行政院國家科學委員會專題研究計畫 成果報告
三維模型之建構與其中軸之表現及物件快速擷取(2/2)
計畫類別: 個別型計畫
計畫編號: NSC92-2213-E-002-015-
執行期間: 92 年 08 月 01 日至 93 年 07 月 31 日
執行單位: 國立臺灣大學資訊工程學系暨研究所
計畫主持人: 歐陽明
報告類型: 完整報告
處理方式: 本計畫可公開查詢
中 華 民 國 93 年 11 月 4 日
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 1 頁 11/3/2004
行政院國家科學委員會補助專題研究計畫期中進度報告
三維模型之建構與其中軸之表現及物件快速擷取(2/2)
計畫編號:NSC92-2213-E-002-015
全程計畫:民國 91 年 8 月 1 日至民國 93 年 7 月 31 日
本年度計畫:民國 92 年 8 月 1 日至民國 93 年 7 月 31 日
計畫主持人:歐陽明 台灣大學資訊工程學系教授
計劃中文摘要
關鍵字:三維模型建構,中軸,三維模型搜尋比對,網格最佳化,漸進式網格,
隱含平面,輻射基底函數
三維模型資料在現今生活各層面中扮演著重要的角色,也是所有工程摸擬工具
與商業動畫及網路電動玩具的基礎。
本計劃為二年期計劃,其主旨為開發一三維模型資料的處理系統,並由此系統
建立出來之模型資料進行有關中軸(medial axis)、骨幹(skeleton)建構,與三維模
型搜尋的研究。
本三維模型處理軟體函式庫係由以下四個模組所構成:
(1) 建構模組:此模組可將從三維雷射測距儀掃描物體所得到的多個深度影像
(range image),加以對齊、合併以建出原本物體的三維模型。
(2) 最佳化處理模組:此模組將得到的模型做最佳化(optimization)或漸進式
(progressive)的處理,以利於壓縮儲存或是網路傳輸。除外,我們利用輻射
基底函數(radial basis functions)建立三維模型的隱含曲面(implicit surface)。
(3) 三維模型搜尋比對模組:在中軸、骨幹建構方面,我們利用模型絕對平面函
式,以微分幾何的方式建立梯度向量流(gradient vector flow),並根據此向量
流做為物體收縮建立骨幹的依據。在本計劃中,我們將針對不同種類的演算
法建立中軸或骨幹並加以比較。在三維模型搜尋方面,利用以物體中軸或是
骨幹做為搜尋時的主要關鍵,我們用以發展一搜尋演算法使得運用此的搜尋
系統可以針對不同目標(如物體形狀,走向,顏色等)加以合併搜索。就文
獻來看,穩定可靠的產生中軸方式為本計劃之特色。而在短時間內可從上千
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 2 頁 11/3/2004
個三維物件中找到最相關者,則為本計劃之軟體產出。
(4) 特效模組(special effects):如三維模型輪廓(silhouette),計算表面曲率等小型
輔助模組。
計劃英文摘要
Keywords: 3D Model Construction, Medial Axes, 3D Model Search and Retrieval,
Mesh Optimization, Progressive Mesh, Implicit Surface, Radial Basis Function
3D models nowadays become an important part of our daily life, and are the
fundamental building blocks of engineering simulation tools, commercial animations,
and networking computer games.
It is our goal to develop a 3D model information processing system in two years.
Besides, using the generated models from the previous system, we will continue the
researches on 3D object medial axis generation and its application in 3D model
retrieval.
The proposed 3D model information processing system contains the following four
software modules:
(1) Model construction module:
This module registers and merges the range images acquired from the 3D laser
scanner and construct the original object 3D model.
(2) Mesh optimization module:
This module optimizes the 3D model for compression. Besides, the progressive
mode of the 3D model will be constructed.
(3) 3D model retrieval module:
We use radial basis function to construct the implicit surface of a 3D model. In
the generation of medial axis and skeleton, we invoke the implicit surface
function to build the gradient vector flow, and use this vector flow to be
guidelines in the construction of object skeleton. In this project, we will develop
algorithms for medial axis and skeleton extraction and analyze them.
In 3D model retrieval, we use the medial axis or skeleton as the primary key of
the search system. We will develop an algorithm to search 3D object with
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 3 頁 11/3/2004
different target (such as topology, shape, color and so on).
According to the survey, reliable and faithful extraction of medial axis or
skeleton for 3D objects is a very difficult task, and will be the major feature of
our system. The deliverable part of the project is a system that can retrieve from
up to thousands of 3D models in reasonably short time, given one target 3D
model.
(4) Special effects module:
Modules for special functionality will be developed such as 3D model silhouette
finding, curvature calculation.
本計畫之目標
本計畫的主要目標是設計一三維模型建立及處理系統,並利用此系統產生的
三維模型從事下面各項研究:
A. 中軸及骨架萃取
B.
在大資料庫中搜尋並取得三維模型
一、 執行進度
第一年為止,我們已將本計劃的三個主要方法執行完畢:
1. 三維模型建構方法 (3D model construction)。
2. 藉由輻射基底函數之隱含曲面建構方法 (Implicit surface construction with
radial basis functions)。
3. 藉 由 隱 含 曲 面 之 物 體 骨 架 擷 取 方 法 (Skeleton extraction with a implicit
surface)。
第二年的進度,
1. 中軸及骨架萃取
我們現在已建立一個網站
http://www.cmlab.csie.ntu.edu.tw/~joyce/skeleton/
將一
百五十多個已經產生中軸的三維模型加上對映的中軸以著名三維建模動畫繪圖
軟體 Maya 之格式,對外發表,並有一篇論文已投稿至 The Visual Computer。
Fu-Che Wu, Wan-Chun Ma, Rung-Huei Liang, Bing-Yu Chen, Ming Ouhyoung,
"Domain Connected Graph: the Essential Skeleton of a 3D Shape
",
submitted to The
Visual Computer, 2004.
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 4 頁 11/3/2004
2. 在大資料庫中搜尋並取得三維模型,
我們已發展一套系統名為“3D Model Retrieval System”見 http://3d.csie.ntu.edu.tw。
此系統包含全世界所有的網路上可公開的 3D Model,剔除重複的,約有一萬一
千多個 3D Mesh Model。可在「側面剪影」模式下,0.1 秒找到按相似度排序之
目標,或直接由“從 3D Object 找 3D Model”模式下,2 秒之內完成搜尋。其結果
之精確度,比現今 State of the art 的 Princeton 大學 Thomas Funkhouser 團隊(ACM
Tr. Graphics and Visualization, Feb. 2003)之成果還超過 23﹪。也因此本人受邀與
其合作,共同設立 3D model test bed,結合兩校之資料庫,成為世界最完整之 3D
Model 資料庫與測試平台,同時本人也利用 sabbatical leave 至 Princeton Univ.作
Visiting Fellow 一學期(9/2003~12/2003)
。
發表之三篇論文如下,其中第一篇已被今年的 SIGGRAPH paper (ACM
Transaction on Graphics)所引用,另外含 IEEE Transaction on Multimedia 等之其
他論文所引用。論文也附在本報告之後。
(1) Ding-Yun Chen, Ming Ouhyoung, Xiao-Pei Tian, Yu-Te Shen, "On Visual
Similarity Based 3D Model Retrieval", Computer Graphics Forum 2003, pp. 223 -
232, (also to appear in EuroGraphics2003, Spain). (SCI)
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 5 頁 11/3/2004
(2) Fu-Che Wu, Bing-Yu Chen , Rong-Hui Liang, Ming Ouhyoung, "Prong Features
Detection of a 3D Model Based on the Watershed Algorithm", in ACM
SIGGRAPH2004 Sketches, Los Angeles, California, USA., August, 2004.
(3) Shuen-Huei Guan, Ming-Kei Hsieh, Chia-Chi Yeh, and Bing-Yu Chen.
Enhanced 3D Model Retrieval System through Characteristic Views using Orthogonal
Visual Hull. ACM SIGGRAPH 2004 Conference Abstracts and Applications (Posters
Program), Los Angeles, California, USA., 2004.
第一年之成果發表之論文如下:
W.-C. Ma, F.-C. Wu and M. Ouhyoung. Skeleton Extraction of 3D Objects with
Radial Basis Functions. Shape Modeling International 2003, Seoul, Korea.
在前述論文中, 沒有完全包含之部分, 分述如後三節。
二、 三維模型建構方法 (3D model construction)
在三維模型的建構方面,我們採用了在國科會計劃 NSC 90-2213-E-002-089 所發
展的技術來進行三維資料擷取、網格對齊 (mesh registration)、網格接合 (mesh
integration) 與網格最佳化 (mesh optimization)。詳細演算法請參見國科會報告
書。
三、 藉由輻射基底函數之隱含曲面建構方法 (Implicit surface
construction with radial basis functions)
3.1 隱含曲面
目 前 有 越 來 越 多 的 研 究 單 位 對 於 隱 含 曲 面 有 更 深 的 探 討 [TURK99]
[YNGVE99]。隱含曲面提供了建構複雜的幾何物件的另外一種選擇,由於隱含
曲面為一可微分之數學式,在應用上的價值遠比單用三角形與節點來描述一個物
體形狀來的大的多。我們定義一個隱含曲面為一個三維的函式
c
x
f
(
)
=
,
x
∈
ℜ
3我們可以將空間中任何的一點代入到此函式中,假設計算出來的結果等於 c 的
話,則我們可得知此點是位在此隱含曲面所代表的物體上。一個簡單的隱含曲面
例子:
2 2 2( , , )
1
f x y z
=
x
+
y
+
z
−
此函式即代表著一個在三度空間中一個以座標 (0,0,0) 為原點,半徑長為 1 的
球。簡單形狀的隱含曲面可以用人來計算,但是如何建立複雜形狀的隱含曲面則
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 6 頁 11/3/2004
是一大難題。目前許多研究朝向以利用非線性內差 (non-linear interpolation) 來
建立任意物體的隱含曲面。而在其中,以輻射基底函數 (radial basis functions,
RBFs) 來進行非線性內差則為最常見的方法。
3.2 利用輻射基底函數來建立隱含曲面
主要的計算過程如下:
1. 將三維模型上面所有的點 (vertices) 當作輸入。假設此模型有 N 個點,則我
們建立出來的隱含曲面有著以下的結構:
)
(
)
(
)
(
2 1x
s
x
x
d
x
f
N i i i−
+
=
∑
=φ
,
∈
ℜ
3x
2. 在模型上的點 (on-surface point) 集合 V 與每個點其法向量集合分別定義為:
1{
,...,
N}
M
=
m
m
,
V
=
{
V
1,...,
V
N}
3. 藉由 V 與 M,我們定義在模型外的點 (off-surface point) 為:
M
w
V
l
l
L
=
{
1,...,
N}
=
+
*
,
w
>
0
4. 我們定義
x
=
{
V
,
M
}
為隱含曲面的邊界限制(boundary constraints)。
5. 對於基底函數的選擇,有以下幾種:
2 2 2/
1
)
(
)
exp(
)
(
)
log(
)
(
2c
r
r
cr
r
r
r
r
+
=
−
=
=
φ
φ
φ
6. 隱含曲面會滿足以下的矩陣運算式:
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
=
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
⎟⎟
⎠
⎞
⎜⎜
⎝
⎛
0
0
f
s
d
P
P
A
T1
0
)
(
,=
→
∈
=
→
∈
=
−
=
i i i i i i j i j if
M
x
f
V
x
x
P
x
x
A
φ
我們利用已知的 A, P, f 解未知的輻射基底函數參數 d 及一次項參數 s。當 d 與 s
都知道之後,則此隱含曲面:
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 7 頁 11/3/2004
)
(
)
(
)
(
2 1x
s
x
x
d
x
f
N i i i−
+
=
∑
=φ
即建立出來。我們可以將任意的三維空間點
p
=
( , , )
x y z
代入公式所得到的值
( )
c
=
f p
來判斷說此三維空間點是在模型的表面、內部、或是外部。圖為一波斯
貓模型的隱含曲面採樣結果。
圖:波斯貓模型的隱含曲面。圖中的點為三維的採樣點(此圖是在
1
×
1
×
1
的正立
方體空間中,以每邊切 40 等份來做採樣)
。點的顏色越接近藍色代表求出來的值
越接近 0,越往紅色代表值越大。
四、 藉由隱含曲面之物體骨架擷取方法 (Skeleton extraction with
an implicit surface)
4.1 骨架簡介
骨架的概念是由 H. Blum [BLUM73] 根據中軸轉換 (Medial Axis Transform,
MAT) 和對稱軸轉換 (Symmetry Axis Transform, SAT) 所提出。中軸轉換為物體
上的每一點找出最接近它的邊界點(可能不只一個),若一個內部點能找到兩個
以上邊界點,則此內部點就在骨架上。骨架化的目的是萃取出一物體地域性的形
狀特徵。此外,骨架應該要用代表一物體最小維度的表示法。例如,二維圖片的
骨架應該是一維的線段,三維模型的骨架則應該由一維的線段和二維的表面組
成。
圖:
(左)義大利領土圖形與其中軸。
(右)楓葉圖形與其中軸。
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 8 頁 11/3/2004
由於從中軸轉換所建立的骨架通常是十分雜亂的(中軸轉換會受到物體表雜訊的
影響,所以我們在這邊藉由不同的想法來提出我們對於骨架的想法。許多研究報
告,如 [LAZARUS99] 等,利用所謂的 Reeb graph [REEB46] 來產生物體的一維
骨架。Reeb graph 骨架保留了物體大致的幾何形態與拓樸關係。因此,在最近幾
年,Reeb graph 骨架是一個十分熱門的課題。我們所提出的骨架概念,除了相同
的保留物體的拓樸關係,更進一步的比 Reeb graph 保留更多的幾何資訊。以下將
簡介我們所提出的骨架擷取演算法。
4.2 骨架擷取演算法
本段將敘述由我們所提出之骨架擷取演算法,主要的內容已發表為國際會議論文
[MA03]。本演算法分為三個主要步驟:A. 利用梯度下降法 (gradient descent) 取
得局部極小值,B. 建立局部極小值之相鄰關係,C. 利用利用主動輪廓模型
(Active Contour Model) 建立骨架。以下我們將分別介紹這部分:
圖:骨架擷取演算法之說明簡圖。
(左)隱含曲面,顏色越深代表隱含曲面值高。
(中)對於每個在物體表面的點,利用梯度下降法來取得局部極小值位置。
(右)
建立局部極小值之相鄰關係,並利用主動輪廓模型 (Active Contour Model) 來連
結局部極小值。
A.
利用梯度下降法來取得局部極小值位置
藉由上述提及的隱含曲面可微分之特性,我們可以建立其梯度場:
( )
( )
g x
= ∇
f x
我們利用所有在三維模型上的節點 (vertices) 當作起始點,我們利用此梯度場進
行梯度下降:
'
( )
x
= +
x
g x
×
step
當所有的節點都收斂完畢的時候,此步驟即停止。這些因收斂而得到的局部極小
值的位置,在我們的研究中被視為骨架上的重要節點。這些位置通常會有兩種在
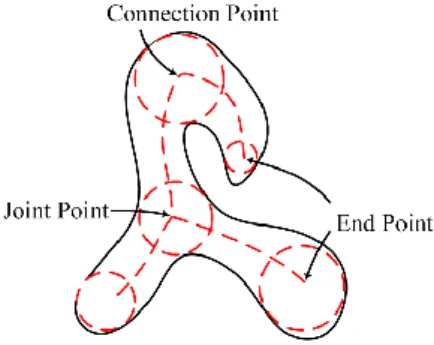
骨架上的意義:一是關節點 (branching point),一是端點 (termination point)。
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 9 頁 11/3/2004
B.
建立局部極小值之相鄰關係
當我們獲得了這些局部極小值位置後,接下來我們就要判斷兩個局部最小值是否
有相鄰關係。我們定義了一個簡單直覺的方法:假設 P
A與 P
B為三維模型上的兩
個獨立節點(收斂起始點)
,其對應的局部最小值分別為 M
A與 M
B,則如果 P
A與 P
B有相鄰關係(即 P
A與 P
B之間有一三角形邊相連)
,M
A與 M
B也會有相鄰關
係(如果 M
A=M
B,則也算相鄰)
。對於每個局部最小值,我們都去做這樣的分析,
即可建立出一個骨架圖 (skeleton graph)。
C.
利用主動輪廓模型 (Active Contour Model) 來連結局部極小值
當我們擷取出骨架圖之後,最後的工作就是讓骨架圖裡的每個連結都變形成其所
屬區域的形狀。在此我們利用主動輪廓模型 [KASS87] 來做形變的動作。主動
輪廓模型為一個將能量最小化 (energy minimization) 的演算法。主要的構想是,
將每個連結都視為一個彈簧,在此彈簧上的每個點同時受到兩種力量的拉扯:外
部力 (external force) 與內聚力 (internal force)。外部力為彈簧外部力場所影響的
力量,在我們這邊為則就是隱含曲面的梯度場。內聚力則為彈簧兩兩相連的點的
引力,我們這邊將相連的點的內聚力利用虎克定律來描述。所以整個彈簧的能量
為:
1 2
( )
( )
( )
acm external internal
E
x
=
w
×
E
x
+
w
×
E
x
將此彈簧的能量調整到最低,此彈簧的位置即可被認為是最後骨架連結變形出來
的結果。我們將每個骨架連結都利用主動輪廓模型來做變形的動作。最後的結果
即符合我們所提出的骨架。
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 10 頁 11/3/2004
4.3 相關結果
再此我們列出六個利用本演算法所計算出來的骨架。我們將原本的三維模型繪製
成藍色半透明狀、骨架為綠色、所有的局部極小值點為紅色。我們可以見得我們
提出的骨架保留了物體大部分的幾何資訊與形態 (morphological) 資訊。但是目
前的結果仍有改進的地方,例如由於我們是利用輻射基底函數來建立隱含曲面,
但是利用此方法建立出來的曲面跟原本的三維模型間會有一定的誤差(尤其是在
物體較細微的部分)
,所以在一些較精細的部分,比如老鼠的手的部分,通常這
邊的幾何資訊會因為隱含曲面的問題而具有不小的誤差,因此這邊所建立的骨架
沒有辦法完整的表達其形態上的資訊。
圖:利用本演算法所擷取出來的骨架資訊。
本演算法的執行資訊如下:
模型名稱
總邊界
限制數
RBF 半徑
建立
隱含曲面
(秒)
梯度下降
(秒)
主動輪廓
模型變形
(秒)
猪
2170 0.1 74.83
74.28
294.30
章魚
2004 0.1 57.44
41.25
344.62
鼠
1912 0.1 51.05
44.80
182.45
蛙
1890 0.06 48.14 21.93
312.27
牛
1982 0.2 55.93
79.96
210.33
蛇
1752 0.2 39.17
62.13
110.04
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 11 頁 11/3/2004
五、 研究成果
本研究成果至今已發表了一篇國際期刊論文以及三篇國際會議論文。其中有兩篇
在今年的 SIGGRAPH 會議中,以 Sketch paper 及 Poster paper 的方式呈現。另
外,還有一篇國際期刊論文已投稿在審查中。
隨 著 本 計 畫 , 我 們 還 建 立 了 兩 個 網 站 , 一 個 做 為 三 維 搜 尋 引 擎
(http://3d.csie.ntu.edu.tw) , 另 一 個 做 為 三 維 骨 架 ( 中 軸 ) 成 果 之 展 現
(http://www.cmlab.csie.ntu.edu.tw/~joyce/skeleton/)。 此兩個網站,都受到國際相
關研究人員之重視,也常常放入他們發表論文的 reference 中。上述論文擇其要
者附在本報告之後。
六、 參考文獻
[BLUM67] H.
Blum.
A Transformation for Extracting New Descriptors of Shape,
pp. 362–380. MIT Press, 1967.
[KASS87]
M. Kass, A. Witkin and D. Terzopoulos. Snakes: Active Contour
Models. International Journal of Computer Vision, 1:321–331, 1987.
[LAZARUS99] F.
Lazarus and A. Verroust. Level Set Diagrams of Polyhedral
Objects. Proceedings of the ACM Symposium on Solid Modeling and Applications,
pp. 130–140, 1999.
[MA03]
W.-C. Ma, F.-C. Wu and M. Ouhyoung. Skeleton Extraction of 3D
Objects with Radial Basis Functions. Shape Modeling International 2003, Seoul,
Korea.
[REEB46] G.
Reeb.
Sur les points singuliers d’une forme de Pfaff completement
integrable ou d’une fonction numerique. Comptes Rendus Acad. Science Paris,
222:847–849, 1946.
[TURK99]
G. Turk and J. F. O'Brien. Variational Implicit Surfaces. Technical
Report GIT-GVU-99-15, Graphics, Visualization, and Usability Center, Georgia
Institute of Technology, 1999.
[YNGVE99] G. Yngve and G. Turk. Creating Smooth Implicit Surfaces from
Polygonal Meshes. Technical Report GIT-GVU-99-42, Graphics, Visualization, and
Usability Center, Georgia Institute of Technology, 1999.
三維模型之建構與其中軸之表現及物件快速擷取
國立台灣大學資訊工程學系
第 12 頁 11/3/2004
[WML04] Fu-Che Wu, Wan-Chun Ma, Rung-Huei Liang, Bing-Yu Chen, Ming
Ouhyoung, Domain Connected Graph: the Essential Skeleton of a 3D Shape,
submitted to The Visual Computer, 2004.
[COT03]Ding-Yun Chen, Ming Ouhyoung, Xiao-Pei Tian, Yu-Te Shen, On Visual
Similarity Based 3D Model Retrieval, Computer Graphics Forum 2003, pp. 223 - 232,
(also to appear in EuroGraphics2003, Spain). (SCI)
[WCL04] Fu-Che Wu, Bing-Yu Chen , Rong-Hui Liang, Ming Ouhyoung, Prong
Features Detection of a 3D Model Based on the Watershed Algorithm, in ACM
SIGGRAPH2004 Sketches, Los Angeles, California, USA., August, 2004.
[GHY04] Shuen-Huei Guan, Ming-Kei Hsieh, Chia-Chi Yeh, and Bing-Yu Chen.
Enhanced 3D Model Retrieval System through Characteristic Views using Orthogonal
Visual Hull. ACM SIGGRAPH 2004 Conference Abstracts and Applications (Posters
Program), Los Angeles, California, USA., 2004.
EUROGRAPHICS 2003 / P. Brunet and D. Fellner (Guest Editors)
Volume 22 (2003), Number 3
On Visual Similarity Based 3D Model Retrieval
Ding-Yun Chen, Xiao-Pei Tian, Yu-Te Shen and Ming OuhyoungDepartment of Computer Science and Information Engineering, National Taiwan University, Taipei, Taiwan
{dynamic, babylon, edwards}@cmlab.csie.ntu.edu.tw, [email protected]
Abstract
A large number of 3D models are created and available on the Web, since more and more 3D modelling and digitizing tools are developed for ever increasing applications. The techniques for content-based 3D model re-trieval then become necessary. In this paper, a visual similarity-based 3D model rere-trieval system is proposed. This approach measures the similarity among 3D models by visual similarity, and the main idea is that if two 3D models are similar, they also look similar from all viewing angles. Therefore, one hundred orthogonal projections of an object, excluding symmetry, are encoded both by Zernike moments and Fourier descriptors as features for later retrieval. The visual similarity-based approach is robust against similarity transformation, noise, model de-generacy etc., and provides 42%, 94% and 25% better performance (precision-recall evaluation diagram) than three other competing approaches: (1)the spherical harmonics approach developed by Funkhouser et al., (2)the MPEG-7 Shape 3D descriptors, and (3)the MPEG-7 Multiple View Descriptor. The proposed system is on the Web for practical trial use (http://3d.csie.ntu.edu.tw), and the database contains more than 10,000 publicly available 3D models collected from WWW pages. Furthermore, a user friendly interface is provided to retrieve 3D models by drawing 2D shapes. The retrieval is fast enough on a server with Pentium IV 2.4GHz CPU, and it takes about 2 seconds and 0.1 seconds for querying directly by a 3D model and by hand drawn 2D shapes, respectively.
Categories and Subject Descriptors(according to ACM CCS): H.3.1 [Information Storage and Retrieval]: Indexing Methods
1. Introduction
Recently, the development of 3D modeling and digitizing technologies has made the model generating process much easier. Also, through the Internet, users can download a large number of free 3D models from all over the world. This leads to the necessities of a 3D model retrieval system. Although text-based search engines are ubiquitous today, multimedia data, such as 3D models, usually lacks meaningful descrip-tion for automatic matching. The MPEG group aims to cre-ate an MPEG-7 international standard, also known as "Mul-timedia Content Description Interface", for the description of multimedia data11. However, little description is about
3D models. The need of developing efficient techniques for content-based 3D model retrieval is increasing.
To search 3D models that are visually similar to a queried model is the most intuitive way. However, most meth-ods concentrate on the similarity of geometric distributions rather than directly searching for visually similar models.
The geometric-based approach is feasible since much ap-pearance for an object is controlled by its geometry. In this paper, however, we present a novel approach that matches 3D models using their visual similarities, which are mea-sured with image differences in light fields. We take this ap-proach to better fit the goal of comparing models that appear to be similar to a human observer. The concept of the vi-sual similarity-based approach is similar to that of the image-driven simplification, proposed by Lindstrom and Turk14.
The geometry-based approach is broadly classified into two categories: shape-based and topology-based matching. The shape-based approach uses the distribution of vertices or polygons to judge the similarity between 3D models
1,2,4,5,6,7. The challenge of the shape-based approach is how to define shape descriptors, which need to be sensitive, unique, stable, efficient, and robust against similarity trans-formations of various kinds of 3D models. The topology-based approach utilizes topological structures of 3D models
c
The Eurographics Association and Blackwell Publishers 2003. Published by Blackwell Publishers, 108 Cowley Road, Oxford OX4 1JF, UK and 350 Main Street, Malden, MA 02148, USA.
D.-Y. Chen et. al / On Visual Similarity Based 3D Model Retrieval
to measure the similarity between them3. The difficulties
of the topology-based approach include automatic topology extraction from all types of 3D models, and the discrimina-tion between topologies from different categories. Each of the two approaches has its inherent merits and demerits. For example, a topology-based approach leads to high similar-ity between two identical 3D models with different gestures, whereas a shape-based approach cannot. On the other hand, a shape-based approach results in high similarity between 3D models with different connections among parts, whereas a topology-based approach cannot. For instance, both a fin-ger and the shoulder of a human model are parts of a human body. The topologies are quite different whether the finger does or does not connect to a human body, but the shapes are similar.
Most previous works of 3D model retrieval focused on defining suitable features for the matching process1∼13, and
were based on either statistical properties, such as global shape histograms, or the skeletal structures of 3D models. Osada et al. 2 proposed and analyzed a method for
com-puting shape signatures of arbitrary 3D polygonal models. The key idea is to represent the signature of a 3D model as a shape distribution, which is a histogram created from the distance between two random points on a surface for mea-suring global geometric properties. The approach is simple, fast and robust, and could be applied as a pre-classifier in a complete 3D model retrieval system.
Funkhouser et al.1proposed a practical web-based search
engine that supports queries based on 3D sketches, 2D sketches, 3D models, and/or text keywords. For 3D shape queries, a new matching algorithm that uses spherical har-monics to compute similarities is developed. It does not re-quire repair of model degeneracy or alignment of orienta-tions. In their system, a multimodal query is applied to in-crease the retrieval performance by combining features such as text and 3D shapes. It is also fast enough to retrieve from a repository of 20,000 models in less than one second.
Hilaga et al.3proposed a technique in which the similarity
between polyhedral models is accurately and automatically calculated by comparing the skeletal and topological struc-ture. The skeletal and topological structure decomposes a 3D model to a one-dimensional graph structure. The graph is in-variant to similarity transformations, robust against simplifi-cation and deformation caused by changing posture of an articulated object, etc. In their experimental results, the av-erage search time from 230 3D models is about 12 seconds with a Pentium II 400MHz processor. Another 3D model retrieval system10, having 445 models in the database, is
extended from the work of Hilaga et al., and takes about 12 seconds on a server with Pentium IV 2.4 GHz processor.
In this paper, a novel visual similarity-based approach for 3D model retrieval is proposed, and the system is also available on the web for practical trial use. The proposed approach is robust against similarity transformations, noise
and model degeneracy, etc. There are more than 10,000 3D models in our database, and a user-friendly interface is pro-vided for 3D model retrieval by drawing 2D shapes, which are taken as one or more projection views.
In general, a retrieval system contains off-line feature ex-traction and on-line retrieval processes. We introduce the
LightField Descriptor to represent 3D models, which is
de-tailed in Section 2, as well as the feature extraction. In Sec-tion 3, comparing 3D models is represented for the on-line retrieval process. The experimental results and the perfor-mance evaluations are shown in Section 4. Section 5 con-cludes the write up.
2. Feature Extraction for Representing 3D Models The proposed descriptor used for comparing the similarity among 3D models is extracted from 4D light fields, which are representations of a 3D object. The phrase light field de-scribes the radiometric properties of light in a space and was coined by Gershun23. A light field (or plenoptic function)
is traditionally used in image-based rendering and is defined as a five dimensional function that represents the radiance at a given 3D point in a given direction24,25. For a 3D model, the representation is the same along a ray, so the dimension of the light field around an object can be reduced to 4D25,14. Each 4D light field of a 3D model is represented by a col-lection of 2D images, which are rendered from a 2D array of cameras. The camera positions of one light field can be put either on a flat surface25 or on a sphere14 in the 3D
world. The light field representation has not only been used in image-based rendering, but also in image-driven simplifi-cation by Lindstrom and Turk14, whose approach uses
im-ages to decide which portions of a model to simplify. In this paper, we extract features from the light fields ren-dered from cameras on a sphere. The main idea of using the approach to get the similarity between two models is intro-duced in Section 2.1. To reduce size of the features and speed up the matching process, the cameras of the light fields are distributed uniformly and positioned on vertices of a regular dodecahedron. We name the descriptor LightField
Descrip-tor, and describe it in Section 2.2. In Section 2.3, we show
that one 3D model is represented by a set of LightField
De-scriptors in order to improve the robustness against rotations
while comparing between two models. One that is also im-portant is the image metric used, and is detailed in Section 2.4. Finally, the flow chart of extracting the LightField
De-scriptors for a 3D model is summarized in Section 2.5.
2.1. Measuring similarity between two 3D models The main idea comes from the following statement, "If two 3D models are similar, they also look similar from all view-ing angles." Accordview-ingly, the similarity between two 3D models can be measured by summing up the similarity from all corresponding images of a light field. However, what
c
D.-Y. Chen et. al / On Visual Similarity Based 3D Model Retrieval
Figure 1: The main idea measuring similarity between two
3D models
must be considered is the transformation, including trans-lation, rotation and scaling. The translation and the scaling problems are discussed in Section 2.5 and ignored by our image metric described in Section 2.4. As for rotation, the key to this problem is visual similarity. The camera system surrounding each model is rotated until the highest overall similarity (cross-correlation) between the two models from all viewing angles is reached. Take Figure 1 as an example, where (a) and (c) are two different airplanes with inconsis-tent rotations. First, for the airplane in Figure 1 (a), we place the cameras of a light field on a sphere, as shown in Figure 1 (b), where cameras are put on the intersection points of the sphere. Then, cameras of this light field can be applied, at the same positions, to the airplane in Figure 1 (c), as shown in Figure 1 (d). By summing up the similarities of all pairs of corresponding images in Figure 1 (b) and (d), the over-all similarity between the two 3D models is obtained. Next, the camera system in Figure 1 (d) can be rotated to a differ-ent oridiffer-entation, such as Figure 1 (e), which leads to another similarity value between the two models. After evaluating similarity values, the correct corresponding orientation, in which the two models look most similar from all correspond-ing viewcorrespond-ing angles, can be found, such as Figure 1 (f). The similarity between the two models is defined as summing up the similarity from all corresponding images between Figure 1 (b) and (f).
However, the computation will be very complicated and impractical to a 3D model retrieval system using current pro-cessors. Therefore, the camera positions of a light field are distributed uniformly on vertices of a regular dodecahedron, such that reduced camera positions are used for approxima-tion.
2.2. A LightField Descriptor for 3D models
To reduce the retrieval time and the size of features, the light field cameras can be put on 20 vertices of a regular dodec-ahedron. That is, there are 20 different views, which are distributed uniformly, over a 3D model. The 20 views can
Figure 2: A typical example of the 10 silhouettes for a 3D
model
roughly represent the shape of a 3D model, as been applied similarly in previous works. Huber and Hubert27proposed
an automatic registration algorithm, which is able to recon-struct real world objects from 15 to 20 various viewpoints from a laser scanner. Lindstrom and Turk14also employ the
20 views in comparing 3D models for image-driven simpli-fication.
Since their applications are different from the retrieval system, the requirements of rendering image and the im-age metric used are also different. First, lighting is different while rendering images of an object. We turn all lights off, so that the rendered images will be silhouettes only, which enhance the efficiency and the robustness of image metric. Second, orthogonal projection is applied in order to speed up the retrieval process and reduce the size of features. There-fore, ten different silhouettes are produced for a 3D model, since the silhouettes projected from two opposite vertices on the dodecahedron are identical. Figure 2 shows a typical ex-ample of the 10 silhouettes of a 3D model. In our implemen-tation, the rendered image size is 256 by 256 pixels. Conse-quently, the rendering process can filter out high-frequency noise of 3D models, and also make our approach reliable from degeneracy of meshes, such as those missing, wrongly-oriented, intersecting, disjoint and overlapping polygons.
Since the cameras are placed on the vertices of a fixed regular dodecahedron, we need to rotate the camera system 60 times (to be explained below), so that the cameras can be switched onto different vertices, while measuring the simi-larity between descriptors of two 3D models. The dissimi-larity, DA, between two 3D models is defined as:
DA = min i 10
∑
k=1 d (I1k,I2k) , i = 1..60 (1)where d denotes the dissimilarity between two images, de-fined in Section 3.1, and i denotes different rotations be-tween camera positions of two 3D models. For a regular do-decahedron, each of the 20 vertices is connected by 3 edges, which results in 60 different rotations for one camera system (mirror mapping is not available). I1kand I2kare correspond-ing images under i-th rotation.
Here is a typical example to explain our approach. There are two 3D models, a pig and a cow, in Figure 3 (a), both
c
D.-Y. Chen et. al / On Visual Similarity Based 3D Model Retrieval
Figure 3: Comparing LightField Descriptors between two 3D models
rotated randomly. First, 20 images are rendered from ver-tices of a dodecahedron for both the 3D model. As shown in Figure 3 (b), we compare all the corresponding 2D images from the same viewing angles, such as, the order 1∼5 be-tween pig and cow model. Thus we get a similarity value un-der this rotation of camera system. Then, we map the orun-der 1∼5 differently as in Figure 3 (d), and get another similarity value. After repeating this process, we find a rotation of cam-era positions with the best similarity (cross-correlation being highest), as shown in Figure 3 (d). Therefore, the similarity between the two models is the summation of the similarities among all the corresponding images.
Consequently, the LightField Descriptor is defined as the basis representation of a 3D model, and is defined as features of 10 images rendered from vertices of dodecahedron over a hemisphere. A LightField Descriptor somehow eliminates the rotation problem, but this is not exact enough. Therefore, a set of light fields is applied to improve the robustness. 2.3. A set of LightField Descriptors for a 3D model To be robust against rotations among 3D models, a set of
LightField Descriptors is applied to each 3D model. If there
are N LightField Descriptors, which are created from dif-ferent camera system orientations for both 3D models, there are (N × (N − 1) + 1) × 60 different rotations between the two models. Therefore, the dissimilarity, DB, between two 3D models is then defined as:
DB = min DA(Lj,Lk), j,k = 1..N (2) where DAis defined in Equation (1), and Ljand Lkare light field descriptors of two models, respectively.
The relationship of the N light fields needs to be care-fully set to ensure that all the cameras are distributed uni-formly and able to cover different viewing angles to solve the rotation problem effectively. The approach of generat-ing the evenly distributgenerat-ing camera positions of the N light fields comes from the idea in relaxation of random points proposed by Turk15. The process can be pre-processed, and
then all 3D models use the same distributed light fields to generate corresponding descriptors. In our implementation, we set N = 10, as shown in Figure 4, that is, the similar-ity between two 3D models is obtained from the best one of 5,460 different rotations. Therefore, the average maximum error of rotation angle between two 3D models is about 3.4 degree in longitude and latitude. That is:
180◦
x ×
360◦
x = 5460 ⇒ x ∼= 3.4◦ (3)
which is small enough for our 3D model retrieval system according to our experimental results. Of course, the number
Figure 4: A set of LightField Descriptors for a 3D model
c
D.-Y. Chen et. al / On Visual Similarity Based 3D Model Retrieval N can be bigger than 10, and we will evaluate in the future
the saturation effect when N becomes bigger. 2.4. Image metric
An image metric is a function measuring the distance be-tween two images. Recently, Content-Based Image Retrieval (CBIR) has become a popular research, and different image metrics have been proposed19∼22. Many approaches of
im-age metrics are robust against transformations such as trans-lation, rotation, scaling, and image distortion.
One of the important features of images is the shape de-scriptor, which can be broadly classified into region-based and contour-based descriptor. The use of a combination of different shape descriptors has been proposed recently in or-der to improve the retrieval performance21,22. In this paper, we adopt an integrated approach proposed by Zhang and Lu
21, which combines a region shape descriptor (Zernike
mo-ments descriptor) and a contour shape descriptor (Fourier descriptor). The Zernike moment descriptor is also used in MPEG-7, which is named RegionShape descriptor11.
Dif-ferent shape signatures have been used to derive Fourier de-scriptor, and the retrieval using Fourier Descriptors derived from the centroid distance has significantly higher perfor-mance than those of the other methods. These were also compared by Zhang and Lu20. The centroid distance
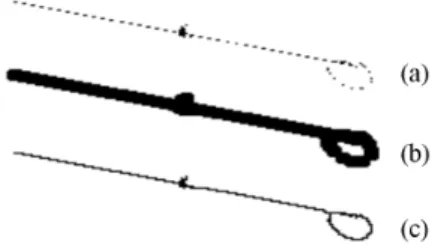
func-tion is expressed by the distance to boundary points from the centroid of the shape. The boundary points of a shape are extracted through a contour tracing algorithm, proposed by Pavlidis31. Figure 5 shows a typical example of the
cen-troid distance. Figure 5 (a) shows a 2D shape rendered from a viewpoint of a 3D model, and the contour tracing result is shown in Figure 5 (b). Figure 5 (c) shows the centroid dis-tance of (a).
Sometimes, however, a 3D model might be rendered into several separated 2D shapes, as shown in Figure 6 (a). When this situation occurs, the following two stages are applied to connect. First, we apply Erosion operation32 from one
to several times to connect the separated parts, as shown in Figure 6 (b). Second, a thinning algorithm32is applied in
order to connect the separated parts, as shown in Figure 6 (c). Note that the pixels of rendered 2D shape cannot be re-moved during the thinning algorithm. The separated parts are then connected, and the high-frequency noise will be fil-tered out by the Fourier descriptor. But if there are still sep-arated parts after running the Erosion operation for several times, a bounding box algorithm will replace the first stage above.
There are 35 coefficients for Zernike moment descriptor and 10 coefficients for Fourier descriptor. Each coefficient is quantized to 8 bits in order to reduce the size of descrip-tors and accelerate the retrieval process. Consequently, the approach is robust against translation, rotation, scaling and image distortion, and is very efficient.
Figure 5: A typical example of the centroid distance for a
2D shape
Figure 6: Connection of different parts of 2D shapes
2.5. Steps of extracting LightField Descriptors for a 3D model
The steps of extracting the LightField Descriptors for a 3D model are summarized in the following.
(1) Translation and scaling are applied first to ensure that 3D model is entirely contained in rendered images. The in-put 3D model is translated from the center of the model to the origin of world coordinate system. The axis is then scaled such that the maximum length is 1.
(2) Render images from the camera positions of light fields, as described in Section 2.3.
(3) For a LightField Descriptor, 10 images are represented for 20 viewpoints, and are in a pre-defined order for storage. For a 3D model, 10 descriptors are created, so that totally 100 images should be rendered.
(4) Descriptors for a 3D model are extracted from the 100 images, as in Section 2.4.
3. Retrieval of 3D Models Using LightField Descriptors In the off-line process mentioned in last section, the
Light-Field Descriptors of each 3D model in the database are
calculated and stored for 3D model retrieval. This section details the on-line retrieving process, which compares the descriptors of the queried one with all the other 3D mod-els in the database. Comparing the LightField Descriptors within two models is described in Section 3.1. Those who are greatly dissimilar to the queried model will be rejected early in the process, detailed in Section 3.2, which accelerates the retrieval with a large database. Practically, when a user wants to retrieve 3D models, he/she can upload a 3D model as a query key. However, early experiences of Funkhouser et al.
1suggest that even a simple gesture interface, such as Teddy c
D.-Y. Chen et. al / On Visual Similarity Based 3D Model Retrieval
system26, is still too hard for novice and casual users to learn
quickly. They proposed that drawing 2D shapes with a paint-ing program to retrieve 3D models is intuitive for users. In this paper, a user-friendly drawing interface for 3D model retrieval is also provided. The approach of comparing 2D shapes with 3D models is described in Section 3.3. 3.1. Similarity between LightField Descriptors of two 3D
models
The retrieving process can be referred as calculating the sim-ilarity one by one between the queried one and each of the models in the database and showing those similar to the queried one. The similarity between two models is defined as summing up the similarity from all the corresponding im-ages, as described in Section 2.3. The comparison of two descriptors is as Equation (2). When comparing the dissimi-larity, d, of corresponding images, we use simple L1 distance to measure:
d (J,K ) =
∑
i|C1i−C2i| (4)
where C1 and C2 denote coefficients of two images, and i denotes the index of their coefficients. There are 45 coeffi-cients for each image, each quantized to 8 bits. To simplify the computation, a table is created and stored for the value of L1 distance from 0 to 255. Thus, a table-look-up method is used to speed up the retrieval process.
3.2. Retrieval of 3D models from database with large number of models
For a 3D model retrieval system, a database with a large number of models should be considered. For example, there are over 10,000 3D models in our database. To efficiently retrieve 3D models from an enormous database, an iterative early-jump-out method is applied in our 3D model retrieval system. First, when comparing the queried model with all the others, only parts of the images and coefficients are used. This can remove almost half of the models. The threshold of removing models is set as the mean of the similarity rather than the median, since the calculation of the mean is simpler. Then, compare the queried model to the remainder models using more images and coefficients. Repeat the above steps in several times. All iterations are detailed as follows.
(1) In the initial stage, all 3D models in the database are compared with the queried one. Two LightField Descriptors of the queried model are compared with ten of those in the database. Three images of each light field are compared, and each image is compared using 8 coefficients of Zernike mo-ment. Each coefficient is quantized to 4 bits.
(2) In the second stage, five LightField Descriptors of the queried model are compared to ten of the others in the
database. Five images of each light field are compared, and each image is compared using 16 coefficients of Zernike mo-ment. Each coefficient is quantized to 4 bits.
(3) Thirdly, seven LightField Descriptors of queried model are compared with ten of the others in the database. The other is the same as the second stage, while another five images of each light field are compared.
(4) The fourth stage is the same as full comparison, but only the Zernike moment coefficients, quantized to 4 bits, are used. In addition, the top 16 of the 5,460 rotations are recorded between the queried one and others.
(5) Each coefficient of Zernike moment is quantized to 8 bits, and the retrieval uses the top 16 rotations, recorded from the 4thstage, rather than 5,460 rotations.
(6) In the last stage, each coefficient of Fourier descriptor is added to the retrieval.
The approach speeds up the retrieval process by early re-jection of non-relevant models. The query performance and robustness of each step will be evaluated in the future. 3.3. A user friendly interface to retrieve 3D models
from 2D shapes
Creating a queried model for retrieval is not easy and fast for general users. Thus, a user-friendly interface, a painting program, is provided in our system. Furthermore, users can again utilize the retrieved model to find more specific 3D models, since 2D shapes carry less information than a 3D model. To sum up, our 3D model retrieval system is easy for a novice user.
Recognizing 3D objects from single 2D shape is an inter-esting and difficult problem, and has been researched long time ago. Dudani et al.16identified aircrafts with moment
invariants derived from the boundary of 2D shapes. They captured 2D images of 3D objects from every 5 degrees of azimuth and roll angle. 3,000 images for 6 aircrafts are used for comparison with an input 2D shape. A 3D aircraft recog-nition algorithm of Wallace and Wintz17 used 143
projec-tions to represent an aircraft over the hemisphere, and per-formed the recognition using normalized Fourier descriptors of the 2D shape boundary. Cyr and Kimia18proposed 3D
object recognition by generating "equivalent view" from dif-ferent positions on the equator for 65 3D objects. They rec-ognized an unknown 2D shape by comparing all views of 3D objects using shock matching, which takes about 5 min-utes. Recently, Funkhouser et al.1proposed a search engine
for 3D models, which also provides a 2D drawing interface for 3D model retrieval. The boundary contours are rendered from 13 viewpoints for each 3D model, and then additional 13 shape descriptors are created. In our 3D model retrieval system, it is intuitive and direct to compare 2D shapes with 3D models, since the descriptors for 3D models are com-posed of features of 100 2D shapes over the hemisphere, as
c
D.-Y. Chen et. al / On Visual Similarity Based 3D Model Retrieval
Figure 7: Retrieval results from user drawn 2D shapes
described in Section 2.3. The image metric we used is de-fined in Section 2.4.
4. Experimental Results
In Section 4.1, the proposed 3D model retrieval system is demonstrated. The performance and robustness of the ap-proach are evaluated in Section 4.2 and 4.3, respectively. 4.1. The proposed 3D model retrieval system
The 3D model retrieval system is on the following web site for practical trial use: http://3d.csie.ntu.edu.tw. There are 10,911 3D models in our database now, all free downloaded via the Internet. Users can query with a 3D model or draw-ing 2D shapes, and then search interactively and iteratively for more specific 3D models using the first retrieved results. Models are available for downloading from the hyperlink of their original downloaded path listed in the retrieval results. Figure 7 shows a typical example of a query with 2D draw-ing shapes, and Figure 8 shows the interactive search by se-lecting a 3D model from Figure 7.
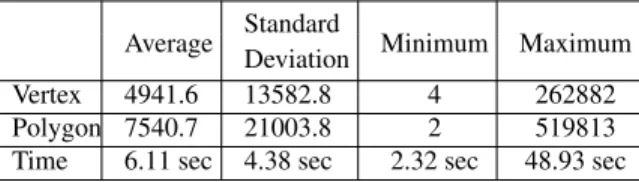
The system consists of off-line feature extraction in pre-processing and on-line retrieval processes. In the off-line process, the features are extracted in a PC with a Pentium III 800MHz CPU and GeForce2 MX video card. On the av-erage, each 3D model with 7,540 polygons takes 6.1 seconds to extract features, detailed in Table 1. Furthermore, the av-erage time of rendering and feature extraction for a 2D shape takes 0.06 seconds. Extracting features are suitable for both 3D model and 2D shape matching. No extra effort should be done for 2D shapes. In the on-line process, the retrieval is done in a PC with two Pentium IV 2.4GHz CPUs. Only one CPU is used for the query at one time, and the retrieval takes 2 and 0.1 seconds with a 3D model and two 2D shapes as the query keys, respectively.
Figure 8: Retrieval results from interactively searching of
selecting a 3D model from Figure 7
4.2. Performance Evaluation
Traditionally, the diagram of "Precision" vs "Recall" is a common way of evaluating performance in documental and visual information retrieval. Recall measures the ability of the system to retrieve all models that are relevant. Precision measures that the ability of the system to retrieve only mod-els that are relevant. They are defined as:
Recall = relevant correctly retrieved all relevant Precise = relevant correctly retrieved
all retrieved
In general, the recall and precision diagram requires a ground truth database to assess the relevance of models with a set of significant queries. Test sets are usually large, but only a small fraction of the relevant models are included30.
Therefore, a test database with 1,833 3D models is used for evaluation. The test database contains free 3D models from 3DCafe34, downloaded in Dec. 2001, but removes several
models with failed formats in decoding. One student inde-pendent of this research, regarded as a human evaluator, clas-sified the models according to functional similarities. The test database was clustered into 47 classes including 549 3D
Standard
Average Deviation Minimum Maximum
Vertex 4941.6 13582.8 4 262882
Polygon 7540.7 21003.8 2 519813
Time 6.11 sec 4.38 sec 2.32 sec 48.93 sec Table 1: Vertex and polygon number of the 10,911 3D
mod-els and the feature extraction time from a PC with a Pentium III 800 MHz CPU
c
D.-Y. Chen et. al / On Visual Similarity Based 3D Model Retrieval
Figure 9: Performance evaluation of our approach, Light-Field Descriptor, and those of others.
models mainly for vehicle and household items (such as cat-egories of airplane, car, chair, table, etc.), and all the other 1,284 models are classified as "miscellaneous".
To compare the performance with others systems, three major previous works are implemented as follows:
(1) 3D Harmonics: This approach is proposed by Funkhouser et al.1, and outperforms many other approaches,
such as Moments 12, Extended Gaussian Images 8, Shape
Histograms9and D2 Shape Distributions2, which are
eval-uated in their paper. The source code of SpharmonicKit 2.5
35, also used in their implementation, is used for computing
the spherical harmonics.
(2) Shape 3D Descriptor: The approach is used in MPEG-7 international standard11, and represents a 3D model with
curvature histograms.
(3) Multiple View Descriptor: This method aligns 3D ob-jects with Principal Component Analysis (PCA)33, and then
compares images from the primary, secondary and tertiary viewing directions of principal axes. Descriptor of the view-ing directions is also recorded in MPEG-7 international stan-dard11, but does not limit the usage of image metrics. To get
better performance, integration with different image metrics described in Section 2.4 are used. Furthermore, for calcu-lating PCA correctly from vertices, each 3D model is re-sampled first to ensure that vertices are distributed evenly on the surface.
Figure 9 shows the comparison of the retrieval perfor-mance of our approach, LightField Descriptors, with those of the others. Each curve plots the graph of "recall and pre-cision" averaged over all 549 classified models in the test database. Obviously, LightField Descriptor performs better than the others. The precision values are 42%, 94% and 25% higher than those of 3D Harmonics, Shape 3D Descriptor and Multiple View Descriptor, respectively, after comparing and averaging over all the "recall" axis.
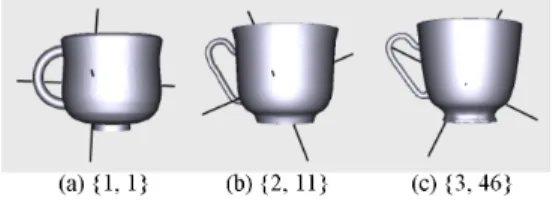
Figure 10: Three similar cups with their principal axes,
ori-enting the models in different directions. Retrieval results of querying are done by the model in (a). The first number in bracket shows the queried number by our method, and the second number shows the Multiple View Descriptor.
However, in our implementation of 3D Harmonics, the precision is not as good as that indicated in the original pa-per1, shown in Table 2. Evaluating by different test database
is one possible reason, and another one may lie in a small amount of different details between our implementation and original paper, even if we try to implement the same as the original paper. The test database used in the original paper is also purchased by us, and will be evaluated in the future. As for PCA applied to Multiple View Descriptor, Funkhouser et al.1found that principal axes are not good while
align-ing orientations of different models within the same class, and also demonstrated this problem using 3 mugs. Retrieval with similar examples in our test database is shown in Figure 10. Clearly, our approach works well against this particular problem of PCA.
4.3. Robustness evaluation
All the classified 3D models in the test database are applied to the following evaluation in order to assess the robustness. Each transformed 3D model is then used for queries from the test database. The average recall and precision of all 549 classified models are used for the evaluation. The robustness is evaluated by the following transformation:
(1) Similarity transformation: For each 3D model, seven random numbers are applied to x-, y-, and z-axis rotations (from 0 to 360 degree), x-, y- and z-axis translations (-10∼+10 times of the length of the model’s bounding box), and scaling (a factor of -10∼+10).
(2) Noise: Each vertex of 3D model is applied three
ran-Recall 0.2 0.3 0.4 0.5 0.6 0.7 Our approach 0.51 0.42 0.36 0.30 0.25 0.20 3D Harmonics 0.37 0.27 0.22 0.18 0.16 0.14 3D Harmonics with different 0.41 0.33 0.26 0.20 0.17 0.14 test database1
Table 2: Precision of 3D Harmonics in the original paper
for comparison. c
D.-Y. Chen et. al / On Visual Similarity Based 3D Model Retrieval
Figure 11: Robustness evaluation of (b) noise and (c)
deci-mation from (a) original 3D model
dom number to x-, y- and z-axis translation (-3%∼+3% times of the length of the model’s bounding box). Figure 11 (b) shows a typical example of the effect.
(3) Decimation: For each 3D model, randomly select 20% polygons to be deleted. Figure 11 (c) shows a typical exam-ple of the effect.
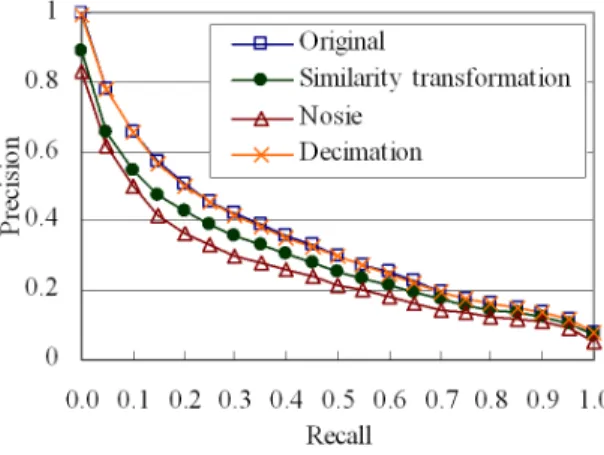
Experimental result of the robustness evaluation is shown in Figure 12. Clearly, our approach is robust against similar-ity transformation, noise and decimation.
5. Conclusion and Future Works
In this paper, a 3D model retrieval system is proposed based on visual similarity. The new metric based on a set of
Light-Field Descriptors is proposed for matching among 3D
mod-els. The visual similarity-based approach is robust against translation, rotation, scaling, noise, decimation and model degeneracy etc. A practical retrieval system that includes more than 10,000 3D models is available on the web for ex-pert and novice users, and the retrieval can be done in less than 2 seconds on a server with Pentium IV 2.4 GHz CPU. A friendly user interface is also provided to query by drawing 2D shapes. The experimental results demonstrate that our approach outperforms 3D Harmonics, MPEG-7 Shape 3D Descriptor and Multiple View Descriptor.
In future work, several investigations are described as fol-lows. First, other image metric for 2D shapes matching may be evaluated and included to improve the performance. In addition, the image metric for color and texture11can also
be included to retrieval 3D model using more visual features. Second, different approaches ("cocktail" approach) can be combined to improve the overall performance. Third, the mechanism of training data or active learning12,13may be used to adjust the weighting among different features. Fi-nally, partial matching from several objects takes a long time to compute in general, and is also an important and difficult research direction in the future work28,29.
Acknowledgements
We would like to thank Miss Wan-Chi Luo, a graduate stu-dent, to help us manually classify the 1833 3DCafe objects into 47 classes plus another class "miscellaneous". We also appreciate Jeng-Sheng Yeh to set up the web server for our
Figure 12: Robustness evaluation of similarity
transforma-tion, noise and decimation
3D model retrieval system. This project is partially funded by the National Science Council (NSC, Taiwan) under the grant number NSC91-2622-E-002-040 and by the Ministry of Education under the grant number 89-E-FA06-2-4-8. References
1. T. Funkhouser, P. Min, M. Kazhdan, J. Chen, A. Halder-man, D. Dobkin and D. Jacobs, "A Search Engine for 3D Models", ACM Transactions on Graphics, 22(1):83-105, Jan. 2003.
2. R. Osada, T. Funkhouser, B. Chazelle and D. Dobkin, "Shape Distributions", ACM Transactions on Graphics, 21(4):807-832, Oct. 2002.
3. M. Hilaga, Y. Shinagawa, T. Kohmura and T. L. Ku-nii, "Topology Matching for Fully Automatic Similarity Estimation of 3D Shapes", Proc. of ACM SIGGRAPH, 203-212, Los Angeles, USA, Aug. 2001.
4. E. Paquet, M. Rioux, A. Murching, T. Naveen and A. Tabatabai, "Description of Shape Information for 2-D and 3-D Objects", Signal Processing: Image
Commu-nication,16:103-122, Sept. 2000.
5. R. Ohbuchi, T. Otagiri, M. Ibato and T. Takei, "Shape-Similarity Search of Three-Dimensional Models Using Parameterized Statistics", Proc. of 10th Pacific
Graph-ics, 265-273, Beijing, China, Oct. 2002.
6. D. V. Vranic and D. Saupe, "Description of 3D-Shape using a Complex Function on the Sphere", Proc. of
IEEE International Conference on Multimedia and Expo (ICME), 177-180, Lausanne, Switzerland, Aug.
2002.
7. I. Kolonias, D. Tzovaras, S. Malassiotis and M. G. Strintzis, "Fast Content-Based Search of VRML Mod-els based on Shape Descriptions", Proc. of
Interna-c
D.-Y. Chen et. al / On Visual Similarity Based 3D Model Retrieval tional Conference on Image Processing (ICIP),
133-136, Thessaloniki, Greece, Oct. 2001.
8. B. K.P. Horn, "Extended Gaussian Images",
Proceed-ings of the IEEE,72(12):1671-1686, 1984.
9. M. Ankerst, G. Kastenmuller, H.-P. Kriegel and T. Seidl, "3D Shape Histograms for Similarity Search and Classification in Spatial Databases", Proc. of 6th
Inter-national Symposium on Advances in Spatial Databases (SSD), Hong Kong, China, 207-228, 1999.
10. D.-Y. Chen and M. Ouhyoung, "A 3D Object Retrieval System Based on Multi-Resolution Reeb Graph", Proc.
of Computer Graphics Workshop, 16, Tainan, Taiwan,
June 2002.
11. S. Jeannin, L. Cieplinski, J. R. Ohm and M. Kim,
MPEG-7 Visual part of eXperimentation Model Ver-sion 7.0, ISO/IEC JTC1/SC29/WG11/N3521, Beijing,
China, July 2000.
12. M. Elad, A. Tal, and S. Ar. "Content Based Retrieval of VRML Objects - An Iterative and Interactive Ap-proach", Proc. of 6th Eurographics Workshop on
Mul-timedia, 97-108, Manchester UK, Sept. 2001.
13. C. Zhang and T. Chen, "An Active Learning Frame-work for Content-Based Information Retrieval", IEEE
Transactions on Multimedia Special Issue on Multime-dia Database,4(2):260-268, June 2002.
14. P. Lindstrom and G. Turk, "Image-Driven Simplifica-tion ", ACM TransacSimplifica-tions on Graphics,19(3):204-241, July 2000.
15. G. Turk, "Generating Textures on Arbitrary Surfaces Using Reaction-Diffusion", Computer Graphics (Proc.
of ACM SIGGRAPH),25(4):289-298, July 1991. 16. S. A. Dudani, K. J. Breeding and R. B. McGhee,
"Aircraft Identification by Moment Invariants", IEEE
Transactions on Computers,C-26(1):39-46, Jan. 1977. 17. T. P. Wallace and P. A. Wintz, "An Efficient Three-Dimensional Aircraft Recognition Algorithm Using Normalized Fourier Descriptors", Computer Graphics
and Image Processing,13:99-126, 1980.
18. C. M. Cyr, B. B. Kimia, "3D Object Recognition Using Shape Similarity-Based Aspect Graph", Proc. of
Inter-national Conference on Computer Vision (ICCV),
254-261, Vancouver, Canada, July 2001.
19. C. E. Jacobs, A. Finkelstein, D. H. Salesin, "Fast Multiresolution Image Querying", Proc. of ACM
SIG-GRAPH, 277-286, Los Angeles, USA, Aug. 1995.
20. D. S. Zhang and G. Lu. "A comparative Study of Fourier Descriptors for Shape Representation and Re-trieval". Proc. of 5th Asian Conference on Computer
Vision (ACCV), 652-657, Melbourne, Australia, Jan.
2002.
21. D. S. Zhang and G. Lu. "An Integrated Approach to Shape Based Image Retrieval". Proc. of 5th Asian
Con-ference on Computer Vision (ACCV), 652-657,
Mel-bourne, Australia, Jan. 2002.
22. D. Heesch and S. Ruger, "Combining Features for Content-Based Sketch Retrieval - A Comparative Eval-uation of Retrieval Performance", Proc. of 24th
BCS-IRSG European Colloquium on IR Research Glasgow (LNCS 2291), UK, Mar. 2002
23. A. Gershun, "The Light Field", Moscow, 1936. Trans-lated by P. Moon and G. Timoshenko in Journal of
Mathematics and Physics,18:51-151, MIT, 1939. 24. L. McMillan and G. Bishop, "Plenoptic Modeling: An
Image-Based Rendering System", Proc. of ACM
SIG-GRAPH, 39-46, Los Angeles, USA, Aug. 1995.
25. M. Levoy and P. Hanrahan, "Light Field Rendering",
Proc. of ACM SIGGRAPH, 31-42, New Orleans, USA,
Aug. 1996.
26. T. Igarashi, S. Matsuoka and H. Tanaka, "Teddy: A Sketching Interface for 3D Freeform Design", Proc. of
ACM SIGGRAPH, 409-416, Los Angeles, USA, Aug.
1999.
27. F. Huber and M. Hebert, "Fully Automatic Registration of Multiple 3D Data Sets", Proc. of IEEE Workshop on
Computer Vision Beyond the Visible Spectrum: Meth-ods and Applications (CVBVS), Kauai, Hawaii, USA,
Dec. 2001.
28. A. E. Johnson and M. Hebert, "Using Spin Images for Efficient Object Recognition in Cluttered 3D Scenes",
IEEE Transactions on Pattern Analysis and Machine Intelligence,21(5):433-449, May 1999.
29. S. M. Yamany and A. A. Farag, "Surfacing Signatures: An Orientation Independent Free-Form Surface Rep-resentation Scheme for the Purpose of Objects Regis-tration and Matching", IEEE Transactions on Pattern
Analysis and Machine Intelligence,24(8):1105-1120, Aug. 2002.
30. A. E. Bimbo, Visual Information Retrieval, Morgan Kaufmann Publishers, Inc., 1999.
31. T. Pavlidis, Algorithms for Graphics and Image
Pro-cessing, Computer Science Press, 1982.
32. R. M. Haralick and L. G. Shapiro, Computer and Robot
Vision, Addison-Wesley Pub. Co., 1992.
33. I. T. Jolliffe, Principal Component Analysis, 2nd edi-tion, Springer, 2002.
34. 3DCAFE, http://www.3dcafe.com
35. SpharmonicKit 2.5: Fast spherical transforms. http://www.cs.dartmouth.edu/∼geelong/sphere/
c