Progressive Pattern Matching Approach Using Discrete Cosine Transform
5
0
0
全文
(2) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan. N −1 N −1 2 α (u )α (v) ∑∑ x(i, j ) N i =0 j =0. C (u , v ) =. × cos(. (2i + 1)uπ (2 j + 1)vπ ) cos( ), 2N 2N. (1). where ⎧⎪ 1. α ( w) = ⎨. ⎪⎩ 1. 2. for w = 0, otherwise.. The corresponding inverse discrete cosine transform (IDCT) is defined as Figure 1. The DCT coefficients of the character image of “佛”.. x(i, j ) =. 2 N. N −1 N −1. ∑ ∑ α (u )α (v)C (u, v) u =0 v =0. × cos(. ance of normalization is not an important issue for the matching method based on the DCT.. (2i + 1)uπ (2 j + 1)vπ ) cos( ). (2) 2N 2N. We notice that DCT is a unitary transform, which has the energy preservation property, i.e.,. Based on above observations, we were motivated to devise a progressive matching approach based on DCT for recognizing handwritten characters in Chinese paleography. In our approach the DCT is applied to transform the character images into elementary frequency components. Due to the energy compacting property of DCT, much of the signal energy has a tendency to lie at low frequencies. Therefore, to recognize an unknown character, only the candidates whose DCT coefficients of low frequencies well-match those of the unknown character need to be further examined. Such that the matching process can be conducted progressively from low frequencies to high frequencies and terminated if the accumulated matching cost exceeds a predefined threshold. So we can recognize an unknown character by finding the prototype character whose DCT coefficients are best fitted for the unknown character. Experimental results show that our approach performs well in this application domain.. N −1 N −1. N −1 N −1. E = ∑∑ (x (i, j ) ) = ∑∑ (C (u , v ) ) , 2. i =0 j =0. 2. (3). u =0 v =0. where E is the signal energy. For most images, much of the signal energy lies at low frequencies; these appear in the upper left corner of the DCT. The lower right values represent higher frequencies, and are often small - small enough to be neglected with little visible distortion. Figure 1 shows the DCT coefficients of a character image (“ 佛 ”) of size 48×48. The number of coefficients is equal to the number of pixels in the character image. In our experiments, we found that about 90% signal energy appears in the upper left corner of size 10×10 for the DCT coefficients of size 48×48.. 3. Progressive Matching Method. This paper is organized as follows. The next section introduces the DCT. Section 3 describes our progressive matching approach based on the DCT. Section 4 presents experimental results. Finally, conclusions are drawn in Section 5.. Before going into the details of our progressive matching method, we first briefly present the problem and related symbols used in this paper. Our goal is to classify an unknown character x to one of M possible classes (c1, c2,…, cM). In order to apply the template matching method, the database that consists of the templates for each class must be established in advance. Therefore, in the training phase, a set of training character images of size N×N is collected and transformed into DCT coefficients. Then the average DCT coefficients of size N×N is obtained for each class, assuming there is at least one training character for each class. Such that M sets of average DCT coefficients are obtained and served as the templates for each class.. 2. Discrete Cosine Transform The DCT is introduced in this section. Its most important feature is its superior energy compacting property. On applying DCT, a frequency spectrum (or the DCT coefficients) C(u, v) of an N×N image represented by x(i, j) for i, j=0, 1, …, N-1 can be defined as. 727.
(3) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. Based on the observation that the most significant DCT coefficients lie in its low frequency area, therefore, the matching process can be performed step by step by adding more and more coefficients from low frequency area to high frequency area. Thus, we can develop a matching algorithm that can progressively measure the distance (or dissimilarity) between the unknown character x and template Ti.. (a). Firstly, we have to define a measure to indicate the degree of matching between a test character and a template. Traditionally, we can apply the sum of absolute differences (SAD) as the matching criterion to avoid multiplications. To exploit the energy preservation property of DCT, we use the sum of squared differences (SSD) instead, which can be implemented efficiently using a look-up table to calculate the square. Assume that Cx(u, v) and CTi(u, v) represent the DCT coefficients of the test character x and template Ti, respectively. Then the SSD between x and Ti can be defined as N −1 N −1. (. ). 2. (4). For the ease of progressive matching, we also define the SSD between x and Ti under the upper left block of size n×n as. (. (d). criterion of energy preservation. On the other hand, to reject the unqualified templates in the early iterations, statistical tools are applied to calculate the theoretical sound thresholds for the SSD under different block size. From the Chebyshev rule [11], we know that the percentage of observations contained within distances of k standard deviations around the mean must be at least (1 − 1 k 2 ) × 100% . For example, 97.2% is guaranteed within the distances of 6 standard deviations. Assume that θn represents the threshold for the block of size n×n. To obtain the threshold θn, all of the SSDs between the test characters and their target templates under the block of size n×n are gathered. Then the mean µn and the standard deviation σn of SSD under the block of n×n can be calculated. Thus, θn can be obtained by. u =0 v =0. n −1 n −1. (c). Figure 2. (a) The original image of size 48×48; (b) The reconstructed image of size 8×8; (c) The reconstructed image of size 16×16; (d) The reconstructed image of size 32×32.. 3.1. Matching criterion. SSD ( x, Ti ) = ∑∑ C x (u , v) − CTi (u , v) .. (b). θ n = µn + k ×σ n .. ). 2 SSD ( x, Ti , n) = ∑∑ C x (u , v) − CTi (u , v) , (5). (6). The input of the progressive matching algorithm is the test character x and a template Ti. The output of the algorithm is either the distance between x and Ti or “Reject” the template. If Ti is accepted as a candidate for the test character, then output the distance between x and Ti, SSD(x, Ti, N’), under the block of size N’×N’, assuming N’ is the minimum block size that satisfies the aforementioned stop criterion. Otherwise, output “Reject the template”. The algorithm is described as follows.. u =0 v =0. assuming the upper left n×n DCT coefficients of x and Ti are correspond to a block of size n×n.. 3.2. Description of the algorithm The matching of x and Ti can be decomposed into K iterations, each of which corresponds to the matching under the block of size nk×nk. After the kth iteration, the block size is enlarged from nk×nk to nk+1×nk+1 (nk+1 = nk+δ). At the first iteration (k=1), the lowest frequency coefficients are measured; then the second lowest frequency coefficients are measured at the second iteration (k=2), and so on, until one of the stop criterions is satisfied. The stop criterions used in our approach are twofold: to preserve enough signal energy in the block and to reject unqualified templates at earlier steps. For example, since about 90% signal energy appears in the block of size 10×10 for an image of size 48×48, the matching process will be stopped as the block size reaches to 10 if 90% signal energy is used as the threshold for stop criterion. Therefore, the maximum number of iterations for a matching depends on the initial block size, the increment δ and the stop. Step 1: Set the initial block size to n. Step 2: Compute SSD(x, Ti, n). Step 3: If SSD(x, Ti, n)>θn, then output “Reject” and stop. Step 4: If n ≥ N’, then output SSD(x, Ti, N’) and stop. Step 5: Set n=n+δ and go to Step 2. This algorithm is very efficient because the results for calculating coefficients of smaller block can be used for calculating the following coefficients of larger block. Finally, to decide the expected class. 728.
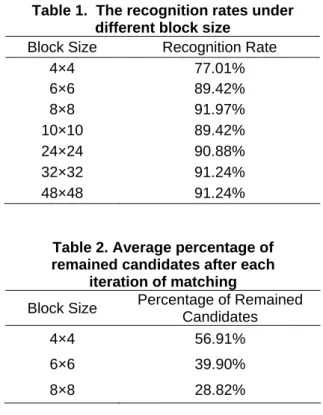
(4) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. Table 1. The recognition rates under different block size Block Size Recognition Rate 4×4 77.01% 6×6 89.42% 8×8 91.97% 10×10 89.42% 24×24 90.88% 32×32 91.24% 48×48 91.24% Figure 3. The percentage of energy preserved as the block size is changed.. Table 2. Average percentage of remained candidates after each iteration of matching Percentage of Remained Block Size Candidates 4×4 56.91%. of the test character x, the class of the template with minimum SSD(x, Ti, N’) is selected. The underlying philosophy of the progressive matching algorithm is the concept of multi-resolution. Adding more DCT coefficients usually imply increasing the resolution level of an image. If current resolution is not high enough to distinguish one character from the others, we have to raise the level of resolution such that the discrimination capability can also be improved. Figure 2 shows the images reconstructed from different block size via IDCT. From this figure, we conclude that the bigger the block size, the higher the resolution of the reconstructed image.. 6×6. 39.90%. 8×8. 28.82%. size and the increment δ are set to 4 and 2, respectively. Thus, during the progressive matching process, the block is enlarged from 4×4 to 8×8 (i.e. 4×4, 6×6 and 8×8), and hence the maximum number of iterations is 3. As to the threshold θn, 6 standard deviations were applied (see EQ. (6)) for θ4 to guarantee that at least 97.2% target templates were remained after the first round pruning, and 5 standard deviations were applied for θ5 to guarantee that at least 96% target templates were remained after the second round pruning and 4 standard deviations were applied for θ4 to guarantee that at least 93.75% target templates were remained after the third round pruning. Table 2 shows the average percentage of remained candidates after each iteration of progressive matching. It can be seen that most of the candidates are pruned in the early iteration and only 28.82% candidates need to be considered in the final decision process. The recognition rate of progressive matching is the same as that of the direct matching under the block of size 8×8, i.e. 91.97%. In other words, the number of squared differences needs to be calculated is reduced to 60.24% ([(1-0.5691)×4×4 + (0.5691-0.399)×6×6 + 0.399×8×8]/8×8) without sacrificing the recognition rate.. 4. Experimental results A preliminary experiment has been made to test our approach. There are a total number of 6000 samples (about 500 categories) extracted from one of the famous handwritten rare books, Kin-Guan (金剛) bible. Each character image was transformed into a 48×48 bitmap. 5000 of the 6000 samples are used for training and the others are used for testing. Figure 3 shows the percentage of energy preserved as the block size of the upper left DCT coefficients is changed. From this figure, it can be seen that about 84% signal energy is preserved in the block of size 8×8 and 89.3% signal energy is preserved in the block of size 10×10. Table 1 shows the recognition rate of test samples under different block size. We can find that the recognition rate cannot be improved further as the block size is larger than 8×8. This evidence supports the hypothesis that if the compacted DCT coefficients preserved enough energy, they possess enough information for classification at the same time. Through the energy compacting property of DCT, the number of features for a character can be reduced from 48×48 to 8×8 without sacrificing the recognition rate. Therefore, the parameter used for stop criterion, N’, is set to 8. Besides, the initial block. 5. Conclusions This paper presents a progressive matching approach based on DCT for recognizing handwritten characters in Chinese paleography. Due to the energy compacting property of DCT, the features of a test character can be extracted progressively. 729.
(5) Int. Computer Symposium, Dec. 15-17, 2004, Taipei, Taiwan.. 123-126, 1992.. according to their importance and hence the potential candidates which are not well-fitted for the test character can be pruned at earlier steps. The advantages of our approach include: z. z. [9] T. Wakahara, K. Odaka, “Adaptive Normalization of Handwritten Characters Using Global/Local Affine Transformation,” IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 20, no.12, pp. 1332-1341, 1998.. Through the energy compacting property of DCT, the number of features for a character is reduced from 48×48 to 8×8.. [10] G. Wallace, “The JPEG still picture compression standard,” Communications of the ACM, vol. 34, no. 4, pp.30-44, 1991.. Through the progressive matching algorithm, the number of squared differences needs to be calculated is reduced to 60.24% without sacrificing the recognition rate.. [11] R. E. Walpole and R. H. Myers, “Probability and statistics for engineers and scientists,” Macmillan Publishing Company, 1985.. Since only preliminary experiment has been made to test our approach, a lot of works should be done to improve this system. For example, since features of different types complement one another in classification performance, by using different types of features simultaneously, classification accuracy could be improved.. [12] Hong Yan, “Comparision of Multilayer Neural Network and Nearest Neighbor Classifiers for Handwritten Digit Recognition," Int. J. of Neural Systems, vol. 6, no.4, pp. 417-423, 1995.. References [1] N. Ahmed, T. Natarajan, and K. R. Rao, “Discrete cosine transform”, IEEE Trans. on Comput., vol. C-23, pp. 90-93, 1974. [2] J. P. Drouhard, R. Sabourin and M. Godbout, “A neural network approach to off-line signature verification using directional PDF,” Pattern Recognition, Vol. 29, No. 3, pp. 415-424, 1996. [3] A. J. Hsieh, Kuo-Chin Fan, and Tzu-I Fan, “Bipartite Weighted Matching for On-line Handwritten Chinese Character Recognition," Pattern Recognition, Vol. 28, no. 2, pp. 143-151, 1995. [4] S. W. Lee, “Off-line recognition of totally unconstrained handwritten numerals using multilayer cluster neural network,” IEEE Trans. Patt. Anal. Machine Intell., Vol. PAMI-18, no.6, pp. 648-652, 1996. [5] S. W. Lee and J. S. Park, “Nonlinear Shape Normalization Methods for the Recognition of Large-Set Handwritten Characters,” Pattern Recognition , vol. 27, no. 7, pp. 859-902, 1994. [6] M. Mohamed and P. Gader, “Handwritten word recognition using segmentation-free hidden Markov modeling and segmentation-based dynamic programming techniques,” IEEE Trans. Patt. Anal. Machine Intell., Vol PAMI-18, no.5, pp. 548-554, 1996. [7] M. Nadler and E. P. Smith, “Pattern Recognition Engineering,” Wesley Interscience, 1993. [8] A. Puri, “Video coding using the MPEG-1 compression standard”, Society for Information Display Digest of Technical Papers, vol. 23, pp.. 730.
(6)
數據
相關文件
Example: gogui-twogtp -white white.exe -black black.exe -games 10 -alternate -size 9 -komi 7 -verbose -sgffile record_name -auto Using Gogui to display: gogui -program
ptrArray:PTR DWORD, ; points to the array arraySize:DWORD ; size of the array ArraySum PROTO,. ptrArray:PTR DWORD, ; points to the array count:DWORD ; size of the array
❖ Features, block size, strip size/width, etc... Mount
In the inverse boundary value problems of isotropic elasticity and complex conductivity, we derive estimates for the volume fraction of an inclusion whose physical parameters
Two examples of the randomly generated EoSs (dashed lines) and the machine learning outputs (solid lines) reconstructed from 15 data points.. size 100) and 1 (with the batch size 10)
According to the Heisenberg uncertainty principle, if the observed region has size L, an estimate of an individual Fourier mode with wavevector q will be a weighted average of
Let us suppose that the source information is in the form of strings of length k, over the input alphabet I of size r and that the r-ary block code C consist of codewords of
Since the subsequent steps of Gaussian elimination mimic the first, except for being applied to submatrices of smaller size, it suffices to conclude that Gaussian elimination
