國 立 交 通 大 學
管 理 科 學 系
碩 士 論 文
銀行信用卡客戶信用風險評估模型之建立
Credit Risk Evaluation for Credit Cardholders
研 究 生:張育菁
指導教授:許和鈞博士
銀行信用卡客戶信用風險評估模型之建立
Credit Risk Evaluation for Credit Cardholders
研 究 生:張育菁 Student: Yu-Jing Chang
指導教授:許和鈞博士 Advisor: Dr. Her-Jiun Sheu
國 立 交 通 大 學
管 理 科 學 系 碩 士 班
碩 士 論 文
A Thesis Submitted to
Department of Management Science
College of Management
National Chiao Tung University
In Partial Fulfillment of Requirements
For the Degree of
Master
in
Management Science
June 2006
Hsinchu, Taiwan, Republic China
銀行信用卡客戶信用風險評估模型之建立
學生:張育菁 指導教授:許和鈞博士
國立交通大學管理科學系碩士班
摘 要
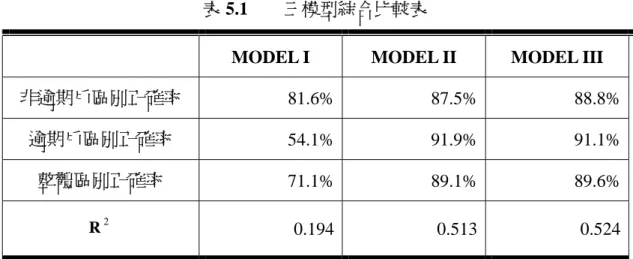
本研究是以國內某金融機構信用卡客戶為研究對象,利用 Logistic 廻歸分析來建立 客戶的信用風險模型,研究目的為:利用客戶個人基本資料及繳款行為資料,找出顯著 影響客戶信用風險之因素,並建立信用風險評估模型,進一步提供金融機構於信用風險 之控管。 研究結果顯示:依繳款行為變數建立之模型(MODEL II)區別能力優於個人屬性 變數所建立之模型(MODEL I),而以繳款行為變數為主,個人屬性變數為輔,所建模 型(MODEL III)之區別能力又優於前二者。因此,以該模型為本研究之最終模型,其 對逾期戶之區別正確率為 91%,非逾期戶之區別正確率為 88.8%,整體之正確率為 89.6%。 關鍵字:信用風險、Logistic 廻歸模型Credit Risk Evaluation for Credit Cardholders
Student: Yu-Jing Chang Advisor: Dr. Her-Jiun Sheu
Department of Management Science
National Chiao Tung University
ABSTRACT
In this study, we attempt to build a credit risk evaluation model for cardholders by using the logistic regression. We hope to find out significant behavior and individual characteristic variables that may cause overdue payment or default behaviors. Furthermore, the model could be used by bank managers to control and manage credit risk.
Results show that behavior variables (MODEL II) are better than individual
characteristic variables (MODEL I) when distinguishing defaulter or not. Moreover, the MODEL III which includes both individual characteristic variables and behavior variables is much better than the former two models. Hence, MODEL III is the final model in this study. The accurate rate of MODEL III is 89.6% of all samples, 91% of defaulters and 88.8% of non-defaulters.
誌 謝
碩士生涯即將畫下句點!回想著剛踏上新竹這塊生疏的土地,接觸來自四面八方、 不同背景的同學,現在總算是和大家”打”成一片。但,一晃眼二年的時間到了,又是大 家各分東西的時刻,心中除了不捨,更多的是百感交集。謝謝班上的同學們,尤其是同 研究室的”室友”們,一起奮鬥、打拚、玩鬧、嘻笑的日子是最美好的回憶! 能順利的畢業,當然,首先要感謝的是:我的指導教授-許和鈞老師!老師在百忙 之中,仍抽空指導,釐清學生許多模糊不清,甚至錯誤的觀念。更重要的是,灌輸學生 許多做研究、學問應有的態度,著實讓我受益良多。而我這個天兵,卻常給老師找麻煩, 很多時候反而是老師在配合我,在此,除了向老師致謝外,還要跟老師說聲:抱歉!另 外,還要感謝所辦的王姐和玉娟姐,在我口試之前幫了我不少的忙,這二年也麻煩你們 不少,十分感謝! 最後,要感謝我的親愛的家人和親威朋友,在我徬徨無助的時候,總是在身旁支持 我、鼓勵我;在我情緒不好的時候,總是容忍我暴躁不當的言行舉止;在我開心的時候, 和我一起分享我的喜悅,陪伴我度過每段開心以及不開心的日子,真的謝謝你們,因為 有你們的支持和關心,才有現在育菁!將來,若幸運能闖出一番小成績,也一定是因為 有你們。 謝謝老爸、老媽、阿公、阿嬤、哥哥、妹妹,還有你!我愛你們~ 張育菁 謹誌 民國 95 年 6 月於交通大學目 錄
中文摘要 ...i 英文摘要 ...ii 誌謝 ...iii 目錄 ...iv 表目錄 ...vi 圖目錄 ...vii 第一章 緒論 ...1 第一節 研究背景與動機 ...1 第二節 研究目的 ...3 第三節 研究範圍 ...4 第四節 研究架構 ...3 第二章 相關理論及文獻回顧 ...6 第一節 授信評估原則 ...6 第二節 信用評估方法 ...9 第三節 信用風險模型 ...12 第四節 新巴塞爾資本協定 ...13 第五節 國內外相關文獻探討 ...17 第三章 研究設計與方法 ...24 第一節 資料來源及處理 ...24 第二節 變數定義與說明 ...25 第三節 研究方法 ...29 第四章 實證分析 ...34 第一節 交叉分析 ...34 第二節 MODEL I... 38 第三節 MODEL II ...45 第四節 MODEL III ...48 第五節 驗證模型 ...52第五章 結論與建議 ...55
第一節 研究結論 ...55
第二節 研究限制 ...58
第三節 後續研究建議 ...58
表 目 錄
表 2.1 信用風險評估方式之優劣比較表 ...11 表 2.2 信用風險模型比較 ...12 表 2.3 BASEL II 的三大支柱...14 表2.4 相關文獻整理表 ...22 表 3.1 本研究樣本資訊 ...24 表 3.2 變數定義與說明 ...27 表 4.1 性別 vs. 逾期狀況之交叉分析...34 表 4.2 (申請)年齡 vs. 逾期狀況之交叉分析 ...34 表 4.3 婚姻狀況 vs. 逾期狀況之交叉分析...35 表 4.4 學歷 vs. 逾期狀況之交叉分析...35 表 4.5 子女數 vs. 逾期狀況之交叉分析...36 表 4.6 職業 vs. 逾期狀況之交叉分析...36 表 4.7 工作年資 vs. 逾期狀況之交叉分析...37 表 4.8 聯絡人關係 vs. 逾期狀況之交叉分析...37 表 4.9 住宅所有 vs. 逾期狀況之交叉分析...38 表 4.10 MODEL I 最大概似法參數估計...40 表 4.11 MODEL I 之分類表... 43 表 4.12 MODEL II 最大概似法參數估計 ...45 表 4.13 MODEL II 之分類表 ...46 表 4.14 MODEL III 最大概似法參數估計 ...49 表 4.15 MODEL III 之分類表 ...50表 4.16 TESTING FINAL MODEL 之分類表...54
圖 目 錄
圖 1.1 84~94 年消費性貸款占金融放款之比率 ...1
圖 1.2 信用卡打銷呆帳趨勢圖 ...2
圖 1.3 研究架構圖 ...5
圖 3.1 Logistic 函數曲線圖 ...31
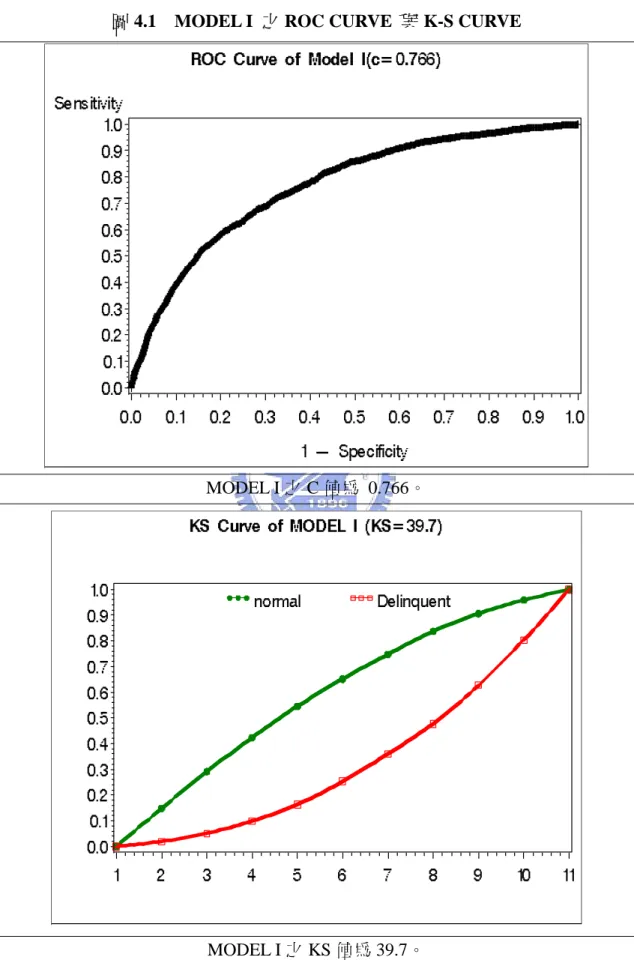
圖 4.1 MODEL I 之 ROC CURVE 與 K-S CURVE...44
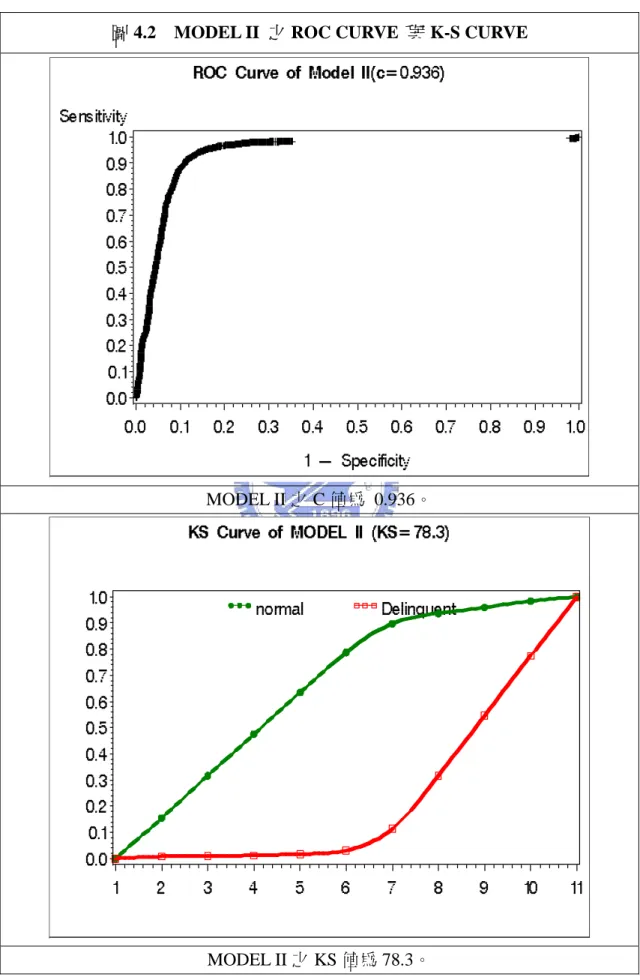
圖 4.2 MODEL II 之 ROC CURVE 與 K-S CURVE ...47
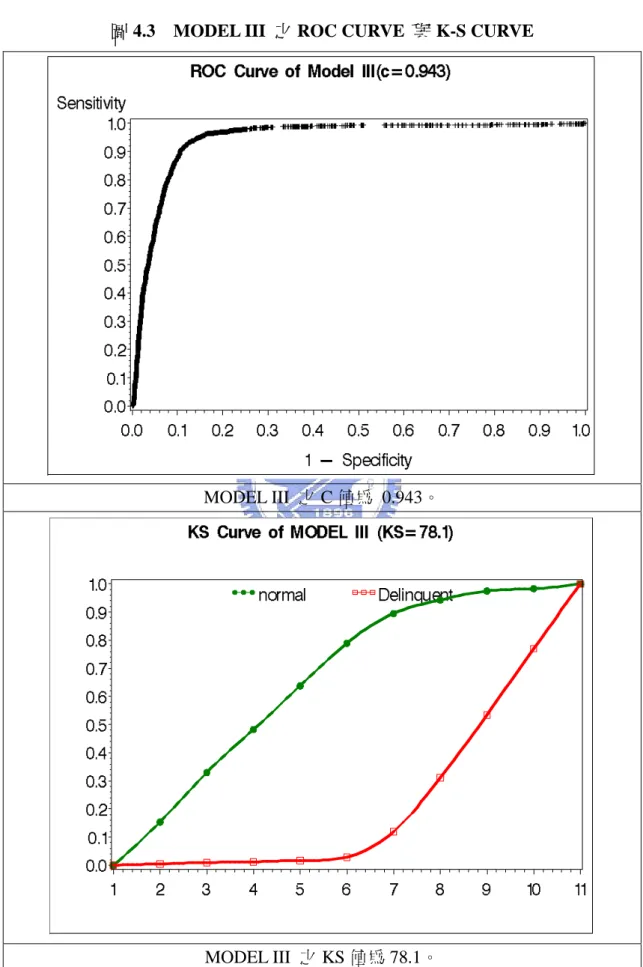
圖 4.3 MODEL III 之 ROC CURVE 與 K-S CURVE ...51
圖 4.5 Population Stability Report ...52
第一章 緒 論
第一節 研究背景與動機
1997 年亞洲金融風暴,雖然沒有重創台灣企業,但也使得國內各大企業進 行債務重整工作,金融機構也因而產生了資產結構上的變化。過去,金融機構著 重於大型企業的貸款業務,然而企業動授信金額動輒上億元,且利率加碼空間 小,一旦形成呆帳則損失慘重,因而促使金融機構調整營運方向,開始重視個人 消費金融業務,由於其業務對象為個人,需求量多且授信金額小,呆帳風險相對 較低,因此近年來個人消費金融業務成了各金融機構的兵家必爭之地。由圖 1.1 可看出近來年,消費性貸款占整體金融機構放款總額的比例持續不斷攀升, 94 年底消費性貸款己占金融放款近四成,尤其於 93 年至 94 年間成長幅度之大 (26.93%),實不容小覷。 圖 1.1 84~94 年消費性貸款占金融放款之比率 消費性貸款占金融機構放款金額之比率 50% 40% 30% 20% 10% 0% 年 84 85 86 87 88 89 90 91 92 93 94 消費者貸款佔放款比率 然而,也就因為個人授信的額度小、債權分散、利息手續費高,使得金融機 構忽視了個人信用惡化的衝擊,再加上巿場上金融機構百家爭鳴,競爭激烈,為 搶得巿場占有率,多半降低了核卡門檻,於是免保人、快速核卡、臨時調額、代 償業務等紛紛出籠,雖然解決了不少民眾的燃眉之急,長期而言卻也導致了信用 擴張的窘境。近年金融業者加強持卡循環信用服務,93 年底信用卡循環信用餘額達新台幣 4,250 億元,根據金管會統計,截至 94 年 8 月底止,信用卡放款餘 額達到 4,800 多億,而現金卡放款餘額為 3,100 多億,兩卡全部放款金額逼近 8,000 億元,持卡人平均欠款約 12 萬至 13 萬元,這些持卡人中已有四十萬人因為繳不 起卡債每天過著躲債的日子,這群卡債族每人負債逾 60 萬元,因此 94 年下半年 度金融機構動作頻頻,打銷呆帳、加強催收,甚至暫停部份消費金融業務,嚴格 監控客戶信用狀況,為的就是要防止這波個人消費金融信用危機的擴大。 94 年 11 月份,立法院財政管理委員會通過決議,欲將原本信用卡或現金卡 逾放比超過 8%才停止業務的政策,(即 358 政策,3%至 5%者,必須提出改善計 畫,5%至 8%者將予糾正,限期三個月改善;若逾放比超過 8%以上,停止新業 務),緊縮為超過 2.5%即停止發行新卡這樣突如其來的提案,讓許多銀行為之恐 慌,無不積極大量的打銷呆帳,如圖 1.2 所示,金融機構打銷呆帳的金額,持續 不斷增加,尤其 94 年下半年度後,打銷呆帳金額愈來愈大,其增加率至 94 年 11 月達到一個高峰,第二波高峰則在 95 年 2 月。然而各家金融機構利用打銷呆 帳的方式來應對並非根本之道,金融政策的目的是要各家銀行審慎核卡,妥善管 理持卡人的信用風險狀況,在其出現不正常的消費或繳款等風險行為時,就能有 所警覺而加以管制、防範,如此,才能真正降低逾放比率,留下優良的客戶群。 圖 1.2 信用卡打銷呆帳趨勢圖 9401~9503信用卡打銷呆帳情況 0 20 40 60 80 100 120 140 160 9401 9402 9403 9404 9405 9406 9407 9408 9409 9410 9411 9412 9501 9502 9503 $:億元 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 年月 % 打銷呆帳金額 打銷呆帳增加率 另外,我國預定於2006年底與國際清算銀行同步實施新巴塞爾資本協定(New Basel Ⅱ Accord)之相關規範,新巴塞爾協定的目標是使金融體系能穩健運行,降
低金融授信風險,建立完整的風險及運作管理機制,以強化金融監理機制及改善 金融產品品質。為了因應新巴塞爾協定的規範,國內金融機構必須在年底前建置 符合國際標準的風險管理機制,方能在國際金融市場中與國外其他國家競爭,在 國內金控整合已邁入第二階段時,落實風險控管已是當務之急。新資本協定實行 後,銀行所面臨信用風險的壓力勢必俱增,信用風險管理的課題則愈顯得重要, 應涵蓋:下達信用決策前所有過程、信用額度承諾與授予信用後之監督過程。 綜合上述所言,強化信用風險管理系統是各金融業的首要要務。然而,從前 著重經由申請進件的授信過程中,依客戶的屬性資料及過去金融往來情況,剔除 風險型客戶的方法已經不敷始用。過去相關學術研究中,多數亦是以卡戶之基本 屬性資料,建立授信評分模型,甚少針對銀行現行客戶之繳款及消費行為面的分 析。然而,目前金融業當務之急,是設法對現有卡戶進行風險性評估,找出潛在 風險型客戶先予以控管,才能有效降低呆帳損失。因此,客戶在持卡期間的行為 表現就顯得相當重要。目前許多銀行採行的方式,多屬主觀的經驗判斷,認為客 戶為高危險群即予以信用緊縮,缺乏客觀的工具來判定客戶之風險係數,這樣 “寧可錯殺一百也不願放過一個"的情況下,非但不能有效篩選出高風險型顧 客,更容易犧牲部份好顧客的權益,除了不利於卡戶,對銀行本身亦是一項損失。 本研究將針對此問題,以客戶行為面做為分析為主軸,企圖建立一套客觀、 有系統的風險等級模型,以期有效幫助銀行過濾出潛在高風險型顧客,以便進一 步採行適當的管控動作。
第二節 研究目的
本研究將以國內某銀行之客戶為研究對象,依其申請信用卡進件時,所填寫 的個人基本資料檔,及核卡後每月消費繳款的記錄,進一步分析研究。並且運用 Logistic 廻歸模型來建立該銀行信卡客戶的信用風險模型,本研究目的如下: 一. 從研究銀行的客戶基本資料及繳款資料檔中,找出顯著影響客戶信用 風險之重要變數。 二. 利用「個人屬性變數」及「繳款行為變數」,建構「個人屬性模型」 (MODEL I)、「繳款行為模型」(MODEL II)及「混合模型」(MODELIII)等三信用風險評估模型。 三. 比較三模型之優劣及區別能力,找出判別客戶風險能力最佳的模型, 進一步提供金融業界應用於信用風險之控管。
第三節 研究範圍
本研究以國內某家銀行機構為研究對象,依民國 94 年 1 月至 10 月期間中, 現存的有效卡卡戶為抽樣母體,共抽取 6,500 件,扣除資料不全者,共 6,320 件, 再依 94 年 11、12 月為觀察期,用來定義抽樣本逾期與否,其中「正常繳款」的 客戶共 3,906 件,定義為「非逾期戶」;「曾經逾期繳款三個月以上」者共 2,414 件,定義為「逾期戶」。並就樣本之信用卡個人基本申請資料,如:性別、年齡、 學歷…等項目,及樣本在抽樣期間內的繳款行為,如:繳款比率、預借現金比率… 等資料,做為本研究之研究範圍。第四節 研究架構
本文之研究架構分為五個章節,各章節之內容概述如下: 第一章為緒論,闡明研究動機與目的,界定研究範圍及本文之架構。第二章 為相關理論及文獻探討,說明信用風險的評估原則及適用模型,並回顧國內外信 用風險評估等相關文獻,希望藉由相關領域之研究回顧,提供本研究建構評等模 型之參考。第三章為研究設計與方法,說明本文的研究對象、期間及資料來源, 並定義研究變數且詳加說明之,另外介紹本研究所運用之研究方法及相關統計分 析。第四章為本研究之實證結果,敘述前章節所建構之模型的顯著性及區別正確 率,找出最佳之風險區別模型。第六章為結綸與建議,闡述本研究之結論與心得, 並提出建議供後續相關研究改進之參考。 下圖為本研究之架構圖:研究背景、動機與目的
MODEL I
個人屬性模型MODEL II
繳款行為模型MODEL II
混合模型實證分析
驗證最終模型
相關理論及文獻回顧
研究方法
Logistic 廻歸模型研究結論與建議
圖 1.3 研究架構圖第二章 相關理論及文獻回顧
第一節 授信評估原則
信用構成的要素隨著時代及觀點的不同,亦隨之改變。傳統上,一般銀行授 信對其客戶信用評估多採用3F原則,即管理要素(Management Factor)、財務要素 (Financial Factor)及經濟要素(Economic Factor),以及五C原則,即品格
(Character)、能力(Capacity)、資本(Capital)、擔保品(Collateral)及企 業條件(Condition of business),隨著整體經濟環境及銀行授信環境的急遽變化, 資金需求日益龐大、所需額度也日益增加,同時中長期大型專案放款亦逐漸增 加,傳統的信用評估方法已無法滿足授信評估的需要,自1970 年代起,歐美銀 行業開始採用有系統的信用分析方式,即以借款戶(People)、資金用途 (Purpose)、還款來源(Payment)、債權保障(Protection)及借款人展望 (Perspective)等五項因素,也就是所謂的授信評估5P原則,作為綜合評估授信 戶信用的標準,目前廣為銀行界所採用。 目前,國內銀行針對信用卡授信、徵審部份,授信人員能參考、評估之文件 雖較信用貸款少,但實務上,大致仍遵循上述信用授信評估理論。因此,將評估 準則分述如下: 一.3F原則: 1955年,美國Milton Drake將品格及能力歸納為管理要素,將資本及擔保品 歸納為財務要素,業務狀況則是為經濟要素,而形成三F理論。 (一)管理要素(Management Factor):指貸款人品德及履行債務之誠意與經 營事業的能力。 (二)財務要素(Financial Factor):指貸款人的財務狀況,擔保品是否擁有 足夠的變現性,貸款人是否有足夠的收入去繳交貸款。 (三)經濟要素(Economic Factor):係指貸款人所從事的業務是否擁有良好 的經營環境,事業的前瞻性及穩定性。 二.5C原則:
能力、資本加上擔保品及業務狀況而形成5C理論。 (一)品格(Character):指債務人之品行及履行債務之誠意與意願。 (二)能力(Capacity):經營者之經營能力,企業營運之規模與設備及其對所 授信 用之妥善運用能力。 (三)資本(Capital):授信企業之財務狀況,採用財務報表方法分析其資本結 構性、流動性、週轉性、安定性及收益性。 (四)擔保品(Collateral):考量擔保品之種類、價值、性質及變現性,雖不能 改進授信企業之信用狀況,但可以減輕放款損失。 (五)業務狀況(Condition):企業所處之經濟環境與市場之供需情形。 三.5P原則: 1970年,美國漢華銀行副總裁Paul Hunn提出5P理論,放款決策之信用評估 立場,目前廣為銀行界所採行,其主要內容如下: (一)借款戶(People) 銀行授信首重借款人之誠信度,因此對借款戶的評估著重於借款戶的責任 感、經營成效及銀行往來情形三方面。從其經營背景瞭解借款戶對於責任的承 擔現狀及能力,其次從其過去或預估的經營及管理績效瞭解借款人的經營能 力,而其過去所承諾事項的履約情形以及有無退票或逾期紀錄等,則可作為瞭 解其誠信程度之依據,如此,則可對借款人有較深入的瞭解,以降低將來授信 違約的可能性。 (二)資金用途(Purpose) 此為審核授信案件的重要因素之一,也就是確立融資需求的正當性。一般 而言,資金的用途以「購買流動性或固定資產」為最佳,如為置產,基於財產 增值可能以及該財產可充作擔保之用,銀行承做意願較高,如為償還既有債 務,由於銀行承受較高的倒帳風險,將不利放款承作,因此用途不同往往會影 響銀行承做意願與貸款之額度。
(三)還款來源(Payment) 此為債權是否能夠確實回收的先決條件,倘若借款人無法提出穩定還款來 源之證明,銀行可能會婉拒其申請。易言之,銀行不是僅接受擔保品之有無, 其最重視者,乃借款人之還款來源,這是銀行債權確保的第一道防線,與資金 用途同為授信5P 中最重要的兩個原則,其評估重點在於借款人能否適時產生 合理且足夠的現金,以供作還款來源。 (四)債權保障(Protection) 銀行為確保其貸放之款項能順利地如期收回,除考量借款人還款來源之 外,為防意外往往要求借款人提供債權擔保作為第二道防線,一般分為「內部 保障」與「外部保障」。「內部保障」是指完善的放款契約條款、借款戶的良好 財務結構及資產擔保;「外部保障」是指債務保證人或第三人所提供的資產擔 保,又分為「人保」與「物保」,人保(即保證人)方面,銀行對保證人之保 證能力予以評估,倘能符合銀行要求即予接受;物保(即擔保品)方面,銀行 對其評估倘具備一定要件,如合法性、完整性、可靠性、具市場性等,即予接 受。 (五)借款人展望(Perspective) 借款人展望是指銀行會評估借款戶本身事業前景及產業趨勢,綜合衡量貸 放風險與報酬,以決定貸放與否或承作的貸款利率,其衡量的標準或方式,可 依據銀行經營的五大原則:安全性、收益性、流動性、成長性及收益性逐項加 以探討。 在自由化的市場經濟裡,銀行也是營利事業的企業個體,就如同中小企業必 須考量的損益風險一般,銀行的授信原則也是以本求利,不得有絲毫的馬虎。反 觀,若是無一定的授信標準,不論是貸放款或信用卡業務,都將流於浮濫,使貸 放資金缺乏使用效率、信用額度過於擴張,最後危害的將不只是銀行本身,還將 損害消費大眾、金融體系及整體經濟的健全穩定。
第二節 信用評估方法
過去,金融業界在評估客戶信用風險時,最常使用的莫過於經驗法則,然隨 著消費金融的市場日異茁壯,單憑藉徵審人員人工的審核方式己趕不上龐大的進 件量。因此,目前業界最常使用的評審方式是,信用評等方法以及信用評分方法, 再配合徵審人員豐富的授信經驗,不但強化了審核的速度和效率,在處理特殊案 件時亦能發揮最佳效果。然除了上述常用的三種評估方法外,仍有其他信用評量 法,以下茲就各評估方法加以說明,並匯整如表2.1: 一、經驗法則(Rules of Thumb): 經驗法則為傳統金融機構用以評斷授信風險的方法,該方法著重由徵審授 信人員憑藉過去的經驗,以主觀的判斷作成案件准駁的依據,因此執行上較為 容易,彈性也較大。但相對地容易受到個人主觀的判斷,而欠缺客觀性,容易 導致相同的案件,在不同的徵審、授信人員審核下,會有不同的結果。 二、信用評等制度(Credit Grading System):信用評等制度是將客戶的各項資訊,細分為若干項目,然後由系統針對各 項目進行評估,並給予適當的等級,用以代表其綜合信用評價。此方法不僅可 消除經驗法則中徵審授信人員主觀判斷造成的差異,亦可避免因徵審授信人員 而產生不同的評價。但其缺點是評等項目不易選擇,評斷標準須明確否則仍會 造成差異。和經驗法則最主要的差異為信用評等法參考判斷的資料較多,也較 客觀。
三、信用評分制度(Credit Scoring System):
信用評分制度是目前銀行在消費金融業務中使用最多的,它可以解決消費 金融業務要求時效性及量大的特性。該方法係將客戶的資料,透過信用評分表 給予各項目一個信用分數,最後加總得到一個總分,總分愈高代表償債能力愈 強。而評分項目之選取,可透過經驗、統計方式、歷史資料等方式,選取顯著 項目。該方式藉由將評估項目由評等改為實際量化資料,明確訂定各種變數實 際分數,使得授信人員可以較客觀的評分,然其最大的問題在於評分項目的選 擇不易。
四、信用評等及評分混合制: 混合制係結合信用評分制度及信用評等制度,依據信用評分表所得到的總 分,予以分級,相同等級者給予相同的授信條件。其優點為結合信用評分制及 信用評等制的特性,但缺點為複雜度太高,執行不易。 五、統計方法: 該方法係透過統計分析的方式來區分信用風險,目前針對銀行信用評估的 研究,大多採用:區別分析、Probit 或Logistic廻歸等統計方法。其具有相當 的客觀性,相對複雜度較高,變數選擇不易,但若能結合用評分制度,將使評 分表更具說服力及可運用性。 六、專家系統法: 專家系統法係利用電腦資訊科技的技術來建立自動評核系統,用以輔助徵 審授信人員的審核工作。其中包涵類神經網絡、範例學習法及傳統知識庫系統 等。此種方法一樣具有客觀性,但缺點一樣為太複雜,且困難度高,執行不易。
表2.1 信用風險評估方式之優劣比較表 信用風險 評估方法 摘要 優點 缺點 經驗法則 授信人員依過去累積 的經驗,主觀判斷作為 案件準駁之依據。 ﹡執行容易 ﹡具彈性 ﹡缺乏客觀性 ﹡經驗傳承不易 ﹡易生弊端 信用評等制度 將客戶資訊分為若干 項進行評估,給予一適 當信用等級。 ﹡較客觀 ﹡徵信成本隨評等 項目增加而遞減 ﹡需一致評等標準 ﹡評等要素選擇不易 ﹡要素評等不易 信用評分制度 透過信用評分表,給予 各項客戶資料一信用 分數,最後加總分數愈 高者信用風險愈低。 ﹡評分準則明確 ﹡評分方式較客觀 ﹡評分項目選擇不易 ﹡評分細項切割不易 ﹡評分制度缺乏彈性 信用評等及評 分混合制 依據信用評分表所得 總分,予以分級,相同 等級者給予相同之授 信條件。 ﹡綜合信用評制度 及信用評分制度之 優點 ﹡複雜度高 ﹡執行不易 統計方法 透過統計分析的方 式,如:區別分析、 Probit或Logit model 等,來區分信用風險。 ﹡具客觀性 ﹡複雜度高 ﹡變數選取不易 ﹡維護成本高 專家系統法 利用電腦資訊科技的 技術來建立自動評核 系統,用以輔助徵審授 信人員的審核工作。 ﹡具客觀性 ﹡複雜度高 ﹡執行不易 資料來源:龔昶元(1998),呂美慧(2002)
第三節 信用風險模型
當前,在實務上能協助金融機構進行信用風險管理的方法,大致分為兩大模 型,一為「市場模型」,是指利用市場資訊,如:股價、選擇權…等來評估信用 風險,二為歷史模型,則是以過去歷史資料,如:公司財務狀況、銀行往來票信 記錄等來評估信用風險,此二模型都有理論上的依據,然是否適用於台灣巿場, 仍需進一步研究調整。下表2.2為此二模型之簡介比較表。 表2.2 信用風險模型比較 市場模型 歷史模型 簡介 利用股票或債券價格及其波 動資訊來加以評估其未來償 債能力。 利用歷史資料來評估,並對未 來信用償債能力之變化情形 加以記錄,如因違約或降等的 機率而產生的信用資訊。 調整頻率 每日 每季(年) 即時性 具即時監控反映 危機反映能力不足 預測性 股價反映預測能力 需另建預測指標 穩定性 對股價波動過於敏感者不適 用 評等變動較穩定 準確性 高估或低估情況較為頻繁 以評等品質為準 複雜度 修正調整難度高 修正調整較易 代表模型 1.Merton選擇權評價模型 2.債券價格法 1.區別分析 2.Probit模型 3.Logistic廻歸模型 4.類神經(Artificial Neural) 網絡模型 資料來源:沈大白與張大成(2003年),林旭青(2004年) 「市場模型」可依據每日的市場價值來做即時性的調整,因此具即時監控能 力且股價能適時的反映其預測能力,然其穩定性對市場價值波動較為敏感者不適 用,常用模型為Merton選擇權評價模型。而「歷史模型」是利用過去之歷史資料來建構模型,因此其調整頻率較長且時間不一定,危機反映能力相對不足,然其 可透過模型之建立,篩選出有效的預測指標,穩定性較佳,常用之模型有:多變 量區別分析模型、Probit模型及Logistic廻歸模型等。 本研究係以信用卡之風險評估為研究方向,故「市場模型」之Merton選擇權 評價模型及債券價格法,將不適用本研究。而「歷史模型」中,依過去歷史資料 來評估違約風險的方式,與本研究資料適切,故本研究將採「歷史模型」中的 Logistic廻歸模型為主要之研究分析方法。
第四節 新巴塞爾資本協定
近年來國內金融改革呼聲不斷,各金融機構除積極打銷壞帳之外,競相成立 金融控股公司,挾資源共享與規模經濟之優勢,連屬從事銀行、證券、保險等業 務,提供消費者在金融百貨一次購足之服務。但在金融商品與服務不斷推陳出新 的同時,風險管理議題亦逐漸受到國內金融機構的重視,其中又以巴塞爾銀行監 理委員會(Basel Committee on Banking Supervision,)所公佈之新巴塞爾資本協 定,近來最受國內金融業之矚目。國際清算銀行(Bank for International Settlements ,BIS)下的巴塞爾監理委員 會,在 1988 年,巴塞爾協議上公布以規範信用風險為主的「巴塞爾資本適足率 公約」(International Convergence of Capital),其目的是透過監督與管理的制 度性安排,來保障銀行貸放款品質及執行程序。隨著金融市場結構的演進,風 險管理不僅適用於銀行,對於其他金融機構更成為不可或缺的重要機制。
之後,巴塞爾監理委員會又於1999年6月發布「新版資本適足性架構」(A New Capital Adequacy Framework)作為修改1988年「巴塞爾資本適足率公約」,歷經 多次討論與修訂,於2004年6月發布最後定版報告,即「新巴塞爾資本協定」(the New Basel Capital Accord,簡稱Basel II ),並預計自2006年底開始實施。
Basel II 對於信用風險加權風險性資產的計算,作了大幅度修正。主要原因 是隨著金融國際化及自由化潮流,金融業務區隔日漸模糊,在競爭日益激烈的金 融環境下,銀行除繼續經營其傳統放款業務,也進入跨業經營新紀元。此外,衍 生性金融工具推陳出新,銀行涉及表外業務日益增加,需留意交易對手違約率或
回收率及提列信用損失準備,以及信用風險管理機制架構、管理、組織等資訊, 而控管信用風險暴險部位之策略、目標與執行資訊。Basel II 不僅強調資本適足 性法規之遵循,更注重金融機構的風險管理,以法規制度之修繕來提供金融機構 建構資本誘因,並透過各國監理機關之審查制度及金融市場之制約力量,以達相 互運用的效益,直接間接地鼓勵金融機構從管理經驗中逐步強化風險管理的水 準。 「信用風險管理」是新版巴塞爾資本協定規範中最主要的要求。其目的在於 積極地透過系統性的方法提出預警性資訊來管理風險,主要的概念在於促使金融 機構審慎選擇資產組合,並相應地針對組合資產的風險進行管理。除此之外,新 協定還特別強調主管機關的審查程序及市場制約,希望能藉由主管機關的監督控 管以及銀行公開資訊的揭露,提高監控機制及透明化程度,使投資人能自行評估 銀行資本適足性,判斷該銀行健全與否,連帶地對銀行產生自我約束的作用。因 此,BASEL II 將這三者列為此一協定相輔相成的三大支柱,將有助於增強金融 體系的安全與穩健。其架構如表2.3: 表2.3 BASEL II 的三大支柱 方法 標準法(standardized approach) 基礎內部評等法
(foundation IRB approach) 信用風險
(credit risk)
進階內部評等法
(advanced IRB approach) 標準法(standardized approach) 市場風險
(market risk) 內部模型法(internal models approach) 基本指標法 標準法(standardized approach) 第一支柱:最低資本需求 作業風險 (operational risk) 內部衡量法
第二支柱:監督檢討程序(supervisory review process)
第三支柱:市場制約(market discipline) 主要財務揭露(core disclosure) 其他附註揭露
(supplementary disclosure) 資料來源:吳玉絹,新版巴塞爾資本適足率簡介
綜合以上所述,銀行如何降低信用風險,可說是刻不容緩。1999年7月,巴 塞爾金融監理委員會曾發表一篇「信用風險管理制度之評估原則」( Principles for the management of credit risk),強調銀行應管理所有業務之信用風險,並提出五 類十七條信用風險管理原則,作為銀行及主管機關監理指南。分述如下: 一.建立適當信用風險管理環境 原則一:銀行董事會應負責批准及定期檢討銀行信用風險策略及主要信用風險 政策。信用風險策略必須反映銀行承擔風險能力,以及遭受各種風險 後,銀行預期獲利的水準。 原則二:銀行高階管理人員應負責執行董事會批准之信用風險策略並擬訂有關 鑑定、衡量、監視及控管信用風險的政策與程序,該項政策與程序之 擬訂必須針對銀行全部業務之信用風險,及針對個別風險與全部資產 之風險。 原則三:銀行必須對全部金融商品與業務之信用風險加以確認並管理。銀行在 推出新產品及業務時,其可能帶來的風險要經過適當的程序與控制, 並獲得董事會或適當的委員會事先批准。 二.督促銀行在安全穩健的授信程序下作業 原則四:銀行應在健全、明確授信準則下作業,作業準則包括對借款者或機構 的全盤了解,對貸款目的、用途及結構,以及還款財源充分加以掌握。 原則五:銀行對個別借款戶或關係企業應訂定授信總額上限,在銀行交易帳及 資產負債表中,各種不同類型的授信合計應具有可比較性且有意義。 原則六:銀行對新貸款的批准及既有貸款展期之批准應訂定一套明確的審核辦 法與標準。
原則七:所有貸款展期之決定不再草率;即對公司及個人貸款必須加以追蹤監 視,並採取適當的措施,以控管或減輕貸款的風險。 三.督促銀行維持妥善的信用管理、風險衡量和監控系統作業 原則八:銀行對於具有風險的各種資產應有一良好的管理制度。 原則九:銀行對個別貸款之情況應有一套監視制度,包括適當呆帳損失之計提 及準備之決定。 原則十:銀行應建立並利用內部風險評等制度,進行信用風險之控管。該信評 制度必須符合銀行業務的性質、規模及複雜程度。 原則十一:銀行必須要有一套資訊系統及分析技術,俾管理階層能夠對所有資 產負債表內與表外的信用風險加以衡量。 原則十二:銀行應建立一套制度,以監視全部信用資產的組成成分及品質。 原則十三:銀行在評估個別貸款及全部貸款資產時,必須考慮未來的經濟情況 的可能變化,並就經濟情況轉壞時,評估銀行的信用風險。 四.確保適足信用風險控管 原則十四:銀行必須建立一套獨立、持續的貸款後檢討制度,檢討的結果應直 接送呈董事會及銀行高階主管。 原則十五:銀行應確保貸款功能適當地運作,並且力求授信與審慎的貸款標準 及自行訂定的限額一致。銀行必須建立並實施內部控制,凡不符銀 行貸款政策、程序與限額之例外貸款案件,必須及時向銀行適當層 級之主管報告。 原則十六:銀行應建立一套制度以管理不良債權及其他各種處置不良資產之方 法。 五.金融監理機構角色 原則十七:金融監理機構應要求銀行建立一套有效制度以鑑定、衡量、監視及 控管信用風險,作為整個風險管理的一環。金融監理機構必須就銀 行的授信策略、政策、實務及程序與全部貸款資產的管理,作獨立
自主的評估,對於單一借款者,或關係企業集團之貸款,金融監理 機構應考慮訂定適當的金額加以限制。 隨著新資本協定的定案,WTO規定所有會員國的金融監管必須在2004年前 達到一定標準,以便在2006年全面施行,國內金融機構必須在年底前建置符合國 際標準的風險管理機制,方能在國際金融市場中與國外其他國家競爭,在國內金 控整合已邁入第二階段時,落實風險控管已是當務之急。未來銀行需審慎因應, 檢討授信、投資、資金運用政策,根據風險權數選擇交易對手及作為訂定利費率 之依據,並加強資產負債管理,落實內控機制,健全授信品質,且藉由有效運用 結合產業知識經驗與先進分析型商業智慧的科技解決方案預測、管理風險,將是 金融業者能否快速勝出之關鍵。因此,積極培訓風險管理財務工程人才及建立一 套有效資訊系統及分析技術將是金融機構當前的首要任務。
第五節 國內外相關文獻探討
Altman(1968) Altman 是首位將多變量分析方法運用於企業經營之預測的學者,他取 1946 年至 1965 年間,相同規模、行業宣告破產之公司各 33 家進行樣本配對,建立 Z-Score 模型。其選用了 22 個財務比率,分成獲利性、流動性、清償能力、財務 槓桿及周轉能力五有項,再利用逐步多元區別分析選出五個最具代表性之財務比 率。 Z-Score 模型的短期預測能力相當良好,破產前一年的正確判別率高達 95%,但預測能力逐年降低。此外,Z-Score 模型,不僅可用於破產公司之預測, 若增加其分界點,則可依公司之 Z 值所落之群組,來決定其信用等級,Z 值愈高 者信用愈好。 Orgler (1970) Orgler,以銀行商業貸款客戶為研究對象,建立貸款信用評等模型,共抽樣 420 筆,其中好貸款 305 筆,壞貸款 115 筆,利用多元廻歸模型篩選出顯著影響 放款品質的變數,分別為:是否為擔保性貸款(secured/unsecured)、是否有逾 期未繳(past-due)、是否有審核機制(audit)、淨損/淨利(/net loss/net profit)、營運資本占目前資產比(working capital/current assets)、上一次的審核評價(criticized last examination)共六項,該研究設定模型區別能力為:好樣本的誤判機率必須小 於 5%,而壞樣本的正確歸類率必須大於 75%,並以成本最小化為其模型限制, 訂定出C1、C2兩臨界點,當Yi≦C ^ 1,判別為壞客戶,若Yi≧C ^ 2,則判別為好客 戶,C1≦Yi≦C ^ 2,則為糊模地帶(marginal loan),模型無法判別。整體而言,該 模型區別能力不高,判別好客戶的正確率僅 24.9%,壞客戶的判別準確率為 80%,另外有 45%的樣本是該模型無法判別的,其模型整體解釋力僅 36.4%。 Ohlson (1980) Ohlson,利用美國 1970-1976 年間的公司資料,排除零售業、運輸業、和金 融業,進行公司破產預測,樣本包括 105 家破產公司及 2,058 家正常公司。以 Logistic 廻歸建立模型,解釋變數有:log(總資產/物價指數)、負債比率、營運資 金占總資產比、流動比率、總資產報酬率、營業現金流量佔總資產比、虛擬變數 1(負債大於資產為 1,反之為 0)、虛擬變數 2(稅後淨利小於零為 1,反之為 0)、 和淨收入的變動,其模型正確率有 84%。另外 Ohlson 在該研究提出「財報時間 點」的問題,認為以前的文獻皆假設公司的年報可以在財務年底獲得,但實際上, 財報需會計師簽證,因此會有延遲,如此一來使用較晚公布的財報,或使用那些 會計報告中已揭露公司將破產的財報來「預測」已發生的破產事件似乎不合理。 而對於變數的選取,該文認為,任何模型的預測能力很大的部分取決於該模型所 採用的預測變數,過去所採用的皆為會計資訊,或許使用股價或股價的變動等非 會計資訊可以提升模型的預測能力。而 Probit 模型大致上和 Logistic 廻歸模型相 似,同樣可以解決自變數非常態的問題。可是由於 Logistic 廻歸模型實證結果多 優於 Probit 模型,故多數學者採用 Logistic 廻歸模型。 趙蔚慈(1991)
本文以 Logistic 廻歸建立信用評等模型。利用因素分析(Factor Analysis)中的 主成份法(Principal Component)和最大概似法(Maximum Likelihood)萃取適當且穩定 的因素來代表財務比率變數,加上企業本身及企業主過去之信用(退票紀錄), 企業規模及授信餘額等之變數,建立完整之 Logistic 廻歸理論架構與分析流程, 並探討選擇代表模式之估計與診斷性檢定等階段之方法,進而建立信用評等模
式,探討各變數對風險評估的影響。 最終建立之評等模型包含四大指標,分別為安定性指標、獲利性指標、活動 性指標及流動性指標,整體區別正確率約為89.7%,不違約之正確率為97.2%, 但違約正確率卻為0,主要原因可能為本研究樣本中違約樣本太少(僅三家)之原 故。 陳錦村、許通安、林蔓蓁(1996) 本研究以金融聯合徵信中心,企業財務資料檔中的授信企業為研究對象,進 行授信客戶違約風險之研究,使用無特定結構訊息之類神經網路建構授信風險, 並將之與傳統多變量方法-區別分析及logit方法進行比較。結果發現:經由類神 經網路一再的摸索與修正後,可分別建構各產業之網路模式,預測率介於 40%~70%間,然整體而言,類神經網路模式之正確率與預測能力,實優於區別分 析及logit方法。 龔昶元(1998) 本研究以民國82年1月起至86年10月止,流通之一般信用卡為研究對象,簡 單隨機抽取正常戶及不良戶各400筆,並依樣本客戶之性別、年齡、婚姻狀況、 子女人數…等,以Logistic廻歸模型建立信用風險審核模型,研究發現:信用卡 申請資料中教育程度、其他資產、申請副卡、居住狀況、婚姻狀況及工作年數等 變數是影響信用卡申請人是否會成為不良戶的重要因素。 李桐豪、呂美慧(2000) 呂美慧,以民國85、86年間,國內某銀行所核准之個人房屋貸款案件為研究 對象,共取樣362筆樣本,其中正常件258筆,不正常件104筆。針對該銀行所使 用的個人擔保放款之信用評分表表列變數及表外變數,以 t 檢定及無母數卡方 檢定,探討正常樣本與不正常樣本間是否存在顯著的差異性,再經由差異性檢定 篩選出使兩組獨立樣本具有顯著差異的變數。另外,利用Logistic廻歸方法分析 該銀行信用評分表上的所有變數是否具顯著性,以決定將顯著變數建構為最終模 型。其研究結論如下: 自變數中,婚姻狀況、學歷、金融往來關係、貸款期間、借款人與擔保人關 係、借款人通信地址與擔保品位置相對關係,為影響房屋貸款品質好壞的主要因
素。若再加入「通訊區域細分」該項變數,則可提高模式之整體歸類預測能力, 由98.07%提昇至98.62%,而對於實際歸類為壞貸款之預測正確率,也由93.27% 提昇至95.19%(好貸款之預測正確率為100%)。 林建州(2001) 以個案銀行於民國86-88年間所提供之個人信用貸款案件為研究對象,欲建 構個人消費信用貸款之信用評估模型,共取樣400筆樣本,正常件200筆,違約件 200筆,並從貸款申請書的內容選出9個自變數,透過 t 檢定法來驗證各變數之 間是否具有顯著性,並分別採用Logistic廻歸模型、Probit廻歸模型、區別分析模 型等三種模型,建立一套個人消費性貸款審核系統,期望能迅速客觀偵測申請人 之信用風險高低狀況,以作為授信之依據,並能降低消費信用貸款的呆帳率,以 提昇銀行之經營績效。實證結果如下: 無論採用Logistic廻歸模型、Probit廻歸模型、區別分析模型,影響個人消費 性貸款申請人信用風險的顯著變數,皆為職稱、教育程度、公司等級及年收入。 在職稱上,非主管之業務人員違約機率高;在教育程度上,學歷低者違約機率高; 在公司等級上,小型企業及自營者違約機率高;在年收入方面,所得低者違約機 率高。三模型中,以Logistic廻歸模型之預測準確率74.5﹪最高,其次為Probit廻 歸模型、區別分析模型,預測正確率分別為73.75﹪及72.75﹪。 林旭青(2004) 以國內某一現金卡發卡銀行之大台北地區為抽樣對象,抽取2002年7月至 2003年7月間,已核卡之持卡人個人申請資料,共930個樣本,其中628個為正常 戶,302個為逾期戶。根據已核卡案件的申請書及銀行間所延用之信用評分表選 出表列變數,以及未被銀行徵授信人員列為書面信用風險審核要素,但可能影響 未來授信成敗、繳款正常與否的表外變數,進行Logistic廻歸分析,探討持卡人 可能發生逾期違約的重要顯著因素,並建構信用風險評估模型,並利用廻歸模式 預測每個申請者可能產生逾期之機率值。研究結論如下: 表內變數:信用評級、性別、學歷、職業、年收入、住宅狀況、信用記錄、 信用債務餘額,及表外變數:持卡(現金卡)張數、近期是否有其他行庫查詢等 十項,為顯著影響信用風險之變數,而年齡及婚姻狀況在該模型中不顯著。
戴堅(2004) 以民國89、90、91年間,某國內家商業銀行貸放之案件為主要研究對象,共 抽取樣本300筆,正常戶150筆,逾期戶150筆。並就授信申請書表所載之借戶基 本資料,以及財團法人金融聯合徵信中心查詢之信用資料為研究範圍,運用 Logistic廻歸模型建立個人消費性信用貸款之授信評量模式。實證結果如下: 顯著風險變數為教育程度、年齡、負債所得比率、現金卡張數、是否使用循 環利息、近三個月是否有他行查詢等六種。其中,以負債所得比率取代年所得, 將提升模型整體預測正確率;此外,加入表外變數後確能大幅提升模型之預測正 確率,故聯徵查詢資訊對貸款成敗實具有相當程度之影響力。 戴錦周、陳研研(2005) 本研究利用台灣地區商業銀行1994-2002年間之授信樣本之資料,探討授信 戶逾期還款行為之研究,採用Probit模型進行實證。利用郵寄訪問方式,發送問 卷給各銀行帳戶管理員及債管人員,就行內己逾期及正常繳款企業戶案件中隨機 取樣,問卷回收後,以逾期案件110件,正常案件187件為分析樣本。結果發現: 「未公開發行公司」、「新客戶」、「保證人數」較多及「業外投資比率」較高 之客戶,成為逾期戶的機率較高;相反地,「資本額」、「存款實績」及「外匯 實績」較高,和「提供擔保品」客戶成為逾期戶的機率較低。另外,北部地區逾 期還款之機率明顯較南部地區高,而中部地區和南部地區則無顯著差異。
表2.4 相關文獻整理表 研究者 研究主題 研究方法 顯著變數及結論摘要 Altman (1968) Financial Ratios, Discriminant Analysis and The Prediction of Corporate Bankruptcy 區別分析 將財務比率,分成獲利性、流動性、清償 能力、財務槓桿及周轉能力五項。模型的 短期預測能力佳,第一年判別正確率高達 95%。 Orgler (1970)
A Credit Scoring Model for Commercial Loans
多元廻歸 顯著變數:是否為擔保性貸款、是否有審 核機制、淨損/淨利、營運資本占現在資 產比、是否有逾期未繳、上一次的審核評 價 Ohlson (1980)
Financial Ratios and the Probabilistic Prediction of Bankruptcy Logit模型 顯著變數有:log(總資產/物價指數)、負債 比率、營運資金佔總資產比、流動比率、 總資產報酬率、營業現金流量佔總資產 比、虛擬變數 1(負債大於資產為 1,反之 為 0)、虛擬變數 2(稅後淨利小於零為 1, 反之為 0)、和淨收入的變動,其模型正確 率有 84%。 趙蔚慈 (1991) 羅輯斯廻歸在信用評等 上之應用 Logistic廻歸 主成份分析法 評等模型指標:安定性、獲利性、活動性 及流動性。整體區別正確率為 89.7%,不 違約正確率為 97.2%,但違約正確率卻為 0%,可能為違約樣本太少(僅三家)之故。 陳錦村 許通安 林蔓蓁 (1996) 銀行授信客戶違約風險 之預測 類神經網路 區別分析 Logit模型 類神經網路模式之正確率與預測能力,優 於區別分析及 logit 方法。 龔昶元 (1998) Logistic Regression 模式 應用於信用卡信用風險 審核之研究-以國內某銀 行信用卡中心為例 Logistic廻歸 顯著變數:教育程度、其他資產、申請副 卡、居住狀況、婚姻狀況及工作年數。
李桐豪 呂美慧 (2000) 金融機構房貸客戶授信 評量模式分析-Logistic 廻歸之應用 Logistic廻歸 顯著變數:婚姻狀況、學歷、金融往來關 係、貸款期間、借款人與擔保人關係、借 款人通信地址與擔保品位置相對關係。加 入「通訊區域細分」將提升整體預測力。 林建州 (2001) 銀行個人消費信用貸款 授信風險評估模式之研 究 Logit模型 Probit 模型 區別分析模型 顯著變數:職稱、教育程度、公司等級及 年收入。Logit模型的預測正確率較Probit 模型及區別分析模型高。 戴堅 (2004) 個人消費性信用貸款授 信評量模式之研究 Logit模型 顯著變數:教育程度、年齡、負債所得比 率、現金卡張數、是否使用循環利息、近 三個月是否有他行查詢。以負債所得比率 取代年所得,模型整體預測力將提升。 戴錦周 陳研研 (2005) 台灣商業銀行 1994~2002年授信戶逾 期還款行為之研究 Probit模型 未公開發行公司、新客戶、保證人數較多 及業外投資比率較高之客戶,成為逾期戶 的機率較高;資本額、存款實績及外匯實 績較高,和提供擔保品客戶成為逾期戶的 機率較低。另外,北部地區逾期之機率較 南部高,而中部和南部地區則無顯著差 異。 資料來源:本研究
第三章
研究設計與方法
第一節 資料來源及處理
本研究係以國內某家銀行機構之信用卡持卡人為研究母體。先將研究母體依 觀察期間內之繳款狀況,分為「逾期戶」及「非逾期戶」兩群,若持卡者於觀察 期間內繳款行為正常無延遲,則定義為「非逾期戶」,反之,在觀察期間內曾逾 期繳款三個月(90天)以上者,則定義為「逾期戶」,再使用簡單隨機抽樣法(Simple Random Sampling),抽取研究樣本,為避免逾期戶之樣本比例過少,缺乏顯著 性,因此以2:3之比例抽取逾期戶及非逾期戶。 本研究樣本共分為「分析樣本」及「驗證樣本」二種,共計9,677戶。其中 「分析樣本」之資料期間為:94年1月至10月,共抽取6,500戶,扣除資料不全者, 有效樣本共計6,320戶,其中非逾期戶為3,906戶;逾期戶為2,414戶。而驗證樣本, 則以94年12月至95年1月為樣本觀察期間,94年2月至94年11月為樣本資料期間, 共計抽取有效樣本3,357戶,其中非逾期戶1,987戶,逾期戶1,370戶。詳細樣本資 訊如下: 表3.1 本研究樣本資訊 分析樣本 驗證樣本 全部樣本 資料期間 9401~ 94010 9402 ~ 9411 觀察期間 9411~9412 9412~9501 逾期戶 2,414 1,370 3,784 非逾期戶 3,906 1,987 5,893 總計 6,320 3,357 9,677 資料來源:本研究 另外,本研究資料分為持卡者之個人屬性資料及行內繳款資料,其中個人屬 性資料是於持卡人申請進件時,所填寫之基本資料,每分析樣本各有一筆個人屬性資料;而繳款資料則是記錄持卡人每個月的繳款狀況,因此,每一分析樣本每 個月份皆有一筆,而本研究則是利用:取數個月之「平均值」及數個月中之「最 大值」的數學運算去建構繳款行為變數,當樣本為逾期戶時,則依其開始逾期繳 款的月份往前推算六個月的資料期間,進行變數值之數學運算,而當樣本為非逾 期戶時,則依資料期間的最後六個月為研究資料進行變數值之運算。因此,本研 究之變數共包含,持卡者個人基本屬性變數,以及經過數學運算後的繳款行為變 數,以此進行風險評估模型之建立。
第二節 變數定義與說明
根據文獻,信用風險的評估大多採用信用評分方式,而信用評分可分為「應 用評分」(Application Scoring)及「行為評分」(Behavior Scoring)兩部份, 一般信用風險評估模型大多採用應用評分,屬於事前的評估預測。而本研究所著 重的是事後的行為評分,以期降低核卡後客戶的逾期繳款所產生的信用風險,避 免金融業者因之需進行催繳等而增加額外成本,甚至形成呆帳造成營業損失。因 此,本研究綜合上述兩類評分模型,將變數區分為兩大類,一為個人屬性變數, 係指持卡人於申請信用卡時所填寫之個人基本資料,屬於應用評分模型變數;二 為繳款行為變數,指核卡後,持卡人於持卡期間的繳款行為表現,屬於行為評分 變數。 本研究所初步採用的「個人屬性變數」包括:性別、申請年齡、婚姻狀況、 學歷、子女數、職業、工作年資、聯絡人關係及住宅所有等九項。其中性別、申 請年齡、婚姻狀況、學歷及子女數等為評估持卡人(People)之品格、特質及責 任感之變數,在過去文獻探討中大都呈現,男性的信用風險高於女性,可能因為 女性在理財與帳務管理方面較男性謹慎細心之故;在婚姻狀況中,通常己婚者會 比未婚者信用風險低,原因是結婚後有家庭責任,謹慎管理開支,維持家濟;而 學歷方面,通常教育程度愈高者產生信用風險的機率愈低,可解釋為學歷高者較具備責任感及道德感,履行償債義務的意願相對較高。至於年齡方面,經濟狀況 穩定的年齡層產生信用風險的機率相對較低,且年齡愈長者會較年輕者性情及經 濟上穩定,而信用評價也會較高,因此,預期在35~45歲的持卡人信用風險會較 低,而25歲以下者產生信用風險的機率較高。子女數該變數在過去相關研究中甚 少用到,本研究將其列入模型中驗證是否為影響持卡人信用風險之顯著變數,預 期子女數愈多者,因為經濟壓力大,產生信用風險的機率可能愈高。 另外,工作年資及職業兩變數為評估「還款來源」(Payment)及「授信展 望」(Perspective)之因子,主要用以衡量持卡人工作穩定性,穩定性愈高者產生 信用風險的程度相對較低,因此,從事公家機關之行業會比從事服務業為穩定, 而工作年資愈高者,穩定性相對高,信用評價也較好。而住宅所有及聯絡人關係 為評估「債權保障」(Protection)之變數,當持卡人對於信用卡債逾期不繳時, 持卡人本身的財產包含不動產可以透過法律程序進行管制,以確保債權,而聯絡 人關係較親密時,通常會因不願見到持卡人信用破產或債台高築而幫忙清償欠 款。 另一「行為變數」初步所採用之變數包含:平均動撥率、平均繳款率、平均 預借現金率、最大動撥率及最大繳款率等五項。「動撥率」表示應繳信用卡金額 占信用卡額度的比例,其中當月應繳金額,包含該月信用卡消費款及未繳款之循 環信用餘額,若動撥率大於1表示該持卡人未如期償還每個月之信用卡債,而產 生循環息,其信用卡尚欠餘額己超過其信用額度,因此,動撥率愈高表信用風險 程度高。而「繳款率」則相反,其表示繳納金額占尚欠金額之比例,繳款率愈高 表持卡人償債比例愈高,信用風險程度相對較低。預借現金為因應持卡人緊急現 金需求時所提供的服務,若持卡人「預借現金比率」愈高,信用風險相對愈高。
表3.2 變數定義與說明 變數 意義 代號 定義 依變數 1 觀察期間內曾發生逾期繳款 3 個月以上之 情形者 Y 逾期戶 0 觀察期間內正常繳款無延遲記錄者 自變數-個人屬性變數 1 男 X1 性別 -1 女 1,0,0,0,0,0,0 年齡≦24 歲 0,1,0,0,0,0,0 25 歲≦年齡≦29 歲 0,0,1,0,0,0,0 30 歲≦年齡≦34 歲 0,0,0,1,0,0,0 35 歲≦年齡≦39 歲 0,0,0,0,1,0,0 40 歲≦年齡≦44 歲 0,0,0,0,0,1,0 45 歲≦年齡≦49 歲 0,0,0,0,0,0,1 50 歲≦年齡≦54 歲 X2 申請年齡 -1,-1,-1,-1,-1,-1,-1 55 歲≦年齡 1,0 己婚 0,1 未婚 X3 婚姻狀況 -1,-1 其他 -1,-1,-1 博碩士、大學 0,0,1 專科 0,1,0 高中 X4 學歷 1,0,0 其他 0,1 2 人以上 1,0 1 人 X5 子女數 -1,-1 無子女 1,0,0,0,0,0,0,0 初級產業 0,1,0,0,0,0,0,0 金屬製造業 0,0,1,0,0,0,0,0 非金屬製造業 0,0,0,1,0,0,0,0 商業 0,0,0,0,1,0,0,0 服務業 X6 職業 0,0,0,0,0,1,0,0 無填
0,0,0,0,0,0,1,0 家管 0,0,0,0,0,0,0,1 高風險行業 -1,-1,-1,-1,-1,-1,-1,-1 公職 1,0,0,0 10 年≦年資 0,1,0,0 無填 0,0,1,0 0 年<年資≦1 年 0,0,0,1 1 年<年資≦4 年 X7 工作年資 -1,-1,-1,-1 4 年<年資≦9 年 1,0 無填 0,1 無親屬關係(朋友、同事、其他) X8 聯絡人關係 -1,-1 親屬關係(父母、兄弟、女子、配偶) 1,0 無填 0,1 非自有住宅(租賃、親屬、宿舍、其他) X9 住宅所有 -1,-1 自有住宅(自置、配偶、父母) 自變數-繳款行為變數 X10 平均動撥率 X11 最大動撥率 動撥率=當月應繳金額/信用卡額度 X12 平均繳款率 X13 最大繳款率 繳款率=當月實際繳納金額/總尚欠金額 X14 平均預借現金率 連續變數 預借現金率=當月預借現金金額/信用卡額 度 資料來源:本研究
第三節 研究方法
一.Logistic廻歸模型 Logistic廻歸模型的基本形式和傳統的線性廻歸模型,都是在描述一個依變 數與多個自變數間的關係。但若廻歸模型之依變數呈現離散型或二分類之特性 時,將無法滿足傳統廻歸模型中依變數為連續性、呈常態分布之假設,此時傳統 廻歸模型可能就不適用。因此,當研究結果的依變數是離散型,其分類只有二類 或少數幾類時,Logistic廻歸分析就變成是很普遍的分析方法,不但適用於依變 數是屬於質化變數(非量化)的廻歸模型,且此模型利用累積機率密度函數將自 變數的實數值轉為機率值,可克服自變數須服從常態分配的假設,而且可進一步 估計事件發生的機率。Logistic廻歸模型是由線性機率模型(Linear Probability Model,LPM)引申 而出,該模型只要求每個自變數不能是其他自變數的完全線性組合,並且自變數 不能與誤差項相關。其自變數可以是連續的,也可以是二元型的,然依變數卻必 須是連續的,正因為如此,當欲研究的依變數是一個分類變數(categorical variable)而不是連續變數時,線性機率模型的估計和預測會存在下列問題: 一. 由於在線性機率模型中殘差的異質性,參數估計的變異數將是有偏的。 因此,任何假設檢驗都是無效的,即使樣本很大也如此。 二. 由線性機率模型估計的事件機率值在遇到很大或很小的xi值時可能會超 出﹝0, 1﹞區間。 三. 線性機率模型中自變數與依變數是呈線性的關係,亦即不論xi取任何 值,其廻歸係數都應是常數,然在LPM中其截距和斜率對所有xi值並非 常數。 因此,以二元變數作為因變數的線性機率模型,在自變數與事件發生機率之
間存在非線性關係。而LPM不能擬合這種非線性關係,於是出現了非線性廻歸模 型。 為了使因變數之估計機率值均落於﹝0, 1﹞之間,學者提出利用logistic機率 密度函數作一次單調轉換(Monotonic Transformation),以保證機率值落在﹝0, 1﹞ 之間,此一模型即為Logistic廻歸模型。其模型如下: 假設Y為一二分類變數,事件發生時為 1,事件不發生時為 0;令Zi=β′ Xi , 為一過渡隨機變數,且服從logistic分配,函數圖型如圖 3.1: 事件發生的機率定義為pi,可得到下列 logistic 模型 i p = F(Zi)=P(Y=1)= zi e− + 1 1 所以pi(1+ )=1 i z e− i i z p p
e
i − = ⇒ 1這個比例被稱之為事件發生比(the odds of experiencing an event),簡稱為 odds,
odds 一定為正值,因為 0< <1。進一步將 odds 取自然對數就能得到一個線性 函數, i p i i i p p
z
=ln1−稱為 logit form,這一轉換的重要性在於,logit (y)有許多線性模型的特質,logit (y) 對其參數而言是性線的,並且與x有關,值域為負無窮到正無窮。因此,Logistic 廻歸模型可重寫成 i i i p p
z
=ln1− =β′Xii p = zi e− + 1 1 = i i z Z e
e
+ 1 圖 3.1 Logistic 函數曲線圖 1 P 0.8 0.6 0.4 0.2 0 -7 -10 -4 -1 2 5 8 X logistic 函數二.Logistic 廻歸模型的適合度(Goodness of fit)
1989 年,Hosmer 和 Lemeshow 研發了一種對 Logistic 廻歸模型擬合優度的 檢驗方法。這種方法是根據模型預測機率值將資料分成大致相同規模的 10 個 組,而不管模型中有多少共變類型,將觀測資料按其預測機率做升序排序,其中 第一組包含預測機率最小的所有觀測資料,而最後一組包含預測機率最大的所有 觀測資料。 Hosmer-Lemeshow(HL)指標是一種類似於 pearson 統計量的指標。它可 從觀測頻數和預測頻數構成的 2×G 交叉表中求得,其統計式如下: 2 χ HL= 2 2 1 ~ ) ˆ 1 ( ˆ ˆ − =
∑
− − G G g g g g g g g p p n p n y χ 其自由度為組數 G-2 的χ2分配,χ2檢定不顯著表示模型擬合資料適切,反之,2
χ 值統計顯著表示模型擬合不佳。
三.Logistic 廻歸模型參數估計及檢定
Logistic廻歸透過最大概似估計法(MLE)求出漸近不偏且有效
(asymptotically unbiased and efficient)的參數估計值,進一步針對個別參數之最 大概似估計值進行Wald統計量檢定。當眾多自變數被放入Logistic廻歸模型時, 透過檢定估計值符號是否合理、正確作為篩選顯著變數的第一道標準,再由Wald 統計量研判係數的顯著性,其檢定假設為: 0 : 0 : 1 0 ≠ = i i H H β β Wald 統計量定義如下: Wald=( ^ ˆ i SE i β β )2 ~
χ
12 其中 為參數估計值,即模式中自變數之係數, 為 之標準誤,Wald 統 計量為服從自由度為1之卡方分配,若Wald大於相對應之卡方值,亦即p-value低 於顯著水準 i βˆ ^ i SE β βi ˆ α ,則認為此自變數對因變數的有影響之顯著。 四.Logistic廻歸模型的區別正確性 對於評估Logistic廻歸模型的預測準確性有多種方法,本研究採用Logistic廻 歸模型被廣泛應用的分類表(Classification Table)來評估。分類表是透過比較預 測的事件機率和設定的機率切點(cutpoint),將案例分成預測事件發生或不發生, 一旦所有觀測樣本被分為兩群,便可計算出事件發生或不發生的頻數,以建立一 2×2的交叉表來比較預測情況和實際觀測的情況,這就是所謂的「分類表」。進一步,經由表中分類的情形可以計算此切點下的敏感度(sensitivity)與精確度 (specificity)。若切點變動則分類結果亦變動,因此敏感度與精確度也隨之改變。 利用預測機率作為分類指標,機率值越高則代表事件發生的風險(risk)越 高。我們使用預測機率作為切點,計算出所有分類表的敏感度與精確度,如果我 們分類的目標是找出最佳切點,我們可以將敏感度與精確度繪製在同一張圖表 上,選擇一個切點同時使敏感度與精確度最大時(即敏感度=精確度),此點的預 測機率即為最佳切點(optimal cutpoint)。當「sensitivity」對應「1-specificity」繪 圖時,得到操作特性曲線 (ROC curve),曲線下方面積是該模型區別分類能力的 指標,以C值表示,當C值越大表示該模型分類能力愈佳。 五、Kolmogorov-Smirnov 檢定法 統計分析上,對於實際次數分配與理論分配是否配合適當的問題,是屬適合 度檢定問題,可依 Kolmogorov-Smirnov 檢定法(簡稱 K-S 檢定法)進行。而 K-S 檢定法亦可用於特定階層之樣本與母體比例的比較,或檢定兩個樣本之分配是否 一致。 本研究為驗證模型區別逾期戶之有效性,在模型預測全體樣本之逾期機率 後,將全體樣本依逾期戶與非逾期戶分為兩組樣本,並以 K-S 檢定法檢定該兩 組樣本之逾期機率分配是否有顯著差異。其檢定統計量如下: D = max│Fd(x)-Fn(x)│~ 2 2 − g
χ
其中Fd(x)為逾期戶之累積機率,Fn(x)為非逾期戶之累積機率,而其自由度為g-2, g表分組數。若D大於相對應之卡方值,亦即p-value低於顯著水準α ,則表示該 模型能有效區別此兩組樣本。第四章
實證分析
第一節 交叉分析
由表 4.1 可看出:在男女幾乎各占一半的樣本中,有 25.13%的男性為逾期 戶,而女性中只有 13.07%為逾期戶,其中 odds 等於「逾期戶發生的次數/非逾期 戶發生的次數」,而 odds=0.914 表示:男性的逾期戶發生率為非逾期戶的 0.914 倍,女性卻只有 0.381 倍,顯示出性別不同可能影響信用風險的高低。 表 4.1 性別 vs. 逾期狀況之交叉分析 性別 男 女 合計 1,738 2,168 3,906 非逾期戶 (27.5%) (34.3%) (61.8%) 1,588 826 2,414 逾期戶 (25.13%) (13.07%) (38.2%) odds 0.914 0.381 0.618 3,326 2,994 6,320 合計 (52.63%) (47.37%) (100%) 表 4.2 為客戶申請信用卡當時的年齡與日後成為逾期客戶之分析,由表中可 看出 24 歲以下的 odds 為 0.841 最高,55 歲以上的 odds=0.46 最低,其他各組 odds 均分布在 0.53~0.67 之間,該變數是否具顯著性仍需進一步分析。 表 4.2 (申請)年齡 vs. 逾期狀況之交叉分析 (申請) 年齡 24 歲以下 25-29 歲 30-34 歲 35-39 歲 40-44 歲 45-49 歲 50-54 歲 55 歲以 上 合計 402 742 736 695 585 386 228 132 3,906 非逾 期戶 (6.36%) (11.74%) (11.65%) (11%) (9.26%) (6.11%) (3.61%) (2.09%) (61.8%) 338 502 425 427 314 215 132 61 2,414 逾期 戶 (5.35%) (7.94%) (6.72%) (6.76%) (4.97%) (3.4%) (2.09%) (0.97%) (38.2%) odds 0.841 0.677 0.577 0.614 0.537 0.557 0.58 0.46 0.618 740 1,244 1,161 1,122 899 601 360 193 6,320 合計 (11.71%) (19.68%) (18.37%) (17.75%) (14.22%) (9.51%) (5.7%) (3.05%) (100%)表 4.3 為婚姻狀況與逾期客戶之交叉分析,其中可發現:未婚者的 odds 較 己婚者高,而婚姻狀態為其他者,其 odds 又較未婚者高,表示未婚及婚姻狀態 為其他的客戶成為逾期戶的機率較己婚者為高。 表 4.3 婚姻狀況 vs. 逾期狀況之交叉分析 婚姻狀況 己婚 未婚 其他 合計 2,355 1,442 109 3,906 非逾期戶 (37.26%) (22.82%) (1.72%) (61.8%) 1,172 1,101 141 2,414 逾期戶 (18.54%) (17.42%) (2.23%) (38.2%) odds 0.498 0.764 1.294 0.618 3,527 2,543 250 6,320 合計 (55.81%) (40.24%) (3.96%) (100%) 由表 4.4 中可發現:學歷在大學以上者,其成為逾期戶的機率的機率最低, 平均一個非逾期戶中有 0.162 個逾期戶,而學歷為高中和其他者,其成為逾期戶 的機率相對碩博士大學及專科者為大,非逾期戶及逾期戶率,將近為 1:1。 表 4.4 學歷 vs. 逾期狀況之交叉分析 學歷 碩博士大學 專科 高中 其他 合計 1,000 989 1,443 474 3,906 非逾期戶 (15.82%) (15.65%) (22.83%) (7.5%) (61.8%) 162 385 1,415 452 2,414 逾期戶 (2.56%) (6.09%) (22.39%) (7.15%) (38.2%) odds 0.162 0.389 0.981 0.954 0.618 1,162 1,374 2,858 926 6,320 合計 (18.39%) (21.74%) (45.22%) (14.65%) (100%) 表 4.5 中顯示子女數在 2 人以上者(odds=0.47),成為逾期戶的機率較其他兩 組低,而無子女及子女數 1 人者,平均一個非逾期戶中就有 0.67 及 0.66 個逾期 戶,形成逾期戶的機率較子女數 2 人以上者為高。
表 4.5 子女數 vs. 逾期狀況之交叉分析 子女數 2 人以上 1 人 無子女 合計 1,016 308 2,582 3,906 非逾期戶 (16.08%) (4.87%) (40.85%) (61.8%) 480 203 1,731 2,414 逾期戶 (7.59%) (3.21%) (27.39%) (38.2%) odds 0.472 0.659 0.67 0.618 1,496 511 4,313 6,320 合計 (23.67%) (8.09%) (68.24%) (100%) 在表 4.6 職業與逾期客戶的交叉分析中,初級產業的 odds=0.955 最高,家管 (odds=0.27)最低,然而,在表中可發現初級產業的樣本數相對其他職業別少 很多,可能因為該類別樣本數過少,而突顯其逾期戶的比例較高,該職業變數是 否為一顯著變數,仍待進一步分析。 表 4.6 職業 vs. 逾期狀況之交叉分析 職 業 初級 金屬製造 非金屬製 造 商 服務業 無填 家管 高風險 公 合計 22 877 427 733 1,190 110 335 48 164 3,906 非逾 期戶 (0.35%) (13.88%) (6.76%) (11.6%) (18.83%) (1.74%) (5.3%) (0.76%) (2.59%) (61.8%) 21 396 332 595 796 71 92 32 79 2,414 逾期 戶 (0.33%) (6.27%) (5.25%) (9.41%) (12.59%) (1.12%) (1.46%) (0.51%) (1.25%) (38.2%) odds 0.955 0.452 0.778 0.812 0.669 0.645 0.27 0.67 0.482 0.618 43 1,273 759 1,328 1,986 181 427 80 243 6,320 合計 (0.68%) (20.14%) (12.01%) (21.01%) (31.42%) (2.86%) (6.76%) (1.27%) (3.84%) (100%) 表 4.7 中可發現:工作年資愈少者,其 odds 愈大,表示其發生逾期戶的機 率愈大,這與研究預期相當,工作年資愈長者,收入與職業相對穩定產生逾期戶 的比率應相對較低。