A watermarking technique based on JPEG quantization table
5
0
0
全文
(2) q_table[i] = stdard_table[i] * quality / 100;. 2: THE PROPOSED SCHEME With the characteristics of the JPEG standard quantization table, we proposed a scheme to embed the watermark into the DCT coefficients of the host image. When an image suffers JPEG compression, it is transformed into frequency domain by the DCT transformation. And for compressing, these DCT coefficients are quantized by the quantization table. Using the correlation between the coefficients which are quantized by the same scale elements, our scheme is robust under JPEG compression attack.. where the q_table[i] and the stdard_table[i] are the elements on the ith position of the derived quantization table and the standard quantization table respectively. When the JPEG compression ratio is less or equal to 0, the quality in Eq. (1) will be set to 1. When the JPEG compression ratio is more than 100, the quality in Eq. (1) will be set to 100. Form the formula above, some conclusions can be drawn: z. 2.1: EMBEDDING PROCESS The standard JPEG 8 × 8 quantization table is shown in Fig. 1.. z. z. z. Fig. 1. JPEG standard quantization table Observing the table, we find that there are pairs of quantization scales which have the same value. For example, in the position (1,0) and (1,1) are both “12”, in the position (5,0) and (2,3) are both “24”, and in (4,1) and (3,2) are both “22”. When the JPEG compression ratio is 50, the DCT coefficients are quantized by the standard table as shown in Fig. 1. The DCT coefficients corresponding to those pairs will be divided by the same magnitude. Other compression ratios use different quantization tables. But those quantization tables are all derived from the standard quantization table. For the JPEG compression ratio is between 0 and 100, the formula used to derive the other tables is as following. quality = the JPEG compression ratio; if (quality < 50) quality = 5000 / quality; else quality = 200 - quality*2;. (1) (2) (3). (4). If a pair of positions with the same value in the JPEG standard quantization table, then they will have the same value in the quantization table for other compression ratios too. From Eq. (2) & (4), if the compression ratio is less than 50, the scale elements in the derived quantization table will be larger than the original ones in the standard quantization table when comparing elements of the same position. From Eq. (3) & (4), if the compression ratio is larger than 50, the derived scale elements in quantization table will be smaller than the original ones in the standard quantization table when comparing elements of the same position. If the compression ratio is low, then the image after decompressed will lose more details. In general, an image, to have acceptable image quality after decompressed, hardly has compression ratio smaller than 50.. Based on these observations, the proposed scheme hides one watermark bit in each pair of the positions with the same scale element. In an 8 x 8 block, let two DCT coefficients S1 and S2 be located at the positions which have the same quantization scale Q in the standard quantization table. If the embedded bit is “1”, alter the values of S1 and S2, when needed, to make sure that Eq. (5) is satisfied. Similarly, if the embedded bit is “0”, alter the values of S1 and S2, when needed, to make sure that Eq. (6) is satisfied. |S1΄| ≥ |S2΄| + Δ.. (5). |S1΄| < | S2΄| - Δ.. (6). where S1΄ and S2΄ are the altered S1 and S2 respectively, and Δ is a reference threshold, in here Q*60% is defined as Δ. When the watermarked image is processed by JPEG compression, S1΄ and S2΄ will be both quantized by Q’ and become S1˝ and S2˝. Q’ is the quantization scale of the desired JPEG compression ration. Without loss of generality, assume the compression ratio is larger than 50, i.e., Q’ is smaller than Q. Then the following. - 1169 -.
(3) relations (7), (8) hold for they are both quantized by a magnitude smaller than Q. |S1΄| ≥ |S2΄| + Δ. implies. |S1˝| ≥ |S2˝|. (7). |S1΄| < | S2΄| - Δ. implies. |S1˝| ≤ |S2˝|. (8) z. Considering the robustness and transparency, we embed two bits into an 8 x 8 block. In here, medium frequency positions [(5,0) , (2,3)] and [ (4,1) , (3,2)] are chosen such that each pair corresponds to the same quantization scale in Fig. (1). Moreover, to increase the imperceptibility further, the theory of Human Visual System (HVS) is adopted. Human eye is sensitive to the noise in smooth area, horizontal, and vertical lines, but less sensitive to the noise in textured area or lines of ± 45º. So we perform the edge detection of ± 45º lines on the host image, and count the edge points in each 8 × 8 block. Assume the watermark size is M x N, then ⎡MN/2⎤ candidate blocks with more edge points are chosen for embedding. Since DCT transform is applied on luminance components, if the host image is a color image, transform the RGB model to the YUV model first. Then the embedding processing is executed in the luminance component Y. Following is the detail procedure of our scheme: z z. z z. To extract the watermark, we need to know which blocks are candidate blocks. But the original image and the watermark are not required. Following is the detail for extracting the watermark:. Perform the edge detection of ± 45º lines to the host image. Count the number of edge points for each 8 × 8 block, and N/2 blocks with more edge points are marked as candidate blocks for embedding, if the watermark size is N. Transform the host image to frequency domain by DCT transformation. In the candidate blocks, manipulate the coefficients in position [(5,0),(2,3)] and [(4,1) , (3,2)] if needed, to embed two bits into a candidate block. Let S1 and S2 represent the DCT coefficients in position (5,0) and (2,3) (or (4,1) and (3,2)) respectively:. z. Perform DCT transformation to the watermark image. In candidate blocks, check the coefficients in position pairs [(5,0), (2,3)] and [(4,1) , (3,2)]. If the coefficient in position (5,0) (or (4, 1)) is larger than or equal to the one in (2,3) (or (3, 2)), then bit “1” is extracted. If the coefficient in position (5,0) (or (4, 1)) is smaller than the one in (2,3) (or (3, 2)), then bit “0” is extracted.. 3: EXPERIMENTAL RESULTS Four color images of size 512 x 512 are used as host images and the watermark is a binary image of size 64 x 64, as shown in Fig. 2 and Fig. 3, respectively. In order to evaluate the performance of our scheme and compare with relative works, the peak signal-to-noise ratio (PSNR) value for imperceptibility, error rate and normalized correlation (NC) value, as in Eq. (9)- (11), for robustness against attacks are used. W( i , j ) and W'( i , j ) are the original watermark and the extracted watermark, and M × N and H ×W are the sizes of the watermark and the host image. For calculation in Eq. (11), bits in W and W' are considered as 1 or -1.. (a) Lena. (b) Baboon. If the embedded bit is “1”: If |S1| ≥ |S2| + Δ, then no modification is required. Else, adjust both S1 and S2 by the amount of Δ/2 to make sure Eq. (5) is satisfied. If the embedded bit is “0”: If |S1| < |S2| - Δ, then no modification is required. Else, adjust those two values to make sure Eq. (6) is satisfied. z. (c) Airplane. (d) Sail boat. Fig. 2. 512 × 512 host images. Perform inverse DCT (IDCT) to obtain the watermarked image.. 2.2: EXTRACTING PROCESS. Fig. 3. 64 × 64 binary watermark. - 1170 -.
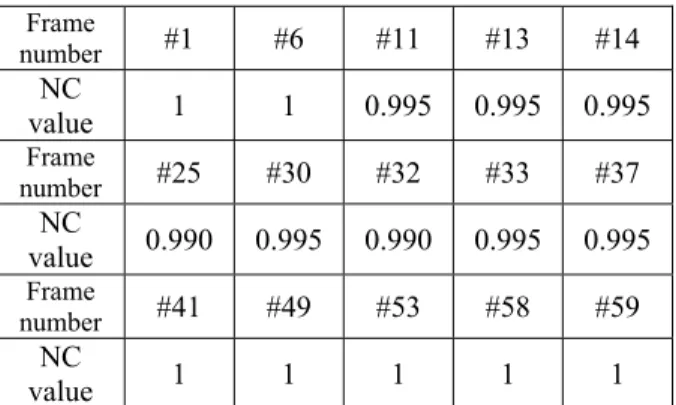
(4) PSNR = 10 log 10. 255 2 MSE. (9). where. ∑ ∑ (( R H −1 W −1. MSE =. ij. i =0 j =0. − Rij ) 2 + (Gij − Gij ) 2 + ( Bij − Bij ) 2. ). 3× H ×W N −1 M −1. ErrorRate =. ∑ ∑W (i, j ) ⊕ W ′(i, j ) i = 0 j =0. (10). N ×M. N −1 M −1. NC =. ∑ ∑W (i, j )W ′(i, j ) i =0 j =0 N −1 M −1. (11). ∑ ∑ [W (i, j )]2 i =0 j =0. In contrast with Wang et al.’s method [2], the watermark size is 4096 bits in our scheme which is much more than their maximal capacity (2205) when a 512 × 512 host image is used. If it is necessary, we can use more blocks in host image and more pairs in each block for embedding to increase the capacity. The PSNR values of our method and methods with Wang et al.’s [2] and Ni et al.’s [1] are compared, as shown in Table 1. The values for [1] and [2] are quoted from their papers, based on the same host images, and the lengths of the watermarks are 4096 in [1] and not more than 2205 in [2]. Our scheme obviously has the superiority on imperceptibility.. our scheme. From Table 3, we observe that the extracted watermarks show the robustness of the proposed scheme against some general attacks. The color image “Baboon” has an error rate of 6.4% when it suffers the blurring attack which is due to high textured natural of the image. The proposed scheme is also extended to video watermarking. Because MPEG video compression uses a similar compression method to JPEG when compress a frame format called “Intraframe” (or I frame). To carry out the experiment, a video with 60 frames is used as the host media with 352 × 240 for each frame and a 32 × 32 binary image is used as the watermark. 15 frames are randomly chosen for embedding the watermark. Instead of choosing the candidate blocks by calculating the edge points in each block as described in Section 2, candidate blocks are chosen randomly by a pseudo-random number generator. This is due to the fact that frames changes very quickly in a video, it is difficult for human eyes to notice the differences between frames. In this way, instead of recording candidate blocks for each frame which is a burden for the system, only a seed for the pseudo-random number generator is needed for extraction. After the watermark is embedded, the video is processed by MPEG compression and decompressed. Then watermark extraction is performed in these 15 embedded frames. The normalized correlation between extracted watermark and original watermark is shown in Table 4. The experimental result shows the watermark can be almost perfectly extracted which means our scheme is feasible in video watermarking. Table 2. Results against JPEG compression (for gray scale “Lena”). Quality Ratio 90. Table 1. Imperceptibility using PSNR (db). ColorImage Lena Baboon Airplane Sailboat. Our method. Method [2]. 47.09 42.78 47.23 46.88. 43.37 39.01 N/A N/A. Method [1] N/A N/A 44.90 N/A. To further compare the robustness against JPEG compression with Ni et al.’s method, a 512 × 512 8-bit grayscale “Lena” and the same length of the watermark 64×64 as in [1] are used. The PSNR of the watermarked image is 44.72 dB in Ni et al.’s method and 42.18 dB in ours. Although our PSNR is a little lower than Ni et al.’s, but from the comparison shown in Table 2, it is obviously that our method in the robustness against JPEG compression is much better than theirs. As recorded in Table 2, the proposed scheme can extract the watermark perfectly up to JPEG compression ratio of 50. Finally, some general attacks are also tested on. NC ([1]). NC (ours). 0.9605. 1. 80. 0.9547. 1. 70. 0.8891. 0.9936. 60. 0.7550. 0.9721. 50. 0.6433. 0.9643. 40. 0.5314. 0.6884. . Table 3. Robustness result against general attacks (error rate %). Attack Sharpen Blur Gaussian noise (2%) Uniform noise (4%). - 1171 -. Lena 0 0.73. Baboon 2.76 6.4. 0.05 1.07. Airplane. Sailboat. 0 0.54. 0.02 1.27. 0.12. 0.15. 0.15. 0.63. 0.68. 0.71.
(5) Wr . Note that W2 ~ N[0, 1] and W2 ⊕ Wr = W1. Thus with some keys and the original watermark W1, we can generate different watermarks. By this way, we can avoid the estimation and elimination consequently from malicious attackers. Second, use different watermarks for different scenes of the video [12]. Since we can produce as many different watermarks as we wish, it is possible to give different watermarks for different scenes (or the same watermark in the frames of the same scene.) By this way, we can avoid watermark being washing out from averaging frames. More over, it is also robust to frame dropping or insertion. Related works is under progress now.. Table 4. Robustness against MPEG attacks Frame number. #1. #6. #11. #13. #14. NC value. 1. 1. 0.995. 0.995. 0.995. Frame number. #25. #30. #32. #33. #37. NC value. 0.990. 0.995. 0.990. 0.995. 0.995. Frame number. #41. #49. #53. #58. #59. NC value. 1. 1. 1. 1. 1. REFERENCES [1]. 4: CONCLUSION AND FUTURE WORK In this paper, a watermarking method based on JPEG quantization table is proposed. Choosing pairs of embedding positions corresponding to the same quantization scale in the JPEG standard quantization table, our watermarking scheme can resist many kinds of attacks, especially the JPEG compression. To improve the imperceptibility, the watermark information is embedded into the middle frequency coefficients of the candidate blocks. Candidate blocks are determined by the number of edge points which has slope of ± 45º since human eye is not sensitive to the ± 45º lines and textured areas pointed out by the Human Visual System (HSV). The experiment results show our scheme is robust to the JEPG compression and some general attacks. In addition, the imperceptibility of the watermarked image by our scheme is highly achieved. In the proposed method, the original image is not required in extraction procedure. Only the positions of the candidate blocks are needed. When the host image size is 512 × 512, there are 4096 8 × 8 blocks. Use an 1 or 0 to indicate a block is or not is a candidate block. So 4096 bits are required to indicate position of candidate blocks, i.e., it only requires an extra information of 512 bytes. In the future work, the Δ value in Eq. (3) and (4) will be further studied to achieve better tradeoff between imperceptibility and robustness. Besides, the maximal capacity with acceptable imperceptibility should be estimated for more applications. The experiments also show our scheme is feasible in video watermarking to against MPEG compression. In here, a fixed watermark is embedded into selected frames. To avoid the collusion attack or watermark elimination by malicious attackers, some steps may be adopted. First, to embed a meaningful fixed watermark W1, such as a logo, we can use a randomly generated watermark sequence Wr such that Wr ~ N[0, 1]and XOR (⊕) operation to produce another watermark W2 = W1⊕. R. Ni, Q. Ruan, H.D. Cheng, “Secure semi-blind watermarking based on iteration mapping and image features,” Pattern Recognition 38, pp. 357-368, 2005. [2] Y. Wang, A. Pearmain, “Blind image data hiding based on self reference,” Pattern Recognition Letters 25, pp. 1681-1689, 2004. [3] C.C. Chang, T.S. Chen, L.Z. Chung, “A steganographic method based upon JPEG and quantization table modification,” Inform. Sci. 141 (1-2), pp. 123-138, 2002. [4] F. Y. Shih, S. Y.T. Wu, “Combinational image watermarking in the spatial and frequency domains,” Pattern Recognition 36, pp. 969-975, 2003. [5] Y.-H. Yu, C.-C. Chang, Y.-C. Hu, “Hiding secret data in images via predictive coding,” Pattern Recognition 38, pp. 691-705, 2005. [6] S.S. Maniccam, N. Bourbakis, “Lossless compression and information hiding in images,” Pattern Recognition 37, pp. 475-486, 2004. [7] C.-K. Chan, L.M. Cheng, “Hiding data in images by simple LSB substitution,” Pattern Recognition 37, 469474, 2004. [8] M.-S. Hsieh, D.-C. Tseng, Y. Huang, “Hiding Digital Watermarks Using Multiresolution Wavelet Transform,” IEEE Transactions on Industrial Electronics, vol. 48, pp. 875-882, Oct. 2001. [9] M. Barni, F. Bartolini, A. Piva, “Improved WaveletBased Watermarking Through Pixel-Wise Masking,” IEEE Transactions on Image Processing, vol. 10, NO.5, May 2001. [10] P. Bao, X. MA, “Image Adaptive Watermarking Using Wavelet Domain Singular Value Decomposition,” IEEE Transactions on Circuits and Systems for Video Technology, vol.15, No.1, January 2005 [11] A. A. Reddy, B.N. Chatterji, “A new wavelet based logo-watermarking scheme,” Pattern Recognition Letters 26, pp. 1019-1027, 2005. [12] S. Biswas, S. R. Das, E. M. Petriu, “An Adaptive Compressed MEPEG-2 Video Watermarking Scheme,” IEEE Transactions on Instrumentation and Measurement, vol.54, No.5, Oct 2005.. - 1172 -.
(6)
數據

![Table 1. Imperceptibility using PSNR (db) ColorImage Our method Method [2] Method [1]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8912625.260508/4.918.92.429.133.460/table-imperceptibility-using-psnr-colorimage-method-method-method.webp)
相關文件
Listen - Check the right picture striped hat polka dotted hat.. Which hat do
Play - Let’s make a big family How many people are in your family1. Write it
Sam: I scraped my knee and bumped my head.. Smith: What happened
straight brown hair dark brown eyes What does he look like!. He has short
While Korean kids are learning how to ski and snowboard in the snow, Australian kids are learning how to surf and water-ski at the beach3. Some children never play in the snow
I am writing this letter because I want to make a new friend in another country.. Maybe you will come to Gibraltar
Sam: It’s really nice, but don’t you think it’s too expensive.. John: Yeah, I’m not going to buy it, but I wish I could
The HDG methods are obtained by discretizing characterizations of the exact solution written in terms of many local problems, one for each element of the mesh Ω h , with suitably
