487–499, 1994.
[2] B.L. Song and Z. Qin, “Efficient mining for frequent itemsets with multiple convertible constraints,”in Proc.
4th Intl Conf. on Machine Learning and Cybernetics, pp.
1503–1508, 2005.
[3] F. Bonchi and C. Lucchese,. “Extending the state-of-the-art of constraint-based pattern discovery,” Data &
Knowledge Engineering, Vol. 60, No. 2, pp. 377–399,
2007.
[4] G. Grahne, L.V.S. Lakshmanan, and X. Wang, “Efficient mining of constrained correlated sets,”in Proc. 16th Intl
Conf. on Data Engineering, pp. 512–521, 2000.
[5] L.V.S. Lakshmanan, R.T. Ng, J. Han, and A. Pang, “Optimization of constrained frequent set queries with 2-variable constraints,”in Proc. ACM SIGMOD Intl
Conf. on Management of Data, pp. 157–168, 1999.
[6] A.J.T. Lee, W. chuen Lin, and C. sheng Wang, “Mining association rules with multi-dimensional constraints,”
Journal of Systems and Software, Vol. 79, No. 1, pp.
79–92, 2006.
[7] N. Lu, J.Z. Zhou, W. Zhe, and C.G. Zhou, “Research on association rules mining algorithm with item constraints,”in Proc. 2005 Intl Conf. on Cyberworlds, pp. 325–329, 2005.
[8] R.T. Ng, L.V.S. Lakshmanan, J. Han, and A. Pang, “Exploratory mining and pruning optimizations of constrained association rules,” in Proc. 1998 ACM
SIGMOD Intl Conf. Management of Data, pp. 13–24,
1998.
[9] J. Pei and J. Han, “Can we push more constraints into frequent pattern mining?”in Proc. 6th ACM SIGKDD
Intl Conf. on Knowledge Discovery and Data Mining,
pp. 350–354, 2000.
[10] J. Pei, J. Han, and L.V.S. Lakshmanan, “Pushing convertible constraints in frequent itemset mining,”
Data Mining and Knowledge Discovery, Vol. 8, No. 3,
pp. 227–252, 2004.
[11] R. Srikant, Q. Vu, and R. Agrawal, “Mining association rules with item constraints,”in Proc. 3rd Intl Conf. on
Knowledge Discovery and Data Mining, pp. 67–73,
1997.
[12] M.J. Zaki, “Scalable algorithms for association mining,” IEEE Trans. on Knowledge and Data