行政院國家科學委員會專題研究計畫 期末報告
多分類器系統的情境感知決策融合機制
計 畫 類 別 : 個別型 計 畫 編 號 : NSC 101-2221-E-004-011- 執 行 期 間 : 101 年 08 月 01 日至 102 年 10 月 31 日 執 行 單 位 : 國立政治大學資訊科學系 計 畫 主 持 人 : 徐國偉 計畫參與人員: 碩士班研究生-兼任助理人員:曾菀柔 碩士班研究生-兼任助理人員:林宏哲 報 告 附 件 : 出席國際會議研究心得報告及發表論文 公 開 資 訊 : 本計畫可公開查詢中 華 民 國 103 年 01 月 02 日
中 文 摘 要 : 本計畫旨在研究多分類器系統的情境感知決策融合機制。給 定一個包含類別標籤資料集,多分類器系統的建置是訓練多 個相異的成員分類器;給定一筆不含類別標籤的資料記錄當 作輸入,每個成員分類器的輸出是它對該筆記錄所隸屬的類 別所做出的決策,而多分類器系統的運作是整合成員分類器 的輸出,或是融合成員分類器的個別決策以形成集體決策。 多分類器系統的原始設計理念是透過這樣的集體決策以達到 更好的分類效能。其他學者已提出多個多分類器系統的決策 融合機制,但這些機制都只有考慮成員分類器的輸出而沒有 考慮它們的輸入,亦即,這些機制都只有考慮成員分類器的 個別決策,而沒有考慮它們各自是在何種情境下做決策。本 計畫的主要成果如下:首先,針對使用自舉採樣的多分類器 系統,我們提出一個加權式投票法,而該方法的主要特點在 於它會依訓練資料的缺失值的比例會做權值調整,使得它適 合搭配對缺失值敏感的分類演算法。然後,針對基於加權投 票機制的多分類器系統,我們提出一個方法,而該方法是在 整合分類結果時使用非線性的函數去調整權值。此外,本計 畫還協助研究應用多分類器系統的串流資料概念飄移偵測模 組。本計畫可對國內外的多分類器系統研究與應用做出實質 貢獻,而部分研究成果已發表於國際會議。 中文關鍵詞: 多分類器系統、情境感知、決策融合
英 文 摘 要 : The purpose of this project is to study context-aware decision fusion mechanisms for multiple classifier systems. Given a data set that contains the class label, the construction of a multiple classifier system is to train several diverse member
classifiers; given a data record that does not
contain a class label as an input, the output of each member classifier is the decision it makes about to which class label the record belongs, and the
operation of a multiple classifier system is to integrate outputs of members classifiers, or to fuse decisions of members classifiers in order to make a group decision. The original concept of multiple classifier systems is to achieve better
classification performance through group decisions. Other scholars have proposed a number of decision fusion mechanisms for multiple classifier systems, but these mechanisms consider only outputs of member classifiers but not their inputs, that is, these
mechanisms consider only individual decisions of member classifiers but not in which context they make decisions. The main results of this project are as follows: First, for multiple classifier systems using bootstrap sampling, we proposed a weighted voting method, and the main feature of the method is that it adjusts weights according the ratio of missing values in the training data and this makes it suitable for classification algorithms are sensitive to missing values. Then, for multiple classifier systems based on the weighted voting mechanism, we proposed a method, which uses nonlinear functions to adjust weights in the aggregation of classification
outcomes. Furthermore, this project also assisted in the study of the application of multiple classifier systems to the detection module for concept drift over streaming data. This project could make
practical contributions to research and applications of multiple classifier systems, and part of the results have been published on international conferences.
英文關鍵詞: Multiple Classifier System, Context-Aware, Decision Fusion
行政院國家科學委員會補助專題研究計畫
□期中進度報告
■期末報告
多分類器系統的情境感知決策融合機制
計畫類別:■個別型計畫 □整合型計畫
計畫編號:NSC101-2221-E-004-011-
執行期間:101 年 8 月 1 日至 102 年 10 月 31 日
執行機構及系所:國立政治大學資訊科學系
計畫主持人:徐國偉
共同主持人:
計畫參與人員:碩士班研究生-兼任助理人員:林宏哲
碩士班研究生-兼任助理人員:曾菀柔
本計畫除繳交成果報告外,另含下列出國報告,共 2 份:
□移地研究心得報告
■出席國際學術會議心得報告
□國際合作研究計畫國外研究報告
處理方式:除列管計畫及下列情形者外,得立即公開查詢
□涉及專利或其他智慧財產權,□一年□二年後可公開查詢
中 華 民 國 102 年 12 月 31 日
I
目錄
中文摘要 ... II Abstract ... III 前言 ... 1 研究目的 ... 2 文獻探討 ... 3 研究方法 ... 6 結果與討論 ... 8 參考文獻 ... 21 計畫成果自評 ... 27II
中文摘要
本計畫旨在研究多分類器系統的情境感知決策融合機制。給定一個包含類別標籤 資料集,多分類器系統的建置是訓練多個相異的成員分類器;給定一筆不含類別 標籤的資料記錄當作輸入,每個成員分類器的輸出是它對該筆記錄所隸屬的類別 所做出的決策,而多分類器系統的運作是整合成員分類器的輸出,或是融合成員 分類器的個別決策以形成集體決策。多分類器系統的原始設計理念是透過這樣的 集體決策以達到更好的分類效能。其他學者已提出多個多分類器系統的決策融合 機制,但這些機制都只有考慮成員分類器的輸出而沒有考慮它們的輸入,亦即, 這些機制都只有考慮成員分類器的個別決策,而沒有考慮它們各自是在何種情境 下做決策。本計畫的主要成果如下:首先,針對使用自舉採樣的多分類器系統, 我們提出一個加權式投票法,而該方法的主要特點在於它會依訓練資料的缺失值 的比例會做權值調整,使得它適合搭配對缺失值敏感的分類演算法。然後,針對 基於加權投票機制的多分類器系統,我們提出一個方法,而該方法是在整合分類 結果時使用非線性的函數去調整權值。此外,本計畫還協助研究應用多分類器系 統的串流資料概念飄移偵測模組。本計畫可對國內外的多分類器系統研究與應用 做出實質貢獻,而部分研究成果已發表於國際會議。 關鍵詞:多分類器系統、情境感知、決策融合III
Abstract
The purpose of this project is to study context-aware decision fusion mechanisms for multiple classifier systems. Given a data set that contains the class label, the construction of a multiple classifier system is to train several diverse member classifiers; given a data record that does not contain a class label as an input, the output of each member classifier is the decision it makes about to which class label the record belongs, and the operation of a multiple classifier system is to integrate outputs of members classifiers, or to fuse decisions of members classifiers in order to make a group decision. The original concept of multiple classifier systems is to achieve better classification performance through group decisions. Other scholars have proposed a number of decision fusion mechanisms for multiple classifier systems, but these mechanisms consider only outputs of member classifiers but not their inputs, that is, these mechanisms consider only individual decisions of member classifiers but not in which context they make decisions. The main results of this project are as follows: First, for multiple classifier systems using bootstrap sampling, we proposed a weighted voting method, and the main feature of the method is that it adjusts weights according the ratio of missing values in the training data and this makes it suitable for classification algorithms are sensitive to missing values. Then, for multiple classifier systems based on the weighted voting mechanism, we proposed a method, which uses nonlinear functions to adjust weights in the aggregation of classification outcomes. Furthermore, this project also assisted in the study of the application of multiple classifier systems to the detection module for concept drift over streaming data. This project could make practical contributions to research and applications of multiple classifier systems, and part of the results have been published on international conferences.
1
前言
本計畫是要研究分類演算法。諸多分類演算法和應用被提出,然而因為分類演 算法各自有不同的限制(例如,演算法是否對缺失值敏感),適用不同特性的資料, 所以目前並沒有所謂的最好的分類演算法。因為如此,學者提出了多分類器系統的 概念。多分類器系統是一個由數個成員分類器所構成的整合型分類器,由群體決策 過程所啟發,基本想法是團隊合作、截長補短,還有群眾智慧[1][2][3][4][5][6]。 分類器的目的是要建立函式,將資料記錄依其輸入變數的特徵,映射到輸出變 數的特徵的標籤,而多分類器系統會整合其內各個成員分類器的函式,融合這些函 式的結果用各個成員分類器的分類結果去產生最終的總成的、整合的分類結果。圖 一呈現的是目前常見的多分類器系統的訓練與使用。一個關於多分類器系統設計與 實作的主題之一,是如何整合成員函數的分類結果。成員分類器的分類結果,可以 視為成員分類器針對某一資料記錄所做出的決策,而這個主題即為如何融合各成員 分類器針對同一資料記錄所做的決策。學者已提出數種整合或融合方法[7][8][9], 而較為常見的機制是像普通或加權投票法[10][11][12]。然而,就目前常見的方法 而言,大多只有考慮成員分類器的個別決策,沒有考慮它們各自是在做決策時的 情境,而本計畫即是對此進行探討與補充。 成員分類器 C1 成員分類器 C2 成員分類器 Ci 成員分類器Cn 決策融合機制 個別決策 ... ... 含有類別標籤的 資料集 分類演算法函數 (程式)庫 輸入: 一筆沒有 類別標籤的資 料記錄 輸出: 一個針對 類別標籤的群 體決策 多分類器系統 訓練 圖一:常見的多分類器系統的訓練與使用。2
研究目的
在學術研究和應用方面,多分類器系統是一個重要的研究主題,而本計畫的 目的就是在協助我們設計更好的多分類器系統。本計畫著重在一個問題:如何在多 分類器系統的決策融合過程中,考慮各個成員分類器的輸入及其採用的分類演算 法的特性,而不只是成員分類器的輸出,使得多分類器系統達到更好的分類效 能? 圖二呈現的是本計畫所研究的多分類器,也就是採用情境感知決策融合機制的 多分類器系統。不同的資料集有不同的特性,而本計畫考量這些不同的特性,將 分類演算法本身的特性,以及用來訓練成員分類器的資料集的特性,定義為該成 員分類器進行分類或做出決策時的情境,發展具有情境感知能力的多分類器系統 決策融合機制。 ... ... 輸入: 一筆沒有 類別標籤的資 料記錄 含有類別標籤的 資料集 分類演算法函數 (程式)庫 訓練 成員分類器 C1 成員分類器 C2 成員分類器 Ci 成員分類器Cn 多分類器系統 個別決策 決策融合機制 輸出: 一個針對 類別標籤的群 體決策 圖二:採用情境感知決策融合機制的多分類器系統的訓練與使用。3
文獻探討
關於如何整合多分類器系統的成員函數的分類結果,也就是如何融合多分類器 系統的成員分類器的個別決策,以形成集體決策,常見方法可以歸納如下: 代數法:只要分類器能夠輸出連續數值,譬如是會針對某一資料樣本給出其屬 於某類別的機率,或是會給出該分類的信心程度,那麼分類器的組合就可以透過這 些數值的代數運算來達成。一個例子是用 max 函數找出最高機率或最高信心程度的 分類,或是用 min 函數去除最低機率或最低信心程度的分類。另一個例子是用 sum 函數計算各分類器所給出的數值的總和,或是用 product 函數計算個分類器所給出 的數值的乘積,然後找出對應最大值的類別標籤。最常見的例子是採用 avg 函數的 平均法。假設成員分類器或函數的輸出不是類別標籤)而是歸屬各類別的機率或分數, 則可用普通或加權平均法。對二元分類問題來說,一個最直覺的對應便是檢視平均 後的值是否大於某個門檻值,若是,則判為其中一個類別;若不是,則判為另外一 個類別。 投票法或多數表決法:這包含普通或加權的方法,可以算是平均法的一種。各 個成員分類器的權值可以透過解最佳線性組合方程式來設定。尋求最好的成員分類 器的組合就變成了對最佳化問題求解。這個過程本身可以是另一個監督式學習問題, 因此成員分類器的整合或總成是可以被訓練的。決定一組適當的(權值)參數變成了 最佳化問題,參考文獻裡面有提供一些範例和應用[13][14][15]。另外,對二元分 類問題而言,考慮絕對多數和相對多數是一樣的,但是對多類別分類問題而言,考 慮絕對多數是較為嚴苛的方法,因此考慮相對多數是比較常見的做法。 選擇法或篩選法:各成員函數會相互比較,最好的那一個,會被拿來對新資料 進行分類或預測,或是最好的那一些成員函數會先被選出來然後經由線性組合的方 式共同對新資料進行分類或預測。然而,單純的選擇法並沒有遵循多分類器系統的 設計理念,並不能利用多個成員分類器互補彼此的不足。選擇法可以經由加權投票 法來實踐,其做法是將不被選取的或是要被篩選掉的成員函數的權值設為 0。選擇法 也可經由類似代數法的 min 以及 max 函數來實踐。若某選擇法的目的是要去除較差 的成員分類器,則它可歸類於剪枝法,而排序法常被用於剪枝法當中 [16][17][18][19]。 貝氏組合法:這裡假設各成員分類器可以給出某一資料樣本屬於某一類別的機 率,並假設各成員分類器各自獨立地給出此機率值。這個方法是基於貝式定理。如 果該分類問題所牽涉的類別種類較多,而資料樣本的數量卻是相對地少,則會有預 估機率值會 0 的情況,針對這個情況,可透過調整上述公式來避免整合後的機率值 也變成是 0 的情況,一個做法是對全部的預估機率值都加上一個很小的值。前面提 到的第二個假設通常都是不成立的,因此這個方法也稱為單純貝氏組合法。這種做 法較常見於特別設計的多分類器系統。 行為知識空間:這種方法主要是將各成員分類器的分類模式記錄在一個資料表4 裡面,然後透過查表法來決定最後的分類結果。譬如說,針對二元分類問題,假設 有五個分類器對一個新的資料樣本的分類是 0、0、1、1、0,或負、負、正、正、負, 而根據查表的結果,之前若出現 0、0、1、1、0 這種模式的時候,大部分的資料樣 本所對應的類別標籤是 1,那麼針對該資料樣本的最後的分類結果會是 1,而不會是 多數分類器所認為的 0。上面這個例子暗示了這個方法會去記錄之前整合各成員分類 器的結果的品質。這種做法較常見於特別設計的多分類器系統。 堆疊泛化:這種方法的核心想法是利用分類器去學習其他分類器的模式。堆疊 泛化法代表一種泛用型的階層式的多分類器系統,在第一階層會有多個分類器,而 這些分類器對訓練資料集的輸出搭配訓練資料集的真實類別標籤會被用來建構一個 新的資料集,其目的是記錄各分類器先前的分類模式,而在第二階層,另一個分類 器會利用這個新的資料集去學習那些情況下的那些分類器輸出組合應該被判斷或修 正為哪個分類標籤。這個方法的代表就稱為 Stacking [20][21]。 決策樣板:這種方法會檢視各成員分類器的分類模式,並記錄對每個類標籤而 言最具代表性的分類組合,之後當各成員分類器對新的資料樣本做出分類時,這些 分類的組合會被拿去跟代表性的組合做比對,最相似的那個組合所對應的類別標籤 就會是最後的結果。另外有一種類似於決策樣板的分類器整合方法(事實上它可以藉 由決策樣板來實踐),但是它不會拿新的資料樣本的分類組合去跟代表性的組合做比 對,而是利用丹柏斯特雪佛證據理論去綜合考量新舊資料樣本的相似程度以及各分 類器的分類結果的可信程度。上述各種做法較常見於特別設計的多分類器系統。參 考文獻裡面有提供使用決策樣板去整合分類器的範例[22][23],以及使用丹柏斯特 雪佛證據理論去整合分類器的範例[24][25]。 丹柏斯特雪佛理論(Dempster-Shafer theory):這種方法屬於數學上的證據理 論,其目的是結合不同來源的證據並利用各個證據之間的可信度去計算各種結果的 可能性[24][25]。這種方法常在工程領域被用來做感知器融合,也稱為資料融合或 資訊融合。傳統的丹柏斯特雪佛理論假設各個證據之間並無衝突,然而實際應用上 常面對資料的模糊性與不確定性,各個證據之間可能會有衝突,解決方法包括不使 用衝突證據,在衝突發生時直接選擇機率較大的一方,依證據的可信度去計算其可 用程度,或是綜合考慮證據來源的可信度、證據的支援,以及證據的合法性[26], 來產生新的結合規則;此外也有方法同時使用丹柏斯特雪佛理論和模糊理論 [27][28]。 針對分類器整合方方法或策略,國內的研究以應用為導向,且多為實證性質的 研究,舉例如下。[29]研究用於決策融合機制的參數式權重估測法。[30]提出一個 稱為“以屬性為基礎的合議分類器演算法”的多分類器系統建構方法,該演算法會 去尋找適當的特徵(或屬性)集合,並採用加權投票法來整合以決策樹為基底的成員 分類器。[31]研究採用混合專家模型的多分類器系統,並將其應用於影像車牌辨識。 [32]研究最佳權重法於交通資料融合的應用。[33]依據丹柏斯特雪佛證據理論進行 分類器整合,並且將多分類器系統應用於網路入侵偵測,而該研究的一項結論是使 用丹柏斯特雪佛理論去整合分類器的效能會比使用投票法或平均法來得好。[34]用
5 丹柏斯特雪佛證據理論協助建置網路安全情境察覺系統。[35]研究選擇性的分類器 整合方法,藉以建置一個包含線性迴歸、支援向量機、類神經網路的多分類器系統, 並用以輔助零售商品的預測。[36]研究權重的融合機制,該機制採用偏斜係數最大 化之線性結合,並被應用於分散式偵測系統建置。[37]用多數投票法來整合由三種 不同演算法所找到的特徵或屬性集合,用以改善決策樹的分類效能,而該研究的一 項結論是多數投票法能夠提升分類正確率。 國內有少數研究是關於如何使用多分類器系統去解決其他機器學習相關的基礎 問題,譬如說,下述範例是關於如何使用多分類器系統去解決不平衡類別分佈問題。 [38]探討多分類器系統在解決這個問題上面所表現出來的效能,而一個結論是建置 在分群過的資料集上面的多分類器可以提供較好的分類效能。[39]則是比較“減少 取樣多數”與“增加取樣少數”方法,並且探討多分類器系統在解決這個問題上面 所表現出來的效能,而一個結論是多分類器系統在各種考慮到的效能指標下都可以 對少數類別提供較好的分類效能。[40]先將資料分群然後針對各群資料去建立專屬 的分類器,然後利用多分類器系統去解決不平衡類別分佈問題。 國內關於多分類器系統的研究大多屬於應用性質的研究,涵蓋的應用領域相當 廣泛,所以本計畫的研究成果在國內將可找到許多應用。舉例如下:[41]將多分類 器系統應用於異常來源辨識,藉以協助找出製程發生異常時的原因。[42]利用多分 類器系統協助進行文件自動分類。[43]將多分類器系統應用於專利文件的自動化分 類,該系統會對資料做取樣並使用不同的分類演算法,而且最後利用投票法來整合 成員分類器。[44]將分類器融合後用於人臉辨識。[45]使用多分類器系統搭配“增 加取樣少數”方法來輔助攝護腺肥大及攝護腺癌的預測。[46]將階層式特別設計的 多分類器系統應用在甲狀腺超音波的影像辨識問題。[47]研究如何將資料融合方法 應用於高速公路旅行時間預測。[48]用多分類器系統協助多種國際疾病分類碼類別 的預測。[49]建立以支援向量機為基礎的多分類器系統,並將其應用在網路入侵偵 測,而該研究的一項結論是既使支援向量機已能提供優異的分類效能然而將其用於 多分類器系統當中可以提供更優異的效能。[50]將多分類器系統應用於哼唱選歌。 [51]應用資料融合方法於產業績效評估。[52]建置一個包含類神經網路與 k 最近鄰 居分類演算法的特別設計的多分類器系統,並將其應用於癌症樣本分類。[53]利用 多分類器系統去判斷網路使用者是否有網路成癮的情況。[54]將多分類器系統去解 決建置消費者貸款信用評估模型時所遭遇的資料類別不對稱的問題。[55]將多分類 器系統應用於旋轉機械之元件鬆脫故障診斷。[56]將感測融合方法用於移動機器人 之避障系統。[57]用多分類器系統去提高垃圾網站偵測率。[58]將感測融合方法用 於自主性移動機器人運動規劃系統。[59]將多分類器系統應用在疾病碼的分類,並 總結多分類器系統確能提高貝氏分類器對疾病碼的分類效能。[60]使用階層式特別 設計多分類器系統去做異常檢測。[61]將多分類器系統用在即時排程系統當中,該 系統包含類神經網路、決策樹、支援向量機,並利用投票法來整合成員分類器。[62] 使用特別設計的多分類器系統去輔助信用評分。[63]建構一個以類神經網路為基底 的多分類器系統,用以支援股市決策,而實驗結果顯示該系統能比傳統技術指標更
6 準確地預測股價的轉折點。[64]將多分類器系統用於血管硬化評估。[65]將多分類 器系統用於手術術後併發症的預測,該系統為一特別設計的多分類器系統,其先使 用聚類演算法來將資料分群,而後使用類神經網路、貝氏網路、決策樹來建立模型。 [66]使用多分類器系統去輔助正常程式與惡意程式的分類。[67]研究如何將資料融 合方法結合類神經網絡並且應用於高速公路事件延遲時間預測。 國外有關多分類器系統之研究在於理論分析與實證研究,而理論分析的研究情 況與重要參考文獻可分為兩大類,第一大類著重於如何產生一組有效的成員函數, 第二大類著重於如何整合成員函數的分類結果。本計畫歸類於第二大類研究。關於 此類研究,早期有混和專家模型[68][69][70],然而該模型的實際應用範例並不多 見。投票法是個簡單而且有用的分類器整合方法,[10]對它的限制作了一些探討, 即便如此這個方法還是被廣泛地使用在其他地方,例如[31][11]。[7]對某些分類器 整合方法或策略提出了理論分析與實驗比較的結果。[9]探討成員分類器的選擇對模 糊式分類器整合方法的重要性。[71]利用負相關來對分類器做線性組合。 國外也有研究是關於如何利用多分類器系統去解決機器學習的基礎問題。[72] 利用多分類器系統的差異性去做自動化特徵擷取。[73]探討如何利用多分類器系統 去減少監督式學習過程所需的主動要求的參考資料。[74]利用多分類器系統做數據 簡化。[75]利用多分類器系統去解決資料序列內的資料分佈改變問題。 國外也有相當多的研究是關於多分類器系統的應用。[12]建置一個基於類神經 網路多分類器系統去對電信網路的流量做預測。[76]探討基於類神經網路的多分類 器系統,並且展示多分類器系統在醫學的應用。[77]探討不同的分類器整合方法搭 配多分類器系統在網路入侵偵測上的應用。[78]、[79],還有[80]使用多分類器系 統去分析功能性磁振造影(fMRI)資料。[81]將基於類神經網路的多分類器系統應 用於類比電路的故障偵測。上述範例皆是採用特別設計的多分類器系統。
研究方法
本計畫延續主持人對多分類器系統的理論探討與實證研究,主題如下:如何 在多分類器系統的決策融合過程中,考慮各個成員分類器的輸入及其採用的分類 演算法的特性,而不只是成員分類器的輸出,使得多分類器系統達到更好的分類 效能? 這裡的範例用來說明情境感知的意義,以及傳統的決策融合機制無法有效地應 付但具有情境感知能力的決策融合機制能夠有效應付的情況。若多分類器系統採用 普通平均法,每個成員分類器的決策,也就是它對某筆資料記錄應歸屬的類別標籤 的判斷或預測,相當於它對記錄應歸屬的類別標籤的投票,最後得票數高的類別標 籤便代表集體決策,也就是多分類器系統對該筆資料記錄的判斷或預測。這方法沒 有考慮到各個成員分類器的效能,一個經常做出正確判斷或預測的成員分類器的一 票,和一個經常做出正確判斷或預測的成員分類器的一票會有同等效力。若多分類7 器系統採用加權平均法,一個資料集會用來測試成員分類器,而成員分類器所表現 出來的效能越高,則被賦予的權重也就越高,它投的票的效力也就越高。這兩種都 是常見的方法,但是都不具有情境感知能力。假設我們用一個資料集去訓練和測試 多個基於不同分類演算法的分類器,而後發現這些分類器表現出來的效能都不好, 則我們簡單地說它是一個困難的資料集;另一方面,假設我們有多個由同一問題領 域而來的資料集,去訓練和測試多個基於某個分類演算法的分類器,而後發現這些 分類器表現出來的效能都不好,則我們簡單地說它就該問題領域而言不是一個有效 的分類演算法。試想,若一個成員分類器的訓練用資料集,相較於別的成員分類器 的訓練用資料集而言,是一個困難的資料集,那我們可以預期它表現出來的效能不 會好,這種情況下,加權平均法沒有太大意義。再試想,若我們用不同的分類演算 法去建立歧異的成員分類器,而就我們用的資料集所屬的問題領域而言,一個成員 分類器所用的分類演算法不是一個有效的演算法,那我們也可以預期它表現出來的 效能不會好,這種情況下,加權平均法也沒有太大意義。如果我們能夠知道成員分 類器的訓練用資料集是不是困難的,或是能夠知道成員分類器所用的分類演算法是 不是有效的,那我們可以利用這些資訊去調整加權平均法裡面的權重的設定,如圖 三所示,藉以改善在上述兩種情況下多分類器系統的決策融合機制的效能。我們稱 這種能力為情境感知能力。這種情境感知能力,不但可以更有意義地融合成員分類 器的決策,也可以用來作為篩選成員分類器的依據之一。 我們可以用另外的範例來解釋具有情境感知能力的決策融合機制。假設我們採 用的分類演算法不只可以判斷或預測某資料記錄應歸屬的類別標籤,還可以輸出它 認為某筆記錄應歸屬於某類別標籤的機率、它對於它做出的某個決策所抱持的信心 程度,或它認為某筆記錄應歸屬於某類別標籤的機率和不屬於某類別標籤的機率之 間的差值(稱為分離邊際值),那情境感知能力可以用來調整這些值,如圖三所示。 第一個範例:假設,一個成員分類器對大部分的測試資料的分離邊際值都不高,或 是說它的判斷或預測的泛化能力並不強,即使它對某一測試資料集做的判斷或決策 都是對的,我們也不能預期它對另一個測試資料集會有好的表現,這種情況下,不 論是單純地用它在測試資料集上的表現來設定它的權重,還是用解最佳線性組合方 程式所得到的權重,都沒有太大的意義。第二個範例:考慮第一個範例,假設我們 發現該成員分類器對某筆資料記錄的分離邊際值,高於它對另一筆記錄的分離邊際 值,即使最後它對兩筆記錄的判斷或預測都是對的,在多分類器系統針對第一筆記 錄形成集體決策的過程中,相較於多分類器系統針對第二筆記錄形成集體決策的過 程中,這個成員分類器的權重應該要更大,也就是它應該要扮演更重要的角色。第 三個範例:考慮第一個範例中的成員分類器,另外考慮一個對大部分的測試資料的 分離邊際值都很高的成員分類器,則在多分類器系統形成集體決策的過程中,第二 個分類器的權重應該要高於第一個的權重,也就是說,第二個成員分類器應扮演較 重要的角色。第四個範例:類似於第二個範例,但考慮第三個範例裡面的第二個成 員分類器,如果它對某筆資料記錄的分離邊際值遠低於它對其他資料記錄的分離邊 際值,那麼在多分類器系統針對該筆記錄形成集體決策的過程中,它的權重不應該
8 太高,也就是說,它在這種情況下所扮演的角色不應該是重要的。上述範例所描述 的情況,都會給傳統的多分類器系統的決策融合機制帶來挑戰,也會影響它們的效 能。一部分是因為許多傳統的機制是靜態的,不會在形成集體決策的過程中做動態、 適當的調整,但絕大部分是因為它們不具有情境感知能力,並不知道該如何有效地 在形成集體決策的過程中做調整。一個具有情境感知能力的決策融合機制,將可應 付上述範例所描述的情況。
校正函數
舊的輸出
新的輸出
情境 (例如,輸入, 訓練
用資料及與分類演算法
的特性)
圖三:情境感知能力可調整成員分類器的輸出。 本計畫所提出的方法,其細節以及討論,可見於文後“計畫成果自評”內提到 的論文。結果與討論
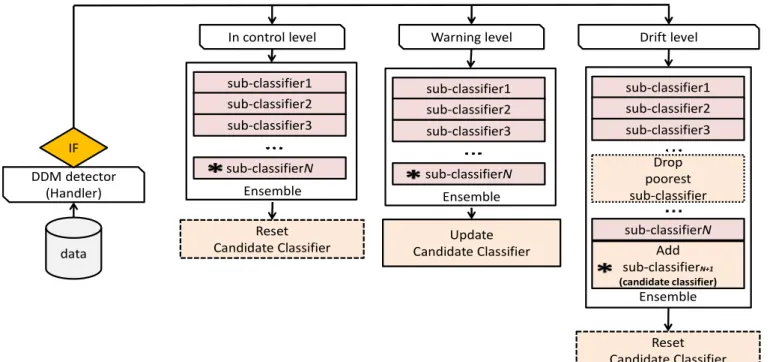
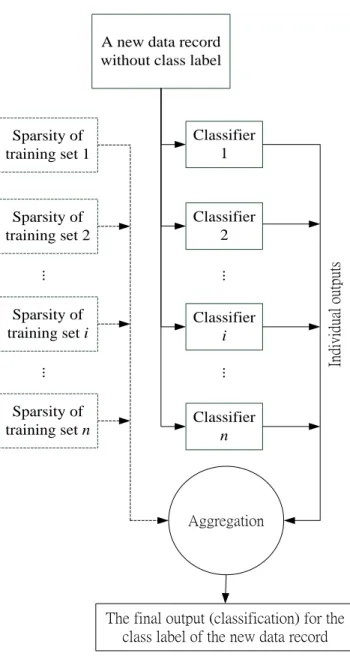
本計畫所提出的方法,相關實驗與結果,可見於文後“計畫成果自評”內提到 的論文。 針對使用自舉採樣的多分類器系統,本計畫提出一個加權式決策融合方法, 而該方法的特點在於它會依訓練資料的缺失值的比例做權值調整,使得它適合搭 配對缺失值敏感的分類演算法。圖四和圖五呈現的是依訓練資料的缺失值對權值 作調整的加權式決策融合方法,圖四是訓練成員分類器的部分,而圖五則是整合 成員分類器的分類結果的部分。在圖四當中,bootstrap sampling 是指用自舉 採樣法從給定的資料集當中,產生多個訓練資料集,用來訓練多個成員分類器, MLP 代表的是 multilayer perceptron 演算法,是一種基於類神經網路的分類演 算法,SMO 代表的是 sequential minimal optimization,是一種支援向量機演 算法,兩者都是對缺失值敏感的分類演算法。9
Training
set 1
...
...
A data set
with class
labels
Bootstrap
sampling
Classifier 1A classification
algorithm, e.g.
MLP or SMO
Training
set 2
Training
set i
Training
set n
Classifier 2 Classifier i Classifier n...
...
圖四:依訓練資料的缺失值對權值作調整的加權式決策融合方法之訓練 在圖五當中,sparsity(s)是指訓練資料的稀疏度,若訓練資料的缺失值越 多,稀疏度越高,反之,若訓練資料的缺失值越少,稀疏度越低。各個成員分類 器的初始權值(woriginal),可由各自所表現出來的正確率(accuracy)或是 F1 量值 (F1-measure)來設定。圖五裡面的彙總函數會考量各個分類器在訓練時所採用的 資料的稀疏度,並自下列兩個公式當中,擇一使用,計算各個員分類器的調整後 權值(wadjusted): ( ) (1) ( ( )) (2)10
A new data record
without class label
Sparsity of
training set 1
...
...
Classifier
1
Aggregation
The final output (classification) for the
class label of the new data record
In
di
vi
du
al
o
ut
pu
ts
Sparsity of
training set 2
Sparsity of
training set i
Sparsity of
training set n
Classifier
2
Classifier
i
Classifier
n
...
...
圖五:依訓練資料的缺失值對權值作調整的加權式決策融合方法之使用11
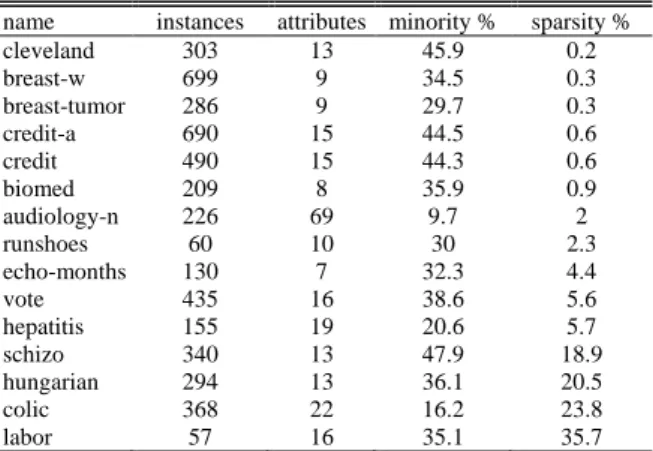
本計畫使用交叉驗證(cross-validation),並用表一所列的資料集,測試上 述依訓練資料的缺失值對權值作調整的加權式決策融合方法。
表一:測試資料集(一)。
name instances attributes minority % sparsity %
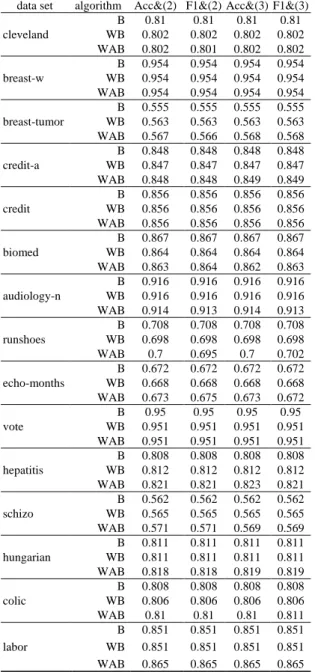
cleveland 303 13 45.9 .2 breast-w 699 9 34.5 .3 breast-tumor 286 9 29.7 .3 credit-a 690 15 44.5 .6 credit 490 15 44.3 .6 biomed 209 8 35.9 .9 audiology-n 226 69 9.7 2 runshoes 60 10 30 2.3 echo-months 130 7 32.3 4.4 vote 435 16 38.6 5.6 hepatitis 155 19 2.6 5.7 schizo 340 13 47.9 18.9 hungarian 294 13 36.1 2.5 colic 368 22 16.2 23.8 labor 57 16 35.1 35.7 測試結果,報告於表二至五。表二和表三是針對 MLP,表四和表五是針對 SMO, 表二和表四內的數字是以正確率,表三和表五內的數字是以 F1 量值。在表二到 表五裡面 B 是代表傳統的 Bagging,是一種用自舉採樣產生成員分類器的訓練資 料集然後用普通投票法彙總成員分類器的結果的多分類器系統,WB 是代表加權 式 Bagging,也就是一種延伸自 Bagging 但加權投票法彙總成員分類器的結果的 多分類器系統,WAB 則是上述(本計畫提出)的方法。Acc&(1)代表用正確率設定 各個成員分類器的初始權值,然後用(1)式去調整各個成員分類器的權值;F1&(1) 代表用 F1 量值設定初始權值,然後用(1)式去調整權值;Acc&(2)代表用正確率 設定初始權值,然後用(2)式去調整權值;F1&(2)代表用 F1 量值設定初始權值, 然後用(2)式去調整權值。
12
表二:針對 MLP 的正確率結果。
data set algorithm Acc&(1) F1&(1) Acc&(2) F1&(2) cleveland B .81 .81 .81 .81 WB .802 .802 .802 .802 WAB .802 .801 .802 .802 breast-w B .954 .954 .954 .954 WB .954 .954 .954 .954 WAB .954 .954 .954 .954 breast-tumor B .555 .555 .555 .555 WB .563 .563 .563 .563 WAB .567 .566 .568 .568 credit-a B .848 .848 .848 .848 WB .847 .847 .847 .847 WAB .848 .848 .849 .849 credit B .856 .856 .856 .856 WB .856 .856 .856 .856 WAB .856 .856 .856 .856 biomed B .867 .867 .867 .867 WB .864 .864 .864 .864 WAB .863 .864 .862 .863 audiology-n B .916 .916 .916 .916 WB .916 .916 .916 .916 WAB .914 .913 .914 .913 runshoes B .708 .708 .708 .708 WB .698 .698 .698 .698 WAB .7 .695 .7 .702 echo-months B .672 .672 .672 .672 WB .668 .668 .668 .668 WAB .673 .675 .673 .672 vote B .95 .95 .95 .95 WB .951 .951 .951 .951 WAB .951 .951 .951 .951 hepatitis B .808 .808 .808 .808 WB .812 .812 .812 .812 WAB .821 .821 .823 .821 schizo B .562 .562 .562 .562 WB .565 .565 .565 .565 WAB .571 .571 .569 .569 hungarian B .811 .811 .811 .811 WB .811 .811 .811 .811 WAB .818 .818 .819 .819 colic B .808 .808 .808 .808 WB .806 .806 .806 .806 WAB .81 .81 .81 .811 labor B .851 .851 .851 .851 WB .851 .851 .851 .851 WAB .865 .865 .865 .865
13
表三:針對 MLP 的 F1 量值結果。
data set algorithm Acc&(1) F1&(1) Acc&(2) F1&(2) cleveland B .788 .788 .788 .788 WB .784 .784 .784 .784 WAB .784 .784 .785 .784 breast-w B .932 .932 .932 .932 WB .933 .933 .933 .933 WAB .933 .933 .933 .933 breast-tumor B .439 .439 .439 .439 WB .422 .422 .422 .422 WAB .426 .428 .429 .43 credit-a B .831 .831 .831 .831 WB .828 .828 .828 .828 WAB .828 .828 .829 .829 credit B .839 .839 .839 .839 WB .836 .836 .836 .836 WAB .837 .837 .836 .836 biomed B .814 .814 .814 .814 WB .806 .806 .806 .806 WAB .805 .806 .803 .805 audiology-n B .578 .578 .578 .578 WB .586 .586 .586 .586 WAB .589 .588 .589 .588 runshoes B .427 .427 .427 .427 WB .431 .431 .431 .431 WAB .441 .434 .444 .445 echo-months B .445 .445 .445 .445 WB .429 .429 .429 .429 WAB .439 .442 .436 .441 vote B .936 .936 .936 .936 WB .938 .938 .938 .938 WAB .937 .937 .937 .937 hepatitis B .549 .549 .549 .549 WB .548 .548 .548 .548 WAB .566 .567 .568 .565 schizo B .501 .501 .501 .501 WB .529 .529 .529 .529 WAB .534 .533 .531 .531 hungarian B .719 .719 .719 .719 WB .726 .726 .726 .726 WAB .739 .739 .741 .74 colic B .726 .726 .726 .726 WB .729 .729 .729 .729 WAB .736 .737 .737 .737 labor B .794 .794 .794 .794 WB .794 .794 .794 .794 WAB .814 .814 .814 .814
14
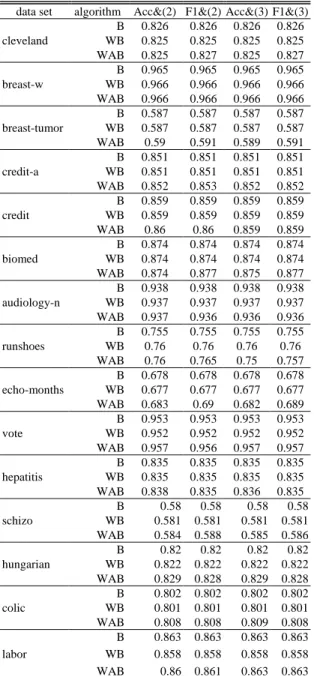
表四:針對 SMO 的正確率結果。
data set algorithm Acc&(1) F1&(1) Acc&(2) F1&(2) cleveland B .826 .826 .826 .826 WB .825 .825 .825 .825 WAB .825 .827 .825 .827 breast-w B .965 .965 .965 .965 WB .966 .966 .966 .966 WAB .966 .966 .966 .966 breast-tumor B .587 .587 .587 .587 WB .587 .587 .587 .587 WAB .59 .591 .589 .591 credit-a B .851 .851 .851 .851 WB .851 .851 .851 .851 WAB .852 .853 .852 .852 credit B .859 .859 .859 .859 WB .859 .859 .859 .859 WAB .86 .86 .859 .859 biomed B .874 .874 .874 .874 WB .874 .874 .874 .874 WAB .874 .877 .875 .877 audiology-n B .938 .938 .938 .938 WB .937 .937 .937 .937 WAB .937 .936 .936 .936 runshoes B .755 .755 .755 .755 WB .76 .76 .76 .76 WAB .76 .765 .75 .757 echo-months B .678 .678 .678 .678 WB .677 .677 .677 .677 WAB .683 .69 .682 .689 vote B .953 .953 .953 .953 WB .952 .952 .952 .952 WAB .957 .956 .957 .957 hepatitis B .835 .835 .835 .835 WB .835 .835 .835 .835 WAB .838 .835 .836 .835 schizo B .58 .58 .58 .58 WB .581 .581 .581 .581 WAB .584 .588 .585 .586 hungarian B .82 .82 .82 .82 WB .822 .822 .822 .822 WAB .829 .828 .829 .828 colic B .802 .802 .802 .802 WB .801 .801 .801 .801 WAB .808 .808 .809 .808 labor B .863 .863 .863 .863 WB .858 .858 .858 .858 WAB .86 .861 .863 .863
15
表五:針對 SMO 的 F1 量值結果。
data set algorithm Acc&(1) F1&(1) Acc&(2) F1&(2) cleveland B .804 .804 .804 .804 WB .805 .805 .805 .805 WAB .805 .807 .805 .807 breast-w B .95 .95 .95 .95 WB .95 .95 .95 .95 WAB .951 .95 .951 .95 breast-tumor B .407 .407 .407 .407 WB .383 .383 .383 .383 WAB .391 .42 .389 .42 credit-a B .844 .844 .844 .844 WB .842 .842 .842 .842 WAB .843 .844 .843 .843 credit B .849 .849 .849 .849 WB .846 .846 .846 .846 WAB .849 .848 .848 .847 biomed B .813 .813 .813 .813 WB .81 .81 .81 .81 WAB .81 .813 .811 .813 audiology-n B .654 .654 .654 .654 WB .664 .664 .664 .664 WAB .662 .659 .658 .659 runshoes B .454 .454 .454 .454 WB .467 .467 .467 .467 WAB .467 .488 .467 .501 echo-months B .327 .327 .327 .327 WB .317 .317 .317 .317 WAB .314 .392 .314 .39 vote B .939 .939 .939 .939 WB .939 .939 .939 .939 WAB .944 .944 .945 .945 hepatitis B .572 .572 .572 .572 WB .556 .556 .556 .556 WAB .569 .566 .562 .565 schizo B .535 .535 .535 .535 WB .547 .547 .547 .547 WAB .55 .559 .552 .556 hungarian B .729 .729 .729 .729 WB .734 .734 .734 .734 WAB .745 .745 .745 .744 colic B .722 .722 .722 .722 WB .727 .727 .727 .727 WAB .738 .737 .738 .737 labor B .801 .801 .801 .801 WB .783 .783 .783 .783 WAB .79 .79 .793 .792
16 針對基於加權投票機制的多分類器系統,本計畫提出一個方法,在決策融合 時使用非線性函數去調整權值。基本的演算法如圖六所示: 圖六:使用權值指派和調整的多分類器建置。 在圖六裡面,可以看出,可以使用先前沒被取樣的資料紀錄來評估各個成員 分類器的效能,而 AssignWeights()和 AdjustWeights()分別是權值指派函式和 權值調整函式。AssignWeights()的運作細節,顯示於圖七,而 AdjustWeights() 的運作細節,則顯示於圖八。跟之前所介紹的方法一樣,這裡可以用各個分類器 的正確率或 F1 量值去設定各自的初始權值。不一樣的地方是,這裡的正確率或 F1 量值,可以是在先前取樣過的資料紀錄(用來當作是訓練資料集)上取得,或 是在先前沒被取樣過的資料紀錄(不是訓練資料集的一部分)上取得。圖八顯示兩 種用來調整權值的函數(擇一使用),一個是基於對數,另一個是基於指數,皆是 非線性函數。 這裡使用 5x2 交叉驗證(2 折交叉驗證,執行 5 次,取平均),還有 10x10 交 叉驗證(10 折交叉驗證,執行 10 次,取平均),並用表六所列的資料集,測試上 述在決策融合時使用非線性函數去調整權值的加權投票機制的多分類器系統。
17
圖七:權值指派函式的運作。
18
表六:測試資料集(二)。
name instances attributes minority
cyyoung8002 189 7 23% sonar 208 60 47% biomed 209 8 36% bodyfat-bin 252 13 19% vote 435 16 39% credit 490 15 44% boston 506 13 26% hprice 546 11 50% breast-w 699 9 34% diabetes 768 8 35% 測試結果報告於表七和表八,分別是用 5x2 和 10x10 交叉驗證做測試所得到 的結果。這裡用決策樹演算法當作基底分類演算法去訓練成員分類器。在這兩個 表裡面,B 代表 Bagging,L 表示使用上述基於對數的函數去調整成員分類器的 權值,E 則是表示使用基於指數的函數去做調整,列的 Acc 表示用正確率去設定 各個成員分類器的初始權值,列的 F1 則表示用 F1 量值去設定初始權值,S 表示 使用取樣的資料紀錄去做成員分類器的效能評估,NS 則表示使用沒被取樣的資 料紀錄去做評估,行的 Accuracy 代表行內的數字是正確率,行的 F1-measure 則是代表行內的數字是 F1 量值。
19 表七:5x2 交叉驗證的結果。 Accuracy F1-measure S NS S NS cy yo un g8 00 2 B .844 .844 .598 .598 A cc L .852 .853 .64 .641 E .851 .854 .638 .645 F1 L .853 .853 .646 .644 E .853 .853 .646 .644 so na r B .745 .745 .73 .73 A cc L .742 .742 .709 .714 E .743 .742 .709 .714 F1 L .738 .746 .705 .717 E .738 .746 .704 .717 bio m ed B .881 .881 .834 .834 A cc L .886 .884 .836 .833 E .887 .884 .837 .833 F1 L .884 .884 .834 .833 E .884 .884 .834 .833 bo dy fa t-bin B .871 .871 .608 .608 A cc L .869 .863 .621 .621 E .869 .864 .621 .625 F1 L .868 .869 .621 .625 E .868 .869 .621 .622 vo te B .96 .96 .949 .949 A cc L .96 .96 .948 .949 E .96 .96 .948 .949 F1 L .959 .96 .948 .949 E .959 .96 .948 .949 cr ed it B .867 .867 .852 .852 A cc L .869 .871 .852 .855 E .869 .871 .852 .855 F1 L .869 .871 .852 .856 E .869 .871 .852 .855 bo sto n B .912 .912 .823 .823 A cc L .911 .912 .825 .827 E .911 .912 .825 .827 F1 L .91 .911 .824 .826 E .91 .912 .824 .828 hp ric e B .782 .782 .767 .767 A cc L .787 .786 .777 .776 E .787 .786 .777 .776 F1 L .786 .786 .776 .777 E .786 .786 .776 .777 br ea st -w B .957 .957 .937 .937 A cc L .958 .958 .939 .939 E .958 .958 .939 .939 F1 L .958 .958 .939 .94 E .958 .958 .939 .939 dia be te s B .749 .749 .606 .606 A cc L .754 .75 .631 .625 E .754 .751 .631 .626 F1 L .752 .752 .631 .631 E .752 .751 .631 .63
20 表八:10x10 交叉驗證的結果。 Accuracy F1-measure S NS S NS cy yo un g8 00 2 B .851 .851 .63 .63 A cc L .856 .858 .66 .666 E .856 .858 .66 .664 F1 L .856 .856 .66 .662 E .856 .857 .66 .663 so na r B .775 .775 .762 .762 A cc L .775 .777 .748 .75 E .775 .777 .748 .75 F1 L .776 .776 .749 .749 E .776 .776 .749 .75 bio m ed B .907 .907 .864 .864 A cc L .908 .91 .865 .868 E .908 .91 .865 .868 F1 L .909 .909 .866 .867 E .909 .91 .866 .868 bo dy fa t-bin B .866 .866 .593 .593 A cc L .864 .863 .604 .601 E .863 .864 .603 .603 F1 L .866 .863 .612 .605 E .866 .863 .612 .605 vo te B .961 .961 .95 .95 A cc L .963 .963 .952 .952 E .963 .963 .952 .952 F1 L .963 .963 .952 .952 E .963 .963 .952 .952 cr ed it B .879 .879 .865 .865 A cc L .878 .878 .863 .863 E .878 .878 .863 .863 F1 L .878 .879 .862 .863 E .878 .879 .862 .864 bo sto n B .919 .919 .837 .837 A cc L .919 .919 .839 .84 E .919 .919 .84 .84 F1 L .919 .919 .84 .84 E .919 .918 .84 .839 hp ric e B .789 .789 .774 .774 A cc L .787 .786 .777 .776 E .786 .786 .777 .776 F1 L .787 .786 .777 .777 E .787 .786 .778 .777 br ea st -w B .959 .959 .941 .941 A cc L .961 .961 .943 .944 E .961 .961 .943 .944 F1 L .96 .961 .943 .944 E .96 .961 .943 .944 dia be te s B .755 .755 .616 .616 A cc L .752 .754 .63 .633 E .751 .753 .629 .633 F1 L .751 .753 .632 .635 E .751 .753 .631 .634
21 在參與本計畫的研究過程中,擔任本計畫兼任助理的研究生,將研究過程中 得到的經驗與想法,加以延伸,或是應用到其他研究,產生兩篇論文(一篇已發 表,一篇已被接受等待發表),後續更延伸為兩篇碩士論文。第一個是關於在串 流資料分析,主題是在台股指數期貨資料的串流資料上進行分類,方法是利用多 分類器系統做概念飄移偵測,更具體地說,用多分類器系統內的成員分類器的權 重的變化,來偵測資料分佈的改變。第二個是針對手機資料進行探勘,使用的方 法不是多分類器系統,但是結果可以用來重建手機使用的情境,所以,如果未來 本計畫要繼續發展,該方法可作為前置處理,產生情境資訊給本計畫或後續計畫 的多分類器使用。 結論與建議:就實際應用而言,為了設計更好的多分類器系統,主持人認為 我們要對多分類器系統的建置和運作有更多的理解,唯有對這部分有通盤的理解, 我們才能將多分類器系統應用在更多、更複雜的問題,故建議國科會能繼續補助 關於多分類器系統的研究。
參考文獻
[1] Opitz, D. and Maclin, R. 1999. Popular ensemble methods: An empirical study. Journal of Artificial Intelligence Research, 11:169–198. [2] Dietterich, T. 200. Ensemble methods in machine learning. In Proc.
of the 1st International Workshop on Multiple Classifier Systems (MCS), 1-15.
[3] Polikar, R. 2006. Ensemble based systems in decision making. IEEE Circuits and Systems Magazine, 6(3):21-45.
[4] Ranawana, R. and Palade, V. 2006. Multi-classifier systems: Review and a roadmap for developers. International Journal of Hybrid Intelligent Systems, 3(1):35-61.
[5] Brown, G. 201. Ensemble learning, Encyclopedia of Machine Learning. Springer.
[6] Rokach, L. 201. Ensemble-based classifiers. Artificial Intelligence Review, 33(1-2):1–39.
[7] Kuncheva, L. 2004. Combining Pattern Classifiers: Methods and Algorithms. John Wiley and Sons.
[8] Zenko, S. 2004. Is combining classifiers with stacking better than selecting the best one? Machine Learning, 54(3):255-273.
[9] Abreu, M. and Canuto, A. 2007. An experimental study on the importance of the choice of the ensemble members in fuzzy combination methods.
22
In Proc. of the 7th International Conference on Intelligent Systems Design and Applications (ISDA), 723-728.
[10] Kuncheva, L., Whitaker, C., Shipp, C., and Duin, R. 2003. Limits on the majority vote accuracy in classifier fusion. Pattern Analysis and Applications, 6(1):22-31.
[11] Orrite, C., Rodriguez, M., Martinez, F., and Fairhurst, M. 2008. Classifier ensemble generation for the majority vote rule. In Proc. of the 13th Iberoamerican congress on Pattern Recognition: Progress in Pattern Recognition, Image Analysis and Applications (CIARP), 340-347.
[12] Brown, G. and Kuncheva, L. 201. “Good” and “bad” diversity in majority vote ensembles. In Proc. of the 9th International Workshop on Multiple Classifier Systems (MCS), 124-133.
[13] Guo, G., Neagu, D., Huang, X., and Bi, Y. 2006. An effective combination of multiple classifiers for toxicity prediction. In Proc. of the 3rd International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), 481-49.
[14] Neagu, D., Guo, G., and Wang, S. 2006. An effective combination based on class-wise expertise of diverse classifiers for predictive toxicology data mining. In Proc. of the 2nd International Conference on Advanced Data Mining and Applications (ADMA), 165-172.
[15] Wu, Q., Chen, Y., and Liu, Z.2008. Ensemble model of intelligent paradigms for stock market forecasting. In Proc. of the 1st
International Workshop on Knowledge Discovery and Data Mining (WKDD), 205-208.
[16] Zhang, Y., Burer, S., and Street, W. N. 2006. Ensemble pruning via semi-definite programming. Journal of Machine Learning Research, 7: 1315-1338.
[17] Martinez-Munoz, G. and Suarez, A. 2006. Pruning in ordered bagging ensembles. In Proc. of the 23rd International Conference on Machine Learning (ICML), 609-616.
[18] Martinez-Munoz, G., Hernandez-Lobato, D., and Suarez, A. 2009. An Analysis of ensemble pruning techniques based on ordered aggregation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(2): 245-259.
[19] Partalas, I., Tsoumakas, G., and Vlahavas, I. 2009. Pruning an ensemble of classifiers via reinforcement learning. Neurocomputing , 27(7-9): 1900-1909.
23
[20] Wolpert, D. 1992. Stacked generalization. Neural Networks, 5(2):241-259.
[21] Ting, K. and Witten, I. 1999. Issues in stacked generalization. Journal of Artificial Intelligence Research, 10:271–289.
[22] Kuncheva, L., Bezdek, J., and Duin, R. 2001. Decision templates for multiple classifier fusion: an experimental comparison. Pattern Recognition, 34(2):299–314.
[23] Kuncheva, L. 2001. Using measures of similarity and inclusion for multiple classifier fusion by decision templates. Fuzzy Sets and Systems, 122(3):401–407.
[24] Rogova, G. 1994. Combining the results of several neural network classifiers. Neural Networks, 7:777–781.
[25] Lu, Y. 1996. Knowledge integration in a multiple classifier system. Applied Intelligence, 6:75–86.
[26] Pu, S., Yang, L., Yang, S., and Hu, W. 2006. A modified evidential reasoning rule in data fusion system. In Proc. of the 1st
International Symposium on Systems and Control in Aerospace and Astronautics (ISSCAA).
[27] Khatibi, V., and Montazer, G.A. 2009. Coronary heart disease risk assessment using Dempster-Shafer theory. In Proc. of the 14th International CSI Computer Conference (CSICC), 361-366.
[28] Khatibi, V., and Montazer, G.A. 201. A fuzzy-evidential hybrid inference engine for coronary heart disease risk assessment. Expert Systems with Applications, 37(12): 8536-8542.
[29] 王絃襁(指導教授: 謝璧妃). 2003. 多源分類決策融合之參數式權重估測 法. 碩士論文. 國立成功大學, 資訊工程研究所. [30] 顧智瑋(指導教授: 李建億). 2004. 一個適用於合議分類器之屬性基礎學 習策略. 碩士論文. 國立臺南大學, 資訊教育研究所. [31] 賴建庭(指導教授: 張財榮). 2006. 混合專家模型應用於影像車號辨識. 碩士論文. 南台科技大學, 資訊工程研究所. [32] 吳瑞豐(指導教授: 王晉元). 2005. 最佳權重法應用於交通資料融合. 碩 士論文. 國立交通大學, 運輸科技與管理學研究所. [33] 洪一文(指導教授: 邱登裕). 2007. 基於丹柏斯特雪佛法證據理論之多分 類器融合於網路入侵偵測之研究. 碩士論文. 中華大學, 資訊管理研究所. [34] 陳婉宜(指導教授: 陳奕明). 2007. 基於 D-S 證據理論之階層式網路安全 情境察覺系統. 碩士論文. 國立中央大學, 資訊管理研究所. [35] 陳勁宏(指導教授: 洪智力). 2008. 一個採用選擇性集成的零售商品預測 模型. 碩士論文. 中原大學, 資訊管理研究所.
24 [36] 賈鈞傑(指導教授: 賴癸江). 2008. 使用偏斜係數最大化之線性結合權重 的融合法則於分散式偵測系統. 碩士論文. 國立成功大學, 電腦與通信工 程研究所. [37] 蔡維倫(指導教授: 林詩偉, 李仁鐘). 2009. 應用群體啟發式演算法與集 成架構改進決策樹之分類效能. 碩士論文. 華梵大學, 資訊管理研究所. [38] 齊玉美(指導教授: 魏志平). 2003. 不對稱性分類分析之研究. 碩士論文. 國立中山大學, 資訊管理研究所. [39] 凌士雄(指導教授: 魏志平). 2004. 非對稱性分類分析解決策略之效能比 較. 碩士論文. 國立中山大學, 資訊管理研究所. [40] 羅隆晉(指導教授: 顏秀珍). 201. 以集群為基礎之多分類器模型對不平 衡資料預測之研究. 碩士論文. 銘傳大學, 資訊工程研究所. [41] 陳忠祐(指導教授: 鄭春生). 1999. 建構辨識多變量管制圖異常來源之整 體式分類系統. 碩士論文. 元智大學, 工業工程與管理研究所. [42] 魏源谷(指導教授: 蔡志忠). 2002. 多分類器系統在自動化文件分類之研 究. 碩士論文. 國立中正大學, 資訊工程研究所. [43] 高志強(指導教授: 劉士豪). 2004. 組合自動化文件分類技術之研究 ─ 以專利文件分類為例. 碩士論文. 中原大學, 資訊管理研究所. [44] 張辰宇(指導教授: 王敬文). 2005. 使用融合鑑別器於人臉辨識系統. 碩 士論文. 國立高雄應用科技大學, 光電與通訊研究所. [45] 劉力瑋(指導教授: 吳帆). 2006. 不對稱分佈混合增加少數法及多專家分 類法之研究 - 以攝護腺肥大及攝護腺癌偵測為例. 碩士論文. 國立中正 大學, 資訊管理研究所. [46] 廖彥華(指導教授: 余松年). 2006. 一個辨識甲狀腺超音波影像中不同病 變組織的系統. 碩士論文. 國立中正大學, 電機工程研究所. [47] 許正憲(指導教授: 魏健宏). 2006. 資料融合技術應用於事故影響下高速 公路旅行時間預測之研究. 碩士論文. 國立成功大學, 交通管理學研究所. [48] 謝玉珊(指導教授: 許中川). 2007. 由病歷摘要判斷國際疾病分類碼. 碩 士論文. 雲林科技大學, 資訊管理研究所. [49] 賴政揚(指導教授: 王偉德). 2007. 基於多特徵集合支持向量機之多分類 器於網路入侵偵測之研究. 碩士論文. 中華大學, 資訊管理研究所. [50] 鄒銘軒(指導教授: 張智星). 2007. 合併分類器用於哼唱選歌的研究. 碩 士論文. 國立清華大學, 資訊工程學研究所. [51] 林君娥(指導教授: 吳植森). 2007. 資料融合方法應用於資訊電子產業績 效評估模式之探討. 碩士論文. 國立成功大學, 工業與資訊管理學研究所. [52] 李怡萱(指導教授: 謝筱齡, 蔡文能). 2008. 運用整體學習分類法對癌症 作樣本分類. 碩士論文. 國立交通大學, 網路工程研究所. [53] 林世彬(指導教授: 施東河). 2008. 應用結合分類器與案例式推理於網路 成癮辨識之研究. 碩士論文. 雲林科技大學, 資訊管理研究所.
25 [54] 王忠引(指導教授: 王孔政, 李強笙). 2008. 資料不對稱情況下應用資料 探勘技術建構消費者貸款信用評估模型. 碩士論文. 國立臺灣科技大學, 工業管理研究所. [55] 洪暉程(指導教授: 黃衍任, 吳天堯), 總體經驗模態分解法(EEMD)結合自 回歸(AR)模型在旋轉機械之元件鬆脫故障診斷之應用. 碩士論文. 國立中 央大學, 光機電工程研究所. [56] 王基旭(指導教授: 蘇國嵐). 2008. 多重感測融合理論應用於移動機器人 之避障系統. 碩士論文. 雲林科技大學, 電機工程研究所. [57] 廖婉淑(指導教授: 洪西進). 2008. 利用整合式的機器學習方式提高垃圾 網站偵測率. 碩士論文. 國立臺灣科技大學, 資訊工程研究所. [58] 洪郁達(指導教授: 羅仁權, 何正榮). 2008. 應用多重感測器融合方法於 自主性移動機器人運動規劃系統之研究. 碩士論文. 國立中正大學, 光機 電整合工程所. [59] 鄭紹偉(指導教授: 許中川). 2009. 集成分類器結合特徵選取與多字詞判 斷疾病分類碼. 碩士論文. 雲林科技大學, 資訊管理研究所. [60] 邱耿義(指導教授: 黃德成). 2009. 多階層混合式分類器之異常偵測模型. 碩士論文. 中興大學, 資訊科學與工程研究所. [61] 林澤岩(指導教授: 薛友仁). 2009. 應用基因演算法與集成式架構於即時 排程系統之研究. 碩士論文. 華梵大學, 資訊管理研究所. [62] 蔡欣仁(指導教授: 謝楠楨). 2009. 整合分類器於信用評分系統之研究. 碩士論文. 國立台北護理學院, 資訊管理研究所. [63] 賴志銘(指導教授: 張百棧). 2009. 叢集式類神經網路在股價轉折點預測 之應用. 碩士論文. 元智大學, 資訊管理研究所. [64] 陳均爾(指導教授: 吳賢財). 2009. 總體經驗模態分析法於血管硬化評估 應用研究. 碩士論文. 國立東華大學, 電機工程研究所. [65] 蔡欣哲(指導教授: 謝楠楨). 201. 集成分類技術用於腹主動脈瘤傳統手 術術後併發症之預測. 碩士論文. 國立台北護理學院, 資訊管理研究所. [66] 何盈橋(指導教授: 許伯秋). 201. 惡意程式威脅分析及分類技術. 碩士 論文. 國防大學理工學院, 資訊科學研究所. [67] 何旺宗(指導教授: 魏健宏). 201. 資料融合技術結合類神經網路對高速 公路事件延遲時間預測之研究. 碩士論文. 國立成功大學, 交通管理學研 究所.
[68] Nowlan, S. and Hinton, G. 199. Evaluation of adaptive mixtures of competing experts. In Proc. of the Conference on Advances in Neural Information Processing Systems (NIPS) 3, 774–78.
[69] Jacobs, R., Jordan, M., Nowlan, S., and Hinton, G. 1991. Adaptive mixtures of local experts. Neural Computation, 3:79-87.
26
to mixtures of experts architectures. Neural Networks, 8:1409–1431. [71] Zanda, M., Brown, G., Fumera, G., and Roli, F. 2007. Ensemble
learning in linearly combined classifiers via negative correlation. In Proc. of the 7th International Workshop on Multiple Classifier Systems (MCS), 440-449.
[72] Brown, G., Yao, X., Wyatt, J., Wersing, H., Sendhoff, B. 2002. Exploiting ensemble diversity for automatic feature extraction. In Proc. of the 9th International Conference on Neural Information Processing (ICONIP), 1786-179.
[73] Melville, P. 2005. Creating Diverse Ensemble Classifiers to Reduce Supervision. Ph.D. Dissertation. University of Texas at Austin, Austin, TX, USA. AAI3217133.
[74] Sanchez, J. and Kuncheva, L. 2007. Data reduction using classifier ensembles. In Proc. of the 11th European Symposium on Artificial Neural Networks (ESANN), 379-384.
[75] Kuncheva, L. 2008. Classifier ensembles for detecting concept change in streaming data: Overview and perspectives. In Proc. of the 2nd Workshop on Supervised and Unsupervised Ensemble Methods and Their Applications (SUEMA), 5-1.
[76] Haraldsson, H. 2003. Neural Network Ensembles and Combinatorial Optimization with Applications in Medicine. Doctoral Dissertation. Department of Theoretical Physics, Lund University, Sweden.
[77] Chan, A., Ng, W., Yeung, D., and Tsang, E. 2005. Comparison of different fusion approaches for network intrusion detection using ensemble of RBFNN, In Proc. of the 4th International Conference on Machine Learning and Cybernetics (ICMLC), 6:3846–3851.
[78] Kuncheva, L. and Rodriguez, J. 201. Classifier ensembles for fMRI data analysis: An experiment. Magnetic Resonance Imaging, 28 (4): 583-593.
[79] Plumpton, C., Kuncheva, L., Linden, D., and Johnston,S. 201. On-line fMRI data classification using linear and ensemble classifiers, In Proc. of the 20th International Conference on Pattern Recognition (ICPR), 4312-4315.
[80] Kuncheva, L. and Plumpton, C. 201. Choosing parameters for random subspace ensembles for fMRI classification, In Proc. of the 9th International Workshop on Multiple Classifier Systems (MCS), 54-63. [81] Liu, H., Chen, G., Song, G., and Han, T. 2009. Neural network ensemble
27
International Symposium on Neural Networks (ISSN), 749-757.
計畫成果自評
研究內容與原計畫大致相符。本計畫產出兩篇論文並協助完成兩篇論文。關 於前者,也就是與本計畫直接相關的論文,一篇已發表,並由主持人於國際會議 進行口頭報告,還有一篇已被接受等待發表;關於後者,也就是與本計畫間接相 關(採用計畫執行過程中產生的想法)的論文,有一篇已發表,並由研究生兼任助 理於國際會議進行口頭報告,還有一篇已被接受等待發表。第一篇論文針對使用 自舉採樣的多分類器系統,提出一個加權式決策融合方法,而該方法的特點在於 它會依訓練資料的缺失值的比例做權值調整,使得它適合搭配對缺失值敏感的分 類演算法。第二篇論文針對基於加權投票機制的多分類器系統,提出一個方法, 在決策融合時使用非線性的函數去調整權值。第三篇論文是關於在串流資料上做 分類,使用台股指數期貨資料,並將多分類器系統的概念,應用於串流資料分析 的概念飄移偵測模組。第四篇論文是研究手機資料探勘,其成果可用於重建手機 使用的情境,可當作本計畫未來繼續發展時的前置處理。由上述論文可知,本計 畫具有實用價值。就社會影響而言,本計畫的研究成果可提供技術基礎予機器學 習的應用,例如,智慧生活。 與本計畫直接或間接相關的論文,包含擔任本計畫的兼任研究助理的研究生 的學位論文,如下所列:1. Weight-Adjusted Bagging of Classification Algorithms Sensitive to Missing Values, in International Journal of Information and Education Technology (IJIET), Vol. 3, No. 5, pp. 560-566, October 2013. 2. K.W. Hsu, On Adjustment Functions for Weight-Adjusted Voting-Based
Ensembles of Classifiers, in Journal of Computer Journal of Computers (JCP) (已被接受等待發表)
3. H.-C. Lin and K.-W. Hsu, An Empirical Study of Concept Drift Detection for the Prediction of TAIEX Futures, in International Workshop on Computational Intelligence and Applications (IWCIA), Hiroshima, Japan, July 13, 2013, pp. 155-16.
4. W.-R. Tseng and K.-W. Hsu, Smartphone App Usage Log Mining, in International Journal of Computer and Electrical Engineering (IJCEE) (已被接受等待發表)
5. 林宏哲. 2013. 串流資料分析在台灣股市指數期貨之應用. 碩士論文,國立 政治大學, 資訊科學學系. (兼任研究助理之畢業論文)
6. 曾菀柔. 2013. 智慧型手機使用模式之探勘. 碩士論文,國立政治大學, 資 訊科學學系. (兼任研究助理之畢業論文)
1
國科會補助專題研究計畫出席國際學術會議心得報告
日期:102 年 8 月 13 日
一、參加會議經過
計算智能與應用會議(International Workshop on Computational Intelligence &
Applications)至今已舉辦至第六屆,今年 7 月 13 日於日本廣島市立大學舉行,參與
者主要來自日本,同時亦有其他來自台灣、英國、泰國等地的參與者,而參與此會
議的台灣人還有中正大學的江佩如教授,並且擔任所屬主題的主持人。此會議涵蓋
了有類神經網路、商業智能、醫藥工程、平行運算、移動裝置網路系統與應用、資
料探勘等共十二個主題。
我本次的發表於 7 月 13 日早上 10 時 20 分,題目為” An Empirical Study of Concept
計畫編號
NSC101-2221-E-004-011-
計畫名稱
多分類器系統的情境感知決策融合機制
出國人員
姓名
林宏哲
服務機構
及職稱
政治大學資訊科學系研究生
會議時間
102 年 7 月 13 日
會議地點
日本廣島市立大學
會議名稱
(中文) 計算智能與應用(IWCIA2013)
(英文) International Workshop on Computational Intelligence &
Applications (IWCIA2013)
發表題目
(中文)概念飄移偵測於台灣股市期貨預測之實證研究
(英文)
An Empirical Study of Concept Drift Detection for the Prediction
2
Drift Detection for the Prediction of TAIEX”。參與者對於本研究所提出的多分類器演
算法感到好奇。
午休時間大會準備了校園導覽。在廣島市立大學裡面設有一個和平鐘,為紀念廣
島原子核爆,並期許未來世界永遠和平。另廣島市立大學因設有藝術學院,因此校
園內有許多藝術學院學生的作品。
二、與會心得
感謝國科會計畫對於這次參加國際會議經費的補助,讓我有機會第一次踏出國外
參與過記會議,與其他不同地區的人進行學術交流。我認為踏出台灣到世界各國去
接觸國內所學的專業領域對於學生是一項很好的經驗,在掌握未來的研究方向上會
有更多的靈感以及看到不同方面的需求。相信這樣的體驗有助於增進國內學生的研
究風氣進而提升國內學術研究的實力。
三、發表論文全文或摘要
四、建議
鼓勵本地舉辦國際學術會議,邀請國際重量級講者。一方面增進學術交流,還能
讓研究生甚至大學生有機會能接觸國際級的講者,另一方面也能透過此機會將推動
台灣觀光能見度,傳達台灣的價值。
五、攜回資料名稱及內容
1.議程:內容為各時段講者及題目
3