A Monte Carlo Method for Estimating the Extended All-terminal Reliability
Shiang-Ming Huang
1, Quincy Wu
2and Shi-Chun Tsai
1 1Department of Computer Science, National Chiao Tung University
{smhuang,sctsai}@csie.nctu.edu.tw
2
Graduate Institute of Communication Engineering,
National Chi Nan University
[email protected]
Abstract
Designing a network with optimal deployment cost and maximum reliability considerations is a hard problem, especially when the all-terminal reliability is required. For efficiently finding out an acceptable solution, Genetic Algorithms (GAs) have been widely applied to solve this problem. In these GAs, the reliability values could be calculated in their objective functions. In year 2002, an extended network reliability model was proposed which considers the connection important level between each pair of nodes. This paper proposes an approximation algorithm based on Monte Carlo simulation for the new network reliability model. This approximation algorithm can be integrated into GAs to solve the optimal cost reliable network design problem under the extended model.
1. Introduction
Reliability and cost are two important considerations for designing communications networks, such as backbone telecommunications networks, wide area networks and data communications networks located in industrial facilities [1]. Based on the reliability and cost considerations, the design goal of a communications network is either to increase network reliability or to decrease deployment cost. However, increasing reliability needs to add redundancy to the network while optimizing cost needs to remove any extra redundancy from the network. It is not easy to find out a saddle point that compromises both maximum reliability and optimal cost considerations at the same time.
To find out an acceptable solution that meets both the reliability and cost considerations, the above network design problem can be transformed into a simpler problem that is to either maximize the
reliability given a maximum cost constraint, or to
minimize the cost given a minimum reliability constraint. Both these two problems are NP-hard [2], which means these problems are unlikely to be solved within polynomial time, and all the existing algorithms require huge computational effort that will increase exponentially as the network size increases.
Several genetic algorithms (GAs) [2,3,4,5] have been proposed for minimizing the topology deployment cost under a given reliability constraint. In these GAs, a communications network is modeled as an undirected probability graph g = G(N, L, p) where N is a set of nodes (e.g., computer sites), L is a set of links (e.g., communication connections), and p is the connection (link) failure probability (0
≤
p≤
1). The GAs encode each of the possible network topologies into a bit-string as a ‘gene’, and then perform GA operations on these genes for cost optimization.A typical execution flow of the GAs is illustrated in Fig. 1 where the population pool (Fig. 1 ○A) stores many encoded genes. From the population pool, several genes are selected as parents (Fig. 1 ○B) for generating the offspring (Fig. 1 ○C). The offspring are also genes that are recombined (Fig. 1 ○2) and mutated (Fig. 1 ○3 ) from the parent genes. These offspring return to the population pool after a survival selection (Fig. 1 ○4). The above process (Fig. 1 ○1, ○2, ○3 and ○4) repeats for a predetermined number of rounds, or until the optimization requirement is reached, depending on which one happens earlier. Both the cost and the reliability could be calculated in the GA objective function that is a scoring system that calculates evolutionary fitness of a gene for the parent selection and survival selection functions (Fig. 1 ○1 and ○4).
A B C 1 4 3 2
Figure 1:A typical execution flow of GAs. The network design problem is especially difficult when considering all-terminal network reliability that is defined as the probability that every pair of nodes can communicate with each other. The all-terminal reliability is difficult because it is also NP-hard [6]. To efficiently estimate the all-terminal network reliability, cut set count [7] and Monte Carlo simulation [8] are widely used in the GAs. These approximation methods ensure the all-terminal reliability to be calculated in polynomial time. Otherwise, the fitness calculation for each gene would be an NP-hard problem and thus the overall calculation of the GAs would not be practical.
In year 2002, Feng et al. proposed an extended network reliability model [9], which extended the original model [1] with a weighting on each pair of nodes. It is more meaningful than the basic model under link failure. Unfortunately, according to our best understanding, no approximation algorithm has been proposed for it. In this paper, we propose an approximation algorithm based on Monte Carlo simulation for the extended network reliability model.
This paper is organized as follows. Section 2 describes the basic network reliability model (the calculation is NP-hard), and introduces two approximation methods for reliability estimation. Also, the extended network reliability model (the calculation is harder than the basic model) is described in this section. In Section 3, we propose an approximation algorithm for the extended reliability model and then prove its correctness. Section 4 demonstrates the proposed algorithm by a numerical example. Finally, Section 5 concludes this paper.
2. Previous works
A network is a set of facilities, i.e., nodes and links, where a failure probability pi is associated with each
facility i. In this network model, the nodes are assumed to be perfectly reliable and the links have independent
failure probabilities. If a network has only three nodes
a, b, c and two links (a, b) and (b, c), then the probability that both the links (a, b) and (b, c) are working is (1 - p(a, b))(1 - p(b, c)), which is also defined
as the reliability of that network.
Given a minimum network reliability constraint Rel0,
the cost optimization problem for the GAs is: Minimizing the total cost C(g) =
∑
− = 1 | | 1 N i
∑
+ = | | 1 N i j cij xijSubject to: Rel(g)
≥
Rel0. (1)Where cij is the cost of the (i, j) link, xij
∈{0, 1}
indicates whether the link (i, j) is working or not, and
Rel(g) is the reliability of the network g (0
≤
Rel(g)≤
1, 0≤
Rel0≤
1).Based on the basic network reliability measure, the all-terminal reliability Relall(g) of a network g = G(N, L,
p) is: Relall(g) =
∑
Ω ∈ s g Rel(gs) (2)Where gs = G(N, Ls, p) is a sub-network of g and
Ls
⊆
L. Ω is the set of g’s sub-networks that every pairof nodes can communicate with each other (e.g., Fig. 2 (B) and (C)). Rel(gs) is the reliability of the
sub-network gs. Each gs corresponds to a link failure
scenario of g, and the reliability of gs is:
Rel(gs) =
∏
∈working i (1- pi)∏
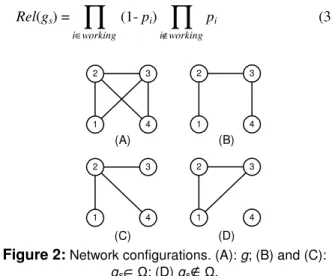
∉working i pi (3) (C) 3 1 2 4 (D) 3 1 2 4 (A) 3 1 2 4 (B) 3 1 2 4Figure 2: Network configurations. (A): g; (B) and (C):
gs
∈
Ω; (D) gs∉
Ω.The |L|-links-network g has 2|L| failure scenarios. It means to obtain Relall(g), there are at most 2|L| failure
scenarios to be examined. The time for calculating
Relall(g) grows exponentially as the number of links in
g increases. To approximate Relall(g) efficiently, cut set
count and Monte Carlo simulation are two widely used
2.1 Cut set count
The cut set count method applies Set Theory to estimate the all-terminal reliability. The basic definitions in this method are: 1) Fi is the event that all
links connected to node i failed, and 2) Fi is Fi’s
complement. Apparently, Fi is a cut set of the network
g = G(N, L, p), and the network g fails (which means some pair of nodes in this network are unable to communicate with each other) under the scenarios containing the event Fi. Since F1, F2, F3…F|N| are
collectively a subset of all the possible network failure scenarios that fail the network g, the network failure probability, i.e., 1 - Relall(g), could be written as:
1 - Relall(g)
≥
Pr[F1∪F2∪…∪F|N|] = Pr[F1] +Pr[F2∩F1] +Pr[F3∩F2∩F1] +…+Pr[F|N|∩F|N|−1∩…∩F1] = Pr[F1] +Pr[F2]Pr[F1|F2] +Pr[F3]Pr[F2∩F1|F3] +…+Pr[F|N|]Pr[F|N|−1∩…∩F1|F|N|] (4)From derivation in [7], inequality (4) could be rewritten as:
Relall(g)
≤
1 –Pr[F1] –Pr[F2]Pr[F1|F2]–Pr[F3]Pr[F2|F3]Pr[F1|F3] –…–
– Pr[F|N|] Pr[F|N|−1| F|N|]…Pr[F1| F|N|] (5)
The cut set count method could be calculated in polynomial time, which is suitable to be used in the GAs. However, sometimes the estimation derived by this method is not accurate enough for practical usage [8].
2.2. Monte Carlo simulation
For larger networks, Monte Carlo simulation is used to approximate the network reliability [10,11]. For the network g = G(N, L, p), Monte Carlo simulation randomly generates failure scenarios gs = G(N, Ls, p).
The random generation process is repeated many times to create multiple failure scenarios. Whenever a failure scenario gs is randomly generated, this gs is examined
to see if every pair of nodes can communicate with each other. After this process is repeated for several iterations, the average of all feasible solutions will give an approximation to the exact all-terminal reliability.
With T iterations, the Monte Carlo simulation algorithm for measuring the all-terminal reliability of the network g is shown in Algorithm 1.
Algorithm 1: Monte Carlo simulation.
As shown in [8], this method can approximate the all-terminal reliability more accurately than the cut set count method.
2.3. Extended reliability model
The all-terminal reliability model in Equation (2) is the summation of the probabilities that every pair of nodes remain able to communicate with each other under different network failure scenarios. According to this model, different network configurations, e.g., Fig. 2 (B) and (C) may have the same all-terminal reliability [9]. This means that the all-nodes-connected probabilities of the two networks are the same.
However, the two network configurations having the same all-nodes-connected probability does not imply that all their network failure scenarios have the same impact on them, e.g., the link failure on link (2, 3) for the network configuration in Fig. 2 (B) causes four pairs of nodes losing their connectivity, while the same link failure only disconnects three pairs of nodes in Fig. 2 (C). Because the all-terminal reliability is the summation of probabilities, it only represents the probability that every pair of nodes can communicate with each other in that network configuration. In real-life networks, different pairs of nodes have different importance to the whole network, and each pair of nodes shall have a connection importance level (CIL) [9]. If the connectivity of a node pair is more important in the network, its CIL would be higher than all other pairs of nodes in the network.
With a CIL defined on each pair of nodes, the extended all-terminal reliability of the network g is:
Rel’all(g) =
∑
Ω ∈ s g Rel(gs) +∑
Ω ∉ s g w(gs)*Rel(gs) (6) Input: A network g = G(N, L, p). Output: an approximation of Rall(g).1. Initialization: X ← 0. 2. For iteration k = 1 to T, do:
(a) Generate a random failure scenario gs
of g: for each link i in g, sample U from Uniform(0,1); if (U > pi), xi=1;
else xi=0.
(b) Use depth first search to check if every pair of nodes in gs can communicate
with each other: if true, X ← X +1. 3. Return X/T.
The Rel’all(g) includes two parts. The first part is the
fully connectivity probability (every pair of nodes can communicate with each other), which is the same as the basic model in (2). The second part is related to partial connectivity probability (not every pair of nodes can communicate with each other). gs = G(N, Ls, p) is a
failure scenario of g. Ω is the set of sub-networks that every pair of nodes can communicate with each other, and Rel(gs) is the reliability of gs. As defined in [9],
w(gs) is the weighting function as follows.
w(gs) = ∑ ∑ ) in pairs node all of CIL ( ) in connected remain pairs node the of CIL ( g gs n, for n
≥
0. (7) The extended model in (6) extends the basic model in (2), and its calculation is thus more complex than that of (2).3. Proposed approximation algorithm
To solve the all-terminal reliability network design (optimal cost) problem using GAs and adopt the extended model in (6) to calculate the reliability constraint, apparently an approximation of the extended reliability measure should be used. If we could not find an approximation algorithm to calculate the reliability constraint in polynomial time, measuring the fitness of each gene would require exponential time, and therefore makes the GAs impractical at all.As described in Section 2, the cut set count method and Monte Carlo simulation are useful for estimating the reliability of the basic model. Based on the Monte Carlo simulation for the basic reliability model, we propose an algorithm (see Algorithm 2) to approximate the extended reliability model.
In this algorithm, a network failure scenario gs is
randomly generated according to the link failure probabilities. With T iterations, (1/T)*W is an estimation for Rel’all(g), W is the summation of all the
w(gs) values generated in the T iterations. U is a
random number sampled uniformly from (0, 1) for each link i in g. Let indicator xi be a random variable
indicating whether the i-th link of g is working or not. That is
1 if U > pi (link working),
xi =
0 otherwise (link failure).
Together, the variables x1, x2,…, x|L| generate a
failure scenario gs of g, gs = G(N, Ls, p) and Ls
⊆
L.Algorithm 2: Estimation algorithm for the extended all-terminal reliability model.
We use these definitions to prove the correctness of Algorithm 2.
Lemma 1: The probability that a gs to be chosen in one
iteration is Rel(gs).
Proof: Pr[a gs is chosen]
= Pr[the variables x1, x2,…, x|L| match the link
configuration in gs] =
∏
∈working i (1- pi)∏
∉working i pi = Rel(gs). ■For a chosen gs, let Yi be an indicator random
variable with
1 if the gs is chosen in the i-th iteration,
Yi =
0 otherwise.
Because we use an independent and identical method for choosing gs in the T iterations, Y1, Y2, …, YT
are independent identically distributed (i.i.d.) random variables. By Lemma 1, we obtain that for a chosen gs
Pr[Yi = 1] = Rel(gs). (8)
Lemma 2: Among T iterations, if Ngs of them choose a
gs, then Rel(gs)
≈
Ngs/T for a sufficientlylarge T.
Proof: Let Y = (1/T)*(Y1 + Y2 +…+ YT) be sample mean
of Y1, Y2, …, YT, then Y = Ngs/T and
E[Y] = (1/T)*T*E[Yi] = Pr[Yi = 1]
= Rel(gs). (by Equation (8)) (9)
Input: a network g = G(N, L, p). Output: an approximation of R’all(g).
1. Initialization: W←0. 2. For iteration k = 1 to T, do:
(a) Generate a random failure scenario gs
of g: for each link i in g, sample U from Uniform(0,1); if (U > pi), xi=1;
else xi=0.
(b) Use depth first search to check if every pair of nodes in gs can communicate
with each other and compute w(gs);
W←W+w(gs).
Because Yi = Yi2, so
E[Y i2] = E[Yi] = Rel(gs), (10)
and
Var[Yi] = E[Yi2] - E2[Yi]
= Rel(gs) - Rel2(gs). (11)
By differentiation on (11), we obtain that Var[Yi]
has a maximum 0.25 when Rel(gs)=0.5.
Applying Chebyshev inequality, we obtain Pr[ |Y – E[Y]|
≥
ε ]≤
Var[Y]/ε2 which isPr[ |Ngs/T –Rel(gs)|
≥
ε ]≤
(Var[Yi]/T)/ε2≤
0.25/Tε2 (12) Therefore, by choosing a sufficiently large number of samples T, the probability that we make an inaccurate estimation (which differs from Rel(gs) by more than ε) will be as close tozero as we wish1
. In other words, it is a high probability that our estimation is accurate. ■
Corollary 3: Suppose among T iterations, if Ngs of
them have chosen a gs , then
w(gs)*Rel(gs)
≈
w(gs)*(Ngs/T) for asufficiently large T.
Proof: Proved by Lemma 2. ■ Lemma 4: w(gs) = 1 if every pair of nodes in gs can
communicate with each other.
Proof: Proved by the definition of w(gs) in (7). ■
Theorem 5 (Correctness of Algorithm 2): Let Ngs be
the total occurrences of chosen gs among
T iterations and gsk be the k-th chosen gs
in the T iterations, Rel’all(g)
≈
(1/T)*∑
= T 1 k w(gsk) for a sufficiently large T.Proof: From (6) and the definition of w(gs), the
reliability of the extended model is
Rel’all(g) =
∑
Ω ∈ s g 1*Rel(gs) +∑
Ω ∉ s g w(gs)*Rel(gs) =∑
Ω ∈ s g w(gs)*Rel(gs) +∑
Ω ∉ s g w(gs)*Rel(gs) (by Lemma 4) 1Note that with the number of samples increases, the required computation effort also increases. To reduce the complexity while retaining the estimated accuracy is an important issue for future study. =
∑
s g w(gs)*Rel(gs)≈
∑
s g w(gs)*(Ngs/T) (by Corollary 3) =(1/T)*∑
s g w(gs)*Ngs =(1/T)*{w(gs1)+w(gs2)+…+w(gsT)} = (1/T)*∑
= T 1 k w(gsk). ■The accuracy of Algorithm 2 increases as the number of iterations increases. It gives an excellent approximation as long as ε is small and we choose T which is large enough to make 0.25/Tε2 sufficiently small (as we has shown earlier in (12)). In other words, if we want to have 1-2δ confidence that the estimated reliability falls in the range of exact reliability
±
ε, we must set 0.25/Tε2≤
δ, i.e., set T≥
0.25/(δ*ε2).4. Numerical results
In this section, we utilize the network configuration in Fig. 2 (A) as an example to demonstrate Algorithm 2. More complex scenarios are under study at the time this paper is written. We set the link failure probabilities and the CIL of the links in Fig. 2 (A) with the values in Tab. 1 (A) and (B). With the parameter n in w(gs) to be 1 (see Eq.(7))2, the exact all-terminal
reliability of the network configuration is 0.98032.
Table 1: Properties of the links. (A) Link failure probabilities.
Links 2 3 4 1 0.1 0.2 1 2 0.2 0.1 3 0.1 (B) CIL. Links 2 3 4 1 2 2 1 2 2 1 3 2
The estimated results of the network configuration are illustrated in Fig. 3 and Fig. 4. Fig. 3 illustrates the relation between the number of the iterations (x-axis) and the estimated reliability (y-axis). Fig. 4 illustrates the relation between the number of iterations (x-axis)
2 Note that the cases for n unequal to 1 are exactly the same as the n=1 case, so they are not elaborated here.
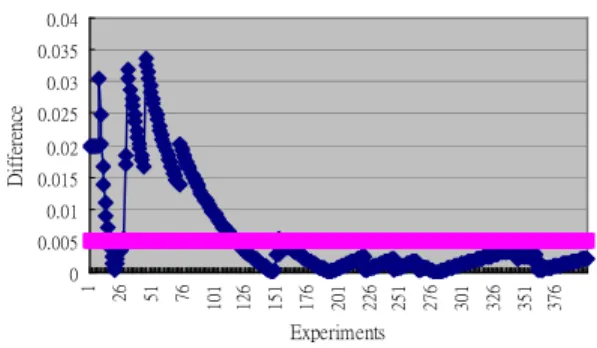
and the difference between the exact reliability and the estimated reliability.
In Fig. 3, the estimated reliability approaches 0.98032 as the number of iteration increases. When more than 118 iterations are performed, the difference between the exact reliability and the estimated reliability is always smaller than 0.005 (see Fig. 4).
Fig. 4 shows that the estimated reliability converges to the exact reliability with a sufficiently large T value. Although for some small network configuration, we could directly examine the 2|L| different gs to calculate
the exact all-terminal reliability, it is almost infeasible to do that for more complex network configurations. For large networks, approximation is required to estimate the all-terminal reliability in order to get the computation done quickly.
0.92 0.93 0.94 0.95 0.96 0.97 0.98 0.99 1 1.01 1 26 51 76 101 126 151 176 201 226 251 276 301 326 351 376 Experiments R el ia bi li ty
Figure 3: Estimated all-terminal reliability.
0 0.005 0.01 0.015 0.02 0.025 0.03 0.035 0.04 1 26 51 76 10 1 12 6 15 1 17 6 20 1 22 6 25 1 27 6 30 1 32 6 35 1 37 6 Experiments D if fe re nc e
Figure 4: Difference between the exact reliability and the estimated reliability.
5. Conclusions
This paper described the optimal cost reliable network design problem which is NP-hard. To solve this complex problem, several GAs were proposed to minimize network cost given a minimum required network reliability constraint. In these GAs, the all-terminal network reliability needs to be calculated very frequently. However, the exact calculation of the all-terminal network reliability is NP-hard, so
approximation is required. For the basic network reliability model, the approximation of all-terminal network reliability was calculated using cut set count and Monte Carlo simulation. Nevertheless, for the extended network reliability model, no approximation algorithm was developed.
We proposed an approximation algorithm based on Monte Carlo simulation for that extended network reliability model. By adopting our network reliability approximation algorithm, the GAs will be capable of solving the optimal cost reliable network design problem under the extended network reliability model.
We did not mention the computational intensive of the proposed algorithm in this paper. This is an important issue for future study.
6. References
[1] A. Kershenbaum, Telecommunications Network Design
Algorithms, McGraw-Hill, New York, NY, 1993. [2] B. Dengiz, F. Altiparmak and A.E. Smith, “Local search
genetic algorithm for optimal design of reliable networks”, IEEE Transactions on Evolutionary Computation, vol. 1, no. 3, Sep. 1997, pp. 179-188. [3] D.E. Goldberg, Genetic Algorithms in Search,
Optimization and Machine Learning, Kluwer Academic Publishers, Boston, MA, 1989.
[4] Y. S. Kavian and M. Naderi, “An Evolutionary Approach to Design WDM Telecommunication Survivable Networks” in Proc. IEEE International
Conference on Engineering of Intelligent Systems, Sep. 2006, pp. 1-6.
[5] S. Zhang, J. Chen, J. Jia and X.-R Bao, “Searching Algorithm of the Optimal Sensor Set in Wireless Sensor Network”, in Proc. IEEE International Conference on
Wireless Communications, Networking and Mobile Computing, Sep. 2006, pp. 1-4.
[6] M.R. Garey and D.S. Johnson, Computers and
Intractability. Freeman, New York, NY, 1979.
[7] A. Konak and A.E. Smith, “An improved general upper bound for all-terminal network reliability”, in revision at
IIE Transactions.
[8] D.L. Deeter and A.E Smith, “Economic design of reliable networks”, IIE Transactions, vol. 30, 1998, pp. 1161-1174.
[9] M. Feng, H.L. Vu and M. Zukerman, “A new reliability measure for telecommunication networks”, IEEE
Communications Letters, vol. 6, no. 9, Sep. 2002, pp. 400-402.
[10] K.-P. Hui, Network Reliability Estimation, Ph. D. Thesis, University of Adelaide, South Australia, 2005. [11] M.O. Ball, T.L. Magnanti, C.L. Monma and G.L.
Nemhauser (eds.), Network Models: Handbooks in
Operations Research and Management Science, vol. 7, North-Holland, Amsterdam, 1995.