Low-Complexity Adaptive Algorithms
for Pre-distortion of Power Amplifiers
Kuan-Hung Chen and Tzi-Dar Chiueh
Graduate Institute of Electronics Engineeringand Department of Electrical Engineering National Taiwan University, Taipei, Taiwan 10617. Abstract—Adaptive systems have been broadly used in a wide
range of applications and can be categorized into linear or nonlinear adaptive systems. Unfortunately, hardware complexity for implementing adaptive systems is usually high. In this paper, a low-complexity LMS algorithm based on a new number system is proposed and applied to multilayer perceptron (MLP). Simulation results show that the proposed adaptive algorithm, with its much lower complexity, can still achieve comparable performance to traditional adaptive algorithms.
I. INTRODUCTION
Adaptive systems are currently being employed in a wide range of applications, including prediction, system identification, interference cancellation, and equalization. From an engineering perspective, an adaptive system consists of the following three functional blocks:
• A network consisting of a set of adjustable weights,
• a comparator for measuring the difference or error between the output of the network due to an input signal and the corresponding desired response, and
• a control algorithm for adjusting the weights of the network in response to the error signal [1].
Depending on whether the network is linear or nonlinear, we may classify adaptive systems as linear or nonlinear, respectively. If the input-output map of the network obeys the principle of superposition whenever its weights are held fixed, an adaptive system is said to be linear. Otherwise, an adaptive system is said to be nonlinear. In this paper, we will focus on a kind of nonlinear network structure, called multilayer perceptron (MLP) [2]. MLP has been applied to many applications such as pattern recognition, nonlinear system identification, etc.
Adaptive system implementation often demands high hardware complexity since many multiplications are required. In this paper, we will first introduce a new number representation system, called grouped signed power-of-two (GSPT) number system and its corresponding adaptive algorithms [3]. The GSPT number system divides each coefficient into several groups of consecutive signed digits and allows at most one nonzero digit in each group. As a result, the complexity of the network is reduced since fewer digits need processing in a multiplication operation. Then, we propose an adaptive algorithm for MLPs with GSPT weights and it operates
like the log-log LMS algorithm [4], yet with a variable step-size and a simple updating mechanism.
As an application of this new adaptive nonlinear system, we choose to solve the power amplifier (PA) nonlinearity compensation problem. A nonlinear radio frequency PA introduces, generally, two types of distortion: AM/AM and AM/PM effects. They result in output signal amplitude and phase modulation when the input signal envelope fluctuates. This can bring about severe signal distortion especially when non-constant-envelope modulation schemes are used, which is generally the case in spectral-efficient communication systems. The combination of non-constant envelope modulation with nonlinearity of PA elicits problems such as spectrum spreading, constellation distortion, inter-modulation products, etc. To eliminate these effects, working a power amplifier with appropriate back-off is one solution. However, this results in reduced power efficiency. Pre-distortion presents another solution to this problem that allows for the use of more efficient, nonlinear amplifiers. Basically, this technique aims to introduce “inverse” nonlinearities that can compensate the AM/AM and AM/PM distortions generated by the nonlinear amplifiers. The MLP network provides the capability to realize adaptive pre-distortion to effectively compensate PA characteristic variations caused by temperature drifting, power supply variation, PA aging, etc [5][6].
The paper is organized as follows. In Section II, we present the GSPT number system and several GSPT-based LMS algorithms. Section III proposes GSPT-based back-propagation algorithm for MLP networks. In Section IV, the pre-distortion problem of power amplifier is selected to verify the feasibility of the MLP networks with GSPT weights and GSPT-based adaptive algorithm. Finally, Section V concludes this paper.
II. GSPT-BASED LMSALGORITHMS
The LMS algorithm is widely used in linear adaptive systems because of its simplicity and robustness. In digital communication systems, LMS adaptive filters are extensively useful and we will use it as an example to explain the GSPT-based LMS algorithms. An LMS adaptive filter can be divided into two parts: the linear filter and the coefficient updating block. The LMS algorithm for an
N-tap adaptive filter is described by the following equations and a
figure illustrating these equations clearly can be found in [7]: , ] [ ] [ ] [n =
∑
kN=−01wk n ⋅xn−k y (1) , ] [ ] [ ] [n dn yn e = − (2) , 1 0 , ] [ ] [ ] [ ] 1 [n+ =w n +µ⋅en ⋅xn−k ≤k≤N− wk k (3)This work was supported in part by MediaTek Inc.
5051
0-7803-8834-8/05/$20.00 ©2005 IEEE.
where n is the time index, and wk[n], d[n], e[n], x[n], and y[n]
represent the k-th filter coefficient, the desired signal, the error signal, the input signal, and the output signal, respectively. In general, we can simplify the LMS adaptive filter using the sign-error (sign-data) LMS algorithm by replacing e[n] (x[n-k]) with simply the sign of e[n] (x[n-k]). Actually, the sign-sign LMS algorithm can be used to further reduce the implementation complexity using only the sign of e[n] and that of x[n-k] in updating [8]. This suggests that the direction of the update is more important than the magnitude of the update if the step-size is kept small.
In the following, we introduce a number representation system and two associated adaptive algorithms [3]. The GSPT algorithms can reduce the complexity of both the linear filter and the coefficient updating block of an adaptive filter.
A. GSPT Number System
The main idea of the Grouped Signed Power-of-Two (GSPT) number system is to represent a number by several groups of digits and in each group at most one nonzero signed digit (1 or -1) is allowed. Suppose that a 12-bit GSPT number is partitioned into three groups. Then, a GSPT number can be represented as
, 0001 00 1 0 0010 1 64 512 449= − + = (4)
where each group is marked by an underline and the digit ‘-1’ is represented by 1 .
B. GSPT LMS Algorithm
As mentioned before, the updating direction is more important than the magnitude of the update. Therefore, only the direction of the term, e[n]⋅x[n-k], is used for the coefficient updating in the GSPT LMS algorithm. The GSPT LMS algorithm for an N-tap adaptive equalizer is described by equations (1)(2)(5). Equation (5) describes the updating equation of the GSPT LMS algorithm as follows: . 1 0 , 0 ] [ ] [ , ] [ 0 ] [ ] [ , ] [ 0 ] [ ] [ , ] [ ] 1 [ ≤ ≤ − < − ⋅ ↓ = − ⋅ > − ⋅ ↑ = + k N k n x n e if n w k n x n e if n w k n x n e if n w n w k k k k (5)
When e[n]⋅x[n-k] is positive (zero or negative), we increase (freeze or decrease) the linear filter coefficient wk[n]. The updating unit is
shown in Figure 1(a) and an illustration of the updating operation is given in Figure 1(b). carryin borrowin 1 0 1 0 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 b0 b1 b2 b3 (a) (b) 1 updating unit carryin carryout reset borrowout borrowin b0 b1 b2 b3
Figure 1. (a) GSPT updating unit. (b) Illustration of the operation in a GSPT updating unit.
When a positive trigger (increase) signal, carryin, is received,
0 1 2 3bbb
b of this updating unit ‘shifts up’ to increase its value. Likewise, when a negative trigger (decrease) signal, borrowin, is received, b3b2b1b0 of this updating unit ‘shifts down.’ If b3b2b1b0
has been already at the upper (lower) limit 1000 ( 0001 ) and a positive (negative) trigger signal is received, the output signal
carryout (borrowout) is sent to the next more significant unit and
0 1 2 3bbb
b is reset to 0000 . The coefficient updating block can be implemented by cascading three updating units in the 12-bit coefficient example. More details about this algorithm can be found in [3].
C. GSPT-AS LMS Algorithm
In mobile communication applications, the convergence speed of an adaptive system in the receiver is crucial. To improve the convergence speed while at the same time keep the complexity at a reasonable level, the idea of the log-log LMS algorithm [4] is adopted. The updating equation of the log-log LMS algorithm is given by , 1 0 ]), [ ( ]) [ ( ] [ ] 1 [n+ =w n +µ⋅Qen ⋅Q xn−k ≤k≤N− wk k (6)
where Q(z) selects the power-of-two value that is closest to z. Applying this idea to the GSPT number system, the updating term is first calculated in the same way as the log-log LMS algorithm. Based on the magnitude of the updating term, we can inject a carry/borrow signal to the corresponding updating unit. For example, in a 12-bit integer coefficient with four groups, numbered from 1 to 4 (from MSB to LSB), we can increase/decrease the coefficient by sending a trigger to the 4th group if the magnitude of
the updating term is smaller than or equal to 2. Similarly, the coefficient is increased/decreased at the 3rd, 2nd and the 1st groups if
the magnitude of the updating term is between 4 and 16, between 32 and 128, and larger than 256, respectively. We call this scheme GSPT-AS LMS algorithm and it is illustrated in Figure 2. Note that the updating term can be computed without multiplication since the step-size is a power of two and an additional updating unit is used for coefficient updating to improve the coefficient precision.
Updating term decision block
linear filter
carryout
borrowout
carryin
borrowin
Updating term decision block
µ x[n-k] e[n] b9 updating unit reset b10 b11 b0 updating unit reset b1 b2 updating unit reset ... ... ...
coefficient updating block
Figure 2. Coefficient updating block of the GSPT-AS LMS algorithm.
III. GSPT-AS-BASED BACKPROPAGATION ALGORITHM FOR MLP
In this section, we first introduce the multilayer perceptron (MLP) and the back-propagation algorithm used to train the MLP [2]. Then, the GSPT-AS-based back-propagation-like training algorithm is proposed.
A. Multilayer Perceptron and Backpropagation Algorithm The multilayer perceptron is an artificial neural network that consists of an input layer of input neurons, one or more hidden layers of computational nodes (hidden neurons), and an output layer also made up of computational nodes (output neurons). The input neurons provide physical access points for the application of input signals. The neurons in the hidden layer act as “feature detectors”. Finally, the output neurons present to the outside world the conclusions reached by the network in response to the input signals. Figure 3 depicts a multilayer perceptron with one input neuron (x) and one bias neuron in the input layer, one single layer of several hidden neurons and one bias neuron, and one output neuron. Connections between neurons have their corresponding weights adjustable by the back-propagation algorithm. Each neuron except the input neuron sums its incoming weighted signals and produces an output that is a function of the sum. This function is called the activation function and, in Figure 3, the output neuron uses the identity function as its activation function.
f(.) f(.) f(.) ... 1 1 x y
Figure 3. An Example of a MLP neural network with bias neurons. Let wj (bj) denotes the weight corresponding to the connection
from the input neuron (bias neuron in the input layer) to the j-th neuron in the hidden layer and tj (c) denotes the weight
corresponding to the connection from the j-th neuron (bias neuron) in the hidden layer to the output neuron. Let f(.) denotes the activation function used by the neurons in the hidden layer, x denotes the input received by the input neuron; and o denotes the output generated by the output neuron. Then, the transfer function of the neural network shown in Figure 3 can be written as:
(
)
, ] [ =∑
J=1 ⋅ ⋅ + + j tj f wj x bj c n o (7)where J represents the number of neurons in the hidden layer. The back-propagation algorithm is a gradient-descent procedure that is frequently used to train the MLP [2]. It is summarized below for a one-hidden-layer MLP with
( )
z 1(1 e z) f = + − : ], [ ] [ ] [n d n on e = −(
)
, 1 J , ] [ ] [ ] 1 [n+ =t n +η⋅en ⋅f w ⋅x+b ≤ j≤ tj j j j ], [ ] [ ] 1 [n cn η en c + = + ⋅(
)
(
1(
)
)
[ ] [ ], 1 J, ] [n = f w ⋅x+b ⋅ − f w ⋅x+b ⋅t n ⋅en ≤ j≤ δj j j j j j , J 1 , ] [ ] [ ] 1 [n+ =w n +η⋅δ n ⋅x ≤ j≤ wj j j , J 1 ], [ ] [ ] 1 [n+ =b n +η⋅δ n ≤ j≤ bj j jwhere d[n] is the desired signal and η is called the learning rate.
B. GSPT-AS-Based Backpropagation Algorithm
Applying the GSPT-AS LMS algorithm to the back-propagation algorithm, all weights including wj, bj, tj, and c are updated via the
GSPT-AS LMS algorithm. Since GSPT-AS LMS algorithm is used for weight updating, the calculation of δj[n] can be simplified as
follows:
(
)
(
)
(
1(
)
) ( )
[ ]( )
[ ], ] [n Q f w x b Q f w x b Qt n Qen δj = j⋅ + j ⋅ − j⋅ + j ⋅ j ⋅ 1≤ j≤J. (8). IV. PREDISTORTION FOR POWER AMPLIFIER USING MLPWITH GSPT-AS-BASED BACKPROPAGATION To verify the feasibility of the proposed GSPT-AS-based back-propagation algorithm in practical applications, an MLP using GSPT-AS-Based back-propagation algorithm is used for computing the pre-distortion for nonlinear power amplifiers.
A. Power Amplifier Model
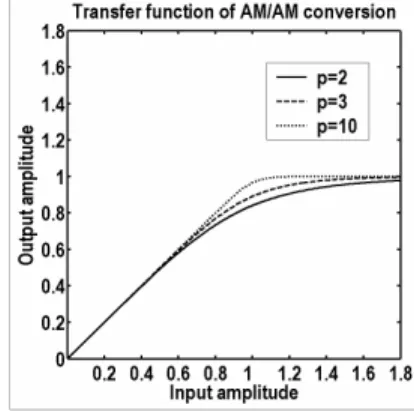
To simulate a solid-state power amplifier, the following model [6] is used for the AM/AM conversion:
(
1)
. ) ( 2 1 2p p A A A g + =The AM/PM conversion of a solid-state power amplifier is usually small enough to be neglected [9]. Figure 4 depicts several examples of the normalized transfer functions. A good approximation of existing amplifiers is obtained by choosing p in the range of 2 to 3. In this experiment, we use p = 2.
Figure 4. Transfer function of AM/AM conversion. B. Pre-distortion Architecture
The learning architecture for the MLP is shown in Figure 5(a) and Figure 5(b) illustrates the architecture used for pre-distortion after learning. During the learning, the magnitude of the input constellation is regarded as the desired signal. The magnitude of the distorted constellation is taken as the input of the MLP. The difference between the neural network’s output and the desired signal is used to train the neural network. After completing the learning, the magnitude of the input constellation is pre-distorted by the trained MLP. The output of MLP and the phase of the input constellation are then translated to rectangular coordinates and sent to PA.
Figure 5. (a) Learning architecture. (b) Pre-distortion architecture.
C. Simulation Results
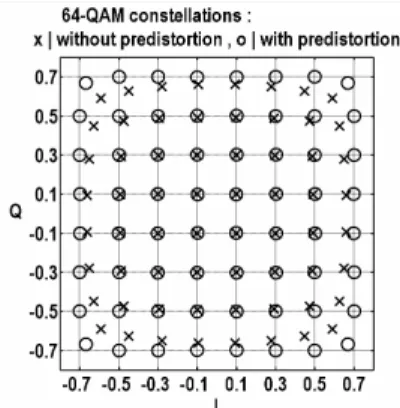
64-QAM modulations are used for simulations and the MLP architecture used is the network shown in Figure 3 and ten hidden neurons, excluding the bias neuron, are used. The MLP is trained by the GSPT-AS-based back-propagation algorithm, and traditional back-propagation algorithm with floating-point and with fixed-point programs. The learning sequences of above three schemes are shown in Figure 6. We can see that the floating-point scheme achieves the best performance but has the lowest convergence speed. The GSPT-AS scheme has the fastest convergence speed but the highest mean square error after convergence. The iterations required for the GSPT-AS scheme to achieve the stable state is only half of that required for the fixed-point scheme. Much larger fluctuations of the convergence curve are caused by inherent variable step-size property of the GSPT-AS scheme. Figure 7 shows the 64-QAM constellations generated by the PA with pre-distortion computed by the GSPT-AS-based MLP. It is obvious that it works very well except for the four corner signal points. Actually, Figure 8 indicates that the GSPT-AS-based MLP pre-distortion has very close performance to the floating-point MLP pre-distortion.
Figure 6. Learning sequences.
V. CONCLUSIONS
In this paper, we extend the application of the GSPT number system to nonlinear adaptive systems, such as MLP. The GSPT-AS-based back-propagation algorithm is proposed to train an MLP that is used for pre-distortion of nonlinear power amplifiers. Simulation results show that the GSPT-AS-based back-propagation algorithm can achieve comparable performance with that of the conventional back-propagation algorithm. However, the complexity required to implement such a GSPT-AS-based back-propagation algorithm is
much lower. Therefore, the GSPT-based MLP can be an efficient solution to many difficult problems in need of nonlinear adaptive systems.
Figure 7. Comparison of PA’s output constellations: without pre-distortion and with GSPT-AS-based MLP pre-pre-distortion.
Figure 8. Comparison of PA’s output constellations: with floating-point tranditional MLP pre-distortion and GSPT-AS-based MLP pre-distortion.
REFERENCES
[1] S. Haykin, “Lessons on Adaptive Systems for Signal Processing, Communications, and Control,” IEEE Signal Processing Magazine, vol. 16, pp. 39-48, Sept. 1999.
[2] Simon Haykin, Neural Network: A Comprehensive Foundation, Prentice Hall, Inc., 1994.
[3] C. N. Chen, K. H. Chen, and T. D. Chiueh, “Algorithm and Architecture Design for a Low-Complexity Adaptive Equalizer,” in
Proc. of IEEE ISCAS ‘03, 2003, pp. 304-307.
[4] S. S. Mahant-Shetti, S. Hosur, and A. Gatherer, “The Log-Log LMS Algorithm,” in Proc. of IEEE ICASSP-97, vol. 3, 1997, pp. 364-367. [5] N. Naskas and Y. Papananos, “Adaptive Baseband Predistortor for
Radio Frequency Power Amplifiers based on a Multilayer Perceptron,” in 9th International Conference on Electronics, Circuits
and Systems, vol. 3, 15-18 Sept. 2002, pp. 1107-1110.
[6] F. Langlet, H. Abdulkader, D. Roviras, A. Maller, and F. Castanie, “Adaptive Predistortion for Solid State Power Amplifier using Multilayer Perceptron,” in GLOBECOM’01, vol. 1, 25-29 Nov. 2001, pp. 325-329.
[7] Simon Haykin, Adaptive Filter Theory, 4th ed., Prentice Hall, Inc., 2001, pp. 254.
[8] L. Der and B. Razavi, “A 2 GHz CMOS Image-Reject Receiver with Sign-Sign LMS Calibration,” in Proc. of IEEE ISSCC-01, 2001, pp. 294-295.
[9] R. V. Nee and R. Prasad, OFDM Wireless Multimedia Communications, Artech House, 2000.