Optimal Data Mapping for Motion
Compensation
in
1.264
Video
Decoding
Guo-Shiuan Yu, and Tian SheuanChang Dep.ElectronicsEngineering, NationalChiao-TungUniversity,
1001 Ta-Hsueh Rd., Hsinchu, Taiwan e-mail: {isis,tschang} @twins.ee.nctu.edu.tw
doesn't take the memory operation scheduling into Abstract- Long initial access cycles of SDRAM arethemajor consideration. With careful scheduling, extra bandwidth due to performance burden of motioncompensationina video decoder. page active operation can be reduced.
To minimize its effect while improve overall available memory Inthis paper, we combine the data
mapping
andoperation
bandwidth, thispaper presentsanoptimaldata mappingscheme cycles
for motion compensation in H.264 video coding. This scheme
scheduling
ineourdesign
toeminimizeqthe SDRAMinitial
cycles
allocates the video data into suitable address and bankaccording and thus decrease the bandwidth requirement for real-time to the access characteristics of SDRAM access and address
decoding.
To find theoptimal
mapping,
we firstuse asimple
transition in motion compensation. The resulted allocation can analyticalmodeltofind thebestdata mappingintheory andin reduce the requiredbandwidth of motioncompensation by36% practice. Then, we use real video sequences to validate the whencomparedtothepreviousdesign for 525SD videosequences. mapping.
Furthermore,
we do notonly
consider the accesswithin a single motion compensation operation for a block (called intra request), which has
high
probabilities
for I. INTRODUCTION continuous address, but also consider the accessbetween the Memory access dominates the performance in a video blocks (called inter request) by operation scheduling. The decoder,especially inmotioncompensation.
In atypical
video resulted design can save37%
ofmemorybandwidthcompared decoder, motion compensation unit will access therequired
with the previousapproaches.reference data from external SDRAM systems. However, a Therest of the paper is organized as follows. First, we brief typicalSDARM accessconsists ofa
long
initialcycle
toopena overview the motion compensation inH.264 video decoding memory row followed by continuous addressed burst access. and SDRAM memory accessinSectionII.
Thenwe presentour Thus,ifthe memoryaccesshas discontinuousaddresses,
it will analytical model for intra request and its simulated results in suffer frequent initialcycles
and thus results inperformance
SectionIII. Furthermore,
we presentouroperation scheduling degradation andlarger
memory bandwidth.Thus,
how tofor
interrequest in Section IV. Thefinal simulationresults are allocate the datatothephysical
SDRAM is animportant
task shown in Section V. Finally, we conclude this paper in Sectionfor video decoder. VI.
Targeted to video codec
applications,
many papers havebeenproposedto
improve
SDRAMbandwidth utilization andII.
OVERVIEWachieve efficient memory access. Li
[1]
develops
a busarbitration algorithm
optimized
with differentprocessing
unit A. Basicsof
SDRAMaccessto meet the real-time
performance.
Ling's
controller[2]
schedulesDRAMaccessesin
pre-determined
ordertolower thepeak bus bandwidth. Kim's memory interface
[3]
adopts
an Cycle 1 2 3 4 5 6 7 8 9 10array-translation
technique
to reducepowerconsumption
andRowMiss
Cteincrease memory bandwidth. Park's
history-based
memory precharge active col access(read)controller
[4]
reduces page break to achieve energy andlP
tRwM
burstlenth
memorylatencyreduction. Precharge ColumnAccess precharge active colaccess(write)
For H.264
application,
Kang's
AHB based scalable bus P o Bank Miss tRCD burstlength architecture and dualmemorycontroller[5]
supports 1080SD aIDLEc
oACTIVE'
a olaccess(write)
under13OMHz. Zhu'sSDRAM
controller[6]
employs
the main burst lengthidea of Kim's memory interface to HDTV
application.
It Active col access(wnite)focuses on data arrangement and memory
mapping
toreduce (a) (b)pageactive overheads sothat itnot
only
improve
throughput
agram,
A (b) a- atncis obut also provides lower power consumption. However, it different access
statuses.[7].
Thecycle for acomplete SDRAM accessdeeplydependson For constantdatalengthN,largersize ofrow meansfewerrow the state ofthe bank addressedbythe SDRAMaccess.Fig.
1(a)
miss and thelonger
datalength
leads tohigher
row-miss and Fig. l(b) show a simplified bank state diagram and the probabilitywith fixedrowsize.Extending
above observations accesslatencies duetodifferentaccess statuses:bankmiss,row to2-Ddomain,
the totalrowmiss with horizontalrowmiss and miss, and row hit. From a data access viewpoint, low cycle verticalrowmiss iscountintherowhit condition ispreferredthan those in bank
NX
-1Ny
-1(2)
missand row miss.Thus, howtominimize such miss is critical Prow-mis-2D
Ly
in SDRAM performance. A more completed discussion on where
Lx,
andLy
denote thelength
of memory window in various accesslatencies ofaSDRAM access canbe found in horizontal and verticalrespectively.
However, therow size isLee's paper[7]. fixedfor a certain type of SDRAM, which implies
LX*LY
B. Memory access in motion compensation Thus,the width and height ofthe rowwindow areaffected each Forvideoapplications, the memory request isusuallytogeta other. Therowmissprobability should be adjusted as follows: determined size ofrectangle image from frame memory like
NX
-1Ny-I
Q*(Nx-1)+LX2
*(Ny
-1)
(3)Pro-nis2D ±
those inmotioncompensation, intra prediction anddeblocking LX Q ILX Lx*Q
filter process.These data are continuous inspatialdomain and whereNx,
Ny,
Lx>0 and Q denotes the row size. For worst thearea wemay requestbetweentwoconsecutive blocks has case,Nx=Ny
is equal to the maximum data length. Thus, thehigh probability to be overlapped. For instance, when we row-miss probability has the minimum value when Lx is equal processmotioncompensation, therequireddata is boundedby to
[.
its block size and search range set during encoding. Ifthe Above formula is quite simplified. To be practical, we search range is L and the block length is N, a 2L
by
2L+N furtherconsider the characteristics of real video sequences. In rectangleisoverlapped.Datainthisregionhashighprobability H.264the data length we may request for motion compensation intheopenedbank duetopreviousblockaccess.Thuswe can is 4,8,9, 13, 16and 21 pixels according to its block modes and find a method to avoid therowmiss and improve bandwidth sub-pixel motion vectors. Besides, the probability of starting utilization. Fig. 2 illustrates an example toexplain
this pointdoes not distribute uniformly in many video sequences.characteristic. Theposition number that is divisible by 4, which means the oth,
4th
8th,12th
.4kth
..pixels
ofrow window invertical or inTheareafor blocko
horizontal,
hashigher probability
to appear.Generally
Theareawemay Theuareawemay fo
(2L+N)*(2L+N)
speaking,
P4kiS 1.5to2.5timeslarger
than othersaccording
toour
simulation,
where P4k denotes theprobability
ofOth,
4th
8th
Theareafor block1;12th
4kh
..positions.
This is because the smallest block(2L+N)*(2L+N)
length
is 4 and the effect ofzeromotionvector.The blocks withzero motion vectors are
usually
referenced forbackground
Block 0 BlockI Theoverlappedarea:
image.
Forlarger quantization
parameter,this effect becomes(2L)*(2L-N) more
significant.
Thus,
the row missprobability
of H.264Theoverlapped
area motioncompensation
isLx Ly
o < o Prow-miss-Ac (PNx 2
Pn)
+ L (PNY ZPm)SearchrangeLBlock L Nx=4,8,9,13,16,21 n=Lx-Nx+l NY=478,9,13,16,21 m=Ly-Ny+1
Search range L lengthNL
5*PNX4
+11*PX9 +10*PX8
+16*PNX13+20*PX16+25*PNX21Fig.2.Possiblerequiredareabetweenadjacentblocks LX +LX/4
5*PNy4
+11*PN +10* PY+16*PNY13 +20*PNY16
+25*PNY2l
(4)III. INTRAREQUESTOPTIMIZATION LY +LY/4
A. Analyticalanalysis
Accordingtothe characteristics ofvideodata,we canderive where the
PNX4
is
theprobability
of datalength equal
to4pixels
the translation betweenphysicallocation in memory andpixel
in horizontal and we assume P4kis
twice than others forcoordinates inspatialdomaintoreduce therowmiss.
simplification.
To easeanalysis without loss ofgenerality,wedegradethis
Combining Eq.
(4)
with simulationstatistics,
we canfind the2-D problem to 1-D domain. Assume that a SDRAM row rowmiss
probability
function iscontains L pixels and N continuous data are
requested.
The 16.866* Q +16.133*L(5
situation ofrowmiss could beasfollows.Forthecasewithout * Q
rowmisses,thestarting pointshall lie in the firstL-N
position
For L>0,
this function has a minimum vale when Lxequal
oftherow.However,ifthe
starting points
lie in lastN-Ipixels,
xrow miss happened. Assuming the probability of starting point to 1 0Q. A typicalQ~, row size of a SDRAM, can be 16384, position is uniform distributed, the probability of row miss is 8192or 4096 bits, which is 2048, 1024 or 512 pixels. For our
_N-i
(1) targeted SDRAM, 2048 pixels in a row, the optimized windowPo-isl-L
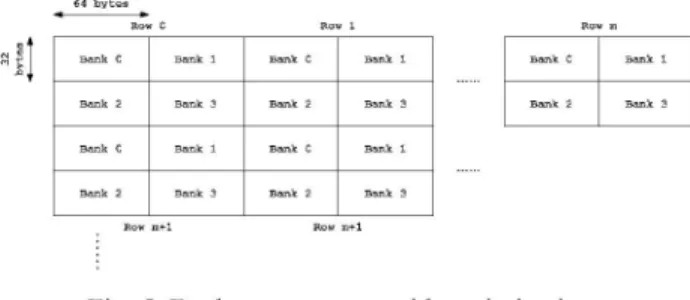
size should be a 46x44 rectangle. However, it is hard toimplement the translation with the 46x44 windows.Weadjust 64bytesR..C R..I R..
the window size to 64x32. Because 32 and 64 are
powers
of2,
N
c
1
the translationcanbeeasily implemented with bit shift. > ...
~~~~~~~~~~~~~~~~~~~. .Bak2 Ban.k < Bank, Bank Bank, Bank
B. Simulation results
IBank C Ban.kI Ban.k C BankI
Fig. 3 shows the statistics ofrowmiss in different window ...
size. Thetestsequences are crew,night,sailormen, and harbour B___k2
Bank
_Bank
Bak_2
in 525 SD frame size. Comparing with the linear translation like lx2048 and 2048xl window size, the 64x32 mapping
reduces about 84% of row miss rate. Compared with the Fig. 5. Bank arrangement with optimization optimal 46x44 mapping, the 64x32 mapping has slightly low
rowmiss dueto morefrequent horizontal motion and 4x4 block With the data arrangement mentioned before, the size. The rowswith large size candecrease the
probability
of requests can be classified to three kinds as shown in Fig. 6, by rowbreak, thus the32x32window hashigherrowmisscount assuming open all required rows at the beginning of every than 64x32. Due to the video sequencescharacteristics,
the request to reduce the control overhead and ease the hardware occurrence of horizontal break is morefrequent than vertical. design.Thus, the64x32mappingcanleadtobetterperformance.
Case 1:all dataofsingleaccessarecontainedina row.
row missprob. in different windows Itis clear that thiscaseintroducesno rowmiss, since all the 70 datatobe
requested
arestoredina row.Thememoryoperation
60 contains therowactivation, data reading and precharging. Fig.
50 2 0 4 7shows the
operations
undercase 1. L+4cycles
areneededto40 C 64x32
complete
thisaccess,whereLdenotes the number of accessed30 *32x64 data.
20 _ 312048
10 Case 2:all data
ofsingle
access arecontainedintworows.The0 qp6
_
q4l
data may be discontinuous in horizontal or in vertical as*2048xl 44.83032999 47.24833619 54.99977362 illustrated inFig.6.
*64x32 6.820379894 7.529893801 9.3924985 Inthis
case,
we suffer two row miss since the accessed data 046x44 6.778230921 7.545193255 9.533249351032x64 6.846469165 7.60661285 9.521609834 are contained in different rows. However, they are in different
E32x32 7.403632408 8.116680411 9.96107406
E31x2048 44.8864127 49.0488445 58.74551384 banks. Wecanshorten the
latency
with bankalternating
access. Fig. 7 shows the operations ofcase 2. We openthe rows weFig.
3. Miss rateindifferentrowwindows mayaccess,
read the data indetermined
order and then precharge the openedrow.TotalcyclecountisL+5.Imagep-sitio inspatiald-min _ R..0
R..0 R..CR. 0 Bank 1
< 8 | ~~~~~~~~~~~~~~~Bank
2 Bank 3 | Bank 1l201Ell
(L~~ ~~ ~ ~ ~ ~ ~ ~ ~DtDaalction1.. inSDRAM
Rowk Row k+1
64 Case 1 Case 2 Case 3
Fig.4.Translation ofphysical location and
image position
Fig.6.Request classification C. ThememorymappingsandoperationsFig. 4 illustrates the mapping between
physical
location in Case 3: all dataofsingle
accessare storedinfour
rows. Thememoryand image positionin spatial domain. The
latency
of data breakinhorizontal and verticalasillustratedinFig.
6.singlerequestcanbe reduced with bank
interleaving operation
Four row breaks are encountered in this case. Due to theasshownin
Fig.
5. limitation of SDRAM accesscycle,
onecycle latency
isintroduced to meet timing requirement.
Fig.
7 illustrates the operations. The number of totalcycles
isL+7.__________ .__ V. SIMULATION RESULTS
L4_ With above intra and inter request optimization, we can
C...2
AG
C A A Aefficiently
reduce the miss rate from 6.8%(without
inter-request optimization) to 1.8% from simulation. Table I
C...3 ATOATRDARAACRARA RAREO shows the
comparisons
ofbandwidth
requirement
with otherdesigns, while the data of [6] is from our implementation. Our proposed scheme can reduce extra memory access overhead, Fig. 7. Request operations in different cases needs less time to transfer data, and thus save
37%
ofbandwidth compared to Zhu's design at 525SD video size. The probability distribution ofthese cases is shown in Fig. 8.
With the increasing quantization parameters, the cross-bank TABLEI. COMPARISONS OF BANDWIDTH REQUIREMENT.
casesdecreaserapidlydueto more zero motionvectorinhigh
QP. Besides, this result also shows that case 1 occurs most in Scheme Format Bandwidth (MBps)
totalaccesses. This means we usually only needtoopen one proposed QCIF 2.60
row in a single request and thus reduce extra bandwidth CIF 12.00
requirement.
525SD
46.96bank cross distribution 720HD 135.54
100%
Zhu[6]
525SD 73.8590.%
m
______________
720HD
187.25
700 VI. CONCLUSION
50- *c 2 This paper presents an optimal data mapping for motion
40% compensation used in H.264 video coding. Our scheme can
30%
~~~~~~~~~~save
3700 of memory bandwidth when compared to the20% previousapproach.This schemecanbe
applied
tothe memory0% controller
design
and can co-work with the selectedqp20 qp32 qp4O on-chip-bus.Besides,this schemecanbe also appliedtoother
Oae31.763961321 1.536542139 1.088995216 B sds a p le
Mcase 2 23.55624675 20.01307293 14.54669593 types of memory access in videodecoding since these types are
*case 1 74.67979193 78.45038493 84.36430885
subset of thatin motion compensation. Fig. 8. Distribution of access types
Acknolwedgement
This research is sponsored by National Science Council, Taiwan, R.O.C., under grant NSC-922215-E-009-014.
IV. INTERREQUESTOPTIMIZATION
In intra-request optimization, we have determined the REFERENCES
optimizeddatamappingtoreduce therowmisses.Furthermore, [1] J.-H. Li, N. Ling, "Architecture and bus-arbitration schemes for MPEG-2
for successive requests, therequesteddata hashigh probability videodecoder,"IEEE TransactiononCircuits andSystemsforVideo
tobe stored in the same row dueto overlappedsearch range. Technology, vol. 9, pp.727-736, Aug. 1999
Thisaccess canget thesamebenefitasthe intrarequest without [2] N.
Ling,
N.-T.Wang,
D.-J.Ho,
"An efficient controller scheme for MPEG-2videodecoder,"IEEETransaction onConsumerElectronics, vol.any rowmiss. However, there is still acertain amountof data 44, pp.451-458, May 1998
stored in different rows. Thusrow miss willoccur ifclosing [3] H.Kim,I.-C.Park, "High-performanceandlow-power memory-interface
unused rows by precharging the banks and opening the new architecture for video processing applications," IEEE Transactionon
rows.T ds
oCircuits
andSystems for VideoTechnology,vol. 11,pp.1160-1170,rows. To reduce such rowmisses,we shallconsiderwhenand Nov. 2001
how to close the rowby precharing. [4] S.-I.Park, Y. Yi,I.-C.Park, "Highperformance memory mode control for There are two types ofprecharge command, precharge all HDTVdecoders,"IEEETransaction on ConsumerElectronics,vol.49,
banks or precharge single bank. Precharing each bank pp.1348-1353, Nov. 2003
separately is preferred to easily reduce row miss. However, [5] H.-Y.Kang,K.-A.Jeong,J.-Y.Bae,Y.-S.Lee, S.-H.Lee,"MPEG4
indivia
pAVC/H.264
decoder with scalable bus architecture and dualmemoryindividual precharging has overheads to send more explicit controller,"proc.International Symposium on Circuits and Systems, vol. commands toclose corresponding rows. Incontrast, only one 2, pp. II-145-8, May2004
command is needed for all banksprecharging.Withsinglebank [6] J. Zhu, L. Hou, W. Wu, R. Wang, C. Huang, J.-T. Li, "HighPerformance
precharging, we can save one rowbreak fromtworowbreaks SynchronousDRAMs ControllerinH.264 HDTVDecoder",proc.
to
break,
which is relatively small when compared with the International ConferenceonSolid-State andIntegrated Circuitsto one break, which is relatively small when compared with the Technology, vol. 3, pp. 1621 - 1624, Oct. 2004
onefromonebreakto zerobreak. The actualgain bysimulation [7] K.-B. Lee and C.-W. Jen, "Design and verification for configurable
is about0.10%in total memory access cycles. The benefit is so memory controller - Memory interface socket soft IP," Journal of the small that we can neglect it. Thus, we choose all banks Chinese Institute of Electrical Engineering, vol. 8, no. 4, pp.309-323, precharging as our solution considering the hardware control 2001.
cost and bandwidth performance.