I-Shou University Institutional Repository:Item 987654321/18662
79
0
0
全文
(2) 基於巨觀與微觀類別模型的 一個機率式影像分類方法 A Probabilistic Approach for Image Categorized Based on Macro and Micro Classification Model 研 究 生. :余松樺. Student:Song-Hua Yu. 指 導 教 授 :郭 忠 民 博士. Advisor:Chung-Ming Kuo. 義守大學 資訊工程研究所 碩士論文. A Thesis Submitted to Department of Information Engineering I-Shou University in Partial Fulfillment of the Requirements for the Master degree in Information Engineering. July, 2015 Kaohsiung, Taiwan, Republic of China.
(3)
(4) 基於巨觀與微觀類別模型的 一個機率式影像分類方法 研 究 生:余 松 樺. 指 導 教 授:郭 忠 民 博士. 義守大學資訊工程研究所. 摘要 影像分類在現在是一個熱門的議題,而把數千數萬張的影像分類 不是一件容易的工作;分類系統是對影像的每個類別做特徵影像分析, 以此為基礎結合影像內容中的色彩特徵,並且應用於分析影像內容以 協助影像分類的工作。 在本研究中,從資料庫中選出訓練樣本,以視覺字塊的方式提取 影像特徵,並且將區塊依照特性分為巨觀字與微觀字兩種類型,將取 出的視覺字訓練成巨觀字典與微觀視覺字典,由巨觀字典與微觀字典 為基礎建立類別模型,每個模型獨特,不易混淆;而後以建立的類別 模型為分類依據,已達成分類影像的目的。. 關鍵字: 視覺字典、分類模型. I.
(5) A Probabilistic Approach for Image Categorized Based on Macro and Micro Classification Model Student : Song-Hua Yu. Advisor : Chung-Ming Kuo. Department of Information Engineering I-Shou University. Abstract This issue of image classification has received much attention recently; however, to classify huge amount of images into different categories is hard. For each category, classification system should first analyze features of image, which is described by visual words, and then the classification model is constructed. Finally, a probabilistic classifier is proposed to effectively category images. The proposed algorithm is first collected training samples from the database, and extract image feature by visual patch. In addition, the patch divided into macro words and micro words according to patch content and then macro and micro visual dictionary is constructed. We then build classification models with representative and effective. Finally, the MAP based classifier is developed to classification image correctly. Simulation results show that the categorization scheme achieve surprising performance. Keyword: Bag of Visual Words. II.
(6) 致謝 兩年的碩士生活,轉眼間就過去了,在碩士班兩年的求學過程中, 很感謝郭忠民老師在我發現問題時給予方向並且解決問題,也感謝楊 乃中老師從大學專題時代就對我用心的照顧與指導,兩位老師不厭其 煩的悉心指導讓我能順利的完成碩士學業,令我獲益良多。另外也要 感謝郭章明學長以及張繼高兩位大學長對我的照顧,兩位學長在兩年 的求學過程中對我幫助很多。而後還要感謝實驗室中共同努力的同學 們,彥廷、㨩瑞、陳彣、品涵和培汝,大家在遇到問題的時候一起想 辦法解決,還有一起開玩笑、放鬆休息的時光,在實驗室的 700 多的 日子裡令我難以忘懷。此外我非常感謝耀陞學長對我的幫助,耀陞學 長不論在文章的閱讀上以及撰寫程式上都對我幫助很多,這些都是我 學生時代無可取代的美好回憶。最後要感謝支持我的家庭,感謝爸爸 對我的養育之恩以及學業上的支持,感謝姊姊對我的關心和幫助,家 人的支持讓我能無後顧之憂的完成碩士學業。. III.
(7) 目錄 摘要............................................................................................................. I Abstract ...................................................................................................... II 致謝...........................................................................................................III 目錄.......................................................................................................... IV 圖目錄..................................................................................................... VII 表目錄...................................................................................................... IX 一、. 緒論 ...............................................................................................1. 1.1 問題描述 .......................................................................................1 1.2 研究動機 .......................................................................................2 1.3 論文架構 .......................................................................................7 二、. 文獻回顧與探討 ...........................................................................8. 2.1 視覺字 ...........................................................................................8 Keyblock 區塊特徵 ......................................................................9 2.2 分類方法 .....................................................................................10 2.2.1.. 低階特徵(全域) ............................................................10. 2.2.2.. 低階特徵(子塊) ............................................................11. 2.2.3.. 語義物件(Semantic objects) .........................................12 IV.
(8) 2.2.4. 線上 Codebook 重新加權(Online Codebook Reweighting) ...............................................................................13 三、. 研究方法與步驟 .........................................................................15. 3.1 建立視覺字典 .............................................................................19 3.1.1.. 區塊特徵擷取 ...............................................................19. 3.1.2.. 區塊特徵訓練 ...............................................................20. 3.1.3.. 區分巨觀及微觀視覺字典 ...........................................21. 3.2 影像分類 .....................................................................................24 3.2.1.類別模型訓練....................................................................26 3.2.2. 四、. 類別機率計算 ...............................................................31. 實驗數據及結果 .........................................................................36. 4.1 數據庫..........................................................................................36 4.2 效能評估......................................................................................38 4.3 訓練模型評估..............................................................................46 4.3.1 模型差異 ............................................................................47 4.3.2 模型差異造成的分類錯誤................................................49 4.3.3 去除視覺字與否的差異測試............................................51 4.3.4 視覺字使用評估................................................................60 五、. 結論與未來研究 .........................................................................66 V.
(9) 參考文獻...................................................................................................67. VI.
(10) 圖目錄 圖 1、一張影像每個人的理解不同............................................2 圖 2、視覺字袋示意圖................................................................4 圖 3、以區塊的方式切割並且重建影像 ...................................5 圖 4、建立特徵模型....................................................................6 圖 5、區塊分割所產生的視覺字..............................................10 圖 6、以全域取得特徵值.......................................................... 11 圖 7、分子區塊取得特徵值......................................................12 圖 8、以標籤描述影像得出本圖屬於雪景分類 .....................13 圖 9、Online Codebook Reweighting 示意圖 ..........................14 圖 10、整體研究架構(a)訓練流程(b)分類流程 ......................17 圖 11、建立通用字典流程圖 ....................................................19 圖 12、圖中方格為區塊(block) ................................................20 圖 13、將視覺字的像素 RGB 值由小至大排序 ....................22 圖 14、區分出巨觀特徵與微觀特徵 ......................................23 圖 15、動物和植物定義廣泛....................................................25 圖 16、天空的視覺特徵接近....................................................26 圖 17、建立類別模型................................................................29. VII.
(11) 圖 18、(a)模型不大時模型獨立(B)隨著模型增大 AB 模型產 生相交 ..................................................................................31 圖 19、類別模型權重說明示意圖...........................................34 圖 20、Corel 影像資料庫 .........................................................36 圖 21、汽車視覺字分析...........................................................60 圖 22、花朵視覺字分析...........................................................61 圖 23、海豹視覺字分析...........................................................61 圖 24、糕點點心視覺字分析...................................................62 圖 25、雪景視覺字分析...........................................................62 圖 26、猩猩視覺字分析...........................................................63 圖 27、古典建築視覺字分析...................................................63 圖 28、直升機視覺字分析.......................................................64 圖 29、煙火視覺字分析...........................................................64. VIII.
(12) 表目錄 表 1、測試類別 .........................................................................37 表 2、以提出方法分類 150 張影像.........................................39 表 3、 Y.S. Sie 的方法分類 150 張影像 .................................39 表 4、以提出方法分類 300 張影像.........................................39 表 5、Y.S. Sie 的方法分類 300 張影像 ...................................39 表 6、準確率比較 .....................................................................40 表 7、以提出方法分類 150 張影像.........................................41 表 8、以提出方法分類 300 張影像.........................................42 表 9、Y.S. Sie 的方法分類 150 張影像 ...................................43 表 10、Y.S. Sie 的方法分類 300 張影像 .................................44 表 11、正確率 ...........................................................................45 表 12、訓練影像數量對模型的差異 ......................................47 表 13、使用 10 張影像建構模型所產生的錯誤分類 ............49 表 14、兩者模型差異...............................................................50 表 15、各類別代表影像篩選巨微觀比例分析 ......................52 表 16、篩選與不篩選視覺字的影像對照表 ..........................53. IX.
(13) 一、 緒論 1.1 問題描述 近年來,由於科技的進步與數位內容的普及,數位相機與智慧型 手機成為日常中的必需品,多媒體類型的資訊資料開始大量增加,因 此如何有效的分類這些與日俱增的龐大資料,找出方法幫助使用者整 理、分類所擁有的多媒體資料成為近年來熱門的研究議題。 最初,大多數的影像是以文字對影像進行註解,再以人力或者註 解文字為基礎進行分類,但是這種分類的方法有著顯著的缺點,在分 類的過程中,必須以人力對每一張影像進行註解。而現今的影像資料 庫非常龐大,動輒有上萬張的影像,這將會耗費大量的人力以及時間, 還可能會遇到意涵鴻溝(Semantic Gap)的產生的語意落差問題,一張 影像在不同人的眼中會同有不的理解,可能會造成每個人所分類的結 果有所出入,如圖 1 所示。. 1.
(14) 機場. 飛機. 軍機. 圖 1、一張影像每個人的理解不同. 1.2 研究動機 早期的研究內容是以影像檢索為主要方向,這相似於搜尋引擎, 將影像的資料輸入後,從龐大的影像資料中找出相似的結果,由於意 涵鴻溝產生的語意落差問題,從影像內容中擷取特徵就成為一個主要 的研究方向,近幾年 MPEG-7 標準中提出了關於特徵描述的標準,例 如形狀、色彩、紋理等低階特徵,但如何連結高階特徵和低階特徵間 的關係,將低階特徵和人類的視覺感受立起關聯,是目前研究努力的 方向。 影像分類相較於影像檢索困難許多,因為影像檢索不需要理解影 像的意涵,只需要特徵相似即可,但影像分類是高階內容的識別,必 須對影像的意涵有明確的認識,才能將多張影像正確的分類到所屬的 類別,因此相較於檢索影像,影像的分類更加的複雜。 影像分類一開始最常見的問題是,該以什麼基準分類?以及這影 2.
(15) 像資料該分成幾類為最佳結果?在分類的實驗中,一開始都是以較簡 單的分類為主,例如區分影像的內容為室內或室外,或者是將影像的 框架限定在特定的主題中,例如有些學者想把影像中的的物件提取出 來,以影像中的物件為線索進行分類[1],也有些學者對於球場的場地 進行分類[2],棒球的運動的賽事影像中,將影像中球場明確劃分出草 地和泥地的的區別,而後也有學者以足球競賽[3]的體育比賽影像為 主,從中提取出精彩畫面的片段(得分、失誤等)。 早期的分類方法較有針對性,對特定的研究主題進行研究,而為 了打破框架的限制,開始對於影像的內容進行研究,分析影像的內容 後,提取影像的特徵來進行分類,MPGE-7 中提出一些標準,這些標 準主要針對於特徵的描述為目的。藉由這些低階的特徵理解高階的意 涵,貼近人類的視覺感官,藉由影像特徵的方式改善語意鴻溝的問題, 可以找出完善的分類方法。 我希望能建立一個可以由使用者自己決定分類主題的模型,可以 依照使用者需求,決定是要以背景(巨觀)或者是主體(微觀)為主進行 分類。而我也希望改善分類模型,可以找出每個類別中共有的特徵, 加入共有特徵後可以建立更為精確的分類模型。 近年來發展出視覺字袋(Bag of Visual Words)的研究[4],這些研究 開始應用在影像上,視覺字袋是由字袋(Bag of words)的概念延伸出 3.
(16) 來的,字袋使用在文本關鍵字,有相關的關鍵字的文件可以被分類為 在同一分類中。而視覺字袋使用其概念用用於影像分類上,取出影像 中的特徵,將特徵做成視覺字,計算影像中視覺字出現的次數,做成 直方圖後可以計算分類影像間的相似度,如圖 2 所示。. 影像. 視覺字袋. 圖 2、視覺字袋示意圖 視覺字袋方法有很多優點,在一個小區塊內可能同時擁有許多特 徵,紋理、顏色、形狀等資訊都包含在內,直接獲得許多特徵,在合 併特徵時可以同時獲得很多資訊,而不會因為單一特徵過於注重而忽 略其他特徵資訊。 而視覺字的特徵擷取有兩種方式,一種是找出影像中特徵點,以 為特徵點為基礎並訓練出視覺字,但是影像的背景特徵難以取得,且 影像上的特徵點會有過於集中的問題,會造成特徵描述太過於集中; 另一種方法是以區塊為基礎的視覺字,在影像中化分區塊,並且訓練 4.
(17) 出較重要的區塊,而這種方法的缺點是,有重複性高、不容易定義區 塊代表性的問題,依照區塊的大小選擇,也會對於影像描述有所影響。 在這裡我們選擇以區塊的方式來切割影像特徵區塊作為視覺字, 這方法在計算上較為單純,也可以得到全面的影像資訊,而且區塊還 有重建影像的能力,如圖 3 所示,可以將特徵點的效果有個清楚的檢 視。. 圖 3、以區塊的方式切割並且重建影像 而進行分類的時候必須要有所依據,需要數據做為基礎才可以計 算出所屬的類別。所以我們要建置機率模型,首先必須從資料庫的影 像中選出初步的類別,接下來從這些類別的影像中取得特徵的資料並 且訓練,最後以這些訓練過的資料建置成特徵模型,如圖 4 所示。. 5.
(18) 場景. 動物. 植物. 圖 4、建立特徵模型 在進行影像的分類時,很少會有絕對的分類類別,分類影像通常 使用機率演算法進行分類,例如貝氏(Bayes' theorem) 、SVM、K-Mean、 KNN 等演算法。 而將影像內容的特徵擷取出來,以此特徵為基礎做出視覺字,這 些視覺字中包含了影像內容的色彩與紋理特徵,可以將這些視覺字用 於分析影像內容加強影像分類的功能。 而除了現有的基本類別外,我們希望可以不受基礎類別框架 的影響,可以由使用者自行的擴充、產生新類別,所以我們使用視覺 字袋方法,從視覺字會保留紋理、色彩的特性做為擷取影像特徵的工 6.
(19) 具。. 1.3 論文架構 本論文中,我在第二章節回顧了使用視覺字以及分類方法的相關 研究,而在第三章節介紹我所提出的分類方法,第四章我的實驗結果 並且對照不同的實驗數據,在第五章是結論與未來研究的方向。. 7.
(20) 二、 文獻回顧與探討 對於人類的視覺而言,看到一張影像的最直接的觀感就是色彩特 徵,而後會注意以向內容的紋理與形狀特徵,所以很多影像內容的研 究會使用色彩特徵作為分類的基礎。在 MPGE-7 中提出了定義色彩描 述 的 方 法 , 其 中 有 一 個 方 法 為 主 要 色 彩 描 述 子 (Dominant Color Descriptor),這個方法是以影像色彩和色彩分佈為主,符合人類視覺 感受也最容易顯示該影像的特徵。 最初在進行分類研究時,通常會對整張影像的色彩、紋理等特徵 進行分析,根據這些數據做出簡單的分類,更進一步發展成將整張影 像分割成小區塊,依據這些小區塊的影像特徵,再將影像分割成更細 微的區塊以期待提高對內容識別的精準度。 而近年來發展出了以視覺字的基礎的研究方式,在影像內容中擷 取特徵區塊,將常用到的特徵區塊收集起來建立視覺字袋,而後以這 些視覺字為機出來描述影像。由描述出的影像可以觀察到影像特徵的 分佈和相似度,以視覺字為基礎的研究漸漸受到關注,許多人投入這 方面的研究。. 2.1 視覺字 視覺字有兩種建立的方式,第一種方法以選取特徵點的方式建立 8.
(21) 視覺字袋(Bag of visual words),L.K Huang 學者以尺度不便轉換(SIFT) 為主要擷取方法[5],而後從有學者從 SIFT 的概念得到靈感發表了加 速穩健特徵(SURF)[6],SURF 相較於 SIFT 運算較為快捷簡單;第二 種方法則是 Y. M. Chen 學者以區塊特徵的截取方式[7],將影像進行 切割後,從切割後的影像內得出重要的特徵區塊以建立視覺字。 Keyblock 區塊特徵 區塊特徵是將影像以區塊的方式找出其特徵內容,雖然區塊的描 述有著區塊重複性高、區塊大小影響描述等問題,但可以加入相似度 門檻值的訓練方式降低其重複性,而且區塊計算可以兼顧到文禮、色 彩及空間分布等訊息,且劇有重建影像的能力,這也是其他方法無法 做到的優點。 區塊特徵最常見的方式為,將影像分為特定大小的區塊,這些區 塊是特徵字建立的根據,由於一張影像中會有許多區塊的性質相似, 必須經過訓練,篩選、合併具代表性的區塊(Keyblocks),而這些具代 表性的區塊稱為視覺字,如下圖 5。將這些視覺字集合起來可以建立 成一本視覺字典,由這本字典可以提供分類的影像描述參考數據。. 9.
(22) 圖 5、區塊分割所產生的視覺字 一般而言區塊大小大多為 2 的 N 次方為規格,而這些區塊的大小 對於影像描述的效果會有所影響,常選用的區塊大小為 4×4 和 8×8 的資料量看來是較為適合的,而我們比較希望可以保留細節的部分所 以選擇 4×4 作為研究的大小。. 2.2 分類方法 分類方法很多種,其中有擷取影像中紋理、顏色等低階特徵後, 以此為基礎做為分類依據,這種方法又分成了分析全域影像以及區塊 影像兩種不同的分類方式。 而後的研究不再只拘限於低階特徵,語義建模(semantic modelling) 的概念開始被提出,開始考慮如何由影像的低階特徵連到到影像的高 階意涵,考慮物件(object)概念的特徵[8]。 2.2.1. 低階特徵(全域) 這個方法是較早期提出的方法,多以低階特徵的取樣為主,以提 取整張影像的邊緣紋理方向及色彩影像空間特徵進行分類,此方法需 要ㄧ些影像做為訓練樣本,將每張影像內容的特徵提取出來並以直方 10.
(23) 圖表示,並且訓練成一組類別特徵向量,如圖 6 所示。 此方法的分類使用分層的概念,每一層依序計算每一種特徵的機率。 例如,先計算紋理特徵於類別的機率,接著紋理特徵的計算結果會影 響顏色特徵的機率計算,機率計算全程使用貝氏演算法計算機率以進 分類。 但此方法有一個缺點,每層計算的結果都會影響下一個特徵 計算的結果,當其中ㄧ個層級的計算出現錯誤時,計算的結果會使分 類的結果產生偏差導致分類的結果錯誤。. 圖 6、以全域取得特徵值 2.2.2. 低階特徵(子塊) 除了以全域影像取得特徵值之外,為了保留更多的細節,提高分 類的效率,提出了對影像切割的概念,將整張影像切割為大小相同的 子區塊。 將整張影像切割成 16 個大小相等的區塊,對每個區塊進行計算, 11.
(24) 取得紋理及顏色等特徵資料,將資料以直方圖的方式分別儲存,如圖 7 所示,此方法與全域低階特徵的不同點在於並非對整張影像做特徵 點計算,而是對分割後的區塊進行分別運算,所以會得到 16 組紋理 與顏色特徵的直方圖。 分類計算的部分,不再是以分層計算的方式進行,而是在各 個區塊以 K-NN 的演算法進行特徵分類計算,而整張影像的分類則由 這些區塊的分類結果,以多數決決定影像的分類。. 圖 7、分子區塊取得特徵值 2.2.3. 語義物件(Semantic objects) 這個做法是把影像內容的物件先定義出來,此方法會定義標籤, 天空、森林、道路等標籤,接著放入影像,將整張影像分割計算後, 12.
(25) 查看影像的內容分所分別對應到的標籤,以這些對硬的標籤內容來分 類此張影像所屬的分類,如圖 8 所示。 此作法已經分析了影像中的物件,但標籤由人工建立,且畫分較 為簡單,會將影像細節部分忽略,只能做簡單的分類。. 圖 8、以標籤描述影像得出本圖屬於雪景分類 (a)原始影像(b)場景標籤(c)影像標籤化 2.2.4. 線上 Codebook 重新加權(Online Codebook Reweighting) 此作法為對 BoW 進行改善[9],重新加權由 ScSPM 產生的 Codebook,使用配對限制(Pairwise Constraints)的方法進行分類模型的 13.
(26) 訓練。 這個做法在產生 Codebooke 後,由下圖 9 所示,得到的 Codebook 並不完善,在進行配對限制後,以線的方式連相結並重新加權可以大 幅改善 Codebook 令分類更加準確,且此算法比傳統的演算法的速度 更加快速。 這方法有效的改善 ScSPM 的模型,但相對的運算量以及所能分類 的類別有限,無法進行多類別的分類。. 圖 9、Online Codebook Reweighting 示意圖. 14.
(27) 三、 研究方法與步驟 我們的研究大致分為兩個階段,第一個階段要從影像中訓練視覺 字,將具代表性的視覺字集合起來建立視覺字典,而這本字典在經過 精簡訓練後建立巨觀與微觀字典;而第二階段則是以巨觀字典與微觀 字典為基礎建立類別模型,類別模型可以做為日後分類的依據,最後 以類別模型為基礎,實作分類的效能測試。 首先要從影像中訓練視覺字,這個部分將視覺字的大小設定為 4×4 的大小區塊,而我們的影像資料庫中有 31 個類別,從每一個類 別分別選用 10 張影像作為樣本訓練影像,將得到的視覺字重建該類 別的影像後,取使用率最高的 25 個視覺字作為代表該類別的代表視 覺字;如此一來 31 類別會得出 775 個具代表性的視覺字,接下來必 須將這些視覺字區為分巨觀視覺字和圍觀視覺字,並且精簡到 64 個 巨觀視覺字和 256 個微觀視覺字。 至此我們已經得到了巨觀字典和微觀字典,作為分類的依據,我 們將視覺特徵相近而且具有該類別代表性的 5 張影像作為訓練影像, 選取的訓練影像為 5 張是因為希望能有明確的視覺特徵,過多的訓練 影像產生的類別模型會模糊視覺特徵,造成分類上的錯誤;將影像以 巨微觀字典進行訓練後,得到了分類所需的類別模型,而在建構類別. 15.
(28) 模型時,我們希望可以找到每一個類別獨特的視覺字,由此分辨出每 個類別的差別,最後就可以這些類別模型為基礎,進行影像分類測試。 下圖 10 為整體研究架構。. (a). 16.
(29) (b) 圖 10、整體研究架構(a)訓練流程(b)分類流程 因此論文研究的重點有兩個主要的議題: (1)類別模型建立:分類是以類別模型為基礎,同樣類別中的影像應該 會具有共同的視覺特徵,因此找出類別的代表性特徵是分類成功的重 要基礎,影像新的類別模型不論種類嘗試提出我們的設想可以用下圖 來說明。 (2)分類器的設計:影像的分類上儘管有各種不同的類別,但是難免會 有一些共同的特徵,因此分類應該用機率的方式來設計分類器較優, 17.
(30) 即影像分類哪一類別的機率較高,在這樣的原則下如何根據類別模型 的內容計算應是設計的重點。. 18.
(31) 3.1 建立視覺字典 首先必須建立視覺字典,從影像中提取特徵區塊在訓練成視覺 字,視覺字集合成通用字典,建立字典流程如下圖 11。. 圖 11、建立通用字典流程圖. 3.1.1. 區塊特徵擷取 從每個類別中各挑選 T=10 張訓練影像獲取區塊特徵,31 個類別 共取 310 張影像,做為字典的影像資料愈多,字典所帶有的資訊愈多 樣;每個區塊大小設定為 4×4,獲取的區塊如下圖 12 所示。. 19.
(32) 圖 12、圖中方格為區塊(block) 3.1.2. 區塊特徵訓練 獲得該影像的區塊特徵後,接下來要將這些區塊特徵進行合併訓 練,我們將使用歐氏距離比對兩個區塊間的相似度,如式(3.1)。當兩 個區塊的相似度小於門檻值時,將兩個區塊視為相似的兩個區塊進行 合併,而兩個區塊相似度大於門檻值時,這兩區塊為獨立的兩個區塊 並且將這兩個區塊都保留,經過區塊特徵訓練,我們可以得到影像中 具代表的區塊,並以這些區塊為基礎建立視覺字典。 D(𝐵𝑖 , 𝐵𝑗 ) 3. 3. 1 𝑅 (𝑖) − 𝐵 𝑅 (𝑗))2 + (𝐵 𝐺 (𝑖) − 𝐵 𝐺 (𝑗))2 + (𝐵 𝐵 (𝑖) − 𝐵 𝐵 (𝑗))2 = ∑ ∑ √(𝐵𝑚𝑛 𝑚𝑛 𝑚𝑛 𝑚𝑛 𝑚𝑛 𝑚𝑛 16 𝑚=0 𝑛=0. 1, 𝑖𝑓 𝐷(𝐵𝑖 , 𝐵𝑗 ) ≤ 𝑇 SIM(𝐵𝑖 , 𝐵𝑗 ) = { 0, 𝑒𝑙𝑠𝑒 𝑇:門檻值為 65 1 為相似;0 為不相似 SIM(𝐵𝑖 , 𝐵𝑗 ):兩區塊是否相似 20. (3.1).
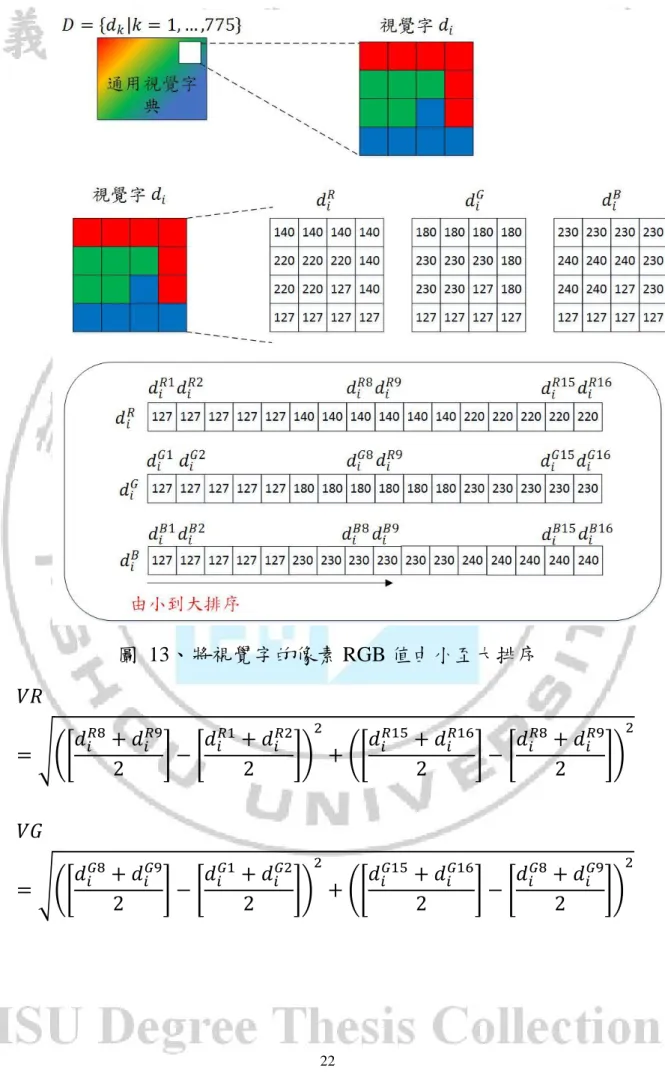
(33) D(𝐵𝑖 , 𝐵𝑗 ):兩區塊之間 RGB 的差異值 3.1.3. 區分巨觀及微觀視覺字典 建立通用視覺字典後,我們想將字典裡的視覺字進行精簡和區分, 篩選更具代表性的視覺字,而就如同人類會有背景和主體的概念,我 們希望將背景和主體做出區分,得出巨觀與微觀的概念。我們定義巨 觀為廣大並且單純的紋理與色彩,而微觀則是有複雜紋理與色彩的部 分;分別得到巨觀視覺字和微觀視覺字。 我們使用視覺字的像素資訊來判斷巨觀與微觀,如下圖 13,通用 視覺字典 D={𝑑𝑘 |k=1,2,…M}中的一個視覺字𝑑𝑖 ,其中視覺字𝑑𝑖 為 (𝑑𝑖𝑅 ,𝑑𝑖𝐺 , 𝑑𝑖𝐵 )三個色彩組成,將像素值 R、G、B 分別取出,並且由大 到小排序。透過式(3.2)、(3.3)的判斷即可得知,如果所有的差值(VR、 VG、VB)皆小於我們設定的門檻值(T=15),就將該視覺字𝑑𝑖 判斷為巨 觀視覺字𝑑𝑖𝑀𝐴𝐶 ,反之則為微觀視覺字𝑑𝑖𝑚𝑖𝑐 。 使 用 通 用 字 典 建 構 字 典 大 小 分 別 為 64 的 巨 觀 視 覺 字 典 𝐷𝑀𝐴𝐶 (𝑘) = {𝑑𝑘𝑀𝐴𝐶 |𝑘 = 1,2, … ,64}及 256 的微觀視覺字典𝐷𝑚𝑖𝑐 (𝑘) = {𝑑𝑘𝑚𝑖𝑐 |𝑘 = 1,2, … ,256}。. 21.
(34) 圖 13、將視覺字的像素 RGB 值由小至大排序 𝑉𝑅 2. 2. 2. 2. 𝑑𝑖𝑅8 + 𝑑𝑖𝑅9 𝑑𝑖𝑅1 + 𝑑𝑖𝑅2 𝑑𝑖𝑅15 + 𝑑𝑖𝑅16 𝑑𝑖𝑅8 + 𝑑𝑖𝑅9 = √([ ]−[ ]) + ([ ]−[ ]) 2 2 2 2 𝑉𝐺 𝑑𝑖𝐺8 + 𝑑𝑖𝐺9 𝑑𝑖𝐺1 + 𝑑𝑖𝐺2 𝑑𝑖𝐺15 + 𝑑𝑖𝐺16 𝑑𝑖𝐺8 + 𝑑𝑖𝐺9 √ = ([ ]−[ ]) + ([ ]−[ ]) 2 2 2 2. 22.
(35) 𝑉𝐵 2. 2. 𝑑𝑖𝐵8 + 𝑑𝑖𝐵9 𝑑𝑖𝐵1 + 𝑑𝑖𝐵2 𝑑𝑖𝐵15 + 𝑑𝑖𝐵16 𝑑𝑖𝐵8 + 𝑑𝑖𝐵9 √ = ([ ]−[ ]) + ([ ]−[ ]) 2 2 2 2. (3.2) 𝑑𝑖𝑅𝑛 、𝑑𝑖𝐺𝑛 、𝑑𝑖𝐵𝑛 :視覺字排序後的第. n 區塊像素值. 𝑉𝑅、 𝑉𝐺、 𝑉𝐵:像素運算後的數值. if max ( 𝑉𝑅、 𝑉𝐺、𝑉𝐵 ) ≤ T 𝑑𝑖 ∈ 𝐷𝑀𝐴𝐶 = {𝑑𝑖𝑀𝐴𝐶 , 𝑖 = 1, … ,64} else. (3.3) 𝑑𝑖 ∈ 𝐷𝑚𝑖𝑐 = {𝑑𝑖𝑚𝑖𝑐 , 𝑖 = 1, … ,256}. 𝑑𝑖 :通用視覺字典的所有視覺字,i=1~775 𝑑𝑖𝑀𝐴𝐶 :巨觀視覺字 𝑑𝑖𝑚𝑖𝑐 :微觀視覺字 max( ):所有條件皆符合 T:門檻值=15. 圖 14、區分出巨觀特徵與微觀特徵. 23.
(36) 3.2 影像分類 微觀字典與巨觀字典建立後,這兩本字典就是我們研究影像分類 的依據。 影像分類是一個十分複雜且難以定義的認知概念,例如從不同的 認知領域對於分類的需求不盡相同。例如:我們說到動物那麼各式各 樣的動物都在同一類,像是大象、飛鳥、魚、蝦…都屬於同一類,但 是從視覺的觀點來看,其中大部份並沒有相似的視覺特徵,如果將生 物歸為一類那屬於植物、動物、微生物都是屬於同一類,但是視覺上 的差異更大,這樣通常無法利用視覺來達到分類的目的,如下圖 15 所示,影像內容的認知領域廣泛。. 24.
(37) 圖 15、動物和植物定義廣泛 因此,如果談到影像的分類,我們首先強調的應該就是依據 視覺特徵將影像歸到不同類別,例如我想將老虎的影像歸類成一 類,那麼猴子就不應該是同一類,因為視覺特徵迥異。因此我們 在訓練類別模型時,視覺上的相似性視主要的依據,如下圖 16, 將相似的影像分在同一類。. 25.
(38) 圖 16、天空的視覺特徵接近 一般視覺特徵會有整體及細節上的差異,例如:同樣的山景並不會 因為多了一匹馬或是少了一些花草而改變我們整體的認知,或許一般 人在乎的是整體的視覺感受,或是有些人進一步區分其中差異或是從 不同的整體感關中找出特徵的細節,這都符合我們影像分類的一般需 求,因此我們使用的巨微觀視覺字典剛好符和我們的需要。 本研究嘗試以視覺特徵為主,將視覺特徵像近的影像分類做得更 加準確,而我們的研究將影像分類的步驟分成建立模類別組和機率計 算兩部分。. 3.2.1.類別模型訓練 為了分類影像,我們必須將每個類別進行訓練,以建成類別模 型,建成類別模型後,這些類別模型是而後分類的依據;每一個類 別可能會由很多種特徵表示,單一特徵或者單一組向量模型可能無 26.
(39) 法表示,所以使用巨微觀字典描述各個類別。 首先建立代表給個類別的類別特徵模型 Cla(i) = {(C𝑏𝑖 (b), P𝑏𝑖 )|. i = 1…L },Cla(i):第 i 類的 𝑏 = 0,1|0 = 𝑀𝐴𝐶, 1 = 𝑚𝑖𝑐. 類別特徵模型,而每一個類別都有巨觀模型與微觀模型。 𝑖 𝑖 𝑖 (𝑘), 𝑑𝑀𝑎𝑐 (𝑘)%), 𝑘 = 0,1, … , 𝑁𝑀𝑎𝑐 ], 巨觀模型C𝑙𝑎𝑀𝑎𝑐 (𝑀) = [(𝑑𝑀𝑎𝑐 𝑖 𝑖 (𝑀)為第 i 類的巨觀模型,𝑑𝑀𝑎𝑐 (𝑘)為巨觀視覺字典中第 k 個視 C𝑙𝑎𝑀𝑎𝑐 𝑖 (𝑘)%為巨觀視覺字典中第 k 個視覺字所佔的百分比。 覺字,𝑑𝑀𝑎𝑐 𝑖 𝑖 𝑖 (𝑘), 𝑑𝑚𝑖𝑐 (𝑘)%), 𝑘 = 0,1, … , 𝑁𝑚𝑖𝑐 ], 微觀模型C𝑙𝑎𝑚𝑖𝑐 (𝑚) = [(𝑑𝑚𝑖𝑐 𝑖 𝑖 (𝑚)為第 i 類別的微觀模型,𝑑𝑚𝑖𝑐 (𝑘)為微觀視覺字典中第 k 個 C𝑙𝑎𝑚𝑖𝑐 𝑖 (𝑘)%為微觀視覺字典中第 k 個視覺字所佔的百分比。 視覺字,𝑑𝑚𝑖𝑐. 而模型中包含了兩項資料,分別是類別代表視覺字的向量直方圖, 以及該類別的代表視覺字所佔訓練影像的百分比。 本研究中我每個類別分別挑選 P=5 張影像做為訓練模型的代表, 挑選的 5 張訓練影像是選用視覺特徵明確的影像,且影像內容相近, 因為太大的差異性會模糊視覺特徵而影響模型的獨特性,如此一來可 以加強物理特徵辨識性,並且將這個模型單純化。接著以巨微觀字典 為基礎,描述該類別所有的訓練影像,建立影像編號,L(𝐵𝑆 (𝑛)), 𝑛 = 1,2, … 𝑁,𝐵𝑆 (𝑛) 代表影像的分割區塊,L(𝐵𝑆 (𝑛)) 代表每個區塊所對 應到最相似的視覺字,接著將標籤區分出巨觀標籤 𝐿(𝐵𝑆𝑀𝐴𝐶 (𝑛)) 與微 27.
(40) 觀標籤 𝐿(𝐵𝑆𝑚𝑖𝑐 (𝑛)),依照標籤統計出每個巨觀視覺字與微觀視覺字 在類別中所使用的比例,並挑選出來建立為該類別的巨觀與微觀視覺 𝑖 𝑖 𝑖 𝑖 (𝑘) ,𝑑𝑀𝐴𝐶 (𝑘)%) 與 (𝑑𝑚𝑖𝑐 (𝑘),𝑑𝑚𝑖𝑐 (𝑘)%) 部分。在 字模型中的 (𝑑𝑀𝐴𝐶. 這當中建立模型時會將視覺字進行篩選,將使用率低於平均的視覺字 排除,增加模型的獨特性,對於分類有所幫助。模型訓練流程如下圖 17。. 28.
(41) 各類別挑選P張影 像. 以巨微觀字典描述 影像. 巨觀. 微觀. 建立訓練影像巨觀 描述. 建立訓練影像微觀 描述. 巨觀編號直方圖, 並去除使用率低的 視覺字. 微觀編號直方圖, 並去除使用率低的 視覺字. 否. 是否為最後一 張訓練影像. 是 將P張訓練影像的 巨觀特徵整合建立 巨觀模型. 將P張訓練影像的 微觀特徵整合建立 微觀模型. 建立類別模型. 圖 17、建立類別模型. 有關於建立模型時將使用率低於平均值的視覺字去除,是因為我 們的視覺字典是由 64 個巨觀字以及 256 個微觀字所組成,模型所得 29.
(42) 到的資訊都來自於這裡,當每個模型之間使用的字越相近,會降低模 型的獨特性,為了提高影像分類的準確率,將使用率不高、不重要的 視覺字去除有助於影像的分類;而去除的視覺字,我們研究是以單張 訓練圖像的巨觀與微觀的平均使用次數做為 T 值,分別計算在巨觀與 微觀中使用次數低於平均值以下的視覺字去除,而有些訓練影像中, 有些在此單張訓練影像中視覺字使用率別高,但其他影像中所沒有的, 那麼這視覺字也納入模型中,這個視覺字俱備單張重要性。 如下圖 17,當 A 模型和 B 模型訓練影像少時,模型小不易混淆。 但隨著訓練影像增加,模型會因使用的視覺字增多,兩個模型增大, 使用的視覺字有所重疊,若有去除低使用率的視覺字可以令 A 模型 和 B 模型有明確的分類,不容易混淆,若沒有去除低使用率的視覺 字,可能會因為不重要的視覺字令兩個模型產生相似,在分類時造成 錯誤分類。 𝑖 (𝑘)%, 𝑘 = 0, ⋯ 𝑁𝑀𝐴𝐶 ) 𝑇𝑀𝐴𝐶 = 𝐴𝑣𝑒𝑟𝑎𝑔𝑒(𝑑𝑀𝐴𝐶. (3.4). 𝑖 (𝑘)%, 𝑘 = 0, ⋯ 𝑁𝑀𝐴𝐶 ) 𝐴𝑣𝑒𝑟𝑎𝑔𝑒(𝑑𝑀𝐴𝐶. (3.5). =. 1 𝑁𝑀𝐴𝐶. 𝑁𝑀𝐴𝐶 𝑖 (𝑘) % ∑ 𝑑𝑀𝐴𝐶. (3.6). 𝑘=0. 𝑖 (𝑘)%, 𝑘 = 0, ⋯ 𝑁𝑚𝑖𝑐 ) 𝑇𝑚𝑖𝑐 = 𝐴𝑣𝑒𝑟𝑎𝑔𝑒(𝑑𝑚𝑖𝑐. (3.7). 𝑖 (𝑘)%, 𝑘 = 0, ⋯ 𝑁𝑚𝑖𝑐 ) 𝐴𝑣𝑒𝑟𝑎𝑔𝑒(𝑑𝑚𝑖𝑐. (3.8). 30.
(43) 𝑁𝑚𝑖𝑐. 1 𝑖 (𝑘) % = ∑ 𝑑𝑚𝑖𝑐 𝑁𝑚𝑖𝑐. (3.9). 𝑘=0. 圖 18、(a)模型不大時模型獨立(B)隨著模型增大 AB 模型產生相交 (C)藉著去除不重要的視覺字令模型獨立. 3.2.2. 類別機率計算 建立類別模型後,分類影像必須由機率模型計算得到最後的分類 結果,首先類別特徵模型為 i = 1…L Cla(i) = {(C𝑏𝑖 (b), P𝑏𝑖 )| } 𝑏 = 0,1|0 = 𝑀𝐴𝐶, 1 = 𝑚𝑖𝑐 𝑖 C𝑙𝑎𝑀𝐴𝐶 (𝑀):巨觀特徵模型 𝑖 C𝑙𝑎𝑚𝑖𝑐 (m):微觀特徵模型 𝑖 P𝑀𝐴𝐶 :類別巨觀百分比 𝑖 P𝑚𝑖𝑐 :類別微觀百分比. 比較影像描述的巨微觀及類別特徵相似度計算,採用最大化是後 31.
(44) 機率模型(MAP),因為巨觀和微觀的區域組成是分開描述的,所以在 計算巨觀區域和微觀區域時巨觀和微觀也必須分別計算。 ̂ (I) = argmax P(Cla(i)|𝐼) Cla 𝐶𝑙𝑎(𝑖). 𝑖 𝐼 𝑖 𝐼 (𝑖)) + P (C𝑙𝑎𝑚𝑖𝑐 (𝑚)|𝐻𝑚𝑖𝑐 (𝑖))] = argmax[P (C𝑙𝑎𝑀𝐴𝐶 (𝑀)|𝐻𝑀𝐴𝐶 𝐶𝑙𝑎(𝑖). (3.10) (3.11). 計算在 I 的特徵描述下,最有可能的類別為哪一個,因此巨微 觀兩個必須分開計算: 𝑖 𝑖 𝐼 𝐼 𝑖 𝑖 (𝑖)|C𝑙𝑎𝑀𝐴𝐶 (𝑀)) + P (𝐻𝑚𝑖𝑐 (𝑖)|C𝑙𝑎𝑚𝑖𝑐 (𝑚)) P(C𝑙𝑎𝑚𝑖𝑐 = argmax[P(𝐻𝑀𝐴𝐶 (𝑀))P (C𝑙𝑎𝑀𝐴𝐶 (𝑚))] 𝐶𝑙𝑎(𝑖). (3.12) 𝐼 𝑖 𝐼 𝑖 (𝑖)|C𝑙𝑎𝑀𝐴𝐶 (𝑀)) 與 P (𝐻𝑚𝑖𝑐 (𝑖)|C𝑙𝑎𝑚𝑖𝑐 (𝑚)) 為最大相似 P (𝐻𝑀𝐴𝐶 𝐼 𝑖 (𝑖) 與 (C𝑙𝑎𝑀𝐴𝐶 (𝑀))及 模型,此計算最大的發生機率在 𝐻𝑀𝐴𝐶 𝐼 𝑖 (𝑖) 與 (C𝑙𝑎𝑚𝑖𝑐 𝐻𝑚𝑖𝑐 (𝑚)) 距離最小的地方,因此必須計算兩者的距. 離,而兩者距離的計算使用: 巨觀 𝑖 (𝑀)) P (𝐼𝑀𝐴𝐶 |C𝑙𝑎𝑀𝐴𝐶 𝑀 𝐼 𝑖 𝐼 𝑖 (𝑗) − 𝑑𝑀𝐴𝐶 = ∑ 𝑤𝑀𝐴𝐶 [(1 − |𝐻𝑀𝐴𝐶 (𝑗)|) × 𝑚𝑖𝑛(ℎ𝑀𝐴𝐶 (𝑗), 𝑑𝑀𝐴𝐶 (𝑗))] (3.13) 𝑗=1. 𝑖 𝑖 P(C𝑙𝑎𝑀𝐴𝐶 (𝑀)) = 𝑃𝑀𝐴𝐶. (3.14). 微觀 32.
(45) 𝑖 (𝑚)) P (𝐼𝑚𝑖𝑐 |C𝑙𝑎𝑚𝑖𝑐 𝑀 𝐼 𝑖 𝐼 𝑖 = ∑ 𝑤𝑚𝑖𝑐 [(1 − |ℎ𝑚𝑖𝑐 (𝑗) − 𝑑𝑚𝑖𝑐 (𝑗)|) × 𝑚𝑖𝑛(ℎ𝑚𝑖𝑐 (𝑗), 𝑑𝑚𝑖𝑐 (𝑗))] (3.15) 𝑗=1. 𝑖 𝑖 (𝑚)) = 𝑃𝑚𝑖𝑐 P (C𝑙𝑎𝑚𝑖𝑐. (3.16). 𝐼 ℎ𝑀𝐴𝐶 (𝑗):來源影像巨觀所代表視覺字 𝑖 𝑑𝑀𝐴𝐶 (𝑗) :類別巨觀所代表視覺字 𝐼 ℎ𝑚𝑖𝑐 (𝑗):來源影像微觀所代表視覺字 𝑖 𝑑𝑚𝑖𝑐 (𝑗) :類別微觀所代表視覺字 𝑖 (𝑘)%:巨觀代表視覺字在該類別所佔的比例 𝑑𝑀𝐴𝐶 𝑖 (𝑘)%:微觀代表視覺字在該類別所佔的比例 𝑑𝑚𝑖𝑐. 𝑤𝑀𝐴𝐶 :在該類別巨觀類別模型視覺字權重,和𝑤𝑚𝑖𝑐 總合為 1。 𝑤𝑚𝑖𝑐 :在該類別微觀類別模型視覺字權重,和𝑤𝑀𝐴𝐶 總合為 1。 𝑤𝑀𝐴𝐶 和𝑤𝑚𝑖𝑐 是類別的巨觀與微觀權重,在計算完相似度後,再乘 以該類別模型的巨觀與微觀模型;如下圖 19,假設 A 的類別模型巨 觀占了 20%微觀占 80%,而有一張影像 B 在比對時巨觀比例和微觀 比例和 A 完全相反,巨觀占了 80%而微觀只占 20%,但 B 影像的巨 觀相似度與 A 的巨觀相似度卻高達 90%,而 B 影像的微觀相似度有 30%,平均下來有 60%的整體相似度。巨觀比例少卻主導整個相似度, 會造成分類錯誤,所以要進行模型比重的調整,A 類別巨觀比重只能 33.
(46) 做 20%的干涉,這樣整體相似度就會只有約 42%。. 圖 19、類別模型權重說明示意圖 𝑖 𝑖 (𝑀)) 與 P (C𝑙𝑎𝑚𝑖𝑐 (𝑚)) , 最 後 巨 觀 微 觀 分 別 乘 上 P (C𝑙𝑎𝑀𝐴𝐶 𝑖 𝑖 (𝑚))分別代表該類別的巨觀比例與微觀比 P(C𝑙𝑎𝑀𝐴𝐶 (𝑀))和P (C𝑙𝑎𝑚𝑖𝑐. 例,這兩個數值決定了巨觀與微觀相似性的重要度,兩者計算結果相 加就可以得到影像之間的相似機率,但這計算會忽略整體分類影像與 影像類別間巨微觀比例的相似度。 𝑖 𝑖 (𝑀)) 與 P(C𝑙𝑎𝑚𝑖𝑐 所以在計算機率時,P (C𝑙𝑎𝑀𝐴𝐶 (𝑚))的重要性對. 於類別來說是不同的,亦即相似度雖然高但是巨微觀比例在類別內佔 的低,重要性就會下降。為了解決影像和類別間巨微觀相似度比例的 34.
(47) 問題,在兩者相加時應該採不同權重。 ̂ (I) = Cla 𝑖 𝐼 𝑖 𝐼 (𝑀)|𝐻𝑀𝐴𝐶 (𝑀)) + w2 × P (C𝑙𝑎𝑚𝑖𝑐 (𝑚)|𝐻𝑚𝑖𝑐 (𝑚))] argmax[w1 × P (C𝑙𝑎𝑀𝐴𝐶 𝐶𝑙𝑎(𝑖). (3.17). 而 w1、w2 為巨微觀權重值: 巨觀 𝑖 𝑤1 = min(%𝐼𝑀𝐴𝐶 , 𝑃𝑀𝐴𝐶 ). (3.18). 𝑖 𝑤2 = min(%𝐼𝑚𝑖𝑐 , 𝑃𝑚𝑖𝑐 ). (3.19). 微觀. %𝐼𝑀𝐴𝐶 :來源影像巨觀所佔比例 𝑖 𝑃𝑀𝐴𝐶 :類別巨觀所佔比例. %𝐼𝑚𝑖𝑐 :來源影像微觀所佔比例 𝑖 𝑃𝑚𝑖𝑐 :類別微觀所佔比例. 最後將原先計算好的各類別巨觀機率與微觀機率全重相整合,找 出影像所屬最有可能的類別。 𝐼̂𝐶𝑙𝑎 = 𝑆 𝑀𝑎𝑐 × 𝑤1 + 𝑆 𝑀𝑖𝑐 × 𝑤2 𝑤1 、𝑤2 :權重值 𝐼̂𝐶𝑙𝑎 :類別機率. 35.
(48) 四、 實驗數據及結果 在這個章節我們將介紹我們的實驗結果,首先是實驗的環境: 開發軟體:Visual Studio C# 2013 作業系統: Microsoft Windows 7 硬體:Intel(R) Core(TM)2 Quad CPU Q8300 (2.5 GHz) 處理器 記憶體: 3.5GB. 4.1 數據庫 本研究使用 Corel 影像資料庫,其中包含 3901 張影像,概略分為 31 個類別,本研究選擇其中 15 個類別,分別選用 10 張影像以及 20 張影像,分別做 150 張及 300 張影像的分類測試。. 圖 20、Corel 影像資料庫. 36.
(49) 下表為我所挑選進行測試的 15 個類別。 表 1、測試類別. 猩 猩. 盆 栽. 夕 陽. 大 象. 恐 龍. 鴨 子. 豹. 枯 葉. 綠 葉. 飛 機. 壁 畫. 戰 鬥 機. 直 升 機. 熱 氣 球. 瀑 布. 37.
(50) 4.2 效能評估 總共將 15 個分類,以每類 10 張及 20 張影像的測試結果,測試 提出方法的結果與 Y.S. Sie 的方法進行比較,由正確率來進行效能評 估。 判斷分類正確率由下式計算: 正確率 =. 分類成功影像 總影像數目. 38. (4.1).
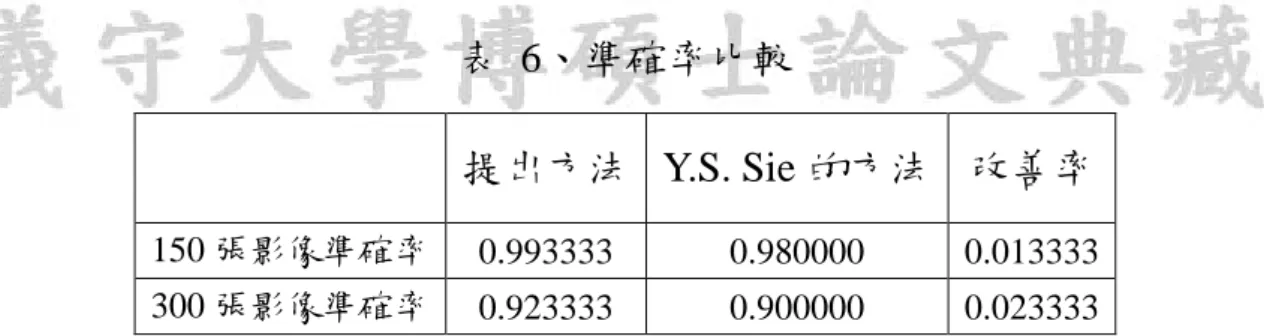
(51) 首先,我們對巨觀影像的分類效能做比較: 表 2、以提出方法分類 150 張影像 土巨觀 土巨觀. 白巨觀. 黃巨觀. 藍巨觀. 1. 29. 白巨觀. 綠巨觀. 30. 黃巨觀. 30. 綠巨觀. 30. 藍巨觀. 30. 表 3、 Y.S. Sie 的方法分類 150 張影像 土巨觀 土巨觀. 白巨觀. 綠巨觀. 藍巨觀. 30. 白巨觀. 30. 黃巨觀. 1. 綠巨觀. 黃巨觀. 29. 1. 藍巨觀. 29 1. 29. 表 4、以提出方法分類 300 張影像. 土巨觀. 土巨觀. 白巨觀. 黃巨觀. 56. 2. 1. 白巨觀 4. 綠巨觀. 4. 藍巨觀. 藍巨觀 1. 6. 54. 黃巨觀. 綠巨觀. 56 1. 55. 3. 1. 56. 表 5、Y.S. Sie 的方法分類 300 張影像 土巨觀. 白巨觀. 土巨觀. 58. 2. 白巨觀. 1. 54. 黃巨觀 綠巨觀 藍巨觀. 黃巨觀. 藍巨觀. 5. 1 8. 綠巨觀. 3. 56. 1. 51. 9. 51. 39.
(52) 表 6、準確率比較 提出方法 Y.S. Sie 的方法 改善率 150 張影像準確率. 0.993333. 0.980000. 0.013333. 300 張影像準確率. 0.923333. 0.900000. 0.023333. 由表格中可以看出,我們所提出的方法對於影像的巨觀判斷率更 高,將不少數的資料去除後,可以更保證模型的獨立性,能更正確的 區別影像的巨觀條件。. 40.
(53) 接下來我們對每個類別的影像做更詳細的類別分類: 表 7、以提出方法分類 150 張影像 猩猩 猩猩 盆栽 夕陽 大象 恐龍 鴨子 豹. 盆栽. 夕陽. 大象. 恐龍. 鴨子. 豹. 枯葉. 8. 綠葉. 飛機. 壁畫. 戰機. 直升. 氣球. 1. 瀑布. 1. 10 10 9. 1 10 10 10. 枯葉. 10. 綠葉. 10. 飛機. 10. 壁畫. 10. 戰機. 10. 直升. 1. 氣球. 8. 1 10. 瀑布. 10. 41.
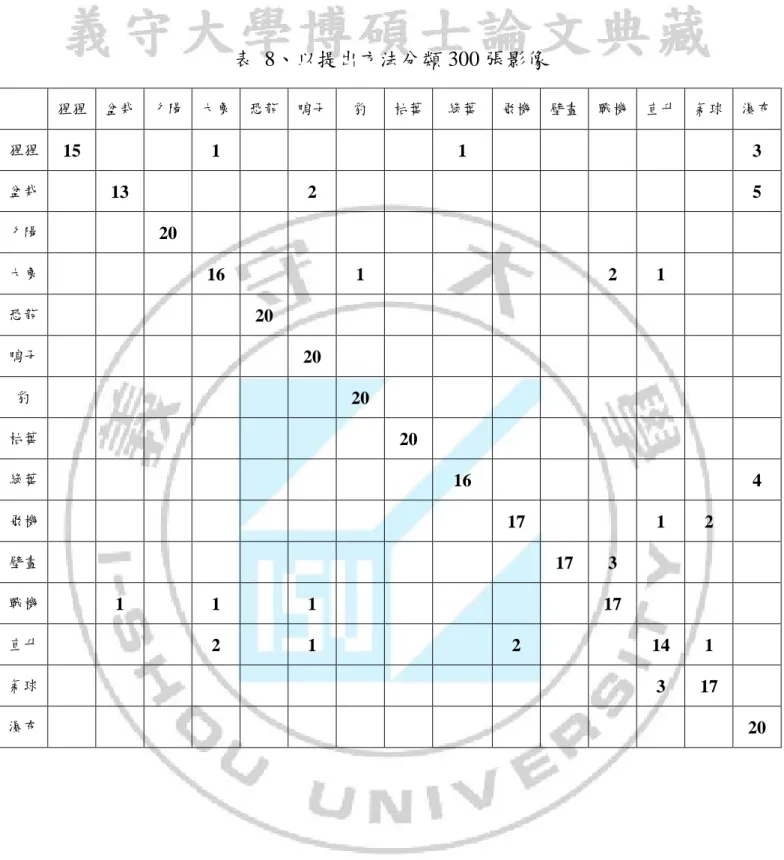
(54) 表 8、以提出方法分類 300 張影像 猩猩 猩猩 盆栽. 盆栽. 夕陽. 15. 大象. 恐龍. 鴨子. 豹. 枯葉. 1. 飛機. 直升. 氣球. 瀑布. 3. 2. 16. 恐龍. 5. 1. 2. 1. 20. 鴨子. 20. 豹. 20. 枯葉. 20. 綠葉. 16. 飛機. 4 17. 壁畫. 直升. 戰機. 20. 大象. 戰機. 壁畫. 1. 13. 夕陽. 綠葉. 17 1. 1. 1. 2. 1. 1. 2. 14. 1. 3. 17. 3 17. 2. 氣球 瀑布. 20. 42.
(55) 表 9、Y.S. Sie 的方法分類 150 張影像 猩猩 猩猩 盆栽 夕陽 大象 恐龍. 盆栽. 夕陽. 大象. 恐龍. 鴨子. 豹. 枯葉. 綠葉. 飛機. 戰機. 直升. 氣球. 8. 瀑布. 2 10 10 9. 1 10. 鴨子. 10. 豹. 10. 枯葉. 10. 綠葉. 9. 飛機. 1 10. 壁畫. 10. 戰機 直升. 壁畫. 10 1. 1. 氣球. 6. 2 10. 瀑布. 10. 43.
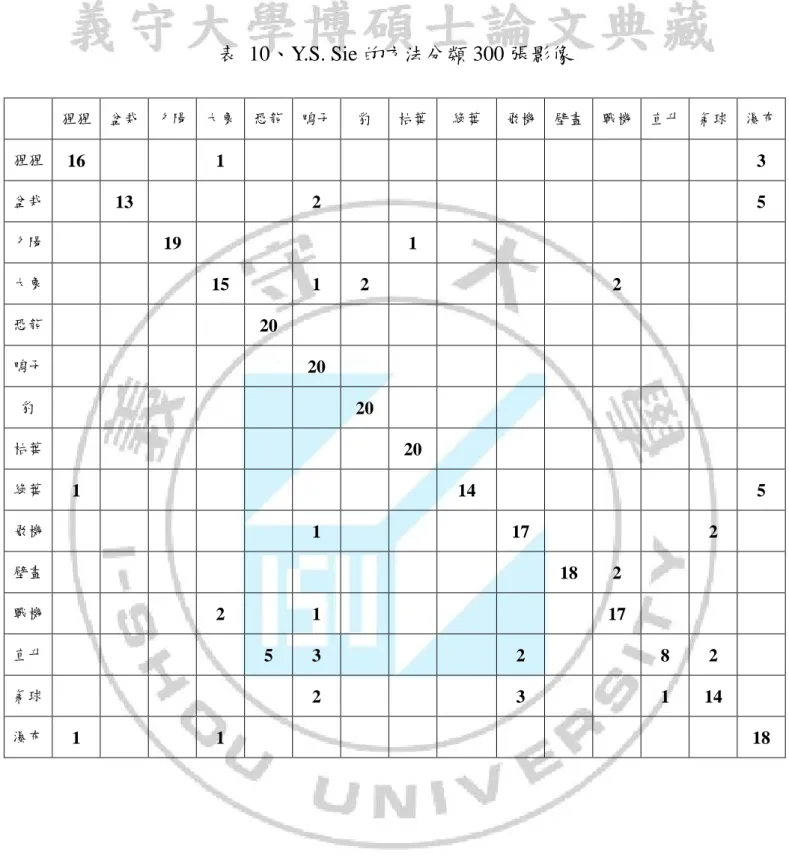
(56) 表 10、Y.S. Sie 的方法分類 300 張影像 猩猩 猩猩. 盆栽. 夕陽. 16. 盆栽. 大象. 恐龍. 豹. 枯葉. 戰機. 直升. 氣球. 瀑布. 5 1. 15. 1. 2. 2. 20. 鴨子. 20. 豹. 20. 枯葉. 20 1. 14. 飛機. 1. 5 17. 壁畫. 2 18. 戰機. 2. 直升. 1 5. 氣球 瀑布. 壁畫. 2. 恐龍. 綠葉. 飛機. 3. 19. 大象. 綠葉. 1 13. 夕陽. 鴨子. 1. 2 17. 3. 2. 8. 2. 2. 3. 1. 14. 1. 18. 44.
(57) 表 11、正確率 提出方法 Y.S. Sie 的方法 改善率 150 張影像準確率. 0.966667. 0.946667. 0.02. 300 張影像準確率. 0.873333. 0.830000. 0.043333. 由表格上可以明顯看出,我們的研究有效的改善了巨觀影像所占 比重較大的影像,如天空為巨觀的影像方面有著有效的改善。. 45.
(58) 4.3 訓練模型評估 這裡是要評估類別模型訓練影像的多寡是否會影響分類的效率, 這裡我找出幾個模型來做代表,這幾個模型分別是由 5 個影像和 10 個影像所訓練出來的類別模型,這幾個類別在兩種訓練方式下分類結 果有所不同,以下為訓練結果以及分類的影響。. 46.
(59) 4.3.1 模型差異 這裡也分成巨觀字以及微觀字,巨觀字有編號 1~64,而微觀為 1~256 的編號,兩者分別獨立編號,此處的差異視覺字為,使用 5 張 影像做訓練時沒有使用到而使用 10 張影像時有使用到的視覺字。 表 12、訓練影像數量對模型的差異 綠葉. 差異的視覺字 巨觀編號: 23,30,37,40 微觀編號: 5,6,55,65,132,139,152,229,237,243 ,249. 飛機. 差異的視覺字 巨觀編號: 21,47,48 微觀編號: 18,24,32,49,72,78,88,100,115,160,191 ,205,215,219,237,248. 壁畫. 差異的視覺字 巨觀編號: 23,30 微觀編號: 20,45,83,89,103,105,143,149,156,193, 242 47.
(60) 由上面的表 12 可以觀察到,5 張訓練影像所訓練出的類別模型和 10 張訓練影像所建構的類別模型不論是巨觀特徵或是微觀特徵都會 有相當數量視覺字的差異,而這些視覺字使用次數也是非常少,這些 使用次數少的視覺字會讓分類結果產生錯誤,我在下一小節一併說明。. 48.
(61) 4.3.2 模型差異造成的分類錯誤 上一小節我們觀察到訓練影像的多寡會對模型造成一定的影響, 而這些影響會對於分類效果有多大的不同呢,下表 13 為分類模型不 同造成的錯誤分類影像。 表 13、使用 10 張影像建構模型所產生的錯誤分類 綠葉影像錯誤分類到瀑布影像. 飛機影像錯誤分類到熱氣球影像. 壁畫影像錯誤分類到枯葉影像. 49.
(62) 我們要分析這三張影像,將影像應該所屬的模型和分類錯誤的影 像的模型,提出來觀察兩者模型在 10 張訓練影像下和 5 張訓練影像 下有什麼差異,下表 14 為在 5 張訓練影像下和 10 張訓練影像比較, 模型由少數視覺字相交變為不相交。 表 14、兩者模型差異 巨觀編號: 綠葉和瀑布模型分析. 30 微觀編號: 5,6,42,55,65,103,112,139,152,165,237 巨觀編號:. 飛機和熱氣球模型分析. 21 微觀編號: 15,18,49,78,88,100,160,205,215,237 巨觀編號:. 壁畫和枯葉模型分析. 43 微觀編號: 45,50,70,83,89,103,149,156,158,169,182 231,242,250. 我們從實驗結果觀察到,並非使用越多的影像對於模型的建構有 越好的結果,而是我們必須要選用有代表性的影像,使用越多影像對 於模型而言會產生許多使用次數不高的視覺字,這些視覺字和其它類 別的模型視覺字重疊,造成分類上的錯誤,因此使用 5 張影像比起 10 張影像有更高的效率,且訓練更加簡單。. 50.
(63) 4.3.3 去除視覺字與否的差異測試 這部分我們在測試,單張影像在篩選掉使用次數少於平均值的視 覺字後產生的影像和巨觀與微觀比例,並且和不篩選的原始影像做比 較進行測試,下表 15 為我們測試的影像以及巨微觀比例的結果。. 51.
(64) 表 15、各類別代表影像篩選巨微觀比例分析 類別. 巨觀視覺字. 微觀視覺字. 篩選前. 篩選後. 差值. 篩選前. 篩選後. 差值. 猩猩. 49%. 38%. 11%. 51%. 40%. 11%. 盆栽. 58%. 45%. 13%. 42%. 30%. 12%. 夕陽. 89%. 87%. 2%. 11%. 10%. 1%. 大象. 30%. 25%. 5%. 70%. 54%. 16%. 恐龍. 82%. 79%. 3%. 18%. 14%. 4%. 鴨子. 85%. 71%. 14%. 15%. 12%. 3%. 豹. 22%. 18%. 4%. 78%. 59%. 19%. 枯葉. 3%. 2%. 1%. 97%. 81%. 16%. 綠葉. 28%. 27%. 1%. 72%. 54%. 18%. 飛機. 91%. 90%. 1%. 9%. 6%. 3%. 壁畫. 29%. 14%. 4%. 71%. 57%. 14%. 戰機. 14%. 12%. 2%. 86%. 71%. 15%. 直升機. 72%. 57%. 15%. 28%. 22%. 6%. 熱氣球. 75%. 68%. 7%. 25%. 19%. 6%. 瀑布. 27%. 21%. 6%. 73%. 58%. 15%. 從上表 15 可以看到,篩選後的結果相較於不篩選的結果會有 1~25%之間的差異,而這些去除的部分將影像的巨觀與微觀部分得到 更純粹的部分,有助於分類的效果,我們從下表 16 可以正直接觀察 到篩選與不篩選的效果。. 52.
(65) 表 16、篩選與不篩選視覺字的影像對照表. 猩猩. 盆栽. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:49%. 未篩選微觀字分 布佔:51%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:38%. 篩選後微觀字分 布佔:40%. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:58%. 未篩選微觀字分 布佔:42%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:45%. 篩選後微觀字分 布佔:30%. 53.
(66) 壁畫. 豹. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:29%. 未篩選微觀字分 布佔:71%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:14%. 篩選後微觀字分 布佔:57%. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:22%. 未篩選微觀字分 布佔:78%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:18%. 篩選後微觀字分 布佔:59%. 54.
(67) 熱氣球. 夕陽. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:75%. 未篩選微觀字分 布佔:25%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:68%. 篩選後微觀字分 布佔:19%. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:89%. 未篩選微觀字分 布佔:11%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:87%. 篩選後微觀字分 布佔:10%. 55.
(68) 大象. 恐龍. 鴨子. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:30%. 未篩選微觀字分 布佔:70%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:25%. 篩選後微觀字分 布佔:54%. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:82%. 未篩選微觀字分 布佔:18%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:79%. 篩選後微觀字分 布佔:14%. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:85%. 未篩選微觀字分 布佔:15%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:71%. 篩選後微觀字分 布佔:12%. 56.
(69) 枯葉. 綠葉. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:3%. 未篩選微觀字分 布佔:97%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:2%. 篩選後微觀字分 布佔:81%. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:28%. 未篩選微觀字分 布佔:72%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:27%. 篩選後微觀字分 布佔:54%. 57.
(70) 飛機. 戰鬥機. 直升機. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:91%. 未篩選微觀字分 布佔:9%. 篩選後. 篩選後巨觀字分. 篩選後微觀字分. 視覺字分布圖. 布佔:90%. 布佔:6%. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:14%. 未篩選微觀字分 布佔:86%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:12%. 篩選後微觀字分 布佔:71%. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:72%. 未篩選微觀字分 布佔:28%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:57%. 篩選後微觀字分 布佔:22%. 58.
(71) 瀑布. 未篩選 視覺字分布圖. 未篩選巨觀字分 布佔:27%. 未篩選微觀字分 布佔:73%. 篩選後 視覺字分布圖. 篩選後巨觀字分 布佔:21%. 篩選後微觀字分 布佔:58%. 從上表來看我們可以明顯看到,巨觀與微觀在經過篩選後可以將 巨觀與微觀部分區分的更好,而且對整體影像而言影響並不到,比較 明顯的視藍巨觀以及白巨觀的部分,這兩個巨觀在經過篩選後,巨觀 模型變得更單純。. 59.
(72) 4.3.4 視覺字使用評估 在我研究中有提到,我們使用每個類別排名前 25 名的視覺字做 為每個類別的代表字,在這裡,我們的研究要評估,對影像而言, 前 25 名的視覺字對於影像是否有代表性。 以下我們以單張影像做測試,影像分別選出能訓練出約 50 字、 100 字、150 字左右的影像,分別分析是覺字的分布情形。. 圖 21、汽車視覺字分析 60.
(73) 圖 22、花朵視覺字分析. 圖 23、海豹視覺字分析 61.
(74) 圖 24、糕點點心視覺字分析. 圖 25、雪景視覺字分析 62.
(75) 圖 26、猩猩視覺字分析. 圖 27、古典建築視覺字分析 63.
(76) 圖 28、直升機視覺字分析. 圖 29、煙火視覺字分析 64.
(77) 以上結果是將左邊的影像訓練後,將視覺字編號並填回原圖,影 像中的右邊是回填的結果,並且將這些回填的結果由大到小重新排列, 得到影像描述直方圖,從直方圖的結果可以很明顯的看出,重新建構 一張影像大部分使用到的視覺字集中在前 25 名的視覺字之前,其餘 的視覺字使用次數甚少,前 25 名的視覺字可以描述出具代表性的影 像。. 65.
(78) 五、結論與未來研究 本研究以文獻[7]的巨微觀視覺字典為基礎,並且加入了文獻[10] 類別模型與分類器權重的概念。以此為基礎提出字典訓練影像的數量 P 增加有助於巨微觀字典的資訊完善,增加巨微觀字典的資訊可以讓 各類型模型的建立更加完善,另外本研究對於類別模型將使用次數少 的視覺字去除,讓模型獨立增加分類的準確度。在實驗結果中,我們 改善的模型對於巨觀影響較多的影像有更好的準確度。 而我們研究目前對於影像中同色系的巨觀分類仍然有可能分類 到同一類別,例如陰天的天空和白色背景同色系而造成的分類錯誤。. 66.
(79) 參考文獻 [1] W. J. Xie, D. Xu, Y. J. Tang, and S. Y. Liu, “Constructing ClassSpecific Codebooks based on Mutual Information Method for Natural Scene Categorization,” JOURNAL OF INFORMATION SCIENCE AND ENGINEERING XX, 1-xxx (xxxx). [2] C.M.Kuo,M.H.Hung,C.S.Liu,Y.Chang and C.H.Hsieh,” Playfield Segmentation for Baseball Videos Using Adaptive GMMs,” International Journal of Innovative Computing, Information and Control, vol. 6, no. 6, pp. 2787–2801, 2010. [3] M. H. Kolekar,” Bayesian belief network based broadcast sport video indexing,” Multimed Tools Appl, pp.27-54,2011. [4] Y. Kang, A. Sugimoto,” Scale-Optimized Textons for Image Categorization and Segmentation,” IEEE International Symposium on Multimedia,2011. [5] L.K Huang,” Visual Words With Scale-Invariant Features and Color Features for Image Description and Classification,” 2012. [6] Alfanindya. A, Hashim. N and Eswaran. C,” Content Based Image Retrieval And Classification Using Speeded-Up Robust Features (SURF) and Grouped Bag-of-Visual-Words (GBoVW),” Technology, Informatics, Management, Engineering, and Environment (TIME-E),” 2013. [7] Y.M.Chen, “Block-based Visual Words for Image Retrieval and Classification,”2012. [8] A. Bosch, X. Mu 𝑛̃ oz, and R. Martı´,” Which is the best way to organize/classify images by content?,” Image and Vision Computing, pp.778-791,2006. [9] Xin Zhao, Weiqiang Ren, Kaiqi Huang, and Tieniu Tan, “Online Codebook Reweighting Using Pairwise Constraints for Image Classification,” 2011 [10] Y.S.Sie, “Image Categorization Based on Bag of Visual Words,”2014.. 67.
(80)
數據

+7





Outline
相關文件
Light rays start from pixels B(s, t) in the background image, interact with the foreground object and finally reach pixel C(x, y) in the recorded image plane. The goal of environment
image processing, visualization and interaction modules can be combined to complex image processing networks using a graphical
臺大機構典藏NTUR (National Taiwan University 二 Repository, http://ntur.lib.ntu.edu.tw) 經驗與協助推 動臺灣學術機構典藏TAIR (Taiwan Academic Institutional Repository,
For example, the ‘Dongwei Daoyu deng yiyi shisan ren zaoxiang ji’ 東魏道遇等邑義十三人造像記 [Record of Image Con- struction by the Yiyi of Thirteen People, Daoyu and Others,
Accordingly, we reformulate the image deblur- ring problem as a smoothing convex optimization problem, and then apply semi-proximal alternating direction method of multipliers
Since we target a general framework for serving different appli- cations, we will first adopt the proposed method to visual domain for image object retrieval in Section VIII-A and
Use images to adapt a generic face model Use images to adapt a generic face model. Creating
To an accuracy of 3 pixels, 72% of interest points are repeated (have correct position), 66% have the correct position and scale, 64% also have correct orientation, and in total 59%
