一個在主從式架構下SSE協議的安全性分析與改良 - 政大學術集成
42
0
0
全文
(2) 一個在主從式架構下 SSE 協議的安全性分析與改良 Security Analysis and Improvement on the SSE Protocol in Client-Server Model 研 究 生:邱哿振. Student: Ko-Cheng Chiu. 指導教授:左瑞麟. Advisor: Dr. Raylin Tso. 國立政治大學 資訊科學系 碩士論文. A Thesis Submitted to Department of Computer Science, National Chengchi University, in partial fulfillment of the requirements for the degree of Master in Computer Science. 中華民國一百零三年7月 July 2014. 2.
(3) 一個在主從式架構下 SSE 協議的安全性分析與改良 中 文 摘 要 所謂的SSE (Symmetric Searchable Encryption;對稱式可搜尋加密)就是將自己 的資料用自己的密鑰加密外包放在一個網路或雲端上的資料庫DB,存放期間使 用者能保有向DB搜尋資料的能力,而DB仍然可以在不知道資料明文的情況下, 把使用者所欲搜尋的資料回傳給他。2013年林峻立等學者針對上述的雲端環境, 提出了具動態維護及合取關鍵字搜尋之無連結性密文搜尋機制,此方案利用SSE 的方式能讓雲端上的伺服器快速搜尋到所提交的關鍵字相關檔案,但此方案所提 出之協議仍有安全上的弱點。因此,在此篇論文中,我們基於此方案,分析其安 全性漏洞,並在兼顧安全性與低成本的特性下,提出新的SSE搜尋機制。. 關鍵詞:SSE,ASE,關鍵字搜尋,雲端運算. 3.
(4) Security Analysis and Improvement on the SSE Protocol in Client-Server Model Abstract Through Symmetric Searchable Encryption (SSE), which uses its own secret key to encrypt data placed on the Internet or a cloud database, users can maintain the capability to search a database during storage. The database may still not know the information in the plaintext, and return back the data that the user wants. In 2013, Lin et al. scholars addressed the above cloud environment, and presented Unlinkable and Conjunctive Keyword Ciphertext Searching with Dynamic Maintenance. This scheme uses an SSE to allow the server in the cloud to quickly search files associated with the submitted keywords. However, the proposed protocol still has security weaknesses. Therefore, in this thesis, we analyze the security vulnerabilities based on this scheme. In addition, in terms of both safety and low-cost characteristics, we propose a new SSE search mechanism.. Keywords: SSE, ASE, Keyword Search, Security, Cloud Computing. 4.
(5) Table of Contents 一個在主從式架構下 SSE 協議的安全性分析與改良............................................... 3 Security Analysis and Improvement on the SSE Protocol in Client-Server Model ...... 4 Table of Content ............................................................................................................ 5 List of Figures ................................................................................................................ 8 List of Tables ................................................................................................................. 8 Chapter 1 Introduction ................................................................................................... 9 1.1 Research Background ........................................................................................... 9 1.2 Research Motivation .......................................................................................... 10 1.3 Research Purpose and Contribution ................................................................... 11 1.4 Research Scope .................................................................................................. 12 1.5 Organization ....................................................................................................... 12 Chapter 2 Background Introduction............................................................................. 14 2.1 Network Architecture ......................................................................................... 14 2.1.1 Client-Server Model .................................................................................... 14 2.1.2 Client-Server Roles...................................................................................... 14 2.1.3 Client-Server Communication ..................................................................... 15 2.1.4 Comparison with Peer-to-Peer Architecture................................................ 16 2.2 Searchable Encryption........................................................................................ 17 2.2.1 Searchable Encryption ................................................................................. 17 2.2.2 Symmetric Searchable Encryption (SSE) .................................................... 18 5.
(6) 2.2.3 Asymmetric Searchable Encryption (ASE) ................................................. 19 2.2.4 Efficient ASE (ESE) .................................................................................... 20 2.2.5 Multi-User SSE (MSSE) ............................................................................. 21 Chapter 3 Related Literature ........................................................................................ 22 3.1 Encryption and Storage Phase ............................................................................ 22 3.2 Search and Decryption Phase ............................................................................. 24 3.3 Dynamic Maintenance........................................................................................ 26 3.4 Conjunctive Keyword Search............................................................................. 26 3.5 What are Unlinkable Search and Ciphertext Patterns? ...................................... 27 3.5.1 Unlinkable Search Pattern ........................................................................... 27 3.5.2 Unlinkable Ciphertext Pattern ..................................................................... 28 Chapter 4 Security Problems of Lin et al. Scheme ...................................................... 29 4.1 Security Vulnerabilities of Unlinkable Search Pattern ...................................... 29 4.2 Security Vulnerabilities of Unlinkable Ciphertext Pattern ................................ 30 4.3 Keywords Vulnerable to Brute Force Attacks ................................................... 31 Chapter 5 Proposed Scheme and Security Analysis .................................................... 32 5.1 Encryption and Storage Phase ............................................................................ 32 5.2 Search and Decryption Phase ............................................................................. 32 5.3 Security Analysis of Proposed Scheme .............................................................. 34 5.3.1 Confidentiality ............................................................................................. 34 5.3.2 Privacy ......................................................................................................... 34 5.3.3 Unlinkable Searching Pattern ...................................................................... 34 6.
(7) 5.3.4 Unlinkable Ciphertext Pattern ..................................................................... 35 5.3.5 Keywords Less Vulnerable to Brute Force Attacks .................................... 35 5.4 Efficiency Comparison of the Two Schemes ..................................................... 35 Chapter 6 Conclusion ................................................................................................... 37 References .................................................................................................................... 38. 7.
(8) List of Figures Figure 1. The relationship among the data sender, receiver, and server ................. 12 Figure 2. Encryption process and storage phase ..................................................... 23 Figure 3. Decryption process and search phase....................................................... 25 Figure 4. Unlinkable search pattern......................................................................... 27 Figure 5. Unlinkable ciphertext pattern ................................................................... 28 Figure 6. Process of decryption and searching phase .............................................. 33. List of Tables Table 1. Symbols used in encryption and storage phase ......................................... 22 Table 2.Symbols used in search and decryption phase............................................ 24 Table 3.Symbols used in search and decryption phase ............................................ 32 Table 4.Comparative analysis of the two schemes .................................................. 36. 8.
(9) Chapter 1 Introduction 1.1 Research Background In today's IT industry, Internet services have entered the mainstream, and after being raised from the concept of cloud computing in 2009, various network services have been born. The easiest cloud computing technologies of Internet services have been ubiquitous, for example, search engines and Web mail. In these cases, by entering simple keywords, users can obtain a great deal of information. In recent years, as a result of fiber-optic networks, cloud computing has expanded quickly along with the emergence of low-cost, high-capacity storage systems, which have allowed the use of cloud storage in everyday life. Cloud storage can be said to be a successor to USB storage, which is a conventional file transfer system without email capability. The most common type of USB is a flash drive; however, flash drives are easily lost and susceptible to computer viruses, among other shortcomings, making cloud storage a viable gradual replacement. In short, cloud storage is a large-capacity computer placed in a fast network environment, and allows users to store data quickly. Uploading data to a cloud is equivalent to placing files in one’s own computer, and the computer’s speed and large-capacity allow access to the files at any location at any time as long as the network is accessible. However, because the data are stored on another computer certain risks exist. Thus, when a user decides whether to adopt a cloud service or not, the most important issues should be related to information security. Although cloud computing brings about many advantages, and the cost is relatively cheap, one question remains: Are users exposing their important data to risk? For a current network environment, information security has been of 9.
(10) considerable emphasis on the user's part. Although the introduction of cloud storage may allow most information safety issues to be placed with the cloud server, this does not mean that the user's data will be perfectly safe. Once users start using a cloud service, all temporary, or even permanent, data will be stored on the cloud; in addition, a cloud user’s behavior and preferences in regard to all operations will also be recorded by the cloud service providers. If the data are not encrypted in advance, then the cloud service provider or a malicious attacker can obtain important and private user information. However, if a cloud user simply encrypts the data onto the cloud server, and does not produce a relatively complete set of search mechanisms, the user will not be able to reach the data they want through a keyword search. Therefore, an extension of the concept of Keyword Searchable Encryption is required [2].. 1.2 Research Motivation Cloud storage allows people to easily access their personal data at any time and any location. However, even when cloud storage service providers claim that they can protect their customers' information from leaking, are such providers trustworthy? The easiest solution to this problem of trustworthiness is to use one’s own private key to encrypt data on the cloud, rather than using the key selected by the cloud storage service provider. As a result, when the users want to search for files that contain certain keywords, the cloud storage servers must have the ability to search for an encrypted ciphertext. Therefore, to simultaneously achieve both confidentiality and search capability, having an effective search ciphertext technique on a cloud storage service is very important. This technique, known as searchable encryption [1], is an encryption technology that provides cloud data confidentiality, and allows a ciphertext search capability of the cloud storage server without the need for decryption. In other words, 10.
(11) during storage, searching, and retrieval, the cloud storage server will not know the plaintext data. In addition, to further protect the privacy of the user's searches, user searching patterns referred to the server must also be unlinkable. Currently, unlinkable ciphertext searches are mainly dependent on public-key cryptography, and are less efficient. This research presents a symmetric key cipher text searching mechanism that uses expansion and substitution technologies, and submits additional redundancy search patterns to the server, which replies with the corresponding search results. This paper presents a mechanism for the search time, storage space, communication burden, and efficient client computations, for dynamic maintenance and unproblematic conjunctive keyword searches; in addition, the search pattern and ciphertext reply require no connectivity and provide users with a high degree of search privacy.. 1.3 Research Purpose and Contribution In 2013, Lin et al. proposed a solution based on the SSE[37], and no matter time, and. execution. performance;. this. scheme. is. better. than. an. ASE-based. scheme[5,6,11,36] in terms of the sizeable amount of data on a cloud environment. Moreover, it uses a simple SSE and can achieve confidentiality and privacy. It has also been claimed that unlinkable search and ciphertext patterns can be achieved. However, for the present thesis, we found that this scheme does not achieve such patterns, and that searches for keywords within the search pattern are vulnerable to brute force attacks. This research describes an improved scheme that, in addition to improvements in its security weaknesses, also retains the advantages of the original scheme. Moreover, the improvements proposed in this paper also greatly reduce the search time and number of tables required on a cloud server. 11.
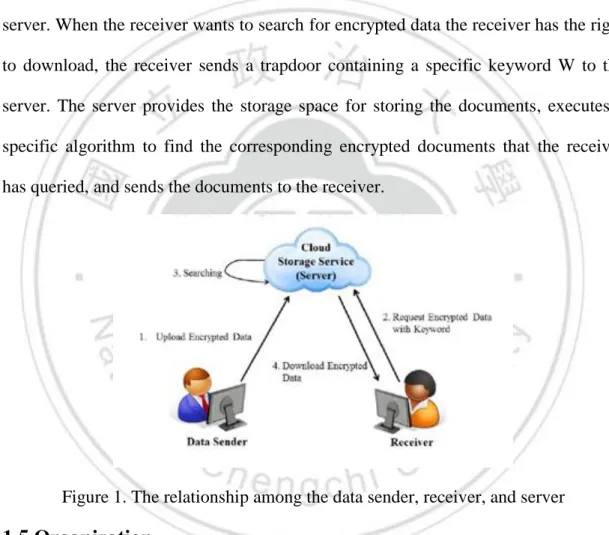
(12) 1.4 Research Scope In the keyword searchable scheme proposed by Boneh et al. [11], there are three entities involved: the data sender, receiver, and server. This relationship is illustrated in Figure 1. The data sender owns the documents and wishes to share them with the receiver. The data sender gives each document some keywords, encrypts them, and then appends the encrypted keywords into the documents and stores them in the server. When the receiver wants to search for encrypted data the receiver has the right to download, the receiver sends a trapdoor containing a specific keyword W to the server. The server provides the storage space for storing the documents, executes a specific algorithm to find the corresponding encrypted documents that the receiver has queried, and sends the documents to the receiver.. Figure 1. The relationship among the data sender, receiver, and server. 1.5 Organization This research is broken into six chapters, the contents of which are as follows: . Chapter 1: We introduce the research background, research motivation, purpose, and research scope of this paper.. . Chapter 2: We introduce background knowledge, for example, illustrating what a client-server architecture is, and compare it with a P2P architecture. Furthermore, we introduce the idea of searchable encryption, and finally, describe various 12.
(13) types of searchable encryption such as Symmetric Searchable Encryption (SSE), Asymmetric Searchable Encryption (ASE), Efficient ASE (ESE), and Multi-user SSE (MSSE). . Chapter 3: We introduce previous related literature, as well as an SSE-based solution proposed by domestic scholars in 2013.. . Chapter 4: We propose a new improved scheme based on the related literature, which is the core contribution of this paper.. . Chapter 5: We conduct security and efficiency analyses of the proposed scheme.. . Chapter 6: We offer some concluding remarks and directions for future work. In addition, we provide a complete summary of the paper, propose some partial improvements, and discuss a new scheme for future research.. 13.
(14) Chapter 2 Background Introduction 2.1 Network Architecture. 2.1.1 Client-Server Model The client-server computing model is a distributed application structure that partitions tasks or workloads between the providers of a resource or service, called servers, and the service requesters, called clients. Clients and servers often communicate over a computer network on separate hardware, although both the client and server may reside on the same system. A server host runs one or more server programs that share its resources with the clients. A client does not share any of its resources, but requests the server's content or service functions. Clients therefore initiate communication sessions with servers, which await incoming requests. Examples. of. computer. applications. that. use. the. client-server. model. include email, network printing, and the World Wide Web.. 2.1.2 Client-Server Roles A client-server characteristic describes the relationship among the cooperating programs in an application. The server component provides a function or service to one or many clients, which initiate requests for such services. Servers are classified based on the services they provide. For instance, a Web server serves Web pages, and a file server serves computer files. A shared resource may be any of the server computer's software or electronic components, ranging from programs and data to processors and storage devices. The sharing of resources of a server constitutes a service. Whether a computer is a client, a. 14.
(15) server, or both, is determined by the nature of the application that requires the service functions. For example, a single computer can run Web server and file server software at the same time to serve different data to clients making different kinds of requests. Client software can also communicate with the server software within the same computer. Communication between servers, such as data synchronization, is sometimes called inter-server or server-to-server communication.. 2.1.3 Client-Server Communication In general, a service is an abstraction of computer resources, and a client does not have to be concerned with how the server performs when fulfilling a request and delivering a response. The client only has to understand the response based on the well-known application protocol, i.e., the content and the formatting of the data for the requested service. Clients and servers exchange messages in a request-response messaging pattern: The client sends a request, and the server returns a response. This exchange of messages is an example of inter-process communication. To communicate, the computers must have a common language, and they must follow rules so that both the client and the server know what to expect. The language and rules of communication are defined in a communications protocol. All client-server protocols operate in the application layer. The application-layer protocol defines the basic patterns of the dialogue. To formalize the data exchange even further, the server may implement an API (such as a Web service).. 15.
(16) The API is an abstraction layer for resources such as databases and custom software.. By. restricting. communication. to. a. specific content. format,. it. facilitates parsing. By abstracting access, it facilitates a cross-platform data exchange. A server may receive requests from many different clients in a very short period of time. Because a computer can perform a limited number of tasks at any moment, it relies on a scheduling system to prioritize incoming requests from clients to accommodate them all in turn. To prevent abuse and maximize the uptime, the server's software limits how a client can use the server's resources. Even so, a server is not immune from abuse. A denial of service attack exploits a server's obligation to process requests by incessantly bombarding it with requests. This inhibits the server's ability to respond to legitimate requests.. 2.1.4 Comparison with Peer-to-Peer Architecture In addition to the client-server model, distributed computing applications often use a peer-to-peer application architecture. In a client-server model, the server is often designed to be a centralized system that serves many clients. The computing power, memory, and storage requirements of a server must be scaled appropriately to the expected work load, i.e., the number of clients simultaneously connecting. Load balancing and failover systems are often employed to scale the server implementation. In a peer-to-peer (P2P) network, two or more computers (peers) pool their resources and communicate in a decentralized system. Peers are coequal, or equipotent, nodes in a non-hierarchical network. Unlike clients in a client-server or client-queue-client network, peers communicate with each other directly. In peer-to-peer networking, an algorithm in the peer-to-peer communications protocol 16.
(17) balances the load, and even peers with modest resources can help share the load. If a node becomes unavailable, its shared resources remain available as long as other peers offer them. Ideally, a peer does not need to achieve high availability because other redundant peers make up for any resource downtime; as the availability and load capacity of the peers change, the protocol reroutes the requests.. 2.2 Searchable Encryption. 2.2.1 Searchable Encryption At a high level, a searchable encryption scheme provides a way to “encrypt” a search index so that its contents are hidden except to a party that is given appropriate tokens. More precisely, consider a search index generated over a collection of files (this could be a full-text index or just a keyword index). Using a searchable encryption scheme, the index is encrypted in such a way that (1) given a token for a keyword one can retrieve pointers to the encrypted files that contain the keyword; and (2) without a token the contents of the index are hidden. In addition, the tokens can only be generated with knowledge of a secret key, and the retrieval procedure reveals nothing about the files or the keywords except that the files contain a common keyword. This last point is worth discussing further as it is crucial to understanding the security guarantee provided by searchable encryption. Notice that over time (i.e., after many searches), knowing that a certain subset of documents contains a word in common may leak some useful information because the server could make some assumptions about the client's search pattern and use this information to make a guess about the keywords being searched. It is important to understand, however, that while searching does leak some information to the provider, what is being leaked is exactly 17.
(18) what the provider would learn from the act of returning the appropriate files to the customer (i.e., that these files contain some common keywords). In other words, the information leaked to the cloud provider is not leaked by the cryptographic primitives, but by the manner in which the service is being used (i.e., fetching files based on the exact keyword matches). This leakage seems almost inherent to any efficient and reliable cloud storage service, and at worst, is less information than what is leaked by using a public cloud storage service. The only known alternative, which involves making the service provider return false positives and having the client perform some local filtering, is inefficient in terms of communication and computational complexity. There are many types of searchable encryption schemes, each one appropriate to a particular application scenario. For example, the data processors in consumer and small enterprise architectures could be implemented using symmetric searchable encryption (SSE), while the data processors in a large enterprise architecture could be based on asymmetric searchable encryption (ASE). In the following, we describe each type of scheme in more detail.. 2.2.2 Symmetric Searchable Encryption (SSE) An SSE is appropriate in any setting where the party that searches through the data is also the one who generated the data. Borrowing from storage systems terminology, we refer to such scenario as a single writer/single reader (SWSR). SSE schemes were introduced in [32], and improved constructions and security definitions were given in [23, 16, 19]. The main advantages of an SSE are its efficiency and security, whereas the main disadvantage is functionality. SSE schemes are efficient for both the party conducting the encryption and (in some cases) the party performing the search. Encryption is efficient because most SSE schemes are based on symmetric primitives such as block ciphers and pseudo-random functions. As shown in [19], a search can be efficient 18.
(19) because the typical usage scenarios for an SSE (i.e., SWSR) allow the data to be pre-processed and stored in efficient data structures. The security guarantees provided by SSE are, roughly speaking, the following: (1) Without any trapdoors, the server learns nothing about the data except the length and (2) given a trapdoor for keyword W, the server learns which (encrypted) documents contain W without learning W itself. Although these security guarantees are stronger than those provided by both asymmetric and efficiently searchable encryption (described below), we stress that they do have their limitations (as described above). The main disadvantage of an SSE is that the known solutions trade efficiency for functionality. This is easiest to see by looking at two of the main constructions proposed in the literature. In the scheme proposed by Curtmola et al. [19], the search time for the server is optimal (i.e., linear in the number of documents that contain the keyword), but updates to the index are inefficient. On the other hand, in the scheme proposed by Goh [23], updates to the index can be conducted efficiently, but the search time for the server is slow (i.e., linear in the total number of documents). We can also state that neither scheme handles searches that are composed of conjunctions or a disjunction of terms. The only SSE scheme that handles conjunctions [24] is based on pairings on elliptic curves, and is as inefficient as the asymmetric searchable encryption schemes discussed below.. 2.2.3 Asymmetric Searchable Encryption (ASE) ASE schemes are appropriate in any setting where the party searching over the data is different from the party that generated the data. We refer to such a scenario as a many writer/single reader (MWSR). ASE schemes were introduced in [11], improved definitions were proposed in [1], and schemes for handling conjunctions were given in [28] and [13]. 19.
(20) The main advantage of an ASE is functionality, whereas the main disadvantages are inefficiency and weaker security. Since the writer and reader can be different, ASE schemes are usable in a larger number of settings than SSE schemes. The inefficiency comes from the fact that all known ASE schemes require the evaluation of pairings on elliptic curves, which is a relatively slow operation compared to evaluations of (cryptographic) hash functions or block ciphers. In addition, in the typical usage scenarios for an ASE (i.e., MWSR), the data cannot be stored in efficient data structures. The security guarantees provided by an ASE are, roughly speaking, the following: (1) without any trapdoors, the server learns nothing about the data except its length and (2) given a trapdoor for a keyword W, the server learns which (encrypted) documents contain W. Note that (2) is weaker here than in the SSE setting. In fact, when using an ASE scheme, the server can mount a dictionary attack against the token and figure out which keyword the client is searching for (Byun, et al. 2006). It can then use the token (for which it now knows the underlying keyword) and conduct a search to determine which documents contain the (known) keyword. Note that this should not necessarily be interpreted as saying that ASE schemes are insecure, just that one has to be very careful about the particular usage scenario and the types of keywords and data being considered.. 2.2.4 Efficient ASE (ESE) ESE schemes are appropriate in any setting where the party that searches through the data is different from the party that generated the data, and where the keywords are difficult to guess. This also falls into the MWSR scenario. ESE schemes were introduced in [8]. The main advantage of an efficient ASE is that searches are more efficient than 20.
(21) in (plain) ASE. The main disadvantage, however, is that ESE schemes are also vulnerable to dictionary attacks. In particular, dictionary attacks against an ESE can be performed directly against an encrypted index (as opposed to against a token, as in an ASE).. 2.2.5 Multi-User SSE (MSSE) Multi-user SSE (MSSE) schemes are appropriate in any setting where many parties wish to search through data that generated by a single party. We refer to such scenarios as a single writer/many reader (SWMR). MSSE schemes were introduced in [19]. In an MSSE scheme, in addition to being able to encrypt indexes and generate tokens, the owner of the data can also add and revoke a user’s privilege to search through the owner’s data.. 21.
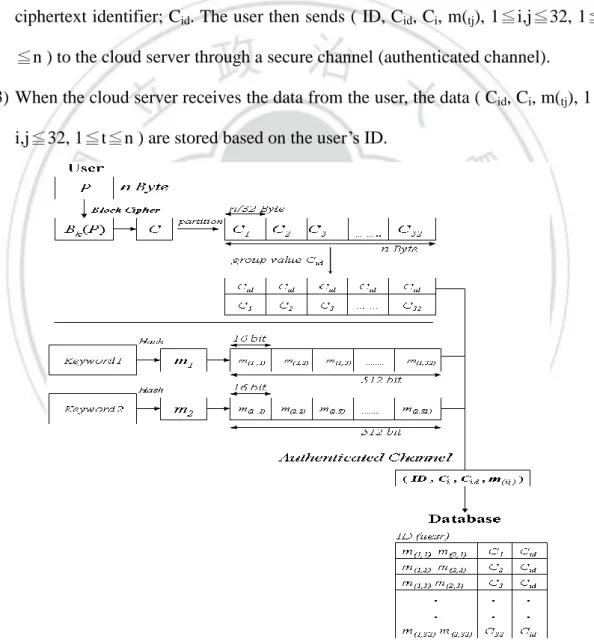
(22) Chapter 3 Related Literature To achieve searching security and privacy, it is necessary to encrypt the search keywords; however, a fixed keyword ciphertext may suffer from a statistical analysis attack, and then extract the user's private information. To resolve this problem, we use the techniques of expansion and substitution, converting a fixed keyword ciphertext into a random and non-stationary keyword ciphertext, which we call an unlinkable search pattern with a random and non-fixed key ciphertext. In this mechanism, each unlinkable search pattern is random and unique. Therefore, an attacker cannot obtain relevant information through a statistical analysis. The following description of the Lin et al. mechanism [37] is divided into two phases: the encryption and storage phase, and the search and decryption phase.. 3.1 Encryption and Storage Phase In this phase, the user determines how their data should be encrypted and stored. Using segmentation, data and keyword ciphertexts are divided into a number of blocks and stored in the cloud space. The size of the blocks is closely related to the search collisions. Table 1 lists the symbols used in this stage, and Figure 2 shows the overall process. Table 1. Symbols used in encryption and storage phase. (1) The user encrypts plaintext P into ciphertext C using a symmetric key system( ie, 22.
(23) Bk(P) = C ), and then the user decides the keywords(kt, 1≦t≦n) corresponding to P. Finally he computes the hash value of kt through a one-way hash function ( ie, h(kt)= mt, 1≦t≦n ), where each mt is 512 bits. (2) Mt is divided into 32 blocks ( ie, mt = m(t1) || m(t2)||……||m(t32)), each m(tj), 1<=j<=32, is 16 bits in size. Ciphertext C is also divided into 32 blocks ( ie, C = C(1) || C(2)||……||C(32)), each Ci, 1≦i≦32. In addition each Ci is given the same ciphertext identifier; Cid. The user then sends ( ID, Cid, Ci, m(tj), 1≦i,j≦32, 1≦t ≦n ) to the cloud server through a secure channel (authenticated channel). (3) When the cloud server receives the data from the user, the data ( Cid, Ci, m(tj), 1≦ i,j≦32, 1≦t≦n ) are stored based on the user’s ID.. Figure 2. Encryption process and storage phase. 23.
(24) 3.2 Search and Decryption Phase For this phase, we describe how to use an extension and permutation to construct an unlinkable search pattern, and show how user can search for servers and obtain ciphertext for decryption. Table 2 lists the symbols used during this stage, and Figure 3 shows the process of this phase. Table 2.Symbols used in search and decryption phase. (1) When a user with identity ID wants to search for a ciphertext he stored on database, he first chooses some keywords. For easy to understand, assume he chooses one keyword kt. He hashes kt to be mt ( ie, h(kt)= mt ), and then randomly generates a random number R with a size of mt( ie, R = 512 bits ). In addition, mt and R are both divided into 32 blocks, m(tj) and Rj ( ie, 1≦j≦32 ), where each block is 16 bits. The user randomly permutates (RP) these 64 blocks to form a new search pattern G ( ie, G = G1||G2||……||G64, |Gi| = 16 bits, 1<=i<=64. For detail, see Figure 3). The user then submits ( ID, G ) to the server to launch a keyword search.. (2) Upon receiving ID and G, the server uses each Gi to search for the corresponding ciphertext block Ci from it's database. W.l.o.g, assume G = G1||G2||……||G64 = mt1||mt2||……||mt32||R1||R2||……||R32. For each Gi, the search result will be a “hit” when i is from 1 to 32 since Gi = mtj. So, Cj can be found when mtj is found. On the other hand, for the search result of Gi, 33<= i <= 64, it may be a hit or a miss since each Gi, 33<= i <= 64, is just a 16-bit random number. When the result is a 24.
(25) hit and Gi is a random number, it is a collision.. (3) The reply of the server will depend on the following two cases. . No collision: The server will generate 32 16-bit random blocks, RC1,…,Rc32, together with Cj corresponding to the search block m(tj), and reply to the user with a total of 64 ciphertext blocks( i.e, C1||C2||…||C32||RC1||RC2||..||RC32). Notice that in this case each Ci will have the same Cid.. . Collision: More than 32 Ci will be found in this case, but there are exactly 32 Ci with the same Cid. The server picks these 32 Ci and then does the same procedure as the previous case.. (4) When the user receives 64 ciphertext blocks, to recover the ciphertext blocks in their original order, the corresponding reverse random permutation( RP-1) is first applied, and the first 32 ciphertext blocks are decrypted.. Figure 3. Decryption process and search phase 25.
(26) 3.3 Dynamic Maintenance User data in a cloud may change at any time. Such changes include modification of the data content, and the addition and reduction of keywords. The mechanism we propose to deal with this situation and conduct the corresponding data operations for the modified data is only conducted during the encryption and storage stage. (1) Modify Data Content: The user uses a symmetric key system to make changes to plaintext P’ encrypted ciphertext C'; ciphertext C' is divided into 32 blocks, where each block, C'i, is still accompanied by the original ciphertext identifier, Cid, and sent to the cloud server for updating. (2) Add Keywords: The user makes new keywords, Keyword', through a one-way hash function by calculating m', which is divided into 32 16-bit blocks, m'(tj), and ID, Cid, and m'(tj) are sent to the cloud server for updating. (3) Reduce Keywords: The user creates unused keywords, Keyword', through a one-way hash function calculating m', in which m' is divided into 32 16-bit blocks, m'(tj), and ID, Cid, and m'(tj) are sent to the cloud server for updating.. 3.4 Conjunctive Keyword Search When the user tries to use a conjunctive keyword for a search, the proposed mechanism only generates a conjunctive keyword search pattern during the search and decryption phase. The server still depends on the corresponding search pattern replies, and the results do not affect the mechanism itself.. (1) When the user wants to use conjunctive keywords (e.g., Keyword1 AND Keyword2) to search a ciphertext, and the hash value of Keyword1 and Keyword2 are m1 and m2( ie : h(kt)= mt ), and two random numbers, R1 and R2, are randomly generated with the same sized m. In addition, m1 and R1 will form a search pattern 26.
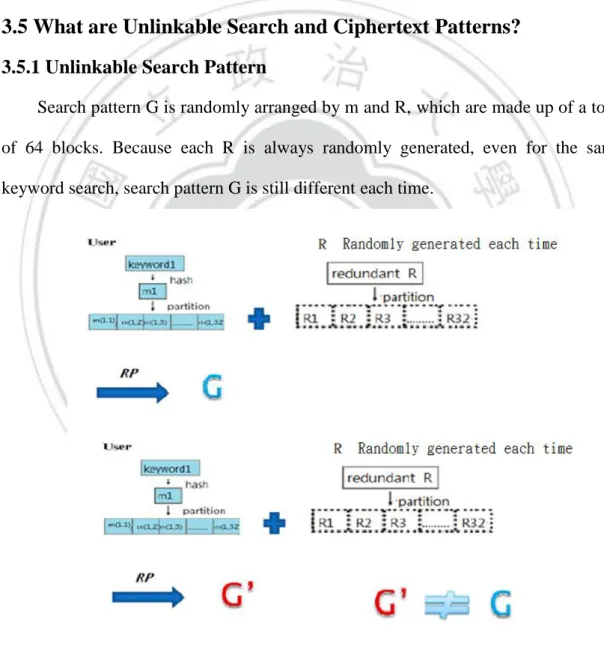
(27) G1, and m2 and R2 will form a search pattern G2. Finally, the user submits G1, G2, and the user ID to the server for the search.. (2) When the server receives G1, G2, and the ID, it uses both m(tj) and R(tj) of G1 and G2 to search for the user's data and find the corresponding ciphertext block, Ci.. 3.5 What are Unlinkable Search and Ciphertext Patterns? 3.5.1 Unlinkable Search Pattern Search pattern G is randomly arranged by m and R, which are made up of a total of 64 blocks. Because each R is always randomly generated, even for the same keyword search, search pattern G is still different each time.. Figure 4. Unlinkable search pattern. 27.
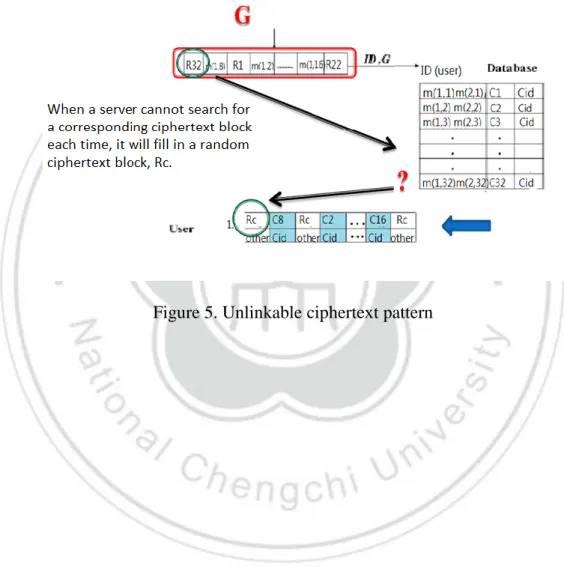
(28) 3.5.2 Unlinkable Ciphertext Pattern For the same keyword search, if the search pattern has no connectivity, the reply ciphertext is still the same, and an attacker can still easily obtain certain information from an unlinkable search pattern. A ciphertext pattern also includes a random block Rc, and is thus also unlinkable.. Figure 5. Unlinkable ciphertext pattern. 28.
(29) Chapter 4 Security Problems of Lin et al. Scheme A security analysis of the original scheme was conducted, with an emphasis on passive attacks, and the security vulnerabilities of the original scheme are discussed herein. The security vulnerabilities of the original scheme is against unlinkable search and ciphertext patterns, and we also found that a keyword of the original scheme can take advantage of the brute force obtained.. 4.1 Security Vulnerabilities of Unlinkable Search Pattern In the search pattern of the original scheme, there are 32 keyword hash blocks and 32 random blocks, with a total of 64 blocks, and thus the original scheme claims that hash blocks are the same despite the different keywords; however, each time 32 different blocks are randomly added, an attacker will not know whether a search pattern is for the same keywords. However, our security analysis found that the original scheme does not reach a so-called unlinkable search pattern. Because the search pattern generated by the same keywords must be at least 32 blocks in size, the keyword hash value blocks will be the same, and thus when we find two search patterns with at least 32 of the same blocks, both can be identified for the same keyword; thus, the claimed unlinkable search pattern was not reached in the original scheme. We used the following method to calculate the probability of a keyword not being the same; the results show that when the probability of the search pattern being made up of at least 32 of the same blocks is very low. The search pattern has a total of 64 16-bit blocks, which means that one block is the same, and that probability is. , 32 blocks are the same and that probability is. . However, randomly. selected 32 blocks from the 64 blocks of search pattern to permutate and that 29.
(30) probability is. . Therefore, the possibility of two search pattern’s blocks are the. same in Permutation is. same, the probability is. , and. . If two search patterns want 32 blocks to be the. *. , this probability is much smaller than. is impossible to happen.. Therefore, from this probability we can know that if the same keywords are not used, then the 32 block searching patterns are the same, the probability of which is very low. In other words, if at least 32 blocks are the same, it means that these two search patterns are generated by the same keyword, which does not reach the unlinkable searching pattern claimed by the original scheme.. 4.2 Security Vulnerabilities of Unlinkable Ciphertext Pattern As with the security vulnerabilities described in 4.1, if 32 blocks of a ciphertext pattern are the same, it can also be said that they belong to the same ciphertext; in addition, if two ciphertext patterns corresponding to a keyword are the same, then the unlinkable ciphertext pattern claimed by the original scheme was not reached. Depending on how the probability of 4.1 is calculated, we can know if ciphertext is not the same , but 32 blocks of ciphertext pattern are the same, the probability of which is very low. In other words, when at least 32 blocks are the same, it means that the two ciphertext are the same, which reveals that they are the same search keywords.. 30.
(31) 4.3 Keywords Vulnerable to Brute Force Attacks According to 4.1, if we find the same keyword, then at least 32 blocks of the search pattern must be same; these 32 blocks are generated through keyword hashing, and thus we can, for a limited number of keywords, throw in a hash function to calculate whether the 32 keywords equal the hash value, and if so, then we can know the keyword, contrary to a continual guess and comparison method.. 31.
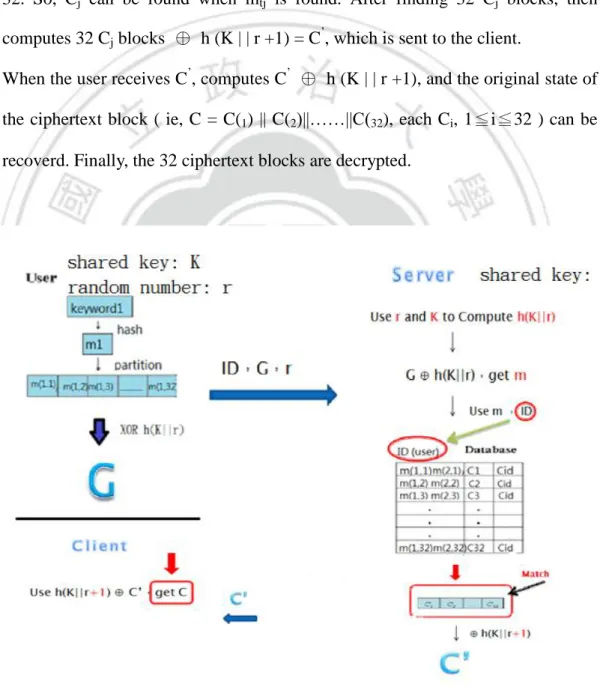
(32) Chapter 5 Proposed Scheme and Security Analysis 5.1 Encryption and Storage Phase The new scheme discussed in this chapter using the same mechanism as the original scheme in the encryption and the storage stages. Table 1 lists the symbols used in this stage, and Figure 2 shows the overall process.. 5.2 Search and Decryption Phase As the biggest difference from the original scheme in the search and decryption phase, in the new scheme, we no longer use random blocks, Rc, but directly apply an XOR operation. In addition, we no longer use the random permutation RP. Further changes allow each client and server to directly share a secret key K in advance, and the client will generate a random number r in each search. Table 3 lists the symbols used in this stage, and Figure 4 shows the overall process.. Table 3.Symbols used in search and decryption phase. (1) When a user with identity ID wants to search for a ciphertext he stored on database, he first chooses some keywords. For easy to understand, assume he chooses one keyword kt. He hashes kt to be mt ( ie, h(kt)= mt ), Then, the user picks a random number r, and computes the mt ⊕ h (K | | r) to be a searching 32.
(33) pattern G. Finally, the user submits (user ID, G, r) to the server for a search. (2) When the server receives ( ID, G, r ) it first uses r and the shared key K to compute h (K | | r), and then uses G ⊕ h (K | | r) to recover mt, mt is divided into 32 blocks ( ie, mt = m(t1) || m(t2)||……||m(t32)), each m(tj), 1<=j<=32, is 16 bits in size. In addition, for each mtj, the search result will be a “hit” when j is from 1 to 32. So, Cj can be found when mtj is found. After finding 32 Cj blocks, then computes 32 Cj blocks ⊕ h (K | | r +1) = C’, which is sent to the client. (3) When the user receives C’, computes C’ ⊕ h (K | | r +1), and the original state of the ciphertext block ( ie, C = C(1) || C(2)||……||C(32), each Ci, 1≦i≦32 ) can be recoverd. Finally, the 32 ciphertext blocks are decrypted.. Figure 6. Process of decryption and searching phase. 33.
(34) 5.3 Security Analysis of Proposed Scheme A secured ciphertext searching mechanism should satisfy the following demands: confidentiality, privacy, and an unlinkable search pattern. The following description of our proposed mechanism shows how to satisfy these needs. As described in this research, we retain the advantages of the Lin et al. [37] in the improved scheme. Whereas the Lin et al. scheme was shown to be unable to achieve unlinkable search and ciphertext patterns, the proposed scheme can achieve. The new scheme proposed herein will ensure that a key cannot be subject to a brute force attack.. 5.3.1 Confidentiality Cloud-stored data are based on the user's own chosen key (k) for encryption, and thus any attacker, even the server itself, cannot know the plaintext data.. 5.3.2 Privacy When users want to conduct a search, a search pattern is formed by an XOR operation combined with a hashed keyword, and because an attacker does not know the shared key K, no attacker can know the user's search keywords and undermine their privacy.. 5.3.3 Unlinkable Searching Pattern Although each keyword will have the same hash value, m, when a client wants to search based on a keyword, the client will generate a random number, r, and after conducting a hash operation with the client and server’s shared K (h (K | | r)), obtain searching pattern G after conducting an XOR operation on m and h (K | | r)( ie, m ⊕ h (K | | r) = G ). Because the user must choose a random number r every time they want to conduct a search, even when using the same keyword, search pattern G will 34.
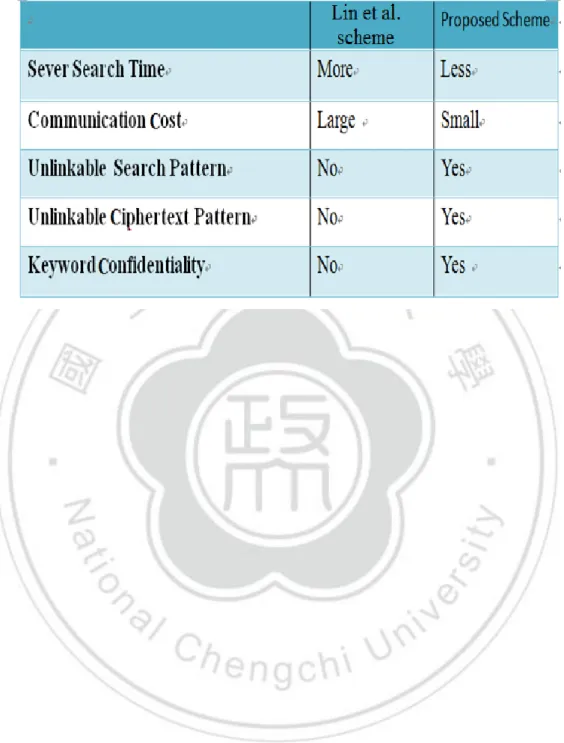
(35) definitely not be the same.. 5.3.4 Unlinkable Ciphertext Pattern Although the same keyword will search out the same ciphertext block, the server will first conduct an XOR operation on a ciphertext block and h(K||r+1) to obtain ciphertext pattern C’ ( ie, C ⊕ h (K | | r+1) = C’ ), and send C’ to the client. Because every time a user wants to conduct a search they must choose a random number r, even for the same keywords, ciphertext pattern C’ will definitely not be the same.. 5.3.5 Keywords Less Vulnerable to Brute Force Attacks Although a random number r is transmitted in plaintext, an attacker does not know the two sides sharing key K, and thus it cannot calculate h (K | | r) to recover the original key hash value, mt; therefore search keywords cannot be known through brute force.. 5.4 Efficiency Comparison of the Two Schemes The newly improved scheme described in this paper was compared with the original scheme, and the search time and transmission burden of the proposed scheme were shown to be much lower. Because the search pattern within our scheme uses no random number blocks, after the server obtains the search pattern, extra time is not spent on searching for random number blocks corresponding to ciphertext blocks, and the transmission burden is reduced from the original 64 blocks to 32 blocks. Table 4 shows a comparative analysis of the two schemes.. 35.
(36) Table 4.Comparative analysis of the two schemes. 36.
(37) Chapter 6 Conclusion A ciphertext search is an important feature of cloud storage services, and an unlinkable search pattern can provide greater search privacy. This paper presented an improved symmetric key ciphertext search mechanism based on an original scheme. This mechanism uses the technology of two sides sharing a key, K. Each search also generates a random number, r. The search pattern is submitted to the server, which replies with the search results.. The scheme proposed in this paper reduces the search time and transmission burden as compared with the original scheme, and the client computations are very efficient. In addition, our scheme also retains the dynamic maintenance and conjunctive keyword search of the original scheme, and the search and ciphertext patterns achieve real unlinkability, providing users with a higher degree of search privacy.. Currently unlinkable search pattern and unlinkable ciphertext pattern of proposed scheme is only against external attackers, for the server can not be achieved. So I hope that whether it is an external attacker and server all can achieve the the so-called unlinkable in the future.. 37.
(38) References [1] M. Abdalla, M. Bellare, D. Catalano, E. Kiltz, T. Kohno, T. Lange, J. M. Lee, G. Neven, P. Paillier, and H. Shi. “Searchable encryption revisited: Consistency properties, relation to anonymous IBE, and extensions.” Advances in Cryptology -CRYPTO '05, volume 3621 of Lecture Notes in Computer Science, pages 205-222. Springer, 2005. [2] G. Ateniese, R. Burns, R. Curtmola, J. Herring, L. Kissner, Z. Peterson, and D. Song. “Provable data possession at untrusted stores.” In P. Ning, S. De Capitani di Vimercati, and P. Syverson, editors, ACM Conference on Computer and Communication Security (CCS '07), pages 598-609. ACM Press, 2007. [3] G. Ateniese, S. Kamara, and J. Katz. “Proofs of storage from homomorphic identication protocols.” Advances in Cryptology - ASIACRYPT '09, volume 5912 of Lecture Notes in Computer Science, pages 319-333. Springer, 2009. [4] G. Ateniese, R. Di Pietro, L. V. Mancini, and G. Tsudik. “Scalable and efficient provable data possession.” In Proceedings of the 4th International Conference on Security and Privacy in Communication Networks (SecureComm '08), pages 1-10, New York, NY, USA, 2008. ACM. [5] J. Baek, R. Safavi-Naini, and W. Susilo. “On the integration of public key data encryption and public key encryption with keyword search.” In International Conference on Information Security (ISC '06), volume 4176 of Lecture Notes in Computer Science, pages 217-232. Springer, 2006. [6] J. Baek, R. Safavi-Naini, and W. Susilo. “Public key encryption with keyword search revisited.” In International conference on Computational Science and Its Applications, volume 5072 of Lecture Notes in Computer Science, pages 1249-1259. Springer, 2008. 38.
(39) [7] J. Bardin, J. Callas, S. Chaput, P. Fusco, F. Gilbert, C. Hoff, D. Hurst, S. Kumaraswamy, L. Lynch, S. Matsumoto, B. O'Higgins, J. Pawluk, G. Reese, J. Reich, J. Ritter, J. Spivey, and J. Viega. “Security guidance for critical areas of focus in cloud computing.” Technical report, Cloud Security Alliance, April 2009. [8] M. Bellare, A. Boldyreva, and A. O'Neill. “Deterministic and efficiently searchable encryption.” Advances in Cryptology - CRYPTO '07, Lecture Notes in Computer Science, pages 535-552. Springer, 2007. [9] J. Benaloh, M. Chase, E. Horvitz, and K. Lauter. “Patient controlled encryption: Ensuring privacy of electronic medical records.” In ACM workshop on Cloud computing security (CCSW'09), pages 103-114. ACM, 2009. [10] J. Bethencourt, A. Sahai, and B. Waters. “Ciphertext-policy attribute-based encryption.” In IEEE Symposium on Security and Privacy, pages 321-334. IEEE Computer Society, 2007. [11] D. Boneh, G. di Crescenzo, R. Ostrovsky, and G. Persiano. “Public key encryption with keyword search.” Advances in Cryptology - EUROCRYPT '04, volume 3027 of Lecture Notes in Computer Science, pages 506-522. Springer, 2004. [12] D. Boneh, E. Kushilevitz, R. Ostrovsky, and W. Skeith. “Public-key encryption that allows PIR queries.” Advances in Cryptology - CRYPTO '07, volume 4622 of Lecture Notes in Computer Science, pages 50-67. Springer, 2007. [13] D. Boneh and B. Waters. “Conjunctive, subset, and range queries on encrypted data.” In Theory of Cryptography Conference (TCC '07), volume 4392 of Lecture Notes in Computer Science, pages 535-554. Springer, 2007. [14] K. Bowers, A. Juels, and A. Oprea. “Proofs of retrievability: Theory and implementation.” In ACM workshop on Cloud computing security (CCSW'09), pages 43-54. ACM, 2009.. 39.
(40) [15] J. W. Byun, H. S. Rhee, H.-A. Park, and D. H. Lee. “Off-line keyword guessing attacks on recent keyword search schemes over encrypted data.” In Secure Data Management, volume 4165 of Lecture Notes in Computer Science, pages 75-83. Springer, 2006. [16] Y. Chang and M. Mitzenmacher. “Privacy preserving keyword searches on remote encrypted data.” Applied Cryptography and Network Security (ACNS '05), volume 3531 of Lecture Notes in Computer Science, pages 442-455. Springer, 2005. [17] M. Chase. “Multi-authority attribute based encryption.” In Theory of Cryptography Conference(TCC '07), volume 4392 of Lecture Notes in Computer Science, pages 515-534. Springer, 2007. [18] M. Chase and S.M. Chow. “Improving privacy and security in multi-authority attribute-based. encryption.”. In. ACM. Conference. on. Computer. and. Communications Security (CCS '09), pages 121-130, New York, NY, USA, 2009. ACM. [19] R. Curtmola, J. Garay, S. Kamara, and R. Ostrovsky. “Searchable symmetric encryption: Improved definitions and efficient constructions.” ACM Conference on Computer and Communications Security (CCS'06), pages 79-88. ACM, 2006. [20] Y. Dodis, S. Vadhan, and D. Wichs. “Proofs of retrievability via hardness ampli cation.” In Theory of Cryptography Conference, volume 5444 of Lecture Notes in Computer Science, pages 109-127. Springer, 2009. [21] C. Erway, A. Kupcu, C. Papamanthou, and R. Tamassia. “Dynamic provable data possession.” In ACM conference on Computer and communications security (CCS '09), pages 213-222, New York, NY, USA, 2009. ACM.. [22] T. Fuhr and P. Paillier. “Decryptable searchable encryption.” In International 40.
(41) Conference on Provable Security, volume 4784 of Lecture Notes in Computer Science, pages 228-236. Springer,2007. [23] E-J. Goh. “Secure indexes.” Technical Report 2003/216, IACR ePrint Cryptography Archive, 2003.. [24] P. Golle, J. Staddon, and B. Waters. “Secure conjunctive keyword search over encrypted data.” Applied Cryptography and Network Security Conference (ACNS '04), volume 3089 of Lecture Notes in Computer Science, pages 31-45. Springer, 2004. [25] V. Goyal, O. Pandey, A. Sahai, and B. Waters. “Attribute-based encryption for fine-grained access control of encrypted data.” In ACM conference on Computer and communications security(CCS '06), pages 89-98, New York, NY, USA, ACM, 2006. [26] A. Juels and B. Kaliski. “PORs: Proofs of retrievability for large files.” ACM Conference on Computer and Communication Security (CCS '07), pages 584-597, New York, NY, USA, ACM, 2007. [27] R. Ostrovsky, A. Sahai, and B. Waters. “Attribute-based encryption with non-monotonic access structures.” In ACM conference on Computer and communications security (CCS '07), pages 195-203, New York, NY, USA, ACM, 2007. [28] D. Park, K. Kim, and P. Lee. “Public key encryption with conjunctive field keyword search.” Workshop on Information Security Applications (WISA'04), volume 3325 of Lecture Notes in Computer Science, pages 73-86. Springer, 2004. [29] A. Sahai and B. Waters. “Fuzzy identity-based encryption.” Advances in Cryptology - EUROCRYPT '05, volume 3494 of Lecture Notes in Computer Science, pages 457-473. Springer, 2005. 41.
(42) [30] H. Shacham and B. Waters. “Compact proofs of retrievability.” In Advances in Cryptology - ASIACRYPT '08, volume 5350 of Lecture Notes in Computer Science, pages 90-107. Springer, 2008. [31] E. Shi, J. Bethencourt, T. Chan, D. Song, and A. Perrig. “Multi-dimensional range query over encrypted data.” In IEEE Symposium on Security and Privacy, pages 350-364, Washington, DC, USA, 2007. IEEE Computer Society. [32] D. Song, D. Wagner, and A. Perrig. “Practical techniques for searching on encrypted data.” In IEEE Symposium on Research in Security and Privacy, pages 44-55. IEEE Computer Society, 2000. [33] Q. Wang, C. Wang, J. Li, K. Ren, and W. Lou. “Enabling public verifiability and data dynamics for storage security in cloud computing.” In European Symposium on Research in Computer Security (ESORICS '09), volume 5789 of Lecture Notes in Computer Science, pages 355-370. Springer, 2009. [34] K. Zetter. “Compay caught in texas data center raid loses suit against FBI.” Wired Magazine, April 2009. [35] S. Kamara and K. Lauter. “Cryptographic Cloud Storage.” Financial Cryptography and Data Security, volume 6054 of Lecture Notes in Computer Science, pages 136-149. Springer, 2010. [36] S. T. Hsu, M.S. Hwang, and C.C. Yang. “A study of keyword Search over encrypted data in cloud storage service.” 2013 [37] 林峻立. “Unlinkable and Conjunctive Keyword Ciphertext Searching with Dynamic Maintenance” Cryptology and Information Security Conference 2013, pages 272-275.. 42.
(43)
數據


+7


相關文件
The Hilbert space of an orbifold field theory [6] is decomposed into twisted sectors H g , that are labelled by the conjugacy classes [g] of the orbifold group, in our case
Performance metrics, such as memory access time and communication latency, provide the basis for modeling the machine and thence for quantitative analysis of application performance..
• Instead of uploading and downloading the dat a from cloud to client for computing , we shou ld directly computing on the cloud ( public syst em ) to save data transferring time.
In this paper, by using Takagi and Sugeno (T-S) fuzzy dynamic model, the H 1 output feedback control design problems for nonlinear stochastic systems with state- dependent noise,
In this chapter, a dynamic voltage communication scheduling technique (DVC) is proposed to provide efficient schedules and better power consumption for GEN_BLOCK
So, we develop a tool of collaborative learning in this research, utilize the structure of server / client, and combine the functions of text and voice communication via
(2004), "Waiting Strategies for the Dynamic Pickup and Delivery Problem with Time Window", Transportation Research Part B, Vol. Odoni (1995),"Stochastic and Dynamic
For better efficiency of parallel and distributed computing, Apache Hadoop distributes the imported data randomly on data nodes.. This mechanism provides some advantages
