國立高雄大學資訊管理學系研究所
碩士論文
考量使用者地點因素以提升社會搜尋結果滿意度之研
究
Improving the Satisfaction of Social Search by
Considering the Factors of User Location
研究生:陳柏宇撰
指導教授:丁一賢教授
致謝
兩年的碩班學習時光過得非常快速,加上大學時期我已在高雄大學待上六年。 回想大一剛進來學校時的羞澀,期間由於在資訊管理系學習到不錯的成績,決定 繼續在同科系之研究所就讀,同時也遇到了對我人生產生重大影響的教授們,尤 其是我的指導老師丁一賢教授。碩士班再次入學,已然沒有剛開始的羞澀,但研 究生的身份有時讓我有否定自己的情緒出現,這時在身邊的同學們與教授成為了 支持我最重要的因素。 這裡遇到的學長姐學弟妹都非常的優秀也好相處,期間我的好同學們更組成 了研究小團體,不僅在心情鬱悶時大家一起出去散心或者報告前的準備,我們都 因為自己的論文研究而讓彼此的感情更好了。感謝至哲、喬心、宗憲、子弘、昕 妍,我會很懷念我們在一起的這段日子。 除了同學們外,資訊管理系的教授們不僅在教學研究上非常地認真,私底下 與學生們的互動更是宛如朋友一般的相處。感謝蕭漢威、楊新章、王學亮、陶幼 慧、林杏子、楊書成、趙建雄、吳建興、郭英峰等教授,這幾年的時光我們的互 動多不勝數,你們帶給我滿滿的收穫與回憶。在此也特別感謝我的指導教授丁一 賢老師,由於第三年後因為私人因素暫時離開了學校,最後的時光變成了我自己 埋頭努力,感謝老師總是不離不棄般的指導我,對您的感謝已經說不盡,沒有您, 我可能會中途放棄這趟路途。感謝一切,總是在我最艱困時又讓我有力量繼續。考量使用者地點因素以提升社會搜尋結果滿意度之研
究
指導教授:丁一賢 博士(教授) 國立高雄大學資訊管理所 學生:陳柏宇 國立高雄大學資訊管理所 摘要 近年來社群網站與行動化裝置在人與人間的關係中扮演著重要的角色,隨著 時間也讓人與人形成強連結的關係。由於可以在這些網站上與朋友互動或傳送打 卡資料,對使用者來說,擁有強連結關係或地緣關係的朋友所提供的資訊,亦有 高度興趣。目前網路上大多數搜尋平台是依據關鍵字和文章之相關程度,尚未加 入文章擁有者與搜尋者間的關係,因此本研究將傳統搜尋引擎加入社會關係與地 理條件關係,預期可改善搜尋品質並提升搜尋者之滿意度。 本研究將透過 Facebook 之塗鴉牆資料作為社會搜尋之依據,接著進行 CKIP 詞 庫小組處理和 TF-IDF 計算,最後結合字頻和社會關係與地理條件計算並進行結 果排名,得到社會搜尋之結果。透過本研究之加入考慮地理條件之排名結果和原 本只有考慮社會關係為基礎之社會搜尋排名結果比較後,證實朋友或這些打卡資 料所提供之資訊確實會影響使用者之決策。 關鍵字:搜尋引擎、社會網絡分析、社群網站、社會搜尋、打卡。Improving the Satisfaction of Social Search by
Considering the Factors of User Location
Advisor(s): Dr. I-Hsien Ting Institute of Information Management
National University of Kaohsiung
Student: Bo-Yu Chen
Institute of Information Management National University of Kaohsiung
ABSTRACT
In recent years, social networking sites and mobile devices have becoming an important platform for users to establish the relationship between each other. As time goes by, the links between people will form the so-called “Strong Links”. For those users, they can interaction with other users or check-in the place where they go. The information provided by the friends with strong link or geo-relationship considered as more interesting and useful. Currently, most of search engines are designed based on only measuring the similarity between keywords and articles. However, the social relations between the authors of articles and searcher have not been taken into account. Therefore, in order to improve the performance of search engines, we include the measurement of social and geopolitical relationship into traditional search engine. We expect to improve the search quality and to enhance the satisfaction of search.
In this study, we will train the data from Facebook to calculate the social relationship and content. About the content, the data will be process by using CKIP and TFIDF. Finally, we proposed a social ranking value which combines traditional TF-IDF and the values of social and geopolitical relationship. The social ranking value will be used as the key to rank the social search results. In this paper, we will also demonstrate a empirical example to explain the proposed methodology as well as the system interface. Comparing social search with adding the geopolitical relationship , we can conclude that the information provided by users’ friends or check-ins are very important for users.
Keywords: search engine, social networks analysis (SNA), social networking sites,
目錄
圖目錄 ... VI 表目錄 ... VII 第一章 緒論... 1 第一節 研究背景與動機 ... 1 第二節 研究目的 ... 4 第三節 論文架構 ... 4 第二章 文獻探討 ... 6 第一節 社會搜尋 ... 6 第二節 社會網絡計算 ... 9 第三節 適地性服務 ... 10 第四節 已地點為考量的搜尋 ... 11 第三章 研究方法 ... 13 第一節 研究流程 ... 13 第二節 研究架構 ... 14 第三節 社會搜尋計算 ... 18 第四節 地理條件計算 ... 21 第五節 實驗設計與驗証方式 ... 26 第四章 實驗結果與評估 ... 31 第一節 資料來源與處理 ... 31 第二節 實驗環境 ... 34 第三節 實驗結果 ... 34 第五章 結論與分析 ... 42 第一節 資料來源與處理 ... 42 第二節 研究限制 ... 44 第三節 未來研究方向 ... 44 參考文獻 ... 46圖目錄
圖 3.1 研究流程 ... 14 圖 3.2 研究架構 ... 15 圖 3.3 GPS 資料的標準化 ... 21 圖 3.4 DBSCAN 各點的定義 ... 22 圖 3.5 核心點持續計算產生的區域 ... 23 圖 3.6 輸入地址或經緯度即可算出距離與預估時間 ... 23 圖 3.7 使用者在各個區域內打卡數表格 ... 24 圖 3.8 餘弦相似度計算 ... 24 圖 3.9 實驗設計-搜尋結果與填寫排名 ... 27 圖 3.10 評估方法流程……….30 圖 4.1 一則貼文訊息與其內容………31 圖 4.2 按讚之資料內容………31 圖 4.3 回應文章之資料內容………32 圖 4.4 標記地點之資料內容………32 圖 4.5 高雄的打卡資料集………33表目錄
表 2.1 一般搜尋與社會搜尋之比較 ... 8 表 2.2 GOOGLE 加入地理條件之搜尋與本研究之比較 ... 12 表 3.1 塗鴉牆內容 ... 16 表 3.2 FB 好友列表 ... 17 表 3.3 FB 個人資料 ... 17 表 3.4 社會關係之權重值 ... 19 表 3.5 文章的發文者與回應者之互動數 ... 20 表 3.6 各種情況權重值的定義 ... 25 表 3.7 一筆 8 位人民的體重與身高資料 ... 28 表 3.8 處理過後的身高體重資料 ... 28 表 4.1 實驗結果………35 表 4.2 不同的搜尋需求與結果………39第一章 緒論
第一節 研究背景與動機
近幾年來網際網路與行動裝置的發展突飛猛進,與 Web 1.0 的時代相比,使 用者們轉變成為接收但也是提供資訊的角色,人們更喜歡在網路上分享自我想法 。而行動裝置則使大眾更容易隨時隨地送出自己的意見,這樣的結果也產生了新 穎且值得研究的 GPS 資料。所以當網路世界中使用者的互動漸趨頻繁,地點的 資料則加強了虛擬世界與現實生活的連結,所呈現的人之間的關係與行為就更為 真實。然而這種現象導致過去的幾十年來資料量幾倍成長,面對這種情況,我們 更難從茫茫資訊海中尋找自己的需求或問題解答,於是一個好的搜尋引擎就顯得 格外重要。 有些開發者自從一九九零年代末期就觀察到這個現象,以台灣為例,蕃薯藤 早在 1995 年就推出第一個華文搜尋引擎,而緊接著之後的奇摩搜尋引擎藉著其 入口網站的豐富多樣性成為當時使用率最普及的搜尋引擎,直到近幾年 Google 的獨霸全球及資料量巨大化的背景下,可以發現使用者對於在網路找尋資料的需 求有增無減,如何讓大眾真正地取得對自己有用的資訊是搜尋引擎最關鍵的技 術。 一般目前的搜尋引擎都是依照關鍵字與內容的相關程度或者網頁排名來進 行排序,這結果的顯示完全以內容為導向。觀察到資訊科技的快速變化,使用者 們不單單是個接收資訊者,有不同學者對於優化搜尋的結果新加入許多想法。有 些學者針對使用者的搜尋習慣進行探討,在搜尋引擎中加入與使用者本身相關的 資訊,這類型的搜尋技術稱之為個人化搜尋(Personalized Searching Technique)。 關於使用者本身之相關資訊大多是指透過分析使用者在線上瀏覽的行為資料,包 括從瀏覽網頁的歷史紀錄(Ucair et al, 2007),和點擊相關連結的紀錄檔(Sun et al., 2005)兩方面來研究,並藉以改善搜尋引擎排名的效率。這類型的方法需要使用者有長時間使用網路與搜尋引擎之經驗,才能累積歷史資料進而透過這些資料來 分析並提供搜尋結果給予使用者。而有另外一派學者則試圖往目前最為熱門的社 群網站著手研究。 由於網路解決了距離隔閡,人們的社交需求得以獲得擴大,使用者們傾向於 在社群網站上提供資訊與獲得回應,這樣越來越頻繁的互動造就了社會網絡 (Social Networks) 的出現。從社會網絡中我們可以觀察出人與人之間的連結度與 緊密程度,透過這些資訊可以發現使用者可能對緊密程度關係越高的人產生更大 的興趣與信任,那他們所推薦的事物某些程度上也符合使用者的喜愛跟興趣。如 此一來,使用者想要搜尋到的結果也與跟這些人的互動關係有著正相關,所以學 者已經針對互動關係對於搜尋結果的改善進行研究(Lu, 2012),並將之稱為社會 搜尋(Social Search)。 然而不同的社群網站也有自己不同的網站介面與運作方式,要在這些網站中 研究出使用者各種動作的數值意義有其難處。直到 2013 年 Facebook 全球會員人 數已達 9 億 8000 萬人(checkfacebook, 2013),儼然已成為目前社群網站的龍頭, 所以有很多學者主要於研究 Facebook 中互動關係的量化與意義。例如 Han 等學 者在 2011 年提出在社群網站中“讚(Like)”扮演著使用者之間的一個重要關係, 使用者分享文章或是表示自己對於這篇文章有高度的興趣,可以透過讚來表達他 們的支持(Han et al., 2011)。透過觀察社群網站使用者間的互動即可推論出使用者 彼此間的關係,而 Facebook 尤其為最代表性的網站。 由於近幾年行動裝置的普及,Facebook 觀察到這樣的潮流推出了全新的打 卡功能(Check-in),所以開始有大量的使用者留下許多 GPS 的紀錄,分析資料的 內容也從原本的社會網絡範疇拓展到結合這些新興的資料。所以另一方面 Google 不僅僅在搜尋引擎上獨占鰲頭,它近年來也在搜尋引擎上作出許多改善,包含圖 片與偏好地點搜尋,而 Google maps 與其附屬的地址與景觀查詢讓使用者們對於 地點位置服務更加信賴,可以合理觀察到在搜尋引擎上考量地理位置的條件是一 個較新的趨勢。
人們對於地圖這樣一個連結網路與真實世界的依賴助展了許多稱為適地性 服務(Location Based Service)的出現,社群網站讓使用者可以分享他們的所在地 點之訊息,這些 GPS 資料的增加,社群網站上的活動與人們生活型態也越來越 相似。最直覺的觀點來看,人們會容易與距離較近的人產生關係與信賴感, Wakamiya 等學者在 2012 年也提出尤其在城市的區域中,因為與日常生活的相關 程度較大,生活在越靠近彼此的人們之行為模式與想法更為接近。若套用到搜尋 引擎上,搜尋者所處的地點與那些提供資訊的人所在地點越接近的話可能會更相 信搜尋到的結果。所以 Google 針對這個特性在搜尋引擎旁增加了一個使用者所 在地的搜尋,藉此可讓使用者找到同個區域內的結果。而這些原本在社群網站上 活絡的互動因為行動裝置的普及,甚至產生了一種稱為行動網絡(Mobile Network) 的出現,意指由行動裝置的易攜帶性帶來的使用者間更流動性之連結關係,GPS 定位為這些關係提供了可被衡量的數據。綜述以上搜尋引擎加入位置的概念與同 樣探討網絡中人與人之間關係的社會網絡與行動網絡,將社群網站中的打卡加入 社會搜尋的概念作結合也是本論文致力於探討的方向。 首先探討使用者彼此間的距離來看,由於行動裝置強調了易攜與流動性,人 們自然也不會固定在某一個地點活動,只考慮使用者間距離的遠近推論關係稍嫌 不足。這時可利用前面提到之個人化搜尋,加入使用者之前所有的打卡歷史紀錄 考慮進去,因為這些地點紀錄可以反映出使用者平常的習慣與喜好(Ye et al., 2009)。社會網絡中人們善於分享自己的想法,行為習性一致則想法越接近,搜 尋的結果會更符合需求。所以可以藉由研究使用者相似度,對於行動網絡來說相 似度越高關係則越強。 所以目前大部分研究將地理服務專注自於城市區域,因為在城市中才有更多 的日常生活的行為與打卡地點,在地圖上就會有不同於世界地圖的區域劃分概念, 而是一個由社交關係產生的社會區域與距離(Wakamiya et al., 2012)。Google 搜尋 引擎也將有考慮地理因素的條件僅限在於一定的區域內,但是使用者所想搜尋的 結果並不一定在一個規定好的範圍內,這時就該考慮城鄉間打卡密度的不同與搜
尋範圍的擴大化作取捨。所以如何在實際距離與上述所述之社會距離進行一定比 重的調配至關重要,才能兼顧世界真實性與社交互動性。 綜合以上,本研究希望能在現有社會搜尋的技術下加入地理概念,就是為搜 尋引擎加上社交關係以及打卡資訊三者結合的模式,使得一個搜尋者所找尋的答 案能不只依照內容與關鍵字的相關性來排名,還能考慮與朋友間的互動關係與地 理位置上的遠近考量與相似性。透過線上虛擬與真實世界的融合去測量出使用者 間的關係與想法上的差異,藉此優化目前搜尋引擎的結果,可以更提高使用者的 滿意度。
第二節 研究目的
本研究主要分析在社會搜尋中加入地點的考量因素來優化搜尋結果。因此, 可利用社群網站中已建立好之社會網絡結構,當作使用者之間之關係權重,將這 些關係權重值作排序,以及與使用者的打卡 GPS 訊息相互影響的結果,可改善 目前搜尋引擎缺乏關係與使用者間相似度之問題,本研究期望達成以下幾點目 的: 1. 將社會搜尋技術加入衡量打卡資訊之概念,並設計一個能與社會搜尋相 互影響之搜尋排名機制。 2. 探討如何從社群網站中萃取出社會關係,以及GPS的資料如何找尋出使用 者間的相似度。 3. 評估本論文所提出之改善社會搜尋技術,並與目前社會搜尋引擎技術進 行比較。第三節 論文架構
本論文之內容架構共分為四章以及參考文獻,依序內容如下:第一章 緒論:包括研究背景與動機、研究目的。 第二章 文獻探討:探討搜尋、以社會搜尋和社會網絡分析與適地性服務之 相關研究。 第三章 研究方法:包括研究流程、研究架構,將研究架構分為前端使用者 研究方法:界面和後端前置資料處理與分析、社群與地理排名計算, 以及最後的驗証方法。 第四章 實驗結果與分析:包括前置資料的處理、研究結果與結果的分析。 第五章 結論:包括論文結論、研究限制與未來可研究之方向。
第二章 文獻探討
本章將說明與本研究相關之文獻。首先,本研究在第一節探討目前所謂的社 會搜尋技術有哪些以及與一般搜尋行為之比較;接著在第二節中說明目前關於社 會關係有哪些計算的方法;在第三節中說明何謂適地性服務,以及目前最多主流 的研究方向;最後在第四節則比較目前 Google 的地理搜尋與本研究想提出的地 理社會搜尋有何不同。第一節 社會搜尋 (Social Search)
從搜尋引擎出現以來,它提供人們對於自己需要在網路上找到的事物得到 快速的回應。本來搜尋結果都是藉由網站內容或文件的相似度以及被連結的熱門 度等等因素進行計算,最終呈現給使用者結果的排名,這些影響排名的因子主要 都為內容相關取向。然而近幾年由於社群網站的蓬勃發展,帶動人群間網絡關係 的建立,有許多學者認為這會改變使用者們想搜尋的行為或結果。所以為因應社 會網絡探討使用者關係影響搜尋行為的情況,產生了新的名詞稱為社會搜尋 (Social Search),目前許多研究都對此名詞有不同定義,完全依照各研究想探討 之搜尋結果而定。在說明社會搜尋之前,本研究先對搜尋行為進行文獻探討。 (一) 搜尋行為 使用者因為有需求而進行搜尋行為,然而不同需求就有不同的搜尋目的。 Marchionini 認為人類在詢問問題時想要得到的答案有兩種情況,一種為有明確 而單一的解答,相反地,另外一種情況為開放式之不具制式的結果,這就例如考 試卷中選擇題與問答題的題目型式。套用到搜尋行為上來說,有些使用者是因為 對某些特定名詞有疑問才進行搜尋,有些使用者則是還不清楚應該會得到怎樣的 結果,只是想藉由搜尋結果來慢慢尋求自己的目的。Matthews 將此定義成主題 搜尋,這樣一個過程複雜度較高,需要對整體使用者的搜尋行為以及演算機制的 掌握,所以 Damon & Sepandar 針對這樣一個情況設計出一個可以用自然語言詢問的搜尋引擎,結果的呈現也相對不同。但考慮到現實上的可行性,目前主要還 是為項目搜尋(Drabenstott, 1984)為主,因為目的明確且單一,複雜度也降低許 多。 儘管主要只能發展項目搜尋,搜尋引擎仍能找到方法增強自己的搜尋結果。 Google 搜尋引擎以 PageRank 聞名,一種以網頁間超連結來計算關係度影響排名, 近幾年更推出地點或圖片等等許多不同條件的搜尋。因為這些都是以搜尋內容為 主的優化,如果能跳脫只看重內容結果的框架,或許能在兩種目的搜尋裡找到一 個結合點。本研究雖然還是主要採用以簡單明確的搜尋目的為主,但套用到社群 網站與不一樣的條件算法,可以讓使用者不只考慮搜尋的內容,也能因為人際的 條件去對結果進行更多自由的選擇。 (二) 社會搜尋 目前對於社會搜尋沒有明確的定義,但主要都是因為社群網站的興起與社 會網絡的建立造成搜尋行為的改變。有一派學者研究如何在人際網絡中去搜尋想 找到的人,這種研究的搜尋結果為人。例如 Duncan 等學者利用使用者間的訊息 傳遞去找尋網絡中目標遙遠但明確的人,Adamic & Adar 則是使用電子郵件聯絡 人所建立之關係讓使用者搜尋另一人。這些研究的探討主要來自於哈佛大學的心 理學教授 Stanley Milgram 創立了六度分割理論 (Six Degrees of Separation) ,一 個人只要不斷地認識到六個人之後,一定能找到想要找到的人,而最近研究中發 現社群網絡的擴大使這個數字又縮小為四個人。所以這些學者致力於研究任何環 境建立起的社會網絡皆能應用分割理論,去找到明確目標的人。而 Damon & Sepandar 認為在社群網路上的搜尋行為目的為搜尋網絡中正確的人並給予解答, 也有研究分析使用者之朋友或同事對於自己的搜尋行為會造成影響 (Brynn & Ed, 2008)。Lu 則是應用社會網絡分析技術將人與人的社會關係影響結果的排名, 這是透過人來改變搜尋之結果。綜合以上,可發現不管最終搜尋結果為社群中的 人還是使用者想得到的人事物之解答,社會搜尋最重要的關鍵因素為影響結果的
人。所以社會搜尋目前並不能算是搜尋引擎的一種優化條件,因為它分成一般搜 尋引擎的行為以及找尋社會網絡中的人。本研究主要探討第一種情況,為了更優 化或提供另一種別於目前主流引擎的概念。
(三) 一般搜尋與社會搜尋
對於一般的搜尋系統與加入有社交概念的搜尋,Damon & Sepandar 作出了
一些比較,主要是探討與有考慮社會網絡關係的搜尋行為之不同處,如表 2.1 所 示: 表 2.1 一般搜尋與社會搜尋之比較 搜尋目的 資訊價值 搜尋語言 答案來源 結果信任 一般 搜尋 對的文件 文件間 關聯性 關鍵字 少數資訊 提供者 權威性 社會 搜尋 對的人 人彼此 傳遞性 自然語言 社群中 任何人 親密性 從目的來看,一般搜尋引擎使用者想找到他們有需求的文件檔案,這些文件 或網頁的價值來自於彼此間有無互相連結或關聯,自然而言有權威性的資訊更容 易被別的網頁拿來引用,所以少數專家提供的資訊憑其專業的能力會提高最後給 使用者之排名,而這也幾乎滿足所有使用者之問題。相反地,社會搜尋中指的是 社會網絡中的搜尋行為,目的在找尋對的人來解答問題,對於資訊注重也轉變為 人彼此間的傳遞與分享,回答問題的人有可能是網絡中的任何人,使用者信任的 對象反而對以這個人跟自己關係夠不夠來考量。本研究除了使用關鍵字搜尋外, 其他因素一樣採用這兩位學者整理的社會搜尋概念。 綜述以上,搜尋行為是為一種有目的性的行為,有需求才會主動進行搜尋。 而目前的社會搜尋分為找人與強化原本的搜尋系統兩個方向,其中這種以社會關 係強化一般的搜尋引擎結果為更少數學者在研究。本研究致力於後者的方向,更
強化了目前還沒有考慮到之同樣在社群網站上可撈取之資料的條件來作為強 化。
第二節 社會網絡關係計算
社會網絡計算是指藉由量化社群網絡人與人之間的關係,便可運用這個技 術在其他應用中發揮,本研究則利用於搜尋結果的優化。以目前計算方式來看可 分為兩種:社會關係與雙向社會關係。 (一) 社會關係 (Social Relationship) 社會關係早在社群網站出現就一直受到學者的關注,有許多學者針對各 類型之社群網站,例如:Facebook、Twitter、LinkedIn 等等,透過這些社群網站 中每位使用者之朋友結構或其互動狀況來確定雙方之社會關係。Han 在 2011 年 研究以 Facebook 中“讚”的機制作為朋友關係的依據,Velardi 在 2008 年提出以 互動內容來定義朋友之間關係的權重。另外,尚有透過文件或影音檔(Gou et al., 2010)、標籤(Zanardi & Capra, 2008)、搜尋日誌檔(Vieira et al., 2007)、超連結 (Mislove et al., 2006)等等作為任意兩人之間之關係依據。除此之外,連一般搜尋 引擎的網頁結果,也有研究考慮以網頁旁邊的註解點當作社交因素來影響結果的 排名(Bao et al., 2007)。(二) 雙向社會關係
社會網絡關係分為有向圖和無向圖(Peng et al., 2010; Wilson et al., 2009)兩 種來表示,雙向社會則是強調有向性。而因為無向圖表示有連線的兩點及有關係, 有向圖則代表兩邊的關係程度不同。舉例來說,在臉書很常去瀏覽某位朋友的塗 鴉牆僅能代表很在乎對方,對方可能對於被查看一無所知。在臉書計算朋友關係 排名的 EdgeRank 演算法中,也可看出雙方的互動程度是有極大的不同。 目前的研究中,尤其在社會搜尋的領域裡,還沒有對社會關係與社會互動關 係兩者皆並重的研究。所以本研究除了探討兩個使用者間的關係依據之外,也會
考慮兩者互相的互動程度。在搜尋引擎上,可能會優先考慮你比較想互動的朋友 之內容,而不是那個完全不知道他有來關心你的朋友的訊息。所以本研究採用自 我中心為出發的有向性社會網絡為基礎。
第三節 適地性服務
由於近幾年行動裝置的普及和應用程式的盛行,越來越多使用者 GPS 的資 料儲存在網路上,分析這些資料以期能提供更符合使用者需求的服務稱為適地性 服務。一般來說,目前最主流的方法為預測系統與推薦系統。 預測一個使用者的行為可藉由過去他們留下來的打卡資料與社會網絡的關 係中,在預設為隨機的狀態下使用者們接下來可能會有怎樣的動作。有些學者透 過在一段時間內使用者不斷地重複作出某些行為,例如工作、在家等等,去推斷 出他們可能接下來會去上班還是放假 (Gonzalez et al., 2008)。Wang 等學者則是 透過行蹤可預測出可能還未被發現之社會關係,因為如果倆使用者的紀錄非常相 像 , 將 來 就 可 能 產 生 新 的 鏈 結 。 為 了 研 究 複 雜 度 高 的 人 類 行 動 力 與 關 係 ,Nguyen & Szymanski 則利用 RWP(Random Waypoint)與 ER(Erdos-Renyi)Model 來整合出能真正根據人類的行為作出預測的動態網絡模型。有了這些預測效果就 能正確地作出推薦,透過這些打卡點研究使用者的偏好,將真正適合該使用者的 資訊推薦給他。所以有學者將對電影的評論以及個人的電影偏好作計算,來推薦 使用者他可能想看的電影(Ono et al., 2007)。Leung 等學者則先將打卡地點與使用 者作叢聚,之後再將相似的地點推薦給他。最後 Ying 等學者再加入社會網絡中 人與人之間的關係概念,搭配設定好的地點分類進行多重相似度的計算,藉此推 薦使用者們與他相似的朋友行為中推論出的合適結果。從以上研究來看,以地點 因素加入相似度的運算最能體現出社會網絡的概念。 有著類似相似度的使用者最了解與接受彼此的喜好,這也是推薦系統使用 相似度計算的原因。Wakamiya 等學者利用打卡者一段時間內的移動方向推論那 些人的相似度最接近,Long 等學者則證明不同時間在同個區域內使用者的打卡行為不同,說明相似度帶來的距離概念與實際的距離有著不一樣的意義,在社會 搜尋中需要著重在這種想法觀念上的虛擬距離,在地圖上就會有不同於世界地圖 的區域劃分概念,而是一個由社交關係產生的社會區域與距離(Wakamiya et al., 2012)。Yuan 等學者透過地點資訊,將原本的地圖劃分為教育區、娛樂區、住宅 區的功能性區域地圖。Mislove 等學者則將推特上發文中探勘出的使用者的心情, 而作出美國的每天情緒地圖。由此可見,要計算使用者間的距離並非單純看倆使 用者在實際地圖上的距離,而應該因應探討什麼樣的主題而作出不一樣的地圖劃 分,則它所代表之每個區域間的分隔就是彼此的相異性。 由於本研究為探討社會搜尋,過往許多的研究幾乎都往自動化推薦的方向邁 進。因為推薦系統的需求,系統必須自動地去了解使用者彼此的相似度,並且得 將大量的資料進行分群與分類,進行許多不同條件的計算,才能完美地預測出使 用者的需求並給予推薦。然而搜尋系統本身是含有需求的釋出才會進行此動作, 並不用像目前大量的推薦系統研究中所研發的許多複雜的推薦演算法,所以本研 究將採用一些適地性服務上的技術,例如簡單的相似度計算以及社交地圖的概念, 將之搭配在現有的社會搜尋技術上結合,探討這樣的一個結合方式能不能提升現 有搜尋者的滿意度。
第四節 以地點為考量的搜尋
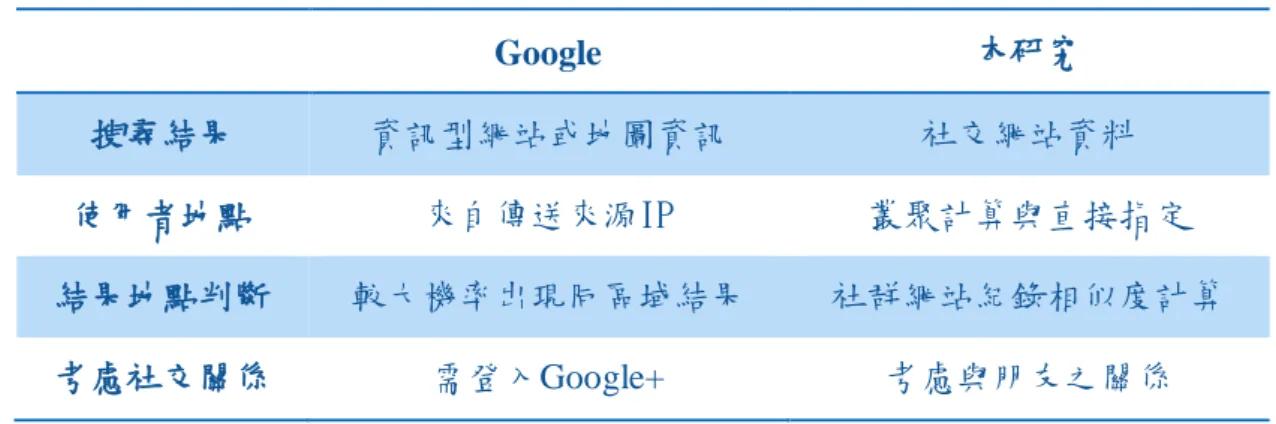
目前僅有極少數搜尋引擎有加入地點之運算,全世界最大的 Google 則在其 一。不同的是,在大部分 Google 使用者不登入 Google+的狀態下,它只能根據 其在項目中已規劃好的世界地圖區域勾選自己的所在區,去搜尋屬於本區的地圖。 而本研究則是希望在搜尋時能考慮到社會網絡以及地點的因素,所以需要能在社 群網站上蒐集一定量的資料以便計算,地點的相似度計算也考量使用者平時的打 卡偏好以及與其他使用者相似度計算的結果。相反地,Google 僅能以較大機率 搜尋與本地相關的資訊型資料,而這些資料是以發出的 IP 位置來斷定地點的, 所以兩者的搜尋引擎有不同的定位,詳細比較如表 3.2。表 2.2 GOOGLE 加入地理條件之搜尋與本研究之比較 Google 本研究 搜尋結果 資訊型網站或地圖資訊 社交網站資料 使用者地點 來自傳送來源IP 叢聚計算與直接指定 結果地點判斷 較大機率出現同區域結果 社群網站紀錄相似度計算 考慮社交關係 需登入Google+ 考慮與朋友之關係
第三章 研究方法
在本章節會探討本研究之主軸-社會搜尋與地點相似度計算,主要所使用之 相關技術與概念包括:TF-IDF、社會關係計算和社會關係排名之計算,地點實 際最短距離計算與 DBSCAN 分群及相似度計算,最後概述本研究評估方式。第一節 研究流程
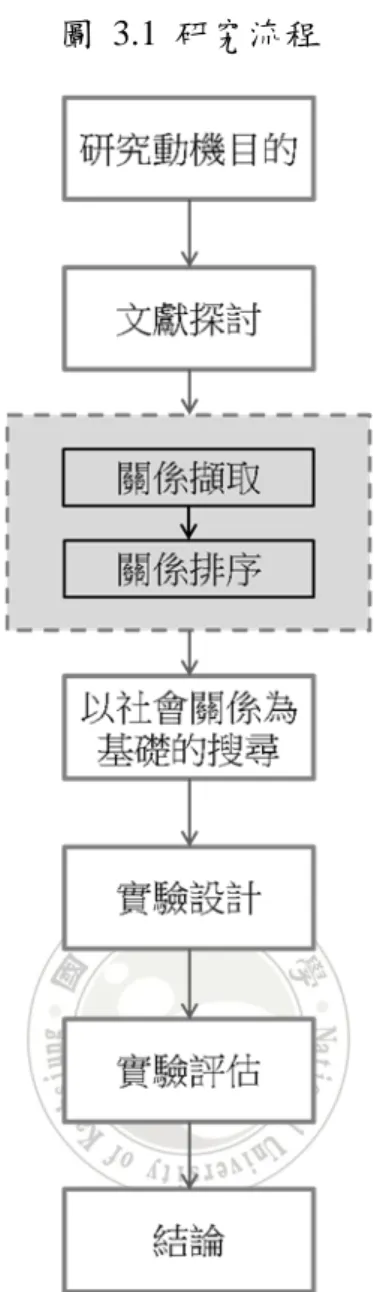
在本研究之研究流程中,首先是介紹研究背景與動機,可以發現目前線上 搜尋平台所面臨的問題,提出明確的目的來改善目前社會搜尋的問題,接著透過 一系列過去學者針對搜尋、社會搜尋以及地點打卡之相關研究,可得知目前學者 對於搜尋領域之研究範疇,最後加入社會網絡分析與地點相似度計算來支持論 點。 利用社群網站存在著關係的特性,本研究以 Facebook 為關係擷取資料依據 ,將抓取回來之關係進行作社會關係之排名,將計算過後之排名資料與 Facebook 中使用者與其好朋友之互動內容以及使用者打卡偏好作結合,形成本研究之主軸 ─以地點因素改善社會搜尋。最後將上述概念以使用者介面呈現,透過使用者完 成搜尋動作並且進行評分與比較,這些比較結果會成為本研究重要的依據。圖 3.1 研究流程
第二節 研究架構
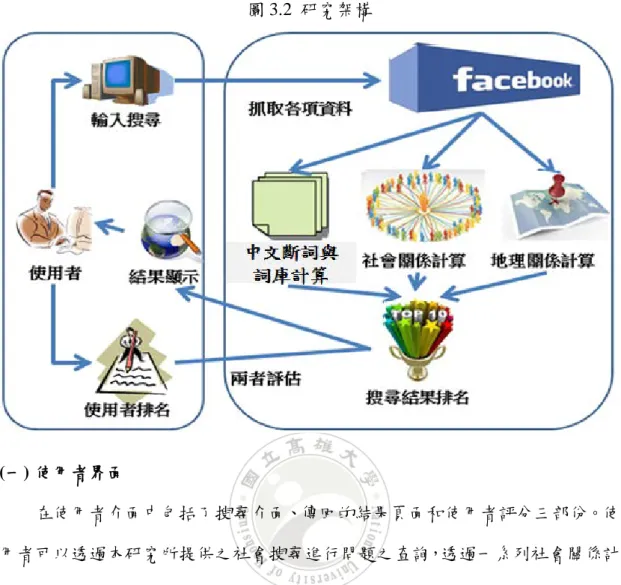
在本研究之系統架構圖中,主要可分為兩部份:一是前端使用者介面;二是 後端計算方法。以下會針對前端使用者介面和後端所使用之計算方法進一步說 明。
圖 3.2 研究架構 (一) 使用者界面 在使用者介面中包括了搜尋介面、傳回的結果頁面和使用者評分三部份。使 用者可以透過本研究所提供之社會搜尋進行問題之查詢,透過一系列社會關係計 算、地點相似度計算和基本斷詞計算處理後,再傳回結果至介面上,使用者可以 透過系統傳回之結果進行相關比較。本研究將採取同樣實驗中不同條件的比較的 結果顯示出使用者不同的喜好,例如第一次的搜尋結果為只考慮 TF-IDF 的計算 來代表一般的搜尋引擎型態,第二步加上社會關係的因素影響,最後再考慮本研 究的地理因素,相互比較在同樣的環境下使用者對於那些條件是有需求的。最後 則將比較結果傳回資料庫中。 (二) 前置資料處理與分析 2013 年 Facebook 的用戶數達 10 億人次,在台灣為目前主要的社群網站, 其他社群網站則稍顯乏力。由於 Facebook 網站註冊的會員數眾多,Facebook 為 了防止有虛名帳號的問題,定期會提醒上網次數小於門檻值的會員要定期上線, 倘若超過一定的次數,便會開始強制上網次數較少的會員進行刪除此帳號的動作
,因此表示在 Facebook 上除了每個人會以實名制來註冊之外,所以可以確定每 個帳號都是真人註冊的,因此人與人之間的關係連線是真實的。透過眾多的會員 數,我們可得知 Facebook 中使用者之間關係特性相當充足。 礙於目前線上資料過於繁多,格式也不盡相同,線上亦無一套既定的方法, 使得資料明顯呈現非結構化。因此本研究將以 Facebook 以 XML 格式之特性, 作為社群網站資料來源之基礎,探討朋友之間互動狀況,並將這種互動狀況稱之 為互動權重,進行一系列的計算。 1. 資料來源擷取
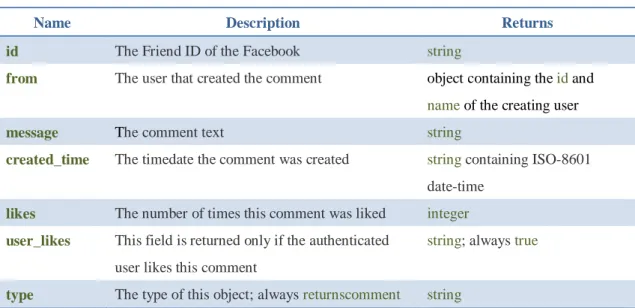
主要利用 Facebook 所提供 API 為資料擷取方法-Graph API。設計一個應用 程式,透過 Facebook 會員允許擷取該會員的相關資料之機制,當會員點選允許 之後,再進一步的擷取該會員之相關資料。因此,在 Facebook 的會員個資部份 是不會隨意的擷取,並且保證個資擷取後並不公開,只單純作為學術研究之用。 本研究資料擷取範圍可分為以下二種:一是從使用者與朋友之間之回應內容 ,主要以塗鴉牆內容為主;二是從使用者的朋友列表;三是使用者本身的個人資 料。如表 3.1、表 3.2 和表 3.3 所示: 表 3.1 塗鴉牆內容
Name Description Returns
id The Friend ID of the Facebook string
from The user that created the comment object containing the id and
name of the creating user
message The comment text string
created_time The timedate the comment was created string containing ISO-8601 date-time
likes The number of times this comment was liked integer
user_likes This field is returned only if the authenticated user likes this comment
string; always true
type The type of this object; always returnscomment string
Name Description Returns
id The Friend list ID string
name The name of the friend list string
type The type of the friends list; Possible values are: close_friends, acquaintances, restricted, user_created, education, work, current_city or Family
string
表 3.3 FB 個人資料
Name Description Returns
id The user ID string
name The name of the user string
close_friend The type of the close friends list; Possible values are: close_friends, acquaintances, restricted, user_created, education, work, current_city or Family
string
education The education of the user string
work The work of the user string
current_city The current city of the user string
interest The interest of the user string
2. CKIP 中文斷詞技術 本研究關於詞彙擷取的部份,以中研院資訊科學研究所詞彙小組(CKIP)所開 發的中文斷詞系統為工具,該系統結合詞庫式斷詞法及統計式斷詞法之優點的混 合式斷詞法,將使用者所輸入之文章或文句自動斷詞後,再標示出每個詞的詞類 標記。此系統分詞依據為此一詞彙庫及定量詞,重疊詞等構詞規律及線上辨識的 新詞,並解決分詞岐義問題。 3. TF-IDF 關鍵字計算
透過 CKIP 斷詞斷字後,將進行 TF-IDF 的計算。首先是詞頻(Term Frequency, TF)作計算,所謂的詞頻是指某一個給定的詞語在該文件中所出現之次數。而逆 向文件頻率 (Inverse Document Frequency, IDF) 的計算是指在總文件中,某一個 給定的詞語所出現之次數。關於 IDF 的概念,首先將某個詞彙設為 t ,如果包 含 t 的訊息或文章數量越少,依公式的算法 IDF 會越大,則說明 t 具有很好的類 別區分的能力,而 TF 與 IDF 公式算出的值相乘會得到 TF-IDF 的最後結果。
從上述所講將塗鴉牆文章內容作基本中文斷詞處理,將每篇文章中出現較不 能列為關鍵字的字詞抽取出來,接著對剩下的字詞進行 TF-IDF 的計算。由所求 得的值得知,本研究所蒐集的訊息或文章數中所代表之關鍵字為何,接著每則訊 息或文章所代表的 TF-IDF 值會與下面的社會關係計算結合。
第三節 社會搜尋計算(Social Search Algorithm)
此階段將藉由 Facebook API 所收集的資料進行使用者關係與互動關係的計 算,計算完的權重值搭配前面 TF-IDF 的影響結果即為本研究實驗設計中關於社 會搜尋的結果。而由於互動關係是有雙向性的,所以本研究將關係表示式定為 W(A,B),即表示使用者 A 對 B 的關係權重值,在之後敘述各情況下權重值計算 時皆採用此表示式。下列將以社會關係與互動關係分別詳述。 (一) 社會關係計算計算 社會關係即為兩使用者間的直接關係,通常為雙向性,一方對於另一方有關 係代表雙方都對彼此有關係。在社群網站上最顯著來看的條件即為兩者是不是朋 友,另外如果在工作上或是就讀相同學校也代表他們有一定的關係。所以本研究 在抓取資料時抓取了朋友列表以及使用者的工作名稱與曾就讀學校等等資訊。值 得一提的是,感興趣的事物本研究也列入考慮,當兩個使用者對同樣的事物有高 度興趣,表示他們的想法也更加雷同,所以額外抓取了 Facebook 上使用者在自 己頁面所填寫之感興趣的資料。 權重值方面,由於彼此是不是朋友最為重要,所以如果是朋友關係直接獲得 權重 1。舉例來說,有 A、B、C 三位使用者,AB 為朋友而 A 與 C 不是朋友, 則 一開始 W(A,C)、W(B,C)、W(C,A) W(C,B)的值為 0,而 W(A,B)、W(B,A)設 為 1。而對於其他個人資料,因為感興趣的事物為非必填選項且數量也能有很多, 本研究將其權重設為偏低,如此並不會因只配對到一項就影響社會關係權重,使 用者若彼此符合更多項興趣則分數就越高。工作與學校方面,若有一項配對吻合
則馬上獲得較高權重,不管是在學時期或工作場合建立的關係都是現實中較確定 已有的社會網絡關係。唯一不同的是若配對到第二項吻合之後,例如使用者 A 與使用者 B 是同大學與研究所的情況,本研究認為第二項之後的數據就不再是 那麼決定性的影響因素,所以從第二項條件配對到的計算權重部分會調降許多。 代表所以將權重值定為下列表: 表 3.4 社會關係之權重值 朋友關係 工作地與就讀學校 感興趣之事物 1(固定值) 0.7(第一筆) 0.2(從第二筆之後) 0.4(每筆) 所以若 A 與 B 為朋友,他們是同事而且喜歡聽同一個歌手的歌曲以及籃球 某一球隊,但以前就讀的學校完全不同的話,目前從個人基本資料來計算社會關 係的值 W(A,B)、W(B,A)為(1+0.7+0.4*2)=2.5。 (二) 社會互動關係計算 社會互動關係主要以 Facebook 上發表訊息以及回文、按讚、標記人名等行動來 查看互動關係。舉例來說,若某 A 在塗鴉牆上 PO 了一則訊息,則表示 A 對所 有的朋友權重值增加 0.1,即 W(A,*)=0.1。此時當 A 的所有好友看到此篇訊息而 進行回應的動作,其權重值則表示使用者 A 的好友群對於使用者 A 的權重值皆 一樣增加 0.1。同理,若對朋友按讚或標記人名等動作皆有對應的互動權重值。 表 3.5 文章的發文者與回應者之互動數 發表文章或回文 對文章按讚或別的情緒 用人名標記文章 0.1 0.01 0.1
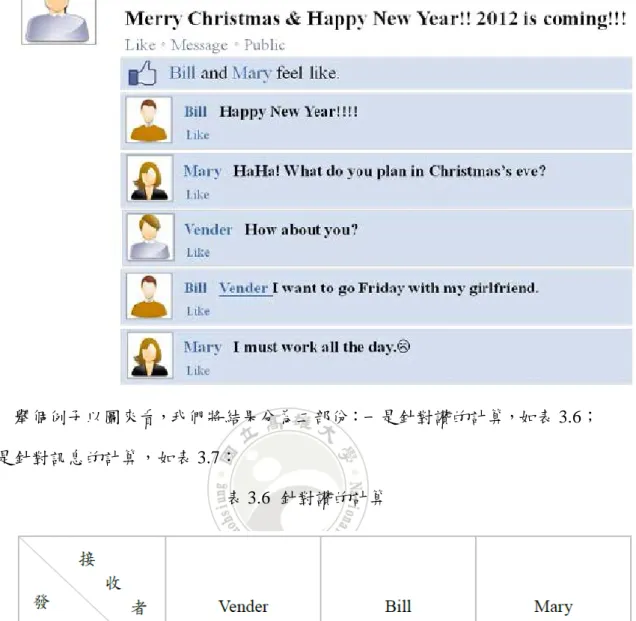
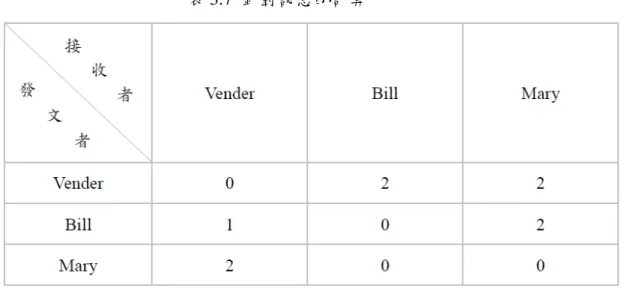
舉個例子以圖來看,我們將結果分為二部份:一是針對讚的計算,如表 3.6; 二是針對訊息的計算,如表 3.7:
表 3.7 針對訊息的計算
透過上述二表的表示法,首先以讚的回應為例,可以看到 Bill 和 Mary 對於 Vender 的回應按了讚,因此在權重表示法是 W(Bill, Vender)、W(Mary, Vender) 皆增加 0.1,其它狀況不增加。接著以訊息的回應為例,其權重值表示法依高低 順序排列為 W(Mary, Vender)、 W(Vender, Bill)、 W(Vender, Mary)、 W(Bill, Mary) 增加 0.2, W(Bill, Vender)增加 0.1,其他皆不增加。
Wr(user A , user B) + Wi(user A , user B)
= Ws(user A , user B) (3.1)
透過以上計算結果後,將關係權重和 TF-IDF 結合後,該數值表示在某篇訊 息或文章某個人所提到的關鍵字與社會關係。
RelA B = Ws * TFIDFj (3.2)
最後依分數高低排序,即為最後的社會搜尋排名。
Social Ranking = RelA B (3.3)
第四節 地理條件計算
目前 Facebook 的貼文中,使用者可為自己的文章標註地點,而個人頁面的 地方也可找到使用者過往的打卡紀錄,所以在人與文章上面都會有關於本研究所 需要的地理資料。觀察這些打卡地點,距離的遠近是直觀的因素之一,若打卡的
資料點距離使用者越近,則使用者可能會對有這些標註地點的文章更有興趣。但 除此之外,這麼大量的資料集一定有除了僅有兩點間的遠近關係以外的現象,由 第二章之文獻探討可知,這些打卡的資料我們有兩個面向可以去探討,分別是距 離與打卡資料的叢聚關係。若能將這些資料作分群,便能觀察出哪些點是屬於同 一個群體,證明這些劃分在同一群的打卡點有一定某個相似的特性。 以下介紹怎麼將使用者與文章的資料轉化成權重分數,本研究在這些打卡紀 錄方面使用兩條件來影響搜尋結果排名,一為先對目前資料進行叢聚分析計算, 將幾個密集度比較高的區域劃分起來。如此,這些在同樣區域內的打卡紀錄被歸 類為相似度高。劃分完後,分別依照不同情況對於兩點間的相似度與距離作計算, 以下各小節將對資料處理與採用的技術進行更詳細的介紹。
(一) DBSCAN (Density-based spatial clustering of applications with noise)叢聚
技術 首先在面對許多 GPS 資料時,必須先對這些資料進行叢聚計算,便可知道哪 幾個資料的相似度為高,應證本研究相似度高即較相信搜尋結果之論點。目前已 經有許多學者提出許多關於叢聚分析的技術,例如分割式與階層式叢聚。本研究 由於現今使用者的習慣仍然會只在某幾個區域有打卡的行為,且以探討熱門區域 之不同特性為主,所以對於資料中的雜質除了單純考慮距離外不會作過多考慮, 這時就需要一個考慮以密度為主的叢聚技術且能忽略雜質因素的演算法。其中 DBSCAN 演算法有著不需要事先預知要分幾群、排除雜質資料以及不規則分布 形狀幾種優點(Thang et al., 2011)(Ali et al., 2010),所以本研究採用 DBSCAN 對於 所有 GPS 資料作第一步叢聚動作。
此演算法必須先設定兩個參數,一為鄰近區域的半徑(Eps),另一個為存在於 該鄰近區域的最小點數(MinPts),只要在鄰近區域的半徑(Eps)內之資料點數大於 MinPts,即形成群聚,接著往外擴展群聚範圍。而最後對每個資料點會產生三種 情況,核心點、邊緣點以及雜訊點。簡單來說,若是半徑設為 5 而最小點數設為
3,那現在在計算第一個點時在它半徑單位 5 內若有超過 3 個別的點在範圍內的 話,此點被歸類為核心點。若是沒有超過 3 個點在範圍內的話但座落在核心點範 圍內,此點被歸內為邊緣點。若範圍內沒有超過規定的值且也不屬於核心點範圍 中的點則為雜訊點。 圖 3.4 DBSCAN 各點的定義 此外,若某核心點也在別的核心點之範圍內,便會持續擴大這個群體的範圍, 直到最後旁邊只剩邊緣點為止。 圖 3.5 核心點持續計算產生的區域 然而,此演算法最大的缺點為必須自己定義半徑以及最小點數,且定義出來 的值會嚴重影響最後分群的結果。 本研究採用 DBSCAN 分群技術主要原因為不用事先定義分幾群以及他能呈 現不規則的分群結果。藉由這樣的分群,可將資料庫中所有的 GPS 地點分成不
同群體,
(二) Google Distance Matrix API
本研究考慮兩點間的距離遠近因素,所以使用 Google Distance Matrix API 進行兩點間的距離計算。此 API 可將輸入的兩點之經緯度,直接計算出兩者間 的距離與預計到達時間。優點為它是利用 Google Map 上的道路來計算,而並非 單純直線距離,如此便可以將中間可能有地形上的干擾因素排除,而就是實際上 使用者間流動之距離差異。 圖 3.6 輸入地址或經緯度即可算出距離與預估時間 (三) 餘弦相似度(Cosine Similarity) 因為 DBSCAN 的分群結果,便可以知道每個使用者在每個區域內有多少打 卡數量。當一個使用者在一個區域內提供了大量的紀錄,便可知道或猜測此使用 者對於這個熱門區域有一定的了解甚至是喜愛。所以當搜尋者在考慮結果時,依 自己本身在各個區域內的打卡習慣,便可能考慮與自己在同樣有興趣的區域內留 下越多紀錄的使用者,較能相信他們提供的訊息。本研究使用餘弦相似度來計算 最後兩使用者間的相似程度,首先必須將各個使用者在分群結果內的打卡數量計 算出來,便可比較使用者之間的差異性。舉例來說,DBSCAN 的分群結果為 r1、 r2、r3、r4、r5,有四個使用者分別在這五個區域內打過卡,下列表格為各個區 域內的打卡數量。 圖 3.7 使用者在各個區域內打卡數表格
當要計算 user i 與 user j 的相似度時,便將(1.0.2.5.0)、(0.10.0.1.0)提取出來利 用餘弦相似度的公式產生結果: 圖 3.8 餘弦相似度計算 (四) 權重值計算 本研究採用兩種方式利用打卡資料來增強原本的社會搜尋系統,兩點距離以 及使用者相似度計算。由文獻探討來看,人們迫於立即的需求會更相信與使用者 所在位置距離越近的文章。但考慮到一種情況,單純考慮某個在高雄的使用者, 高雄到台北的距離是高雄到台中的兩倍,計算上會將它們的差異歸類為兩倍,但 事實上使用者對於自己不熟悉的地方的感覺應該都是差不多的,這也是本研究不 只考慮距離因素的理由。而本研究將所有打卡地點分群的目的也在此,分群的所 有結果即為各自的熱門生活圈,如果某個點在某個區域內則定義為在當地,對於 其他的區域都定義為不熟悉。對於當地來說,使用者可能會比較考慮距離自己遠 近的條件,而對於非當地來說,則得藉由計算使用者相似度來衡量。所以在權重 值計算方面,本研究將如果兩個點皆在同個群聚內的情況下考慮距離遠近的條件 權重放到最大,相反地兩個點沒有在同個區域內的話距離權重將會大大地減少。 Wl(user A , B) =
α * Wd(user A , B ) + Wsi(user A , B ) (3.4) RelA B =( Wl + Ws )* TFIDFj (3.5) 其中α為距離權重常數,若搜尋者與某篇文章地點相屬同一個群聚,此常數 設為 1,若為不同群聚但相同縣市則設為 0.7,若為完全不同縣市則設為 0.2,意 即其影響力會隨不同區域的相異性而擴大。整個算式(3.7)表示為使用者 A 對於 某篇文章 B 的地理關係。式(3.8)為結合社會關係與地理條件的計算所產生的社會 關係權重。 (五) 詳細實驗流程 首先搜尋行為的進行,從搜尋者本身撈取其塗鴉牆的資料,針對每個文章擷 取出其作者與被打卡之地點,對這些所有地點資料進行 DBSCAN 分群技術得到 不同群聚點。接著計算搜尋者與這些文章之作者的社會關係與打卡相似度,也詢 問搜尋者本身所在的地點位置。最後將所有資訊以公式計算出數值高低進行排 名。
第五節 實驗設計與評估方式
在本節中將說明本研究之實驗設計與驗證方式,主要會找 10 位使用者進行 本實驗所提出的搜尋系統。由於本研究以個人打卡紀錄來改善原本只考慮人際關 係的排名,所以這些使用者也必須是至少擁有智慧型手機,並會在 Facebook 上 面提供一定量之個人打卡點的人,我將它設定為至少一個月會有一次的打卡行為, 且累積至少三十 次的紀錄以 上。下列將實驗設計與評估方式兩部分進行說 明。 (一) 實驗設計 本研究主要是為了改進社會搜尋結果滿意度,由於跟一般搜尋系統並不相同, 搜尋結果為每個人的社群貼文內容,對每個人心目中的價值皆不相等,排名第一 名並不一定是最充實或最正確的內容,往往決定於搜尋者當下的需求或感覺。所 以本研究採用比較排名的評估法,對兩種搜尋模式的排名進行比較,一個為僅加 入考慮社會關係與互動程度之搜尋,另一個則在此方法上加入打卡紀錄之相似度 與打卡紀錄的條件之搜尋。實驗設計分為兩輪的搜尋,總共有十次對於兩系統輸 入相同字詞的搜尋動作。每次搜尋結果後都會要求使用者對於各系統的結果進行 排名,這時系統會列出搜尋結果前五項的內容而先不排名,受測者先針對此五項 內容進行自己心目中的排名,然後系統再根據兩類別的搜尋系統各列出前五名的 結果。實驗最後將依照受測者自己的排名與系統兩種排名進行比對比較相似度, 所以最後每位受測者對每個系統將產生總共 20 個實驗結果。 圖 3.9 實驗設計-搜尋結果與填寫排名(二) 評估與驗證方式 在實驗評估階段需建立一套可標準衡量之方法,在傳統的文字檢索中,通常 都是使用查全率(Recall)與查準率(Precision)。但由於此兩項衡量值需要定義文件 的相關與不相關性,換句話說就是文件有沒有達成查詢條件的屬性。傳統文件檢 索以字詞出現數量來定義,但在社會搜尋之研究中卻很難去定義任何搜尋結果有 沒有真的正確,因為這完全依照使用者自己的感覺與判斷。所以本研究讓使用者 對於本系統之搜尋排名結果進行自己的排名,便可以知道系統與使用者心目中的 排名相似度。 在統計上有數種分析兩變數間相依關係的方法,其中 Kendall 的相關係數 (Kendall tau rank correlation coefficient)並不需要去探討屬性值之間的差異,它 是直接針對值之間的比較排行高低建立一個排行列表,便可以針對兩屬性的排名 計算其相似性,以下為此相關係數之公式。 (3.10) 其中 n 為物件數,P 為在兩個排名間,某個物件的排名放在另一個排名列表 中的話,有多少個排名對它來說是同個方向,並對所有物件計算之總數的值。算 出來的結果數值範圍為-1 到 1 之間,1 表示完全相關而-1 表示完全不相關。舉例 來說,有一筆以下之資料。 表 3.8 一筆 8 位人民的體重與身高資料 person A B C D E F G H 身高 192 187 185 183 178 172 168 165
體重 80 79 100 83 75 64 58 71 為了計算 Kendall 的相關係數就必須先將資料處理,將資料個別的屬性值進 行排名,如表 3.7。 表 3.9 處理過後的身高體重資料 person A B C D E F G H 身高排名 1 2 3 4 5 6 7 8 體重排名 3 4 1 2 5 7 8 6 接著看對 A 來說,在身高他的排行是第一位,但在體重排行是第三位,所 以比對兩排行間在第一與第三名之後發現有 5 個排名在兩者後面,所以對 A 來 說 P 值為 5。以 B 來看,身高排名第二在體重排名第四,所以同樣排在兩者後面 的排名為 4,所以 P 值為 4,以下以此類推。最後並可以計算其總數為 P = 5 + 4 + 5 + 4 + 3 + 1 + 0 + 0 = 22,套用到公式上計算得數值為 0.57,表示兩排行間有 著很大的相關。 利用其不考慮資料間數值的差異,而本研究也可藉由實驗產生系統排名與使 用者自己的排名,本實驗採用此相關係數來評估兩個系統間各兩個排名間的相似 度來比較。第一階段的任務中,直接讓使用者對兩系統輸入相同字詞搜尋,並分 別計算其排名相似度比較,,所以整個實驗與評估流程如圖。 圖 3.10 評估方法流程
第四章 實驗結果與評估
第一節 資料來源與處理
(一) 塗鴉牆資料庫 要開始進行實驗前必須先收集臉書使用者之塗鴉牆資料以供搜尋,而塗鴉牆 的擷取內容關係到本實驗的結果,所以首先必須明確定義本實驗要擷取的範圍。 本實驗設計的人數為十人,所以要取得的塗鴉牆資料來源就設定為此十人為主, 畢竟實驗對象想要得到的搜尋結果必定期望與自己相關。 以下舉某一實驗對象之塗鴉牆內容列表為例,這是他的某一篇訊息內容,詳細 資料格式如圖 4.1。資料格式主要為發佈訊息者與按“讚”的人,因此在訊息發佈者的 內容中可看到使用者 ID 與發佈該篇文章之編號、使用者帳號名稱、使用者 ID、訊 息內容(message)、發佈文章時間、回應訊息以及標註地點。在按“讚”的內容中包括 按“讚”的使用者 ID,如圖 4.2。 圖 4.1 一則貼文訊息與其內容 圖 4.2 按讚之資料內容圖 4.3 為訊息之回應文章內容,在回應之內容中包括回應文章之使用者名稱、回 應文章之使用者 ID、回應文章之內容、回應文章之時間與回應文章之按讚數量。 圖 4.3 回應文章之資料內容 圖 4.4 為這篇文章的標註地點內容,包含地點的 ID、地點資訊與經緯度以及 地點名稱。 圖 4.4 標記地點之資料內容 透過圖 4.1、圖 4.2、圖 4.3 和圖 4.4 所示,本實驗便可得出影響社會搜尋結 果的幾項必要數值。在社會關係計算上,使用作者、按讚、回應和回應的讚來處 理,而在地理資訊裡則直接撈出本文章之 ID 與地點經緯度資料。 本研究透過所篩選之 10 位受測者之塗鴉牆中擷取出 2745 則訊息量作為本研 究的資料庫集,實驗中受測者直接輸入想要的關鍵字進行搜尋,系統將會由這資 料庫集中找出有符合關鍵字之文章,再將這些文章與其作者進行社會關係計算。 而其中有 183 則訊息有標註打卡地點,則先將這 183 個資料點使用第三章提到的 DBSCAN 進行叢聚分析後,再對社會搜尋之結果改變排序。
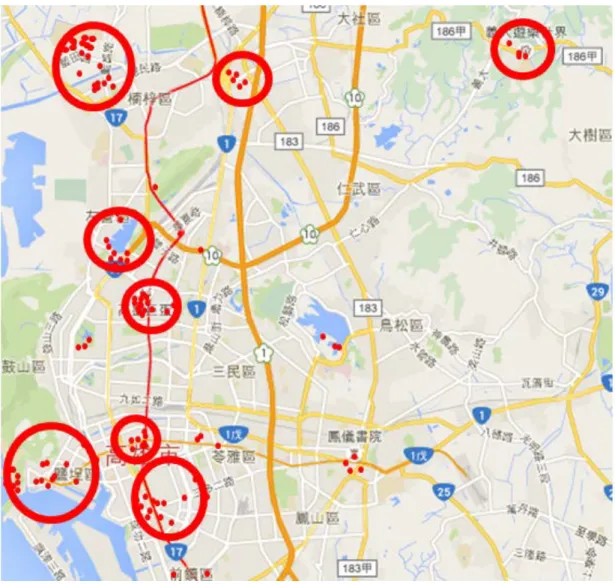
(二) DBSCAN 叢聚資料集 本次實驗總共得到 183 個 GPS 資料點,由於實驗對象大多數位於高雄的關係, 其中有 114 個點都位於高雄,下列以特別放大高雄的分佈情形來展示,如圖 4.5: 圖 4.5 高雄的打卡資料集 如上圖所示為高雄資料的分佈,然後用分析工具中的 DBSCAN 套件進行分 群,由於需要先設定半徑與數量的數值,本實驗再經過反覆設定後獲得一個最佳 的分群結果,如圖:
圖 4.6 高雄的打卡資料集(分群後) 由以上可觀察高雄地區可分為八個群聚,其中楠梓區高雄大學為本研究作者 在讀的學校,受測者有部分同為這裡的學生。其他有例如蓮池潭、義大與鹽埕等 觀光熱門區域,或是三多、巨蛋等人口聚集區域。另外有一個較零散的打卡地點 在分群完後屬於雜訊點,意即不屬於任何群聚。
第二節 實驗環境
在實驗環境中,針對十位受訪者進行訪談,當訪談開始時,會先讓受訪者了解 對於 Social Search 的概念為何,並讓所有受測者了解搜尋結果出來後該作的排序動 作以利實驗結果的產出,接著給予任務,讓受訪者進行搜尋。由於每一位受訪者所 搜尋得到之結果盡不相同,因此盡量讓受訪者在搜尋時以多方面的詞彙去搜尋。受測內容挑出至少有前五名的結果為主,並記錄受訪者使用的搜尋詞彙並加入標記, 紀錄他是什麼原因想進行這個詞彙的搜尋,以及他可能會想要得到的結果。例如搜 尋「畢業」時可能因為為應屆畢業生,想搜尋朋友們對於畢業典禮的想法。而搜尋 「美食」的話可能單純在想午餐的地點,希望能由朋友推薦一間近距離的餐廳。本 論文將此特別標註下來,希望也有可能利於實驗結果的分析。 實驗過程受訪者進行搜尋,搜尋結果將依有關鍵字之內容加入社會關係計算排 出前五名,但此時結果將會以亂數排序呈現給受訪者,以便能讓受訪者以自己的感 覺進行此五個結果的排名,然後將未加入地理因素影響之結果呈現給使用者便可馬 上得到第一階段的結果。最後將地理因素的條件加入,再排序一次此五個結果,便 可再得到一個排名,如此,一個完整的搜尋任務便會得到三個排名結果。
第三節 實驗結果
透過上述實驗步驟進行 10 位受訪者之任務指派後,將 10 位受訪者之任務結果, 共 50 筆排名結果進行評估。如表 4.1 所示。 表 4.1 實驗結果 第一階段 第二階段 第一階段 第二階段 第一階段 第二階段 第一階段 第二階段 第一階段 第二階段 Person1 0.6 0.6 0 0.6 0.4 0.8 1 1 0.2 0.4 0 0.4 -0.4 -0.2 -0.6 0.4 0.2 0.4 0.4 0.8 Person2 0.4 0.6 -0.4 0.2 0.40.6 0.4 0.2 0.4 0.6 0.2 0.6 -0.4 0 -0.2 -0.2 0 0.6 0.6 0.6 Person3 0.2 -0.2 -0.8 -0.4 0.2 0.4 0.2 -0.4 0.4 0.4 -0.4 -0.4 0.2 -0.6 -0.4 -0.6 0.4 0.8 0.4 -0.4 Person4 0 0.4 -0.6 -0.6 -0.4 -0.6 -0.8 -0.6 -0.2 0.2 -0.4 -0.2 -0.6 -0.6 -0.6 0.2 -0.2 -0.2 0.2 0.4 Person5 -0.2 0.2 -0.4 0.2 0.6 1 0.8 1 0.6 0.6 -0.4 -0.4 0 0.6 0.8 0.4 0.8 0.6 0.6 0.8 Person6 -0.6 -0.6 -0.6 -0.4 0.2 0.4 -0.6 -0.4 -0.2 -0.2 -0.6 -0.4 -0.4 0.4 -0.4 -0.2 0.4 0.4 0.4 0.8
Person7 -0.4 0.4 0.4 0.8 -0.2 0.4 0.6 0.4 0.6 0.8 0.4 0.2 1 0.4 -0.4 0.4 -0.2 -0.2 0.4 0.6 Person8 0.2 -0.2 0.4 0.8 0.6 0.2 0.8 0.4 0.4 0.2 -0.2 -0.6 -0.2 0 0.2 -0.4 0.6 0.6 0.4 0 Person9 -0.2 0 1 0.2 0.4 0.8 0.2 0.6 -0.4 0.2 0.2 0 -0.6 -0.4 0 0.6 0.6 0.8 0.2 0.2 Person10 0.4 0.4 0.4 0.6 0.4 0.2 -0.2 0.2 0.2 0.4 0 0.4 -0.6 0.4 0.2 0.4 -0.4 -0.2 0.6 0.6 表 4.1 中,可得知總體而言,加入地理條件計算之搜尋結果普遍比只考慮社
會關係之搜尋結果要來得好,其分數平均大於 0.2,結果是加入地理條件之搜尋 排名結果與受訪者所給定之排名結果較為符合。不過差異並不很多,原因其一可 能為原本的社會關係搜尋已能在社群網站上達到大部分的需求。其二為有標註地 點的文章內容只佔了整體資料庫數量中不到 10%,代表一般來講使用 Facebook 的使用者還沒有一定會有標註地點的行為,那多考慮地理條件的情況下可能沒有 改變任何結果。其三,觀察到 Facebook 發表文章之現象,常態性會有標註地點 的發文者固定是某些人,而其他人會特別標註地點的文章都會有特別的目的,例 如正在旅遊或到外地。本論文將繼續探討這些原因。 首先在實驗結果中,有某些測試者兩種計算方式均偏低或者有時高有時低, 為探討這個現象,本研究特別針對 Person3、Person4、Person6 和 Person8 三位受 訪者進行深入調查,其中 Person3 為較混亂型的結果,而 Person8 則是普遍未加 入地理條件之搜尋結果分數較高。Person4、Person6 為兩種方法計算結果都偏低, 推論因為第一階段的社會關係的加入就無法優化排名結果,原因有二: 1. 一些使用者在臉書上的朋友人數眾多,但在現實世界中並不一定都 很熱絡,尤其一些對外表很有自信的人勇於展現自我而擁有眾多的臉書朋友 互動,或是使用者本身在使用網路與本人是比較不一樣的感覺。這種情況下, 社會關係搜尋的意義並不會很大,在網路上的熱絡行動可能並不一定代表真 實的關係,不會因社會關係密切而增加興趣。 2. 真正的受訪者所認定的朋友在 Facebook 中活耀性較低,在塗鴉牆 中的互動過低,進而影響在受訪者的好友排名結果較低。 而針對 Person3 與 Person8 兩位受訪者的結果來說,一位是本研究所提出的理 論對搜尋結果的優化不明顯。另一位則是僅需要考慮社會關係之搜尋結果反而比 較符合需求,這說明本研究的假設不適合應用在 Person8 此類的使用者上。面對 這種情況,本研究需要歸納出一個條件,或者對於使用者來說,不一定任何搜尋
需求都需要考量地理因素的條件。 社交需求會隨著地理條件的改變而變化,例如若是常居住在某地的居民,因 為已經是自己熟悉的地方,自然不會對該地有較多的探索需求。而需求的內容也 因為當下搜尋者的狀況不同而有著很大的不同,舉例來說,若搜尋有地緣相關的 物件或感想時,此時考慮地理條件理想情況下是能優化整個搜尋結果。相反地, 若是想搜尋大熱門新聞或某個廣泛的資訊知識這種無關各區域生活作息等等的 需求,或許就不用去探討本研究所提出的論點。在進行實驗過程中,特別詢問受 訪者提出的搜尋需求以及心目中想要達到什麼結果,試想若能從這些需求中與實 驗結果找到一些規律,便能判斷何種情況更適用本研究所提出的論述。以下表為 受訪者在 10 項問題中所提出的需求與期望結果之範例,由於不一定每項搜尋行 動必然有五項結果進行比較,受訪者在思索搜尋時若有無法順利提出需求時,本 實驗會給一些題目。如表 4.2 是比較多數人有提出或者比較特別的一些項目。 表 4.2 不同的搜尋需求與結果 搜尋需求 期望結果 實驗結果 畢業 回憶畢業典禮照片、看畢業離 別文 Person1(2) : 0/0.6 Person9(8) : 0/0.6 好吃 查看附近好吃的食物、看照片 Person1(3) : 0.4/0.8 Person2(3) : 0.2/0.4 Person6(3) : 0.2/0.4 Person10(2) : 0.4/0.6 高雄 了解高雄的消息、外地人來高 雄找吃喝玩樂 Person1(10) : 0.4/0.8 Person4(1) : 0/0.4
Person7(3) : -0.2/0.4 Person8(9) : 0.6/0.6 日本 暑假旺季搜尋誰去日本旅遊、 查詢日本景點 Person6(6) : -0.6/-0.6 Person9(2) : 1/0.2 貓 看寵物趣聞舒壓、找貓同好、 找貓資訊 Person5(3) : 0.6/1 Person7(4) : 0.6/0.4 Person9(10) : 0.2/0.2 業障 網路大量 Kuso 搞笑 Person3(2) : -0.8/-0.4 Person5(6) : -0.4/-0.4 XD 找尋朋友發表逗趣的事 Person1(4) : 1/1 Person5(9) : 0.8/0.6 麥當勞 想吃麥當勞看評價或有無新活 動分享 Person6(10) : 0.4/0.8 電影 查朋友評論、查預告片、揪好 友 Person2(10) : 0.6/0.6 Person3(10) : 0.4/0.4 Person9(9) : 0.6/0.8 上表中最右項為比對此次實驗結果的數值,Person(1)代表受訪者一號,0.4/0.6 則代表此次的實驗結果為第一階段 0.4 提升到第二階段的 0.6。由此表可觀察出 一些有趣的現象,首先在搜尋「畢業」與「好吃」的部分,兩者皆為正值,代表 不論是僅計算社會網絡關係或者加入地理條件搜尋,結果皆符合使用者的排名。
唯一的差別在於「畢業」在加入地理條件後差距提升幅度較大,而「好吃」則是 較常出現之提升 0.2 的值。顯示此兩種搜尋都有地理位置的因素,想搜尋畢業的 使用者較想得知自己學校的文章而非所有朋友所發的文。而想要搜尋美食的人, 距離或叢聚因素也能提升滿意度,但效果沒有這麼強。接下來看看「高雄」與「日 本」的部分,兩者都是地名,可是結果卻是完全不一樣。「高雄」在第二階段的 提升幅度皆算明顯,只有八號受測者沒有提升,而「日本」卻一個打平一個大幅 下降。在詳細了解使用者的需求後,經由推測為「高雄」的實驗結果在本研究的 預期當中,有地緣關係的人會對自己居住地有較高的興趣,其中受測者四號是到 高雄旅遊的人,他想要就近搜尋高雄的餐廳與景點等,結果也很符合預期結果。 在「日本」方面依前述所說,受測者六號是屬於很活絡之 Facebook 的使用者, 但朋友數量眾多與平時發表文章互動熱烈的他,在平台上的交流並不代表他現實 的朋友。所以當他在搜尋日本方面的資訊要為出國做謹慎的準備時,社會網絡關 係並無法引起他更大的興趣,而因為地點位在國外的關係,本研究提出的地緣關 係也無法優化此搜尋結果。其他的項目中,「麥當勞」符合研究預期,而「貓」、 「XD」、「電影」皆無明顯一致提升,推測為此種搜尋看重社交內容,由朋友提 供之訊息較為喜愛,地理因素無法提升滿意度。最後「業障」皆為負值,表示此 使用者的排名跟社交關係也沒有正相關,或許因為此一用詞為近期熱門之網路用 語,很多網路惡搞的圖片影片都非常有趣,所以不受社會網絡關係之影響。 由以上的推論,在社會搜尋上使用者本身的搜尋目的是會影響整個結果的排 名,而這或許也為 Person8 實驗結果大幅不如本研究預期之原因。Person8 所搜 尋的項目有: 「韓劇」、「書」、「爽」、「楠梓」、「五月天」等項目,可以看出除了 「楠梓」外,其他的項目直觀來說都與地理因素較為無關,而「楠梓」也恰巧是 Person8 少數幾項有提升的項目之一。綜觀以上,本實驗結果大致上符合本論文 之理論。
第五章 結論與分析
第一節 結論
近年來社群網站之成立以及行動裝置的普及連結起人與人之間之關係,透過 強連結所連繫之兩人可透過彼此之共同事物來提供更多之資訊給其他人,而手機 與平板則讓每個人都能隨地分享自己的資訊,也可讓區域相近的人們更加地緊密。 就使用者而言,擁有強連結關係的朋友或有地緣關係相近的人所提供之相關資訊 會使人更有高度興趣。因此本研究將傳統搜尋引擎加入社會關係以及地理條件的 計算,預期可改善搜尋品質並提升搜尋者之滿意度。 本研究將透過 Facebook 之塗鴉牆資料作為社會搜尋之依據,接著進行 CKIP 詞庫小組處理和 TF-IDF 計算,最後結合字頻、社會關係與地理條件進行結果排 名,得到社會搜尋之結果。透過本研究之社會搜尋排名結果和加入地理條件之搜 尋排名結果比較後,證實朋友所提供之資訊確實會影響使用者之決策。 本章將針對本研究之結果進行總結分析與探討,從前一章之評估方法結果可 得知不管距離的遠近或是叢聚的相似度等因素都可以優化使用者對於搜尋結果 的滿意度。實驗中針對加入地理條件之社會搜尋結果和未加入地理條件之社會搜 尋結果二部份進行測試比較,並得知在大部分情況下都能讓結果更符合搜尋者的 期望,本研究最後也推測出哪些搜尋行為可考慮不加入地理條件之搜尋,在這些 狀況下僅需透過一般社會搜尋就已足夠。以下章節將依序針對本研究作一個整體 性之結論,以及深入探討其他發現。 本論文在第一章曾經提出三項研究目的,經過研究的進行以及研究方法的實 驗與驗證,可以證明三項目的皆已達成,包括: 1.將社會搜尋技術加入衡量打卡資訊之概念,並設計一個能與社會搜尋相互 影響之搜尋排名機制。 2.探討如何從社群網站中萃取出社會關係,以及GPS的資料如何找尋出使用 者間的相似度。3.評估本論文所提出之改善社會搜尋技術,並與目前社會搜尋引擎技術進行 比較,結果證明有加入地理條件計算所產生的結果真的優於現有社會搜尋技 術。
第二節 研究限制
1.擷取資料較不完整 你本研究所使用之資料依據為 Facebook 平台,礙於 Facebook 過往之隱私權 問題相當重視,因此本研究進行資料擷取過程中十分困難。透過 Facebook API 所提供之擷取資料方法,所傳回之資料可得到塗鴉牆所有資料。以 like 為例, 若發現資料顯示此筆訊息有 15 人按讚,但資料卻只抓回一筆,因此關於其他按 讚之使用者必須利用手動方式抓回資料,這將耗費相當多的時間。 2.打卡資料不足 由前文所述,所有文章的總數與有打卡的資料相比的差距過大,證明使用者 的打卡行為還不近普遍。所以本研究所提出的論述對於社會搜尋的影響力還並不 非常足夠。 3.權重值無法分析 由於前一點所提的打卡數量不足,目前僅能先對於有無加入地理條件兩者的 情況去分析。本研究中所提出之距離對於搜尋結果之影響度有設定權重常數來決 定,但數量還不足以去證實這樣的設定是否符合實際需求。第三節 未來研究方向
1.搜尋需求分析 由研究結果來分析,不同於一般搜尋系統單純看字詞量或者網頁的連結重要 程度,社會搜尋著重在人與人之間的關係與多樣的需求,不同的搜尋需求其想要 的結果也為之不同。本研究對於此現象已有作了初步的分析,但僅僅用實驗的結 果數據來分析,未來可針對這樣的問題,去訂定更加明確的實驗步驟,以觀察怎 樣的搜尋需求需要考量什麼樣的條件。 2. 與 Ontology 結合以本研究實作狀況來說,由於目前尚未有一套關於社會關係之字詞庫。因此 若能與 Ontology 結合,建立起以社群關係為基礎之主題性字詞庫,將可有利於 未來開發者進行研究。