國立臺灣大學工學院土木工程學系 碩士論文
Department of Civil Engineering College of Engineering National Taiwan University
Master Thesis
應用小波分析辨識地下水水位模擬之類神經網路架構 Structure Identification of Artificial Neural Networks for
Groundwater Simulation Using Wavelet Analysis
林聖鈞 Lin, Sheng-Chun
指導教授:徐年盛 教授
Major Professor:Hsu, Nien-Sheng
中華民國 97 年 7 月
Jul. 2008
誌謝
啊,終於畢業了~一不小心就唸了三年=_=
這篇論文交出去,算是為當初選錯的十多年的升學人生劃下句點,
由衷希望以後不會再和這些有的沒的東西打交道,
可以認真地去做自己真正有興趣的事...:)
最後要謝謝在論文完成過程中給過我幫助的大家,
像我這種腦袋空空的小孩,自己一個人是寫不出啥東西的...(汗)
只不過因為要感謝的人太多,就不一個一個點名感謝了,
以免不小心有人被漏掉了這樣反而不好意思,啊哈哈...|||
總之,不才我畢業了,謝謝大家,大家再見~
bye
2摘 要
本研究將倒傳遞類神經網路之隱藏神經元個數的決定,視為一般參數檢定的 過程,使用 AIC 指標(Akaike’s Information Criterion)來決定隱藏神經元個數並 優選模式。
此外,因為類神經網路的各個權重
w 主要是模擬不同生物神經元間的連結
i 強弱,權重為正且越大表示連結越強且增益越大;權重為負且越小表示連結雖強 但是為抑制的功用;若權重接近零,表示連結很弱。因此本研究分析在不同隱藏 層神經元個數下,各個權重值的大小之變化趨勢,將每一組權重視為一系列的頻 譜,找出一適合的門檻值,使用小波分析將之過濾,把過於接近零,也就是連結 度越弱的權重予以剔除,進而得出一種更加快速的方式以決定隱藏層神經元個 數,以期建立一精確之類神經模式以模擬地下水水位。結果顯示,以小波分析過濾權重,的確能夠快速地找出合理的隱藏層神經元 個數,而且隨著訓練資料筆數的增加,所決定之隱藏神經元個數亦隨之增加,證 明了本論文方法論之可行性與可靠度。
關鍵字:類神經網路、小波分析、地下水、AIC 指標
Abstract
Artificial neural network (ANN) is a flexible mathematical structure which is capable of idengifying complex nonlinear relationships between input and output data sets. ANN models have been found useful and efficient, particularly in problems for which the characteristics of the processes are difficult to be described using physical equations. Thus, in this paper, the capability of an artificial neural network to provide a data-driven approximation of groundwater flow model is demonstrated.
To identify an ANN model, the number of nodes in every layer must be selected, especially in the hidden layer. In this paper, AIC criterion (Akaike’s Information Criterion) is applied to calibrate the ANN model, and the weights of the network are analyzed as a signal by wavelet analysis in orde to decide the number of nodes in the hidden layer.
After an mathematical simulation, the result improve that the new approach deduced in this study can quickly offer a useful reference and application for the decision of the number of nodes in the hidden layer.
Keywords: Artificial Neural Networks, Wavelet, Groundwater, AIC criterion
目 錄
誌謝 ... Ⅰ 摘要 ... Ⅱ Abstract ... Ⅲ 目錄 ... Ⅳ 圖目錄 ... Ⅶ 表目錄 ... Ⅸ 第一章 緒論
1.1 研究背景與目的 ... 1
1.2 研究方法概述 ... 2
1.3 類神經網路文獻回顧 ... 3
1.3.1 國外的類神經網路相關論文 ... 3
1.3.2 國內的類神經網路相關論文 ... 4
1.4 小波分析文獻回顧 ... 6
1.4.1 國外的小波分析相關論文 ... 6
1.4.2 國內的小波分析相關論文 ... 6
1.5 論文大綱 ... 7
第二章 小波分析與類神經網路理論介紹 2.1 前言 ... 8
2.2 類神經網路概述 ... 8
2.2.1 類神經基本介紹 ... 9
2.2.2 類神經網路系統架構 ... 12
2.2.3 類神經網路的學習方式 ... 14
2.3 小波分析概述 ... 15
2.3.1 連續小波轉換 ... 15
2.3.2 離散小波轉換 ... 18
2.3.3 Mallat 運算法 ... 20
2.3.4 小波包 ... 22
第三章 隱藏層神經元個數之決定 3.1 前言 ... 23
3.2 倒傳遞類神經網路概述 ... 23
3.2.1 BPA 學習演算法 ... 23
3.2.2 BPA 回想演算法 ... 27
3.3 傳統的隱藏層神經元個數決定方式 ... 28
3.4 以 AIC 指標決定隱藏層神經元個數 ... 30
3.4.1 AIC 指標之介紹 ... 30
3.4.2 AIC 指標決定最佳隱藏層神經元個數方法 ... 31
3.5 小波濾除冗餘權重 ... 33
3.5.1 小波濾除冗餘權重理論 ... 33
3.5.2 小波濾除冗餘權重方法 ... 34
第四章 實驗步驟與結果討論 4.1 前言 ... 36
4.2 實驗流程與詳細步驟 ... 36
4.2.1 均方差與 AIC 之計算 ... 37
4.2.2 小波濾除冗餘權重步驟 ... 47
4.3 AIC 指標方法實驗結果討論 ... 53
4.4 小波濾除冗餘權重結果討論 ... 55
4.5 AIC 指標方法與小波濾除冗餘權重方法之綜合比較 ... 60
第五章 結論與建議 5.1 研究結論 ... 63
5.2 建議事項 ... 64
參考文獻 ... 65
附錄一 倒傳遞類神經網路公式計算範例 ... 70
附錄二 小波濾除權重範例 ... 75
圖 目 錄
圖 2.1 生物神經元示意圖 ... 9
圖 2.2 類神經網路的基本設計概念 ... 10
圖 2.3 常見的活化函數 ... 12
圖 2.4 前饋式類神經網路 ... 13
圖 2.5 回饋式類神經網路 ... 13
圖 2.6 尺度參數 a 的作用 ... 17
圖 2.7 平移參數 b 的作用 ... 17
圖 2.8 小波的分解與重建示意圖 ... 22
圖 2.9 小波包分解示意圖 ... 22
圖 3.1 倒傳遞類神經網路架構圖 ... 23
圖 3.2 傳統隱藏神經元個數決定範例用圖 ... 29
圖 3.3 以 AIC 指標決定隱藏層神經元個數流程圖 ... 34
圖 3.4 小波濾除冗餘權重流程圖 ... 36
圖 4.1 輸入類神經網路訓練之資料架構 ... 36
圖 4.2 60 筆訓練資料下隱藏神經元個數與停止誤差值之關係圖 ... 43
圖 4.3 60 筆訓練資料下隱藏神經元個數與 AIC 之關係圖 ... 43
圖 4.4 120 筆訓練資料下隱藏神經元個數與停止誤差值之關係圖 ... 43
圖 4.5 120 筆訓練資料下隱藏神經元個數與 AIC 之關係圖 ... 44
圖 4.6 180 筆訓練資料下隱藏神經元個數與停止誤差值之關係圖 ... 44
圖 4.7 180 筆訓練資料下隱藏神經元個數與 AIC 之關係圖 ... 44
圖 4.8 240 筆訓練資料下隱藏神經元個數與停止誤差值之關係圖 ... 45
圖 4.9 240 筆訓練資料下隱藏神經元個數與 AIC 之關係圖 ... 45
圖 4.10 300 筆訓練資料下隱藏神經元個數與停止誤差值之關係圖 ... 45
圖 4.11 300 筆訓練資料下隱藏神經元個數與 AIC 之關係圖 ... 46
圖 4.12 360 筆訓練資料下隱藏神經元個數與停止誤差值之關係圖 ... 46
圖 4.13 360 筆訓練資料下隱藏神經元個數與 AIC 之關係圖 ... 46
圖 4.14 (a)db3 函數圖 ... 48
圖 4.14 (b)墨西哥小帽函數圖 ... 48
圖 4.15 權重排列方式一 ... 48
圖 4.16 權重排列方式二 ... 49
圖 4.17 權重排列方式三 ... 49
圖 4.18 權重排列方式四 ... 49
圖 4.19 權重濾除前示意圖 ... 50
圖 4.20 權重濾除後示意圖 ... 50
圖 4.21 不同資料筆數下最佳隱藏神經元個數示意圖(小波方法) ... 52
圖 4.22 180 筆訓練資料下隱藏神經元個數與 AIC 之關係圖(C=3)... 54
圖 4.23 240 筆訓練資料下隱藏神經元個數與 AIC 之關係圖(C=4)... 54
圖 4.24 訓練資料筆數與最佳隱藏神經元數關係圖(AIC 方法)... 54
圖 4.25 訓練資料筆數與最佳隱藏神經元數關係圖 (小波方法,門檻值=0.6)... 58 圖 4.26 AIC 與小波方法結果比較 ... 60
圖 4.27 小波方法不同門檻值對最佳隱藏神經元個數之影響 ... 61
表 目 錄
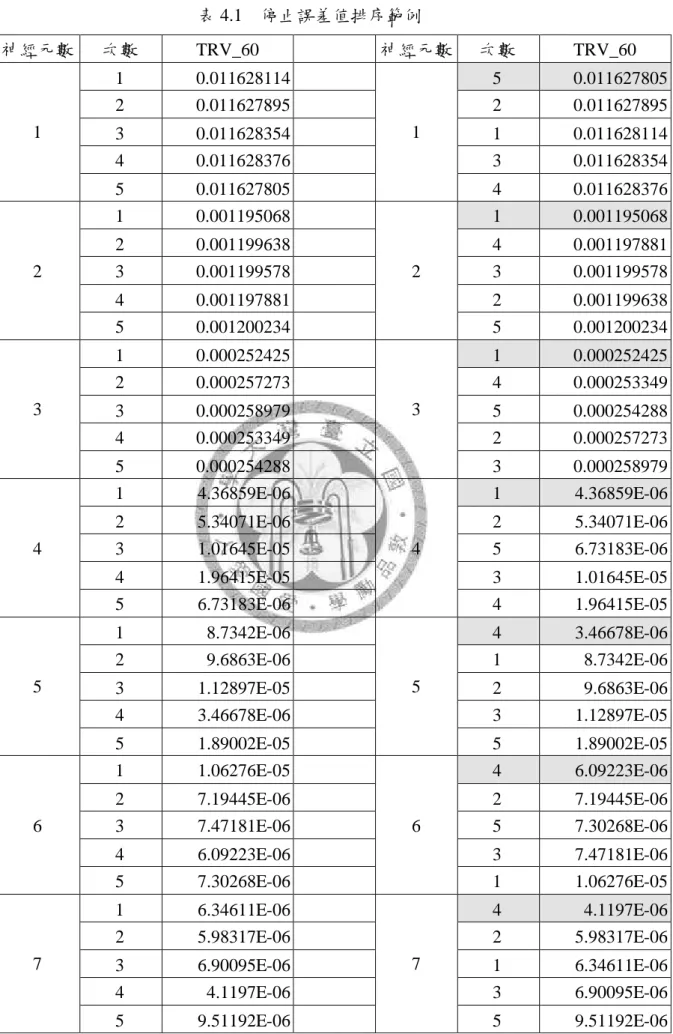
表 4.1 停止誤差值排序範例 ... 39
表 4.2 60 筆訓練資料下之 AIC 值與計算過程 ... 40
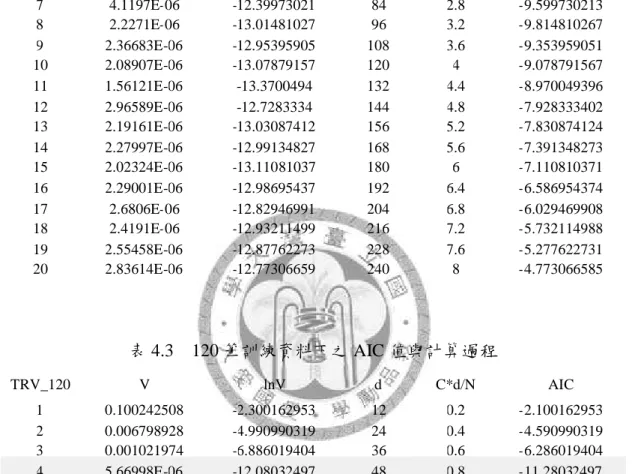
表 4.3 120 筆訓練資料下之 AIC 值與計算過程 ... 40
表 4.4 180 筆訓練資料下之 AIC 值與計算過程 ... 41
表 4.5 240 筆訓練資料下之 AIC 值與計算過程 ... 41
表 4.6 300 筆訓練資料下之 AIC 值與計算過程 ... 42
表 4.7 360 筆訓練資料下之 AIC 值與計算過程 ... 42
表 4.8 小波濾除權重範例 ... 51
表 4.9 不同資料筆數下隱藏神經元個數決定過程 ... 52
表 4.10 訓練資料筆數與最佳隱藏神經元數(AIC 方法) ... 54
表 4.11 120 筆訓練資料下權重過濾後神經元減少路徑 ... 55
表 4.12 180 筆訓練資料下權重過濾後神經元減少路徑 ... 56
表 4.13 240 筆訓練資料下權重過濾後神經元減少路徑 ... 56
表 4.14 300 筆訓練資料下權重過濾後神經元減少路徑 ... 57
表 4.15 360 筆訓練資料下權重過濾後神經元減少路徑 ... 57
表 4.16 訓練資料筆數與最佳隱藏神經元數(小波方法,門檻值=0.6).... 58
表 4.17 不論訓練資料筆數被濾除之隱藏神經元個數(門檻值=0.6)... 57
表 4.18 AIC 與小波方法結果比較 ... 60
第一章 緒論
1.1 研究背景與目的
台灣屬於季風海島型氣候,年平均降雨量約在 2500 公厘左右,比起世界各 國來說,水資源算是相當豐佩;但是因為降雨分佈不均,而且山勢坡陡流急,水 資源無法有效儲蓄利用,再者近年台灣不論是民生或是工業用水需求量皆大增,
便造成了缺水的問題;地上水不足,民眾便轉而抽取地下水,在過量的抽取之後,
已經造成海水入侵地下水鹽化、台灣西南沿海地區地層下陷等等嚴重問題;因此 如何有效管理並適度使用地下水資源,便成為現今水資源管理的重要課題之一。
欲管理地下水資源,首先必須知道地下水水位的分佈與變化,以便在水位過 低的地區禁止抽取並進行補注,在水位尚足的地區適度地抽取利用;傳統欲得地 下水水位,通常是透過地下水水流方程式建立地下水水流模擬模式(simulation model)求解,欲求解地下水水流方程式便需要知道方程式裡各個參數的參數值。
然而自然界中地下水含水層之變化大而複雜,實測地下水文參數如流通係數、貯 蓄係數等,往往因經濟或技術因素之限制,只能侷限於某些特定位置,而這些特 定點所測得的地下水參數值未必能代表整個區域的參數型態;要獲得整個分佈式 系統之參數實際上是不可能的,通常的作法是以抽水試驗(pumping test),由洩 降曲線反推該抽水井位置附近的流通係數和貯蓄係數值,再利用這些參數將整個 區域性地下水系統以參數分區法(zonation method)或內插法(interpolation method)表示成有限維度之方程式,再由參數檢定(parameter identification method)求出參數值,然後將所求之參數應用於地下水水水流模擬模式(例如:
MODFLOW)中;整個過程繁雜且計算量龐大,進行管理規劃時耗時甚鉅,故 本論文之研究目的在於,利用小波分析建構一可靠之倒傳遞類神經網路以供模擬 地下水水位,希望能夠解決上述困難。
1.2 研究方法概述
類神經網路(Artificial Neural Networks, ANNs)或譯為人工神經網路,其主 要的基本概念是嘗試著模仿人類的神經系統,因為人類的神經系統在語音、聽 覺、影像和視覺方面均有很完美的表現,所以期望建立能夠在這些方面也有出色 表現的人工模型。過去幾年裡,在不斷進展的研究過程中,已確定類神經網路具 有誤差容忍度高(fault tolerance)、平行運算(parallel computation)以及強大的 學習能力等特性,可利用於非線性動態系統之鑑別與求解,並且也已經證明人工 類神經網路可近似大範圍變化的非線性函數,且能達到所要求的精度並準確到特 定條件下;故在不知道現地各種參數的情況下,僅以觀測到的輸入與輸出之成對 資料(input and output data sets)訓練類神經網路來取代需要大量精準參數與觀 測資料方能運作的 MODFLOW 成為新的地下水流模擬模式,理論上是可行的,
而且已經有不少前輩做過類似的研究。
小波分析為一門新發展之數學科學,經過十幾年之發展,小波分析在理論及 方法上均獲致突破性之進展;小波轉換亦稱為小波分解(wavelet ecomposi- tion),為一種線性運算,可對訊號進行不同分辨層(尺度)之分解,能將各種交 織在一起之混合訊號分解成不同分辨層或不同頻率之區塊訊號,可有效地應用於 訊號及噪音之分離,提高時頻兩域之分辨能力;它改善了傅立葉轉換(fourier transformation)只能觀察到頻率域資料的特性,其二維(時間和頻率)分析的功 能使得信號在時間和頻率域內的變化能同時被偵測到;故本論文應用小波分析來 過濾訓練完成的類神經網路之權重值,觀察其中是否有不必要之噪音存在,以期 藉此優選出最佳的隱藏神經元個數,建構一可靠之倒傳遞類神經網路。
1.3 類神經網路文獻回顧
近幾年來,因為理論簡單、結構單純,而且不需使用由複雜的物理或數學理 論所建構之物理統計模型,並且容易透過演算法則建立不同條件下所需的特定模 式,因此類神經網路大量被應用於各個領域上,在水利相關的研究當然也不少,
以下將列舉相關的國內外論文如後。
1.3.1
國外的類神經網路相關論文French 等(1992),將 BPN 運用於空間與時間之降雨強度預測,預測一小時 之後的降雨。Daliakopoulos 等(1994),使用類神經網路做地下水水位預報,討 論不同的類神經網路模式在地下水位預報上的表現以求得最佳的類神經網路架 構所模擬出來之退減曲線。Lorrai 等(1995),使用二層隱藏層的 BPN 來架構「降 雨-逕流」模式,分析月雨量與月流量間的關係;Hsu 等(1995),則使用自己 提出的新演算方法(LLSSIM)來優化並決定 BPN 架構以探討「降雨-逕流」間 的關係,並將結果與兩種傳統的模式(ARMAX 與 SAC-SMA)做比較,顯示倒 傳遞類神經網路的確能準確模擬「降雨-逕流」間的關係。
Loke 等(1997),將類神經網路應用在都市排水的研究上,利用流量歷線或 雨量紀錄來預測下一時刻的流量;Asaad 等(1997),探討不同的輸入層資料對 模擬結果有何影響,其輸入層資料包含雨量、季節性資料、鄰近區域資訊等。
Sajikumar 等(1997),將類神經網路應用在月流量的研究上,討論雨量資料 缺乏時如何建立模式以推求月流量。Cameron 等(1997),探討多種類輸入層資 料之應用對月流量之推估有何影響,其輸入層資料包含雨量、溫度及流量。
Zhang 與 Rao(2000),主要將類神經網路應用於多流域的集流現象,其輸 入層資料含雨量及平均溫度;Parios 等(2000),以回饋式類神經網路進行多階 段的水位預測。Abdalla 與 Grcia(2003),將類神經網路應用於地下水水流模式 之參數檢定,探討地下水水利傳導係數與地下水水頭之間的關係。
1.3.2
國內的類神經網路相關論文陳昶憲、楊朝仲、王益文(1996),以倒傳遞類神經網路對烏溪流域之洪流 預報作研究,以現時及過去 2 小時的資料預測未來 1 小時流量。孫建平(1997),
利用 BPN 及 GMDH,取前數小時之流量及雨量資料來預測下一個小時的流量;
黃智顯(1997),利用 BPN 研究坡地集水區的特性,取前數個小時的雨量及流量 來預測一或多個小時後的流量。
楊朝仲(1997),以類神經網路為模式設計之主體,適時地與線性轉換函數、
灰關聯分析及自迴歸移動平均模式作搭配組合使用,設計適用於集水區洪水流量 預測之類神經網路,發展出時序類神經洪流預測模式與灰色類神經降雨逕流模 式,利用上游的流量資料來預測下游之洪流量。
郭益銘(1998),應用因子分析將雲林沿海地區地下水質資料進行歸納、整 理和分類,以評估雲林沿海地區地下水質污染情形,然後應用倒傳遞類神經網路 來預測地下水質變化,結果顯示 BP 具有模擬水質複雜變化之能力,並於預測時 能獲得良好之可信度。
胡湘帆、黃源義(1998),結合規則庫控制、模糊控制及倒傳遞類神經網路 建立一種架構簡單、應用方便,而且具有良好的推估能力及濾波的功能的「模糊 類神經網路」,以進行流量推估的工作。
黃群岳(2000),發表之「颱風洪流量之神經網路預測」,以流域內各雨量站 不同延時之逐時雨量為輸入值,水庫入流量為輸出值,利用倒傳遞網路建立「降 雨─逕流」模式,預測洪峰到達時間及洪峰值。
梁晉銘(2000),彙整並針對多種具代表性之類神經網路模式進行深入的剖 析,並逐一歸納其優劣特性,得出若干可行之原則後,結合模糊理論與模糊「最 小-最大」團塊分類法對一複合型類神經網路模式(幅狀基底函數類神經網路)
進行結構性之改良,建構完成之新模式其結構不但具有建構迅速、組成彈性之優 點外,並且能以最簡單的方式快速而有效地完成不同性質水文問題的需求,對於
未來整合河系全渠段不同成因多種水文問題推估系統之建立,提供了進一步實用 化之參考。
胡永國(2002),針對已於 2001 年開工的高雄捷運主要的紅線路段,利用倒 傳遞類神經網路,將現有地層鑽探資料中之土層孔隙比、洩降水位高度以及總體 單位重做為輸入參數,分別以三種不同組合模式,來建立各參數與地表壓密沉陷 量之相對最佳模式,進而推算出捷運紅線沿線從地表至施工基礎開挖面(地表下 17 至 20 公尺)所可能產生之沉陷量與分佈地區,以作為防治因施工所造成之潛 在災害之評估參考。
曾國源(2001),以過去幾年曾多次發土石流災害之陳有蘭溪集水區為主要 的研究區域,蒐集各類土石流發生資料,配合土石流災害之水文與地文條件進行 發生機制辨識,架構一共用臨域類神經網路(Shared Near Neighbors Network, SNN Network)作為土石流預警系統之用,並評判其準確度及實用的效果性,藉 以對未來可能發生之情況做模擬。
鍾芸菁(2004),使用地理資訊系統建置影響因子資料庫,經因素分析選定 影響地下水流發生之參數為累積降雨量、降雨強度、主流長度、平均高程等項,
隨後採用倒傳遞網路分析影響地下水水位變化因素之相關程度,並決定類神經網 路結構之最佳參數,以針對集水區降雨與地下水水位之模擬學習、輸入影響因素 個數及加入地文因子學習表現進行探討。
賴建元(2006),利用地理統計方法來決定屏東平原地下水位推估之點位數 量,再以類神經網路來推估地下水位,發現類神經網路方法於各月份之推估值均 能接近實際觀測值,尤以空間推估最為優秀,而且其結果精度比傳統 SURFER 軟體所提供之克利金法佳。
1.4 小波分析文獻回顧
比起類神經網路,目前國內外應用小波分析的水利相關論文其實不多,以下 列舉相關的國內外論文如後。
1.4.1
國外的小波分析相關論文Coulibaly 等(2000),應用遞迴神經網路(recurrent neural networks)方法 及小波分析,探討低頻(low-frequency)部分之氣候變化指標,以預測研析區域 之年逕流量。Labat 等(2000),利用連續小波及離散正交多分辨分析(discrete orthogonal multiresolution analyses)於半小時、一小時、日雨量及日流量等不同 尺度之記錄資料,探討石灰岩地層(karstic springs)之「降雨-逕流」關係。
Masuda 與 Aihara(2001),應用小波轉換將時間序列表示成不同頻率成分 之加總,並應用小波係數進行混沌時間序列(chaotic time series)之預測。Bayazit 與 Ahsoy(2001),將小波視為資料繁衍(data generation)之工具,把觀測資料 分解成細節,最後藉由隨機加總這些細節以重構並產生新資料來應用於年流量與 月流量之預測,以驗證所提方法之可行性。
1.4.2
國內的小波分析相關論文李宗穆(1994),應用小波分析之噪音抽取能力及類神經網絡模式之非線性 計算能力,建立一種可以同時分析流量資料噪訊及模擬「降雨-逕流」相互關係 之時間序列小波串聯模式,用以從事坡地上游集水區「降雨-逕流」歷程之模擬。
王志雄(1995),研析感潮河段內「水位-流量」之率定關係,藉著小波理 論分解、去噪及重建之功能,串聯合適之水文模式,以建立一種濾除潮汐效應後 之修正「水位-流量」率定曲線。
王瀚德(2001),以水位資料為背景,利用小波函數將水位訊號做多重解析 度分析,藉此過濾潮汐中之高頻雜訊部份,並透過分潮延時差的觀念建立一種可 以有效預測及補遺水位資料的類神經網路模式。
周建明(2001),利用 à trous 小波分解方法,將欲研析之水文序列分解成 多個分辨層成份之疊加,將水文序列各分辨層輸入離散系統線性黑盒模式與微分 擬合之水文灰色模式,以分別模擬各分辨層「降雨-逕流」之歷程。
廖啟佑(2004),應用類神經網路與小波分析理論,探索地下水位測站之長 時程地下水水位之多分辦層結構,將地下水位各種交織在一起之混合訊號分解成 不同分辨層或不同頻率區塊訊號,使用小波收縮(wavelet shrinkage)方法選取 一合適的臨界值將所得的高頻小波係數做修剪(clipping)收縮處理,並將門檻 值以外之各高頻小波係數與地震發生時間做一分析整理,藉此可明顯指出地下水 水位出現頻率異常之時間點,因而將有助於減災及延長避難反應時間。
由以上的文獻回顧可知,一般來說小波除了很少應用於水利方面之外,應用 時亦常與其他科學技術(例如:類神經網路)互相結合;而且通常的作法是先用 小波分析序列資料,藉此濾除訊號裡的噪音之後,再將分析後的資料放入類神經 網路裡訓練模擬,以提升類神經網路的模擬能力。
1.5 論文大綱
本論文首先以 MODFLOW 產生水位資料,然後訓練類神經網路,最後配合 AIC 指標與小波分析,決定最佳的隱藏神經元個數,各章節安排如下:第一章為 緒論,介紹本論文之內容及大綱,與文獻回顧。第二章簡述類神經網路、小波理 論。第三章首先簡述本論文的想法與方法論,並且詳細交代本論文中所使用的方 法流程。針對本論文所提出的研究方法,以第四章的數值模擬和實作結果來驗證 所提出之方法論之有效性。最後第五章述說結論,對本論文作一總結。
第二章 小波分析與類神經網路理論介紹
2.1 前言
本論文以小波分析與類神經網路為主要的研究工具,因此在本章裡將依次介 紹類神經網路、小波分析的基本理論。
2.2 類神經網路概述
在1943年,心理學家Warren McCulloch和數學家Walter Pitts共同提出了神經 元最早的數學模式(即MP模式),開創了腦神經科學理論研究的時代。西元1949 年Hebbian提出了神經細胞的學習規則,其規則描述為「當人腦在學習不同事物 時,每個細胞的連結隨時都在改變,如果一個腦細胞受到另一個腦細胞連續的作 用時,它們之間的連結力量就會增強」,此學習規則引導了日後類神經網路的發 展。在1958年,Frank Rosenblatt首先引用感知器觀念來模擬大腦感知和學習兩大 能力;而感知器是由具活化轉移函數的神經元組成的層狀網路,它具有學習功 能;但是Marvin Minsky和Seynour Papert合著的「Perceptron」一書指出,由於感 知器結構上的限制,它不能產生複雜的邏輯函數,因為Minsky在MIT有崇高學數 地位,類神經網路的研究從該書發表後,就一直陷入低潮無所進展。
所幸在1962年Bernard Windrow提出所謂的適應性線性元件(adaline),由於 它是一種線性網路,而且具有學習能力,在訊號處理與系統識別等領域受到廣泛 的重視和應用。此外,在此挫折時期(1967~1982年),依然有不少學者從事類 神經網路方面的研究,為類神經網路以後的發展埋下了堅固的基礎。
到了1980年代初期,著名的物理學家John Hopfield提出了HNN網路,他在此 網路中首先引用了能量函數的觀念,為判定網路的穩定性給了依據;Hopfield的 研究論文推動了類神經網路的研究,此後,美國國防的DARPA計畫更是大大地 推動了類神經網路的研究和進展;當1986年,David Rumelhart和James McClel- land共同編著的「Parallel Distributed Processing: Explorations in the Microstructure
of Cognition」一書發表後,更是將類神經網路的研究帶入了新的里程碑,書中所 提的倒傳遞網路更是目前最廣為使用的網路;至此,類神經網已進入了蓬勃發展 階段。
2.2.1
類神經基本介紹人類大約有
10
11個神經細胞,每個神經細胞大約有 1000 根連結與其他神經 細胞相連結,組成巨大的神經網路系統。生物神經元模型如下圖 2.1。每個生物 神經細胞主要由四部分所構成,以下分別說明其功能及其之間的關聯性:1.細胞體(soma):是由細胞核、細胞膜、細胞質所組成。
2.軸突(axon):是一條由細胞體向外延伸的神經纖維(nerve fiber),它主要的工 作是將由細胞體發射出來的脈波,送到其他的神經元去。
3.樹突(dendrites):是由細胞體向外延伸的樹狀架構,它主要的功用是被用來接 收從其他神經元傳送過來的脈波訊號。
4.突觸(synapse):神經元之間的訊號是透過軸突和樹突來傳遞,而連接軸突和 樹突的界面就是突觸;軸突所傳送出來的脈波訊號會在突觸的地方分泌一種傳 導物質,稱為神經傳導物(neuro transmitter),這種傳導物是會接收神經元的 細胞體,產生電位的變化。
圖 2.1 生物神經元示意圖
人體的神經元是神經系統中最小的訊息及傳遞單元,也是整個神經系統運作 的基礎,因此模仿人體神經元的類神經網路,自然係由諸多人工神經元連結而成 的網路;人工神經元也可稱為處理單元,圖 2.2 是一個人工神經元的模型,表現 類神經網路的基本設計概念,清楚地顯示一個人工神經元的輸入向量(X)、權 重組(W)、活化函數(F(.))與輸出值(Y)的基本關係架構。人工神經元主 要分成三個部分:
圖 2.2 類神經網路的基本設計概念
1.一組權重:權重
w 主要是模擬不同生物神經元間的連結強弱。權重為正且越
i 大,表示連結越強且增益越大;權重為負且越小,表示連結雖強但是為抑制的 功用;若權重接近零,表示連結很弱。2.輸入訊號疊加器:主要是模擬生物神經元受多方刺激時膜電位的總變化量;輸 入訊號經過不同的權重加權後,在疊加器作線性的疊加。
3.活化函數:原本是用來模擬生物神經元的門檻值,但目前在運用上已不僅僅用 來模擬門檻值,大部分是用來轉化輸入訊息疊加後的輸出值範圍,一般來說經 過正規化(normalized)的輸出值通常在0~1或是-1~1之間。對一個輸入節點
i之單一輸入訊號
x 而言,可藉由
ix 與其連結權重
iw
ji相乘而將資料傳輸給處理 單元j。處理單元的工作包含兩部分:第一部分為耐其所有傳遞至此神經元的 權重信號值做一加總;第二部分的工作則將第一部分之加總值作一非線性的轉 換,此部分稱為活化函數。就數學上而言,一個神經元j可以用下列二個方程式來描述:
mi
j i ij
j
w x b
net
1
(2.1)
) (
ji
F net
y
(2.2)式中
y 為第j個人工神經元輸出訊號,模擬人體細胞的軸突送出訊號;
inet
j為輸 入值加權值與偏權值b
j之總和,模擬人體細胞的膜電位總改變量;F ( net
j)
為人工神經元的活化函數,是用來轉換
net
j的數學函數;w
ji為連結第i個輸入值與第j 個人工神經元之加權值,模擬神經元間的連結強度;x 為人工神經元的輸入訊
i 號,模擬樹突傳入訊號;b
j為偏權值,若為正則對輸入是增益,若為負則抑制輸 入值。常用的活化函數有下列四種:
(1)門檻值函數(圖2.3(a))
0 0
0 ) 1
( if v
v v if
F
(2.3)(2)片段線性函數(圖2.3(b))
2 1 2 1 2 1
2 1
0 1 ) (
v if
v if
v if v v F
,
,
,
(2.4)
(3)S形函數(圖2.3(c))
) exp(
1 ) 1
(
v
F
(2.5)(4)雙曲線函數(圖2.3(d))
)) tanh(
)
( v v
F
(2.6)以上四個活化函數的定義範圍都在-1~1之間,可以讓神經元的輸出值維持在合 理的範圍內;而活化函數一般為非線性函數,這是因為若採用線性函數,可能會 在處理資料時漏失了輸入資料的非線性特性,可能會嚴重影響類神經網路模擬非 線性特性的效果,進而對最後的結果造成誤差。
(a)門檻值函數 (b)片段線性函數
(c) S 形函數 (d)雙曲線函數
圖 2.3 常見的活化函數
2.2.2
類神經網路系統架構以連結架構來看,類神經網路可分為前饋式與回饋式兩種:
1.前饋式類神經網路(feed-forward):
前饋式類神經網路之架構,其連結方式為單一方向地向前傳遞連結,且網 路的所有神經元皆無後向或是側向的傳遞連結,如圖2.4所示。
2.回饋式類神經網路(feed-back Networks):
回饋式類神經網路與前饋式最大的不同在於,回饋式類神經網路至少會含
有一回饋迴圈,如圖2.5所示,一個回饋式類神經網路可能僅包含一層神經元,
而在此層的神經元會各自將其輸出之訊號,回傳給同一層中的其他神經元或前 一層中的神經元,以作為輸入資料。
若以網路的層數而言,類神經網路分為單層式(single-layer)與多層式
(multi-layer)兩種;單層式的網路架構只有輸入層(input layer)與輸出層(output layer),而多層式架構裡除了輸入層與輸出層,至少含有一層隱藏層(hidden layer);換言之,單層式與多層式的主要差別就是在於隱藏層之有無,因此若 將圖2.4裡的隱藏層拿掉,那它就成為單層的前饋式網路了。
輸入層 隱藏層 輸出層
圖2.4 前饋式類神經網路
圖2.5 回饋式類神經網路
有一點要在這裡特別提出的是,即便單層式含有輸入與輸出共兩層,但我 們仍稱它為「單」層,理由在於輸入層不對訊息作任何處理,只是純粹把資料 傳入網路裡,所以不把它視為一層。(當然,也是有其他的學者專家習慣把輸 入層視為一層,但本論文不採用這種說法。)
2.2.3
類神經網路的學習方式類神經網路是以模擬大腦的功能而成,人體大腦的其一特徵即是從經驗中學 習,故類神經也有各種不同的學習演算法來模擬這種特性:學習的過程即是調整 各人工神經元間的連結權重,而學習的結果(或稱為知識)即為最終所調成出來 的權重值大小。此學習的過程大致可分為監督式學習與非監督式學習兩類:
1.監督式學習(supervised learning):
監督式學習意即我們監督它學習,以期網路結果可達到我們想要的目標;
故在此一學習方式中,我們會給予類神經網路一個訓練範例,範例中同時包含 輸入項與監督用的目標輸出值(desired output),然後藉由「學習」不斷修正 網路中的連結權重,來降低網路輸出值與目標輸出值間的差距,直到差距小於 我們想要的程度才停止。
2.非監督式學習(unsupervised learning):
非監督式學習與監督式學習相比較,不同點在於訓練過程中只有提供輸入 資料而不提供目標輸出值,讓網路自行依輸入資料的特性自己去學習及調整權 重,換言之即是一種聚類(clustering)的過程。
在此學習法裡,類神經網路本身必須從我們輸入的巨量且未經處理的雜亂 資料裡,找出任何可能存在的規律性、相關性與個別屬性...等等;當類神 經網路找出這些特性後,網路本身便會修改其自身的變數以符合資料特性,這 一過程稱之為自我組織(self-organization),故非監督式學習適用於真資料之 分類特性不確定之時。
2.3 小波分析概述
小波分析的基本理論在於:以數學上函數轉換的方式,將資料分成數個頻率 分量;傳統的頻譜分析是以傅利葉轉換 (Fourier transform)為數學上的理論依 據,函數
f (t )
的傅利葉轉換定義為:
f t e
dt w
F ( ) ( )
iwt (2.7)其中 w 為頻率,所以式(2.7)的意義是將時間函數
f (t )
經過基底函數e
iwt 投影至各 頻率的分量。若以尤拉公式(Euler formula)展開e
iwt 可得:) sin(
)
cos(
wt i wt
e
iwt (2.8)所以
F (w )
表示的是f (t )
在整個頻域上的分佈量;而且式(2.7)的時間分佈包括正 負無窮大,所以傅利葉轉換缺乏局部時間的解析度。一般來說,如果訊號的性質並沒有隨時間變化而發生很大變動,則稱這類訊 號屬於固定性(stationary)的訊號。但是大多數的情形下,訊號中屬於固定性的分 量並非真正希望量測到的,反而是非固定性的分量才是要研究的部分,例如一些 不定時產生的突波(spike)或是不規則的漂移。這個時候傅利葉分析在應用上就顯 得不夠充分,因為若以傅利葉分析轉換至頻域,將失去時域之相關訊息。
為了修正這個缺點,D. Gabor 提出將訊號切割成許多小段,逐段作傅利葉分 析以得到較多時域上的訊息,就是所謂的短時間傅利葉轉換(Short-Time Fourier Transform,STFT)。但是這個方法也同樣有其限制,就是切段的長度究竟該如何 選擇?如果要分析的頻率很高的訊號,當然必須選擇較短的訊號視窗長度 (win- dow length),如果訊號的頻率很低,則訊號長度必須拉長。但是如果事先無法得 知要分析的訊號究竟屬於那個頻帶,則方法也無法使用,小波分析就是為了解決 這個問題而推導出來。
2.3.1
連續小波轉換(Continuous Wavelet transform, CWT)所謂小波,是指一個定義為有限長度且平均值為零的波形,我們可以藉著拉 伸(stretch)或壓縮(compress)小波函數之後,逐段平移(shifting),展開被分 析的訊號。各式各樣的小波函數,大多延伸自學者 Haar 於西元 1910 年所提出之
Haar 小波函數,所有小波函數皆須滿足
0 ) ( dt t
之條件,意指小波函數的平
均值必須為零,且定義函數能量有限,故當 x 趨近正負無限大時,小波函數
(t )
將衰減至零。綜合以上所述,再依據 Rao and Bopardikar(1998)及 Bayazit and Aksoy
(2001)所定義,小波 為具有以下二個性質之函數(Rao and Bopardikar,
(t )
1998):1.函數之積分值為 0:
0 ) ( dt t
(2.9)
2.函數之能量有限:
dt t )
2
(
(2.10)假設 f(t)為平方可結合性的函數,則連續小波轉換與小波(wavelet)相關之定義 如下:
dt
a b t t
a f b a
CWT 1 ( ) *
) ,
(
(2.11)其中 CWT 為函數
f (t )
之連續小波轉換值,a 與 b 為實數,分別代表母波 之(t )
尺度參數與平移參數,星號代表共軛複數。 與(t ) f (t )
是屬於L
2 R
n 空間。在這裡
L
2 R
n 是屬於一種信號類別,其包含所有的有限的、定義明確的平方積分函式:
L f t dt E
f
2 ( )2 (2.12)而這類別簡單代表信號擁有之能量。因此由(2.11)式所知,小波轉換是含有雙變 數的函數。小波基底函數為將單一母波函數 經擴張及轉移後所產生的一組函
(t )
數,藉由a,b( t )
可將母波定義為:
a b t t a
b
a
,
( ) 1
(2.13)因為1,0
( t )
( t )
,且正規化因子a
1 可保證對所有參數 a 與 b 能量維持一定,
因此對於任何以給定的值 a,函數a,b
( t )
只能隨著時間軸將函數a,0( t )
移動 b 的 距離;換言之小波轉換之所以有別於 FFT 及 STFT,即因為它具有此兩個重要的參數:尺度參數 a(scalar parameter,a)與平移參數 b(translate parameter,b);
其中尺度參數 a 是將函數圖形作壓縮或伸展,如圖 2.6 所示;而平移參數 b 是將 函數圖形在時間軸上作平移,如圖 2.7 所示。
圖 2.6 尺度參數 a 的作用
圖 2.7 平移參數 b 的作用
又尺度參數 a 和頻率成倒數,亦即 a 值(尺度)愈小則頻率愈大,圖形被伸 展開;而 a 值(尺度)愈大則頻率愈小,圖形被壓縮;尺度參數與頻率間的關係 我們可以整理得出如下:
▪ a 值小(低尺度) 壓縮小波(compress wavelet)
快速變化、細部特徵(rapidly changing、details features)
高頻(high frequency w)
▪ a 值大(高尺度) 伸展小波(stretched wavelet)
緩慢變化、粗糙特徵(slowly changing、coarse features)
低頻(low frequency w)
這個關係使得小波在頻域中具有縮小(zoom-in)及放大(zoom-out)的功能。
2.3.2
離散小波轉換(Discrete Wavelet transform, DWT)由於連續小波轉換受到冗餘性(redoundancy)和不可實現性(impractical- ity)的兩個限制,因此為了兼顧理論的完整性與實用性,可透過(2.5)式對尺度參 數 a 和平移參數 b 的取樣而將之離散化(discretization)。對應於上述連續小波轉換 函數而言,離散小波轉換可表示如下:
k
m
a
mn k k
x a n m DWT
0 0
* ) 1 (
) ,
( (2.14)
其中
DWT ( m , n )
為信號x (t )
的離散小波轉換係數值,k 為運算指標,也可以小波 級數(wavelet Series)表示之:
k m m
n k k
x n
m
DWT
( ) * 22 ) 1 ,
( (2.15)
比較(2.14)式與(2.15)式可得知,在(2.11)式中的參數 a 與 b 可使用整數參數 m 與 n,以
a
a
0m和b an
的方式替換,因此又稱為二的轉換(dyadic trans-formation)。值得特別注意的是,離散小波轉換仍然是一種連續信號的轉換,其
「離散」所指的部分只有在 a 與 b 兩變數而已,時間還是連續的。
Mallat 於 1989 年根據 Lapalcian Pyramid Scheme 之架構,推導出多層解析度 分析(multi-resolution analysis)之基本架構,多層解析度分析主主要是將滿足
R
nL
2 空間之任意函數,依連續近似法則作適當分解,分解過程所依據之基底函 數(basis function)即為小波函數。依據空間分解(spatial decomposition)之觀念,若近似空間
V
j(approxi- mation space)為依照一定解析度自原始訊號中萃取出來的各種趨勢訊號函數之 集合,則可視為低頻訊號之集合,亦即V
j之近似訊號A
jf
表達了訊號函數中最主 要的趨勢訊息,當解析度越高(j 值越大時),則近似空間V
j所能提供的細節訊 息就越豐富。於相鄰近似空間V
j1與V
j對應的兩個趨勢分量A
j 1f
及A
jf
之差值 訊號D
jf
的集合稱為細節空間O
j(detail space)。換言之,細節空間O
j為近似空 間V
j在近似空間V
j1裡之正交補集,亦即V
j1可分解為彼此相互正交的子集合V
j與
O
j,此可以下列數學式表示之:1
j jj
O V
V
(2.16) 0
jj
O
V
(2.17)根據(2.8)和(2.9)式,可以得到:
R O
O
O
O O O
L
2 n...
2 1 0 1...
(2.18) 上式之意義為平方可積分之函數空間L
2 R
n 是彼此相互正交之差值空間O
j的正 交直和(orthogonal direct sum),這種空間也是一種 Hilbert 空間;根據多重解析 度分析,我們可以得到:1.
V
j V
j1 j Z
(2.19) 亦即在於A
j 1f
具有A
jf
之所有訊號訊息。2. j j
njlim
V
V
L
2R
(2.20)
亦即在於解析度無窮精細時
j
,A
jf
將趨近於原始訊號 f。3. lim
0
j j
j
V
V
(2.21)亦即在於解析度無窮粗糙時
j
,信號之訊息將完全遺失。4.
g ( x ) V
j, g ( x k ) V
j, k Z Z j V x g V x
g ( )
j, ( 2 )
j,
(2.22)
5.
f L R
j Z f A
jf
n
, >0
2 (2.23)
其中
f
A
jf
f x
A
jf x dx
) 2
( )
(
(2.23)式表示對於任一個訊號函數
f
L
2 R
n ,吾人均可以找到一個存在於某一 近似空間V
j內之近似函數A
jf
,使其近似誤差小於某個給定之有限值。在多層解析分析裡,吾人定義一個存在於
L
2 R
n 空間內之標度函數,而且在每一個近似空間
V
j定義了正規(orthonormal)基底函數 ,jk k Z
;相似地,吾人亦定義了一個存在每一個細節空間
O
j中正規化之基底函數 ,jk k Z
,稱 為小波函數。多層解析度分析是以存在於近似空間
V
j內之標度函數 及細節空間jkO
j內 之小波函數 為基礎,藉著存在於彼此具有逐層包含關係的空間jkV
j和O
j之正交 基底函數,吾人可對L
2 R
n 空間內之任意訊號進行反覆多次之分解,將訊號函數 在不同頻率層內之分量自原始訊號中萃取出來,達成多層解析度分析;反之,我 們亦可以利用 與j ,k 將j,kL
2 R
n 空間內之任意訊號還原,因此L
2 R
n 空間內之任意訊號函數
f (x )
亦可利用正交小波函數依(2.15)式表示為:) ( )
(
x Wf
, ,x
f
jkj k
k j
(2.24)
上式即稱為小波級數(wavelet series),根據上述多層解析度分析的概念,(2.24) 式可進一步作如下之分解為:
1
) ( )
( )
(
j n
n
j
f x D f x
A x
f
(2.25)其中
A f
(x
)W
, n,k(x
)j
n k
k n
j
為訊號函數
f (x )
在近似空間V
j內之近似函數;
k
k n k n
n
f x W x
D ( )
,,( )
為訊號函數f (x )
在細節空間O 之分量,
nn 1 j
,Z
n
。2.3.3 Mallat 運算法
在離散小波分解與重構(wavelet decomposing reconstruction)中,使用Mallat 運算法,可將訊號一層層進行分解,每一層分解的結果是將上次分解得到的低頻 訊號分解成低頻和高頻兩部分,每一次分解後的數據量減半,因此分析後得到的 低頻成分和高頻成分的時域解析度比分解前訊號減低一半。重構算法是分解算法 的逆過程,經每一層重構之後,訊號的數據量增加一倍,因此可提高訊號時域解
析度,如圖2.8所示。Mallat分解及重構的過程中,分別需要跳取(downsample or decimate)及零內插(subsample or zero interpolation),舉例說明如下:
1﹒跳取(downsample or decimate):
假設一訊號序列為[0 1 2 3 4 5 6 7 8];令跳取因子為2,
則新的序列為[0 2 4 6 8]。
2﹒零內插(subsample or zero interpolation):
經過跳取之後由於序列減半,所以於上述新的序列裡,
依次在每個值之間內插零,即[0 0 2 0 4 0 6 0 8]。
由於小波分解為一個正交分解,因此在訊號分解與重構過程中是不會發生假象現 象(aliasing),當然在訊號取樣的過程必須符合Nyquist取樣定理。
訊號分解是將訊號經由與濾波器摺積(convolution)計算後得到一個新的子空 間訊號,濾波器可分為低通濾波器(lowpass filters)及高通濾波器(highpass
filters),低通濾波器由比例函數係數所組合,高通濾波器則是由母小波係數所組 合。經由低通濾波器的運算可得到低頻子訊號,經由高通濾波器的運算則可得到 高頻子訊號。
訊號重建是將低頻子訊號及高頻子訊號分別經由濾波器的摺積後,將低頻及 高頻訊號加起來就可以合成原來的訊號。符號↓2是做次取樣(subsampling),符號
↑2是做升取樣(upsampling);次取樣是將分解後的訊號用每兩個點取一點的方式 重新排序,升取樣是在前面做次取樣後每兩個點之間插入一點零再重新排序。
將訊號一層層進行分解,每一層分解的結果為將前次分解得到的低頻訊號分解成 低頻及高頻訊號兩部分,且每一次分解後的數據量減半,也因此分析後得到的低 頻及高頻成分的時域解析度比分解前之訊號減低一半。
2.3.4
小波包(Wavelet Packet)小波包是將一組訊號依 Mallat 演算法與小波運算的結果。假設有一組訊號 S(t),則可經由 H 濾波器(父小波)與 G 濾波器(母小波)分別分解成低頻的近 似訊號(approximation signal)A1 和高頻的差值訊號(difference signal)D1,然 後再一次以 H 濾波器將近似訊號 A1 分解成下一層的近似訊號 AA2 與差值訊號 DA2,而 G 濾波器也將差值訊號分解成下一層的近似訊號 AD2 與差值訊號 DD2,一直重複這個分解過程直到滿足某個條件為止,而這種將訊號分解的過程 稱之為小波包分解,它的分解過程如圖 2.9 所示。
圖 2.8 小波的分解與重建示意圖
圖 2.9 小波包分解示意圖
第三章 隱藏層神經元個數之決定
3.1 前言
在類神經網路的使用上,除了要選定適當的網路之外,其餘各個參數的決定 也是重點,例如隱藏層的層數決定、活化函數的選擇、權重初始化...等等,
而本研究與本章節則是著重於隱藏層神經元數的決定方式之探討。
3.2 倒傳遞類神經網路概述
倒傳遞類神經網路是最早發明的類神經網路,架構非常簡單,但是精度高而 且回想速度快,因此被廣泛地應用,網路架構如圖 3.1 所示;其運作主要分為學 習及回想兩部份,學習過程是一種監督式學習,它讀入訓練範例及目標輸出值,
將訓練範例輸入至網路中,利用最陡坡降法反覆地調節網路的加權值及偏權值,
使得網路輸出值能與目標輸出值更加相近;所謂的回想,即讀入待預測之輸入資 料,使用訓練完成的網路模擬然後輸出吾人欲知之值。因為本論文以此種類神經 網路為主要分析工具,故分別詳細說明該網路之建構理論與應用步驟於後。
輸入層 隱藏層 輸出層
圖 3.1 倒傳遞類神經網路架構圖 X1
X2 →
XNinp →
.
.
.
Y1
.
.
. YNout
← T1
← TNout W_xh W_hy
B_h
↓
B_y
↓
3.2.1 BPA 學習演算法
1.決定網路的層數及各層間神經元數目
一般而言,網路只要具備輸入層,隱藏層一層,和輸出層即可,意即設 定網路是三層的架構,令輸入層神經元個數 Ninp 個,隱藏層神經元個數 Nhid 個,輸出層神經元數目 Nout 個;又採用批次學習,令訓練資料 Ntrain 筆。
2.以均佈隨機亂數設定網路的初始加權值與初始偏權值
不同層的神經元彼此相連,令 W_xh(i,n)為輸入層第 i 個神經元與隱藏層 第 n 個神經元間的加權值,由於有 Nip 個輸入神經元與 Nhid 個隱藏神經元,
故所以可以用一個二層迴圈來設定所有輸入層與隱藏層間的初始加權值如下 所示:
random
= n) xh(i, W_
1 Ninp, 1,
= i do
1 Nhid, 1,
= n do
同理,令 W_hy(n,j)為隱藏層第 n 個神經元與輸出層第 j 個神經元間的加權值,
則可以設定所有隱藏層與輸出層間的初始加權值如下:
random
= j) hy(n, W_
1 Nhid, 1,
= n do
1 Nout, 1,
= j do
再來設定網路的偏權值,只有隱藏層及輸出層才有偏權值,輸入層是沒有的;
因為輸入層並沒有運算能力,它只是將一個神經元接收到的訊號平行輸出至 隱藏層各個神經元中。令 B_h(n)為隱藏層第 n 個神經元的偏權值,B_y(j)為輸 出層第 j 個神經元的偏權值,則程式設定如下:
random B_h(n)
1 Nhid, 1,
= n
do
random B_y(j)
1 Nhid, 1,
= j
do
3.輸入訓練樣本 X[Ninp]與目標輸出值 T[Nout]
4.計算網路的計算輸出值 Y[Nout]
首先計算隱藏層的輸出值:
Ninp1 i
) ( _ ) ( ) , ( _ net_h(n)
1 Nhid, 1,
= n do
n h B i x n i xh W
-net_h(n)
exp 1 [n] 1
1 Nhid, 1,
= n do
H
其中 net_h(n)為隱藏層第 n 個神經元的加權乘積和,而 H[n]為隱藏層第 n 個 神經元的輸出值,它將收集到的加權值乘積和 net_h(n)再做一次非線性轉換。
接著,將隱藏層的訊號傳至輸出層:
Nhid1 n
) ( _ ) ( ) , ( _ net_y(j)
1 Nout, 1,
= j do
n y B n h j n hy W
-net_y(j)
exp 1 [j] 1
1 Nout, 1,
= j do
Y
其中 net_y(j)為輸出層第 j 個神經元的加權乘積和,Y[j]為網路計算出來的推 論輸出值。
5.計算輸出層、隱藏層與目標結果的差距量 輸出層差距量可如下計算:
1 - Y[j] [ ] [ ]
Y[j]
_y(j) 1 Nout, 1,
= j do
j Y j T
d
其中 d_y(j)是輸出層第 j 個神經元與目標值的差距量,(T[j]-Y[j])表示輸出值與 目標值間的誤差。
隱藏層差距量的計算如下:
Nout1 j
) ( _ ) , ( _ ]
[ 1 ] [ d_h(n)
1 Nhid, 1,
= n do
j y d j n hy W n H n H
其中 d_h(n)表示隱藏層第 n 個神經元與目標值的差距量;比較特殊的是上式包 含了一個子項式:
Nout
1 j
) ( _ ) , (
_
hy n j d y j
W
,此式表示輸出層與目標值差距量的加權乘積和,故 d_h(n)的計算與輸出層本身的差距量有關,這代表我們將輸
出層的誤差倒傳至隱藏層來計算隱藏層本身的差距量,這也是此種網路「倒傳 遞」之稱的由來。
6.計算各層間的加權值修正量與偏權值修正量
令 dW_hy(n,j)表示隱藏層第 n 個神經元與輸出層第 j 個神經元間的加權值 修正量,則計算其間所有加權值修正量的方法如下:
h(n) d_y(j)
= j) dW_hy(n, j = 1, Nout, 1 do
1 Nhid, 1,
= n do
令 dB_y(j)為輸出層第 j 個神經元的偏權值修正量,則偏權值修正量的計算方 法如下:
) ( _ _y(j)
1 Nout, 1,
= j do
j y d d
在上面兩個式子中,η為學習速率,一般取值為 0.1~1.0。有時為了網路的收 斂速度,可將上兩式改寫成:
j) dW_hy(n, H(n)
d_y(j)
= j)
dW_hy(n,
_y(j) )
( _
_y(j) d y j d d
其中α稱為慣性因子,一般取值為 0.0~0.9。
同理,令 dW_xh(i,n)為輸入層第 i 個神經元與隱藏層第 n 個神經元間的加權值 修正量,則計算其間所有加權值修正量的方法如下:
x(i) d_h(n)
= n) dW_xh(i,
1 Nhid, 1,
= n do
1 Ninp, 1,
= i do
令 dB_h(n)為隱藏層第 n 個神經元的偏權值修正量,則偏權值修正量的計算方 法如下:
) ( _ _h(n)
1 Nhid, 1,
= n do
n h d d
7.更新各層間的加權值及偏權值j) W_hy(n, j)
W_hy(n, j)
W_hy(n, t1 t
d
n) W_xh(i, n)
W_xh(i, n)
W_xh(i, t1 t
d
) ( _ B ) ( _ B ) ( _
B
h n
t1h n
td h n
) ( _ B ) ( _ B ) ( _B
y j
t1y j
t d y j
8.重複步驟 3.~步驟 7.,直至網路收斂學習過程通常每載入一組範例即更新權重值,但我們亦可採用批次學習,
亦即將一批範例載入後,依次求得每一組的權重改變量,將其累加起來再平均 以更新權重值(本論文採用批次學習),然後讓網路重複學習數個學習循環,
直至網路收斂為止。
為了測試網路是否收斂,定義下列誤差函數來表示網路的學習品質:
j
j Y j j T
E 1 ( ) ( )
2此式表示輸出層各個神經元的平方誤差和;因為在學習過程中,我們希望網路 的推綸輸出值 Y(j)與目標輸出值 T(j)越接近越好,所以亦可在程式中替上式加 上一個合理的限制值來做為收斂的條件。
3.2.2 BPA 回想演算法
所謂的回想,即讀入待預測之輸入資料,使用訓練完成的網路模擬然後輸出 吾人欲知之值,其過程如下所示:
1.設定網路的層數及各層間神經元的數目。
2.讀入已訓練好的網路加權值及偏權值。
3.讀入已準備好的測試範例
X ( 1 ), X ( 2 )..., X ( Ninp )
。4.使用與學習演算法相同的步驟 4.,計算網路輸出值
Y ( 1 ), Y ( 2 )..., Y ( Ninp )
, 隨後便可將結果與真值資料互相比對。以上即為倒傳遞類神經網路之基礎理論與運作過程,本論文亦以此種類神經 網路取代傳統的地下水流模擬模式(MODFLOW);而取代過程中必須決定的各 種網路參數將逐一詳述如後面章節,唯本研究之重點著重於最佳隱藏神經元個數 之決定。