國立高雄大學統計研究所
碩士論文
Single Photon Emission Computed Tomography
Images Classification System of Parkinson’s Disease
帕金森氏症單光子電腦斷層掃描影像分類系統
研究生:同悅誠 撰
指導教授:黃士峰 教授
I
致謝
時光飛逝,碩士的兩年生活也即將在這裡畫下句點了,過去兩年的點點滴滴 都令人難以忘懷。這篇論文最後能夠如期完成,要感謝周遭陪伴著我成長的所有 師長們、同學們與學弟妹們。 首要感謝的是我的指導教授—黃士峰老師,謝謝老師您總是不辭辛勞的教導 與不厭其煩的提點我們,老師總是提醒我們要有自己的想法,不是僅僅將老師吩 咐的事情完成而已,如此一來只會像是老師的秘書,在經歷這麼多次共同討論的 情況下,很多資料的分析方向與呈現方式,大致上能夠先猜想到老師會想看到什 麼樣的結果而先去做,這是我得到最大最珍貴的收穫。而老師不僅僅是我碩士論 文的推手,也是我從大學以來的排球教練,在大學時期不知道要打什麼球類,就 被室友拉近了系上的排球隊,從而認識了老師。老師每每在聚餐上都會講述他精 采的人生經歷並教導我們很多待人處事的道理,相信這對我們在未來社會上將有 很大的幫助,非常謝謝您這六年來的照顧與培養。 其次,感謝口試委員張志鴻老師與劉青松老師能在百忙之中抽空來替我們的 碩士論文給予建議與指導,使我的論文的在各種層面能夠再近一步的完善。也要 感謝所上所有的老師們,您們總是在課堂上盡心盡力的傳授於我們專業知識,讓 我們得以從統計入門,期望我們未來能夠順利一點,不過還有更多需要我們去學 習與挑戰的地方。感謝蘭屏姐的幫助與關心,您總是要提醒我們很多待辦事項, 而每次到所辦與您聊天總是能讓人感受到心靈的慰藉。感謝一直以來幫助我的弘 屏學長,謝謝你在我有問題時都能夠提供想法來幫我解決。 感謝碩班的同學們,婷穎、建中、書豪、筱雅、益誠、星達、宇瀚、炳男、 孟瑾和暐詒,大家一起順利度過這多采多姿的兩年研究所生活,感謝政葦和奕婷, 大家在口試前一起奮鬥的日子相當的難忘,相信大家在不遠的將來都能夠拿到一 份很好的工作。感謝學弟温永暄與學妹吳蕙均,在一起做研究的過程中,在一些 繁雜的部分給予我很大的協助。感謝總是陪伴我打球的應用數學系的學弟妹,總 是讓我在課業與研究上有煩惱時,還能有運動能夠宣洩壓力,期待你們在未來的 日子裡能有出色的表現。 最後感謝我的父母與家人,沒有你們的包容、支持與鼓勵,我是沒有辦法在 這條路上堅持走下去的,在這期間沒有打工,是你們讓我沒有後顧之憂的向上求 學,碩士要畢業了,要邁向人生另外一段嶄新的開始。希望在未來的路途上,也 能遇見這麼多的良師益友,即使遇到任何的困難,也能保有一顆堅定的心智來去 面對並且解決所有的問題。 同悅誠 撰 中華民國一零八年七月II
Single Photon Emission Computed Tomography
Images Classification System of Parkinson’s Disease
by
Tung, Yue Cheng
Advisor
Huang, Shih Feng
Institute of Statistics
National University of Kaohsiung
Kaohsiung, Taiwan 811 R.O.C.
III
帕金森氏症單光子電腦斷層掃描影像分類系統
指導教授:黃士峰博士
國立高雄大學應用數學系
學生:同悅誠
國立高雄大學統計學研究所
摘要
本研究建立一套透過單光子電腦斷層掃描(single-photon emission computed tomography,簡記為 SPECT)影像判斷受檢者是否罹患帕金森氏症的系統,以協 助提升診斷效率與節省醫療資源。該系統首先透過提取帕金森氏症影像特徵,並 使用支持向量機將醫生可以初判的影像資料歸類為正常或是異常;對於醫生無法 初判的影像資料,則提出一主動式學習的方法,建議優先進行進一步臨床檢測以 判別是否異常的影像資料順序,再將檢測結果用於更新分類器。實證研究方面, 共收集634 張受檢者的 SPECT 影像資料,包含醫生無法進行初判的 204 張影像, 經過所提出方法依序建議其中 10 張影像進行進一步檢測以辨識其類別後,數值 結果呈現更新後的分類器可提升分類準確度。 關鍵詞: 主動式學習、醫療影像、帕金森氏症、支持向量機。
IV
Single Photon Emission Computed Tomography Images
Classification System of Parkinson’s Disease
Advisor:Professor Shih-Feng Huang
Department of Applied Mathematics, National University of Kaohsiung
Student: Yue-Cheng Tung
Institute of Statistics, National University of Kaohsiung
Abstract
This study established a system for judging whether a subject is suffering from Parkinson's disease through single-photon emission computed tomography (SPECT) images to help improve diagnostic efficiency and save medical resources. The system first extracts the image characteristics of Parkinson's disease and uses the support vector machine to classify the image data that the doctor can initially judge as normal or abnormal. For the image data that the doctor cannot initially judge, a method of active learning is proposed. It is recommended to conduct further clinical tests to determine whether the abnormal image data sequence is used and then use the test results to update the classifier. In the empirical study, a total of 634 images of SPECT images were collected, including 204 images that the doctor cannot initially judge. After the proposed method was used to further detect 10 of them to identify their categories, the numerical results present the updated classifier improves classification accuracy.
keywords: Active learning, Medical imaging, Parkinson’s disease, Support vector machine
V 目錄 摘要 ... III ABSTRACT ... IV 一、 簡介 ... 1 二、 文獻回顧 ... 4 三、 分析流程 ... 7 1. 資料敘述 ... 7 2. SPECT 的獲取和重建 ... 7 3. 特徵提取 ... 7 4. 特徵正規化 ... 9 四、 數值結果 ... 11 1. 數值結果 I ... 11 2. 數值結果 II ... 12 五、 討論與未來發展 ... 14 參考文獻 ... 15 附錄 ... 17
VI 圖目錄 圖 1:紋狀體之三部分 ... 17 圖 2A:SVM 與 HINTSVM 之超平面比較圖 ... 17 圖 2B:經 ALHS 迭代之結果圖 ... 17 圖 3:本系統分析流程圖 ... 18 圖 4:編號 1 受檢者之最清晰影像與前後 4 張 ... 18 圖 5:第一維特徵數值與年齡之散布圖 ... 19 圖 6:第一維特徵之殘差盒鬚圖 ... 19 圖 7:ROC 曲線 ... 20 圖 8:第一維特徵之殘差盒鬚圖 ... 20 圖 9:第一維特徵之正規化區間 ... 21 圖 10:標號 1 受檢者在特徵正規化前後之特徵數值... 21 圖 11:變數之重要性排序比較圖。 ... 22 圖 12:本系統和醫生 ABC 與四分法結果對照圖 ... 23 圖 13:排除機率𝝓𝒊(𝒙̃ )大於 0.4 之訓練集分類準確率 ... 24 𝒋 圖 14:排除機率𝝓𝒊(𝒙̃ )大於 0.4 之測試集分類準確率 ... 24 𝒋 圖 15:排除歐式距離小於 0.5 之訓練集分類準確率... 25 圖 16:排除歐式距離小於 0.5 之測試集分類準確率... 25 圖 17:排除歐式距離小於 0.4 之訓練集分類準確率... 26 圖 18:排除歐式距離小於 0.4 之測試集分類準確率... 26 圖 19A:第 1~9 維特徵在四分法下的分布盒鬚圖 ... 27 圖 19B:第 10~18 維特徵在四分法下的分布盒鬚圖... 27 圖 19C:第 19~27 維特徵在四分法下的分布盒鬚圖... 27
VII 表目錄 表 1 各分法之結果對應與資料筆數 ... 28 表 2 各特徵變數在四分法下,其平均數±標準差 ... 28 表 3 本系統在訓練集之分類準確率 ... 29 表 4 本系統在測試集之分類準確率 ... 29 表 5 訓練集:真實為異常→系統判別為正常編號 ... 29 表 6 測試集:真實為異常→系統判別為正常編號 ... 29 表 7 測試集:真實為正常→系統判別為異常編號 ... 29 表 8 在訓練集中,醫生 AB 之間之相似矩陣 ... 30 表 9 在訓練集中,醫生 AC 之間之相似矩陣 ... 30 表 10 在訓練集中,醫生 BC 之間之相似矩陣 ... 30 表 11 在訓練集中,本系統與醫生 A 之相似矩陣 ... 31 表 12 在訓練集中,本系統與醫生 B 之相似矩陣 ... 31 表 13 在訓練集中,本系統與醫生 C 之相似矩陣 ... 31 表 14 在測試集中,醫生 AB 之間之相似矩陣 ... 32 表 15 在測試集中,醫生 AC 之間之相似矩陣 ... 32 表 16 在測試集中,醫生 BC 之間之相似矩陣 ... 32 表 17 在測試集中,本系統與醫生 A 之相似矩陣 ... 33 表 18 在測試集中,本系統與醫生 B 之相似矩陣 ... 33 表 19 在測試集中,本系統與醫生 C 之相似矩陣 ... 33 表 20 在訓練集中,呈現出各分類器之五種量。 ... 34 表 21 在測試集中,呈現出各分類器之五種量。 ... 34 表 22 在兩種不同排除方式與三種不同的挑點方式下,最高之挑點方法加總。 35
1
一、 簡介
相較於人類對其他身體部位的研究相比,腦部研究的起步較晚,相關的分析 結果也較缺乏。然而,近年來由於各式各樣腦部儀器的創新與發展,例如:深層 腦部刺激系統、超音波腦神經治療儀器、腦組織氧分壓器…等,產生許多腦部活 動的觀測數據,藉由有效地運用這些數據,除了刺激醫學界發展出許多創新的腦 部疾病治療方式以外,也對於在腦部方面的研究有極大的幫助與影響。此外,也 因為最近幾年大數據分析方法的蓬勃發展,讓我們有機會掌握適當的工具分析腦 部影像資料。 在分析腦部影像資料,近年來常使用的方法為深度學習與支持向量 機 (support vector machine,簡記為 SVM)的應用,在帕金森氏症(parkinson’s disease簡記為 PD)影像中,藥劑將會顯色於腦部中之紋狀體,紋狀體又可依照前中後 區分割為三部分,前殼核、後殼核與尾狀核如圖1,不論是深度學習或是找特徵 時,都將著重於尋找紋狀體之各種變量來做分析。在深度學習方面,Choi et al. (2017)使用了 431 張罹病影像、193 張正常影像,將 379 張正常與 170 罹病影 像作為訓練集,並使用了 10 次交叉驗證來訓練分類器,52 張正常與 23 張罹病 影像作為測試集,此分組是為了讓兩集合內的正常與罹病之比例相同,訓練集分 類準確率可到96%,最佳測試集分類準確率為 92%。Kim et al.(2018)使用了 54 張正常與 54 張罹病影像作為訓練集,以另一組完全獨立的 45 張影像作為測 試集,訓練集與測試集結果為95%與 84%。在 SVM 之應用下,Illán,a et al. (2012) 提出了一種計算機輔助診斷(CAD)系統的方法對於帕金森綜合徵(parkinsonian syndromes,簡記為 PS)檢測的決策輔助,基於模板的自動化的對影像進行預處 理,然後使用兩種強度歸一化之方法,並比較SVM 與其他統計分類器(KNN 與
Nearest mean),敏感度(sensitivity)為 89%,特異度(specificity)為 93%,這 裡提到的敏感度與特異度為醫學上常看之比例,敏感度為所有罹病之資料中,被 正確地判斷成罹病之比率,特異度為所有正常之資料中,被正確地判斷成正常之 比率。Palumbo et al.(2014)採用 Basal Ganglia V2 軟件(BasGan)半定量分析
得到90 張受檢者之變數結合 SVM 模型,其中 42 張為正常之影像,56 張為異常
之影像,藉由leave-one-out 方法將所得之變數做挑選,最終得到整筆資料之分類
準確率為96%。Prashanth et al.(2014)利用123𝐼-Ioflupane SPECT 儀器所得出參
數使用 SVM,將 181 張為正常之影像,493 張為異常之影像做分類,並採用高
斯徑向基函式(radial basis function,簡記為 RBF)得到一分類準確率為 96%模
型。Taylor and Fenner(2017)得知臨床上已廣泛運用123𝐼-Ioflupane SPECT 儀器
等半定量方法,而研究表明機器學習算法(machine learning,簡記為 ML)可提
高其準確率,所以該文獻使用 PD 進展標記計畫(PPMI)以及該地衍生之臨床
2 (semi-quantification,簡記為 SQ)進行比較,皆進行分層抽樣以及 10 次的交叉 驗證,重複10 次。PPMI 資料為 113 張為正常之影像,191 張為異常之影像,衍 生之臨床資料為209 張為正常之影像,448 張為異常之影像,數值結果顯示在 SQ 方法下,PPMI 與衍生資料之準確率為 89%到 95%與 78%到 87%,而在最佳 ML 方法下,兩者之準確率為95%到 97%與 88%到 92%,最佳 ML 方法下皆能得到
比SQ 較高的準確率與精準度。Oliveira et al.(2018)藉由 Bin vivo 儀器從 SPECT
影像中提取七個特徵:與攝取比率相關的五個標準特徵與正常紋狀體區域的體積
和長度。資料為PPMI 中 209 張正常之影像,443 張為異常之影像,並利用三種
ML 方式:SVM、KNN 和羅吉斯迴歸,在使用所有特徵的情況下其分類準確率
為97.9%、97.2%與 96.9%,雖然 SVM 之結果最佳但無法說明與其他分類器有統
計上之顯著差異。Nicastro et al.(2019)提供一退化性 PS 以 SVM 做分析,其中 PS 包含 PD、多系統萎縮-帕金森病型(multiple system atrophy-parkinsonian type,
簡記為MSA-P)、伴進行性核上性麻痹(progressive supranuclear palsy,簡記為
PSP)與伴皮質基底綜合症(corticobasal syndrome,簡記為 CBS)。資料為 280 名PD、21 名 MSA-P、41 名 PSP、28 名 CBS 與 208 名正常對照組(controls, 簡記為 CTL)。特徵的選取為紋狀體之體積、不對稱性與尾狀核與殼核之比例, 並使用5 次交叉驗證。在各種類型比較的準確率如下,PS 與 CTL 為 92.9%,PS 之間的交互為61.1%至 83.7%,PS 中,該症狀與非該症狀為 58.4%至 76.7%,可 看出PS 內各症狀之間要分開是較困難的,而在將 PS 與 CTL 分開則是有很好的 結果。 藉由上述文獻提及的各種方法,歸納出基於SVM 與 RBF 核函數轉換能得到 不錯之結果,在此不討論與深度學習相關的做法,本研究藉由高雄長庚醫院所提 供的634 位受檢者的 SPECT 影像與其他相關資料,包括性別、年齡、四分法結 果、三分法結果、二分法結果,此類的影像資料大部分醫生都可以直接在影像的 階段下判斷此受檢者們是否有異常,而有約3 成 2 的影像,醫生無法經由影像直 接判斷該受檢者是否正常與異常,雖然在大多數影像是醫生可以輕易地辨別,但 當數量太過於龐大時,醫生所擁有的珍貴時間不適合在這些小問題上多著墨,由 於對影像資料的處理在統計上是較少碰觸到的一塊,所以我們可以利用將影像資 料視為一矩陣來對其做一些特徵的提取,在經過一些統計的手段將其轉變成我們 熟悉的數列後,就能依照我們較熟稔的手法下去做分析,這裡我們運用了 SVM 與嘗試其各種核函數轉換,最終還是以 RBF 做為最終的訓練出的模型之轉換。 本研究的主要目的之一為建立一套系統性方法以提高腦部 SPECT 影像對受檢者 是否罹患PD 的判斷能力,期能協助醫生加速診斷效率與節省因無法藉由直接對 SPECT 影像判斷而衍生後續檢測所需耗費的醫療資源。 第二目的為試著提出解決那些 SPECT 影像醫生無法經由直接判斷該受檢者 是否正常與異常。此目的想法為我們現處於一個大數據的時代下,我們會蒐集到 巨量尚未經過處理之資料數據,其中就包含了有標記與無標記之資料,有標記的 資料直接拿來做分類,再將無標記之資料當作預測,這是非常自然的想法,但是
3 此類做法通常很難有好效果,因為有標記的資料量通常遠小於無標記之資料量, 而且將資料標記是一件需要消耗相當的人力、時間與金錢成本的問題,尤其是在 醫療上,受檢者在被判斷需要近一步的檢查是否罹病時,常常需要排隊等待儀器 檢查,並且再等候一段時間才能再到醫院聽結果報告,過程相當的瑣碎與耗費心 力。等候期間要等許多的精密儀器掃描得出受檢者之各種詳細數據,再經由醫生 的專業知識分析與過往經驗才能判斷此受檢者罹病與否。每位受檢者若都需要如 此進行近一步地確認,此過程將會耗費太大量的成本,在此試以主動式學習之方 式來解決問題,我們先將有標記之資料做為基礎訓練集訓練分類器,再藉由主動 式學習的方式將較難標記之點標記完後,將其加入我們的訓練集,在理想的情況 下,我們將較難標記之點讓分類器學習到,會對於未來無標記的資料會有幫助, 但是在定義何者為難標記之點是一個最大的問題。本研究嘗試以改良 Li et al. (2012)提出之一結合 SVM 與 SVR 的優化問題,提示支持向量機(hinted support vector machine,簡記為 HintSVM)與結合 HinstSVM 和 SVM 之主動式學習(Active Learning with HintSVM,簡記為 ALHS)對影像做進一步檢查之優先順序,使得 後續需要進一步檢測之數量減少。上述提及大部分的影像為醫生可以直接判斷, 而有約3 成 2 的影像是醫生很難直接下判斷該受檢者們是否罹病,我們將這兩種 情況分開,並嘗試利用所提出之改良之 ALHS 的方式,先以可以直接判斷之資 料當成訓練集訓練分類器,每次再將無法直接判斷的資料加入1 筆資料進入訓練 集,並在每次的迭代中重新訓練分類器,比較不同方法之間對於無法直接判斷的 影像資料之準確率是否會有提升的成效,探討在這些方法下,哪一些準則在不同 的情況下會有較好的結果。 本論文的章節安排如下:第二章回顧所用到的方法之文獻:支持向量機、支 持向量迴歸、提示支持向量機與主動式學習;第三章論述我們提出的分析流程, 包含 SPECT 的獲取和重建、特徵提取與特徵正規化;第四章呈現兩種分組方式 的數值結果,並比較第二種分組方式下,我們提出之改良方法與原方法之間的差 異;第五章討論與未來發展;圖形與表格則置於附錄中。
4
二、 文獻回顧
支持向量機
在機器學習中,Boser et al.(1992)提出之 SVM 是分類與迴歸分析中分析資 料的監督式學習模型的演算法。假設給定一組訓練資料,每組訓練資料皆為兩種 類別,在線性分類中,SVM 訓練演算法為建立一個將新資料標記成兩種類別之 一的模型。SVM 模型是將資料表示為空間中的點,找出一超平面使得資料的類 別被盡可能給分開。將新的資料對應到同一空間,基於它們落在超平面的哪一側 來標記其所屬類別。這裡應用了軟間隔與核技巧進行非線性分類,將其輸入RBF 核函數到高維特徵空間中。 我們考慮以下形式的n點測試集: (x⃗⃗⃗ , 𝑦i 1), … , (x⃗⃗⃗⃗ , 𝑦n 𝑛) 其中 yi ∈ (−1, 1),表明 x⃗⃗⃗ 點所屬的類別,每個都是一個p維向量。我們將i yi = 1的點集與yi = −1的點集分開的超平面,並最大化超平面與最近的點 𝑥i 之 間的距離。 𝑤𝑇𝑥𝑖 + 𝑏 ≥ 1 − 𝜉𝑖 , ∀ 𝜉𝑖 ≥ 0 (1) 𝑤𝑇𝑥𝑖+ 𝑏 ≤ −1 + 𝜉𝑖 , ∀ 𝜉𝑖 ≥ 0 (2) min 𝑤,𝑏,𝜉 1 2𝑤 𝑇𝑤 + 𝐶 ∑ 𝜉 𝑖 𝑛 𝑖=1 (3) 限制式: yi(wTx i+ b) ≥ 1 − ξI , ∀𝜉𝑖 ≥ 0 , 𝑦𝑖 ∈ {−1,1} (4) 其中 𝜉𝑖 為標記錯誤的類別到軟間隔之距離。支持向量迴歸
不同於SVM 是找出將資料分開之一超平面,Drucker et al.(1997)提出支援向量迴歸(Support Vector Regression,簡記為 SVR)是找出一超平面接近所有的
資料。假設給定一組訓練資料,我們會有每筆資料的迴歸數值,類似於SVM 的
標記,SVR 模型也是將資料表示為空間中的點,目標是找出距離每筆資料皆為 0 的一超平面,並給予一ε ≥ 0代表預測值與實際值的最大距離。將新的資料對應 到同一空間,基於它們對應到超平面計算出的數值即為預測新資料的數值。
5 (x⃗⃗⃗ , 𝑦i 1), … , (x⃗⃗⃗⃗ , 𝑦n 𝑛) 其中 yi為 x⃗⃗⃗ 點所屬的迴歸數值,每個都是一個p維向量。 i 𝑦𝑖 − 𝑤𝑇𝑥 𝑖 − 𝑏 ≤ ε + 𝜉𝑖 , ∀𝜉𝑖 ≥ 0 (5) 𝑤𝑇𝑥𝑖 + 𝑏 − 𝑦𝑖 ≤ ε + 𝜉𝑖∗ , ∀𝜉𝑖∗ ≥ 0 (6) min 𝑤,𝑏,𝜉, 𝜉𝑖∗ 1 2𝑤 𝑇𝑤 + 𝐶 ∑(𝜉 𝑖+ 𝜉𝑖∗) 𝑛 𝑖=1 (7) 限制式:ε + 𝜉𝑖 ≥ 𝑦𝑖 − 𝑤𝑇𝑥 𝑖 − 𝑏 ≥ ε + 𝜉𝑖∗ , ∀𝜉𝑖, 𝜉𝑖∗ ≥ 0 (8) 其中 𝜉𝑖與𝜉𝑖∗ 為落在距離超平面±ε以外的點,到界線之垂直距離。
提示支持向量機(HintSVM)
Li et al.(2012)提出一結合 SVM 與 SVR 的優化問題,用以處理包含有標 記與無標記之資料,D𝑙為資料中已標記的點,其他所有未標記的點為D𝑢,且定 義Dh為部分未標記的點為提示池,Dℎ ⊆ D𝑢。HintSVM 的目標是找到一個在兩個 目的上做得很好的超平面:(1)分類標記D𝑙中的資料,以及(2)接近Dℎ中的未 標記點。這第一個目標與一般的監督式SVM 一樣,它將未標記的點推離超平面。 為了處理第二個目標,我們考慮支持向量迴歸(SVR)和集合在Dℎ中為所有點接 近0 的斜直線,這意味著Dℎ中的點應該靠近此超平面。通過結合SVM 和 SVR 的目標函數HintSVM 一起解決了以下優化問題,即同步問題實現這兩個目標。 min 𝑤,𝑏,𝜉,𝜉̃,𝜉̃∗ 1 2𝑤 𝑇𝑤 + 𝐶 𝑙∑ 𝜉𝑖 + |𝐷𝑙| 𝑖=1 𝐶ℎ∑(𝜉̃𝑗+ 𝜉̃𝑗∗) |𝐷ℎ| 𝑗=1 (9) 限制式:𝑦𝑖(𝑤𝑇𝑥 𝑖+ 𝑏) ≥ 1 − 𝜉𝑖 for (𝑥𝑖 , 𝑦𝑖) ∈ 𝐷𝑙 (10) 𝑤𝑇𝑥𝑗+ 𝑏 ≤ 𝜀 + 𝜉̃𝑗 for 𝑥𝑗 ∈ 𝐷ℎ (11) −(𝑤𝑇𝑥 𝑗+ 𝑏) ≤ 𝜀 + 𝜉̃𝑗∗ for 𝑥𝑗 ∈ 𝐷ℎ (12) 𝐶𝑙 = max (|𝒟ℎ| |𝒟𝑙| , 1) × 𝐶 (13) 𝐶ℎ = 𝐶 (14)6
主動式學習(ALHS)
Li et al.(2012)提出一結合了 HintSVM 與 SVM 之主動式學習方法 ALHS,
起初Dℎ從D𝑢選取,利用HintSVM 找出將D𝑙分開且靠近Dℎ之超平面,最靠近此超
平面之資料,將其做完標記後從D𝑢加入D𝑙,並將D𝑢內距離此點很近的資料排除
在D𝑢之外,最後依照這些D𝑙的點集訓練一SVM 模型來做預測,依序迭代,以下
列出其演算法。
Algorithm The ALHS algorithm
input: the number of rounds 𝑹; a labeled pool 𝑫𝒍; an unlabeled pool 𝑫𝒉 ; parameters of HintSVM and SVM
for r ← 1 to 𝑹 do Select 𝑫𝒉 from 𝑫𝒖 𝒉 ← Train HintSVM(𝑪𝒍, 𝑪𝒉, 𝝐, 𝑫𝒉∪ 𝑫𝒍) (𝑿̃, 𝒚𝒔 𝒔) ← Query(𝒉, 𝑫𝒖) 𝑫𝒖 ← 𝑫𝒖\𝑿̃ ; 𝑫𝒔 𝒍 ← 𝑫𝒍∪(𝑿̃, 𝒚𝒔 𝒔) 𝑫𝒖 ← 𝑫𝒖\Around(𝑿̃) 𝒔 𝒇(𝒓) ← Train SVM(𝑪, 𝑫𝒍) end 在圖2A 中,紫色虛線為 HintSVM 挑出之超平面,黑線則為 SVM 挑出之超 平面,左邊的紅色叉叉完全無法被 SVM 之超平面辨識出來,而 HintSVM 可以 在此情況下將超平面往多數未標記之點靠近,進而對其中最靠近之點進行標記。 圖 2B 的黑線為利用 HintSVM 得到的點並迭代得出之新的超平面,左邊的紅色 叉叉已經可以辨識出來,經由ALHS 迭代後能得到一完美的結果。 本研究對於上述演算法時提到之兩部分做更動:每次挑選靠近此超平面之資 料與距離此點很近的排除方式。挑選出靠近此超平面之資料,很自然地想是因為 此點是最難辨別的,如果能夠將其標記出來後,猜想在訓練上會有好的結果。但 如果此時的分類器尚未成熟,那這些點可能只是此時的分類器最難辨別的點,並 不一定是真正難辨別的點。在此時的分類器對於所有的資料都算與超平面之距離, 我們每次取最靠近這些距離的中間數與平均數來作為標記的點。距離此點很近的 方式我們簡單的計算要排除的資料與其他Dℎ資料的歐式距離,而不採用本來提 出之排除機率𝜙𝑖方式符合三種限制(1)𝜙𝑖(𝑥𝑖) = 1,重複的資料排除(2)最靠 近的𝜙𝑖的有標記資料𝑥𝑖為𝑃(3)最遠離的𝜙𝑖的有標記資料𝑥𝑖為𝑝,𝑝 ≤ 𝑃,其排除 之函數如下: 𝜙𝑖(x̃) = Pj (𝑟𝑗𝛼𝑖) (15) 其中𝑟𝑗 = ‖𝑥̃ − 𝑥𝑗 𝑖‖/𝑑𝑖,為𝑥̃ 藉由𝑥𝑗 𝑖算出之正規化距離,𝑑𝑖為最靠近𝑥𝑖之距離。 𝛼𝑖 = log (log 𝑝 log 𝑃) log 𝑅⁄ 𝑖,𝑅𝑖為最遠離𝑥𝑖之距離。
7
三、 分析流程
圖 3 為本研究之分析流程圖,先將每一名受檢者之 SPECT 影像藉由醫生的 幫助疊合出一完整影像後,將矩陣數值進行標準化到[0, 1]區間,再針對每一完 整影像做特徵提取,最後將這些特徵做完正規化後,即可開始針對本研究的分析 方向訓練 SVM 模型。1.
資料敘述
本研究蒐集634 位受檢者的 SPECT 影像與其他相關資料,包括性別、年齡、 四分法結果、三分法結果、二分法結果。其中四分法結果:0, 1, 2, 3 分別為確定 正常(共174 筆)、可能正常(共127 筆)、可能異常(共77 筆)與確定異常(共 256 筆),三分法結果:0,1,2 分別為正常(共 174 筆)、輕微異常(共 204 筆)與 異常(共256 筆),二分法結果:0, 1 分別為正常(共 301 筆)與異常(共 333 筆)。四分法結果是由三位醫生的投票結果決定,若三位醫生有兩位以上判別為 相同類別,該受檢者將被標記成為該類別,若是三位醫生的判別為0, 1, 2 該受檢 者將被標記成為1;若是三位醫生的判別為 1, 2, 3 該受檢者將被標記成為 2,而 三分法結果與二分法結果為四分法結果再細分的結果:四分法的0 對應為三分法 的0、1;2 對應為三分法的 1、3 對應為三分法的 2,四分法的 0, 1 對應為二分 法的0;2, 3 對應為二分法的 1,各分法之對應列於表 1。2.
SPECT 的獲取和重建
SPECT 影像的各項參數如下:矩陣大小為128 × 128像素、像素尺寸為 4.4mm、 切片厚度為4.4mm、能量窗口為159keV ± 10%。 本研究藉由醫生所選取紋狀體較完整之連續 9 張影像如圖 4,選取了中間三 張來做疊合。將每一張影像的數值皆先歸一化到[0, 1]區間,疊合的方式為對三 張矩陣數值做算術平均,再進行一次歸一化到[0, 1]區間,如此一來得到一張疊 合之完整影像來做後續的統計分析。3.
特徵提取
本研究尋找了影像內與紋狀體相關的變量作為本系統所需之特徵,部分特徵則是參考了Iwabuchi et al.(2019)與 Prashanth et al.(2016)中提及與紋狀體相
關之變數,前一篇主要以三大特徵做為變數,紋狀體之分布或形狀、左右側的不 對稱性和紋狀體與枕葉之間的數值比例,不過其特徵皆是由機器將 SPECT 影像 算出三種特徵值後才下去做分析。後一篇也分三部分,分別為形狀分析、曲面的 擬合與紋狀體與枕葉之間的數值比例,形狀分析的部分計算了紋狀體的區域大小、 用橢圓來表示紋狀體的形狀,以橢圓的長短軸與各項比例來做為特徵、偏心率、 等效直徑、方向與圓度,此形狀分析使用了兩種不同的加權和來做為不對稱性的
8 考量,一是將左右特徵值直接做算術平均,二是將特徵值左減右除以左右特徵值 平均在取絕對值。曲面的擬合是以一三次曲面函數擬合紋狀體之數值,而將其函 數中的各個係數作為特徵,概念上為在不同紋狀體下,擬似的三次曲面可能在曲 率上的不同就會在某些係數上有所差異,還算出擬似曲面與原始之平均誤差總和 與決定係數做為特徵。在紋狀體與枕葉之間的數值比例方面,分成了兩部分,殼 核與枕葉之間的數值比例與尾核與枕葉之間的數值比例。本研究借鑒了後一篇之 橢圓擬似、等效直徑與曲面的擬合,其餘特徵則是經過多方考量紋狀體的各種變 量與不斷地嘗試增加與篩減變數和醫生討論得出之結果。我們基於正常紋狀體的 大小、形狀,對紋狀體外框出一方框將其包含住,用來提取大多數我們需要的特 徵。我們將針對每一張疊合後的SPECT 影像,提取出 27 維特徵:顏色分布(共 八維)、紋狀體佔大腦之比例、長軸之比例、長軸平均長度、短軸之比例、短軸 平均長度、長短軸之比例、左右紋狀體之散度、紋狀體單邊之活躍程度、紋狀體 吸收程度、尾核單邊之活躍程度、尾核面積比、紋狀體之等效直徑與擬合曲面之 估計參數。 在顏色分布方面,找出較具代表紋狀體之顏色占比(C1, C2, …, C7, C8),數 值從0.65, 0.7, …, 0.95, 1,得到 8 維向量,在正常的情況下,這些顏色的數值會 有相似的分布,只有紋狀體的區域會出現較多偏高的數值且會有一定量,在異常 的情況下,紋狀體的區域會因萎縮而讓數值較少或是異常的多,當整顆腦袋在除 了紋狀體以外出現了有較大的數值,這就會導致顏色分布相異,多了一些非自然 的數值,可以做為區別正常異常的依據。 在紋狀體佔大腦之比例方面,則由方框內紋狀體區域與整顆頭腦的面積算比 例,由於每位病人的頭腦大小不同,紋狀體的大小也不同,以相對的比例做為變 數較為可信,當兩影像的紋狀體大小相近,但頭腦的大小不等,其得到之特徵變 數就會不同,此比例為單純看紋狀體之大小,較為一般正常的想法。 在長短軸之各項比例方面,藉由對紋狀體區域做橢圓形的擬似,這裡會得出 五項的特徵變數,分別是左右長軸比、左右長軸之平均、左右短軸比、左右短軸 之平均與長短軸比例,這邊使用了平均與比例是為了將不對稱性抓出,長短軸的 比例算法為左右先算出長短軸的比例後加權和。此橢圓形的擬似為先找出紋狀體 區域內的第一主成分與第二主成分的向量,以紋狀體中心為原點,第一主成分與 第二主成分的向量做為座標軸向外延伸,找出最相符紋狀體之橢圓。 在左右紋狀體之散度方面,算出紋狀體中心到紅色區域各點之距離平均,這 裡將左右之結果都做為特徵變數,散度可視為其聚集程度,在正常的影像中,紋 狀體會有一定的量,所以散度也會有一定量,而在一些異常的影像中,紅色區域 的部分將非常的散開,又或是萎縮到很小的區域,在數值特別小或大都會視為是 有異常的情況。 在紋狀體單邊之活躍程度方面,取左右紋狀體較小之深色面積做為特徵變數, 當其中一邊的深色面積已經消失,代表其紋狀體的功能可能正在衰退,無法吸收 藥劑,在顯色的時候會有所區別。
9 在紋狀體吸收程度方面,是醫生提出之醫學方面常拿來做判斷之主要依據, 取紋狀體之顏色數值與背景平均值做比例,該紋狀體如果吸收的情況大不如背景 的吸收程度,代表其紋狀體可能已經逐漸失去了活性,此對比的數值要高。 在尾核單邊之活躍程度與面積比方面,將尾狀核取左右較小之面積與左右面 積做比例,這裡是把活躍程度針對尾核的部分拿來做進一步的探討,如果數值很 小或是零,便代表了紋狀體開始萎縮,面積比也是為了其目的。 在紋狀體之等效直徑方面,將左右紋狀體的面積平均作為一圓的面積,在逆 推出其對應的直徑,此變數是對於紋狀體的面積做了一非線性的轉換。 在擬合曲面之估計參數方面,擬合了一三次的曲面,曲面函數如下: f(x, y) = P1+ P2𝑥 + P3𝑦 + P4𝑥2+ P 5𝑥𝑦 + P6𝑦2+ P7𝑥3+ P 8𝑥𝑦2+ P9𝑥2𝑦 + P10𝑦3 (16) 本研究使用兩種方式挑選了其中6 個係數,第一為任意篩掉 4 個係數找出的 最佳參數,P1, P2, … , P5, P6作為我們此模型之特徵變數,第二為使用ROC 曲線辨 別確定正常與確定異常之影像,將其曲面下面積皆不到0.5者篩掉,其中 6 個參 數P1, P2, P3, P5, P6, P10有達到此標準,作為我們此模型之特徵變數,其餘4 個參數 P4, P7, P8, P9,無法有效的區別正常與異常影像,在此我們不採用這些參數,在數 值結果I 會將此兩種方法之結果分別做說明。 以上計算出所有受檢者各個特徵變數後,將每個特徵都標準化到[0, 1]區間, 在四分法的分類下顯示其平均數±標準差如表 2。
4.
特徵正規化
醫生提及在年齡較長者的判別將會較寬鬆,因細胞在年齡增長到一定的情況 下都會呈現較低的活性,此類的 SPECT 影像背景數值稍微高是可以接受的,我 們亦考慮加入年齡此特徵,但不是將其當作是一特徵變數,而是將各個特徵變數 都將年齡對確定正常之特徵數值做迴歸線,因年齡在各個時間點時會導致不同的 數值,此步能夠將年齡在每個特徵變數上都能有一些表現,第一維特徵之迴歸線 與資料數值呈現於圖5。 在算出所有資料與迴歸線之垂直距離,將第一維特徵針對四分法結果之盒鬚 圖(如圖6)畫出,可看出前兩者確定正常與異常中,大部分的資料是能夠有效 地分開的,而後面可能正常與異常的兩個部分與前兩者都有很大的重疊處,是醫 生比較難以做判別的,且在此盒鬚圖中也是有相當難度的的。 對上述的盒鬚圖畫出ROC 曲線(如圖 7),我們將上界到下界均分 100 等分, 從上依序往下切割出101 條線,假設線以下將判為正常,線以上判為罹病,算出 每條線對應之sensitivity 與 specificity 作為 xy 軸的座標記在圖 7,我們取兩者之和最大者作為最佳之切點(如圖 7 之紅圈),且算出此曲面下面積(area under the curve,簡記為 AUC)為 0.897。
將此最佳切點對應回去盒鬚圖以一條紅線於圖8 呈現,在前面確定的資料內,
10 的部分也能夠將接近75%的資料辨別為正常,而可能懷疑的部分就僅有一半不到 可以辨別到異常,其他部分的辨別還需其他特徵的幫助。 我們從特徵變數之特徵圖(如圖 5)可發現,正常的資料較為集中,異常則 較為發散,便想出如果能建立一個正規化區間,將區間內的數值代換為0,其餘 部分則為距離比例,如果 SPECT 影像為正常者,其每一特徵在正規化後的數值 將會改寫成多個 0;如果 SPECT 影像為異常者,則會有較多非 0 或是比較大的 數值,這對於將正常與異常的資料分開是有幫助的。上述之最佳切點則為我們需 要的正規化區間參數,將迴歸線加減最佳切線做為正規化的區間,但在特徵10、 12 與 19(長短軸比例與尾核面積比)中,我們將其下區間降低至 0,而在特徵 18(紋狀體與背景之對比)中,我們將其上區間提升至 1,因這些特徵數值在過 低或是過高情況下仍是正常的情況,在此四個特徵變數下,我們會有不對稱的正 規化區間,圖9 之三條黑線為迴歸線與我們建立出的正規化區間之示意圖,我們 能夠大膽的猜測受檢者為正常人,若其 SPECT 影像的特徵數值大部分都落在區 間內。在進行特徵正規化時會有 3 種情況: ⚫ 落在區間裡的特徵數值,我們將其代換為 0 ⚫ 特徵數值高於上界,代換為該數值到下界與上下界的距離比例後再−1 ⚫ 特徵數值低於下界,代換為該數值到下界與上下界的距離比例加負號 以下給予兩範例如圖 10(A) (B),分別為特徵數值落在上下界之外的情況: 範例一: P17 = 0.38, up17= 0.9, low17= 0.58 P17′ = −紅線線段長 綠線線段長= − |0.38 − 0.58| |0.9 − 0.58| = −0.63 範例二: P11 = 0.66, up11= 0.59, low11= 0.37 P11′ = 藍線線段長 黑線線段長− 1 = |0.66 − 0.37| |0.59 − 0.37|− 1 = 1.32 − 1 = 0.32 此正規化區間不單單只是拿來做正規化,也一定程度代表了確定正常者特徵 的數值範圍,在圖 10 之左圖的兩條紅線即為此區間,由此圖得知該受檢者的特 徵落在何處,是否有大多落在區間內,還是已經有特徵距離區間很靠近,快要到 危險邊緣,或是在某些特徵下有非常異常的表現,這些都可以提供給醫生除了標 記以外的資訊。經特徵正規化後所有資料後,便能針對我們研究之方向訓練分類 器。大致上分為兩種分組模式,一為依照資料的收集時間將資料切割成訓練集與 測試集,二為針對確定的資料與可能的資料分為訓練集與測試集,我們想利用主 動式學習的方式,在醫生較難判斷的資料下,我們讓機器藉由迭代的方式去學習 這些資料,每次從可能的資料中加入 1 筆資料進入確定的資料,探討在加入多少 筆的情況下,能夠提升剩餘資料之分類準確率。
11
四、
數值結果
1.
數值結果 I
實證研究方面,共收集634 張受檢者的影像資料,其中醫生確定正常或異常 的影像為430 張,其餘 204 張則為醫生判別為可能正常或異常。依據資料收集的 時間順序,將107 年前之資料的 534 筆影像資料定義為訓練集,107 年之 100 張 影像資料定義為測試集。 在曲面函數經過最佳係數之挑選下,數值結果呈現如表3 與表 4,訓練集的 準確率可以達到 98.88%,其中 242 張正常的影像資料與 286 張異常的影像資料 在此分類系統可以分類正確,測試集可以達到85%,其中 47 張正常的影像資料 與 38 張異常的影像資料也能判斷正確,本研究更深入探討各個變數之重要性, 當一次扔掉一個變數後使用同一組參數去重新訓練分類器,直至每個變數都扔掉 過,將每一次更新後的測試集分類準確率與未扔變數前之測試集分類準確率相減, 算出所有變數與其扔掉後的測試集準確率下降數值,並結果加以排序呈現於圖 11。由此圖可看出 C6、p4 與 C5 這三個變數在此系統中是較重要的變數,在少 掉這三個變數其中一個就會使測試集之分類準確率下降兩到三個百分點。 我們將分錯的張數依編號對照回去四分法的結果呈現於表5、表 6 與表 7 中, 在訓練集中有6 張是真實為異常,我們判別為正常,這些都是可能異常的影像, 測試集則是有3 張是真實為異常,我們判別為正常,這 3 張也皆為可能異常的影 像,仍需醫生進一步的藉由臨床資料加以判斷。在真實為正常,我們判別為異常 的情況只有在測試集發生,共有12 張,有 8 張為可能正常的影像,其中有 4 張 為醫生僅看影像就能確認正常之影像編號為543、568、587 與 616,這些影像尚 需醫生協助進一步的檢測去排除,在此部分將正常的人視為異常雖然無傷大雅, 但是讓受檢者有不必要的擔心也是我們需要改進的部分,希望能與醫生討論出更 多有區別性的變數使系統精進,或是醫生能提供如文獻上提及的半定量儀器結果, 相信一定能夠在讓系統的準確率上升。在本系統沒有出現四分法為確定異常我們 卻將判斷成正常的情況發生,因此情況為相當嚴重的錯誤,如果發生可能會造成 延誤就醫而導致病情更加惡化的可能性。 在第三章資料敘述中有提到的四分法結果是由三位醫生(醫生A、B 與 C) 皆對每張 SPECT 影像標記後之投票結果,由於每位醫生的著重方面不盡相同, 且經歷過的臨床經歷也大相逕庭,所以本研究將三位醫生之原本標記合本系統一 起與四分法結果做比較如圖 12,乍看之下可能較難分辨出哪幾個是醫生們的標 記結果,但可以在機器與人的判斷方式下去辨別,醫生們就算是依照著編號順序 往下依序辨別,但他們將會是一樣的標準,但本系統的建立即為以前面534 筆之 影像資料做訓練,對後100 筆影像做測試,醫師們在本研究所切割的兩集合下, 會得出類似的準確率,而本系統則是在訓練集會有較好的效果,而在測試集的結12 果就會略嫌遜色,不過此圖仍可看出三位醫生在對 SPECT 影像標記的時候確實 會有所差異,而本系統是由三位醫生之綜合結果來做訓練,在某些方面上可能無 法很精準地到抓到每位醫生的要點。 在考量本系統是否與醫生們各自的標記結果有很大的差異,我們將三位醫生 與本系統之間的標記來探討其相似度,在訓練集部分,三位醫生之間的相似度依 照醫生AB、醫生 AC 與醫生 BC 的順序為 90%、93%與 90%,而三位醫生與本 系統之相似度依照ABC 順序為 96%、93%與 95%,在測試集中,三位醫生之間 的相似度為 86%、86%與 78%,三位醫生與本系統的相似度則為 84%、84%與 78%,上述之相似矩陣在表 8 至表 19 中列有詳細的對應數值。在訓練集可發現 醫生A 與醫生 C 較為相像,系統與醫生 ABC 都有相當高的相似度,在測試集中, 醫生AB 與醫生 AC 有一樣的相似度,系統則是與醫生 AB 有較高的相似度,總 的來說,本系統與三位醫生標記結果的相似程度都相當的接近,就此一方面下來 說,本系統給予之SPECT 影像判結果是值得信賴的。 在曲面函數利用ROC 篩選出的係數下並利用前面的 534 筆訓練集使用 10 次 交叉驗證挑選SVM 中的懲罰項與 RBF 的係數後與四種不同的分類器做比較,分
別為Naïve Bayes、XGboost、Random Forests 與羅吉斯迴歸,此四種分類器為文
獻中較常被拿來做比較的方法,通常也有較好的結果,其餘訓練分類器的設定如 下,Naïve Bayes 使用預設值,XGboost 使用 10 次的迭代,Random Forests 建立
了500 棵樹來穩定準確度,羅吉斯迴歸的分布假設使用二項式。數值結果呈現如
表21 與表 22,SVM、Naïve Bayes、XGboost、Random Forests 與羅吉斯迴歸的
訓練集的準確率依序為可以達到 96%、85%、97%、100%與 89%,測試集的準
確率可以達到85%、79%、82%、82%與 81%,可看出羅吉斯迴歸與 Naïve Bayes
在訓練集有較差的表現,而Random Forests 有著完美結果,但可能會有過度配飾
導致測試集較差的可能性,再結合測試集來看,SVM 表現最優,XGboost 與 Random Forests 次之,再者為羅吉斯迴歸,Naïve Bayes 最後。表中仍有四個變 量探討各種方法之優劣,分別為敏感度(sensitivity)表示在所有實際為異常的 資料中,被正確地判別為異常之比率,特異度(specificity)表示在所有實際為 正常的資料中,被正確地判別為正常之比率,陽性預測值(PPV)表示在所有判 斷為異常的資料中,被正確地判別為異常之比率,與陰性預測值(NPV)表示在 所有判斷為正常的資料中,被正確地判別為正常之比率,訓練集中,當整體分類 準確率高時,此四種量的比較與準確率之推論差異不大,測試集中,在敏感度的 部分除了Naïve Bayes 為較低的 68%,其餘除了羅吉斯迴歸為 78%,三者都相同 為85%,對於判別異常的資料有相同的效果,特異度的部分,Naïve Bayes 為最 高86%,SVM 次之為 85%,再者為羅吉斯迴歸之 83%,其餘兩者為 80%,Naïve Bayes 與 SVM 較能對於判別正常的資料有較好的效果,PPV 的部份,SVM 最優 為 80%、Naïve Bayes 次之為 78%,再來為羅吉斯迴歸之 76%,其餘兩者皆為 75%,在判斷為異常的資料 SVM 與 Naïve Bayes 能夠較準確的抓到真實異常的 資料,NPV 的部分,SVM 也是最優 89%,XGboost 與 Random Forests 次之為
13
88%,羅吉斯迴歸為 84%,最後為 Naïve Bayes 之 80%,除了 Naïve Bayes 的四 種分類器在判斷為正常的資料時,都能夠較準確的抓到真實正常的資料。綜合了 上述比較,對於此筆資料SVM 為最好之分類器。
數值結果 II
這裡應用主動式學習的方式,先將確定正常異常的資料定義為訓練集(共430 筆),可能正常異常的資料定義為測試集(共 204 筆),這裡基於 ALHS 做法, 改良挑點方式與排除方式,排除方式分為兩種:𝜙𝑖(x̃)大於 0.4 和歐式距離小於j 0.5 與 0.4,在此討論兩種排除方式與三種挑點方式下,最終將加入 50 筆影像資 料,每次加入1 筆影像資料時,便算出各種情況下之分類準確率,計算每次迭代 最高分類準確率者次數加總結果作為比較之依據。 在三種方式下,結果如圖13~圖 18 與表 22 所示,訓練集都有些許的下滑, 在加入了50 筆資料後,最低的分類準確率也不會小於 99%,迭代進入訓練集的 資料不致影響降低太多,而測試集的分類準確率也能提高的話,該方法將可以認 為有不錯的表現。 在測試集的部分,在排除方式ϕi(x̃)大於 0.4 的情況下,在加入 20 筆資料後,j 各挑點方式都有從68%提升至70%左右,但在持續迭代後,Hint 的分類效果回到 了68%,挑選中位數的分類效果也持續降低至68%,不過挑選平均數的分類效果 能提升到72%。在 50 次最高分類準確率者次數加總結果中,Hint、平均數、中 位數三種挑點方式為17/25/8,在 20 筆時切割,前 20 筆的次數為 15/0/5,後 30 筆為2/25/3,可看出挑點方式在前期 Hint 的表現較佳,後期則是平均數最佳。 在排除方式歐式距離小於0.5 的情況下,在加入 12 筆資料後,各挑點方式也 能從68%提升至70%左右,但在持續迭代後,Hint 的分類效果一直在68%與70% 徘徊,挑選中位數的分類效果在加入 42 筆後達到最高點72%後平緩至70%,挑 選平均數的分類效果則一度掉至66%,但最後有爬升至70%,50 次中 Hint、平 均數、中位數三種挑點方式下,分類準確率最高的次數為6/5/39,在此方法下沒 有兩方法有前後交叉的結果,中位數的挑點方式最佳。 在排除方式歐式距離小於0.4 的情況下,在加入 20 筆資料後,各方法在持續 迭代後開始出現明顯的分歧,Hint 的分類效果保持在70%左右,挑選中位數的分 類效果在70%與72%徘徊,挑選平均數的分類效果則是在68%附近,50 次中 Hint、 平均數、中位數三種挑點方式下,分類準確率最高的次數為5/34/11,。14
五、 討論與未來發展
此分類系統在兩種參數下分別在訓練集與測試集能達到98.88%、85%與 96.07%、85%,雖然在測試集時的準確率尚無到完美的階段,但在此資料下, 我們所找出的各特徵之盒鬚圖(如圖18(A)(B)(C)),可看出在這些特徵下資料的 交疊情況是相當嚴重的,尤其是在四分法中1 與 2 的部分,也就是盒鬚圖的後兩 種資料分布,就算我們使用區間將其正規化,其在多個特徵變數下也仍會有許多 在正常的區間內是無法分離的。所幸,我們在標記的結果上不會給予醫生太多的 錯誤資訊,從數值結果I 得知,我們會發生較嚴重之錯誤是讓確定正常的受檢者 複檢,但不會讓確定異常之受檢者成為漏網之魚,而此嚴重的情況在醫生肉眼觀 察便可避免此問題,因此類型的 SPECT 影像是醫生能夠很直觀認定是否罹病, 此系統也僅有幾張是此種的錯誤判別,對於幫助醫生的前提下不會造成太大的困 擾。因本系統主要目的是為協助醫生判斷影像是否為正常或異常,並不是為了取 代醫生的工作,而且期望減低醫生在對於大量的影像之工作量,在影像資料送至 醫生眼前判斷前,先經由流程將圖片轉成系統可辨識之影像後,系統將會給出一 個標記結果,再讓醫生藉由自己的臨床經驗與專業知識來做進行判斷。甚至我們 可以給與醫生的不單單只是我們預測的標記結果,還可以給與醫生每個特徵下, 將該張影像的每維特徵數值點標在歷史的正常影像資料中,提供醫生更多的參考 價值,以利醫生做出準確的判斷。 利用主動式學習,我們可以不需要將所擁有的資料資訊全部都丟進分類器做 訓練,只要將某部分對於分類器是有益的資料加入並重新訓練,我們就可以在花 費較少的時間與資源上得到相近甚至是優於對全部資訊都做訓練之分類器。且在 醫療上,我們擁有的已知資料都是耗費了許多精密儀器的檢查與醫生們的臨床經 驗判斷,加入主動式學習能夠利用少量的資料能達到提升效果,可以達到減少醫 療資源的消耗與幫助醫生判斷的目的。我們目前對於此筆資料做了三種挑點方式 與兩種捨棄方式的三種結果來做比較,在這些方法內尚無法比較出到底是何種匹 配方式能達到最佳的結果,但在我們提出的改良構想上,已經不會遜色於原始的 方法,未來可以根據未標記資料的聚集程度再定義新的排除方式,或是因為其距 離超平面的偏差而對於選取的點有所改變,可能不是最靠近的點,又或是平均數 與中位數,這都是可以經過建立模型模擬後推倒的。經由我們多方的假設嘗試, 再仔細的去找尋其中的關連,肯定能尋找到優於現階段算法之方法,甚至可以提 出不同的結合方式,HintSVM 為分類器與迴歸線之結果,ALHS 則為綜合分類器 與 HintSVM 的演算法,只是要能夠做分類器與迴歸線之方法,都可以拿來做替 換,在結合上可能不一定是直觀的,但一定能夠得到不同於現在的方式,並再結 合任何一種分類器,就能夠創造新的主動式學習方法,改變現狀。15
參考文獻
1. Boser, B., Guyon, I. and Vapnik, V. (1992). A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, pages 144-152.
2. Chang, C. C. and Lin, C. J. (2011) LIBSVM: A Library for Support Vector Machines. ACM Trans-actions on Intelligent Systems and Technology, pages 27:1-27:27.
3. Choi, H., Ha, S., Im, H. J., Paek, S. H., Lee, D. S. (2017). Refining diagnosis of Parkinson's Disease with Deep Learning-based Interpretation of Dopamine Transporter Imaging. NeuroImage: Clinical, pages 586-594.
4. Drucker, H., Burges, C., Kaufman, L., Smola, A. and Vapnik, V. (1997). Support Vector Regression Machines. Advances in Neural Information Processing Systems, pages 155-161.
5. Illán, I. A., Górriz, J. M., Ramírez, J., Segovia, F., Jiménez‐Hoyuela, J. M. and Lozano, S. J. O. (2012). Automatic Assistance to Parkinson’s Disease Diagnosisin DaTSCAN SPECT Imaging. Nuclear medicine physics, pages 5971-5980.
6. Iwabuchi, Y., Nakahara, T., Kameyama, M., Yamada, Y., Hashimoto, M., Matsusaka, Y., Osada, T., Ito, D., Tabuchi, H. and Jinzaki, M. (2019). Impact of a Combination of Quantitative Indices Representing Uptake Intensity, Shape, and Asymmetry in DAT SPECT using Machine Learning: Comparison of Different Volume of Interest Settings. EJNMMI Research 9:7. 7. Kim, Daniel, H., Wit, Huub, Thurston, Mark. (2018). Artificial Intelligence in the Diagnosis of Parkinson’s Disease from Ioflupane-123 Single-Photon Emission Computed Tomography Dopamine Transporter Scans using Transfer Learning. Nuclear Medicine Communications, pages 887-893(7). 8. Li, C. L., Ferng, C. S. and Lin, H. T. (2012). Active Learning with Hinted
Support Vector Machine. Proc. ACML’12, pages 221-235.
9. Li, C. L., Ferng, C. S. and Lin, H. T. (2015). Active Learning using Hint Information. Neural Computation 27, pages 1738-1765.
10. Nicastro, N., Wegrzyk, J., Preti, M. G., Fleury, V., Van de Ville, D., Garibotto, V. and Burkhard, P. R. (2019). Classifcation of Degenerative Parkinsonism Subtypes by Support‐Vector‐Machine Analysis and Striatal
𝐼
16
11. Oliveira, F. P. M, Faria, D. B., Costa, D. C., Castelo-Branco, M. and Tavares, J. M. R. S. (2018). Extraction, Selection and Comparison of Features for an Effective Automated Computer-Aided Diagnosis of Parkinson’s Disease based on 123𝐼-FP-CIT SPECT Images. European Journal of Nuclear Medicine and Molecular Imaging, pages 1052-1062.
12. Palumbo, B., Fravolini, M. L., Buresta, T., Pompili, F., Forini, N., Nigro, B., Calabresi, P. and Tambasco, N. (2014). Diagnostic Accuracy of Parkinson Disease by Support Vector Machine (SVM) Analysis of 123𝐼-FP-CIT Brain SPECT Data: Implications of Putaminal Findings and Age. Medicine (Baltimore), e228.
13. Prashanth, R., Roy, S. D., Mandal, P. K. and Ghosh, S. (2014). Automatic Classification and Prediction Models for Early Parkinson’s Disease Diagnosis from SPECT Imaging. Expert Systems with Applications, pages 3333-3342.
14. Prashanth, R., Roy, S. D., Mandal, P. K., Mandal and Ghosh, S. (2017). High Accuracy Classification of Parkinson‘s Disease through Shape Analysis and Surface Fitting in 123𝐼-Ioflupane SPECT Imaging. IEEE Journal of Biomedical and Health Informatics, pages 794-802.
15. Taylor, J. C. and Fenner, J. W. (2017). Comparison of Machine Learning and Semi-Quantification Algorithms for 123𝐼 -FP-CIT Classification: the beginning of the end for Semi-Quantification? EJNMMI Physics 4:29.
17
附錄
圖1:紋狀體之三部分,前殼核、後殼核與尾狀核 圖2A:SVM 與 HintSVM 之超平面比 較圖,黑色實線為SVM 之超平面,紫 色虛線為HintSVM 之超平面 圖2B:經 ALHS 迭代之結果圖,經 ALHS 迭代後得到最後之分類超平面18 SPECT 影像 影像標準化 特徵提取 特徵正規化 訓練模型 圖3:本系統分析流程圖 圖4:編號 1 受檢者之最清晰影像與前後 4 張
19 0 3 1 2 殘 差 圖5:第一維特徵數值與年齡之散布圖,黑線為正常資料與年齡做出之迴歸線, 黑點為正常資料,紅點為異常資料 圖6:第一維特徵之殘差盒鬚圖,在四分法下之殘差分布 年齡 特 徵 數 值
20 圖7:ROC 曲線,紅色點為能將圖 6 之盒鬚圖前兩個類別區分的最佳切點 圖8:第一維特徵之殘差盒鬚圖,紅線為圖 7 最佳切點之對應直線 殘 差 0 3 1 2
1−specificity
sensitivity
AUC = 0.897
21 圖9:第一維特徵之正規化區間 圖10:編號 1 受檢者在特徵正規化前後之特徵數值 年齡 特 徵 數 值
22
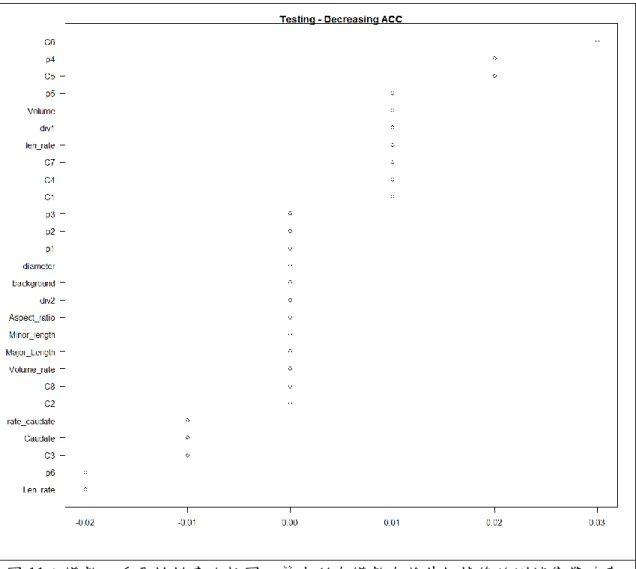
圖11:變數之重要性排序比較圖。算出所有變數在將其扔掉後的測試集準確率
23
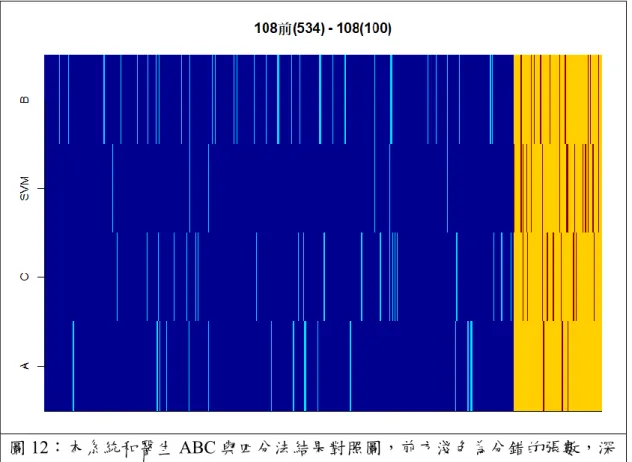
圖12:本系統和醫生 ABC 與四分法結果對照圖,前方淺色為分錯的張數,深
色為分對的張數;後方淺色為分對的張數,深色為分錯的張數,x 座標為照時 間順序之編號,y 座標為四種本系統和醫生 ABC 的結果
24 圖13:排除機率𝜙𝑖(x̃)大於 0.4 之訓練集分類準確率 j 圖14:排除機率𝜙𝑖(x̃)大於 0.4 之測試集分類準確率 j 0.9 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98 0.99 1 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 Hint Mean Median 0.65 0.66 0.67 0.68 0.69 0.7 0.71 0.72 0.73 0.74 0.75 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 Hint Mean Median
25 圖15:排除歐式距離小於 0.5 之訓練集分類準確率 圖16:排除歐式距離小於 0.5 之測試集分類準確率 0.9 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98 0.99 1 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 Hint Mean Median 0.65 0.66 0.67 0.68 0.69 0.7 0.71 0.72 0.73 0.74 0.75 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 Hint Mean Median
26 圖17:排除歐式距離小於 0.4 之訓練集分類準確率 圖18:排除歐式距離小於 0.4 之測試集分類準確率 0.9 0.91 0.92 0.93 0.94 0.95 0.96 0.97 0.98 0.99 1 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 Hint Mean Median 0.65 0.66 0.67 0.68 0.69 0.7 0.71 0.72 0.73 0.74 0.75 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 Hint Mean Median
27
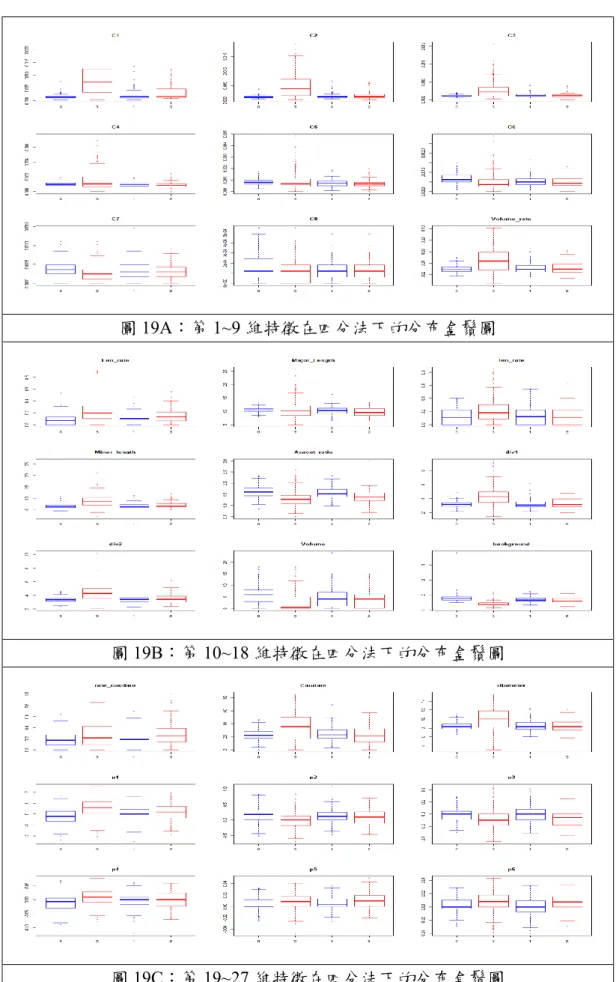
圖19A:第 1~9 維特徵在四分法下的分布盒鬚圖
圖19B:第 10~18 維特徵在四分法下的分布盒鬚圖
28 表1 各分法之結果對應與資料筆數 表2 各特徵變數在四分法下,其平均數±標準差 個數 特徵變數 正常 可能正常 可能異常 異常 1 C1 0.05 ± 0.04 0.08 ± 0.09 0.12 ± 0.13 0.36 ± 0.26 2 C2 0.05 ± 0.02 0.06 ± 0.05 0.08 ± 0.07 0.25 ± 0.2 3 C3 0.07 ± 0.02 0.07 ± 0.03 0.08 ± 0.04 0.17 ± 0.15 4 C4 0.13 ± 0.04 0.13 ± 0.04 0.12 ± 0.05 0.2 ± 0.17 5 C5 0.17 ± 0.05 0.15 ± 0.07 0.14 ± 0.07 0.18 ± 0.14 6 C6 0.23 ± 0.09 0.18 ± 0.08 0.17 ± 0.1 0.17 ± 0.14 7 C7 0.27 ± 0.14 0.24 ± 0.14 0.22 ± 0.14 0.18 ± 0.14 8 C8 0.3 ± 0.21 0.27 ± 0.19 0.25 ± 0.19 0.2 ± 0.19 9 紋狀體佔大腦之比例 0.26 ± 0.06 0.27 ± 0.08 0.28 ± 0.11 0.42 ± 0.2 10 長軸之比例 0.09 ± 0.09 0.11 ± 0.09 0.15 ± 0.13 0.24 ± 0.2 11 長軸之平均長度 0.47 ± 0.08 0.46 ± 0.1 0.42 ± 0.13 0.46 ± 0.19 12 短軸之比例 0.14 ± 0.13 0.17 ± 0.15 0.17 ± 0.16 0.25 ± 0.21 13 短軸之平均長度 0.32 ± 0.07 0.32 ± 0.08 0.36 ± 0.09 0.45 ± 0.16 14 長短軸之比例 0.42 ± 0.09 0.4 ± 0.09 0.34 ± 0.11 0.31 ± 0.12 15 左紋狀體之散度 0.33 ± 0.07 0.33 ± 0.1 0.36 ± 0.14 0.51 ± 0.2 16 右紋狀體之散度 0.26 ± 0.08 0.26 ± 0.1 0.28 ± 0.14 0.44 ± 0.19 17 紋狀體單邊活躍程度 0.76 ± 0.16 0.82 ± 0.16 0.82 ± 0.16 0.89 ± 0.16 18 紋狀體吸收程度 0.19 ± 0.07 0.16 ± 0.04 0.15 ± 0.05 0.08 ± 0.04 19 尾核面積比 0.28 ± 0.1 0.29 ± 0.12 0.27 ± 0.16 0.41 ± 0.24 20 尾核單邊之活躍程度 0.2 ± 0.16 0.22 ± 0.15 0.31 ± 0.23 0.28 ± 0.24 21 紋狀體之等效直徑 0.42 ± 0.07 0.43 ± 0.09 0.44 ± 0.11 0.55 ± 0.19 22 P1 0.46 ± 0.14 0.48 ± 0.15 0.54 ± 0.15 0.61 ± 0.16 23 P2 0.49 ± 0.14 0.46 ± 0.13 0.44 ± 0.14 0.38 ± 0.13 24 P3 0.48 ± 0.12 0.49 ± 0.16 0.42 ± 0.14 0.41 ± 0.17 25 P4 0.56 ± 0.16 0.59 ± 0.14 0.6 ± 0.14 0.65 ± 0.13 26 P5 0.53 ± 0.11 0.55 ± 0.12 0.59 ± 0.14 0.57 ± 0.14 27 P6 0.51 ± 0.13 0.49 ± 0.17 0.56 ± 0.15 0.57 ± 0.18 四分法結果 三分法結果 二分法結果 0:174 筆 0:174 筆 0:301 筆 1:127 筆 1:204 筆 2:77 筆 1:333 筆 3:256 筆 2:256 筆
29 表3 本系統在訓練集之分類準確率 預測 真實 正常 異常 正常 242 0 準確率 異常 6 286 98.88% 表4 本系統在測試集之分類準確率 預測 真實 正常 異常 正常 47 12 準確率 異常 3 38 85.00% 表5 訓練集:真實為異常→系統判別為正常編號 編號 78 166 188 377 394 459 四分法 2 2 2 2 2 2 表6 測試集:真實為異常→系統判別為正常編號 編號 596 620 631 四分法 2 2 2 表7 測試集:真實為正常→系統判別為異常編號 編號 535 543 545 550 555 568 587 595 604 613 616 625 四分法 1 0 1 1 1 0 0 1 1 1 0 1
30 表8 在訓練集中,醫生 AB 之間之相似矩陣 醫生B 醫生A 正常 異常 正常 219 13 相似率 異常 40 262 90% 表9 在訓練集中,醫生 AC 之間之相似矩陣 醫生C 醫生A 正常 異常 正常 221 11 相似率 異常 28 278 93% 表10 在訓練集中,醫生 BC 之間之相似矩陣 醫生C 醫生B 正常 異常 正常 226 33 相似率 異常 23 252 90%
31 表11 在訓練集中,本系統與醫生 A 之相似矩陣 系統 醫生A 正常 異常 正常 229 3 相似率 異常 19 283 96% 表12 在訓練集中,本系統與醫生 B 之相似矩陣 系統 醫生B 正常 異常 正常 236 23 相似率 異常 12 263 93% 表13 在訓練集中,本系統與醫生 C 之相似矩陣 系統 醫生C 正常 異常 正常 236 13 相似率 異常 12 273 95%
32 表14 在測試集中,醫生 AB 之間之相似矩陣 醫生B 醫生A 正常 異常 正常 52 6 相似率 異常 8 34 86% 表15 在測試集中,醫生 AC 之間之相似矩陣 醫生C 醫生A 正常 異常 正常 48 10 相似率 異常 4 38 86% 表16 在測試集中,醫生 BC 之間之相似矩陣 醫生C 醫生B 正常 異常 正常 45 15 相似率 異常 7 33 78%
33 表17 在測試集中,本系統與醫生 A 之相似矩陣 系統 醫生A 正常 異常 正常 46 12 相似率 異常 4 38 84% 表18 在測試集中,本系統與醫生 B 之相似矩陣 系統 醫生B 正常 異常 正常 47 13 相似率 異常 3 37 84% 表19 在測試集中,本系統與醫生 C 之相似矩陣 系統 醫生C 正常 異常 正常 40 12 相似率 異常 10 38 78%
34
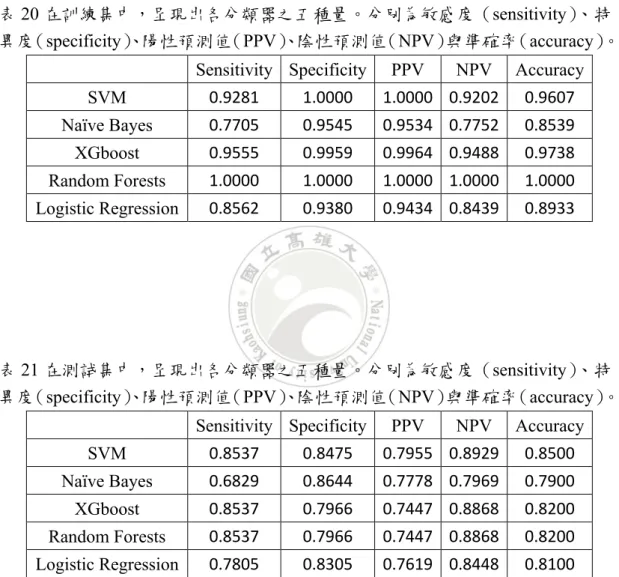
表20 在訓練集中,呈現出各分類器之五種量。分別為敏感度(sensitivity)、特
異度(specificity)、陽性預測值(PPV)、陰性預測值(NPV)與準確率(accuracy)。
Sensitivity Specificity PPV NPV Accuracy
SVM 0.9281 1.0000 1.0000 0.9202 0.9607 Naïve Bayes 0.7705 0.9545 0.9534 0.7752 0.8539 XGboost 0.9555 0.9959 0.9964 0.9488 0.9738 Random Forests 1.0000 1.0000 1.0000 1.0000 1.0000 Logistic Regression 0.8562 0.9380 0.9434 0.8439 0.8933 表21 在測試集中,呈現出各分類器之五種量。分別為敏感度(sensitivity)、特 異度(specificity)、陽性預測值(PPV)、陰性預測值(NPV)與準確率(accuracy)。
Sensitivity Specificity PPV NPV Accuracy
SVM 0.8537 0.8475 0.7955 0.8929 0.8500
Naïve Bayes 0.6829 0.8644 0.7778 0.7969 0.7900
XGboost 0.8537 0.7966 0.7447 0.8868 0.8200
Random Forests 0.8537 0.7966 0.7447 0.8868 0.8200
35 表22 在兩種不同排除方式與三種不同的挑點方式下,最高之挑點方法加總。在 每次迭代加入1 筆至 50 筆下,將每次迭代下測試集準確率最高之挑點方法記 1, 比較加總50 筆之結果,在𝜙𝑖(x̃)大於 0.4 的情況下,在加入 20 筆的前後有分歧,j 故將其前後分別呈現。 挑點方式
加入筆數 Hint Mean Median
𝜙𝑖(x̃)大於 0.4 j 50 筆 17 25 8 𝜙𝑖(x̃)大於 0.4 j 前20 筆 15 0 5 𝜙𝑖(x̃)大於 0.4 j 後30 筆 2 25 3 歐式距離小於0.5 50 筆 6 5 39 歐式距離小於0.4 50 筆 5 34 11