國 立 交 通 大 學
生物資訊及系統生物研究所
碩 士 論 文
利用剪下-圓形化-線性化-插入的運算
排序基因體
Sorting Genomes Using
Cut-Circularize-Linearize-and-Paste Operations
研 究 生: 黃亙亘
指導教授: 邱顯泰 博士
盧錦隆 博士
利用剪下-圓形化-線性化-插入的運算
排序基因體
Sorting Genomes Using
Cut-Circularize-Linearize-and-Paste Operations
研 究 生:黃亙亘
Student:Keng-Hsuan Huang
指導教授: 邱顯泰 博士 Advisor:Dr. Hsien-Tai Chiu
盧錦隆 博士
Dr. Chin Lung Lu
國 立 交 通 大 學
生 物 資 訊 及 系 統 生 物 研 究 所
碩 士 論 文
A Thesis Submitted to Institute of Bioinformatics College of Biological Science and Technology National Chiao Tung University in partial Fulfillment of the
Requirements for the Degree of Master in Biological Science and Technology
中文摘要
在演化的過程中,基因體可能會經歷一些被稱為基因體重組的大規 模突變。隨著愈來愈多的基因體被完整地定序,基於基因次序分析 的基因體重組研究在演化樹的重建上扮演著重要的角色。在過去, 有許多傳統的重組運算已被提出以評估兩個相關基因體基因次序的 演化距離,例如反轉、移位、區塊互換、易位、分裂與融合。通常 基因體重組的計算研究被定義成一個利用重組運算來排序一個排列 的問題。在這個論文中,我們介紹一個利用剪下-圓形化-線性化-插 入 (簡稱 CCLP)的運算來進行排序的問題,目的是要找出最少次數 的 CCLP 運算來排序一個表示一條染色體的有號整數排列。CCLP 運 算是一種基因體重組的運算,它會把染色體的某一個片段剪下,然 後再把剪下的片段圓形化成一個暫時性的環狀染色體,接著再把這 個環狀染色體線性化為一條線性染色體,最後再把線性化的染色體 貼回到原來的染色體中,但在線性染色體被貼回去之前允許它被反 轉。CCLP 運算可以模擬一些上述為人所熟知的重組,例如反轉、移 位與區塊互換,以及其他未在生物文獻中被報導的重組。為了與反 轉作區別,我們把其它的 CCLP 運算稱為非反轉的 CCLP 運算。最 後,當反轉與非反轉 CCLP 運算的權重比為 1:2 時,我們提出一個時 間複雜度為 𝑂(𝛿𝑛) 的演算法來解決有加權重的 CCLP 運算排序問題, 其中 𝑛 為一條染色體內的基因個數,而 𝛿 為排序過程中所需的 CCLP 運算次數。Abstract
During evolution, genomes may undergo large-scale mutations called as genome rearrangements. With more and more genomes have been sequenced completely, genome rearrangement studies based on genome-wide analysis of gene orders play an important role in reconstructing phylogenetic trees. In the past, a variety of traditional rearrangement operations, such as reversals, transpositions, block-interchanges, translocations, fissions and fusions, have been proposed to evaluate the evolution distance between two related genomes in gene order. Usually, the computational studies of genome rearrangements are formulated as a problem of sorting a permutation by rearrangement operations. In this thesis, we introduce a problem, called as a sorting problem by cut-circularize-linearize-and-paste (CCLP) operations, which aims to find a minimum number of CCLP operations to sort a signed permutation representing a chromosome. The CCLP operation is a genome rearrangement operation that cuts a segment out of a chromosome, circularizes the segment into a temporary circle, linearizes the temporary circle as a linear segment, and possibly inverts the linearized segment and pastes it into the remaining chromosome. The CCLP operation can model many well-known rearrangements mentioned above, such as reversals, transpositions and block-interchanges, and others not reported in the biological literature. To distinguish those CCLP
operations from the reversal, we call them as non-reversal CCLP operations. Finally, we propose an 𝑂(𝛿𝑛) time algorithm for solving the weighted sorting problem by CCLP operations when the weight ratio between reversals and non-reversal CCLP operations is 1:2, where 𝑛 is the number of genes and 𝛿 is the number of needed CCLP operations.
Acknowledgement
一轉眼,兩年的研究所生活過去了,我的求學生涯也將告一段落, 繼續往人生的下一階段邁進,不管未來的發展如何,都要感謝一路 上曾經陪伴、幫助過我的人,特別是我的家人,感謝你們無怨無悔 地為我付出,得以讓我完成我的學業。也很感謝我的指導教授,盧 錦隆教授,一步一步地指引我的研究方向,讓我可以順利畢業,雖 然你常對我們碎碎念,但那些話對我們來說並不刺耳,反而讓我們 體會到研究生的本分不只是做好研究,還有很多做人處事的態度及 方法值得去學習。 謝 謝 拖 鞋 學 姐 和 拖 弟 , 你 們 的 一 搭 一 唱 讓 我 對 genome rearrangements 感到興趣。謝謝忠翰寶貝,讓我知道誰是菇菇界的 霸主。謝謝科科以及勞倫濕,讓我在吃肉的旅途上不孤單。謝謝芸 蓁,對於從我口中說出的五四三,你都能適時地做出回應。謝謝昱 全在 embedded system 的不離不棄以及常常討論對付查某人的策略。 謝謝皮老闆和學妹為我跟昱全的口試奔波準備食物,也祝你們的研 究順利。Contents
中文摘要 ... I
Abstract ... II
Acknowledgement ... IV
Contents ... V
List of figures ... VI
Chapter 1 Introduction ... 1
Chapter 2 Preliminaries ... 8
Chapter 3 Algorithm ... 14
Chapter 4 Conclusion ... 22
References ... 23
List of figures
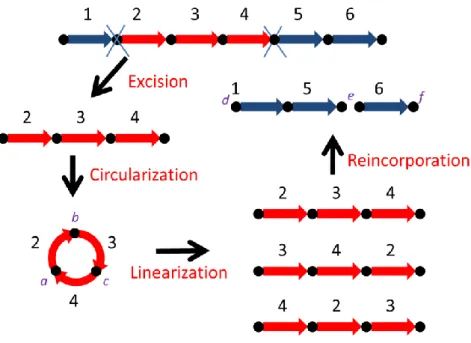
Figure 1-1. (1) Excision: a fragment of genes 2, 3 and 4 is cut from a
linear chromosome. (2) Circularization: the two ends of the excised segment are joined together as a circular chromosome that is temporary. (3) Linearization: the temporary circular chromosome is cut at place a, b or c so that it becomes again a linear chromosome. (4) Reincorporation: the linearized chromosome is pasted back to the original chromosome at new site d, e or f. ... 3
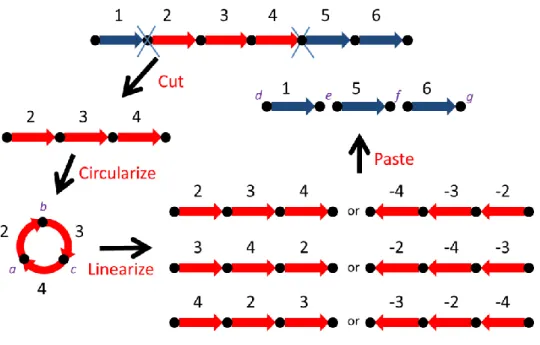
Figure 1-2. A modified cut-circularize-linearize-and-paste operation
that can model seven different kinds of rearrangement, where the cutting site of the temporary circle with genes 2, 3 and 4 can be either a, b or c, and the inserting place of the linearized segment at the remaining chromosome can be either d, e, f or g. ... 6
Figure 2-1. The illustration of a permutation 𝛼 = (1,4,7,2)(3,6,5),
where 𝛼(1) = 4 , 𝛼(2) = 1 , 𝛼(3) = 6 , 𝛼(4) = 7 , 𝛼(5) = 3 , 𝛼(6) = 5 and 𝛼(7) = 2. ... 9
Figure 4-1. A CCLP operation acting on genes -1 and -5 on a circular
Chapter 1
Introduction
Genome rearrangement studies based on genome-wide analysis of gene orders play an important role in the phylogenetic tree reconstruction [5, 11, 13, 22, 23]. In these studies, a gene is usually represented by a signed integer, where the associated sign indicates on which of the two complementary DNA strands the gene is located, a chromosome by a sequence of genes and a genome by a set of chromosomes. In the last two decades, a variety of rearrangement operations have been proposed to evaluate the evolutionary distance between two related genomes in gene order. Basically, these operations can be classified into two categories: (1) ‘intra-chromosomal’ rearrangements, such as reversals, transpositions and block-interchanges (also called ‘generalized transpositions’), and (2) ‘inter-chromosomal’ rearrangements, such as fusions, fissions and translocations. Reversals, also called inversions, affect a segment of consecutive integers in the chromosome by reversing the order and flipping the signs of the integers [2, 13, 14, 17, 24]. Transpositions affect two adjacent segments in the chromosome by exchanging their positions [4, 9, 10]. Block-interchanges are generalized transpositions by allowing the exchanged segments not being adjacent in the chromosome [8, 10, 14,
16, 18]. Translocations exchange the end segments between two chromosomes [7, 11, 12, 14, 21]. Fusions join two chromosomes into a bigger one and fissions break a chromosome into two smaller ones [11, 14, 19, 20].
Recently, the study on the genome rearrangement using block-interchanges has increasingly drawn great attention, since block-interchanges contain transpositions as a special case and, currently, the computational models involving block-interchanges are more tractable than those involving transpositions. More recently, Yancopoulos et al. introduced the double cut and join (DCJ) operation, which cuts the chromosome(s) in two places and rejoins the four cut ends in a new way, as a basis for modeling all the rearrangement operations described previously [25]. Particularly, transpositions and block-interchanges can be modeled by two consecutive DCJ operations, while others by one DCJ operation. In fact, as mentioned in [1], the two consecutive DCJ operations can be viewed as the following procedure to model transpositions or block-interchanges (see Figure 1-1 for a reference). (1) Excision: cut a segment from a chromosome that can be linear or circular. (2) Circularization: join the ends of the excised segment into a temporary circle. (3) Linearization: cut the temporary circle in any place as a linear segment. (4) Reincorporation: paste the linearized segment back to the remaining chromosome at a new site. As also pointed out in [1], this process of fragment excision, circularization, linearization and reincorporation indeed happens in the configuration of the immune response in higher animals. Here, we make a little modification to the reincorporation step in the above process by allowing the linearized segment to be possibly inverted before its reinsertion and also allowing
Figure 1-1. (1) Excision: a fragment of genes 2, 3 and 4 is cut from a
linear chromosome. (2) Circularization: the two ends of the excised segment are joined together as a circular chromosome that is temporary. (3) Linearization: the temporary circular chromosome is cut at place a, b or c so that it becomes again a linear chromosome. (4) Reincorporation: the linearized chromosome is pasted back to the original chromosome at new site d, e or f.
inverted or non-inverted linearized segment to be pasted back to the remaining chromosome at any site (see Figure 1-2 for the modified model). This modification enables the above cut-circularize-linearize-and -paste (CCLP for short) operation to model seven different kinds of rearrangements, as will be detailed below. It is interesting to note that in addition to transposition and block-interchange, a CCLP operation can model reversal, inverted transposition (or transversal) [3] and others that are currently not reported in the biological literature. The seven rearrangements modeled by the CCLP operation are described as follows (see Figure 1-2 for a reference).
Case I – Reversal:
As illustrated in Figure 1-2, a segment with genes 2, 3 and 4 is cut from a chromosome (1,2,3,4,5,6) and joined as a temporary circle, which is then cut in the same place as it was created by the join (i.e., the a site in Figure 1-2), and inverted and pasted back to the chromosome at the cutting site (i.e., the e site in Figure 1-2). As a result, this CCLP operation performs as a reversal that changes the chromosome (1,2,3,4,5,6) into (1,-4,-3,-2,5,6).
Case II – Transposition:
The temporary circle is cut at a new place (e.g., the b site in Figure 1-2) and pasted back to the chromosome at the cutting site. This CCLP operation performs as a transposition that changes (1,2,3,4,5,6) into (1,3,4,2,5,6).
Case III – Two consecutive, adjacent reversals:
The temporary circle is cut at a new place (e.g., the b site in Figure 1-2), and then inverted and pasted back to the chromosome at the cutting site. This CCLP operation changes (1,2,3,4,5,6) into (1,-2,-4,-3,5,6), which is equivalent to that (1,2,3,4,5,6) is first changed into (1,2,-4,-3,5,6) by a reversal, which is further changed into (1,-2,-4,-3,5,6) by another reversal. Note that the chromosomal regions affected by these two consecutive reversals are adjacent. Case IV – Transposition:
The temporary circle is cut in the same place as it was joined and then pasted back to the chromosome at a new site (e.g., the f site in Figure 1-2). This CCLP operation performs as a transposition that
changes (1,2,3,4,5,6) into (1,5,2,3,4,6). Case V – Transversal:
The temporary circle is cut in the same place as it was joined, and then inverted and pasted back to the chromosome at a new site (e.g., the f site in Figure 1-2). This CCLP operation performs as an inverted transposition (i.e., transversal) that changes (1,2,3,4,5,6) into (1,5,-4,-3,-2,6).
Case VI – Block-interchange:
The temporary circle is cut at a new place (e.g., the b site in Figure 1-2) and then pasted back to the chromosome at a new site (e.g., the f site in Figure 1-2). This CCLP operation performs as a block-interchange that changes (1,2,3,4,5,6) into (1,5,3,4,2,6). Case VII – Two consecutive, overlapping reversals:
The temporary circle is cut at a new place (e.g., the b site in Figure 1-2), and then inverted and pasted back to the chromosome at a new site (e.g., the f site in Figure 1-2). This CCLP operation changes (1,2,3,4,5,6) into (1,5,-2,-4,-3,6), which is equivalent to that (1,2,3,4,5,6) is first changed into (1,2,-5,-4,-3,6) by a reversal, which is further changed into (1,5,-2,-4,-3,6) by another reversal. Note that the chromosomal regions affected by these two consecutive reversals are overlapping.
Figure 1-2. A modified cut-circularize-linearize-and-paste operation that
can model seven different kinds of rearrangement, where the cutting site of the temporary circle with genes 2, 3 and 4 can be either a, b or c, and the inserting place of the linearized segment at the remaining chromosome can be either d, e, f or g.
All these seven rearrangements described above are simply called CCLP operations. But, to distinguish those CCLP operations from the reversal, we call them as non-reversal CCLP operations in the sequel of this paper. In this article, we are interested in designing efficient algorithms to solve the genome rearrangement problem involving all the seven CCLP operations. If all these CCLP operations are weighted equally, the problem aims to find a minimum number of operations to sort a signed permutation of representing a chromosome. In this case, however, non-reversal CCLP operations are favored in the rearrangement scenario of the optimal solution, as will be clear later, which contradicts with the observation made by biologists that in most organisms, reversals are observed much more frequently when compared with other
rearrangements. Therefore, it may require a reversal to be weighted differently from other CCLP operations. In this differently weighted case, the problem is then called weighted sorting problem by CCLP operations, which is to find a sequence of CCLP operations such that the sum of the operation weights in the sequence is minimum. In this study, we focus our attention on the case in which the weight ratio between reversals and non-reversal CCLP operations is 1:2 and use the permutation group in algebra to design an 𝑂(𝛿𝑛) time algorithm for solving the problem, where n is the number of genes in the given chromosome and 𝛿 is the number of needed CCLP operations.
Chapter 2
Preliminaries
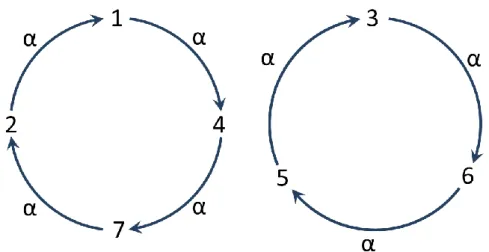
Given a set 𝐸 = *1,2, … , 𝑛+ of n positive integer, a permutation is a one-to-one mapping from E into itself. For instance, as shown in Figure 2-1, we may define a permutation 𝛼 of the set *1,2,3,4,5,6,7+ by 𝛼(1) = 4, 𝛼(2) = 1, 𝛼(3) = 6, 𝛼(4) = 7, 𝛼(5) = 3, 𝛼(6) = 5 and 𝛼(7) = 2. In the study of genome rearrangement, it is convenient to express the permutation in cycle form as 𝛼 = (1,4,7,2)(3,6,5) , in which for each 𝑥 ∈ 𝐸 , 𝛼(𝑥) is placed directly right to x. A cycle of length k, say (𝑎1, 𝑎2, … , 𝑎𝑘), is simply called k-cycle and it also can be written as (𝑎𝑖, 𝑎𝑖+1, … , 𝑎𝑘, 𝑎1, … , 𝑎𝑖−1) (i.e., indices are cyclic), where 2 ≤ 𝑖 ≤ 𝑘. Any two cycles are said to be disjoint if they have no elements in common. Basically, a permutation can be written in a unique way as the product of disjoint cycles, which is called the cycle decomposition of this permutation, if we ignore the order of the cycles in the product. Usually, a 1-cycle, in which its element is said to be fixed, in a permutation is not written explicitly. Especially, the permutation whose elements are all fixed is called an identity permutation and is denoted by 1, i.e., 𝟏 = (1)(2) ⋯ (𝑛).
Figure 2-1. The illustration of a permutation 𝛼 = (1,4,7,2)(3,6,5),
where 𝛼(1) = 4, 𝛼(2) = 1, 𝛼(3) = 6, 𝛼(4) = 7, 𝛼(5) = 3, 𝛼(6) = 5 and 𝛼(7) = 2.
Given two permutations 𝛼 and 𝛽 of E, the composition (or product) of 𝛼 and 𝛽, denote by 𝛼𝛽, is defined to be a permutation of E with 𝛼𝛽(𝑥) = 𝛼(𝛽(𝑥)) for all 𝑥 ∈ 𝐸 . For instance, let 𝛼 = (2,1) and 𝛽 = (2,5,3,1,6,4) be two permutations of 𝐸 = *1,2,3,4,5,6+ . Then 𝛼𝛽 = (2,5,3)(1,6,4). If 𝛼 and 𝛽 are disjoint cycles, then 𝛼𝛽 = 𝛽𝛼. The inverse of 𝛼 is a permutation, denoted as 𝛼−1, such that 𝛼𝛼−1 = 𝛼−1𝛼 = 𝟏. Notably, if a permutation is expressed by the product of disjoint cycles, then its inverse can be obtained by just reversing the order of the elements in each cycle. For example, if 𝛼 = (2,5,3)(1,6,4) , then 𝛼−1 = (3,5,2)(4,6,1). The conjugation of 𝛽 by 𝛼, denoted by 𝛼 ∙ 𝛽, is the permutation α𝛽𝛼−1, which is a permutation with the same cycle structure of 𝛽 but each element x is changed by 𝛼(𝑥). More clearly, if 𝛽 = ( 𝑏1, 𝑏2, … , 𝑏𝑖 )( 𝑏𝑖+1, 𝑏𝑖+2, … , 𝑏𝑘 ), then 𝛼 ∙ 𝛽 = ( 𝛼(𝑏1), … , 𝛼(𝑏𝑖) ) ( 𝛼(𝑏𝑖+1), … , 𝛼(𝑏𝑘)).
Let 𝛼 = (𝑎1, 𝑎2) be a 2-cycle and 𝛽 be an arbitrary permutation of E. Then the effect of applying 𝛼 to 𝛽 can be described as follows:
If 𝑎1 and 𝑎2 are in the same cycle of 𝛽, then this cycle is broken into two smaller ones in 𝛼𝛽 (or 𝛽𝛼), that is, 𝛼 functions as a split operation of 𝛽. For instance, 𝛼 = (1,2) and 𝛽 = (1,6,4,2,5,3), then 𝛼𝛽 = (1,6,4)(2,5,3) and 𝛽𝛼 = (5,3,1)(6,4,2).
If 𝑎1 and 𝑎2 are in two different cycles of 𝛽, then these two cycles are joined into a bigger one in 𝛼𝛽 (or 𝛽𝛼 ), that is, 𝛼 functions as a join operation of 𝛽. For instance, 𝛼 = (1,3) and 𝛽 = (1,6,4)(2,5,3) , then 𝛼𝛽 = (1,6,4,3,2,5) and 𝛽𝛼 = (6,4,1,2,5,3).
Every permutation 𝛼 of E can be expressed as a product of 2-cycles. However, there are many ways of expressing 𝛼 as a product of 2-cycles. For instance, (𝑎1, 𝑎2, … , 𝑎𝑘) = (𝑎1, 𝑎2)(𝑎2, 𝑎3) ⋯ (𝑎𝑘−1, 𝑎𝑘) = (𝑎1, 𝑎𝑘) (𝑎1, 𝑎𝑘−1) ⋯ (𝑎1, 𝑎2), where 𝑘 ≥ 3. The norm of 𝛼, denoted by ‖𝛼‖, is defined to be the minimum number k such that 𝛼 can be expressed by a product of k 2-cycles. Let 𝑛𝑐(𝛼) denote the number of disjoint cycles in the cycle decomposition of 𝛼 . Notice that 𝑛𝑐(𝛼) also counts the non-expressed 1-cycles. For example, if 𝛼 = (1,3,2)(5,6) is a permutation of *1,2,3,4,5,6+ , then we have 𝑛𝑐(𝛼) = 3 , instead of 𝑛𝑐(𝛼) = 2, since 𝛼 = (1,3,2)(4)(5,6). For any permutation 𝛼 of E, it can be shown that ‖𝛼‖ = |𝐸| − 𝑛𝑐(𝛼) [14, 18]. For two permutations 𝛼 and 𝛽 of E, 𝛼 is said to divide 𝛽, simply denoted by 𝛼|𝛽, if and only if ‖𝛽𝛼−1‖ = ‖𝛽‖ − ‖𝛼‖ . For example, let 𝛼 = (2,1) and
𝛽 = (2,5,3,1,6,4) be two permutations of 𝐸 = *1,2,3,4,5,6+ . Then 𝛽𝛼−1 = (1,5,3)(2,6,4) . Thus we have ‖𝛽𝛼−1‖ = 4 , ‖𝛽‖ = 5 and
‖𝛼‖ = 1. As a result, ‖𝛽𝛼−1‖ = ‖𝛽‖ − ‖𝛼‖ and hence 𝛼|𝛽. Actually,
we can easily determine if 𝛼 divides 𝛽 using the following lemma.
Lemma 1 [14]. Let 𝑎1, 𝑎2, … , 𝑎𝑘 ∈ 𝐸 and 𝛽 be any permutation of 𝐸.
Then 𝑎1, 𝑎2, … , 𝑎𝑘 are in the same cycle of 𝛽 and appear in this cycle in the order of 𝑎1, 𝑎2, … , 𝑎𝑘 if and only if (𝑎1, 𝑎2, … , 𝑎𝑘)|𝛽.
As mentioned before, a gene is usually represented by a signed integer in the genome rearrangement studies. To properly model a DNA, which is well known as a double stranded molecule, we let 𝐸 = *±1, ±2, … , ±𝑛+, in which 𝑛 is the number of genes and each gene 𝑖 has counterpart gene – 𝑖 in the same location in the opposite strand. Let Γ = (1, −1)(2, −2) ⋯ (𝑛, −𝑛). Clearly, Γ2 = 𝟏, that is Γ−1 = Γ. A cycle
is said to be admissible if it does not contain 𝑖 and – 𝑖 simultaneously for some gene 𝑖 ∈ 𝐸. Then we can use an admissible 𝑛-cycle to represent a DNA strand that is constituted by 𝑛 genes in some order. Given a DNA strand, say 𝜋+ , 𝜋− = Γ ∙ (𝜋+)−1 is its reverse complement, since (𝜋+)−1 is the reverse of 𝜋+ and Γ ∙ (𝜋+)−1 is the complement of
(𝜋+)−1. For our purpose, we here represent the DNA molecule, named 𝜋,
by the product of the two strands 𝜋+ and 𝜋−, that is, 𝜋 = 𝜋+𝜋− = 𝜋−𝜋+ (since 𝜋+ and 𝜋− are disjoint).
Lemma 2 [14]. Let 𝜋 and 𝜎 represent two different chromosomes. If 𝛼
is a cycle in 𝜎𝜋−1, then (𝜋𝛤) ∙ 𝛼−1 is also a cycle in 𝜎𝜋−1.
According to Lemma 2, 𝛼 and (𝜋Γ) ∙ 𝛼−1 are each other’s mate cycle in 𝜎𝜋−1.
that is, (𝑢, 𝑣) ∤ 𝜋 . Then 𝛾 = (𝜋𝛤(𝑣), 𝜋𝛤(𝑢)) (𝑢, 𝑣) acts on 𝜋 as a reversal.
Note that in Lemma 3, (𝑢, 𝑣) acts on 𝜋 as a join operation and (𝜋Γ(𝑣), 𝜋Γ(𝑢)) acts on (𝑢, 𝑣)𝜋 as a split operation. In other words, a reversal acting on 𝜋 can be implemented by the composition of two 2-cycles and 𝜋. In fact, it can be verified that other non-reversal CCLP operations can be implemented by multiplying four 2-cycles (𝜋Γ(𝑥), 𝜋Γ(𝑤))(𝑤, 𝑥)(𝜋Γ(𝑣), 𝜋Γ(𝑢))(𝑢, 𝑣) with the given chromosome 𝜋 if the following conditions are satisfied: (1) (𝑢, 𝑣)|𝜋, (2) (𝑤, 𝑥) ∤ (𝑢, 𝑣)𝜋 (3) 𝑤 ≠ Γ(𝑥) or Γ(𝑤) ≠ 𝑥 and (4) (𝑤, Γ(𝑥)) ∤ (𝑢, 𝑣)𝜋 or (Γ(𝑤), 𝑥) ∤ (𝑢, 𝑣)𝜋. The first condition is to make sure that (𝑢, 𝑣) and (𝜋Γ(𝑣), 𝜋Γ(𝑢)) respectively act on the two strands of 𝜋 as splits, which lead to two temporary circles excised from 𝜋 . Note that these two temporary circles are complement to each other. The second condition is to make sure that (𝑤, 𝑥) and (𝜋Γ(𝑥), 𝜋Γ(𝑤)) respectively act on the two temporary circles and the cycles of the remaining 𝜋 as joins, which paste back the two temporary circles into the remaining 𝜋 . It is worth mentioning that the joins also fulfill the process of linearization with possible inversion. The inversion is performed when the temporary circles are reinserted into the chromosome strands different from the ones they come from. The third and fourth conditions are to make sure that the resulting 𝜋 are admissible (i.e., no 𝑖 and −𝑖 are in the same chromosome strand). Therefore, we have the following lemma.
Lemma 4. Let 𝜋 be a chromosome and 𝛽 = (𝜋𝛤(𝑥), 𝜋𝛤(𝑤))(𝑤, 𝑥)(𝜋𝛤(𝑣), 𝜋𝛤(𝑢))(𝑢, 𝑣) . Suppose that the following four conditions are satisfied: (1) (𝑢, 𝑣)|𝜋, (2) (𝑤, 𝑥) ∤ (𝑢, 𝑣)𝜋 (3) 𝑤 ≠ 𝛤(𝑥) or 𝛤(𝑤) ≠ 𝑥 and (4) (𝑤, 𝛤(𝑥)) ∤ (𝑢, 𝑣)𝜋 or
(𝛤(𝑤), 𝑥) ∤ (𝑢, 𝑣)𝜋 . Then 𝛽 acts on 𝜋 as a non-reversal CCLP operation.
Chapter 3
Algorithm
In this chapter, we shall utilize the permutation groups to design an efficient algorithm for sorting a given chromosome 𝜋 into 𝐼 = (1,2, … , 𝑛)(−𝑛, … , −2, −1) using the CCLP operations when the weight ratio between reversals and non-reversal CCLP operations is 1:2. Recall that any permutation can be expressed as a product of 2-cycles and every reversal (respectively, non-reversal CCLP operation) affecting 𝜋 can be implemented by a product of two (respectively, four) 2-cycles and 𝜋. Furthermore, the composition of 𝐼𝜋−1 and 𝜋 is I, suggesting that 𝐼𝜋−1 can be expressed as a product of 2-cycles that functions as a sequence of CCLP operations to optimally transform 𝜋 into I. In the following, we shall show how to fulfill such an idea. For simplicity, we say that x and y are adjacent in a permutation 𝛼 if 𝛼(𝑥) = 𝑦 or 𝛼(𝑦) = 𝑥.
Lemma 5. Let 𝜋 = 𝜋+𝜋− be a chromosome. Suppose that (𝑥, 𝑦)|𝐼𝜋−1 and (𝑥, 𝑦)|𝜋, that is, there are two elements 𝑥 and 𝑦 in a cycle of 𝐼𝜋−1 such that (𝑥, 𝑦) acts on 𝜋 as a split. Let 𝛽 = (𝜋Γ(𝑦), 𝜋Γ(𝑥))(𝑥, 𝑦). Then there are two adjacent elements 𝑥′ and 𝑦′ in a cycle of 𝐼(𝛽𝜋)−1 such that (𝑥′, 𝑦′) and (𝛽𝜋Γ(𝑦′), 𝛽𝜋Γ(𝑥′)) act on 𝛽𝜋 as joins. Moreover, the cycles in 𝛽′𝛽𝜋 are admissible, where
𝛽′ = (𝛽𝜋Γ(𝑦′), 𝛽𝜋Γ(𝑥′))(𝑥′, 𝑦′).
Proof. For convenience, let 𝜋 = 𝜋+𝜋− = (𝑎1, 𝑎2, … 𝑎𝑛) (−𝑎𝑛, −𝑎𝑛−1, … , −𝑎1). The assumption (𝑥, 𝑦)|𝜋 indicates that 𝑥 and 𝑦 are in the same cycle of 𝜋, say in 𝜋+, and hence 𝜋Γ(𝑥) and 𝜋Γ(𝑦) are in 𝜋−. Hence, both (𝑥, 𝑦) and (𝜋Γ(𝑦), 𝜋Γ(𝑥)) act on 𝜋 as splits and
𝛽 = (𝜋Γ(𝑦), 𝜋Γ(𝑥))(𝑥, 𝑦) divides 𝜋 into four cycles. Let 𝛽𝜋 = 𝜋1+𝜋2+𝜋1−𝜋
2− = (𝑎1, … , 𝑎𝑘−1)(𝑎𝑘, … , 𝑎𝑛)(−𝑎𝑘−1, … , −𝑎1)(−𝑎𝑛, … , −𝑎𝑘).
For simplicity of our further discussion, we assume that 𝑎𝑖 < 𝑎𝑖+1 < 𝑛 for 1 ≤ 𝑖 ≤ 𝑘 − 2. This indicates that 𝑎𝑘−1 is the maximum in 𝜋1+ and hence 𝑎𝑘−1 + 1 is not in 𝜋1+. Moreover, 𝐼(𝛽𝜋)−1(𝑎1) = 𝐼(𝑎𝑘−1) = 𝑎𝑘−1+ 1, meaning that 𝑎1 and 𝑎𝑘−1 + 1 are adjacent in 𝐼(𝛽𝜋)−1. In other words, there are two adjacent elements 𝑎1 and 𝑎𝑘−1 + 1 in 𝐼(𝛽𝜋)−1 such that (𝑎
1, 𝑎𝑘−1 + 1) , as well as
(𝛽𝜋Γ(𝑎𝑘−1+ 1), 𝛽𝜋Γ(𝑎1)), acts on 𝛽𝜋 as a join. If the two cycles in (𝛽𝜋Γ(𝑎𝑘−1+ 1), 𝛽𝜋Γ(𝑎1))(𝑎1, 𝑎𝑘−1 + 1)𝛽𝜋 are admissible (i.e., they represent a chromosome), then we have completed the proof of this lemma based on Lemma 4. Now, suppose that the two cycles in (𝛽𝜋Γ(𝑎𝑘−1+ 1), 𝛽𝜋Γ(𝑎1))(𝑎1, 𝑎𝑘−1 + 1)𝛽𝜋 are not admissible (i.e., for some 1 ≤ 𝑖 ≤ 𝑛, both 𝑖 and – 𝑖 are in the same cycle). We then show below that we can still find two other adjacent elements 𝑥′ and 𝑦′ in a cycle of 𝐼(𝛽𝜋)−1 such that (𝑥′, 𝑦′) and (𝛽𝜋Γ(𝑦′), 𝛽𝜋Γ(𝑥′)) can join 𝛽𝜋 into two admissible cycles. First of all, 𝑎𝑘−1 + 1 must be in 𝜋1−
(otherwise, (𝛽𝜋Γ(𝑎𝑘−1 + 1), 𝛽𝜋Γ(𝑎1))(𝑎1, 𝑎𝑘−1+ 1)𝛽𝜋 is an admissible chromosome), leading to that the cycle created by joining 𝜋1+𝜋1− using (𝑎
1, 𝑎𝑘−1 + 1) is not admissible. Further suppose that 𝑎𝑗 is
the minimum in 𝜋1+. Then Γ(𝑎𝑗) = −𝑎𝑗, which is the maximum in 𝜋1−. Therefore, we have −𝑎𝑗 ≥ 𝑎𝑘−1 + 1 (since 𝑎𝑘−1 + 1 is also in 𝜋1−). In
addition, −𝑎𝑗−1 and 𝐼(−𝑎𝑗) are adjacent in 𝐼(𝛽𝜋)−1 because 𝐼(𝛽𝜋)−1(−𝑎
𝑗−1) = 𝐼(−𝑎𝑗) . In the following, we consider five
possibilities.
Case 1. 𝑎𝑗 ≠ −𝑛 and 𝑎𝑗 ≠ 1. Then 𝐼(−𝑎𝑗) = −𝑎𝑗 + 1, which is not
in 𝜋1− since −𝑎𝑗 is the maximum in 𝜋1−. If −𝑎𝑗 + 1 is in 𝜋1+, then 𝑎𝑘−1 cannot be the maximum in 𝜋1+, since −𝑎𝑗 ≥ 𝑎𝑘−1 + 1 and hence −𝑎𝑗 + 1 > 𝑎𝑘−1, which contradicts to our assumption that 𝑎𝑘−1 is the maximum in 𝜋1+. In other words, 𝐼(−𝑎𝑗) belongs to either 𝜋2+ or 𝜋2− and hence (−𝑎𝑗−1, 𝐼(−𝑎𝑗)) acts on 𝛽𝜋 as a join and the cycles in (𝛽𝜋Γ𝐼(−𝑎𝑗), 𝛽𝜋Γ(−𝑎𝑗−1))(−𝑎𝑗−1, 𝐼(−𝑎𝑗))𝛽𝜋 are admissible.
Case 2. 𝑎𝑗 = −𝑛 and both 1 and −1 are not in 𝜋1+. Then 𝐼(−𝑎𝑗) =
1 (instead of 𝐼(−𝑎𝑗) = −𝑎𝑗 + 1 = 𝑛 + 1 ). Because 𝜋1+ and 𝜋
1− are
complement to each other from chromosomal point of view, both of them contains no 1 and −1, as a result, 𝐼(−𝑎𝑗) belongs to either 𝜋2+ or 𝜋2−. Therefore, (−𝑎𝑗−1, 𝐼(−𝑎𝑗)) acts on 𝛽𝜋 as a join and (𝛽𝜋Γ𝐼(−𝑎𝑗), 𝛽𝜋Γ(−𝑎𝑗−1))(−𝑎𝑗−1, 𝐼(−𝑎𝑗))𝛽𝜋 contains only admissible cycles.
Case 3. 𝑎𝑗 = 1 and both 𝑛 and −n are not in 𝜋1+. Then 𝐼(−𝑎𝑗) =
−𝑛 (instead of 𝐼(−𝑎𝑗) = −𝑎𝑗 + 1 = 0 ). Clearly, 𝐼(−𝑎𝑗) belongs to either 𝜋2+ or 𝜋2−. Therefore, (−𝑎𝑗−1, 𝐼(−𝑎𝑗)) acts on 𝛽𝜋 as a join and (𝛽𝜋Γ𝐼(−𝑎𝑗), 𝛽𝜋Γ(−𝑎𝑗−1))(−𝑎𝑗−1, 𝐼(−𝑎𝑗))𝛽𝜋 have two admissible cycles.
Case 4. 𝑎𝑗 = −𝑛 and 1 or −1 is in 𝜋1+. Because 𝜋1+ and 𝜋1− are complement strands, 1 is in 𝜋1+ if and only if −1 is in 𝜋1−. Hence, both 𝜋2+ and 𝜋
2− contains no −𝑛, 1 and −1. Then we can exchange the roles
of 𝜋1+ and 𝜋1− with 𝜋2+ and 𝜋2−, respectively, and follow the similar discussion as given in Case 1 to show that we can still find two adjacent elements 𝑥′ and 𝑦′ in a cycle of 𝐼(𝛽𝜋)−1 such that (𝑥′, 𝑦′) and (𝛽𝜋Γ(𝑦′), 𝛽𝜋Γ(𝑥′)) can join the four cycles of 𝛽𝜋 into two admissible
cycles.
Case 5. 𝑎𝑗 = 1 and 𝑛 or −n is in 𝜋1+. Actually, we need not consider
this case, because we have initially assumed that all the elements in 𝜋1+ are less than 𝑛 and among them, 𝑎𝑗 is the smallest.
Based on the above discussion, we have completed the proof of this
lemma. ∎
Theorem 1. Let Φ denote a minimum weighted sequence of CCLP
operations needed to transform 𝜋 into 𝐼. Then the weight of Φ is great than or equal to |𝐸|−𝑛𝑐(𝐼𝜋
−1)
2 .
Proof. Let Φ contain a reversals and b non-reversal CCLP operations. Clearly, the weight of Φ is 𝑎 + 2𝑏. As discussed previously, a reversal can be expressed by a product of two 2-cycles and a non-reversal CCLP operation by a product of four 2-cycles. Therefore, Φ can be written as a product of 2𝑎 + 4𝑏 2-cycles such that Φ𝜋 = 𝐼, equivalently meaning that 𝐼𝜋−1 can be expressed by a product of 2𝑎 + 4𝑏 2-cycles and, therefore, ‖𝐼𝜋−1‖ ≤ 2𝑎 + 4𝑏. As mentioned before, based on the lemma
proposed in [14,18], we can obtain that ‖𝐼𝜋−1‖ = |𝐸| − 𝑛
𝑐(𝐼𝜋−1). In
of Φ is great than or equal to |𝐸|−𝑛𝑐(𝐼𝜋
−1)
2 . ∎
Suppose that there are at least two adjacent elements 𝑥 and 𝑦 in a cycle of 𝐼𝜋−1 such that (𝑥, 𝑦)|𝜋. Then, according to Lemma 5, we can always find a non-reversal CCLP operation 𝛽′𝛽 from 𝐼𝜋−1 to rearrange 𝜋 into 𝛽′𝛽𝜋 , where 𝛽 = (𝜋Γ(𝑦), 𝜋Γ(𝑥))(𝑥, 𝑦) and 𝛽′ = (𝛽𝜋Γ(𝑦′)
, 𝛽𝜋Γ(𝑥′))(𝑥′, 𝑦′). Suppose that there are no any two adjacent elements 𝑥
and 𝑦 in a cycle of 𝐼𝜋−1 such that (𝑥, 𝑦)|𝜋 , which implies that (𝑥, 𝑦) ∤ 𝜋. Then based on Lemma 3, (𝜋Γ(𝑦), 𝜋Γ(𝑥))(𝑥, 𝑦) can serve as a reversal to transform 𝜋 into (𝜋Γ(𝑦), 𝜋Γ(𝑥))(𝑥, 𝑦)𝜋 . Using these properties, we design Algorithm 1 to sort 𝜋 into I by CCLP operations. It is not hard to see that a non-reversal CCLP operation derived in Algorithm 1 decreases the norm of 𝐼𝜋−1 by 4 and a reversal by 2. Since non-reversal CCLP operations are weighted 2 and reversals are weighted 1, Algorithm 1 decreases the norm of 𝐼𝜋−1 by 1 at the weight of 1
2 and hence its total
weight equals to ‖𝐼𝜋
−1‖
2 =
|𝐸|−𝑛𝑐(𝐼𝜋−1)
2 , which is optimal according to
Theorem 1.
Algorithm 1
Input: A chromosome 𝜋 = (𝑎1, 𝑎2, … , 𝑎𝑛)(−𝑎𝑛, −𝑎𝑛−1, … , −𝑎1).
Output: An optimal scenario Φ of CCLP operations with weight 𝜔(𝜋, 𝐼). 1: Compute 𝐼𝜋−1 and 𝜋Γ;
2: Let 𝜔(𝜋, 𝐼) = |𝐸|−𝑛𝑐(𝐼𝜋
−1)
3: while 𝜋 ≠ 𝐼 do
3.1: if there exist two adjacent elements 𝑥 and y in a cycle of 𝐼𝜋−1
such that (𝑥, 𝑦)|𝜋 then
3.1.1: Let 𝛿 = 𝛿 + 1 and 𝛽 = (𝜋Γ(𝑦), 𝜋Γ(𝑥))(𝑥, 𝑦);
3.1.2: Find two adjacent elements 𝑥′ and 𝑦′ in a cycle of 𝐼𝜋−1𝛽 such that (1) (𝑥′, 𝑦′) ∤ 𝛽𝜋, (2) 𝑥′ ≠ Γ(𝑦′) or Γ(𝑥′) ≠ 𝑦′ and
(3) (Γ(𝑥′), 𝑦) ∤ 𝛽𝜋 or (𝑥′, Γ(𝑦′)) ∤ 𝛽𝜋;
3.1.3: Let 𝛽′ = (𝛽𝜋Γ(𝑦′), 𝛽𝜋Γ(𝑥′))(𝑥′, 𝑦′) and 𝛽𝛿 = 𝛽′𝛽;
3.1.4: Compute new 𝜋 = 𝛽𝛿𝜋 and new 𝜋Γ = 𝛽𝛿𝜋Γ;
3.1.5: Obtain new 𝐼𝜋−1 by removing 𝑦, 𝜋Γ(𝑥), 𝑦′ and 𝛽𝜋Γ(𝑥′) from the cycles in original 𝐼𝜋−1;
3.2: else
3.2.1: Find two adjacent elements x and y in a cycle of 𝐼𝜋−1 such that (𝑥, 𝑦) ∤ 𝜋;
3.2.2: Let 𝛿 = 𝛿 + 1 and 𝛽𝛿 = (𝜋Γ(𝑦), 𝜋Γ(𝑥))(𝑥, 𝑦);
3.2.3: Compute new 𝜋 = 𝛽𝛿𝜋 and new 𝜋Γ = 𝛽𝛿𝜋Γ;
3.2.4: Obtain new 𝐼𝜋−1 by removing 𝑦 and 𝜋Γ(𝑥) from the cycles in original 𝐼𝜋−1;
end while
4: Output Φ = 𝛽1, 𝛽2, … , 𝛽𝛿 as an optimal scenario with weight 𝜔(𝜋, 𝐼);
Theorem 2. Given a chromosome 𝜋, the weighted sorting problem by
CCLP operations can be solved in 𝑂(𝛿𝑛) time when with weight ratio between reversals and non-reversal CCLP operations is 1:2, where 𝛿 is the number of CCLP operations needed to transform 𝜋 into 𝐼. Moreover, the weight of the optimal solution is |𝐸|−𝑛𝑐(𝐼𝜋
−1)
2 that can be calculated in
𝑂(𝑛) time in advance.
Proof. As discussed previously, Algorithm 1 transforms 𝜋 into 𝐼 with a minimum weighted sequence of 𝛿 CCLP operations, whose total weight is |𝐸|−𝑛𝑐(𝐼𝜋
−1)
2 that can be calculated in 𝑂(𝑛) time. Below, we analyze the
time-complexity of Algorithm 1. Basically, steps 1 and 2 can be done in 𝑂(𝑛) time. There are 𝛿 iterations to perform in step 3. For each iteration of step 3, it takes 𝑂(𝑛) time to find (𝑥, 𝑦) and (𝑥′, 𝑦′) by determining every pair of adjacent elements in all the cycles of 𝐼𝜋−1 and 𝐼𝜋−1𝛽, respectively, and a constant time to perform other operations in step 3.1, and also takes 𝑂(𝑛) time to perform step 3.2. Therefore, the total cost of step 3 is 𝑂(𝛿𝑛) . Step 4 is executed in constant time. Totally, the time-complexity of Algorithm 1 is 𝑂(𝛿𝑛). ∎ It should be noted that although the algorithm we presented above takes the circular chromosomes as the instances, it still works for the linear chromosomes because it can be shown that the problem of sorting by CCLP operations is equivalent for circular and linear chromosomes
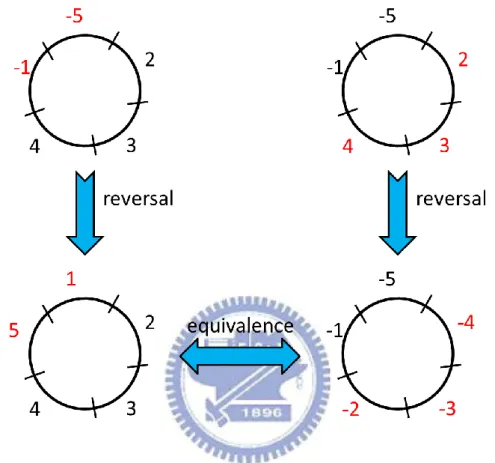
based on a property, that is, a CCLP operation acting on a gene, say 𝑢, on a circular chromosome has an equivalent one that does not act on 𝑢 (see Figure 4-1 for an example).
Figure 4-1. A CCLP operation acting on genes -1 and -5 on a circular
Chapter 4
Conclusion
In this thesis, we have introduced and studied the sorting problem by CCLP operations, where CCLP is a cut-circularize-linearize-and-paste operation that can model several known and unknown rearrangements. In addition, we have proposed an 𝑂(𝛿𝑛) time algorithm for solving the weighted sorting problem by CCLP operations when the weight ratio between reversals and non-reversal CCLP operations is 1:2, where n is the number of genes and 𝛿 is the number of needed CLLP operations. As described in this thesis, this algorithm is very simple so that it can be easily implemented using data structure of 1-dimensional arrays and useful in the studies of phylogenetic tree reconstruction and human immune response to tumors. As a future work, it would be interesting to design efficient algorithms for solving the problem of sorting by CCLP operations when all the CCLP operations are weighted equally.
References
1. Adam, Z. and Sankoff, D., The ABCs of MGR with DCJ, Evolutionary Bioinformatics, Vol. 4, pp. 69-74, 2008.
2. Bader, D. A., Moret, B. M. and Yan, M., A linear-time algorithm for computing inversion distance between signed permutations with an experimental study, Journal of Computational Biology, Vol. 8, pp. 483-491, 2001.
3. Bader, M. and Ohlebusch, E., Sorting by weighted reversals, transpositions, and inverted transpositions, Journal of Computational Biology, Vol. 14, pp. 615-636, 2007.
4. Bafna, V. and Pevzner, P. A., Sorting by transpositions, SIAM Journal on Discrete Mathematics, Vol. 11, pp. 221-240, 1998.
5. Belda, E., Moya, A. and Silva, F. J., Genome rearrangement distances and gene order phylogeny in 𝛾-Proteobacteria, Molecular Biology Evolutionary, Vol. 22, pp. 1456-1467, 2005.
6. Bergeron, A., Mixtacki, J. and Stoye, J., A unifying view of genome rearrangements, Lecture Notes in Computer Science, Vol. 4175, pp. 163-173, 2006.
7. Bergeron, A., Mixtacki, J. and Stoye, J., On sorting by translocations, Journal of Computational Biology, Vol. 13, pp. 567-578, 2006.
8. Christie, D. A., Sorting by block-interchanges, Information Processing Letters, Vol. 60, pp. 165-169, 1996.
9. Elias, I. and Hartman, T., A 1.375-approximation algorithm for sorting by transpositions, in: Casadio, R. and Myers, G., Eds., Proceedings of the 5th Work shop on Algorithms in Bioinformatics (WABI 2005), Lecture Notes in Computer Science, Vol. 3692. Springer-Verlag, pp. 204-215, 2005.
10. Feng, J. X. and Zhu, D. M., Faster algorithms for sorting by transpositions and sorting by block Interchanges, ACM Transactions on Algorithms, Vol. 3, No. 3, 2007.
11. Hannenhalli, S. and Pevzner, P. A., Transforming men into mice (polynomial algorithm for genomic distance problem), in: Proceedings of the 36th IEEE Symposium on Foundations of Computer Science (FOCS 1995). IEEE Computer Society, pp. 581-592, 1955.
12. Hannenhalli, S., Polynomial algorithm for computing translocation distance between genomes, Discrete Applied Mathematics, Vol. 71, pp. 137-151, 1996.
13. Hannenhalli, S. and Pevzner, P. A., Transforming cabbage into turnip: polynomial algorithm for sorting signed permutations by reversals, Journal of the ACM, Vol. 46, pp. 1-27, 1999.
14. Huang, Y.-L. and Lu, C. L., Sorting by reversals, generalized block-interchanges, and translocations using permutation groups, Journal of Computational Biology, Vol. 17, pp. 685-705, 2010.
15. Huang, Y.-L., Huang, C.-C., Tang, C. Y. and Lu, C. L., SoRT2: a tool for sorting genomes and reconstructing phylogenetic trees by reversals, generalized transpositions and translocations, Nucleic Acids Research, Vol. 38, pp. W221-227, 2010.
16. Huang, Y.-L., Huang, C.-C., Tang, C. Y. and Lu, C. L., An improved algorithm for sorting by block-interchanges based on permutation groups, Information Processing Letters, Vol. 110, pp. 345-350, 2010.
17. Kaplan, H., Shamir, R. and Tarjan, R. E., Faster and simpler algorithm for sorting signed permutations by reversals, SIAM Journal on Computing, Vol. 29, pp. 880-892, 1999.
18. Lin, Y. C., Lu, C. L., Chang, H.-Y. and Tang, C. Y,. An efficient algorithm for sorting by block-interchanges and its application to the evolution of vibrio species, Journal of Computational Biology, Vol. 12, pp. 102-112, 2005.
19. Lu, C. L., Huang, Y.-L., Wang, T. C. and Chiu, H.-T., Analysis of circular genome rearrangement by fusions, fissions and block-interchanges, BMC Bioinformatics, Vol. 7, No. 295, 2006. 20. Meidanis, J. and Dias, Z., Genome rearrangements distance by
fusion, fission, and transposition is easy, in: Navarro, G., Ed., Proceedings of the 8th International Symposium on String Processing and Information Retrieval (SPIRE 2001), IEEE Computer Society, pp. 250-253, 2001.
21. Ozery-Flato, M. and Shamir, R., An 𝑂(𝑛3 2⁄ √ 𝑛) algorithm for sorting by reciprocal translocations, in: Lewenstein, M. and Valiente, G., Eds., Proceedings of the 17th Annual Symposium on Combinatorial Pattern Matching (CPM 2006), Lecture Notes in Computer Science, Vol. 4009. Springer, pp. 258-269, 2006.
22. Pevzner, P. and Tesler, G., Genome rearrangements in mammalian evolution: lessons from human and mouse genomes Genome Research, Vol. 13, pp. 37-45, 2003.
23. Sankoff, D., Leduc, G., Antoine, N., Paquin, B., Lang, B. F. and Cedergren, R., Gene order comparisons for phylogenetic inference: evolution of the mitochondrial genome, Proceedings of the National Academy of Sciences, Vol. 89, pp. 6575-6579, 1992.
24. Tannier, E., Bergeron, A. and Sagot, M.-F., Advances on sorting by reversals, Discrete Applied Mathematics, Vol. 155, pp. 881-888, 2007.
25. Yancopoulos, S. Attie, O. and Friedberg, R., Efficient sorting of genomic permutations by translocation, inversion and block-interchanges, Bioinformatics, Vol. 21, pp. 3340-3346, 2005.