408 IEEE TRANSACTIONS ON RELIABILITY, VOL. 42, NO. 3, 1993 SEPTEMBER
A Heuristic Task Assignment Algorithm to Maximize Reliability of
a
Distributed System
Gwo-Jen Hwang, Member
IEEE
Shian-Shyong Tseng, Member
IEEE
National Chiao Tung University, Hsin-Chu National Chiao Tung University, Hsin-Chu
Key Words
-
Distributed computer system, system reliabili- ty, task assignment, distributed software designReader Aids
-
General purpose: Propose an algorithm
Special math needed for explanations: Probability Special math needed to use results: Same Results useful to: Distributed-system designers
Summary & Conclusions
-
Distributed systems potentially provide high reliability owing to the program and data-file redun- dancy possible. In many applications, high reliability is the major consideration for system design. Some work by Kumar, Hariri, Raghavendra shows that the distribution of programs and data- files can affect the system reliability appreciably, and that redun- dancy in resources such as computers, programs, and data-filescan improve the reliability of distributed system. This paper first formulates a practical application for a reliability-oriented distributed task assignment problem which is NP-hard. Then, to cope with this challenging problem, we p r o p a greedy algorithm, based upon some heuristics, to find an approximate solution. The simulation shows that, in most cases tested, the algorithm f i d s suboptimal solutions efficiently; therefore, it is a desirable approach to solve these problems.
1. INTRODUCTION
Distributed systems can provide appreciable advantages, including high performance, high reliability, resource sharing, and extensibility [5,17,19]. Potential reliability improvement of a distributed system is due to possible program & data-file redundancy. The reliability evaluation of distributed systems is widely published [l-4,6,11-13,15-16,201. To evaluate the reliability of a distributed system, including a given distribu- tion of programs and data-files, it is important to obtain a global reliability measure that describes how reliable the system is. Kumar,
Hariri,
Raghavendra [9,13] proposed the concepts of distributed system reliability (DSR) which measures the reliability of a distributed system by determining the probability that all the distributed programs are working. They introduced the KHR’ algorithm [9,13] based on graph theory to evaluate the reliabihty measures. Some of their previous work also shows that the distribution of programs and data-files can affect the system reliability appreciably [ 13-15], and that redundancy in resources such as computers, programs, and data-files can im-prove the reliability of distributed systems [8]. Therefore, the study of program and data-file assignment with consideration of redundancy is important in improving the DSR.
Since the evaluation of task’s reliability is NP-complete [3], Hariri & Raghavendra [7] proposed an algorithm to solve some reliability-oriented task-allocation problems
-
assuming that each computer had the same reliability and each communica- tion link had the same reliability [7]. Shatz 8t Wang solved the task allocation problems in redundant distributed-computer systems by assuming that the system is a cycle-free network [18]. In their model, software redundancy was not considered, and the mission reliability (continuous time interval that is suf- ficiently long for unit failures) was the major concern.This paper formulates
a
practical application, of reliability- oriented design for a distributed information system, to thek-
DTA problem; the k-DTA models the assignment ofk
copies of both distributed programs and their data-files to maximize the DSR under some resource constraints. Since the k-DTA problem is NP-hard [21], we then propose a greedy algorithm based upon some heuristics [ 101 to find an approximate solu- tion. We conclude from the simulation results that in almost every case the approximate solution is suboptimal with relative error<
0.05 and the average absolute error = 0.02.2. MOTIVATION OF THIS RESEARCH The GDTA problem originated from a project of install- ing several copies of a file server into the network which con- nects all of the universities in Taiwan ROC. The file server con- sists of a set of programs and a large database. The main pur- pose of having several copies of the server working at the same time is to ensure that the information system is not affected by local failures of computer sites or network links. If a server program can not access its data- files owing to disk failure, it can access the data of other operational copies through network to continue its work. If a host which holds some server pro- grams fails, its users can still get the same services from other Copies of the server.
There are many computers over several universities in ques- tion. Those schools are willing to offer their computer resources but with several resource constraints (eg, CPU time, memory space, disk quota). Therefore, the programs and data-files of each server are distributed among several computers under resource constraints on each computer. The schools are requested to list what their computers can afford (eg, how many processes, how many MB of memory space, how many GB of disk space), so that the whole information system can be planned.
‘Editors note: we have assigned this acronym for easy, clear reference.
Because a server is constantly executing, its reliability strongly depends on the failure probabilities of the associated computer sites and communication links. Therefore, the reliability of each computer or communication link can be
Other, standard notation is given in “Information for Readers
& Authors” at the rear of each issue. Dejnitions
evaluated according to the ratio of time periods of its historical failures. Section 4 puts this application into a formal descrip- tion, in which a server is considered as a distributed system consisting of several programs and data- files; each communica- tion link is a link in a graph with a reliability measure, and each computer is a node in the graph with a reliability measure and some resource constraints.
3. Distributed system: A system involving cooperation among several loosely coupled computers (processing elements); the system communicates (by links) over a network.
3.2 Distributed program: A program of some distributed system which requires one or more files. For successful execu- tion of a distributed program, the local host, the processing elements having the required files, and the interconnecting links
3. NOTATION & DEFINITIONS
must all be operational [13,15]. system are operational} [13,15].
3.3 DSR: Pr { all the specified distributed programs for the
file G V E DSR KHR Xi Lij R ( X i ) R(Lij) Pi
Fi
PF;3.4 Dependent set: A set S of distributed programs & files such that there does not exist a partition which divides S into two disjoint subsets
s1
&s,,
wheres1
Us,
=s,
ands1
n
S2 = 0 such that each program and the files required are within the same subset.3.5 DTA problem: Find an assignment for a dependent set under some resource constraints on the distributed system such that the distributed system reliability is maximum.
Bidirectional communication channels operate between processing elements. A distributed network can be modeled by a simple undirected graph.
Notation & Acronyms
AR-tree
access-relation treeA..*,. Gl,.
~ ~ - 1 l l G
3.6 k-DTA problem: Find an assignment for k copies of a dependent set to maximize the DSR under some resource con- 4 straints on the distributed system.
simple undirected graph: ( V , E )
set of nodes representing the processing elements set of links representing bidirectional communication channels
distributed-system reliability
Kumar, Hariri, Raghavendra reliability-computing
Example 3.1
Let AFL(P1) = {F,, F 2 } , AFL(P2) = (F2, F3}.
According to definition 3.4, S
.
( P I , P2, Fl, F2, F j } is a dependent set. If P2 requires only file F3, S is not a dependent set sinceS
can be divided into SI = {Pl, F1, F2} and S2 =( P 2 , F3} such that both S1 & S, are dependent sets. 4
Assume that in a dependent set, one arbitrary program is not operational or can not access the required file because of algorithm [9,13]
node representing processing element i link between Xi and
Xj
Pr{Xi is operational} Pr{LU is operational} distributed program i
c1- :
I l l G I
distributed program or file i
AFL ( P i ) list of files required for program i to complete its execution
APL ( Fi) list of programs which must access file i to com- plete their executions
FST file spanning tree consisting of the root node (process- ing element that runs the program) and some other nodes which hold all the files needed for the program held in the root node under consideration [13,15] MFST minimal FST containing no subset file spanning tree
U51
MFST ( P i ) set of minimal file spanning trees associated with program i
ASS (S, G) assignment which allocates all programs & files to a set of nodes S of network G
DSR (S, G) DSR for ASS (S, G)
FSF file spanning forest: a set of FSTs whose root nodes hold all of the programs under consideration [15] MFSF minimal FSF containing no subset FSF
DTA distributed task assignment k-DTA k-copies DTA.
the failure of network nodes or links. Then all other programs of the dependent set must stop executing. In example 3 . 1 , let P I & P2 be 2 processes of a parallel algorithm, it is pointless for P2 to continue executing if PI has already halted due to failure of some nodes or links. By definition, the operation of a dependent set S relies on the operation of the programs & files of S . Therefore, the reliability of a dependent set in the distributed system can be evaluated by KHR which measures the DSR by determining the probability that all the distributed programs are working.
This paper is concerned with the assignments of depen- dent sets to maximize the distributed system reliability evaluated by KHR.
4. HEURISTIC ALGORITHM FOR THE k-DTA ProbLEM
4. I Background
This section proposes an efficient heuristic algorithm to find an approximate solution of the k-DTA problem. Without loss of generality, we use memory constraints instead of resource constraints to simplify the discussion.
410 IEEE TRANSACTIONS ON RELIABILITY, VOL. 42, NO. 3, 1993 SEPTEMBER
Theorem 1. Denote the set of minimal file spanning trees for an assignment ASS ( S , G ) of a dependent set by MFST ( S , G )
.
If there exists another assignment ASS (S- { v} , G) , where v is a terminal node of some MFST in MFST(S,G), then DSR(S,G)<
DSR(S-{v},G).Proof: The theorem is obvious from the definition of DSR. 4 Definitions
4.1 Node
XI
is more reliable than node X2 iff the degree of Xl is higher than that ofX2.
[The node with higher degree is more likely to have more paths to the destination nodes than those with lower degrees. Thus according to DSR(S,G) = Ui Pr{MFSFi), Xl could provide higher reliability than X2.]4.2 Program PI is weaker than program P2 (or, P2 is stronger than P1) iff the minimum number of nodes required to assign P1 and its associated files are greater than those re- quired for P2. [If any associated file is not accessible, the pro- gram fails. From theorem 1, we can always find an assignment such that P2 is in a more reliable situation than P1; therefore,
P I is weaker than P2.]
4.3 File Fl is more influential than file F2 iff Fl is ac- cessed by more programs than F2. [By definition of DSR, if any program can not access its associated file, the whole distributed system fails. Therefore, if Fl is accessed by more programs than F2, then the probability that some program can not access Fl is likely to be greater than the probability for Fz.] Finding the minimum number of nodes needed to hold a program and its associated fdes is interesting and difficult. Basically, in most cases the total required memory size dominates the number of nodes needed; therefore, we simply use the total memory size of Pi and its associated files to ap- proximate the number of nodes required. The weakness deci- sion function is:
WEAKNESS
(Pi)SIZE
(Pi)+
C q E m L ( p i ) SIZE(5).
Example 4.1
tions of a dependent set are:
All the program & files are the same size. The access rela-
The order of the programs from weakest to strongest is: P2, PI, P3r
P4.
fieorem 2. The most reliable assignment for k copies of some program or file is to assign these copies to k distinct nodes.
Proof: The theorem is obvious from the definition of DSR. 4 Heuristics 1 - 6 ire ideas about approximate efficient solu- tion of the task assignment problem.
Heuristics
1. Assign the weaker programs first.
2. Assign the weaker programs to the more reliable nodes. 3. Assign the more influential files before the less influen- 4. Assign the more influential files to the more reliable 5 . Assign the copies of the same program or file to dif- 6. Assign a program as close to its files as feasible.
Our approximation algorithm is generally a greedy ap- proach which uses heuristics 1
-
6 as optimization measures and an AR-tree as the data structure to represent the requirement relation between the distributed programs and their files. To construct an AR-tree-
a. Assign the weakest program, say Pi, to the root of the b. Assign each file in AFL(Pi) to the Pi-children nodes. c. Assign the programs in APL($) to the $-children nodes, etc.
That is, AFL ( P i ) & APL
( 4 )
are assigned alternately to the children nodes of Pi &$
for each Pi on odd depth and$
on even depth of the AR-tree. Moreover, the children of the same parent are assigned sequentially from weakest to strongest. tial ones.nodes. ferent nodes.
4.2 Access Relation Tree
AR-tree.
Construction of AR-tree for Example 4. I
1. Determine the order of the programs from weakest to strongest (see example 4.1).
2. Construct the APL(Fi) for each Fi and determine the order of these files from most influential to least influential:
According to the size of APL ( Fi) , the order of the files is F3,
3. Sort the elements of AFL (Pi) &
APL
( 5 )
for each Pi and each$
accordihg to the orders determined in steps 1 & 2: F2, Pi, F4, F5.4. Assign each program and file alternately to form an
AR-
tree. Initially, assign the weakest program P2 to the root of the AR-tree. Assumek
= 2 (2 copies of each program & file). The following rules are used to assign the programs & files until all of them appear twice:A. AFL(Pi) is assigned to the children nodes of
Pi.
If any file appears more thank (in this example, k = 2 ) times, discard it.B. If Fj E AFLP,) and F, has been assigned to the parent node of Pi, reorder
4
to be the last (rightmost) child ofPi
to be assigned.C. Assign APL(Fi) to the children nodes of Fi. If any program appears more than
k
times, discard it.D. If
Pi
E APL(Fi) andPi
has been assigned to the parent-node ofFi,
then reorder Pj to be the last (rightmost) child of Fi to be assigned.E. If all modules appear k times, STOP the extension of the AR-tree; else go back to A.
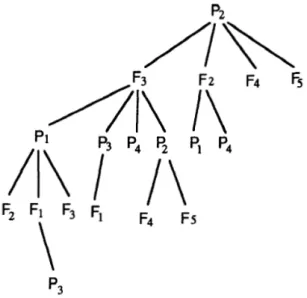
After several iterations, an AR-tree of example 4.1 is con- The AR-tree represents two important relations among the k copies of programs & files in a dependent set:
1. Parent & children have access relation; hence they should be put as near as possible.
2. For the programs or files of the same parent, the left one is weaker
than
the right one; therefore, the priority of assign-4
structed as figure 1. 4
ment should decrease from left to right.
For these reasons, it seems that better solutions can result from assigning the programs & files in breadth-first order. 4.3 Greedy Approach
After the AR'-tree is constructed, the greedy algorithm bas- ed upon some heuristics is used to assign the programs & files to the network:
1. Initially the program in the root of AR-tree is selected and assigned to the node with the maximum environment weight. The environment weight represents the composite reliability for the nodes and links surrounding a node.
p3
Figure 1. An AR-Tree of Example 4.1
ENVIRONMENT-WEIGHT(Xi) R(Xi)
*E&
E ADJ(X~)ADJ(Xi) = set of nodes which are adjacent to Xb
2. Once a program or file PF, is assigned to some node
4,
we then try to assign the children of PF, to the nodes as close to3
as possible. The children of PF, are assigned from weakest to strongest.3. For some child of PF,, say PFk, we
try
first to assign PFk to Xi if the current available memory of3
is large enough to hold PFk; otherwise, the i-movement nodes of4
(for such nodes, all of the paths to5
must include at least i edges and at least 1 path including exactly i edges) are tried for i = 1,2,.. .
,n-
1. In figure 2, the 1-movement nodes ofX,
are: XI, X2, X,; the 2-movement nodes ofX,
are:&,
&.
4. If there are at least 2 i-movement nodes with enough memory space, assign PFk to the one with maximum access weight. As an i-movement node, X, becomes the candidate node, the access weight for
Xs
is:ACCESS-WEIGHT
(4,
Xs)PA = some i-movement path from
4
to Xs.Access weight is an estimate of the reliability of assigning PFk to some i-movement node
Xs
while the parent of PF, is in4;
it considers the degree of parent node and the reliabilities of412 IEEE TRANSACTIONS ON RELIABILITY, VOL. 42, NO. 3, 1993 SEPTEMBER
0.95
0.92 0 . 9 2
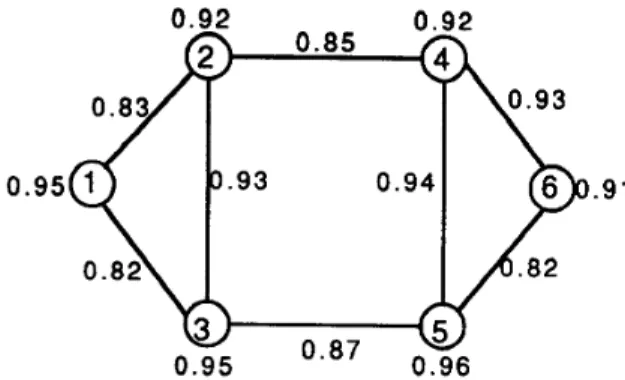
Figure 2. Example of Network Topology
91
associated nodes & links. For each pair of nodes, the access weight can be found by the all-pairs-shortest-paths algorithm [lo].
5. If the breadth-first order of PFk, is greater than that of PFk, in the AR-tree, then PFk, must be assigned before PFk,. This rule assures that the programs & files in AR-tree are assign- ed to the network according to the priority of breadth-first order.
4
For programs of short execution time, the process reliabili- ty is related to its execution time, communication time, and cur- rent system load; hence the environment weights and access weights will be changed. However, in considering the constant (long term) execution, the program reliability strongly depends on the failure probabilities of relative nodes & links; ie, the en- vironment weights and access weights are constants in such case. Example 4.2
For a dependent set {Pl, Fl, F2} to be assigned to the net- work of figure 2, let the available memory space of each node be C1 = 8, C2 = 8, C3 = 12, C, = 8, C5 = 10, C, = 10. SIZE(F2) = 7, and the number of copies
k
= 2.Let AFL(P1) = {FI, F2}, SIZE(P1) = 4, SIZE(F1) = 6,
F2
91
F1
Figure 3. An AR-Tree of Example 4.2
The AR-tree in figure 3 can be constructed. First compute the environment weight for each node:
ENVIRONMENT-WEIGHT( 1) = 1.465470 ENVIRONMENT-WEIGHT(2) = 2.257680 ENVIRONMENT-WEIGHT(3) = 2.3463 10 ENVIRONMENT-WEIGHT(4) = 2.328244 ENVIRONMENT-WEIGHT(5) = 2.34oooO ENVIRONMENT-WEIGHT(6) = 1.494948.
According to the environment weights and the AR-tree, initially P1 is assigned to X3. The children of PI
(viz,
F1, F 2 )are the next two files to be assigned. Fl is assigned to node X3; hence C, becomes 12
-
(4+6 ) = 2. Since SIZE(F2) = 7, X3 does not have enough available memory to hold F2; therefor, the X3 l-movement nodes(viz,
Xl, X2, X5) which have enough memory space to hold F2 are tried. Their access weights are: ACCESS-WEIGHT (X3, Xi) = 0.740050,ACCESS-WEIGHT(X3, X2) = 0.812820, ACCESS-WEIGHT
(X3,
X5) = 0.793440.Since X2 has the maximum access weigd associated w 1
X3, then F2 is assigned to X2. We then consider the second copy of P1 in depth 3 of the AR-tree (we call it P’l). Since P’l is the child of F2, and since F2 has been assigned to X2, therefore, we try to assign PIl to X2 first. However, the available memory space of X2 is 8
-
7 = 1<
SIZE(P’1) =4;
so, the 1-movement nodes of X2 are tried.The algorithm continues iterating until
k
copies of all the Notation programs & files are assigned to the network. The final resultof example 4.2 is in figure 4. By KHR, the distributed system reliability of figure 4 is 0.980363.
M
Nk.(number of programs & files)
number of nodes in the distributed system.
4.3 Formal Description of the Greedy Algorithm The time complexities for the algorithm are: Greedy Algorithm
1. Calculate the environment weight of each
Xi.
1.1 ADJ(Xi) ={Xjl%
is adjacent to Xi}1.2 ENVIRONMENT-WEIGHTX,) = [use (4-l)] 2.1 For each Pi &
4,
reorder the AFL(P,) & A P L ( 4 ) . 2.2 Choose Ph as the root of the AR-tree,2. Construct an Assignment-Relation tree.
WEAKNESS
(Ph)
= MAXi(S1ZE ( P i )+
+AFL(P,) S I Z E ( 5 ) ).2.3 I* D
=
depth of the current AR-tree) *I D=O UNTIL k copies of all programs & files are in the AR- 2.3.1 IF D is oddtree DO
THEN expand the tree for eacWi of level D; the files of AFL ( P i ) become the children of ELSE expand the tree for each Fi of level D; the programs of APL(F,) become the children of
Fi
Pi
E N D J F
2.3.2 For the new expanded programs or files, remove the excess ones if more than k copies are be- ing expanded
2.3.3 IF (PFj is expanded from PFi) AND (PFj =
parent of PF,)
THEN reorder PFj to be the rightmost child of E N D J F
END-UNTIL PFi 2.3.4 D =
D
+
13.
Apply the all-pairs-shortest-paths algorithm to find the ac- cess weight for each pair of nodes in the distributed system. 4. Assign each program & file to the network according tothe greedy strategy and the AR-tree.
4.1 Choose node Xs which has the maximum environment weight. Assign the root program of AR-tree to
X,.
4.2 Select one program or file PFj from the AR-tree ac-cording to the breadth-first order
UNTIL all programs & files are selected DO 4.2.1 Assume that PARENT(PFj) is assigned to
X,
4.2.2 i = 04.2.3 WHILE none of the i-movement nodes of
X,
has enough resources for PFj DOi = i i - 1 END-WHILE
4.2.4 Choose 1 node X, from the i-movement nodes 4.2.5 Assign PFj to X, and update the available
END-UNTIL 4
of X, that have maximum access weight resources of X,
Step Complexity
5. SIMULATION & ANALYSIS
To evaluate the performance of our approach, we applied the heuristic algorithm to a wide variety of distributed task assign- ment problems.
5.1 Quantitative Evaluation
The results of our algorithm are compared to those of a Random Assignment algorithm and an Exhaustive Search algorithm, The reliabilities of the assignments were evaluated by applying KHR. To verify the accuracy & efficiency of our algorithm, the simulation programs are implemented in C language on a VAX-8800 and by COMMON LISP on a PCIAT, respectively. Some parts of the simulation results are depicted in tables 1 & 2. Since k (number of copies) = 2, the numbers of programs & files are twice as large as those shown in the tables. Two error measures, E, & E,,, are used.
Notation
E, relative error E,,, average absolute error
DSR,,, solution of the approximation algorithms
DSK,,, optimal solution from exhaustive-search algorithm. E, 3 1
-
DSRapp/DS&ptimalE,,,
= (E
I
DSR,,,,id - D S k p pI
)/(number of cases) The simulation shows that our algorithm performs ac- curately & efficiently for most cases without dependence on the languages or computers used:E,
<
0.05 for each case E,, = 0.02 on the average.Therefore, in almost every case, our algorithm can find subop- timal assignments.
414 IEEE TRANSACTIONS ON RELIABILITY, VOL. 42, NO. 3, 1993 SEPTEMBER
TABLE 1
Simulation Results of C Program Executed on VAX-8800 Exhaustive
Size Random Alg. Greedy Alg. Search
time time
L P F DSR E, (sec) DSR E, (min) DSR
TABLE 2
Simulation Results of LISP Program Executed on PClAT Exhaustive Size Random Alg. Greedy Alg. Search
time time L P F DSR E, (sec) DSR E, (min) DSR ~~~~~ ~ 8 1 2 0.924 0.068 0.07 0.971 0.020 18.4 0.991 8 1 2 0.925 0.067 0.08 0.971 0.020 18.6 0.991 8 1 2 0.902 0.088 0.08 0.980 0.009 18.6 0.989 8 1 2 0.933 0.058 0.07 0.982 0.009 18.4 0.991 8 1 2 0.903 0.080 0.08 0.972 0.010 19.1 0.982 8 1 2 0.824 0.157 0.06 0.931 0.048 10.7 0.97 8 1 2 8 1 2 8 1 2 8 1 2 8 1 2 9 1 1 9 1 1 9 1 1 9 1 1 9 1 1 0.871 0.852 0.897 0.860 0.844 0.909 0.915 0.918 0.785 0.781 0.112 0.122 0.093 0.123 0.131 0.082 0.077 0.073 0.185 0.182 0.07 0.08 0.07 0.06 0.07 0.06 0.05 0.06 0.06 0.05 0.956 0.951 0.968 0.965 0.951 0.989 0.975 0.989 0.944 0.947 0.026 0.021 0.022 0.016 0.021 0.001 0.017 0.002 0.020 0.008 18.7 19.2 18.8 19.1 18.6 48.2 46.6 49.1 48.5 48.4 0.98 0.97 0.99 0.98 0.97 0.990 0.992 0.990 0.963 0.955 8 2 2 0.895 0.094 0.06 0.961 0.027 934 0.988 8 1 3 0.908 0.081 0.07 0.974 0.015 928 0.989 8 2 3 0.907 0.069 0.09 0.960 0.014 > l o 4 0.974 8 2 4 0.911 - 0.09 0.954
-
>IO6 - 10 1 2 0.932 0.039 0.07 0.967 0.003 616 0.970 10 1 2 0.886 0.083 0.08 0.950 0.016 597 0.965 10 1 3 0.918 0.054 0.10 0.968 0.001 >lo4 0.970 10 2 3 0.946-
0.12 0.973- >io5
- Eav,(Random) = 0.094; Eave(Greedy) = 0.015 L = number of Links P = number of programsF = number of data files
1 year = 5.105 minutes; 1 month = 4.104 minutes
5.2 Qualitative Evaluation
We analyze the performance of our algorithm by compar- ing it with the same Random Assignment algorithm used in sec- tion 5.1 and with the heuristic Algorithm-S.
Algorithm-S
#3) node which has enough memory. holds the most programs that access it.
1. Assign programs to the most reliable and allowable (see 2. Assign each file to the allowable (see #3) node which 3. If the node has held a copy of some program or file, 4 do not assign the same one to it.
Discussion of Algorithm4 (AlgS)
A l g S seems straight-forward and reasonable; however, AlgS has 2 problems.
Problem #1: AlgS ignores the relationships among copies of the modules. For example, let
Pi
& P’i be 2 copies of the8 1 2 8 1 2 8 1 2 8 1 2 8 1 2 8 1 2 8 1 2 8 1 2 8 1 2 8 1 2 8 1 2 0.924 0.925 0.902 0.933 0.903 0.824 0.871 0.852 0.897 0.860 0.844 0.068 0.067 0.088 0.058 0.080 0.157 0.112 0.122 0.093 0.123 0.131 0.16 0.17 0.17 0.16 0.17 0.15 0.16 0.17 0.16 0.16 0.16 0.971 0.971 0.980 0.982 0.972 0.931 0.956 0.951 0.968 0.965 0.951 0.020 0.020 0.009 0.009 0.010 0.048 0.026 0.021 0.022 0.016 0.021 31.9 37.4 37.5 37.5 37.1 21.2 37.5 37.4 37.5 37.7 37.8 0.991 0.991 0.989 0.991 0.982 0.978 0.982 0.971 0.990 0.981 0.971 9 1 1 0.909 0.082 0.16 0.989 0.001 92.3 0.990 9 1 1 0.915 0.077 0.11 0.975 0.017 95.8 0.992 9 1 1 0.918 0.073 0.16 0.989 0.002 92.4 0.990 9 1 1 0.785 0.185 0.16 0.944 0.020 97.7 0.963 9 1 1 0.781 0.182 0.16 0.947 0.008 92.9 0.955 8 2 2 0.895 0.094 0.16 0.961 0.027 1770 0.988 8 1 3 0.908 0.081 0.17 0.974 0.015 1696 0.989 8 2 3 0.907 0.069 0.18 0.960 0.014 > l o 5 0.974 > l o 6 - 0.19 0.954
-
8 2 4 0.911 - 10 1 2 0.932 0.039 0.16 0.967 0.003 3100 0.970 10 1 2 0.886 0.083 0.17 0.950 0.016 1013 0.965 10 1 3 0.918 0.054 0.22 0.968 0.001 = l o 5 0.970 10 2 3 0.946-
0.28 0.973-
> l o 6 - E,,,(random) = 0.094; E,,(greedy) = 0.015[see footnotes on table 11
same program, and similarly with Fj & F:. If AFL(Pl) =
{Fl, F 2 } ; then AlgS implies that only P1 or P‘l needs to ac- cess one of {Fl, F z } , {F’I, F2}, { F l , F i } ,
{F1,
Fi}
to keep the whole system operational.Problem #2: AlgS does not decide the order of assigning modules by considering their relationships; hence a program is most likely to be assigned far from the files it needs, and vice versa. For example, the assigning orders of F1 & F2 can be much later than that of
P1.
Let P1 be assigned toX,.
The nodes that are close toX,
might already be occupied when Fl4 & F2 are going to be assigned.
Discussion of Random-Assignment Algorithm (AlgR) AlgR works in an even simpler way: AlgR applies only rule #3 of Algorithm-S shown above.
Problem #3: The performance of AlgR can be terrible if most of the modules are assigned to some unreliable nodes which Problems #1& #2 for Algorithm-S can be avoided by ap-
are far apart. 4
April
11-1
4
Fairmont Hotel
San
Jose,
California
USA
For further information, write to the Managing Editor. Sponsor members will receive more information in the mail.
L
Problem #3 for Algorithm-R usually can be solved by applying environment weights and access weights which lead the
algorithm to assign the modules to more reliable nodes with more reliable links surrounded. Therefore, satisfiable results can be derived by our approach.
ACKNOWLEDGMENT
This research was partially supported by the National Science Council of the Republic of China under Contract NSC79-0408-E009-17.
kEFERENCES
K.K. Aggarwal, S. Rai, “Reliability evaluation in computer- communication networks”, IEEE Trans. Reliability, vol R-30,1981 Apr, A. Agrawal, R.E. Barlow, “A survey of network reliability and domina- tion”, Operations Research, vol 32, 1984 May, pp 478-492. M.O. Ball, “Complexity of network reliability computation”, Nezworks, D. Brown,“A computerized algorithm for determining the reliability of redundant configurations”, IEEE Trans. Reliability, vol R-20,1971 Aug, P. Enslow, “What is a distributed data processing system”, Computer,
S. Hariri, C.S. Raghaven&, “SYREL: A symbolic reliability algorithm based on path and cutset methods”, IEEE Trans. Computers, vol C-36, 1987 Oct, pp 1224-1232.
S. Hariri, C.S. Raghavendra, “Distributed functions allocation for reliability and delay optimization”, Proc. IEEE/ACM I986 Fall Joint
Computer Con$, 1986, pp 344-352.
S. Hariri, C.S. Raghavendra, V.K.P. Kumar, “Reliability analysis in distributed systems”, Proc. 61h Int ’1 Conf. Distributed Computing Systems, 1986 May, pp 564-571.
S. Hariri, C.S. Raghavendra, V.K.P. Kumar, “Reliability measures for distributed processing systems”, Proc. Inr’l Symp. New Directions in Computers, 1985 Aug; Trondheim, Norway.
E. Horowitz, S . Sahni, Fundamenrals of Computer Algorithms, 1978;
Computer Science.
C.L. Hwang, F.A. Tillman, M.H. Lee, “System reliability evaluation techniques for complex large systems - A review”, IEEE Trans. Reliabili- K.B. Misra, “An algorithm for the reliability evaluation of redundant networks”, IEEE Trans. Reliability, vol R-19, 1970 Nov, pp 146-151.
V.K.P. Kumar, C.S. Raghavendra, S. Hariri, “Distributed program pp 32-35.
VOI 10, 1980, pp 153-165.
pp 121-124.
V O ~ 11, 1978 Jan, pp 13-21.
ty, V O ~ R-30, 1981 Dec, pp 411-423.
reliability analysis”, IEEE Trans. Sofhvare Engineering, V O ~ SE-12, 1986 C.S. Raghavendra, S . Hariri,“Reliability optimization in the design of distributed systems”, IEEE Trans. Software Engineering, vol 1 1 , 1985
[I51 C.S. Raghavendra, V.K.P. Kumar, S. Hariri, “Reliability analysis in distributed systems”, IEEE Trans. Computers, vol 37, 1988 Mar, pp [16] S. Rai, K.K. Aggarwal, “An efficient method for reliability evaluation”,
IEEE Trans. Reliability, vol R-27, 1978 Jun, pp 101-105. [17] D.A. Rennel, “Distributed fault-tolerant computer systems”, Computer,
vol 13, 1980 Mar, pp 55-56.
[I81 S.M. Shatz, J.P. Wang, “Models and algorithms for reliability-oriented task-allocation in redundant-computer systems”, IEEE Trans. Reliability,
vol 38, 1989 Apr, pp 16-27.
[19] J.A. Stankovic, “A perspective on distributed computer systems”, IEEE
Trans. Computers, vol C-33, 1984 Dec, pp 42-50.
[20] A. Satyanarayana, “A unified formula for analysis of some network reliability problems”, IEEE Trans. Reliability, vol R-31, 1982 Apr, pp 23-32.
[21] S.S. Tseng, G.J. Hwang, “Task assignment to maximize reliability of a distributed system is NP-hard”, Tech. Report NCTU-CC-80123001, 1991; National Chiao Tung University, Taiwan - ROC.
Jan, pp 42-50. [14]
Oct, pp 1184-1193.
352-358.
AUTHORS
Dr. Gwo-Jen Hwang; Computer Center; National Chiao Tung University; Hsin- chu 300 TAIWAN - R.O.CHINA.
Gwo-Jen Hwahg (M’92) was born 1963 April 16 in Taiwan - ROC. In 1991, he received his PhD from the Department of Computer Science and In- formation Engineering at National Chiao Tung University in Taiwan. He is now an Associate Professor and is Director of R&D Department of Computer Center at that university. His research interests are distributed systems, expert systems, and knowiedge engineering.
Dr. Shidn-Shyong Tseng; Department of Computer and Information Science; National Chiao Tung University; Hsinchu 300 TAIWAN - R.O.CHINA.
Shian-Shyong Tseng received his PhD in Computer Engineering from National Chiao Tung University in 1984. He is now a Professor in the Depart- ment of Computer and Information Science at National Chiao Tung Universi- ty, and is Director of Computer Center at Ministry of Education. He was elected
an Outstanding Talent of Information Science of R.O.C. in 1989 and was award- ed the Outstanding Youth Honor of R.O.C. in 1992. His research interests in- clude computer algorithms, distributed / parallel computing, artificial in- telligence, and compilers.
Manuscript TR89-224 received 1989 December 29; revised 1991 January 10; revised 1992 January 16; revised 1992 September 4.
IEEE Log Number 06540 4TRF