以協力演化遺傳演算法求解容器堆疊問題
吳泰熙
台北大學企業管理系
邱創鈞 賴志昌
大葉大學工業工程與科技管理系
摘 要
在貨品運送過程或工廠的生產部門中,棧板 (pallet) 或方形容器 (con- tainer) 往往是堆疊零件、半成品與成品之工具。而物體堆疊方式是否能有效利 用容器空間,關係到各項作業成本是否能有效降低。本研究發展協力演化遺傳 演算法,首先設計一「下後左」之啟發式堆疊法則為核心模組,但在外部控制 機制上則導入「協力演化」之觀念,數個遺傳演算法同時進行演化,各自搜尋 不同之解答空間 (solution space),但卻週期性地交換各母體間之演化資訊,以 提昇搜尋之品質及效率。演算法測試時,先以部分例題對所提出之協力演化遺 傳演算法之參數進行實驗,以獲取參數組合建議。接著經由建議之參數組合,
對國際文獻演算例題進行測試,再與國際文獻演算結果進行比較。結果顯示本 研究所提出之協力演化遺傳演算法,只要子群體之數目足夠,其演算結果可超 越國際文獻最佳結果。
關鍵詞:協力演化遺傳演算法、容器堆疊問題。
SOLVING CONTAINER LOADING PROBLEM USING COOPERATIVE COEVOLUTIONARY GENETIC ALGORITHM
Tai-Hsi Wu
Department of Business Administration National Taipei University Taipei, Taiwan 237, R.O.C.
Chuang-Chun Chiou Chih-Tsang Lai Department of Industrial Engineering and Technology Management
Da-Yeh University Changhua, Taiwan 515, R.O.C.
Key Words: container loading problem, cooperative coevolutionary ge- netic algorithm.
ABSTRACT
In this study, a cooperative coevolutionary genetic algorithm (CCGA) is proposed for solving the container loading problem. A heuristic rule,
“bottom-back-left (BBL)”, for loading objects into a container is developed as the core, while CCGA controls the improving process at the outer level.
The introduction of CCGA aims at bringing in different species to the same environment, where the interactions among them affect the genetic compo- sition of all the constituents, so that better solutions can be obtained. In- tensive testing is implemented to search for proper CCGA parameter com- binations. Promising computational results are obtained and reported by running examples from the literature.
一、緒 論
長期以來,如何在容器內堆疊物體,以減少空間的浪 費,是眾多產業持續面臨的重要作業問題之一。例如在貨 品運送或工廠的生產部門中,往往使用棧板 (pallet) 或方 形容器 (container) 作為堆疊零件、半成品與成品之工具。
而物體堆疊方式是否能有效利用容器空間,絕對地影響了 貨車的裝載率、運送頻次,以及倉庫的儲存空間等各項作 業成本是否能有效降低。
容 器 堆 疊 問 題 (container loading problem) 之定義 為:在已知尺寸大小的容器中,按照某一特定法則,在不 得超出容器邊界的限制下,依序將物體堆疊、擺放在容器 內,直至所有物體均已置入容器中,或容器內已無空間可 允許剩餘物體繼續置入時,方停止擺放動作。然而因應各 項考量因素不同,伴隨而來則有諸多不同類型之堆疊問 題,例如需要考量物件的尺寸、形狀、重量、材質、方向,
及容器的尺寸、形狀、載重等特性。考量的特性越多,問 題的難度越高,求解過程所需之演算時間也隨之遽增。雖 然如此,文獻中大多數之研究仍是討論如何將長方體物件 堆疊擺放至長方體容器內。
因著容器堆疊問題之兩大要件 (堆疊物體、容器) 之 變化,相關之文獻可分為下列三類:(1) 多個單一尺寸的 長方體物件和單一長方體容器 (2) 多種尺寸的長方體物 件和單一長方體容器 (3) 多種尺寸的長方體物件和多個 不同尺寸之長方體容器。
第一類問題之複雜度較低,屬於較易解的問題。由於 長方體物件的大小均相同,所以也有研究將其簡化成二維 裝載之問題加以探討。張美忠[1]探討棧板裝載問題,將問 題簡化成二維問題,利用整數規劃來求解,並以此數學模 式為基礎將其延伸應用在多種規格之長方體容器裝載問 題上。Liu and Hsiao[2]探討相同的問題,亦把問題簡化成 二維裝載模式進行求解。他們把長方體物件不同的三個面 各視為二維的問題進行排列,且具相同高度之長方體才能
排在同一層,使得物體能平穩堆疊,然後再以數學模式求 得最佳解。
多種尺寸的長方體物件和單一長方體容器堆疊問題 在目前的討論最為廣泛。此類問題之長方體容器只有一 個,且其尺寸大小固定;而長方體物件的尺寸較為多樣,
至少有三種以上之不同尺寸。當然隨著物件的尺寸更為多 樣,問題複雜度自然增加。Gehring and Bortfeldt [3]曾提出 以塔式堆疊來擺放物件,將物件中底面積較大者放置在最 下方,如欲往上擺放時,該物件的底面積需小於其下已放 置好之物件。如此重複放置,成一塔型擺放。完成數個塔 型之後,再考慮交換各個塔型之間的物件,並以啟發式演 算法來控制其演算機制。Bortfeldt and Gehring[4]亦提出了 另一種堆疊邏輯:先將數個物件堆疊成「層」,再以堆好 的各個「層」 ,來考慮其擺放順序。Nagoi 等人[5]則是使用 陣列來記錄物件擺放之座標點,而長方體物件在堆疊時,
可選擇在容器中由後往前堆疊,或是由下往上堆疊。 Eley[6]
則應用貪心法則來產生物件堆疊而成之區塊 (block) ,接 著再透過使用樹狀搜尋策略 (tree search) 來改善原先之 區塊位置安排。George and Robinson[7]等人也是採用區塊 的方式堆疊,但是當每個區塊堆疊完時會彼此結合,以減 少空間的浪費。
在多個單一尺寸長方體容器與多種不同尺寸的長方 體物件中,Terno 等人[8]使用分枝界限法來逼近,求得最 少的長方體容器數量與最大容器使用率。他們先找出長方 體容器數量的下界和上界,然後從容器的上界開始堆疊。
堆疊時,首先將物件均分給各容器來進行堆疊,然後再依 次減少一個容器,再把物件均分給剩下容器來進行堆疊,
直至容器無法再減少。Scheithauer[9]則是針對單一及多容 器 堆 疊 問 題 之 數 學 模 式 建 立 對 應 之 鬆 弛 模 式 (relaxa- tion)。此鬆弛後之線性規劃模式,可產生極佳之限值 (tight bounds)。
由如上之文獻回顧,不難發覺:針對容器堆疊問題,
過去文獻通常直接發展啟發式堆疊計畫;少數則是在堆疊
完成後,再應用改善策略進一步產生更佳之堆疊計畫。由
於容器堆疊問題之結構複雜,實屬於組合最佳化問題
(combinatorial optimization problem)。對於組合最佳化問題 之求解,由於問題結構之複雜,且隨著問題規模增加,解 題時間會呈現指數遞增之情形。因此近年來之研究通常避 免使用雖能保證獲致最佳解、但卻演算耗時之數學規劃工 具,而改採能於效率上更勝一籌且品質不惶多讓之啟發式 演算法,特別是萬用型啟發式演算法 (meta-heuristic),例 如模擬退火演算法 (simulated annealing, SA)、禁忌搜尋法 (tabu search, TS)、遺傳演算法 (genetic algorithm, GA)等。
採用萬用型啟發式演算法來求解容器堆疊問題之文獻通 常延續過去先產生可行堆疊計畫之方式,再透過萬用型啟 發式演算法於外部控制之機制,持續地讓內部之堆疊計畫 改 善 , 直 至 達 到 演 算 終 止 之 條 件 。 例 如 Gehring and Bortfeldt [3]使用遺傳演算法;Bortfeldt and Gehring [4]使用 混合遺傳演算法;Bortfeldt 等人[10]則是採用平行禁忌搜 尋法 (parallel TS)。
遺傳演算法是由 Holland 於 1975 年首先提出[11],為 一根據物競天擇、適者生存之道理所發展出之優選技術,
近年來已被廣泛應用於各領域中。它透過選擇物種中具有 較好特性的上一親代,並隨機的相互交換親代中彼此基因 之資訊及特性,以適合度函數為引導,希望保留親代中較 被喜好之特性並繁衍至子代,以產生較上一親代更為優秀 的子代。如此一再地重複,藉以產生適合度最強的物種,
來達到最佳化的目的。由於 GA 在演化過程中隨機的相互 交換親代中彼此基因之並繁衍至子代,此項特性其實賦予 物種相當程度之多元演化,對照於演算法而言,相當於具 有某種程度之平行搜尋之功能。
由於許多實務問題實在太複雜,在效能及效率之考量 上,並不適合採用單一母體直接求取問題之最佳解。
Potter[12]所提出之協力演化 (cooperative coevolution) 之 邏輯乃是將原本複雜的問題/系統,區分成為數個模組或子 系統,各子系統可被視為一個不同的物種 (species)。各物 種間獨立地進行各自之演化,最終再透過某些機制將各系 統之解答整合成為原先問題之最終解答,因此也被認為其 具有「各個擊破」(divide and conquer) 之特性。雖然協力 演化之觀念容易被人接受,然而其中存在三個議題必須被 克服,方能讓協力演化之功效得以發揮,此三個議題分別 為 (1) 如何依問題之特性,將原本之大問題加以分割成數 個規模較小之子問題 (sub-problem)?(2) 如何針對各子問 題設計其對應之子母體 (sub-population)?(3) 如何將子問 題中各自演化後所獲致之解答整合成為原來問題之解 答?這些都是需要詳盡考慮之議題。協力演化可以被應用 到任何演化型之演算法 (evolutionary algorithm),例如類神 經網路[13, 14]或 GA[15, 16]。Sakawa and Yauchi[16]發展 協力演化之 GA 演算法 (cooperative coevolutionary genetic algorithm, CCGA) 來求解多目標非凸型規劃 (multiobjec- tive nonconvex programming) 之型問題。Potter and De Jong [17]對於協力演化之應用做了非常詳盡之說明及介紹。
本研究採用 GA 之演算架構,先設計一「下後左」之
表一 各種堆疊限制所造成之可能堆疊情況
類別 長轉成高 寬轉成高 高 可堆疊的情況
1 ― ― √ 2 種(長寬互換)
2 √ ― √ 4 種
3 ― √ √ 4 種
4 √ √ √ 6 種
啟發式堆疊法則為核心模組,但在外部控制機制上則導入
「協力演化」之觀念[12],數個 GA 同時進行演化,各自 搜尋不同之解答空間 (solution space),但卻週期行地交換 各母體間之演化資訊,以提昇搜尋之品質及效率。希望透 過此機制之導入,設計出表現更好之 GA 演算法,以期能 有效地產生容器使用率最高之物件堆疊計畫。
本研究針對單一容器、多尺寸長方體物件之堆疊問題 發展協力演化遺傳演算法。研究進行過程中所使用之假設 條件列示於後:
1. 物件在堆疊之過程中不能超出長方體容器;
2. 容器無承載重量之限制;
3. 物件堆疊時,底面一定要水平擺放;
4. 物件堆疊時,長方體至少要有 1/2 底面積與其下的長方 體接觸,擺放才會穩固。
二、 「下後左」啟發式堆疊法則
1. 物件堆疊方向分析
長方體物件在堆疊時,可能會因產品的特性而有限定 的堆疊方向,例如冰箱。冰箱雖然在運送時已被裝箱成長 方體物件,物件的六個面均可當成“底”來堆疊。但是因 為冰箱冷煤之因素,所以一定要正擺,而不能橫擺或倒 擺。由於考量到產品可能有特定堆疊方向之限制,亦即有 的可橫擺,即長或寬可當成高、高變成長或寬,表一整理 出各種條件下可堆疊之情況。由表一可觀察出一個長方體 物件最少有 2 種、最多有 6 種堆疊可能。
2. 啟發式堆疊法則之建立
我們首先提出一「下後左」之啟發式堆疊法則。此種 堆疊方式不僅考慮了擺放物件之穩定度,也簡化擺放時所 要考慮眾多可行之擺放位置。只要依照「下後左」之邏輯,
盡可能先找尋“下”、再“後”、再“左”之座標點,即 為物件之擺放位置,圖 1 說明此項堆疊法則之物件擺放方 式。首先將容器的長、寬、高等三邊分別以三維座標的 X 軸、Y 軸和 Z 軸來代表。每一容器有八個角,物件在堆疊 時從容器的“下後左”角開始堆疊,如圖 1 中之容器「下 後左」置入點 O,而物件堆疊時也以其“下後左”角,如 圖 1 中之物件「下後左」堆疊點 A 對齊點 O 後置入物件,
此時物件的長、寬、高分別投影在 X 軸、Y 軸和 Z 軸的座
O
下
後
Y Z
左
X
容器「下後左」置入點
後 A
左 下
物件「下後左」堆疊點
O
Z1
Y
Y1Z
X
X1 1
單一物件堆疊及參考點產生
Z1
Y1
Y Z
1
X
2
Z2 3
Y2Z1
X1Y2
X1 X2
Y2
多重物件堆疊及參考點產生 圖 1 「下後左」啟發式堆疊法則示意圖
標即可產生 X1、Y1、Z1 三個參考點 (reference point) 座 標。每堆疊一個物件時,物件會和容器或已堆疊的物件產 生新的參考點,這些參考點即為下一個物件可以置入之候 選點。因此後面接續堆疊的物件,依序按照「下後左」邏 輯,自所有候選點中選擇適當之置入點。例如物件 2 在堆 疊時,先選擇 X1 參考點,若 X1 參考點不能堆疊,再選擇 Y1 參考點,若 Y1 參考點也不能堆疊,最後才選擇 Z1 參 考點。物件 2 堆疊在 X1 參考點後又新增了 X2、Z2、X1Y2 和 Y2Z1 等四個可以堆疊的參考點,因此物件 3 就有 Y1、
Z1、X2、Z2、X1Y2 和 Y2Z1 等六個參考點可以堆疊。重 覆以「下後左」之邏輯來選擇堆疊座標順序,則此六個參 考點之選擇順序依序為 X2、X1Y2、Y1、Z1、Y2Z1、Z2。
圖 1 中若物件 3 不能堆疊到 X2,則依照表 1 改變物件 3 其他的堆疊情況來置入;若依然不可行,則依物件順序尋
找下一個可堆疊的物件。若仍然無法進行堆疊,則仍依「下 後左」原則,更換下一個可堆疊的參考點。因所有物件皆 無法堆疊到 X2、X1Y2 和 Y1 等三個參考點,物件 3 最後 因此堆疊到 Z1 參考點。重複此「下後左」之啟發式堆疊 原則,直到所有物件皆已堆疊完畢才終止此程序。
三、結合堆疊法則之協力演化遺傳演算法
遺傳演算法即是模仿遺傳學上物競天擇、適者生存之 原理,再運用電腦模擬所發展出來的一種人工智慧搜尋演 算法。其主要流程係經由程式的編譯決定一個由眾多染色 體所組成之起始母體,其內之染色體則是對應到欲求解問 題之一組解。經由考量每條染色體對於環境的適應度 (fitness),模擬大自然優化選擇 (selection) 之觀念,再決 定如何複製 (reproduction) 適應較佳之染色體,經由染色 體間之交配 (crossover) 及突變 (mutation) 機制,讓母體 不斷地演化,一直演化至最適合染色體出現或是達到預設 的迭代數。
協力演化遺傳演算法乃採用 GA 之基本概念,但是更 加強其「平行搜尋」之功能。其透過一次產生數個 GA 母 體,並讓其同時進行演化,各自搜尋不同之解答空間,以 提昇搜尋之品質及效率。本節之內容即是以所發展之「下 後左」啟發式堆疊法則為核心,再由協力演化遺傳演算法 作為外部控制及改善解答品質之工具。
1. 協力演化遺傳演算法概念
從「協力演化」這個名辭中,不難想像至少要有兩個 以上的母體,經由某種「資訊交換」的溝通模式,達到「合 作 進 化 」 的 目 的 , 因 此 實 可 將 協 力 演 化 遺 傳 演 算 法 (cooperative coevolutionary genetic algorithm, CCGA) 視為 一個包含數個遺傳演算法之集合。在此模式下,每一個遺 傳演算法負責演化一個族群,而族群間彼此各自搜尋問題 空間的不同區域,最後再透過某些結合機制將各族群逐漸 整合。然而應用在不同的問題領域上,每個族群所代表的 意義互異,因此彼此交換的資訊及結合機制可能不同。
2. 結合堆疊法則之協力演化遺傳演算
CCGA 之內容仍為一遺傳演算法,因此本節就其編 碼、母體產生、適合度函數、複製、交配、突變等運算子 分別介紹。由於 CCGA 乃透過多個子族群同時演化,因此 各子族群均需使用到前述之運算子。
(一) 編碼
假設物件總類有 M 種,而各種尺寸的物件數量為
Ni,
i= ( 1 ,...,
M) ,並且按照物件尺寸種類之體積由大 到小依序編號,相同尺寸的物件編在同一群組且給予 相同之編號,即可合成一條染色體,代表物件被置入 容器之次序,如圖 2 所示。在本研究中我們定義物
下 下
左 後 後
左
圖 2 染色體編碼示意
圖 3 第一條染色體編碼示意
件最長的邊為長、次長的邊為寬、最短的邊為高。
(二) 起始母體產生及染色體數目
母體的大小 (population size) 及其內染色體之組成對 於遺傳演算法之績效有絕對之影響,良好的母體與恰 當的染色體數有助於快速求得近似最佳解,因此產生 母體時,為因應 CCGA 多個母體同時演化之概念,我 們將物件群組區分為
P 個子族群,例如大型物件與小型物件等兩個子族群,每一子族群同時進行演化,其 餘編碼方式如上節所述。母體內之染色體數目 (令其 為 S) 過多雖然帶來更多元之組成,卻也將在演化進 行時造成演算之負擔,因此適當
S 值之決定,實需要經由大量實驗測試得知。
母體中第一條染色體之產生乃是按物件之體積大小 排列,其餘
S-1 條染色體則是各自在大小物件兩大子族群中隨機排列基因而產生。假設現有 8 種不同尺寸 之物件欲進行堆疊、各尺寸之物件僅有一件,且
S = 4、P = 2。
將物件體積由大至小排列後,將前四個物件歸為大型 物件,剩餘者列入小型物件。第一條染色體之編碼如 圖 3 所示;其餘 3 條染色體隨機更動其排序,如圖 4 所示。
(三) 適合度函數及複製
適合度是用來評估每條染色體所代表之解答品質之 優劣。在本研究中,每一條染色體代表一組物件被置 入容器中堆疊之次序。這些次序經由「下後左」啟發 式堆疊法則實際堆疊後,即是一組堆疊計畫,並且產 生此堆疊計畫之容器使用率。本研究之適合度函數乃 參照國際文獻共同之寫法,即是容器之使用率,定義 如下:
容器使用率 1
nVi R iC
∑ =
=
圖 4 母體中其餘三條染色體之編碼示意
圖 5 染色體交配示意
n=長方體物件的數量 Vi =第 個長方體物件的體積i C=長方體容器的體積
複製,是指生物體對自身的複製,複製出來的子代可 以跟親代完全一樣;也可以有部份的不同,其目的就 是讓母代的特徵不同程度地保留到子代。本研究所採 用之複製機制乃是將各個子族群各自的
S 條染色體相互合併組合,因此共將產生
SP 條染色體。若以圖 3為例,將產生 16 條染色體,再依適合度函數值,挑 選出最佳之 4 條。
(四) 交配
母體中不同染色體間可以經由隨機交錯各自之數個 基因之過程,以產生新的子代,稱為交配。由於本研 究中之母體乃由不同特性之子族群組成,因此交配過 程中,族群間不能互相交配,僅能於同一族群中進 行。首先在母體中任選兩條染色體,然後隨機在親代 各族群之基因區段當中挑出兩點,稱之為交配點,再 將位於兩交配點間之基因進行交換,且每一族群皆須 進行。如此生成子代,如圖 5。
(五) 突變
突變的目的是在於防止複製和交配過程中,陷入區域 最佳解。CCGA 之突變進行方式是自每一子族群中,
隨機選取一條染色體及其內兩個突變點,再交換兩突 變點之基因,並且自表一中隨機選取一種可行之堆疊 情況進行堆疊。
(六) 終止條件
直至所有物件皆已堆疊進入容器內,或達到事先設定 之演化代數,程式將自動結束並輸出最終結果。
(七) CCGA 演算法
CCGA 之演算邏輯乃透過數個「子族群」分別進行演 化,再透過逐漸整合各子族群,以交換各子族群間之 演化資訊。子族群數目越多,雖有能探索更多元解答 N
4=3
N
3=4 N
2=4
N
1=2
物件種類=4
1 1 2 2 2 2 3 3 3 3 4 4 4
小型物件族群 大型物件族群
1 2 3 4 5 6 7 8
2 4 3 1 7 6 8 5 1 3 2 4 8 6 7 5 3 2 1 4 6 5 8 7
1 2 3 4 5 6 7 8 4 3 2 1 8 7 6 5
1 3 2 4 5 7 6 8
4 2 3 1 8 6 7 5
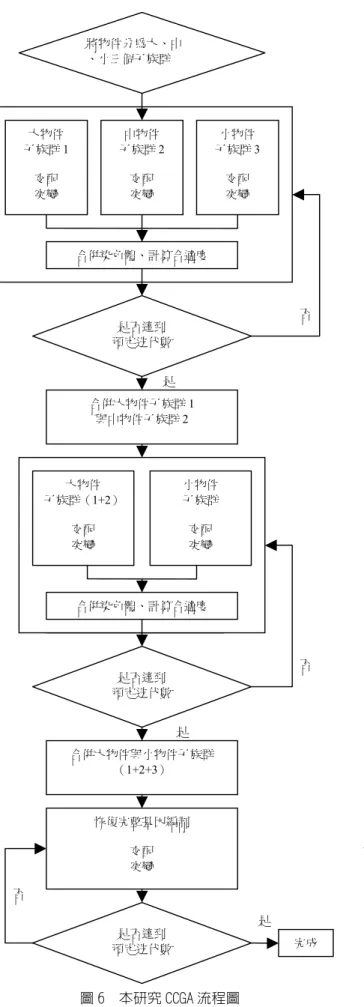
圖 6 本研究 CCGA 流程圖
空間之潛在優點,但整合之過程將耗費相當多之演算 時間。反之,太少之子族群數(例如 2)又恐無法獲得分 群演算之優點。著眼於演算效能及效率間之取捨,決 定採用三個子族群。研究一開始將產生大、中、小物 件三個子族群,各子族群之編碼與起始解已於上節說 明。CCGA 演算法之精神在於程式執行之初,各子族 群各自進行 GA 之演算步驟;當三個子族群歷經一定 迭次之演化後,挑選當代最佳的基因群體,將此基因 群體由原先三個子族群區分,合併為兩個子族群,再 重複如上步驟,各自進行 GA 至一定的迭次後,挑選 當代最佳的基因群體,再將兩個子族群的基因合併為 單一群體的基因,再進行最終之 GA 運算,直至滿足 終止條件。這樣的演算邏輯表現出 CCGA 經由某種
「資訊整合」之溝通模式及平行搜尋之方式,達到「合 作進化」的目的。本研究之 CCGA 流程圖如圖 6 所示。
對於子族群之合併過程,除了現有之 (大、中、小)、
(大+中、小)、(大+中+小),我們亦嘗試過其他選擇,
例如 (大、中、小)、(大、中+小)、(大+中+小),
但是在演算結果上並未有顯著之差異,我們因此選擇 了現行之合併過程。
四、演算結果及分析
本研究針對單一容器、多尺寸長方體物件之堆疊問題 發展協力演化遺傳演算法。首先以部分例題對此 CCGA 演 算法之參數進行實驗,以期能獲取最佳參數組合,進而有 效率地求算出最佳演算結果。本研究所採用之程式編譯軟 體為 Visual C++ 6.0,測試環境為 Pentium IV 3.2G 及 RAM 為 DDR 512M 之個人電腦。
1. 文獻例題介紹
Bischoff and Ratcliff [18]所提出的 BR 系列例題,是眾 多文獻中常被廣泛使用測試的,因此本研究亦採用這些例 題做為測試本研究所發展之 CCGA 演算法之演算績效,所 有例題皆能從如下網址之連結取得:
http://people.brunel.ac.uk/~mastjjb/jeb/orlib/files/ 。例題 BR1 到 BR7 每一大類各有 100 小題,共計 700 測試題。
BR1 是單一容器有三種不同尺寸大小之物件群組,BR2 則 是五種不同尺寸大小之物件群組,隨著越後面的題目,物 件群組也跟著增加,至 BR7 時則有二十種不同尺寸大小之 物件群組,因此編號愈大的題目,由於其物件尺寸增多,
求解的難度與所耗用的時間也相對地增加。
2. CCGA 演算法參數分析
在決定 CCGA 演算參數設定時,由於 BR1~BR3 等三 類問題之物件尺寸大小差異不大,屬於難度較小之測試 例;相較之下,BR4~BR7 較為困難。因此本研究分別從 是
是
否 將物件分為大、中
、小三個子族群
大物件 子族群 1
交配 突變
中物件 子族群 2 交配 突變
小物件 子族群 3
交配 突變
合併染色體、計算合適度
是否達到 預定迭代數
合併大物件子族群 1 與中物件子族群 2
合併染色體、計算合適度
是 否
大物件 子族群(1+2)
交配 突變
小物件 子族群 交配 突變
是否達到 預定迭代數
否
合併大物件與小物件子族群
(1+2+3)
恢復完整基因編制 交配 突變
是否達到
預定迭代數 完成
合併染色體、計算合適度
表二 各參數組合演算測試例題之演算結果
測試例題 #1 #2 #3 #4 平均績效
No. 參數 組合
容器 使用率
(%)
演算 時間 (sec)
容器 使用率
(%)
演算 時間 (sec)
容器 使用率
(%)
演算 時間 (sec)
容器 使用率
(%)
演算 時間 (sec)
平均容 器使用 率(%)
平均演 算時間 (sec) 1 3-3-3-2 84.552 76 83.993 52 82.566 607 79.503 367 82.654 275.50 2 3-3-3-3 84.789 193 83.608 138 84.257 1525 79.592 1087 83.062 735.75 3 3-3-3-4 85.132 436 84.893 374 84.606 3173 80.534 2241 83.791 1556.00 4 3-3-3-5 84.796 492 83.990 455 84.129 3758 79.803 2471 83.180 1794.00 5 3-3-3-10 85.208 526 84.991 486 84.796 5028 80.678 3458 83.918 2374.50 6 3-3-6-2 84.051 103 80.246 55 82.258 512 79.190 477 81.436 286.75 7 3-3-6-3 86.226 181 81.901 176 85.470 1482 80.582 1141 83.545 745.00 8 3-3-6-4 85.183 364 83.521 409 85.241 2923 79.659 2523 83.401 1554.75 9 3-3-6-5 86.283 589 82.012 532 85.580 4123 80.617 3521 83.623 2191.25 10 3-3-6-10 85.916 984 83.713 931 85.581 7452 80.451 6211 83.915 3894.50 11 3-6-3-2 84.404 68 82.357 78 84.204 776 79.980 490 82.736 353.00 12 3-6-3-3 85.110 196 83.800 173 84.472 1942 80.187 1099 83.392 852.50 13 3-6-3-4 85.432 357 84.318 384 85.016 4494 83.007 2744 84.443 1994.75 14 3-6-3-5 85.522 415 83.948 435 84.531 5044 80.160 3121 83.540 2253.75 15 3-6-3-10 85.745 443 84.482 545 85.269 4608 83.093 2819 84.647 2103.75 16 3-6-6-2 81.906 75 82.228 65 82.961 602 78.059 435 81.289 294.25 17 3-6-6-3 82.686 265 82.554 174 84.613 1954 81.003 1354 82.714 936.75 18 3-6-6-4 87.359 426 83.281 410 85.028 3536 81.794 2431 84.366 1700.75 19 3-6-6-5 87.461 785 82.842 780 84.863 4132 81.135 3521 84.075 2304.50 20 3-6-6-10 87.472 941 83.461 820 85.345 5679 81.875 4191 84.538 2907.75 21 6-3-3-2 83.474 107 80.507 88 83.738 671 78.234 650 81.488 379.00 22 6-3-3-3 86.210 450 85.473 287 86.104 2481 80.730 2160 84.629 1344.50 23 6-3-3-4 87.653 715 83.476 666 84.207 5849 82.160 4600 84.374 2957.50 24 6-3-3-5 86.530 870 85.535 812 86.124 6234 80.824 5331 84.753 3311.75 25 6-3-3-10 87.664 1021 84.216 995 85.207 8932 82.357 8211 84.861 4789.75 26 6-3-6-2 82.190 130 85.347 114 84.908 793 78.127 706 82.643 435.75 27 6-3-6-3 82.611 308 85.100 259 84.911 4076 80.508 2063 83.283 1676.50 28 6-3-6-4 86.473 723 83.251 648 85.909 7851 82.589 4834 84.556 3514.00 29 6-3-6-5 82.780 931 84.385 899 85.009 9528 80.781 6817 83.239 4543.75 30 6-3-6-10 86.819 1203 84.587 1159 85.969 11314 82.628 8458 85.001 5533.50 31 6-6-3-2 84.415 111 84.386 87 83.790 998 78.671 717 82.816 478.25 32 6-6-3-3 86.210 365 82.109 289 83.904 2954 81.734 1937 83.489 1386.25 33 6-6-3-4 85.921 912 83.593 663 85.451 6725 81.365 4566 84.083 3216.50 34 6-6-3-5 86.655 1275 83.092 991 83.969 8029 81.781 7111 83.874 4351.50 35 6-6-3-10 86.515 1459 83.677 1325 85.583 9993 81.662 9028 84.359 5451.25 36 6-6-6-2 82.572 131 82.249 129 84.404 1030 79.842 701 82.267 497.75 37 6-6-6-3 84.185 334 84.010 227 85.207 3049 80.341 2339 83.436 1487.25 38 6-6-6-4 84.600 867 83.881 714 86.250 7805 82.597 4095 84.332 3370.25 39 6-6-6-5 84.358 1320 84.510 1101 85.352 9109 80.390 7731 83.653 4815.25 40 6-6-6-10 84.603 1555 84.289 1299 86.358 12937 82.633 9803 84.471 6398.50
BR4、BR5、BR6 與 BR7 的國際例題中,各抽取一題做為 參數測試範例。演算參數則考慮「迭代數」及「母體染色 體數」兩因子。由於本研究進行之 CCGA 分成三個階段:
先由三個子族群結合成兩個子族群,最終再結合成一個族 群,因此參數組合之格式為「第一階段迭代數 ― 第二階 段迭代數 ― 第三階段迭代數 ― 母體染色體數」。若在 各階段之迭代數設定太大,對於某些規模較大之測試例 題,單單演算某類例題所花費之時間可能超過數小時,因 此我們設定「迭代數」之水準分別為迭代數 3 及 6;母體 染色體數則有 2、3、4、5 及 10 等五種水準,總計有 40
種參數組合。各種參數組合之演算結果詳列於表二,表二
內之數值為三次演算之平均數值。由表二可發現,當染色
體數目愈大時,往往能求得較佳之容器使用率;但相對
地,也花費更多的演算時間。在迭代次數方面,也有類似
之觀察:迭代數愈大,所花費之演算時間愈多,然而所求
得之結果並未明顯較佳。表二列出各種參數所獲致之使用
率及演算時間外,為方便評斷各種參數之綜合表現,亦列
出各種參數之四題平均容器使用率及對應之演算時間,再
由其中挑出四題平均容器使用率最高之五種參數組合如
表三所示。
表三 四題平均容器使用率最高之五種參數組合
參數組合 平均容器使用率 平均演算時間
6-3-3-3 84.629 1344.50 3-6-3-10 84.647 2103.75
6-3-3-5 84.753 3311.75 6-3-3-10 84.861 4789.75 6-3-6-10 85.001 5533.50
綜觀表三之五種參數組合為表現較佳之參數組合,在 求解品質上皆有不錯的表現。雖然參數組合 6-3-6-10 所獲 致之平均容器使用率最高,但在演算績效與演算時間之取 捨後,本研究建議使用參數組合 6-3-3-5,做為下節演算測 試的參數設定。
3. 執行結果與分析
接著使用上節建議之參數組合,對 BR 國際例題進行 測試。每一演算例進行五次之演算,並記錄五次演算之最 佳及平均結果,再與國際文獻演算結果進行比較,如表四 所示。表四中第一欄為測試例題類別,其後之數字則是該 題型中物件之尺寸數,例如 BR4 (10) 意指 BR4 題型中之 物件尺寸有 10 種不同大小。第 2 欄為 Bischoff and Ratcliff [18] (B/J/R) 之最佳執行結果。為了測試本研究所提出之 CCGA 是否會因子族群數目不同而有不同之演算績效,我 們提出 CCGA1 及 CCGA2,分別代表 2 個子族群及 3 個子 族群之 CCGA,並且將它們之演算結果列於表四中。觀察 表四之內容,我們發覺 CCGA1 在 BR1~BR7 七種題型中,
有兩類題型之演算結果優於文獻之表現,分別為 BR1 及 BR6;CCGA2 則有六種題型之演算結果優於文獻之表現,
除了 BR5 外。CCGA2 之演算績效優於 CCGA1 應來自 CCGA2 提供較多之子族群,讓 CCGA「平行搜尋」及「協 力」之機制有充分發揮之空間。當然較多之子族群數在演算 過程中需要耗費更多之演算時間,從表三中亦得到了驗證。
五、結論及建議
本研究針對單一容器、多尺寸長方體物件之堆疊問題 發展協力演化遺傳演算法。首先設計一「下後左」之啟發 式堆疊法則為核心模組,但在外部控制機制上則導入「協 力演化」之觀念,數個 GA 同時進行演化,各自搜尋不同 之解答空間,最後透過逐次結合子族群,發揮協力演化遺 傳演算法「平行」搜尋之能力,以提昇搜尋之品質及效率。
協力演化遺傳演算法設計完成後,本研究再對 CCGA 演算法之演算迭代數、母體染色體數目等參數進行實驗測 試,以求得最佳之參數組合,並以此建議之參數組合進行 所有測試例題之演算,並與文獻所得之演算結果進行比 較。透過文獻例題之演算,本研究所提出之 CCGA 演算法 在大部分例題之容器使用率均優於文獻最佳結果。本研究
表四 CCGA 與文獻最佳結果比較
CCGA1 CCGA2 No. B/J/R
[18] % CPU
(sec) % CPU (sec) BR1 (3) 85.40 86.45 41.43 86.81 65.13 BR2 (5) 86.25 86.22 213.16 86.82 249.71 BR3 (8) 85.86 85.20 246.43 86.26 310.04 BR4 (10) 85.08 84.79 618.09 85.66 701.17 BR5 (12) 85.21 84.43 842.46 84.95 1119.43 BR6 (15) 83.84 84.15 1241.73 84.73 1628.33 BR7 (20) 82.95 82.79 1356.16 83.44 1911.67
亦發現較多之子族群數,讓 CCGA 「平行搜尋」及「協 力」之機制有充分發揮之空間,唯必須付出更多演算時間 之代價。
參考文獻
1. 張美忠,「貨物運輸棧板裝載問題啟發式解法之應 用」 ,碩士論文,交通大學,新竹 (1992)。
2. Liu, F.-H., and Hsiao, C-J., “A Three-Dimensional Pallet Loading Method for Single-size Boxes,” Journal of Op-
erational Research Society, Vol. 48, pp. 726-735 (1997).3. Gehring, H., and Bortfeld, A., “A Genetic Algorithm for Solving the Container Loading Problem,” International
Transactions of Operational Research, Vol. 4, pp.401-418 (1997).
4. Bortfeldt, A., and Gehring, H., “A Hybrid Genetic Algo- rithm for the Container Loading Problem,” European
Journal Operational Research, Vol. 131, pp. 143-161(2001).
5. Ngoi, B. K. A., Tay, M. L., and Chua, E. S., “Applying Spatial Representation Techniques to the Container Pack- ing Problem,” International Journal of Production Re-
search, Vol. 32, pp. 111-123 (1994).6. Eley, M., “Solving Container Loading Problem by Block Arrangement,” European Journal Operational Research, Vol. 141, pp. 393-409 (2002).
7. George, J. A., and Robinson, D. F., “A Heuristic for Pack- ing Boxes into a Container,” Computers and Operations
Research, Vol. 7, pp. 147-156 (1980).8. Terno, J., Scheithauer, G., Sommerweiβ, U., and Riehme, J., “An Efficient Approach for the Multi-Pallet Loading Problem,” European Journal Operational Research, Vol.
123, pp. 372-381 (2000).
9. Scheithauer, G., “LP-Based Bounds for the Container and
Multi-Container Loading Problem,” International Trans-
actions in Operational Research, Vol. 6, pp. 199-213(1999).
10. Bortfeldt, A., Gehring, H., and Mack, D., “A Parallel Tabu Search Algorithm for Solving the Container Loading Problem,” Parallel Computing, Vol. 29, pp. 641-662 (2003).
11. Holland, J. H., “Adaptation in Natural and Artificial Sys- tems,” Ph.D. Thesis, University of Michigan Press, Ann Arbor, MI, USA (1975).
12. Potter, M. A., “The Design and Analysis of a Computa- tional Model of Cooperative Coevolution,” Ph.D. Thesis, George Mason University, FairFax, VA, USA (1997).
13. Garcia-Pedrajas, N., Hervas-Martinez, C., and Munoz- Perez, H., “CONVET: A Cooperative Coevotionary Model for Evolving Artificial Neural Networks,” IEEE
Transactions on Neural Networks, Vol. 14, pp. 575-596(2003).
14. Garcia-Pedrajas, N., Hervas-Martinez, C., and Ortiz- Boyer, D., “Cooperative Coevolution of Artificial Neural Network Ensembles for Pattern Classification,” IEEE
Transactions on Evolutionary Computation, Vol. 9, pp.271-302 (2005).
15. Potter, M. A., and DeJong, K. A., “A Cooperative Coevo- lutionary Approach to Function Optimization,” Proceed-
ings of the Third Parallel Problem Solving From Nature,Jerusalem, Israel, pp. 249-257 (1994).
16. Sakawa, M., and Yauchi, K., “Interactive Decision Mak- ing for Multiobjective Nonconvex Programming Prob- lems with Fuzzy Numbers Through Coevotionary Genetic Algorithms,” Fuzzy Sets and Systems, Vol. 114, pp.
151-165 (2000).
17. Potter, M. A., and DeJong, K. A., “Cooperative Coevolu- tion: An Architecture for Evolving Coadapted Subcom- ponents,” Evolutionary Computation, Vol. 8, pp. 1-29 (2000).
18. Bischoff, E. E., and Ratcliff, M. S. W., “Issues in the De- velopment of Approaches to Container Loading,”
OMEGA, Vol. 23, No. 4, pp. 377-390 (1995).
2006 年 01 月 16 日 收稿 2006 年 01 月 18 日 初審 2006 年 09 月 08 日 複審 2007 年 03 月 02 日 接受