Probabilistic File Indexing and Searching
in Unstructured Peer-to-Peer Networks
An-Hsun ChengDepartment of Information Management National Taiwan University
Taipei, Taiwan r90052 @im.ntu.edu.tw
Abstract
We propose a simple, practicd, yet powe$ul index scheme to enhance search in unstructured P 2 P nehvorks. The index scheme uses a data structure “Bloom Filters” to indexfiles shared ut each node, arid then let tiodes gossip to one another to e.rchange their Bloomfilters. In effect, each node indexes a random set offiles in the network, thereby
ulhwing eveiy query to have a constant probahiliq to be successfully resolved within a jixed search space. The ex- perimental results show that our approach can improve the search in Gnutella by an order of magnitude.
1 Introduction
Thanks to the advance of computing and network tech- nology, Peer-to-Peer (P2P) is becoming a popular way for
tile sharing. A legend of such P2P applications is Napster, which at one time attracted millions of users to share MP3 files concurrently [ 5 ] . Since then, many popular P2P net- works have been built on top of the Internet, and an enor- mous number of files can now he directly accessed and downloaded by a simple mouse click.
Depending on how file indexing is implemented, the ar- chitecture of P2P file sharing systems can be divided into the following categories: centra/ized, hybrid, andfulry dis- tributed. In ccntralized systems, a dedicated, centralized server is employed to provide indexing functions for the files to he shared. A user can query the server to find a
spccific file and its hosting peer, and then connects to the peer to access the tile. Centralized P2P systems, in general, are easier to build, but are difficult to scale and vulnerable to attacks and failures.
In hybrid systems, the index scheme in the centralized systems is decentralized and distributed into a number of servers. For example, in KaZaa some ‘supernodes’ are se- lected to act as index servers. Ordinary nodes connect to the supernodes, and transmit the information
OF
the files they wish to share to the supernodes. All queries from ordinary nodes are transmitted to the supernodes, and routed through supernodes. Once the desired file is located, download isdone directly between the querying node and the source node. The success of these hybrid systems relies on the sta- bility and the performance of the servers and on the cooper-
Yuh-Jzer Joung
Department of Information Management National Taiwan University
Taipei, Taiwan joung @ccms.ntu.edu.tw
ation among them. Still, the servers could become the target to paralyze the network.
In a fully distributed P2P system, no separate server is used. All the participating peers must cooperate together to provide the index service. To do so, each participating pecr establishes a connection with some other peers, cre- ating an ovcrlay network over which query messages can be forwarded and answered. Depending on the structure of the network, fully distributed P2P systems can he further divided into two types: structured and unstructured.
In the structured category, the topology of the overlay resembles some data structure, e.g., tree, grid, ring, hyper- cube, mesh, etc. Each peer is mapped to a node in the data structure by hashing certain strings, such as IP. The data structure also determines for each node its neighboring nodes to which it logically connects. The collection of this neighboring nodes information then determines how a mes- sage routes from a given source to a destination. Similarly, file indexing is provided by hashing a tile to a node in the data structure. The node is responsible for the file so that all queries to the file will he directed to the node. So, searching for a file becomes simply a message routing on the overlay from the querying node to the node handling the file. Be- cause such systems are effectively maintaining a hash table for the mapping between objects and nodes, they are also commonly referred to as Distributed Hash Tahles (DHTs). Examples include CAN [IO], Chord [17], Tapestry [20], and Pastry [14].
Structured P2P systems have several advantages. For ex- ample, query messages in Chord and Pastry are guaranteed to reach destinations in O(1ogn) steps, where n is the total number of nodes in the overlay. The storage requirement for routing per node is also O(1ogn). Moreover, because of the nature of hash functions, the indexing load can he uniformly distributed to all peers in the network. However, nodes are closely coupled in a structured P2P system. Main- taining the routing table at each node is usually not an easy task, especially when nodes may join and leave the network frequently. Although current research has shown that it is
possible to achieve high performance and reliability with
low maintenance cost even in an adversarial condition [I I], it is still unclear whether structured P2P architectures can be successfully deployed over the Internet.
On the other hand, peers are loosely coupled in an un-
established in a more casual way, usually when one knows the existence of the other. Because little cost has been paid
to maintain the network (other than connectivity), unstruc- tured P2P networks arc very resilient to external and inter- nal failures, and to frequent joins and leaves of peers. Sev- eral successful systems have been deployed over the Inter- net, e.g., Gnutella and Freenet [4]. However, because no structure is assumed in the topology, a node has virtually
no knowledge about which node may resolve the query.
So searching a file is more or less an exhaustive process, from some initiating node to the entire network, usually in
a breadth-first-search style (e.g., broadcast in Gnutella) or in a depth-first-search manner (e.g., the sequential search in Freenet. In practice, some
Tn
(Time-To-Live) is set to limit the search space, so as not to flood the network. The search methods, although inefficient and unscalable, are very simple and easy to implement. They are actu- ally quite effective when queried files are popular and one copy is nearby. But search cannot he guaranteed in boundedTn,
and search for rare files is extremely difficult. Sev- eral techniques and heuristics have been proposed to reduce search space in the broadcast and to increase the perfor- mance [19. 9, 6, 15, I], but none of them is effective in finding files that are far away from the qucrying node.In this paper we propose a probabilistic file index and search scheme for unstructured P2P networks. We aim
to preserve the simplicity and robustness of the nctworks, while offering
a
file index scheme that satisfies the follow- ing properties:0 If the desired file exists somewhere in the network, then our search algorithm is able to locate it with high probability, even though there might be only one copy of the file in the entire network.
The index scheme is simple and easy to maintain, and
is also quite resilient to failures.
2004 IEEE International Symposium on Cluster Computing and the Grid
is a set of edges. Each node represents a peer participating in this network. An edge between two nodes means that the two nodes are neighbor to each other in the overlay. The neighboring node information is maintained by each node U in its neighbor table
N T , .
Every node has the ability to communicate directly with any other node in the overlay, just like that a host can com- municate directly with any other host in the Internet by for- warding packets to a proper IP address. However, in order for
a
node U to he able to communicate with another node zi, U must know the existence of v and its contact information (just like that in the Intemet, U must know the IP of U ) . Anode always knows the existence of its neighbors (and being able to communicate with them), but it may know more.
We assume that the overlay network is maintained by the underlying P2P protocol. Our probabilistic file indexing and searching is built on top of this overlay. Because nodes may join and leave the network dynamically, the topology may change over time, possibly resulting in partitions. However, recent research [ 131 has shown that the numberofconnected components is relatively small: the largest connected com- ponent always includes more than
95%
of the active nodes. Hence, we shall assume that the entire network is connected in the remaining sections.Each node in the overlay is home to a set of files that are available to other nodes. T h e f i k locating problem then is
that, given a query containing some keywords, returns a set of nodes that have files matching thcse keywords.
2.2
Bloom Filters
Bloom filters [3] are compact data structures for a proba- bilistic representation of
a
set of objects. A Bloom filter isa
bit array
B
of length m withk
independent hash functions. which map elements of the set to an integer in 10, m), To construct a filter for a set. each element of the set is hashed withk
functions, and the bits corresponding to the hashed results are set. Therefore, if ai is an element of the set, in the resulting Bloom filterB ,
all bits corresponding to the hashed results of a; isI .
To determine whether an element The response time of each query is fast, while thememory and bandwidth consumption are kept at a
moderate level, thereby allowing the system to scale, The load of each node is balanced.
The index scheme facilitates keyword search.
The rest of the paper is organized as followed. Section 2
presents our system model and the main data structure. Sec- tion
3
presents our probabilistic index scheme, and Section 4presents search algorithms for the scheme. Simulation re- sults of the index and search scheme is presented
in
Sec- tion 5 . Finally, Section 6 concludes and provides some di- rections for future work.2
Preliminaries
In this section we present our system model, the problem, and the main data structure used in our index scheme.
2.1 System Model
We can model an unstructured P2P overlay as an undi- rected g a p h
G
=
( N ,
E ) ,
whereN
is a set of nodes, andE
e is in the set,
e
is hashed with the samek
functions. If allthe corresponding bits of the hashed results in the Bloom filter are set, the represented set may contain
e . If
any one of the hits is not set, the set must not contain the element. Bloom filters exhibit afulse positive phenomenon, meaning that they may return a truth value to a query even thought the queried element is not in the set. Let m be the length ofa Bloom filter,
n
be the size of the represented set, andk
he the number of hash functions used. Then, the probability of false positivef
can he calculated as follows,k
f
=
( 1 - P )
where p % eckntm.
Bloom filters are quite useful in supporting keyword search
[7].
Recall that in our system model each node shares some files to others. We shall assume that each file is sum- marized by some keywords. The collection of keywords of all the files shared by a node v is then represented by aBloom filter
B,.
So by first querying the filter, one can see if a queried file could he at the node. An actual search to the2004 IEEE Grid Initialization
This process is performed when a node U joins the network for the first time. It creates a Bloom filter
B,
of the format in Figure 1 to summarize the files it shares. Then, it replicates d copies of the filter and stores them in an index tableI T ,
it maintains at its site.Leave
Before a node U leaves the network, it must distribute all of
the entries in its index table to its neighbors (presumably in a uniform and balanced style). This ensures that the Bloom filters in its index table are still available while the node is ofnine.
Rejoin
When a node rejoins the network, it asks its neighbors Lo distribute some entrics in their index tables to the node to
fill up its index table.
Gossip
The kernel OF the index scheme is a gossip protocol for ex- changing index table entries between two nodes, so as to disseminate node information. The protocol is performed at each node U in every
6
time units as follows:Bloom m e r IP Address Pon Crsalkmms FaiILAUsmpI LBSI_UPdale VeNon
Figure I. Data format of a
node’s
Bloom filter.node’s directory is performed only if the query is positively answered. To allow copies of this filter to be distributed to other nodes, each copy is attached with some tags: IP, Pori, Create-Time, FailAttempt, LastNpdate, Version (see Figure I).
1P
address and access port allow other nodes to contact with the node when a query is performed outside the nude. The other tags are used to maintain a fresh version of the Bloom filter. They will be explainedin
Section 3.2. Inthe rest of the paper, by Bloom filters we mean the filers of the format in Figure I.
3
A
Probabilistic File Index Scheme
Recall from Section 2.2 that each node U has a Bloom
filter B , summarizing the files it sharcs. If
B,
is repli- cated and distributed to other nodes in the network, then every node U that hasB,
can answer queries about whetherU might have a particular file one is looking for.
If
the an-swer is yes, t~ can ask U to perform an actual check to its
local directory to see if U does have the file.
In general, the replication allows a query to U’S file to
be answered by any node having a copy of B,. So if ev- ery node has a copy of
B,,
then file search can he efti- ciently performed in the system. However, for the system to scale, only a limited number of replicas ofB,
can be dis- tributed. In practice, the number of replicas should allow aquery initiating from a node to be answered within a reason- able search space. Here, the search space refers to the set of
nodes to be visited for the query. It corresponds directly to the set of (replicas at) Bloom filters to be searched during the query resolving process.
However, the distribution of a node’s Bloom filters may
not be so uniform to let the search space starting from a node U to contain a copy of a particular
B,.
As a result, a query to U ’ S tiles will not he resolved at U. To solve this prob- lem, we let nodes dynamically exchange their Bloom filtersso that the search space of each node is also dynamically changing. This then allows every query from a node to have some probability to be successfully resolved, regardless of the time the query is issued. By properly setting the system parameters. we can tune thc probability to be reasonably high.
3.1
Construction and Maintenance
of
the
Index
Scheme
The index scheme at each node consists of four parts: initialization, rejoin, leave, and gossip.
Node U uniformly selects an entry from its index ta-
ble
IT,,
with probability p , or selects an entry from its neighbor table NT, with probability (1-
p ) , wherep
is a system wide parameter. We say that an entry in IT., represents U if the entry is a Bloom filterB,
of U. Similarly, an entry in N T , represents U if the entry describes node U.Note that in the above step if the selected entry repre- sents U itself, then U must repeat the step until an entry representing another node is obtained.
Let U be the node represented by the selected entry. Node U informs U that they are going to exchange Bloom filters in their index tables.
Node U then randomly selects 1s
*
lITu/]
entries fromI T ,
(where(IT,1
denotes the size ofIT,),
and simi- larly node zr also randomly selects 1s*
IIT,IJ
entries fromIT,,.
The variable s, 0<
s<
1, is again a system parameter.Both U and U send the selected entries to the other to
exchange their information.
3.2
Remarks
Thcre are several issues left to be addressed in the in- dex scheme, including the prohibitive setting of p , obsolete information, load balancing, information update, and node failure.
2004 IEEE International Symposium on Cluster Computing and the Grid some threshold tupdyir. Moreover, when U sends the copy to another node
w
in the gossip protocol,w
needs to translate the timestamp in the copy (which was set according to U’Sclock) tow’s clock. Prohibitive Setting o f p
We note that the system parameterp in the gossip protocol cannot he set to 1.
To
see this, we can use a directed graph to model the relationship among nodes according to their index tables: there is an edge from node U to U if U holdsa copy of U’S Bloom filter in
IT,.
If p is set to 1, then a node U can exchange Bloom filters with U only if (U, U ) isan edge in the graph. The exchange might remove (U, U )
from the graph if U sends U its only copy of B,. This then
might break any link from U to v, resulting in a partition in which U and U belong to different blocks. Since U can only
exchange Bloom filters with nodes in the same block, once a partition occurs, there is no way for the partition to heal. Moreover, the partition might get worse (resulting in more blocks), and eventually drive the system into the initial state in which every node has only its own Bloom filters!
Setting p to he less than 1 allows U to exchange Bloom filters with its neighbors in the overlay. Recall that the ovcr- lay is connected. So the exchange allows U to obtain infor- mation From other blocks should partitions occur, and there- fore to heal the partitions.
Obsolete Information
In a P2P network, nodes may fail or go offline permanently. So their Bloom filters need to he removed from the system. If a node U discovers that another node v is not available
(when U attempts to contact with 2) for some information), U
increases the counter FailAttempt (see Figure 1) in its copy of B, by one. If the counter exceeds some constant, U can
simply discard
B,
from its index table. On the other hand,U resets the counter to zero if it has successfully contacted
with U .
Load balancing
The departure of a node U may affect the load of other nodes because U will distribute all the entries in its indcx table to
its neighbors. Moreover, after U leaves the network, some
nodes will detect its leaving, and then delete U’S Bloom fil- ters from their index tables. So U ‘ S departure causes some
nodes to increase their index tables, while some others to decrease. However, our gossip protocol has the ability to balance the.load. ?is is because in each gossip operation, the node that has more entries will send more to the other, thereby decreasing its index table while increasing that of
the other.
Information Update
The files shared by a node U may change over time, and
therefore U’S Bloom filters need to he updated across the
network. To do so, the tag Createdime in a Bloom filter B, records the time at node U the Bloom filter is created. Then, we let nodes holding a copy of B, periodically check with U the status of their copies using the tag Create.7ime in the copies, and to update their copies if needed. The times- tamp Lust.Updute in a Bloom filter B, records the latest time at which the status of the copy is checked. It is the lo-
cal time of the node (say U ) at which the copy resides. Node
2) checks with U if its local clock exceeds the timestamp by
Node Failure
In the above index scheme we assumed that nodes will dis- tribute their index tables to their neighbors when they leave the network. This process cannot he guaranteed if nodes fail during the operation. As a result, the Bloom filters in their index tables will be lost. Another situation that causes
a node’s Bloom filter to be lost is when other nodes attempt to contact with the node while the node is offline. After a number of fail attempts they may discard their copies of the node’s Bloom filter. The tag Version in a Bloom filter is used to resolve this problem. The tag consists of two values: (replica-no, generation). When a node U creates d copies
of B,, it numbers these copies in the replica-no field. For
each copy number, U also writes into generation an integer
recording the number oltimes U has generated B,.
Recall that every node that has a copy of
B,
will check with U for the status of Uin
every tu,,dc,a units. So U can determine if a particular copy is lost if no node has checked the copy with U for a certain time. I f this is the case, U generates in its index table a new copy ofB,
with the same replico.no as that of the lost one. However, U incrementsgeneration in the new copy. This new value allows U to tell which copy of the same replica-no is new should the old copy still exist in the network (the owner of the old copy fails to check with U its status due to, say, some network problems). When a stale copy is detected, U can simply ask the possessing node to discard the copy.
4 Search Algorithms
In this section we discuss how search can he performed on the above probabilistic file index scheme. We begin with a basic search algorithm that resolves a query with some high probability. The probability can he increased to ap- proach to one by performing multiple instances of the hasic search. Two such algorithms are presented at the end of this section.
4.1
Basic Search Algorithm
The search algorithm is almost the same as in Gnutella. A node initiating a query broadcasts the query to its neigh- bors with nonzero TIL. A query contains keywords such as ‘“BA”, “Jordan”, “2001”, etc. Nodes which receive the query message check the
TTL
to determine whether or not to broadcast the query message. (If they have already re- ceived and processed the messages before, then they simply discard the messages.) If the TTL is less than one, they drop the messages: otherwise. they decrease theTTL
by one and broadcast the queries to their neighbors.By examining the Bloom filters in their index tables, the receiving nodes can know whether some particular node
might have the files. Node U then forwards the query mes- sage to U with
TTL
set to -1. Note that when a node re-ceives a query, if the
TTL
is no less than zero, both the local directory' and the Bloom filters inits
index table will he ex- amined. Otherwise(TTL
is - l ) , only local directory willbe
checked. If some matched files are found there, the reply message goes through the same path, but in the reverse di-rection, hack to the querying node as the way query replies are routed in Gnutella (or goes directly to the querying node if one wishes).
4.2
Analysis of the
Basic
Search
A l g o r i t h m We analyze the probability that a query will be resolvedin the basic search algorithm. Suppose that Bloom filters
of the nodes are randomly and uniformly distributed over the overlay network. Let
n
he the number of nodes in the network. Assume that each qucry message is sent withTIL
h.
Let N(u,h) denote the sct of nodes that are within h hops from node U. Suppose that U initiates a query for a file that exists at nod: U. Let A be .the event that the query is resolved, and let A denote the event otherwise.There are
nd
ways to distribute the d-replicas of U ' SBloom filter
B.,
to the n nodes. The event A occurs if noneTable 1. T h e probability of a successful query
under various
n,
d, andIN(u,
h)J.between the two queries is long enough, the second query will have an equal probability to be resolved as the first one (because Bloom filter replicas have been randomly re-distributed over the network). If the sec- ond one also fails, the a third query can be issued, and so on. If the desired file exists in the network, then the probability that the queries continue to Fail ap- proaches to zero. For example, consider the setting of
d = 400 and IN(u, h)l
=
400 in Table I , The prob- ability that three continuous queries all fail to return a file is (1 - 0.7988)3 GZ 0.0081. That is, 99.15% of thequeries will he successfully resolved in three continu-
ous queries.
The problem, of course, is how long a retry should wait'? We will answer this question in Section 5 . of the nodes in h ( u , h ) currently holds a replica of
B,
whilethe query is being resolved. There are
(n-IN(h,
ways to distribute the d replicas ofB,
so that none of the nodes in N(u, h ) gets a copy. Therefore, the probability that eventA
occurs is:Then,
In practice, IN(u, h)l is relatively small compared to
n.
So
P r ( A )
GZ 1 - (1 -v)
=
v.
Hence, ifIN(%,
h)l is fixed, d grows linearly with n in order to retain equal success probability. Table 1 gives a numerical illus- tration ofP T ( A )
for some values o f n, d, and IN(u,h)l.One can see that when
B,
is distributed to 0.4% of the pop- ulation of the network, thc probability that a query can be successfully resolved is about 0.8 if the query is broadcast to0.4%
of the nodes (which, as we shall see in the simula- tion, is withinTTL
=
4 in a typical network).4.3
Multiple-Query
Algorithms
If one wishes to increase the success probability of a query without increasing either d (the number of replicas
of a Bloom filter) or ~ N ( u , h)l (the search space), then mul- t$le queries can he performed. There are two alternatives:
Surrogate Queries: If time is critical, then, instead of
waiting for a retry at the same node, one can ask a ran- domly selected node to execute the retry. The node can be selected from the index table of the original query- ing node. The motivation behind this approach is that the search space of the randomly selected node should be independent of the search space of the original node. Therefore, the second query will have an equal proba- bility to he resolved as the first one; and similarly for the third, the fourth, etc.
5
Simulations
There are several important parameters left to he ad- dressed in the index scheme and in the gossip protocol. De- termination of their appropriate values are nontrivial and crucial to the performance of the query algorithms on the index scheme. In this section we conduct some experiments to address these issues. The simulation programs are written
in Java.
5.1
N e t w o r k TopologyAccording to [13], unstructured P2P networks like Gnutella tend to exhibit power-law distribution. Therefore, we use BRITE 1181 topology generator to construct an over-
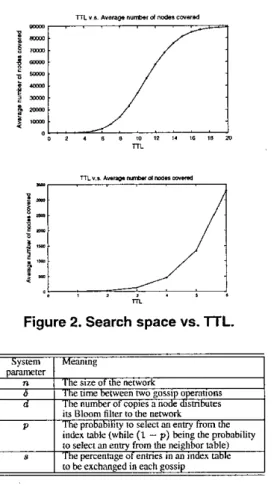
Figure 2. Search space vs.
l T L .
I Syiiem I Meanmi IP
iu B l w m filter tithe nerwork
index wblr (while (1 - p) k i n g rhe prabvbiliry
10 select un e n q fmm the neighbor wble)
The p r c a w g e of cnmes an an index wble robeerch'ulgedinevchlarsip
The probabiiity to select an e n q from the
Table 2. System Parameters
stated otherwise, nodes d o not leave or join the network dur- ing the simulation.
To see the average number of nodes covered within a cer- tain Tn, we randomly sample 2000 nodes from the net- work, and calculated the average number o f nodes covered within each
Tn.
The result is plotted in Figure 2.5.2
GossipPerformance
Because our index scheme relies on the ability of the gossip protocol to disseminate information, it is important to understand the performance of the gossip protocol under various configurations. The gossip protocol defines several system parameters. For ease of reference, they are summa- rized
in
Table 2.5.2.1 System Initialization
In this experiment, we study the time the gossip protocol takes to make an initial network stable. Here, 'stable' means that Bloom filters of
all
nodes have been uniformly dissem- inated over the network. In general, if the network is stable, then the expected search size for a node t o find a copy of another node's Bloom filter should be n Id.We start a network of 89000 new nodes, each of which shares a unique file. Then, we let nodes gossip to each other
2004 IEEE International Symposium on Cluster Computing and the Grid
to disseminate their Bloom filters. We count how many it- erations of gossip are required to make the network stable. After every 10 gossip operations per node, we generate sev- eral queries to search files. By measuring the mean search size of the queries, we can see if the network is stable. The results are shown in Figure 3(a).
From Figure 3(a), one can see that
d
does not affect the converging time much. Our gossip protocol needs about2500 gossip operations per node to make the network sta- ble.
If
6
is 20 minutes, it takes ahout35
days to converge. Fortunately, the bootstrapping process only needs to he ex- ecuted once.Still, there is much room for improvement. But, first, let's see why the gossip protocol takes such
a
long time to converge. We observe that we can envisage an index graph induced by the index tables as follows: there is an edge (U, U ) if U holdsa
B,
in its index table. Then, setting p close to 1 means that the gossip protocol tends to use the index graph to exchange Bloom filtcrs, rather than using the underlying overlay network. Note that initially every node has nothing but its own Bloom filters in its index table. So,at the beginning, thc index graph consists of 89000 discon- nected components, each of which is a singleton. Due to the
protocol, each node in its first gossip operation must find
a
neighbor in the overlay to exchange Bloom filters (because each node must select a node other than itselr Lo exchange information). This then extends the singleton
of
the node toa component of two. When a component is not a singleton,
the high value of p means that each node in the component tends to select a node in the same component, rather than a neighboring node from the underlying overlay, to exchange information. Clearly, the former has
no
help to extend the component, while the later has, as the neighbor (w.r.t. the overlay) may be in a different component (w.r.t. the index graph). So, when p is large, the chance to merge two con- nected components is low. Hence, it takesa
long time to merge all the initial singleton components.To
justify our argument, we also measure the converg- ing time for other values of p : 0.1 and 0.5. The results are shown in Figure 3(b). One can see that small p significantly improves the performance, as now a node tends to use theunderlying overlay network to exchange information. So
from this experiment we see that p should he set small dur- ing the system initialization phase.
5.2.2
In this experiment, we study the performance of our gos- sip protocol by measuring the interval from the time
a
new node joinsa
stable network to the time its Bloom filters have been uniformly disseminated over the network. This mea- surement indicates how long some remote users can utilize files brought into the network bya
new member.We start
a
network of 88800 nodes and let them gossip to each other until the network becomes stable. Then, 200 new members join the network simultaneously, and each of them hasa
unique file to he shared. We count how many gossips are required until the network becomes stable again. To d oso,
we randomly choose some nodes and generate queries tosearch files owned by the new members, and then calculate the mean search size for those queries. If the network is
G-ip Pedomance: pO.9. -0.5
ltWa"o"*
(a) When p = 0.9. 9 = 0.5. md d = 50 and 100
Ife,~t,O"*
(b) Whenp= O . l , O . S , O . 9 . s = O . S . u n d d = 50
F i g u r e 3. T h e c o n v e r g i n g
time
ofan
initial net-work.
stable, the mean search sizc should be close to the expected search size n Id.
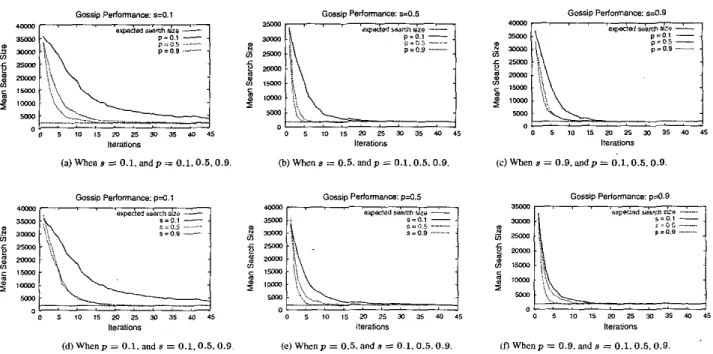
In the first part of the experiment we study the perfor- mance with respect to various p and s, given a fixedd = 50.
Figure 4 presents the results of the simulation. One can see that, with appropriatc configuration,
our
gossip protocol is quite fast to disseminate new information. For example, Figure 4(b) shows that if we set p = 0.9 and s = 0.5, our gossip protocol needs only 6 iterations to stabilize the net- work. From Figure 4(a)-(c) we can see that a large p resultsin better performance than a smallpdoes. To see this, recall that a large p means that nodes tend to use the index graph induced by the index tables to exchange Bloom filters. Note that the topology of the index graph varies after each gos- sip operation. In contrast, the underlying overlay network
is static (as no node joins or leaves). So, to each node, any node selected from its index table to exchange Bloom fil- ters tends to be a random node in the underlying overlay network; while any node selected from its neighbor table
is always its neighbor in the overlay. When the network is stable, the index graph should be connected. As a result,
information disseminates quickly in the index graph than in
the overlay. So, when a new node joins a stable network, the first gossip operation by the node will connect the node to the existing index graph. Thereafter, its Bloom filters will be disseminated to the network quickly if we have a largep setting. The results in the simulation indicates that setting p
in between 0.5 and 0.9 is recommended.
From Figure 4(d)-(f) we see that setting s to 0.5 yields better performance than setting s to 0.1 or 0.9. The reason
is as follows. The time to stabilize the network after a new
node joins depends on the time to disseminate the d Bloom
lleialiom
F i g u r e 5. G o s s i p p e r f o r m a n c e w h e n s
=
0.5, p =0.9,
and
d=
20,50,100,200.filters of the new member to the network. Recall that ini- tially all the d Bloom filters are in the new member's index table. I f s is ret to 0.5, after the first gossip operation the d
entries is divided into two equal parts, one hold by the new member itself, the othcr by an existing node. Each of thesc two parts tends to be partitioned into a set of 1 / 4 d size in the next gossip by its holder, and so on. On the other hand, ifs
is sct to 0.9 or 0.1, the d entries of the new member tend to be partitioned into two unbalanced sets in each gossip op- eration, with one significantly larger than the othcr. So, it takes longer time to divide the original d-element set into pieces to be hold by different nodes.
Since setting p = 0.9 and s =
0.5
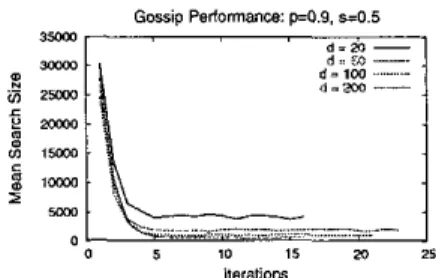
can yield fast propa- gation time in a stabilized network, we will use this config- uration to our gossip protocol in the following experiments. In the second part of this experiment, we study the performance of the gossip protocol with respect to d = 20,50,100,200, given thatp = 0.9 and 8 = 0.5. The resultsare shown in Figure 5. It takes about 5 , 6,7, and 7 iterations of gossip to make the network stable when d is 20,50, 100,
and 200, respectively. One can see that different settings of d do have some impact on the gossip protocol. This is because the larger d is, the longer time the gossip protocol needs to partition the d Bloom filters of a new member into pieces. However, the impact is not very significant (in loga- rithmic growth).
5.3
Query Performance
In this section we study search performance in our prob-
abilistic index scheme. In particular, we compare it with Gnutella, which is equivalent to our system without the in- dex scheme.
5.3.1 File Distribution
The experiments in this section need a large amount of real data to configure our simulator, such as the placement of files and the number of files shared per node. However, this kind of data are not publicly available. We instead use the information obtained from the Web proxy 1ogs.ofBoeing [8] as our simulation data. In Web proxy logs, the field 'user ID'
denotes a client and the field 'hostname' represents a WWW
server the client requests. So for each entry in the Boeing logs, we extract the two fields and treat 'user I D as a node,
2004 IEEE International Symposium on Cluster Computing and the Grid ... ... p=o.,
-
f p m a pio,o ... c - 5-t\
.9. G-o Performance: 0;0.5 GoSIiD Performance: -4.9 O FIteiall0ns lte,.QtlO"l lfe,a"O%
(d) W h e n p = 0.1. and s = 0.1.0.5,O.Q ( e ) W h e n p = 0 , 5 , a n d s = O 1.0.5.0.9 i n W h ~ " p = 0 9 , ~ d ~ = O . l , O . S , 0 . 9
Figure 4. Gossip performance with respect to various s and
p
for a fixed d = 50.WE. nmbero, IYsrp,dadeur<ms*mofmaer"dw4% C O F w r % $ $ o " D v l , r ~ m n d l l s r
&z&2
.-=
70:v]4
-
r. 6 0 s ( 4 ,i:"
0 . 0 2 Im I_ Im 3- "um&erd m r p s r m a s P B B r r W M IFigure 6. Cumulative density function of the
number of files shared per peer. The distri- support.
butions of Boeing logs in different days are
almost the same, so only two of them are
shown.
Figure 7. Cumulative density function of peer
her of nodes owning this file in the network.
To
the hestof our knowledge. the distribution of Deer S U D D O I ~ has not
been analyzed in the literature. Therefire, wecannot verify the validity of our simulation data set.
It
onlyas
a
statistic reference. ~n Figure 7, we observe that 90% of the
files
belong to rare files (peer support less than lo), and only1.5% of the files are popular (peer support lager than 100).
and
'hostname'as
a file.
The distribution of the number offiles shared per node
of
this mapping, depicted in Figure6.
is similar to the one shown in [161. SO we believe that the extracted information can represent a typical file distribution in real P2P networks.
Some researches [2, 131 have shown that free riders d o exist in many P2P networks. Hence, besides assigning nodes to share files, we also add some nodes that d o not share any file into the network. According to [13], they
found that about 25% of peers are free riders. The network
in
our
simulation contains 89000 nodes, and about 66000 of them share files to reflect the free-rider phenomenon.Figure 7 shows the cumulative counts of the fraction of
files vs. peer support. The peer support of a file is the num-
In [13], it said that: "While most nodes share few files
and maintain only a couple of connections, a small group provides more than half of the information shared, while an- other, distinct, group provides most of the essential connec- tivity." In addition to the above remark, there is also a figure
in 1131 showing the correlation between the number of con- nections a node maintains and the amount of files a node shares. In the experiment, we simply map the data layer onto the overlay network randomly, and make
sure
that thecorrelation between the number of files a node shares and the number of links
a
node maintains is similar to the figure in [13].5.3.2
Performance of Basic SearchTo study the performance of the basic search algorithm, we consider four cases: d =
50,100,200,
and400
(where p=
0.9 and s=
0.5). We also study the performance ofthe search algorithm without the index scheme, which is es- sentially a Gnutella network.
Because the size
of
the Boeing data set is too large, we evaluate the performance based on a sample of queries. Each query consists of two parts: a “Node I D and a “FileI D . “Node I D is the initiating node of the query, and “File
ID” represents the queried file. In this experiment, we only search filcs withpeer support I, IO, and 100. We generate
2000 queries for each peer support, with a total of 8000
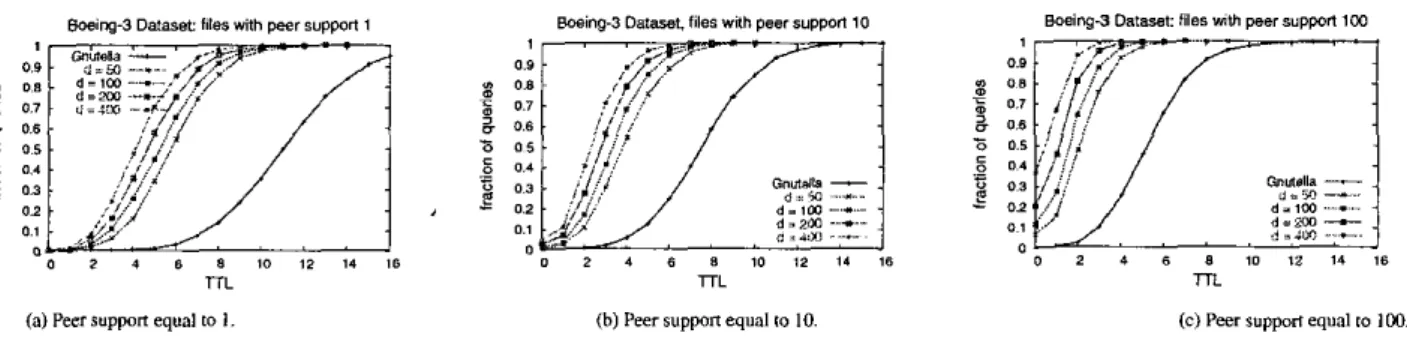
queries in the simulation. For each query, we count the num- ber of hops required to locate the first copy of a desired file. The results of the simulation are shown in Figure 8.
From the figure we can see that our probabilistic index scheme improves search rcsults significantly ovcr that in Gnutella. For example, in Figure X(a), by setting the ?TL of each query to
5,70%,
57%,45%,
33% of the queries are an- swered for d = 400,200,100,50, respectively. In contrast, only I % of the queries are successfully resolved in Gnutella.5.3.3 Performance of Repeated Queries
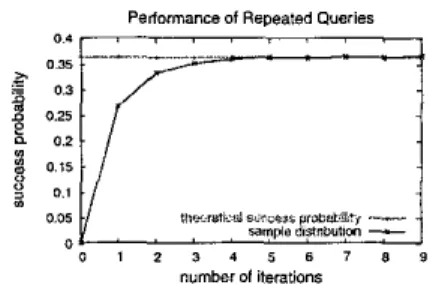
In Section 4.3 we presented a “Repeated Queries” algorithm that allows a user to wait for some period of time before reissuing the same query at the same node. Here we study the time one should he waiting.
We s t m a network of 89000 nodes, each of which shares a unique file. The system parameter d is set to 100. We let nodes gossip to each othcr until the network is stable. Then, we generate queries to search files, with search space equal to 400 nodes per query (about TTL= 4). We can use Equa- tion (1) to calculate the success probability of each query, which is 0.3626 in the setting.
For each unsuccessful query, we reissue the same query after
k
iterations of gossip per node, and record whether the reissue is successfully resolved or not. The percentage ofthe successful queries among the second attempts can then he calculated to see if it is close to the success probability. The experiment is conducted for
k
ranging from I to 9, and for each possible value ofk,
95000 samples were collected. The success probability under different setting ofk
is then calculated and plotted in Figure 9.One can see that after 4 or 5 iterations of gossip, the suc-
cess probability is close to 0.3626. We offer an explanation for this: In each iteration of gossip system wide, each node will execute two gossip operations on average (one initiated by the node itself, and the other by its neighbor). Recall that
s is set to 0.5, which means that half of
a
node’s index ta- ble will he refreshed in each single gossip operation. Then, ahout 15% of the index entries stored at each node will he refreshed in an iteration of gossip. After 4 iterations of gos- sip system wide, about 99.6% of entries at each node are renewed. Therefore, the index entries stored at each node:
(1.21
I
Figure 9. The success probability of repeated
queries under different settings of
k.
I
D 5 10 l i zo 25
number Of t”1S
Figure 10. Cumulative number of trials in the
“Surrogate Queries” algorithm.
before 4 iterations of gossip are almost independent of the entries stored at the same node after 4 iterations of gossip. Hence, the success probability should he close to 0.3626 af- ter 4 iterations of gossip.
5.3.4 Performance of Surrogate Queries
In this experiment we study how many queries should he reissued in the “Surrogate Queries” algorithm. The setting
is similar to the previous one. We start a network of 89000 nodes, each of which shares a unique file. The parameter
d
is set to100.
We let nodes gossip to each other until the network is stable. Then we generate querics to search files, with search size equal to 400 per query. In theory, the suc- cess probability of each query is 0.3626. So the expected number of trials is the reciprocal of the success probability, which is 2.75. For each unsuccessful query, we continue to issue queries using the “Surrogate Queries” algorithm un-til a desired file is located. We count how many additional queries are required to locate the desired file after the first unsuccessful query. There are a total of 4900 samples col- lected in this simulation. Each sample is a number recording the number of additional queries issued to locate a desired file. The result of simulation is shown in Figure IO.
The sample mean is 3.103, and the standard deviation of the sample mean is 0.0405. From Figure I O and the statistic data, one can see that “Surrogate Queries” performs slightly worse than the theoretical estimate. The reason is because the search area among each query might overlap. However,
2004 IEEE International Symposium on Cluster Computing and the Grid
Wing-3 Oataset files with p e ~ r suppan 1 Wing-3 Oafaset. filer wth peer S U P P O ~ 10 0aeing-3 Oataset: files wh p e e r s u p p i 1w
0 e 1 b 8 10 12 1. I 6 0 2 I B 8 10 12 14 16 0 2 1 6 8 10 12 I 4 76
m TrL T T l
(b) Peer suppan equal IO lo.
Figure 8. Basic search performance.
the performance is not too far from the theoretical estimate. Since “Surrogate Queries” can save a lot of time, it is still a feasible alternative to improve search results.
[6] V. Kalogeraki, D. Gunopulos, and D. Zeinalipour-Yarti. A local search mechanism for peer-to-peer networks. In
Pmc. of CIKM, pages 30&307. 2002.
Efficient peer-to-pecr keyword searching. In Middleware 2003, W C S 2672, pages 2 1 4 0 , 2003.
171 A. V. Patrick Reynolds.
6 Concluding Remarks
In the paper we have assumed that the computing power and the network bandwidth per node are the same. In real networks, some nodes do have much resource than the oth- ers. For these nodes, w e can enlarge their index tables to give them more responsibility in the index scheme. More- over, experiences have shown that a query might have higher chance t o he resolved by a node that shares many files than
by a node that shares few. So w e may also let the number of
Bloom filters a node inserts into the network be proportional to the number of files the node share. Therefore, query mes- sages will have higher chance to be forwarded to nodes that have many files than nodes that have fewer.
Note that security is treated as a separate issue in the pa- per. Because peers are quite autonomous, all peer-to-peer networks are vulnerable to various security attacks, e.g., a
peer responds with a ‘poisoned’ file, o r blocks queries and fakes search results. All these issues are certainly very com-
plicated and are still an active and ongoing research in the
field.
Finally, although in the paper w e use Gnutella as our pri- mary example, w e believe that our approach can be directly applied to many other unstructured P2P networks without
too
much modification.[8] Boeing proxy logs. http://www.weh-caching.com/traccs- logs.html.
191 M. K. Ramanathan, V. Kalogeraki. and J. Pruyne. Finding good peers in peer-to-peer networks. In Proc, IPDPS, 2002. [IO] S. Ratnasamy, P. Francis, M. Handley, R. Karp, and
S. Schenker. A scalable content-addressable network. In
Proc. SICCOMM, pages 161-172. 2001.
[ I 11 A. R. Ratul Mahajan, Miguel Castro. Controlling the cost of reliability in peer-to-peer overlays. In Proc. IFTPS. pages 21-32,2003.
[I21 S. Rhea and J. Kuhiatowicz. Probabilistic location and rout- ing. In Proc. INFOCOM, pages 1248 -1257, volume 3,2002. [I31 M. Ripeanu. Peer-to-peer architecture case study: Gnutella network. In Pmc. Firs! Inr’l Conference on Peer-lo-peer
Computing, pages 99-100.2001.
[I41 A. Rowstron and P. Druschel. Pastry: Scalable, decentral- ized object location, and routing for large-scale peer-to-peer systems. In Proc. Middleware, LNCS 2218, pages 329-350, 2001.
Efficient con- tent location using interest-based locality in peer-to-peer sys- tems. In Pmc. INFOCOM 2003, pages 216622176, vol- ume 3,2003.
[lS] K. Sripanidkulchai, Bruce, and H. Zhang.
[I61
P.
K.G.
Stefan Saroiu and S .D.
Gribble. A measurement study of peer-to-peer file sharing systems. In Proc. MMCN’02, pages 407418, 2002.
[I] L. A. Adamic. R. M. Lukose, A. R. Puniyani, and B. A. Hu- [I71 I. Stoica, R. Morris, D. Karger, M. E Kaashoek, and H. Bal- herman. Search in power-law networks. Physical Review E, akrishnan. Chord A scalable peer-to-peer lookup service for
M(4). 2001. internet applications. In Pmc. SIGCOMM, pages 149-160.
2001. [2]
E.
Adar andB.
A. Huberman. Free riding on gnutella. FirstMonduy, S(10). Oct. 2000.
131 B. H. Bloom. Spaeeltime trade-offs in hash coding with al. lowable errors. CACM, 13(7):422426, 1970.
[4] 1. Clarke. 0. Sandherg, B. Wiley, and T. W. Hong. Freenet: A distributed anonymous information storage and retrieval sys- tem. In Proc. Inr’l Workhop on Design Issues in Anonymiry
und Unobservubility. W C S 2009, pages 4666.2001.
References
[IS] Boston University. Brite.
[I91 B . Yang and H. Garcia-Molina. Improving search in peer-to- peer networks. In Pmc. ICDCS, 2002.
[20] B. Y. Zhao, J. D. Kubiatowicz, and A. D. Joseph. Tapestry: An infrastructure for fault-tolerant wide-area location and routing. TR UCB/CSD-OI-I141,