國
立
交
通
大
學
資訊學院
資訊科學與工程研究所
博 士 論 文
「富含訊息多媒體」
– 一種普及溝通
之新工具
Message-rich Multimedia – A New Tool for
Pervasive Communication
研 究 生: 李雅琳
指 導 教 授: 蔡 文 祥 博士
「富含訊息多媒體」 – 一種普及溝通
之新工具
Message-rich Multimedia – A New Tool for
Pervasive Communication
研 究 生:李 雅 琳
Student: Ya-Lin Lee
指 導 教 授:蔡 文 祥 博士
Advisor: Dr. Wen-Hsiang Tsai
國 立 交 通 大 學 資 訊 學 院
資 訊 科 學 與 工 程 研 究 所
博 士 論 文
A Dissertation Submitted to
Institute of Computer Science and Engineering
College of Computer Science
National Chiao Tung University
in Partial Fulfillment of the Requirements
for the Degree of Doctor of Philosophy
in Computer Science and Engineering
November 2013
Hsinchu, Taiwan, 300
Republic of China
「富含訊息多媒體」 – 一種普及溝通之新工具
研究生:李雅琳 指導教授: 蔡文祥博士
國立交通大學資訊學院
資訊科學與工程研究所
摘 要
隨著資訊科技的進步,越來越多的裝置被設計出來跟周遭的環境互動,以 做各種普及溝通之應用。普及溝通是指人們可以和生活周遭的物體於任何地點與 時間做資訊交換;而存在於生活周遭的許多物體可用來容納資訊,達到普及溝通 的目的。本論文定義「富含訊息多媒體」,並探討以這種多媒體做普及溝通的方 法。 此外,資訊隱藏可將訊息嵌入多媒體中,因此資訊隱藏為達到普及溝通的 其一重要技術。然而,目前大部分的數位裝置,如智慧型手機與平板,並不能感 知周遭環境的內容,意即他們不能瞭解周遭環境所含有的資訊,因此需要嶄新之 資訊隱藏技術,以應用這些裝置和多種不同的富含訊息多媒體做溝通,達到普及 溝通之目的。本論文提出了五種富含訊息的多媒體,包含:大張影像、加密影像、 文字形式之協作文件,以及特別設計之兩種影像的硬刻版本,並提出對應於此五 種富含訊息多媒體的新資訊隱藏方法。 首先,本論文提出一種可將一秘密影像隱藏於任一同樣大小之目標影像之 中的資訊隱藏方法。本方法利用色彩轉換技術,建立一「可視秘密碎片馬賽克影 像」,該影像看起來類似使用者挑選的目標影像,可將秘密影像隱藏起來成為一 馬賽克影像,此種馬賽克影像不僅可有傳輸秘密影像之功能,更解決了傳統資訊 隱藏方法無法於影像中嵌入大量資訊的問題。接著,針對加密影像,本論文利用 兩次影像加密及空間相關性之比對技術來隱藏資訊,對每一區塊畫素的幾個 LSBs 做加密達到嵌入一位元資訊的作用。此方法解決了先前已發表兩個技術會 遭遇到的平滑影像問題。 除了影像以外,本論文亦提出一可於協作平台隱藏資訊的新方法。此方法 能根據秘密訊息產生擬造的修訂歷史,並將秘密訊息隱藏於模擬過程之中。能達此作用,主要是利用多人協作的幾個特性來隱藏資訊,包含:每個修訂版本的作 者、被更改文字序列的數量、被更改文字序列的內涵、取代被更改文字序列的文 字序列。此外,還利用一下載的 XML 格式之英文版維基百科來建置模擬多人協 作之資料庫。此一所提方法提供了一種利用協作平台進行秘密通訊與安全保存秘 密訊息之應用。 最後,本研究另外提出了可從事「自動識別與資料抓取」之兩種資訊隱藏 方法,讓普及溝通實現於特別設計之兩種影像的硬刻版本上。此兩種影像之第一 種為富含訊息之字元影像,第二種為富含訊息之編碼影像,這些影像可列印於紙 上或顯示於螢幕或電視上。詳言之,富含訊息之字元影像其建立方式是先將字元 訊息切碎,再產生跟目標影像一樣大的字元影像,接著利用一區塊亮度調變方法 來改變字元影像每塊碎片的亮度值,最後將調變之位元影像注入於目標影像之 中。而富含訊息之編碼影像其建立方式是先將一訊息轉換為一由二元圖樣區塊所 組成的圖樣影像,並同樣透過區塊亮度調變方法,改變每塊圖樣區塊的亮度值, 最後將調變之圖樣影像注入於目標影像之中。這兩種影像擁有類似條碼及 QR 碼 的功能,且其外觀看起來類似一任一選擇的目標影像,故可達到普及溝通的效果。 以上所提出的方法皆為創新之作,深入的理論分析及實驗結果顯示這些方 法皆具有可行性及實用性。
Message-rich Multimedia – A New Tool for
Pervasive Communication
Student: Ya-Lin Lee
Advisor: Dr. Wen-Hsiang Tsai
Institute of Computer Science and Engineering
College of Computer Science
National Chiao Tung University
Abstract
With the advance of information technologies, more and more devices are designed to interact with environments for various pervasive communication applications; thereby people can exchange information with the identities existing in the environment everywhere and anytime. Many kinds of identities exist in the environment can be utilized to accommodate information for the purpose of pervasive communication. In this study, identities called message-rich multimedia are defined and investigated for pervasive computing.
Data hiding can be employed to embed message information into multimedia existing in various application environments, creating message-rich multimedia as the result; therefore, data hiding is regarded as one of the key techniques to achieve pervasive communication. In addition, most existing digital devices like smart phones and tablets are “unaware” of the environment context, i.e., they cannot “understand” the environmental surrounds even if they can “see” them by image taking with the built-in cameras. Therefore, numerous possibilities for achieving pervasive computing through uses of these devices by data hiding techniques via various message-rich multimedia are worth investigation.
In this dissertation study, five types of message-rich multimedia are proposed, including: 1) image with large data volumes; 2) encrypted image; 3) text-typed collaborative writing work; and 4) hard copies of two types of specially-designed images; and five new data hiding techniques creating respectively these types of message-rich multimedia are designed.
Firstly, a new large-volume data hiding method for hiding a secret image into any target image of the same size is proposed. The method creates automatically from an arbitrarily-selected target image a so-called secret-fragment-visible mosaic image as a disguise of the given secret image. Based on color transformation, the method not only creates mosaic images useful for secure image communication, but also provides a new way to solve the difficulty of hiding secret images with huge data volumes into target images. Next, via encrypted images, a new data hiding method based on the techniques of double image encryption and spatial correlation comparison is proposed as well, solving a problem encountered by two previously-proposed methods when dealing with flat cover images. Specifically, the proposed method encrypts the LSBs of each block pixel in a given encrypted image to embed a message bit.
In addition to dealing with images, a new data hiding method via collaboratively-written articles with camouflaged revision history records for use on collaborative writing platforms is proposed. Characteristics of article revisions are identified subtlely and used to embed secret messages, including the author of each revision, the number of corrected word sequences, the content of the corrected word sequences, and the word sequences replacing the corrected ones. An English Wikipedia XML dump is utilized to construct a database for forging the revisions by data hiding techniques. The proposed method is useful for covert communication or secure keeping of secret messages via collaborative writing platforms.
Finally, two other data hiding techniques for automatic identification and data capture applications are proposed to enable pervasive communication via hard copies of two types of specially-created images, where the first type is message-rich character image and the second message-rich code image. These image copies may be printed versions on papers or displayed versions on monitors or TVs. Specifically, a digital message-rich character image is created from an arbitrarily-selected target image for use as a carrier of a given message by fragmenting the shapes of the composing characters of the message and injecting the resulting character fragments randomly into the target image by a block luminance modulation scheme. And a message-rich code image is created by converting a given message into a pattern image composed of binary pattern blocks and injecting the resulting pattern image into the target image by a block luminance modulation scheme. With functions similar to those of barcodes or QR codes, the created two types of message-rich images look similar to the target image, achieving the effect of pervasive communication.
The feasibility and effectiveness of all the proposed methods are demonstrated by theoretical analyses and good experimental results.
Acknowledgements
The author is in hearty appreciation of the continuous guidance, discussions, and support from her advisor, Dr. Wen-Hsiang Tsai, not only in the development of this dissertation study, but also in every aspect of her personal growth. The author would also like to acknowledge the very helpful comments and suggestions from the members of the oral defense committee as well as those from the reviewers for parts of this dissertation that were submitted for journal publication.
Appreciation is also given to the colleagues of the Computer Vision Laboratory in the Institute of Computer Science and Engineering at National Chiao Tung University for their suggestions and helps during her dissertation study. The author would like to acknowledge as well the financial support received from the National Science Council during the course of this dissertation study.
Finally, the author also extends her profound thanks to her dear family and boy friend for their lasting love, care, and encouragement. This dissertation is dedicated to them.
Table of Contents
摘 要 ... i
Abstract ... iii
Acknowledgements ... vi
Table of Contents ... vii
List of Figures ... x
List of Tables ... xvii
Chapter 1 Introduction ... 1
1.1 Background and Motivation ... 1
1.2 Issues in Study of Message-rich Multimedia ... 2
1.3 Survey of Related Works ... 3
1.3.1 Review of techniques for data hiding via images ... 3
1.3.2 Review of techniques for data hiding via image barcodes ... 4
1.3.3 Review of techniques for data hiding via text documents ... 5
1.3.4 Review of techniques for barcode reading ... 6
1.4 Overview of Proposed Techniques and Ideas ... 6
1.4.1 Data hiding by nearly-reversible color transformation ... 6
1.4.2 Data hiding by techniques of image encryption and spatial correlation comparison ... 7
1.4.3 Data hiding via revision history records on collaborative writing platforms ... 8
1.4.4 Data hiding via message-rich character images... 8
1.4.5 Data hiding via message-rich code images ... 9
1.5 Dissertation Organization ... 11
Chapter 2 A New Data Hiding Technique via Secret-fragment-visible Mosaic Images by Nearly-reversible Color Transformation ... 12
2.1 Introduction ... 12
2.2 Idea of Proposed Method ... 14
2.3 Problems and Proposed Solutions for Mosaic Image Creation ... 15
2.4 Algorithms of Proposed Method ... 21
2.5 Experimental Results ... 25
2.7 Summary ... 33
Chapter 3 A New Data Hiding Technique via Encrypted Images by Image Encryptions and Spatial Correlation Comparisons ... 34
3.1 Introduction ... 34
3.2 Review of Existing Methods ... 35
3.3 Proposed Method ... 39
3.3.1 Message embedding ... 39
3.3.2 Message extraction and image recovery ... 39
3.4 Experimental Results ... 42
3.5 Summary ... 46
Chapter 4 A New Data Hiding Technique via Revision History Records on Collaborative Writing Platforms ... 47
4.1 Introduction ... 47
4.2 Basic Idea of Proposed Method ... 49
4.3 Data Hiding via Revision History ... 52
4.3.1 Collaborative writing database construction ... 52
4.3.2 Secret message embedding ... 54
4.3.3 Secret message extraction ... 67
4.4 Experimental Results ... 69
4.5 Security Consideration ... 79
4.5.1 Camouflage ... 79
4.5.2 Randomness ... 80
4.5.3 Possible extensions for the proposed method using natural language processing methods ... 82
4.6 Summary ... 82
Chapter 5 A New Data Hiding Technique via Message-rich Character Image for Automatic Identification and Data Capture Applications ... 84
5.1 Introduction ... 84
5.2 Idea of Proposed Method ... 86
5.3 Generation of Message-rich Character Image ... 87
5.3.1 Message image creation ... 87
5.3.2 Block luminance modulation ... 87
5.3.3 Algorithm for message-rich character image creation ... 92
5.4.1 Message-rich character image localization and inverse perspective transform 93
5.4.2 Block number identification and block segmentation ... 94
5.4.3 Binarization and optical character recognition ... 95
5.4.4 Message extraction algorithm ... 96
5.5 Experimental Results ... 97
5.6 Summary ... 100
Chapter 6 A New Data Hiding Technique via Message-rich code Image for Automatic Identification and Data Capture Applications ... 102
6.1 Introduction ... 102
6.2 Idea of Proposed Method ... 103
6.3 Generation of Message-rich Code Image ... 104
6.3.1 Pattern image creation ... 104
6.3.2 Block luminance modulation ... 107
6.3.3 Algorithm for message-rich code image creation ... 108
6.4 Message Extraction ... 110
6.4.1 Localization of message-rich code image and inverse perspective transform 110 6.4.2 Block number identification and block segmentation ... 110
6.4.3 Binarization and recognition of pattern blocks ... 111
6.4.4 Message extraction algorithm ... 114
6.5 Experimental Results ... 116
6.6 Summary ... 124
Chapter 7 Conclusions and Suggestions for Future Studies ... 126
7.1 Conclusions ... 126
7.2 Suggestions for Future Studies... 129
References ... 131
Vitae ... 138
List of Figures
Figure 1.1. A result yielded by proposed method. (a) Secret image. (b) Target image. (c) Secret-fragment-visible mosaic image created from (a) and (b). ... 7 Figure 1.2. Example of created message-rich character image. (a) Target image. (b)
Created message-rich character image. ... 9 Figure 1.3. Example of created message-rich code image. (a) Target image. (b)
Created message-rich code image. ... 10 Figure 2.1. Illustration of creation of secret-fragment-visible mosaic image proposed
in [39]. ... 13 Figure 2.2. Flow diagram of the proposed method. ... 15 Figure 2.3. Illustration of fitting tile images into target blocks. ... 17 Figure 2.4. Illustration of effect of rotating tile images before fitting them into target
blocks. (a) Secret image. (b) Target image. (c) Mosaic image created from (a) and (b) without block rotations (with RMSE = 23.261). (d) Mosaic image created from (a) and (b) with block rotations (with RMSE = 20.870). ... 18 Figure 2.5. An experimental result of mosaic image creation. (a) Secret image. (b)
Target image. (c) Mosaic image created with tile image size 88. (d)
Recovered secret image using a correct key with RMSE = 0.948 with respect to secret image (a). (e) Recovered secret image using a wrong key. (f)-(i) Mosaic images created with different tile image sizes 1616, 2424, 3232, and 4040. ... 26 Figure 2.6. Comparison of results of Lai and Tsai [39] and proposed method. (a)
Secret image. (b) Target image. (c) Mosaic image created from (a) and (b) by [39] with RMSE = 47.651. (d) Mosaic image created from (a) and (b) by proposed method with RMSE = 33.935. ... 27 Figure 2.7. Two other experimental results of mosaic image creation. (a) and (d)
Secret images. (b) and (e) Target images. (c) and (f) Mosaic images created from (a) and (b), and (d) and (e), respectively, with tile size 88. (g) and (h) Zoom-out images of red square regions of (c) and (f), respectively. ... 28 Figure 2.8. Created mosaic images with the same secret image. (a) Secret image. (b)
Mosaic image created from (a) and Figure 2.7(b) with RMSE = 26.067. (c) Mosaic image created from (a) and Figure 2.7(e) with RMSE = 33.102. ... 29
Figure 2.9. Created mosaic images with the same secret image shown in Fig. 5(a) and small-sized target images. (a) Created image for target image shown in Fig. 5(b) with size 768×1024. (b) Created image for target image shown in Fig. 5(b) but with size reduced to (1/5)×(1/5). (c) Created image for target image shown in Fig. 5(b) but with size reduced to (1/10)×(1/10). ... 30 Figure 2.10. Plots of trends of various parameters versus different tile image sizes
(88, 1616, 3232) with input secret images shown previously and coming from a large dataset. (a) RMSE values of created mosaic images with respect to target images. (b) Numbers of required bits embedded for recovering secret images. (c) RMSE values of recovered secret images with respect to original ones. (d) MSSIM values of created mosaic images with respect to target images. ... 31 Figure 2.11. Correct permutations of tile images in the mosaic image without
recovering the original color characteristics. (a) The correct permutation of tile images of Figure 1.1(c). (b) The correct permutation of tile images of Figure 2.7(c). ... 33 Figure 3.1. Recovery results showing problems of [55] and [56] with block size 88,
incorrectly-recovered blocks marked as white, and error rate denoted by err. (a) Input flat X-ray image. (b) Result with err = 50.81% yielded by [55]. (c)
Result with err = 44.53% yielded by [56]. (d) Result with err = 0% yielded by proposed method. (e) Input original image of (a). (f) Result with err = 16.53% yielded by [55]. (g) Result with err = 14.99% yielded by [56]. (h) Result with
err = 0% yielded by proposed method. ... 38
Figure 3.2. Illustration of block contents for computing |Hm,n,0' Hx,y,1'| for 44 blocks,
where currently-processed adjacent block of Bm,n′ is Bm+1,n′. ... 40
Figure 3.3. Recovery results showing effects of using both recovered and unrecovered blocks for measuring smoothness of 88 blocks, with incorrectly-recovered blocks marked as white, and error rate denoted by err. (a) Result with err = 2.66% yielded by [56]. (b) Result with err = 0.46% yielded by proposed method without using side-match. (c) Result with err = 0.27% yielded by proposed method using only recovered blocks in side-match scheme. (d) Result with err = 0.22% yielded by proposed method using both recovered and unrecovered blocks in side-match scheme. ... 41
Figure 3.4. Four test images of size 512512. ... 42
Figure 3.5. Comparisons of bit-extraction error rates yielded by proposed method with those yielded by [55] and [56] versus different block sizes. (a) Error rates with cover image Figure 3.4(a). (b) Error rates with cover image Fig. Figure 3.4(b). (c) Error rates with cover image Figure 3.4(c). (d) Error rates with cover image Figure 3.4(d). ... 43
Figure 3.6. Comparisons of execution time in message embedding required by proposed method with that required by [55] and [56] versus different block sizes. ... 44
Figure 3.7. Recovery results showing effects of using different numbers NL of LSBs for 88 blocks with incorrectly-recovered blocks marked as white and error rate denoted by r. (a) Cover image. (b) Decrypted image with message embedded. (c) Result with r = 0.90% yielded by proposed method for NL = 3. (d) Result with r = 0.07% yielded by proposed method for NL = 4. (e) Result with r = 12.87% yielded by [55] for NL = 3. (f) Result with r = 29.27% yielded by [55] for NL = 4. (g) Result with r = 10.21% yielded by [56] for NL = 3. (h) Result with r = 27.76% yielded by [56] for NL = 4. ... 45
Figure 4.1. Basic idea of proposed method that generates a revision history of a stego-document as a camouflage for data hiding. ... 48
Figure 4.2. A screenshot of the revision history of an article about computer vision on Wikipedia. ... 49
Figure 4.3. A screenshot of two consecutive revisions of an article about computer vision on Wikipedia. ... 51
Figure 4.4. Flow diagram of the proposed method. ... 51
Figure 4.5. Illustration of used terms and notations. ... 52
Figure 4.6. An example of found correction pairs between Di and Di–1 ... 53
Figure 4.7. Illustration of encoding authors of revisions for data hiding. ... 55
Figure 4.8. Illustration of the dependency problem. (a) Revision Di1 and candidate set Qr where the dependent word sequences are surrounded by red squares. (b) Set I that corresponds to the set Qr for solving the dependency problem. ... 57
Figure 4.9. Illustration of the selection problem. (a) Huffman codes for the word sequences and the message bits that are encountered in the selection problem.
(b) Dividing of the word sequences into groups to solve the selection problem. ... 59 Figure 4.10. Illustration of the consecutiveness problem. (a) An example for
illustration of the consecutiveness problem. (b) Choosing splitting points randomly to solve the consecutiveness problem. ... 61 Figure 4.11. The number of entries of chosen sets with the size from 2 to 40. ... 71 Figure 4.12. An example of generated stego-documents on constructed Wiki site with
input secret message “Art is long, life is short.” (a) Cover document. (b) Revision history (c) Stego-document. (d) Previous revision of revision of (e) with words in red being those corrected to be new words in revision of (e) in red. (e) Newest revision of created stego-document. (f) Correct secret message extracted with the right key “1234.” (g) Wrong extracted secret message with a wrong key “123.” ... 73 Figure 4.13. The embedding capacities. (a) Embedding capacities of documents with
chosen sets of different sizes. (b) Embedding capacities of documents with different number of revisions. ... 75 Figure 4.14. Comparison of embedding capacities yielded by Liu and Tsai [64] and
proposed method using different numbers of revisions. ... 76 Figure 4.15. An example to show the interoperability of the proposed method which
can be applied on Chinese articles. ... 77 Figure 5.1. Examples of commonly-used barcodes. (a) Code 39. (b) PDF 417. (c) QR
code. (d) Data matrix code. ... 85 Figure 5.2. Illustration of proposed method. ... 86 Figure 5.3. Message-rich character image generation. (a) Image of character “T.” (b)
Ending pattern. (c) Target image. (d) Message image. (e) Y-channel of (c). (f) Modulated message image. (g) Zoom-out of red square region in (f). (h) Resulting printed message-rich character image. ... 89 Figure 5.4. Modulated character-fragments resulting from uses of different contrast
threshold values of for the difference between the two representative values
r1 and r2. (a) = 0. (b) = 10. (c) = 20. (d) = 30. (e) = 40. (f) = 50. ... 90
Figure 5.5. Localization and correction of perspective distortion in captured message-rich character image. (a) Localized message-rich character image
portion (enclosed by red rectangle). (b) Result of perspective distortion
correction applied to red portion region in (a). ... 93 Figure 5.6. Message extraction. (a) Captured modulated message image IM′′. (b)
Gradient values of (a). (c) Average gradient values of pixels on candidate spitting lines for different NS. (d) Image division result according to
determined number of blocks NS = 16. (e) Fragment reordering result of (d). (f)
Binarization result of (e). (g) OCR result of (f). (h) Extracted message. ... 95 Figure 5.7. Created message-rich character images. (a)-(c) Test target images. (d)-(f)
Resulting message-rich character images with NS = 32 and = 40. ... 98
Figure 5.8. Plots of trends of results using various parameters. (a) Accuracy rates of extracted messages with different contrast threshold values , with #blocks NS
= 16. (b) RMSE values of created message-rich character images with respect to target images for different contrast threshold values of , with #blocks NS =
16. (c) Accuracies of extracted messages with different #blocks NS, where
contrast threshold value = 40. ... 99 Figure 5.9. Robustness of proposed method. (a) A captured message-rich character
image under defacement attack. (b) A captured message-rich character image under another defacement attack. (c) A message-rich character image captured from a monitor screen. ... 100 Figure 6.1. Examples of message-rich images yielded by the method in Chapter 5 and
proposed method. (a) Target image. (b) Message-rich character image created by the method in Chapter 5. (c) Message-rich code image created by proposed method. ... 103 Figure 6.2. Illustration of major steps of two phases of proposed method. ... 104 Figure 6.3. An example of undistinguishable binary code patterns. ... 105 Figure 6.4. Performing proposed bit expansion scheme on every three message bits to
yield eight binary code patterns represented by pattern blocks. ... 106 Figure 6.5 Message-rich code image generation. (a) Target image. (b) Pattern image IP.
(c) Y-channel of (a). (d) Modulated pattern image. (e) Zoom-out of red square region in (d). (f) Resulting message-rich code image. ... 107 Figure 6.6. Modulated pattern block resulting from uses of different contrast threshold values of for the absolute difference between the two adjusted representative
values r1′ and r2′. (a) = 0. (b) = 5. (c) = 10. (d) = 20. (e) = 30. (f) = 40. ... 109 Figure 6.7. Localization and correction of perspective distortion in captured
message-rich code image. (a) Localized message-rich code image portion (enclosed by red rectangle). (b) Result of perspective distortion correction applied to red portion region in (a). ... 110 Figure 6.8. Block number identification. (a) Captured modulated pattern image IP′′. (b)
Gradient values of (a). (c) Average gradient values of pixels on candidate spitting lines for different NS. (d) Image division result according to
determined number of unit blocks, NS = 64. ... 112
Figure 6.9. Binarization and code-pattern recognition. (a) Captured modulated pattern image. (b) Binarization result of (a). (c) Result of code-pattern recognition of (b). (d) Extracted message. ... 115 Figure 6.10. Created message-rich code images. (a), (c), and (e) Target images. (b), (d)
and (f) Resulting message-rich code images with NS = 128 and = 40. ... 117
Figure 6.11. Created message-rich code images with different contrast threshold values of , where NS = 64. (a) Resulting message-rich code image with
RMSE = 66.35 and accuracy rate = 85.60%, where = 0. (b) Resulting code image with RMSE = 66.57 and accuracy rate = 98.97%, where = 20. (c) Resulting code images with RMSE = 68.47 and accuracy rate = 100%, where
= 40. (b) Resulting images with RMSE = 72.27 and accuracy rate = 100%, where = 60. ... 118 Figure 6.12. Plots of trends of results using various parameters. (a) Accuracy rates of
extracted messages with different contrast threshold values , with #unit blocks NS = 32. (b) RMSE values of created message-rich code images with
respect to target images for different contrast threshold values of , with #unit blocks NS = 32. (c) Accuracy rates of extracted messages with different #unit
blocks NS with contrast threshold = 40. (d) RMSE values of created
message-rich code images with respect to target images with different #unit blocks NS and contrast threshold = 40. ... 119
Figure 6.13. Created message-rich code images with different #unit blocks NS, where
contrast threshold value = 40. (a) Resulting message-rich code image with RMSE = 47.66 and accuracy rate = 100%, where NS = 16. (b) Resulting
message-rich code image with RMSE = 44.63 and accuracy rate = 100%, where NS = 32. (c) Resulting message-rich code image with RMSE = 42.05
and accuracy rate = 100.00%, where NS = 64. (d) Resulting message-rich code
image with RMSE = 39.43 and accuracy rate = 99.11%, where NS = 128. ... 120
Figure 6.14. Binarized captured message-rich images created by method in Chapter 5 and proposed method in this chapter and respective message extraction accuracy rates, where the target image of these resulting images is Figure 6.10(c). (a) Binarized image by method in Chapter 5 with NS = 32 and
accuracy rate = 98.61%. (b) Binarized image by proposed method in this chapter with NS = 32 and accuracy rate = 99.80%. (c) Binarized image by
method in Chapter 5 with NS = 64 and accuracy rate = 41.25%. (d) Binarized
image by proposed method in this chapter with NS = 64 and accuracy rate =
99.76%. ... 122 Figure 6.15. Performing another bit expansion scheme on every three message bits to
yield 14 binary code patterns represented by pattern blocks. ... 123 Figure 6.16. Results yielded by using two different bit expansion schemes with NS =
64 and = 20. (a) Pattern image yielded by the original bit expansion scheme. (b) Pattern image yielded by the new bit expansion scheme. (d) Message-rich code image yielded by the original bit expansion scheme with RMSE = 55.97. (d) Message-rich code image yielded by the new bit expansion scheme with RMSE = 55.44. ... 124
List of Tables
Table 4.1.Top twenty frequently used correction pairs. ... 70
Table 4.2. Some correction pairs each with more than one word either in the original word sequence or in the new word sequence. ... 71
Table 4.3.An example of a chosen set with the new word sequence “such as”. ... 72
Table 4.4. The information of experimental documents. ... 74
Table 4.5. Comparison of methods for data hiding via texts. ... 78
Table 6.1. An example of code pattern recognition. ... 114
Table 6.2. Comparison of results of proposed method in this chapter and method in Chapter 5 with = 40. ... 121
Chapter 1
Introduction
1.1 Background and Motivation
With the advance of information technologies, more and more devices are designed to interact with environments for various pervasive communication applications; thereby people can exchange information with the identities existing in the environment everywhere and anytime [1]–[2]. For example, one can use the camera on a smart phone to scan a QR code on a merchandise item and obtain the detailed related information. Recently, Davis [3] proposed a new concept, called
signal rich art: the art that communicates its identity to context-aware devices,
through data hiding techniques mainly, to realize pervasive communication.
In our daily life, many kinds of identities existing in the environment can be utilized to accommodate information for the purpose of pervasive communication. However, identities discussed in [3] are mainly those with artistic flavors, such as illustrations, posters, sculptures. It is desirable in this study to explore various types of multimedia, such as images, texts, hard copies, advertisements, displays on monitors or TVs, etc., for pervasive computing. Messages are expected to be injected into such identities, like the information encoded into the QR codes, and can be extracted by people using a “message reader.” We call such multimedia message-rich multimedia in this study.
Moreover, data hiding is a type of technique which can embed messages into multimedia existing in our daily life for various applications, creating message-rich multimedia which achieve the effect of pervasive communication. A lot of data hiding techniques have been developed in the past decade [4]-[5]. They may be regarded to play key roles in our study of pervasive communication via message-rich multimedia.
However, current progresses towards our new vision of technology advancement
pervasive communication by message-rich multimedia are impeded by computers, networks, and digital devices that are largely unaware of the environmental context [3]; that is, they cannot “understand” the environmental surrounds even if they can “see” them by image taking with the built-in cameras. Therefore, numerous possibilities for achieving pervasive computing by data hiding
techniques via message-rich multimedia are still open research topics worth studying. It is desired in this study to solve possible issues which might be encountered in the study of message-rich multimedia.
1.2 Issues in Study of Message-rich Multimedia
About issues which might be encountered in the study of message-rich multimedia,
firstly it is well known that conventional data hiding methods often face the difficulty to embed a large amount of message data into a single image [4]-[16]. Up to now, most existing methods can hide only text messages or images with small data volumes into cover images. Specifically, if one wants to hide a secret image into a cover image of the same size, the secret image must be compressed greatly in advance, resulting in the undesired effect of unrecoverability of the orginal higher-quality secret image. This study tries to solve this issue of transmitting images with large data volumes secretly without degrading the original quality of the secret image.
Next, an image may contain private or confidential information that is usually encrypted before being transmited on the Internet to ensure its security. However, designs of most conventional data hiding methods are based on the properties of natural images so that they are not suitable for use in embedding messages into
encrypted images which usually appear to be noise or random data. Hence, this
dissertation study is devoted, as the second goal, to this issue of embedding messages in encrypted images.
Thirdly, attacking the weaknesses of human auditory and visual systems, most researches on data hiding focused on non-text multimedia as cover media. Less data hiding techniques using text-type cover media have been proposed. Recently, more and more collaborative writing platforms are becoming popular, and some of them have been exploited for data hiding applications. However, most of the data hiding methods can only be applied to documents with single authors and single revision versions [29]-[38], meaning that they are not suitable for hiding data on collaborative writing platforms. Therefore, a third goal of this study is to design new data hiding methods which can hide data into documents created on collaborative writing platforms.
Moreover, conventional data hiding methods can be employed to transfer data though “digital files” only, such as images and text documents; they are “incompetent” for enabling pervasive communication when one wants to interact with the
environmental surround. A type of data hiding, called hardcopy data hiding, have been proposed, which embeds information into image barcodes using halftone techniques [17]-[19], and the encoded information can survive “print-and-scan
attacks.” However, if one uses a mobile device to capture images of hardcopy image barcodes, the information might not be decoded successfully since the captured image
will suffer from additional types of distortions other than those acquired by scanning. Therefore, also as a goal of this study it is desirable to devise new automatic
identification and data capture techniques via the use of hard copies of message-rich images that have functions similar to barcode or QR-code reading, with the generated
hard copies of the images looking visually similar to pre-selected target images, achieving the effect of pervasive commutation once again in different ways.
In summary, the goals of this dissertation study are to propose data hiding techniques to create various types of message-rich multimedia for pervasive communication, including: 1) image with large data volumes; 2) encrypted image; 3) text-typed collaborative writing work; and 4) hard copies of images. Fulfillments of aforementioned goals of this dissertation study together will be expected to enhance the state-of-art studies on data hiding techniques, yielding a new vision of pervasive communication and a further step of extending its applications.
1.3 Survey of Related Works
Works related to this study are categorized into several directions and reviewed as follows.
1.3.1 Review of techniques for data hiding via images
Data hiding is useful for applications like covert communication, copyright protection, document authentication, secret keeping, etc., and is a key component to achieve the function of pervasive communication as mentioned previously. Recently, many methods for data hiding via images have been proposed. Petitcolas [4] and Bender et al. [5] made good surveys of data hiding techniques via images, which may be classified into two major types: spatial-domain based and transform-domain
based.
Spatial-domain based methods hide messages directly into the spatial-domain data of given images, such as LSB substitution, histogram modification, difference expansion, etc. [6]-[10]. For example, Chan and Cheng [6] proposed a simple LSB
substitution method that applies an optimal pixel adjustment process to the input image. Ni et al. [7] and Lee and Tsai [8] proposed histogram modification methods, each of which shifts some values in the histogram around the peak to embed secret messages. Tian [9] proposed a difference expansion method that explores data redundancy in an image to achieve a high embedding capacity. Hu et al. [10] proposed another difference expansion method that utilizes horizontal as well as vertical difference images for data embedding.
Transform-domain based methods hide messages into the transform-domain data of given images, using transformations like discrete cosine, integer wavelet, etc. [11]-[14]. For example, Fridrich et al. [11] proposed two discrete cosine transform (DCT) based methods that compress JPEG coefficients or modify quantization matrices to embed messages. Chang et al. [12] proposed another DCT based method that uses two successive zero coefficients of the medium frequency components in each block to hide messages. Lee et al. [13] proposed an integer wavelet transform based method that embeds a watermark into the high-frequency wavelet coefficients of each block. Lin et al. [14] proposed a data hiding method for copyright protection based on the use of the so-called significant differences of the blocks of the wavelet coefficients during the wavelet coefficient quantization process.
1.3.2 Review of techniques for data hiding via image barcodes
Another type of data hiding, which is called “hardcopy” data hiding, can embed information into so-called image barcodes using halftone techniques [17]-[19]. These image barcodes have the visual appearances of other images and the encoded information can be decoded from their hardcopy versions acquired by scanners. That is, the encoded information can survive “print-and-scan attacks.” For example, Bulan
et al. [17] proposed a framework for data hiding in images printed with clustered dot
halftones via a pattern orientation modulation technique. Bulan and Sharma [18] proposed another pattern orientation modulation technique that utilizes three printing channels and modulates the orientations of elliptical-shaped dots for data encoding. Damera-Venkata et al. [19] proposed a block-error diffusion method that embeds information into hardcopy images by using dot-shape modulation.
1.3.3 Review of techniques for data hiding via text documents
Attacking the weaknesses of human auditory and visual systems, many researches on data hiding focused on non-text cover media. Less data hiding techniques using text-type cover media have been proposed. Bennett [28] made a good survey about hiding data in text and classified related techniques into three categories: format-based methods, random and statistical generation, and linguistic
methods.
Format-based methods use the physical formats of documents to hide messages. Some of them utilize spaces in documents to encode message data. For example, Alattar and Alattar [29] proposed a method that adjusts the distances between words or text lines using spread-spectrum and BCH error-correction techniques, and Kim et
al. [30] proposed a word-shift algorithm that adjusts the spaces between words based
on concepts of word classification and statistics of inter-word spaces. Some other methods utilize non-displayed characters to hide messages, such as Lee and Tsai [31] which encodes message bits using special ASCII codes and hides the result between the words or characters in PDF files.
Random and statistical methods generate directly camouflage texts with hidden messages to prevent the attack of comparing the camouflage text with a known plaintext. For example, Wayner [32]-[33] proposed a method for text generation based on the use of context-free grammars and tree structures. Another method available on a website [34] extends this idea to generate fake spam emails with hidden messages, which are usually ignored by people.
Linguistic methods use written natural languages to conceal secret messages. For example, Chapman et al. [35] proposed a synonym replacement method that generates a cover text according to a secret message using certain sentence models and a synonym dictionary. Bolshakov [36] extended the synonym replacement method by using a specific synonymy dictionary and a very large database of collocations to create a cover text, which is more believable to a human reader. Shirali-Shahreza and Shirali-Shahreza [37] proposed a third synonym replacement method that hides data in a text by substituting words which have different terms in the UK and the US. Stutsman et al. [38] proposed a method to hide messages in the noise that is inherent in natural language translation results without the necessity of transmitting the source text for decoding.
1.3.4 Review of techniques for barcode reading
In addition to data hiding, the use of the barcode is another technique for pervasive communication, where a barcode is usually attached to objects for various identification purposes, and represents machine-readable data by patterns of lines, rectangles, dots, etc. To extract the data encoded into barcodes, such as Code 39 [20], PDF417 [21], QR code [22], data matrix code [23], etc., several barcode reading techniques have been proposed in the past. Ouaviani et al. [24] proposed an image processing framework for 2D barcode reading, including four main phases: region of interest detection, code localization, code segmentation, and decoding. Zhang et al. [25] proposed a real-time barcode localization method by using a two-stage processing, where the barcode is found first through a region-based analysis of low-resolution images and then read and analyzed in their original resolutions. Yang
et al. [26] proposed another accurate barcode localization method by using the prior
knowledge of the barcode to obtain the initially localized corners, and then using a post-localization process to find the accurate corner locations. Yang et al. [27] proposed an adaptive thresholding technique for the binarization of the barcode image by constructing a dynamic search window centered at the nearest edge pixel of the pixel to be binarized.
1.4 Overview of Proposed Techniques and Ideas
In this section, we describe the main ideas and techniques of the proposed data hiding techniques via various message-rich multimedia.
1.4.1 Data hiding by nearly-reversible color transformation
A new large-volume data hiding method is proposed, which creates automatically from an arbitrarily selected target image a so-called secret-fragment-visible mosaic image as a disguise of a given secret image, achieving the effect of hiding a secret image into any target image of the same size. Specifically, after a target image is selected arbitrarily, the given secret image is first divided into rectangular fragments called tile images, which then are fit into similar blocks in the target image, called target blocks, according to a similarity criterion based on color variations. Next, the color characteristic of each tile image is transformed to be that of the corresponding target block in the target image, resulting in a mosaic image which looks like the target image. Figure 1.1 shows a result yielded by the proposed method.
(a) (b) (c)
Figure 1.1. A result yielded by proposed method. (a) Secret image. (b) Target image. (c) Secret-fragment-visible mosaic image created from (a) and (b).
The proposed method removes the weakness found in [39] that requires a large image database for the user to select a color-similar target image for each input secret image while keeping its merit of high-volume data embedding capability. That is, the proposed method can hide a secret image into any pre-selected target image of the same size to create a secret-fragment-visible mosaic image without the need of a
database. The method not only creates mosaic images useful for secure keeping of
secret images, but also provides a new way to solve the difficulty of hiding secret images with huge data volumes into target images.
1.4.2 Data hiding by techniques of image encryption and spatial
correlation comparison
A new data hiding method on encrypted images based on the techniques of double image encryption and spatial correlation comparison is proposed. The proposed method solves a problem encountered in the two previously-proposed methods [55]-[56] when dealing with flat cover images. In this study, the LSBs of each block pixel in an encrypted image are encrypted further to embed one message bit, so the aforementioned problem encountered in [55] and [56] caused by flat cover images is solved.
Furthermore, four LSBs of each pixel of a block in the encrypted image are utilized for message embedding. Also, a side-match scheme that utilizes the spatial correlations of both recovered and unrecovered blocks is proposed to decrease the bit-extraction error rate, in contrast with [56] which utilizes the spatial correlations of
recovered blocks only. Experimental results showing the proposed method greatly improves the performance of the two previously-proposed methods in dealing with flat cover images.
1.4.3 Data hiding via revision history records on collaborative
writing platforms
A new data hiding method via collaboratively-written articles with forged revision history records on collaborative writing platforms is proposed. The hidden message is camouflaged as a stego-document consisting of a stego-article and a revision history created through a simulated process of collaborative writing. The revisions are forged using a database constructed by mining the word sequences used in real cases from an English Wikipedia XML dump. Four characteristics of article revisions are identified and utilized to embed secret messages, including the author of each revision, the number of corrected word sequences, the content of the corrected word sequences, and the word sequences replacing the corrected ones. Related problems arising in utilizing these characteristics for data hiding are identified and solved skillfully, resulting in an effective multi-way method for hiding secret messages into the revision history.
To create more realistic revisions, Huffman coding based on the word sequence frequencies collected from Wikipedia is applied to encode the word sequences. Therefore, the resulting stego-document is more realistic than other text data hiding methods. The proposed method is useful for covert communication or secure keeping of secret messages on collaborative writing platforms. Moreover, to the best of our knowledge, this is the first work that can simulate the collaborative writing process with multiple authors and revisions and utlize the characteristics in the collaborative writing process effectively for message embedding.
1.4.4 Data hiding via message-rich character images
A new data hiding method via message-rich character images is proposed, where the character image is a new kind of message-rich multimedia and may be printed as a hardcopy for use in applications of pervasive communication. Figure 1.2 shows an example of the created message-rich character image yielded by the proposed method. The created image is then “re-imaged” by a mobile-phone camera and “understood”
by some automatic identification and data capture (AIDC) techniques [40] proposed in this study.
Specifically, a message-rich character image is created from a target image used as a carrier of a given message by fragmenting the shapes of the composing
characters of the message and “injecting” the resulting character fragments randomly
into the target image by a block luminance modulation scheme. Each message-rich character image so created has the visual appearance of the corresponding pre-selected target image.
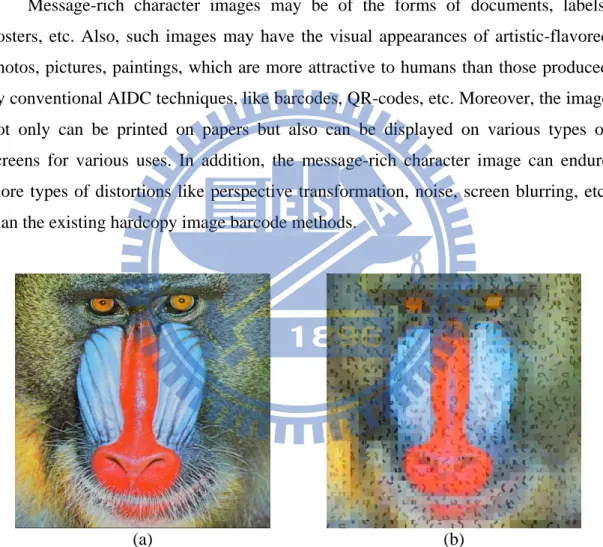
Message-rich character images may be of the forms of documents, labels, posters, etc. Also, such images may have the visual appearances of artistic-flavored photos, pictures, paintings, which are more attractive to humans than those produced by conventional AIDC techniques, like barcodes, QR-codes, etc. Moreover, the image not only can be printed on papers but also can be displayed on various types of screens for various uses. In addition, the message-rich character image can endure more types of distortions like perspective transformation, noise, screen blurring, etc. than the existing hardcopy image barcode methods.
(a) (b)
Figure 1.2. Example of created message-rich character image. (a) Target image. (b) Created message-rich character image.
1.4.5 Data hiding via message-rich code images
Another new data hiding method via message-rich code images is proposed, where the message-rich code image is a new kind of message-rich multimedia. It may also be printed as a hardcopy for use in applications of pervasive communication just
like the use of the message-rich character image. The proposed method improves the previous method presented in Section 1.4.4 above, as described in the following.
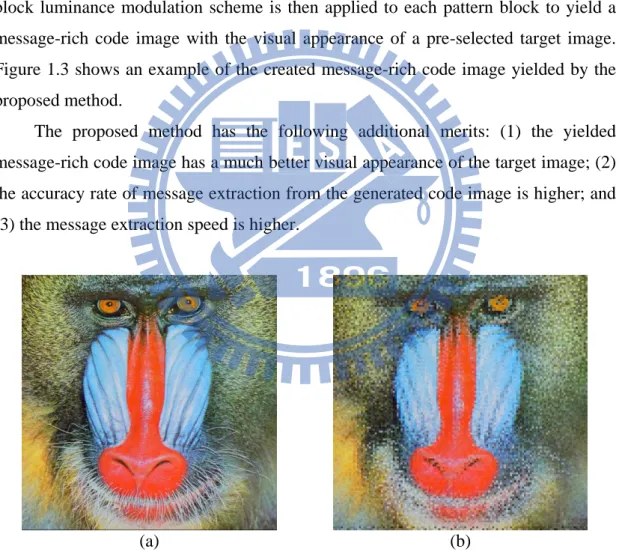
As shown in Figure 1.2(b), each message-rich character image contains many small character fragments with undesired visual effects. Also, it requires an optical character recognition (OCR) scheme to extract the embedded message. Moreover, to keep the resolution in the captured image sufficiently good for correct message extraction, the size of each block cannot be too small. In order to solve these problems, instead of transforming the given message to be embedded into a message image, the proposed method converts a given message into a bit stream of codes first, which is then represented by binary pattern blocks, each being composed of 2×2 unit blocks. A block luminance modulation scheme is then applied to each pattern block to yield a message-rich code image with the visual appearance of a pre-selected target image. Figure 1.3 shows an example of the created message-rich code image yielded by the proposed method.
The proposed method has the following additional merits: (1) the yielded message-rich code image has a much better visual appearance of the target image; (2) the accuracy rate of message extraction from the generated code image is higher; and (3) the message extraction speed is higher.
(a) (b)
Figure 1.3. Example of created message-rich code image. (a) Target image. (b) Created message-rich code image.
1.5 Dissertation Organization
The remainder of this dissertation is organized as follows. In Chapter 2, the proposed large-volume data hiding technique for secure image transmission is described. In Chapter 3, the proposed new data hiding technique on encrypted images based on the techniques of double image encryption and spatial correlation comparison is described. The proposed new data hiding technique via creations of fake collaboratively-written documents on collaborative writing platforms is presented in Chapter 4. In Chapter 5, the proposed new data hiding technique via message-rich character images is described, while the proposed new data hiding technique via message-rich code images is described in Chapter 6. Finally, conclusions of this study and some suggestions for future researches are included in the last chapter.
Chapter 2
A New Data Hiding Technique via
Secret-fragment-visible Mosaic Images by
Nearly-reversible Color Transformation
2.1 Introduction
Data hiding is useful for applications like covert communication, copyright protection, document authentication, secret keeping, etc. Many methods for data hiding via images have been proposed [6]-[16]. In order to reduce the distortion of the resulting image, an upper bound for the distortion value is usually set on the payload of the cover image. A discussion on this rate-distortion issue can be found in [41]. Thus, a main issue of the methods for hiding data in images is the difficulty to embed a large amount of message data into a single image.
Specifically, if one wants to hide a secret image into a cover image with the same size, the secret image must be highly compressed in advance. For example, for a data hiding method with an embedding rate of 0.5 bits per pixel, a secret image with 8 bits per pixel must be compressed at a rate of at least 93.75% beforehand in order to be hidden into a cover image. But, for many applications, such as keeping or transmitting medical pictures, military images, legal documents, etc., that are valuable with no allowance of serious distortions, such data compression operations are usually impractical. Moreover, most image compression methods, such as JPEG compression, are not suitable for line drawings and textual graphics, where sharp contrasts between adjacent pixels are often destructed to become noticeable artifacts after being compressed [42].
Therefore, most existing methods can hide only text messages or images with small data volumes into cover images. However, in a recently published paper by Lai and Tsai [39], a new type of computer art image was presented, called secret-fragment-visible mosaic image, which is the result of rearrangement of the fragments of a secret image in disguise of another image called target image pre-selected from a database. The above-mentioned difficulty of hiding a huge volume of image data behind a cover image is solved automatically by the use of this
type of mosaic image, where a secret image of the same size is hidden in the mosaic image without any compression.
In more detail, as illustrated by Figure 2.1, a given secret image is first “chopped” into tiny rectangular fragments, and a target image with a similar color distribution is selected from a database. Then, the fragments are arranged by using a fast greedy algorithm to fit into the blocks of the target image, yielding an image with a mosaic appearance looking like the target image. The mosaic image preserves all the secret image fragments in appearance, but no one can figure out what the original secret image looks like due to the tiny sizes and the randomness of the re-arranged fragments. The method may be adopted as a new way for secure keeping of secret images.
Figure 2.1. Illustration of creation of secret-fragment-visible mosaic image proposed in [39].
However, using their method, the user is not allowed to select freely his/her favorite image for use as the target image. It is therefore desired in this study to remove this weakness of the method while keeping its merit, that is, it is aimed to design a new method to transform a secret image into a secret-fragment-visible mosaic image of the same size that has the visual appearance of any freely-selected target image without the need of a database.
Specifically, after a target image is selected arbitrarily, the given secret image is first divided into rectangular fragments called tile images, which then are fit into
similar blocks in the target image, called target blocks, according to a similarity criterion based on color variations. Next, the color characteristic of each tile image is transformed to become that of the corresponding target block in the target image, resulting in a mosaic image which looks like the target image. Relevant schemes are also proposed to conduct nearly lossless recovery of the original secret image from the resulting mosaic image. The proposed method is new in the fact that it can transform a secret image into a disguising mosaic image without compression, while other data hiding methods must hide a highly compressed version of the secret image into a cover image when the secret image and the cover image have the same data volume.
2.2 Idea of Proposed Method
The proposed method includes two main phases as shown by the flow diagram of Figure 2.2: 1) mosaic image creation; and 2) secret image recovery.
In the first phase, a mosaic image is yielded, which consists of the fragments of an input secret image with color corrections according to a similarity criterion based on color variations. The phase includes four stages as described in the following. Stage 1-1 – fit the tile images of the secret image into the target blocks of a
pre-selected target image.
Stage 1-2 – transform the color characteristic of each tile image in the secret image to become that of the corresponding target block in the target image.
Stage 1-3 – rotate each tile image into a direction with the minimum RMSE value with respect to its corresponding target block.
Stage 1-4 – embed relevant information into the created mosaic image for future recovery of the secret image.
And in the second phase, the embedded information is extracted to recover nearly losslessly the secret image from the generated mosaic image. The phase includes two stages as described in the following.
Stage 2-1 – extract the embedded information for secret image recovery from the mosaic image.
Figure 2.2. Flow diagram of the proposed method.
2.3 Problems and Proposed Solutions for Mosaic Image
Creation
Problems encountered in generating mosaic images are discussed in this section with solutions to them proposed.
A. Color Transformations between Blocks
In the first phase of the proposed method, each tile image T in the given secret image is fit into a target block B in a pre-selected target image. Since the color characteristics of T and B are different from each other, how to change their color distributions to make them look alike is the main issue here. Reinhard et al. [43] proposed a color transfer scheme in this aspect, which converts the color characteristic of an image to be that of another in the l color space. This idea is an answer to the issue and is adopted in this study, except that the RGB color space instead of the l one is used to reduce the volume of the required information for recovery of the original secret image.
More specifically, let T and B be described as two pixel sets {p1, p2, …, pn} and
{p1′, p2′, …, pn′}, respectively. Let the color of each pi be denoted by (ri, gi, bi) and
that of each pi′ by (ri′, gi′, bi′). At first, we compute the means and standard deviations
of T and B, respectively, in each of the three color channels R, G, and B by the following formulas:
1 1 1 1 , n n c i c i i i c ' c' n n
; (1) 2 2 1 1 1 1 ( ) , ( ) n n c i c c i c i i c ' c' ' n n
(2) where ci and ci′ denote the C-channel values of pixels pi and pi′, respectively, with c =r, g, or b and C = R, G, or B. Next, we compute new color values (ri′′, gi′′, bi′′) for
each pi in T by:
( )
i c i c c
c'' q c ', (3)
where qc = c′/c is the standard deviation quotient and c = r, g, or b. It can be
verified easily that the new color mean and variance of the resulting tile image T′ are equal to those of B, respectively. To compute the original color values (ri, gi, bi) of pi
from the new ones (ri′′, gi′′, bi′′), we use the following formula which is the inverse
of :
(1/ )( )
i c i c c
c q c''' . (4)
Furthermore, we have to embed into the created mosaic image sufficient information about the new tile image T′ for use in the later stage of recovering the original secret image. For this, theoretically we can use (4) to compute the original pixel value of pi. However, the involved mean and standard deviation values in the
formula are all real numbers, and it is impractical to embed real numbers, each with many digits, in the generated mosaic image. Therefore, we limit the numbers of bits used to represent relevant parameter values in (3) and (4). Specifically, for each color channel we allow each of the means of T and B to have 8 bits with its value in the range of 0 to 255, and the standard deviation quotient qc in (3) to have 7 bits with its
value in the range of 0.1 to 12.8. That is, each mean is changed to the closest value in the range of 0 to 255, and each qc is changed to the closest value in the range of 0.1 to
12.8. We do not allow qc to be 0 because otherwise the original pixel value cannot be
B. Choosing Appropriate Target Blocks and Rotating Blocks to Fit Better with Smaller RMSE Value
In transforming the color characteristic of a tile image T to be that of a corresponding target block B as described above, how to choose an appropriate B for each T is an issue. For this, as shown in Figure 2.3, we use the standard deviation of the colors in the block as a measure to select the most similar B for each T. Specially, we sort all the tile images to form a sequence, Stile, and all the target blocks to form
another, Starget, according to the average values of the standard deviations of the three
color channels. Then, we fit the first in Stile into the first in Starget, fit the second in Stile
into the second in Starget, and so on.
Figure 2.3. Illustration of fitting tile images into target blocks.
Additionally, after a target block B is chosen to fit a tile image T and after the color characteristic of T is transformed, we conduct a further improvement on the color similarity between the resulting tile image T′ and the target block B by rotating
version of T′ with the minimum root mean square error (RMSE) value with respect to
B among the four directions for final use to fit T into B. Furthermore, the color
similariy between the resulting tile image T′ and the target block B is measured in the
luminance channel only, instead of in the RGB three color channels, to reduce the
execution time of the proposed method. Figure 2.4 shows a result of applying this block rotation scheme to the secret image and the target image shown in Figures 2.4(a) and 2.4(b), respectively, where Figure 2.4(c) is the mosaic image created without applying this scheme and Figure 2.4(d) is the one created instead. It can be seen that Figure 2.4(d) has a better fitting result with a smaller RMSE value than Figure 2.4(c).
(a) (b)
(c) (d)
Figure 2.4. Illustration of effect of rotating tile images before fitting them into target blocks. (a) Secret image. (b) Target image. (c) Mosaic image created from (a) and (b) without block rotations (with RMSE = 23.261). (d) Mosaic image created from (a) and (b) with block rotations (with RMSE = 20.870).
C. Handling Overflows/Underflows in Color Transformation
After the color transformation process is conducted as described previously, some pixel values in the new tile image T′ might have overflows or underflows. To deal with this problem, we convert such values to be non-overflow or non-underflow ones and record the value differences as residuals for use in later recovery. Specifically, we convert all the transformed pixel values in T′ not smaller than 255 to be 255, and all those not larger than 0 to be 0. Next, we compute the differences between the original pixel values and the converted ones as the residuals and record them as part of the information associated with T′. Accordingly, the pixel values which are just on the bound of 255 or 0, however, cannot be distinguished from those with overflow/underflow values during later recovery since all the pixel values with overflows/underflows are converted to be 255 or 0 now. To remedy this, we define the residuals of those pixel values which are on the bound to be “0” and record them as well.
But as can be seen from (3), the ranges of possible residual values are unknown, and this causes a problem of deciding how many bits should be used to record a residual. To solve this problem, we record the residual values in the un-transformed color space rather than in the transformed one. That is, by using the following two formulas we compute first the smallest possible color value cS (with c = r, g, or b) in T
that becomes larger than 255 as well as the largest possible value cL in T that becomes
smaller than 0, respectively, after the color transformation process has been conducted:
cS = (1/qc)(255 c′) + c;
cL = (1/qc)(0 c′) + c. (5)
Next, for an un-transformed value ci which yields an overflow after the color
transformation, we compute its residual as |ci cS|; and for ci which yields an
underflow, we compute its residual as |cL ci|. Then, the possible values of the
residuals of ci will all lie in the range of 0 to 255 as can be verified. Consequently, we
can simply record each of them with 8 bits. And finally, because the residual values are centralized around zero, we use further in this study the Huffman encoding
scheme to encode the residuals in order to reduce the numbers of required bits to
![Figure 2.1. Illustration of creation of secret-fragment-visible mosaic image proposed in [39]](https://thumb-ap.123doks.com/thumbv2/9libinfo/8420283.180471/32.892.160.740.456.818/figure-illustration-creation-secret-fragment-visible-mosaic-proposed.webp)


![Figure 2.6. Comparison of results of Lai and Tsai [39] and proposed method](https://thumb-ap.123doks.com/thumbv2/9libinfo/8420283.180471/46.892.160.749.432.972/figure-comparison-results-lai-tsai-proposed-method.webp)



