基於認知成分之代數推理測驗自動化 命題模式之發展
蘇義翔 洪碧霞
國立臺南大學教育學系
摘 要
本研究的目的在提出認知成分依據自動化命題模式,研究中針對國小高 年級學生常見的代數推理作業,分析解題的核心認知成分,選取運算子、表 徵轉換、計算複雜度等三項認知成分,操作性定義其內涵與編碼方式。依據 認知成分的定義,自動化產出代數推理能力測驗共 36 題,並針對國小五、
六年級 177 名學生進行施測,實徵檢視模式的適用性。本研究採用 Rasch 模 式進行難度參數校準,再以多元迴歸進行認知成分編碼對試題難度參數的預 測分析。結果顯示運算子和表徵轉換對試題實徵難度參數的解釋量約為 78%。本研究所提出認知成分及自動化命題模式,初步試用結果呈現合理的 生產性,可作為未來代數推理測驗自動命題的基礎,因應代數學習落後學生 補救教學的需求。
關鍵字: 代數推理測驗、認知成分、試題難度參數、試題模型、自動化命題
壹、前 言
數學教育是一項重要的公民權益,缺乏數學素養的學童在長大成人後常淪為次等的社 會經濟階層 (Moses & Cobb, 2001)。代數推理能力發展是數學教育重要的目標之一 (Kaput, 1998;Smith & Thompson, 2007),基本的代數能力不僅是進入高等數學的敲門磚,也是生 活在未來數位時代所不可或缺的利器。學界有越來越明顯的共識必須及早在學校教育中教 導學生運用代數推理解決問題 (Driscoll, 1999;Jacobs, Franke, Carpenter, Levi, & Battey, 2007;Kaput, 1999;Kaput, Carraher, & Blanton, 2008;NCTM, 2000)。在未來科技快速變 遷的社會裡,數學素養 (特別是代數能力) 是脫離弱勢地位的重要能力之一。
測驗電腦化是測驗發展的重要趨勢,善加利用新興電腦科技優勢,常能比傳統紙筆測 驗更能節省經費與時間,也可呈現更高互動且貼近真實情境的新題型 (Sireci & Zenisky, 2006;Zenisky & Sireci, 2002)。近年來結合認知心理學、心理計量和統計理論的發展對教 育測驗已造成深遠的影響 (Bartram, 2006;Bennett, 2001;Drasgow, Luecht, & Bennett, 2006;Embretson & Yang, 2007;Irvine & Kyllonen, 2002),許多研究者認為在測驗的發展 過程中,對試題進行難度或複雜度的認知分析扮演極為重要的角色 (Carpenter, Just, &
Shell, 1990;Embretson, 1999;Freund, Hofer, & Holling, 2008;Graf, Peterson, Steffen, &
Lawless, 2005;Irvine & Kyllonen, 2002)。
認知成分分析嘗試對試題難度或複雜度的變異來源加以操作性界定,期望能透過操弄 影響試題難度的成分,進而提供直接的構念效度證據。也就是說深入分析瞭解試題難度的 變異來源,將關聯的認知成分與適切的心理計量模式結合運用,以便更有效率的產出教育 或心理測驗,同時對測驗效度的論證能提供嚴謹的理論支持與解釋 (Embretson & Daniel, 2008)。實務上,先依據文獻分析,界定一組影響試題難度的基本成分 (radicals) 以及與試 題難度無關的隨機成分 (incidentals),再透過實驗操弄和心理計量的分析,歸納檢視可合 理預測和解釋試題難度的認知成分,方能有效產出目標難度的試題。電腦化自動命題
(computerized automatic item generation) 技術必須以良好的測驗認知分析證據為基礎,以 確保產出試題符合預期的心理計量特質,讓測驗編製具有品質。例如 GRE (Graduate Record Examination) 數量推理測驗的自動化命題系統,所採用的試題複製即是選取自現有 題庫中具備良好心理計量參數的試題。此外,認知成分分析的結果也有助於提供教學實務 上回饋。例如:洪碧霞、林素微與林娟如 (2006),以及洪碧霞、蕭嘉偉與楊佩馨 (2008)
曾針對臺灣國小二至六年級的數學成就測驗,從認知負荷的觀點進行試題難度或複雜度的 分析;同時洪碧霞、蕭嘉偉與林素微 (2009) 亦曾針對 PISA 數學素養試題進行認知成分分 析,這些研究結果均能對教學實務提供豐富的回饋資訊,利後續補救教學介入焦點的擬 定。
國小學生代數學習重要性不言而喻,然而目前相關研究多是偏重探討教學方法及學生 解題策略等面向,測驗的分析亦大多針對既有的題庫,甚少直接對代數推理試題的特徵和 結構加以實驗操弄。以認知分析的結果作為代數題庫建構依據的電腦化命題系統也不多 見,亟待開發。本研究基於代數推理能力測驗發展的需求,結合數學教育、認知心理學和 心理計量方法,嘗試提出一套認知成分依據自動化命題發展模式,並針對國小學童代數推 理作業進行認知成分分析及模式適用性的驗證。依據上述研究目的,詳述研究問題如下:
一、國小代數推理能力測驗的心理計量特徵為何?
二、不同題型試題難度參數與認知負荷分配差異為何?
三、代數推理認知成分與試題難度參數的相關組型為何?
四、代數推理認知成分對試題難度參數變異的解釋力為何?
本研究所分析的心理計量特徵包含傳統測驗分析的答對率和鑑別度、以及 Rasch 模式 校準的難度參數。代數推理認知成分則包含三項可能影響國小學童代數推理試題難度的基 本成分變項,分別為運算子 (arithmetic operator)、表徵轉換 (representation transformation)
和計算複雜度 (computational complexity),詳細的操作性定義呈現於研究工具中。
貳、文獻探討
一、代數推理為數學學習的核心成分
推理能力 (reasoning ability) 是指學習困難教材的一種關鍵性向 (aptitudes),它不但是 有效教學的輸入,同時也是在完成學習後的一種重要成果 (Snow, 1996)。推理能力亦是智 力的核心 (Sternberg, 1986),是探討人類智力時非常重要的面向。國內外的課程標準都認 為抽象推理能力是數學學習重要的一環 (NCTM, 2000),更是日常生活中解決一般問題所 不可或缺的基本能力 (Greeno, 1978)。在傳統智力理論 (如 CattellHorn-Carroll model, CHC model)中,代數推理能力歸屬於數量推理因素 (quantitative reasoning),與一般智力
(general intelligence) 存在高度相關,是測量人類智力必要的成分之一 (Arendasy, Sommer, Gittler, & Hergovich, 2006;Bickley, Keith, & Wolfle, 1995;Carroll, 1993;Horn & Noll, 1997)。
如何培養在日常生活、職場和民主社會中具備理智決策行為的公民,數學一直被視為 核心的科目之一 (NCTM, 2000;Schoenfeld, 2002)。代數推理能力的發展是數學教育不可 或 缺 的 一 環, 而 且 代 數 概 念 往 往 是 數 學 學 習 的 一 個 關 鍵 點 (Kaput, 1998;Smith &
Thompson, 2007)。許多學者、教育工作者和決策官員均強調培養學童代數能力的重要性,
並宣稱在基礎教育階段學童代數推理能力的發展攸關數學教育改革的成敗 (Kaput, 1998;
NCTM, 2000;Silver, 1997)。國小高年級的代數課程正處於由算術思考轉變為正式代數思 考的轉換時期,並為更高層次且更抽象的代數學習預作準備。研究顯示,在國小數學課程 中適當的引入前置代數,強化數量關係的覺察,確實能促進學童進行代數式的推理思考
(Bastable & Schifler, 2007;Carpenter & Levi, 2000;Kaput, 2008;Kaput et al., 2008)。有鑒 於此,數學教育社群已有一致的共識,認為學校教育應儘早提供學生從事代數思考和推理 的機會和經驗,以便建立學生日後高階數學學習的基礎 (Driscoll, 1999;Jacobs et al., 2007;Kaput, 1999;Kaput et al., 2008;Katz, 2007;NCTM, 2000)。
二、認知分析在代數推理測驗發展的重要性
就科學的證據理論而言,認知或教育測驗的目的無非是從觀察受試者如何解題來推論 他們能做什麼?以及具備什麼能力?而測驗分數推論的有效程度與測驗的構念效度
(construct validity) 關係密切,構念效度可說是探討測驗品質時最核心的議題 (Embretson, 1983、2002;Embretson & Gorin, 2001)。為了獲取建構效度立論的支持證據,測驗專家對 受試者解決問題的認知歷程及知識結構作深入的探究,以瞭解其解題過程的困難來源。
從認知分析的角度而言,構念表徵的概念也相當於探討及界定解題歷程的認知複雜 度,為了設計和預估作業難度的來源和水準,首先必須探究隱含在作業中複雜度因素
(Embretson & Gorin, 2001;Embretson & Yang, 2007;Gorin, 2006;Primi, 2002)。一般而言,
對試題特徵 (item feature) 加以實驗操弄,檢視實驗操弄對試題難度的影響程度,是廣為 採用的研究方法。在學理上假定為,試題特徵和受試者運用的解題策略及知識結構之間在 個體認知差異上存在著理論上的關連 (Embretson, 1983、1998、2002)。
依據認知心理學理論和心理計量模型,可建構出試題的刺激項特徵對解題歷程和認知 處理難度之間相互關聯,並進而有效的預測試題難度 (Embretson, 1983、1998;Embretson
& Yang, 2007)。 預 測 試 題 難 度 的 認 知 成 分 區 分 為 基 本 成 分 (radicals) 和 隨 機 成 分
(incidentals)(Arendasy et al., 2006;Dennis, Handley, Bradon, Evans, & Newstead, 2002)。基 本成分是指對試題難度參數具有顯著影響的試題刺激特徵,例如在推理測驗中與工作記憶 運作有關的規則數量,即被假定對試題難度會產生顯著的影響。相反的,隨機成分被定義 為對試題難度參數沒有顯著影響的刺激特徵,如數學文字題中涉及人物或物品的名稱等,
即被假定僅有微量或甚至完全不會影響試題的難度 (Irvine, 2002)。認知成分分析即是在透 過認知心理學理論和心理計量模型驗證所提出的認知成分是屬於與難度有相關的基本成 分,或是與難度沒有相關的隨機成分。合理的基本成分界定不僅要能符合心理計量上的適 配度,同時也要在構念表徵 (Embretson, 1983) 上能達到令人滿意的程度 (Arendasy, 2005;
Arendasy & Sommer, 2005、2007)。在統計方法上,使用多元迴歸分析檢驗提出的成分是 否能顯著影響試題的難度,乃是認知成分分析研究廣為採用的方法。
在過去的實務上,運用心理學理論為依據的認知分析法已被廣泛而成熟的應用在各種 認知測驗中,例如圖形旋轉測驗 (Bejar, 1990) 和圖形推理測驗 (Arendasy & Sommer, 2005;Carpenter et al., 1990;Embretson, 2002;Primi, 2002)。然而,在目前教育測驗 (如 數學測驗) 的編製實務仍大都依賴領域專家或教師的命題經驗進行題庫建構,或以電腦化 直接複製現有的試題,而比較少依據認知分析的結論來發展成就測驗。在代數或數量推理 測驗發展的實務上,國際知名的測驗 GRE 納入數量推理和分析式推理等測驗,顯見代數 或數量推理能力在學術能力發展上的重要性。Arendasy 等人 (2006) 曾利用電腦自動產生
應用問題對研究所學生進行施測,驗證數量推理與智力結構關係,且證實測驗的構念效度 並不受電腦自動命題機制的影響。在國內,洪碧霞等人曾針對臺灣學生數學成就測驗
(STASA-MAT) 及 PISA 數學素養試題進行認知成分分析 (洪碧霞、林素微與林娟如,
2006;洪碧霞、蕭嘉偉與楊佩馨,2008;洪碧霞、蕭嘉偉與林素微,2009)。表 1 呈現歷 年來國內外不同測驗認知成分個數、難度變異解釋量及分析模式對照,從中可發現合理而 充足的模式解釋力大致介於 60%~80% 之間。
然而,上述研究的分析標的大多為現有的測驗題庫,較少直接對試題特徵和認知結構 加以操弄,進行認知成分分析。代數學習在國小階段的重要性不言而喻,現有的相關研究 大多是偏重探討教學方法及學生解題策略等面向。以認知分析的結果作為後續題庫建構的 依據並適用在國中小教育階段的代數推理能力測驗並不多見,亟待開發。
表 1 認知成分分析研究成分數、難度變異解釋量及分析模式對照
測驗內容 成分數 題數 難度
解釋力 測驗對象 分析模式 資料來源
電腦化圖形推理測驗 8 30 90% 國小高年級 多元迴歸 張世強與
洪碧霞 (2010)
二度空間視覺化測驗 4 38 87% 大學一至四年級 多元迴歸、
LLTM
林世華、劉子鍵與 梁仁楷(1998)
比率代數文字題 4 35 78% 12 至 70 歲 多元迴歸 Arendasy 與 Sommer (2007)
PISA 2006 數學試題 3 48 77% 臺灣 15 歲學生 多元迴歸 洪碧霞、蕭嘉偉與 林素微(2010)
電腦化空間感測驗 5 31 73% 國小四 ~ 六年級 LLTM 李岳勳(2004)
瑞文氏高級圖形推理測驗 4 20 72% 高中和大學生 LLTM 劉子鍵(2000)
GRE 數學測驗 12 101 67% 大學生 多元迴歸、
LLTM
Embretson 與 Daniel (2008)
GRE 段落理解測驗 11 200 35~72% 大學生 多元迴歸、
LLTM
Gorin 與
Embretson (2006),
Embretson 與 Wetzel (1987)
數字系列完成測驗 3 40 65% 高中二年級學生 多元迴歸、
LLTM
林世華與 葉嘉惠(1999)
矩陣圖形推理測驗 5 36 64% 大學生 多元迴歸 Carpenter et al. (1990)
平衡桿問題 9 41 60% 10-15 歲學生 多元迴歸、
LLTM 丁振豐 (1997)
數與計算成就測驗 3 42 53% 國小二至四年級 多元迴歸 洪碧霞等人 (2008)
臺灣學生數學成就測驗 6
1~2 53 4~21
全部領域:
27%
個別領域:
50%
國小六年級 多元迴歸 洪碧霞等人 (2006)
三、電腦化自動命題
所謂電腦化自動命題是指以演算法 (algorithmic) 方式自動產出大量試題的一種測驗編 製技術。測驗的過程中,系統依據測驗編製人員或電腦化適性測驗 (computerized adaptive test, CAT) 程式提出的心理計量需求,在試題產生算則 (item generation algorithm) 的導引 下,即時自動產出大量立即可供施測的試題 (Embretson & Yang, 2007;Irvine, 2002)。從表 面上看來,最明顯的優勢是透過電腦軟硬體系統所帶來的生產效率和成本效益,特別是當 試題包含傳統測驗編製時必須透過人工繪製的圖形或數學式。而且電腦自動產生的試題不 必再重複進行預試和量尺校準,因此可節省許多開發的人力和金錢。另一方面,從更深層 的測驗效度而言,以認知分析作為系統發展依據的自動化命題,可提供受試反應行為與欲 測量的技能 (或潛在特質) 之間實質的關聯資訊,藉由認知理論基礎和心理計量技術能對 測驗分數和結果提供更合理的解釋 (Bejar, 2013)。在心理計量專家的適當控制下,自動化 命題系統可產生內容平衡且難度相當的平行試卷,滿足動態評量或縱貫性研究對多次教學 介入後形成性評量重複測驗的需求,顯見這是一支有待積極投入的應用研究方向 (Bennett
& Gitomer, 2009;Graf, 2009)。此外,由於施測的試題都是由電腦即時產生的,對於解決 試題曝光和高風險測驗中試題保密議題而言是頗具前瞻的一項技術,因而廣受測驗研究發 展學者和專家的重視。
根據 Embretson 與 Yang (2007) 的看法,自動化命題的研發可分成以下五個步驟:
(一) 瞭解試題變異的來源。(二) 依據設計原則產生試題並修正認知模式。(三) 以出題算 則 (algorithms) 自動化產生試題。(四) 實徵性試驗自動化命題系統。(五) 結合電腦化適 性命題程式。在瞭解試題變異的來源方面,大多數結合認知成分分析與心理計量方法所關 注的焦點是試題的難度參數,也就是所謂的試題難度模式 (item difficulty model, IDM)
(Gorin, 2006)。以 IDM 模式發展的測驗,最終目標是在結合認知或學習理論與解題歷程 的試題特徵,建立一個完整解釋試題難度的模式。IDM 的重要性在於確認試題處理的相 關特徵,初步的試題特徵經常藉由內容領域相關文獻分析產生,實際運作的難度模式通常 需要不斷反覆修正 (洪碧霞、蕭嘉偉、楊佩馨,2008)。
分析測驗難度成分的研究中,最廣為使用之心理計量模式為 IRT (Item Response Theory) 理論中的線性邏輯模式 (linear logistic latent trait model, LLTM),該模式最早由 Fischer (1973、1995) 所提出,是一種單向度 Rasch 模式的延伸。在 LLTM 中,Rasch 模 式的試題難度參數被分解為數個基本成分,也就是透過界定數個基本成分,建構試題與認 知成分編碼矩陣,進而分析各認知成分對試題難度參數的影響程度,以及對難度參數變異 的解釋量。由於難度預測解釋力的大小與測驗構念效度息息相關,因此必須透過反覆的嘗 試與修正認知模式,直到認知成分可以充分預測難度的變化,才能對測驗的結果或分數作
更明確而有效的解釋。(Embretson & Gorin, 2001;Freund et al., 2008;Gorin, 2006)。此外,
在測驗統計分析方法上 LLTM 類似 Rasch 模式與多元迴歸統計兩者的結合,以兩種方法進 行 試 題 成 分 分 析 所 得 結 果 頗 為 一 致 (Embretson & Daniel,2008; 林 世 華、 葉 嘉 惠,
1999), 所 估 計 的 係 數、 試 題 難 度 預 測 值 和 試 題 難 度 變 異 解 釋 力 都 幾 乎 相 同 (Chen, Macdonald, & Leu, 2011)。
依自動命題產題方法對心理學理論的依賴度,或是試題所涉及的心理歷程複雜度的不 同而加以區分,在實務上常見的自動化命題方法大致可分成兩種:試題模型法 (item model approach)(Bejar, Lawless, Morley, Wagner, Bennett, & Revuelta, 2003) 和認知設計系 統法 (cognitive design system approach)(Embretson & Yang, 2007)。在學習成就測驗方面,
以試題模型法較為常見;而認知測驗則以認知設計系統法較為常見。在實作上,試題模型 法是透過替換那些與問題解決歷程無關的特徵,如物體名稱、具體數字等,產生一群外表 相異的試題,也就是產生多個同構異形題 (isomorphic instance)。此一方法假定,雖然這 些新的試題外表看起來與原來的試題不同,但內容和本質上卻是類似的,實質內容和心理 計量特性上都被視為相同。產出的題目不僅繼承了樣板試題的特性,在心理計量的特性上 與原先樣板的特性非常相近,可以直接使用產生的題目去估計受試者能力,而不需要再次 進行實徵的預試分析。
在有關出題系統設計的格式方面,Gierl、Zhou 與 Alves (2008) 提出一套試題模型類 型的分類法 (taxonomy),目的在提供內容領域專家在設計試題模型的指引。一組試題模 型包含題幹 (stem)、選項 (options) 和輔助資訊 (auxiliary information)。其中輔助資訊包 含題幹及選項以外的其他材料,如圖片、表格和圖表等。題幹和選項內可能包含多個變 數,每個變數包含多個合理的文字或數值以供隨機替換,組合出不同的題目。題幹或選項 內的變數分成四種類型,包含獨立元素、相依元素、獨立/相依混合元素及固定元素。此 外,Gierl 等人 (2008) 也使用 JAVA 發展一套名為 IGOR (Item GeneratOR) 的桌上型應用 軟體,作為設計試題模型或產出試題的開發工具。
四、代數推理能力測驗的重要內涵
在 NCTM (2000) 所出版 「學校數學的原則與標準」 一書中,針對 「代數」 主題明白指 出 K-12 年級的學生應該學會:(一) 瞭解規律、關係 (relation) 和函數 (functions);(二)
使用代數符號呈現和分析數學的情境和結構;(三) 使用數學模式來表示和瞭解數量關係;
( 四 ) 分 析 在 不 同 脈 絡 情 境 下 的 規 律 改 變。 學 童 早 期 的 代 數 學 習 階 段 中, 一 般 化
(generalization) 位居代數推理的核心,是成功解決代數推理問題的重要概念 (Carraher, Schliemann, Brizuela, & Earnest, 2006;Kaput, 2008)。當學童面對複雜的數量關係和較大幅
度的數量預測,若是無法掌握一般化概念進行解題,往往陷入於冗長的算術運算之中而錯 誤百出。學生是否能應用系統性和符號性的算式表徵問題,並進行一般化解題歷程是區別 代數推理與算術推理的關鍵要素 (Bednarz, Kieran, & Lee, 1996;Carraher & Schliemann, 2007;Smith & Thompson, 2007)。
此外,NCTM 的標準也強調辨識及延伸樣式 (pattern) 對國小學生代數學習的重要性,
通常先從不同的數字或圖形表徵中辨識相同的樣式,並運用樣式來預測後續的結果,最後 才引入代數符號的學習。因此,具備探究樣式的能力乃是發展代數能力之基礎,在引入代 數符號操作之前,樣式概念的學習佔有舉足輕重的份量 (NCTM, 2000)。學童對於樣式的 探究應該要具有以下的能力:(一) 對於廣義有變化的規律能描述、延伸、分析及創造;
(二) 能以表格、圖形或算式描述和表示數量之間的關係;(三) 分析函數關係並解釋一個 變數如何產生出另一個變數;(四) 能運用樣式及函數呈現並解決數學問題 (NCTM, 2000)。在學童早期的代數學習階段中,教師需掌握以下三個概念有效的進行代數推理教 學:(一) 一般化是代數推理的核心;(二) 算術或數字的運算可被視為函數;(三) 代數的 符號表示法可用來支持更廣泛的數學推理 (Carraher et al., 2006;Kaput, 2008)。學生解決 樣 式 和 一 般 化 線 性 問 題 所 使 用 的 策 略 大 致 分 為:( 一 ) 計 數 (counting);( 二 ) 差 異
(difference);(三) 整體物件/單元化 (whole-object or unitizing);(四) 線性 (linear);(五)
循環規則 (recursive rule);(六) 明確規則 (explicit rule)(Stacey, 1989;Lannin, Barker &
Townsend, 2006)。能正確解出一般化線性問題的學生,大多可透過循環、差異與線性等策 略進行推理與臆測,歸納出自變數、依變數數值的變化,總結項次階差的數值,釐清變項 與常數之間結構的關係,進而以算式表徵數學問題,解出更遠項次的結果。而錯誤解題的 學生則常對問題的目的混淆或誤解,無法掌握其中關鍵的變項線索,只欲求得答案,傾向 將注意力集中在情境之計數關係,使用簡化的算術推論答案,致使一般化歷程中所需應用 的推理方式、解題策略無法有效的與解題目的連結,而導致解題失敗。綜言之,如何讓學 生辨識問題、正確推論獲得一般化的能力,是代數概念連結與發展的重要課題 (Nathan &
Kim, 2007)。
五、代數推理能力測驗的認知成分
從認知心理學而言,代數推理的構念表徵相當於在探討及界定代數問題解題歷程的認 知複雜度或難度。為了設計和預估作業難度的來源和水準,首先必須探究隱含在作業中可 能的影響難度的成分。針對代數或數量推理測驗中何種試題特徵決定了試題難度,許多研 究已經從問題解決歷程、實驗研究設計以及心理計量模式分析等各種的角度進行探究。
Sebrecht, Enright, Bennett, & Martin (1996) 指出影響代數應用問題的兩大主要難度來源為
工作記憶 (Baddeley, 1992)以及學生具備的真實世界和數學領域的背景知識。當學生解代 數應用問題時,從長期記憶中提取出真實世界和數學領域這兩種背景知識,必須在工作記 憶中與問題的文字敘述相互調和,以衍生解題的計畫 (Koedinger & Nathan, 2004)。
Arendasy et al. (2006) 總結代數應用問題解題的歷程包含五個階段,其各別歷程內含 的可能難度來源如下:(一) 問題表徵轉譯階段 (Mayer, Larkin, & Kadane, 1984):問題的 內部表徵建構與非關數量推理的晶體智力 (crystallized intelligence) 有關,作業的難度取決 於語法和語言的複雜度 (grammatical and linguistic complexity)。(二) 問題統整階段
(Kintsch, 1998):學生從長期記憶中用問題基模 (schemata) 提取出真實世界的背景知識與 數學知識來解讀試題文本的意涵,並進行問題表徵轉換。研究指出 (Blessing & Ross, 1996;Enright, Morley, & Sheehan, 2002) 問題情境的典型程度 (the typicality of the cover story) 會顯著的影響某些試題的難度。(三) 數學化過程 (actual mathematization process)
(Kintsch, 1998;Nathan, Kintsch, & Young, 1992):此階段構成數量或代數推理的核心成分
(Koedinger & Nathan, 2004),問題元素中函數關係的推衍難度,以及相對應的方程式數量 會顯著的影響試題難度 (Enright, Morley, & Sheehan, 2002;Sebrecht et al., 1996)。(四) 解 題計畫及監控階段 (Mayer et al., 1984):受試者利用策略性知識從數學問題模型中產生解 題計畫,並監控此一解題計畫的執行。其複雜度的成分包含未知元素數量 (the number of unknown elements) 和內嵌的未知元素數量 (the number of embedded unknown elements)
(Enright, Morley, & Sheehan, 2002)。(五) 執行解題階段 (Mayer et al., 1984):在此階段受 試者運用算術的程序知識計算出代數問題的解答,試題的計算量和受試者的計算能力往往 影響解題的難度。
在國小階段的代數問題常常使用樣式呈現一般化代數推理作業,其特徵通常包含:
(一) 表徵的供應、(二) 自變項值的變化、(三) 問題的數學結構 (陳嘉皇,2010;Nathan
& Kim, 2007)。學生透過問題表徵瞭解數量的變化,發現自變項 (輸入值) 與依變項 (輸出 值) 之間的函數關係,進而覺察其蘊含的數學結構。在自變項的值方面,Swafford 與 Langrall (2000) 建議,讓學生檢驗巨大及漸增的輸入值,可提升學生運用線性關係的代數 推理能力。
依據問題空間理論 (Newell & Simon, 1972),當描述個體進行問題解決時涉及兩個概 念:問題解決狀態 (problem-solving state)與問題解決運作 (problem solving operation)。
前者是指問題解決有一開始的初始狀態,經由一系列的中間狀態,最後會到達滿足目標的 目標狀態;後者為問題解決過程中所採取的合法行動或運作,即將問題由一個狀態轉成另 一個狀態的行動 (陳學志、彭淑玲與吳清麟,2011)。問題解決過程是個體透過各種問題 解決運作,從問題初始狀態到目標狀態完成轉換的過程,問題解決運作的多寡決定個體解 決問題的過程中所承受的認知負荷。影響認知負荷的因素相當多,與問題結構本身有相當
密切的關係,例如子目標的數量 (number of subgoal)(Embretson & Daniel, 2008)、資訊的 轉換或整合的次數、限制條件的數量、運算次數和複雜性等 (Enright, Morley, & Sheehan, 2002)。 其 中, 子 目 標 數 量 是 預 測 問 題 難 度 的 重 要 因 素 (Daniel & Embretson, 2010;
Embretson & Daniel, 2008)。子目標數量某種程度就已經定義了問題空間的大小 (Newell &
Simon, 1972),而且與個體在問題表徵和解決過程中需要整合的元素數量、表徵轉換程 度、運算步驟等有著緊密的關聯。在國小代數問題中,學童從文字、圖形樣式或圖表資訊 的表徵中進行代數推理思考時,問題結構內所隱含的算術運算子或是未知項數量,即代表 問題從初始狀態到目標狀態所需轉換的次數或待完成的子目標數量。由此可見,學童代數 解題過程所要推論的算術運算子數量多寡可能是試題難度的重要來源之一。
此外,不同的問題表徵有可能造成個體採取不同的問題解決策略。基模為個體解決特 定問題類型而組織的各種知識或典型問題情境的資訊。個體利用本身所擁有的基模進行問 題的表徵轉換,其過程為一個假設-檢驗的演繹推理過程 (Chi, Feltovich, & Glaser, 1981)。而問題陳述的語義、數字、符號、圖形或統計圖表的結構往往會影響問題表徵轉 換過程的難易。在 Enright 與 Sheehan (2002) 的研究曾發現,答案的型式 (數字或未知數 符號) 對高中生在解決 GRE 代數及算術試題的難度上有顯著的影響存在。在數字計算的 複雜度方面,題幹或選項中出現不同的數字型態 (number type),如整數、負數、小數和 分數的不同會影響難度,例如分數或小數越多,則難度越高 (Koedinger & Nathan, 2004)。
不同的四則算術也會導致問題難度的不同。例如在相同的情況下,加法和乘法運算相對容 易,而減法和除法則較難 (Nesher & Hershkovitz, 1994)。
在國內,洪碧霞等人 (2006) 曾分析臺灣國小高年級數學成就測驗進行認知複雜度分 析,提出六種可解釋試題難度的認知分成,包含計算量、步驟數、表徵轉化、關係推衍、
情境新穎、和抽象邏輯。洪碧霞等人 (2009) 曾對國小中年級數與計算測驗提出運算種類 數、未知數表徵轉換、和除法加權等三種認知負荷成分,約可解釋 53% 的試題難度參數 變異。綜上所述,由於代數學習是數學教育的核心,代數概念是解決數學問題不可或缺的 工具,顯見代數推理測驗與數學問題解決的認知運作原理會有許多共通之處。從認知負荷 或是工作記憶容量的角度而言,代數問題解題歷程中的數學化過程所涉及的運算子個數或 運算種類數的多寡,會造成解題的負荷而反映在試題難度上,極可能是影響試題難度的重 要因素 (Enright, Morley, & Sheehan, 2002;Koedinger & Nathan, 2004)。其次,在問題統整 過程中涉及從長期記憶用問題基模提取出數學知識來解讀試題刺激的涵義,進行問題表徵 轉換時也可能決定了部份的試題難度。最後,在執行解題階段,題目的計算複雜度或計算 量與個體運用算術程序知識或心算自動化能力息息相關,對小學生而言,較繁複而多位數 的數字、小數、分數或除法計算也可能影響試題的難度大小。
依據上述文獻分析,本研究歸納提出三個可能影響國小學童代數推理試題難度的基本
成分變項,分別為運算子、表徵轉換和計算複雜度,作為本研究代數推理能力測驗
(Algebra Reasoning Test, ART) 認知成分編碼的依據和產出試題的藍圖。本研究實際研發 編製、施測及量尺化試題難度參數,並進一步將認知成分與試題難度參數進行多元迴歸分 析,以便檢視代數推理認知成分對試題難度參數變異的解釋力。
參、研究方法
一、研究設計
本研究提出認知成分依據自動化命題模式 (如圖 1),作為試題產出品質監控的實徵建 議。此模式先從測驗內容領域的認知成分文獻開始分析,歸納文獻相關要義、選定核心認 知成分、操作性界定成分編碼邏輯、針對試題進行成分編碼、判斷試題難度層次、自動化
認知成分文獻分析
解釋力 < 60%或部份 成分未達顯著?
解釋力 > 80%?
是
否 否
是 選定認知成分
操作性界定成分
自動化產生試題
實測獲得試題參數
線上產生試題
圖 1 認知成分依據自動化命題模式
產生試題、實際施測獲取試題難度參數、檢視認知成分對難度的解釋力。表 1 呈現歷年來 國內外不同測驗認知成分個數、難度變異解釋量及分析模式對照,從中可發現合理而充足 的模式解釋力大致介於 60%~80% 之間。成分解釋力未達顯著或是模式解釋力未達 60% 則 持續調整認知成分。如果解釋力高於 60% 但未達 80%,則進行編碼的操作性定義調整。
若認知成分對試題難度變異解釋力達到 80% 以上,則可上線產生試題,實際應用於測驗 或教學實務。這個模式目的在務實而有效監控自動化命題系統的試題產出品質。
依據文獻回顧的結論,本研究選取 「運算子」、「表徵轉換」、「計算複雜度」 等三項難 度成分變項,清晰定義其認知運作,發展國小代數推理能力測驗,對國小五、六年級學生 進行測試,並以 Rasch 模式進行單參數 (難度) 校準試題參數,分析不同題型試題難度參 數與認知負荷的分配差異,再以多元迴歸統計分析實徵檢驗該認知成分架構對試題難度參 數的解釋力。
二、研究樣本
施測樣本取自台南市三所市立國小五、六年級學生共 177 人,表 2 呈現受試樣本人數 分配。其中五年級兩班共 60 人、六年級四班共 117 人,合計 6 班。男生人數合計 93 人。
女生人數合計 84 人。全部採用電腦化線上測驗系統進行施測。測驗時間以一節課 40 分鐘 為限。
表 2 代數推理能力測驗施測樣本人數分配
年級 A 校 B 校 C 校 合計
五 60 60
六 24 37 56 117
合計 24 37 116 177
三、研究工具
(一)測驗雙向細目
本研究工具為研究者根據文獻及現行國小代數課程分析後,所自行設計的代數推理能 力測驗。測驗包含 「數列對照」、「胚騰圖形」、「天平比較」 和 「圖表應用」 等四種題型。題 數分別為 10、9、9、8 題,合計 36 題。為了更聚焦於代數推理構念的測驗,測驗時允許 使用計算機 (小算盤程式)。除了圖表應用題型中的三個題目使用到小數外,其餘題目使 用的數字皆為整數。
數列對照、胚騰圖形和圖表應用等三種題型主要在測驗學生是否能辨識及延伸樣式,
並運用樣式來預測後續的結果。呈現樣式的方法分別為數字、圖形、以及語文描述搭配統 計圖表等三種形式。學生解題時若能掌握一般化推理作業的策略即可輕易進行解題。這些 一般化推理試題背後隱藏一組線性函數關係,學生可透過計數、差異、循環、單元化與線 性等策略 (Stacey, 1989;Lannin et al., 2006) 進行推理與臆測,推算項次之間的階差數值,
歸納出自變數和依變數之間的數量關係,以算式或函數表徵數學問題,進而預測較大輸入 項次之輸出結果。另外,天平比較題型在測驗學生等量公理及物件或變數替換以及解簡單 方程式的能力,當天平數量越多,運用等量公理或符號替換的代數操作也越多。
在組卷設計方面,從題庫中抽取 6 題作為共同試題 (預估難度為難、中、易各 2 題),
編成甲、乙兩卷,每卷 21 題。Rasch 參數分析以甲、乙兩卷間 6 題共同試題進行試題參 數的同時估計,因此兩卷的試題參數是在同一個量尺上。甲卷配給學 (座) 號為奇數的學 生施測,乙卷配給學 (座) 號為偶數的學生施測。6 題共同試題的題號分別為 A03、A07、
B02、B08、C05、D08。表 3 呈現測驗題型與認知層次雙向細目。表 4 為認知成分編碼及 認知負荷對照表。其中表 3 的認知負荷層次是依據各認知成分編碼加總後進行歸類。認知 負荷層次分類的標準為編碼總和在 3 以下歸類為層次一,總和在 4~5 之間歸類為層次二,
總和在 6 以上歸類為層次三。
表 3 代數推理測驗題型與認知負荷層次雙向細目 題型
認知負荷 數列對照 胚騰圖形 天平比較 圖表應用 題數
層次一 負荷 3 以下
A01, A02, A03, A04
B01 C01, C02, C03, C04, C05, C06, C07, C08, C09
na 14
層次二 負荷 4~5
A05, A06, A08, A09
B02, B03, B04, B05, B08, B09
na D03, D07 12
層次三 負荷 6 以上
A07, A10 B06, B07 na D01, D02, D04, D05, D06, D08
10
題數 10 9 9 8 36
註:加粗體的題號為共同試題。na 表示不適用 (not applicable)。
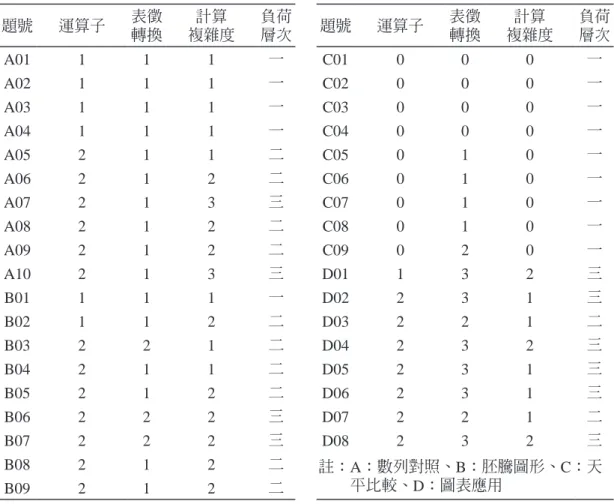
表 4 代數推理能力測驗認知成分編碼及認知負荷層次對照
題號 運算子 表徵
轉換
計算 複雜度
負荷
層次 題號 運算子 表徵
轉換
計算 複雜度
負荷 層次
A01 1 1 1 一 C01 0 0 0 一
A02 1 1 1 一 C02 0 0 0 一
A03 1 1 1 一 C03 0 0 0 一
A04 1 1 1 一 C04 0 0 0 一
A05 2 1 1 二 C05 0 1 0 一
A06 2 1 2 二 C06 0 1 0 一
A07 2 1 3 三 C07 0 1 0 一
A08 2 1 2 二 C08 0 1 0 一
A09 2 1 2 二 C09 0 2 0 一
A10 2 1 3 三 D01 1 3 2 三
B01 1 1 1 一 D02 2 3 1 三
B02 1 1 2 二 D03 2 2 1 二
B03 2 2 1 二 D04 2 3 2 三
B04 2 1 1 二 D05 2 3 1 三
B05 2 1 2 二 D06 2 3 1 三
B06 2 2 2 三 D07 2 2 1 二
B07 2 2 2 三 D08 2 3 2 三
B08 2 1 2 二 註: A:數列對照、B:胚騰圖形、C:天
平比較、D:圖表應用
B09 2 1 2 二
(二)認知成分界定及編碼架構
本研究選取 「運算子」、「表徵轉換」、「計算複雜度」 等三項認知成分變項,認知成分 的界定及編碼架構如表 5 所示,操作性定義如下:
(1) 運算子成分是指代數推理試題所包含欲推理的運算或是未知項的數量。例如,僅包含 加減乘除單一運算關係的問題,其未知項個數為 1,對應的函數關係如 Y = a × X,或 如 Y = X + b。而普通的線性關係推理問題,其未知項個數為 2,線性函數關係如 Y = a × X + b。此外,在題型為 「天平比較」 的試題中,由於僅需運用等量公理即可解出天 平比較情境中未知的物體或符號的數值,並不需要進行一般化推論未知項的歷程,故 編碼為 0。
(2) 表徵轉換是指從不同的表徵形式推論未知項歷程的轉換幅度。編碼大小分別為從直接 明確的數列對應推論、從間接的數列對應推論、從文字描述發現數量關係、到從統計 圖表中推論未知項等加以編碼。此外,如果題目為天平比較問題,受試者須運用等量
公理解出問題中未知物體或符號代表的數值,則編碼大小定義為試題中天平的數量。
(3) 計算複雜度是指代數問題情境中,刺激項呈現於表格或圖形中所表徵的數量改變幅 度。考量的因素包含起始量、項差、以及是否包含小數。
(4) 認知負荷層次:研究中將上述三項認知成分加總成為認知成分總和,以做為試題認知 負荷大小的指標。並且依據認知成分總和的大小區分出三種不同的認知負荷層次,認 知成分總和在 3 以下的試題歸類為層次一,成分總和在 4 到 5 歸類為層次二,成分總 和在 6 以上歸類為層次三。
(5) 認知負荷分配是指四種不同題型 (數列對照、胚騰圖形、天平比較和圖表應用) 的試 題在經過成分編碼後,依照認知成分總和的大小歸類到不同的認知負荷層次。
表 5 代數推理測驗認知成分的界定及編碼架構 編碼
成分 0 1 2 3
運算子 • 無需函數關係
推論。如:天 平問題
• 函數關係包含 1 個運算子。
如:Y = X + a 或 Y = a × X
• 函數關係包含 2 個運算子。
如:Y = a × X + b
na
表徵轉換 • 1 個天平問題 • 從明確的數列 對照進行推論 2 個天平問題
• 從間接的數列 對 照 進 行 推 論。如,樣式 圖形的邊長與 圖形編號不一 致。
• 從文字描述發 現未知數。
• 3 個天平問題
• 從文字描述及 統計圖表進行 推論
推論複雜度 • 無 數 列 情 境 如:天平問題
• 輸入項的數列 起始量為 1 且 項 差 為 1,
如:1, 2, 3, …
• 數字序列中包 含小數則編碼 再加 1
• 輸入項的數列 起 始 量 不 是 1, 且 項 差 為 1, 如:7, 8, 9, …
• 數字序列中包 含小數則編碼 再加 1
• 輸入項的數列 起 始 量 不 是 1, 且 項 差 為 K,如:8, 11, 14, …
• 數字序列中包 含小數則編碼 再加 1
註:na 表示不適用 (not applicable)。
(三)試題與編碼示例
以下針對各成分的界定及編碼架構提出若干個試題示例,以利溝通成分編碼的意涵。
運 算 子
函數關係為 Y= X + 15,包含 1 個運算 子,因此運算子編碼為 1
函數關係為 Y = X × 7 + 3,包含 2 個運算 子,因此運算子編碼為 2
函 數 關 係 為 Y = X × 4,包含 1 個運算 子,因此運算子編碼為 1
函數關係為 Y = X × 4 + 2,包含 2 個運算 子,因此運算子編碼為 2
表 徵 轉 換
從明確的數列對照中推論,因此表徵轉 換編碼為 1
從間接的數列對照中推論 (圖形 1 須先加 1 後成為邊長為 2,再乘 3),因此表徵轉 換編碼為 2
從文字描述發現數量關係 (起始量 5000 元、項差 300 元),因此表徵轉換編碼為 2
從文字描述及統計圖表進行推論 (之後
「每天騎的距離都相同」 以及圖表中的數 字進行推論),因此表徵轉換編碼為 3
問題中出現一個天平,編碼為 0 問題中出現兩個天平,編碼為 1
計 算 複 雜 度
輸入項的數列起始量為 1 且項差為 1,編 碼為 1
輸入項的數列起始量不是 1 且項差為 1,
編碼為 2
輸入項的數列起始量不是 1 且項差為 K,
編碼為 3
四、資料分析
本研究進行下列資料分析:
(一) 以 ITEMAN 進行傳統測驗項目分析,評鑑試題參數與測驗信度的適切性。
(二) 以 ConQuest 進行 Rasch 難度參數校準。
(三) 以 Pearson 積差相關分析試題 Rasch 難度參數與認知成分之間的相關組型。
(四) 以多元迴歸分析,檢視認知成分編碼模式對試題難度參數變異的解釋力。
肆、研究結果與討論
鑑於試題難度參數的統計資訊對於第一線數學教師在溝通上有其限制之處,本研究提 出一套代數推理試題認知成分的分析架構,對高年級代數推理試題認知成分進行評定,希 望合理解釋試題難度參數的變異來源。研究中發展出一個三成分的代數推理試題認知成分 分析架構,並以此三項認知成分對試題實徵難度參數的預測力,探討此一成分分析架構的 適用性。
一、國小代數推理能力測驗的心理計量特徵
(一)傳統項目分析
表 6 呈現本研究甲、乙兩卷的傳統項目分析摘要表。兩卷的內部一致性分別為 0.85 和 0.84,平均答對率分別為 0.55、0.58 且全部都在 0.25 以上。在鑑別度方面,兩卷的平 均鑑別度分別為 0.58、0.54,只有一題 (C02) 偏低為 0.19,其餘皆達 0.25 以上。該題
(C02) 的答對率為 0.95,難度偏低,點二系列相關 (point-biserial correlation) 為 0.34,鑑 別度尚可接受。由於本測驗發展定位於補救教學的用途,為了激發學生測驗動機,有效測 量落後學生的學習結果,故予以保留。在學生的表現方面,五年級學生平均答對題數為 9.07 題 (能力值平均為 –0.29),答對五題以下的人數百比率為 18.33% (11 人/ 60 人),對 五年級學生而言難易適中,大多數學生應能勝任。六年級學生平均答對題數為 13.36 題
(能力值平均為 0.91),答對五題以下的人數百比率為 5.13% (6 人/ 117 人),對六年級學 生而言相對容易許多。整體而言,此份電腦化代數推理測驗的難度 (答對率) 適中,具有 適切的鑑別度。
表 6 國小代數推理能力測驗甲、乙兩卷傳統項目分析摘要
卷別 題數 人數 內部一
致性α
二系 列相關
平均答對率 (P)
( 最小,最大 )
平均鑑別度 (D)
( 最小,最大 ) 甲 21 91 .85 .67 .55 (.27, .95) .58 (.19, .77) 乙 21 86 .84 .65 .58 (.30, .90) .54 (.26, .74)
全體 42 177
(二)單參數試題難度分析
本研究採用 Rasch 模式分析試題難度參數。表 7 呈現本測驗 36 題的試題難度參數及 成分編碼對照。
表 7 代數推理測驗試題難度值及成分編碼總和對照 題號 難度值
(b 值)
成分
總和 題號 難度值
(b 值)
成分
總和 題號 難度值
(b 值)
成分
總和 題號 難度值
(b 值)
成分 總和 A01 -1.10 3 B01 -1.17 3 C01 -2.21 0 D01 1.21 6 A02 -1.09 3 B02 -.73 4 C02 -3.01 0 D02 1.34 6 A03 -.40 3 B03 .84 5 C03 -1.43 0 D03 .13 5 A04 .48 3 B04 .07 4 C04 -2.29 0 D04 1.15 7 A05 1.13 4 B05 .01 5 C05 -.76 1 D05 .93 6 A06 .43 5 B06 1.13 6 C06 -.44 1 D06 .56 6 A07 .98 6 B07 1.48 6 C07 -.54 1 D07 .72 5 A08 .44 5 B08 .19 5 C08 -.71 1 D08 1.66 7 A09 .68 5 B09 .13 5 C09 -.54 2
A10 .72 6
註:A:數列對照、B:胚騰圖形、C:天平比較、D:圖表應用
二、不同題型試題難度參數與認知負荷分配差異
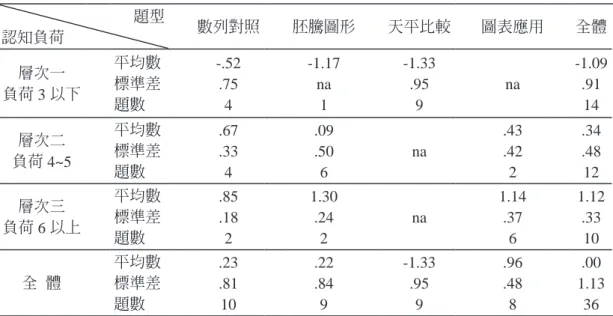
本研究依據表 3 和表 4 認知負荷層次的分類,以及上述試題難度參數的分析結果,進 行描述性統計分析。表 8 為不同認知負荷層次與題型難度值描述統計對照。圖 2 呈現本測 驗試題 Rasch 難度值的分佈 (item map)。從這些圖表結果明顯可見,天平比較題型的難度
表 8 不同認知負荷層次與題型難度值描述統計對照 題型
認知負荷 數列對照 胚騰圖形 天平比較 圖表應用 全體
層次一 負荷 3 以下
平均數 標準差 題數
-.52 .75 4
-1.17 na
1
-1.33 .95
9
na
-1.09 .91
14 層次二
負荷 4~5
平均數 標準差 題數
.67 .33 4
.09 .50 6
na
.43 .42 2
.34 .48 12 層次三
負荷 6 以上
平均數 標準差 題數
.85 .18 2
1.30 .24
2
na
1.14 .37
6
1.12 .33 10 全 體
平均數 標準差 題數
.23 .81 10
.22 .84 9
-1.33 .95
9
.96 .48 8
.00 1.13
36 註:na 表示不適用 (not applicable)。
值偏低 (平均數 –1.33),而圖表應用題型的難度值則偏高 (平均數 0.96)。可見文字情境的 一般化推論試題,對國小學童數學推理解題產生較大的困難;而只須利用等量公理概念解 題的天平比較試題則較不構成解題困難。認知負荷層次一到三的難度值平均數分別 為 –1.09、0.34 和 1.12。整體而言,試題難度值與認知成分總和之間呈現合理的關聯。隨 著試題的認知負荷層次的提昇,試題難度值也隨之增高。
圖 2 代數推理測驗 Rasch 試題難度值分佈 (item map)
三、試題難度參數與認知成分的相關組型
表 9 呈現代數推理測驗試題難度參數與認知成分的相關。整體而言,三個成分與難度 參數間均存在極高的相關,其中以運算子和試題難度參數的相關最高,大約有 62% 的難 度預測力,可解釋大部份試題難度參數的變異。針對試題難度值進行多元逐步迴歸分析結 果呈現於表 10 及表 11,結果顯示運算子和表徵轉換兩個成分與試題難度參數的相關達 0.88,可共同解釋難度的變異達 78%。然而,第三個成分計算複雜度卻未能如預期進入迴
歸預測模式,無法有效的解釋試題難度。對難度預測力的係數,運算子為 0.73,表徵轉換 為 0.57。相對應的標準化係數分別為 0.56、0.46。其中運算子的標準化迴歸係數最大,可 見運算子對於難度值的提昇有明顯影響。成分間的相關約在 0.30 ∼ 0.78,其中以運算子 和計算複雜度間相關最高達 0.78,顯示兩個成分之間有極高的重疊之處。
參照圖 1,本研究依據所選定的認知成分對初步發展試題難度的解釋力未達 80%,而 且計算複雜度尚未能提供有效、獨立的試題難度解釋力。檢視試題計算複雜度成分編碼操 作性定義,發現本研究中大部分試題的計算負荷偏低,因此,與運算子的重疊過高。後續 修訂須進一步檢視計算複雜度的操作性定義,讓計算負荷與運算子合理脫鈎,或微幅擴大 試題計算複雜度的變異,確認計算複雜度的獨立性。
表 9 試題難度與認知成分間的相關係數 (題數 = 36)
運算子 表徵轉換 計算複雜度 成分總和
試題難度 .79** .74** .66** .88**
運算子 .51** .78** .92**
表徵轉換 .30 .73**
計算複雜度 .83**
*
p
< .05, **p
< .01表 10 認知成分對代數推理試題難度多元迴歸結果摘要
認知成分 R R2 R2 改變量 F 值 顯著性
運算子 .79 .62 .62 55.62** .00
運算子、表徵轉換 .88 .78 .16 57.24** .00
**
p
< .01表 11 認知成分對代數推理試題難度多元迴歸預測分析摘要 (題數 = 36)
預測變項
未標準化係數 標準化係數
t 值 顯著性
B 之估計值 標準誤差 Beta (
β
)截距 -1.75 .19 -9.32** .00
運算子 .73 .13 .56 5.82** .00
表徵轉換 .57 .12 .46 4.79** .00
**
p
< .01伍、結論與建議
本研究依據文獻探究的結果對代數推理測驗提出三項認知成分,分別為運算子、表徵 轉換、計算複雜度,以實徵的反應資料進行試題難度參數估計。透過對難度參數的多元迴 歸分析發現,運算子和表徵轉換兩項成分可有效共同解釋 78% 的試題難度參數變異,其 標準化迴歸係數分別為 0.56、0.46。換句話說每增加運算子認知成分一個單位,對試題難 度參數大致會提升 0.73 單位左右;而每增加表徵轉換認知成分一個單位,對試題難度參 數大致會提升 0.57 個單位左右。其中又以運算子的迴歸係數最大,顯見本代數推理測驗 中,運算子明顯決定試題難度參數的大小。運算子認知成分的定義客觀清晰是後續代數推 理測驗自動化命題可運用的重要成分。然而,計算複雜度與運算子對試題難度值的預測力 有些重疊,宜進一步調整操作性定義,或考慮刪除該成分。此外,計算複雜度無法進入迴 歸方程式中,也有可能是試題取樣上的限制,無法使計算複雜度在排除運算子對難度的相 關後仍有顯著的影響存在,而並非計算複雜度成分定義的問題,未來或許可透過擴充更多 其他代數題目來解決。
本研究所提出認知成分依據自動化命題發展模式及認知成分操作定義,初步試用結果 呈現合理的生產性,運算子與表徵轉換兩成分已能達到解釋力大於 60% 的基本要求,且 已相當接近 80% 的目標。顯示成分分析有利試題主要難度變異來源的掌握與操弄。後續 研究將進一步檢視計算複雜度成分,微調試題計算量的變異,並以更具代表性樣本進行試 題難度參數資料蒐集,交叉檢核模式的試用性。本研究模式依據試題編擬的邏輯和認知分 析實徵文獻統整而成,所提出的內涵成份大致符合專業共識,模式中實務操作的建議性標 準(如成分數與解釋力的同時斟酌)可提供未來成分依據自動化命題系統發展的實徵參考,
以確保自動化命題的品質,同時降低試題編製和參數取得的成本。運用自動化命題系統所 產出的測驗,認知結構清晰、題數充裕。可作為學生推理診斷評量,協助教師清楚掌握學 習者的認知運作優勢與限制,非常適合學習落後學生補救教學的應用。