MCFPTree: A FP-Tree-Based Algorithm for Multi-Constrained Patterns
Discovery
Wen-Yang Lin
1and Ko-Wei Huang
21Dept. of Computer Science and Information Engineering, National University of Kaohsiung 2Institute. of Computer and Communication Engineering, National Cheng Kung University
1
[email protected];
2[email protected]
Abstract
In this paper, the problem of constraint-based pattern discovery is investigated. By allowing more user-specified constraints other than traditional rule measurements, e.g., minimum support and confidence, research work on this topic endeavor to reflect real interest of analysts and relief them from the overabundance of rules. Surprisingly very little research has been conducted to deal with multiple types of constraints. In our previous work, we have studied this problem, specifically focusing on three different types of constraints, including item constraint, aggregation constraint, and cardinality constraint. And an efficient Apriori-like algorithm, called MCFP, is proposed. In this paper, we propose a new algorithm called MCFPTree, which is based on the FP-tree structure and thus does not suffer from the problem of candidate itemsets generation. Experimental results show that our MCFPTree algorithm is significantly faster than MCFP and an intuitive method FP-Growth+, i.e., post processing the frequent patterns generated by FP-Growth, against user-specified constraints.
1. Introduction
In the early stage of the development of association mining algorithms, most researches were devoted to designing efficient algorithms for generating frequent itemsets, ignoring the fact that lots of frequent patterns generated are not user interested. This leads to the development of constraint-based association mining [2, 3, 5, 7, 10, 12, 13-17, 19, 20]. By allowing user-specified constraints other than minimum support and minimum confidence, the discovered patterns can reflect real interest of the analysts and, in this way, can relief them from the overabundance of rules.
So far most work on constraint-based association mining has been single-constraint oriented, i.e., only
one type of constraint is considered. Surprisingly little research has been conducted to deal with multiple types of constraint. This motivates us to the study of multi-constraint based frequent pattern mining.
In our previous work [13], we have investigated this problem considering three different types of constraints, including item constraint, aggregation constraint, and cardinality constraint. We also have proposed an efficient Apriori-like algorithm, called MCFP, for accomplishing this task. The proposed MCPF algorithm, however, has two significant weak points: First, its performance is heavily affected by the size of item constraint and the number of aggregation constraints, due to the paradigm of candidate generation and pruning it adopts. Second, it can not deal with item constraints containing negative items.
In this regard, we proposed a new algorithm called MCFPTree. The main advantage of MCFPTree over MCFP is that MCFPTree is a FP-Growth-like algorithm. By adopting the FP-tree structure, it heavily eliminate the load of candidate generation. Besides, by incorporating a new approach for exploiting item constraint, MCFPTree can handle item constraints that contain negative items.
An preliminary experiment on a real dataset show that our MCFPTree algorithm is significantly faster than MCFP and an intuitive method FP-Growth+, i.e., post processing the frequent patterns generated by FP-Growth [9], against user-specified constraints.
The remainder of this paper is organized as follows. The background knowledge and related work is described in Section 2. Section 3 defines some terminologies, formalizes the problem of constraint-based association rules mining, and describes the proposed algorithm, MCFTPree. Evaluations of our MCFPTree algorithm are described in Section 4. Finally, conclusions and future work are stated in Section 5.
2. Background and related work
Traditional techniques for mining association rules may generate thousands of rules or frequent patterns. Unfortunately, most of which are uninteresting to the users; only a relatively small subset of the complete frequent patterns and association rules is of interest to users. In light of these, constraint-based techniques have been developed for mining frequent patterns and associations rules.
The main purpose of constraint-based mining is to let users specify what kinds of knowledge or patterns that really are of interest to guide the mining methods to search for useful patterns, rather than spending much time on discovering patterns that the users have no interest. According to Han and Kamber [11], there are five different categories of constraint.
(1) Knowledge type constraints: this refers to the type of knowledge to be mined, such as the association rules, classification, etc.
(2) Data constraints: this refers to the set of the task-relevant data, such as about the bookstore sales mining.
(3) Dimensional / level constraints: this refers to the desired dimensions of data, or levels of the concept hierarchies.
(4) Interestingness constraints: this refers to the measures of rule interestingness, such as minimum support and minimum confidence. (5) Rule constraints: this refers to the form of rules
to be mined, such as aggregation constraints, meta-rule, and item constraint.
Our study in this paper is focused on the rule constraints. Specifically, three different types of rule constraints are considered, including item constraint, aggregation constraint, and cardinality constraint.
2.1. Item constraint
The concept of item constraint was first proposed by Srikant et al. [20], which is expressed in the form of a Boolean expression, indicating the presence or absence of items that are interesting to the users. Specifically, an item constraint expressed as a Boolean expression is in disjunctive normal form
D1∨ D2∨ ....∨ Dm, where each disjunct Di is of the
form of the a1∧ a2∧ ...∧ an, and each element ai is
either li or ~li for some li∈I.
For example, the Boolean expression (a∧ b) ∨ (c∧ ~d) denotes that the user is interested to see any patterns containing both items a and b or any patterns containing items c but not d.
In [20], Srikant et al. also proposed three algorithms to accomplish the task of mining frequent itemsets that satisfy a given item constraint, called Multiple Joins, Reorder, and Direct. All of these methods are developed following the classical Apriori framework, i.e., a level-wise, bottom-up generation and inspection of candidate itemsets, but each differing in the procedure for generating next (k+1)-level candidates from previous k-level frequent patterns. However, no implementation and empirical evaluation of the proposed algorithms were conducted.
Lu et al. [14] introduced an ECLAT-based algorithm, Eclat II, which is featured by pushing the Boolean expression item constraint into the ECLAT [22] framework. Their work also provided no algorithmic implementation and empirical evaluation.
2.2. Aggregation constraint
An aggregation constraint is a constraint defined on an aggregation function of itemsets, such as avg, sum, and media, etc. An aggregation constraint is of the form avg(S)θv, sum(S)θv, or median(S)θv, where S is a n itemset, v a real value, and θ a comparison operator, i.e., θ ∈ {≥, >, ≤, <}. For example, avg(S) ≥ 30 or sum(S) ≤ 20.
According to the study conducted by Pei et al. [16, 17] and Grahne et al. [7], the aggregation constraints can be classified as anti-monotone,
monotone, and succinct. A constraint Cam is
anti-monotone if and only if whenever an itemset S violates Cam, so does any superset of S. A constraint
Cm is monotone if and only if whenever an itemset S
satisfies Cm, so does any superset of S. A constraint
Cs is succinct if given Ai, the set of items satisfying Cs,
then any set S satisfying Cs is based on Ai, i.e., S
contains a subset belonging to Ai. For example, avg(S)
≤ 20 is an anti-monotone aggregation constraint,
sum(S) ≥ 20 is a monotone aggregation constraint, and
min(S) ≥ 30 is a succinct aggregation constraint, supposed that some of items have nonnegative values. Besides, an aggregation constraint can be
convertible or inconvertible. An aggregation
constraint Cag is convertible provided there is an
order R (ascending or descending) on items such that constraint is convertible anti-monotone or convertible monotone; otherwise, we say that aggregation constraint is inconvertible.
Ng et al. [15] first introduced the concept of anti-monotone and succinct constraints, and proposed a mining algorithm CAP for handling such types of constraints within the Apriori-based framework. Pei and Han [17] then proposed a new constraint-based
frequent pattern mining algorithm called CFG. The method of mining association rules in large, dense databases by user defined constraints was studied by Bayardo et al. [2]. Constraint-based mining of correlations, by exploration of anti-monotone, succinct, and monotone constraints, was developed in Grahne et al. [7].
The technique of pushing convertible aggregation constraint into association mining algorithm was first studied by Pei and Han [17], and later extended by Song and Qin [19] into that can handle multiple convertible aggregation constraints. Then Bonchi and Lucchese [3] proposed data reduction technique and considered pushing tougher constraints in frequent pattern mining. Lee et al. [12] proposed an approach to mine association rules with multiple aggregation constraints involving multi-dimensional attribute values.
2.2. Cardinality constraint
A cardinality constraint specifies requirement on the length of each pattern, which can also be referred to as the number of distinct items, or even the maximal number or minimal number of items per transactions. Such a requirement can be expressed in the form of
Card(S)θv, v ≥
0. For example, Card(S) ≤ 7 specifies
that the cardinality (length) of each itemset S should be at most 7.
3. Mining frequent patterns with multiple
constraints
3.1. Problem statement
Let I = {i1, i2, …, im} be a set of items, where each item is associated with a value attribute, such as cost, profit, or price, etc. Let D be a transaction database consisting of a set of transactions, where a transaction
T = 〈tid, It 〉 is a set of items It with identifier tid and It
⊆ I. An itemset S, S ⊆ I, is contained in a transaction T if S ⊆ It. The support sup(S) of an itemset S in a
transaction database D is the fraction of transactions in
D containing S. Given a support threshold ξ (0 ≤ ξ ≤
1), an itemset S is frequent provided sup(S) ≥ ξ. A constraint C is a predicate on the powerset of I,
C: P(I) → {True, False}. An itemset S satisfies C if
and only if C(S) = True. The complete set of itemsets satisfying constraint C is SATC(I) = {S|S ⊆ I∧ C(S) = True}.
In our research, we consider three different kinds of constraints, including an item constraint CB, a set of
aggregation constraints SC, and a cardinality constraint
CL. The problem of concern is to discover the set of itemsets F satisfying all constraints and minimum support threshold, i.e.,
F = {S | S ∈ SATCB ∩ SATSC ∩ SATCL∧ sup(S) ≥ ξ}
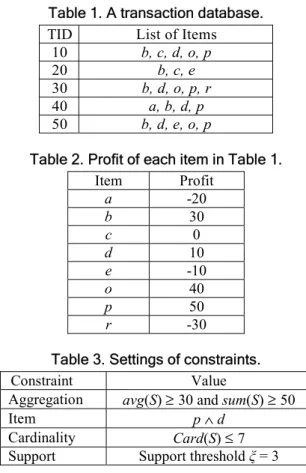
Example 1. Consider the transaction database in Table 1 and the profit of each item in Table 2. Suppose that the user-specified constraints and support threshold are as shown in Table 3. Then the set of frequent itemsets that satisfy the specified constraints are {pd, pdo, pdb, pdob}.
Table 1. A transaction database. TID List of Items
10 b, c, d, o, p
20 b, c, e
30 b, d, o, p, r
40 a, b, d, p
50 b, d, e, o, p
Table 2. Profit of each item in Table 1. Item Profit a -20 b 30 c 0 d 10 e -10 o 40 p 50 r -30
Table 3. Settings of constraints. Constraint Value
Aggregation avg(S) ≥ 30 and sum(S) ≥ 50
Item p ∧ d
Cardinality Card(S) ≤ 7 Support Support threshold ξ = 3
3.2. Algorithm MCFPTree
In this subsection, we introduce the proposed algorithm, named MCFPTree (Multi-Constrained Frequent Pattern Tree mining), which exploits the item constraint to construct the tree and conditional FP-tree structures to discover satisfied frequent patterns. Compared with our previously proposed MCFP algorithm, MCFPTree is a relatively efficient method for mining constrained frequent patterns because by adopting the FP-tree structure MCFPTree does not have to generate candidate itemsets except the first phase for initial candidate generation.
Our MCFPTree algorithm is composed of five main phases: (1) Initial candidate construction phase; (2) Database reduction and item counting phase; (3) FP-Tree construction phase; (4) Frequent pattern generation; and (5) Constraint checking phase.
In what follows, we will first detail each phase of MCFPTree, and then give an example to illustrate its execution.
3.2.1. Initial candidate construction phase. The initial candidate generation phase is the most critical step. MCFPTree exploits the item constraint directly to construct an initial set of candidate itemsets, with the intention to lessen the overhead in generating lots of intermediate candidates.
We consider two different cases: (1) The item constraint CB does not contain any negative item,
and (2) CB contains some negative items.
Case 1: CB constraint contains no negative item.
In this case, we exploit the disjuncts of item constraint CB to generate an initial set of
candidate itemsets. For example, if CB =
(a∧ b)∨ (c∧ d), then K = {ab, cd}.
Case 2: CB contains some negative items. This
case is far more complicated than the first case. The intuition is to avoid generating any candidate containing all positive items and part of the negative items in a disjunct Di in CB composed of
negative items while not refrain the construction of cross-disjunct candidates that contain proper subsets of negative items in Di and all positive items
of another Dj.
In light of this, we first exploit the disjuncts of item constraint CB to generate an initial set of
candidate itemsets K that is composed of only positive items and move all negative items to a negative set N. Then we generate the powerset of N, i.e., P(N). Finally, we perform a cross union between K and P(N), and prune those new initial candidate itemsets that contradict item constraint CB.
Example 2. Consider an item constraint CB = (a ∧ b) ∨
(b ∧ ∼d) ∨ (c ∧ ∼p ∧ ∼r). First, we decompose the item constraint CB to get the K = {ab, b, c} and N = {d, p, r}.
Then we find out the powerset of N,
P
(N) = {d, p, r,dp, dr, pr, dpr}. Finally, we perform a cross union
between K and
P
(N), and prune those new initial candidates that do not satisfy CB, resulting in the initialset of candidate itemsets K = {ab, b, c, abp, abr, abpr,
bp, br, bpr, cd}.
3.2.2. Database reduction and item counting phase. In this phase, we scan the database to count the support of each item, and during which we also reduce and trim the transaction database according to the following rules: A transaction is pruned if it does not contain any initial candidate itemset. Finally, we prune all infrequent items.
3.2.3. FP-Tree construction phase. The task of this phase is to construct the FP-tree by scanning the reduced transaction database. The FP-tree structure and the steps for building it follow those used in FP-Growth [9].
3.2.4. Frequent pattern generation phase. In this phase, we traverse the FP-tree to find out all frequent itemsets with support greater than or equal to ξ. Again, the approach used in FP-Growth is adopted. That is, we construct the conditional pattern base of each frequent 1-itemset, then construct its conditional FP-tree, and perform mining recursively on that tree to generate all of the frequent itemsets.
3.2.5. Constraint checking phase. In this phase, we check each of the frequent itemsets against the item constraint, aggregation constraints, and the cardinality constraint to generate the set of satisfied frequent itemsets.
3.3. An Example
Consider Example 1 again. Below we illustrate the process for executing MCFPTree on this example. Phase 1: Exploit the item constraint CB to obtain
initial candidate {pd}.
Phase 2: Scan the transaction database to find all frequent 1-itemsets, obtaining {b, d, o, p}, and perform transaction trimming and reduction when appropriately. The resulting database is shown in Table 4.
Table 4. The reduced transaction database. TID List of items
10 b, c, d, o, p
30 b, d, o, p, r
40 a, b, d, p
50 b, d, e, o, p
Phase 3: Scan the reduced database to construct the FP-tree; the resulting FP-tree is shown in Figure 1. Phase 4: This phase constructs the conditional FP-tree of each frequent 1-itemset to generate all frequent
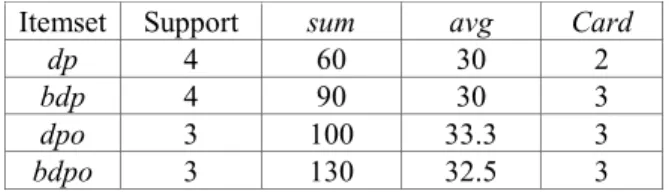
patterns, obtaining {bdpo, dpo, po, bdp, dp, bd}.
Figure 1. Initial FP-tree.
Phase 5: Finally, all frequent itemsets are checked against all constraints. The resulting set of satisfied frequent patterns is shown in Table 5.
Table 5. The frequent itemsets that satisfy all sets of constraints.
Itemset Support sum avg Card
dp 4 60 30 2
bdp 4 90 30 3
dpo 3 100 33.3 3
bdpo 3 130 32.5 3
4. Performance Evaluations
In this section, we evaluate the performance of the proposed algorithm MCFPTree for mining frequent patterns with multiple constraints. The Accidents [6] dataset is used in this evaluation, which is a real dataset about traffic accident. Table 6 shows some characteristics of Accidents.
Table 6. Characteristics of Accidents.
Parameters Value
|D| Number of transactions 341K |T| Average size of transactions 33.8
N Number of items 469
For comparison with our algorithms, we also implemented two methods: the MCFP algorithm and FP-Growth+ algorithm. Here, FP-Growth+ refers to the approach of applying the FP-Growth algorithm, followed by a post processing of the frequent patterns. All experiment were performed on a two 1.8GHz Intel Xeon CPUs ASUS server with 4GB main memory and 450 GB hard disk running on Windows server 2003.
All comparisons were investigated from three different aspects, including support threshold, size of
item constraints, and number of aggregation constraints.
4.1. Effect of support threshold
First we consider the effect of varying support threshold, ranging from 10% to 35%. The other constraints consist of two aggregation constraints, one item constraint composed of five disjuncts, and a cardinality constraint. Table 7 shows the detailed settings.
Table 7. Constraint settings. Constraint Value
Aggregation avg(S) ≥ 35 and sum(S) ≥ 150 Item (183∧ 34)∨ (59∧ 24)∨ 82∨
(12∧ 36)∨ 173 Cardinality Card(S) ≤7
The results in Figure 2 show that MCFPTree is significantly faster than MCFP and FP-Growth+, and the gap is increasing as the support threshold decreases, while FP-Growth+ outperforms MCFP.
0 100 200 300 400 500 600 700 800 900 0.1 0.15 0.2 0.25 0.3 0.35 Support threshold Ti m e( se c) FP-Growth+ MCFPTree MCFP
Figure 2. Performance comparison of FP-Growth+, MCFP, and MCFPTree with varying support thresholds.
4.2. Effect of size of item constraints
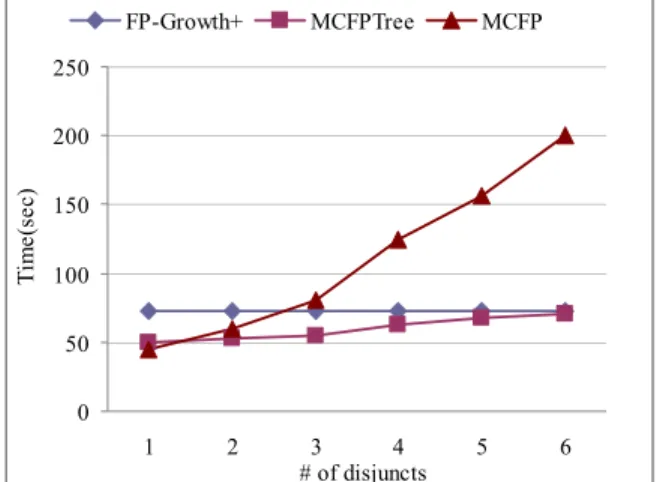
Next, we consider the effect of varying the size of item constraint, which is measured by the number of disjuncts ranging from 1 to 6. The other parameter settings are the same as before except that the support threshold is set to 0.25.
From the results in Figure 3, we observe that the performance of MCFP is affected by the number of disjuncts the most among the three algorithms. This is Header Table
Item Count Link
b 4 d 4 p 4 o 3 Root{} b: 4 d: 4 p: 4 o: 4
because MCFP is an Apriori-like algorithm, which heavily relies on the number of candidates. The more the number of disjucts is, the less the number of candidates will be generated. Note that the size of item constraints has almost no effect on algorithm FP-Growth because it does not utilize this constraint until the end of frequent itemset generation.
0 50 100 150 200 250 1 2 3 4 5 6 # of disjuncts Ti me (s ec ) FP-Growth+ MCFPTree MCFP
Figure 3. Performance comparison of FP-Growth+, MCFP, and MCFPTree with varying number of disjuncts.
4.3 Effect of number of aggregation constraints
Finally, we consider the effect of varying the number of aggregation constraints, which is set from 1 to 6. The other parameter settings in this experiment are the same as before.
As the results shown in Figure 4, the number of aggregation constraints does not affect the performance of FP-Growth+ and MCFPTree because this constraint is inspected only in the post processing phase. However, MCFP is heavily affected by the number of aggregation constraints; the more the number of constraints, the less its performance.
5. Conclusions
Recent work has highlighted the essence of allowing user-specified constraints into the model of association rules to facilitate an on-line, interactive mining environment of association rules. The key for realizing such a mining system is the design of an efficient frequent patterns mining algorithm that takes account of all user-specified constraints.
In this paper, we have proposed a new algorithm MCFPTree for discovering patterns that satisfy three types of user-specified constraints, including item constraint, aggregation constraint, and cardinality
constraint. Experimental results show that our algorithm MCFPTree is significantly faster than our previously proposed Apriori-like algorithm MCFP and also outperform an intuitive approach, post processing the frequent patterns generated by the leading algorithm FP-Growth against user-specified constraints. 0 50 100 150 200 250 1 2 3 4 5 6 # of aggregation constraints T im e( sec) FP-Growth+ MCFPTree MCFP
Figure 4. Performance comparison of FP-Growth+, MCFP, and MCFPTree with varying number of aggregations constraints.
In recent years, the ontology concept has become popular in the domain of computer science for web mining and knowledge management [23]. In its simplest form, an ontology is a concept hierarchy in a specific domain [4, 8, 21], wherein each concept owns some constrained properties represented by corresponding and relationships to other concepts attributes. We will consider incorporating ontology concept and extend the proposed algorithms by allowing multiple minimum support specifications to mine more generalized association rules. The long-term goal of our work is to integrate the ontology and constraint information to develop a framework for mining multi-dimensional association rules [5, 18] in an interactive environment. For example, this system can provide a query interface to allow the users specify different types of constraints and/or different templates of interesting multidimensional association rules by using the drop and drug operation.
Acknowledgment
This work is partially supported by National Science Council of Taiwan with grant No. 95-2221-E-390-024.
References
[1] R.J. Bayardo Jr, “Efficiently mining long patterns from databases,” in Proc. of ACM SIGMOD International
Conference on Management of Data, pp. 85–93, 1998.
[2] R.J. Bayardo Jr, R. Agrawal and D. Gunopulos, “Constraint-based rule mining in large, dense databases,” Data Mining and Knowledge Discovery, Vol. 4, pp. 217–240, 2000.
[3] F. Bonchi and C. Lucchese, “Extending the state-of-the-art of constraint-based pattern discovery,” Data
and Knowledge Engineering, Vol. 60, No. 2, pp. 377–
399, 2007.
[4] M. Domingues and S. Rezende, “Using taxonomies to facilitate the analysis of the association rules,” in Proc.
of 2nd International Workshop on Knowledge Discovery and Ontologies, pp. 59–66, 2005
[5] Y. Fu and J. Han, “Meta-rule-guided mining of association rules in relational databases,” in Proc. of
Knowledge Discovery in Databases with Deductive and Object-Oriented Databases (KDOOD) and Temporal Reasoning in Deductive and Object-Oriented Databases (TDOOD), pp. 39–46, 1995.
[6] K. Geurts, G. Wets, T. Brijs, and K. Vanhoof, “Profiling high frequency accident locations using association rules,” in Proc. of the 82nd Annual
Transportation Research Board, 2003.
[7] G. Grahne, L.V.S. Lakshmanan, and X. Wang, “Efficient mining of constrained correlated sets,” in
Proc. of the 16th International Conference on Data Engineering, pp. 512–521, 2000.
[8] J. Han and Y. Fu, “Mining multiple-level association rules in large databases,” IEEE Transactions on
Knowledge and Data Engineering, 11(5):798–804,
1999.
[9] J. Han, J. Pei, and Y. Yin, “Mining frequent patterns without candidate generation,” in Proc. of the 2000
ACM SIGMOD International Conference on Management of Data, pp. 1–12, 2000.
[10] J. Han, M. Kamber and J. Chiang, “Metarule-guided mining of multi-dimensional association rules using data cubes,” in Proc. of 3rd International Conference
on Knowledge Discovery and Data Mining, pp. 207–
210, 1997.
[11] J. Han and M. Kamber, Data Mining: Concepts and
Techniques, Morgan Kaufmann Publishers, 2004.
[12] A.J.T. Lee, W.C. Lin and C.S. Wang, “Mining association rules with multi-dimensional constraints,”
Journal of Systems and Software, Vol. 79, No. 1, pp.
79–92, 2006.
[13] W.Y. Lin, K.W. Huang, H.Y. Li, and C.L. Jiang, “Mining frequent patterns with item, aggregation, and cardinality constraints,” in Proc. of 3rd International
Conference on Innovative Computing, Information and Control, pp. 325–328, 2008.
[14] N. Lu, W. Zhe, C.G. Zhou and J.Z. Zhou, “Research on association rules mining algorithm with item constraints,” in Proc. of 2005 International Conference
on Cyberworlds, pp. 325–329, 2005.
[15] R.T. Ng, L.V.S. Lakshmanan, J. Han, and A. Pang,
“Exploratory mining and pruning optimizations of constrained association rules,” in Proc. of 1998 ACM
SIGMOD International Conference on Management of Data, pp. 13–24, 1998.
[16] J. Pei and J. Han, “Can we push more constraints into frequent pattern mining?” in Proc. of 6th ACM
SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 350–354, 2000.
[17] J. Pei, J. Han, and L.V.S. Lakshmanan, “Pushing convertible constraints in frequent itemset mining,”
Data Mining and Knowledge Discovery, Vol. 8, No. 3,
pp. 227–252, 2004.
[18] C.S. Perng, H. Wang, S. Ma, and J. L. Hellerstein, “Farm: A framework for exploring mining spaces with multiple attributes,” in Proc. of 2001 IEEE
International Conference on Data Mining, pp. 449–456,
2001.
[19] B.L. Song and Z. Qin, “Efficient mining for frequent itemsets with multiple convertible constraints,” in Proc.
of 4th International Conference on Machine Learning and Cybernetics, pp. 1503–1508, 2005.
[20] R. Srikant, Q. Vu, and R. Agrawal, “Mining association rules with item constraints,” in Proc. of 3rd
International Conference on Knowledge Discovery and Data Mining, pp. 67–73, 1997.
[21] R. Srikant and R. Agrawal, “Mining generalized association rules,” in Proc. of 21st International
Conference on Very Large Data Bases, pp. 407–419,
1995.
[22] M.J. Zaki, “Scalable algorithms for association mining,” IEEE Transactions on Knowledge and Data
Engineering, Vol. 12, No. 3, pp. 372–390, 2000.
[23] OWL Web Ontology Language Use Cases and
Requirements, available at