國立交通大學
管理學院碩士在職專班財務金融組
碩 士 論 文
台灣股價指數時間序列之研究
THE TIME SERIES ANALYSIS FOR TAIWAN STOCK
EXCHANGE INDEX
指導教授:王克陸 教授
研究生:連偉志
台灣股價指數時間序列之研究
THE TIME SERIES ANALYSIS FOR
TAIWAN STOCK EXCHANGE INDEX
學生:連偉志 Student:Wei-Chin Lien
指導教授:王克陸 教授 Advisor:Dr. Keh-Luh Wang
國立交通大學
管理學院碩士在職專班財務金融組
碩士論文
A Thesis
Submitted to Graduate Institute of Finance College of Management
National Chiao Tung University In partial Fulfillment of the Requirements
For the Degree of Master In Finance January 2011
Hsinchu, Taiwan, Republic of China
台灣股價指數時間序列之研究
學生:連偉志 指導教授:王克陸 教授
國立交通大學管理學院碩士在職專班財務金融組
摘要
本文利用時間序列分析工具探討台股加權指數並建立其單變量與 多變量時間序列模型。隨著政府開放外資投資台股,加上科技產業進 入國際市場,使得美股對於台灣股市的影響力逐漸增加,而美國的經 濟與股市的變動往往對台股也產生不可忽視的影響力。而近年來中國 經濟成長迅速,再加上中國強勁的出口貿易與內需市場,使得中概股 在台股中的重要性逐漸增加。本研究嘗試將中國上海綜合指數與人民 幣匯率加入多變量時間序列模型中,並且探討各國指數與台股之間的 相互關係。 關鍵字:時間序列;ARIMA;GARCH;VARTHE TIME SERIES ANALYSIS
FOR TAIWAN STOCK EXCHANGE INDEX
Student:Wei-Chin Lien Advisor:Dr. Keh-Luh Wang
Graduate Institute of Finance
College of Management
National Chiao Tung University
ABSTRACT
The purpose of this study is to develop the optimal time series model for Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX). Due to foreign capital investment in Taiwan, together with the international trade by Taiwan’s IT industry. The influence of the US stock market on TAIEX is increasing. Furthermore, the economic growth if China is tremendous. The signification of China related firms in Taiwan Stock Exchange is also increasing in recent years. Therefore, Shanghai Unify Index and China currency Exchange are also used explain the multivariate model foe TAIEX.
誌 謝
本論文得以付梓,首先要感謝的是我的恩師-王克陸老師,在老 師細心的教導下,讓一個對於計量完全沒有背景的學生,可以依照自 己的興趣來完成此相關研究,並且在研究中可以建立相關的邏輯與學 習到完整的知識,在此,獻上我最深的敬意。 並且要感謝我的家人(父親、母親及弟弟),在我決定要取得此學位 的同時,完全支持我的決定,當我最大的後盾。並且在面對他人的質 疑與不諒解時可以在第一時間為我辯護,讓我可以在沒有後顧之憂的 環境下完成此學業。親愛的家人,這份榮耀是完完全全的屬於您們的。 親愛的盈潔,感謝你在這十年來的一路相伴,對於我的任何決定 都給予我最大的支持,並且在我感到猶豫與困惑的時候給予我最大的 信心。因為你的辛苦與付出讓我可以更不顧一切的勇往直前。沒有你, 我不會念這個文憑;沒有你,我也撐不到今天。You complete me!! Alex 譚、Jerry 劉,我只能說你們是我永遠的兄弟!!!還有 GIA 的好同學們,因為課程而讓我認識了你們這一票好朋 友,也因為你們的協助讓這份論文可以更完整。
最後要感謝的交大的好同學,正玉、麗娟、鳳如、泰霖、連國還 有小安,從學分班到一起考上研究所,現在終於可以一起提早畢業。
謝謝你們照顧我這個小老弟,並且給予我很多在職場上應有的知識與 認識。也許我們的年紀有些許的差距,但是我相信我們的友誼是沒有 距離的。 還有蠻頭,雖然你只會吃跟睡,而且我還會踢你屁股,但是你在我 心目中還是有一定的位置。 在此將最深的榮耀與祝福獻給我最愛的親人與好友!! 偉志 謹誌於 國立交通大學管理學院碩士在職專班財務金融組 庚寅年
目 錄
中文提要………...i 英文提要………...ii 誌謝………....……...iii 目錄………...……...v 表目錄………...viii 圖目錄………...x 第一章 緒論……….1 1.1 研究動機與背景………...1 1.2 研究目的………...2 1.3 研究架構………...4 第二章 理論基礎與文獻探討………...5 2.1 股票價格理論………...5 2.1.1 效率市場假說………...5 2.1.2 股票價格分析………..7 2.1.3 隨機漫步理論………...8 2.2 文獻探討……….10 第三章 研究方法………..….17 3.1 時間序列………..17 3.1.1 架構流程圖………...18 3.2 單根檢定………...19 3.3 落後期數決定………...203.4 Granger 因果檢定………21 3.4.1 Granger 因果檢定之定義………..21 3.4.2 Granger 因果關係檢定………..23 3.5 單變量 ARIMA 模型………..25 3.6 多變量 ARIMA 模型………..28 3.7 ARCH 模型……….32 3.7.1 經濟與財務時間序列統計資料之特性………..32 3.7.2 ARCH-GARCH 模型………32 3.7.3 模型的檢定………..34 3.8 向量自我迴歸……….35 3.9 Chow 轉變點檢定………..37 3.9.1 Chow 轉變點檢定………..37 3.10 評估模型預測能力之方法………..38 第四章 資料來源與處理……….………..40 第五章 實證結果與分析………..……….41 5.1 單變量時間序列……….………...41 5.1.1 研究流程………41 5.1.2 數列單根檢定………41 5.1.3 結構轉變 CHOW 檢定………...53 5.1.4 ARIMA 模型假設………..57 5.1.5 樣本外預測能力………63 5.2 多變量時間序列………...65 5.2.1 研究流程………..65
5.2.2 單根檢定………..66 5.2.3 ARCH-GARCH 模型假設………....67 5.2.4 ARIMA-GRACH 模型樣本外預測………...73 5.3 向量自我迴歸………...74 5.3.1 ADF 單根檢定……….74 5.3.2 選取落後期數………..75 5.3.3 預估模型………..76 5.3.4 衝擊反應………..77 5.3.5 預測值之變異數分解………..78 第六章 結論與建議……….79 6.1 結論………80 6.2 後續研究與建議……….80 參考文獻………..81
表目錄
表 4.1 變數定義………42 表 5.1 台股加權指數單根檢定(含截距項)……….44 表 5.2 台股加權指數單根檢定(含截距與趨勢項)……….45 表 5.3 台股加權指數單根檢定(不含截距與趨勢項)……….46 表 5.4 台股加權指數單根檢定(含截距項)……….47 表 5.5 台股加權指數單根檢定(含截距與趨勢項)……….48 表 5.6 台股加權指數單根檢定(不含截距與趨勢項)……….49 表 5.7 台股加權指數單根檢定(含截距項)……….50 表 5.8 台股加權指數單根檢定(含截距與趨勢項)……….51 表 5.9 台股加權指數單根檢定(不含截距與趨勢項)………52 表 5.10 CUSUM 檢定來找出結構轉變點………...53 表 5.11 CUSUM 檢定來找出結構轉變點………..55 表 5.12 ARIMA(6,1,9) 殘差自我相關 Q 統計量………..56 表 5.13 ARIMA(8,1,8) 殘差自我相關 Q 統計量………..57 表 5.14 JB 統計量比較表………57 表 5.15 ARIMA(6,1,9)-GARCH(1,1)的回歸參數估計表………..59 表 5.16 ARIMA(6,1,9)-GARCH(1,1) 殘差自我相關 Q 統計量…….60 表 5.17 ARIMA(8,1,8)-GARCH(1,1)的回歸參數估計表………...61 表 5.18 ARIMA(8,1,8)-GARCH(1,1) 殘差自我相關 Q 統計量……..62 表 5.19 樣本外預測結果整理……….64表 5.20 個變數名稱……….65 表 5.21ADF 單根檢定……….66 表 5.22ARIMA(2,1,2)模型檢測………..67 表 5.23 ARIMA(2,1,2)的 Q 統計量………..68 表 5.24 ARIMA(2,1,2)-GARCH( 2, 2 ) 模型配適度診斷………..69 表 5.25 ARIMA(2,1,2) -GARCH( 2, 2 )的 Q 統計量……….70 表 5.26 ARIMA(2,1,2) -GARCH( 2, 2 )的模型回歸參數………...71 表 5.27 ADF 單根檢定……….73 表 5.28 選取落後期數………..74 表 5.29 模型估計………..75 表 5.30 預測值之變異數分解………..77
圖目錄
圖 1.1 論文架構圖………..4 圖 3.1 ARIMA 時間序列模式建構流程圖………..18 圖 3.2 多變量 ARIMA 模型流程圖……….29 圖 3.3 多變量 ARIMA 模型流程圖……….33 圖 5.1 台股加權指數圖(原始資料)……….44 圖 5.2 台股加權指數圖(原始資料取自然對數)……….47 圖 5.3 台股加權指數圖(原始資料取自然對數取一階差分)………….50 圖 5.4 ARIMA(6,1,9) -GARCH(1,1)樣本外預測結果………63 圖 5.5 ARIMA(8,1,8) -GARCH(1,1)樣本外預測結果………63 圖 5.6 ARIMA(2,1,2) -GARCH(2,2)樣本外預測結果………72 圖 5.7 衝擊反應………76第一章
緒論
1.1 研究動機與背景
台股在過去歷史上有三次衝破萬點,分別為 1990 年 2 月、1997 年 8 月 及 2000 年的時候。其中三次站上萬點的因素分別為貿易出口大幅成長、台 灣科技公司進入國際舞台及總統大選策略作多。 分析台股三次站上萬點的市值結構,由 1990 年的 7.6 兆,到 2000 年的 13.5 兆,甚至到 2010 年,股票市值已經突破了 122 兆新台幣,此其中代表 著台灣股市在國際股市與亞洲股市產生了不可忽略的影響力。 過去隨著政府開放外資投資台股、台灣科技產業進入國際市場,使得 美股對於台灣的影響力逐漸增加,因此,美國經濟市場的變動與股市的漲 跌往往對於台股也產生不可忽視的影響,也成為台股投資人與投資機構必 觀察的重點。 近年來隨著中國經濟的崛起,中國股市的市值也由 4.7 千萬美元 (2000),成長到 3.21 兆美元(2009),躍升至全球第三。受惠於中國經濟跳躍 性的成長,使得台灣中概股近幾年在股市中重視程度逐漸增加。然而中國 強勁的内需市場與出口貿易在亞洲甚至是世界上展現出其不可忽視的影響 力。1.2 研究目的
近年來台灣電子產業雖然在世界各國還是具相當的影響力,但是隨著 中國經濟市場的崛起,兩岸金融貿易頻繁,使得中概產業與金融產業也開 始呈現不可忽視的影響力。而台灣加權指數的漲跌也不再單單以電子股為 主。因此,本研究標的將鎖定於台灣加權平均指數。 然而從長期來看,股市反應出一個國家的經濟實力以及投資大眾對於 未來經濟成長的預期,而股市的漲跌也往往為經濟活動的先行指標。但是 一般社會大眾難以掌握對於未來的經濟發展作理性的預測,因此,預測股 市未來的價值與方向變成一件相當困難的工作。 近年來由於計量技術的成熟,使得已經有不少得預測方法與研究陸續 的應用於實際的投資市場;以時間序列模型而言,其發展至今的程度與複 雜度自然不在話下,相較於一般傳統回歸模型其有得簡易性與普遍性而 言,時間序列模型所具有的捕捉特定顯像功能更具其優勢,並且隨著資訊 電腦技術的進步與結合,更使得計算門檻下降。然而在建模與預測的過程 中,如何在有限的資源環境下,做最適的配適與模擬,並且兼顧『計算的 環境』與『預測的績效』亦將是本研究的重點。 承上所述,隨著區域經濟與資訊時間差的縮小,加上台灣本屬於淺碟 型市場經濟,在探討台灣股市報酬模式的過程中,研究上似乎更著重於外 生變數的討論,方可對於台灣股市報酬有更真實的表達。基於上述的研究動機,本文將利用各種不同的時間序列模型,藉以嘗 試推估股價指數未來的走向,其主題有以下數點: 1. 建立台灣加權平均指數的時間序列模式,本研究之單變量與多變量 模型,將以日資料試圖找出最適模型解,並且分析其最適預測能力。 2. 探討國際股市 (美國道瓊工業指數、上海綜合指數) 及匯率(美金、 日幣、人民幣)與台股之間的相關性,藉由研究與探討台股指數與諸 多變數之間的相互關係,有助於確定或是估計台股與各變數之間的 連動性,並且能更準確的預測台股未來的走向。
1.3 研究架構
本研究共分為五章,第一章為緒論,主要為說明研究動機背景及目的; 第二章為理論基礎與文獻探討;第三章為研究方法,介紹時間序列與其相 關統計方法;第四章為實證結果與分析,真對本研究資料做適當的統計分 析,並且提出相關策略與比較;第五章為結論與建議,說明本研究之成果 與貢獻,並且提供未來可供研究之方向與建議。 其架構如下圖 1.1 所示: 圖 1.1 論文架構圖 第一章:緒論 第二章: 理論基礎與文獻探討 第三章:研究方法 第四章: 實證結果與分析 第五章:結論與建議第二章 理論基礎與文獻探討
本章首先將對於股票市場的形成、價格、分析做一概念性之敘述,並 且對於本研究相關之國內外文獻做一重點式的回顧。2.1 股票價格理論
由經濟學理論得知,商品之價格是由市場的供需所決定。股票為金融 商品的一種,因此股票市場的供需決定了股票的價格。但決定股票的供需 的因素相當多,因此各種股票價格分析方法便因應而生,其介紹如下:2.1.1 效率市場假說(Efficient Market Hypothesis)
根據 Fama(1970)的效率市場假說,若證券市場之價格可以正確且充分 反應全部相關的資訊,如經濟、金融等相關的消息面,則稱該市場是有效 率的。換言之,當影響市場股票價格的訊息出在市場時,該訊息會迅速且 正確的反應在股價上,因此投資者無法在市場上賺取超額的報酬,其主要 的假設有下列三項:(1)投資者皆為理性。(2)資訊即時公開,且獲得資訊無 須負擔額外的資訊成本。(3)市場上沒有任何的投資者具有單獨影響股價的 能力。然而按照市場上資訊集中的不同類型,Fama 將市場效率劃分為以下 三種型態:
證券價格以充分反應過去證卷價格變化所提供的所有資訊,因此證卷價 格的未來走向與其歷史價格變化為互相獨立,並服從隨機漫步理論。投 資人無法藉由運用技術分析來獲取超額報酬。
(2) 半強勢效率市場(Semi-strong Form Efficient Market)
證券價格不但充分反應過去所有的歷史資訊,並且也完全反應了所有公 開資訊,因此投資人無法藉由基本分析(Fundamental Analysis)來獲取超 額報酬。
(3) 強效率市場(Strong Form Efficient Market)
證券價格以充分反應『過去』及『現在』的所有公開與未公開資訊,因 此投資人無法藉由公開或是未公開消息來獲取超額報酬。
Fama 與 Blume(1966)利用濾嘴法則(Filter Rules)測試美國道瓊工業平均 指數,其結果所獲得之報酬遜於買進持有之獲利,即技術分析無法獲得超 額報酬,符合弱勢效率市場假說。Rosenthal(1983)以序列相關和連檢定(Run Test)測試美、英、德等市場,其結果符合弱勢效率市場假說。杜金龍(2001) 認為國內市場因為漲跌幅的限制,呈現出比弱勢效率市場還弱的資本市 場,再加上投資管道不足,國內股市充斥著內線交易與短線交易、政府干 預護盤、市場做手炒作、與非理性投資人等…,使得國內股市不具弱勢效 率市場的條件。當股市不具弱勢效率市場的條件時,投資者可藉由基本分 析、技術分析、甚至是內線消息來獲取超額報酬。
基於上述理由,在國內基本分析與技術分析廣為一般投資者、法人投 資機構擬定投資策略的重要參考指標。 2.1.2 股票價格分析 由於台灣股票市場呈現比弱勢效率市場還弱,因此基本分析與技術分 析有其價值,其介紹如下: 1.基本分析 利用經濟指標找出公司股票的合理價值,分析各產業的興衰。並且更 進一步的利用財報觀測各企業之營收的現況與未來前景,從中對企業作出 客觀的評價,並且盡可能預測其未來的變化,作為投資的依據。基本分析 方可利用以下三方面評估公司未來的成長與獲利的能力: (1)總體經濟面 藉由各政府所頒布的經濟指標如:經濟成長率、國民生產毛額、貨幣供給 額、失業率、利率…等,並伴隨著國際情勢來做整體區域性的分析。 (2)產業面 產業的興盛衰落對於所處該產業的公司有直接性的影響,藉由分析產業的 所處階段與產業上下游的結構,作整體性的分析。 (3)公司基本面分析 依各公司的實質營運狀況來分析研究。藉由公開發佈之財務報表來了解並
分析期公司體質與期營運狀況,藉此擬定投資策略。 2.技術分析 技術分析主要為利用過去的資料如價格、成交量、波動度…等,藉由 統計方法來研判未來股價的走勢,其基本假設如下: (1) 歷史會重演,因為技術分析主要為對於過去歷史價格的研究,因此主要 為根據過去價格出現的機率作為未來價格走勢的基礎。 (2) 價格具有趨勢,且價格會隨著趨勢運動。 (3) 價格包含所有的資訊,表示價格為市場供需影響下所產生的結果,因此 涵蓋了所有影響價格的因素,此有使得技術分析研究的資料更具說服 力。
2.1.3 隨機漫步理論(Random Walk Theory)
隨機漫步理論指出,投資市場內每一個投資者接為理性的,而且市場 的資料皆為公開,也因此股票價格就會完全的反應出供需關係。股票價格 代表著供需之間的平衡,因此會構成一個合理的價位,而市價會圍繞著合 理價值上下波動,這些波動為隨意且沒有固定頻率。波動的產生為市場上 新的消息導致投資者重新估計股票的價值,而做出買賣策略,導致股票價 格產生波動。 隨機漫步理論指出股價在市場上的價格若已經反應出其基本的價值, 則此價值就不會再產生變化,除非有新的消息衝擊股價。由於新的消息對
於股價的衝擊無人知曉,所以股票價格俱備的無記憶性(memoryless)與隨機 性。換言之,每日間股價的漲跌並無相關。 關於市場的波動呈現隨機漫步,下列文章將提出佐證: (1) 法國數學家巴里亞(Bachelier),1900 在其數學博士論文『投機的數學理論』中,首次證明股票期貨價格為隨 機漫步。也因此買賣雙方的盈虧機會為均等,在同一時刻價格漲跌的可 能性會同時存在,也因此投機者其報酬率期望值為零。而理論最重的發 現為時間越長波動越小。 (2) 史丹佛大學統計教授 Working,1934 1934 年 3 月在『美國統計學會學報』發表『時間序列分析之隨機序列』 論文。運用大量的統計證明股票與期貨價格為測不準。同時利用隨機過 程求出隨機數目的方法,證明每個價位都是獨立的個體,並於與過去產 生相關。 (3) 倫敦經濟學院(LSE)統計學教授 Kendall,1953 其在『皇家統計學會學報』第九十六卷第一期發表的『時間序列分析』 論文,利用大量的統計數學證明股票市場為不可測。其分析 19 類不同性 質股票的價格變化,結果發現由統計上無法找出價格結構。
2.2 文獻探討
時間序列為一組資料隨著時間的先後順序所取得,就可稱為是一組時 間序列的資料。如:股票市場每日的指數價格、大陽黑子的數目等。然而, 為了可以解釋時間序列的不確定性,一般都是將時間序列視為一個隨機過 程的實現值,也就是取得一組資料後,下一步即是尋找一個較能適切的解 釋此組序列的模型,並且更進一步的希望能應用 此模型來預測此組序列未來的值。起初最常使用的模型為線性自廻歸 移動平均模型,然而在市場與自然中,許多現象為非線性模型,例如在時 間序列中常見的極限週期與隨機參數等,由於線性自廻歸移動平均模型無 法解釋這些非線性的現象,因此後續的研究漸漸的著重在非線性時間序列 模型的研究。最早有關時間序列相關的研究可以追溯到 Wiener(1958)所提出 的 Volterra 無窮級數展開。後來人們又先後的提出各種不同的非線性時間序 列模型,嘗試解釋所觀測的非線性現象。 直到 1970 年由 Box 與 Jenkins 大力推廣並完成自我回歸移動平均整合 模式(Autoregressive Integrate-Moving Average Model, ARIMA)後續的研究也 才開是系統性的展開,下列將對此相關文件做一整體性的回顧與討論: (1) 陳斐紋,民國 84 年利用 GARCH-family 及時間序列單變量 ARIMA 模型來做台灣股市報酬 率與波動性之預測。其研究結果顯示:GARCH(1,1)-MA(1)模型所配置
之條件變異數參數在統計上相當顯著。其研究並發現過去資訊對於所有 其間的變異數預測有持續性的影響力,而對於高頻資料(日報酬)累積變 異現象更為明顯。 (2) 洪瑞蓮,民國 93 年 探討在不同頻率(日、週、月)資料下,股價、匯率與利率之價格行為, 採用共整合檢定、因果關係檢定、恆常與短暫成份對平均數複回歸方 法,並採用三項金融資產價格的動態關係。研究實證結果:股價與匯率 之日、週與月資料報酬存在短期正向自我相關與長期負自我相關,而利 率日報酬、週報酬與月報酬則是短期與長期呈現負自我相關,表示股價 匯率與利率皆存在平均數複迴歸現象。在探討股價、匯率與利率間的長 期均衡與短期動態因果關係,實證結果發現,不管任何頻率資料、股價、 匯率與利率間均不存在長期均衡。在短期動態關係部分,在日資料部 分,股價與利率均對匯率具有單向因果關係;在週資料部分,股價與利 率具有雙向因果關係,利率對匯率具有單向因果關係;在月資料部分, 股價與利率呈現雙向因果關係,匯率對利率有單向因果關係。
其後,Sims 於 1980 年提出向量自我回歸(Vector Autoregression, VAR), 相關的文獻有:
本研究為利用時間序列:單變數時間序列模式(ARIMA)、轉換時間模式 (TFM)、向量自我回歸模式(VAR),以台灣加權股價指數之相關資料與 經濟資料(銀行拆款利率、物價指數…等)為實證對象。資料自 1994 年 1 月至 1998 年 12 月共 60 筆,找出何者對於股價波動性提供較佳的預測 績效。結果顯示:向量自我回歸模式預測效果較佳,其次為轉換函數模 式,最差為單變量時間序列模式;並且參考變數較多的模型其預測效果 較佳。 (4) 曾淑婷,民國 94 年 比較 VAR 與 ARIMA 模式。結果顯示:台灣、美國股價、台灣重貼現 率及隔夜拆款利率 ARIMA 模式之配適度較 VAR 模式佳,表示此四個 變數本身過去歷史資訊即可反應本身的走勢;美國重貼現率 VAR 模式 之配適度較 ARIMA 佳,即美國重貼現率可由自身及股價指數之歷史資 料來反應。
(5) Eun and Shim, 1989
利用向量自我回歸 VAR 研究 1980 年 1 月至 1985 年 12 月紐約、巴黎、 倫敦、法國、多倫多、蘇黎世、雪梨、香港與東京九個股市,探討國際 國是得連動性之強弱。結果顯示:研究期間,各國股市的確存在著密切 的關聯性。而且美國股市為主要因子,反應美國在世界經濟具主導地位。 (6) Lin, Pan and Shieh, 1996
台灣、泰國等六國股市日資料,研究其間自 1985 年 1 月至 1990 年 12 月分為金融風暴前後兩期探討各國股市間相依關係與連動性。結果顯 示:在泰國股市崩盤後,各國股市相依程度增強,而台灣與其他股市相 關性最低,顯示台灣股市之封閉性較其他國家高;由衝擊反應分析顯 示,亞太股市間訊息傳遞不如西方市場來的有效率。 直到 1982 年發展出自我回歸條件異質變異數分析模式(Autoregressive Conditional Heterosecdasticity, ARCH),時間序列模型又更進了ㄧ步。相關 的文獻整理如下:
(7) 汪曉雯,民國 88 年
利用雙元 GRACH-M 模型來檢視美國股票市場:S&P 500、Nasdaq、道 瓊工業指數與台灣股票市場:上市股票指數、上市電子類股指數之報酬 率、波動性外溢效果、市場風險貼水…等,並且探討 1997 亞洲金融風 暴前後對於美股對台股連動性的強弱。實證結果顯示:Nasdaq 與電子 類股指數在金融風暴前後之報酬率外溢效果皆極為顯著,顯示出美國高 科技產業景氣榮枯市值接影響著台灣電子廠商,並且在金融風暴後,美 國對台灣的影響有增強的趨勢;且條件變異遞延一期對條件變異影響顯 著,可知台灣股價之報酬率條件變異主要是受本身前期波動之影響,較 不受跨國間之影響。
(8) 柯志昌,民國 89 年 本研究以台灣、美國、日本、香港股市為研究標的,採用 EC-AECH 模 型來討論各國股價指數報酬率、波動外溢效果與連動關係。實證結果發 現:在台灣、美國、日本、香港股市中,美國股市是與其他三國股市相 關性最強的國家,此結果反應出美國為一重要的經濟市場,研究結果並 顯示台股扮演著美股的追隨者。 (9) 李敏生,民國 89 年
本研究探討 Nasdaq 綜合指數、Nasdaq 電腦類指數、Nasdaq-100 指數對 於台灣上市、上櫃及電子類指數報酬率與波動性之影響,並且將資料分 為多頭、空頭時期,研究不同時期美國科技類股影響台股表現之波動 性,其研究方法為使用 AR-GARCH(1,1)模型,並且利用單根檢定、 Ljunq-BoxQ 檢定、AIC 準則、LM 檢定來決定模型的配適性。實證結果 發現:不管是 Nasdaq 綜合指數、Nasdaq 電腦類指數、Nasdaq-100 指數 對於台灣股市皆有正面的影響。就波動性而言,Nasdaq 電腦類指數對 台股影響最大。就報酬率而言,Nasdaq 綜合指數對台股影響最大。其 研究也顯示,在空頭時期對台股的影響比多頭要來的大。 (10)姚志泯,民國 90 年 以費城半導體、美光股價為研究標的,探討對於台灣電子股的影響程 度。利用 VAR 模型分析報酬率領先落後的關係,並且以 GARCH 模型
探討波動性之外溢效果,研究其間為 1997 年 8 月至 2000 年 7 月共三年 之日資料。實證結果顯示:費城半導體對於台灣電子股的影響較 Nasdaq 大,而美光之骨架對台灣的 IC 製造(EX 華邦電子、茂矽電子)有實質的 影響性。 (11) 游梓堯,民國 90 年 以台灣指數:上市指數、上櫃指數、上市電子指數等,以及美國股市: 道瓊工業指數、那斯達克指數、標準普爾 500、指數費城半導體指數為 資料,研究其間為 1998 年 12 月至 2001 年 12 月,進行股價相關性之研 究,並且利用 VAR 檢定、GARCH 模式及人工智慧方法-模糊關連分析 來進行股價波動性之外溢效果。研究結果顯示美國股市對於台灣股市在 報酬率與波動性之影響為顯著。 (12)Theodossious, 1993 以多元 GARCH-M 模型來探討 1980 年 1 月 11 日至 1991 年 12 月 27 日 美國、加拿大、英國、德國、日本五個股市的股價指數週報酬率的傳遞 效果。結果顯示:美國股市對於其餘四個股市具有波動效果,即美國前 一期之報酬率會影響其餘四國本其報酬率。
(13)Pan and Hsueh, 1998
以美國 S&P500 與日本 Nikkei255 期貨指數為研究標的,運用兩階段 GARCH 和 GJR-GARCH 來探討美國與日本期貨指數間之報酬率與連動 關係。結果顯示:美國對日本的報酬率與波動性都明顯的受落後期數影
響,來自國外負面的衝擊比正面的消息有較強烈的落後外溢效果。 (14)Chou, Lin and Wu, 1998
利用多元 GARCH 模型,檢視台股指數與美國 S&P500 指數是否存在報 酬率與波動性的外溢效果。結果顯示:美國股市引發了台灣股市日報酬 波動性 12%,尤其以收盤至開盤這段期間(隔夜報酬)最為顯著,在收盤 至開盤期間,因無法透過交易來反應資訊,故國外市場的資訊扮演著一 個很重要的角色,待開盤後,透過交易活動反應的國內資訊凌駕國外資 訊。因此開盤到收盤這段期間連動性較不顯著。
第三章 研究方法
3.1 時間序列
所謂時間序列係指以時間順序型態出現之一連串觀測集合,換言之, 對某動態系統(Dynamic System)隨著時間連續觀察所產生有順序的觀察值 得集合。一般時間序列均呈隨機現象,並且對於數列的未來結果無法確定。 若集合屬於連續型(continusous),則稱連續型時間序列,若集合屬於離散型 (discrete),則稱離散型時間序列。 時間序列一般均呈現隨機之現象,即對序列未來結果無法確定,只能 以機率分配來表示者,稱之為隨機性時間序列;若一時間序列是依據數學 定率而變化,其預測未來結果是被確定的,稱之為確定性時間序列。3.1.1 架構流程圖 圖 3.1 架構流程圖 DGP輸入 變數的定異 變數修正 取差分或是對數 結構轉變檢定 建構模型 ARIMA(p,d,q) 模型 VAR模型 殘差白噪音檢定 落後期數判斷 自我相關 檢定 異質變異 檢定 Cochrance- Orcutt校正 利用WLS 估計法 增加落後期數 殘差檢定 決定最適落後期數 自我相關檢定 模型管理比較分析 是 否 否 否 是 是
3.2 單根檢定
由於對於非平穩(nonstationary)型時間序列變數的誤差變異數並不是常 數,根據 Gauss-Markov 定理,如果變數的誤差變數不是常數,則使用普通 最小平方法(ordinary least square, OLS)來估計模型中的參數將無法得到一致 的參數估計值而導致錯誤的結論。因此在進行時間序列分析時,資料變數 皆必須先達到平穩,使其誤差變異數為常數,則模型的估計與分析才有意 義。辦定變數是否平穩時,通常有圖型認定法與計量檢定法兩大類。圖型 認定法是以變數的時間序列圖以及自我相關函數(autocorrelation function, ACF)來判斷變數是否平穩。計量檢定法以 Dickey 與 Fuller 於 1976 年發表 的 DF 檢定法為主,以假設檢定的統計基礎來檢定序列是否平穩。DF 檢定 法是考慮方程式(3.1)的 AR(1)模型: (3.1) 當參數 Φ1=1 時,時間序列是非平穩的隨機漫步(random walks)模式。 Dickey 與 Fuller 在假設起使值 Y0 = 0 的情形下,檢定 H0 :Φ1 =1 是否成立。 更一般化的形式加入漂移項(drift)α 和時間趨勢項 βt,如方程式(3.2)和(3.3)。 (3.2) (3.3) 方程式(3.1) ~ (3.3)僅適用於 AR(1)的情形,而且他並未考慮到殘差項
( et )的自我相關現象。為了克服此問題,考慮方程式(3.3)的另一種表示方法: (3.4) 其中ΔYt = Yt –Yt-1仿造方程式(3.4)的作法,可將更高階的自我相關回歸 AR(p)過程改寫成: (3.5) 其中: 檢定的虛無假設為 H0 :ρ =1,若檢定結果拒絕虛無假設,則 Yt是平穩型 態時間序列。反之,Yt是非平穩時間序列,必須差分之後在進行檢定值到拒
絕虛無假設,稱為 ADF 檢定法(Augmented Dickey-Fuller test)。在 ADF 檢定 法中,主要是透過選擇適當的 p 值來消除殘差序列相關現象,使得 et為白 噪音(White noise)干擾,因此若是選擇不適當的落後期數,將會導致錯誤的 檢定結論。 3.3 落後期數決定 常用決定若後期數的方法有:
(3.6)
2. SIC 準則(Schwarz Information Criterion),計算方法為:
(3.7) 其中|Σ|為誤差項共變異矩陣的行列式值,T 為觀測樣本數,k 為獨立變 數個數,就每一個不同的落後期數計算 AIC 值或 BIC 值,取最小者的模型 之落後期數即為最適當落後期數 p。 3.4 Granger 因果檢定 3.4.1 Granger 因果關係之定義 因果關係的探討由來已久,早期有關因果關係的定義欠缺一致認可的 看法,就檢定而言,也為考慮事件發生的時間順序即變數隨機變化的性質, 僅僅以普通迴歸參數來判定因果關係之有無。但是,許多學者的論著中均 強調,由相關係數或一條迴歸式所觀察到的變數觀係。實際上,因果關係 的探查,主要牽涉其定義的內涵,因此,給予明確的因果定義是檢定因果 關係的首要之務。 Granger 對於因果關係之定義如下:
定義一:因果關係(causality) 表示預測變數 X 時,除了利用變數 X 本身的過去值外,加入變數 Y 之 歷史資料將降低預期誤差之均方誤,有助於預測能力的提升。 定義二:回饋關係(Feedback causality) 此時變數 X 對變數 Y 存在因果關係,且變數 Y 對變數 Y 存在因果關係。 定義三:同時期因果關係(Instantaneous causality) 表示預測變數 X 時,除了利用 X 本身與 Y 之歷史資料,加入 Y 當期值, 將提高 X 之預測能力。 定義四:獨立關係(Independency) 若 且 變數 X 與變數 Y 間互為獨立變數,不存在因果關係。表示預測 X 時, 額外加入變數 Y 的訊息並無法改變對變數 X 的預測能力;同樣的,預測變 數 Y 時,額外加入變數 X 的訊息並無法改變對變數 Y 的預測能力。
3.4.2 Granger 因果關係之檢定 1. 不具共整合關係之因果檢定 Granger 提出因果關係之定義,若變數 X 對變數 Y 有因果關係存在, 則表示加入變數 X 對變數 Y 有因果關係存在,即加入變數 X 的歷史資料可 改善對變數 Y 的預測。Sims(1972)採用 Wiener-Granger 因果關係概念來檢定 美國貨幣與所得之間的因果關係,假設 Xt、Yt 均為平均數為零得定態過程, 自我迴歸模型如(3.8)與(3.9)所示: (3.8) (3.9) 上式中, m 代表遞延落後期數, [εX,t,εY,t]為雙量白噪音過程,且
E[εtεs]=0,for all t and s ;E[εX,t,εX,s] = E[εY,t,εY,s] for t ≠ s。
(3.8)式中的變數 Y 及(3.9) 式中的變數 X 均稱為因果性變數。 β1=β2=β3…=βm=0 或 γ1=γ2=γ3…=γm=0 之虛無假設式對因果性變數是否 為零的聯合檢定,為 F 統記量。對(3.9)式來說,如果拒絕虛無假設,表示 因果性變數係數不為零,因果性變數 Y 會影響變數 X,則變數 Y 對變數 X 存在因果關係;同理,如果拒絕 γ1=γ2=γ3…=γm=0 虛無假設,表示有足夠的 證據顯示變數 X 對變數 Y 不存在因果關係。
2. 具有長期關係之因果檢定
Granger(1986)提及,兩共整合的序列至少存在一個方向的因果關係, 所以如果變數之間具有長期關係,則差分值的動態行程將不在適合以傳統 VAR 模型來表示,如果以忽略長期資訊的 VAR 近行因果檢定,可能因為模 型誤差而忽略某些因果關係。根據 Engle and Granger(1987)的 Granger Representation Theorem,如果兩變數之間具有長期均衡關係,則兩變數之間 的關係必可以向量誤差修正模型來表示。所以確定了變數之間存有長期均 和關係之後,進一步便是以誤差修正模型來探求變數間的短期動態關係。
Toda and Phollops(1993)用水準值 VAR 來分析因果關係時,對於體系中 單根數目及共整合空間中特定子矩陣之順序缺乏充分訊息時,無法式先決 定適當的漸進分配。故提議使用 Johansen 的方法進行事先檢定來獲取推論 所需之資訊,並且發展出以誤差修正模型近息因果關係檢定的 Wald 統記 量,其漸進於卡方分配。 對於具有共整合關係的 I(1)序列 Xt 與 Yt 誤差修正模型表示如(3.10)所 示: (3.10)
上式中,[εX,t,εY,t]為雙量白噪音過程,ΘXt及 ΘYt分別為 Xt 與 Yt 之線 性趨勢,m 代表遞延落後期數。Yt-1 –Φ-βXt-1代表傳達長期資訊均衡向量;ξX 與 ξY為其調整因子,衡量上一期偏離均衡不分可以在本期反應於自變數變 化的能力。至於解式變數的落後項則提供變數的短期動態訊息。 若變數間具有共整合關係,則向量誤差修正模型中至少存在ㄧ個誤差 修正項係數不為零的迴歸式,由於誤差修正項為所有變數之線型組合,因 此其他變數之前期訊息能增加本期對某一變數之預測能力。所以,利用誤 差修正模型進行因果關係檢定時,除了對 βj及 γj等統計量進行 F 檢定外, 亦須針對ξX與ξY進行單係數檢定,以確定變數間之因果關係來自長期失衡 或是短期訊息。 3.5 單變量 ARIMA 模型 Box 與 Jenkins(1970)提出ㄧ套時間序列分析方法,認為影響時間序列資 料變動的主要原因可分為兩種,其中可藉由序列中的歷史資料來推估未來 的趨勢,稱此序列符合自我迴歸過程(Autoregressive Process, AR Process); 若當期的不規則變異可以藉由過去的不規則變異所估計,稱此數列符合平 均移動過程(Moving Average Process, MA Process)。
ARMA( p , q )模型為ㄧ種時間序列的『資料產生過程』((Data Generating Process,DGP),所謂的 DGP 在時間序列理論來看,及代表現在的變數與過
去的變數的函數 yt=f(yt-1)或統計關係。 ARMA( p , q )模型建構為 (3.11) 其中: a0:常數的截距項 p:落後期數 a1:代表 yt-i 的係數,本身亦是常數 εt:白噪音 yt:應變數 yt-1:自變數 AR(p)即為現在的 y 變數和過去 p 期的 y 變數都有關係 (3.12) a0:常數的截距項 q:落後期數 b1:代表 y t–i的係數,本身亦是常數 εt-i:白噪音 yt:應變數 MA(q)即為現在的 yt和過去 q 期的隨機變項 εt-q有關,MA 模型隱含著
經濟行為中誤差修正的特性。 綜合(3.11)、(3.12)式,可以得到 ARMA( p , q )的完整公式: (3.13) 時間序列式由資料的過去實際值與隨機震動(Random Vibretion)所組成 的,稱之為自我迴歸整合移動平均模式。 ARIMA 模式的建立式系統化辨識、估計、診斷與預測時間序列之方 法,實際資料全部被用來將一個時間序列分解成三個 ARIMA 成份,期 ARIMA( p , d , q )模型表示如下: (3.14) 其中 B 為後移運算子(Backkward Shirt Operator),BYt=Yt-1,Yt為一穩
定狀態的時間序列值,c 為常數項,et為干擾項,且符合白噪音假設,即期 望值為零,變異數為一固定常數之假設。 而Ψp(B)及 Θq(B)分別代表 B 的多項式,可表示如下: (3.15) (3.16) p、d、q 為非負整數 B:後移運算子,BYt=Yt-1,B 的所有根均落在單位圓之外,參數(Ψ1、 Ψ2、Ψ3、Ψ4…Ψp)稱為自我迴歸參數 AR,(Θ1、Θ2、Θ3…Θq)稱為移動平均 參數。
建構 ARIMA 模型流程圖如圖 3.2 所示: 圖 3.2 ARIMA 時間序列模式建構流程圖 3.6 多變量 ARIMA 若要了解數個外在變數之間的因果關係,則須採用多變量 ARIMA 模型 來建構。多變量模型以應變數與自變數落後期數的特性大致可以分兩種型 式,其介紹如下: 1. 靜態時間序列模型 指一個變數當期的值(以 Yt表示),與另一個或多個變數當期的值(以 X1t, X2t, X3t…Xkt表示)有因果關係。
以數學函數式表達即如下: (3.17) 若變數間的函數關係是線性的,則可表示呈複迴歸模型: (3.18) 若變數間的函數關係是非線性的,則可經由變數轉換,而轉變成線性 模型。 2. 動態時間序列模型 動態時間序列模型與靜態時間序列模型最大的不同,就是模型中因變 數(Yt)與自變數(Xt)有跨期性的影響。動態時間序列模型的一般化表示如下: (3.19) 將上式落遲運算元函數來表示成: (3.20)
由一般化的式子可以看出因變數的落後期數(Yt-1、Yt-2、Yt-3…)可以當
成自變數,而其他本身的自變數(X1t, X2t, X3t…)等也都各自有其落後期數;
求取長期均衡值同樣可以取期望值的方式來計算,用此方法計算出來的係 數組合,可以巧妙的變成經濟意義的統計檢定假設。
複迴歸類似,若以 OLS 模型來估計時,其中作重要的假設都是殘差(et)必須
符合古典一般線性模型的假設(Classical Normal Linear Assumption)。 (1) 殘差為常態性(Normality)。
(2) 殘差期望值為零(Zero Mean),E(et)=0 for all t。
(3) 殘差距同質變異(Homoskedasticity);var(et)=σ 2,σ2
為一固定常 數 for all t。
(4) 殘差無自我相關(Non-Autocorrelation);cov(et, et-s)=0 for s≠0。
(5) 自變數與殘差無相關(Orthogonality);cov(xit, et)=0 for any i。
(6) 自變數與自變數之間無相關(Independence); cov(xit, xjt)=0 for
any i≠j。
所以在時間序列的分析與探討中,殘差有無自我相關、殘差具同質變 異等的問題,必須是審慎處理。
殘差自我相關之處理可分為兩部分說明:
Cochrane-Orcutt 兩步驟遞迴估計(Two-Step and Iterative Estimation) 先估計 yt=a0+a1x1t+et
取殘差以計算估計值b
(3.21) 以此估計值b代入 Cochrane-Orcutt 進行估算
不斷重複上述步驟,直到估計值b收斂為止 修正殘差中存在自我相關的方法。使用非線性模型來估計,可將一階 自我相關(3.22)式轉換成(3.23)式 (3.22) (3.23)
然後直接利用 Marquardt 非線性迴歸演算法(Nonlinear Least Squares Algorithm)估計 b、a0、a1等參數。
建構多變量 ARIMA 模型流程圖如圖 3.3 所示:
3.7 ARCH(autoregressive conditional heteroscedasticity, ARCH)模型 ARCH 模型就是將自我相關的概念運用在條件變異數的估計,因為古 典迴歸模型在估計時,其假設為迴歸殘差的變異數為一固定不變的常數。 在財務和經濟的時間序 列資料中,都 具有條件變異不齊一的 現象,即 Var(yt∣yt-1)=σt 2 ,也就是說條件變異數會隨著時間改變。 3.7.1 經濟與財務時間序列統計資料之特性 1. 高狹峰分配(Leptokurtic):常見於財務資產報酬的統計資料,指其變數 的峰態係數(Kurtosis)大於 3,亦稱為厚尾會是胖尾現象。 2. 波動叢聚現象(volatility clustering):指變數的變動,會有聚集在一起的 現象。也就是將變數畫成時間序列圖時,可觀察到大波動跟隨著大波 動,小波動跟隨著小波動現象。 3. 金融資產之風險與以模型量化處理,也可以研究財務市場上常被提起的 槓桿效果、星期效果、宣告效果、以及不同資產間的報酬波動關連性。 上述特性結存在風險與不確定的問題,然而 ARCH/GARCH 可以適切 的描述這些特性。 3.7.2ARCH/GARCH 基本模型 ARCH(p)的基本模型如(3.24)式
(3.24) 變數說明: Ωt-1:在 t-1 期所有可利用知訊息所形成的集合 Yt:時間序列資料 Xtb:由遞延內生和外生變數線性組合而成 ht:條件變異數 GARCH(p)的基本模型如(3.25) 、(3.26)式 (3.25) (3.26) 變數說明: Yt:符合 GARCH 過程之時間序列資料 Ψt-1:前 t-1 期為止所有可更利用的資訊集合 Yt∣Ψt-1:為平均數 Xtb,變異數 ht之常態分配 ht:受 t-1 至 t-p 期殘差影響之 Yt條件變異數 α、β、b:為未知參數的向量
p、q:為 GARCH 過程之階數 A(L)=1+α1L+…+αqL L:落後運算元 由上述模型可以發現,其與 Engel 最大的不同在於條件變異數除了受了 前幾期的殘差項的平方影響外,同時也受到本身之落後期數的影響。因為 GARCH 比 ARCH 更具一般性。 3.7.3 模型之檢定 對於 GARCH 的檢定,由於其未知參數估計過程相當繁複,無法由殘 差項平方自我相關係數與偏自我相關函數來作模型檢定。故 Bollerslev 提出 了以拉格蘭茲統計量作為檢定資料配置 GARCH 模型的合適性。 LM(lagrange mulyiplier, LM)統計量: 令 θ:Euclindean(Θ)空間中的一個子空間 θ0:真實參數 εt:具有有限的兩階動差 若真的的參數是 θ0,則原來 GARCH( p , q )可以改寫為:
(3.27) 將(3.27)式中之條件變異數分解成兩部分: 在 H0:w2為真之下的 LM 統計量為: (3.28) 其中 在 H0:w2為真時,ξ * LM為一近似自由度為 r 之卡方分配,r 為 w2中參數限 制的個數。另外,若 GARCH 模型之條件分配為常態,則可以導出另一個 類似的統計量 其中 R2為 f0與 z0間複相關係數的平方。 3.8 向量自我迴歸(vector autoregressions,VAR) 前述所討論的計量模型都是屬於結構化的模型,換言之,也就是變數 之間的關係都是以經濟理論為基礎所建構的。但是,當經濟理論態複雜時, 或是變數間存在著回饋(feedback)的關係使我們無法確定何種變數究竟應視
為內生變數或外生變數,當無法精準的設定模型時,將導致錯誤的實證結 論。 Sims(1980)認為此結構為相當困難且令人懷疑該設定的可信度,因此提 出向量自我迴歸(vector autoregressions,VAR)用來解決傳統上結構化模型認 定困難的問題。VAR 不需有先驗的經濟理論,僅由資料本身的特性來建立 動態的模型,將所有的變數視為內生變數,而有一條對應之迴歸方程式, 其右邊的解釋變數由各內生變數的落後期數所組成,故可被用來處理非結 構性的模型。 一個三變數的 VAR 模型可以表示為: n 個變數且落後期數為 p 的 VAR 模型可以用符號 VAR(p)表示,VAR(p) 模型的表示如下: (3.29) 其中: Zt = (Z1,t, Z2,t, Z3,t,…Zn,t)’的 n x 1 向量 ð1、ð2、ð3…ðp為 n x n 的係數矩陣
et =( e1,t, e2,t…en,t)’的 n x 1 的誤差矩陣
Ó 為誤差項的變異數和共變數 n x n 矩陣
因 為 (3.29) 的 右 邊 並 無 包 含 非 落 後 期 數 得 內 生 變 數 (unlagged endogenous variables),且每個方程式的右邊變數是相同的,因此 VAR 模型 可以用 OLS 加以估計。而最適落後期數 p 的選擇則以 AIC 或 SIC 決定。
3.9 Chow 轉變點檢定
在時間序列資料(Data Generating Process,DGP)在股價資料分析阿,資料 來源取自過去歷史資料。若選用樣本資料期間過長,或是樣本期間內發生 重大的經濟事件,則過去與現在的價格可能會產生模型結構的改變。然而 考量模型是否產生結構轉變(Structural Changes or Structural Breaks)方能降 低模型估計的錯誤。Chow(1960)提出結構轉變模型概念,由於結構轉變不 見得只會影響模型的常數項,也有可能使模型的自變數係數發生改變,所 以需要藉由『加入虛擬變數』方法來進行估計。
3.9.1 Chow 結構轉變檢定
Chow 結構轉變點檢定(Breakpoint Test)如下所示:
檢定樣本中的子樣本(sub-sample)之間,是否有不一樣的性質(迴歸係數 是否相同、DGP 是否相同),其數學表示如下:
(3.30) (3.31) 比較(3.11)與(3.12)式,令虛無假設 H0 : ai=a’i i=0,1…p 加入虛擬變數的 Chow 轉變點檢定步驟如下: 1. 已知轉變點為 k 的前提下,自定ㄧ個虛擬變數 Dt,並令其值為: (3.32) 2. 接著使用全部樣本(1,2,…,T)估計以下的為受限式: (3.33) 3. 計算 F 統計量,並以自由度(p+1,T-2p-2)的 F 分配進行聯合檢定: (3.34) 4. 針對個別係數作 t 檢定。 3.10 評估模型預測能力方法 對於各種計量經濟模型而言,預測能力的高低為檢驗該模型的理論或 是假說優劣的重要標準。一般而言,預測能力的評量可分為樣本內的比較 與樣本外的比較。本文將使用樣本外的比較來評量模型的預測能力,因為 樣本外預測能力的成功表示模型的設定被一組新的樣本所證實,將比樣本
內配適度更具說服力。 本文使用評量預測能力的統計工具如下所示: 1. 平均絕對離差(MAD) (3.35) 2. 均方差平方根(RMSE) (3.36) 3. 平均絕對百分比誤差(MAPE) (3.37)
第四章 資料來源與處理
1. 資料期間:2000/1/1~2008/12/31 日資料共有 2251 筆,作為建構模型的 樣本內資料,並以 2008/3/2~2009/12/31 日資料共 248 筆作為比較模型 預測能力之樣本外資料。 2. 變數定義:如表 4.1 所示: 表 4.1 變數定義 變數名稱 變數符號 變數差分 變數定義 台股指數 TW DTW 台灣證卷交易所集中市場上 市股票每日收盤指數,再經自 然對數轉換。 美股道瓊指數 DJ DDJ 美國道瓊工業指數每日收盤 指數,再經自然對數轉換。 上海綜合指數 SH DSH 上 海 綜 合 指 數 每 日 收 盤 指 數,再經自然對數轉換。 台幣匯率 NT DNT 台幣對美元外匯每日數字,再 經自然對數轉換。 日幣匯率 JPY DJPY 日幣對美元外匯每日數字,再 經自然對數轉換。 人民幣匯率 CN DCN 人 民 幣 對 美 元 外 匯 每 日 數 字,再經自然對數轉換。 資料來源:本研究 3. 變數來源:上述各變數資料取自台灣股票市場統計資料庫(TSE.bnk)。 4. 分析軟體:本研究為使用 Eviews6 軟體進行統計計量計算。第五章 實證結果分析
5.1 單變量時間序列
本研究主題為探討台股加權股價指數在時間序列模型中,求出最適模 型。 5.1.1 研究流程 本節研究流程: 1.輸入原始資料 2.對序列做單根檢定(ADF) 3.序列結構轉變 Chow 檢定 4.ARIMA( p , d , q )模型假設 5.ARIMA 模型診斷(自我相關 Q 統計量檢定、常態性檢定) 6.選擇最適之 ARIMA 模型 7.樣本內(配適度檢定) 8.樣本外(預測力檢定) 5.1.2 數列單根檢定Nelson and Plosser(1982)研究指出總體經濟變數普遍存在單根現象(unit root)。若迴歸式的自變數為非定態,以傳統 OLS 方法進行迴歸分析,將會
產生假性迴歸。一般來說,時間數列的資料常存在著趨勢的特性,也就是 變數會隨時間改變呈現不穩定的狀態。 若一開始就對資料作差分分析,將會形成過度差分導致低效率,因此 先進行單根檢定以確保變數不致過度差分。 首先先對台股加權指數製圖,由圖 5.1 可以發現台股加權指數為『含有 趨勢』之時間序列圖,因此先對原始資料進行單根檢定,其結果如表 5.1、 表 5.2、表 5.3 所示。由資料可以發現,及使在最大落後期數第 15 期時, ADF 依舊大於檢定臨界值,及無法拒絕 H0,DGP 為單根的假設。即 DGP 為非穩定態。 圖 5.1 台股加權指數時間序列圖(原始資料) 資料來源:本研究
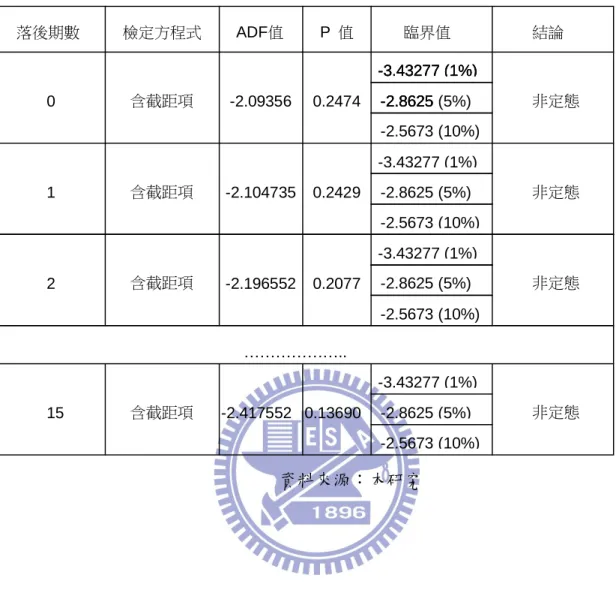
表 5.1 台股加權指數單根檢定(含截距項) 資料來源:本研究 落後期數 檢定方程式 ADF值 P 值 臨界值 結論 0 1 2 15 含截距項 含截距項 含截距項 含截距項 ……….. 非定態 非定態 非定態 非定態 -2.09356 -2.104735 -2.196552 -2.417552 0.2474 0.2429 0.2077 0.13690 -3.43277 (1%) -2.8625 -2.5673 (10%) -3.43277 (1%) -2.8625 -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%)
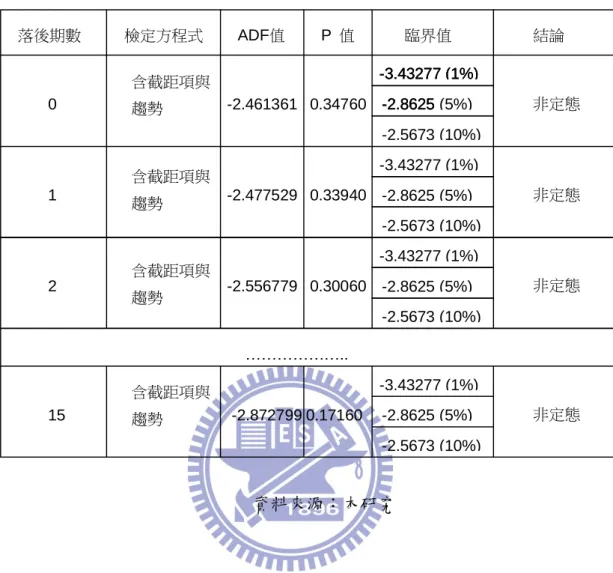
表 5.2 台股加權指數單根檢定(含截距與趨勢項) 資料來源:本研究 落後期數 檢定方程式 ADF值 P 值 臨界值 結論 0 1 2 15 含截距項與 趨勢 含截距項與 趨勢 含截距項與 趨勢 含截距項與 趨勢 ……….. 非定態 非定態 非定態 非定態 -2.461361 -2.477529 -2.556779 -2.872799 0.34760 0.33940 0.30060 0.17160 -3.43277 (1%) -2.8625 -2.5673 (10%) -3.43277 (1%) -2.8625 -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%)
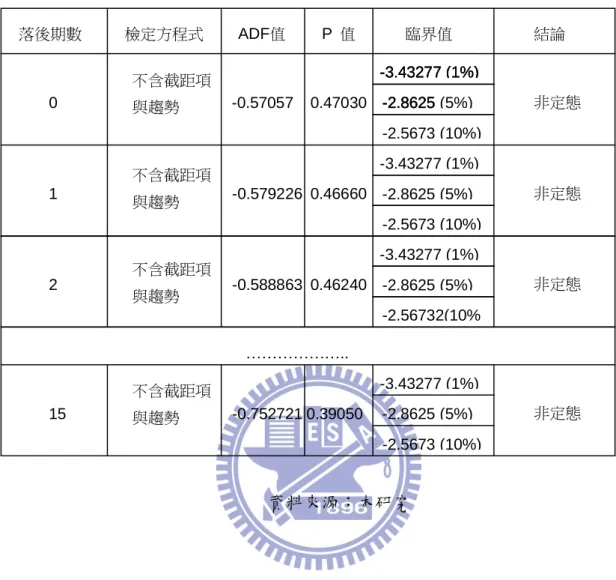
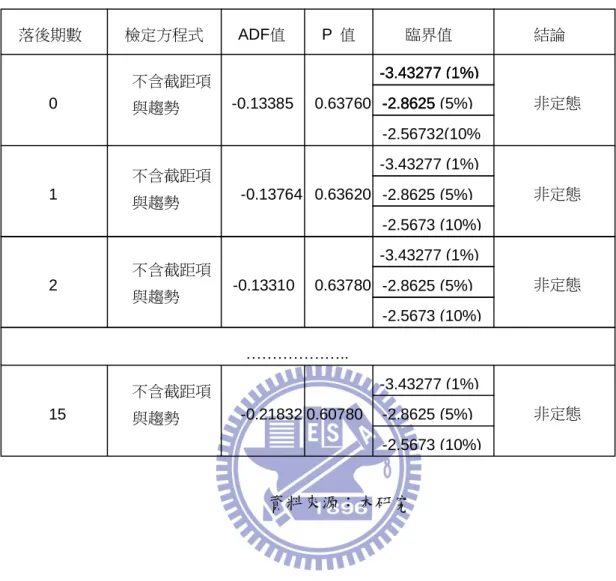
表 5.3 台股加權指數單根檢定(不含截距與趨勢項) 資料來源:本研究 落後期數 檢定方程式 ADF值 P 值 臨界值 結論 0 1 2 15 不含截距項 與趨勢 不含截距項 與趨勢 不含截距項 與趨勢 不含截距項 與趨勢 ……….. 非定態 非定態 非定態 非定態 -0.57057 -0.579226 -0.588863 -0.752721 0.47030 0.46660 0.46240 0.39050 -3.43277 (1%) -2.8625 -2.5673 (10%) -3.43277 (1%) -2.8625 -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.56732(10% -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%)
將台股指數先取自然對數,再做一次單根檢定,檢定是否為穩定態。 其結果如圖 5.2、表 5.4、表 5.5、表 5.6 所示。由資料可以發現,及使在最 大落後期數第 15 期時,ADF 依舊大於檢定臨界值,及無法拒絕 H0,DGP 為單根的假設。即 DGP 仍然為非穩定態。 圖 5.2 台股加權指數圖(原始資料取自然對數) 資料來源:本研究
表 5.4 台股加權指數單根檢定(含截距項) 資料來源:本研究 落後期數 檢定方程式 ADF值 P 值 臨界值 結論 0 1 2 15 含截距項 含截距項 含截距項 含截距項 ……….. 非定態 非定態 非定態 非定態 -2.09523 -2.14011 -2.22259 -2.34444 0.24680 0.22900 0.19830 0.15810 -3.43277 (1%) -2.8625 -2.5673 (10%) -3.43277 (1%) -2.8625 -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%)
表 5.5 台股加權指數單根檢定(含截距與趨勢項) 資料來源:本研究 落後期數 檢定方程式 ADF值 P 值 臨界值 結論 0 1 2 15 含截距項與 趨勢 含截距項與 趨勢 含截距項與 趨勢 含截距項與 趨勢 ……….. 非定態 非定態 非定態 非定態 -2.48802 -2.53231 -2.60536 -2.80288 0.33410 0.31230 0.27790 0.19630 -3.43277 (1%) -2.8625 -2.5673 (10%) -3.43277 (1%) -2.8625 -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%)
表 5.6 台股加權指數單根檢定(不含截距與趨勢項) 資料來源:本研究 落後期數 檢定方程式 ADF值 P 值 臨界值 結論 0 1 2 15 不含截距項 與趨勢 不含截距項 與趨勢 不含截距項 與趨勢 不含截距項 與趨勢 ……….. 非定態 非定態 非定態 非定態 -0.13385 -0.13764 -0.13310 -0.21832 0.63760 0.63620 0.63780 0.60780 -3.43277 (1%) -2.8625 -2.56732(10% -3.43277 (1%) -2.8625 -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%)
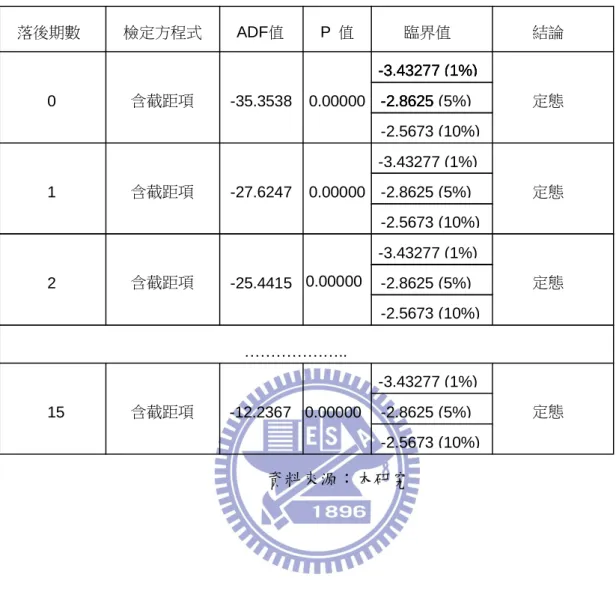
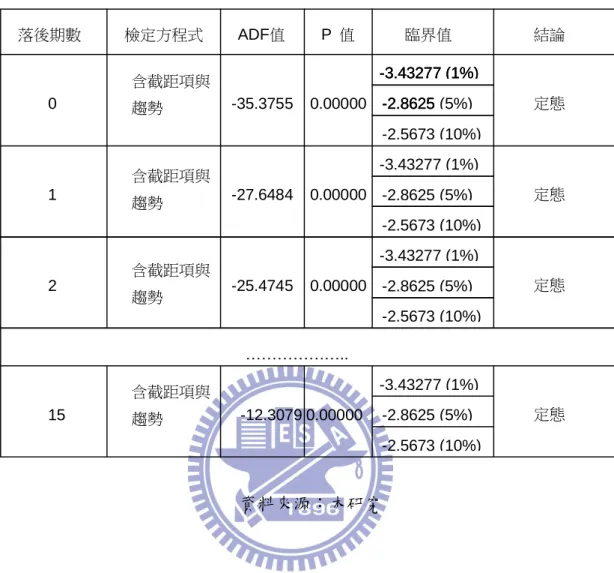
接著將對數值取一次差分,再做一次單根檢定,檢定是否為穩定態。 其結果如圖 5.3、表 5.7、表 5.8、表 5.9 所示。當延長落後期數時,隨然 ADF 值呈現遞增的現象,但是還是通過定態檢定(ADF<臨界值),所以 DGP 拒 絕虛無假設,即資料變數已屬定態。 圖 5.3 台股加權指數圖(原始資料取自然對數取一階差分) 資料來源:本研究
表 5.7 台股加權指數單根檢定(含截距項) 資料來源:本研究 落後期數 檢定方程式 ADF值 P 值 臨界值 結論 0 1 2 15 含截距項 含截距項 含截距項 含截距項 ……….. 定態 定態 定態 定態 -35.3538 -27.6247 -25.4415 -12.2367 0.00000 0.00000 0.00000 0.00000 -3.43277 (1%) -2.8625 -2.5673 (10%) -3.43277 (1%) -2.8625 -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%)
表 5.8 台股加權指數單根檢定(含截距與趨勢項) 資料來源:本研究 落後期數 檢定方程式 ADF值 P 值 臨界值 結論 0 1 2 15 含截距項與 趨勢 含截距項與 趨勢 含截距項與 趨勢 含截距項與 趨勢 ……….. 定態 定態 定態 定態 -35.3755 -27.6484 -25.4745 -12.3079 0.00000 0.00000 0.00000 0.00000 -3.43277 (1%) -2.8625 -2.5673 (10%) -3.43277 (1%) -2.8625 -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%)
表 5.9 台股加權指數單根檢定(不含截距與趨勢項) 資料來源:本研究 5.1.3 結構轉變 Chow 檢定 本研究利用 CUSUM 檢定來找出結構轉變點,其中 CUSUM 檢定是利 用逐次回歸殘差來進行檢定的。 經由掃描後發現 CUSUM 數值約在 450 筆位置分近開始發生變化,因 此將第 401 筆資料到第 500 筆資料的 F 值結果呈現出來,如表 5.10 所示。 落後期數 檢定方程式 ADF值 P 值 臨界值 結論 0 1 2 15 不含截距項 與趨勢 不含截距項 與趨勢 不含截距項 與趨勢 不含截距項 與趨勢 ……….. 定態 定態 定態 定態 -35.3608 -27.6301 -25.4462 -12.238 0.00000 0.00000 0.00000 0.00000 -3.43277 (1%) -2.8625 -2.5673 (10%) -3.43277 (1%) -2.8625 -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%) -2.5673 (10%) -3.43277 (1%) -2.8625 (5%)
表 5.10 CUSUM 檢定結構轉變點 資料來源:本研究 轉變點 F統計量 轉變點 F統計量 轉變點 F統計量 轉變點 F統計量 401 402 403 404 405 410 409 406 407 408 411 412 415 414 413 416 417 420 419 418 421 422 425 424 423 426 427 430 429 428 431 432 435 434 433 436 437 440 439 438 441 442 445 444 443 446 447 450 449 448 451 452 455 454 453 456 457 460 459 458 461 462 465 464 463 466 467 470 469 468 471 472 475 474 473 476 477 480 479 478 481 482 485 484 483 486 487 490 489 488 491 492 495 494 493 496 497 500 499 498 2.661615 2.82757 2.902034 3.227639 3.229665 3.056369 3.462151 3.462151 3.260047 3.345651 2.601848 2.671054 3.031494 3.081509 2.985981 2.63006 2.743063 2.557631 2.728957 2.772981 2.359598 2.330122 2.375725 2.594205 2.3773 2.896135 2.61632 2.629969 2.497644 2.458367 2.634398 2.609 2.562262 2.826048 2.880272 2.901931 2.819069 2.738128 2.743634 2.566025 3.97723 4.055907 3.705073 2.909311 3.145216 4.161206 4.716363 4.502847 4.4162 4.739299 4.514792 4.634167 4.642481 4.323238 4.177357 3.148466 3.109743 3.071424 3.132464 3.210412 3.600059 3.556552 4.129825 4.403047 4.403047 2.402392 2.537044 2.744438 2.982656 3.066801 3.598094 3.711107 3.601268 3.806112 3.623387 2.279619 2.387592 2.19567 2.168256 2.373033 3.232593 3.232593 3.297742 3.409078 3.526392 2.435815 2.409233 2.435986 2.112512 2.221542 3.335572 3.465161 3.473681 3.228589 3.508055 1.204852 1.31529 1.701633 2.128224 1.916996
將上述資料中 F 值陳列出來,如表 5.10 所示,其中以第 447 筆處的 F 值最大,所以結構轉變的位置應該在此。同樣的做法也可以求出在第 2289 筆處的 F 值最大,如表 5.11 所示。
表 5.11 CUSUM 檢定來找出結構轉變點 資料來源:本研究 轉變點 F統計量 轉變點 F統計量 轉變點 F統計量 轉變點 F統計量 2201 2202 2203 2204 2205 2210 2209 2206 2207 2208 2211 2212 2215 2214 2213 2216 2217 2220 2219 2218 2221 2222 2225 2224 2223 2226 2227 2230 2229 2228 2231 2232 2235 2234 2233 2236 2237 2240 2239 2238 2241 2242 2245 2244 2243 2246 2247 2250 2249 2248 2251 2252 2255 2254 2253 2256 2257 2260 2259 2258 2261 2262 2265 2264 2263 2266 2267 2270 2269 2268 2271 2272 2275 2274 2273 2276 2277 2280 2279 2278 2281 2282 2285 2284 2283 2286 2287 2290 2289 2288 2291 2292 2295 2294 2293 2296 2297 2300 2299 2298 2.420646 2.431426 2.750373 3.105526 3.485394 2.688446 3.169273 3.810376 4.397638 3.737367 3.278446 3.454805 2.597144 2.417705 2.443905 4.048379 4.306383 3.582799 3.280803 3.700376 5.270056 5.943319 4.415948 4.113978 4.466729 4.336826 4.427069 5.039574 5.559701 5.073538 5.452682 5.596814 5.408277 4.216589 5.213746 5.072315 4.152234 4.076209 4.653957 4.690345 4.32187 4.261616 4.363072 4.527296 4.610787 5.524865 5.419711 5.51657 4.87367 5.629585 4.497393 4.614084 5.021016 5.494425 4.930529 6.415009 6.026178 6.043446 5.976149 6.534521 5.797375 6.012683 5.81056 4.352467 5.68213 7.05243 6.823073 7.108127 6.313469 6.54823 6.507362 6.622341 6.979872 5.471222 5.502607 7.360129 7.53834 6.482078 6.681308 6.630164 7.033856 7.5263 7.018163 6.471639 7.084635 6.13548 6.275061 6.256809 6.7627 6.402691 6.225481 6.400904 6.458976 6.703129 7.123247 4.679014 5.00895 5.23938 5.735479 5.778593
5.1.4 ARIMA 模型假設 經由模型的配適度判斷,選出了最適的兩組,分別為 ARIMA(6,1,9)、 ARIMA(8,1,8),接著針對檢定殘差自我相關的問題,如表 5.12、5.13 所示。 由表中可以知道,P 值都大於 5%,無法拒絕此殘差都沒有自我相關的虛無 假設。 表 5.12 ARIMA(6,1,9) 殘差自我相關 Q 統計量 資料來源:本研究 期數 AC PAC Q統計量 P值 10 11 12 ……….. -0.005 34 35 36 -0.009 0.016 0.081 -0.014 -0.027 -0.005 -0.009 0.016 0.083 -0.01 -0.028 0.86 1.02 1.46 32.87 33.25 34.62 0.352 0.599 0.691 0.134 0.155 0.149
表 5.13 ARIMA(8,1,8) 殘差自我相關 Q 統計量 資料來源:本研究 接著針對估計模型之殘差是否符合常態分配的檢定,其中兩模型檢定 的結果如下表 5.14 所示。由表中可以發現 K>3,JB>5.991 即表示模型無法 通過常態性的檢定。 表 5.14 JB 統計量比較表 Kurtosis Jarque-Bear ARIMA(6,1,9) 6.06328 737.627 ARIMA(8,1,8) 6.16711 780.0875 資料來源:本研究 期數 AC PAC Q統計量 P值 9 10 11 ……….. -0.019 34 35 36 0.014 0.037 0.072 -0.005 -0.042 -0.019 0.015 0.038 0.071 0.004 -0.047 2.6275 3.0049 5.4738 40.249 40.295 43.57 0.105 0.223 0.14 0.137 0.148 0.131
自我相關條件異質變異 由於 ARIMA 僅能運用於定態的時間序列,然而實際上的經濟與商業資 料,大多為非定態(Pankratz, 1983),尤其是在股價的時間序列中。雖然非定 態續列經由差分或是轉換函數的方式轉為定態序列,在此限制下,必須有 一種可以處理時間序列的變異數會隨時間改變的方法,而 Engle(1982)所提 出的 ARCH 模型即可來彌補 ARIMA 的不足。 首先將得到可能模型 ARIMA(6,1,9)-GARCH(1,1)模型的回歸參數估計 表分別列於如下表 5.15 所示。表中可以發現其參數的 P 值均小於臨界值, 表示設參數具有其意義性。
表 5.15 ARIMA(6,1,9)-GARCH(1,1)的回歸參數估計表
下表為 ARIMA(6,1,9)-GARCH(1,1)模型殘差自我相關檢定,如表 5.16 所示。表中可以發現其 P 值均大於 5%,因此無法拒絕此殘差由第 10 階到 第 36 階沒有自我相關的虛無假設。 表 5.16 ARIMA(6,1,9) -GARCH(1,1) 殘差自我相關 Q 統計量 資料來源:本研究 期數 AC PAC Q統計量 P值 10 11 12 ……….. -0.007 34 35 36 0.012 -0.013 0.048 0.004 -0.048 -0.007 0.012 -0.012 0.045 0.005 -0.05 2.677 2.9196 3.2222 21.572 21.595 25.791 0.102 0.232 0.359 0.66 0.717 0.53
ARIMA(8,1,8)-GARCH(1,1) 模 型 的 回 歸 參 數 估 計 表 分 別 列 於 如 下 表 5.17 所示。表中可以發現其參數的 P 值均小於臨界值,表示設參數具有其 意義性。
表 5.17 ARIMA(8,1,8)-GARCH(1,1)的回歸參數估計表
下表為 ARIMA(8,1,8)-GARCH(1,1)模型殘差自我相關檢定,如表 5.18 所示。中可以發現其 P 值均大於 5%,因此無法拒絕此殘差由第 9 階到第 36 階沒有自我相關的虛無假設。 表 5.18 ARIMA(8,1,8) -GARCH(1,1) 殘差自我相關 Q 統計量 資料來源:本研究 在上述兩表中,殘差平方的檢定中,P 值皆> 0.05,表示模型中殘差項 已經符合白噪音的假設。 5.1.5 樣本外預測能力 比較不同模型的預測力常見的指標有誤差的方均根(RMSE)、平均誤差 絕對值(MAE)、平均誤差百分比(MAPE)等指標,其中這些指標越小越好。 期數 AC PAC Q統計量 P值 9 10 11 ……….. -0.011 34 35 36 -0.001 0.02 0.046 0.006 -0.048 -0.011 -0.001 0.021 0.045 0.005 -0.047 1.5398 1.5427 2.2579 19.805 19.863 24.031 0.215 0.462 0.521 0.801 0.863 0.68
將 本 文 所 選 取 的 模 型 ARIMA(6,1,9) -GARCH(1,1)及 ARIMA(8,1,8) -GARCH(1,1)兩模型分別做樣本外預測力檢定,所使用的軟體為 E-views, 採用的方法為逐次更新預測,樣本時間為 2008/3/2 至 2009/3/2,圖 5.4 為 ARIMA(6,1,9) -GARCH(1,1) 樣 本 外 預 測 結 果 , 圖 5.5 為 ARIMA(8,1,8) -GARCH(1,1) 樣本外預測結果。
圖 5.4 ARIMA(6,1,9) -GARCH(1,1)樣本外預測結果
資料來源:本研究
圖 5.5 ARIMA(8,1,8) -GARCH(1,1) 樣本外預測結果。
綜合上述圖 5.4、5.5 的樣本外預測結果,整理如下表 5.19 所示: 表 5.19 樣本外預測結果整理
RMSE MAE MAPE ARIMA(6,1,9)-GARCH(1,1) 0.026296 0.019246 113.6683
ARIMA(8,1,8)-GARCH(1,1) 0.026179 0.019161 107.8710
資料來源:本研究
由上述資料可知:RMSE、MAE、MAPE 皆以模型 ARIMA(8,1,8) -GARCH(1,1)為最小,所以最後以 ARIMA(8,1,8) -GARCH(1,1)模型為最適 解。
5.2 多變量時間序列
多變量時間序列可以深入的了解變數間的「因果關係」。因此我們希望 可以藉由多變量時間序列了解各國股價指數與匯率對於台灣股票市場的影 響程度為何,故採用多變量時間序列探討之。 研究其間為 2002/1/4 至 2008/3/2 日資料,其中各資料將以新名稱代替 原始的名稱,如表 4.1 所示: 5.2.1 研究流程 本節研究流程: 1.輸入原始資料2.序列單根檢定(ADF) 3.ARIMA( p , d , q )-GARCH( m , n )模型假 4.ARIMA 模型診斷(自我相關 Q 統計量檢定、常態性檢定) 5.選擇最適之 ARIMA-GRACH 模型 6.模型樣本內(配適度檢定) 7.模型樣本外(預測力檢定) 5.2.2 單根檢定 首先對各原始資料進行單根檢定,其做法流程如上一節相同,其順序 為原始資料做 ADF 檢定à取自然對數做 ADF 檢定à再取一階差分做 ADF 檢定。其結果如表 5.21 所示: 表 5.21 ADF 單根檢定 資料來源:本研究 0.00000 -1.61658 -1.941 -2.56628 -19.02215 原始資料 -->取 LOG-->取一階差分 日幣匯率 0.00000 -1.61658 -1.941 -2.56628 -7.745382 原始資料 -->取 LOG-->取一階差分 人民幣匯率 0.00000 -1.61658 -1.941 -2.56628 -8.108096 原始資料 -->取 LOG-->取一階差分 台幣匯率 0.00000 -1.61658 -1.941 -2.56628 -17.21664 原始資料 -->取 LOG-->取一階差分 上海綜合指數 0.00000 -1.61658 -1.941 -2.56626 -18.97879 原始資料 -->取 LOG-->取一階差分 道瓊工業指數 0.00000 -1.61658 -1.941 -2.56628 -17.97644 原始資料 -->取 LOG-->取一階差分 台股指數 步驟 ADF統計量 1 % 5 % 10 % P-Value