國 立 交 通 大 學
電信工程研究所
碩 士 論 文
雙向性可變長度碼的軟性訊源解碼機制
Soft-Decision Decoding of Reversible
Variable-Length-Codes
研究生:洪肇遠
指導教授:張文輝 博士
雙向性可變長度碼的軟性訊源解碼機制
Soft-Decision Decoding of Reversible Variable-Length-Codes
研 究 生:洪肇遠 Student:Chao-Yuan Hung 指導教授:張文輝 Advisor:Wen-Whei Chang 國 立 交 通 大 學 電信工程研究所 碩 士 論 文 A Thesis
Submitted to Institute of Computer and Information Science College of Electrical Engineering and Computer Science
National Chiao Tung University in partial Fulfillment of the Requirements
for the Degree of Master
in
Computer and Information Science
June 2011
Hsinchu, Taiwan, Republic of China
i
雙向性可變長度碼的軟性訊源解碼機制
學生:洪肇遠
指導教授:張文輝 博士
國立交通大學電信工程研究所碩士班
中文摘要
近年來多媒體通訊的快速發展,使得針對影音資料的壓縮已成為 重要的研究課題,特別是多項國際標準制定的可變長度碼。本論文主 要探討可變長度碼的軟性訊源解碼機制,並將其應用於心電圖訊號的 壓縮。首先針對可變長度碼在索引層級的籬柵結構,推導其軟性訊源 解碼演算法,並整合其軟性輸出與籬柵結構以發展基於維特比演算法 的索引估測方法。其次,針對具有特定機率分佈的訊源,可建構其霍 夫曼碼,並以此發展具有錯誤更正能力的雙向性可變長度碼。我們將 引入訊源解碼的軟性資訊,配合一階相關性的事前資訊進行索引指定 的設計。系統模擬證實我們提出的方法能有效對抗通道雜訊干擾,進 而提升系統的強健性。ii
Soft-Decision Decoding of Reversible
Variable-Length-Codes
Student:Chao-Yuan Hung Advisor:Dr. Wen-Whei Chang
Institute of Communications Engineering
National Chiao Tung University
Abstract
Reversible variable length codes (RVLCs) were proposed for facilita- ting the bidirectional decoding, which mitigate the transmission errors in case of losing synchronization between the encode and decoder. This thesis focuses on the RVLC design and its application to ECG signal compression. Our work starts with a soft-decision source decoding algo- rithm based on a symbol-level trellis also proposed is a viterbi algorithm which exploit the soft output of source decoder to better estimate the tran- smitted index. For construction of RVLC, we proposed an index assign- ment scheme based on the channel-related information and the first-order correlation of source. Simulation results show that the proposed scheme can generate RVLC of higher robustness in comparison to other construct algorithms.
iii
誌謝
得以完成本篇論文,首先要感謝我的指導教授張文輝老師,就讀 研究所兩年中,老師一對一地細心指導與循循善誘,使我瞭解做研究 所應有的態度和方法,並於其中獲得許多寶貴的專業知識。 其次要感謝在這兩年中從旁協助我研究的吳俊鋒學長,學長總能 不厭其煩地解答我許多生活與研究上的問題。也要感謝吳鴻材、徐子 凡、陳柏強三位同學這兩年的幫助與照顧,三位學弟王韋超、林志賢、 曾鴻竣一年來的陪伴。最後要特別感謝我的父母與求學路上一路相伴 的女朋友,沒有他們的支持,將讓我無法如此順利地完成學業,謹以 此論文獻給所有照顧過我及我愛的人。iv
目錄
中文摘要...i 英文摘要...ii 致謝...iii 目錄...iv 圖目錄...vi 表目錄...vii 第一章 緒論...1 第二章 心電圖簡介及量化...5 2.1 心電圖簡介...5 2.2 心電圖量測...7 2.3 心電訊號的量化...10 第三章 索引層級軟性訊源解碼機制...15 3.1 系統架構...16 3.2 索引層級籬柵圖...17 3.3 索引後驗機率的推導...18v 3.4 索引估算...21 第四章 雙向性可變長度碼之設計...23 4.1 雙向性可變長度碼...24 4.2 基於最小平均長度之設計...25 4.3 基於錯誤更正能力之設計...29 4.4 基於解碼效能之索引指定設計...32 第五章 實驗模擬與結果分析...38 5.1 實驗環境設定...38 5.2 實驗一...39 5.3 實驗二...43 5.4 實驗三...47 第六章 結論與結果展望...50 參考文獻...52
vi
圖目錄
圖 2.1 心電圖之 PQRST 波...7 圖 2.2 Einthoven 三角形...8 圖 2.3 單極胸前導程電極...9 圖 2.4 MIT-BIH 編號 100 心電圖...11 圖 2.5 向量量化誤差(K=2 及 M=4)...12 圖 2.6 向量量化誤差(K=2 及 M=6) ...12 圖 2.7 向量量化誤差(K=4 及 M=4) ...13 圖 2.8 向量量化誤差(K=4 及 M=6) ...13 圖 3.1 可變長度碼之傳輸模型...16 圖 3.2 索引層級籬柵圖...18 圖 4.1 位元樹狀圖...24 圖 4.2 二位元置換演算法...37 圖 5.1 四種可變長度碼之軟性訊源解碼效能...42 圖 5.2 不同通道環境訓練所得之索引指定的效能比較...46 圖 5.3 RVLC1之不同索引檢測方式比較...47 圖 5.4 RVLC2之不同索引檢測方式比較...48 圖 5.5 RVLC3之不同索引檢測方式比較...48vii
表目錄
表 2.1 MIT-BIH 編號 100 心電圖向量量化的 PRD 值...14 表 4.1 第三層碼字之可用候選碼字表...27 表 5.1 不同可變長度碼設計之碼書...42 表 5.2 與通道環境匹配之RVLC3碼書...451
第一章 緒論
1.1 研究動機與方向
隨著生活水準及醫療服務的日趨進步,高齡化將是現代人所要 面臨的一個趨勢,許多先進國家也開始發展遠距醫療照護(wireless telemedicine)相關的服務。在台灣因為山脈地形的關係,容易造成 城鄉醫療資源的差距,許多住在偏遠地區的民眾必須花費更多的時間 與金錢才能獲得醫療品質的保障。遠距醫療照護將可縮短這些落差, 例如澎湖離島地區已運用遠距視訊系統,配合醫生的同步會診以克服 醫療人手不足的問題。基於預防勝於治療的觀念,遠距居家照護 (Mobile e-Health)也成為醫療照護的重要項目。主要是利用隨身的 無線感測器,隨時隨地偵測病患的重要生理訊號,如心電圖、腦電波、 體溫…等等,並傳至醫院中讓醫生得以隨時監控此病人的身體狀況。 長久以來,心臟病一直是國人的常見死因,心電圖的偵測對患者而言 尤為重要,因此本論文將針對心電圖深入探討。 隨時隨地監控患者所量測的心電圖訊號,其所需傳送的資料量是 非常龐大的,且有即時性的要求,因此如何更有效率傳送這些資料成 為一個重要的議題。由於多媒體通訊的相關服務蓬勃發展,國際標準 化組織已制定發表了許多的影音資料壓縮標準,例如 MPEG 系列、
2
H.264…等且大部分皆使用了可變長度碼(Variable Length Code,VLC) 作為編碼機制的核心。可變長度碼的壓縮率接近理論熵值,但常受限 於傳輸錯誤而發生同步失序的問題。可變長度碼是利用訊源中資料機 率分布不平均的特性,讓出現機率較大的索引使用較短的碼字而發生 機率較小的索引則用較長的碼字,因此碼字平均長度將會短於固定長 度碼(fixed length code),其中最為人熟知的是霍夫曼碼(Huffman Code),而不同的資料型態及傳輸目的也會有不同的編碼方法。可變 長度碼因其傳遞每個索引時,用以編碼的位元數不如固定長度碼般的 固定,因此對位元錯誤非常敏感,單一個位元錯誤就可能使得接下來 連續性索引誤判。一個可行的解決方案是開發新的訊源解碼機制,利 用訊源編碼之後殘存的冗息(residual redundancy),除了希望能將 低位元錯誤率外,也希望能控制連續性的索引錯誤。雙向性可變長度 碼(Reversible VLC,RVLC)兼具前向與後向的解碼能力,可定位連續 錯誤發生的位置,使其漸漸在標準中取代可變長度碼的地位。因此本 論文的另一個研究方向是設計雙向性可變長度碼,使其在傳輸過程中 有效提升系統的強健性。
軟性訊源解碼機制(soft-bit source decoding,SBSD)在[1] 被提出,利用殘餘冗息使得訊源解碼器得以隱藏通道解碼器無法消除 的殘餘錯誤,其處理模式可以分為位元[2]與索引層級[3]的可變長度
3
解碼機制。在前人研究[2]中,利用碼字間位元狀態的轉移,建構其 樹狀圖(code tree)與籬柵圖(code trellis),並以 BCJR(Bahl- Cocke-Jelinek-Raviv)演算法計算每個位元的後驗機率(A poster- iori probability,APP),藉以估測所傳遞的位元。而文獻[3]則在假 設傳送端的索引與位元數目已知的前提下,以此建立索引層級的籬柵 圖以計算每個索引的後驗機率,再透過最大後驗機率原則(Maximum a posteriori,MAP)估測傳送之索引。 在[4]中,首次提出了可提供即時性前向與後向解碼的雙向性可 變長度碼。文獻[5]則是針對對稱性與非對稱性 RVLC 分別提出最小平 均長度的演算法,並進一步設計一組兼具錯誤更正能力與最小平均長 度的 RVLC[6]。[7]希望能利用索引指定,改變索引與對應碼字之間 的關係,以提升訊源解碼的效能。同時提供一個找尋其區域最佳值 (local optimal)的演算法,降低所需複雜度。
1.2 章節概要
第二章將介紹心電圖訊號的量測與特性,以及基於向量量化 (vector quantization)的壓縮模式。第三章則介紹本論文所使用的 傳輸系統及其軟性訊源解碼器,主要是利用索引層級籬柵圖提出一個 軟性輸出的維特比演算法(viterbi)。第四章詳述設計非對稱性 RVLC
4
的演算法,其中包括基於最小長度與具有錯誤更正能力兩種設計,並 以此延伸提出符合訊源解碼器的索引指定設計。第五章將提供實驗數 據及其結果分析,第六章則為結論與未來展望。
5
第二章 心電圖簡介及量化
遠距居家照護的目標是希望能隨時監控在家病人的生理狀況,透 過生理訊號的感測並將資料傳送至醫院,以便醫生得知病人是否有突 發性狀況。根據行政院衛生署國民健康局的調查發現,國內 65 歲以 上民眾幾乎每四人就有一人曾罹患心臟病,而急性心肌梗塞更持續高 居台灣十大死因的第二位,因此心臟相關疾病的預防是一項重要課 題。急性心肌梗塞病因是冠狀動脈血液供應急劇減少,以致心肌發生 嚴重的急性缺血,而臨床表現症狀為心律不整或心臟衰竭。心電圖儀 是評估心臟循環功能的主要工具,有助於診斷病患的心律不整症狀, 如心跳速率、規則性、電脈衝的發源地及傳導路徑的異常。不間斷地 傳送心電圖需要龐大的資料量,在本章中我們將透過對個別患者的心 電圖進行訓練與向量量化,以期能壓縮傳送的資料量並兼顧其重建品 質。2.1 心電圖簡介
心電圖(Electrocardiography, ECG)是記錄心臟組織電壓變化的 一個圖形,心臟的肌肉是人體肌肉中,唯一具有自發性跳動及節律性 收縮的肌肉。心臟傳導系統發出電波,刺激整個肌肉纖維而產生收6 縮。電波的產生及傳導,皆會產生微弱的電流分佈全身,若將心電儀 的電極連接到身上不同的部位,就可記錄而得心電圖。心電圖可檢驗 下列八種情況: (1) 心房肥大及心室肥大。 (2) 心房及心室電波的傳導遲延。 (3) 心肌缺血及心肌梗塞。 (4) 判定心律不整來源及監視它的活動情形。 (5) 心包膜炎。 (6) 侵犯心臟的全身性疾病。 (7) 判定心臟藥物的影響。 (8) 電解值代謝障礙,特別是鉀。 心電圖訊號屬於低頻範圍 0.05 至 100HZ,且振幅微小僅 1 至 10mV,因此在心電圖訊號的擷取上便需要訊號放大器與濾波裝置。市 面上常見的一般心電儀,其靈敏度便是 0.25mV,記錄的頻率範圍為 0.5HZ 至 80HZ,臨床上用以測量 ECG 訊號的電極通常為銀∕氯化銀電 極,其電位特性、雜訊以及回復特性適合用於生理訊號的感測。 美國 MIT-BIH 醫療機構公開提供的心電圖資料庫,已廣泛應用於 心電訊號處理分析的相關研究。心跳的一個週期如圖 2.1 所示,起始 於竇房結發出每秒約 60 次的電脈衝,以漸進方式傳遞至左右心房引
7 起收縮(P 波),P 波區間通常不大於 0.12 秒且高度不大於 2.5 mv, 抵達房室結後停滯約 0.1 秒讓血液充分流至心室(Q 波),接著藉由傳 遞纖維傳至左右心室而引起收縮(R 波),之後心臟暫時靜止直到心室 再極化(T 波)。整體而言,一個心電圖週期以 QRS 波最為顯著,一個 QRS 複合波週期大約介於 0.08 至 0.12 秒之間,其位置的自動化偵測 能提供病患心律不整的診斷資訊。
2.2 心電圖量測
心電圖為身體表面記錄之心臟週期性電氣活動的電位變化,現階 段臨床上使用最多的為十二導程心電圖(12 leads ECG),分為胸導程 與肢端導程兩類。心電圖的六個單極胸前導程分別為 V1、V2、V3、 圖 2.1 心電圖 PQRST 波8
V4、V5、V6,能夠從水平面上測得心臟的狀況。而來自四肢電極的情 況,則可由六個肢端導程 I、II、III、aVR、aVL、aVF 從心臟垂直面 測得,這十二個導程將整合成標準的心電圖。
六個肢端導程又細分為兩類,aVR、aVL、aVF 為單極肢端導程( Unipolar limb Leads),I、II、III 為標準雙極肢端導程(Bipolar Standard Leads),量測方法如下:
Lead I 肢端導程: 左手為正極,右手為負極,角度為 0 度,即 Lead I= LA–RA(左手電壓與右手電壓之電位差)。
Lead II 肢端導程: 左腳為正極,右手為負極,角度為 60 度,即 Lead II= LL–RA(左腳電壓與右手電壓之電位差)。
Lead III 肢端導程: 左腳為正極,左手為負極,角度為 120 度, 圖 2.2 Einthoven 三角形[15]
9
即 Lead III= LL - LA(左腳電壓與左手電壓之電位差)。
此三個導程之向量關係可用 II=I+III 表示,相關位置如圖 2.2 所示。 Lead aVL 肢端導程: 左手為正極,左腳與右手為負極,角度為 -30 度,aVL = I-(II/2)。 Lead aVR 肢端導程: 右手為正極,左腳與左手為負極,角度為 -150 度,aVR = -(I+II)/2。 Lead aVF 肢端導程: 左腳為正極,右手與左手為負極,角度為 90 度,aVF = II- (I/2)。
六個胸前導程電極位置如圖 2.3 所示,量測方法如下: V1 是放在胸骨右側的第四肋間。
V2 是放在胸骨左側的第四肋間。
10 V3 是放在 V2 和 V4 之間。 V4 是放在第五肋間的左鎖骨中線之處。 V5 是放在 V4 和 V6 之間。 V6 是放在第五肋間的腋中線(midaxillary line)之處。
2.3 心電訊號的量化
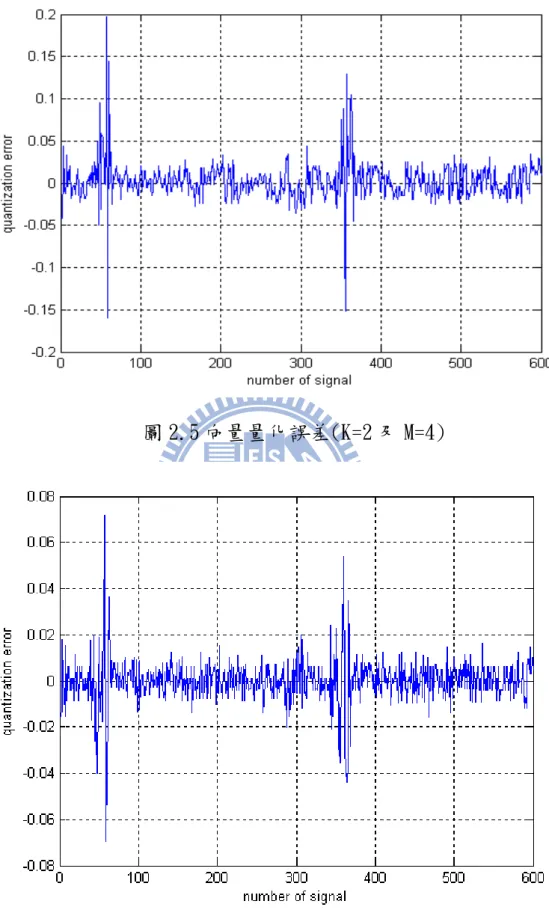
量化處理為數位傳輸系統裡很重要的一環,因取樣過後的訊源取 樣點其實數值的範圍是無限的。經過量化步驟後,可將這些數值分隔 成若干個區域,分別以一個代表位階來表示,如此一來,所有的數值 皆可以用有限的位階來代替,傳輸上也只要傳送這些代表數值的索引 即可。向量量化(vector quantization)為資料壓縮領域的重要方 法,因其具有良好的壓縮率與較小的失真。以K維M 位元的向量量化 為例,將訊源取樣點依序以K點組成一個向量,將此K維空間分隔成 2M區域,每個區域皆有一個事前訓練所得而具有代表性的碼向量, 每個輸入向量將被劃分至與碼向量之失真(distortion)最小的區 域。失真的評估方式很多,常見的是以較直觀的平方差為準。最原始 的向量量化演算法在 1980 年由 Y.Linde、 A.Buzo 和 R.Gray 共同提 出[13],後人稱其為 LBG 演算法。流程如下:11 2. 將代表向量分別加減一個特定向量後,分裂為兩個新代表向量。 3. 所有的訓練向量皆計算其與代表向量間的失真,並劃分在與其失 真最小的群。 4. 分別計算各個分群裡向量的重心,若各個分群裡重心與代表向量 的差異收斂在一極小的範圍內,則回到第 2 步驟,反之,則以新 重心為代表向量,接著執行第 3 步驟。直至代表向量個數為所需 個數,且分群重心皆收斂,演算法結束。 量化機制皆會產生量化誤差,雖可以透過碼書的設計來降低,但 仍有其限制。圖 2.4 為 MIT-BIH 資料庫編號 100 的心電圖,圖 2.5 至 2.8 為其分別依不同 K 與 M 值做向量量化所產生的誤差圖。一般而言, 維度K越小或碼書尺寸2M越大,失真就越小,但如此一來,也會造成 壓縮率的降低。 圖 2.4 MIT-BIH 編號 100 心電圖
12
圖 2.5 向量量化誤差(K=2 及 M=4)
13
圖 2.7 向量量化誤差(K=4 及 M=4)
14 在本論文中將使用 LBG 演算法訓練心電圖的量化碼書,而我 們採用的解碼機制之複雜度與2M值大小成正比,但因心電圖的監 控有其品質要求,若M 值太小則使得失真太大,應妥善選擇K與M 的折衷值。心電圖的品質大多以均方根誤差百分比(Percent Root-mean-square Difference,PRD)做為評比的標準,其與訊雜 比有一轉換關係,公式如下: PRD 1 100% SNR = × (2.1) 從式子(2.1)可得知,SNR 越高則 PRD 越低,量化品質也較好。一 般而言,PRD 能低於 10%的心電圖是可接受的重建品質。由表 2.1 可發現達成低標以上的向量量化之(K,M)組合為(K,M)=(2,5)、 (2,6)、(2.7)、(4.6)、(4.7),考慮到訊源解碼器複雜度的關係, 在進行心電圖向量量化時暫不考慮 M=7 的兩種組合,而在剩存的 三種組合中,(K,M)=(2,6)向量量化的 PRD 值最低,效果最好,故 在本論文中對心電圖的向量量化將採用 K=2、M=6 的向量量化。 K/M 4 5 6 7 2 14.0328% 9.3334% 6.3987% 4.5674% 4 17.9685% 11.7524% 8.9175% 7.0909% 表 2.1 MIT-BIH 編號 100 心電圖向量量化的 PRD 值
15
第三章 索引層級軟性訊源解碼機制
在訊源編碼的相關研究中,可分為可變長度碼(variable length code,VLC)與固定長度碼(fixed length code)兩大類別,各有其不同 之應用領域。針對具有特定機率分佈的訊號源,相較於固定長度碼而 言,可變長度碼在資料壓縮處理上有較好的效率。然而其解碼過程對 於錯誤位元相當敏感,少許的位元錯誤便可造成嚴重之索引同步的失 序。早期的文獻中,軟性訊源解碼機制主要是針對固定長度碼而開 發,其解碼演算法又可細分為位元層級與索引層級兩種,相關演算法 也逐漸推廣應用在可變長度碼的軟性解碼機制。位元層級的訊源解碼 機制[2],主要是運用可變長度碼字位元間狀態(state)的轉移關係與 其籬柵(trellis)結構,並配合 BCJR 演算法提供一個可靠的解碼輸 出。然而此解碼方式並未充分利用相鄰索引間的相關性,而且在位元 轉換成索引的同步失序問題上仍有待解決。索引層級的解碼則是以傳 送序列之索引數目與位元數目當做邊訊息(side information),依此 建立其籬柵圖,配合前向與後向遞迴運算(forward-backward recur- sion)逐步計算每個索引的後驗機率,故可避免位元轉換索引時出現 的失序問題。本章節將針對索引層級解碼器做深入探討,推導其解碼 之軟性輸出,並以此輸出估算其最大可能性的傳送索引序列。
16
3.1 系統架構
系統傳輸模型如圖 3.1 所示。 1 [ 1, 2,..., ] L L v = v v v 為一具有L個訊號源 取樣點之序列,經由維度K且M 位元之向量量化器處理後,產生一組 長度為T之索引序列 1T [ ,1 2,..., ] T u = u u u ,其中T =L K/ 。定義量化索引的 集合為I ={0,1,..., 2M −1},即ut = ∈λ I。經由事前訓練得其索引的機率分 佈P( )λ ,再據以產生一組可變長度碼的碼字C ={ (0), (1),...,c c c(2M −1)}, 其中c( )⋅ 代表該索引所對應的可變長度碼字。訊源編碼器將輸入之索 引序列 1 T u 依序對應該碼書,接著使用二進位相位鍵移(Binary Phase Shift Keying)調變,產生一長度為N位元之二位元序列 1 [ ,1 2 N b = b b ,... ,bN],其中第n個位元值表示為bn∈ −{1, 1}。經過附加性白高斯雜訊
(Additive White Gaussian noise,AWGN)通道後,得到雜訊干擾的實 數序列b1N =[ ,b b 1 2,...,bN],令其對應的索引序列為u1T =[ ,u u 1 2,...,uT]。在接 收端,將序列 1 T u 經由索引層級訊源解碼器的處理,計算每一個索引值 的後驗機率 ( | 1) T t P u =λ u ,並以此軟性輸出資訊進行索引ut的最佳化估 算,最後得到索引的估算序列ˆˆˆˆ [ ,1 1 2,..., ] T T u = u u u ,uˆt∈I。 VQ Quantizer VLC Encoder AWGN Channel VLC Source Decoder Index estimation 圖 3.1 可變長度碼之傳輸模型 1 L
v
u
1T 1 N bb
1Nu
ˆ
1T17
3.2 索引層級籬柵圖
多媒體通訊中通常以封包作為一個傳輸的單位,在本論文中將 視T個索引組成的序列 1T [ ,1 2,..., ] T u = u u u 為一個封包,並針對T已知的情 形進行系統設計。而進行可變長度碼的編碼後,因為索引數目T固 定,所以每個封包的位元總數大小N皆不固定,但接收端可依接收到 的實數值數目來得知。所謂的索引層級籬柵圖,是在已知T及N兩個 資訊的前提下建構,而每個封包所產生之籬柵圖也不盡相同。 圖 3.2 為T =5及N =10之索引層級籬柵圖,其中橫軸t為索引位 置,縱軸n為位元數目。假設索引集合為I ={0,1, 2, 3},對應的可變長 度碼字集合為C={ (0)c =[0],c(1)=[10], (2)c =[01], c(3)=[111]},而碼字長度 分別為l c( (0))=1、l c( (1))=2、l c( (2))=2、l c( (3))=3,其中l( )⋅ 為該碼字所 對應的位元長度。此圖是在封包所屬的索引數目與位元長度已知的限 制條件下,列舉出所有可能發生的索引組合。定義編碼進行到第t個 索引時的節點狀態為gt,gt =n則代表前t個索引使用了n個位元做編 碼。兩節點之間的狀態轉移路徑皆標記著一個碼字,例如,g1=2轉 移至g2 =4表示第二個索引的編碼使用了4 2− =2個位元。而在此例子 中,位元長度為 2 的碼字有兩個,分別為c(1)與c(2),故在此狀態轉 移中會有兩條平行路徑。直覺以為每個節點狀態的轉移皆應有四條路 徑,因為碼書中共有四個碼字,然而因為封包索引數與位元長度的限
18 制,使得有些路徑不可能出現。例如從g4 =9轉移出去的合法狀態只 有g5 =10,即碼字c(0)=[0],因不允許使用超過位元長度大於 1 的碼字 做編碼。若使用c(3)=[111]做編碼,將會使狀態轉移至g5 =12,超過位 元長度N =10的限制。另一個例子是g3 =4無法轉移至g4 =5與g4 =6, 因碼字的最大位元長度為 3,造成下一個狀態最多只能轉移至g5 =8與 5 9 g = ,並不符合N =10位元長度的限制,故也應予以刪除。
3.3 索引後驗機率的推導
本節將利用 3.2 節之索引層級籬柵圖,推導軟性輸入及軟性輸 出(soft-input soft-output,SISO)的訊源解碼演算法,進而提供索 圖 3.2 索引層級籬柵圖
19 引層級的後驗機率 ( | 1) T t P u =λ u 。其中關鍵是引入通道的軟性資訊與訊 源的一階事前相關性,並配合已知的T及N所建構之籬柵圖的狀態轉 移,進行前向與後向遞迴計算。推導如下: 1 1 1 1 ( | ) ( , , | ) t t T T t t t t g g P u λ u P g u λ g u − − = =
∑∑
= (3.1) 進一步使用貝氏定理(Bayes Theorem),將 ( 1, , | 1 ) T t t t P g− u =λ g u 此項拆解 為 ( 1, , | 1 ) ( , ) ( , ) / ( 1 ) T T t t t t t t t P g− u =λ g u =α λ g ⋅β λ g P u (3.2) 其中前向機率 ( , ) ( 1, , , 1) t t gt P gt ut g ut α λ = − =λ ,而後向機率β λt( ,gt)= 1 1 1 ( T | , , , t) t t t t P u+ g− u =λ g u 。接著利用量化索引間的一階馬可夫相關特性與 AWGN 通道之無記憶特性,推導此兩項機率的前向與後向遞迴運算公 式為 2 1 2 2 1 1 1 : ( ) ( , ) ( , , , , , ) t t t t t t t t t t t g q l q g g g P g u q g u g u α λ λ − − − − − − = − =∑ ∑
= = (3.3) 2 1 2 1 2 1 1 1 : ( ) ( , , | , , , ) t t t t t t t t t t g q l q g g P u λ g u g u q g u − − − − − − − = − =∑ ∑
= = 1 2 1 1 1 ( t , t , t , t ) P g− u− q g− u− ⋅ = 2 1 2 , 2 1 1 : ( ) ( , , ) ( , ) t t t q t t t t t g q l q g g u g g q g λ γ α − − − − − − = − =∑ ∑
⋅ 1 1 1 1 1 1 1 : ( ) ( , ) ( , , | , , , ) t t t T t t t t t t t t t g q l q g g g P u g u q g u g u β λ λ + + + + + − = − =∑ ∑
= = (3.4) 1 1 2 1 1 1 1 1 : ( ) ( , , , | , , , ) t t t T t t t t t t t t g q l q g g P u u g u q g u λ g u + + + + + + − = − =∑ ∑
= = 1 1 2 1 1 1 1 1 : ( ) ( | , , , , , , ) t t t T t t t t t t t t g q l q g g P u u g u q g u λ g u + + + + + + − = − =∑ ∑
= = ⋅P u(t+1,gt+1,ut+1=q g| t−1,ut =λ,g ut,1t)20 1 1 1 2 1 1 1 1 : ( ) ( | t , , , , , ) t t t T t t t t t t g q l q g g P u u+ g u q g u λ g + + + + + − = − =
∑ ∑
= = 1 1 1 1 1 ( t , t , t | t , t , t, t) P u+ g+ u+ q g− u λ g u ⋅ = = 1 1 1 2 1 1 1 : ( ) ( | t , , , ) t t t T t t t t g q l q g g P u u+ g u q g + + + + + = − =∑ ∑
= 1 1 1 1 1 ( t , t , t | t , t , t, t) P u+ g+ u+ q g− u λ g u ⋅ = = 1 1 , 1 1 1 1 1 : ( ) ( , , ) ( , ) t t t q t t t t t g q l q g g u g g q g λ γ β + + + + − + + = − =∑ ∑
⋅ 在式子(3.3)中 1 , ( , , 2) ( , , | 2, 1 , 1, 1 ) t q u g gt t t P ut g u gt t t ut q gt u λ γ λ − − = = − − = − (3.5) 1 2 1 1 1 ( t | t , t, t , t , t , t ) P u u λ g g− u− q g− u− = = = 1 2 1 1 1 ( t , t | t , t , t , t ) P u λ g g− u− q g− u− ⋅ = = =P u u(t | t =λ,gt)⋅P u( t =λ,g ut | t−1 =q g, t−1) 進一步分析得知,式子(3.5)中的第二項可簡化為 P u( t =λ,g ut| t−1=q g, t−1) 1 1 1 ( | ) , ( ( )) 1 { 0 , ( , ) t t t t t P u u q l c g g otherwise C q g λ − λ − − = = = − = (3.6) 其中P u( t =λ|ut−1=q)為事前訓練所得的一階相關性資訊,而正規化常 數(normalization factor)則為 1 1 1 : ( ( )) ( , ) ( | ) t t t t t t g I l c g g C q g P u u q λ λ λ − − − ∈ = − =∑
∑
= = (3.7) 至於式子(3.5)中的第一項P u u(t | t =λ,gt)的計算,則可利用通道特性 做簡化。假設一附加性白高斯雜訊通道,其期望值為 0,變異數為 2 0 / 2 n N Es σ = ,訊號功率ES =1,則21 ( ( )) ( ( )) 1 ( | , ) ( | ( )) t l c t t t m g l c m P u u =λ g =
∏
=λ p b − λ + a m (3.8) ( ( )) 2 ( ( )) 1 0 0 1 1 ( ) exp( ( ( )) ) t l c M g l c m m b a m N N λ λ π − + = = ⋅ −∑
− 其中[ (1), (2),... ( ( ( )))]a a a l c λ 為碼字c( )λ 經過 BPSK 的雙極(bipolar)位元 序列。3.4 索引估算
經由 3.3 節之公式推導,我們可以得知傳送封包裡每個索引值的 後驗機率 ( | 1) T t P u =λ u 。根據此軟性輸出之後驗機率,再以最大後驗機 率(Maximum a posteriori,MAP)原則估算其索引序列uˆt如下: ˆ, arg{max( ( | 1 ), )} t T t MAP t u u = P u =λ u λ∈I (3.9) 經此估算後所得的最佳索引序列為ˆˆˆˆ1, [ 1, , 2, ,..., , ] TMAP MAP MAP T MAP
u = u u u ,配合向 量量化碼書的對應關係,即可還原其輸出訊號為ˆˆˆˆ [ , ,... ]1 1 2 L L v = v v v 。 最大後驗機率原則固然提供了一個簡易的估算方法,然而因其在 估測過程中是針對單一索引個別處哩,這可能造成索引序列 ˆ1, T MAP u 所對
應的碼字序列[ (c uˆˆˆ1,MAP), (c u2,MAP),..., (c uT MAP, )]的位元總長度並不等於已知
之長度N。針對此項議題,我們將使用 3.2 節之籬柵圖,在已知T及 N條件下發展一個軟性輸出的維特比(viterbi)演算法。首先定義每 個節點的權值(metric),如圖 3.2 中,節點gt在時間 t 的權值定義為 ( ) t t M g 。擬發展的維特比演算法將引入一階馬可夫模型,並依下列遞
22 迴公式來計算每個節點之權值: ( ) max{ ( | 1 ) ( , | 1 , 1, 2) 1( 1)} T t t t t t t t t t P u u g t M g = =λ P u =λ u− =q g− g− M − g− (3.10) 執行此演算法的遞迴運算直到MT(gT =N),再由此最終節點往回尋找 機率最大化並符合T與N值的索引組合路徑,依此估測的索引序列所 對應的碼字序列之位元長度也將自動符合N 的條件。
23
第四章 雙向性可變長度碼之設計
針對具有特定機率分佈的訊號源,可變長度碼可依照其機率大小 使用不同長度的碼字加以編碼。機率較大的資料使用較短的碼字,機 率相對較小的資料則使用較長的碼字,使其平均碼字長度能夠更接近 理論熵值,以達到節省資料傳送量的目的。可變長度編碼方式眾多, 其中以霍夫曼碼最為著名,它的前置條件(Prefix condition) 允許 前向解碼過程能夠符合索引同步,且其平均碼字長度經證實最接近理 論熵值。可變長度碼對於位元的錯誤相當敏感,少數位元錯誤可能造 成索引判斷的連續錯誤,如何克服位元錯誤的同步失序問題是可變長 度解碼的一大課題。較理想的解決方案是雙向性可變長度碼(Rever- sible variable length code,RVLC),同時符合前置條件與後置條件 (Suffix condition),因此能提供雙向性的即時解碼,並可定位連續 錯誤發生的位置,進一步修復以加強解碼的錯誤更正能力。本章將介紹非對稱性 RVLC 碼的不同編碼方式,其中包括基於最 小平均長度的設計以及將其延伸而具有錯誤更正能力的設計,最後提 出基於解碼效能的索引指定設計。
24
4.1 雙向性可變長度碼
雙向性可變長度碼之特性為兼具前置與後置條件,故可提供雙向 性的解碼效能。前置條件是指任一碼字不得為其他較長碼字的字首, 而後置條件則是指任一碼字不得為其他較長碼字的字尾。進一步又可 分為對稱性(symmetric)與非對稱性兩種(asymmetric)兩種,主要差 別在於由左至右的位元組合是否與由右至左的位元組合相同。 圖 4.1 位元樹狀圖 雙向性可變長度碼的設計,一般是利用位元樹狀圖表示目標碼字 選取的分佈情況,如圖 4.1 所示。Level n 代表碼字長度為 n 位元的 層級,其中A A1, 2,...,A8代表位於第三層(位元長度為 3)中有可能被選 取的碼字,定義為「候選碼字」,例如A3即為碼字"010"。假設一個 雙向性可變長度碼書內已選了"10"這個碼字,則為了符合前置條件, 以碼字"10"為根節點的樹狀分支皆不能成為可用的候選碼字,代表 5, 6 A A 不能出現在碼書中。而為了符合後置條件,A A3, 7也不能留在接下 來所挑選的碼字中。因此,若我們挑選"10"為「目標碼字」(即準備要25 選取的碼字),便會造成"010"、"110"、"100"、"101",即A A A A3, 5, 6, 7這 四個碼字不能出現在接下來所要選的碼字中,此時第三層的「可用候 選碼字」便只剩下A A A A1, 2, 4, 8。另一個例子為目標碼字挑選"11"時,則 依據前置條件A A7, 8不能出現在碼書中,而後置條件則排除A A4, 8兩個碼 字,故「可用候選碼字」為A A A A A1, 2, 3, 5, 6。由這兩個例子可以發現,選 取不同的目標碼字時因受限於前置與後置條件的影響,使得可用的候 選碼字數量存在不同的情形。 因此我們應該填選一組碼字集合,且所屬的碼字若皆符合前置與 後置條件,便可稱此集合為一組雙向性可變長度碼。若是沒有效率的 任選集合內的碼字,其平均長度可能遠離於理論熵值,因而使得訊源 編碼的壓縮效率下降。以下我們將針對非對稱性 RVLC 碼,先介紹基 於最小平均長度的設計,再討論兩種將其延伸而發展出具有錯誤修正 能力的設計。
4.2 基於最小平均長度之設計
基於最小平均長度的設計理念,旨在將其編碼所得的平均長度儘 可能接近理論熵值,而其中又以符合前置條件的霍夫曼碼為代表作。 因此 RVLC 碼的設計一般是參考霍夫曼碼,並修改之以符合額外考量 的後置條件,主要是讓每一層都能有最多的可用候選碼字提供我們選26 擇。為了同時符合前置與後置條件,若已選碼字與霍夫曼碼一樣的情 況下,則在下一層可挑選的碼字數目勢必小於或等於霍夫曼碼。參考 4.1 節的兩個例子也可以發現,不同碼字的選擇會影響到後續可用候 選碼字數目的多寡。因此當我們要挑選某一層的碼字時,應配合其他 選擇機制讓該層的候選碼字有其挑選的優先順序。針對非對稱性 RVLC 碼,台灣大學資工系吳家麟教授提出一個碼字選擇機制[5],主要是 依據碼字的最小重複間隔(Minimum Repetition Gap,MRG),定義如下:
給定一個具有k位元的碼字C=C C1 2...Ck,若在其後加上一個k位元
的碼字X,且碼字X 內的每一個位元可任選是 0 或 1,將此重新形成
的碼字定義為D=CX 。C的重複間隔q代表在D的位元組合將每隔q
位元重複一次,而其最小值則定義為最小重複間隔g,即
1min{≤ ≤g k Di =Dj} ,for all i ≡ jmod g and ≤1 i j, ≤2k (4.1)
舉例而言,給定一個碼字C="010",則D="010X X X1 2 3",我們令X= "101",因此D1=D3=D5 (i,e.,X2)=0,D2=D4(X1)=D6(X3)=1,則 q=2。另一個例子為令X="010",因此D1=D4=0,D2=D5=1,D3=D6=0, q=3,則碼字C="010"的 MRG=min{2,3}=2。 當我們要排列某一層候選碼字的優先挑選順序時,首先將候選碼 字中位元互補的碼字兩兩成為一組,因為位元互補的碼字其 MRG 的大 小是一樣的。接著將不同的組別依 MRG 的值由小至大排列,若不同組
27 別有相同的 MRG 值,則以擁有十進位制中較小碼字的組別為優先。表 第三層 可用候選碼字數量 候選碼字 MRG 第四層 第五層 第六層 000 1 13 24 44 111 1 13 24 44 010 2 12 21 37 101 2 12 21 37 001 3 12 20 33 110 3 12 20 33 011 3 12 20 33 100 3 12 20 33 表 4.1 第三層碼字之可用候選碼字表 4.1 列出第三層所有的候選碼字,並以 MRG 由小至大排序,並列出挑 選該碼字後在第四、五、六層可用候選碼字的數量。我們可以發現 MRG 的大小排序與後續可用候選碼字的數量息息相關,因此挑選 MRG 越小的碼字做為目標碼字,可保證我們在下一層挑選碼字時可用的候 選碼字數量較多。以下詳述其編碼演算法: 1. 首先我們利用訓練資料求出每個索引的機率,並依此機率分佈進 行霍夫曼編碼。將這組霍夫曼碼當作參考的可變長度碼,定義n i( ) 為其第i層的碼字數量。定義 RVLC 目標碼字之第i層數量為nrev( )i , 並以n i( )為其初始值,即nrev( )i =n i( )。定義cr為已選目標碼字之集 合,mas為已選目標碼字之數量且初始值為 0。 2. 針對第i層候選碼字而言,利用已選碼字的前置與後置條件刪去不 可使用的碼字,保留下來的碼字即為可用候選碼字。定義可用候
28 選碼字數量為avail i( ),再將可用候選碼字的優先挑選順序依 MRG 值由小至大依序排列,並定義排序後的可用候選碼字集合為: 1 ( ) { ( ) a a S i = c i 2 ( ) , ( ),..., avail i ( )} a a c i c i 。接下來,針對兩種可能發生的情況分 別處理: (1) 當nrev( )i ≤avail i( ),代表該層所需要的目標碼字數量小於或等於 該層提供的可用候選碼字數量,則nrev( )i 保持不變。 (2) 當nrev( )i >avail i( ),代表需要的目標碼字數量大於可用的候選碼 字數量,因此無法在此層選到足夠的目標碼字,補救方法是 將不足的數量(nrev( )i −avail i( ))加到下一層所需要的碼字數量
,即nrev(i+ =1) nrev(i+ +1) nrev( )i −avail i( ),且將本層的碼字數更改
為nrev( )i =avail i( )。 3. 依照前述 MRG 的排序選取該層前nrev( )i 個可用候選碼字納入目標碼 書,即 ( mas j) j( ), 1, 2,..., ( ) r a rev c u + =c i j= n i ,且mas =mas +nrev( )i 。若mas <ntotal, 則 i= +i 1並重複上述步驟 2,反之則結束演算法,其中ntotal為應選 目標碼字的數目。 上述的演算法因參考最接近理論熵值的霍夫曼碼在每一層中挑 選的碼字數目,在選取碼字時都儘可能達到目標數量,且 MRG 排序也 能保證在下一層可用候選碼字儘可能達到最多,因此能夠找尋到一組 具有最小平均長度的非對稱性雙向可變長度碼。
29
4.3 基於錯誤更正能力之設計
基於最小平均長度的設計,提供了一組高壓縮效率的雙向性可變 長度碼,但我們希望能進一步改良以兼顧其錯誤更正能力。根據前人 研究[6],錯誤更正能力與可變長度碼本身的自由距離(free distan- ce)有強烈的相依性。自由距離越大,則錯誤更正能力越強,但也因 而造成更加嚴苛地碼字選擇條件。 考慮一組M 位元的量化索引集合I ={0,1, 2,..., 2M−1},定義C={ (0)c , (1),..., (2c c M −1)}為索引集合I 所對應的可變長度碼字集合。假設一個長 度為T之索引序列 1T { ,1 2,..., } T u = u u u ,經過可變長度編碼後得到一組位元 長度為N之二位元序列 1N [ ( ), (1 2),..., ( )] [ ,1 2,..., ] L N b = c u c u c u = b b b ,為了方便 說明,我們將T個索引所對應的位元序列 1N b 視為一個N位元的碼字, 並將所有可能的碼字集合定義為B。定義自由距離df為集合B中任兩 個不同碼字 ( ) ( ) {bm,bn }之間的最小漢明距離(Hamming Distance),而區 塊距離db則定義為集合C中任兩個位元等長度的不同碼字之最小漢 明距離。若令dH為漢明距離,則df與db分別定義如下: ( ) ( ) ( ) ( ) ( ) ( ) min{ ( m, n ) | m , n ; m n} f H d = d b b b b ∈B b ≠b (4.2) db =min{dH( ( ), ( )) | ( ), ( )c i c j c i c j ∈C l i, ( )=l j i( ); ≠ j} (4.3) 其中l i( )為索引i所對應之碼字長度。我們藉由觀察霍夫曼碼之碼字, 可發現位元等長的碼字彼此間最小的漢明距離為 1,且因其只具有前30 置特性,故df ≥1。而根據文獻[6]中所證明,雙向性可變長度碼具有 前置與後置條件,所以具有df ≥min(2,db)之性質,故若能讓db ≥2則 2 f d ≥ 。藉由上述的討論我們可以得知,若能將集合C中位元等長的 不同碼字之最小漢明距離提升至 2,即db ≥2,則能夠使得雙向性可變 長度碼的錯誤更正能力提高。以下之演算法將基於此特性,並配合 4.2 節最小平均長度的設計概念,找尋一組符合df ≥2條件下最小平 均長度之雙向性可變長度碼: 1. 首先我們利用訓練資料求出每個索引的機率,並依此機率分佈進 行霍夫曼編碼,將這組霍夫曼碼當作參考的可變長度碼,定義n i( ) 為其第i層的碼字數量。定義目標雙向性可變長度碼之第i層數 量為nrev( )i ,並以n i( )為其初始值,即nrev( )i =n i( ),定義cr為已選 目標碼字之集合,mas為已選目標碼字之數量且初始值為 0。 2. 針對第i層候選碼字而言,利用已選碼字的前置與後置條件刪去不 可使用的碼字,保留下來的碼字為可用候選碼字。定義可用候選 碼字數量為avail i( ),再將可用候選碼字的優先挑選順序依 MRG 值 由小至大依序排列,並定義排序後的可用候選碼字集合為: 1 ( ) { ( ), a a S i = c i 2 ( ) ( ),..., avail i ( )} a a c i c i 。
3. 在指定較優先選取的min(nrev( ),i avail i( ))個目標碼字之前,先確認 ( )
a
31 min{ ( j( ), k( )) |1 , min( ( ), ( )); } 2 H a a rev d c i c i ≤ j k≤ n i avail i j≠k ≥ (4.4) 若≥2,則進行步驟 4,反之則進行步驟 5。 4. 分為兩種情形處理: (1) 當nrev( )i ≤avail i( ),代表該層所需要的碼字數量小於等於該層 可提供的可用候選碼字數量,則nrev( )i 不變。 (2) 當nrev( )i >avail i( ),代表需要的碼字數量大於可用的候選碼字數 量,因此不能在此層提供足夠的碼字數目,此時將不足數量 的(nrev( )i −avail i( ))加到下一層所需要的碼字數量中,即
nrev(i+ =1) nrev(i+ +1) nrev( )i −avail i( ),且將本層的碼字數更改為
nrev( )i =avail i( )。 依照前述 MRG 的排序選取該層前nrev( )i 個可用候選碼字納入目標碼 書,即: ( mas j) j( ), 1, 2,..., ( ) r a rev c u + =c i j= n i ,接著進行步驟 6。 5. 將S ia( )分成兩個集合,S io( )與S ie( ),其中S io( )代表S ia( )中漢明權重 (Hamming weight)為奇數的碼字,而S ie( )則代表漢明權重為偶數 的碼字。因為此兩集合中碼字的漢明權重皆為偶數或者奇數,故 在同一集合內的不同碼字彼此之間漢明距離必定≥2。定義此兩集 合的碼字數量分別為n io( )與n ie( ),且令n is( )=max(n i n io( ), e( )),並從 碼字數量較多的集合中去挑選目標碼字,即: ( mas j) j( ), 1,..., min( ( ), ( )) r e rev s c u + =c i j= n i n i if n ie( )≥n io( )
32 ( mas j) j( ), 1,..., min( ( ), ( )) r o rev s c u + =c i j= n i n i if n ie( )<n io( ) (4.5) (1) 當nrev( )i ≤n is( ),代表該層所需要的碼字數量小於等於該層 可提供的可用候選碼字數量,則nrev( )i 不變。 (2) 當nrev( )i >n is( ),代表需要的碼字數量大於可用的候選碼字數 量,因此不能在此層選取足夠的碼字數目,此時將不足的數 量(nrev( )i −n is( ))加到下一層所需要的碼字數量中,即
nrev(i+ =1) nrev(i+ +1) nrev( )i −n is( ),且將本層的碼字數更改為
nrev( )i =n is( )。 依照前述 MRG 排序選取該層前nrev( )i 個可用候選碼字編入碼書,即: ( mas j) j( ), 1, 2,..., ( ) r a rev c u + =c i j= n i ,接著進行步驟 6。 6. 更新已選碼字之數目mas =mas+nrev( )i ,若mas <ntotal,則i= +i 1並重複 上述步驟 2,反之則結束演算法。
4.4 基於解碼效能之索引指定設計
索引指定設計旨在置換 RVLC 碼書中碼字與其索引間之對應關 係,以期能找出一組最佳的對應組合以提升訊源解碼效能。我們提出 的索引指定設計,主要的置換對象是位元等長的碼字集合,以避免置 換位元長度不同的碼字而導致碼字平均長度的增加。我們的構想是在 置換過程中,先將碼書中的碼字依位元長度分成不同的集合,每次置33 換只置換特定集合內的碼字,其他集合的索引指定則不變。進行置換 之集合的順序是依位元長度由小至大,例如有位元長度 3、4、5 的三 個碼字集合,將先置換位元長度 3 之集合內的碼字,完成後再置換位 元長度 4 的集合,以此類推。 最佳的索引指定必須將訊源解碼效能納入設計的考量,在此論文 中使用的軟性輸出訊源解碼器主要是利用 AWGN 通道資訊與一階事前 相關性來做解碼,本節將利用此兩個資訊定義一項可具體反應訊源解 碼效能的目標函數。評估解碼效能的一個重要指標參數是訊雜比 (Parameter Signal to Noise Ratio,PSNR),我們利用此機制來定義 目標函數: 2 1 2 1 ˆ ( ) L l l L l l l v v v ρ = = = −
∑
∑
(4.6) 令 1 [ ,1 2,..., ] L L v = v v v 為一L個數值之訓練資料,經過一K維度為且M 位元 的向量量化器產生一索引序列 1 [ ,1 2,..., ] T T u = u u u ,其中T =L K/ 。再將T個 索引依序進行可變長度編碼,令其位元長度依序為 1 [ , ,..., ]1 2 T T l = l l l = 1 2 [ ( ( )), ( (l c u l c u )),..., ( (l c uT))]。此外,接收端解碼輸出ˆˆˆ [ , ,...1L 1 2 v = v v ,vˆL]= 1 2 ˆˆˆ [ ( ), (q u q u ),..., (q uT)],其中q u( )ˆt 為索引估測值uˆt對照查表所得的K維碼 向量。至於索引uˆt的估測方式,我們將在下一段詳細說明。 可變長度碼的特性是針對不同的量化索引編碼所得之位元數並34 不固定,因而造成傳輸錯誤所衍生的索引同步的問題。針對此問題, 論文[3]中假設接收端已知傳送封包的位元總數N與索引總數T,提 供一索引層級的最大後驗機率解碼演算法。其主要構想是建構可變長 度碼索引層級籬柵圖,代表滿足N 與T的所有可能組合序列,並基於 此籬柵圖而計算每一個索引的後驗機率。問題是後驗機率的計算,必 須考量到N及T限制下所有可能的路徑,整體運算量將隨著T的增長 而無可預期。針對此議題我們將在接收端已知N、T及 1T [ , ,..., ]1 2 T l = l l l 的 假設下,重新推導其後驗機率 ( | 1, )1 t t t P u =i u l ,並引入通道的軟性資訊 與一階事前相關性進行遞迴運算。令前t個索引的接收序列為 1t [ ,1 u = u 2, u ..., ]ut ,其中ut = 2 ... 1 1 [ l t l l l b + + +−+ 2 ... 1 2 2 ... , ,..., ] l t l t l l l l l l b+ + + −+ b + + + ,bn為接收端收到的第 n個實數值。若令S l(t−1)代表位元長度為lt−1的可變長度碼字組成的集 合,索引層級後驗機率可推導如下: 1 1 ( t | t, )t P u =i u l 1 1 1 1 1 ( ) ( , | , , ) t t t t t t j S l P u i u j u u l − − − ∈ =
∑
= = 1 1 1 1 1 ( ) 1 1 1 ( , , , , ) ( , ) t t t t t t t t j S l P u i u j u u l P u l − − − ∈ =∑
= = 1 1 1 1 1 1 1 1 1 1 ( ) ( | , , , ) ( | , , ) t t t t t t t t t t j S l C P u u i u j u l P u i u j u l − − − − − ∈ =∑
= = = = 1 1 1 1 1 ( | t , t ) t P u− = j u− l− (4.7) 其中正規化常數 1 1 1 ( 1 , 1 ) / ( , )1 t t t t C =P u− l− P u l 。進一步考慮通道的無記憶性, 1 1 1 1 ( | , , t , )t t t t P u u =i u− = j u− l 可簡化為 ( | , )1t t t P u u =i l 。而 ( | , )1t t t P u u =i l =35 1 2 ... 1 1 2 ... 1 1 ( | ) t t t l l l l l l l l l l P b + + −+ b + + −+ =
∏
。此外,基於事前資訊是一階馬可夫模型的假 設, 1 1 1 1 ( | , t , )t t t P u =i u− = j u− l = P u( t =i u| t−1= j)。綜合整理後,可得出下式: 1 1 1 1 1 1 ( ) ( | , ) ( | , ) ( | ) t t t t t t t t t j S l P u i u l C P u u i l P u i u j − − ∈ = =∑
= = = 1 1 1 1 1 ( | t , t ) t P u− = j u− l− (4.8) 其中 ( | , )1 t t t P u u =i l 為通道的軟性資訊, P u( t =i u| t−1= j)為一階的事前資 訊, 1 1 1 1 1 ( | t , t ) t P u− = j u− l − 則是代表前一時刻的索引後驗機率。最後依據最 大後驗機率原則進行估測: 1 1 ˆt arg{max( ( t | t, ))}t i u = P u =i u l ∈,i S l( )t (4.9) 不同的索引指定皆可以透過事先訓練而計算出ρ,ρ越大則代表 其訊源解碼效能更佳。因此一組最佳的索引指定必須使得ρ最大化, 但此最佳化問題所需考慮的碼字置換組合數目相當的多。例如一個雙 向性可變長度碼書,其中具有位元長度 3 的碼字五個、長度為 4 的六 個、長度為 5 的八個,依前述的原則置換位元等長度的碼字,所有的 排列組合共有 9 5! 6! 8! 3.4836 10× × = × 種。為了得到一組具有最大ρ值的索 引指定,必須針對所有可能組合個別計算其ρ值並做交叉比較,而這 在實際運作上有其困難。因此在進行置換過程中,我們將採用具體可 行的二位元置換演算法(Binary Switching Algorithm,BSA)方式。二 位元置換演算法只能找出區域最佳值(local optimal),但可以省去 全域最佳值(global optimal)的龐大運算量。36 進行二位元置換演算法時,置換的目標為索引所對應的碼字,在 不改變索引順序之前提下,改變索引所對應之碼字的順序。首先,根 據 4.3 節之演算法產生具有錯誤更正能力的雙向性可變長度碼,將其 所屬的碼字依其對應索引機率由大至小的排列,並將這組索引與碼字 的對應設為初始的索引指定,計算此索引指定的ρ,且將其設為參考 值ρref。接著將碼字中最小及最大位元長度分別記為 min和max,不同
位元長度組成的碼字集合定義為{level(min),level(min 1),...,+ level(max)},進
行置換的集合順序從level(min)至level(max)。先考慮具有位元長度 (min)
level 之碼字集合,定義為c={ (1), (2),..., ( (c c c n level(min)))},n level( (min))
為碼字數量,初始設定i=1 及 j= +i 1,即碼字c i( )與c j( )順序進行置 換,置換後計算新的參考值 ref new ρ 。如果 ref new ρ 大於ρref ,則將此兩個碼字 之順序進行置換,並且重新設定i=1及 j= +i 1。反之,則碼字索引維
持不變。令 j= +j 1,直到 j=n level( (min))且 ref new
ρ 依然小於ρref 時,使得
1
i= +i 、 j= +i 1,並重複上面動作,至i=n level( (min))且已不再發生置
換情形時,則此索引指定為level(min)此層區域最佳之索引排列組合。
這樣的步驟由level(min)一直執行到level(max),即可找出每層的區域最
佳索引指定。圖 4.2 為二位元置換演算法之流程圖:
37 設定初始索引指定
選擇處理層為level num( ),初始值num=min,取
出該層碼字及數目n level num( ( )) 設定起始索引指定,計算參考值ρref 設定碼字位置i∈{1, 2,..., (n level num( ))} 設定與i置換位置之 j∈ +{i 1,..., (n level num( ))}, 並置換c i c j( ), ( ),置換後計算新參考值ρnewref ref ref new ρ >ρ 由i與 j判斷是否收斂 ( ) (max)
level num =level
找出最佳索引指定!! 1 num=num+ 1 i= 2 j= 1 j= + j 1 i= +i YES NO NO YES ( ( )) i n level num= ( ( )) i<n level num ( ( )) j<n level num ( ( )) i<n level num ( ( )) j n level num= 圖 4.2 二位元置換演算法
38
第五章 實驗模擬與結果分析
在前面的章節中,詳細地介紹傳輸系統的架構與非對稱性 RVLC 的編解碼過程,並將其運用在心電圖的傳輸上。可變長度碼字間存在 的殘存冗息可運用於軟性訊源解碼,而基於不同的可變長度碼之殘存 的冗息也有多寡之分。若一可變長度碼字的平均長度可達理論熵值, 即代表著沒有任何冗餘,也可達到最好的壓縮效率。然而前面章節所 介紹 RVLC 編碼雖使得碼字平均長度較傳統的霍夫曼碼來得大,但也 使得解碼時有較多的殘存冗息來增進其強健效能。為了進一步驗證其 效能,我們將在此章中模擬系統傳輸端與接收端,計算心電圖訊號源 與接收端還原訊號之訊雜比,並進行結果的比較與分析。 本章將分為三個實驗,首先實驗一將對第四章中基於不同觀點所 設計的 RVLC 及索引指定設計進行傳輸效益的探討。實驗二利用 4.5 節中訓練索引指定的方式,針對不同通道情況訓練 RVLC,並對其解 碼效能加以討論比較。最後我們將利用第三章的軟性訊源解碼機制, 針對兩種不同的索引估計方式做效能比較。5.1 實驗環境設定
本節主要敘述後續實驗的基本設定,而對於每個實驗所需設定 的細節將在往後的實驗過程中逐次說明。
39 整體架構如圖 3.1 所示,其中訊號源將採用 MIT-BIH 資料庫的第 100 號心電圖。每次傳送以一個封包為單位,一個封包內有 100 個心 電圖的離散取樣值,經維度為 K=2 且 M=6 的向量量化處理而得 50 個 量化索引。再使用二進位相位鍵移調變方式,位元"0"→+1、"1"→-1, 位元平均能量為 1。傳送通道的雜訊以無記憶可加性白色高斯雜訊模 擬,其平均值為 0 且變異數為N0 / 2。接收端採用第三章所敘述的軟 性訊源解碼機制,並以其軟性輸出進行索引的估測。至於心電圖重建 品質之評估方式,我們是採用參數訊雜比(Parameter SNR,PSNR)。 在進行實驗之前,我們將會透過大量的訓練資料取得專屬 100 號患者 的心電圖中每個索引發生的機率及其一階的事前資訊。
5.2 實驗一
目 的 : 探討不同的可變長度碼設計對於軟性訊源解碼效能的影 響。 模擬環境 : 透過事前的訓練可知每個索引發生的機率,並據以建構 其霍夫曼碼,依 4.2、4.3 節敘述,可延伸出基於最小長 度及具有錯誤更正能力的兩種設計。索引指定則同樣透 過 MIT-BIH 資料庫 100 號心電圖的資料,依 4.4 節的流 程進行訓練,而訓練時的通道環境設定為 3dB。接著依 5.1 節敘述進行相關的環境設定,再將訊源編碼的碼書40 依序變更為霍夫曼碼與第四章中三種雙向性可變長度碼 的設計,索引的估算則採用 3.4 節的維特比演算法。 結 果 : 量 化 索 引 值 索引機率 Huffman RVLC 1 RVLC 2 RVLC 3 0 0.051007 [1 0 1 0] [0 0 0 0] [0 0 0 0] [1 0 1 0] 1 0.049087 [1 0 1 1] [1 1 1 1] [1 1 1 1] [1 1 1 1] 2 0.04867 [1 1 0 0] [0 1 0 1] [0 1 0 1] [0 1 0 1] 3 0.046467 [1 1 1 0] [1 0 1 0] [1 0 1 0] [0 0 0 0] 4 0.045663 [1 1 1 1] [0 0 1 0] [0 1 1 0] [0 1 1 0] 5 0.045483 [0 0 0 0 0] [1 1 0 1 1] [1 1 0 1 1] [1 0 1 1 1] 6 0.045333 [0 0 0 0 1] [0 1 0 0 1] [0 1 0 0 1] [0 1 0 0 1] 7 0.042283 [0 0 0 1 0] [1 0 1 1 0] [1 0 0 1 0] [1 0 0 1 0] 8 0.042273 [0 0 0 1 1] [0 1 1 0 1] [1 1 1 0 1] [1 1 1 0 1] 9 0.04196 [0 0 1 0 0] [1 1 1 0 1] [1 0 1 1 1] [1 1 0 1 1] 10 0.03939 [0 0 1 1 0] [0 0 1 1 0] [1 0 0 0 1] [1 0 0 0 1] 11 0.03728 [0 0 1 1 1] [1 1 0 0 1] [0 0 0 1 1] [0 0 0 1 1] 12 0.036893 [0 1 0 0 0] [0 1 0 0 0] [1 1 0 0 0] [1 1 0 0 0] 13 0.03678 [0 1 0 0 1] [1 0 1 1 1] [0 0 0 1 0 0] [0 0 1 1 1 0] 14 0.032693 [0 1 1 0 0] [0 1 1 0 0] [0 0 1 0 0 0] [0 0 1 0 0 0] 15 0.032203 [0 1 1 0 1] [1 0 0 1 1] [0 0 1 1 1 0] [0 0 0 1 0 0] 16 0.03148 [0 1 1 1 0] [0 1 1 1 0] [0 1 1 1 0 0] [0 1 1 1 0 0] 17 0.031467 [0 1 1 1 1] [1 0 0 0 1] [0 0 1 0 1 1] [0 0 1 0 1 1] 18 0.029803 [1 0 0 0 0] [0 0 0 1 1] [1 1 0 1 0 0] [1 1 0 1 0 0] 19 0.026457 [1 0 0 0 1] [1 1 1 0 0] [0 0 1 1 0 1] [0 0 1 1 0 1] 20 0.025127 [1 0 0 1 1] [0 0 1 1 1] [1 0 1 1 0 0] [1 0 1 1 0 0] 21 0.024163 [1 1 0 1 0] [1 1 0 0 0] [0 1 0 0 0 1 0] [0 1 0 0 0 0 1] 22 0.022707 [1 1 0 1 1] [1 0 0 1 0 0] [0 0 1 1 0 0 1] [0 0 1 1 0 0 1] 23 0.021273 [0 0 1 0 1 0] [0 0 0 1 0 0] [1 0 0 1 1 0 0] [0 1 0 0 0 1 0] 24 0.01674 [0 1 0 1 0 1] [0 1 1 1 1 0] [1 1 1 0 0 1 1] [1 1 1 0 0 1 1] 25 0.016337 [0 1 0 1 1 1] [1 0 0 0 0 1] [0 0 1 0 1 0 0] [0 0 1 0 1 0 0]
41 26 0.01353 [1 0 0 1 0 0] [1 1 0 1 0 0] [1 1 0 1 0 1 1] [1 1 0 1 0 1 1] 27 0.00958 [0 0 1 0 1 1 1] [1 1 0 1 0 1 1] [1 1 0 0 1 1 1] [1 1 0 0 1 1 1] 28 0.00841 [0 1 0 1 1 0 0] [1 0 0 1 0 1 1] [0 1 0 0 0 0 1] [1 0 0 1 1 0 0] 29 0.0031533 [1 0 0 1 0 1 0 1] [1 0 0 1 0 1 0 0] [0 0 1 0 0 1 0 0] [0 0 1 0 0 1 0 0] 30 0.0028133 [0 0 1 0 1 1 0 0 0] [1 1 0 1 0 1 0 1 1] [1 0 1 1 0 1 1 0 1] [0 0 1 1 1 1 0 0 1] 31 0.0025367 [0 0 1 0 1 1 0 1 1] [1 0 0 1 0 1 0 1 1] [0 1 1 1 0 1 1 1 0] [0 1 1 1 0 1 1 1 0] 32 0.0022433 [0 1 0 1 0 0 0 1 1] [0 1 1 1 1 1 1 1 0] [1 0 0 1 1 1 0 0 1] [1 0 0 1 1 1 0 0 1] 33 0.0021267 [0 1 0 1 0 0 1 1 1] [1 0 0 0 0 0 0 0 1] [0 0 0 1 0 1 0 0 0] [0 0 0 1 0 1 0 0 0] 34 0.0021133 [0 1 0 1 1 0 1 0 0] [0 0 0 1 0 1 0 1 1] [1 1 1 0 0 0 1 1 1] [1 1 1 0 0 0 1 1 1] 35 0.0019933 [0 1 0 1 1 0 1 1 0] [1 0 0 1 0 1 0 1 0 0] [0 0 1 1 0 0 0 0 1] [0 0 1 1 0 0 0 0 1] 36 0.0016833 [1 0 0 1 0 1 0 0 0] [0 0 0 1 0 1 0 1 0 0] [0 0 1 1 1 1 0 0 1] [1 0 0 1 1 1 1 0 0] 37 0.0016633 [1 0 0 1 0 1 0 0 1] [1 0 0 0 0 0 1 0 1 1] [0 1 0 0 0 0 0 1 0] [0 1 0 0 0 0 0 1 0] 38 0.00155 [1 0 0 1 0 1 1 0 0] [0 1 1 1 1 1 1 1 1 0] [1 0 0 1 1 1 1 0 0] [1 0 1 1 0 1 1 0 1] 39 0.0015467 [1 0 0 1 0 1 1 0 1] [1 0 0 0 0 0 0 0 0 1] [1 0 0 0 0 1 1 0 0] [1 0 0 0 0 1 1 0 0] 40 0.0015467 [1 0 0 1 0 1 1 1 0] [1 1 0 1 0 1 0 1 0 0] [0 0 1 0 1 0 1 0 0] [0 0 1 0 1 0 1 0 0] 41 0.0015467 [1 0 0 1 0 1 1 1 1] [1 0 0 0 0 0 1 0 1 0 0] [1 1 0 1 0 1 0 1 1] [1 1 0 1 0 1 0 1 1] 42 0.0013533 [0 0 1 0 1 1 0 0 1 0] [1 1 0 1 0 1 0 1 0 1 1] [1 1 0 0 1 1 0 0 1 1] [0 1 1 1 0 1 1 0 0 1] 43 0.0013067 [0 0 1 0 1 1 0 0 1 1] [0 0 0 1 0 1 1 1 1 1 0] [1 1 1 0 0 0 0 1 1 1] [0 1 0 0 0 0 0 0 0 1] 44 0.0013067 [0 0 1 0 1 1 0 1 0 0] [1 0 0 1 0 1 0 1 0 1 1] [1 1 0 0 1 0 1 1 1 0] [1 1 0 0 1 0 1 1 1 0] 45 0.00123 [0 1 0 1 0 0 0 0 0 0] [1 0 0 0 0 0 0 1 0 1 1] [0 0 1 1 1 1 1 0 0 1] [1 0 0 1 1 1 1 1 0 0] 46 0.0012233 [0 1 0 1 0 0 0 0 0 1] [0 1 1 1 1 1 1 1 1 1 0] [0 1 0 0 0 0 0 0 1 0] [0 1 0 0 0 0 0 0 1 0] 47 0.0011933 [0 1 0 1 0 0 0 0 1 0] [1 0 0 0 0 0 0 0 0 0 1] [1 0 0 1 1 1 1 1 0 0] [0 0 1 1 1 1 1 0 0 1] 48 0.00118 [0 1 0 1 0 0 0 0 1 1] [0 0 0 1 0 1 0 1 0 1 1] [0 1 1 1 0 1 0 0 1 1] [1 1 0 0 1 0 1 0 1 1] 49 0.00117 [0 1 0 1 0 0 0 1 0 0] [0 0 0 1 0 1 0 0 0 0 0 1] [1 1 1 0 0 1 0 0 1 1] [1 1 1 0 0 1 0 0 1 1] 50 0.00117 [0 1 0 1 0 0 0 1 0 1] [1 0 0 1 0 1 0 1 0 1 0 0] [1 1 0 1 0 1 0 0 1 1] [1 1 0 1 0 1 0 0 1 1] 51 0.0011267 [0 1 0 1 0 0 1 0 0 0] [1 0 0 0 0 0 0 1 0 1 0 0] [1 1 0 0 1 0 1 0 1 1] [1 1 1 0 0 0 0 1 1 1] 52 0.0011133 [0 1 0 1 0 0 1 0 0 1] [0 0 0 1 0 1 0 1 0 1 0 0] [1 1 0 0 1 0 0 1 1 1] [1 0 0 1 1 0 1 1 1 0] 53 0.0011067 [0 1 0 1 0 0 1 0 1 0] [0 1 1 1 1 1 0 0 0 0 0 1] [0 0 1 1 1 1 1 1 0 0] [0 0 1 1 1 1 1 1 0 0] 54 0.0010967 [0 1 0 1 0 0 1 0 1 1] [1 0 0 0 0 0 1 1 1 1 1 0] [0 1 0 0 0 0 0 0 0 1] [1 1 1 0 0 0 0 0 0 1] 55 0.00107 [0 1 0 1 0 0 1 1 0 0] [0 0 0 1 0 1 1 1 1 1 1 0] [1 0 0 1 1 0 1 1 1 0] [1 1 0 0 1 0 1 1 0 1] 56 0.0010667 [0 1 0 1 0 0 1 1 0 1] [1 1 0 1 0 1 0 0 0 0 0 1] [0 1 1 1 0 1 1 0 0 1] [1 1 0 0 1 1 0 0 1 1] 57 0.00105 [0 1 0 1 1 0 1 0 1 0] [0 1 1 1 1 1 0 1 0 1 0 0] [1 0 0 0 0 0 0 0 1 0] [1 0 1 1 0 1 1 0 0 1] 58 0.00102 [0 1 0 1 1 0 1 0 1 1] [0 1 1 1 1 1 1 1 1 1 1 0] [1 1 1 0 0 0 0 0 0 1] [0 1 1 1 0 1 0 0 1 1] 59 0.00097667 [0 1 0 1 1 0 1 1 1 0] [1 0 0 0 0 0 0 0 0 0 0 1] [1 1 0 0 1 0 1 1 0 1] [1 1 0 0 1 0 0 1 1 1] 60 0.00089 [0 1 0 1 1 0 1 1 1 1] [1 1 0 1 0 1 0 1 0 1 0 0] [1 0 1 1 0 1 1 0 0 1] [1 0 0 0 0 0 0 0 1 0] 61 0.00082 [0 0 1 0 1 1 0 1 0 1 0] [0 1 1 1 1 1 0 1 1 1 1 1 0] [0 0 1 1 0 0 0 1 1 0 0] [0 0 1 1 0 0 0 1 1 0 0] 62 0.0004433 [0 0 1 0 1 1 0 1 0 1 1 0] [1 0 0 0 0 0 1 0 0 0 0 0 1] [1 0 0 0 0 1 0 0 0 0 1 0] [1 0 0 0 0 1 0 0 0 0 1 0]
42 63 3.00E-05 [0 0 1 0 1 1 0 1 0 1 1 1 ] [0 0 0 1 0 1 0 0 0 0 0 0 1] [0 1 1 1 1 0 0 1 1 1 1 0] [0 1 1 1 1 0 0 1 1 1 1 0] 平均長度 5.0824 5.1548 5.49 5.49 分 析 : RVLC1為基於最小平均長度的設計,RVLC2為具有錯誤更 正能力的設計,而RVLC3為 4.4 節所建議的索引指定設 計。可以從表 5.1 中得知霍夫曼碼的碼字平均長度為 5.0824,RVLC1的選取較霍夫曼碼多了後置條件的這項限 制,故其平均長度提升至 5.1548,而RVLC2則因為位元 等長度的碼字間之漢明距離必須不小於 2,使得平均長 表 5.1 不同可變長度碼設計之碼書 圖 5.1 四種可變長度碼之軟性訊源解碼效能
![圖 2.2 Einthoven 三角形[15]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8751558.206040/17.892.180.715.292.715/圖22Einthoven三角形15.webp)
![圖 2.3 單極胸前導程電極[14]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8751558.206040/18.892.155.702.480.953/圖23單極胸前導程電極14.webp)