國
立
交
通
大
學
資訊工程系
碩
士
論
文
降低行程環境切換導致效能損失之轉換搜尋緩衝器設計
Translation Look-aside Buffer with Low Context Switch Penalty
研 究 生:張繼文
指導教授:陳昌居 教授
降低行程環境切換導致效能損失之轉換搜尋緩衝器設計
Translation Look-aside Buffer with Low Context Switch Penalty
研 究 生:張繼文 Student:Chi-Wen Chang
指導教授:陳昌居 Advisor:Chang-Jiu Chen
國 立 交 通 大 學
資 訊 工 程 學 系
碩 士 論 文
A ThesisSubmitted to Department of Computer Science and Information Engineering College of Electrical Engineering and Computer Science
National Chiao Tung University in
partial Fulfillment of the Requirements for the Degree of Master
in
Computer Science and Information Engineering
June 2004
Hsinchu, Taiwan, Republic of China
降低行程環境切換導致效能損失之
轉換搜尋緩衝器設計
研究生:張繼文
指導教授:陳昌居
國立交通大學 資訊工程學研究所
摘要
一般人所熟悉的轉換搜尋緩衝器是用來將虛擬記憶體轉換成實體記憶體的 一種機制,在整個電腦系統運作中扮演極重要的角色。如果有任何的失誤發生 時,都會造成處理器的效能嚴重的下降。為了減低任何失誤的可能性發生,有不 少的研究方法和理論被提出。有些理論是利用改進轉換搜尋緩衝器的關聯性或增 加其容量大小來降低其因衝突產生的失誤和容量不足而導致的失誤,有些研究者 則提出使用超級分頁的概念來涵蓋更多的記憶體空間。這些眾多的方法當中,特 別是超級分頁對於大部分的應用程式能夠有效率的降低失誤的可能性。可惜的是 對於行程切換導致轉換搜尋緩衝器效能降低方面的研究卻是少之又少。為了支援 近代的作業系統當中都有多重程式操作的特色,作業系統必須要有行程環境切換 機制以方便將正在處理的行程切換到下一個行程,此時須清除目前轉換搜尋緩衝 器所暫存的位址轉換資訊。而清除轉換搜尋緩衝器資訊的這樣一個行為,將會造 成處理器效能嚴重的下降,特別是對於近代高效能的處理器。這篇論文提出了一 種新穎且容易實作的轉換搜尋緩衝器架構來降低行程環境切換機制所帶來的損 失同時我們更整合多重分頁的機制來降低失誤的機會。我們修改 SimpleScalar 3.0d 模擬器及使用 SPEC2000 作為我們的模擬平台環境,並比較其它轉換搜尋緩 衝器的架構,模擬結果顯示出所提出的轉換搜尋緩衝器架構在傳統的 4KB 分頁大 小底下可以比傳統轉換搜尋緩衝器的失誤率小上 1.3 倍,在此可見所提出之架構 非常適合用於多重程式環境底下。Translation Look-aside Buffer with Low
Context Switch Penalty
Student : Ji-Wen Zhang Advisor : Dr. Chang-Jiu Chen
Department of Computer Science and Information Engineering
National Chiao-Tung University
Abstract
It is widely known that the Translation Look-aside Buffer (TLB) plays an
important role in the address translation mechanism from virtual addresses to physical
addresses. If any miss occur, the performance of the processor will seriously degrade.
There are many methods for improving TLB performance, such as increasing the
associativity, the number of entries, or page sizes, and using superpages to cover more
memory spaces. These methodologies, especially superpage, can effectively reduce
lots of misses for most applications. However, very few designs really focused on the
context switching issue. In order to support the multiprogramming characteristics in
all modern OS, the context switching mechanism is needed and it will cause all TLB
entries be flushed and will impact on the performance very seriously, especially on
today’s high performance processors. This thesis presents a novel and easy
implemented TLB architecture to reduce the misses in context switching with
complete-subblock mechanism. All simulations were done with modified
SimpleScalar 3.0d tool suite and SPEC2000 benchmarks. The thesis also compares
several designs, including the conventional TLB, the complete-subblock TLB, and the
promotion TLB. The simulations show that the new design can achieve about 1.3
times of relative improvement of miss rate in average with 4KB page size and reveal
Acknowledgment
I wish to express my gratitude to my prime professor, Dr. Chang-Jiu Chen, and
Wei-Min Cheng for their helpful suggestions, detailed comments, and constant
support. I am also indebted to a number of my laboratory colleagues at National
Chiao-Tung University, especially to Nian-Zhi Huang, Yuan-Teng Chang, Ming-Feng
Shen and Shi-Wei Chen, for their encouragement and help. I am most grateful to my
Contents
摘要... I ABSTRACT ... II ACKNOWLEDGMENT ... III CONTENTS ...IV LIST OF FIGURES...VI LIST OF TABLES...VIII CHAPTER 1 INTRODUCTION...1 1.1 PROBLEM DEFINITION... 2 1.2 ROADMAP... 3CHAPTER 2 RELATED WORKS ...4
2.1 TLB MECHANISMS... 4
2.1.1 Conventional TLB Structure ...4
2.1.2 Several TLB implementations ...6
2.2 ENHANCEMENTS FOR THE TLB ... 6
2.2.1 Reducing TLB Access Time... 6
2.2.2 Reducing TLB Miss Rate... 7
2.2.3 Reducing TLB Hardware Cost ... 10
2.2.4 Low Power TLB ... 11
2.3 THE CONTEXT SWITCHING PENALTY IN TLB ... 13
2.4 RELATIONSHIPS BETWEEN THE MISS RATES,PAGE SIZES AND TLBSIZES... 20
CHAPTER 3 PROPOSED MECHANISMS ...27
3.1 THE ORIGINAL TLBSTRUCTURE WITH LOW CONTEXT SWITCH PENALTY... 27
3.1.1 Structure...27
3.1.2 OS Support and Implementation ...29
3.1.3 Expected Performance ... 29
3.2 THE NEW TLBSTRUCTURE WITH LOW CONTEXT SWITCH PENALTY... 33
3.2.1 Overview ...36
3.2.2 Proposed TLB Structure...37
3.2.3 Implementation of the novel TLB ...39
4.1 INTRODUCTION TO THE SIMPLESCALAR TOOL SET... 42
4.1.1 Overview ...42
4.1.2 Instruction Set Architecture ...44
4.2 EXPERIMENTAL METHODOLOGY... 45
4.2.1 TLB Implementation in SimpleScalar Simulator... 46
4.2.2 Modifications to implement our novel TLB structure ...47
4.2.3 Benchmarks...47
4.3 SIMULATION RESULTS... 49
CHAPTER 5 CONCLUSIONS ...56
APPENDIX A: DETAILED RELATIVE IMPROVEMENT FIGURES ... 58
List of Figures
FIGURE 1: STRUCTURE OF A SINGLE-PAGE-SIZE TLB BLOCK ... 5
FIGURE 2: STRUCTURE OF CONVENTIONAL TLB. ... 5
FIGURE 3: SUPERPAGE TLB ENTRY ... 8
FIGURE 4: SCHEMATIC OF HARDWARE FOR PREFETCHING... 10
FIGURE 5: COMPLETE-SUBBLOCK TLB BLOCK (SUBBLOCK FACTOR N). ... 10
FIGURE 6: DUAL TLB STRUCTURE ... 11
FIGURE 7: THE RELATIONSHIP BETWEEN THE TLB SIZE AND THE MISS RATE WITH CONTEXT SWITCHING DIVIDED BY THE MISS RATE WITHOUT CONTEXT SWITCHING. ... 17
FIGURE 8: THE RELATIONSHIP BETWEEN THE PAGE SIZE, TLB SIZE AND THE MISS RATE WITH CONTEXT SWITCHING DIVIDED BY THE MISS RATE WITHOUT CONTEXT SWITCHING. ... 19
FIGURE 9: THE RELATIONSHIP BETWEEN THE TLB MISS RATE AND TLB SIZES WITH TRADITIONAL 4KB PAGE SIZES. ... 23
FIGURE 10: THE RELATIONSHIP BETWEEN THE TLB MISS RATE AND PAGE SIZE.... 26
FIGURE 11: A LOW CONTEXT SWITCHING MISS RATE TLB ARCHITECTURE. ... 28
FIGURE 12: DTLB/ITLB MISS RATE COMPARISON WITH 1MB PAGE SIZE... 32
FIGURE 13: TLB MISS RATE COMPARISON WITH 4KB PAGE SIZE. ... 35
FIGURE 14: NEW PROPOSED TLB ARCHITECTURE WITH LOW CONTEXT SWITCHING PENALTY. ... 37
FIGURE 15: SIMULATOR STRUCTURE. ... 43
FIGURE 16: SIMPLESCALAR ARCHITECTURE INSTRUCTION FORMATS. ... 45
FIGURE 17: THE COMPARISON OF RELATIVE IMPROVEMENT WITH DIFFERENT PAGE SIZES... 53
FIGURE 18: THE MEAN OF THE AVERAGE RELATIVE IMPROVEMENT FOR THE TWELVE SPEC2000 BENCHMARKS. ... 54
FIGURE 19: THE RELATIVE IMPROVEMENT OF MISS RATE IN GZIP. ... 59
FIGURE 21: THE RELATIVE IMPROVEMENT OF MISS RATE IN GCC. ... 61
FIGURE 22: THE RELATIVE IMPROVEMENT OF MISS RATE IN CRAFTY. ... 62
FIGURE 23: THE RELATIVE IMPROVEMENT OF MISS RATE IN VORTEX. ... 63
FIGURE 24: THE RELATIVE IMPROVEMENT OF MISS RATE IN LUCAS... 64
FIGURE 25: THE RELATIVE IMPROVEMENT OF MISS RATE IN TWOLF. ... 65
FIGURE 26: THE RELATIVE IMPROVEMENT OF MISS RATE IN SWIM... 66
FIGURE 27: THE RELATIVE IMPROVEMENT OF MISS RATE IN PERLBMK. ... 67
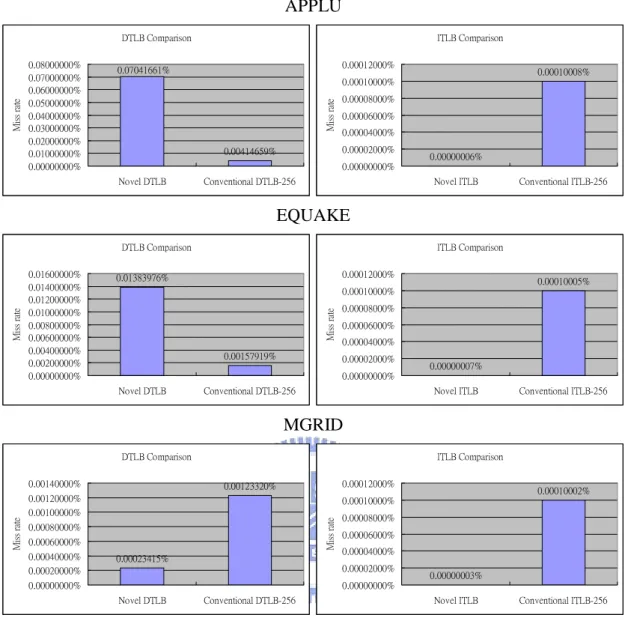
FIGURE 28: THE RELATIVE IMPROVEMENT OF MISS RATE IN APPLU... 68
FIGURE 29: THE RELATIVE IMPROVEMENT OF MISS RATE IN EQUAKE. ... 69
List of Tables
TABLE 1: SUMMARY OF THE SIMULATED SPEC2000 BENCHMARKS ALONG WITH THE INPUT SETS. ... 48 TABLE 2: SPEC 2000 BENCHMARKS DESCRIPTION... 48 TABLE 3: MEMORY SPACE COVERAGE COMPARISON OF FOUR TLBS... 50
Chapter 1
Introduction
To support large memory requirements for modern applications, all new
advanced general-purpose processors will support the virtual memory. The virtual
memory is one of the few interfaces through which the architecture and operating
system interact directly and is developed to automate the movement of program code
and data between main memory and secondary storage to give the appearance of a
single large memory system.
In order to support virtual memory, the address translation mechanism is needed.
It is well known that all the address translations are stored in main memory and
maintained by the operating system; to reduce the cost of address translation, the
translation look-aside buffers (TLBs) [10] are implemented inside the processor. If
there’s any TLB miss occurring, at least two or three memory accesses are needed to
fetch the translation from main memory by the memory management unit (MMU).
A case study on TLB miss handling [16]: It has been shown to constitute as
much as 40% of execution time and up to 90% of a kernel’s computation. Studies
with specific applications have also shown that the TLB miss rate can account for
over 10% of execution time even with an optimistic 30-50 cycles miss overhead.
With the VLSI technology improving rapidly, the new microprocessors become
much faster than ever before and it causes the gap between memories and the
processor core larger and larger. We can easily find that the TLB is in the critical path
1.1 Problem Definition
To enhance the TLB performance, several studies have been made in this field.
However, little attention has been given to the context switching problem under
multiprogramming environment. The context switches are wiping out locality from
one application to another and cause the flush operations for whole of the TLB entries.
It affects the TLB performance very seriously.
In [6], we propose a novel and easy implement TLB structure to reduce the miss
rate caused by the context switching. We divide the 256 entries into 32 banks storing
translation information of different tasks to avoid flushing all TLB when context
switching occurs. The structure is so easy to implement and reducing miss rate
effectively. However, it needs large page size as base page in our previous structure,
for example, 512KB, 1MB or larger page size. Large page sizes will waste memory
space seriously by increasing internal fragmentation, although it can provide the
advantage of increasing the overall coverage of memory mapping.
To overcome and improve the limitation in our original structure, our research is
intended as a study of how to reduce the miss rate under context switching but using
smaller base page size, such as 4KB, 8KB, or 16KB, to implement our new novel
TLB architecture. In the study of banked-promotion TLB structure proposed by Lee et
al. [17] [18], they promoted four consecutive 4KB pages from one banked-TLB into a
16KB page stored in another banked-TLB dynamically via simple hardware control
without any O/S support. We improve and develop this idea a little further to design
our novel TLB structure. We combine both the features of the dual TLB and our
original TLB with many TLB banks in our new structure. Our TLB architecture not
switching occurs. With the new design, we can obtain the advantages of low power
consumption by decreasing the amount of fully associative TLB entries to be accessed
at one time and less internal fragment problem compared with our original TLB
design.
The simulations were be done by the modified SimpleScalar version 3.0d tool
suite with SPEC 2000 benchmark. We modified the original SimpleScalar version
3.0d tool suite to accommodate our requirements.
1.2 Roadmap
The rest of the thesis is organized as follows. In Chapter 2, we begin with
reviewing several hardware enhancements for TLB. Then we show that the context
switching will be the performance bottleneck in TLB and discuss the relationships
between the miss rates, page sizes and TLB sizes. In Chapter 3, we will first review
our recently TLB architecture with low context switching penalty. Then, we will
develop our new novel TLB architecture to reduce miss rate in context switching. The
expected performance is demonstrated in Chapter 4. Finally, in Chapter 5 we
Chapter 2
Related Works
In chapter 1 we discussed that virtual to physical address translation is one of the
most critical operations in computer systems since this is invoked on every instruction
fetch and data reference. To speed up the address translation, computer systems that
use page based virtual memory provide a cache of recent translations called the
Translation Look-aside Buffer (TLB). With the instruction level parallelism, clock
frequencies, and the working sets increasing, the amount of research about
enhancement for TLB increases. In Section 2.1 we will begin with reviewing the
conventional TLB structure. Then we classify all the represented method according to
their research purposes, and give a survey of these mechanisms. In Section 2.2, we
will study the context switching penalty in TLB. In Section 2.3, we will discuss the
relationships between the miss rates, page sizes and TLB sizes.
2.1 TLB mechanisms
2.1.1
Conventional TLB Structure
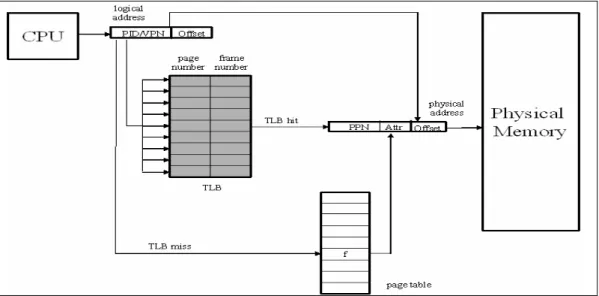
The address translation acceleration mechanism using translation look-aside
buffer (TLB) is based on the principle of temporal locality. A TLB can be considered
to be a hardware cache used to contain recently used virtual-to-real address
translations. If the TLB has a matching translation — a TLB hit, it outputs the physical address and memory access attributes. If the TLB has no matching
translation — a TLB miss, special hardware or software fetches the missing translation and loads it into TLB.
The tag contains the virtual page number (VPN) of the translation and a valid bit (V).
The data part stores the corresponding physical page number (PPN) bits and page
attributes (ATTR), e.g., protection, cache-ability, referenced/ modified bits, as shown
in Figure 1.
Figure 1: Structure of a single-page-size TLB block
Many such TLB blocks can be combined in either fully-associative or
set-associative. In either case, a tag array stores all the tags and includes comparators
to compare them with the input VA. A random-access-memory (RAM) stores the data
parts of the blocks. During a TLB lookup, the input VA is split into two parts that are
the VPN and offset. The offset field, without any translation, appends to the PPN
output from the TLB. The TLB compares the VPN stored in the tag with the input
VPN. Only TLB blocks that contain a valid translation participate in the comparison.
The result of tag comparison outputs the correct PPN and attributes from the RAM. If
no block has matching tag, the TLB generate a TLB miss signal, as
shown in Figure 2.
Figure 2: Structure of conventional TLB.
VPN V PPN ATTR
2.1.2
Several TLB implementations
The TLB is a cache used to speeding up access to entries in the page tables,
where complete information on virtual memory to physical memory mapping are
maintained. We consider two general possibilities for the TLB implementation:
z A single TLB shared between instruction and data caches.
To reduce the contention miss, we can implement dual-ported TLB. This
introduces complex circuitry, doubling the size of the TLB without increasing its
capacity.
z Independent TLBs for instruction and data caches.
In general, the instruction reference streams exhibit greater locality than
data reference streams. So, the instruction TLB should be mad smaller than data
TLB. Furthermore, the instruction TLB and data TLB could be implemented
independently to get best TLB performance.
2.2 Enhancements for the TLB
2.2.1 Reducing TLB Access Time
z Multi-level TLB
Cache has a property that the smaller hardware is faster. Many processors,
such as the Itanium IA-64 [11] (32-entry L1, 96-entry L2), AMD Athlon
(32-entry L1, 256-entry L2) etc. provide multi-level TLB structures, instead of a
single large TLB. The larger L2 TLB will be accessed only after the smaller L1
TLB miss occurs. With a smaller first level TLB, the average TLB access time
Assume that the access time for a single monolithic TLB is a. Let the access
time for the first and second level TLBs in the hierarchical alternative be a1 and
a2 respectively. Let us denote the miss fraction of the monolithic TLB, the first
and second level of the hierarchical TLB to be m, m1, and m2 respectively. Also,
let the cost of fetching a translation that is not in the TLB be denoted by C.
Then, the cost of translating an address in the monolithic structure (Cm) is
given by
C m a
Cm = + × (2.1) The cost of translating an address in the 2-level TLB (Cs) is given by
) ( 2 2 1 1 m a m C a Cs = + × + × (2.2) The 2-level TLB is a better alternative when
C m a C m a m a1+ 1×( 2 + 2× )p + × (2.3)
2.2.2 Reducing TLB Miss Rate
The classical approach to improve TLB performance is to reduce the miss rates,
and we present several techniques here to accomplish this goal.
z
Making the TLB hold more entries
This is a conventional and easy method to improve TLB performance.
Processors, such as Intel Pentium !!! Processor [11] use 512 entries 4K page
fully-associative or set-associative TLB to reduce the miss rate. But the side effect
is that
Longer memory reference latency can be occurred.
z
Using large page size
This is a method with less hardware support to improve the overall coverage
of memory mapping and to reduce the miss rate effectively; however, the
disadvantages is that
It wastes memory space seriously because of increasing internal fragment.
z
Using Superpage to improve TLB coverage
Applications with larger working sets can incur many TLB misses and
suffer from TLB penalty. To alleviate the problem of wasting memory coverage
without increasing the number of TLB entries or page size, most modern
general-purpose CPUs, such as the new Intel Processors from Pentium Pro begin
to provide larger page with sizes of 2MB and 4MB [13]. TLBs that support
superpage use a single entry for translating a set of consecutive virtual pages as
long as these pages are located physically contiguous.
Figure 3 shows the format of a superpage TLB entry. The MASK field
prevents certain tag bits from participating in tag comparison for superpage
mappings and the SZ attribute controls a multiplexer during physical address
generation.
Figure 3: Superpage TLB entry
Log2(n)
n=number of supported page sizes Log2(s) 1
max superpage size s=
base page size
VPN MASK V PPN ATTR SZ
The restrictions for superpage are:
The superpage must be mapped only to contiguous and aligned
physical pages.
Using superpage requires large operating system support and causes
significant overhead. For example, it increases the amount of I/O, page
utilization overhead, and page fault penalty.
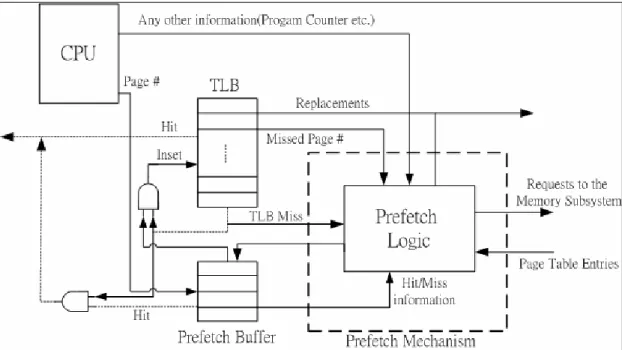
z Prefetching TLB Mechanisms
Although there are many literatures on prefetching techniques for memory
hierarchy, it is only recently [15] [19] that the issue of prefetching TLB entries to
hide all or some of the miss costs has started drawing interest. The reason is that
the TLB is more important than other levels of memory hierarchy and we fear of
slowing down the critical path of TLB accesses due to memory traffic.
Generally speaking, the prefteching mechanisms can be viewed in two
classes: Arbitrary Stride prefetching (ASP) and Stride prefetching (SP) capture
the strided reference pattern, and Markov prefetching (MP), Recency prefetching
(RP) and Distance prefetching (DP) exploit history information about relative
recent usage of pages to predict future TLB misses. All of these techniques bring
the prefetched entry into a prefetch buffer that is concurrently looked up with the
TLB; the entry is moved to the TLB entry only after an actual reference to that
entry by the application. In the Figure 4 we show the schematic of generic
Figure 4: schematic of hardware for prefetching.
2.2.3 Reducing TLB Hardware Cost
z
Complete-Subblock TLB
Complete-subblock TLB structure is a TLB that have the same TLB reach
advantages of medium sized superpages and exploit spatial locality to improve
TLB performance without any operating system support [25] [26]. The main idea
of complete-subblock is to allow a single TLB block to map multiple base pages
to increase the coveraged memory space, as shown in Figure 5.
Figure 5: Complete-subblock TLB block (subblock factor n).
Take a complete-subblock TLB with subblock facor 4 and with 4KB base VPN BV V0 PPN0 ATTR0
Tag Data
V1 PPN1 ATTR1
page for example, the VPN in tag RAM represents the tag of a 16KB page and
each PPN in data RAM represents one of four sequential 4KB pages. The
disadvantages of complete-subblock TLB are:
The unused slots at each TLB block may occur and seriously waste
hardware cost.
If one small page entry is to be updated, all four 4KB pages could be
invalidated, resulting in performance degradation.
2.2.4 Low Power TLB
z
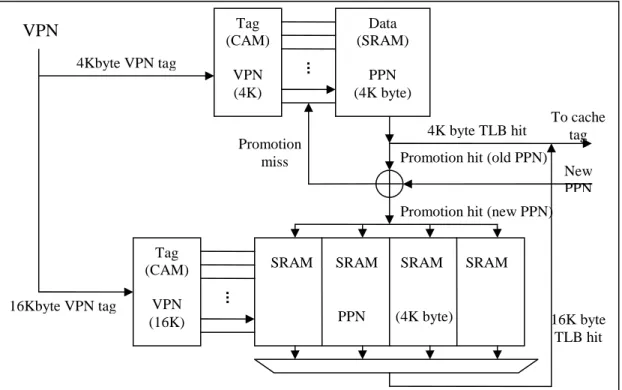
Banked-promotion TLB structure
The proposed dual TLB is a new structure which counteracts the defects
of the complete-subblock TLB and supports two page sizes via a hardware
approach. The proposed dual TLB is organized as two parts of a conventional
small page (4KB size) TLB and a large page (16KB size) TLB. Both are
designed with fully associative structures. Figure 6 shows the promotion TLB.
Figure 6: Dual TLB structure
16K byte TLB hit 4K byte TLB hit
Promotion hit (old PPN)
Promotion hit (new PPN) Promotion miss 16Kbyte VPN tag 4Kbyte VPN tag Tag (CAM) VPN (4K) Tag (CAM) VPN (16K) Data (SRAM) PPN (4K byte)
SRAM SRAM SRAM SRAM
PPN (4K byte) VPN To cache tag New PPN
When one virtual address is generated, the 4KB page and 16KB page TLBs
will be searched at the same time. The behavioral principle of the dual TLB is as
follows:
Case 1: Hit in small page TLB
If a small page is founded in the small page TLB, the actions are not
different at all from any conventional TLB hit. The requested physical address is
sent to the cache and compared with tag bit of cache.
Case 2: Hit in large page TLB
If a hit occurs at the large TLB, only one of four PPNs in the large TLB is
enabled at the same time. Thus the power consumption is decreased. As in the
case of a small page TLB hit, the requested physical address is sent to the cache
and compared with tag bit of cache.
Case 3: Miss in both places
When one virtual address turns out to be a TLB miss in both small page and
large page TLB, O/S performs miss handling. When a TLB miss occurs and if its
corresponding three sequential VPN exists in the small page TLB, those four
sequential VPNs belonging to a 16KB page boundary are chosen to be promoted,
and the three sequential VPNs in the small page TLB are invalidated at the same
2.3 The Context Switching Penalty in TLB
In the chapter 1 we discuss the context switching problem which causes the TLB
in the MMU to be flushed, and the miss penalty will impact on TLB performance
seriously. However, very few attempts have been made for this issue. In this section
we will show some simulations to confirm that flushing TLB entries when context
switching would cause the miss rate increase.
Before the first step in our analysis of TLB misses, we must know what category
of the TLB misses caused by context switching belongs to. General speaking, we can
classify all TLB misses into three simple categories:
z Compulsory misses— The first access to a block cannot be found in the TLB,
so the block must be brought from main memory into the TLB. These are also
called cold-start misses or first-reference misses.
z Capacity misses — If the TLB cannot contain all the blocks need during
execution of a program, capacity misses will occur because of blocks being
discarded and later retrieved.
z Conflict misses — If the block placement is set associative or direct mapped,
conflict misses will occur because a block may be discarded and later retrieved
if too many blocks map to its set. These are also called collision misses or
interference misses.
Obviously, the TLB misses caused by context switching belong to the
compulsory misses due to flushing TLB when context switching. Now, we will take a
close look at some simulations of TLB misses under context switching in comparison
with TLB misses without context switching. We assume the context switching would
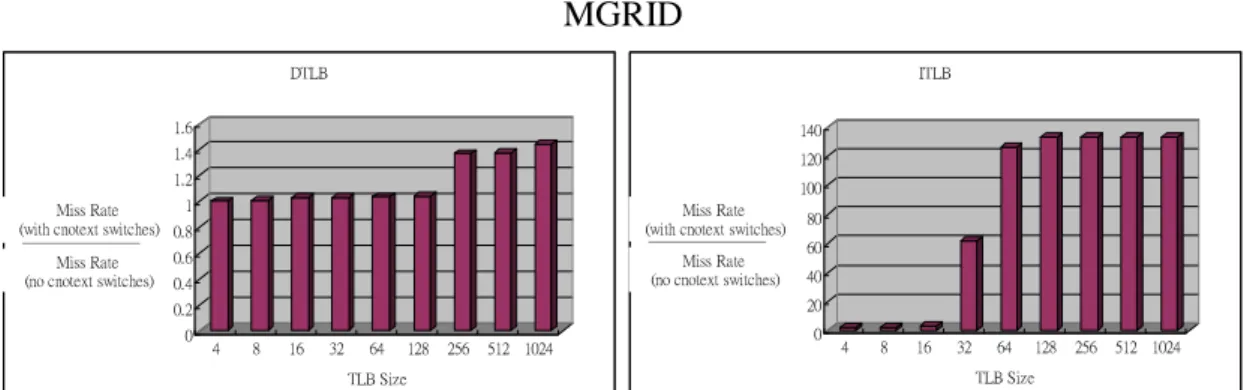
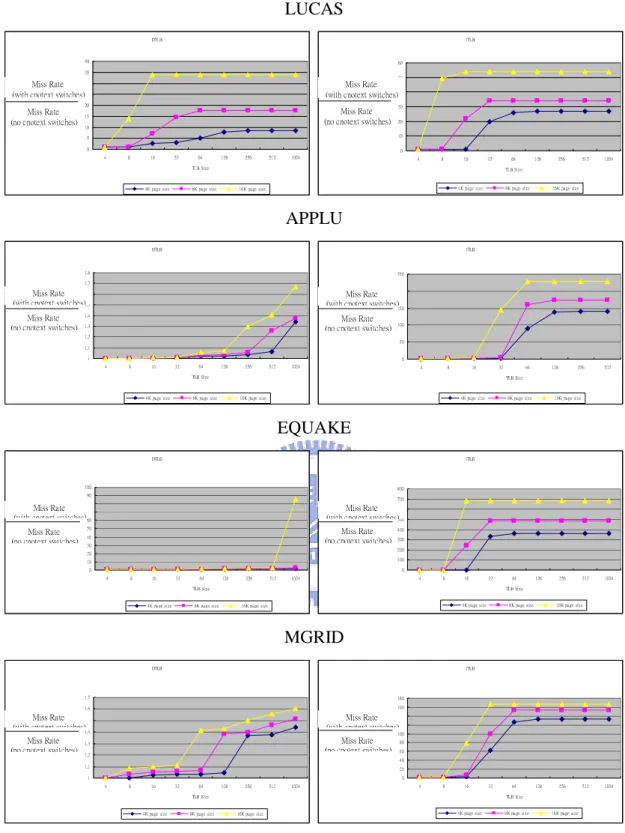
We want to see how many times the miss rate with context switching are as large
as with no context switching. Figure 7 shows the times of the miss rate with context
switching divided by the miss rate without context switching for the twelve
SPEC2000 benchmarks using from 4-entry to 1024-entry fully-associative TLB with a
page size of 4KB. In addition, we make a comparison between different page size,
4KB, 16KB and 64KB for the times in Figure 8.
The Figure 7 and Figure 8 tell us that:
z The times of the miss rate with context switching divided by the miss rate
without context switching would increases if the number of TLB blocks
increases. In other words, the context switching would impact on the TLB
performance more seriously if we have more TLB entries. However, the most
simple way of reducing the TLB miss rate is to increase TLB entries; for
example, the lease AMD OpteronTM processor has both 512-entry L2
instruction TLB (ITLB) and L2 data TLB (DTLB) [1] and the IBM POWER
processor has a common 1024-entry TLB for each processor core [28].
z If the application, such as vortex, need only short computation time and the
computation can be finished before the first context switching, the TLB could
keep performance from decreasing.
z The context switching would impact on the TLB performance more seriously if
we increase page size.
GZIP 0 5 10 15 20 25 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 20 40 60 80 100 120 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
VPR GCC CRAFTY PERLBMK VORTEX 0 100 200 300 400 500 600 700 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 50 100 150 200 250 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 10 20 30 40 50 60 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 10 20 30 40 50 60 70 80 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 20 40 60 80 100 120 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 10 20 30 40 50 60 70 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 0.5 1 1.5 2 2.5 3 3.5 4 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.91 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.91 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
TWOLF SWIM LUCAS APPLU EQUAKE 0 20 40 60 80 100 120 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 10 20 30 40 50 60 70 80 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0.98 0.99 1 1.01 1.02 1.03 1.04 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 2 4 6 8 10 12 14 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 1 2 3 4 5 6 7 8 9 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 5 10 15 20 25 30 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 20 40 60 80 100 120 140 160 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 0.2 0.4 0.6 0.81 1.2 1.4 1.6 1.82 4 8 16 32 64 128 256 512 1024 DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 50 100 150 200 250 300 350 400 4 8 16 32 64 128 256 512 1024 ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
MGRID
Figure 7: The relationship between the TLB size and the miss rate with context switching divided by the miss rate without context switching.
GZIP VPR GCC DTLB 0 10 20 30 40 50 60 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 50 100 150 200 250 300 350 400 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
DTLB 0 200 400 600 800 1000 1200 1400 1600 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 200 400 600 800 1000 1200 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
DTLB 0 50 100 150 200 250 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 50 100 150 200 250 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 4 8 16 32 64 128 256 512 1024 TLB Size DTLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
0 20 40 60 80 100 120 140 4 8 16 32 64 128 256 512 1024 TLB Size ITLB Miss Rate (no cnotext switches)
Miss Rate (with cnotext switches)
CRAFTY PERLBMK VORTEX TWOLF SWIM DTLB 0 20 40 60 80 100 120 140 160 180 200 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 20 40 60 80 100 120 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
DTLB 0 1 2 3 4 5 6 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 1 2 3 4 5 6 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
DTLB 0 0.2 0.4 0.6 0.8 1 1.2 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 0.2 0.4 0.6 0.8 1 1.2 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
DTLB 0 50 100 150 200 250 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 50 100 150 200 250 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
DTLB 0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 4 8 16 32 64 128 256 512 1024 TLB Size Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 5 10 15 20 25 30 35 40 45 50 4 8 16 32 64 128 256 512 1024 TLB Size Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
LUCAS
APPLU
EQUAKE
MGRID
Figure 8: The relationship between the page size, TLB size and the miss rate with context switching divided by the miss rate without context switching.
DTLB 0 5 10 15 20 25 30 35 40 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 10 20 30 40 50 60 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
DTLB 1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 50 100 150 200 250 4 8 16 32 64 128 256 512 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
DTLB 0 10 20 30 40 50 60 70 80 90 100 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 100 200 300 400 500 600 700 800 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
DTLB 1 1.1 1.2 1.3 1.4 1.5 1.6 1.7 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
ITLB 0 20 40 60 80 100 120 140 160 180 4 8 16 32 64 128 256 512 1024 TLB Size
4K page size 8K page size 16K page size
Miss Rate (with cnotext switches)
Miss Rate (no cnotext switches)
2.4 Relationships between the Miss Rates,
Page Sizes and TLB Sizes
In this section we will limit the discussion to the relationships between the miss
rates, page sizes and TLB sizes, and will not be concerned with the issue of context
switching. It is well-known that the most important two issues for cache system
performance are to reduce the miss rate and miss penalty. It is almost the same for the
TLB performance. In fact, the most important of all is the miss rate issue. That’s why
we focused on the miss rate in our research. In order to select the suitable page size,
we did some study on the relationships between the miss rates, page sizes and TLB
sizes.
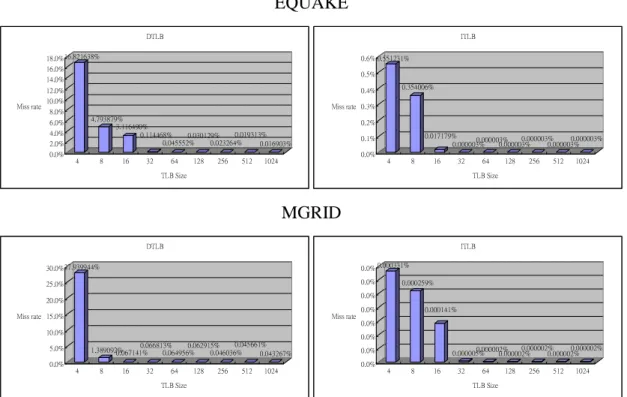
First, we consider the relationship between the miss rate and TLB sizes with
traditional 4KB page sizes. Figure 9 illustrates the relationship between TLB sizes and
the miss rate for twelve SPEC2000 benchmarks.
The Figure 9 tells us that:
z Some applications such as gzip, gcc, crafty, perlbmk, vortex, swim, applu, equake
and mgrid have better performance with sizes over 128 entries.
z For some applications such as the vpr, twolf and lucas benchmarks, it is very
clear that only 64 or less entries are enough and it is helpless to increase the
number of TLB entries.
z These benchmarks seeks to capture the fact that it does not really need to provide
TLB with over 128 or 256 entries with 4KB page size and we can consider what
GZIP VPR GCC CRAFTY PERLBMK 26.051412% 9.414523% 2.605881% 0.000457%0.000020%0.000014%0.000014%0.000014%0.000014% 0.0% 5.0% 10.0% 15.0% 20.0% 25.0% 30.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.264745% 0.000439%0.000119%0.000005%0.000003%0.000003% 0.000003% 0.000003% 0.000003% 0.0% 0.1% 0.1% 0.2% 0.2% 0.3% 0.3% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB 12.522859% 2.355942% 0.561549% 0.022578%0.008764%0.006546%0.006422%0.006241%0.001011% 0.0% 2.0% 4.0% 6.0% 8.0% 10.0% 12.0% 14.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.000191% 0.000081% 0.000028% 0.000005%0.000005%0.000005%0.000005%0.000005%0.000005% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB 23.643239% 10.299283% 4.611126% 2.284842% 0.854234%0.179235%0.034337%0.000708%0.000708% 0.0% 5.0% 10.0% 15.0% 20.0% 25.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.583282% 0.318779% 0.014422% 0.001330%0.000104%0.000040%0.000040%0.000040%0.000040% 0.0% 0.1% 0.2% 0.3% 0.4% 0.5% 0.6% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB 9.997447% 3.727393% 1.252109% 0.308511%0.055602%0.019287%0.014659%0.003731%0.000507% 0.0% 1.0% 2.0% 3.0% 4.0% 5.0% 6.0% 7.0% 8.0% 9.0% 10.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.492205% 0.320007% 0.186461% 0.048003% 0.005662% 0.001399% 0.000167% 0.000058% 0.000058% 0.0% 0.1% 0.1% 0.2% 0.2% 0.3% 0.3% 0.4% 0.4% 0.5% 0.5% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB 16.715474% 6.974124% 2.802387%0.834551% 0.036460%0.006401%0.006309%0.006309%0.006309% 0.0% 2.0% 4.0% 6.0% 8.0% 10.0% 12.0% 14.0% 16.0% 18.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 1.525389% 1.048359% 0.596435% 0.219500% 0.013633%0.002772%0.002734% 0.002734%0.002734% 0.0% 0.2% 0.4% 0.6% 0.8% 1.0% 1.2% 1.4% 1.6% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB
VORTEX TWOLF SWIM LUCAS APPLU 48.089902% 35.231291% 0.348408%0.306035%0.294403%0.294398%0.294393%0.294384%0.287964% 0.0% 5.0% 10.0% 15.0% 20.0% 25.0% 30.0% 35.0% 40.0% 45.0% 50.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.000492% 0.000361% 0.000143% 0.000036%0.000021%0.000021%0.000020%0.000020%0.000020% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB 12.732166% 3.202485% 0.587290%0.001947%0.000075%0.000074%0.000074%0.000074%0.000074% 0.0% 2.0% 4.0% 6.0% 8.0% 10.0% 12.0% 14.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.536178% 0.346814% 0.003395% 0.001617%0.000037%0.000034%0.000034%0.000034%0.000034% 0.0% 0.1% 0.2% 0.3% 0.4% 0.5% 0.6% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB 2.654981% 1.001725% 0.002871%0.002320%0.001234%0.000807%0.000733%0.000733%0.000733% 0.0% 0.5% 1.0% 1.5% 2.0% 2.5% 3.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.770339% 0.513528% 0.354544% 0.000128%0.000098%0.000094%0.000094%0.000094%0.000094% 0.0% 0.1% 0.2% 0.3% 0.4% 0.5% 0.6% 0.7% 0.8% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB 2.116731% 0.466686% 0.093479%0.072942%0.067040%0.062791%0.059014%0.059014%0.059014% 0.0% 0.5% 1.0% 1.5% 2.0% 2.5% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.459231% 0.237901% 0.026081% 0.010087%0.007349%0.007349%0.007349%0.007349%0.007349% 0.0% 0.1% 0.1% 0.2% 0.2% 0.3% 0.3% 0.4% 0.4% 0.5% 0.5% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB 19.608754% 2.121957%0.963909%0.683002% 0.196602%0.196050%0.185343%0.175293%0.123493% 0.0% 2.0% 4.0% 6.0% 8.0% 10.0% 12.0% 14.0% 16.0% 18.0% 20.0% Miss rate 4 8 16 32 64 128 256 512 1024 DTLB 0.022996% 0.000805%0.000506%0.000202%0.000006%0.000004%0.000004% 0.000004%0.000004% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% Miss rate 4 8 16 32 64 128 256 512 1024 ITLB
EQUAKE
MGRID
Figure 9: The relationship between the TLB miss rate and TLB sizes with traditional 4KB page sizes.
Next, we consider the relationships between the miss rates and page sizes.
Another solution to improve the performance of TLB is to extend the page size into
larger one. It is easy to find that some modern processors begin to provide multiple
page sizes, such as 4KB, 2MB and 4MB sizes, on all Intel advanced x86 processors
after the Pentium Pro processor [13]. The advantages of larger page sizes are not only
obtaining better performance but saving the implementation cost with less tags
(virtual page number, VPN) and translations (physical page number, PPN) needed to
be stored. It is also a good method to reduce the cost on TLB implementation of
processors with larger addressing space, such as processors with 64-bit addressing
space. Certainly, it is suitable to implement on the processors core of SoC or
embedded systems.
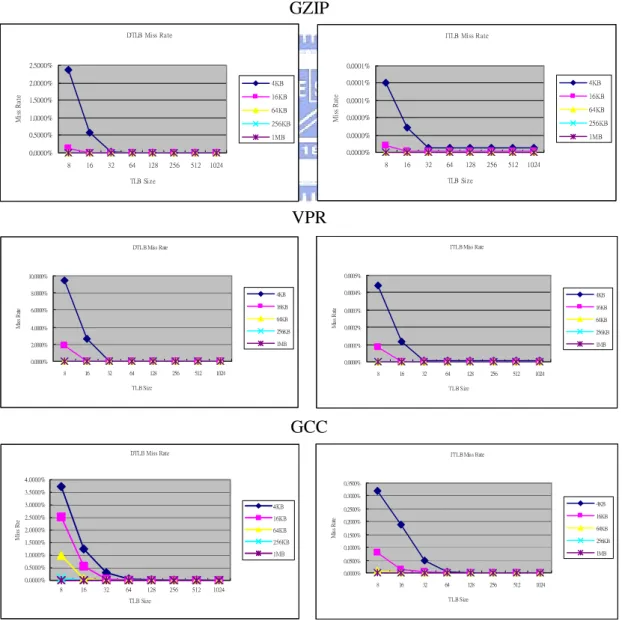
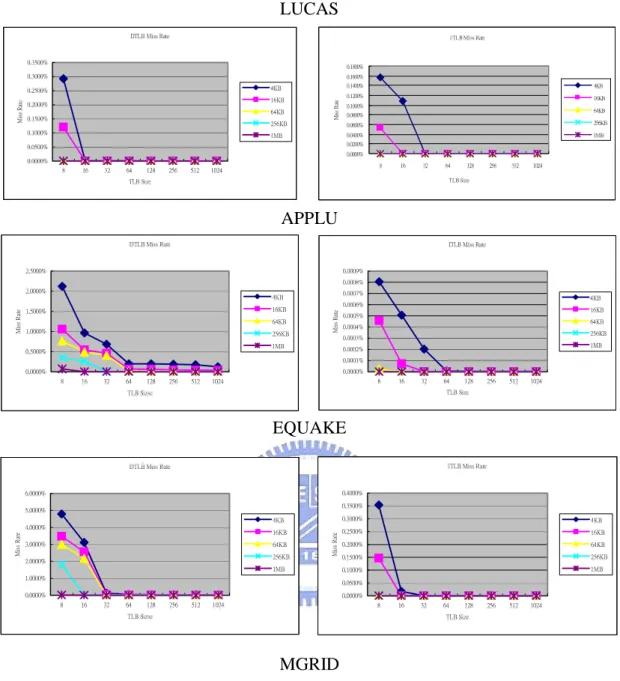
What would happen if we extend the page size to 16KB, 64KB, 256KB and 1MB. 16.821638% 4.793879% 3.116490% 0.114468% 0.045552%0.030129%0.023264%0.019313%0.016903% 0.0% 2.0% 4.0% 6.0% 8.0% 10.0% 12.0% 14.0% 16.0% 18.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.551231% 0.354006% 0.017179% 0.000003%0.000003%0.000003%0.000003%0.000003%0.000003% 0.0% 0.1% 0.2% 0.3% 0.4% 0.5% 0.6% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB 27.939944% 1.389092%0.067141%0.066813%0.064956%0.062915%0.046036%0.045661%0.043267% 0.0% 5.0% 10.0% 15.0% 20.0% 25.0% 30.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size DTLB 0.000331% 0.000259% 0.000141% 0.000005%0.000002%0.000002%0.000002%0.000002%0.000002% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% 0.0% Miss rate 4 8 16 32 64 128 256 512 1024 TLB Size ITLB
Figure 10 below shows the miss rate for twelve SPEC2000 benchmarks of 4KB,
16KB, 64KB, 256KB and 1MB page sizes with eight TLB sizes – 8, 16, 32, 64, 128,
256, 512 and 1024. Observing the results, the figure indicates that for all benchmarks:
z The ITLB/DTLB performance of 1MB (or 256KB) page with eight entries can
greatly outperform that of 4KB page with 256 entries.
z It is helpless to increase the number of TLB entries when we using large page
size for all benchmarks.
z Benchmarks which scatter references across a sparse address have little needs
from large pages without significantly increased memory usage.
GZIP DTLB Miss Rate 0.0000% 0.5000% 1.0000% 1.5000% 2.0000% 2.5000% 8 16 32 64 128 256 512 1024 TLB Size M is s R at e 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0000% 0.0000% 0.0001% 0.0001% 0.0001% 8 16 32 64 128 256 512 1024 TLB Size M is s R at e 4KB 16KB 64KB 256KB 1MB VPR DTLB Miss Rate 0.0000% 2.0000% 4.0000% 6.0000% 8.0000% 10.0000% 8 16 32 64 128 256 512 1024 TLB Size M iss R ate 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0001% 0.0002% 0.0003% 0.0004% 0.0005% 8 16 32 64 128 256 512 1024 TLB Size M iss R ate 4KB 16KB 64KB 256KB 1MB GCC DTLB Miss Rate 0.0000% 0.5000% 1.0000% 1.5000% 2.0000% 2.5000% 3.0000% 3.5000% 4.0000% 8 16 32 64 128 256 512 1024 TLB Size M iss R te 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0500% 0.1000% 0.1500% 0.2000% 0.2500% 0.3000% 0.3500% 8 16 32 64 128 256 512 1024 TLB Size M iss R ate 4KB 16KB 64KB 256KB 1MB
CRAFTY DTLB Miss Rate 0.0000% 2.0000% 4.0000% 6.0000% 8.0000% 10.0000% 12.0000% 8 16 32 64 128 256 512 1024 TLB Size M is s R at e 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0500% 0.1000% 0.1500% 0.2000% 0.2500% 0.3000% 0.3500% 8 16 32 64 128 256 512 1024 TLB Size M is s R at e 4KB 16KB 64KB 256KB 1MB PERLBMK DTLB Miss Rate 0.0000% 1.0000% 2.0000% 3.0000% 4.0000% 5.0000% 6.0000% 7.0000% 8.0000% 8 16 32 64 128 256 512 1024 TLB Sizse M iss R ate 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.2000% 0.4000% 0.6000% 0.8000% 1.0000% 1.2000% 8 16 32 64 128 256 512 1024 TLB Size M iss R at e 4KB 16KB 64KB 256KB 1MB VORTEX DTLB Miss Rate 0.0000% 0.0500% 0.1000% 0.1500% 0.2000% 0.2500% 0.3000% 0.3500% 0.4000% 0.4500% 0.5000% 8 16 32 64 128 256 512 1024 TLB Size M iss R at e 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0500% 0.1000% 0.1500% 0.2000% 0.2500% 8 16 32 64 128 256 512 1024 TLB Size M iss R at e 4KB 16KB 64KB 256KB 1MB TWOLF DTLB Miss Rate 0.0000% 0.5000% 1.0000% 1.5000% 2.0000% 2.5000% 3.0000% 3.5000% 8 16 32 64 128 256 512 1024 TLB Size M iss R at e 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0500% 0.1000% 0.1500% 0.2000% 0.2500% 0.3000% 0.3500% 0.4000% 8 16 32 64 128 256 512 1024 TLB Size M iss R at e 4KB 16KB 64KB 256KB 1MB SWIM DTLB Miss Rate 0.0000% 5.0000% 10.0000% 15.0000% 20.0000% 25.0000% 30.0000% 35.0000% 40.0000% 8 16 32 64 128 256 512 1024 TLB Size M iss R at e 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0001% 0.0001% 0.0002% 0.0002% 0.0003% 0.0003% 0.0004% 0.0004% 8 16 32 64 128 256 512 1024 TLB Size M iss R ate 4KB 16KB 64KB 256KB 1MB
LUCAS DTLB Miss Rate 0.0000% 0.0500% 0.1000% 0.1500% 0.2000% 0.2500% 0.3000% 0.3500% 8 16 32 64 128 256 512 1024 TLB Size M iss R at e 4KB 16KB 64KB 256KB 1MB
ITLB MIss Rate
0.0000% 0.0200% 0.0400% 0.0600% 0.0800% 0.1000% 0.1200% 0.1400% 0.1600% 0.1800% 8 16 32 64 128 256 512 1024 TLB Size M iss R ate 4KB 16KB 64KB 256KB 1MB APPLU DTLB Miss Rate 0.0000% 0.5000% 1.0000% 1.5000% 2.0000% 2.5000% 8 16 32 64 128 256 512 1024 TLB Sizse M iss R at e 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0001% 0.0002% 0.0003% 0.0004% 0.0005% 0.0006% 0.0007% 0.0008% 0.0009% 8 16 32 64 128 256 512 1024 TLB Size M iss R at e 4KB 16KB 64KB 256KB 1MB EQUAKE DTLB Miss Rate 0.0000% 1.0000% 2.0000% 3.0000% 4.0000% 5.0000% 6.0000% 8 16 32 64 128 256 512 1024 TLB Sizse M iss R at e 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0500% 0.1000% 0.1500% 0.2000% 0.2500% 0.3000% 0.3500% 0.4000% 8 16 32 64 128 256 512 1024 TLB Size M iss R at e 4KB 16KB 64KB 256KB 1MB MGRID DTLB Miss Rate 0.0000% 0.2000% 0.4000% 0.6000% 0.8000% 1.0000% 1.2000% 1.4000% 1.6000% 8 16 32 64 128 256 512 1024 TLB Sizse M iss R at e 4KB 16KB 64KB 256KB 1MB
ITLB Miss Rate
0.0000% 0.0001% 0.0001% 0.0002% 0.0002% 0.0003% 0.0003% 8 16 32 64 128 256 512 1024 TLB Sizse M iss R at e 4KB 16KB 64KB 256KB 1MB
Chapter 3
Proposed Mechanisms
Chapter 3 describes in detail with the two TLB structures we proposed for lowcontext switching penalty. Our TLB structures can be implemented not only in
contemporary processors but future processors comprised with one billion of
transistors. Furthermore, they are especially suitable to be implemented on processors
with larger addressing space than current processors with just 32-bit addressing ability.
We will review our original TLB architecture for processors with larger page size
support in Section 3.1. Then, we propose our new TLB architecture with general page
size, such as 4KB, 8KB, or 16KB, in the Section 3.2. Last, we will discuss the
mechanisms of our new novel TLB in Section 3.3.
3.1 The Original TLB Structure with Low
Context Switch Penalty
To reduce the miss rate, most designs just try to increase the TLB size to reduce
the capacity misses; however, we have showed in previous chapter that it is also
helpful if the page sizes can be enlarged. Furthermore, with large page size, we can
make use of more redundant TLB entries to store translation information of other
tasks and the size of tags and translations needed to be stored can be much smaller.
Thus, we used 1MB page size in our design.
3.1.1
Structure
Figure 11 shows in detail our original TLB structure to reduce the miss rate in
TLB banks with group tags, and a multiplexer to select a specific TLB banks.
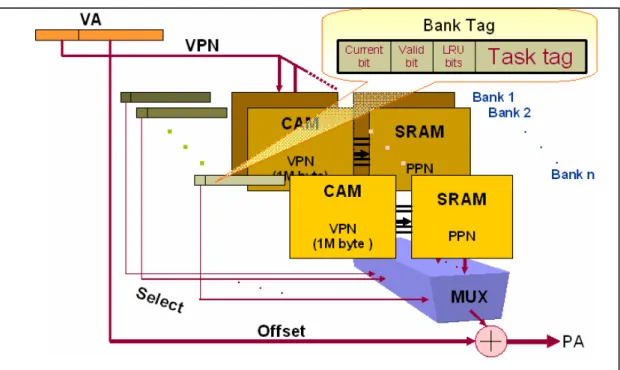
Figure 11: A low context switching miss rate TLB architecture.
Each TLB bank contains eight entries, and the tag can be implemented with
CAM (content addressable memory) which is the same as that being implemented on
conventional TLB. In addition, each TLB bank is implemented with fully associative
with LRU replacement policy. There are total 32 or more TLB banks. Though there
are 32 banks, compared with 256-entry conventional TLB the total cost is not
increased very much. In fact, there are also total 256 (32×8) entries in our original proposed structure. Furthermore, because of larger page size, the cost of each entry is
decreased. Thus the increased cost can be counteracted.
Except the 32 TLB banks, there are also 32 extra registers to store the bank tag
as shown in Figure 3.1. The register contains
z Task tag: Identify each task.
z Current bit: Identify current working task.
We have to point out that the task tag can be PID (process ID) or the PPN
(physical page number) of the executing instruction when context switching occurs.
The PID is selected as task tag on systems that the PID will be sent into the processor;
otherwise, the PPN of the executing instruction when context switch occurs from the
PPN field (or last translation) is selected. Considering the general case, the PPN is
selected; however, the PID can be more easily selected and implemented under the
previous situation. The discussion will be ignored in this thesis.
3.1.2
OS Support and Implementation
In order to implement our original TLB mechanism, the OS is need to do a little
modification. Except larger page size, the OS needs to send ‘the clear TLB signal’ to
the processor only when swapping pages with disks occurs or page frames release.
Fortunately, it is very easy to realize. Most modern processors provide some ways to
flush TLB entries, such as using STA instruction with alternative address on Sparc
processors [22].
3.1.3 Expected Performance
We simulated the twelve SPEC2000 benchmarks to demonstrate the expected
performance. We assumed that the context switching would happen after executing
one million instructions. We compared the miss rates of conventional 256-entry TLB
with flushing all entries after context switching and our novel TLB structure with
8-entry each bank after correctly keeping entries. The page size is 1MB. Figure 12
shows the simulation results of the SPEC2000 benchmarks.
We can find that for most benchmarks we can deliver better performance than
applu and equake benchmarks because the working set of the three benchmarks need
more coverage space of memory mapping than other benchmarks. It is noteworthy
that the vortex benchmark needs only shorter computation time than others, and
therefore has the same performance as conventional TLB.
GZIP VPR GCC CRAFTY DTLB Comparison 0.00000514% 0.00088424% 0.00000000% 0.00020000% 0.00040000% 0.00060000% 0.00080000% 0.00100000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000015% 0.00010008% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.00000053% 0.00082991% 0.00000000% 0.00020000% 0.00040000% 0.00060000% 0.00080000% 0.00100000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000006% 0.00010002% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.00000230% 0.00124329% 0.00000000% 0.00020000% 0.00040000% 0.00060000% 0.00080000% 0.00100000% 0.00120000% 0.00140000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000030% 0.00019796% 0.00000000% 0.00005000% 0.00010000% 0.00015000% 0.00020000% 0.00025000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.00000562% 0.00109438% 0.00000000% 0.00020000% 0.00040000% 0.00060000% 0.00080000% 0.00100000% 0.00120000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000051% 0.00010032% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000%
Novel ITLB Conventional ITLB-256 M
iss ra te
PERLBMK VORTEX TWOLF SWIM LUCAS DTLB Comparison 0.00013916% 0.00083497% 0.00000000% 0.00020000% 0.00040000% 0.00060000% 0.00080000% 0.00100000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00001912% 0.00011472% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000% 0.00014000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 12.40346491% 0.00414461% 0.00000000% 2.00000000% 4.00000000% 6.00000000% 8.00000000% 10.00000000% 12.00000000% 14.00000000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000023% 0.00010012% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.00000340% 0.00088095% 0.00000000% 0.00020000% 0.00040000% 0.00060000% 0.00080000% 0.00100000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000039% 0.00010009% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.00070817% 0.00070817% 0.00000000% 0.00010000% 0.00020000% 0.00030000% 0.00040000% 0.00050000% 0.00060000% 0.00070000% 0.00080000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00014410% 0.00014410% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000% 0.00014000% 0.00016000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.00001164% 0.00090025% 0.00000000% 0.00020000% 0.00040000% 0.00060000% 0.00080000% 0.00100000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000126% 0.00010072% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000%
Novel ITLB Conventional ITLB-256 M
iss ra te
APPLU
EQUAKE
MGRID
Figure 12: DTLB/ITLB miss rate comparison with 1MB page size.
DTLB Comparison 0.00414659% 0.07041661% 0.00000000% 0.01000000% 0.02000000% 0.03000000% 0.04000000% 0.05000000% 0.06000000% 0.07000000% 0.08000000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000006% 0.00010008% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.01383976% 0.00157919% 0.00000000% 0.00200000% 0.00400000% 0.00600000% 0.00800000% 0.01000000% 0.01200000% 0.01400000% 0.01600000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000007% 0.00010005% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.00023415% 0.00123320% 0.00000000% 0.00020000% 0.00040000% 0.00060000% 0.00080000% 0.00100000% 0.00120000% 0.00140000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00000003% 0.00010002% 0.00000000% 0.00002000% 0.00004000% 0.00006000% 0.00008000% 0.00010000% 0.00012000%
Novel ITLB Conventional ITLB-256 M
iss ra te
3.2 The New TLB Structure with Low
Context Switch Penalty
We have surveyed our original TLB mechanism with low context switching
penalty in section 3.1. It works well and has good performance when page size is
large. On the contrary, it works badly with small page size, such as 4KB, 8KB or
16KB page size. We represent the results when using 4KB page size in our original
TLB with 8-entry per bank in Figure 13. As the diagram indicates, the performance
obviously degrades and our original structure is not suitable for small page size.
GZIP VPR GCC DTLB Comparison 0.023559417 0.00020937 0 0.005 0.01 0.015 0.02 0.025 Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 8.06162E-07 5.65191E-06 0 0.000001 0.000002 0.000003 0.000004 0.000005 0.000006
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.094145235 8.98897E-05 0 0.02 0.04 0.06 0.08 0.1 Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 4.38947E-06 8.11576E-06 0 0.000002 0.000004 0.000006 0.000008 0.00001
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.037273927 0.000322012 0 0.005 0.01 0.015 0.02 0.0250.03 0.035 0.04 Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00320007 4.28911E-05 0 0.0005 0.001 0.0015 0.002 0.0025 0.003 0.0035
Novel ITLB Conventional ITLB-256 M
iss ra te
CRAFTY PERLBMK VORTEX TWOLF SWIM DTLB Comparison 0.102992835 0.000825084 0 0.02 0.04 0.06 0.08 0.1 0.12 Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.003187791 2.57409E-05 0 0.0005 0.001 0.0015 0.002 0.0025 0.003 0.0035
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.069741239 0.000255129 0 0.01 0.02 0.03 0.04 0.05 0.06 0.07 0.08 Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.010483593 0.000102675 0 0.002 0.004 0.006 0.008 0.01 0.012
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.004666863 0.000590145 0 0.001 0.002 0.003 0.004 0.005 Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.002379011 7.34885E-05 0 0.0005 0.001 0.0015 0.002 0.0025
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.032024853 8.43307E-05 0 0.005 0.01 0.015 0.02 0.025 0.03 0.035 Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.003468143 2.68246E-05 0 0.0005 0.001 0.0015 0.002 0.00250.003 0.0035 0.004
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 0.352312907 0.002983162 0 0.050.1 0.15 0.2 0.250.3 0.35 0.4 M iss ra te ITLB Comparison 3.60843E-06 2.67446E-06 0 0.00000050.000001 0.0000015 0.000002 0.00000250.000003 0.0000035 0.000004 M iss ra te
LUCAS
APPLU
EQUAKE
MGRID
Figure 13: TLB miss rate comparison with 4KB page size.
This section presents our second novel TLB structure designed which is targeted
toward using small page improving the limitation in the original design. Although
using large page size can have better coverage of memory space and the translation
needed to be stored can be smaller, it also waste memory due to internal
DTLB Comparison 0.010017251 6.17372E-05 0 0.002 0.004 0.006 0.008 0.01 0.012 Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.005135275 2.56594E-05 0 0.001 0.002 0.003 0.004 0.005 0.006
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 2.12195705% 0.19153414% 0.00000000% 0.50000000% 1.00000000% 1.50000000% 2.00000000% 2.50000000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00080513% 0.00052773% 0.00000000% 0.00020000% 0.00040000% 0.00060000% 0.00080000% 0.00100000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 4.79387851% 0.03246184% 0.00000000% 1.00000000% 2.00000000% 3.00000000% 4.00000000% 5.00000000% 6.00000000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.35400634% 0.00099221% 0.00000000% 0.05000000% 0.10000000% 0.15000000% 0.20000000% 0.25000000% 0.30000000% 0.35000000% 0.40000000%
Novel ITLB Conventional ITLB-256 M iss ra te DTLB Comparison 1.38909159% 0.06294093% 0.00000000% 0.20000000% 0.40000000% 0.60000000% 0.80000000% 1.00000000% 1.20000000% 1.40000000% 1.60000000% Novel DTLB Conventional DTLB-256 M iss ra te ITLB Comparison 0.00025921% 0.00028948% 0.00024000% 0.00025000% 0.00026000% 0.00027000% 0.00028000% 0.00029000% 0.00030000%
Novel ITLB Conventional ITLB-256 M
iss ra te
fragmentation and most modern OS only support small page size under
multiprogramming environment. Our new proposed TLB is not only capable of
reducing miss rate in context switches with small page size but supporting multiple
page sizes. Further, the hardware cost in our new design is almost as same as the
conventional TLB.
3.2.1
Overview
Our new TLB structure combines both the features of Lee’s dual TLB [17] [18]
and our original TLB [6] with many TLB banks. We use a shared conventional small
page (4KB size) TLB and many large page (16KB size) promotion-TLB banks. The
difference compared to our original design is that only the shared TLB need to be
flushed when context switching. The shared TLB works together with only one of the
promotion-TLB banks at a time. The TLB banks can keep from flushing when context
switching. As a result, we can reduce the miss rate in context switches with small
page size because the shared TLB can effectively reduce the miss rate. The remainder
of this section we will present our new TLB structure, implementations and
3.2.2
Proposed TLB Structure
Figure 14 shows in detail our new novel TLB structure to reduce miss rate in
context switch. The proposed structure can be broken down into four parts to discuss:
Figure 14: New proposed TLB architecture with low context switching penalty.
1. The Shared TLB and the promotion-TLB banks
Only one of the promotion-TLB banks can work together with the shared TLB at
the same time. The shared TLB and all the promotion-TLB banks are designed as
fully associative structures. The shared TLB is the same as that being implemented on
conventional TLB while the promotion-TLB banks are all implemented as the
complete-subblock TLBs.
The shared TLB is constructed as a set of m page entries, where the page size is
page entries, i.e., 16KB. Thus the total number of 4KB page entries is
m+n×(16KB/4KB)×the number of banks in this example.
In our novel TLB structure we assume that the m is 128, n is 2 and total 4KB
page entries is 256. In other words, our structure has 16 promotion-TLB banks. In
comparison with the conventional 256-entry TLB, the area cost does not increased
very much although we add 16 bank tag registers, multiplexers and de-multiplexers.
The reason is that we use complete-subblock TLB structure in our promotion-TLB
banks which several based pages are managed with one TLB tag such that the total
increased cost can be ignored.
In addition, it should also be added that the shared TLB can also work as the
victim cache. When the least recently used entry would be evicted from the current
TLB bank, the large page entry would be broken down many small page entries and
then sent back to the shared TLB through control logic. We do this action while one
virtual address misses in both the shared TLB and the current bank TLB. We have
sufficient time to do it because fetching the translation from main memory needs more
time.
2. Control logic
The control logic has two functions. The one is that it requests the memory
system for the translation when both shared TLB and current bank TLB miss. Then,
the control logic will send the translation to shared TLB when getting it. The other is
that it sends the evicted entry from current bank TLB back to the shared TLB.
3. Multiplexers and de-multiplexers
The multiplexers and de-multiplexers are used to select right current bank TLB.
4. Bank tag registers
Each bank TLB has its own bank tag register. The behavior of the bank tag
registers are the same as of our original TLB structure as described in Section 3.1. It
consists of four parts:
z Task tag: Identify each task.
z Current bit: Identify current working task.
z Valid bit: Validate/Invalidate a bank.
z LRU bits: Replace the victim bank.
3.2.3
Implementation of the novel TLB
As our original TLB design, in order to realize our new proposed mechanism, the
OS is just needed to do a little modification. The OS needs to send ‘the clear TLB
signal’ to the processor only when swapping page with disk occurs or page frames
release.
3.2.4
Mechanisms of the novel TLB
The mechanisms of the novel TLB can be divided into four situations to
consider:
1) Task matching in one of the bank tag registers.
Once the virtual address is generated from the CPU, the virtual page number is
sent to the shared TLB and all TLB banks at the same time. The shared TLB works
the same as conventional TLB and each bank works the same as the
complete-subblock TLB. In addition, the select signals are obtained from the current
bit of all group tags in order to select right bank. The possible three cases are:
are all 16KB page size in this example.)
z Hit in the shared TLB.
If the VPN is found in the shared page TLB, the actions are the same as any
conventional TLB hit. Then, the requested physical address would be sent to the
cache.
z Hit in a bank TLB which is current working.
If a hit occurs at a bank TLB which is current bank, only one of four PPNs in the
bank TLB is enabled at the same time. The actions are the same as any
complete-subblock TLB hit. Then, as in the case of the shared TLB hit, the requested
physical address would be sent to the cache.
z Miss in both places.
When one virtual address misses in both the shared TLB and the current bank
TLB, O/S perform miss handling. When a TLB miss occurs and if its corresponding
three sequential VPNs exist in the shared TLB, those four sequential VPNs belonging
to a 16KB page boundary are chosen to be promoted. The 16KB page is stored into
the current bank TLB as a new single entry. And also the three sequential VPNs in the
shared TLB are invalidated at the same time, causing to increase the effective entry
space in the shared TLB.
What has to be noticed is that we did some difference from Lee et al. When the
space of the current working bank is not enough, the least recently used entry has to
be discarded in Lee et al. But we divide the large page into four small page entries and
send back to the shared TLB through control logic to reuse them. The reason is that
the bank TLB usually have higher hit rate than the shared TLB and we can get better