行政院國家科學委員會專題研究計畫 期末報告
標籤社群網絡之影響力最佳化
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 100-2221-E-004-012- 執 行 期 間 : 100 年 08 月 01 日至 102 年 01 月 31 日 執 行 單 位 : 國立政治大學資訊科學系 計 畫 主 持 人 : 沈錳坤 計畫參與人員: 碩士班研究生-兼任助理人員:林志傑 報 告 附 件 : 出席國際會議研究心得報告及發表論文 公 開 資 訊 : 本計畫涉及專利或其他智慧財產權,2 年後可公開查詢中 華 民 國 102 年 05 月 27 日
中 文 摘 要 : 利用社群網絡,我們可以將消費者之間的關係用節點跟邊表 示。影響力最佳化問題是由社群網絡上,選擇最具有影響力 的多個消費者以影響最多的消費者。然而,廣告相當重視目 標消費群,廣告目的就是希望能夠影響目標消費群,使目標 消費群購買產品。因此,我們針對標籤社群網絡提出標籤影 響力最佳化的問題。不同與現有的相關研究,我們加入了標 籤的條件,希望在標籤社會網絡中影響到最多符合標籤條件 的節點。針對標籤社會網絡,我們修改四個解決 Influence maximization problem 的方法,Greedy、NewGreedy、 CELFGreedy 和 DegreeDiscount,以找出影響最多符合類別條 件的節點的趨近解。我們也提出了兩個新的方法 Proximity Discount 和 Maximum Coverage 以更有效率地解決標籤影響 力最佳化。我們所提出的方法在離線時,先計算節點與節點 之間的 Proximity。當行銷人員線上即時擬定行效策略時, 系統利用 Proximity,將可即時有效率的找出趨近解。實驗 所採用的資料是 Internet Movie Database 的社會網絡。根 據實驗結果顯示,在兼顧效率與效果的情況下,適合用 Proximity Discount 來解決標籤影響力最佳化的問題。 中文關鍵詞: 標籤影響力最佳化, 社群網絡, 目標式行銷
英 文 摘 要 : The influence maximization problem is to find a set of seed nodes which maximize the spread of influence in a social network. The identified influencers are used for the viral marketing to gain the maximum profits through the effective word-of-mouth. However, in more real-world cases, marketers would like to advertise certain products, and thus have a set of targeted audience. Since the influence maximization considers no product information (i.e., targeted audience), it cannot be directly applied to such kind of targeted marketing. In this project, we focus on addressing the targeted marketing. We propose the labeled influence maximization problem, which aims to find a set of seed nodes which can trigger the
maximum spread of influence on the targeted audience in a labeled social network. That says, the targeted advertisements through the identified influencers will be able to bring the largest profits for marketers. We propose six algorithms to solve such labeled influence maximization problem. We first extend four existing greedy methods of original
influence maximization to consider the targeted audiences. In addition, we develop two novel
algorithms, Proximity-Discount and Maximum-Coverage, whose central idea is to offline compute the pairwise proximities of nodes in the labeled social network and online allow the marketers to make strategies through the attempts of different kinds of
information about targeted products. We conduct the experiments on the labeled social network constructed from IMDB. Experimental result shows the proposed Proximity-Discount achieve promising performances on both effectiveness and efficiency.
英文關鍵詞: labeled influence maximization, social networks, targeted marketing
目錄
目錄... I 摘要... II ABSTRACT ... III 1. INTRODUCTION ... 1 2. PROBLEM DEFINITION ... 23. EXTENDING GREEDY METHODS ... 3
3.1 LABELED GENERAL GREEDY ALGORITHM ... 3
3.2 LABELED CELFGREEDY ALGORITHM ... 4
3.3 LABELED NEW GREEDY ALGORITHM ... 4
3.4 LABELED DEGREE DISCOUNT ALGORITHM ... 5
4. PROXIMITY DISCOUNT HEURISTIC ... 6
4.1 PROXIMITY FOR INDEPENDENT CASCADE MODEL ... 7
4.2 OFFLINE COMPUTING PROXIMITY ... 8
4.3 ONLINE PROXIMITY DISCOUNT ALGORITHM ... 8
5. MAXIMUM COVERAGE GREEDY ... 10
6. EXPERIMENTS ... 11
6.1 SINGLE TARGETED LABEL ... 12
6.2 MULTIPLE TARGETED LABELS WITH EQUAL PROFIT WEIGHTS ... 13
6.3 MULTIPLE TARGETED LABELS WITH DIFFERENT PROFIT WEIGHTS ... 14
6.4 TIME EFFICIENCY ... 15
7. CONCLUSION ... 15
摘要
利用社群網絡,我們可以將消費者之間的關係用節點跟邊表示。影響力最佳化問題
是由社群網絡上,選擇最具有影響力的多個消費者以影響最多的消費者。然而,廣
告相當重視目標消費群,廣告目的就是希望能夠影響目標消費群,使目標消費群購
買產品。因此,我們針對標籤社群網絡提出標籤影響力最佳化的問題。不同與現有
的相關研究,我們加入了標籤的條件,希望在標籤社會網絡中影響到最多符合標籤
條件的節點。針對標籤社會網絡,我們修改四個解決 Influence Maximization Problem
的方法,Greedy、NewGreedy、CELFGreedy 和 DegreeDiscount,以找出影響最多符
合類別條件的節點的趨近解。我們也提出了兩個新的方法 Proximity Discount 和
Maximum Coverage 以更有效率地解決標籤影響力最佳化。我們所提出的方法在離線
時,先計算節點與節點之間的 Proximity。當行銷人員線上即時擬定行效策略時,系
統利用 Proximity,將可即時有效率的找出趨近解。實驗所採用的資料是 Internet
Movie Database 的社會網絡。根據實驗結果顯示,在兼顧效率與效果的情況下,適
合用 Proximity Discount 來解決標籤影響力最佳化的問題。
關鍵詞:標籤影響力最佳化, 社群網絡, 目標式行銷
Abstract
The influence maximization problem is to find a set of seed nodes which maximize the spread of influence in a social network. The identified influencers are used for the viral marketing to gain the maximum profits through the effective word-of-mouth. However, in more real-world cases, marketers would like to advertise certain products, and thus have a set of targeted audience. Since the influence maximization considers no product information (i.e., targeted audience), it cannot be directly applied to such kind of targeted marketing. In this project, we focus on addressing the targeted marketing. We propose the labeled influence maximization problem, which aims to find a set of seed nodes which can trigger the maximum spread of influence on the targeted audience in a labeled social network. That says, the targeted advertisements through the identified influencers will be able to bring the largest profits for marketers. We propose six algorithms to solve such labeled influence maximization problem. We first extend four existing greedy methods of original influence maximization to consider the targeted audiences. In addition, we develop two novel algorithms, Proximity-Discount and Maximum-Coverage, whose central idea is to offline compute the pairwise proximities of nodes in the labeled social network and online allow the marketers to make strategies through the attempts of different kinds of information about targeted products. We conduct the experiments on the labeled social network constructed from IMDB. Experimental result shows the proposed Proximity-Discount achieve promising performances on both effectiveness and efficiency.
1. INTRODUCTION
Social networks play a significant role in the spread of information and influence for word-of-mouth marketing and immunization setting. The problem, influence maximization [12], is to find a small set of influential individuals (as seeds) such that they can eventually influence the people as more as possible under certain influence cascade model in a social network. Some greedy algorithms [12][16][26] and heuristic methods [3][27] are proposed to effectively and efficiently solve the influence maximization problem. There are also some important variations of the influence maximization problem for addressing different real-world requirements. For example, Leskovec et al. [16] propose to select a set of social
sensors such that their placements can efficiently detect the propagation of information or virus in a
social network. Lappas et al. [25] propose to find a set of effectors who can cause an activation pattern as similar as possible to the given active nodes in a social network. Chen et al. [17] consider negative
opinions (due to product defects) into the influence maximization problem.
Given some seed individuals, who could be identified by existing solutions to the influence maximization problem, marketers can effectively advertise certain products through the notable spreads of influence from these seed ones to their friends and friends of friends in the social network. Such means of marketing is referred to the viral marketing. The general viral marketing has two default implications, (a) the advertised products are equally important to all the audiences, and (b) all the audiences equally care about those advertised products. However, in real-life cases, the marketers usually target certain products at particular groups of users. That says, different products have diverse targeted audiences. In addition, for diverse products, the gained profits are different from one category of users to another. For example, a certain company aims to promote the iPhone 5 and targets at the students. Among the students, the expected profits of the graduate and undergraduate students could be higher than those of the high-school students. We refer to such idea as targeted marketing. As a result, for the effective marketing to earn more benefit, the selection of viral seed individuals should take both targeted audiences and diverse profits on different categories of users into considerations.
We propose the labeled influence maximization problem, which considers both the targeted audiences for different products and various profits on diverse kinds of users into the selection of seed individuals in a social network. The basic idea is to use the label information of each individual in the network to model the ideas of advertised products, targeted audiences, and profits. In current social networking services, such as Facebook and LinkedIn, people use some attributed labels to describe themselves, including interests, graduated colleges, hometown, age, skills, and favorites. We regard and exploit such kind of label information. Given (a) a social network, in which each node possesses a set of labels and each edge is associated with a weight of influence probability, (b) a set of targeted labels, (c) a designated profit value for each targeted label, and (d) the budget of selected seed nodes, the labeled influence
maximization problem is to find a small set of individuals whose spread of influence in a network can
earn the total profit as more as possible. The selected seed individuals can be either those nodes with targeted labels or not.
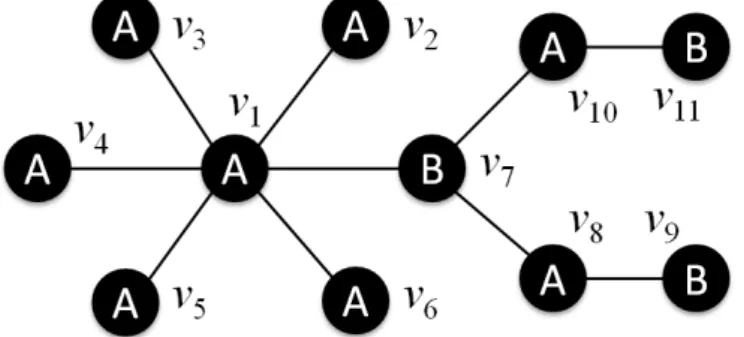
Here we use an example to illustrate the idea of the proposed labeled influence maximization. As shown in Figure 1, there are eleven nodes and two labels {A, B} is a social network. Let the budge of seed nodes is set to be 1 and the influence probability on each edge is equal. For the original influence maximization problem that considers only the number of successfully influenced nodes and neglects the labels on nodes, several effective algorithms (e.g. the degree heuristics and the greedy method) will select the node v1 as the seed to have maximum influence spread. If it is under the proposed labeled influence maximization problem, which considers the number of influenced nodes possessing the targeted labels, and assuming the targeted label is B, the best seed node is v7 which has the maximum probability to affect nodes with label B. An intuitive method to find the effective seed node for labeled influence
maximization is to remove the label-A nodes and use existing methods of unlabeled versions to select seeds. However, such approach suffers from two fatal drawbacks. First, the network will become disconnected, and thus the cascades of influence are constrained to happen locally and cannot propagate from one component to another. Second, such removing could delete the best seeds from the network because the best ones could be those without targeted labels.
Figure 1. A toy network for illustrating the idea of labeled influence maximization.
To solve the labeled influence problem, we propose a series of greedy and heuristic methods, which can be divided into two categories. The first category is to consider the label information and extend existing algorithms of the original influence maximization to labeled versions. Four methods, including the General Greedy [12], the CELF Greedy [16], the New Greedy [3], and the Degree Discount Heuristic [3], are modified to consider the targeted labels and profits. The second one is to provide the interactive mechanisms for allowing marketers to make the advertising plans in a real-time manner. Ideally, the labeled social network can be derived before marketers plan the promotions, and we can offline find the seed individuals for all kinds of combinations of labels in an exhaustive way so that the marketers can wait no time to online test their advertising strategies for different products. However, such enumeration of all possible seed nodes is infeasible because of three reasons: (a) the number of the combinations of labels is an astronomical figure, (b) the profit values of targeted labels are undefined, and (c) it is impossible to compute all kinds of targeted influencers for every possible combination of labels and profits. Due to such facts, we propose two methods, the Proximity Discount and the Maximum Coverage, which allows offline computing pairwise topological proximities as the influence potentials, and provides
online querying targeted labels and finding the top-k seed nodes, to efficiently solve the labeled influence
maximization problem.
We organize the rest of this report as follows. The problem definition of labeled influence maximization is given in Section 2. Four baseline methods extending from the greedy method are described in Section 3. We present the proposed online Proximity Discount algorithm as well as offline proximity computation algorithm in Section 4. Section 5 propose another online Maximum Coverage algorithm. Section 6 shows and compares the effectiveness and time efficiency of the proposed methods. We conclude this report in Section 7.
2.
P
ROBLEMD
EFINITIONGiven (a) a labeled social network , in which is the vertex set, is the edge set, is the set of labels , and each vertex is associated with a set of labels , (b) a budget (integer) representing the number of selected seed nodes, (c) a set of targeted labeled representing the information of targeted consumers, and (d) a designated profit value for each the
targeted label , the labeled influence maximization problem is to find a set of seed nodes , such that the labeled influence spread (i.e., total profit) caused by , denoted by , is
maximized, where , , and is the set of nodes
activated by the seed set S.
3. E
XTENDINGG
REEDYM
ETHODSSince the influence maximization problem is NP-hard [12], current studies focused on devising approximation algorithms to efficiently and effectively find the seed nodes in a greedy manner. In this section, we attempt to extend existing methods, including the general greedy algorithm [12], CELF algorithm [16], new greedy algorithm [3], and degree discount algorithm [3], to the labeled version for solving the new labeled influence maximization in the social network. We will also analyze some properties, complexity and approximation ratio for these extended greedy methods.
3.1 Labeled General Greedy Algorithm
The earliest solution to maximize the spread of influence in a network is proposed by Kempe et al. [12]. They propose a general greedy strategy to approximately find the seed nodes. In each round t of the general greedy, the algorithm selects one node vt and adds it into the seed set St-1 such that the new set maximizes the influence spread. Specifically, the selection of each seed node vt is based on the maximization of the marginal gain of influence spread, i.e.,
, in which is the expected activated nodes using the seed set S in the simulation of the independent cascade model. Note that the simulations are usually performed up to enough times (i.e., 10,000) and then computes the average activated nodes as the .
We extend the general greedy algorithm to solve the labeled influence maximization problem. We consider the targeted label when estimating the labeled influence spread of certain seed set. And thus the expected number of activated nodes is replaced by . Then the greedy method is the same to select the node which maximizes of the marginal gain of labeled influence spread,
. In addition, based on Kempe et al.’s study [12], we can further show is a submodular function:
,
where the seed set and . The labeled general greedy algorithm is described in Algorithm 1.
Algorithm 1. Labeled General Greedy (G, k)
1: Initialize and .
2: for to do
3: for each node do
4: . 5: for to do 6: . 7: . 8: . 9: Return .
Since the labeled influence spread is submodular (i.e., becoming lower as the round t increases), we guarantee the labeled general greedy algorithm can reach 63% approximation according the analytics in [20]. In other words, let be the set of k nodes which has the optimal labeled influence spread, , where is the seed set which is selected using our labeled general greedy
algorithm and .
3.2 Labeled CELF Greedy Algorithm
Followed by the general greedy, Leskovec et al. [16] aim to solve the original influence maximization problem more efficiently. They exploit the submodularity property and propose the Cost-Effective Lazy
Forward (CELF) selection method. Let , , and thus .
The central idea of CELF is that it is not necessary to recalculate of each node when a new seed node has been added into S (i.e., the recalculation of is performed in the labeled general greedy). Here we extend the CELF greedy to tackle the labeled influence maximization problem.
The new labeled CELF greedy algorithm is shown in Algorithm 2. First, we set of each node to be infinite and put all into a priority queue in a descend order based on . And then we pop out v from the priority queue. If is infinite, we calculate and poll back into the priority queue. Due to the submodularity property of , is diminished returns as the seed set S increases. In round , therefore, a node will be pop out, recalculate the , and poll back. The recalculated value will not be too low, and thus still locates in the front of the queue. If a certain node is pop out again after one time of recalculation, then is exactly the seed node what we want to select in the current round.
Algorithm 2. Labeled CELF Greedy (G, k)
1: Initialize .
2: for each node do
3: = .
4: for to do
5: for each node do
6: . 7: while true do 8: . 9: if then 10: . 11: break. 12: else 13: . 14: . 15: Return .
3.3 Labeled New Greedy Algorithm
In addition to the CELF greedy, Chen et al. [3] propose the new greedy algorithm to improve the efficiency of the general greedy as well. They exploit the assumption of the independent cascade model: each active node u has only one chance to activate one of its inactive neighbor v, and no matter u successfully activate v or not, u will never make an attempt to activate v. Due to all edges has only one chance to be propagated, their method determines which edges will be propagated in prior according to
the probabilities on edges. And thus those nodes reachable from one to another are considered being able to influence each other. Such strategy significantly reduces the execution time spent on the influence simulation. Here we extend the new greedy to solve the labeled influence maximization problem.
Our labeled new greedy algorithm is described in Algorithm 3. First, based on the influence probability on each edge, we determine which edges are selected in prior. Those edges do not be selected are removed from the graph, and a trimmed network is derived. We use to represent the node set which can be successfully activated by the seed set S in . And those nodes reachable from the seed set S in are those ones can be successfully influenced. Using the depth-first search, we can easily derive and . For each , we can obtain the set of nodes which can be activated by node . And the labeled influence spread can be derived by
If , If , In each round, we generate up to times
and select the node with highest average value as the seed node.
Algorithm 3. Labeled New Greedy (G, k)
1: Initialize and .
2: for to do
3: Set , for all .
4: for to do
5: Derive by removing each edge from according to the probability .
6: Compute .
7: Compute , for all .
8: for each node do
9: if then .
10: Set , for all .
11: .
12: Return .
3.4 Labeled Degree Discount Algorithm
Other than the new greedy algorithm, Chen et al. [3] further propose the degree discount heuristic to efficiently find the effective seed nodes. Their degree discount assumes that the propagation of influence has lower potentials to spread globally. And thus it is natural to consider only one-step neighbors of nodes and select nodes with high degree values, which tends to has higher expectations of influence, to be the seed ones. The central idea is to compute and update such expectations of influence in each round of selection. If one wants to select k seed nodes, the DegreeDiscount will be performed k times. After selecting one node w as a seed in each round, the DegreeDiscount will recalculate the expectation of influence of each w’s neighbor v because v’s expectation of influence will get discount due to selecting w as the seed. The formula for the recalculation of the expectation of influence is
, where , is the number of neighbors
and are contained by the seed set S. In other words, is the expectation value that v is not only never influenced by existing seed nodes, but also able to activate those do not be selected as the seed nodes yet.
We consider the targeted labels to modify the degree discount heuristic for addressing the labeled influence maximization problem. Algorithm 4 describes the proposed labeled degree discount algorithm. The central idea of estimating the expectation of influence is two-fold. First, consider not only the probability that v is failed to be activated by existing seed nodes, but also the expected influence profit that v is able to successfully activate those neighbors with targeted labels. Second, the v’s degree is modified to be the number of neighbors with targeted labels, . Regarding whether v possesses the targeted labels or not, the calculation of can be divided into the following
two cases. If , ; if ,
, where is the set of v’s neighbors nodes which have been
selected as seed nodes and possess the targeted labels, . is the
set of v’s neighbors which have been selected as seed nodes,
. Such two cases can be combined into line 13 in Algorithm 4. Note that
is the set of v’s neighbors, .
Algorithm 4. Labeled Degree Discount (G, k)
1: Initialize .
2: for each node do
3: Compute its degree
4: .
5: Initialize .
6: for do
7: Select .
8: .
9: for each and do
10: if then
11: .
12: else do .
13: .
14: Return .
4. P
ROXIMITYD
ISCOUNTH
EURISTICIn real-life cases, the social network can be derived before marketers employ it to make advertising strategies. Hence, for the original influence maximization problem, we can perform some preprocessing to find the top-k influencers in advance so that marketers can immediately determine the advertising plans without waiting the execution. However, such preprocessing is infeasible for the labeled influence maximization problem. The reason is three-fold. First, the combinations of the labels as targeted ones are numerous. Second, the profit values on targeted labels are undefined. Such first two parts will be unknown until the marketers attempt to make advertising strategies with best profits by testing all kinds of combinations of labels and profit weights for some products. Third, it is impossible to compute all kinds of targeted influencers for every possible combination of labels and their profit values. Due to such facts, we propose the proximity discount method, which allows offline computing proximity and provides
online querying targeted labels and finding the top-k seed nodes, to efficiently solve the labeled influence
maximization problem.
The basic idea of our proximity discount method is to consider the topological proximities between nodes as the potentials of successful influence from one to the other. If node u has higher proximity towards node v, we think u will have higher probability to activate v such higher proximity indicates (a) u is separated from v by fewer hops, (b) u and v are connected by multiple disjoint paths, and (c) walking from u to v tends to avoid going through nodes with higher degrees. Such three facts implies respectively that (a) u can easily affect v with fewer propagation steps, (b) u has more times to affects v through multiple disjoint paths, and (c) the propagations from u to v can avoid passing through edges with lower influence probabilities. In other words, the proximity considers the pairwise reachable probability from the global structural view as the influence potential from one to the other, instead of existing degree-related heuristics that use only egocentric local information. Therefore, we believe the proximity should be a better measure to capture the propagations of influence in a network. The computation of proximity is done in the offline stage.
On the other hand, we consider the discount idea, which is inspired from the degree discount heuristic, into the design of our proximity discount method. When each time a new seed node has been determined, the proximity scores (i.e., the expectation of influence) of some unselected nodes will get discounts because they have been affected by existing seeds. We will online perform such proximity discount in the online stage.
In the following, we will first describe the relationship between the proximity measure and the independent cascade influence model. And then we elaborate how to compute the proximity offline in the network. Finally, we present the online proximity discount algorithm with a data structure to efficiently perform the discounting.
4.1 Proximity for Independent Cascade Model
For the computation of proximity scores between nodes in a network, there are many proposals [8][9][14][23] for different scenarios. To integrate with the influence propagation in the independent cascade model, in this work, we modify the Cycle Free Effective Conductance (CFEC) [14] method to compute the pairwise proximity scores. The CFEC method applies the random walk mechanism to compute the probability that one node surfs in the graph and ever arrives the other. The major difference between CFEC and other proximity computation methods [8][9][23] is that when the random surfers walks in the graph, it never passes through the same node twice. All walking routes are simple paths, and no cycles will appear. Such random walk strategy complies with the influence propagation in the independent cascade model, in which each node has only one chance to be activated.
The propagation of influence in the independent cascade model can be regarded as a kind of random walk based on the influence probabilities on edges. Assuming there is a path
between and , the probability starting from and arriving is
Combing with the abovementioned cycle-free idea, therefore, the proximity from to equals to the probability that a random surfer starts from to without staying at the same node twice in the walking path. Let represent the probability the random surfer walks from to and does not stop by the same node. is the sum of probabilities of all simple paths from to .
where is the set of simple paths from to .
4.2 Offline Computing Proximity
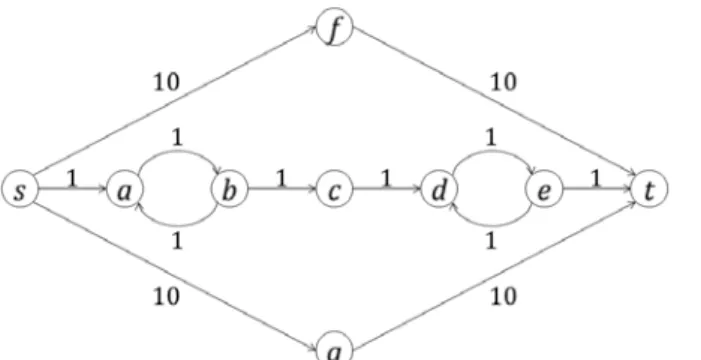
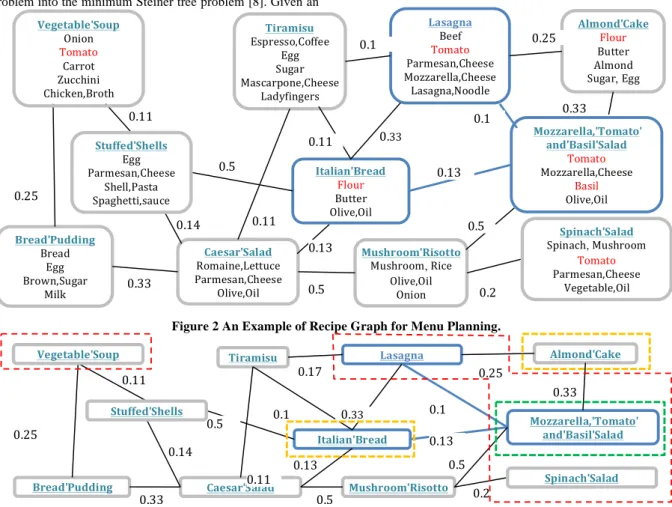
Before computing as the proximity score, we need to find the set of simple paths between and . Finding simple paths is computationally infeasible in large-scaled networks. Nevertheless, the provides us a clue to have an approximated computation. The derived probability is usually very small. By sorting the probabilities ( ) in the ascend order, it is apparent to find that the probability of the 100th simple path could be one millionth of the 1th simple path . It is nearly impossible to influence a certain node with such low probability. As a result, we consider only the top- simple paths to approximately compute the since top ones have higher potentials of effective influences. Here we use an example to illustrate the difference between top- simple paths and top- paths, as shown in Figure 2. If , the lengths of top- simple paths are 6, 20, and 21, and the lengths of top- paths are 6, 8, and 10 respectively.
Figure 2. An example graph to elaborate the difference between the top-k simple paths and the top-k paths.
The propagation of influence is based on the probabilities on edges. Each movement from one node u to its neighbor v in the network corresponds to the one more multiplication by the edge probability . The path length is related to the multiplication of edge probabilities. To find the lengths of simple paths, therefore, we transform the edge probabilities of influence into the length . As a result, the simple path with the low length will have the high influence probability. Finding the top- paths with highest probabilities equals to find the top- lowest simple paths. In this report, we do not give the specific . We continue to find the top lowest simple paths until the of the simple path is one twentieth (0.05) lower than the one . In details, we refer to Martins and Pascoal’s method to find the top- simple paths. The Hadoop/MapReduce framework is exploited for the implementation.
4.3 Online Proximity Discount Algorithm
Based on the offline derived pairwise proximity scores, in this subsection, we propose the proximity
discount method for finding the seed nodes according to the online querying targeted labels. The idea of
proximity discount method has two further benefits. First, the proximity discount method considers the high-order neighborhood of each node, instead of using only the degree in the labeled degree discount. Second, when computing the expectation of influence of each node v, the proximity not only discounts the profits of v’s neighboring seed nodes, but also considers that v’s neighboring seeds could affect v’s other neighbors as well.
Each time a node w is selected as the seed one, the proximity discount method will update and
discount the expectation of influence for each node . The
computation of proximity discount for node ’s expectation of influence consists of three parts. First, we compute the probability that is not successfully activated by the seed set . Such probability equals to . The second step is to compute the expected profit of . If the proximity from to
is not zero, has a certain chance to successfully activate . Hence, if the value is higher, will tend to be higher and will be more influential. Third, we also need to consider the probability that seed nodes could affect . Since could have been activated by the seed set , the expectation of influence of should get discount. The discounted value is . We summarize the update of ’s expectation of influence in the following formula.
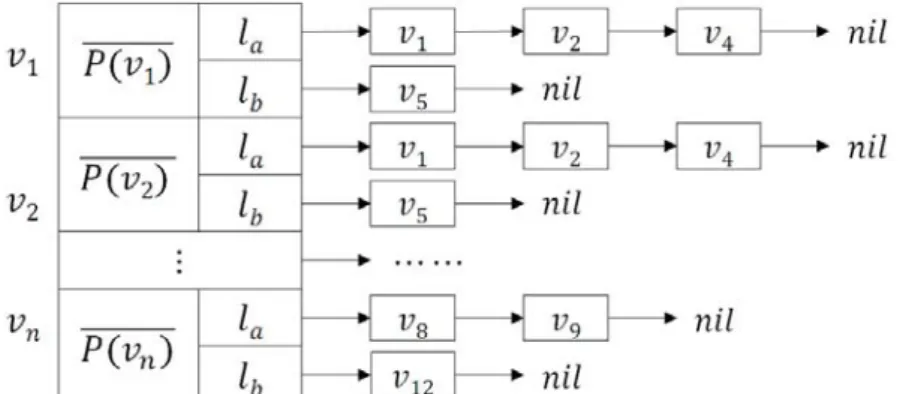
To efficiently compute the proximity discount, we also develop a special data structure to store the graph with the information about the targeted labels. For each node , we create cells to connect nodes , . For each cell of , we create a linked list to store those nodes with the target label , subject to . As a result, if we want to know which nodes with that
could attempt to activate, we can simply search the elements in the linked list .
Here we use an example to illustrate the proposed data structure, as shown in Figure 3. Assuming there are nodes , we create an array to store them. Also assuming there are two labels and . Let be the probability that node does not be influenced by seed nodes. For each node , we create an element to store and two pointers to two linked lists and to store nodes with targeted label and respectively.
Figure 3. The proposed data structure to store the neighbors with certain targeted labels. The overall method of the proposed proximity discount is described in Algorithm 5.
Algorithm 5. Proximity Discount (G, k)
1: Initialize .
2: for do
3: if then
4: for each node do
5:
6: else do
7: s = new added seed node in the i-1 loop
8: for each do 9: 1 0: for each do 1 1: 1 2:
Choose the highest , add v to S. 1
3:
Return .
5. M
AXIMUMC
OVERAGEG
REEDYBased on the offline derived scores of pairwise proximity in the previous section, we propose another greedy method to solve the labeled influence maximization problem. The central idea aims to consider the original problem as the Maximum Coverage Problem. The desired set of seeds, consequently, will be the set of nodes that can cover nodes with maximum total profit.
Given a graph , for each , it has a set of nodes , where the
proximity score . Let be the set of for each , i.e.,
and . The original maximum coverage problem is to find a set and such that the coverage (i.e., number) of , which equals to , is maximized. By applying such concept to the labeled influence maximization problem, the goal aims to find a seed set and such that the labeled influence spread (i.e., total profit) of , which equals to
, is maximized.
Algorithm 5. Maximum Coverage (G, k)
1: Initialize . 2: for to do
3: for each node do
4: .
5: .
6: Return .
Since finding nodes with maximum coverage is a NP-hard problem, which implies that using such concept to find the top- targeted influencers in a labeled social network is a NP-hard problem as well, we develop a greedy algorithm to solve it, as described in Algorithm 5. The basic idea is to find the node that can increase the total profit as more as possible in each round of seed selection. In details of
implementation, we create an array of bits ( ) for each to store the set of nodes
, where the proximity score . If has nonzero
proximity score on , the corresponding bit of is set to be 1; otherwise the bit is 0. As a result, when we want to know which nodes can be affected by the seeds, we can simply perform the OR operation on the corresponding arrays and efficiently derive the profit values.
6. E
XPERIMENTSIn this section, we conduct a series of experiments to evaluate the effectiveness and efficiency of the methods for the proposed labeled influence maximization problem. We employ the Internet Movie Database (IMDb) to construct the labeled social network. We use the movies in 1994 and 1995 and consider those actors and actresses in such period as the nodes in the network. Those who have ever co-worked for a certain movie are linked together. On the other hand, each movie has a set of categories. For example, the movie Toy Story has the categories of animation, adventure, comedy, family, and
fantasy. The labels associated with each node are derived from the categories of their involved movies.
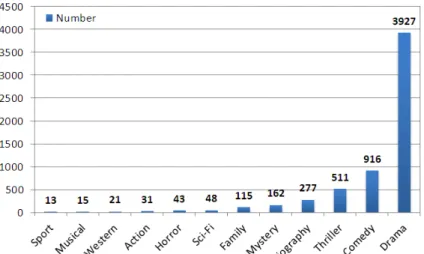
For each node, we take the most frequent category among his/her involved movies as the label. For example, the label of the actor Jim Carrey is comedy, which is the most frequent category of his ever involved movie. Eventually the constructed labeled social network consists of 6,079 nodes and 120,610 edges. We show the number of actors/actresses of each label in Figure 4. Totally there are 12 labels, in which the label sport has the least actors/actresses while the label drama has the most ones.
Figure 4. The number of actors/actresses of all the labels in the IMDb labeled social network. We proposed six algorithms for the labeled influence maximization problem, including the Label General Greedy, Labeled CELF Greedy, Label New Greedy, Labeled Degree Discount, Proximity Discount, and Maximum Coverage. In this report, we only execute and report the performances of last four algorithms because the expected running time of the first two ones is too long for us to obtain the results (more than one month). On the other hand, we measure the effectiveness by the labeled influence spread (i.e., total profit value produced by the seed nodes) and estimate the efficiency by the run time in second. We will report the results as the number of seed nodes increase from 1 to 20. For the simulations using the independent cascade model, we set the edge influence probabilities to be equally 0.05.
The evaluation plan can be divided into three parts according to the provided targeted labels and their profit weights: (1) given single targeted label, (2) given multiple targeted labels with equal profit weights, and (3) given multiple targeted labeled with different profit weights. Finally, we show the time efficiency (in second) for the four abovementioned methods. We present the results for each part in the following.
6.1 Single Targeted Label
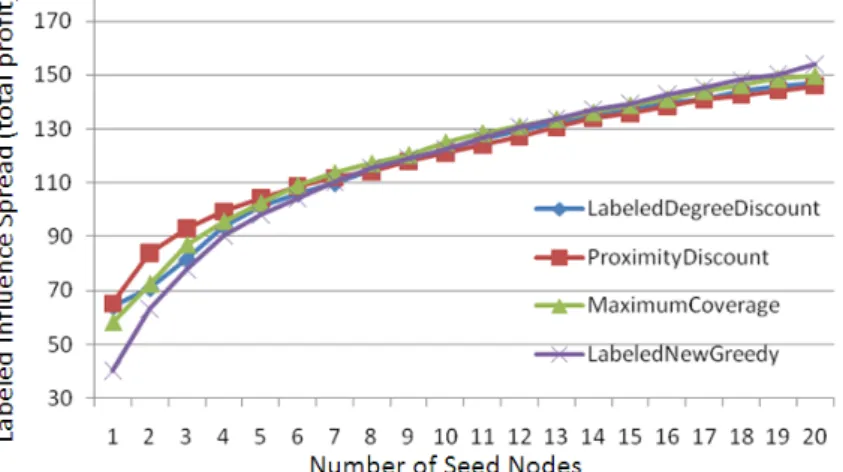
Figure 5 and 6 show the effectiveness of the targeted label drama and comedy respectively. We can find that, in general, the Proximity Discount algorithm outperforms the Labeled New Greedy when the number of seed nodes is low. The Maximum Coverage shows similar trends. When the number of seed nodes exceed about 3~6, the Labeled New Greedy is a little better than the other three ones gradually. However, as we will elaborate later in time efficiency, the Labeled New Greedy has an infeasible execution time for online making marketing strategies. On the other hand, the total profit of the Labeled Degree Discount is the worst one when the targeted label is drama. We think it is because the nodes with
drama label dominate the network and those belonging to drama usually gather together, and the Labeled
Degree Discount fails to capture such kind of distribution. As for the comedy label, which is distributed around the network, the Labeled Degree Discount can normally perform closely to the other threes.
Figure 5. The effectiveness of , .
6.2 Multiple Targeted Labels with Equal Profit Weights
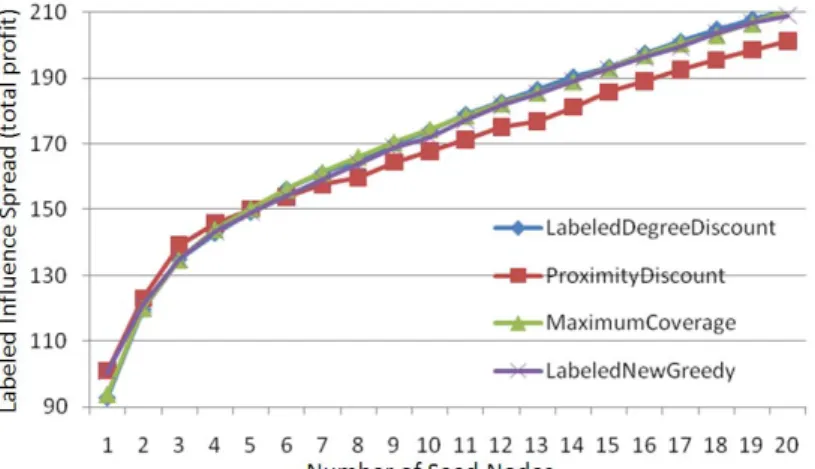
Next we demonstrate the results when the online queries contain multiple targeted labels with equal profit weights. Figure 7 and Figure 8 show the effectiveness of queries consisting of two targeted labels {comedy, biography} and {comedy, thriller} with equal weights. Again, the results exhibit the Proximity Discount outperforms the other three when the number of seed nodes is small (about 1~6). As the seed number further increases, other two methods, the Maximum Coverage becomes the better one. In general, the Labeled Degree Discount also performs well.
Figure 7. The effectiveness of , .
Figure 8. The effectiveness of , .
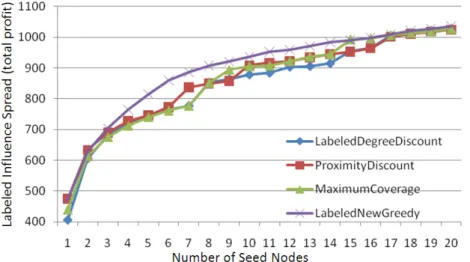
We further want to know how the proposed methods can perform when all the labels are considered as the targeted ones. That says, it turns out to be the original influence maximization problem. The experimental result in Figure 9 shows that Labeled New Greedy outperforms the other three methods no matter how the number of seed nodes is low or high, while the worst one is the Labeled Degree Discount. However, since the time efficiency of the Labeled New Greedy is infeasible for real-time querying, as will be shown in Figure 12, we suggest using the Proximity Discount when the number of seeds is low and using the Maximum Coverage when the number of seeds becomes high.
Figure 9. The effectiveness of , and each label’s profit equals is set to be 1.
6.3 Multiple Targeted Labels with Different Profit Weights
In the third part, we designate the online queries contains multiple targeted labels with different profit weights. Figure 10 shows the results of that the targeted labels are drama and comedy with profits of 1 and 3 respectively while Figure 11 presents the effectiveness of that the targeted labels are drama,
comedy, and thriller with 1, 3, and 5 profit weights. In general, the Labeled New Greedy outperforms the
other three ones. We can find, again, the Labeled New Greedy is the better one, though its execution time is infeasible for online marketing analytics (as shown in Figure 12). The more feasible is the Proxmity Discount method, which can not only earn higher total profits but also allow real-time querying. The Labeled Degree Discount performs relatively worse for such kind of varying profit weights.
Figure 11. The effectiveness of , .
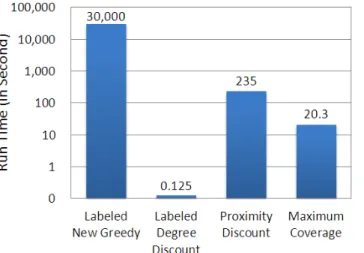
6.4 Time Efficiency
Figure 12 formally presents the execution time (in second) for both the four methods. The results are derived under the case that the targeted label contains only comedy with single profit weight since the other cases show the same trends. We can find that Labeled Degree Discount is fastest one, which even needs no more than one second, because it considers only the one-step neighbors. The time efficiency of the Proximity Discount and Maximum Coverage is acceptable. They also have promising effectiveness in different cases, as shown previous elaborations. For the Labeled New Greedy, though it performs well in some cases, its run time is totally infeasible for the online marketing analytics. Note that the Labeled General Greedy and Labeled CELF Greedy are not reported here because their execution time is too long for us to complete the execution and thus not applicable to the real-time interactive analytics for marketers.
Figure 12. The time efficiency (in second) of , .
7. C
ONCLUSIONWe introduce the labeled influence maximization problem in social networks for target marketing which focuses on target customers. We first present four baseline methods by extending the greedy
algorithm developed for the original influence maximization problem. We propose an efficient online algorithm based on the proximity to find the seeds for maximizing the influence spread. The experiment result suggests that the proposed methods perform faster while maintaining the influence spread guarantee. Future work includes the development of algorithms under weighted cascade model and linear threshold models.
R
EFERENCES1. F. Bass, “A New Product Growth Model for Consumer Durables,” Management Science, Vol. 5, No. 5, 1969.
2. J. Brown and P. Reinegen, “Social Ties and Word-of-mouth Referral Behavior,” Journal of Consumer Research, Vol. 14, No. 3, 1987.
3. W. Chen, Y. Wang, and S. Yang, “Efficient Influence Maximization in Social Networks,” Proc. of ACM International Conference on Knowledge Discovery and Data Ming KDD, 2009.
4. A. Goyal, F. Bonchi, and L. V. S. Lakshmanan. Learning Influence Probabilities In Social Networks. Proc. of ACM International Conference on Web Search and Data Mining WSDM, 2010. 5. G. Cornuejols, M.Fisher and G. Nemhauser, “Location of Bank Accounts to Optimize Float,”
Management Science, Vol. 23, 1997
6. P. Domings and M. Richardson, “Mining the Network Value of Consumers,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining KDD, 2001.
7. P. G. Doyle and J. L. Sell, “Random Walks and Electrical Networks,” The Mathematical Association of America, 1985.
8. C. Faloutsos, K. S. McCurley, and A. Tomkins, “Fast Discovery of Connection Subgraphs,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining KDD, 2004.
9. B. Gallagher, H. Tong, T. Eliassi-Rad, and C. Faloutsos, “Using Ghost Edges for Classification in Sparsely Labeled Networks,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining KDD, 2008.
10. J. Goldenberg, B. Libai, and E. Muller, “Using Complex Systems Analysis to Advance Marketing Theory Development,” Academy of Marketing Science Review, Vol. 2001, No. 9, 2001.
11. J. Goldenberg, B. Libai, and E. Muller, “Talk of the Network: A Complex Systems Look at the Underlying Process of Word-of-Mouth,” Marketing Letters, Vol.12, No. 3 , 2003.
12. D. Kempe, J. Kleinberg, and E. Tardos, “Maximizing the Spread of Influence through a Social Network,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining KDD, 2003.
13. N. Katoh, T. Ibaraki and H. Mine, “An Efficient Algorithm for k Shortest Simple Paths,” Networks, Vol.12 , pages.411-427,1982.
14. Y. Koren, S. C. North, and C. Volinsky, “Measuring and Extracting Proximity in Networks,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining KDD, 2006.
15. C. Budak, D. Agrawal, and A. E. Abbadi. Limiting the Spread of Misinformation in Social Networks. Proc. of International World Wide Web Conference WWW, 2011.
16. J. Leskovec, A. Krause, C. Guestrin, C. Faloutsos, J. VanBriesen, and N. Glance, “Cost-effective Outbreak Detection in Networks,” Proc. of ACM International Conference on Knowledge Discovery and Data Ming KDD, 2007.
17. W. Chen, A. Collins, R. Cummings, T. Ke, Z. Liu, D. Rincon, X. Sun, Y. Wang, W. Wei, and Y. Yuan. Influence Maximization in Social Networks When Negative Opinions. Proc. of SIAM International Conference on Data Mining SDM, 2011.
18. V. Mahajan, E. Muller, and F. Bass, “New Product Diffusion Model in Marketing: A Review and Directions for Research,” Journal of Marketing, Vol.54, No.1m pages.1-26, 1990.
19. E. Q. V. Martins and M. M. B. Pascoal, “A New Implementation of Yen’s ranking loopless paths algorithm,” Quarterly Journal of the Belgian, French and Italian Operations Research Societies, 2002.
20. G. Nemhauser, L. Wolsey, and M. Fisher, “An Analysis of the Approximations for Maximizing Submodular Set Functions,” Mathematical Programming, Vol.14, No.1, 1978.
21. M. Richardson and P. Domingos, “Mining Knowledge-Sharing Sites for Viral Marketing,” Proc. of ACM International Conference on Knowledge Discovery and Data Mining KDD, 2002.
22. W. Chen, Y. Yuan, and L. Zhang. Scalable Influence Maximization in Social Networks under the Linear Threshold Model. Proc. of IEEE International Conference on Data Mining ICDM, 2010. 23. H. Tong, C. Faloutsos, and J. Y. Pan, “Fast Random Walk with Restart and Its Applications,” Proc.
of IEEE International Conference on Data Mining ICDM, 2006.
24. H. Ma, Haixuan Yang, M. R. Lyu, and I. King. Mining Social Networks Using Heat Diffusion Processes for Marketing Candidates Selection. Proc. of ACM International Conference on Information and Knowledge Management CIKM, 2008.
25. T. Lappas, E. Terzi, D. Gunopulos, and H. Mannila. Finding Effectors in Social Networks. Proc. of the ACM International Conference on Knowledge Discovery and Data Mining KDD, 2010.
26. Y. Wang, G. Cong, G. Song, and K. Xie. Community-based Greedy Algorithm for Mining Top-k Influential Nodes in Mobile Social Networks. Proc. of the ACM International Conference on Knowledge Discovery and Data Mining KDD, 2010.
27. W. Chen and C. Wang. Scalable Influence Maximization for Prevalent Viral Marketing in Large-Scale Social Networks. Proc. of the ACM International Conference on Knowledge Discovery and Data Mining KDD, 2010.
28. S. Datta, A. Majumder, and N. Shrivastava. Viral Marketing for Multiple Products. Proc. of IEEE International Conference on Data Mining ICDM, 2010.
29. M. Gomez-Rodriguez, J. Leskovec, and A. Krause. Inferring Networks of Diffusion and Influence. Pro
30. C. T. Li, S. D. Lin, and M. K. Shan. Finding Influential Mediators in Social Networks. Proc. of International World Wide Web Conference WWW, 2011.
31. J. Yang, and J. Leskovec. Modeling Information Diffusion in Implicit Networks. Proc. of IEEE International Conference on Data Mining ICDM, 2010.
32. E. Sadikov, M. Medina, J. Leskovec, and H. Garcia-Molina. Correcting for Missing Data in Information Cascades. Proc. of ACM International Conference on Web Search and Data Mining WSDM, 2011.
國科會補助專題研究計畫出席國際學術會議心得報告
日期: 年 月 日
一、參加會議經過
本計劃的研究成果包括兩篇分別發表在 IEEE International Conference on Social Computing 與 ACM International Workshop on Multimedia for Cooking and Eating Activities 的論文。
前者是影響力最佳化的演算法。2011 年的 IEEE SoialCom 在 MIT 舉行,其 accepting Rate 9%。由於 機會難得,因此鼓勵參與研究計劃的學生出國增廣見聞。但受限於經費與法規的限制,因此個人自掏 腰包補助學生到 IEEE SocailCom 發表。
後者是研究過程中,所衍生出的創意構想。我們將社群網絡演算法應用在食譜網站的智慧型套餐規 劃 。 此 成 果 投 稿 到 發 表 ACM International Workshop on Multimedia for Cooking and Eating Activities(CEA),在 15 篇投稿論文中,被選為 oral presentation 的 3 篇論文之中(8 篇 poster), accepting rate 20%。
計畫編號 NSC-100-2221-E-004-012
計畫名稱
標籤社群網絡之影響力最佳化
出國人員
姓名
沈錳坤
服務機構
及職稱
國立政治大學資訊科學系
會議時間
101 年 10 月 29 日至 101 年 11 月 2 日會議地點
日本奈良
會議名稱
(中文) ACM 計算機學會國際多媒體會議烹飪與飲食多媒體技術工作坊
(英文) ACM International Workshop on Multimedia for Cooking and Eating
Activities in conjunction with ACM International Conference on Multimedia,
2012.
發表題目
(中文) 智慧型套餐規劃:根據食材推薦套餐的食譜
(英文) Intelligent Menu Planning: Recommending Set of Recipes by
Ingredients
都有不少精彩的研究成果發表。每年的 ACM MM 都同時舉辦多場 Workshop,其中 CEA 已經舉辦了四 屆。本屆 ACM MM 會議分別收到 331 篇與 407 篇來自全球五大洲的 long paper, short paper 投稿,所發 表的論文包括了 67 篇 Full Paper 的 Oral Presentation。其中,Full Oral Presentation Paper 的 Accepting Rate 為 20.2%,Short Oral Presentation Paper 的 Accepting Rate 為 31.2%。今年的會議在日本的奈良舉行。台 灣今年包括台大資工的洪一平教授、徐宏民教授,中央研究院資訊所廖弘源,王新民、鄭文皇等研究 員、交大資工蔡文錦教授、成大資工系胡敏君教授,師大資工系葉梅珍教授、畢業於成大資工的黃建 霖博士等都有發表論文。日本人舉辦會議非常用心。無論是 Reception, Banquet 都非常令人驚艷。以 Banquet 為例,大會就安排了傳統的日本藝妓在會場。除了介紹藝妓文化,也讓與會人士與其合照。
ACM International Workshop on Multimedia for Cooking and Eating Activities 主要是由日本東京大 學、京都大學與法國的學者共同發起。至今已經舉辦了四屆,也是目前結合資訊技術與美食烹飪領域 的頂尖會議。
我的報告安排在 2 日下午,Session Chair 是來自於京都大學的 Yoko Yamakata 教授。Oral Session 總 共三篇論文發表。除了我們有關智慧型套餐規劃的研究之外,還包括自動辨識切菜時的食材、食物影 像中的 Segmentation 兩篇論文。
海報發表則有包括來自法國 Orange Lab.結合 Web Service 與智慧型智慧型廚房、來自於日本 Kyoto Sangyo University 的 Hirotada Ueda 烹飪機器人等有趣的研究。Poster 結束之後,很特別地邀請來自於 Osaka Institute of Technology 的 Mutsuo Sano 教授,由文化的角度,為大家介紹日本的飲食歷史、風俗、 特色與文化背景。
會後,大會還安排了傳統的日本晚宴,邀請有興趣的學者到傳統的日本餐廳用餐。因為是會議最後 一天,因此只有包括來自於京都大學、交通大學、法國 Orange Lab.、Osaka Institute of Technology 六位 學者參加。
二、與會心得
這幾年ACM MM都舉辦Grand Challenge,今年的Grand Challenge也非常精采,印象最深刻的包括 Analyzing Social Media via Event Facets, Automatic Cinemagraphs for Ranking Beautiful Scenes, "Where is the Interestingness?" Retrieving Appealing Video Scenes by Learning Flickr-based Graded Judgments, Scaring or Pleasing: Exploit Emotional Impact of An Image, Classification of Photos based on Good Feelings, Understanding the Emotional Impact of Images, The Acousticvisual Emotion Guassians Model for Automatic Generation of Music Video。其中Automatic Cinemagraphs for Ranking Beautiful Scenes是師大葉梅珍教授
王新民教授研究團隊的研究。在研究深度上,果然王新民教授的研究團隊獲得Grand Challenge的最大 獎。在成果的呈現上最令我印象深刻的是中國清華大學。他們的學生在準備Presentation非常用心,除 了投影片非常精采之外,開場白所播放的情境影片更令人印象深刻。除了研究深度與研究創意之外, 我們也應多培養學生呈現研究成果的能力,才能躍上國際舞台。
ACM International Workshop on Multimedia for Cooking and Eating Activities的會議上也看到日本與 法國對於結合資訊技術與美食文化的「數位廚房」之創意。或許這兩個國家也是重視飲食文化的國家。 在會議過程的討論中,也看到不少技術上的創意。例如有位日本教授就建議可以透過語音處理,辨識 切菜節奏的快慢,以辨別切菜的人是專家還是生手,進而推薦適合的食譜。目前全球也都興起不少與 廚房烹飪有關的新創公司,台灣就有批年輕人創立了iCook食譜網站,獲得媒體與創投資金的注目。透 過數位技術可以激發不少相關的研究創意。食衣住行育樂中,食是我們生活中的首要。飲食在人類生 活與文化中扮演重要的角色,台灣美食聞名全球,結合資訊技術與飲食,這也是台灣值得投入的研究 領域。
三、發表論文全文或摘要(如附件)
四、建議:無
五、攜回資料名稱及內容:論文集
Xie et al. [16] proposed a hybrid semantic item model for recipe search by example. The hybrid semantic item model represents different kinds of features of recipe data. Forbes presents an approach for recipe recommendation to incorporate recipe content into matrix factorization method [1]. Experimental results showed the algorithm not only improves the recommendation accuracy but is also useful for swapping ingredients and creating recipe variations. While most research models recipes in terms of ingredients, Wang et al. [15] model cooking procedures of Chinese recipes as directed graphs and proposed a substructure similarity measurement based on the frequent graph mining. Another branch of research has focused on the recipe recommendation for healthy food. Mino et al. investigated the recommendation of cooking recipes for a diet in which the evaluation value of intake or consumption of calorie is considered in the events of a user's schedule during the period of a diet [5]. Linear programming approach is utilized with the constraints of carbohydrate, lipid, protein, salt, and increasing the amount of vegetable intake. Karikome and Fujii propose a system to help users for planning nutritionally balanced menus [3]. Considerations of recipes that correct the user’s nutritional imbalance are incorporated into the recipe retrieval process. Visualization of dietary habits are also provided by this system. Shidochi et al. proposed an approach to extract replaceable ingredients from recipes in to satisfy users' various demands, such as calorie constraints and food availability [9]. In order to develop a strategy for changing users eating and cooking behaviors, Pinxteren et al. proposed a user-centered similarity measure for recommendation of healthier alternatives which are perceived to be similar to users commonly selected meals [7]. The similarity measure can be used to promote new recipes that fit users’ lifestyle. By considering the user’s cooking competence, Wagner et al. presented a context-aware recipe retrieval and recommendation system to motivate users for healthy food preparation [14]. The system tracks the user’s cooking activities with sensors in kitchen utensils and recommends healthy recipes that may increase the user’s cooking competence.
While most work on cooking related research focus on recipe recommendation and retrieval, to the best of our knowledge, little work has been done on the menu planning by ingredients.
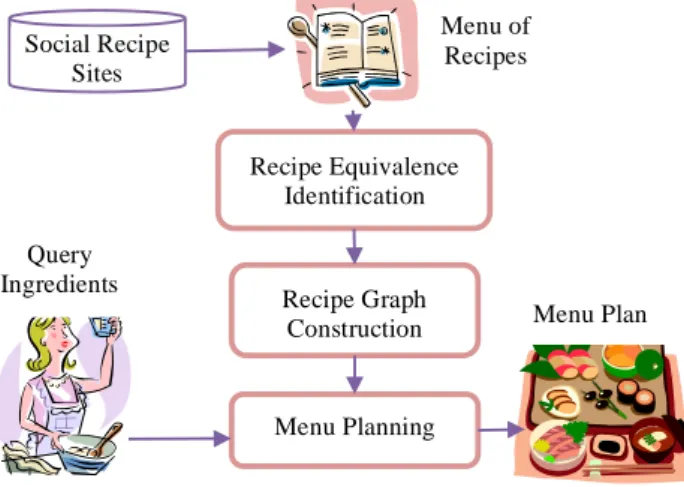
Figure 1. Proposed Framework for Intelligent Menu Planning. 3. PROPOSED FRAMEWORK
The framework of the proposed approach for intelligent menu planning is shown in Figure 1. First, menus of recipes generated by users are collected from social recipe sites such as food.com, allrecipe.com and myrecipes.com. Then, the equivalent recipes
are identified. Next, the recipe graph which captures the accompaniment information between recipes is constructed from collected menus of recipes as well as the recipe equivalence information. Finally, given query ingredients, the Menu Planning module with approximate Steiner Tree algorithm on the constructed recipe graph is utilized to generate the menu of recipes satisfying the query ingredients.
Figure 2 shows an example of the recipe graph. The graph consists of eleven nodes; each corresponds to a recipe. For ease of illustration, each node is labeled with recipe name and part of ingredients. There is an edge between two recipe nodes if two recipes appear in the same menu. Each edge is associated with its cost, which will be described in the later section. If two recipes tend to be more fit, the weight of their edge is lower.
4. RECIPE EQUIVALENCE IDENTIFICATION
In the crawled recipes from food.com (details are described in Section 7), since these recipes are manually contributed by users, some recipes, which actually represents for the same one, are considered to be different. To deal with such problem for accurate recipe recommendation, we develop the recipe equivalence
identification component in our framework. The goal aims at
identifying those very similar recipes and regarding them as the same recipe. From the collected data, each recipe is associated with a set of ingredient labels (after some preprocessing on the free texts of ingredient descriptions for each recipe). We consider that if two recipes possess more the same ingredients, they tend to be the equivalence with one another (i.e., have higher potential to be the same recipe). Given two recipes ! and ! , with the corresponding sets of ingredients !! and !! , we use Jaccard
similarity to measure their extent of equivalence. Specifically, the
Jaccard similarity is defined as ! !!, !! |!! ∩ !!| |!! ∪ !!|.
If ! !!, !! is higher than a pre-defined threshold ! , the recipes !
and ! are regarded to be equal one. We apply such similarity computation to all the recipes for aggregating equivalent recipes to the same one. The threshold ! is set to be 0.5 in this work. Note that in fact we can refer to Wang et al.’s sophisticated method [15], which considers the cooking procedure, to measure the similarity between two recipes. Since this is not our main purpose, here we devise the abovementioned simple but effective manner.
5. RECIPE GRAPH
In this section, we give the definition of the recipe graph and the formal definition of the menu planning problem.
[Definition 1] (Recipe Graph) Let A = {a1,..., am} be a universe of
m ingredients. A recipe graph is defined as an undirected
weighted graph G = (V, E). Each node i in V = {1,..., n} is a recipe that possesses a set of ingredients Ti ⊆ A. Each edge (i, j) in E is
the relationship between two recipes, i and j, and edge weight represents the distance between recipes.
[Definition 2] (Recipe Distance) Given a recipe graph G = (V, E)
and a collection of menus, the recipe distance between two recipes
i and j is defined as the reciprocal of the number of
co-occurrences of recipes i and j within the collection of menus. In other words, if two recipes tend to be co-occurring in menus, the weight of their edge is lower.
[Definition 3] (Menu Cost) Given a recipe graph G = (V, E) the
cost of a menu, i.e. a set of recipes, P, P ⊆ V, is defined as the sum of the weights of edges of the minimum spanning tree on the induced subgraph G[P], denoted by C(P).
Social Recipe Sites Recipe Equivalence Identification Recipe Graph Construction Menu Planning Menu of Recipes Menu Plan Query Ingredients
[Definition 4] (Menu Planning Problem) Given a recipe graph G
= (V, E) and a query consisting of a set of query ingredients Q,
and the designated number of required courses r, the menu planning problem is to return a menu plan, i.e., a set of recipes, P ⊆ V, |P| = r, such that (1) ! ⊆ ! ∈! !!, and (2) the menu cost
C(P) is minimized.
Take Figure 2 as an example, the recipe node “Italian Bread” has co-occurrence relationship with five recipes. Among the recipes, Tiramisu has the highest co-occurrence relationship since the cost is the lowest, while Stuffed Shells has the lowest relationship with Italian Bread. For the menu {“Mozzarella, Tomato and Basil Salad”, “Lasagna”, “Italian Bread”}, the menu cost is 0.23 and the minimum spanning tree is shown with blue color in the graph. In this example, given query ingredients {tomato, flour, basil} (shown in red color on the figure), the Menu Planning module will generate the set of recipes {“Mozzarella, Tomato and Basil Salad”, “Lasagna”, “Italian Bread”} (nodes with blue frame), rather than {“Mozzarella, Tomato and Basil Salad”, “Lasagna”, “Almond Cake”}.
6. MENU PLAN GENERATION
To solve the menu planning problem, one approach is to transform this problem into the minimum Steiner tree problem [8]. Given an
undirected graph with non-negative costs on edges, and some required nodes, the minimum Steiner tree problem is to find the minimum-cost spanning tree that connect the required nodes. We can transform the menu plan problem into the minimum Steiner tree problem by adding a new node wj for each ingredients aj. Each
new vertex wj is connected to a node i V if and only if aj Ti. In
other words, a new ingredient node corresponding to ingredient aj
is connected to each recipe node that possesses ingredient aj. The
distance between an ingredient node and a recipe node is a large number, larger than the sum of all the pairwise distances of the nodes.
However, since the Steiner tree problem is NP-hard, it will take much time to generate the menu when the recipe graph is large. To tackle the large recipe graph, this paper presents an efficient algorithm modified from our previous work on people search in attributed social networks [4]. Our proposed method is an approximation algorithm consisting of three major steps. First, according to the query ingredients, an abstract structure, called
group graph is extracted from the recipe graph. The group graph
will be helpful in reducing the search space to generate the set of
Figure 2 An Example of Recipe Graph for Menu Planning.
Figure 3 The New Graph with Recipe Nodes with respect to Figure 2.
recipes. Then, a compact recipe graph, called query relevance
graph is constructed from the original recipe graph based on the
group graph. Finally, we propose a Connector-Steiner algorithm to compose the menu from the recipe relevance graph.
6.1 Group Graph Construction
The first step is to group the nodes in the recipe graph according to query ingredients. A group, with respect to a query ingredient, for example, ai, is a connected subgraph, in which each node
Italian'Bread Flour Butter Olive,Oil Mushroom'Risotto Mushroom Rice Olive,Oil Onion Mozzarella,'Tomato' and'Basil'Salad Tomato Mozzarella,Cheese Basil Olive,Oil Almond'Cake Flour Butter Almond Sugar Egg Tiramisu Espresso,Coffee Egg Sugar Mascarpone,Cheese Ladyfingers Lasagna Beef Tomato Parmesan,Cheese Mozzarella,Cheese Lasagna,Noodle Caesar'Salad Romaine,Lettuce Parmesan,Cheese Olive,Oil Bread'Pudding Bread Egg Brown,Sugar Milk 0.13 0.1 0.11 0.13 0.5 0.11 0.14 0.11 0.25 0.33 0.5 0.33 0.2 0.5 0.1 0.25 0.33 Stuffed'Shells Egg Parmesan,Cheese Shell,Pasta Spaghetti,sauce Vegetable'Soup Onion Tomato Carrot Zucchini Chicken,Broth Spinach'Salad Spinach Mushroom Tomato Parmesan,Cheese Vegetable,Oil Italian'Bread Mushroom'Risotto Mozzarella,'Tomato' and'Basil'Salad Almond'Cake Tiramisu Lasagna Caesar'Salad Bread'Pudding 0.13 0.17 0.1 0.13 0.5 0.11 0.14 0.11 0.25 0.33 0.5 0.33 0.2 0.5 0.1 0.25 0.33 Stuffed'Shells Vegetable'Soup Spinach'Salad
國科會補助計畫衍生研發成果推廣資料表
日期:2013/05/27國科會補助計畫
計畫名稱: 標籤社群網絡之影響力最佳化 計畫主持人: 沈錳坤 計畫編號: 100-2221-E-004-012- 學門領域: 資料庫系統及資料探勘無研發成果推廣資料
100 年度專題研究計畫研究成果彙整表
計畫主持人:沈錳坤 計畫編號: 100-2221-E-004-012-計畫名稱:標籤社群網絡之影響力最佳化 量化 成果項目 實際已達成 數(被接受 或已發表) 預期總達成 數(含實際已 達成數) 本計畫實 際貢獻百 分比 單位 備 註 ( 質 化 說 明:如 數 個 計 畫 共 同 成 果、成 果 列 為 該 期 刊 之 封 面 故 事 ... 等) 期刊論文 0 0 100% 研究報告/技術報告 0 0 100% 研討會論文 0 0 100% 篇 論文著作 專書 0 0 100% 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 1 1 100% 博士生 0 0 100% 博士後研究員 0 0 100% 國內 參與計畫人力 (本國籍) 專任助理 0 0 100% 人次 期刊論文 0 1 100% 研究報告/技術報告 0 0 100% 國外 論文著作 研討會論文 2 2 100% 篇 1. Labeled Influence Maximization in Social Networks for Target Marketing, IEEE International Conference on Social Computing SocialCom, Boston, MA. 2. Intelligent Menu Planning:Activities in conjunction with the ACM International Conference on Multimedia 2012, Nara, Japan. 專書 0 0 100% 章/本 申請中件數 0 0 100% 專利 已獲得件數 0 0 100% 件 件數 0 0 100% 件 技術移轉 權利金 0 0 100% 千元 碩士生 0 0 100% 博士生 0 0 100% 博士後研究員 0 0 100% 參與計畫人力 (外國籍) 專任助理 0 0 100% 人次 其他成果