行政院國家科學委員會補助專題研究計畫成果報告
※※※※※※※※※※※※※※※※※※※※※※※※※※
※
在資料平行程式中有效的產生複雜註標之位址
※
※
Efficient Address Generation for Complex Subscripts in
※
※
Data-Parallel Programs
※
※※※※※※※※※※※※※※※※※※※※※※※※※※
計畫類別:■個別型計畫 □整合型計畫
計畫編號:NSC 90-2213-E-110-033
執行期間:90 年 08 月 01 日至 91 年 07 月 31 日
計畫主持人:黃宗傳博士
計畫參與人員: 許良政
高嘉宏
王嗣諠
本成果報告包括以下應繳交之附件:
□赴國外出差或研習心得報告一份
□赴大陸地區出差或研習心得報告一份
□出席國際學術會議心得報告及發表之論文各一份
□國際合作研究計畫國外研究報告書一份
執行單位:國立中山大學電機工程學系
中 華 民 國
91 年 9 月 30 日
在資料平行程式中有效的產生複雜註標之位址
Efficent Address Generation for Complex Subscripts in
Data-Parallel Programs
計畫編號:NSC 90-2213-E-110-033
執行期限:90 年 8 月 1 日至 91 年 7 月 31 日
主持人:黃宗傳博士 國立中山大學電機工程學系
計畫參與人員:許良政
國立中山大學電機工程學系
高嘉宏
國立中山大學電機工程學系
王嗣諠
國立中山大學電機工程學系
一、中文摘要 在諸多記憶體存取序列的研究中,大 多集中於簡單註標上,但當註標型式複雜 時,記憶體存取方式也會變複雜,本計劃 係針對註標型式為多重引導變數(Multiple Induction Variable)―多個迴圈引導變數以 affine 函數的型式出現在單一維的註標 中,以及耦合註標 (Coupled Subscript)―同 一個迴圈引導變數(Loop Induction Variable) 同時出現在兩維以上的註標中,加以分 析。對於前者研究一種有效的方法將每一 個處理機的起使元素(Start Element)找出, 對 於 後 者 則 將 每 一 個 處 理 機 所 負 責 的 Iteration 找出,並計算該處理機所需存取之 陣列元素,藉以產生記憶體存取序列。 關鍵詞:多重引導變數、耦合註標、區塊 ―循環分散 AbstractMost of the local memory access sequence generation methods presented up to now are for simple subscript array. But the problem of memory access sequence generation will become quite difficult when the array contains complex subscripts. In the project, we focus on two types of array subscripts: Multiple Induction Variable (MIV) and Coupled subscripts. An MIV is the affine combination of two or more nested loop indices in a single dimension. Coupled subscripts arise when the same loop index variable occurs in two distinct dimensions.
For MIV, we propose a new method to find the start element for the case where the stride is greater than the block size. For the coupled subscripts, we devise an efficient method to find all the iterations executed in a processor, by which the array elements located at the local memory are enumerated and then the memory access sequence is generated.
Keywords: multiple induction variable, coupled subscript, block-cyclic distribution
二、緣由與目的
The general methods for compiling array reference with block-cyclic distribution,
i.e., cyclic(k), have been widely studied.
Chatterjee et al.[1] proposed a table-based approach using finite-state-machines(FSM) to access the local memory access sequence. Their method has to solve k linear Diophantine equations and requires a sorting operation during the table construction. The studies proposed in [6,9] are improvements of the above FSM method. They use integer lattice to enumerate the local memory access sequence such that the sorting operation can be avoided. Gupta et al. [3] developed
virtual-block and virtual-cyclic schemes, in
which a block-cyclic distribution is viewed as a block (or cyclic) distribution on a set of virtual processors which are then cyclically (or block-wise) mapped to processors. The other approaches are similar to either FSM or virtual processor approach with some modifications.
However, generating local memory access sequences becomes rather complicated when the array references contain complex subscripts. Various methods have been proposed [4,7,8] to deal with this case. In this project, we focus on two particular types of complex subscripts―MIV subscripts and coupled subscripts. An
Multiple induction variable (MIV subscripts)
is the affine combination of two or more nested loop indices in a single dimension. The following HPF-like program code is a typical example of MIV.
!HPF$ PROCEESORS PROCS(P)
!HPF$ DISTRIBUTE A(CYCKICIC(k)) ONTO PROCS do i1=0,n1
do i2=0,n2
A(l1+s1i1+l2+i2s2)=…
enddo enddo
where array A is distributed with cyclic(k) onto P processors; i1 and i2 are the induction
variables with access strides s1 and s2,
respectively. We propose a method to find the start element for the case of s>k, which avoids expensive operations and the time complexity remains the same as in [7].
Coupled subscripts arises when the same loop index variable occurs in two distinct dimensions. We devise an efficient scheme to compute the iterations executed by processor pxy when a two-dimensional array
is distributed with CYCLIC(k1,k2) onto P1×P2 processors (numbered as pxy, for
x∈[0,P1-1] and y∈[0,P2-1]); that is, the array
is distributed with CYCLIC(k1) over P1
processors along its first dimension and distributed with CYCLIC(k2) over P2
processors along its second dimension, where the access strides for the first and second dimension are assumed to be s1 and s2,
respectively. We compute the dimensional iteration table first for each processor in each dimension, and then evaluate the common iteration table for each processor pxy The
common iteration table is used to generate the SPMD code.
四、結果與討論
In this project, we develop a new approach to generate the local memory access sequence of array elements involving multiple induction variables (MIV subscripts), by using the concepts of local
block cycle and global block cycle that we
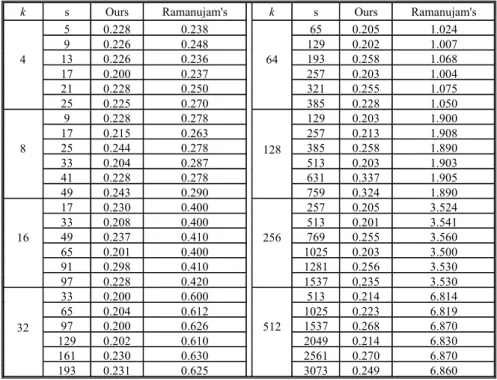
proposed in [4]. The course distance is evaluated first, and then a new approach is developed to find the start element using the course distance. Our method concentrates on the case of s>k and is compared with Ramanujam's by simulation.
The experiments were conducted on an IBM SP-2 by the cc compiler. The function
gettimeofday() was used to measure
the time in microseconds. Table 1 shows the results of our simulation for 32 processors by varying the block size k and the stride s. The block sizes are in powers of 2 ranging from 4 to 512 and the strides are selected as one to six times of the block size plus one to conform to the case of s>k . For comparison, our experiment covered all the (k,s) pairs used in Ramanujam's. We find that our method consistently outperforms the Ramanujam's. In our method, the execution times have no much variation in different values of s and k. But in Ramanujam's, the execution times are in proportion to the block sizes. This is because their implementation must evaluate the l, r vectors of the processor for each global start element and requires time-expensive operations of division and
mod to check the space boundary of
processors.
We also propose a method by exploiting the repetitive pattern of memory access to generate SPMD codes for multi-dimensional array references with coupled subscripts. The arrays are assumed to be distributed with CYCLIC(k1,k2) onto P1×P2 processors. To
compute the iterations executed on processor
pxy , we do not require to use the iteration gap
table. The iteration table that we use is shorter than that of Ramanujam [7]. Besides, the size of dimensional iteration table is the
same as the ∆M table, rather than a multiple
of ∆M table as in [7]. The experimental
results show the efficiency of our method. The experiments were also conducted on an IBM SP-2, using the cc compiler with -O3 level optimizations turned on. The function, gettimeofday(),was employed to measure the time in microseconds. The table construction time is measured for different processor geometries and access strides, by varying the block sizes, k1 and k2.
In Table 2, the processor geometry is 4×5 and the array is accessed with s1=11 and s2=17. In Table 3, the processor geometry is
7×5 and the array is accessed with s1=15 and s2=17. Our method consistently outperforms
the Ramanujam's [7]. 五、參考文獻
[1] S. Chatterjee, J. Gilbert, F. Long, R. Schreber, and S. Teng. Generating local addresses and communication sets for data parallel programs. Journal of Parallel
and Distributed Computing 1995:26(1):72-84.
[2] Swaroop Dutta. Compilation and run-time techniques for data-parallel programs. M.S. Thesis, Department of Electrical and Computer Engineering, Louisiana State University, Dec. 1997. [3] S. K. S. Gupta, S. D. Kaushik, C.-H.
Huang, and P. Sadayappan. On compiling array expressions for efficient execution on distributed-memory machines. Journal of Parallel and Distributed Computing
1996:32(2):155-172.
[4] T. C. Huang, L. C. Shiu, and J. H. Huang. Efficient local memory access sequence generation for data parallel programs using permutation. Journal of
Systems Architecture 2001:47(6):505-515.
[5] K. Kennedy, N. Nedeljkovic and A. Sethi. Efficient address generation for block-cyclic distributions. In: Proc ACM International Conference on Supercomputing, Madrid, Spain, July 1995. p.180-184.
[6] K. Kennedy, N. Nedeljkovic and A. Sethi. A linear-time algorithm for computing the memory access Sequence in data-parallel programs. In: Proc. of the Fifth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, July 1995. p.102-111.
[7] J. Ramanujam, S. Dutta and A. Venkatachar. Code generation for complex subscripts in data-parallel programs. In: Languages and Compilers for Parallel Computing. Springer-Verlag, Vol. 1366, 1998. p. 49-63.
[8] Ajay Sethi. Communication generation for data-parallel languages. Ph.D. Thesis, Department of Computer Science, Rice University, Dec. 1996.
[9] Thirumalai and J. Ramanujam. Efficient computation of address sequences in data parallel programs using closed form for basis vectors. Journal of Parallel and Distributed Computing Nov. 1996:38(2): 188-203.
Table 1. Execution time (in us) of computing the start element on IBM SP-2 when the array is distributed over 32 processors with various block sizes and strides.
k s Ours Ramanujam's k s Ours Ramanujam's
5 0.228 0.238 65 0.205 1.024 9 0.226 0.248 129 0.202 1.007 13 0.226 0.236 193 0.258 1.068 17 0.200 0.237 257 0.203 1.004 21 0.228 0.250 321 0.255 1.075 4 25 0.225 0.270 64 385 0.228 1.050 9 0.228 0.278 129 0.203 1.900 17 0.215 0.263 257 0.213 1.908 25 0.244 0.278 385 0.258 1.890 33 0.204 0.287 513 0.203 1.903 41 0.228 0.278 631 0.337 1.905 8 49 0.243 0.290 128 759 0.324 1.890 17 0.230 0.400 257 0.205 3.524 33 0.208 0.400 513 0.201 3.541 49 0.237 0.410 769 0.255 3.560 65 0.201 0.400 1025 0.203 3.500 91 0.298 0.410 1281 0.256 3.530 16 97 0.228 0.420 256 1537 0.235 3.530 33 0.200 0.600 513 0.214 6.814 65 0.204 0.612 1025 0.223 6.819 97 0.200 0.626 1537 0.268 6.870 129 0.202 0.610 2049 0.214 6.830 161 0.230 0.630 2561 0.270 6.870 32 193 0.231 0.625 512 3073 0.249 6.860
Table 2. Table construction times (in µsec) for 4×5 processors and s1=11, s2=17.
k1 k2 Ramanujam's Ours k1 k2 Ramanujam's Ours
4 4 71.9 41.8 64 4 3967.2 407.2 4 8 57.3 50.4 64 8 3926.2 493.3 8 4 124.8 65.8 8 64 317.0 290.5 8 8 123.0 78.0 64 64 3967.9 1612.5 16 4 332.4 112.1 128 4 14597.1 797.6 16 8 338.9 141.3 128 8 14935.4 961.5 8 16 123.5 104.6 8 128 996.6 543.1 16 16 342.8 186.4 128 128 14843.1 5588.2 32 4 1100.3 211.8 256 4 57231.7 1661.9 32 8 1093.6 258.1 256 8 57500.9 1966.1 8 32 124.7 153.1 8 256 3652.4 1064.6 32 32 1098.6 496.6 256 256 58216.5 20919.7
Table 3. Table construction times (in µsec) for 7×5 processors and s1=15, s2=17.
k1 k2 Ramanujam's Ours k1 k2 Ramanujam's Ours
4 4 74.7 43.9 64 4 6489.8 412.9 4 8 178.8 68.3 64 8 6536.2 488.5 8 4 175.0 66.7 8 64 6707.8 484.7 8 8 176.0 80.8 64 64 6687.4 1575.0 16 4 537.2 110.3 128 4 24345.4 814.9 16 8 557.4 131.3 128 8 25232.8 968.5 8 16 508.9 139.1 8 128 25160.2 947.4 16 16 515.2 180.8 128 128 25407.5 5614.4 32 4 1769.6 210.8 256 4 99547.3 1619.6 32 8 1810.3 251.3 256 8 97886.5 1912.9 8 32 1755.1 248.5 8 256 98115.3 1894.3 32 32 1770.9 492.5 64 256 99878.7 20885.6