RDF-Chord: A Hybrid PDMS for P2P Systems
Yi-Hui Chen1, 3,Eric Jui-Lin Lu2,*, Yao-Tsan Chang2 and Shiuan-Yin Huang2
1 Department of Applied Informatics and Multimedia, Asia University, Taichung 413, Taiwan 2 Department of Management Information Systems, National Chung Hsing University, Taichung 402, Taiwan 3 Department of Medical Research, China Medical University Hospital, China Medical University, Taichung 404,
Taiwan
Abstract — In recent years, peer-to-peer (P2P) computing has gained great attention in both research and industrial communities. Although many P2P systems, such as CAN, Pastry, Chord, Tapstry, etc., have been proposed, they can only support exact-match lookups. To overcome the limitation, a new area of P2P research, called peer data management system (PDMS), has emerged. In PDMS, metadata were used for annotating resources so that complex queries can be supported. In this paper, we propose a hybrid PDMS called RDF-Chord. In RDF-Chord, a set of keys is ingeniously designed so that the advantages of metadata are further utilized to significantly reduce the search spaces. From the experimental results, it shows that RDF-Chord is highly scalable and efficient, especially in range queries.
Index Terms—Peer Data Management System; RDF, RDF Repository; Peer-to-Peer Networks.
I.INTRODUCTION
Since the wide spread usage of Napster and KazAa, people started to realize the power of resource sharing in a Peer-to-Peer (P2P) manner. In recent years, P2P systems have been widely used in several applications, such as file sharing [4], [32], multimedia delivery [23], video streaming [16], knowledge management [34], etc. P2P systems can be roughly classified into three categories: centralized, decentralized and unstructured, as well as decentralized and structured. Centralized P2P systems, such as Napster, require a centralized directory server and thus are not scalable. For decentralized and unstructured P2P systems such as Gnutella, queries are flooded throughout the entire network which generates a large volume of traffic with no guarantee to find the desired resource even if it exists. For efficiency and scalability, decentralized and structure P2P systems such as CAN [25], Pastry [28], Chord [30], Kademlia [18], and Tapstry [35] have been proposed. To integrate the advantages of both types of peer-to-peer networks and minimizes the disadvantages, Yang [33] proposed a hybrid peer-to-peer system for distributed data sharing. These P2P systems were also called DHT-based (Distributed Hash Table) systems, because they use a hash function to generate indices which are distributed among nodes. The query cost of DHT-based P2P systems can be guaranteed in logarithmic bounds. Although DHT-based P2P systems are scalable and efficient, only exact-match queries are supported [11].
Recently, a new branch of P2P research, called semantic-based P2P systems, has emerged. Related semantic-based P2P systems include RDFStore [26], Edutella [20], RDFPeers [2], Expertise [10], ContextPeers [9], SuperRing [1], SCS [7], R-Chord [14], Squid [29], M-Chord [21], Distributed Suffix Tree (DST) [36], ML-Chord [15], Mandreoli et al.’s scheme [17], Layered Adaptive Semantic-based Destination Management Systems (LA_DMS) [13], Dynamic Semantic Space (DSS) [8], RDF Trigger Language (RDFTL) [22], Gao et al. [6], Heine et al. scheme [12], and Super-Peer [19]. These semantic-based P2P systems can be roughly classified into three categories semantic-based on their main objectives. The main objective of the first category is to provide efficiency semantic reconciliations [6, 11, 15] to resolve the problems of heterogeneity of data representations. For applications that require timely notification of metadata change, Papamarkos et al. proposed a mechanism, called RDFTL [22], to monitor and process the changes of RDF metadata in P2P environment. The main objective of the second category is to provide faster queries by reducing search space according to the metadata of shared resources, such as Expertise,
*Corresponding author: E. J. Lu is with the Department of Management Information Systems, National Chung Hsing University, Taichung, Taiwan R.O.C.. (Phone: +886-4-22840864; fax: +886-4-22857173; e-mail: jllu@ nchu.edu.tw).
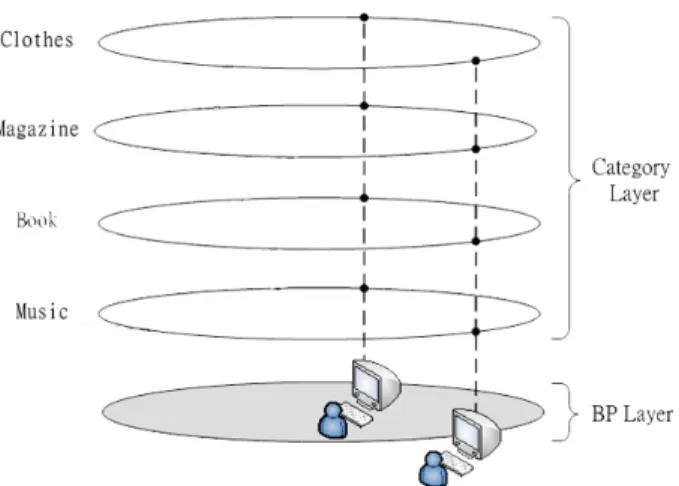
ContextPeers, SCS, ML-Chord, and SuperRing. Among them, ML-Chord proposed a multi-layered P2P resource sharing model. In ML-Chord, all resources are classified into categories based on a selected ontology and each category is corresponding to an overlay layer. The number of overlay layers depends on the number of categories for a specific domain or ontology. Moreover, ML-Chord used bridge nodes to help in finding the successor of a node n when node n and its successor are not in the same category. The experiments showed that ML-Chord is superior than both Chord and SCS. However, the P2P systems categorized into the second category, including ML-Chord, do not fully utilize the richness and flexibility of metadata (such as RDF) such that they are unable to handle complex queries, such as disjunctive, range and conjunctive multi-predicate queries.
To support the complex queries, the third category, called peer data management systems (PDMS) [5], [31], were proposed. A PDMS is a decentralized architecture for sharing data among peers. The key issue in PDMS is how to organize and manage distributed resource indexes in P2P networks for routing queries efficiently. Many efforts have been devoted to study the key issue, they use metadata to generate indexes, and then distribute indexes to appropriate peers. Queries are sent to peers to locate the nodes that host the requested resources. That is, PDMS is constituted of the nodes that host the indices. Examples of such P2P systems include RDFStore, Edutella, RDFPeers, M-Chord, DST, Squid, R-Chord, Gao et al.’s, Heine et al.’s scheme and Super-Peer.
The organization of PDMS systems can be either centralized (ex. RDFStore), fully distributed (ex. Edutella, M-Chord, DST, RDFPeers, Gao et al.’s scheme, Heine et al.’s scheme and Squid), or hybrid (ex. R-Chord and Super-Peer). Centralized PDMS systems require a central server and thus not scalable. All nodes in the network have to take part in fully distributed PDMS systems. This results in large search space that in turn results in higher query cost. In hybrid PDMS systems, because only selected nodes are in charge of query processing, the search space is smaller than that of fully distributed PDMS systems, and thus queries are generally faster.
Resource Description Framework (RDF) [27], developed by World Wide Web Consortium (W3C), is one of the popular languages for representing metadata about resources. A RDF document is composed of a set of RDF triples. Each triple is in the form of (subject, predicate, object) where the subject denotes a resource, the predicate defines a specific property of the resource, and the object describes the actual value of the predicate. For example, “the creator of http://some.url/ is Eric Lu” can be represented as (http://some.url/, creator, Eric Lu) in RDF. Because the richness of RDF, queries that support RDF can be flexible and complex. Among the PDMS systems, only RDFStore, Edutella, Super-Peer, Gao et al.’s scheme, Heine et al.’s scheme, and RDFPeers support RDF-like queries. However, RDFStore suffers performance bottleneck and a single point of failure. Edutella does not scale well to a large number of nodes [2]. To be scalable, Super-Peer is the improved version of Edutella, but it requires definitions of schemata in advanced [2]. In addition, both Gao et al.’s scheme [6] and Heine et al.’s scheme [12] do not support range queries. To compare with previous works, RDFPeers defines eight possible atomic triple queries, summarized in Table I, which is efficient and scalable to support disjunctive and range queries as well as conjunctive multi-predicate queries.
Table I
THEEIGHTPOSSIBLEATOMICTRIPLEQUERIES No
. PatternQuery Cost Query Semantics
Q1 (si, ?p, ?o) logN given subject si, find all predicates and objects of the
resource identified by si
Q2 (?s, pi, ?o) logN given predicate pi, find the subjects and objects of
the triples having this predicate
Q3 (?s, ?p, oi) logN given object oi of any predicate, find the subjects and
predicates of matched triples
Q4 (si, pi, ?o) logN given subject si, find its object of predicate pi
Q5 (?s, pi, oi) logN given object oi of predicate pi, find the subjects of
matched triples
Q6 (si, ?p, oi) logN given subject si, find its predicate which has object oi
Q7 (si, pi, oi) logN return this triple if it exists otherwise return nothing
Q8 (?s, ?p, ?
o) O(N) find all possible triples
Although RDFPeers is efficient and scalable, it has a few major drawbacks. RDFPeers is a fully distributed PDMS. RDFPeers does not take full advantages of metadata in range queries. For example, a node wishes to find products whose price falls within 100 and 500 and issues a range query, (?s, price, ?o) AND 100 ?o && ?o500. In RDFPeers, the search space of the query includes not only price that falls within 100 and 500, but also all other predicates (?p) that falls within 100 and 500. A better approach is only to lookup the price that falls within 100 and 500.
To support complex queries like RDFPeers and overcome its major drawbacks, a flexible PDMS for P2P networks, called RDF-Chord, is proposed in this paper. RDF-Chord contains three ring sets, namely subject ring set, predicate ring set and object ring set. Each ring set contains several categories, as shown in Fig. 1, and nodes in each category are organized as a Chord-like ring. The connections between different category layers are linked by bridge peers. Also, the bridge peers are formed as a Chord-like ring. Shared resources and nodes are assigned into the appropriate ring sets based on a set of newly designed keys. RDF keys are designed to provide more efficient range queries by fully utilizing the relationships between any two fields of a RDF triple. With such design, as for the example range query, (?s, price, ?o) AND 100 ? o && ?o500, RDF-Chord only looks up the prices that fall in the range of 100 and 500. In other words, if the search space of range queries in RDFPeer is 2m, the search space in RDF-Chord is 2m/2. The design of
RDF keys in RDF-Chord makes execution speeds of range queries at least 100 times faster than those of RDFPeers, proved by experimental results. From various experimental results, it can be concluded that RDF-Chord is far superior than RDFPeers.
Fig. 1 The design of RDF-Chord model
The rest of the paper is organized as follows: In section II, previous works in PDMS are briefly reviewed. The design of RDF-Chord is described in section III. In section IV, various simulation experiments and their results are presented and analyzed. Finally, we conclude our work in section V.
II. REVIEWOF PDMS SYSTEMS
RDFStore [26] is a centralized RDF repository which provides fast queries. However, like other centralized approaches, it is not only generally un-scalable, but also may suffer a single processing bottleneck and a single point of failure. M-Chord [21], Squid [29] and DST [36] use some special technique (such as iDistance, Hilbert space filling curve, and suffix tree, respectively) to map multiple keywords to a single key. By using the key, resources can be queried on a Chord overlay network. Although they are efficient, complex queries are not supported. In R-Chord [14], the metadata of shared resources are stored in super peers which are organized in a Chord overlay network. The relationships; such as join, union, similar, etc.; between super peers are built and can be used to speed up queries. Although R-Chord fully utilized semantics, it unfortunately does not support range queries.
Edutella [20] is built on a Gnutella-like network. The RDF documents of each shared resource are stored in its owner node. Because RDF-like queries are flooded to all nodes in the network, Edutella does not scale well. To overcome the problem, Nejdl et al. [19] proposed Super-Peer, a successor of Edutella, which arranges super peers in a hypercube topology that consists of 2d super peers in a d-dimensional hypercube.
Each normal node has a direct link to a super peer and provides the super peer with its metadata information. Although Super-Peer provides better scalability, it does not support range queries and requires definitions of schemata in advance [2]. Gao et al. [6] developed an efficient method to improve query performance by using semantic similarity between queries and resources. Later on, Heine et al. [12] proposed a query evaluation algorithm to query RDF triples stored in peers. Both methods did not consider maintenance issues, such as node join and leave, which are common in P2P networks. Furthermore, they did not support complex queries such as range queries.
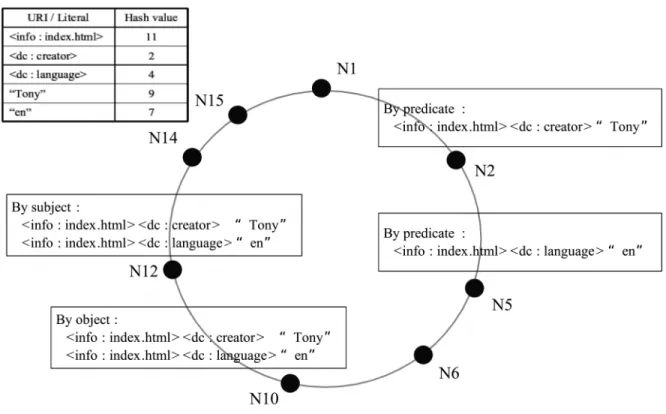
RDFPeers [2] is built on a multi-attribute addressable network (MAAN) [3] which is an extension of Chord [30]. The central concept of RDFPeers is to generate three hash keys based on the values of subject, predicate, and object for each RDF triple. Each triple will be stored at nodes based on the hash keys. For example, as shown in Fig. 3, N6 has a RDF document which is composed of two RDF triples. The hash
values of the triples are shown in the top left corner of Fig. 3. As shown in Fig. 3, the hash values of the first triple (<info:index.htm>, <dc:creator>, “Tony”) are 11, 2, and 9, respectively. Therefore, based on RDFPeers, the triple must be stored at their corresponding successors and they are N12, N2, and N10,
Fig. 2 An example RDF document
Fig. 3 The example of distributing triples in RDFPeers
RDFPeers defines ten types of queries including eight types of atomic queries, disjunctive and range queries, and conjunctive multi-predicate queries. The eight possible atomic queries are shown in Table I. Except for Q8, either one of the specified values (si, pi, or oi) in an atomic query is hashed. The query is
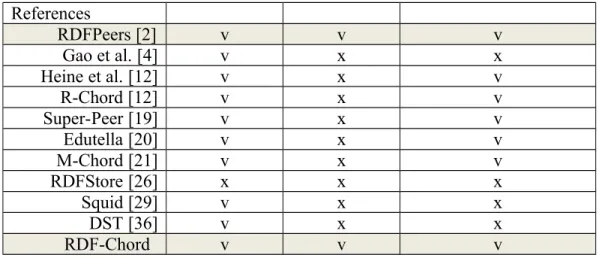
forwarded to a node based on the hash value. The node will look up the triples it has and return the results to the requesting node. Disjunctive and range queries as well as conjunctive multi-predicate queries are the extension of atomic queries. The details of the query types will be described in details in Section 3. All surveyed P2P networks are compared and listed in Table II based on the supported complex query types. As easily seen in the table, both RDF-Chord and RDFPeers provides the same complex queries, and thus their performances will be evaluated in our experiments.
Table II
The Comparisons of Schemes for Supporting Complex Queries
Query types Disjunctive
Query Range Query Conjunctive QueryMulti-predicate
References RDFPeers [2] v v v Gao et al. [4] v x x Heine et al. [12] v x v R-Chord [12] v x v Super-Peer [19] v x v Edutella [20] v x v M-Chord [21] v x v RDFStore [26] x x x Squid [29] v x x DST [36] v x x RDF-Chord v v v
III. THE DESIGNOF RDF-CHORD
A.The Architecture
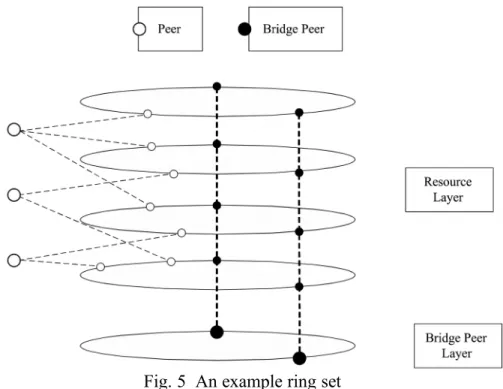
RDF-Chord is a PDMS which is built on the top of an unstructured P2P network. Nodes that have shared resources in the network will join PDMS; in other words, the structure of RDF-Chord can be either fully distributed or hybrid. The architecture of Chord is shown in Fig. 4. There are three ring sets in RDF-Chord, and they are subject ring set, predicate ring set and object ring set. Each ring set contains multiple resource layers. In each resource layer, nodes are organized in a Chord-like ring. The nodes with higher processing power or bandwidth will be chosen as bridge peers (BPs). A BP in a ring set is linked to all resource layers in the ring set. Also, all BPs in a ring set are organized in a Chord-like overlay layer, called BP layer. An example ring set is shown in Fig. 5, where the white balls and black balls are peers and bridge peers, respectively.
Fig. 5 An example ring set
A node is assigned to a resource layer on each ring set based on the RDF triple(s) it has. The resource layer for each ring set is calculated based on (1).
lr = floor(H
x(tr) * Cr) / Hmax), where 0 r 2 (1)
In (1), the value of r is either 0, 1, or 2 which denotes the subject, predicate, or object, respectively. lr
denotes the l th resource layer in r ring set. tr represents the rth element of triple t. For example, t0 represents
the subject value of triple t. Cr is the number of resource layers in r ring set. Hx is a locality preserving hash
function of x bits where Hx(v) = (v - vmin) * (2x - 1) / (vmax - vmin) [3]. In general, the hash space for tr can be
different. It is assumed that the largest hash space of tr is x. Therefore, v
min and vmax are 0 and 2x – 1,
respectively. Hmax is the maximum value of Hx plus one.
The ID of every node is calculated as Hm(node’s IP address and port number), where Hm is a SHA-1
hash function of m-bits and m = 2 * x. For example, it is assumed that Cr is 22 for all r and node N45 has a
RDF triple (http://some.url/, creator, Eric Lu). If x = 3, the value of Hmax is 8 and m is 6. Supposed that the
hash values of the triple are 2, 6, and 3; N45 is assigned to the resource layer 1 in subject ring set because l0
= floor(2 * 4 / 8) = 1 by (1). Similarly, N45 is also assigned to the resource layer 3 (floor(6 * 4 / 8) = 3) in
predicate ring set and the resource layer 1 (floor(3 * 4 / 8) = 1) in object ring set. B. Successor and Predecessor
The successor of node n is the node that is arranged after node n and closest to node n. The predecessor of node n is the node that is organized before node n and closest to node n. Node n can use n.find_successor(r, l, id) to find the successor of node id in lr. The pseudo code for n.find_successor(r,
l, id) is shown in Fig. 6. In n.find_successor(r, l, id), if n is not connected to lr, it will ask a bridge peer to
find the successor by invoking bp.find_successor(r, l, id). Otherwise, it will check whether or not node id is between n and its successor. If yes, node n returns its successor; otherwise, the predecessor n' of id is obtained first, and then n' will be asked to find the successor for id. In Fig. 6, n.find_predecessor(r, l, id) is used to find the predecessor for node id in lr. In n.find_predecessor(r, l, id), n.finger[r, l] denotes n’s
finger table in lr, and n.finger[r, l, i] denotes the ith entry of n.finger[r, l]. For each entry in n.finger[r, l],
n.find_predecessor(r, l, id) checks whether or not n.finger[r, l, i] is between n and id, excluding n and id. If yes, n.finger[r, l, i] is returned; otherwise, n is returned. Note that a finger table is a routing table
kept by a node. If a node has a shared resource, it has three finger tables (one for each ring set). Each finger table contains up to m entries. The ith entry of node n will contain the address of successor ((n+2i-1)
mod 2m). With such a finger table, the number of nodes that needs to be searched to find a successor in an
N-node network is O(logN). In fact, because nodes are allocated to multiple layers (denoted as C layers), the query time is O(log(N/C)).
Fig. 6 The pseudocode for obtaining id’s successor and predecessor C. Finger Tables
To accelerate lookups, every node not only has a successor and a predecessor, but also maintains additional routing information called finger tables. If a node has a shared resource, it has three finger tables (one for each ring set).The size of each finger table is m. The ith entry of node n will contain the address of
successor ((n+2i-1) mod 2m). With such a finger table, the number of nodes that needs to be searched to find
a successor in an N-node network is O(logN). In fact, because nodes are allocated to multiple layers (denoted as C layers), the query time is O(log(N/C)). The procedure for node n to create finger tables in lr
is shown in Fig. 7. In setup_finger(r, l), n calculates kj = (n+ 2j-1) mod 2m for all j where 1 j m.
Then n invokes n.find_successor(r, l, kj) to find the successor of kj. The procedure will be repeated until
all successors of kj are obtained.
In addition to finger tables, an extra table, called BP table, is required. For bridge peers, the BP table is used to provide routing information in BP layer. Thus, the procedure of creating BP tables for bridge peers is identical to setup_finger(). Because normal peers do not have routing information in all resource layers, it is required for normal peers to contact a bridge peer to forward queries to an appropriate resource layer. Therefore, each normal peer needs a BP table that contains bridge peers. The procedure for creating BP tables for normal peers is described as follows: a normal peer randomly selects a node from its finger tables. Then, the peer retrieves the first entry, which is a bridge peer, from the BP table of the selected node, and the selected bridge peer becomes the first entry of its BP table. The second entry of its BP table is the successor of the first entry. The same procedure will continue until all entries are filled up. The size of BP tables for normal peers is d where 1 d m.
Fig. 7 The pseudocode for building finger tables
Partial finger tables and BP tables for N45 (a normal peer) and N51 (a BP) is shown in Fig. 8. As shown in
Fig. 8, d is 2, the resource layer i in r ring set is denoted as ir, the finger table for ir is denoted as FTr i, and
the BP finger table for r ring set is denoted as BP-Tabler. As stated earlier, because l0 and l1 of N
45 are 1
and 0, respectively, N45 has FT01 and FT10. The first entry of BP-Table0 for N45 is selected from the first
entry of its FT0
1. Because the successor of N51 is N23, N23 became the second entry of BP-Table0. Because
N51 is a bridge peer for all ring sets, it has only one BP table which is BP-Table0. Also, N51 has FTri for all
resource layers in all ring sets.
Fig. 8 Finger tables and BP tables of a BP and a normal peer
D.Distributing Indices
The indices of resources are generated by hashing function and then the indices are saved in the corresponding nodes. While receiving a query request, the request is also hashed to generate a key, and the node is obtained if its index matches the key. To efficiently process queries and manage distributed RDF triples, a set of keys is ingeniously designed so that the advantages of metadata are further utilized to significantly reduce the search spaces. The designed keys are shown in Eq. (2) to Eq. (10), where Hx is a
locality-preserving hash function with 2x hash space. The space of all keys is 2m where m = 2 * x. k
s, kp,
and ko are the hash values of subject, predicate, and object of triple t, respectively. The design of ks, kp, and
ko has at least two main advantages: (1) all query types supported by RDFPeers are also supported in
RDF-Chord; (2) Because ks, kp, and ko are used in subject, predicate, and object ring sets, respectively, the search
space is smaller than that of RDFPeers which results in faster queries.
The design of kpo clearly links the relationships between predicate and object. With kpo, for a specific
predicate value (i.e. t1), the key space of its associated object value (i.e. t2) falls within the range of H x(t1) *
2x + 0 and H
x(t1) * 2x + 2x - 1. Therefore, in range queries, the search space is restricted to 2x. On the
contrary, for RDFPeers, the search space is 2m in range queries. For example, if the hash value of “price” is
5 and x = 3, kpo ensures that the key space of object values associated with “price” is within the range of 5
* 8 and 5 * 8 + 7. Similar explanations also apply to kso, ksp,kps, kos, and kop.
ks = Hx(t0) * 2x (2) kp = Hx(t1) * 2x (3) ko = Hx(t2) * 2x (4) kso = Hx(t0) * 2x + Hx(t2) (5) ksp = Hx(t0) * 2x + Hx(t1) (6) kpo = Hx(t1) * 2x + Hx(t2) (7) kps = Hx(t1) * 2x + Hx(t0) (8) kos = Hx(t2) * 2x + Hx(t0) (9) kop = Hx(t2) * 2x + Hx(t1) (10)
The pseudo code for distributing indices is shown in Fig. 9. The distribution of indices has to be done in all three ring sets. Every node may have zero or more resources, and each resource is described by one triple (denoted as ti). For the subject ring set, node n calculates l0, ks, ksp and kso for each triple ti it has.
Then, n uses n.find_successor(0, l0, k
s, ti) to find the node ns which is the successor of ks and stores ti in
ns. Because kso and ksp are greater than or equal to ks, ns is used to find successors nso and nsp for kso and ksp
by invoking ns.find_successor(0, l0, kso, ti) and ns.find_successor(0, l0, ksp, ti), respectively. The triple ti
is also stored in both nso and nsp. Similar procedure has to be carried out in both predicate and object ring
sets. For example, it is assumed that x = 3, and N45 has a hashed-triple (2, 6, 3). To distribute indexes, N45
calculates the values of l0, k
s, ksp, and kso which are 1 (floor(2 * 4 / 8)), 16 (2 * 23), 22 (2 * 23 + 6), and 19
(2 * 23 + 3), respectively. Then, N
45 invokes find_successor(0, 1, 16, t) and obtains N16 which is
responsible for key 16. N16 stores ti, calls find_successor(0, 1, 22, ti) and find_successor(0, 1, 19, ti),
and obtains N23 and N20 which are the successors of 22 and 19, respectively. The triple ti is also stored in
both N23 and N20. Similarly, ti is stored at nodes based on kp, kps, and kpo in predicate ring set. In object ring
set, ti is stored at the nodes which are the successors of ko, kos, and kop. Note that, although the
find_successor() in Fig. 9 has 4 parameters which is different from the find_successor() in Fig. 6, they are all used to find successor for a specified node. The only difference is that, for the find_successor() in Fig. 9, the triple ti is stored at successor nodes.
Fig. 9 The pseudocode for distributing indexes E. Query
Like RDFPeers, RDF-Chord supports eight types of atomic queries as shown in Table I. These atomic queries are further classified into three query types as shown in Table III. When an atomic query Qi is
initiated, the query node n will invoke n.query(Qi) to locate the nodes which can resolve the query. If the
subject of Qi is an exact value, it is a type-I query; if Qi is not of type I and its predicate is an exact value, it
is then a type-II query; otherwise, it is a type-III query. All the costs of Type I, II, and III are log(N/Cr),
which are lower than that of Table I.
Table III
THEPOSSIBLEQUERYPATTERNSIN RDF-CHORD
Type Query Query Type Cost
I (si, ?p, ?o) Q1 log(N/Cr) (si, pi, ?o) Q4 log(N/Cr) (si, ?p, oi) Q6 log(N/Cr) (si, pi, oi) Q7 log(N/Cr) II (?s, pi, ?o) Q2 log(N/Cr) (?s, pi, oi) Q5 log(N/Cr) III (?s, ?p, oi) Q3 log(N/Cr)
The pseudo code for query(Qi) is shown in Fig. 10. When node n issues Qi and if Qi is of type I, the
subject ring set is used to resolve the query. After l0 and k
s are obtained, the nodes that host the requested
resource are returned by find_successor(). Similarly, if Qi is of type II, l1 and kp are calculated, and the
query is resolved by using the predicate ring set. If Qi is of type III, l2 and ko are calculated, and the query
is resolved by using the subject ring set. If node n has no direct link to lr, n will look up its BP-Tabler to 11
find a BP and forward the query to the BP. Finally, the BP calls bp.find_successor(r, l, key) to find the location of the requested resources.
Fig. 10 The pseudocode for query
For example, as shown in Fig. 11, N34 issues a query (2, ?p, 3). Because the subject value of the query is
not a variable, the subject ring set is used to resolve the query. After calculation, N34 obtains l0 and key (i.e.
ks) which are 1 and 19, respectively. However, because N34 does not have FT10 (i.e. does not have a direct
link to l0), it looks up its BP-Table0 and obtains a BP N
51. The query is forwarded to N51, and then N51 uses
its FT10 to obtain N8 which is close to key 19. N51 passes the query to N8. The procedure will be repeated
until the query is delivered to N20. When N20 receives the query, it looks up its indices, finds the matched
Fig. 11 An query example
In RDFPeers, disjunctive and range queries (i.e. Q9) are defined as follows, where “*” denotes zero or more of occurrences, and “(A|B|C)” denotes either A, B, or C is chosen:
Q9 :: = Query ‘AND’ ConstraintList Query :: = Q1|Q2|Q3|Q4|Q5|Q6|Q7
ConstraintList :: = OrExpression (‘&&’ OrExpression)* OrExpression :: = Expression (‘| |’ Expression)*
Expression :: = Variable (NumericExpression |StringExpression) NumericExpression :: = (‘>’ | ‘<’ | “=” | ‘!=’ | ‘<=’ | ‘>=’) NumericLiteral
StringExpression :: = (‘=’ | ‘!=’) Literal
Literal :: = PlainLiteral | URI | NumericLiteral
An example disjunctive query can be defined as (?s, name, ?o) AND ?o = “Java Programming” || ?o = “Java and XML”, and the query is to find resources whose name is either “Java Programming” or “Java and XML”. In RDF-Chord, disjunctive queries can be accomplished by issuing query(Qi) multiple times
and merging their query results.
When a node issues a range query, for example, (?s, p, ?o) AND l ?o u, where l is the lower bound and u is the upper bound of the object value, because p is an exact value, l1 is calculated. Also,
because the object value is within the range of l and u, kpol and kpou, respectively; will be calculated based
on (7). If either lower or upper bound is not given, 0 or 2x-1 is used to replace k
pol or kpou, respectively. 13
Then, the query is forwarded to Nl which is returned by find_successor(1, l1, kpol). When N1 receives the
query, it will check whether or not it is the successor of kpou. If yes, it will lookup its indices and return the
matched results back to the requested node. Otherwise, it forwards the query to its immediate successor. The process will be repeated until the query reaches Nu, the successor of kpou. Due to the design of kpo, all
nodes that host resources in the range of kpol or kpou are guarantee to be in the same resource layer. For
example, to query the resources whose year is in the range of 2005 and 2011, a range query can be defined as (?s, year, ?o) AND ?o 2005 && ?o 2011.
The conjunctive multi-predicate queries (i.e. Q10) in RDFPeers are defined as follows, where “+” denotes
one or more of occurrences:
Q10 := Queries ‘AND’ ConstraintList Queries := (Q2|Q5)+
Conjunctive multi-predicate queries can be resolved by using predicate ring set. When a node n issues a conjunctive multi-predicate query, l1 and k
p are calculated. If ConstrainList contains range queries, the
lower and upper bounds of kpo and kps are also calculated to accelerate lookups. For example, to query
resources authored by “Eric Lu” and the year is in the range of 2005 and 2011, a conjunctive multi-predicate query can be defined as (?s, author, “Eric Lu”) (?s, year, ?o) AND ?o 2005 AND ?o 2011. F. Node Join
Because only nodes with resources join RDF-Chord, the structure of RDF-Chord can be either fully distributed (when every node has resources) or hybrid (when partial nodes have resources). When a new node joins RDF-Chord, it has to find out its successor node in each ring set. The procedure of node join is described as follows: If a node n wants to join RDF-Chord, it randomly selects a node snode from existing nodes and invokes join(snode) as shown in Fig. 12. If node n has any RDF triple, l0, l1, and l2 are
calculated. If there is no existing node in lr, node n will invoke create(r, l) as shown in Fig. 12. In
create(r, l), n simply sets its predecessor to nil and its successor to itself. If lr is not empty, n invokes
init(r, l, snode) to set its predecessor to nil, obtain its successor via snode.find_successor(r, l, n), and reset the successor’s predecessor to n. Then, n calls setup_finger(r, l) to build all required finger tables. Finally, n invokes distribute_indexes() to distribute indices. If n does not have any RDF triple, it still needs routing information to PDMS. This can be done by copying some finger tables from snode. For simplicity, n simply copies snode’s BP table as its finger table.
Fig. 12 The pseudocode for node join
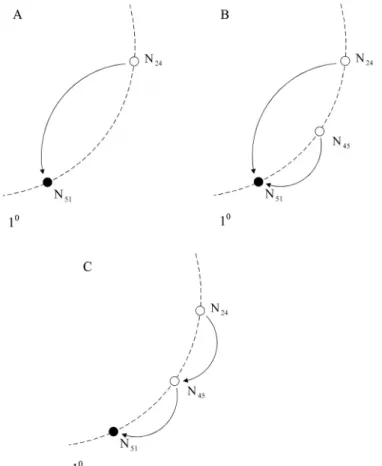
As shown in Fig. 13(A), N51 is the successor of N24 in resource layer 1 of subject ring set (i.e. 10).
When N45 joins, it invokes init() and finds out that N51 is its successor as shown in Fig. 13(B). N45 not only
assigns N51 as its successor, but also sets its predecessor to nil. Additionally, the predecessor of N51 is
changed to N45. However, the successor of N24 is still N51 at this point which will be fixed after the
maintenance is completed. As shown in Fig. 13(B), the correct successor of N24 should be N45, because N45
is between N24 and N51 in the ring. Therefore, the error will be fixed after stabilize() is executed which
shown in Fig. 13(C). The details of stabilize() will be described in the next section.
Fig. 13 Node join: (A) Before N45 joins 10 (B) After N45.init(10) (C) After N24.stabilize()
G. Maintenance
Because nodes may join or leave RDF-Chord frequently, it is required to maintain routing information such as finger tables, successors, and predecessors periodically. For normal nodes, the maintenance task is simply to copy the latest routing information (i.e. any finger table or BP table) from snode which is described in the previous section. If snode failed, normal nodes have to connect to the first available node from finger tables and update finger tables. For nodes in PDMS, each node runs check_predecessor(), stabilize(), fix_fingers(), and distribute_indexes() in sequence during maintenance. The main function of check_predecessor() is to check whether or not n’s predecessor has failed. If yes, n’s predecessor will be set to nil which is shown in Fig. 14. In stabilize() as shown in Fig. 15, for each FTr
l, the predecessor of
n’s successor is assigned to p. Then, if p is within the range of n and n.successor[r, l] (excluding n and n.successor[r, l]), p will be assigned to n.successor[r, l]. Finally, n.successor[r, l].notify(n) is invoked. The main purpose of n.notify(node) is to set node as n’s predecessor if n’s predecessor is nil or node is within the range of n’s predecessor and n (excluding n’s predecessor and n).
For example, as shown in Fig. 13(B), after N45 joined the network, its predecessor is nil, and the
successor of N24 is N51. They are incorrect at this stage. When N24 performs stabilize(), its successor is
replaced with N45 because the predecessor of N24’s successor is N45, and because N45 is in the range of N24
and N51. Also, N45 executes notify(N24). Since the predecessor of N45 is nil, N24 is assigned to be the
successor of N45. After stabilize() is completed, all errors were corrected as shown in Fig. 13(C).
fix_fingers() was designed to maintain finger tables and its pseudocode is shown in Fig. 16. Each node will rebuild its finger tables and BP tables by calling fix_fingers () as shown in Fig. 16. After finger tables were rebuilt, distribute_indexes() is executed to distributed indexes.
Fig. 14 The pseudocode for check_predecessor
Fig. 15 The pseudocode for stabilize
Fig. 16 The pseudocode for fix_fingers IV. SIMULATION EXPERIMENTSAND ANALYSIS
PeerSim [24], a popular P2P simulator, was used for all experiments presented in this section. All experiments were executed on a PC with an Intel Core 2 Duo CPU (3.0GHz), 4GB RAM, and JDK 1.6.0_14.
A. Simulation Environment
Unless otherwise stated, all experiments presented below are based on the parameters summarized in Table IV. The number of nodes varies from 4096 to 524288 (i.e. 212 - 219). The number of resource layers
in each ring set varies from 16 to 256. The number of bits for the SHA-1 hash function is 20. The numbers of bits for the locality preserving hash function used in RDF-Chord and RDFPeers are 10 and 20, respectively. Because RDFPeers is built on MAAN which is extension of Chord, there is only one layer for RDFPeers. It is assumed each node has a resource which is described by a RDF triple. The number of BPs is 8, and they are used in all ring sets. The size of BP tables in normal peer is 1.
Table IV
SIMULATIONPARAMETERS
Number of nodes 2k, where k = 12, 13, 14, …, 19
RDFPeers RDF-Chord
Number of resource layers 1 2c,where c = 4,5, …, 8
ID BITs (m) 20 20
Number of bits of locality
preserving hash function (x) 20 10
Number of BPs - 8
The size of BP table (d) - 1
B. Average Query Cost
The average query cost is the average number of hops a query message has to go through. It is calculated as follows: every node in the network issues a query in turn and the average number of hops is calculated. The average query costs for all types of atomic queries are shown in Fig. 17, Fig. 18, and Fig. 19. The experimental results show that the average query cost of RDF-Chord is about 2 hops less than that of RDFPeers for all types of atomic queries. Therefore, the smaller the search space, the faster the queries. Additionally, for a given number of nodes, the average query costs for Q1-Q7 queries are almost the same.
For simplicity, only Q1 queries are used to study the performance of atomic queries in the following
experiments, unless otherwise stated.
Fig. 18 The average query costs of type II queries vs. number of nodes
Fig. 19 The average query costs of type III queries vs. number of nodes
To study the possible impacts of various range sizes on range queries, (?s, p, ?o) AND l ?o u was first examined. The experimental results are shown in Fig. 20. In the experiments, the number of nodes is 131072 and the range size varies from 50 to 400. From Fig. 20, it can be observed that the average query cost of RDFPeers is much larger than that of RDF-Chord. The average query costs for RDF-Chord in
various range sizes are about 8 hops. The average query cost of RDFPeers increases as the range size increases. For the range size of 400, the average query cost of RDFPeers is 52430 hops. The main reason why RDF-Chord is far superior than RDFPeers in range queries is because kpo not only correctly links
object values to its associated predicate value, but also successfully restricts the search space of the object values to 2x instead of 2m. Because the design of keys in (4), (5), (6), (7), (8), (9), and (10); the
experimental results of other types of range queries are similar to Fig. 19.
Fig. 20 Average query costs of range query vs. range sizes
In the aforementioned experiments, the number of resource layers in each ring set is fixed at 128. To study the effects of the number of resource layers on average query costs, experiments were carried out to evaluate the average query costs as the number of resource layers is changed. The network size is fixed at 131072 and the number of resource layers in each ring set varies from 16 to 256. The experiment result s are illustrated in Fig. 21. It is shown that the average query cost decreases when the number of resource layers increases.
C. Node Join
When a node joins the network, it is required to transmit messages to update routing information. The average cost of joining a node is calculated as follows: when a node joins the network, the total number of messages required to find successors, build finger tables, and distributing indexes is recorded. The process will be repeated 10 times by randomly selecting 10 different nodes (i.e. snode in Fig. 12), and the average number of messages is calculated. The number of resource layers varies from 16 to 256 and the number of nodes varies from 4096 to 524288. From the experimental results which are summarized in Table V, it shows that RDF-Chord is better than RDFPeers when the number of resource layers is greater than or equal to 256. The joining cost is dominated by the cost to execute find_successor(). Whereas the cost of find_successor() in RDFPeers is O(logN), it is O(log(N/C)) in RDF-Chord for each ring set; that is, 3 * O(log(N/C)) in total. In other words, the search spaces of RDFPeers and RDF-Chord in each ring are N and N/C, respectively. Therefore, as long as C increases along with N, the average cost of joining a node in RDF-Chord is less than that in RDFPeers.
Table V
JOININGCOSTSVS. NUMBEROFNODES
D. Maintenance Costs
The average maintenance cost is measured by the total number of messages transmitted during maintenance and divided by the number of nodes. In the experiments, it is assumed that there is no node joining or leaving the network during maintenance. The number of resource layers varies from 16 to 256 and the number of nodes varies from 4096 to 524288. From the experimental results shown in Table VI, the maintenance cost of RDF-Chord is lower than that of RDFPeers when the number of resource layers is greater than or equal to 128. Because the maintenance cost is also dominated by find_successor(), it can be observed that the cost (either maintenance cost or join cost) decreases as the number of resource layers increases.
Table VI
MAINTENANCECOSTSVS. NUMBEROFNODES
E. Total Costs
To further verify RDF-Chord is an efficient and scalable PDMS, the total costs of RDF-Chord in various situations are investigated. The total cost includes query cost and maintenance cost.
In the experiments, the network size is 131072 and the number of resource layers varies from 16 to 256. It is assumed that each node performs maintenance once every 30 seconds. Within one 30-second period, there are 32768, 65536, 98304, 131072, 163840, 196608 atomic queries (i.e. Q1). The total costs are shown
in Fig. 22. From the experimental results, it can be observed that the total cost of RDF-Chord is less than that of RDFPeers when the number of resource layers is greater than 128.
So far, only atomic queries are considered in the study of total costs of RDF-Chord. In the following experiments, range queries are also included in the calculation of total costs. The number of nodes and the number of queries is fixed at 131072 and 98304, respectively. The ratios of range queries (the number of range queries over the total number of queries) vary from 0.5% to 2.5%. The experimental results are shown in Fig. 23. It is observed that the total cost of RDF-Chord is less than that of RDFPeers when the ratio of range queries is not smaller than 1.2%.
Fig. 23 Total costs for atomic and range query F. The Number of Bridge Peers
In the previous experiments, the number of BPs is fixed. It is interesting to investigate the effects of the number of BPs on average query costs. The network size varies from 4096 to 524288 and the number of bridge peers varies from 2 to 2048. Each node in the network requests an atomic query (ie. Q1) in turn, and
the average number of hops is recorded. The experimental results are shown in Fig. 24. From the figure, it is shown that the average query cost grows slightly when the number of BPs increases. This is because BPs link to every resource layer, and thus the number of nodes in each resource layers is increased. It is noted that the average number of hops is decreased when the number of BPs is 1024. The decline is due to the fact that the ID of the lower 10 bits of the chosen BPs is 0, and thus the triples which are hashed by a 10-bits locality persevering hash function are stored at the BPs. As a result, queries are processed directly by the BPs which is faster.
Fig. 24 Average query costs vs. the number of BPs
G.The Sizes of PDMS
To investigate the effects of the sizes of PDMS on RDF-Chord, the following experiments are carried out. In the experiments, the total number of nodes is 524288 and the number of resource layers is 128. The number of seeds varies from 4096 to 131072; in other words, only 4096, 8192, 16384, 32768, 65536, and 131072 nodes join PDMS. Every node in the network issues a query and the average number of hops is calculated. The experimental results are presented in Fig. 25. From the figure, it is shown that the average query costs of RDF-Chord grow slightly when the number of seeds is increased, and the average query costs of RDFPeers are fixed because the search space of RDFPeers is always the whole network. For all cases, the average query costs of RDF-Chord are less than that of RDFPeers. The average query costs were also calculated for Q4, Q5, Q6, and Q7, and the results are similar to Fig. 25.
In addition to the average query costs, the total costs (includes maintenance cost and query cost) of RDF-Chord and RDFPeers are also investigated. The total number of nodes is 524288, and the number of seeds varies from 4096 to 131072. It is assumed that each node will perform the maintenance tasks once every 30 second and there are 131072 queries (i.e. Q1) within one 30-second period. For normal nodes,
they simply copy the BP table from snode, and thus the maintenance cost is 1 hop. The experimental results are presented in Fig. 26. From the figure, it can be observed that the total cost of RDF-Chord is less than RDFPeers when the number of resource layers is not less than 16. Similarly, the total costs are also calculated when the numbers of queries are 262144, 393216, 524288, 655360, and 786432. The experimental results are similar to Fig. 26.
Fig. 26 Total costs vs. the sizes of PDMS
V.CONCLUSIONAND FUTURE WORK
In this paper, we presented a hybrid PDMS called RDF-Chord. It is composed of three ring sets, and each ring set contains multiple Chord-like rings. In addition to atomic queries, RDF-Chord also supports complex queries such as multi-attribute queries and range queries. From various experimental results, it is demonstrated that RDF-Chord outperforms RDFPeers. One major advantage of RDF-Chord over RDFPeers is that the semantics relationships among subject, predicate, and object are properly utilized. In the future, we intend to further explorer the relationships among resources to improve query capabilities and possibly reduce maintenance cost. For example, “RDB” (relational database) can be defined as the super-concept of “MySQL” and “Oracle”. When users search for “RDB”, PDMS may suggest searching for “MySQL” or “Oracle”. To speed up queries, keys may be generated based on “RDB”, ”MySQL”, and “Oracle” such that ”MySQL” and “Oracle” are in the sub-space of “RDB”.
Like other RDF-based P2P networks, RDF-Chord was designed based on the assumption of only one triple per resource. However, the assumption is not true. For example, a MP3 (a subject) song is usually described by singer (predicate and object), production year, etc. The future plan is to consider multiple triples into RDF-Chord.
REFERENCES
[1] N. Antonopoulos, J. Salter, and R. Peel, “A multi-ring method for efficient multidimensional data
lookup in P2P networks,” Proceedings of the 1st international conference on scalable information
systems, 2006, pp. 10-16.
[2] M. Cai, M. Frank, B. Yan, and R. MacGregor, “A subscribable peer-to-peer RDF repository for
distributed metadata management,” Journal of Web Semantics, vol. 2, 2004, pp. 109-130.
[3] M. Cai, M. Frank, J. Chen and P. Szekely, “MAAN: A multi-attribute addressable network for grid
information services,” Journal of Grid Computing, vol. 2, no. 1, 2004, pp. 3-14.
[4] C. Carbunaru, Y. M. Teo, B. Leong, and T. Ho, “Modeling flash crowd performance in peer-to-peer
file distribution,” IEEE Transactions on Parallel and Distributed Systems, vol. 25, no. 10, 2014, pp. 2617-2626.
[5] X. Dong, A. Y. Halevy, and I. Tatarinov, “Containment of nested XML queries,” Proceedings of the
30th VLDB Conference, 2004, pp. 132-143.
[6] Q. Gao, Z. H. Qiu, Y. Wu, J. Tian and Y. Dai, “An interest-based P2P RDF query architecture,” First
International Conference on Semantics, Knowledge and Grid, 2005, pp. 11-16.
[7] T. Gu, H. K. Pung and D. Zhang, “A peer-to-peer overlay for context information search,”
Proceeding of the 14th International Conference on Computer Communications and Networks, October 2005, pp. 395-400.
[8] T. Gu, H. K. Pung and D. G. Zhang, “Information retrieval in schema-based P2P systems using
one-dimensional semantic space,” Computer Networks, vol. 51, no. 16, 2007, pp. 4543-4560.
[9] T. Gu, E. Tan, H. K. Pung and D. Zhang, “ContextPeers: scalable peer-to-peer search for context
information,” Proceedings of International Workshop on Innovations in Web Infrastructure, Japan, May 2005.
[10] P. Haase, R. Siebes and F. Harmelen, “Expertise-based peer selection in peer-to-peer networks,”
Knowledge and Information Systems, vol. 15, no. 1, 2008, pp. 75-107.
[11] M. Harren, J. M. Hellerstein, R. Huebsch, B. T. Loo, S. Shenker and I. Stoica, “Complex queries in
DHT-based peer-to-peer networks,” Proceedings of First International Workshop on Peer to Peer Systems, Cambridge, MA, USA, March 2002, pp. 242-259.
[12] F. Heine, M. Hovestadt and O. Kao, “Processing complex RDF queries over P2P networks,”
Proceedings of the 2005 ACM Workshop on Information Retrieval in Peer-to-Peer Networks, 2005, Bremen, Germany.
[13] D. N. Kanellopoulos, A. A. Panagopoulos, “Exploiting tourism destinations’ knowledge in an
RDF-based P2P network,” Journal of Network and Computer Applications, vol. 31, no.2, 2008, pp. 179-200.
[14] J. Liu and H. Zhuge, “A semantic-based P2P resource organization model R-Chord,” Journal of
Systems and Software, vol. 79, no. 11, 2006, pp. 1619-1631.
[15] E. J. Lu, Y. F. Huang, and S. C. Lu, “ML-Chord: A multi-layered P2P resource sharing model,”
Journal of Network and Computer Applications, vol. 32, no. 3, 2009, pp. 578-588.
[16] C. W. Lo, C. W. Lin, Y. C. Chen and J. Y. Yu, “Contribution-guided peer selection for reliable
peer-to-peer video streaming over mesh networks,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 9, 2012, pp. 1388-1401.
[17] F. Mandreoli, R. Martoglia, W. Penzo and S. Sassatelli, “Data-sharing P2P networks with semantic
approximation capabilities,” IEEE Internet Computing, vol. 13, no. 5, 2009, pp. 60-70.
[18] P. Maymounkov and D. Mazières, “Kademlia: A peer-to-peer information system based on the XOR
metric,” the First International Workshop on Peer-to-Peer Systems, March 2002, p.53-65.
[19] W.Nejdl, M. Wolpers, W. Siberski, C. Schmitz, M. Schlosser, I. Brunkhorst and A. Loser,
“Super-peer-based routing and clustering strategies for RDF-based peer-to-peer networks,” Web Semantics: Science, Services and Agents on the World Wide Web, vol. 1, no. 2, 2004, pp. 177-186.
[20] W. Nejdl, B. Wolf, C. Qu, S. Decker, M. Sintek, A. Naeve, M. Nilsson, M. Palmer and T. Risch,
“Edutella: A P2P networking infrastructure based on RDF,” Proceedings of the 11th International Conference on World Wide Web, Honolulu, Hawaii, USA, 2002, pp. 604-615.
[21] D. Novak, P. Zezula, “M-Chord: a scalable distributed similarity search structure,” Proceedings of the
2005 international conference on foundations of computer science (FCS’05),2005.
[22] G. Papamarkos, A. Poulovassilis and P. T. Wood, “Envent-condition-action rules on RDF metadata in
P2P environments,” Computer Networks, vol. 50, no. 10, 2006, pp. 1513-1532.
[23] E. D. Pascale, D. B. Payne, L. Wosinska, M. Ruffini, “Locality-aware peer-to-peer multimedia
delivery over next-generation optical networks,” vol. 6, no. 9, 2014, pp. 782-792.
[24] PeerSim, 2006. Available: http://peersim.sourceforge.net/.
[25] S. Ratnasamy, P. Francis, M. Handley, R. Karp and S. Shenker, “A scalable content-addressable
network,” Computer Communication Review, vol. 31, no. 4, 2001, pp. 161-172.
[26] RDFStore, 2006. Available: http://rdfstore.sourceforge.net/.
[27] Resource description framework. Available: http://www.w3c.org/RDF/.
[28] A. Rowstron and P. Druschel, “Pastry: Scalable, decentralized object location, and routing for
large-scale peer-to-peer systems,” Proceedings of the IFIP/ACM International Conference on Distributed Systems Platforms, Heidelberg Germany, November 2001, pp. 329-350.
[29] C. Schmidt and M. Parashar, “Squid: Enabling search in DHT-based systems,” Journal of Parallel
and Distributed Computing, vol. 68, no. 7, 2008, pp. 962-975.
[30] I. Stoica, R. Morris, D. Liben-Nowell, D. R. Karger, M. F. Kaashoek, F. Dabek and H. Balakrishnan,
“Chord: A scalable peer-to-peer lookup protocol for internet applications,” IEEE/ACM Transactions on Networking, vol. 11, no. 1, 2003, pp. 17-32.
[31] I. Tatarinov, A. Y. Halevy, “Efficient query reformulation in Peer-data management systems,”
Proceedings of the 2004 ACM SIGMOD international conference on Management of data, 2004, pp. 539-550.
[32] H. Y. Wang, F. Wang, J. C. Liu, C. Lin, K. Xu, and C. Wang, “Accelerating peer-to-peer file sharing
with social relations,” IEEE Journal on Selected Areas in Communications, vol. 31, no. 9, 2013, pp. 66-74.
[33] M. Yang and Y. Y. Yang, “An efficient hybrid peer-to-peer system for distributed data sharing,”
IEEE Transactions on Computers, vol. 59, no. 9, 2010, pp. 1158-1171.
[34] H. L. Yang and H. C. Ho, "Emergent standard of knowledge management: Hybrid peer-to-peer
knowledge management,” Computer Standards & Interfaces, vol. 29, no. 4, 2007, pp. 413-422.
[35] B. Y. Zhao, L. Huang, J. Stribling, S. C. Rhea, A. D. Joseph, and J. D. Kubiatowicz, “Tapestry: A
resilient global-scale overlay for service deployment,” IEEE Journal on Selected Areas in Communications, vol. 22, no. 1, 2004, pp. 41-53.
[36] H. Zhuge and L. Feng, “Distributed suffix tree overlay for peer-to-peer search,” IEEE Transactions
on Knowledge and Data Engineering, vol. 20, no. 2, 2008, pp. 276-285.