Local Refinement Algorithms for Protein Structure
Comparison and Alignment
Wei-De Jiang
Hsiang-Sheng Shin
Yaw-Ling Lin
∗Department of Computer Science and Information Engineering,
Providence University,
200 Chung Chi Road, Shalu, Taichung County, Taiwan 433.
[email protected], [email protected], [email protected]
Abstract. Proteins are an important class of biological macromolecules present in all biological organisms. Protein structures are essential for correct function because it al-lows molecular recognition. Thus protein structures provide the opportunity to recognize homology that is undetectable by sequence comparison, and they are powerful means of discovering functions, yielding direct insight of the molecu-lar mechanisms. In this paper, we propose algorithms and develop tools for local alignment between two protein struc-tures by means of local adjustments.We show the effective-ness of the proposed refinement methods and initialization algorithms by a set of experiments; the results show im-provement comparing to several previous results.
Keywords: structural proteomics, structure ments and comparisons, local refinement, initial align-ment
1
Introduction
Protein structures play critical roles in vital biolog-ical functions [9]. The three dimensional structure of proteins is highly conserved during evolution [4]. Pro-teins are constructed by one or more polypeptide chains that fold into complicated 3D structures. Detection of proteins with a similar fold can suggest a common an-cestor and often a similar function [5, 19].
With more than 50,000 protein structures deter-mined by the advances in X-ray crystallography and NMR spectroscopy to date, molecular biologists these days proceed in the direction of analyzing and classi-fying these protein structures in order to discover the structural relationships with protein functions [6]. This is why structural alignment of proteins increases our understanding of more distant evolutionary relation-ships [3, 13]. The link between structural classification and sequence families enables us to study functions of various folds, or whole proteins [15].
The VAST system [10] is based on continuous distri-bution of domains in the fold space. The FSSP/DALI
∗Corresponding author. This work is supported in part by
the National Science Council (NSC-96-2221-E-126-002), Taiwan, Republic of China.
system [12] provides two levels of description – a coarse-grained one and one with a fine-grained resolu-tion. The method, CATH, provides the complete PDB fold classification by domains and links to other sources of information. The two methods, CE and LGscore2 [24] focus on the local geometry rather than global features such as orientation of secondary structures and overall topology (as in the case of VAST or DALI). VAST has been used to compare all known PDB do-mains to each other. The results of this computation are included in NCBI’s Molecular Modelling Database at http://www.ncbi.nlm.nih.gov/Structure/-VAST/vast.html.
Incorporating with ideas of bipartite matching and 3-parameter isometric transformation, Lin et al. [14, 22] proposed methods of using parametric searching strate-gies with adaptive controls, and demonstrated that more accurate and similar protein structure pairings are possible comparing to previous known results like VAST [10] or CE [24].
In our previous work [23], we propose algorithms for efficiently locating more suitable isometric transforma-tions of one structure and aligning it to the other struc-ture. In this paper, we propose algorithms for local refinement and the new initialization method.
2
Background and Terminology
Consider the point of north-pole n = (0, 0, 1) on the unit sphere. After the rotation, R, say n is rotated to another point p = (x, y, z); i.e., p = Rn. Let α denote the angle ∠nOp. Note that α determines the z-coordinate of p. To determine x-coordinate and y-coordinate of p, the point is rotated around the z-axis for the angle β on the unit sphere. Note that there are infinitely numbers of rotation that transform n to p. The particular rotation R can be decided by rotating all other points around the vector p by the angle γ. It is not hard to verified that, in such a way, any rigid rota-tion transformarota-tion can be parameterized by the three-tuple (α, β, γ). Thus, we call a vector p = (x, y, z) on the surface of the unit sphere a probe. Note that the
movement of each probe is started from the north-pole (0, 0, 1) to other points in the sphere. The position of p is decided by the parameters (α, β), and exact rotation is fixed by the self-rotation angle γ.
The main idea of our algorithm for finding a suitable matching between two sets of points before utilizing the Rmsd procedure to fine-tune the final result is by searching the suitable (parametric) probe. After that, we use the minimum bipartite matching algorithm to find the best matching between two sets to decide the best matching for the Rmsd procedure. Let P0= T ◦P ,
and Q being translated to Q0such that the mass center
of Q0 is located at the origin. We construct a weighed
graph G = (V, E) with V being labelled with points of P0 and Q0, and each (p, q) in E being weighted with
the squared Euclidean (3D) distance; i.e., w(p, q) = kp, qk2. We then solve the weighted minimum bipartite
matching problem [8] to obtain the best matching of P0
and Q0. By the matched pairing, we perturb and refine
the final alignment to obtain a possible lower rmsd.
2.1
Root mean squared deviation
The smallest root mean squared deviation (rmsd) is a least-squares fitting method for two sequences of points [12]. The idea is to align atom vectors of the two given (molecular) structures, and use the common least av-eraged squared errors as a measurement of differences between these two (paired) sequences. Formally, let P = hp1, . . . , pni and Q = hq1, . . . , qni be two sequences
of points. We assume that P is translated so that its centroid (1
n
Pn
k=1pk) is at the origin. We also assume
that Q is translated in the same way. For each point or vector x, let (x)i(i = 1, 2, 3) denote the i-th (X, Y, Z)
coordinate value of x, and kxk denote the length of x. Let rmsd(P, Q, R, a) = q 1 n Pn k=1kRpk+ a − qkk2,
where R is a rotation matrix and a is a translation vec-tor. Then, the rmsd value d(P, Q) between P and Q is defined by d(P, Q) = minR,ad(P, Q, R, a). Schwartz
[21] showed that d(P, Q, R, a) is minimized when a = 0 and R = (AtA)1
2A−1, where the matrix A = (Aij)
i, j = 1, 2, 3 is given by Aij =
Pn
k=1(pk)i(qk)j, where
A12 = B means BB = A , and o denotes the zero
vec-tor. Thus, d(P, Q), R and a can be computed in O(n) time [17].
We refer to Martin’s ProFit package (standing for protein fitting system) [16] and write a program to cal-culate the rmsd between C-α atoms of paired protein backbones with C language. Fitting was performed us-ing the McLachlan algorithm [17].
2.2
Isometric Rotation Transformation
According to Euler’s rotation theorem [7] , any rota-tion about the origin point can be described by using three angles. The rotation is determined by 3 consec-utive rotations with 3 Euler angles (α, β, γ). The first rotation is done by the angle α around the z-axis, the
second is done by the angle β around the x-axis, and the third rotation is done by the angle γ around the z-axis. see [11] for related discussions about the trans-formation.
As a result, we reduce the problem of finding a good rotation matrix to the new problem of finding a good 3-parameter. The rotation matrix is thus characterized by just adjusting the 3 uniformly distributed parame-ters.
2.3
Minimum Bipartite Matching
We use the minimum bipartite matching to find the best matching between two sets of points to decide the best matching for the rmsd procedure. We adopted the Munkres [18, 2, 1, 20] algorithm. The public avail-able implementation is written with Perl language. To improve the efficiency of computation, we implement the Munkres algorithm and write hundreds lines of C Codes.
2.4
Parametric Adjustment with
Trigono-metric Series
In our previous work [23], the trigonometric series estimation method, the three parameters are assumed to be independent. We adjust the three parameters one by one and increase the power of the estimated function. The trigonometric series function is described as the following: f (θ) = C1+ C2cos πθ + C3sin πθ + C4cos 2πθ + C5sin 2πθ + C6cos 3πθ + C7sin 3πθ + . . . + C2kcos k − 1 2 πθ + C2k+1sin k − 1 2 πθ (1)
, where the f (θ) denote the corresponding value of rmsd with respect of one of the three parameters, (α, β, γ). The k usually reflects the numbers of local maximal points in the approximated curve.
3
Methodology
In this section, first we introduce the motivation about why we want to use the local refinement algo-rithm to find the better list between two proteins. Sec-ondly, we show the initial algorithm according to the structure of protein. The detail experimental result is showed in next section.
3.1
Motivation
In our previous work, the trigonometric series es-timation method is used to find a better position in protein structure comparison. When comparing with the VAST, there are 15.89% improvement by our pro-posed method.It is appropriate to the local alignment algorithm in finding the better alignment. Therefore,
Struc-Mir(P, Q, A) ¤ Structure Alignment with Mirror.
Input: (P, Q, A), where P = {p1, p2, . . . , pnP} and Q = {q1, q2, . . . , qnQ} are two set of 3D
coordinates of points, and A is a initial alignment.
Output: (r, A), where r is a sufficiently low rmsd, and A is the new alignment
1 started ← true
2 repeat improve ← true
3 repeat ( P, Q0) ← Φ
A(P, Q) ; r ← rA ¤ adjust atoms of Q to atoms of P
4 A0← Mbm(P (A), Q0) ; succ ← false ¤ P (A) is the aligned atoms of P
5 if rA0 < r then succ ← improve ← true; A ← A0; Q ← Q0
6 until not succ
7 if not improve and not started then exit
8 improve ← false ; started ← false
9 repeat ( P, Q0) ← Φ
A(P, Q) ; r ← rA ¤ adjust atoms of Q to atoms of P
10 A0← Mbm(Q0(A), P ) ; succ ← false ¤ Q0(A) is the aligned atoms of Q0
11 if rA0 < r then succ ← improve ← true; A ← A0; Q ← Q0
12 until not succ
13 until not improve
14 return (r, A)
Mbm(P (A), Q0) returns the minimum bipartite matching of two point sets P (A) and Q0.
ΦA(P, Q) ¤ adjust atoms of Q to atoms of P by the alignment, A.
Input: (P, Q), where P = {p1, p2, . . . , pn} and Q = {q1, q2, . . . , qm} are two set of 3D coordinates of points.
Output: Q0, where Q0is adjusted from Q.
1 MR← Rot(A) ¤ MRis a rotation matrix calculated from the alignment, A.
2 Q0← Trans(P, Q, M
R) ¤ adjust atoms of Q to atoms of P by MR.
3 return Q0
Figure 1: The mirroring method tries to find a better local alignment by reflection atoms of two structures.
we propose a local refinement algorithm, mirroring method, to have a better alignment. The procedure for all the algorithms is shown in Figure 3. P A and P B are two protein structures. We get the fixed numbers of aligned atom in PA by initial algorithm and then proceed with trigonometric series estimation method to adjust the parameters. The use of the mirroring method depends on global alignment or local align-ment. Besides, we also develop two new initial meth-ods, main vector and segment alignment, to substitute for the well-known methods, such as the VAST and CE. In the following we introduce the local refinement by mirroring method, then initial with main vector or segment alignment.
Figure 3: Algorithms for structure alignments of protein pairs.
3.2
Local
Refinement
by
Mirroring
Method
The principle for the mirroring method is to fix one side of protein pairings and find the minimum bipartite matching of the protein pairings. The mirroring algo-rithm is illustrated at Figure 1. Given P and Q two protein structures, let np and nQ denote the numbers
of atom in P and Q. Q0 is the rotated Q. There is an
initial alignment, A, whose length is nAbetween P and
Q, where nA ≤ nP, nQ. P (A) stands for the aligned
atoms in P , and Q(A) stands for the aligned atoms in Q. P (A) and Q(A) are included in A. ΦA(P, Q) means
adjusting atoms of Q to atoms of P . The mirroring al-gorithm is divided into two parts:
1. Find a better matching by reflecting from Q0(A)
to P .
2. Find a better matching by reflecting from P (A) to Q0.
The mirroring algorithm stops if it doesn’t improve the presently best rmsd value for two consecutive times. The mirroring algorithm tries to find a better local alignment by reflection atoms of two structure. It fixes the numbers of atom for one side and finds a better matching in another side.
3.3
Initialization by Main Vector Method
The initial method, such as VAST and CE, supports the trigonometric series estimation method to improve the rmsd value. A better initial alignment is very im-portant for the trigonometric series estimation method to adjust a better result. Therefore, we try to develop a initial method according to the shape of protein struc-ture. The main vector method is to find a main vector about protein structure in 3-dimension and a second main vector in 2-dimension. We apply the inner and outer product to find the rotation and vertical vector. Let x, y be two vectors and θ be the included angle of x and y. We can have θ = cos−1 hx·yi
Vect-Alig(P, deg, Z) ¤Vector Aligment ¤ Find the initial rotate for protein structure Input: a set of 3D coordinates of points P = {p1, p2, . . . , pn}.
deg is the dimension for protein structure coordinates.
(Z[2], Z[3]) stands for (x-axis, z-axis).
Output: (P ) rotated P
1 for i ← 3 to 2
2 do g ← Center(P, i, Z[i]) ¤ g is the mass center of P in the i-th dimension.
3 a ← Farthest(P, g) ¤ a is a farthest point of P from g.
4 b ← Farthest(P, a) ¤ b is a farthest point of P from a.
5 v ← b − a ¤ v is−→ab.
6 MR← Matrix(V, Z[i]) ¤ MR is the matrix which rotates V to Z[i].
7 P ← Rot(P, MR) ¤ rotate P by MR.
8 return P
Matrix(P, Q) returns the matrix that rotate point P to point Q on the unit sphere.
Figure 2: The initial rotation by the main vector method, When i = 3, there is a first main vector in 3-dimension and then rotate the protein structure by the matrix which rotates it to z-axis. When i = 2, there is a second main vector in 2-dimension which is x-axis and y-axis, and then rotate the protein structure by the matrix which rotates it to x-axis.
outer product to find the vertical vector, v, which is defined as v = x × y, then we use θ and v to rotate the protein structure. The algorithm is shown in Figure 2. In this algorithm, we have a first main vector and a sec-ond main vector. If we assume a, b to stand for the two points of first main vector and c, d to to stand for an-other. There are totally four possible combinations for them, (−ab,→ −cd), (→ −ba,→ cd), (−→ −ab,→ −dc), (→ −ba,→ −dc). We choose→ the minimum rmsd of them to be the initial rotation. Besides the main vector method, we also use a random initial rotation to execute the trigonometric series esti-mation method. The experimental results of those two different settings are discussed in next section.
3.4
Initialization by Segment Alignment
Comparing to the more sophisticated methods like CE or VAST, the main-vector initialization position does have the advantage of saving valuable processor computation resources. Yet the found initial orienta-tion by the main-vector method seems a little bit rough and not being able to produces satisfactory final orien-tation even after the fine-tune procedures. The idea here is trying to find a more suitable starting posi-tion and still conserve enough computaposi-tion time just for the better tryout. Since the protein structure is just a chain sequence of atoms, we can subdivide the sequence and use the subsequence matching informa-tion to find a better starting. Thus, the atom chains of a structure is divided into several (consecutive) seg-ments. Here is a list of (consecutive) atoms appeared in the PDB file. One way of dividing protein chains of a structure depends on the secondary structures of the given protein. The other passable partitions can also be obtained by slicing a fixed number of atoms of the given protein. In the following experiment, we test the effectiveness of the method by using the fixed number partition method. After the segments of structures is decided, the segment alignment uses the standard dy-namic programming technique to obtain feasible
pair-ings between segments by maintaining a suitable score table. The dynamic programming evaluation function is described as the following:
score(s, λ) = U mp · | s | score(λ, t) = U mp · | t | score(sx, ty) = min Rmsd(L(s, t) ◦ Match(x, y)) · ` + U mp · (| sx | + | ty | −2`) score(sx, t) + U mp · | y | score(s, ty) + U mp · | x |
here λ denotes the empty list; s, t are two segment lists. L(s, t) is the alignment between segment lists s and y, and nL denotes the number of atoms in L;
` =| L(s, t) ◦ Match(x, y) |.
The recurrence relation for evaluating the value score relies on three possible alignments between sx and ty. Here s and t are two prefix segment lists, and x and y are the two currently (last) considered segments. The first alignment, L is the pairing list from L(s, t) merg-ing with Match(x, y) which stands for the match be-tween segment x y. Since Rmsd() returns the average precalculated rmsd value, the number is multiplied by the number of matched pairs `. However, if one can not find any match for an atom, a given punishment con-stant, U mp, must be added to encourage most atom be aligned with some atoms on the other sequence. An-other possibility is the case of score(sx, t); in that case, the segment y is not able to match with segment on the other list. Thus we need to add in the punish-ment values for all atoms of the y segpunish-ment. The case of score(s, ty) is also treated similarly, and the corre-sponding table lookup algorithm is shown in Figure 4. In this algorithm, we first initiate the table. lenA[i] is prefix segment list when it treats the i-th segment. s is the score of new atoms just joint into. We choose the minimum and record into the score table. It also records L[i, j] as the current merged list L. Finally, we get the value of the bottom right hand side corner in
Seg-Alig ¤Segment Alignment algorithm
1 for i ← 0 to ns ¤ initiate the table
2 do score[i, 0] ← U mp · lenAs[i] ¤ U mp : unmatched penalty
3 for j ← 0 to nt 4 do score[0, j] ← U mp · lenBs[j] 5 for i ← 1 to ns 6 for j ← 1 to nt 7 do L ← L[i − 1, j − 1] ◦ Match(i, j) 8 r ← Rmsd(L);
9 s ← r · nL+ U mp · (lenAs[i] + lenBs[j] − 2 · nL) .nL← (nL[i−1,j−1]+ nM[i,j])
10 if s ≤ score[i, j − 1] + U mp · lenA[i] and s ≤ score[i − 1, j] + U mp · lenB[j]
11 then score[i, j] ← s; L[i, j] ← L
12 elseif score[i, j − 1] + U mp · lenB[j] ≤ s and score[i, j − 1] + U mp · lenB[j] ≤ score[i − 1, j] + U mp · lenA[i]
13 then score[i, j] ← score[i, j − 1] + Ump · lenB[j]; L[i, j] ← L[i, j − 1]
14 else
15 score[i, j] ← score[i − 1, j] + Ump · lenA[i]; L[i, j] ← L[i − 1, j]
Figure 4: The segment alignment .
the table. And the L[ns, nt] is the desired answer using
the segment alignment method.
4
Experimental Results
In this section, we introduce the target of experimen-tal data set first. Then we show the difference with VAST, CE, main vector, random and segment align-ment. Finally, the experimental results for mirroring method is shown.
4.1
Data Set
We choose the PDB for our experimental sample source, and we randomly pick 200 protein structures in the PDB database as our experimental subjects by the uniform distribution sampling. For each chosen protein structures we randomly choose 30 structure alignments listed on the database of VAST as the tested targets. We use the term, P , to stand for one of the 200 ran-domly picked protein structures, and we use Q to stand for one of the 30 neighbors of each P . Note that P and Q include all un-aligned and aligned atoms. We use the term, P A, to stand for the aligned atoms of P by VAST. Totally, there are 6,000 protein pairings tested by our previous experiment.
4.2
Comparison of Five Methods
There are five different initial rotations in the fol-lowing algorithms- VAST, CE, main vector, random and segment alignment. We use the numbers of atom found by VAST for our standard. CE always finds its own alignment, but we hope to compare the difference with the five methods in the same standard. There-fore, we also transform it back to the standard after the trigonometric series estimation method. When it finishes the trigonometric series estimation method, we use the P A which is standard from VAST to run one time MBM with Q. Therefore, the five methods are compared in the same PA. We randomly select 1,000
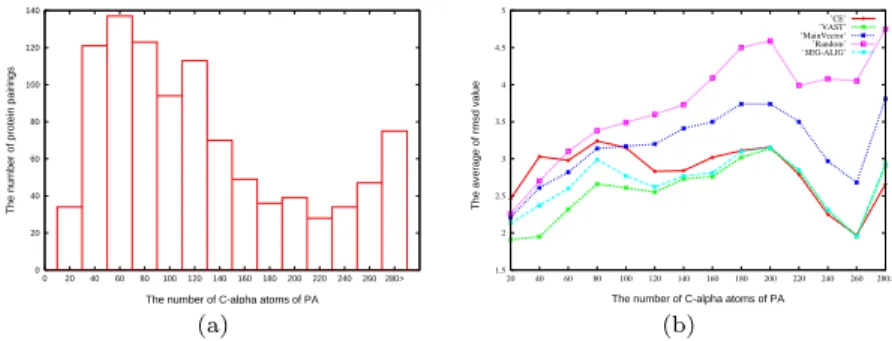
of 6,000 samples pairings for our experiments, and the distribution of them is shown in Figure 5
The MBM provides the effect of fine-tuning when there is a correct initial rotation. But there are still 2%, 2.3% and 4.9% to improve VAST, CE and segment alignment by trigonometric series estimation method. The result indicates that the initial alignment with a MBM is not perfect.
After VAST and CE execute the MBM and the trigonometric series estimation method, VAST drops the rmsd to 2.51. For this reason, it seems that VAST is a better initial seeding method than CE. The segment alignment drops the rmsd to 2.68 after execute the MBM and the trigonometric series estimation method. It is better then main vector, random and almost better then CE. It is very close VAST and sometimes defeat VEST. We think if we choose the way of dividing pro-tein chains of the secondary structures, it should be more better.
4.3
Experimental Results for Mirroring
method
We apply the mirroring method to the 6,000 protein pairings. We obtain 3.11 after the VAST, 2.55 after the VAST and a MBM and 2.27 after the VAST, a MBM and the mirroring method. For all the 6,000 sample pairings, the MBM improves the result of the VAST about 18.1%. The mirroring method improves the result of the VAST about 27%. The value of rmsd is down to 2.27 after mirroring method. We only need to execute 6.81 times MBM.
5
Concluding Remarks
In this paper, we develops algorithms to improve the rmsd value of a protein structure pair by finding bet-ter alignment of two structures. Our method substan-tially improves the alignments found by VAST method (the averaged improvement ratios is about 27%). A set of experiments is tested which leads to the conclusion
0 20 40 60 80 100 120 140 280> 260 240 220 200 180 160 140 120 100 80 60 40 20 0
The number of protein pairings
The number of C-alpha atoms of PA
(a) 1.5 2 2.5 3 3.5 4 4.5 5 20 40 60 80 100 120 140 160 180 200 220 240 260 280>
The average of rmsd value
The number of C-alpha atoms of PA ’CE’ ’VAST’ ’MainVector’ ’Random’ ’SEG-ALIG’ (b)
Figure 5: (a) The distribution of the 1000 randomly picked protein structure pairings. (b) The average of rmsd value for VAST, CE, Main Vector, Random and Segment alignment.
that good initialization orientation and its correspond-ing alignment list is crucial before adjustcorrespond-ing parame-ters. Ways of finding suitable and feasible initalization orientation, including the Vect-Alig and Seg-Align methods, are proposed and tested; it can be concluded that the segment alignment method is a reasonable way of setting up the initial orientation of the given protein pair. Furthermore, the local refinement algorithm, the mirroring method, is proposed and the experimental results confirm the rmsd values can then be reduced substantially by the mirroring method.
References
[1] F. Bourgeois and J. C. Lassalle. Algorithm 415: Algorithm for the assignment problem (rectangular matrices). In
Com-munications of the ACM, volume 14, pages 805 – 806, New
York, NY, 1971. USA.
[2] F. Bourgeois and J. C. Lassalle. An extension of the
munkres algorithm for the assignment problem to rectangu-lar matrices. In Communications of the ACM, volume 14, pages 802 – 804, New York, NY, 1971. USA.
[3] J. M. Bujnicki. Phylogeny of the restriction endonuclease-like superfamily inferred from comparison of protein struc-tures. J Mol Evol., 50:38–44, 2000.
[4] C. Chothia and A. M. Lesk. The relation between the di-vergence of sequence and structure in proteins. EMBO J., 5:823–826, 1986.
[5] S. Dietmann and L. Holm. Identification of homology in protein structure classification. Nature Struct. Biol., 8:953– 957, 2001.
[6] N. Echols, D. Milburn, , and M. Gerstein.
Mol-movdb:analysis and visualization of conformational change and structural flexibility. Nucleic Acids Res., 31:478V482, 2003.
[7] L. Euler. Formulae generales pro trandlatione quacunque corporum rigidorum. Novi Acad. Sci. Petrop., 20:189–207, 1775.
[8] Z. Galil. Efficient algorithms for finding maximum matching in graphs. ACM Computing Surveys, 18:1:23–38, 1986. [9] M. Gerstein, R. Jansen, T. Johnson, J. Tsai, and W. Krebs.
Motions in a database framework: from structure to
se-quence. Rigidity Theory and Applications, pages 401–
442 (ed. M F Thorpe and P M Duxbury, Kluwer Aca-demic/Plenum Publishers), 1999.
[10] J. F. Gibrat, T. Madej, and S. H. Bryant. Surprising
sim-ilarities in structure comparison. urr Opin Struct Biol,
6(3):377–385, 1996 Jun.
[11] A. Gray. A treatise on gyrostatics and rotational motion. MacMillan,London, 1918.
[12] L. Holm and C. Sander. Touring protein fold space with DALI/FSSP. Nucleic Acids Res., 26:316–319, 1998. [13] M. S. Johnson, M. J. Sutcliffe, and T. L. Blundell.
Molec-ular anatomy: Phyletic relationships derived from three-dimensional structures of proteins. J Mol Evol., 30:43–59, 1990.
[14] Y. L. Lin and S. P. Huang. Tools and algorithms for refined comparison of protein structures. In The 6th WSEAS
Inter-national Conference on Microelectronics, Nanoelectronics, Optoelectronics (MINO ’07), Istanbul, Turkey, 2007.
[15] Y. L. Lin, Y. H. Lin, P. S. Yu, and H. C. Chang. Ran-domized algorithms for three dimensional protein structures alignment. The 6th International Symposium on
Computa-tional Biology and Genome Informatics., pages 122 – 125,
2005.
[16] A. C. R. Martin.
http://www.bioinf.org.-uk/software/profit/.
[17] A. D. McLachlan. Rapid comparison of protein structures.
Acta Cryst, A38:871–873, 1982.
[18] J. Munkres. Algorithms for the assignment and transporta-tion problems. Journal of the Society for Industrial and
Applied Mathematics, 5:32–38, 1957.
[19] C. A. Orengo, D. T. Jones, and J. M. Thornton. Protein superfamilies and domain superfolds. Nature, 372:631–634, 1994.
[20] R. A. Pilgrim.
http://csclab.murraystate.edu/-bob.pilgrim/445/munkres.html.
[21] J. T. Schwartz and M. Sharir. Identification of partially obscured objects in two and three dimensions by matching noisy characteristic curves. Int. J. Robotics Research, 6:29– 44, 1987.
[22] H. S. Shin, S. P. Huang, and Y. L. Lin. Parametric searching algorithms with adaptive strategy for three dimensional pro-tein structures alignments. In National Computer
Sympo-sium (NCS’2007), pages 144–154, Taichung, Taiwan, 2007.
[23] H. S. Shin, Y. L. Lin, and W. D. Jiang. Protein struc-tures alignment algorithms by parametric searching with trigonometric series. In Proceedings of the 25th Workshop
on Combinatorial Mathematics and Computation Theory,
pages 44–54, Hsinchu, Taiwan, 2008.
[24] I. N. Shindyalov and P. E. Bourne. Protein structure align-ment by increalign-mental combinatorial extension (CE) of the optimal path. Protein Eng., 11:739–747, 1998.