Software-Controlled Cache Architecture
for Energy Efficiency
Chia-Lin Yang, Member, IEEE, Hung-Wei Tseng, Chia-Chiang Ho, and Ja-Ling Wu, Senior Member, IEEE
Abstract—Power consumption is an important design issue of
current multimedia embedded systems. Data caches consume a sig-nificant portion of total processor power for multimedia applica-tions because they are data intensive. In an integrated multimedia system, the cache architecture cannot be tuned specifically for an application. Therefore, a significant amount of cache energy is ac-tually wasted. In this paper, we propose the software-controlled cache architecture that improves the energy efficiency of the shared cache in an integrated multimedia system on an application-spe-cific base. Data types in an application are allocated to different cache regions. On each access, only the allocated cache regions need to be activated. We test the effectiveness of the software-con-trolled cache of the MPEG-2 software decoder. The results show up to 40% of cache energy reduction on an ARM-like cache archi-tecture without sacrificing performance.
Index Terms—Dynamic power dissipation, energy consumption,
MPEG-2, multimedia applications, software-controlled cache.
I. INTRODUCTION
T
HERE is a growing demand in supporting multimedia applications on portable devices, such as cellular phones and personal digital assistants. For these battery-operated devices, energy consumption is a critical design issue. Re-searchers seek to reduce energy consumption at various levels of the design hierarchy (i.e., technology, circuit, architectures, operating system, and compiler). Energy reduction often comes at the cost of lower performance. Therefore, how to satisfy the high performance demand of multimedia applications while minimizing energy consumption is challenging.Caches are a commonly used technique for performance improvement. It has been reported that caches consume a significant portion of the total processor power. For example, 42% of processor power is dissipated in the cache subsystem in StrongARM 110 [1], which is the mainstream processor in the embedded market. Applications in the multimedia and communication domains are data dominated. Data storage and transfer account for a significant portion of overall power consumption. Whether a reference goes to the main memory or not, it must access the data cache. Therefore, techniques
Manuscript received September 30, 2003; revised January 31, 2004. This work was supported in part by the National Science Council of Taiwan, R.O.C. under Grant NSC-91-2215-E-002-43, Grant NSC-92-2213-E-002-014, Grant NSC-92-2220-E-002-013, and Grant NSC-93-2752-E-002-008-PAE and in part by the Ministry of Economics of Taiwan under Grant 93-EC-17-A-01-S1-031.
C.-L. Yang, H.-W. Tseng, and J.-L. Wu are with the Department of Com-puter Science and Information Engineering, National Taiwan University, Taipei, Taiwan 106, R.O.C. (e-mail: yangc@csie.ntu.edu.tw; r92022@csie.ntu.edu.tw; wjl@csie.ntu.edu.tw).
C.-C. Ho is with CyberLink Corporation, Taipei, Taiwan 231, R.O.C. (e-mail: conrad@cmlab.csie.ntu.edu.tw).
Digital Object Identifier 10.1109/TCSVT.2005.846444
to reduce energy dissipation in the data cache are critical to deliver an energy-efficient multimedia embedded system.
For an embedded system dedicated to a specific application, the cache architecture can be tuned to meet the need of that particular application. For an integrated multimedia system, a shared cache architecture among devices is often utilized to reduce hardware cost. Therefore, the conventional energy optimization technique which explores the design space in searching for the optimal energy-efficient cache architecture for a particular application can no longer be applied. The cache architecture can be only chosen to achieve energy optimization in an average sense. Instead of tailoring the cache architecture to meet an application’s need, in this paper, we propose a methodology that allows embedded software to manage the on-chip cache explicitly to improve the energy efficiency of the shared cache on an application-specific basis.
In the traditional memory hierarchy, the cache management is transparent to software; that is, a program does not control where a data item is located in the cache. This abstraction causes unnecessary energy consumption of a cache access. For a fast implementation of set-associative caches, the data and tag arrays are accessed in parallel. Therefore, all ways are probed at the same time but only one of the ways provides useful data on a hit. For an example, a four-way set-associative cache discards three of the four ways on every access, wasting nearly 75% of the energy dissipation.
If the data allocation is known a priori, we can pinpoint the allocated region to avoid energy waste for each cache access. Based on the observation, we design a software-controlled cache that allows a program to control data allocation on the cache in the granularity of data types in an application. Most multimedia applications contain several major data types that contribute to most of the memory accesses. The MPEG-2 software decoder, for an example, contains six data types which account for 80% of memory accesses according to our experiments (see Section II-A). The proposed software-control cache architecture is a hardware/software cooperative scheme. The mapping between data types and cache regions is deter-mined statically based on a programmer’s knowledge on the application’s behavior and profiling information. We derive the allocation methodology based on the optimization goal that achieves energy savings without sacrificing performance. The allocation information is then conveyed to the hardware through instruction annotations. The proposed software-con-trolled cache architecture only requires minimal hardware support, which is attractive to a low-power processor design.
Since the ARM processor is commonly used in a plat-form-based design for an integrated multimedia system, the software-controlled cache is designed based on an ARM-like
Fig. 1. StrongARM SA-1110 architecture.
on-chip cache architecture which contains a relatively small on-chip cache (mini-cache) in addition to a four-way set-asso-ciative L1 data cache as shown in Fig. 1. Data could be assigned to the mini-cache, ways of the L1 caches or bypass the on-chip caches altogether. In this paper,we use the software MPEG-2 decoder as the testing vehicle. The software MPEG-2 decoder has large data set and requires high data processing rate, which are two important characteristics of real-time signal processing applications. We use a cycle-accurate simulator coupled with a detailed power model to perform experiments. The results show that the software-controlled cache reduces energy consumption of an ARM-like cache by 40% without performance degrada-tion. We also perform a thorough design space exploration to identify the optimal energy-efficient cache architecture for the MPEG-2 software decoder. We find that a cache architecture tuned specifically for the MPEG-2 software decoder results in 23% energy reduction compared with an ARM-like cache. The results tell us that if we use an ARM-like cache architecture as the shared cache for an integrated multimedia system, a significant amount of cache energy is actually wasted for the MPEG-2 software decoder. However, by employing the proposed software-controlled cache, an ARM-like cache archi-tecture consumes even less energy than a dedicated cache tuned for the MPEG-2 software decoder. The software-controlled cache does provide a way to improve the energy efficiency of a shared cache architecture on an application-specific basis.
The rest of the paper is organized as follows. Section II pro-vides background information on the MPEG-2 software decoder and energy consumption on caches. Section III describes the de-tails of the software-controlled cache. Section IV describes our experimental methodology and Section V presents the results. Section VI discusses related work. Section VII concludes this paper.
II. BACKGROUND
A. MPEG-2 Overview
MPEG-2 was released in 1994 to provide coding algorithms for video and associated audio targeting at bit rate between 2 and 10 Mb/s. It has been widely used in applications such as digital cable TV service, network database video service and
Fig. 2. MPEG-2 decoding process.
TABLE I
SUMMARY OFDECODERDATATYPES, SIZE AND%OFMEMORYREFERENCES
DVD playback. In this section, we briefly describe the decoding process and main data types in the software MPEG-2 decoder.
A MPEG-2 bitstream consists of three different frame types: I-frame, P-frame, and B-frame. Each frame is partitioned into macroblocks and each macroblock is separately encoded. Macroblocks in I-frames are intracoded only (without temporal prediction); macroblocks in P- and B-frames are intercoded which exploits the temporal redundancy of reference frames. For intercoded macroblocks, motion estimation is performed to find the best motion vector and coding mode. Image data of intracoded macroblocks and motion compensated error of intercoded macroblocks go through DCT, quantization, and run-length entropy coding to become a compressed bitstream. The decoding of a compressed MPEG-2 bitstream, the ap-plication our work focuses on, is the inverse of the above encoding process, but without motion estimation. Fig. 2 shows a simplified decoding process of a MPEG-2 bitstream.
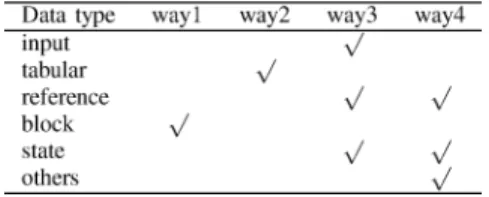
We can break down the data types in the MPEG-2 software decoder into the following classes.
Input—The MPEG-2 bitstreams. Bitstreams coming
from network or storage are temporarily stored in a fixed size buffer which is refreshed when the stored data has been decoded.
Output—The decoded picture data. The output data is
write-only and transferred to the frame buffer through system calls.
Fig. 3. n-way set-associative cache architecture.
Fig. 4. Access energy consumption of different cache configurations. Note that CACTI does not report access energy for the configuration 4-K 128-B 8-ways because of too few sets.
Tabular—Static and read-only tables used in the
coder, such as lookup tables for variable length de-coding.
Reference—Buffers for both current and reference
frames.
Block—The buffer for pixel values of a single
mac-roblock. The inverse quantization and inverse DCT are performed in-place in this buffer.
State—Variables needed for setting and operation of
the decoder. Note that we do not include those local variables for temporary usage in various decoding modules/functions.
Table I lists the data set size and percentage of total memory references for different data types. We obtain these data through profiling. We can see that the access percentage from the major data types adds up to 82%. A significant portion of the remaining references comes from accessing the stack region (12% of total memory references). Since stack references have small dynamic footprints and high access frequency, previous studies [2] has
suggested to take advantage of its access pattern for energy re-duction. Therefore, in this paper, stack references are treated as one major data type.
B. Power Consumption in Caches
Caches are composed of CMOS static RAM. The power dis-sipation of CMOS circuits includes both static and dynamic por-tions. The static power consumption is the result of the leakage current between the substrate and the diffusions of a CMOS gate while the input of the circuit is in the steady state. When the input toggles, the circuit is subject to dynamic power dissipa-tion caused by charging or discharing capacitors. The dynamic power dissipation is defined as
where is the capacitance, is the supply voltage, is the clock frequency, and represents the average number of
circuit state transition in each cycle. For 0.18- m process tech-nology assumed in this study, the dynamic switching power is the dominate component of cache power consumption [3]. Therefore, we focus on optimization techniques for reducing the dynamic power consumption of caches in this paper.
The architecture of an -way set associative cache is shown in Fig. 3. It consists of banks and each bank contains both data and tag arrays. The th row of all the arrays constitutes the th set. Each array contains as many wordlines as the number of rows in the array. Each column of the arrays is associated with two bitlines. To reduce the impact of large bitline and wordline capacitances on energy and performance, caches are normally divided into smaller subarrays.
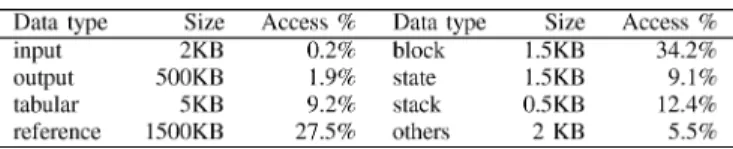
For each cache access, The decoder first decodes the address and selects the appropriate wordline. Each bitline is initially precharged high to allow fast cache access time. Each memory cell along the selected wordline pulls down one of the bitlines depending on the stored value. A sense amplifier monitors associated bitlines and determines what is in the memory cell. The column decoder then determines a part of columns for output based on the result of tag comparisons. Therefore, the energy consumed for each cache access can be broken into 5 components: row decoder, bitlines, wordlines, sense amplifier and column decoder. Fig. 4 shows how different cache architecture affects the cache energy consumed per access. We obtain the data using CACTI 3.1 [4] assuming 0.18 process technology. CACTI is an integrated cache access time, power and area model, and has been widely used in studies on cache architecture [5]–[7]. We can observe that a larger cache increases cache access energy because of a larger decoder and the larger load capacitance alone the wordlines/bitlines. The degree of set-associativity also has significant impact on the access energy. A larger degree of set-associativity means that more data and tag blocks need to be probed on a cache access thereby consuming more energy. The relation between the cache block size and access energy is not as predictive as the other two parameters. The impact on energy from increasing the cache block size is often hidden by dividing a cache into several subarrays.
Cache partitioning and way-prediction are two commonly used techniques to reduce the dynamic energy dissipation in caches. The former approach partitions caches into smaller com-ponents since a smaller cache has a lower load capacitance. One example is the filter cache proposed in [8]. The idea is to add a relatively small cache (the filter cache) between the CPU and L1 cache as shown in Fig. 5. On a cache access, this small cache is first checked to see if it is hit. The conventional L1 cache is only accessed when a miss occurs. This scheme increases the effec-tive latency of an L1 access if the filter cache hit rate is low. The way-prediction scheme [9] targets at reducing the power dis-sipation for a set-associative cache by predicting the matching way and accessing only the predicted way instead of all the ways as in a conventional way-associative cache. This technique re-quires extra hardware for way prediction and could increase the cache access time if the prediction accuracy is low. From these two examples, we know that reducing power often comes at the cost of performance degradation. To solve this dilemma, we pro-pose a software-controlled cache that allows a program to
con-Fig. 5. Filter cache.
Fig. 6. Software-controlled cache.
trol data allocation on the cache. In this way, the allocated region of a memory access can be identified without prediction. In the next section, we describe the details of the software-controlled cache.
III. FRAMEWORK OFSOFTWARE-CONTROLLEDCACHE
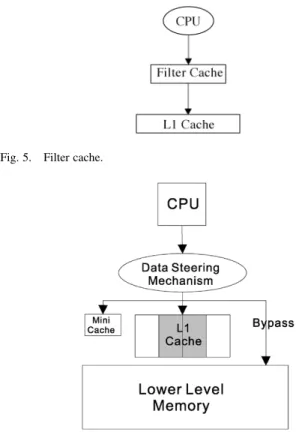
The proposed software-controlled cache is designed based on an ARM-like cache architecture which contains a relatively small, directed-mapped cache (mini-cache) and a set-associa-tive L1 cache on chip. Each way of the L1 cache is treated as a separate region. Each data type is either allocated to the mini-cache, ways of the L1 cache (way-partition) or bypasses the on-chip caches as shown in Fig. 6. Bypassing memory ref-erences that have little reuse has been used to improve the L1 cache performance because it results in less cache pollution [10]. The cache bypassing technique can also be adopted for energy optimization. Most multimedia applications have a sig-nificant amount of output data that are written and never read by the processor. Bypassing these write-only data can reduce energy consumed in the memory subsystem for two reasons. First, it reduces off-chip accesses as a result of less cache pol-lution. Second, it reduces accesses to the L1 cache without in-creasing accesses to the lower level of the memory hierarchy since written data is never accessed again by the processor.1
The software-controlled cache is a hardware-software coop-erative scheme. The data allocation decision is made statically and conveyed to the memory subsystem through instruction an-notations. Below we discuss the resource allocation policy and required architectural support.
1We assume a write-buffer between the L1 cache and the next level of the
A. Data Allocation Policy
The data allocation is determined statically by utilizing a pro-grammer’s knowledge on an application’s behavior and infor-mation gathered from the off-line profiling runs using a cache simulator. We rely on a programmer to identify major data types and output data for bypassing in an application. Recall that our optimization goal is to achieve energy savings without causing performance degradation. Therefore, the data allocation deci-sion is guided by two principles. First, resources allocated to a data type should be minimized as long as the performance does not degrade. Second, the data allocation should avoid over-uti-lizing certain cache regions, otherwise, it could cause perfor-mance degradation and may even result in more energy con-sumption.
The data allocation scheme is composed of two phases. The first phase is to identify minimal amount of resources (associa-tivity and size) for each data type through profiling. The second phase is to determine the mapping between data types and cache regions based on the profiling information. The profiling methodology is summarized in Algorithm 1. To reduce the energy consumption, a data type should be allocated as few ways as possible. Therefore, we test cache configurations in the increasing order of the degree of set-associativity. For each possible size given an associativity, we calculate the number of cache misses from the tested data type. For performance consideration, we use the number of misses for the tested data type in the base cache architecture (i.e., without implementing the proposed scheme)2 as a selection criteria for the required
minimal cache resources. If the number of misses is not greater than that in the base architecture, the minimal resources for that data type is identified. No more profiling runs are needed for that data type. A single-pass multiconfiguration cache sim-ulator, such astor, such as the Cheetah simulator [11], can be used to reduce the profiling complexity. Cheetah can simulate multiple cache configurations with fixed line size in a single simulation run. Using this approach, the profiling phase only requires separate simulation runs for each data type.
The next step is to determine which data types should be mapped to the mini-cache since accessing the mini-cache con-sumes less energy than accessing a single way of the L1 cache. The selection algorithm is summarized in Algorithm 2. We first identify data types that are eligible for the mini-cache; that is, the required associativity is one and the size is not greater than the mini-cache size. To achieve more energy savings, we would like to have more memory accesses satisfied in the mini-cache. Therefore, we place the most frequently accessed data types to the mini-cache provided that their size is not greater than the mini-cache size.
The last step is to determine the mapping between ways of the L1 cache and the rest of data types (referred to as way-partition). The allocation principle is to keep the utilization of each cache way as even as possible. In other words, a data type should be mapped to ways with minimal utilized resources. We quantify the utilized resources of a way as the total sizes of data types allocated to that way. The mapping information for each data type is represented as a bit vector. For example, if a data type is
2The number of misses for each data type in the base cache architecture is
also obtained through profiling.
mapped to the first two ways of a four-way cache, its mapping vector is (1, 1, 0, 0). The details of the way-partition algorithm is summarized in Algorithm 3.
Based on the data allocation information, the compiler can control memory allocation to avoid interferences among data types allocated to the same cache region and generate correct load instructions which are described in the next section. B. Architectural Support
To convey the allocation information to the cache controller, we use instruction annotation. Previous studies have proposed to statically annotate load/store instructions [12]–[15] to intelli-gently manage cache resources for better performance. Several commodity processors provide different flavors of load instruc-tion type for more sophisticated cache management policy. For example, the ULTRA SPARC [16] processor provides a block load instruction that loads several floating-point registers while bypassing the first level cache. We introduce three new load instructions: load mini, load bypass, and load Type . Loads corresponding to data that bypass the caches or are mapped to the mini-cache use load bypass or load mini, respectively. The rest of data types are assigned unique iden-tifiers and use load Type , where is the type ID. The way allocation information is loaded into a table indexed by data
Fig. 7. Architectural support of software-controlled cache on a standard five-stage pipeline
Fig. 8. Structure of the Wattch simulator.
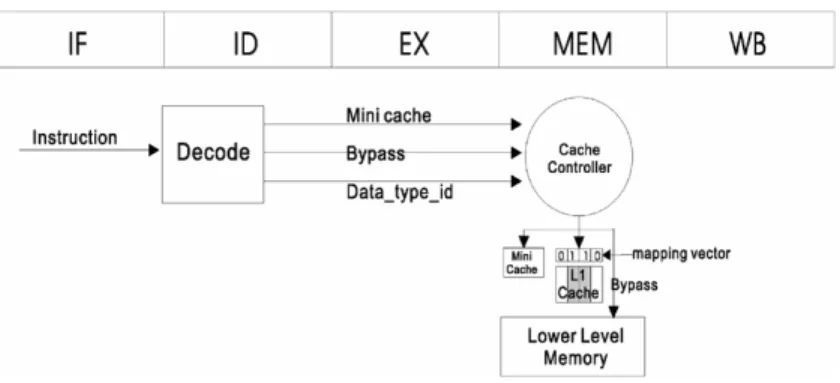
type identifiers through memory-mapped I/O prior program execution. During the decode stage, the allocation information (mini-cache or bypass) or the data type id are extracted and passed to the memory access stage alone with other control signals as shown in Fig. 7. If the mini-cache signal is set, the memory request is directed to the mini-cache. If the bypass signal is set, the memory request is passed to the next level of the memory hierarchy directly. Otherwise, the way allocation information of the corresponding data type is loaded into the mapping vector. Only the allocated ways for this data type are accessed. On a miss, a cache block of the allocated ways is selected to be replaced based on a least recently used (LRU) policy.
IV. EXPERIMENTALMETHODOLOGY
We use the Wattch toolset [17] developed at Princeton University to conduct our experiments. Wattch is an architecture-level power simulator. The overall architecture of Wattch is illustrated in Fig. 8. It performs cycle-by-cycle execution-driven simulation and stores the event occurrences of each functional unit during simulation. The overall energy consumption is then calculated based on the power model of each functional unit and its access counts. Wattch adopts SimpleScalar [18] as the performance simulator. SimpleScalar simulates a modern
superscalar processor with five-stage pipelines: fetch, decode, issue, writeback, and commit. The cache power model estimates the dynamic power consumption defined as
where is the capacitance, is the supply voltage, is the clock frequency, and represents the average number of circuit state transition in each cycle. The activity factor, , which is related to the executed program, is obtained through the architectural simulator. For circuits in which the switching factor can not be estimated through the simulator, an active factor 0.5 is assumed. To calculate the capacitance, a cache access is divided into the following stages: decoder, wordline drive, bitline discharge, and sense amplifier. The capacitance of each stage is summed together. Since the wordline drive and bitline discharge contribute to most of the cache power con-sumption, here we only list the capacitance of wordlines/bitlines below
where
capacitance of the wordline; diffusion capacitance of the word-line driver;
gate capacitance of the cell access transistor;
number of bitlines.
capacitance of the wordline’s metal wire;
length of wordlines; capacitance of the bitline;
diffusion capacitance of the precharge transistor;
number of wordlines; length of bitlines.
We obtain the MPEG-2 software decoder from the MPEG Software Simulation Group [19]. For input sensitivity study, we test three video sequences with a resolution of 704 480 pixels
at 30 frames/s and a compressed bitrate of 6 Mbits/s. We found little variation among different video sequences regarding their memory behavior (i.e., access frequency of different data types and cache miss ratios). Therefore, we obtained the results in the next section using one test stream and restricted each run to 15 frames to limit the simulation time.3
Our baseline machine model is an ARM-like single-issue in-order processor which contains an 8 K, four-way associative data cache. We select the cache size based on the SA-1110 design [20]. All the caches are single-ported. We do not model an L2 cache since most embedded processors do not have an L2 cache [21]. We obtain the energy consumption for DRAM ac-cess from Samsung K4M28163PD-R(B)G/S [22]. We evaluate energy consumption assuming 0.18- m process technology. The important energy/performance parameters are summarized in Table II.
To evaluate the effectiveness of the software-controlled cache, a 512 B, direct-mapped mini-cache is added. We eval-uate the effectiveness of the proposed software-controlled cache mechanism in terms of performance, energy, and energy-delay product (ED). As mentioned before, energy reduction often comes at the cost of performance degradation. Therefore, to evaluate the energy-efficiency of an architecture, we should consider both the performance and energy at the same time. Horowitz et al. [23] propose that an energy-efficient design should optimize for the ED product (cycles joules instead of the traditional energy metric. In this way, if a processor trades off performance for energy, its ED value is very likely to increase. Therefore, for the results presented in the next sec-tion, in addition to performance and energy, we also compare various architectures based on their ED values. The energy consumed in the memory subsystem of the baseline model and the software-controlled cache is obtained using the following two equations, respectively:
where
baseline model cache energy consumption; software-controlled cache energy consump-tion;
number of accesses to the L1 cache; number of L1 misses;
energy consumed per L1 access;
the energy consumed accessing the main memory;
the number of accesses to the L0 cache; the number of L0 misses;
the energy consumed per L0 access.
3We oberved that decoding 15 frames has the similar memory behavior as
decoding a complete sequence.
TABLE II SIMULATIONPARAMETERS
TABLE III
REQUIREDMINIMALCACHERESOURCES FOREACHDATATYPE
TABLE IV
DATAALLOCATION ONL1 CACHEBASED ONWAY-PARTITIONALGORITHM
V. RESULTS
In this section, we first show how much energy reduction can be achieved from the proposed software-controlled cache com-pared to the base cache architecture. We then perform a thor-ough design space exploration to find the ED optimal cache for the software MPEG-2 decoder and compare its ED value to that of the software-controlled cache.
A. Software-Controlled Cache
Before presenting the effectiveness of the software-controlled cache, we first summarize the minimal resources required for each data type in Table III. We can see that the required cache size is smaller than the data set size presented in Table I. For example, the data set size of the reference data type is 1500 KB while the required cache size is only 256 Bytes. For data types that are not allocated contiguously in memory, such as reference and state, multiple ways are required to eliminate self-interfer-ences. Based on the mini-selection algorithm described in Sec-tion III-A, only the stack data are mapped to the mini-cache. The way allocation information of the rest data types are shown in Table IV. Note that the output data bypasses the on-chip caches. To analyze the effectiveness of the proposed software-con-trolled cache in details, we evaluate the proposed scheme in three configurations: bypassing, bypassing mini-cache, bypassing mini-cache way-partition. Fig. 9 shows the execution time, energy and ED normalized to the base archi-tecture for these three configuration. We can see that bypassing output data reduces the energy by 1.4%. The performance
Fig. 9. Normalized execution time, energy consumption, and ED product of different software-controlled techniques.
TABLE V
DATAALLOCATION ONL1 CACHEBASED ONDATASETSIZES
advantage of bypassing is not significant. For the MPEG-2 software decoder, the output data only accounts for 2% of memory references. For applications performing output opera-tions more often, we expect the bypassing mechanism should present more performance and energy advantages. Mapping the stack data to the mini-cache in addition to bypassing can achieve up to 9.5% energy reduction with slight performance improvement. Partitioning the L1 cache among the remaining data types can further reduce the energy by more than 30% without performance degradation. In summary, the proposed software-controlled cache achieves up to 40% energy reduction while maintaining the comparable performance as the base architecture.
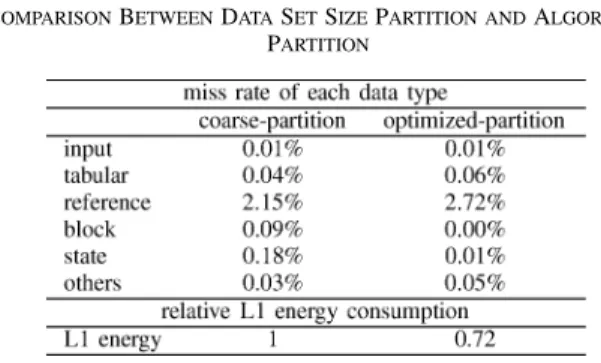
To further demonstrate the importance of the data allocation policy described in Section III-A, we compare the above data allocation with another one derived simply by the information presented in Table I. The output data still bypass the on-chip caches, and the stack variables are mapped to the mini-cache since it is the only data type whose size is not greater than the mini-cache. The rest of data types are mapped to different ways of the L1 cache as shown in Table V. Note that the allocation policy still tries to keep the utilization of each way as even as possible.Since the differences between these two data alloca-tions are in how the L1 cache is partitioned among data types, we focus on the comparison between these two way-partition methods. A good way-partition method should reduce the en-ergy consumed in the L1 cache without increasing that of other memory components; that is, way-partition should not increase L1 misses significantly. Therefore, in Table VI, we list the miss ratio of each data type4and the L1 energy consumption for these 4The miss ratio of the data type x is given by (Misses DataType x/
Total Misses).
TABLE VI
COMPARISONBETWEENDATASETSIZEPARTITION ANDALGORITHM
PARTITION
two way-partition methods. The way-partition method deter-mined by the proposed algorithm is referred to as optimized-par-tition, and the other one is referred to as coarse-partition. We can see that optimized-partition consumes 28% less L1 energy than that of coarse-partition with less than 1% differences in the L1 miss ratios. Note that the slight increase in the L1 miss ra-tios comes from the interferences among data types allocated to the same region. As mentioned in Section III-A, compiler op-timizations can be performed to reduce these interferences if necessary. However, this is beyond the scope of this study.
B. Software-Controlled Cache versus ED Optimal Cache To find the ED optimal cache architecture for the software MPEG-2 decoder, we perform a thorough design space explo-ration. We vary the cache size from 4 to 128 K, degree of set as-sociativity from direct-mapped to four-way and block size from 8 to 128 B. A 64-B, two-way 8 K cache has the lowest ED value among the configurations tested. To give the flavor of the ex-ecution time, energy, and ED trends for various architectures, Fig. 10 shows the behavior of the three metrics with respect to the cache size and associativity assuming a 32-B cache block. We can see that in the aspect of performance, increasing size beyond 8 K does not give any more performance advantage and a two-way associativity is enough to remove most of conflict misses. As for energy consumption, we can observe that in-creasing cache size, in general, increases energy consumption unless it improves performance significantly (e.g., 16 K versus 32 K direct-mapped cache). This can be explained by revisiting the energy equation shown in Section IV. A larger cache has a larger L1 access energy but it reduces the number of L1 misses significantly thereby reducing the overall energy consumed in the memory subsystem. This is the same reason why a two-way cache consumes less energy than a direct-mapped cache. To ob-serve the effect of different block size, Fig. 11 shows the nor-malized execution time, energy, and ED trends with respect to the cache block size and cache size for a fixed two-way asso-ciativity. We can see that the optimal cache block size varies for various cache sizes in considering different metrics. For ex-ample, an 8 K cache favors a 32-B cache block if only perfor-mance is considered. However, a 64-B cache block should be chosen if we consider energy and ED values.
Fig. 12 compares the normalized execution time, energy and ED of the software-controlled cache and the ED optimal cache (64 B, two-way, 8 K). All three metrics are normalized to the base architecture (32 B, four-way, 8 K). We can see that the ED
Fig. 10. Execution time, energy consumption, and ED product for caches with difference cache size and way-associativity. All three metrics are normalized to a 32-B block, direct-mapped, 4-K cache.
Fig. 11. Execution time, energy consumption, and ED product for caches with difference cache size and block size. All three metrics are normalized to a 32-B block, direct-mapped, 4-K cache.
optimal cache performs slightly worse than the base architecture but it consumes 23% less energy. This tells us that if we simply use the cache architecture in an ARM-like processor, a signifi-cant amount of cache energy is wasted. However, by employing
Fig. 12. Normalized execution time, energy consumption, and ED product of best design space point and algorithm optimization.
the proposed software-controlled cache technique, an ARM-like cache architecture consumes even less energy than a dedicated cache tuned for the MPEG-2 software decoder.
VI. RELATEDWORK
Several studies have proposed to partition caches for power optimization. Block buffering [24] uses a block buffer to latch the last cache line. The filter cache [8] extends this idea further by using a larger buffer (smaller than the L1 cache) to store re-cently accessed blocks. Region-based caching [2] reduces cache energy dissipation by partitioning the L1 data cache into three components: stack, global and heap. Data accesses are directed to different components based on their memory region types. The minimax cache [21] looks at the effect of storing scalar data types in a mini-cache for a set of multimedia applications.
To reduce the energy dissipation of set-associative caches specifically, Powell et al. [9] propose to predict the way that contains the accessed data and probe only the predicted way to save energy. Albonesi et al. [25] statically turn off unneeded ways in a set-associative cache (selective-ways) while Yang et al. [26] suggest a dynamic approach to disable unused sets (selective-sets). Yang et al. [27] also develop a hybrid cache organization to exploit advantages of both selective-ways and selective-sets.
Several studies have proposed to use a software-managed cache for performance optimization. Panda et al. [28] map scalar data to the scratch-pad memory for embedded applica-tions. Chiou et al. [29] provide a flexible method to partition cache regions dynamically. Soderquist et al. [30] suggest to exploit application-specific information for better cache resource management to improve cache efficiency for the MPEG-2 software decoder. This paper is the first attempt to use a software-managed cache for energy optimization.
Low power design for a MPEG-2 hardware decoder can be categorized as followings: multimedia instruction sets, simpli-fication of signal processing modules, energy-centric designs of signal processing modules, and energy-efficient I/O bus designs. In the aspect of multimedia instruction set design, SIMD-like instructions were proposed to perform operations on multiple data in one instruction since lower instruction
counts reduces execution time thereby cutting down total en-ergy consumption [31], [32]. Another way for enen-ergy reduction is to simplify the signal processing modules at the expense of reduced video quality. For an example, using 4 4 DCT/IDCT instead of 8 8 DCT/IDCT consumes less energy [33]. Such an approach is more suitable for portable devices with limited display resolution. Energy-centric designs of signal processing modules of a MPEG-2 codec are different from traditional speed-centric designs. For an example, Cho et al. [34] proposed fine-grain lookup table partition for variable-length decoding to reduce switched capacitance based on codeword frequency. Since MPEG-2 applications incur large amount of data trans-ferring, the energy consumed in the I/O bus is significant. In [35], the Gray code encoding scheme is used to recode the image data such that the bus switching activity is lowered thereby reducing the I/O bus power consumption.
VII. CONCLUSION
In this paper, we propose to use a software-controlled cache for energy-efficiency optimization on a shared cache architec-ture of an integrated multimedia system. The proposed soft-ware-controlled cache allocates data types in an application to different cache regions. A data type is either mapped to the mini-cache, ways of the L1 cache or bypass on-chip caches. The optimization goal is to achieve energy reduction without performance degradation. We test the effectiveness of the soft-ware-controlled cache on the MPEG-2 software decoder. The results show that the software-controlled cache reduces 40% of energy on an ARM-like cache architecture without sacrificing performance. It consumes even less energy in comparison with a cache architecture tuned specifically for the MPEG-2 decoder. This study has shown that the proposed software-controlled cache does provide a way to improve the energy efficiency of a shared cache architecture for an integrated multimedia system on an application-specific basis. In the future, we will apply the software-controlled cache technique to other multimedia applications, such as the MPEG-4 decoder.
REFERENCES
[1] J. Montanaro et al., “A 160-mhz, 32-b, 0.5-w CMOS risc micropro-cessor,” IEEE J. Solid-State Circuits, vol. 31, no. 11, pp. 1703–1714, Nov. 1996.
[2] H.-H. S. Lee and G. S. Tyson, “Region-based caching: An energy-delay efficient memory architecture for embedded processors,” in Proc. Int.
Conf. Compilers, Architectures, and Synthesis for Embedded Systems,
Nov. 2000, pp. 120–127.
[3] F. Pollack, “New microarchitecture challenges in the coming genera-tions of CMOS process technologies,” in Proc. 32nd Annu. Int. Symp.
Microarchitecture, Nov. 1999, pp. 2–3.
[4] P. Shivakumar and N. P. Jouppi, “CACTI 3.0: An integrated cache timing, power, and area model,”, Tech. Rep. WRL-2001–2, Compaq Computer Corp., Aug. 2001.
[5] M. Huang, J. Renau, S.-M. Yoo, and J. Torrellas, “The design of DEETM: A framework for dynamic energy efficiency and temperature management,” J. Instruction-Level Parall., vol. 3, 2002.
[6] D. Parikh, K. Skadron, Y. Zhang, M. Barcella, and M. R. Stan, “Power issues related to branch prediction,” in Proc. Int. Symp.
High-Perfor-mance Computer Architecture, Feb. 2002, pp. 233–246.
[7] S. Steinke, L. Wehmeyer, B. Lee, and P. Marwedel, “Assigning pro-gram and data objects to scratchpad for energy reduction,” in Proc.
De-sign, Automation and Test in Europe Conf. Exhibition, Mar. 2002, pp.
409–417.
[8] J. Kin, M. Gupta, and W. H. Mangione-Smith, “The filter cache: An energy efficient memory structure,” in Proc. 30th Annu. Int. Symp.
[9] M. Powell, A. Agarwal, T. Vijaykumar, B. Falsafi, and K. Roy, “Re-ducing set-associative cache energy via way-prediction and selective direct-mapping,” in Proc. 34th Int. Symp. Microarchitecture, Dec., pp. 54–65.
[10] T. L. Johnson, D. A. Connors, M. C. Merten, W. Mei, and W. Hwu, “Run-time cache bypassing,” IEEE Trans. Comput., vol. 48, no. 6, pp. 1338–1354, Dec. 1999.
[11] R. A. Sugumar and S. G. Abraham, “Multi-configuration simulation al-gorithms for the evaluation of computer architecture designs,”, Tech. Rep. CSE-TR-173-93, 1993.
[12] G. Tyson, M. Farrens, J. Matthews, and A. R. Pleszkun, “A modified approach to data cache management,” in Proc. 28th Annu. Int. Symp.
Microarchitecture, Dec. 1995, pp. 93–103.
[13] C. A. A. Gonzalez and M. Valero, “A data cache with multiple caching strategy tuned to different type of locality,” in Proc. ACM 1995 Int. Conf.
Supercomputing, 1995, pp. 338–374.
[14] O. Temam and N. Drach, “Software assistance for data caches,” in Proc.
11th Int. Symp. High Performance Architecture, 1995, pp. 154–163.
[15] A. R. Lebeck, D. R. Raymond, C.-L. Yang, and M. Thottethodi, “Annotated memories references: A mechanism for informed cache management,” in Proc. Eur. Conf. Parallel Processing, Aug. 1999, pp. 1251–1254.
[16] B. Case, “SPARC V9 adds wealth of new features,” Microprocessor
Rep., vol. 7, p. 9, Feb. 1993.
[17] D. Brooks, V. Tiwari, and M. Martonosi, “Wattch: A framework for architectural-level power analysis and optimizations,” in Proc. 27th Int.
Symp. Computer Architecture (ISCA), Vancouver, BC, Canada, Jun.
2000, pp. 83–94.
[18] D. Burger and T. M. Austin, “The SimpleScalar toolset version 2.0,”
Comput. Architect. News, pp. 13–25, Jun. 1997.
[19] S. Echart and C. Fogg, “ISO/IEC MPEG-2 software video codec,” in
Proc. SPIE Conf. Digital Video Compression: Algorithms and Technolo-gies, vol. 2419, San Jose, CA, Feb. 1995, pp. 100–109.
[20] Intel StrongARM SA-1110 Microprocessor Brief Datasheet, Apr. 2000. [21] O. S. Unsal, I. Koren, C. M. Krishna, and C. A. Moritz, “The minimax cache: An energy-efficent framework for media processors,” in Proc.
8th Int. Symp. High-Performance Computer Architecture, Feb. 2002, pp.
131–140.
[22] Samsung K4M28163PD-R Brief Datasheet, Dec. 2002.
[23] R. Gonzalez and M. Horowitz, “Energy dissipation in general purpose microprocessors,” IEEE J. Solid-State Circuits, vol. 31, no. 9, pp. 1277–1284, Sep. 1996.
[24] C.-L. Su and A. M. Despain, “Cache design tradeoffs for power and performance optimization: A case study,” in Proc. Int. Symp. Low Power
Design, Apr. 1995, pp. 63–68.
[25] D. H. Albonesi, “Selective cache ways: On-demand cache resource al-location,” J. Instruction-Level Parall., vol. 2, 2000.
[26] B. F. K. R. S.-H. Yang, M. D. Powell, and T. N. Vijaykumar, “Se-Hyun Yang and Michael D. Powell and Babak Falsafi and Kaushik Roy and T. N. Vijaykumar,” in Proc. 7th IEEE Symp. High-Performance Computer
Architecture, Jan. 2001, pp. 147–158.
[27] S.-H. Yang, M. D. Powell, B. Falsafi, and T. N. Vijaykumar, “Exploiting choices in resizable cache design to optimize deep-submicron processor energy-delay,” in Proc. 8th Int. Symp. High-Performance Computer
Ar-chitecture, Feb. 2002, pp. 151–164.
[28] P. R. Panda, N. D. Dutt, and A. Nicolau, “Efficient utilization of scratch-pad memory in embedded processor applications,” in Proc. Eur.
Conf. Design and Test, 1997, pp. 7–11.
[29] D. Chiou, P. Jain, L. Rudolph, and S. Devadas, “Application-specific memory management for embedded systems using software-controlled cache,” in Proc. Design Automation Conf. (DAC), Los Angeles, CA, 2000, pp. 416–419.
[30] P. Soderquist and M. Leeser, “Memory traffic and data cache behavior of an MPEG-2 software decoder,” in Proc. Int. Conf. Computer Design, 1997, pp. 417–422.
[31] K. Nadehara, H. Lieske, and I. Kuroda, “Software MPEG-2 video de-coder on a 200-mhz low-power multimedia microprocessor,” in Proc.
Int. Conf. Acoustics Speech and Signal Processing, vol. 5, San Jose, CA,
1998, pp. 3141–3144.
[32] K. Nadehara, H. J. Stolberg, M. Ikekawa, E. Murara, and I. Kuroda, “Real-time software MPEG-1 video decoder design for cost, low-power applications,” in Proc. Workshop VLSI Signal Processing, 1996, pp. 438–447.
[33] S. Molloy and R. Jain, “System and architecture optimizations for low power MPEG-1 video decoding,” in Proc. Dig. Technical Papers, IEEE
Symp. Low Power Electronics, Oct. 1994, pp. 26–27.
[34] S. Cho, T. Xanthopoulos, and A. P. Chandrakasan, “A low power vari-able length decoder for MPEG-2 based on nonuniform fine-grain tvari-able partitioning,” IEEE Trans. Very Large Scale (VLSI) Integr. Syst., vol. 7, no. 6, pp. 249–257, Jun. 1999.
[35] C. Lin, C. Chen, and C. Jen, “Low power design for MPEG-2 video decoder,” IEEE Trans. Cons. Electron., vol. 42, no. 8, pp. 513–521, Aug. 1996.
Chia-Lin Yang (M’02) received the B.S. degree from the National Taiwan Normal University, Taiwan, R.O.C., in 1989, the M.S. degree from the University of Texas at Austin in 1992, and the Ph.D. degree from the Department of Computer Science, Duke University, Durham, NC, in 2001.
In 1993, she joined VLSI Technology Inc. (now Philips Semiconductors) as a Software Engineer. She is currently an Assistant Professor in the Department of Computer Science and Information Engineering, National Taiwan University, Taipei, Taiwan, R.O.C. Her research interests include energy-efficient microarchitectures, memory hi-erarchy design, and multimedia workload characterization.
Dr. Yang is the recipient of a 2000–2001 Intel Foundation Graduate Fellow-ship Award and she is a member of the ACM.
Hung-Wei Tseng received the B.S. degree from the Department of Computer Science and Information Engineering, National Taiwan University, Taipei, Taiwan, R.O.C., in 2003, where he is presently working toward the M.S. degree.
His research interests include energy-efficient de-sign and network applications.
Chia-Chiang Ho received the B.S. and Ph.D. degrees in computer science and information engi-neering from National Taiwan University, Taipei, Taiwan, R.O.C., in 1996 and 2003, respectively.
He joined Cyberlink Corporation, Taipei, Taiwan, as a Senior Engineer. His current research interests include video coding and communication.
Ja-Ling Wu (M’72–SM’95) received the B.S. degree in electronic engineering from TamKang University, Tamshoei, Taiwan, R.O.C. in 1979, and the M.S. and Ph.D. degrees in electrical engineering from Tatung Institute of Technology, Taipei, Taiwan, R.O.C., in 1981 and 1986, respectively.
From 1986 to 1987, he was an Associate Professor in the Electrical Engineering Department, Tatung In-stitute of Technology. Since 1987, he has been with the Department of Computer Science and Informa-tion Engineering, NaInforma-tional Taiwan University, Taipei, Taiwan, R.O.C., where he is presently a Professor. He was also the Head of the Department of Information Engineering, National Chi Nan University, Puli, Taiwan, R.O.C., from August 1996 to July 1998. He has published more than 200 journal and conference papers. His research interests include algorithm de-sign for DSP, data compression, digital watermarking techniques, and multi-media systems.
Prof. Wu was the recipient of the 1989 Outstanding Youth Medal of the R.O.C., the Outstanding Research Award sponsored by the National Science Council (NSC) from 1987 to 1992, and the Excellent Research Award from the NSC in 1999.