利用OWL於階層式物件導向資料探勘
79
0
0
全文
(2) Hierarchical Object-Oriented Data Mining by OWL Advisor: Dr.(Professor) Tzung-Pei Hong Institute of Electrical Engineering National University of Kaohsiung Student: Jun-Song Dong Institute of Electrical Engineering National University of Kaohsiung. ABSTRACT. When association rules are mined out from a certain data source, they may need to be widely utilized through the internet environments. Appropriate semantic interpretation may expand the usage of the association rules. In this thesis, we propose an integrated OWL data mining and query system architecture for expressing the mined knowledge in the OWL format and for effectively answering users’ queries. The system consists of five sub-systems: query parser, rule inference system, ontology management system, knowledge generation system, and knowledge management system. We expect the architecture can provide users to query mined knowledge through the internet and with a more machine-understandable format. Besides, the object-oriented concepts have been very popular and used in a variety of applications, such as complex data representation and object-oriented data mining. In this thesis, we will also improve Huang et al’s approach to increase the efficiency, flexibility and problem complexity of object-oriented data mining. We propose two object-oriented data mining approaches. The first one derives frequent itemsets from object-oriented data with more pruning effects. There are three kinds of knowledge to be discovered: inter-class association rules, intra-class association rules and inter-intra association rules. There are three phases in the algorithm, with each for a kind of knowledge. The results from a former phase can be used to prune candidates in a latter phase. The second approach further extends the first one by considering the sequential relations in object-oriented programming. Keywords:. semantic. web,. OWL,. data. mining,. association rules, sequential patterns, ontology. I. object-oriented. transaction,.
(3) 利用 OWL 於階層式物件導向資料探勘. 指導教授:洪宗貝 博士 (教授) 國立高雄大學電機工程所 學生:董俊松 國立高雄大學電機工程所. 摘要. 當關連規則從特定的資料被挖掘出來時,它們可能需要透過網際網路的環境來加以 廣泛利用。適當的語意解釋可以擴充關聯規則的使用。因此在本篇論文中,我們提出一 個基於 OWL 語言的整合型資料挖掘查詢系統,讓使用者可以透過此系統有效的查詢。此 系統由五個子系統所組成,包括問句剖析器、規則推論系統、知識本體管理系統、知識 產生系統及知識管理系統。我們希望此架構能以一種機器更容易理解的格式提供使用者 透過網路查詢已探勘的知識。此外最近物件導向概念在多種應用方面深受歡迎且廣被使 用,例如其用於複雜的資料表示和物件導向資料探勘上。在這篇論文中,我們也將改善 黃先生等人所提出的方法以增加效率、彈性和物件導向資料探勘問題的複雜度。我們提 出兩個物件導向資料探勘的方法。第一個方法是從物件導向資料推導出高頻項目並能有 更多的刪減效果。其可找出三種不同的知識:分別為跨類別關聯規則、類別內關聯規則、 及混合類別關聯規則。此演算法可分為三個階段且每階段可推導出一種知識。此外,前 ㄧ個階段的結果可以被用於刪除後ㄧ階段的候選項目。而第二個方法更進ㄧ步擴充前項 結果以考慮在物件導向程式中的循序關係。. 關鍵字:語意網路、網路知識本體語言、資料探勘、物件導向交易、關聯規則、 循序關係、本體知識。. II.
(4) 誌謝 首先要感謝我的指導教授,洪宗貝博士。在我研究生的生涯中,不管是在學業上或 是生活上都能細心的教導,對我在日後的工作或待人處事上有莫大的幫助。在論文ㄧ開 始的構思上,老師總是給予我很多的建議跟思考空間,讓我受益良多。而在撰寫此份倫 文時,由於撰寫的時間點太慢,以致於讓老師過於費心,在此致上深深的歉意。 同時,我要感謝我的碩士論文的口試委員:林文揚教授和黃國楨教授。謝謝他們能 撥空來參加我的碩士論文的口試,並且對於我碩士論文的內容給予寶貴的建議,使我的 碩士論文更趨於完整。此外也要感謝實驗室的正明學長、偉碩學長、詠琪學長、俊豪學 長、浚瑋學長、名泰學長、國能學長、彥良、承熹、廷政、明訓、瀞誼等同班同學和實 驗室的怡穎、雅芳、韋体、卓翰等學弟妹,在課業和生活上互相的幫助,讓我的學習生 涯更多采多姿。 最後要感謝我的父母親、外婆及我的家人,感謝他們對我的支持、鼓勵和無怨無悔 的付出,使得我能專心於學業上,能夠順利的取得碩士學位。在此我也向所有幫助我的 朋友,致上我最深的謝意。. 董俊松 2007.08 於知識工程與人工智慧 Lab. III.
(5) Contents ABSTRACT.......................................................................................................... I 摘要......................................................................................................................II 誌謝.................................................................................................................... III CONTENTS ........................................................................................................... IV LIST OF FIGURES ................................................................................................. VI LIST OF TABLES .................................................................................................. VII CHAPTER 1 INTRODUCTION ................................................................................ 1 1.1 MOTIVATION..................................................................................................................1 1.2 CONTRIBUTIONS ............................................................................................................4 1.3 READER’S GUIDE ..........................................................................................................4. CHAPTER 2 RELATED WORKS ............................................................................ 5 2.1 APRIORI ALGORITHM ....................................................................................................5 2.2 APRIORIALL ALGORITHM ..............................................................................................9 2.3 OBJECT-ORIENTED TRANSACTIONS .............................................................................10 2.4 OWL AND OWL-QL...................................................................................................12. CHAPTER 3 THE FRAMEWORK OF THE AN INTEGRATED OWL DATA MINING AND QUERY SYSTEM ............................................................................. 15 3.1 THE VIEWPOINT OF END USERS ..................................................................................16 3.2 THE VIEWPOINT OF SYSTEM ADMINISTRATORS ...........................................................17. CHAPTER 4 MODULE DESIGN IN THE INTEGRATED OWL DATA MINING AND QUERY SYSTEM ............................................................................. 19 4.1 QUERY PARSER ............................................................................................................19 4.2 THE RULE INFERENCE SYSTEM ...................................................................................20 4.2.1 OWL QUERY PATTERN .....................................................................................20 4.2.2 INFERENCE ENGINE ..........................................................................................21 4.3 THE ONTOLOGY MANAGEMENT SYSTEM ....................................................................22 4.3.1 THE DOMAIN ONTOLOGY .................................................................................23 4.3.2 THE ONTOLOGY EDITOR ..................................................................................25 4.4 THE KNOWLEDGE GENERATION SYSTEM ....................................................................28 4.4.1 THE DATA MANAGER .......................................................................................28 4.4.2 THE OBJECT-ORIENTED TRANSACTION DATABASE ..........................................29 4.4.3 THE RULE MINING ENGINE ..............................................................................29 4.4.4 THE ASSOCIATION RULES .................................................................................30 4.5 THE KNOWLEDGE MANAGEMENT SYSTEM .................................................................31 4.5.1 THE RULE CONVERSION ENGINE ......................................................................31 IV.
(6) 4.5.2 THE RULE EDITOR ............................................................................................32 4.5.3 THE OWL RULE BASE .....................................................................................32 4.5.4 THE KNOWLEDGE INTEGRATION MODULE .......................................................33 4.6 A QUERY EXAMPLE .....................................................................................................35. CHAPTER 5 DISCOVERY OF THREE KINDS OF OBJECT-ORIENTED KNOWLEDGE 39 5.1 THE NOTATIONS ..........................................................................................................40 5.2 THE PROPOSED ALGORITHM .......................................................................................41 5.3 AN EXAMPLE ..............................................................................................................44. CHAPTER 6 OBJECT-ORIENTED DATA MINING FOR SEQUENTIAL PATTERNS ..... 53 6.1 THE NOTATIONS ..........................................................................................................53 6.2 THE PROPOSED ALGORITHM .......................................................................................54 6.3 AN EXAMPLE ..............................................................................................................58. CHAPTER 7 CONCLUSIONS AND FUTURE WORKS ............................................. 67 REFERENCES ....................................................................................................... 69. V.
(7) List of Figures Figure 2-1: Structure of a typical class ...............................................................11 Figure 2-2: An example of the class “wine” ...................................................... 12 Figure 2-3: Level relation of OWL language .................................................... 13 Figure 3-1: The proposed system framework .................................................... 15 Figure 3-2: The ingredients of the framework in light of user viewpoint ......... 16 Figure 3-3: The ingredients of the framework from administrator viewpoint .. 18 Figure 4-1: The RDF Graph representing the triple in the example.................. 21 Figure 4-2: The match process of the query in visualization of the RDF Graph22 Figure 4-3: An example of ontology regarding food ......................................... 23 Figure 4-4: The OWL representation of the ontology in Figure 4-3 ................. 24 Figure 4-5: A snapshot of the interface of Protégé ............................................ 25 Figure 4-6: The integration of rule 1 with its relevant domain ontology .......... 34 Figure 4-7: The RDF Graph about the query example ...................................... 36. VI.
(8) List of Tables Table 2-1: The Transaction data in this example ................................................. 7 Table 2-2: The count of each item in Table 2-1 ................................................... 7 Table 2-3: The set of large 1-itemsets L1 in this example .................................... 8 Table 2-4: The count of each sequential candidate pattern in C2......................... 8 Table 2-5: The large 2-itemsets kept in L2 ........................................................... 9 Table 5-1: The six transaction data in this example........................................... 45 Table 5-2: The count of each purchased item in Table 5-1................................ 46 Table 5-3: The set of large inter-class 1-itemsets L1 in this example ................ 46 Table 5-4: The count of each inter-class candidate itemset in C2 ...................... 47 Table 5-5: The large inter-class 2-itemsets kept in L2 ........................................ 47 Table 5-6: The count of each attribute in I2, I3 and I4 ........................................ 48 Table 5-7: The set of large intra-class 1-itesmets L1' ........................................... 49 Table 5-8: The counts of the intra-class candidate 2-itemsets in C2' .................. 49 Table 5-9: The large intra-class itemsets in L'2 .................................................. 50 Table 5-10: The count results of each inter-intra candidates in C2'' .................... 51 Table 5-11: The large inter-intra 2-itemsets in L''2 ............................................... 52 Table 6-1: The ten browsing data in this example ............................................. 59 Table 6-2: The count of each web page in Table 3-1 ......................................... 60 Table 6-3: The set of large sequential inter-class 1-patterns L1 in this example 60 Table 6-4: The count of each sequential inter-class candidate pattern in C2 ..... 61 Table 6-5: The large sequential 2-patterns kept in L2 ........................................ 61 Table 6-6: The count of each attribute in I2, I3 and I4 ........................................ 62 Table 6-7: The set of large intra-class 1-patterns L1' ........................................... 63 Table 6-8: The count results of the itra-class candidate 2-itemsets in C2' .......... 64 Table 6-9: The large intra-class itemsets in L'2 .................................................. 64 Table 6-10: The count results of each sequential inter-intra candidates in C2'' .. 65 Table 6-11: The large sequential inter-intra 2-patterns in L''2 .............................. 66. VII.
(9) CHAPTER 1 Introduction 1.1 Motivation. Knowledge discovery in databases (KDD) means the application of nontrivial procedures for identifying effective, coherent, potentially useful, and unknown patterns in large databases [9]. The KDD process generally consists of the following three. phases. [10][18]:. pre-processing,. data. mining,. and. post-processing.. Pre-processing consists of all the actions taken before the actual data analysis starts [10]. Data mining involves the application of specific algorithms for extracting patterns or rules from data sets in a particular representation. Post-processing usually includes format translation and visualization of extracted patterns. Due to the importance of data mining for KDD, many researchers in the fields of databases and machine learning are primarily interested in this research area because it offers opportunities to discover useful information and important relevant patterns in large databases. It further helps decision-makers easily analyze data and make good decisions regarding the domains concerned. According to the classes of knowledge derived, the mining approaches may be 1.
(10) classified as finding association rules, classification rules, clustering rules, and sequential patterns, among others. Among them, finding association rules in transaction databases is most commonly seen in data mining [1][2][3][4][21]. It is used to discover the relationships or information among the transaction items. An association rule can be expressed as the form A Æ B, where A and B are sets of items, such that the presence of A in a transaction will imply the presence of B. Two measures, support and confidence, are evaluated to determine whether a rule should be kept. The support of a rule is the fraction of the transactions that contain all the items in A and B. The confidence of a rule is the conditional probability of the occurrences of items in A and B over the occurrences of items in A. The support and the confidence of an interesting rule must be larger than or equal to a user-specified minimum support and a minimum confidence respectively Besides, the concept of semantic web [26] has attracted much interest in recent years. It is proposed by Lee [5] in 1998 and a method to effectively express materials on WWW. It provides a common framework that allows data to be shared and reused across applications and enterprises. There are many languages designed to implement semantic web. The Web Ontology Language (OWL) is the most popular among them. It can easily express the ontology needed in a particular domain. The advantages of OWL are listed as follows: (1) User can use the OWL format to easily express the complex relationships of different concepts. (2) It is easy to maintain, share and reuse. 2.
(11) (3) There are three sublanguages in the OWL language. The user can choose an appropriate sublanguage that is needed.. In this thesis, we try to use the OWL to represent the association rules. When association rules are mined out from a certain data source, they may need to be widely utilized through the internet environments. Appropriate semantic interpretation may expand the usage of the association rules. An integrated semantic-web rule system architecture based on the OWL language is thus proposed for expressing the mined knowledge. The system consists of five sub-systems. They are query parser, rule inference system, ontology management system, knowledge generation system, and knowledge management system. We expect the architecture can provide users to query mined knowledge effectively and flexibly through the internet and with a more machine-understandable format. Besides, the system can be examined from the viewpoints of two different types of actors: the end user and the system administrator. From the viewpoint of end users, the system functions on dealing with user’s query and generating answers. From the viewpoint of system administrators, the system acts as a back end to support the query processing. These will be illustrated in the thesis.. 3.
(12) 1.2 Contributions. This section states the main contributions of the thesis. The contributions can be divided into the following three parts. 1. Using OWL Language to represent association rules. 2. Proposing an integrated OWL data mining and query system. 3. Proposing two improved object-oriented data mining algorithms.. 1.3 Reader’s Guide. The remaining parts of this thesis are organized as follows: In chapter 2, we introduce some related researches which include Apriori algorithm, AprioprAll algorithm, object-oriented transactions, OWL and OWL-QL. In chapter 3, we describe the framework of the proposed integrated OWL data mining and query system. In chapter 4, we describe the architecture of the system and design. In chapter 5, we propose an object-oriented mining approach for three kinds of association rules. In chapter 6, we extend the previous results to sequential transactions. Conclusions and future works are finally discussed in chapter 7.. 4.
(13) CHAPTER 2 Related Works In this chapter, we introduce some related researches to this thesis. Section 2.1 describes the Apriori algorithm for discovering association rules. Section 2.2 reviews the AprioriAll algorithm for sequential patterns. Section 2.3 reviews object-oriented transactions. Section 2.4 reviews OWL and OWL-QL.. 2.1 Apriori Algorithm. The goal of data mining is to discover important associations among items such that the presence of some items in a transaction will imply the presence of some other items. To achieve this purpose, Agrawal and his co-workers proposed several mining algorithms based on the concept of large itemsets to find association rules in transaction data [1][2][3][4][21]. The processes of Apriori algorithm as following: Step 1: Calculate the number (count) of each item in the transaction data. Assume the total number of transaction data is n. If one item appears more than once in a transaction, count its occurrence only once. Set the support (support) of each item as count/n.. 5.
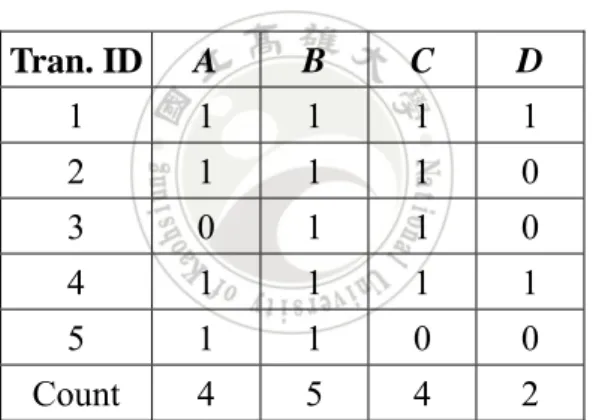
(14) Step 2: Check whether the support of each item is larger than or equal to the predefined minimum support value. If the item satisfies the condition, put it in the set of large 1-itemsets (L1). Step 3: If L1 is null, then exit the algorithm; otherwise, do the next step. Step 4: Set r = 1, where r is the number of items in the large itemsets currently being processed. Step 5: Generate the candidate set Cr+1 by joining Lr. Step 6: Calculate the number (counts) of each candidate (r+1)-itemset s in Cr+1; set its support (supports) as counts/n. Step 7: Check whether the support of each candidate (r+1)-itemset s is larger than or equal to the predefined minimum support value. If s satisfies the condition, put it in the set of large (r+1)-itemsets (Lr+1). Step 8: If Lr+1 is null, then exit the algorithm; otherwise, set r = r +1 and repeat Steps 5 to 7. Below is a simple example to show how the Apriori algorithm can be used to generate the association rules from transaction data as following. There are five transaction data in Table 2-1. Assume in this example, the minimum support is set at 0.6. The Apriorari algorithm proceeds as follows.. 6.
(15) Table 2-1: The Transaction data in this example Tran. ID 1 2 3 4 5. Item ABCD ABC BC ABCD AB. Step 1: The count value of item appearing in the ten transaction data is calculated. The count results of each item are shown in Table 2-2.. Table 2-2: The count of each item in Table 2-1 Tran. ID. A. B. C. D. 1. 1. 1. 1. 1. 2. 1. 1. 1. 0. 3. 0. 1. 1. 0. 4. 1. 1. 1. 1. 5. 1. 1. 0. 0. Count. 4. 5. 4. 2. The support of each item can be derived by its count value over the number of transaction data. In this example, the number of transaction data is 5. Step 2: The support of each item is checked to determine whether it is larger than or equal to the predefined minimum support value. Assume in this example, the minimum support is set at 0.6. Since the support values of A, B and C are larger than or equal to 0.6, the three itmes are put in the set of large 1-itemsets L1 (Table 2-3).. 7.
(16) Table 2-3: The set of large 1-itemsets L1 in this example Large 1-itemset A B C. Support 4/5 5/5 4/5. Step 3: If L1 is null, then the algorithm is exited; otherwise the next step is done. In this example, since L1 is not null, Step 4 is then executed. Step 4: The variable r is set at 1, where r is the number of itemset in the large 1-itemset currently being processed. Step 5: The candidate set Cr+1 is formed by joining Lr. C2 is first generated from L1 as follows: (A, B), (A, C) and (B, C). The results are shown in Table 2-4.. Table 2-4: The count of each sequential candidate pattern in C2 Candidate 2-itmemset (A, B) (A, C) (B, C). Count 4 3 4. The support of each candidate s in C2 is then calculated as its count divided by 5. Step 7: The support of each candidate 2-itemset is then compared with the predefined minimum support value 0.6. In this example, the three s candidate 2-itmemsets (A, B), (A, C) and (B, C) are larger than or equal to 0.6. They are thus kept in L2 (Table 2-5).. 8.
(17) Table 2-5: The large 2-itemsets kept in L2 Large 2-itemset (A, B) (A, C) (B, C). Support 4 3 4. Step 8: If Lr+1 is null, then exit the algorithm; otherwise, r = r + 1 and Steps 5 to 7 are repeated. Since L2 is not null in the example, r = r + 1 = 3. Steps 5 to 7 are repeated to get L3. C3 is then generated from L2, and the candidate 3-itemset (A, B, C) is formed. Its support is calculated as 0.6. Since only the candidate 3-itemset (A, B, C) is larger than 0.6, it is put in L3. In this example, no candidate 4-itemsets can be formed. L4 is null and then exit the algorithm.. 2.2 AprioriAll Algorithm. Agrawal and Srikant also proposed the AprioriAll mining approach to mine sequential patterns from a set of transactions [4]. Five phases were included in this approach. In the first phase, the transactions were sorted first by customer IDs as the major key and then by transaction time as the minor key. This phase thus converted the original transactions into customer sequences. In the second phase, the set of all large itemsets were found from the customer sequences by comparing their counts. 9.
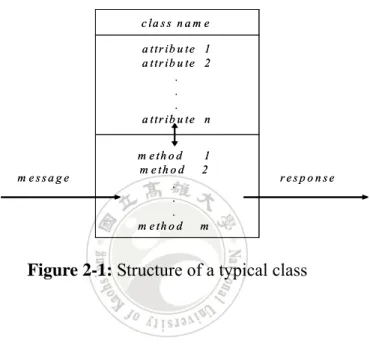
(18) with a predefined support parameter. This phase was similar to the process of mining association rules. Note that when an itemset occurred more than one time in a customer sequence, it was counted once for this customer sequence. In the third phase, each large itemset was mapped to a contiguous integer and the original customer sequences were transformed into the mapped integer sequences. In the fourth phase, the set of transformed integer sequences were used to find large sequences among them. In the fifth phase, the maximally large sequences were then derived and output to users.. 2.3 Object-Oriented Transactions. An object-oriented data sequence (also called transaction in this thesis) includes one or more purchased items, each of which is represented as an object or an instance. Each instance inherits its characteristics from a superior object, called class, which defines the basic structure of objects with common properties, including attributes, default values, and methods. The roles of classes and instances in an object-oriented transaction data are like those that schema and tuples play in a relational database [15]. A simple structure of a class is shown in Figure 2-1, which includes at least three. 10.
(19) major components: the class name, the attributes and the methods. The class name is an identifier used to identify a class, the attributes are used to represent the characteristics of a class, and the methods are used to implement the operations and functions of a class.. c la s s n a m e a ttr ib u te 1 a ttr ib u te 2 . . . a ttr ib u te n. m essag e. m e th o d m e th o d . . . m e th o d. 1 2. respo nse. m. Figure 2-1: Structure of a typical class. An example for a class “wine” is shown in Figure 2-2 to illustrate the above concept. The class name is specified as “wine”. The class includes four attributes, cost, expiration, age and alcohol. It also has two methods, confirmation and acknowledgement.. 11.
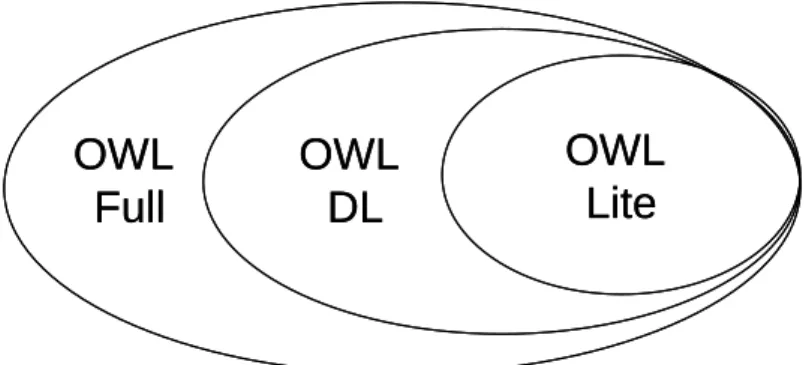
(20) wine 1. 2. 3. 4.. cost expiration age alcohol. 1. confirmation 2. acknowledge. Figure 2-2: An example of the class “wine”. In this thesis, each item itself (or item name) is thought of as a class, and each item purchased in a transaction is thought of as an instance. Instances with the same class (item name) may have different attribute values since they may appear in different transactions.. 2.4 OWL and OWL-QL. The Web Ontology Language (OWL) [26] [28] is the most popular for implementing semantic web applications. It is a makeup language for sharing and publishing data using ontology on the World Wide Web (WWW). It also can easily express the ontology needed in a particular domain. There are three sub-languages in OWL. They are OWL Lite, OWL DL and OWL Full [28]. Figure 2-3 shows the inclusion relation of them.. 12.
(21) OWL Full. OWL DL. OWL Lite. Figure 2-3: Level relation of OWL language. In Figure 2-3, OWL-Lite is the smallest among the three. It is used to support the users who primarily need only a classification hierarchy and simple constraints. OWL-DL supports users with the maximum expressiveness while retaining computational completeness. Finally, OWL- Full can also support users with the maximum expressiveness, but its syntactic freedom of RDF has no computational guarantees. OWL is developed based on DAML (DARPA Agent Markup Language) and OIL (Ontology Inference Layer) [22], and is now a W3C [27] recommendation. The OWL includes class, property, object, some logics, and among others. For example, a class can be defined as owl:Class and a subclass can be defined as owl:SubClass. In this thesis, we take the OWL Query Language (OWL-QL) as the query language [20]. OWL-QL is a formal language and protocol for querying answers represented in OWL. It is an updated version of the DAML Query Language (DQL).. 13.
(22) A query request is parsed into three parts that are subject, property and object. These components are then filled in the OWL-QL query patterns that are a set of triples with the form (<property> <subject> <object>), where any item in the triple can be a variable. The patterns formed are then used to retrieve appropriate results.. 14.
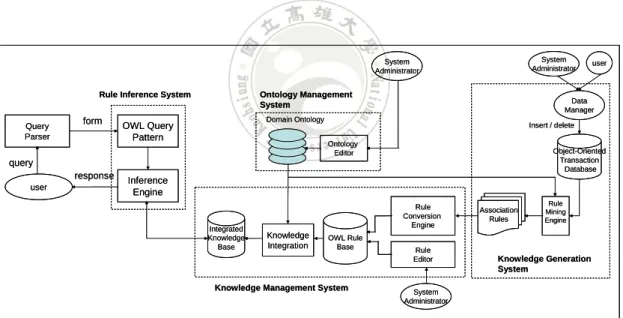
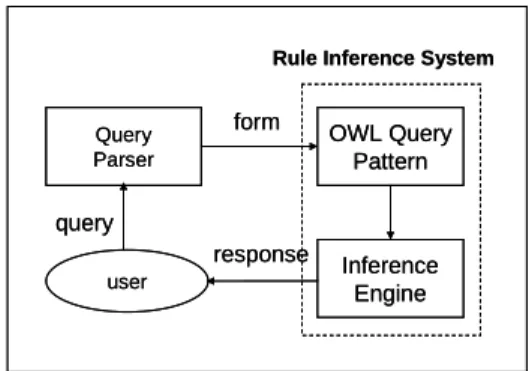
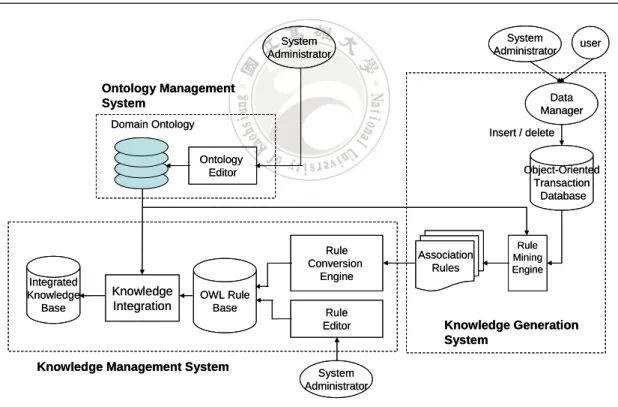
(23) CHAPTER 3 The Framework of the An Integrated OWL Data Mining and Query System In this chapter, we describe the framework of the proposed integrated OWL data mining and query system. It consists of five sub-systems, including query parser, rule inference system, ontology management system, knowledge generation system and knowledge management system. The framework of the proposed system architecture is shown in Figure 3-1.. System Administrator. System Administrator. Rule Inference System. Query Parser. form. Ontology Management System. Data Manager. Domain Ontology. OWL Query Pattern. Insert / delete Ontology Editor. Object-Oriented Transaction Database. query response user. user. Inference Engine. Integrated Knowledge Base. Rule Conversion Engine. Knowledge Integration. OWL Rule Base. Knowledge Management System. Rule Editor. Association Rules. Rule Mining Engine. Knowledge Generation System. System Administrator. Figure 3-1: The proposed system framework. Figure 3-1 will be examined from the viewpoints of two different types of actors: the end user and the system administrator. From the viewpoint of end users, the system functions on dealing with user’s query and generating answers. From the viewpoint of system administrators, the system acts as a back end to support the query 15.
(24) processing. They are illustrated below.. 3.1 The Viewpoint of End Users As mentioned above, from the viewpoint of end users, the system functions mainly on dealing with user’s query and generating answers. It mainly consists of the two sub-systems of query parser and rule inference system. The rule inference system further includes the two modules of the OWL query patterns and the inference engine. When a query comes, the system processes it in the following scenario. On receiving a query launched by an end user, the query parser first identifies the subject, predicate and object from the input query. It then sends the extracted items to the module of the OWL query patterns, where the relationship among the subject, predicate and object are found and expressed in a query pattern. The query pattern is then forwarded to the inference engine for finding matched knowledge. The inference engine thus searches the integrated knowledge base, and performs appropriate reasoning if necessary, to find the answers and output them to the user. The ingredients of the framework under this scenario are shown in Figure 3-2.. Rule Inference System. Query Parser. form. OWL Query Pattern. response. Inference Engine. query user. Figure 3-2: The ingredients of the framework in light of user viewpoint. 16.
(25) 3.2 The Viewpoint of System Administrators From the viewpoint of system administrators, the system acts as a back end to support the query processing. It mainly consists of the three sub-systems of ontology management system, knowledge generation system and knowledge management system. The ontology management system is responsible for the building and management of domain ontology that is used to expand the semantic meaning of the data stored in the transaction database and the rule stored in the rule base. It includes two modules, the ontology editor and the domain ontology. The ontology editor is used by the system administrator to edit the ontology stored in the domain ontology module. The knowledge generation system is in charge of the actual mining job from transaction data. It includes four modules. They are data manager, object-oriented transaction database, rule mining engine and association rules. The administrator or the user can update the data stored in the object-oriented transaction database through the data manager. The object-oriented transaction database stores the data in the form of objects, which may consists of the same set of attributes in a class of objects. The rule mining engine then finds inter- and intra-class association rules among data items from the object-oriented transaction database. The rules generated are then collected in the module of association rules. The knowledge management system is used to convert the mined rules into the OWL format and to properly maintain them. It includes rule conversion engine, rule editor, OWL rule base, knowledge integration and integrated knowledge base. The rule conversion engine is responsible for automatically transforming the rules into the OWL format. It performs this according to some transformation rules and constraints. 17.
(26) In addition to the rules generated from the rule conversion engine, new OWL rules can also directly be created and existing OWL rules can be edited by an administrator through the rule editor. The system framework also allows an administrator to utilize some ontology editing tools, such as protégé, to manually transform the rules into the OWL format. The rules from the rule conversion engine or from the rule editor are kept in the OWL rule base. Finally, the OWL association rules are combined with the relevant part of the OWL ontology to form an integrated knowledge base through the knowledge integration module for answering users’ queries in a semantic way. The ingredients of the framework under this scenario are shown in Figure 3-3.. System Administrator. System Administrator. Ontology Management System. Data Manager. Domain Ontology. Insert / delete Ontology Editor. Integrated Knowledge Base. Object-Oriented Transaction Database. Rule Conversion Engine. Knowledge Integration. user. OWL Rule Base. Knowledge Management System. Rule Editor. Association Rules. Rule Mining Engine. Knowledge Generation System. System Administrator. Figure 3-3: The ingredients of the framework from administrator viewpoint. 18.
(27) CHAPTER 4 Module Design in the Integrated OWL Data Mining and Query System In this chapter, the functions of every sub-system and its components are described as follows.. 4.1 Query Parser Keywords usually have to be extracted to reflect the real request of a sentence or a query. The Query Parser is thus designed to achieve this purpose. For matching the OWL patterns, it recognizes subjects, properties and objects in a sentence or a query as keywords. There are two kinds of queries usually appearing. The first one is the data query, which is a simple one and is the most commonly used in past applications. For example, assume we give the query “Who owns the car?”. It is first parsed to get the unknown subject (who), the exact property (owns) and the known object (car) according to the format of the OWL-QL Patterns [6][20]. The second one belongs to rule queries, which has still seldom been seen in the current applications. For example, assume the query related to the association rule “If beverage is an antecedent and snack is a consequent, what confidence is the rule?” is to be parsed. In the example, the words beverage, snack and rule are set as subjects; antecedent, consequent and confidence are set as objects; and “is” is set as a property (type). These items extracted are thus stored as the OWL query pattern and used for inference. 19.
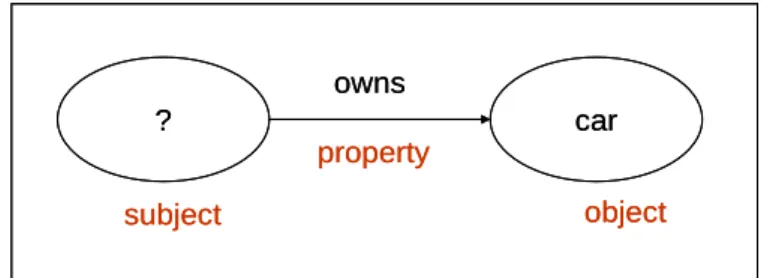
(28) 4.2 The Rule Inference System The work of this sub-system is to infer appropriate answers according to user queries. It is based on the OWL Query Language. It consists of the two components: the OWL query patterns and the inference engine. The functions of each component are described as follows.. 4.2.1 OWL Query Pattern. The component is implemented by OWL Query Language (OWL-QL) [20]. which is a formal language and protocol for querying answers and represented in OWL. An OWL-QL query pattern is a set of triples of the form:. (<property> <subject> <object>). Items in the triple may be constants or variables (with their names beginning with the character “?”). For the above example, the OWL query pattern receives the three keywords owns (property), who (subject) and car (object) from the query parser. It then judges that the word “who” represents an unknown subject and replaces it with the variable “?”. The following triple is then formed:. (<owns> <?> <car>). 20.
(29) The triple may be presented by a RDF Graph [25] as shown in Figure 4-1.. owns ?. car property object. subject. Figure 4-1: The RDF Graph representing the triple in the example. 4.2.2 Inference Engine. The main function of the inference engine is to infer appropriate answers through the integrated knowledge base according to the OWL query pattern. Continuing the above example, assume the fact about “Tom owns a car” stored in the integrated knowledge base is expressed in the OWL form as follows:. <rdf:RDF> <rdf:Description rdf:about="#Tom"> <owns rdf:resource="#car"/> </rdf:Description> </rdf:RDF> </owl-ql:premise>. The inference engine will derive the answer as Tom in the following process:. Query: (“Who owns the car?”) Query Pattern: (owns ?p car) 21.
(30) Must-Bind Variables List: (?p) Answer: Tom. Note that the symbol “?p” represents a variable, and the inference engine must reason about the variable and output it to users. Figure 4-2 represents the match process of the query in visualization of the RDF Graph.. own Tom. car. own ?p. car. Figure 4-2: The match process of the query in visualization of the RDF Graph. There have been several products in the market which can be used to achieve the inference function. In our system, we use the OWL-QL Server to implement the functions. The server is developed by the Knowledge Systems Laboratory in Stanford University.. 4.3 The Ontology Management System The Ontology Management System is responsible for the building and management of the domain ontology that is related to the transaction data stored in the object-oriented transaction database. It includes two modules, the ontology editor and. 22.
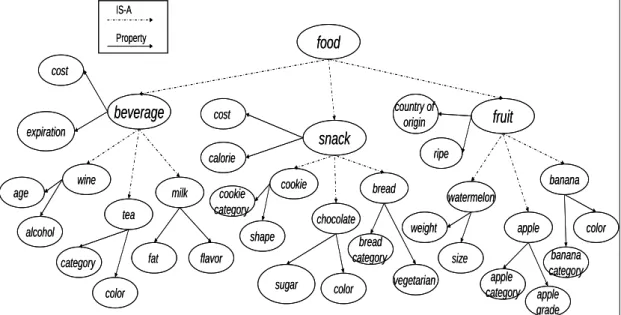
(31) the domain ontology. They are described as follows.. 4.3.1 The Domain Ontology. The term Ontology [11][12][13][17][19] was proposed in the field of philosophy at the earliest. It is now commonly used for the research of semantic web. Ontology mainly presents the entries or things in the world, and relationships between the entries. Ontology also includes descriptions of classes, properties, their instances, and among others. It can be thought of as the representation of knowledge. In this system, we use ontology to describe items in the transactions, their classes (concepts), properties, class relationships, association rules, and among others. It can be built, handled and maintained by the system administrator through the ontology editor. An example of ontology regarding food is shown in Figure 4-3, which describes the concept hierarchy of food and its relationships among the concepts (classes).. IS-A Property. food. cost. beverage. country of origin. cost. expiration. fruit. snack ripe. calorie wine age. milk tea. cookie. cookie category. alcohol. chocolate shape. fat. category color. banana. bread. watermelon weight. bread category. flavor sugar. color. apple size. vegetarian. apple category. Figure 4-3: An example of ontology regarding food 23. color banana category. apple grade.
(32) In this thesis, the domain ontology is represented in the OWL format. The domain ontology in Figure 4-3 is thus transformed into the representation depicted in Figure 4-4 through the ontology editor.. cost. food. hasCost hasExpiration expiration. beverage. hasCost calorie. age. hasAge wine. hasAlcohol alcohol. milk. hasCategory category. objectProperty. snack. hasCalorie cookie category. hasCookie_Category. cookie. tea. bread hasVegetarian. chocolate hasFat fat. hasShape. hasSugar. hasBread_Category. hasFlavor shape flavor. sugar. hasColor. bread category. vegetarian. color subClassOf. hasColor. Figure 4-4: The OWL representation of the ontology in Figure 4-3. In Figure 4-4, each node is a concept and each link is a property. Some original attributes of an item are also represented as concepts in the OWL representation. For example, the class wine has an attribute age, which is also thought of as a class in the OWL representation. In the context of the OWL syntax, a class is defined by owl:Class. The semantic relationships among classes are represented by the properties and are specified through the OWL syntax of owl:OjectProperty. Besides, classes may have their subclasses. For the above example, beverage, snack and fruit are the subclasses of the class food, and the property hasCost connects the two classes of beverage and cost. In the representation of the RDF format, beverage is the subject, cost is the object, and hasCost is the property. Each subject should have its domains and each object have ranges. The link of has hasCost thus connects the domain of. 24.
(33) beverage and the range of cost. That is, it relates instances of the class beverage to instances of the class cost.. 4.3.2 The Ontology Editor. The ontology editor allows the system administrator to edit the domain ontology in the OWL format. The module can utilize an existing ontology editing tool, such as protégé, to achieve this purpose. If the system administrator has known that some classes or relationships about the data items need to be added, deleted or updated, he/she can directly edit the domain ontology through the ontology editor. In this paper, the ontology editor, Protégé [24] is used. It can allow users to build ontology for semantic web functions, in particular in the W3C's Web Ontology Language (OWL). The interface of the Protégé software is illustrated in Figure 4-5.. Figure 4-5: A snapshot of the interface of Protégé 25.
(34) The ontology in Figure 4-4 is represented by OWL as follows:. <?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:xsd="http://www.w3.org/2001/XMLSchema#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:owl="http://www.w3.org/2002/07/owl#" xmlns="http://www.owl-ontologies.com/unnamed.owl#" xml:base="http://www.owl-ontologies.com/unnamed.owl"> <owl:Ontology rdf:about=""/> <owl:Class rdf:ID="food"/> <owl:Class rdf:ID="beverage"> <rdfs:subClassOf> <owl:Class rdf:ID="food"/> </rdfs:subClassOf> </owl:Class> <owl:Class rdf:about="#wine"> <rdfs:subClassOf> <owl:Class rdf:about="#beverage"/> </rdfs:subClassOf> <owl:disjointWith rdf:resource="#milk"/> <owl:disjointWith> <owl:Class rdf:about="#tea"/> </owl:disjointWith> </owl:Class> <owl:Class rdf:about="#tea"> <rdfs:subClassOf> <owl:Class rdf:about="#beverage"/> </rdfs:subClassOf> <owl:disjointWith rdf:resource="#milk"/> <owl:disjointWith> <owl:Class rdf:about="#wine"/> </owl:disjointWith> </owl:Class> <owl:Class rdf:ID="milk"> <rdfs:subClassOf> <owl:Class rdf:ID="beverage"/> </rdfs:subClassOf> <owl:disjointWith> <owl:Class rdf:ID="wine"/> </owl:disjointWith> <owl:disjointWith> <owl:Class rdf:ID="tea"/> </owl:disjointWith> 26.
(35) </owl:Class> <owl:Class rdf:ID="cost"/> <owl:Class rdf:ID="expiration"/> <owl:Class rdf:ID="alcohol"/> <owl:Class rdf:ID="age"/> <owl:Class rdf:ID="category"/> <owl:Class rdf:ID="color"/> <owl:Class rdf:ID="fat"/> <owl:Class rdf:ID="flavor"/> <owl:ObjectProperty rdf:ID="hasCost"> <rdfs:domain> <owl:Class rdf:about="#beverage"/> </rdfs:domain> <rdfs:range rdf:resource="#cost"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasExpriation"> <rdfs:range rdf:resource="#expiration"/> <rdfs:domain rdf:resource="#beverage"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasAge"> <rdfs:domain rdf:resource="#wine"/> <rdfs:range rdf:resource="#age"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasAlcohol"> <rdfs:domain rdf:resource="#wine"/> <rdfs:range rdf:resource="#alcohol"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasCategory"> <rdfs:domain rdf:resource="#tea"/> <rdfs:range rdf:resource="#category"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasColor"> <rdfs:domain rdf:resource="#tea"/> <rdfs:range rdf:resource="#color"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasFat"> <rdfs:range rdf:resource="#flavor"/> <rdfs:domain rdf:resource="#milk"/> </owl:ObjectProperty> 27.
(36) <owl:ObjectProperty rdf:ID="hasFlavor"> <rdfs:domain rdf:resource="#milk"/> <rdfs:range rdf:resource="#flavor"/> </owl:ObjectProperty> </rdf:RDF>. 4.4 The Knowledge Generation System. The subsystem mainly manages the association rules and transforms them into the OWL format. It includes rule conversion engine, rule editor, OWL rule base, knowledge integration and integrated knowledge base. They are described as follows. The function of this sub-system is to generate association rules from an object-oriented transaction database. It includes the four modules: data manager, object-oriented transaction database, rule mining engine and association rules. They are introduced below.. 4.4.1 The Data Manager. The data manager stores the data in a particular domain into the object-oriented transaction database. It can use operations such as insertion, deletion and update to handle the data. Any object-oriented database management system (DBMS) can play the role.. 28.
(37) 4.4.2 The Object-Oriented Transaction Database. An object-oriented transaction includes one or more purchased items, each of which is represented as an object or an instance. Each instance inherits its characteristics from a superior object, called class, which defines the basic structure of objects with common properties, including attributes, default values, and methods. The roles of classes and instances in an object-oriented transaction data are like those that schema and tuples play in a relational database [15].. 4.4.3 The Rule Mining Engine This component aims at finding relationships among data items. It extracts the data stored in the object-oriented transaction database to generate inter- and intra-class association rules. Our previously proposed approach for mining rules from object-oriented transactions [15] is used here. There are three kinds of knowledge to be discovered: inter-class association rules, intra-class association rules and inter-intra class association rules. Objects and attributes are assumed to be binary, with the number 1 representing that the objects and the desired attributes appear. If they are not binary, they can be preprocessed by transforming an attribute with n values into n new binary attributes. The mining process is processed in a top-down way to find the associations. It can be divided into three main phases. The first phase mines inter-class itemsets. That is, it discovers the association rules among the classes. The second phase mines the intra-class itemsets in individual classes. The third phase uses the results from the 29.
(38) above two phases to find the inter-intra itemsets. The results from the previous phase can be used to prune candidates in the current phase. Besides, the approach can be easily modified to stop at an intermediate phase if only the desired kind of knowledge is to be obtained. That is, the algorithm can stop at Phase 1 for getting only inter-class association rules or at Phase 2 for getting intra-class association rules. It can thus provide a flexible way according to users’ desires.. 4.4.4 The Association Rules. The module of association rules store the knowledge mined from the data by the rule mining engine. As mention before, there are three kinds of knowledge to be discovered: inter-class association rules, intra-class association rules and inter-intra class association rules. Some examples of the three kinds of rules are shown below. The inter-class association rules: 1. If the subclass = watermelon, then the subclass = apple with a confidence factor of 0.8; 2. If the subclass = watermelon, then the subclass = apple with a support factor of 0.6; The intra-class association rules: 1. If the cookie (cost = 1), then cookie (category = 1) with a confidence factor of 1; 2. If the cookie (cost = 1), then cookie (category = 1) with a support factor of 0.7; The inter-intra association rules: 1. If the watermelon (ripe = 1), then apple (grade = 2) with a confidence factor of 30.
(39) 0.9; 2. If the watermelon (ripe = 1), then apple (grade = 2) with a support factor of 0.5;. 4.5 The Knowledge Management System. The subsystem mainly manages the association rules and transforms them into the OWL format. It includes rule conversion engine, rule editor, OWL rule base, knowledge integration and integrated knowledge base. They are described as follows.. 4.5.1 The Rule Conversion Engine. The function of the rule conversion engine is to automatically transform the association rules mined from the rule mining engine into the OWL format. In the system, Jena [23] is used to implement the engine. Jena is an open software developed by the HP Semantic Web Labs. It is a Java API for manipulating RDF, RDFS, OWL, SPARQL and is thus suitable as a tool to implement the engine. Besides, it includes a rule-based inference engine.. 31.
(40) 4.5.2 The Rule Editor. In addition to automatic conversion from mined rules to OWL rules by the conversion engine, the rule editor allows the system administrator to manually transform the mined rules into the OWL format. The module can utilize an existing ontology editing tool, such as protégé, to achieve this purpose because the OWL rules are also expressed in the OWL syntax. If the system administrator has known that some rules about the data items need to be added, deleted or updated, He/She can directly edit the rules through the rule editor into the OWL rule base. In this paper, the ontology editor, Protégé [24] is used as the rule editor. The administrator can easily edit classes and relationships about classes through it. The class edition includes class descriptions, properties and their instances.. 4.5.3 The OWL Rule Base. The OWL rule base stores the OWL rules both from the conversion engine and from the rule editor. All the rules stored in it are represented in the OWL format. Take the rule “If (item = snack), then (item = beverage) with a confidence factor of 1” as an example. Its corresponding OWL representation is shown below.. <owl:Class rdf:ID="Rule1"/> <owl:Class rdf:ID="beverage"/> <owl:Class rdf:ID="snack"/> <owl:ObjectProperty rdf:ID="hasConsquent1"> <rdfs:domain rdf:resource="#Rule1"/> <rdfs:range rdf:resource="#beverage"/> 32.
(41) </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasAntecdent1"> <rdfs:range rdf:resource="#snack"/> <rdfs:domain rdf:resource="#Rule1"/> </owl:ObjectProperty> <owl:DatatypeProperty rdf:ID="hasConfidence1"> <rdfs:range> <owl:DataRange> <owl:oneOf rdf:parseType="Resource"> <rdf:rest f:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#nil"/> <rdf:first rdf:datatype=http://www.w3.org/2001/XMLSchema#float>1.0 </rdf:first> </owl:oneOf> </owl:DataRange> </rdfs:range> </owl:DatatypeProperty>. 4.5.4 The Knowledge Integration Module. The knowledge integration module integrates together the OWL rules stored in the OWL rule base and the relevant part of the domain ontology stored in the ontology management system. The integrated knowledge base can then support the inference engine in the rule inference systems to answer users’ queries in a semantic and flexible way. Users can thus easily find the super-classes of purchased items, their attributes, and other interesting information. An example showing rule 1 combined with its relevant semantic concepts is depicted in Figure 4-6.. 33.
(42) food. beverage. wine. snack. hasConsquent1. tea. hasConfidence hasAntecedent1. Rule 1. 1. Figure 4-6: The integration of rule 1 with its relevant domain ontology The integrated OWL representation is represented below.. <owl:Class rdf:ID="beverage"> <rdfs:subClassOf> <owl:Class rdf:ID="food"/> </rdfs:subClassOf> </owl:Class> <owl:Class rdf:ID="snack"> <rdfs:subClassOf> <owl:Class rdf:ID="food"/> </rdfs:subClassOf> </owl:Class> <owl:Class rdf:about="#wine"> <rdfs:subClassOf> <owl:Class rdf:about="#beverage"/> </rdfs:subClassOf> <owl:disjointWith rdf:resource="#milk"/> <owl:disjointWith> <owl:Class rdf:about="#tea"/> </owl:disjointWith> </owl:Class> <owl:Class rdf:about="#tea"> <rdfs:subClassOf> <owl:Class rdf:about="#beverage"/> </rdfs:subClassOf> <owl:disjointWith rdf:resource="#milk"/> 34.
(43) <owl:disjointWith> <owl:Class rdf:about="#tea"/> </owl:disjointWith> </owl:Class> <owl:Class rdf:ID="Rule1"/> <owl:ObjectProperty rdf:ID="hasConsquent1"> <rdfs:domain rdf:resource="#Rule1"/> <rdfs:range rdf:resource="#beverage"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasAntecedent1"> <rdfs:range rdf:resource="#snack"/> <rdfs:domain rdf:resource="#Rule1"/> </owl:ObjectProperty> <owl:DatatypeProperty rdf:ID="hasConfidence1"> <rdfs:range> <owl:DataRange> <owl:oneOf rdf:parseType="Resource"> <rdf:rest f:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#nil"/> <rdf:first rdf:datatype=http://www.w3.org/2001/XMLSchema#float>1.0 </rdf:first> </owl:oneOf> </owl:DataRange> </rdfs:range> </owl:DatatypeProperty>. 4.6 A Query Example. In this section, an example is given to illustrate the query process of the proposed integrated OWL data mining and query system. Assume a user inputs the query “If beverage is an antecedent and snack is a consequent, what confidence is the rule?” This query is first sent to the query parser to analyze the query and find out the subjects, properties and objects as the OWL-QL patterns. In this example, the sentence can be divided into three clauses: “beverage is an antecedent”, “snack is a consequent”, and “ what confidence is the rule”. Each clause is then parsed to get its subject, property and object. The results are shown below: 35.
(44) <type beverage antecedent> <type snack consequent> <confidence rule ?p>, where the term type represents the a-kind-of property, which usually appears in the word of “is”. The three patterns are then sent to the The three OWL query patterns are then sent to the inference engine to search for the answers through the integrated knowledge base. Assume the RDF graph for a part of the integrated knowledge base is shown in Figure 4-7.. food. beverage. snack. fruit. hasAntecedent1 hasConsquent1. hasAntecedent2. hasConfidence1 1. Rule 1. ?p. Rule 2. hasConsquent2. hasConfidence2. 0.85. Figure 4-7: The RDF Graph about the query example. The following steps show the entire execution process. Query: (“If beverage is an antecedent and snack is a consequent, what confidence is the rule?”) Query Patterns: (type beverage antecedent), (type snack consequent), (confidence rule ?p) Must-Bind Variable List: (?p) Answer: 1 36.
(45) The answer to the confidence of the rule in the query is thus 1. Note that the knowledge in Figure 4-7 combines the association rules and the domain ontology. Its code in the OWL format is represented as follows.. <owl:Class rdf:ID="beverage"> <rdfs:subClassOf> <owl:Class rdf:ID="food"/> </rdfs:subClassOf> </owl:Class> <owl:Class rdf:ID="snack"> <rdfs:subClassOf> <owl:Class rdf:ID="food"/> </rdfs:subClassOf> </owl:Class> <owl:Class rdf:ID="fruit"> <rdfs:subClassOf> <owl:Class rdf:ID="food"/> </rdfs:subClassOf> </owl:Class> <owl:Class rdf:about="#wine"> <rdfs:subClassOf> <owl:Class rdf:about="#beverage"/> </rdfs:subClassOf> <owl:disjointWith rdf:resource="#milk"/> <owl:disjointWith> <owl:Class rdf:about="#tea"/> </owl:disjointWith> </owl:Class> <owl:Class rdf:ID="Rule1"/> <owl:ObjectProperty rdf:ID="hasConsquent1"> <rdfs:domain rdf:resource="#Rule1"/> <rdfs:range rdf:resource="#beverage"/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasAntecedent1"> <rdfs:range rdf:resource="#snack"/> <rdfs:domain rdf:resource="#Rule1"/> </owl:ObjectProperty> <owl:DatatypeProperty rdf:ID="hasConfidence1"> <rdfs:range> <owl:DataRange> <owl:oneOf rdf:parseType="Resource"> <rdf:rest f:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#nil"/> <rdf:first rdf:datatype=http://www.w3.org/2001/XMLSchema#float>1 </rdf:first> 37.
(46) </owl:oneOf> </owl:DataRange> </rdfs:range> </owl:DatatypeProperty> <owl:Class rdf:ID="Rule2"/> <owl:ObjectProperty rdf:ID="hasConsquent2"> <rdfs:domain rdf:resource="#Rule2"/> <rdfs:range rdf:resource="# fruit "/> </owl:ObjectProperty> <owl:ObjectProperty rdf:ID="hasAntecedent2"> <rdfs:range rdf:resource="# beverage "/> <rdfs:domain rdf:resource="#Rule2"/> </owl:ObjectProperty> <owl:DatatypeProperty rdf:ID="hasConfidence2"> <rdfs:range> <owl:DataRange> <owl:oneOf rdf:parseType="Resource"> <rdf:rest f:resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#nil"/> <rdf:first rdf:datatype=http://www.w3.org/2001/XMLSchema#float>0.85 </rdf:first> </owl:oneOf> </owl:DataRange> </rdfs:range> </owl:DatatypeProperty>. 38.
(47) CHAPTER 5 Discovery of Three Kinds of Object-Oriented Knowledge In this chapter, an algorithm is proposed for discovering useful knowledge from object-oriented transaction data. It is an improved version of Huang et al’s [14] for object-oriented data mining. There are three kinds of knowledge to be discovered: inter-class association rules, intra-class association rules and inter-intra association rules. There are three phases in the algorithm, with each for a kind of knowledge. In this thesis, objects and attributes are assumed to be binary, with the number 1 representing that the objects and the desired attributes appear. The mining process is processed in a top-down way to find the associations. It can be divided into three main phases. The first phase mines inter-class itemsets. That is, it discovers the association rules among the classes. The second phase mines the intra-class itemsets in individual classes. The third phase uses the results from the above two phases to find the inter-intra itemsets. The results from the previous phase can be used to prune candidates in the current phase. The generated candidates will thus become much less than those without pruning. Besides, the approach can be easily modified to stop at an intermediate phase if only the desired kind of knowledge is to be obtained. That is, the algorithm can stop at Phase 1 for getting only inter-class association rules or at Phase 2 for getting intra-class association rules. It can thus provide a flexible way according to users’ desires.. 39.
(48) 5.1 The Notations Before the algorithm is introduced, the notation used in this algorithm is first listed below. n: the number of transactions; w: the number of classes; Ij: the j-th class, 1≦j≦w; mj: the number of attributes for the j-th class (Ij); Ajk: the k-th attribute in the j-th class, 1≦k≦mj, 1≦j≦w; countj: the count of Ij; countjk: the count of Ajk; supportj: the support of Ij; supportjk: the support of Ajk; α: the predefined minimum support; λ: the predefined minimum confidence; Cr: the set of inter-class candidate itemsets with r classes; Lr: the set of large inter-class itemsets with r classes;. Cz' : the set of intra-class candidate itemsets with z attributes in the same class; L'z : the set of large intra-class itemsets with z attributes in the same class;. Ct'' : the set of inter-intra candidate itemsets with t composite items; L't' : the set of large inter-intra itemsets with t composite items.. 40.
(49) 5.2 The Proposed Algorithm The proposed algorithm can be divided into three main phases. The first phase mines inter-class itemsets. That is, it discovers the association rules among the classes. The second phase mines the intra-class itemsets in individual classes. The third phase uses the results from the above two phases to find the inter-intra itemsets. The results from the previous phase can be used to prune candidates in the current phase. The details of the proposed algorithm are described below.. The proposed three-phased data mining algorithm for object-oriented transactions: INPUT: A set of w classes (items) with mj attributes, 1≦j≦w, a body of n transaction data, each with some objects derived from the classes and their attribute values, a predefined minimum support value α, and a predefined confidence value λ. OUTPUT: A set of inter-class, intra-class and inter-intra-class association rules.. Phase 1: Find the inter-class relationships Step 1: Calculate the number (countj) of each class Ij appearing in the n transaction data, 1≦j≦w; If one class appears more than once in a transaction, count its occurrence only once; Set the support (supportj) of each class Ij as countj/n. Step 2: Check whether the support of each class Ij is larger than or equal to the predefined minimum support value α. If Ij satisfies the condition, put it in the set of large inter-class 1-itemsets (L1). That is, L1 = {Ij | countj /n ≥ α, 1 ≤ j ≤ w}.. 41.
(50) Step 3: If L1 is null, then exit the algorithm; otherwise, do the next step. Step 4: Set r = 1, where r is the number of classes in the inter-class itemsets currently being processed. Step 5: Generate the inter-class candidate set Cr+1 by joining Lr. Step 6: Calculate the number (counts) of each inter-class candidate (r+1)-itemset s in Cr+1; set its support (supports) as counts/n. Step 7: Check whether the support of each inter-class candidate (r+1)-itemset s is larger than or equal to the predefined minimum support value α. If s satisfies the condition, put it in the set of large inter-class (r+1)-itemsets (Lr+1). That is, Lr+1 = {s | counts /n ≥ α, s ∈ Cr+1}. Step 8: If Lr+1 is null, do the next step; otherwise, set r = r +1 and repeat Steps 5 to 7.. Phase 2: Find the intra-class relationships Step 9: For each large inter-class 1-itemset Ij, calculate the count (countjk) of its each attribute Ajk, 1≦k≦mj, where mj is the number of attributes for Ij; Set the support (supportjk) of Ajk as countjk /n. If Ajk appears more than once in a transaction, count it only once. Step 10: Check whether the support of each attribute Ajk is larger than or equal to the predefined minimum support value α. If Ajk satisfies the condition, put it in the set of large intra-class 1-itemsets ( L1' ). That is,. L1' = {Ij. Ajk | countjk /n ≥ α, Ij ∈ L1, 1≤ k ≤ mj}. Step 11: If L1' is null, then exist the algorithm; otherwise, do the next step. Step 12: Set z = 1, where z is the number of attributes in the intra-class itemsets currently being processed.. 42.
(51) Step 13: Generate the intra-class candidate itemset Cz' +1 by joining L'z , and remove those without their class relation existing in the large inter-class itemsets. Step 14: Calculate the number (counts) of each intra-class candidate (z+1)-itemset s in. Cz' +1; set its support (supports) as counts /n. Step 15: Check whether the support of each intra-class candidate (z+1)-itemset s is larger than or equal to the predefined minimum support value α. If s satisfies the condition, put it in the set of large intra-class (z+1)-itemsets ( L'z +1 ). That is,. L'z +1 = {s | counts /n ≥ α, s ∈ Cz' +1}. Step 16: If L'z +1 is null, do the next step; otherwise, set z = z +1 and repeat Steps 13 to 15.. Phase 3: Find the inter-intra class relationships Step 17: Each large intra-class itemset found so far is then thought of as a composite item and is put in the large inter-intra 1-itemset ( L''1 ). Step 18: Set t = 1, where t is used to represent the number of composite items in the inter-intra itemsets currently being processed. Step 19: Generate the inter-intra candidate set Ct''+1 by joining L''t , and remove those without their class relations existing in the large inter-class (t+1) itemsets. Step 20: Calculate the number (counts) of each inter-intra candidate (t+1)-itemset s in. Ct''+1 ; Set the support (supports) of each s as counts / n. Step 21: Check whether the support of each inter-intra candidate (t+1)-itemset s is larger than or equal to the predefined minimum support value α. If s satisfies the condition, put it in the set of large inter-intra (t+1)-itemsets ( L''t +1 ). That is,. L''t +1 = {s | counts /n ≥ α, s ∈ Ct''+1 }. 43.
(52) Step 22: If L''t +1 is null, do the next step; otherwise, set t = t + 1 and repeat Steps 19 to 21.. Finding the Outputs: Step 23: Derive the inter-class association rules with confidence values larger than or equal to λ from L2 to Lr. Step 24: Derive the intra-class association rules with confidence values larger than or equal to λ from L'2 to L'z . Step 25: Derive the inter-intra class association rules with confidence values larger than equal to λ from L''2 to L''t .. After STEP 25, the three kinds of object-oriented knowledge are found from the given set of data. Note that the minimum supports and the minimum confidences for the three phases may also be set at different values.. 5.3 An Example In this section, an example is given to illustrate the proposed three-phased object-oriented data mining algorithm. This is a simple example to show how the proposed algorithm can be used to generate the association rules from object-oriented data. Assume there are several classes, with each being a purchased item. Each class consists of its own attributes (e.g. delivery service). A purchased item in a transaction is thus an object generated from a certain class. In this example, we assume there are five classes, I1 to I5. The purchased items from the same class in the transactions have 44.
(53) the same attributes and the ones from different classes may have different attributes. Here, for simplicity, we assume all the classes have four attributes. Note that the proposed approach can handle the classes with different numbers of attributes. Let Aij denote the j-th attribute for the i-th class. For example, I1 has four different attributes A11 to A14, I2 has four attributes A21 to A24, and so on. The value of each attribute is either 0 or 1. Also assume the six transactions shown in Table 5-1 are to be processed.. Table 5-1: The six transaction data in this example Tran. ID 1 2. Transaction items. 3. I1, I4. 4. I2, I3, I4, I2, I3. 5 6. I4, I2, I3 I4, I3, I5, I2. I2, I5, I3 I4, I2, I4, I3. Transaction items with their attributes (A21, A22, A23), (A52, A53), (A31, A33) (A41, A43), (A21, A22, A23), (A41, A43), (A31, A33) (A11, A12,, A13, A14), (A41, A43) (A21, A22), (A31, A33 ,A34), (A41), (A22, A23), (A31, A33, A34) (A43), (A21, A22), (A31, A33, A34) (A41),(A33, A34),(A52, A53),(A21, A22, A23). In Table 5-1, A11 represents that the value of the attribute A11 in the purchased item I1 is 1. If A11 doesn’t appear in the table, its value is 0. Only the association relations among the appearing attribute behaviors (i.e. the value is 1) are to be found. The proposed algorithm can also be easily extended to find relations for non-appearing attribute behaviors. For the transaction data in Table 5-1, the proposed three-phased object-oriented data mining algorithm proceeds as follows.. Step 1: The count value of each class (purchased item) appearing in the six transaction data is first calculated. Take the class I1 as an example. Its count value =. 45.
(54) (0+0+1+1+0+1+0+1+0+1) = 5. This step is repeated for the other classes, with the results show in Table 5-2.. Table 5-2: The count of each purchased item in Table 5-1 Trans ID. 1 2 3 4 5 6 Count. I1 0 0 1 0 0 0 1. I2 1 1 0 1 1 1 5. I3 1 1 0 1 1 1 5. I4 0 1 1 1 1 1 5. I5 1 0 0 0 0 1 2. The support of each class can be derived by its count value over the number of transaction data. In this example, the number of transaction data is 6. Step 2: The support of each class is checked to determine whether it is larger than or equal to the predefined minimum support value α. Assume in this example, the minimum support is set at 0.6. Since the support values of I2, I3 and I4 are larger than or equal to 0.6, the three classes are put in the set of large inter-class 1-itemsets L1 (Table 5-3).. Table 5-3: The set of large inter-class 1-itemsets L1 in this example Large inter-class 1-itemset I2 I3 I4. Support 5/6 5/6 5/6. Step 3: If L1 is null, then the algorithm is exited; otherwise the next step is done. In this example, since L1 is not null, Step 4 is then executed. Step 4: The variable r is set at 1, where r is the number of classes in the 46.
(55) inter-class itemset currently being processed. Step 5: The inter-class candidate set Cr+1 is formed by joining Lr. C2 is first generated from L1 as follows: (I2, I3), (I2, I4) and (I3, I4). Step 6: The count of each inter-class candidate itemset s in C2 is calculated. The results are shown in Table 5-4.. Table 5-4: The count of each inter-class candidate itemset in C2 Inter-class candidate 2-itemset (I2, I3) (I2, I4) (I3, I4). Count 5 4 4. The support of each candidate s in C2 is then calculated as its count divided by 6. Step 7: The support of each inter-class candidate 2-itemset is then compared with the predefined minimum support value 0.6. In this example, all the three inter-class candidate 2-itemsets are larger than or equal to 0.6. They are thus kept in L2 (Table 5-5).. Table 5-5: The large inter-class 2-itemsets kept in L2 Large inter-class 2-itemset (I2, I3) (I2, I4) (I3, I4). Support 5/6 4/6 4/6. Step 8: If Lr+1 is null, the next step is done; otherwise, r = r + 1 and Steps 5 to 7 are repeated. Since L2 is not null in the example, r = r + 1 = 3. Steps 5 to 7 are repeated to get L3. C3 is then generated from L2, and the inter-class candidate 47.
(56) 3-itemsets (I2, I3, I4) is formed. Its support is calculated as 0.67, which is larger than the minimum support 0.6. It is thus put in L3. In this example, no inter-class candidate 4-itemsets can be formed. L4 is thus null and the next step begins. Step 9: The count value of each attribute in each large inter-class 1-itesmet is calculated. In this example, the three classes I2, I3 and I4 are large, so only the count values of the attributes for the three classes are calculated. Take the attribute A21 for the class I2 as an example. Its count value is (1+1+0+1+1+1), which is 5. This step is repeated for the other attributes, with the results shown in Table 5-6.. Table 5-6: The count of each attribute in I2, I3 and I4 Tran. I2 I3 I4 ID A21 A22 A23 A24 A31 A32 A33 A34 A41 A42 A43 A44 1 1 1 1 0 1 0 1 0 0 0 0 0 2. 1. 1. 1. 0. 1. 0. 1. 0. 1. 0. 1. 0. 3. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 1. 0. 4. 1. 1. 1. 0. 1. 0. 1. 1. 1. 0. 0. 0. 5. 1. 1. 0. 0. 1. 0. 1. 1. 0. 0. 1. 0. 6 count. 1 5. 1 5. 1 4. 0 0. 0 4. 0 0. 1 5. 1 3. 1 4. 0 0. 0 3. 0 0. The support of each attribute can be derived by its count value over the number of transaction data. In this example, the number of transaction data is 6. Step 10: The support of each attribute is checked to determine where it is larger than or equal to the predefined minimum support value α, which is 0.6 in this example. Since A21, A22, A23, A31, A33 and A41 satisfy the condition, these attributes are put in the set of large intra-class 1-itemsets L1' (Table 5-7).. 48.
(57) Table 5-7: The set of large intra-class 1-itesmets L1' Large intra-class Support 1-itesmet A21. 5/6. A22. 5/6. A23. 4/6. A31. 4/6. A33. 5/6. A41. 4/6. Step 11: If L1' is null, the algorithm is exited; otherwise the next step is done. In this example, L1' is not null, such that the next step is executed. Step 12: z is set at 1, where z is the number of attributes in the intra-class itemsets currently being processed. Step 13: The intra-class candidate itemset C z' +1 is generated by joining L'z under the condition that all the items in each (z+1)-itemset must have the same class.. C2' is first generated from L1' as follows: (A21, A22), (A21, A23), (A22, A23) and (A31, A33). Step 14: The count of each intra-class candidate 2-itemset in C2' is calculated, with the results shown in Table 5-8. The support of each intra-class candidate itemset is derived by its count over 6. Table 5-8: The counts of the intra-class candidate 2-itemsets in C2' Intra-class candidate 2-itemset (A21, A22) (A21, A23) (A22, A23) (A31, A33). 49. Count 5 4 4 4.
數據

+7

Outline
相關文件
The research proposes a data oriented approach for choosing the type of clustering algorithms and a new cluster validity index for choosing their input parameters.. The
This paper presents (i) a review of item selection algorithms from Robbins–Monro to Fred Lord; (ii) the establishment of a large sample foundation for Fred Lord’s maximum
In the past researches, all kinds of the clustering algorithms are proposed for dealing with high dimensional data in large data sets.. Nevertheless, almost all of
• An algorithm is any well-defined computational procedure that takes some value, or set of values, as input and produces some value, or set of values, as output.. • An algorithm is
Following the supply by the school of a copy of personal data in compliance with a data access request, the requestor is entitled to ask for correction of the personal data
• A cell array is a data type with indexed data containers called cells, and each cell can contain any type of data. • Cell arrays commonly contain either lists of text
The remaining positions contain //the rest of the original array elements //the rest of the original array elements.
For a data set of size 10000, after solving SVM on some parameters, assume that there are 1126 support vectors, and 1000 of those support vectors are bounded.. Soft-Margin
