用户指南
文档版本 01
发布日期 2021-06-16
版权所有 © 华为技术有限公司 2022。 保留一切权利。
非经本公司书面许可,任何单位和个人不得擅自摘抄、复制本文档内容的部分或全部,并不得以任何形式传 播。
商标声明
和其他华为商标均为华为技术有限公司的商标。
本文档提及的其他所有商标或注册商标,由各自的所有人拥有。
注意
您购买的产品、服务或特性等应受华为公司商业合同和条款的约束,本文档中描述的全部或部分产品、服务或 特性可能不在您的购买或使用范围之内。除非合同另有约定,华为公司对本文档内容不做任何明示或暗示的声 明或保证。
由于产品版本升级或其他原因,本文档内容会不定期进行更新。除非另有约定,本文档仅作为使用指导,本文 档中的所有陈述、信息和建议不构成任何明示或暗示的担保。
目 录
1 数据湖探索简介... 1
2 注册华为云帐号并进行服务授权... 3
3 权限管理...6
3.1 权限管理概述... 6
3.2 创建 IAM 用户并授权使用 DLI... 9
3.3 DLI 自定义策略... 11
3.4 DLI 资源... 16
3.5 DLI 请求条件... 16
3.6 常用操作与系统权限关系... 17
3.7 参考资料... 31
4 入门操作指导...32
4.1 创建并提交 Spark SQL 作业...32
4.2 使用 TPC-H 样例模板开发并提交 Spark SQL 作业... 35
4.3 创建并提交 Spark Jar 作业... 37
4.4 创建并提交 Flink SQL 作业... 41
4.5 创建增强型跨源连接访问 RDS...50
5 DLI 控制台总览...57
6 SQL 编辑器... 59
7 作业管理...67
7.1 SQL 作业管理... 67
7.2 Flink 作业管理...72
7.2.1 Flink 作业管理概述...72
7.2.2 Flink 作业权限管理...75
7.2.3 准备 Flink 作业数据... 78
7.2.4 创建 Flink SQL 作业... 79
7.2.5 创建 Flink Jar 作业... 85
7.2.6 创建 Flink OpenSource SQL 作业...92
7.2.7 创建 Flink SQL 边缘作业... 99
7.2.8 边缘鉴权码管理... 104
7.2.9 调试 Flink 作业... 106
7.2.10 操作 Flink 作业... 108
7.2.11 Flink 作业详情... 114
7.2.12 标签管理... 121
7.3 Spark 作业管理...123
7.3.1 Spark 作业管理概述... 123
7.3.2 创建 Spark 作业... 125
8 队列管理... 131
8.1 队列管理概述... 131
8.2 队列权限管理... 137
8.3 创建队列... 138
8.4 删除队列... 143
8.5 修改队列网段... 143
8.6 规格变更... 144
8.7 弹性扩缩容... 146
8.8 弹性扩缩容定时任务... 148
8.9 测试地址连通性... 151
8.10 创建消息通知主题... 151
8.11 队列标签管理...153
9 数据管理... 156
9.1 库表管理... 156
9.1.1 库表管理概述...156
9.1.2 数据库权限管理... 158
9.1.3 表权限管理... 163
9.1.4 创建数据库和表... 171
9.1.5 删除数据库和表... 177
9.1.6 修改数据库和表所有者... 178
9.1.7 导入数据... 179
9.1.8 将 DLI 数据导出至 OBS... 182
9.1.9 查看元数据... 184
9.1.10 预览数据... 185
9.2 程序包管理... 185
9.2.1 程序包管理概述... 185
9.2.2 程序包组和程序包权限管理...186
9.2.3 创建程序包... 189
9.2.4 删除程序包... 190
9.2.5 修改所有者... 191
9.2.6 内置依赖包... 192
10 作业模板... 207
10.1 SQL 模板管理... 207
10.2 Flink 模板管理... 211
10.3 附录... 217
10.3.1 SQL 模板下 TPC-H 样例数据说明...217
11 跨源连接... 220
11.1 跨源连接和跨源分析概述... 220
11.2 增强型跨源连接(推荐)... 227
11.2.1 增强型跨源连接概述... 227
11.2.2 创建/查找/删除增强型跨源连接...228
11.2.3 绑定/解绑队列...231
11.2.4 修改主机信息... 233
11.2.5 自定义路由信息... 234
11.2.6 增强型跨源连接权限管理...235
11.2.7 增强型跨源连接标签管理...235
11.3 经典型跨源连接... 237
11.4 跨源认证权限管理... 245
11.5 创建及管理跨源认证...246
12 全局配置... 253
12.1 全局变量... 253
12.2 服务授权... 254
13 自定义镜像... 257
13.1 自定义镜像概述... 257
13.2 下载基础镜像...257
13.3 使用自定义镜像... 258
13.4 基础镜像组件说明... 261
14 其他常用操作... 263
14.1 导入数据至 DLI 表的方式... 263
14.2 数据湖探索监控指标说明及查看指导... 263
14.3 云审计服务支持的 DLI 操作列表说明... 267
1 数据湖探索简介
什么是 DLI
数据湖探索(Data Lake Insight,简称DLI)是完全兼容Apache Spark、Apache
Flink、openLooKeng(基于Apache Presto)生态,提供一站式的流处理、批处理、
交互式分析的Serverless融合处理分析服务。用户不需要管理任何服务器,即开即用。
支持标准SQL/Spark SQL/Flink SQL,支持多种接入方式,并兼容主流数据格式。数据 无需复杂的抽取、转换、加载,使用SQL或程序就可以对云上CloudTable、RDS、
DWS、CSS、OBS、ECS自建数据库以及线下数据库的异构数据进行探索。
功能优势
● 纯SQL操作
DLI提供标准SQL接口,用户仅需使用SQL便可实现海量数据查询分析。
● 存算分离
DLI的存储和计算解耦,分开申请和计费,降低成本的同时,提高了资源利用率。
● 企业级多租户
支持计算资源按租户隔离,数据权限控制到队列、作业,帮助企业实现部门间的 数据共享和权限管理。
● 免运维、高可用
用户无需感知底层运维、升级,跨AZ高可用,跨AZ双活。
DLI 核心引擎:Spark+Flink+openLooKeng(Presto)
● Spark是用于大规模数据处理的统一分析引擎,聚焦于查询计算分析。DLI在开源 Spark基础上进行了大量的性能优化与服务化改造,不仅兼容Apache Spark生态 和接口,性能较开源提升了2.5倍,在小时级即可实现EB级数据查询分析。
● Flink是一款分布式的计算引擎,可以用来做批处理,即处理静态的数据集、历史 的数据集;也可以用来做流处理,即实时地处理一些实时数据流,实时地产生数 据的结果。DLI在开源Flink基础上进行了特性增强和安全增强,提供了数据处理所 必须的Stream SQL特性。
● openLooKeng使用了业界著名的开源SQL引擎Presto来提供交互式查询分析基础 能力,并继续在融合场景查询、跨数据中心/云、数据源扩展、性能、可靠性、安 全性等方面发展,让数据治理、使用更简单。
DLI 服务架构:Serverless
DLI是无服务器化的大数据查询分析服务,其优势在于:
● 按量计费:真正的按使用量(扫描量/CU时)计费,不运行作业时0费用。
● 自动扩缩容:根据业务负载,对计算资源进行预估和自动扩缩容。
2 注册华为云帐号并进行服务授权
使用数据湖探索服务之前,您需要注册华为云帐号,进行实名认证并进行服务授权。
说明
注册华为云后,如果需要对DLI资源进行精细管理,请使用IAM服务创建IAM用户及用户组,并 授权,以使得IAM用户获得具体的操作权限。具体内容请参考创建IAM用户并授权使用DLI。
注册华为云帐号
如果您已完成华为云帐号注册,可跳过该步骤。
步骤1 打开华为云官方网站。
步骤2 单击华为云官网右上角“注册”进入注册页面。
步骤3 在注册页面,根据提示信息完成注册。具体操作可参见账号注册。
----结束
实名认证
根据国家法律规定,所有用户必须完成实名认证后才能使用云服务。
如果您已完成实名认证,可跳过该步骤。具体操作可参见实名认证。
服务授权
登录华为云,进入数据湖探索管理控制台后,为保证正常使用数据湖探索功能,建议 先进行委托权限设置。
第一次登录时进行设置后,后续无需重复设置。如果需要进行调整,可在“全局配 置”>“服务授权”中进行修改。
1. 帐号登录后,在数据湖探索产品页面,单击“进入控制台”。
2. 进入管理控制台,进入“服务授权”页面,参考表2-1,根据需要勾选对应委托权 限,单击“更新委托授权”。
说明
授权需要主帐号或者用户组admin中的子帐号进行操作。
3. 同意授权后,DLI将在统一身份认证服务IAM为您创建名为dli_admin_agency的委 托,授权成功后,可以进入服务委托列表查看。详细可以参考下图,单击界面链 接查看。注意:委托dli_admin_agency创建成功后,请勿删除。
表2-1 DLI 委托权限列表
权限名 详细信息 备注
Tenant
Administrator (全局 服务)
DLI Flink作业访问和使用OBS或 者DWS数据源、日志转储(包括 桶授权)、开启checkpoint、作 业导入导出等,需要获得访问和 使用OBS(对象存储服务)的 Tenant Administrator权限。
由于云服务缓存需要 时间,该权限60分钟 左右才能生效。
DIS Administrator DLI Flink作业访问和使用DIS数 据源,需要获得访问和使用DIS
(数据接入服务)的DIS Administrator权限。
由于云服务缓存需要 时间,该权限30分钟 左右才能生效。
CloudTable
Administrator DLI Flink作业访问和使用 CloudTable数据源,需要获得访 问和使用CloudTable(表格存储 服务)的CloudTable
Administrator权限。
由于云服务缓存需要 时间,该权限3分钟 左右才能生效。
VPC Administrator DLI跨源连接需要使用VPC、子 网、路由、对等连接功能,因此 需要获得使用VPC(虚拟私有 云)的VPC Administrator权限。
由于云服务缓存需要 时间,该权限3分钟 左右才能生效。
权限名 详细信息 备注 SMN Administrator DLI作业执行失败需要通过SMN
发送通知消息,因此需要获得访 问和使用SMN(消息通知服务)
的SMN Administrator权限。
由于云服务缓存需要 时间,该权限3分钟 左右才能生效。
Tenant
Administrator(项目 级)
DLI 边缘Flink作业执行需要使用 IEF(智能边缘平台)服务,IEF 服务必须具有Tenant
Administrator权限才能运行。使 用其他必须具有Tenant
Administrator权限才能运行的服 务也需要获得该权限。
由于云服务缓存需要 时间,该权限3分钟 左右才能生效。
IAMReadOnlyAccess DLI对未登陆过DLI的用户进行授 权时,需获取IAM用户相关信 息。因此需要IAM
ReadOnlyAccess权限。
由于云服务缓存需要 时间,该权限3分钟 左右才能生效。
3 权限管理
3.1 权限管理概述
DLI服务不仅在服务本身有一套完善的权限控制机制,同时还支持通过统一身份认证服 务(Identity and Access Management,简称IAM)细粒度鉴权,可以通过在IAM创 建策略来管理DLI的权限控制。两种权限控制机制可以共同使用,没有冲突。
IAM 鉴权使用场景
企业用户在华为云上使用DLI服务时,需要对不同部门的员工使用DLI资源(队列)进 行管理,包括资源的创建、删除、使用、隔离等。同时,也需要对不同部门的数据进 行管理,包括数据的隔离、共享等。
DLI使用IAM进行精细的企业级多租户管理。该服务提供用户身份认证、权限分配、访 问控制等功能,可以帮助您安全地控制华为云资源的访问。
通过IAM,您可以在华为云帐号中给员工创建IAM用户,并使用策略来控制他们对华为 云资源的访问范围。例如您的员工中有负责软件开发的人员,您希望他们拥有DLI的使 用权限,但是不希望他们拥有删除DLI等高危操作的权限,那么您可以使用IAM为开发 人员创建用户,通过授予仅能使用DLI,但是不允许删除DLI的权限策略,控制他们对 DLI资源的使用范围。
说明
对于新建的用户,需要先登录一次DLI,记录元数据,后续才可正常使用。
IAM是华为云提供权限管理的基础服务,无需付费即可使用,您只需要为您帐号中的 资源进行付费。关于IAM的详细介绍,请参见《IAM产品介绍》。
如果华为云帐号已经能满足您的需求,不需要创建独立的IAM用户进行权限管理,您 可以跳过本章节,不影响您使用DLI服务的其他功能。
DLI 系统权限
如表3-1所示,包括了DLI的所有系统权限。
权限类别:根据授权精程度分为角色和策略。
● 角色:IAM最初提供的一种根据用户的工作职能定义权限的粗粒度授权机制。该 机制以服务为粒度,提供有限的服务相关角色用于授权。由于华为云各服务之间
存在业务依赖关系,因此给用户授予角色时,可能需要一并授予依赖的其他角 色,才能正确完成业务。角色并不能满足用户对精细化授权的要求,无法完全达 到企业对权限最小化的安全管控要求。
● 策略:IAM最新提供的一种细粒度授权的能力,可以精确到具体服务的操作、资 源以及请求条件等。基于策略的授权是一种更加灵活的授权方式,能够满足企业 对权限最小化的安全管控要求。例如:针对DLI服务,管理员能够控制IAM用户仅 能对某一类云服务器资源进行指定的管理操作。
了解DLI SQL常用操作与系统策略的授权关系,请参考常用操作与系统权限关系。
表3-1 DLI 系统权限 系统角色/策略 名称
描述 类别 授权方式
DLI FullAccess 数据湖探索所有权限。 系统策 略
具体的授权方式请参考创 建IAM用户并授权使用
DLI以及《如何创建子用
户》和《如何修改用户策 略》。DLIReadOnlyAcces s
数据湖探索只读权限。 系统策 略
Tenant
Administrator 租户管理员。
● 操作权限:具有所有云 服务的管理和使用权 限。创建后,可通过 ACL赋权给其他子用户 使用。
● 作用范围:项目级服 务。
系统角 色
DLI Service
Admin DLI服务管理员。
● 操作权限:具有数据湖 探索服务队列、数据的 管理和使用权限。创建 后,可通过ACL赋权给 其他子用户使用。
● 作用范围:项目级服 务。
系统角 色
DLI 权限分类
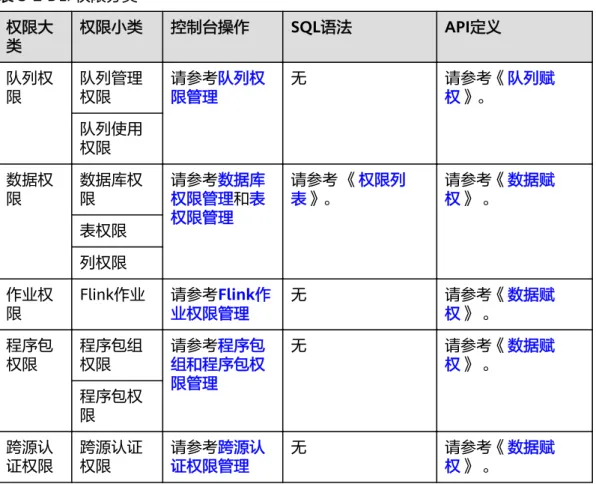
DLI服务权限分类如表3-2所示,其可控制的资源请参考表3-7。
表3-2 DLI 权限分类 权限大
类
权限小类 控制台操作 SQL语法 API定义
队列权 限
队列管理 权限
请参考队列权 限管理
无 请参考《队列赋
权》。
队列使用 权限 数据权
限
数据库权 限
请参考数据库 权限管理和表 权限管理
请参考 《权限列 表》。
请参考《数据赋 权》 。
表权限 列权限 作业权
限 Flink作业 请参考Flink作 业权限管理
无 请参考《数据赋
权》 。 程序包
权限
程序包组 权限
请参考程序包 组和程序包权 限管理
无 请参考《数据赋
权》 。 程序包权
限 跨源认 证权限
跨源认证 权限
请参考跨源认 证权限管理
无 请参考《数据赋
权》 。
场景举例
某互联网公司,主要有游戏和音乐两大业务,使用DLI服务进行用户行为分析,辅助决 策。
如图3-1所示,“基础平台组组长”在华为云上申请了一个“租户管理员”(Tenant Administrator)帐号,用于管理和使用华为云的各个服务。因为“大数据平台组”需 要使用DLI进行数据分析,所有“基础平台组组长”增加了一个权限为“DLI服务管理 员”(DLI Service Admin)的子帐号用于管理和使用DLI服务。“基础平台组组长”
按照公司两个业务对于数据分析的要求,创建了“队列A”分配给“数据工程师A”运 行游戏数据分析业务,“队列B”分配给“数据工程师B”运行音乐数据分析业务,并 分别赋予“DLI普通用户”权限,具有队列使用权限,数据(除数据库)的管理和使用 权限。
图3-1 权限分配
“数据工程师A”创建了一个gameTable表用于存放游戏道具相关数据,userTable表 用于存放游戏用户相关数据。因为音乐业务是一个新业务,想在存量的游戏用户中挖 掘一些潜在的音乐用户,所以“数据工程师A”把userTable表的查询权限赋给了“数 据工程师B”。同时,“数据工程师B”创建了一个musicTable用于存放音乐版权相关 数据。
“数据工程师A”和“数据工程师B”对于队列和数据的使用权限如表3-3所示。
表3-3 使用权限说明
用户 数据工程师A(游戏数据分析) 数据工程师B(音乐数据分析)
队列 队列A(队列使用权限) 队列B(队列使用权限)
数据
(表)
gameTable(表管理和使用权 限)
musicTable(表管理和使用权限)
userTable(表管理和使用权限) userTable(表查询权限)
说明
队列的使用权限包括提交作业和终止作业两个权限。
3.2 创建 IAM 用户并授权使用 DLI
如果您需要对您所拥有的DLI资源进行精细的权限管理,您可以使用统一身份认证服务
(Identity and Access Management,简称IAM),具体IAM使用场景可以参考权限 管理概述。
如果华为云帐号已经能满足您的要求,不需要创建独立的IAM用户,您可以跳过本章 节,不影响您使用DLI服务的其它功能。
本章节介绍创建IAM用户并授权使用DLI的方法,操作流程如图3-2所示。
前提条件
给用户组授权之前,请您先了解用户组可以添加的DLI权限,并结合实际需求进行选 择。DLI支持的系统权限,请参见:DLI系统权限。
示例流程
图3-2 给用户授权 DLI 权限流程
1. 创建用户组并授权
在IAM控制台创建用户组,并授予DLI服务普通用户权限“DLI ReadOnlyAccess”。
2. 创建用户并加入用户组
在IAM控制台创建用户,并将其加入1中创建的用户组。
3. 用户登录并验证权限
使用新创建的用户登录控制台,切换至授权区域,验证权限:
– 在“服务列表”中选择数据湖探索,进入DLI主界面。如果在“队列管理”页 面可以查看队列列表,但是单击右上角“购买队列”,无法购买DLI队列(假 设当前权限仅包含DLI ReadOnlyAccess),表示“DLI ReadOnlyAccess”已 生效。
– 在“服务列表”中选择除数据湖探索外(假设当前策略仅包含DLI ReadOnlyAccess)的任一服务,若提示权限不足,表示“DLI ReadOnlyAccess”已生效。
更多操作
● 创建子用户请参考《如何创建子用户》。
● 修改用户策略请参考《如何修改用户策略》。
3.3 DLI 自定义策略
如果系统预置的DLI权限,不满足您的授权要求,可以创建自定义策略。自定义策略中 可以添加的授权项(Action)请参考权限策略和授权项。
目前华为云支持以下两种方式创建自定义策略:
● 可视化视图创建自定义策略:无需了解策略语法,按可视化视图导航栏选择云服 务、操作、资源、条件等策略内容,可自动生成策略。
● JSON视图创建自定义策略:可以在选择策略模板后,根据具体需求编辑策略内 容;也可以直接在编辑框内编写JSON格式的策略内容。
具体创建步骤请参见:创建自定义策略。本章为您介绍常用的DLI自定义策略样例。
策略字段介绍
以授权用户拥有在所有区域中所有数据库的创建表权限为例进行说明:
{ "Version": "1.1", "Statement": [ {
"Effect": "Allow", "Action": [
"dli:database:create_table"
],
"Resource": [ "dli:*:*:database:*"
] } ] }
● Version
版本信息,1.1: 策略。IAM最新提供的一种细粒度授权的能力,可以精确到具体 服务的操作、资源以及请求条件等。
● Effect
作用。包含两类:允许(Allow)和拒绝(Deny),既有Allow又有Deny的授权 语句时,遵循Deny优先的原则。
● Action
授权项,指对资源的具体操作权限,不超过100个,如图3-3所示。
图3-3 DLI 授权项
说明
● 格式为:服务名:资源类型:操作,例:dli:queue:submit_job。
● 服务名为产品名称,例如dli、evs和vpc等,服务名仅支持小写。资源类型和操作没有大 小写,要求支持通配符号*,无需罗列全部授权项。
● 资源类型可以参考表3-7中的资源类型。
● 操作:操作以IAM服务中已经注册的action为准。
● Condition
限制条件:使策略生效的特定条件,包括条件键和运算符。
条件键表示策略语句的 Condition 元素中的键值,分为全局级条件键和服务级条 件键。
– 全局级条件键(前缀为g:)适用于所有操作。详细请参考策略语法中的条件 键说明。
– 服务级条件键(前缀为服务缩写,如dli:,目前DLI未提供服务级条件键)仅 适用于对应服务的操作。
运算符与条件键一起使用,构成完整的条件判断语句。具体内容请参考表3-4。
DLI通过IAM预置了一组条件键,例如,您可以先使用hw:SourceIp条件键检查请 求者的IP地址,然后再允许执行操作。下表显示了适用于DLI服务特定的条件键。
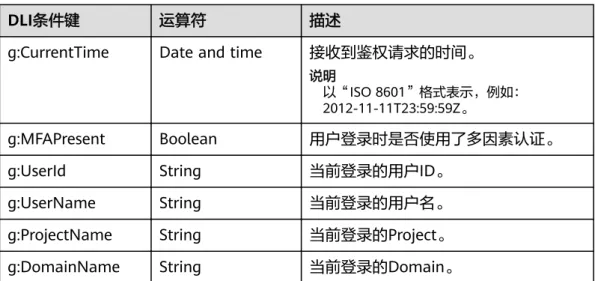
表3-4 DLI 请求条件
DLI条件键 运算符 描述
g:CurrentTime Date and time 接收到鉴权请求的时间。
说明以“ISO 8601”格式表示,例如:
2012-11-11T23:59:59Z。
g:MFAPresent Boolean 用户登录时是否使用了多因素认证。
g:UserId String 当前登录的用户ID。
g:UserName String 当前登录的用户名。
g:ProjectName String 当前登录的Project。
g:DomainName String 当前登录的Domain。
● Resource
格式为:服务名:region:domainId:资源类型:资源路径, 通配符号*表示所有,资源 类型和资源路径可以参考表3-7。
示例:
"dli:*:*:queue:*": 表示所有的队列。
创建 DLI 自定义策略
用户可以根据场景设置不同级别的Action和Resource。
1. 定义Action
Action由服务名:资源类型:操作三段组成,通配符为*。例如:
表3-5 Action
Action 说明
dli:queue:submit_job DLI队列的提交操作 dli:queue:* DLI队列的全部操作
dli:*:* DLI所有资源类型的所有操作
更多操作与系统权限的关系请参考常用操作与系统权限关系。
2. 定义Resource
Resource由<服务名:region:domainId:资源类型:资源路径>5个字段组成,通配符 号*表示所有资源。5个字段可以灵活设置,资源路径可以按照场景需要,设置不 同级别的权限控制。当需要设置该服务下的所有资源时,可以不指定该字段。
Resource定义请参考表3-6。Resource中的资源类型和资源路径请参考表3-7。
表3-6 Resource
Resource 说明
DLI:*:*:table:databases.dbname.t
ables.* DLI服务,任意region,任意帐号ID下,数 据库名为dbname下的所有表资源。
DLI:*:*:database:databases.dbna
me DLI服务,任意region,任意帐号ID下,数 据库名为dbname的队列。
DLI:cn-north-1:xxx:column:
databases.db.tables.tb.columns.c ol
DLI服务,cn-north-1,帐号ID为xxx,数 据库名为db,表名为tb,列名为col的资 源。
DLI:*:*:queue:queues.* DLI服务,任意region,任意帐号ID下,任 意队列资源。
DLI:*:*:jobs:jobs.flink.1 DLI服务,任意region,任意帐号ID下,作 业Id为1的flink作业。
表3-7 DLI 的指定资源与对应路径
资源类型 资源名称 资源路径
queue DLI队列 queues.queuename database DLI数据库 databases.dbname
table DLI表 databases.dbname.tables.tbname
column DLI列 databases.dbname.tables.tbname.columns.c olname
jobs DLI Flink作业 jobs.flink.jobid
resource DLI程序包 resources.resourcename group DLI程序包组 groups.groupname datasource
auth DLI跨源认证信
息 datasourceauth.name
– 特定资源:
图3-4 特定资源
– 所有资源: 指该服务下的所有资源 图3-5 所有资源
3. 将上述的所有字段拼接为一个json就是一个完整的策略了,其中action和resource 均可以设置多个,当然也可以通过IAM提供的可视化界面进行创建,例如:
授权用户拥有DLI服务,任意region,任意帐号ID下,任意数据库的创建删除权 限,任意队列的提交作业权限,任意表的删除权限。
{ "Version": "1.1", "Statement": [ {
"Effect": " Allow", "Action": [
"dli:database:create_database", "dli:database:drop_database", "dli:queue:submit_job", "dli:table:drop_table"
],
"Resource": [
"dli:*:*:database:*",
"dli:*:*:queue:*", "dli:*:*:table:*"
] } ] }
DLI 自定义策略样例
● 示例1:允许
– 授权用户拥有在所有区域中所有数据库的创建表权限
{ "Version": "1.1", "Statement": [ {
"Effect": "Allow", "Action": [
"dli:database:create_table"
],
"Resource": [ "dli:*:*:database:*"
] } ] }
– 授权用户拥有在所在区域中数据库db中表tb中列col的查询权限
{ "Version": "1.1", "Statement": [ {
"Effect": "Allow", "Action": [
"dli:column:select"
],
"Resource": [
"dli:cn-north-7:*:column:databases.db.tables.tb.columns.col"
] } ] }
● 示例2:拒绝
拒绝策略需要同时配合其他策略使用,否则没有实际作用。用户被授予的策略 中,一个授权项的作用如果同时存在Allow和Deny,则遵循Deny优先。
– 授权用户不能创建数据库,删除数据库,提交作业(default队列除外),删 除表{
"Version": "1.1", "Statement": [ {
"Effect": "Deny", "Action": [
"dli:database:create_database", "dli:database:drop_database", "dli:queue:submit_job", "dli:table:drop_table"
],
"Resource": [ "dli:*:*:database:*", "dli:*:*:queue:*", "dli:*:*:table:*"
] } ] }
– 授权用户不能在队列名为demo的队列上提交作业
{ "Version": "1.1", "Statement": [ {
"Effect": "Deny", "Action": [
"dli:queue:submit_job"
],
"Resource": [
"dli:*:*:queue:queues.demo"
] } ] }
3.4 DLI 资源
资源是服务中存在的对象。在DLI中,资源如下,您可以在创建自定义策略时,通过指 定资源路径来选择特定资源。
表3-8 DLI 的指定资源与对应路径
资源类型 资源名称 资源路径
queue DLI队列 queues.queuename database DLI数据库 databases.dbname
table DLI表 databases.dbname.tables.tbname
column DLI列 databases.dbname.tables.tbname.columns.coln ame
jobs DLI Flink作业 jobs.flink.jobid
resource DLI程序包 resources.resourcename group DLI程序包组 groups.groupname datasourcea
uth DLI跨源认证信息 datasourceauth.name
3.5 DLI 请求条件
您可以在创建自定义策略时,通过添加“请求条件”(Condition元素)来控制策略何 时生效。请求条件包括条件键和运算符,条件键表示策略语句的 Condition 元素,分 为全局级条件键和服务级条件键。全局级条件键(前缀为g:)适用于所有操作,服务 级条件键(前缀为服务缩写,如dli)仅适用于对应服务的操作。运算符与条件键一起 使用,构成完整的条件判断语句。
DLI通过IAM预置了一组条件键,例如,您可以先使用hw:SourceIp条件键检查请求者 的IP地址,然后再允许执行操作。下表显示了适用于DLI服务特定的条件键。
表3-9 DLI 请求条件
DLI条件键 运算符 描述
g:CurrentTime Date and time 接收到鉴权请求的时间。
说明以“ISO 8601”格式表示,例如:
2012-11-11T23:59:59Z。
g:MFAPresent Boolean 用户登录时是否使用了多因素认证。
g:UserId String 当前登录的用户ID。
g:UserName String 当前登录的用户名。
g:ProjectName String 当前登录的Project。
g:DomainName String 当前登录的Domain。
3.6 常用操作与系统权限关系
表3-10列出了DLI SQL常用操作与系统策略的授权关系,您可以参照该表选择合适的系 统策略。更多SQL语法赋权请参考《权限列表》章节。
表3-10 DLI 常用操作与系统权限的关系 资
源 操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
队 列DR
OP_Q UEUE
删 除 队 列
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
SUB MIT_J OB
提 交 作 业
√ × √ √
CANC EL_J OB
终 止 作 业
√ × √ √
REST ART
重 启 队 列
√ × √ √
GRAN T_PRI VILEG E
队 列 的 赋 权
√ × √ √
REVO KE_P RIVIL EGE
队 列 权 限 的 回 收
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
SHO W_PRI VILEG ES
查 看 其 他 用 户 具 备 的 队 列 权 限
√ × √ √
数 据 库
DROP _DAT ABAS E
删 除 数 据 库
√ × √ √
CREA TE_T ABLE
创 建 表
√ × √ √
CREA TE_VI EW
创 建 视 图
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
EXPL AIN
将SQ L语 句 解 释 为 执 行 计 划
√ × √ √
CREA TE_R OLE
创 建 角 色
√ × √ √
DROP _ROL E
删 除 角 色
√ × √ √
SHO W_RO LES
显 示 角 色
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
GRAN T_RO LE
绑 定 角 色
√ × √ √
REVO KE_R OLE
解 除 角 色 绑 定
√ × √ √
SHO W_US ERS
显 示 所 有 角 色 和 用 户 的 绑 定 关 系
√ × √ √
GRAN T_PRI VILEG E
数 据 库 的 赋 权
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
REVO KE_P RIVIL EGE
数 据 库 权 限 的 回 收
√ × √ √
SHO W_PRI VILEG ES
查 看 其 他 用 户 具 备 的 数 据 库 权 限
√ × √ √
DISP LAY_
ALL_
TABL ES
显 示 数 据 库 中 的 表 信 息
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
DISP LAY_
DATA BASE
显 示 数 据 库 信 息
√ × √ √
CREA TE_F UNC TIO N
创 建 函 数
√ × √ √
DROP _FU NCTI ON
删 除 函 数
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
SHO W_FU NCTI ONS
显 示 所 有 函 数
√ × √ √
DESC RIBE _FU NCTI ON
显 示 函 数 详 情
√ × √ √
表DROP _TAB LE
删 除 表
√ × √ √
SELE CT
查 询 表
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
INSE RT_I NTO_
TABL E
插 入
√ × √ √
ALTE R_TA BLE_
ADD_
COLU MNS
添 加 列
√ × √ √
INSE RT_O VER WRIT E_TA BLE
重 写
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
ALTE R_TA BLE_
RENA ME
重 命 名 表
√ × √ √
ALTE R_TA BLE_
ADD_
PARTI TIO N
在 分 区 表 中 添 加 分 区
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
ALTE R_TA BLE_
RENA ME_P ARTIT ION
重 命 名 表 分 区
√ × √ √
ALTE R_TA BLE_
DROP _PAR TITIO N
删 除 分 区 表 的 分 区
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
SHO W_PA RTITI ONS
显 示 所 有 分 区
√ × √ √
ALTE R_TA BLE_
RECO VER_
PARTI TIO N
恢 复 表 分 区
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
ALTE R_TA BLE_
SET_
LOCA TIO N
设 置 分 区 路 径
√ × √ √
GRAN T_PRI VILEG E
表 的 赋 权
√ × √ √
REVO KE_P RIVIL EGE
表 权 限 的 回 收
√ × √ √
资 源
操 作
说 明 D
LIF ull Acc ess
DL IR ea dO nl yA cc es s
Tenant Administrator DLI Service Admin
SHO W_PRI VILEG ES
查 看 其 他 用 户 具 备 的 表 权 限
√ × √ √
DISP LAY_
TABL E
显 示 表
√ √ √ √
DESC RIBE _TAB LE
显 示 表 信 息
√ × √ √
3.7 参考资料
策略相关内容
● 策略基本概念
●
RBAC策略语法
● 细粒度策略语法
● 创建自定义策略
项目
创建项目
委托
● 委托其他华为云账号管理资源
● 委托其他云服务管理资源
4 入门操作指导
4.1 创建并提交 Spark SQL 作业
使用DLI提交SQL作业查询数据。基本流程如下:
步骤1:登录华为云 步骤2:上传数据至OBS 步骤3:登录DLI管理控制台 步骤4:创建队列
步骤5:创建数据库 步骤6:创建表 步骤7:查询数据
如下操作以查询OBS的数据为例,DLI的数据查询操作类同。
步骤 1:登录华为云
1. 打开华为云首页。
2. 在登录页面输入“帐号名”和“密码”,单击“登录”。
步骤 2:上传数据至 OBS
DLI可以查询存储在OBS中的数据,查询数据前,需要将数据文件上传至OBS中。
1. 在华为云页面的上方导航栏中,选择“产品”。
2. 在基础服务列表中,单击“存储”中的“对象存储服务OBS”。
3. 在OBS服务产品页,单击“进入控制台”,进入OBS管理控制台页面。
4. 创建一个桶,桶名全局唯一,这里以桶名“obs1”为例。
a. 单击页面右上角“创建桶”。
b. 进入“创建桶”页面,选择“区域”,输入“桶名称”。
说明
创建OBS桶时,需要选择与DLI管理控制台相同的区域,不可跨区域执行操作。
c. 单击“立即创建”。
5. 单击所建桶“obs1”,进入“概览”页面。
6. 单击左侧列表中的“对象”,选择“上传对象”,将需要上传的文件
“sampledata.csv”上传到指定目录,单击“上传”。
“sampledata.csv”样例文件可以通过新建“sampledata.txt”,复制如下英文逗 号分隔的文本内容,再另存为“sampledata.csv”。
12,test
文件上传成功后,待分析的文件路径为“obs://obs1/sampledata.csv”。
关于OBS管理控制台更多操作请参考《对象存储服务控制台指南》。
OBS上传文件指导,请参见《OBS工具指南》。
说明
针对大文件场景,由于OBS管理控制台对文件大小和数量限制较多,所以推荐使用OBS工 具上传大文件,如OBS Browser+或obsutil工具上传。
● OBS Browser+是一个比较常用的图形化工具,支持完善的桶管理和对象管理操作。推 荐使用此工具创建桶或上传对象。
● obsutil是一款用于访问管理OBS的命令行工具,对于熟悉命令行程序的用户,obsutil是 执行批量处理、自动化任务的好的选择。
您可以通过以下多种方式将文件上传至桶,OBS最终将这些文件以对象的形式存 储在桶中。
表4-1 OBS 上传对象的不同访问方式 访问方式 上传对象方法
控制台 通过控制台上传对象
OBS Browser
+ 通过OBS Browser+上传对象
obsutil 通过obsutil上传对象
SDK 使用SDK上传对象 ,具体参考各语言开发指南的上传对象章节
API
PUT上传 、POST上传
步骤 3:登录 DLI 管理控制台
1. 在华为云页面的上方导航栏中,选择“产品”。
2. 在列表中,选择“大数据”>“大数据计算”中的“数据湖探索 DLI”。
3. 在DLI服务产品页,单击“进入控制台”,进入DLI管理控制台页面。第一次进入 数据湖探索管理控制台需要进行授权,以获取访问OBS的权限。
步骤 4:创建队列
队列是使用DLI服务的基础,执行SQL作业前需要先创建队列。
● DLI有预置的可用队列“default”。若使用default队列,将按照扫描量计费。
● 用户也可根据需要自己创建队列。使用自建队列,将按照CU时或包年包月计费。
a. 在DLI管理控制台,单击左侧导航栏中的“SQL编辑器”,可进入SQL作业
“SQL编辑器”页面。
b. 在左侧导航栏,选择队列页签,单击右侧的 创建队列。
图4-1 创建队列
创建队列详细介绍请参考创建队列。
具体计费方式请参考《数据湖探索产品介绍》。
步骤 5:创建数据库
在进行数据查询之前还需要创建一个数据库,例如db1。
说明
“default”为内置数据库,不能创建名为“default”的数据库。
1. 在DLI管理控制台,单击左侧导航栏中的“SQL编辑器”,可进入SQL作业“SQL 编辑器”页面。
2. 在“SQL编辑器”页面右侧的编辑窗口中,输入如下SQL语句,单击“执行”。阅 读并同意隐私协议,单击“确定”。
create database db1;
数据库创建成功后,新建的数据库db1会在左侧“数据库”列表中出现。
说明
在DLI管理控制台第一次单击“执行”操作时,需要阅读隐私协议,确认同意后才能执行作 业,且后续“执行”操作将不会再提示阅读隐私协议。
步骤 6:创建表
数据库创建完成后,需要在数据库db1中基于OBS上的样本数据“obs://obs1/
sampledata.csv”创建一个表,例如table1。
1. 在“SQL编辑器”页面右侧的编辑窗口上方,选择队列“default”和数据库
“db1”。
2. 在编辑窗口中,输入如下SQL语句,单击“执行”。
create table table1 (id int, name string) using csv options (path 'obs://obs1/sampledata.csv');
表table1创建成功后,单击左侧“库表”页签,再单击db1,新创建的表table1会 在“表”区域下方显示。
步骤 7:查询数据
完成以上步骤后,就可以开始进行数据查询了。
1. 单击“SQL编辑器”页面左侧的“库表”页签,选择新创建的表table1,双击表,
在右侧编辑窗口中,自动输入SQL查询语句,例如查询table1表的1000条数据:
select * from db1.table1 limit 1000;
2. 单击“执行”,系统开始查询。
SQL语句执行成功后,可在SQL作业编辑窗口下方“查看结果”页签查看查询结 果。
后续指引
完成Spark SQL作业快速入门操作后,如果您想了解更多关于Spark SQL作业相关操 作,建议您参考以下指引阅读。
分类 文档 说明
界面 操作
SQL编辑器
提供执行Spark SQL语句操作的界面指导,包含SQL编辑 器界面基本功能介绍、快捷键以及使用技巧等说明。Spark SQL作业
管理 提供Spark SQL作业管理界面功能介绍。
Spark SQL模板
管理 DLI支持定制模板或将正在使用的SQL语句保存为模板,
便捷快速的执行SQL操作。
开发 指导
Spark SQL语法
参考 提供Spark SQL数据库、表、分区、导入及导出数据、自 定义函数、内置函数等语法说明和样例指导。
使用Spark作业
访问DLI元数据 提供Spark SQL作业开发的操作指引和样例代码参考。
Spark SQL 相关
API
提供Spark SQL相关API的使用说明。4.2 使用 TPC-H 样例模板开发并提交 Spark SQL 作业
为了便捷快速的执行SQL操作,DLI支持定制模板或将正在使用的SQL语句保存为模 板。保存模板后,不需编写SQL语句,可通过模板直接执行SQL操作。
当前系统提供了多条标准的TPC-H查询语句模板,可以根据当前需求选择使用。本样 例演示通过一个TPC-H样例模板开发并提交Spark SQL作业的基本流程:
步骤1:登录华为云
步骤2:登录DLI管理控制台
步骤3:执行TPC-H样例模板并查看结果 更多样例模板操作,请参考SQL模板管理。
步骤 1:登录华为云
1. 打开华为云首页。
2. 在登录页面输入“帐号名”和“密码”,单击“登录”。
步骤 2:登录 DLI 管理控制台
1. 在华为云页面的上方导航栏中,选择“产品”。
2. 在列表中,选择“大数据”>“大数据计算”中的“数据湖探索 DLI”。
3. 在DLI服务产品页,单击“进入控制台”,进入DLI管理控制台页面。
说明
第一次进入数据湖探索管理控制台需要进行授权,具体请参考服务授权。
步骤 3:执行 TPC-H 样例模板并查看结果
1. 在DLI管理控制台,选择“作业模板”>“SQL模板”>“样例模板”,在
“tpchQuery”下选择“Q1_价格摘要报告查询”样例模板,单击操作列的“执 行”进入“SQL编辑器”。
2. 在“SQL编辑器”页面右侧的编辑窗口上方,“执行引擎”选择“spark”,“队 列”选择“default”,“数据库”选择“default”,单击“执行”。
3. SQL作业编辑窗口下方“查看结果”页签查看查询结果。
本示例使用系统预置的“default”队列和数据库进行演示,也可以在自建的队列和数 据库下执行。
创建队列请参考创建队列。创建数据库请参考创建数据库。
后续指引
完成TPC-H样例模板开发并提交Spark SQL作业操作后,如果您想了解更多关于Spark SQL作业相关操作,建议您参考以下指引阅读。
分类 文档 说明
界面 操作
SQL编辑器
提供执行Spark SQL语句操作的界面指导,包含SQL编辑 器界面基本功能介绍、快捷键以及使用技巧等说明。Spark SQL作业
管理 提供Spark SQL作业管理界面功能介绍。
Spark SQL模板
管理 DLI支持定制模板或将正在使用的SQL语句保存为模板,
便捷快速的执行SQL操作。
开发 指导
Spark SQL语法
参考 提供Spark SQL数据库、表、分区、导入及导出数据、自 定义函数、内置函数等语法说明和样例指导。
使用Spark作业
访问DLI元数据 提供Spark SQL作业开发的操作指引和样例代码参考。
Spark SQL 相关
API
提供Spark SQL相关API的使用说明。4.3 创建并提交 Spark Jar 作业
使用DLI提交Spark作业进行实时计算。基本流程如下:
步骤1:登录华为云 步骤2:上传数据至OBS 步骤3:登录DLI管理控制台 步骤4:创建队列
步骤5:创建程序包 步骤6:提交Spark作业
步骤 1:登录华为云
使用DLI服务,首先要登录华为云。
1. 打开华为云首页。
2. 在登录页面输入“帐号名”和“密码”,单击“登录”。
步骤 2:上传数据至 OBS
参考Spark作业样例代码开发Spark Jar作业程序,编译并打包为“spark- examples.jar”。参考以下操作步骤上传该作业程序。
提交Spark作业之前,需要在OBS中上传数据文件。
1. 在华为云页面的上方导航栏中,选择“产品”。
2. 在基础服务列表中,单击“存储”中的“对象存储服务OBS”。
3. 在OBS服务产品页,单击“管理控制台”,进入OBS管理控制台页面。
4. 创建一个桶,桶名全局唯一,这里以桶名“dli-test-obs01”为例。
a. 单击“创建桶”。
b. 进入“创建桶”页面,选择“区域”,输入“桶名称”。
说明
创建OBS桶时,需要选择与DLI管理控制台相同的区域,不可跨区域执行操作。
c. 单击“立即创建”。
5. 单击所建桶“dli-test-obs01”,进入“概览”页面。
6. 单击左侧列表中的“对象”,选择“上传文件”,将需要上传的文件,例如
“spark-examples.jar”上传到指定目录,单击“确定”。
例如,文件上传成功后,待分析的文件路径为“obs://dli-test-obs01/spark- examples.jar”。
关于OBS管理控制台更多操作请参考《对象存储服务控制台指南》。
OBS上传文件指导,请参见《OBS工具指南》。
说明
针对大文件场景,由于OBS管理控制台对文件大小和数量限制较多,所以推荐使用OBS工 具上传大文件,如OBS Browser+或obsutil工具上传。
● OBS Browser+是一个比较常用的图形化工具,,支持完善的桶管理和对象管理操作。
推荐使用此工具创建桶或上传对象。
● obsutil是一款用于访问管理OBS的命令行工具,对于熟悉命令行程序的用户,obsutil是 执行批量处理、自动化任务的好的选择。
您可以通过以下多种方式将文件上传至桶,OBS最终将这些文件以对象的形式存 储在桶中。
表4-2 OBS 上传对象的不同访问方式
访问方式 上传对象方法
控制台 通过控制台上传对象
OBS Browser+ 通过OBS Browser+上传对象
访问方式 上传对象方法
obsutil 通过obsutil上传对象
SDK 使用SDK上传对象 ,具体参考各语言开发指南的上
传对象章节
API
PUT上传 、POST上传
步骤 3:登录 DLI 管理控制台
使用DLI提交Spark作业,需要先进入Spark作业编辑页面。
1. 在华为云页面的上方导航栏,选择“产品”。
2. 在列表中,选择“大数据”>“大数据计算”中的“数据湖探索 DLI”。
3. 在DLI服务产品页,单击“进入控制台”,进入DLI管理控制台页面。
说明
第一次进入数据湖探索管理控制台需要进行授权,以获取访问OBS的权限。请参考服务授 权。
步骤 4:创建队列
第一次提交Spark作业,需要先创建队列,例如创建名为“sparktest”的队列,队列类 型选择为“通用队列”。
1. 在DLI管理控制台的左侧导航栏中,选择“队列管理”。
2. 单击“队列管理”页面右上角“购买队列”进行创建队列。
3. 创建名为“sparktest”的队列,队列类型选择为“通用队列”。创建队列详细介 绍请参考创建队列。
4. 单击“立即购买”,确认配置。
5. 配置确认无误,单击“提交”完成队列创建。
步骤 5:创建程序包
提交Spark作业之前需要创建程序包,例如“spark-examples.jar”。
1. 在管理控制台左侧,单击“数据管理”>“程序包管理”。
2. 在“程序包管理”页面,单击右上角“创建”可创建程序包。
3. 在“创建程序包”对话框,“包类型”选择“JAR”,“OBS路径”选择步骤2:
上传数据至OBS中“spark-examples.jar”的包路径,“分组设置”参数选择为
“不分组”。
4. 单击“确定”,完成创建程序包。
程序包创建成功后,您可以在“程序包管理”页面查看和选择使用对应的包。
创建程序包详细介绍请参考创建程序包。
步骤 6:提交 Spark 作业
1. 在DLI管理控制台,单击左侧导航栏中的“作业管理”>“Spark作业”,进入创建 Spark作业页面。
2. 在Spark作业编辑页面中,“所属队列”选择步骤4:创建队列中创建的队列,
“应用程序”选择步骤5:创建程序包创建的程序包。
其他参数请参考创建Spark作业中关于Spark作业编辑页面的说明。
3. 单击Spark作业编辑页面右上方“执行”,阅读并同意隐私协议,单击“确定”。
提交作业,页面显示“作业提交成功”。
4. (可选)可到“作业管理”>“Spark作业”页面查看提交作业的状态及日志。
说明
在DLI管理控制台第一次单击“执行”操作时,需要阅读隐私协议,同意确定后,后续操作 将不会再提示。
后续指引
完成Spark Jar作业快速入门操作后,如果您想了解更多关于Spark Jar作业相关操作,
建议您参考以下指引阅读。
分类 文档 说明
界面
操作
Spark Jar作
业管理 提供Spark Jar作业管理界面功能介绍。
Spark程序包
管理针对不同角色用户,您可以通过权限设置分配不同的程序 包组或程序包,不同用户之间的作业效率互不影响,保障 作业性能。
开发 指南
Spark SQL语
法参考 提供Spark SQL相关的数据库、表、分区、导入及导出数 据、自定义函数、内置函数等语法说明和样例指导。
Spark Jar 相
关API 提供Spark Jar相关API的使用说明。
Spark 作业
SDK参考
提供执行Spark批处理作业的接口样例说明。4.4 创建并提交 Flink SQL 作业
使用DLI提交Flink SQL作业进行实时计算。基本流程如下:
步骤1:登录华为云
步骤2:准备数据源和数据输出通道 步骤3:创建OBS桶保存输出数据 步骤4:登录DLI管理控制台 步骤5:创建队列
步骤6:创建增强型跨源连接 步骤7:创建跨源认证
步骤8:配置安全组规则和测试地址连通性 步骤9:创建Flink SQL作业
样例场景需要创建一个Flink SQL作业,并且该作业有一个输入流和一个输出流。输入 流用于从DIS读取数据,输出流用于将数据写入到Kafka中。
步骤 1:登录华为云
使用DLI服务,首先要登录华为云。
1. 打开华为云首页。
2. 在登录页面输入“帐号名”和“密码”,单击“登录”。
步骤 2:准备数据源和数据输出通道
DLI Flink作业支持其他服务作为数据源和数据输出通道,具体内容请参见准备Flink作 业数据 。
本样例中,假设作业名称为“JobSample”,采用DIS服务作为数据源,开通数据接入 服务(DIS),具体操作请参见《数据接入服务用户指南》中的“开通DIS通道”章 节。采用分布式消息服务Kafka作为数据输出通道,创建Kafka专享版实例,具体操作 请参见《分布式消息服务Kafka用户指南》中的“购买实例”章节。
● 创建用于作业输入流的DIS通道:
a. 登录DIS管理控制台。
b. 在管理控制台左上角选择区域和项目。
c. 单击“购买接入通道”配置相关参数。通道信息如下:
▪
区域:选择与DLI服务相同的区域▪
通道名称:csinput▪
通道类型:普通▪
分区数量:1▪
生命周期(小时):24▪
源数据类型:BLOB▪
自动扩缩容:关闭▪
企业项目:default▪
高级配置:暂不配置d. 单击“立即购买”,进入“规格确认”页面。
e. 单击“提交”,完成通道接入。
● 创建用于作业输出流的Kafka专享版实例:
a. 在创建Kafka实例前您需要提前准备相关依赖资源,包括VPC、子网和安全 组,并配置安全组。
▪
创建VPC和子网的操作指导请参考创建虚拟私有云和子网,若需要在已 有VPC上创建和使用新的子网,请参考为虚拟私有云创建新的子网。说明
● 创建的VPC与使用的Kafka服务应在相同的区域。
● 创建VPC和子网时,如无特殊需求,配置参数使用默认配置即可。
▪
创建安全组的操作指导请参考创建安全组,为安全组添加规则的操作指 导请参考添加安全组规则。更多信息请参考《分布式消息服务Kafka用户指南》中的“准备实例依赖资 源”章节。
b. 登录分布式消息服务Kafka管理控制台。
c. 在管理控制台左上角选择区域。
d. 在“Kafka专享版”页面,单击右上角“购买Kafka实例”配置相关参数。实 例信息如下:
▪
计费模式:按需付费▪
区域:选择与DLI服务相同的区域▪
项目:默认▪
可用区:默认▪
实例名称:kafka-dliflink▪
企业项目:default▪
版本:默认▪
CPU架构:默认▪
规格:选择对应的规格▪
代理个数:默认▪
存储空间:默认▪
容量阈值策略:默认▪
虚拟私有云: vpc-dli,子网:dli-subnet▪
安全组:default▪
Manager用户名:dliflink(用于登录实例管理页面)▪
密码:****(请妥善管理密码,系统无法获取您设置的密码内容)▪
确认密码:****▪
更多配置:开启参数“Kafka SASL_SSL”,根据界面提示配置SSL认证 的用户名和密码。其他参数可暂不配置。e. 单击“立即购买”,弹出“规格确认”页面。
f. 单击“提交”,完成实例创建。
g. 在分布式消息服务Kafka管理,单击“Kafka专享版”,单击已创建的Kafka 实例名称,例如kafka-dliflink,进入实例详情页面。
h. 在“基本信息 > 高级配置 > SSL 证书”所在行,单击下载按钮。下载压缩包 到本地并解压,获取压缩包中的客户端证书文件:client.truststore.jks,给后 续步骤做准备。
步骤 3:创建 OBS 桶保存输出数据
在本样例中,需要为作业“JobSample”开通对象存储服务(OBS),为DLI Flink作业 提供Checkpoint、保存作业日志和调试测试数据的存储功能。
具体操作请参见《对象存储服务控制台指南》中的“创建桶”章节。
1. 在OBS管理控制台左侧导航栏选择“对象存储”。
2. 在页面右上角单击“创建桶”,配置桶参数。
– 区域:选择与DLI服务相同的区域 – 桶名称:smoke-test
– 存储类别:标准存储 – 桶策略:私有 – 默认加密:关闭 – 归档数据直读:关闭 – 企业项目:default – 标签:不填写 3. 单击“立即创建”。
步骤 4:登录 DLI 管理控制台
1. 在华为云官网首页的上方导航栏中,单击“产品”页签。
2. 在列表中,选择“大数据”>“大数据计算”中的“数据湖探索 DLI”。
3. 在DLI服务产品页,单击“进入控制台”,进入DLI管理控制台页面。第一次进入 数据湖探索管理控制台需要进行授权,以获取访问OBS的权限。
步骤 5:创建队列
创建DLI Flink SQL作业,不能使用系统已有的default队列,需要您创建队列,例如创 建名为“Flinktest”的队列。创建队列详细介绍请参考创建队列。
1. 在DLI管理控制台总览页,单击右上角“购买队列”进入购买队列页面。
2. 配置参数。
– 计费模式:按需计费 – 当前区域:默认区域 – 队列名称:Flinktest
– 队列类型:通用队列。勾选“专属资源模式”。
– AZ策略:单AZ – 队列规格:16CUs – 企业项目:default
– 描述:不填
– 高级配置:自定义配置
– 网段:配置的网段不能与Kafka的子网网段冲突 – 标签:不填
3. 单击“立即购买”,确认配置。
4. 配置确认无误,提交请求。
步骤 6:创建增强型跨源连接
创建DLI Flink作业,还需要创建增强型跨源连接。具体操作请参考创建增强型跨源连 接。
说明
● 增强型跨源仅支持包年包月队列和按需专属队列。
● 绑定跨源的DLI队列网段和数据源网段不能重合。
● 系统default队列不支持创建跨源连接。
● 访问跨源表需要使用已经创建跨源连接的队列。
1. 在DLI管理控制台左侧导航栏中,选择“跨源连接”。
2. 选择“增强型跨源”页签,单击左上角的“创建”按钮。配置参数:
– 连接名称:diskafka – 绑定队列:Flinktest – 虚拟私有云:vpc-dli – 子网:dli-subnet
说明
创建跨源连接的虚拟私有云和子网需要和Kafka实例保持一致。
3. 单击“确定”,完成创建增强型跨源连接。
4. 在“增强型跨源”页签,单击创建的连接名称:diskafka,查看对等连接ID及连接 状态,连接状态为“已激活”表示连接成功。
步骤 7:创建跨源认证
创建跨源认证的具体操作请参考跨源认证。
1. 将步骤2:准备数据源和数据输出通道中获取的kafka认证文件
“client.truststore.jks”上传到步骤3:创建OBS桶保存输出数据中的OBS桶
“smoke-test”下。
2. 在DLI管理控制台选择“跨源连接”。
3. 在“跨源认证”页签,单击“创建”,创建认证信息。配置参数:
– 认证信息名称:Flink – 类型:Kafka_SSL
– Truststore路径:obs://smoke-test/client.truststore.jks – Truststore密码:dms@kafka
其余参数可不用配置。
4. 单击“确定”,完成创建跨源认证。
步骤 8:配置安全组规则和测试地址连通性
1. DLI管理控制台,单击“队列管理”,选择绑定的队列,在操作列,单击“详情”
获取队列的网段信息。
2. 登录分布式消息服务Kafka管理控制台,单击“Kafka专享版”,单击已创建的 Kafka实例名称,例如kafka-dliflink,进入实例基本信息页面。
3. 在实例基本信息页面,在“连接地址”配置下的获取Kafka的连接地址和端口。
4. 在实例基本信息页面,在“网络”配置下的“安全组”,单击安全组名称,进入 安全组配置页面。
5. 在Kafka实例对应的安全组配置页面,单击“入方向规则 > 添加规则”,协议选 择“TCP”,端口选择“9093”,源地址填写DLI队列的网段。单击“确定”完成 配置。
6. 登录DLI管理控制台,选择“队列管理”,在所在Flink队列行,单击“更多 > 测 试地址连通性”,在“地址”参数中按照“IP:端口”的格式输入Kafka的连接地址 和端口,单击“测试”,返回地址可达后进行后续操作步骤。注意多个地址要分 开单独测试。
步骤 9:创建 Flink SQL 作业
准备好数据源和数据输出通道之后,就可以创建Flink SQL作业了。
1. 在DLI管理控制台的左侧导航栏中,单击“作业管理”>“Flink作业”,进入
“Flink作业”页面。
2. 在“Flink作业”页面右上角单击“创建作业”,弹出“创建作业”对话框。配置 参数:
– 类型:Flink SQL – 名称:DIS-Flink-Kafka – 描述:不填
– 模板名称:不选择 – 标签:不填
3. 单击“确定”,进入作业“编辑”页面。
4. 编辑SQL作业。
在SQL语句编辑区域,输入详细的SQL语句。具体如下,注意以下加粗的参数值都 需要根据注释提示修改。
CREATE SOURCE STREAM car_info ( a1 string,
a2 string, a3 string, a4 INT )WITH ( type = "dis",
region = "cn-north-4",//需要修改为当前DLI队列所在的region channel = "csinput",
encode = "csv", FIELD_DELIMITER = ";"
);
CREATE SINK STREAM kafka_sink ( a1 string,
a2 string, a3 string, a4 INT ) // 输出字段 WITH ( type="kafka",
kafka_bootstrap_servers = "192.x.x.x:9093, 192.x.x.x:9093, 192.x.x.x:9093",//需要修改为kafka实例
的连接地址
kafka_topic = "testflink", // 要写入kafka的topic,进入kafka控制台,单击已创建的Kafka实例名称,在 Topic管理查看Topic名称
encode = "csv", // 编码格式,支持json/csv kafka_certificate_name = "Flink", kafka_properties_delimiter = ",",
//kafka_properties中的username和password的值xxx需要替换为步骤2中kafka创建SSL认证的用户名 和密码 kafka_properties = "sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username=\"xxx\" password=\"xxx\";,sasl.mechanism=PLAIN,security.protocol=SASL_SSL"
);
INSERT INTO kafka_sink SELECT * FROM car_info;
CREATE sink STREAM car_info1 ( a1 string,
a2 string, a3 string, a4 INT )WITH ( type = "dis",
region = "cn-north-4",//需要修改为当前DLI队列所在的region channel = "csinput",
encode = "csv", FIELD_DELIMITER = ";"
);
insert into car_info1 select 'id','owner','brand',1;
insert into car_info1 select 'id','owner','brand',2;
insert into car_info1 select 'id','owner','brand',3;
insert into car_info1 select 'id','owner','brand',4;
insert into car_info1 select 'id','owner','brand',5;
insert into car_info1 select 'id','owner','brand',6;
insert into car_info1 select 'id','owner','brand',7;
insert into car_info1 select 'id','owner','brand',8;
insert into car_info1 select 'id','owner','brand',9;
insert into car_info1 select 'id','owner','brand',10;
5. 单击“语义校验”,确保语义校验成功。
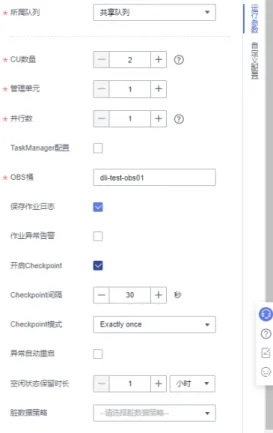
6. 设置作业运行参数。配置必选参数:
– CU数量:2 – 管理单元:1 – 并行数:1
– 所属队列:Flinktest – 保存作业日志:勾选
– OBS桶:选择作业日志保存的OBS桶,并进行授权。