應用基因演算法與模糊理論於供應鏈之多目標決策問題
李郁賢、黃士滔 高雄應用科技大學 工業工程與管理系副教授 E-MAIL:1097317110@cc.kuas.edu.tw摘 要
本文主要著重於以模糊理論為基礎,針對供應鏈中的多目標問題進行求解,並利用基因演算法求解目標函 數所轉成的隸屬函數中的隸屬度最大化,以提供決策者下決策的參考。另外並探討在供應鏈中,不確定的因素 在供應鏈中所造成的影響。在研究中,所提出的兩個重要目標函數,分別以利潤最大化與服務水準做為考量, 配合例子中的供應鏈結構的假設數值,發展出一套適當的模型,並使用基因演算法對多目標的目標函式進行求 解以取得更加的結果。另外,在相同的模型之中,將工廠產能進行模糊化,估算出在每個階段,每個時期的最 適配送量,結果顯示在進行產能模糊化之後,所得之利潤相較於進行模糊化之前的演算結果為佳。運用基因演 算法以及模糊理論使得決策者在生產上面可以更有彈性並能從事多方面的生產策略的擬定並取得更滿意的結 果。 關鍵字:多目標決策、供應鏈、模糊理論、基因演算法。1. 前 言
在全球化的市場競爭下,如何更佳的執行供應鏈的管理,使得供應鏈的成員獲得最大的收益已是相當重要 的議題。而關於供應鏈的研究議題,也由早期的單一目標,轉變為多方面考量的多目標問題,以避免因為一味 追求單一目標的最佳值,而可能導致供應鏈的成員有利益不均的情形。 而在多目標問題中,目標函數的部份可能會產生利益衝突的情形,所以最佳解是相當難以求得,可以說所 得之解大多是某個決策之下的妥協解,而如何讓決策者根據不同的情境,能清楚且迅速的下決策,並在該決策 之下,尋求該種情境下的最適解便是本研究所要探討的議題。2. 文獻探討
2.1 供應鏈管理 根據供應鏈協會(Supply-Chain Council,SCC)對於供應鏈之定義,其將供應鏈解釋為從生產到運送最終 產品過程中的所有活動,並連結從供應商到顧客端間的所有成員,包含四項基本處理作業─規劃、資源、生產、 運送,廣泛的定義包含了供需平衡、取得原物料與零件、製造組裝、倉儲與存貨管理、訂單管理、物流配送以 及運送到最末端消費者的整個過程。關於供應鏈的管理,Sabri and Beamon[1]將供應鏈管理分為兩個層次─策略性模式與作業性模式,並提出比 傳統單一目標更為廣泛的供應鏈評估方法。Talluri and Baker[2]提出多階段的數學規劃模型,確認在效率面、廠 址選擇、產能等目標的限制條件,找出較佳的方案,以增進供應鏈的效率。
2.2 模糊理論於供應鏈管理的應用 在處理供應鏈問題時,經常需要面對供應鏈中的不確定因素,與凡產能、運輸時間、預測等等,或者是一 些無法用確切的數據來表達的情況,像是顧客的滿意度以及各廠商之間的成本接受度等諸如此類的情況,而運 用模糊理論,則可以有效的對於這些不確定的因素進行處理。相關的文獻,Amid et al.[3]針對供應鏈中的供應 商選擇提出模糊線性多目標模型,在輸入的資訊不是很精確時,找出適當選擇決策。Chen et al.[4]提出在供應鏈 網路中最佳倉儲與配銷中心選址的多目標模糊決策,考慮多產品、多階層、多規劃週期的生產配送網路,並使 用二階段法,使得多目標問題有相當滿意的解。 而 Xu et al.[5]提出在隨機模糊環境下之多目標供應鏈最佳化模型與其應用,做法是利用期望值運算子與機 會運算子,將不確定的因素轉成確定性的數據再代入數學模型中,並利用基因演算法進行求解。 2.3 基因演算法於供應鏈的應用與文獻回顧 基因演算法(Genetic Algorithm,GA)近年來被廣泛的應用在供應鏈網路設計,並利用基因演算法的優點,尋 求多目標最佳解等方式,尋求整體供應鏈的利潤最大化。
於 Altiparmak et al.[6]的文中指出,使用 GA 並與 Ulungu et al.[7]所提出運用 Simulated Annealing(SA)法則所 運算的結果做比較,證明在文中所得的Pareto-optimal 解的平均數優於 SA 法則。在封閉迴路(Closed-loop)的供 應鏈型態中, Hokey et al.[8]則是針對回收品在考量回收時間與回收量以降低成本為目標,利用基因演算法做回 收站的配置與決策。而 Nachiappan and Jawahar[9]提出結合 VMI(vendor managed inventory,供應商庫存管理系 統)針對 2 階供應鏈,運用 GA 找出最佳化的運作參數,取得最佳的通道利潤。
基因演算法也常結合其他的演算法去做實務上的研究,如Borisovsky et al.[10]便使用了貪婪演算法簡化了 繁雜的運算式,並運用MIP(mixed integer programming)重組因子,找出 2 父代(母代)的基因型 Y1 與 Y2 中的最 佳可能組合,並在供應鏈管理的層面上進行應用。Li and Kuo[11]在對汽車備用零件於中央倉庫倉儲管理系統的 改善與研究一文中提出了強化模糊神經網路(EFNN,enhanced fuzzy neural network),將連結的權重由模糊層 級分析法指定,省去繁雜的轉換後,藉著基因演算法所產生與改善的活化函數,使得 EFNN 能利用並提供更詳盡 且精確的活化函數並可設定更廣泛的非線性模型。 在過去的文獻之中,多數討論多階供應鏈間的問題,而較少提及在各時間區段的決策,本文的方向,便是 探討在供應鏈中各階各時間區段中較為適當的決策,發展出一套適合的數學模型。首先針對多目標的目標函數 以數學規劃的方法進行求解,並與基因演算法的求解結果進行比較。另一部分則導入模糊理論的觀念,將產能 的限制進行模糊化,以隸屬度最大為前提,找出更好的目標解,將進行模糊化前與模糊化後的演算結果進行比 較,估算出各階段於各時間區段的配送量與存貨量,觀察其中的差異,並提供決策者在執行面的參考。
3.研究方法
3.1 問題描述 於本研究中所討論的供應鏈模型,涵蓋的範圍包函供應商、工廠、倉庫、零售商等構面,各階層的相互關 係與整體供應鏈的結構圖如圖 1 所示 圖 1 本研究之範圍 3.2 模糊理論 模糊理論用於定義無法詳細描述的數據或狀態,例如對於顏色的喜好、對於年齡層的定義等等,其用途在 於幫助決策者或是執行研究等相關的人,方便且能夠較精確的表達資料所傳遞的訊息。模糊理論提供一種方法, 將研究對象以0 與 1 之間的數值來表示模糊概念的程度,稱為「隸屬函數」(membership function),將人類的主 觀判斷數值化,使得研究結果更能符合人類思考模式。而隸屬函數又分為許多種,藉由資料所定義的模糊數, 建構出隸屬函數的模型,並觀察隸屬度的大小,以分辨程度的高低以及其數學上的意義。在本文中,所使用之 模糊集合所代表的隸屬函數為連續型模糊集合,如圖2 所示。 ‧‧‧ ‧‧‧ ‧‧‧ ‧‧‧ 供應商j 供應商J 工廠i 工廠I 倉庫k 倉庫K 零售商n 零售商N 1 b a 0 圖2 連續型模糊集合 除了對於問題進行模糊化之外,解模糊化的手法亦是相當的重要。舉凡面積法、重心法等等經典的算法, 在進行解模糊化時,有關問題形態是否適合其運算手法,運算的過程是否過於繁雜等等,皆是在處理數學模型 問題上需注意的地方。3.3 基因演算法的架構
基因演算法是一種啟發性的求解法則,藉由生物基因工程的概念解決組合最佳化問題,並具有在非線性模 型搜尋最佳解與近似解的能力。成熟的基因演算法概念則首次出現於1975 年 Holland[12]之著作 Adaptation in Natural and Artificial Systems ,Holland 在該書中明確指出基因演算法的三項基本操作─交配( cross-over )、反轉 ( inversion )與突變( mutation )為 GA 整體運算核心,而後續的研究則提出較周全的操作程序( Man et al. [13])。整 體的流程如圖3 所示。 產生初始群體 染色體編碼 評估染色體(目標函 數適應函數)
選擇 是否已達到 運算次數?
交配
突變
重組
結束程序 輸出結果 產生結果染色體編碼 是 否 圖 3 基因演算法的運作程序(修改自林昇甫、徐永吉[14]) 基因演算法之參數設定並無絕對好壞,也沒有一套完整的機制能確保我們找到最適的參數設定值,因此必 須依靠付出許多實驗訓練的代價來找尋理想的參數(Srinivas and Patnaik [15])。
雖然問題的目標函數可用來評估個體的適應度,但問題的屬性不盡相同,使得有些目標函數須經修正後才 能適用。為避免目標函數產生的適應值過於狹窄,以至於降低染色體的多樣性從而發生提早收斂的情況,因而 需做適應函數的調整。根據過去的文獻資料,有兩種基本調整類型:一種是靜態比率調整 (static scaling),另一 種則是動態比率調整 (dynamic scaling) (Goldberg[16] ; Michalewicz[17]; Gen and Cheng[18])。在此採用靜態比率 調整,步驟如下:
g
=
α
f
+
β
(1)f
=
g
(2) m a xg
=
k f
(3) m i n0
g
>
(4) 式(1)中 f 為原來設定的目標函數,g 則為調整後的適應函數,α與β則為參數,式(2)表調整前的群體平均 適應值應等於調整後的群體平均適應值。式(3)則說明 gmax(調整後的最大適應值)應等於調整前平均適應值的 k 倍,式(4)則宣告調整後的最小適應值必為正。在本實驗中,並未產生適應值範圍過於狹小,而無法增加多樣性 的問題,而兩目標皆是望大,符合適應函數值越高,染色體適應程度越高的條件,因此將目標函數值直接作為 適應函數進行演算。3.4 模式假設 工廠所需的原物料向上游的供應商訂購,生產的產品則運輸到倉庫並依照零售商所下之訂單供貨。而驗證 求解的部份,本研究以一簡例進行求解的動作,對於更複雜的問題,亦可使用本文所提出的模式進行求解。 本文提出的例子為一較精簡的供應鏈結構,包含了三個供應商,兩間工廠,兩間倉庫以及三個零售商,規 劃期間為三期。 3.5 參數與變數資料 參數與變數定義如下:Fi表工廠i=1,2,Sj表供應商,j=1,2,3,Wk表倉庫k=1,2,Vn表零售商,N=1,2,3,FitSj 表工廠i 在第 t 期向供應商 j 的原物料訂購量,TFitSj表第t 期由供應商運輸至工廠的原物料量,MFit表第t 期工 廠i 剩餘的原物料存貨,PFit表第t 期在工廠 i 的產品生產數量,TFitWk表第t 期由工廠 i 運輸至倉庫 k 的產品數 量,IFit表第t 期工廠 i 的產品存貨數量,TWktVn表第t 期由倉庫 k 運輸至零售商 n 的產品數量,IWkt表第t 期 在倉庫的產品存貨量。SjC 表向供應商購買的物料成本,PFiC 表工廠 i 生產產品的單位成本,FiSjC 表供應商 j 運送原物料至工廠i 的單位成本,FiWkC 表工廠 i 運送產品至倉庫 k 單位成本,WkVn表倉庫 k 運產品至零售商 n 的單位成本,MFC 表原物料於工廠的存貨成本,IFC 表產品於工廠的單位存貨成本,IWC 表產品於倉庫的單位 成本,DVnt表在第t 期零售商 n 的需求量,PrVn表零售商n 的產品售價,SjA 表供應商 j 的產能限制,FiA 表工 廠i 的產能上限,IFiA 表工廠 i 的產品存貨上限,MFiA 表工廠 i 的物料存貨上限,IWKA 表倉庫 k 的存貨上限。 3.6 數學模型 由 3.4 節的參數與變數,針對此供應鏈依最大利潤與服務水準發展出以下模型: 目標函數 f1 nt n it j j n t i j t it j i j it i i j t i t it k i k kt n k n i k t k n t it it kt i t i t k t Max DV Pr V F S S C TF S FS C PF PFC TF W FW TW V W V C MF MFC IF IFC IW IWC = × − × − × − × − × − × − × − × − ×
∑∑
∑∑∑
∑∑∑
∑∑
∑∑∑
∑∑∑
∑∑
∑∑
∑∑
(5) 目標函數f2(
kt n)
nt k n tMax
=
∑∑∑
TW V / DV
(6) 限制式 it j j i j tTF S
≤
S A
∑∑∑
(7) it i i tPF
≤
FA
∑∑
(8) kt k k tIW
≤
IW A
∑∑
(9) it j it j i j t i j tF S
=
TF S
∑∑∑
∑∑∑
(10)( ) it it j it i t 1 i j i t
MF
+
∑∑
TF S
−
∑∑
PF
=
MF
+ (11) it it it k i(t 1) i t i k tIF
+
∑∑
PF
−
∑∑∑
TF W
=
IF
+ (12) kt it k kt n k(t 1) i k t k n tIW
+
∑∑∑
TFW
−
∑∑∑
TWV IW
=
+ (13) kt n nt k n t n tTW V
=
DV
∑∑∑
∑∑
(14) 其中,式(7)為供應商的產能限制,式(8)為工廠的最大製造量,式(9)表倉庫的存貨不可超過倉庫的存貨上限。 式(10)表向供應商買的原物料數量須等於由供應商運至工廠的數量相同,式(11)為工廠的每期原物料存貨計算 式,式(12)為工廠每期產品存貨計算式,式(13)為倉庫存貨的計算式,式(14) 倉庫給零售商的產品量總合應等於 期間內的顧客總需求。 根據所設定的目標函數進行求解,取得最優解與最差解後,以解的範圍來做隸屬函數的制定,以避免在隸 屬函屬的定義上有過於主觀的認定。假設目標函數f1 取得的解範圍為[a,b],目標函數 f2 取得的解範圍為[c,d], 則因兩目標函數都是以最大值作為最佳化的目標,隸屬度的範圍界定在[0,1]的情形之下,取兩目標函數的隸屬 度為α1與α2,根據斜率公式可得以下的式子(修改自王文俊[19]): 1f1 a
b a
−
= α
−
(15) 2f 2 c
d c
−
= α
−
(16) 接著使用基因演算法求目標函數的隸屬度的最大值,以達到適當的效果。決策者可根據目標函數的隸屬度, 來決定適當的決策。 3.7 產能為不確定的情形 由 3.6 節的式(7)可知,生產產品的產能不得超過工廠的產能上限,而在實務面上,機器或是工廠可能會有 維修或是產生故障的狀況,故維持一定的產能是有其困難性,因此在本研究的另一部分,便是在產能為不確定 的情況之,以模糊化的手法,在決策者所定義的適當產能範圍內,找出最佳解,而此手法的另一個好處是,在 決策者進行類似的決策時,可以給予一個模糊的區間,不需將問題描述成極為精確且嚴格的形式,通過此方式, 可以了解增加某些附加的條件之後可以達到的更大利潤。4. 數值例子
4.1 資料數據 數據資料如表 1 至表 7 所示(資料來源皆為本研究假設): 表1 向供應商購買的單位物料成本(單位:元) S1 S2 S3 物料成本 800 9000 780 表 2 供應商運送原物料至工廠的單位成本(單位:元) S1 S2 S3 F1 200 250 220 F2 200 280 220 表 3 工廠運送產品至倉庫的單位成本(單位:元) F1 F2 W1 100 200 W2 200 100 表 4 倉庫運產品至銷售商的單位成本(單位:元) W1 W2 V1 100 80 V2 120 100 V3 80 60 表 5 零售商每期的需求量(單位:個) V1 V2 V3 t=1 720 280 1000 t=2 1380 1270 2500 t=3 1800 1290 1800 表 6 各零售商的產品售價(單位:元) V1 V2 V3 3900 4100 4000表 7 產能限制(單位:個) S1A S2A S3A 2000 1000 1500 F1A F2A 2500 2500 MF1A MF2A 400 400 IF1A IF2A 500 500 IW1A IW2A 500 500 存貨成本部分,單位原物料於工廠的存貨成本為 20(元),產品於工廠與倉庫的存貨成本皆為 30(元)。 本實驗於Intel® Pentiunm®4 CPU2.8GHz,RAM512MB 的環境進行測試,並針對本文所提出的假設數據利用
LINGO8.0 與 MATLAB7.1 軟體為工具,以模糊多目標以及基因演算法進行演算。 4.2 演算結果 將前文所提的目標函數加以模糊化後尋求隸屬度最大的適當解,以基因演算法與線性規劃所得之解進行比 較。另一部分則為將工廠產能進行模糊化前與模糊化後的演算結果進行比較,並估算每期每階段的運輸量。 由第 3 節的目標函式與限制式,個別推算出最優解與最差解,如表 8 所示。 表 8 個別目標函數優化值 最優解 最差解 f1 27866000 23302000 f2 1 0 根據表 8 的區間值將目標函數模糊化,尋求最大隸屬度之後,演算出其決策資訊。根據式(15)與式(16)分別 以線性規劃與基因演算法所求得之解進行比較。結果如表 9 所示。 表 9 線性規劃與基因演算法所求得之解比較 最優解 目標函數f1 隸屬度 目標函數f2 隸屬度 線性規劃解 26953200 0.8001 0.98852 GA 26953200 0.8 0.8
而在產能限制為不確定的情形下,在 4.1 節的資料數據中,原先模式的產能設定為 2500(見表 7)作為產能的 上限,而當決策者對於產能無法給出一個相當精確的數值時,進行模糊化處理便是一個適當的方法,如表 10 所 示。首先目標函數的值與前述的處理方法相同,演算出最優與最差的解作為隸屬函數的區間,而在產能的部份, 區間則給予下限值 2400 與上限值 2600,當然,此處的產能上下限值可依照決策者的經驗或是現場的情形加以判 斷,在此只是使用一個假設性的數據,而決策者代入不同數值時,模型依然可以演算出適當的結果。 表 10 產能模糊化前後之目標函數值與產能限制 產能模糊化之後 進行產能模糊化之前 α3=0 α3=1 目標函數 26953200 23302000 27866000 限制式(8) 2500 2400 2600 表 10 中數值 26953200 為進行產能模糊化之前,所得之最大利潤,進行產能模糊化之後,α3=[0,1]表目標函 數值所對應的隸屬度,23302000 為最差解,對應的隸屬度為 0,而 27866000 則為最優解對應利屬度為 1。2500 表原先的產能設定,2400 與 2600 則為模糊化的產能區間。 在使用[2400,2600]做為工廠產能的模糊區間下,目標函數與限制式(8)也各以式(17)與式(18)的形式表之,而 此時式(17)所求的目標值則轉換為以隸屬度望大的情形下進行處理。 3
f1 23302000
27866000 23302000
−
= α
−
(17) it 3 i tPF
−
2000
×α ≤
600
∑∑
(18) 其演算結果與比較如表11 至表 19,而為求方便比較,以模糊化前使用基因演算法找尋適當解稱為方法 1, 工廠產能為不確定時以模糊化的方式找尋隸屬度最大,並以基因演算法求解則稱為方法 2。 表11 工廠 F1訂購原物料 第一期 F11S1 F11S2 F11S3 方法1 0 0 500 方法2 0 0 140 第二期 F12S1 F12S2 F12S3 方法1 360 640 1500 方法 2 24 1000 1500 第三期 F13S1 F13S3 F13S3 方法1 0 1000 1200 方法 2 1176 1000 0表12 工廠 F2訂購原物料 第一期 F21S1 F21S2 F21S3 方法1 1500 0 1000 方法 2 2200 0 300 第二期 F22S1 F22S2 F22S3 方法1 1840 0 0 方法 2 2176 0 0 第三期 F23S1 F23S3 F23S3 方法1 2200 0 300 方法 2 1024 0 1500 表13 配送決策(工廠 F1→倉庫) 第一期 TF11W1 TF11W2 方法1 500 0 方法 2 140 0 第二期 TF12W1 TF12W2 方法1 2500 0 方法 2 2176 0 第三期 TF13W1 TF13W2 方法1 2200 0 方法 2 2524 0 表 14 配送決策(工廠 F2→倉庫) 第一期 TF21W1 TF21W2 方法1 0 2500 方法 2 0 2500 第二期 TF22W1 TF22W2 方法1 0 1840 方法 2 0 2176 第三期 TF23W1 TF23W2 方法1 0 2500 方法 2 0 2524
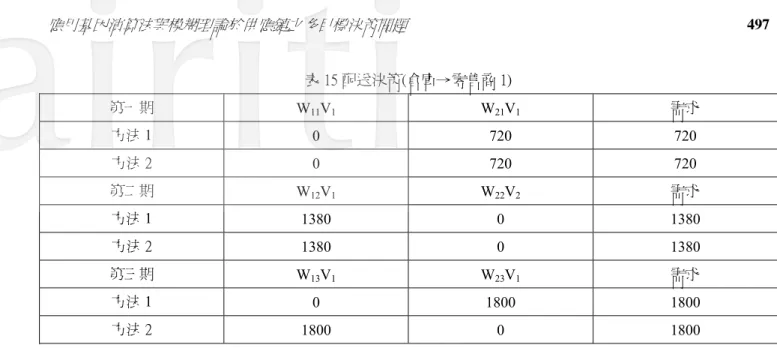
表 15 配送決策(倉庫→零售商 1) 第一期 W11V1 W21V1 需求 方法1 0 720 720 方法 2 0 720 720 第二期 W12V1 W22V2 需求 方法1 1380 0 1380 方法 2 1380 0 1380 第三期 W13V1 W23V1 需求 方法1 0 1800 1800 方法 2 1800 0 1800 表 16 配送決策(倉庫→零售商 2) 第一期 W11V2 W21V2 需求 方法1 0 280 280 方法 2 0 280 280 表 16 配送決策(倉庫→零售商 2)(續) 第二期 W12V2 W22V2 需求 方法1 0 1270 1270 方法 2 1270 0 1270 第三期 W13V2 W23V2 需求 方法1 1290 0 1290 方法 2 390 900 1290 表 17 配送決策(倉庫→零售商 3) 第一期 W11V3 W21V3 需求 方法1 0 1000 1000 方法 2 0 1000 1000 第二期 W12V3 W22V3 需求 方法1 1620 880 2500 方法 2 0 2500 1800 第三期 W13V3 W23V3 需求 方法 1 0 1800 1800 方法2 910 890 1800
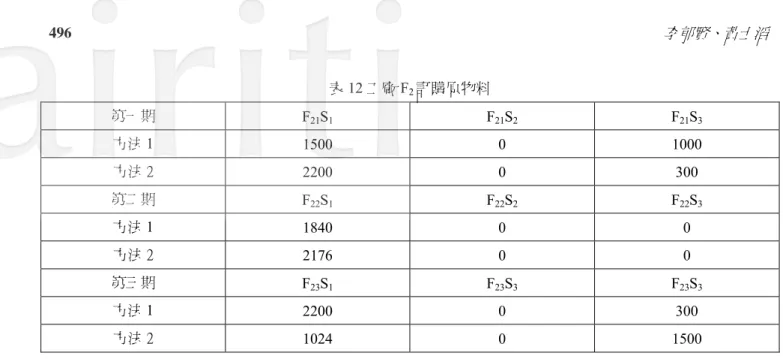
表18 倉庫的產品存貨數量 第一期 IW11 IW21 方法1 500 500 方法2 140 500 第二期 IW12 IW22 方法1 0 190 方法2 14 176 第三期 IW13 IW23 方法1 0 0 方法2 0 0 表19 服務水準最佳下方法 1 與方法 2 利潤比較 方法1 方法2 利潤 26953200 27692710 目標函數f1 隸屬度 0.8001 0.9615031 目標函數f2 隸屬度 0.98852 1 由表 19 可知,在未進行模糊化之前,使用方法 1 進行演算之後所得到之利潤為 26953200,目標函數f1、f2 隸屬度分別為 0.8001 與 0.98852。而方法 2 在目標函數經模糊化轉換後,為求隸屬度最佳的情況下,取得各隸屬 度最大值,在滿足各時期皆可達成服務水準的情況之下,透過方法 2,目標函數 f1 的隸屬度可達 0.9615031,目 標函數 f2 的隸屬度可達到 1。也就是說,當決策者要求服務水準最高的情況之下(α2=1),最佳化的利潤為 27692710。相較在產能進行模糊化的處理前,所得之最佳解為 26953200,可知在利潤與隸屬度方面方法 2 較方 法1 有著更佳的結果。 模式所運算出的決策結果,在方法1 的利潤值大致與傳統的線性規劃結果相符,不同的地方在於隸屬度的 差異以及倉庫的配送決策,有不同的配送量產生。而方法2 則是在於將產能限制進行模糊化之後,決策者可依 據考量,在服務水準與利潤最大的目標中找出對於公司最有利的決策,並評估增加資源的多寡對於整體收益的 影響。
5. 結論與未來研究方向
本研究根據供應鏈的形式發展出以利潤最大化與服務水準最佳為考量的數學模型,將目標函數進行模糊化 的處理,轉而利用基因演算法尋找在多目標中的隸屬度最大值,並以簡要的例子進行驗證取得較為適當的解與 配送決策。其中並考慮產能為不確定性的問題,將其進行模糊化,並與方法 1 進行比較。 運用尋找在多目標中的隸屬度最大值可以找到在限制條件下的較佳解,而模糊化的好處便在於決策者可依 不同的情形進行決策調度,而隸屬度便是評估目標值展現優良與否的一個指標,使得決策者可以輕易且快速的 判斷決策是否理想。而另一部分,由於供應鏈中有著許多的不確定性,在本文之中取產能的部份進行探討,而 實際上相同的手法也可運用在例如供應商的產能限制,或是工廠的產品存貨限制,或倉庫的產品存貨限制等等。 而在第 4 節可以明白的看出,產能進行模糊化過後的結果與模糊化之前的結果進行比較,發現使用模糊化後, 一方面決策者可以不必將產能精準的定義為某個數值,只需給適當的區間,並且可以減低當產能不是精確值時所造成的風險。而另一方面,進行模糊化的結果,也可以讓決策者考慮並評估增加資源的多寡對於整體收益的 影響。 在本文中雖已加入許多限制以求較為接近實務的情境,但供應鏈的生態可說是瞬息萬變,以下幾點是未來 仍需探討的方向: 1. 本文僅以利潤最大化與服務水準最佳為考量,未來應加入存貨水準等其他的目標作為改善的方向。 2. 實驗中的零售商需求,是由零售商發單之後,工廠才進行訂購物料與加工的動作,因此便不需要預測零 售商的需求,但是需要注意的是臨時的抽單或是加單等動作,在本文中,由於是考慮服務水準最高,對 於存貨的問題便是以出貨為最高原則,而對於臨時的變更訂單,存貨水準的制定也是相當值得注意的地 方。 3. 本文中進行模糊化的部份是針對產能,未來還可對於其他不確定的因素進行模糊化,並評估變更決策後, 對於整體效益是否有提升。
參考文獻
[1] Sabri, E.H. and B.M. Beamon, “A multi-objective approach to simultaneous strategic and operational planning in supply chain design,” Omega, 28, 581-598, 2000.
[2] Talluri, S. and R.C. Baker,” A multi-phase mathematical programming approach for effective supply chain design”, European
Journal of Operational Research, 41,544-558, 2002.
[3] Amid, A., S.H. Ghodsypour, and C. O’Brien,” Fuzzy multiobjective linear model for supplier selection in a supply chain”,
International Journal of Production Economics, 104, 394–407, 2006.
[4] Chen, C.L., T.W. Yuan, and W.C. Lee,” Multi-criteria fuzzy optimization for locating warehouses and distribution centers in a supply chain network”, Journal of the Chinese Institute of Chemical Engineers , 38, 393–407, 2007.
[5] Xu, J., Q. Liu, and R. Wang, ” A class of multi - objective supply chain networks optimal model under random fuzzy environment and its application to the industry of Chinese liquor ”, Information Sciences 178, 2022–2043, 2008.
[6] Altiparmak, F., G. Mitsuo, L. Lin, P. Turan, “A genetic algorithm approach for multi-objective optimization of supply chain networks”, Computers & Industrial Engineering, 51, 197-216, 2006.
[7] Ulungu, L. E., J. Teghem, P. H. Fortemps, and D. Tuyttens, ”MOSA: a tool for solving multiobjective combinatorial optimization problem”, Journal of Multi-Criteria Decision Analysis, 8, 221–236, 1999.
[8] Hokey, M., C.S. Ko and H.J. Ko, “The spatial and temporal consolidation of returned products in a closed-loop supply chain network”, Computers & Industrial Engineering, 51, 309-320, 2006.
[9] Nachiappan, S.P. and N. Jawahar, “A genetic algorithm for optimal operating parameters of VMI system in two-echelon supply chain”, European Journal of Operational Research, 182, 1433-1452, 2007.
[10] Borisovsky, P., A. Dolgui, A. Eremeev, “Genetic algorithms for a supply management problem: MIP-recombination vs. greedy decoder”, European Journal of Operational Research, 195, 770-779, 2007.
[11] Li, S.G. and X.Kuo, “The inventory management system for automobile spare parts in a central warehouse”, Expert Systems
with Applications, 34, 1144-1153, 2008.
[12] Holland, J.H., Adaptation in Natural and Artificial Systems, Ann Arbor, MI: The University of Michigan Press, 1975. [13] Man, K.F., K.S. Tang and S. Kwong, Genetic algorithms: Concepts and designs, Springer Verlag London, 1999. [14] 林昇甫、徐永吉,遺傳演算法及其應用,台北:五南圖書出版有限公司,2009.
[15] Srinivas, M. and L.M. Patnaik.,” Genetic Algorithms: A Survey”, IEEE Computer, 27, 17-26, 1994.
[16] Goldberg, D. E., Genetic Algorithms in Search, Optimization & Machine Learning, Addison Wesley, Reading, MA, 1989. [17] Michalewicz, Z., Genetic algorithms + data structures = evolution programs, Artificial Intelligence, Berlin: Springer, 1992. [18] Gen, M. and R. Cheng, Genetic Algorithms and Engineering Design, New York: John Wiley and Sons, Inc, 1997.